1. Introduction
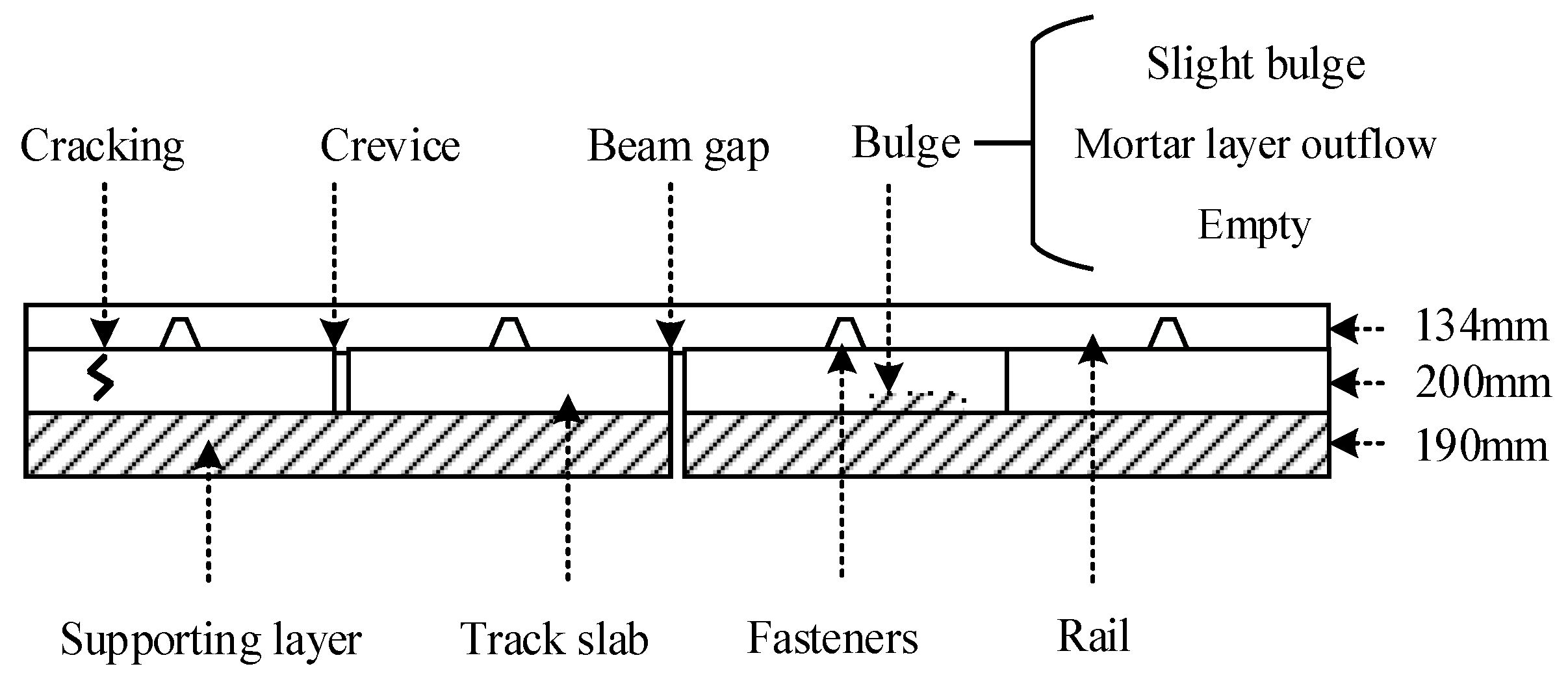
Track defect detection: As a result of the high frequency and intensity of track operation in open air, track defects occur constantly. There are four typical defects in track detection: crevice, beam gap, cracking, and bulge, as shown in
Figure 1. It should be noted that in the horizontal direction, we did not draw under the actual size. For actual track, the length of the track slab is 6450 mm. Bulges can be divided into multiple states according to their severity, such as slight bugles, mortar layer outflow, and empty [
1]. Since the monolithic concrete structure of the track and the reinforcement are densely distributed, it is difficult to identify the defects inside. In traditional detection, in addition to the lack of real-time performance, the track detection vehicle has a long operating period and high deployment cost, and manual detection is restricted by the high error rate [
2,
3]. Therefore, approaches based on optical sensors have become the most remarkable methods in terms of deployment costs and real-time performance.
Optical sensors in track detection: Bao et al. [
4] monitored the temperature and strain of joints by pulse-pre-pumped Brillouin optical time-domain analysis (PPP-BOTDA) with a single-mode fiber as a distributed sensor. Kang et al. [
5] developed an FBG sensing system and graphical user interface (GUI) to monitor the wheel thickness changes in real time, which has been verified through the 1/6th sub-scale model test. Zhang et al. [
6] proposed a track temperature prediction system based on FBG sensors and relevance vector regression theory, developed a real-time online monitoring system for railway track temperature, displacement, and strain, and deployed it as a Guangzhou–Shenzhen–Hong Kong high-speed railway track state warning system. Buggy et al. [
7] monitored the condition of fishplates, stretcher poles, and switch blades using FBG strain sensors. However, due to broken bare fibers and low-strain-sensitivity jacketed fibers, the high cost and difficulty of deployment cannot be avoided [
8]. In this case, in terms of deployment, DAS is considered the most suitable optical sensing system for track detection. However, DAS is mostly applied to detect train locations, speeds, and track incidents, but it has not yet been applied to multi-type minor defects detection [
9,
10,
11]. Furthermore, the existing methods often provide a particularly determined output (so-called hard decision), which strongly depends on human knowledge, and the unique characteristics of the defects are required. Unfortunately, the unique characteristics of many defects have not been clearly defined.
Deep learning-based methods: As a result of the high-frequency sampling and low deployment cost, DAS is considered a data collection method that is perfectly suitable for various track detection technologies, especially deep learning methods. As a soft-decision method, deep learning provides a probability for each possible decision. An increasing number of researchers are focusing on deep learning for track detection. Based on deep learning, Wang et al. [
12] pre-processed training data and defined the severity level to classify different severity levels for cracks in ballast-less tracks. ENSCO’s RIS (Railway imaging systems) has advanced high-resolution image acquisition systems and image processing algorithms, which can continuously detect fasteners during the day and night [
13]. In [
14], 2D images are transformed into 1D signals by Gabor filter, and then, the multiple signal classification (MUSIC) algorithm is used to detect the 1D signals, which can classify the signals produced by different track components. Yao et al. [
15] used an artificial neural network (ANN) and a long short-term memory (LSTM) network to predict the frost heave deformation of a railway subgrade with four sections of data. Wei et al. [
16] used Dense-SIFT, CNN, and R-CNN to detect defects in fasteners. Zheng et al. [
17] developed a deep transfer learning (DTL) framework for rail surface crack detection using a limited volume of training images. Based on the YOLO V3 method, Wei et al. [
18] proposed a fast detection model for exterior substances. Wang et al. [
19] proposed a scheme for rail track state detection with a deep convolutional network as the core. Fan et al. [
20] has shown how DAS system can be used for crack detection without the use of deep learning. They used vibration pulses to locate cracks on the track. However, many track defects, such as bulge, do not cause obvious vibration pulses, so it is difficult to detect them by Fan’s method. In addition, there are many kinds of track defects (event) that may lead to vibration pulses, such as switch, crack, and corrugation, and Fan’s method cannot distinguish them. Therefore, deep learning is a reasonable solution for multi-type defect detection.
Deep networks often achieve their strong performance through supervised learning, which requires labeled datasets. Therefore, the performance benefit conferred by the use of a larger dataset can come at a significant cost, because labeling data often requires human labor [
21]. On the other hand, for track detection, there are many hidden defects that are difficult to be found or labeled, such as crack and bulge, which occur frequently during daytime operation and gradually disappear at night as the temperature drops. Therefore, we considered realizing track detection in a semi-supervised deep learning method. Semi-supervised learning (SSL) often achieves outstanding performance in the extremely scarce-label regime, with the efficient leveraging of unlabeled data [
22,
23,
24]. In SSL models, decision boundaries are reinforced by unlabeled data, which enables the use of large, powerful models [
25]. Owing to the fact that there are more unlabeled data than labeled data in actual conditions, the application of SSL in engineering has become a hot research field. Summarizing the previous work, the current DAS-based track defect detection system can be roughly divided into three categories: amplitude visualization, methods based on traditional machine learning, and methods based on deep learning. The existing deep learning-based methods mostly extract features from single-point vibration data and use MLP models to build classifiers. In this paper, we propose a track detection system that innovatively leverages semi-supervised deep learning based on image recognition. The innovation of this article is as follows:
- (1)
To increase the sample information density, we use multi-point amplitude rather than single-point;
- (2)
To alleviate the impact of the lack of high-frequency components caused by an insufficient sampling rate, we use amplitude rather than frequency features to train the model;
- (3)
We convert the data into images and classify the samples through a CNN network to achieve better convergence speed and capacity;
- (4)
We use the deep network to adaptively extract the sample features rather than manually extract them;
- (5)
We use semi-supervised learning to efficiently leverage unlabeled data to further improve the performance of the model.
Through the above-mentioned innovations, we successfully implemented a real-time track defect detection system and achieved superior performance, especially for multi-type minor defects. The structure of this paper is as follows. In the
Section 2, we describe the deployment of the DAS and the distribution of defects on the experimental track. In the
Section 3, we introduce the mechanism of SSL and several SSL models for comparison in the experiment. In the
Section 4, we present a particular dataset pre-processing for our semi-supervised learning model, and we validate it in the
Section 5. In the
Section 6, we summarize our work and future research.
2. Sensor Deployment
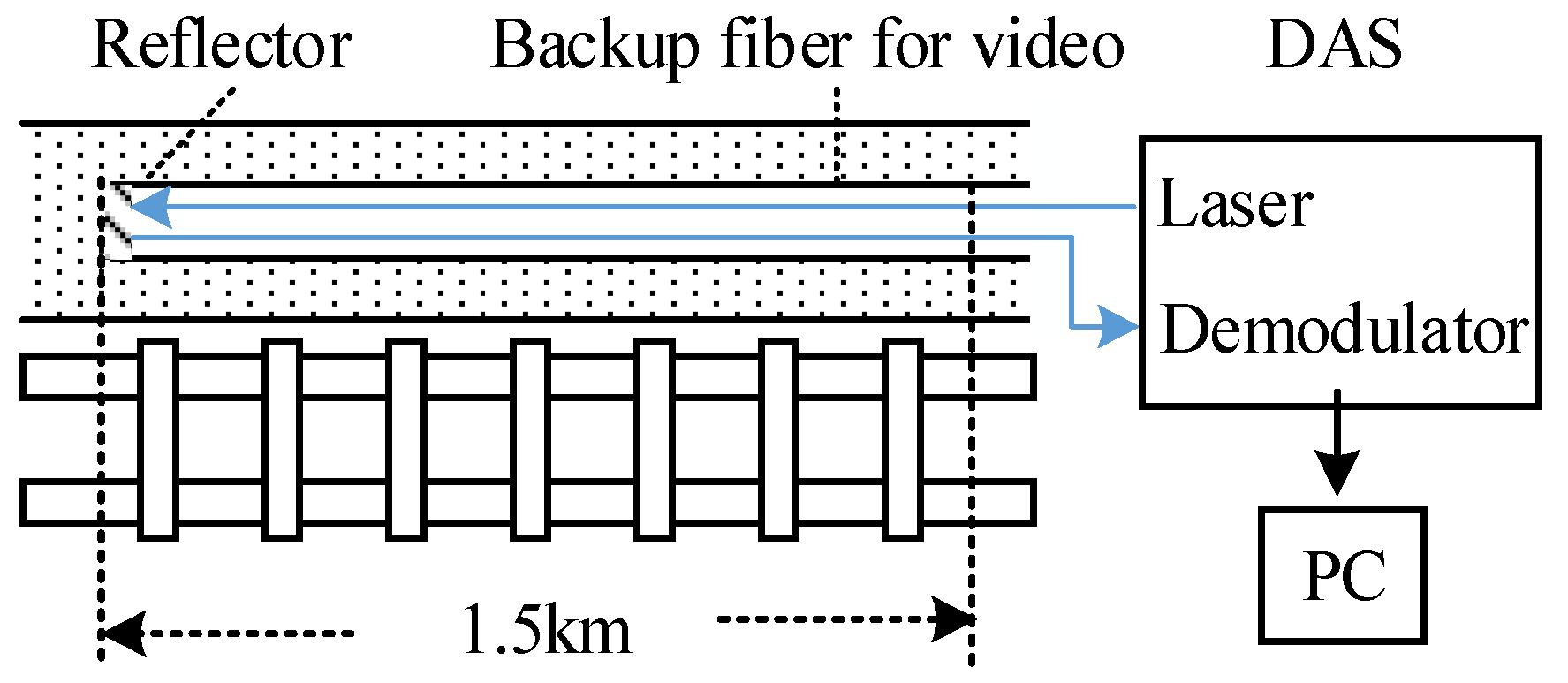
Due to the security policy, experimental deployment along the railway track is not allowed. So, the existing backup fiber for video along the track is used as sensors, which means that additional installation is not needed. The fiber joint was connected to the DAS in the computer room. We deployed the commercial DAS with 5.8 m spatial resolution, measurement frequency range <5 kHz, and the fiber is G652D type. The DAS we used is an intensity-based DAS capable of only detecting vibrations. The vibration amplitude of the measurement points at each moment is buffered in the DAS in the form of a line of data; then, it is received and stored in a PC, as shown in
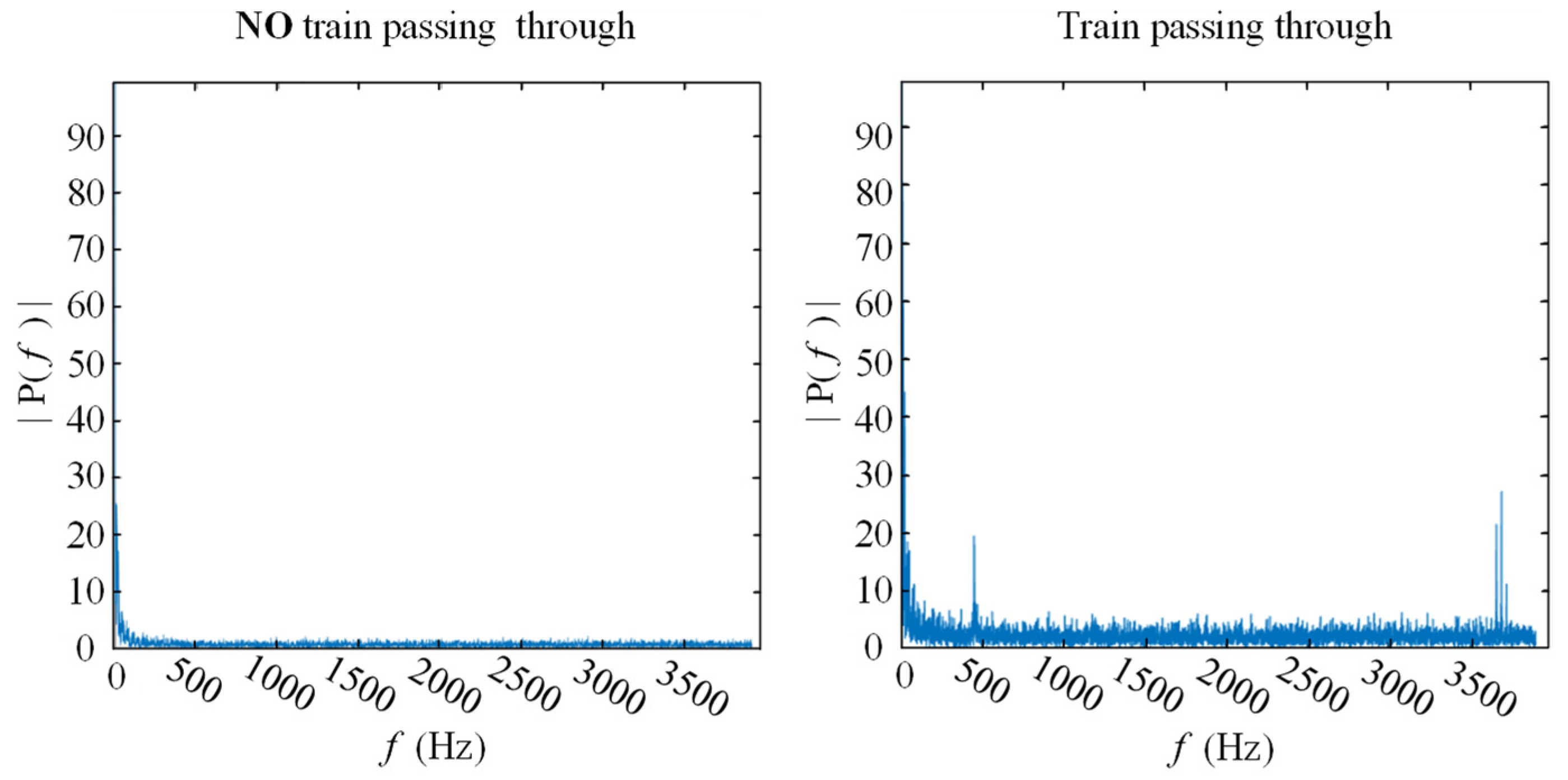
Figure 2. The length of the optical path was measured to be 3000 m. By knocking around the fiber and observing the pulse position, we determined that the length of the optical path corresponding to the experimental track segment was approximately 1500 m, and the sampling rate is 2 kHz (2000 rows/s). The spectrograms of the measured points in the raw data are shown in
Figure 3.
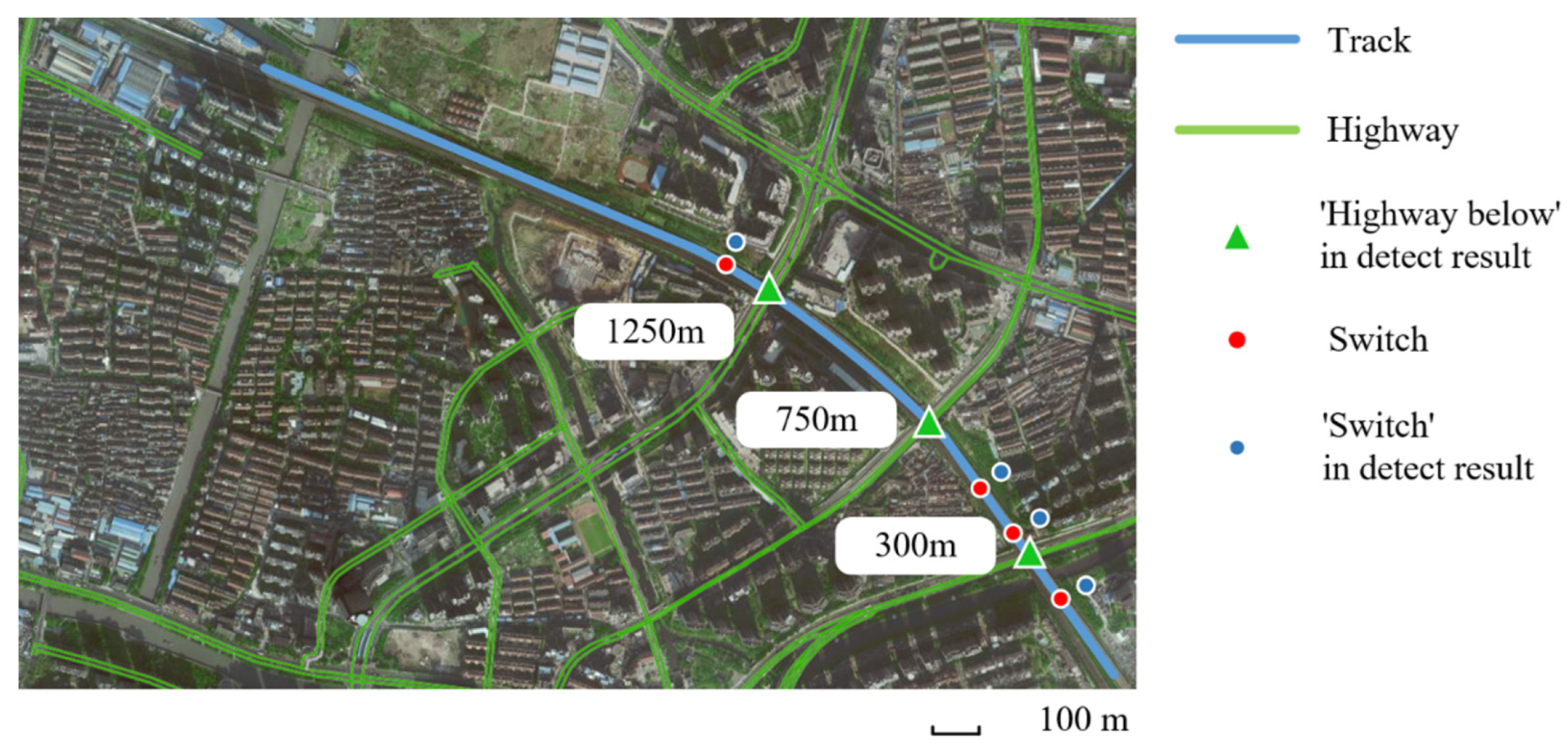
There are four typical defects to be recognized in our work including crevice, beam gap, cracking, and bulge, and in order to facilitate the analysis, two events causing peculiar vibrations serve as ‘defects’ for experimental object expansion, including switches and highway below. The distribution of defects is shown in
Table 1. In actual conditions, events are difficult to locate accurately, so we roughly estimate it at 10 m intervals, which has been approved by maintainers. For ease of analysis, positions without events will be labeled ‘no-event’ in the experiment, but we did not list them in
Table 1.
3. Data Representation
Most of the existing methods are based on values, and our method focuses on the pattern behind them, which is called feature representation in deep learning methods. Fitting the actual data into deep learning models is one of the most important steps in deep learning. To make sure that the data values are comparable instances widely, Min–Max normalization is performed in order to prevent neuron output saturation or small values being ignored caused by excessive input absolute value:
where
and
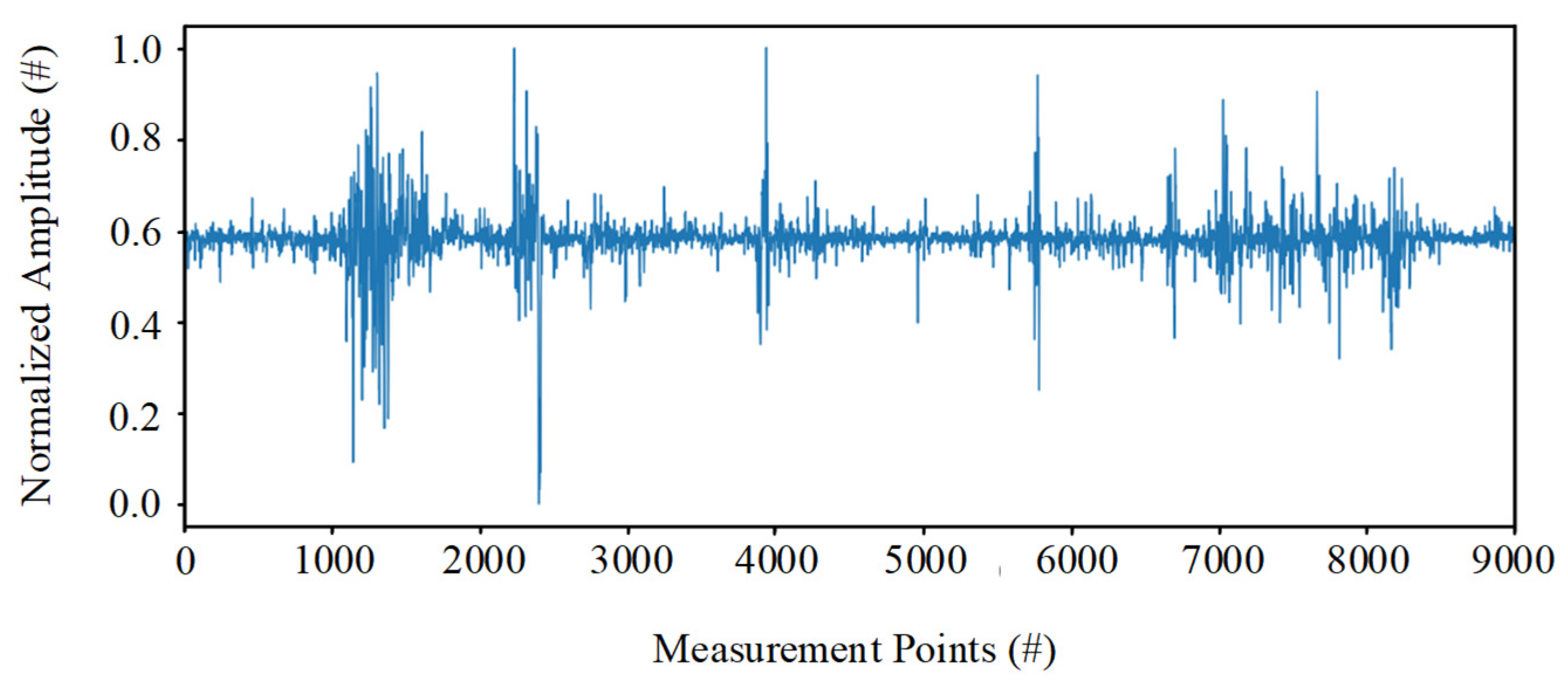
are the maximum and minimum of the entire dataset, respectively. An example of normalized data is shown in
Figure 4.
Note that not all of the vibration data were added to the dataset. We filter the data by amplitude and then concatenate the fragments from different moments to ensure that the dataset is composed of vibrations caused by train passing. The train can be considered a scanner, and when the train passes through the entire experimental track, the vibration caused by the train will be recorded. To facilitate further descriptions, the row of the dataset can be considered a snapshot of the track at moment .
Since data in the same row actually come from different moments and represent the vibration amplitudes of the entire track, we divide the data into spatial fragments in rows. In this way, the sampling rate requirement of the Nyquist criterion for DAS is avoided (only if can the integrated information be retained), because it is unnecessary to analyze the vibration modes of the measurement points in continuous periods in the frequency domain. Instead of detecting all of the measurement points, we only need to detect the fragments, thus reducing the computational cost.
In our scheme, an instance can only describe the amplitude of a fragment at a certain moment, which is considered not comprehensive enough to represent the condition of the fragment. According to the mutual reasoning relationship among the instances at different moments, we merge the instances corresponding to the same fragment with a time interval
into a qualified instance in the form of an RGB image. An example of merging instances is shown in
Figure 5. The time interval t is selected for validation as a hyper-parameter.
4. Semi-Supervised Deep Learning
Semi-supervised deep learning (SSL) leverages unlabeled data to assist the training under four basic assumptions: smoothness assumption, low-density assumption, manifold assumption, and cluster assumption [
26,
27]. SLL reinforces the decision boundary according to the distribution of unlabeled data, as shown in
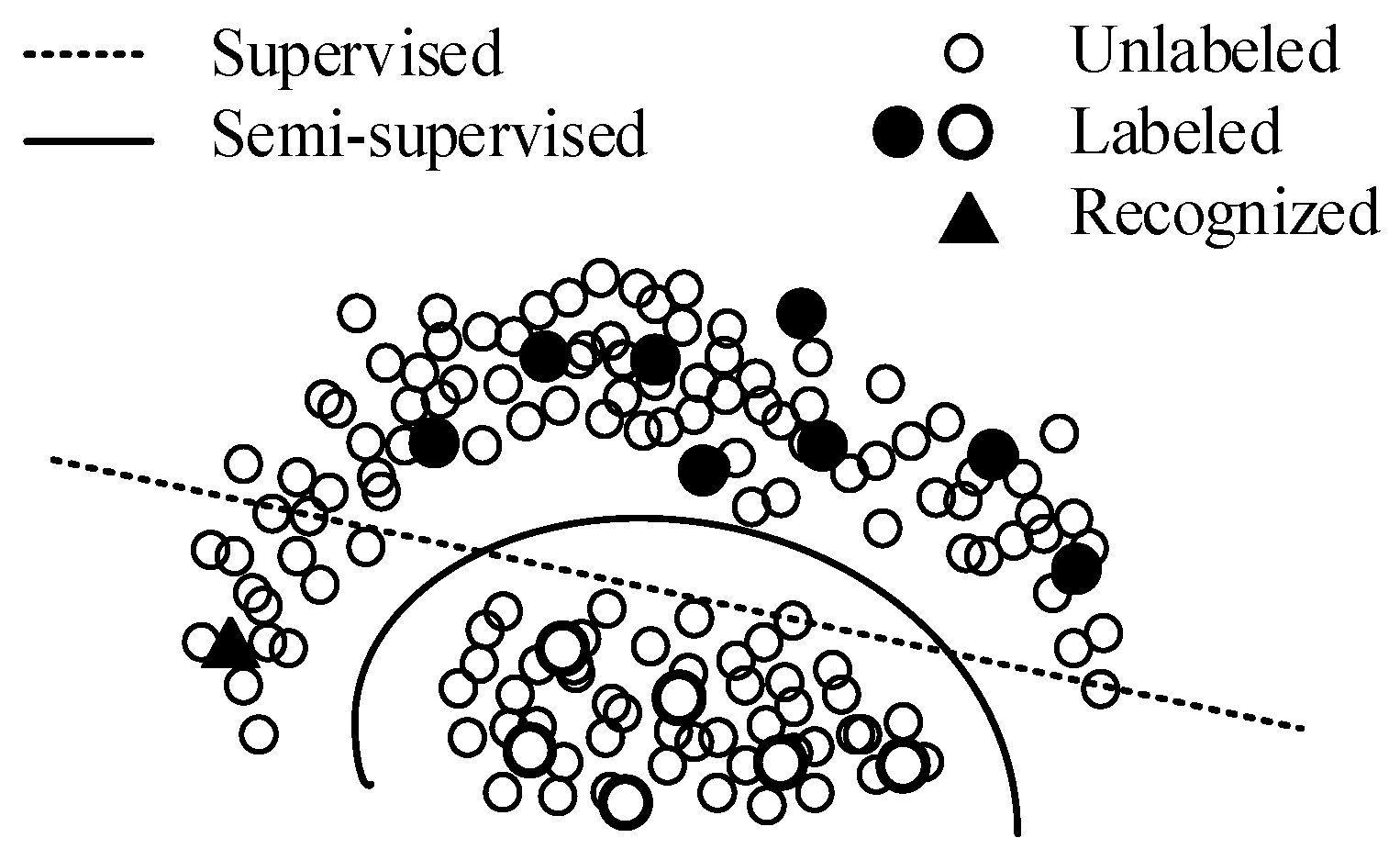
Figure 6.
Figure 6 is a two-dimensional schematic diagram, which abstractly describes the classification using the deep learning method. Solid circles and hollow circles represent the labeled samples in different classes respectively, smaller circles represent unlabeled samples, and the triangle is a sample belonging to the solid class. In the supervised learning method, the samples are represented in the form of vectors, and the model learns a decision boundary for dividing vector clusters (as shown by the dotted line in
Figure 6). Under the decision boundary, the triangle sample will be determined to the hollow class. However, considering the unlabeled samples, even if they have no labels, we can still obtain a more reasonable decision boundary through their distribution (as shown by the solid line in
Figure 6). Now, the triangle sample will be correctly determined to the solid class.
Figure 6 shows how semi-supervised learning helps the model establish a more reasonable decision boundary leveraging the unlabeled samples.
SSL has been extensively studied by researchers, and various solid SSL models have been proposed. One commonly used class of SSL is based on the theory called consistency regularization [
28], which is based on the intuition that the predictions of an instance and its perturbed version should be consistent for a qualified classifier. Therefore, to reinforce the decision boundary, we can minimize the divergence between the predictions of perturbed versions of the same unlabeled instance, such as the temporal ensemble (Pi model) [
29], mean teachers [
30], and UDA [
31]. Another main approach to leverage unlabeled data is called ‘pseudo labeling’, where unlabeled data are given ‘guessed’ labels and join the labeled dataset for further training, such as Co-training [
32] and Tri-training [
32]. In addition, many holistic SSL strategies with superior performance have been proposed in recent years, such as Mix-match [
33], Remix-match [
34], and Fix-match [
22]. Fix-match obtained state-of-the-art in the standard experimental setting described by Odena et al. [
35].
4.1. Approaches of Data Augmentation for SSL
Most SSL strategies build loss functions with the help of data augmentation based on consistency regularization. Data augmentation in SSL can be divided into two types: weak and strong. Weak augmentation includes flip, shift, rotation, and scale, which can only produce slight distortion. On the contrary, strong augmentation can cause heavy distortion by crops, Gaussian blur, dropout, and so on. According to research in UDA, the SSL model can be significantly improved by suitable data augmentation [
31]. Enlightened by this, the commonly used strong augmentations, such as Auto-Augment, Rand-Augment, and CT-augment, are dedicated to the selection of a set of transformations suiting the task better. CT-Augment outperforms the others in terms of computational cost and efficiency [
24].
4.2. Loss Function and Pipeline
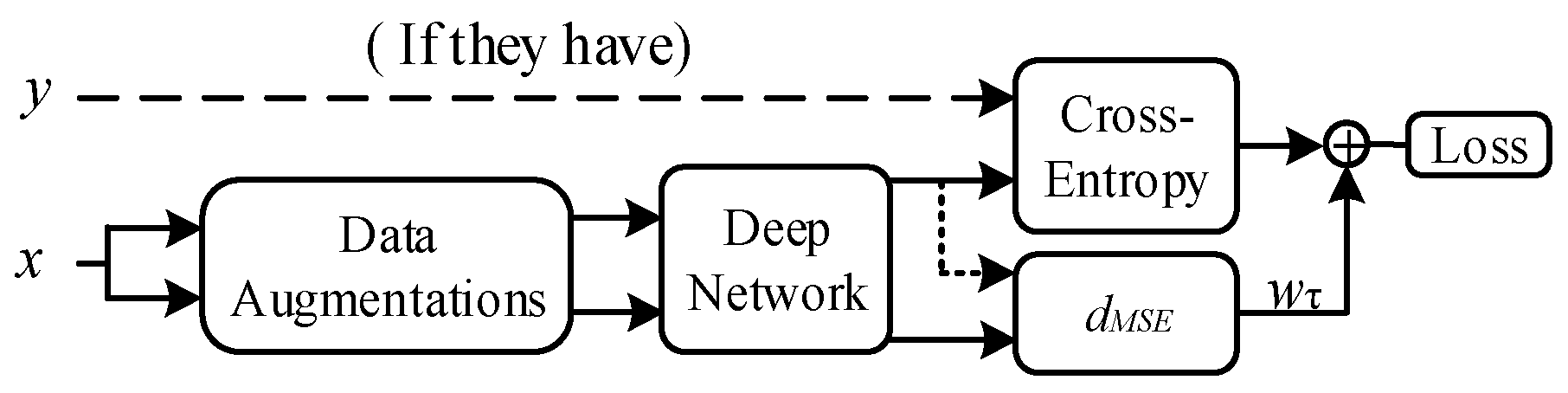
Except for wrapper methods (such as Co-training, Tri-training, and Co-forest), there is always a loss term corresponding to the unlabeled data in the loss function in SSL. Consistency regularization methods build loss terms utilizing the predictions of two different perturbed versions of the same unlabeled data via the loss function:
where
is the amount of unlabeled data,
and
are two different perturbed versions of unlabeled data
,
is the prediction presented by the model, and
is the weight of the unlabeled loss term. We need to change
over the training because unlabeled data cause too much disturbance in the early stages. The pipeline of the SSL based on consistency regularization is shown in
Figure 7.
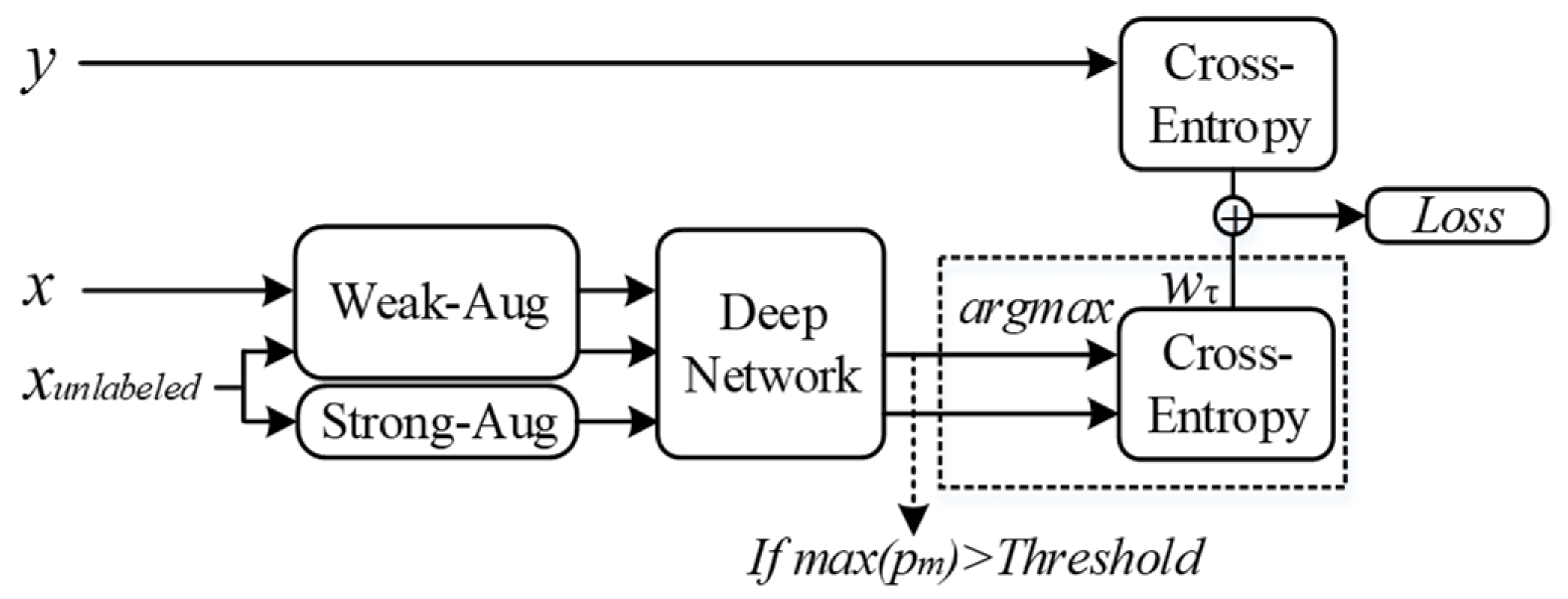
In pseudo-labeling methods, unlabeled data will be given a pseudo label if the model is confident enough in the prediction. In each round of iteration, the cross-entropy between the prediction of unlabeled data and their pseudo labels (if they have) will be made and join the global loss via the loss function:
where
is the threshold that determines whether the model is confident enough.
is the pseudo label of unlabeled data
under weak augmentation
, and
is a strong augmentation. The pipeline of the Fix-match is shown in
Figure 8.
In order to select the most suitable SSL model for track detection, we will use the SSL models as a hyper-parameter in validation, including UDA, Tri-training, and Fix-match.
6. Discussion
In this paper, we propose a track detection method that innovatively leverages semi-supervised deep learning based on image recognition, with a particular dataset pre-processing and a greedy algorithm for the selection of hyper-parameters. The accuracy reached 97.91%, which is satisfactory. In this section, we discuss some details of our research and point out our limitations, and the ideas for further research are proposed.
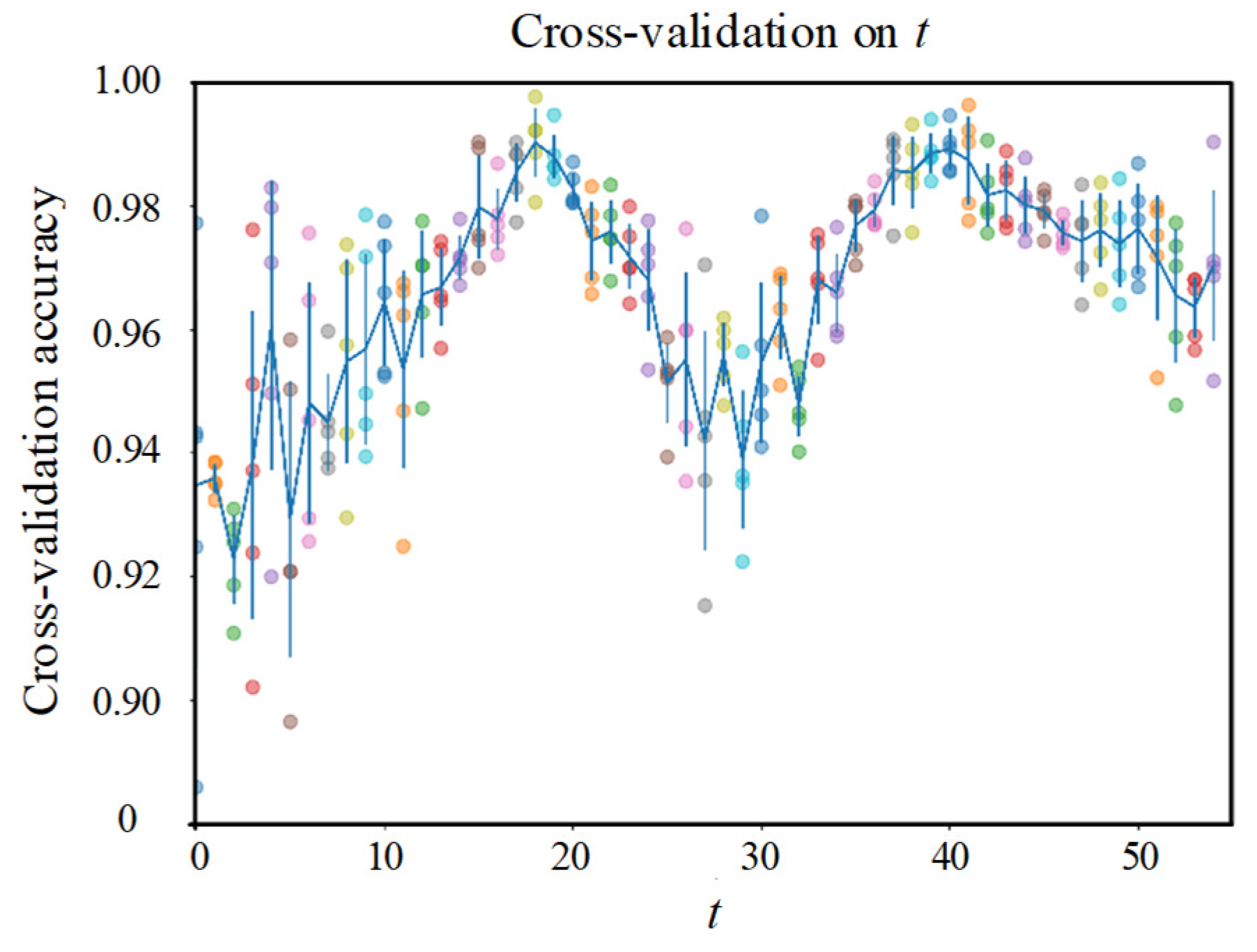
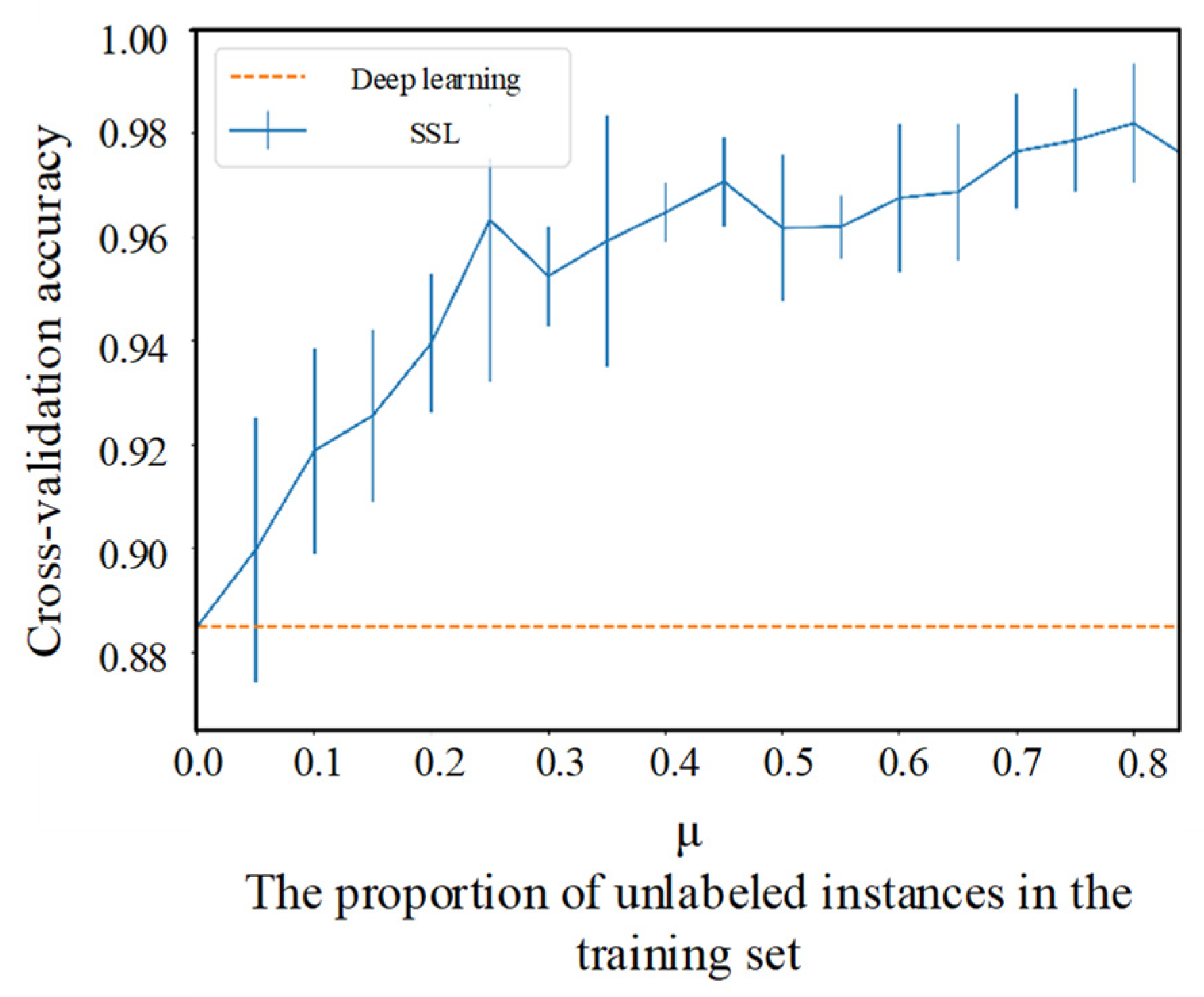
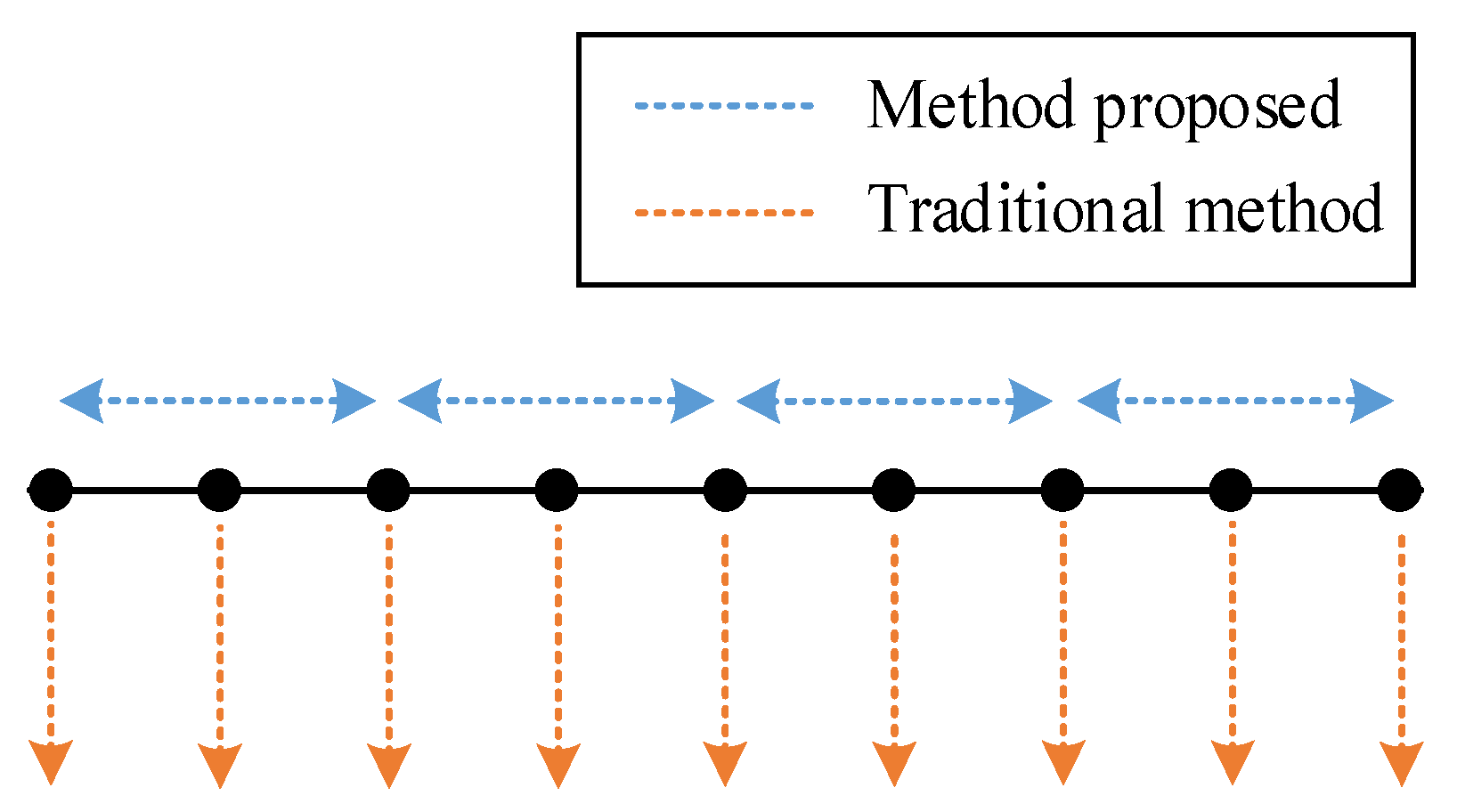
Firstly, there is a trade-off between the traditional deep learning-based methods and our method. We achieved a low computational cost and low sampling frequency requirement in detection with the cost of spatial accuracy, as shown in
Figure 14. However, traditional methods perform better in terms of spatial accuracy. Moreover, according to the validation results on
t, time and environment can make a difference in the vibration modes of the track, which is consistent with the intuition of the researchers. This may bring some new solutions on how to expand (or augment) datasets when labeled data are limited in engineering situations. Using data from different times and environments may be a type of data augmentation analogous to flip and shift for image recognition. In addition, an outperformed classifier is not always a good solution for specific tasks. Only when meeting the different biases of each class required in the actual project can a classifier be applied, which is an important factor in the application of deep learning. For DAS, higher spatial resolution may lead to higher prices. However, in our method, higher spatial resolution means that each device can cover a longer distance. Therefore, using expensive equipment is counter-intuitively a more economical approach. In addition, due to the bottleneck of transmission rate, embedding the defect detection system into the DAS is a low-cost method to improve the actual sampling rate and detection accuracy of the system.
The main drawback of our method is that our method cannot evaluate the severity of defects and their evolution. We used deep learning models, so in fact, we did not actually model the mechanism of defects. To evaluate the severity and the evolution, we must use a dataset with severity labels. It is difficult to obtain such a dataset because it requires professionals to manually label the severity of the defects and requires high labor cost. In addition, there are still some limitations of our research:
- (1)
Since the defects are rare on the railways in operation, and the tracks that can be used for research are very limited due to the security policy, there are not enough defects that can be used in our research to prove that all kinds of defects can be found by the proposed method. Considering the base assumption of SSL mentioned in
Section 3, in other defects, there may not be a special density area for classification.
- (2)
Under special conditions, such as in a tunnel full of echoes, vibration may be distorted owing to the influence of complex environmental noise, leading to classification errors. In addition, it is almost impossible to detect under a large amount of environmental noise in a data-driven manner. Therefore, it is necessary to preprocess the data according to the environment.
- (3)
The vibration modes of the defects may change with environment, and automatic online learning may lead to errors being inherited and amplified. Therefore, a traditional track detection method is necessary for updating the proposed method.
- (4)
According to the security requirements of high-speed railways, a detection system based on black-box models cannot be fully trusted. Thus, it can only be used as a supplement in real-time detections.
- (5)
In fact, our method is a classification task rather than a recognition task, and the number of categories is set in advance. Therefore, we need all types of defects to be marked before the training. However, it is difficult to guarantee that all defects are marked in a general situation. In order to solve this problem, we can add an additional ‘unknown’ category and classify samples that are not similar to existing training samples into this category.
There are two main research directions in this area. The first is the interpretability of the black-box models. Although we have explained the safety-related cost sensitivity classification in
Section 5.4, the black-box models based on deep learning still cannot be fully trusted in safety-related areas. We should try to combine deep learning with traditional machine learning, such as decision trees, and try to use white-box models to explain the intermediate steps of the black-box models. Secondly, data representation is another direction of concern. It is the key to deep learning applications in engineering tasks that transform engineering problems into general deep learning problems. Finding a more suitable data representation to fit actual data into the existing deep learning model will be one of our main research topics in the future.



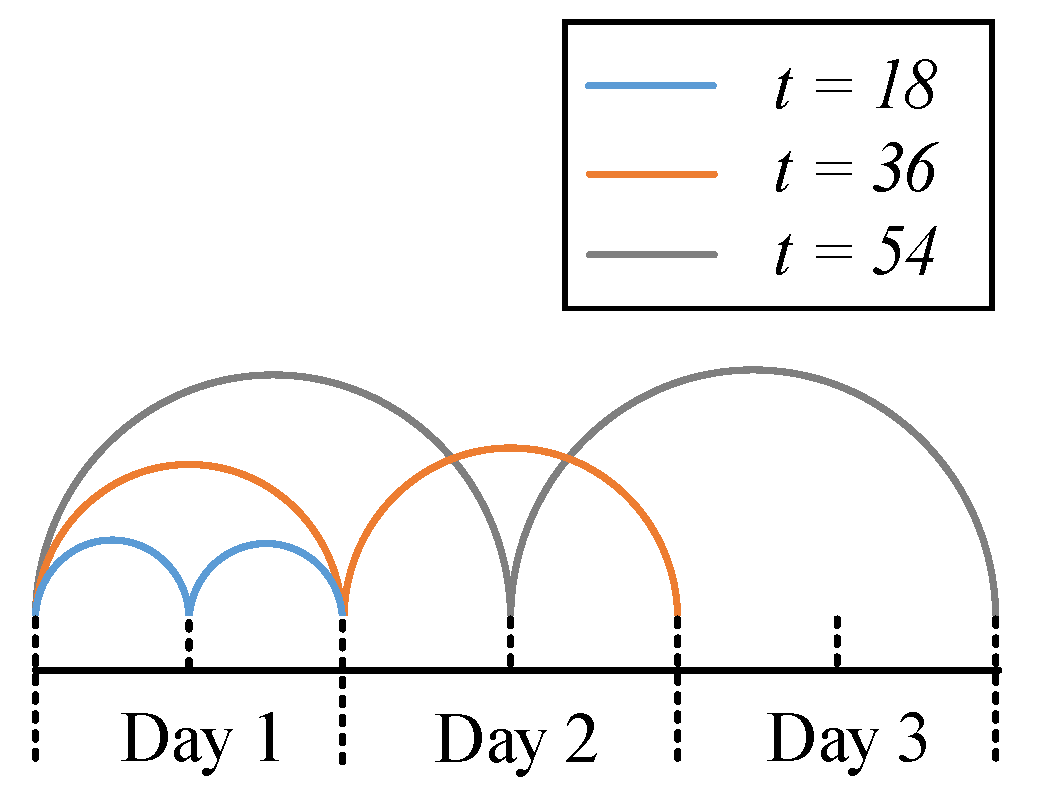

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}