

A Method of Deep Learning Model Optimization for Image Classification on Edge Device


Abstract
:1. Introduction
2. Related Work
3. System Model
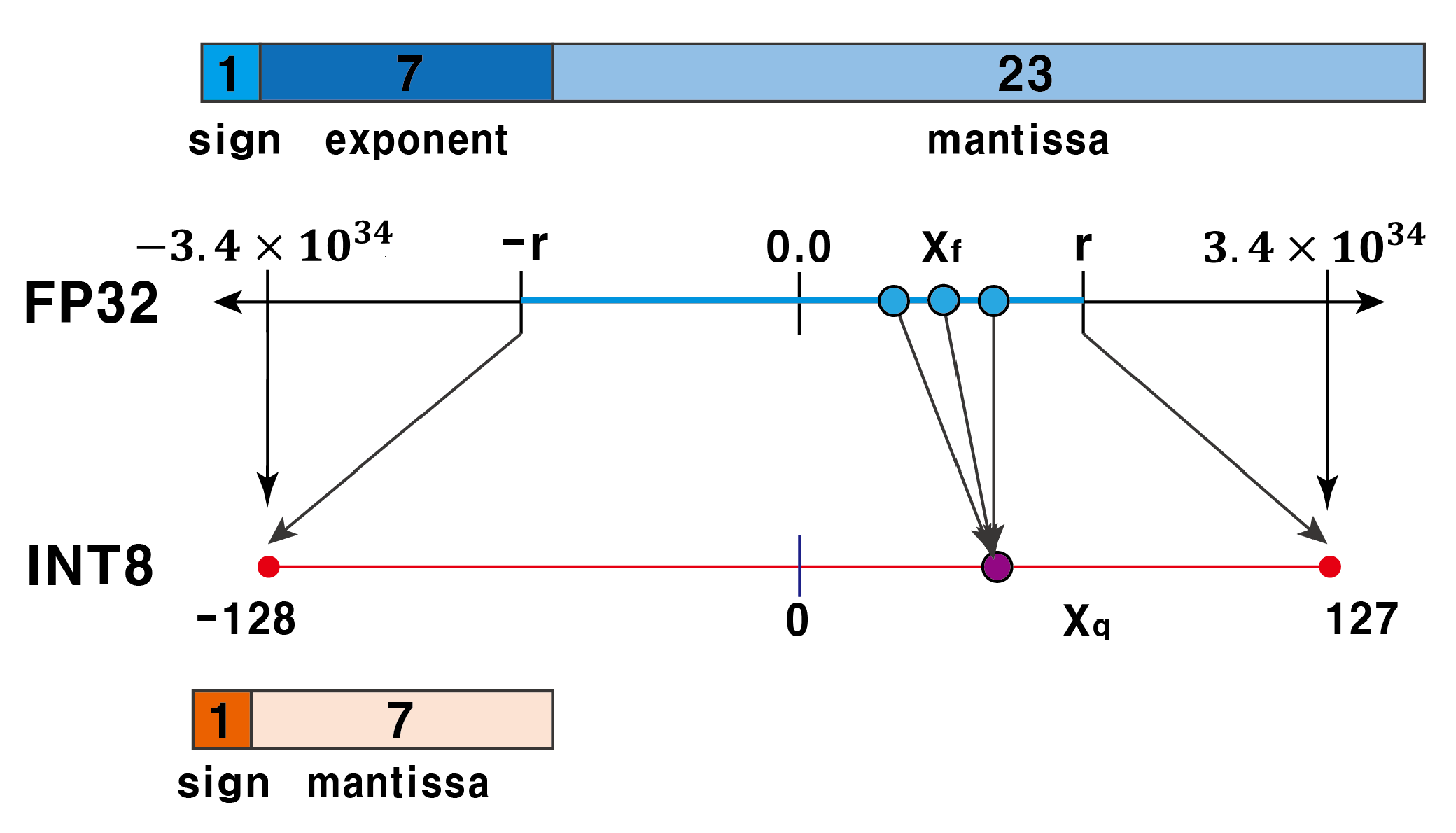
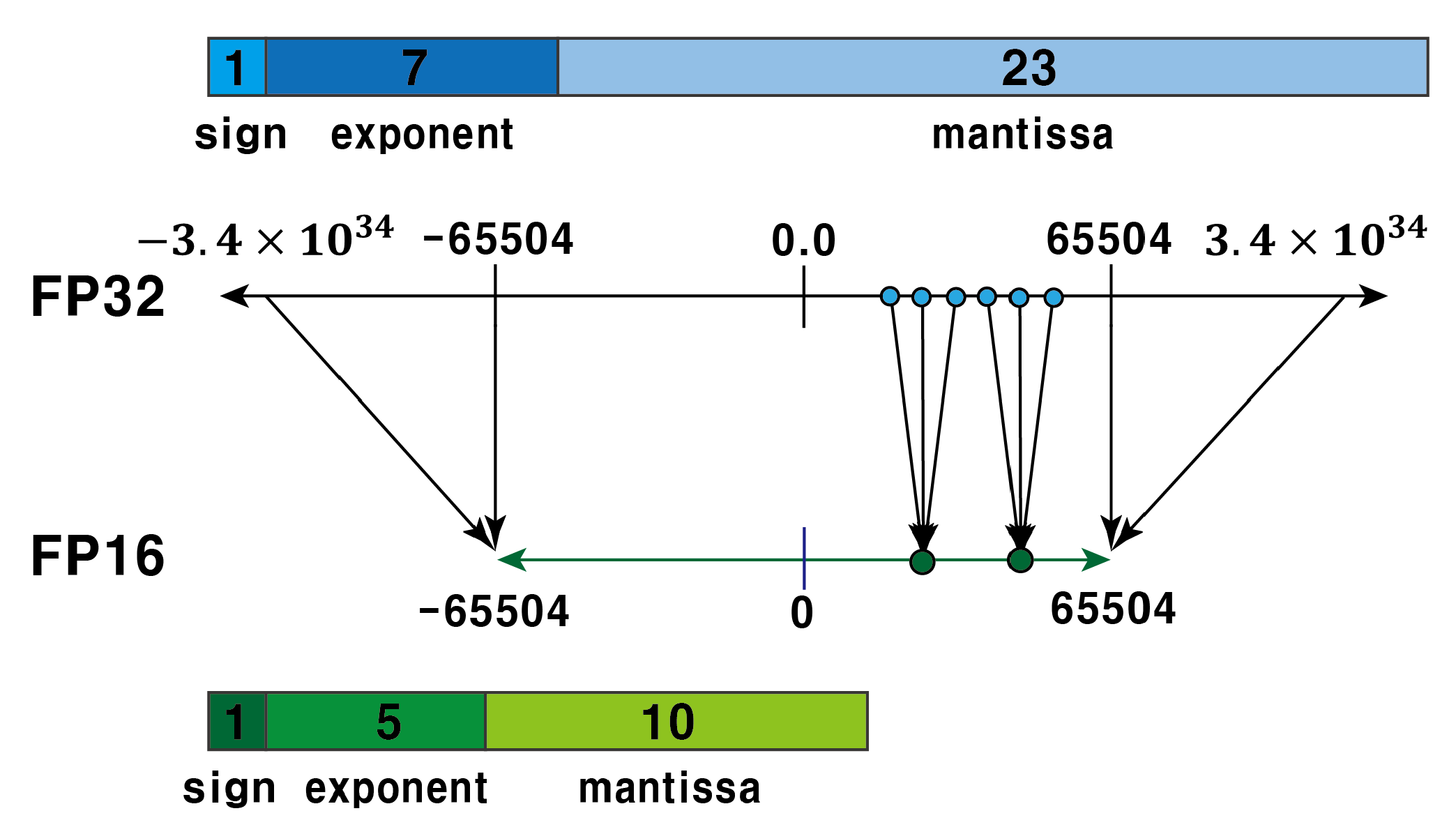
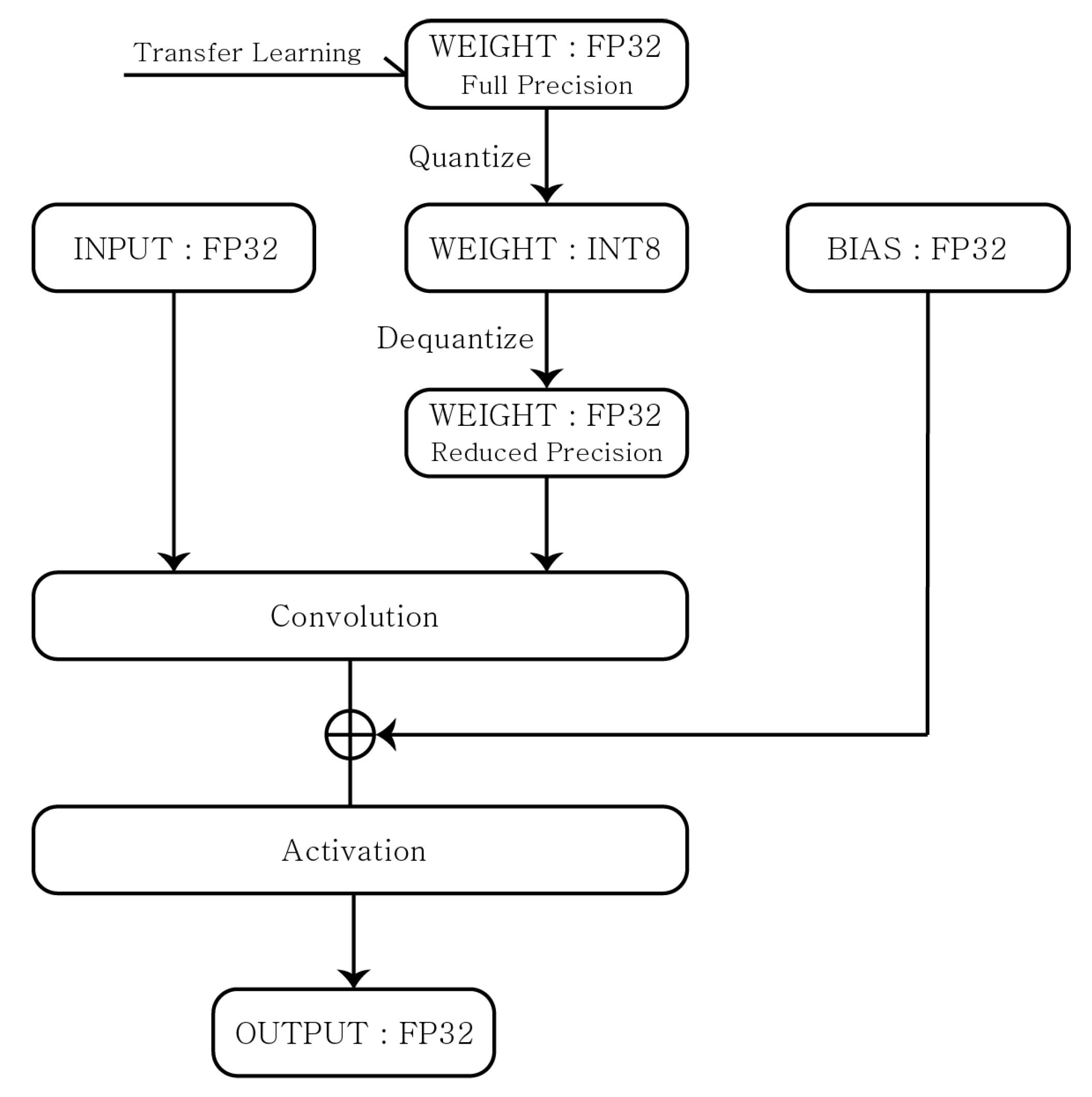
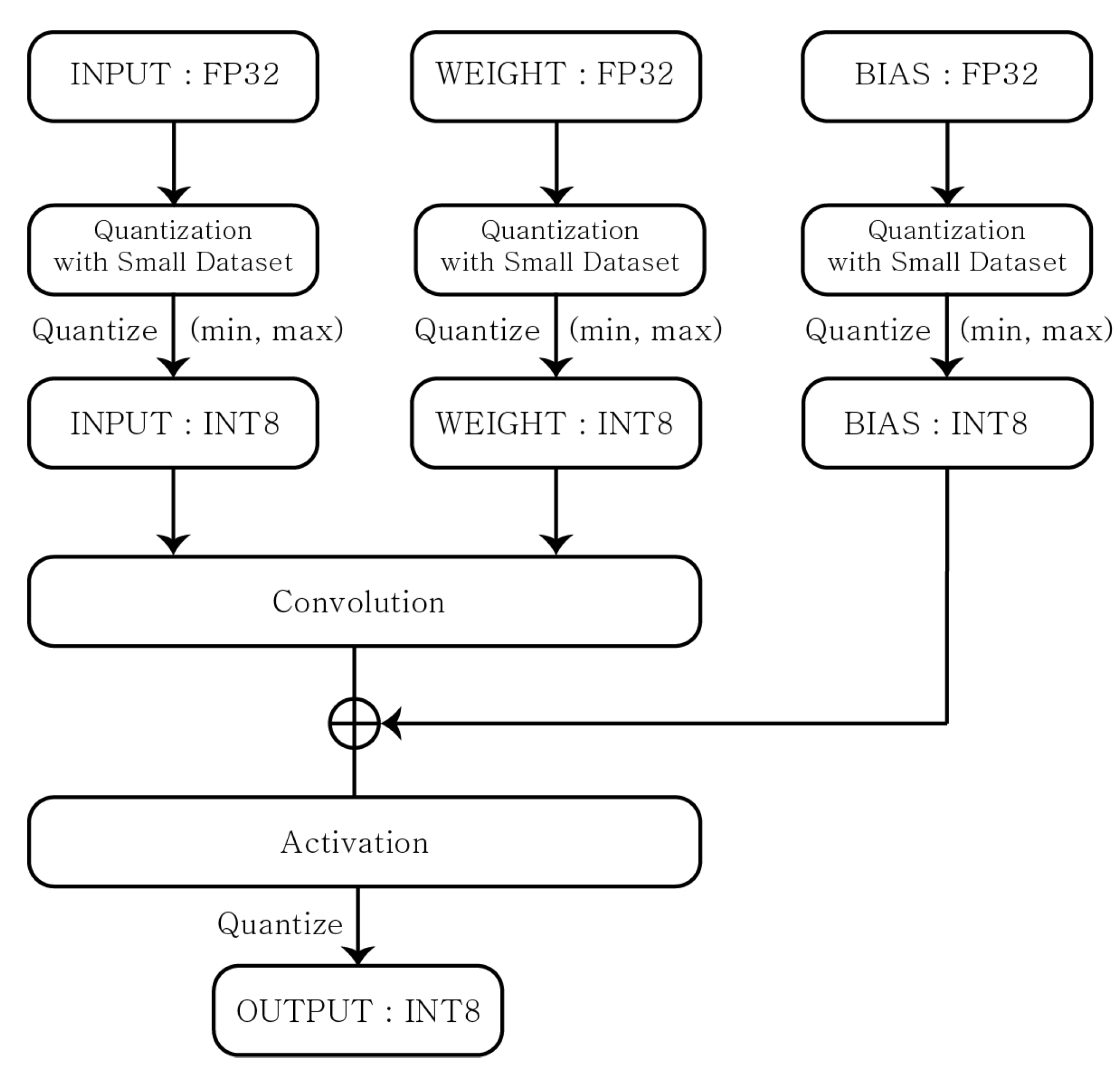
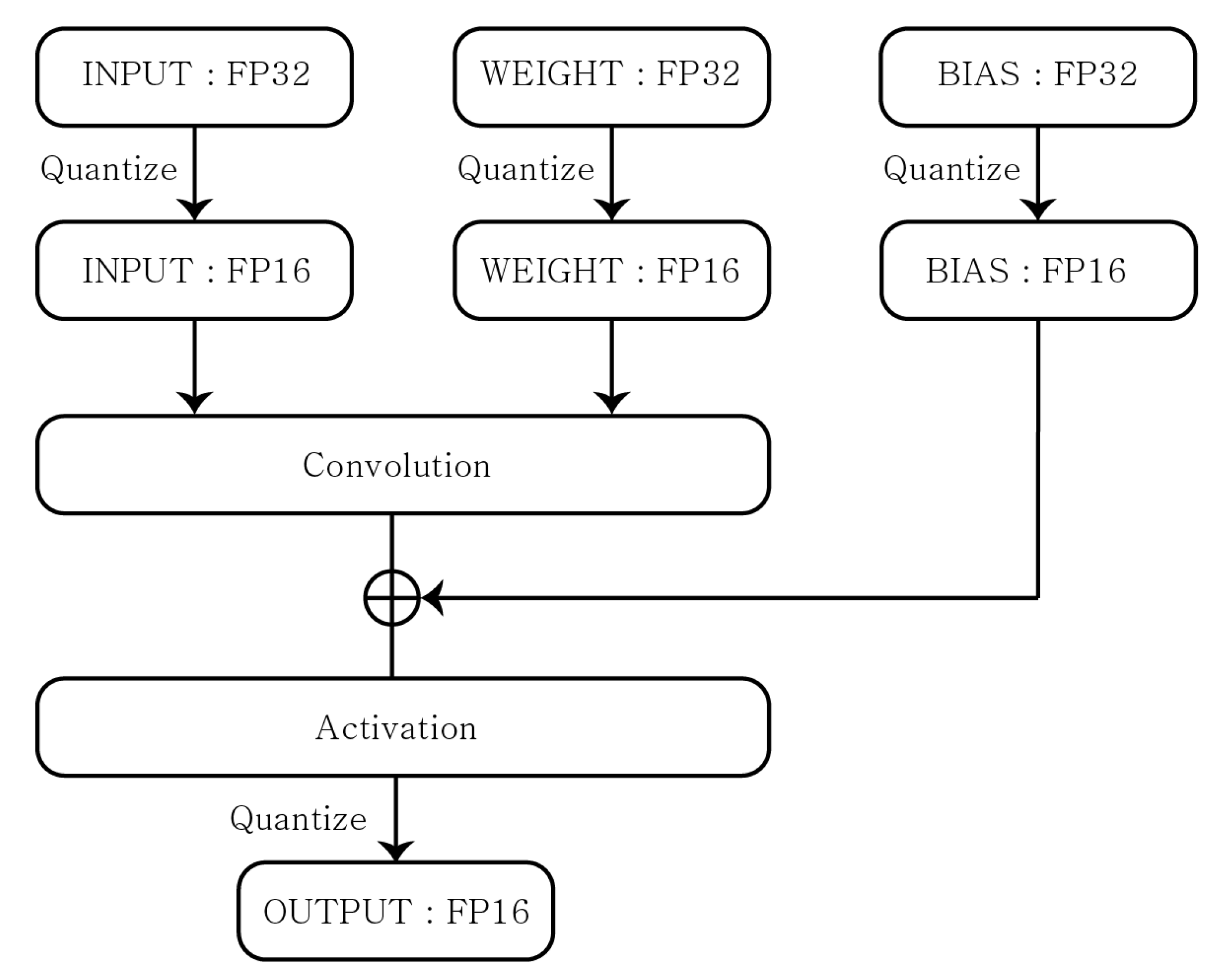
3.1. Quantization Technique
- Post-Training Quantization(PTQ): A method of training weights with FP32 and then quantizing the results into smaller datatypes;
- Quantization Aware Training (QAT): A method of training weights for maximizing their accuracy with the quantized datatype.
3.2. Pruning
3.3. Knowledge Distillation
4. Simulation Results
4.1. Performance of Quantization and Pruning
4.2. Performance Evaluation of Light-Weight CNNs
4.3. Optimization Strategy
- Low-end AIoT Service: Aims for low-end AIoT service such as vacant parking space detection. Their deep learning models are loaded on the small memory of the IoT device in each parking lot, but the service is not delay-sensitive. In addition, the scale of the required dataset is small, e.g., two classes with vacant and occupied classes:
- Mid-end AIoT Service: Aims for Mid-end AIoT Service, such as license plate recognition. The number of classes to be recognized is around 10∼20, and the difficulty of recognition is easy. In addition, the model is normally embedded on IoT devices, and real-time performance is required.
- High-end AIoT Service: Aims for High-end AIoT Service, such as autonomous driving. Both real-time performance and accuracy are required.
- Neural Network Selection: The neural network model for DLMO needs to be selected considering the scale of the datasets.
- Low-end AIoT Service: It is recommended to utilize PRQ because it can minimize the model size with minimal accuracy drops.
- Mid-end AIoT Service: It is recommended to utilize PRN because it guarantees all performances of accuracy, latency and size reduction.
- High-end AIoT Service: It is better to use F16 or PRN because it guarantees all performances of accuracy, latency and size reduction.
- KD: For the low-to-high end AIoT services, KD can be used simultaneously with the aforementioned techniques for boosting the accuracy of the reduced model.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, F.; Tang, G.; Li, Y.; Cai, Z.; Zhang, X.; Zhou, T. A Survey on Edge Computing Systems and Tools. Proc. IEEE 2019, 107, 1537–1562. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Gundluru, N.; Rajput, D.S.; Lakshmanna, K.; Kaluri, R.; Shorfuzzaman, M.; Uddin, M.; Rahman Khan, M.A. Enhancement of Detection of Diabetic Retinopathy Using Harris Hawks Optimization with Deep Learning Model. Comput. Intell. Neurosci. 2022, 2022, 8512469. [Google Scholar] [CrossRef] [PubMed]
- Palve, A.; Patel, H. Towards Securing Real Time Data in IoMT Environment. In Proceedings of the International Conference on Communication Systems and Network Technologies (CSNT), Bhopal, India, 24–26 November 2018. [Google Scholar]
- Lakshmanna, K.; Kaluni, R.; Gundluru, N.; Alzamil, Z.; Rajput, D.S.; Khan, A.A.; Haq, M.A.; Alhussen, A. A Review on Deep Learning Techniques for IoT Data. Electronics 2022, 11, 1604. [Google Scholar] [CrossRef]
- Rajput, D.S.; Reddy, T.S.K.; Raju, D.N. Investigation on Deep Learning Approach for Big Data: Applications and Challenges. Deep. Learn. Neural Netw. Concepts Methodol. Tools Appl. 2020, 11, 1604. [Google Scholar]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model Compression and Hardware Acceleration for Neural Networks: A Comprehensive Survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.; Keutzer, K. A Survey of Quantization Methods for Efficient Neural Network Inference. arXiv 2021, arXiv:2103.13630. [Google Scholar]
- TensorFlow for Mobile and Edge. Available online: https://www.tensorflow.org/lite (accessed on 1 March 2022).
- Zhu, M.; Gupta, S. To Prune, or Not To Prune: Exploring the Efficacy of Pruning for Model Compression. arXiv 2017, arXiv:1710.01878. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Conference on Neural Information Processing Systems(NeurIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Lin, J.; Chen, W.-M.; Lin, Y.; Cohn, J.; Gan, C.; Han, S. MCUNet: Tiny Deep Learning on IoT Devices. Adv. Neural Inf. Process. Syst. 2020, 33, 11711–11722. [Google Scholar]
- Lin, J.; Chen, W.-M.; Cai, H.; Gan, C.; Han, S. MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zoph, B.; Le, Q. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning(PMLR), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Bello, I.; Fedus, W.; Du, X.; Cubuk, E.; Srinivas, A.; Lin, T.; Shlens, J.; Zoph, B. Revisiting ResNets: Improved Training and Scaling Strategies. Adv. Neural Inf. Process. Syst. 2021, 34, 22614–22627. [Google Scholar]
- Custom On-Device ML Models with Learn2Compress. Google AI Blog. 2018. Available online: https://ai.googleblog.com/2018/05/custom-on-device-ml-models.html (accessed on 1 March 2022).
- David, R.; Duke, J.; Jain, A.; Reddi, V.J.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Regev, S.; et al. Tensorflow Lite Micro: Embedded Machine Learning for TinyML systems. arXiv 2021, arXiv:2010.08678. [Google Scholar]
- Lai, L.; Suda, N.; Chandra, V. CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs. arXiv 2018, arXiv:1801.06601. [Google Scholar]
- Gural, A.; Murmann, B. Memory-Optimal Direct Convolutions for Maximizing Classification Accuracy in Embedded Applications. In Proceedings of the 36th International Conference on Machine Learning(PMLR), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Sakr, F.; Bellotti, F.; Berta, R.; De Gloria, A.; Doyle, J. Memory-Efficient CMSIS-NN with Replacement Strategy. In Proceedings of the IEEE International Conference on Future Internet of Things and Cloud(FiCloud), Rome, Italy, 23–25 August 2021. [Google Scholar]
- Müksch, S.; Olausson, T.; Wilhelm, J.; Andreadis, P. Quantitative Analysis of Image Classification Techniques for Memory-Constrained Devices. arXiv 2020, arXiv:2005.04968. [Google Scholar]
- IEEE STD 754-2019; IEEE Standard for Floating-Point Arithmetic. IEEE: Piscataway, NJ, USA, 2019; pp. 1–84.
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. arXiv 2021, arXiv:2006.05525. [Google Scholar] [CrossRef]
- Meng, Z.; Zhao, Y.; Gong, Y. Conditional Teacher-Student Learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Kim, S.W.; Kim, H.E. Transferring Knowledge to Smaller Network with Class-Distance Loss. In Proceedings of the International Conference on Learning Representations(ICLR) RobustML Workshop, Toulon, France, 24–26 April 2017. [Google Scholar]
- Muller, R.; Kornblith, S.; Hinton, G.E. When Does Label Smoothing Help? In Proceedings of the Conference on Neural Information Processing Systems(NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Ding, Q.; Wum, S.; Sun, H.; Gou, J.; Xia, S. Adaptive Regularization of Labels. arXiv 2019, arXiv:1908.05474. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for Thin Deep Nets. arXiv 2015, arXiv:1412.6550. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer. In Proceedings of the International Conference on Learning Representations(ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Kim, J.; Park, S.; Kwak, N. Paraphrasing Complex Network: Network Compression via Factor Transfer. In Proceedings of the Conference on Neural Information Processing Systems(NeurIPS), Montréal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Passalis, N.; Tefas, A. Learning Deep Representations with Probabilistic Knowledge Transfer. In Proceedings of the European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Heo, B.; Lee, M.; Yun, S.; Choi, J.Y. Knowledge Distillation with Adversarial Samples Supporting Decision Boundary. In Proceedings of the Association for the Advancement of Artificial Intelligence(AAAI), Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Heo, B.; Lee, M.; Yun, S.; Choi, J.Y. Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lee, S.H.; Kim, D.H.; Song, B.C. Self-supervised Knowledge Distillation using Singular Value Decomposition. arXiv 2018, arXiv:1807.06819. [Google Scholar]
- Zhang, C.; Peng, Y. Better and Faster: Knowledge Transfer from Multiple Self-supervised Learning Tasks via Graph Distillation for Video Classification. In Proceedings of the International Joint Conferences on Artificial Intelligence(IJCAI), Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Passalis, N.; Tzelepi, M.; Tefas, A. Heterogeneous Knowledge Distillation using Information Flow Modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Huang, Z.; Wang, N. Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. arXiv 2019, arXiv:1707.01219. [Google Scholar]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Ghasemzadeh, H. Improved Knowledge Distillation via Teacher Assistant. In Proceedings of the Association for the Advancement of Artificial Intelligence(AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Li, T.; Li, J.; Liu, Z.; Zhang, C. Few Sample Knowledge Distillation for Efficient Network Compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Chen, D.; Mei, J.P.; Wang, C.; Feng, Y.; Chen, C. Online Knowledge Distillation with Diverse Peers. In Proceedings of the Association for the Advancement of Artificial Intelligence(AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Xie, J.; Lin, S.; Zhang, Y.; Luo, L. Training Convolutional Neural Networks with Cheap Convolutions and Online Distillation. arXiv 2019, arXiv:1909.13063. [Google Scholar]
- Anil, R.; Pereyra, G.; Passos, A.; Ormandi, R.; Dahl, G.E.; Hinton, G.E. Large Scale Distributed Neural Network Training through Online Distillation. In Proceedings of the International Conference on Learning Representations(ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhou, G.; Fan, Y.; Cui, R.; Bian, W.; Zhu, X.; Gai, K. Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net. In Proceedings of the Association for the Advancement of Artificial Intelligence(AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Phuong, M.; Lampert, C.H. Distillation-based Training for Multi-exit Architectures. In Proceedings of the International Conference on Computer Vision(ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Mobahi, H.; Farajtabar, M.; Bartlett, P.L. Self-distillation Amplifies Regularization in Hilbert Space. Adv. Neural Inf. Process. Syst. 2020, 33, 3351–3361. [Google Scholar]
- Zhang, Z.; Sabuncu, M.R. Self-Distillation as Instance-Specific Label Smoothing. Adv. Neural Inf. Process. Syst. 2020, 33, 2184–2195. [Google Scholar]
- Yuan, L.; Tay, F.E.; Li, G.; Wang, T.; Feng, J. Revisit Knowledge Distillation: A Teacher-free Framework. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Yun, S.; Park, J.; Lee, K.; Shin, J. Regularizing Class-wise Predictions via Self-knowledge Distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Hahn, S.; Choi, H. Self-knowledge Distillation in Natural Language Processing. In Proceedings of the International Conference on Recent Advances in Natural Language Processing(RANLP), Varna, Bulgaria, 2–4 September 2019. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Furlanello, T.; Lipton, Z.; Tschannen, M.; Itti, L.; Anandkumar, A. Born Again Neural Networks. In Proceedings of the International Conference on Machine Learning(ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean Teachers Are Better Role Models: Weight-averaged Consistency Targets Improve Semi-supervised Deep Learning Results. In Proceedings of the Conference on Neural Information Processing Systems(NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, H.; Zhao, H.; Li, X.; Tan, X. Progressive Blockwise Knowledge Distillation for Neural Network Acceleration. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Zhu, X.; Gong, S. Knowledge Distillation by On-the-fly Native Ensemble. In Proceedings of the Conference on Neural Information Processing Systems(NeurIPS), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Polino, A.; Pascanu, R.; Alistarh, D. Model Compression via Distillation and Quantization. In Proceedings of the International Conference on Learning Representations(ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Mishra, A.; Marr, D. Apprentice: Using Knowledge Distillation Techniques to Improve Low-precision Network Accuracy. In Proceedings of the International Conference on Learning Representations(ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wei, Y.; Pan, X.; Qin, H.; Ouyang, W.; Yan, J. Quantization Mimic: Towards Very Tiny CNN for Object Detection. In Proceedings of the European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Shin, S.; Boo, Y.; Sung, W. Empirical Analysis of Knowledge Distillation Technique for Optimization of Quantized Deep Neural Networks. arXiv 2019, arXiv:1909.01688. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Proceedings of the Conference on Neural Information Processing Systems(NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference # | Proposed |
|---|---|
| Lin et al., 2020 [17] | A framework that jointly designs the efficient neural architecture and the lightweight inference engine, enabling ImageNet-scale inference on microcontrollers (MCUNet v1). |
| Lin et al., 2021 [18] | A generic patch-by-patch inference scheduling, which operates only on a small spatial region of the feature map and significantly cuts down the peak memory (MCUNet v2). |
| Tan et al., 2019 [24] | A new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple effective compound coefficient (EfficientNet). |
| Bello et al., 2021 [25] | Training and scaling strategies: (1) scale model depth; (2) increase image resolution depending on the training regime. |
| David et al., 2021 [27] | A model-architecture framework that enables hardware vendors to provide platform-specific optimizations and is open to a wide machine-learning ecosystem (TensorFlow Lite Micro). |
| Lai et al., 2018 [28] | An efficient kernels developed to maximize the performance and minimize the memory footprint of neural network applications on Arm Cortex-M processors targeted for intelligent IoT edge devices(CMSIS-NN) |
| Gural et al., 2019 [29] | Memory-optimal direct convolutions as a way to push classification accuracy as high as possible given strict hardware memory constraints at the expense of extra compute. |
| Sakr et al., 2021 [30] | An in-place computation strategy to reduce memory requirements of neural network inference. |
| Müksch et al., 2020 [31] | A comparison among several CNN variations (as like ProtoNN, Bonsai and FastGRNN) to apply 3-channel image classification using CIFAR10. |
| Category | Meaning |
|---|---|
| Response | logit outputs of TSA |
| Feature | intermediate representations of TSA |
| Relation | relation between the feature maps |
| Category | Meaning |
|---|---|
| Offline | KD from a pre-trained teacher model |
| Online | Update the TSM simultaneously |
| Self-Distillation | Online method with same TSA |
| Category | Meaning |
|---|---|
| Same as Teacher | Same architecture with Teacher |
| Reduced Teacher | Reduced architecture from Teacher |
| Light Network | Design with Light-Weight Conv, |
| Quantization and Pruning |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 71.9 | 56 | 4 | 43.5 | 425 | 18 |
| BLQ | 71.9 | 19 | 20 | 43.7 | 112 | 35 |
| FIQ | 72.5 | 18 | 44 | 43.5 | 110 | 53 |
| F16 | 72.1 | 30 | 6 | 43.8 | 214 | 19 |
| QAT | 72.5 | 18 | 42 | 42.5 | 106 | 45 |
| PRN | 68.7 | 16 | 2 | 39.7 | 123 | 2 |
| PRQ | 68.6 | 7 | 19 | 39.7 | 37 | 19 |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 80.7 | 94,052 | 177 | 36.5 | 94,790 | 129 |
| BLQ | 80.3 | 24,161 | 2348 | 36.5 | 24,346 | 2642 |
| FIQ | 80.4 | 24,269 | 2078 | 37.2 | 24,454 | 1997 |
| F16 | 80.6 | 47,072 | 152 | 39.4 | 47,441 | 162 |
| QAT | 80.5 | 24,281 | 2069 | 36.9 | 24,431 | 2001 |
| PRN | 81.2 | 27,503 | 155 | 43.2 | 27,857 | 148 |
| PRQ | 81.2 | 8023 | 2399 | 43.1 | 8059 | 2379 |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 79.6 | 169961 | 336 | 41.3 | 170,698 | 365 |
| BLQ | 79.5 | 43776 | 4576 | 41.5 | 43,960 | 4646 |
| FIQ | 80.8 | 43990 | 4555 | 37.4 | 44,174 | 4726 |
| F16 | 80.2 | 85072 | 329 | 41.4 | 85,441 | 352 |
| QAT | 80.1 | 43799 | 4529 | 37.0 | 44,111 | 4731 |
| PRN | 79.8 | 49704 | 347 | 38.7 | 49,697 | 337 |
| PRQ | 79.8 | 14812 | 4603 | 38.6 | 14,670 | 4587 |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 81.8 | 12,840 | 18 | 42.2 | 13,208 | 34.6 |
| BLQ | 81.8 | 3477 | 346 | 42.2 | 3560 | 379.7 |
| FIQ | 82.4 | 3517 | 332 | 43.1 | 3612 | 330 |
| F16 | 80.9 | 6435 | 22 | 45.1 | 6620 | 30.4 |
| PRQ | 81.0 | 1319 | 350 | 46.1 | 1349 | 350 |
| PRN | 81.0 | 3934 | 18 | 45.9 | 4063 | 19 |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 81.6 | 8924 | 11 | 45.7 | 9386 | 21.7 |
| BLQ | 81.5 | 2663 | 224 | 45.5 | 2782 | 213.6 |
| FIQ | 81.2 | 2730 | 173 | 45.9 | 2848 | 161 |
| F16 | 82.0 | 4509 | 10.6 | 41.5 | 4740 | 21.6 |
| PRQ | 80.2 | 1082 | 213 | 47.2 | 1118 | 221 |
| PRN | 80.5 | 2876 | 8 | 47.1 | 2997 | 7 |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 68.8 | 12,161 | 10 | 34.8 | 12,624 | 24 |
| BLQ | 68.7 | 3269 | 73 | 34.9 | 3389 | 97 |
| FIQ | 69.7 | 3301 | 41 | 35.4 | 3419 | 43 |
| F16 | 72.1 | 6128 | 10 | 35.2 | 6359 | 20 |
| PRQ | 69.6 | 1172 | 64 | 36.0 | 1187 | 69 |
| PRN | 69.7 | 3740 | 6 | 36.2 | 3862 | 7 |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 77.9 | 34,939 | 26 | 37.1 | 35,401 | 37 |
| BLQ | 78.0 | 9122 | 195 | 37.2 | 9239 | 218 |
| FIQ | 77.2 | 9178 | 149 | 36.7 | 9295 | 150 |
| F16 | 77.9 | 17,525 | 26 | 38.1 | 17,756 | 28 |
| PRQ | 75.7 | 3062 | 206 | 39.4 | 3122 | 211 |
| PRN | 75.6 | 10,510 | 19 | 39.3 | 10,653 | 29 |
| Network | Top-1 | MAdds | Params |
|---|---|---|---|
| V3-Large1.0 | 75.2 | 219 | 5.4M |
| V2 1.0 | 72.0 | 300 | 3.4M |
| V3-Small 1.0 | 67.4 | 56 | 2.5M |
| DLMO | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| NQ | 88.8 | 1899 | 39 | 60.5 | 192 | 50 |
| BLQ | 88.8 | 537 | 1820 | 59.4 | 544 | 1860 |
| FIQ | 88.7 | 538 | 1913 | 59.3 | 544 | 2009 |
| F16 | 86.7 | 982 | 39 | 60.0 | 994 | 51 |
| QAT | 88.6 | 540 | 1916 | 58.9 | 549 | 2002 |
| PRN | 87.6 | 547 | 42 | 60.2 | 572 | 37 |
| PRQ | 87.6 | 195 | 1902 | 60.3 | 200 | 1860 |
| DLMO | Original | KD | ||||
|---|---|---|---|---|---|---|
| Eval | Acc | Size | Lat | Acc | Size | Lat |
| Setup | (%) | (KB) | (ms) | (%) | (KB) | (ms) |
| M1 | 81.8 | 12,840 | 18 | 86.3 | 12,840 | 18 |
| M2 | 81.6 | 8924 | 11 | 85.4 | 8924 | 11 |
| M3L | 77.9 | 34,939 | 26 | 60.5 | 34,939 | 26 |
| M3s | 68.8 | 12,161 | 10 | 60.5 | 12,161 | 10 |
| M1-F16 | 80.9 | 6435 | 22 | 86.3 | 192 | 50 |
| M2-F16 | 82.0 | 4509 | 10.6 | 85.4 | 192 | 50 |
| M1-PR | 81.0 | 3934 | 18 | 86.3 | 192 | 50 |
| M2-PR | 80.5 | 2876 | 8 | 85.4 | 192 | 50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.; Lee, N.; Lee, S. A Method of Deep Learning Model Optimization for Image Classification on Edge Device. Sensors 2022, 22, 7344. https://doi.org/10.3390/s22197344
Lee H, Lee N, Lee S. A Method of Deep Learning Model Optimization for Image Classification on Edge Device. Sensors. 2022; 22(19):7344. https://doi.org/10.3390/s22197344
Chicago/Turabian StyleLee, Hyungkeuk, NamKyung Lee, and Sungjin Lee. 2022. "A Method of Deep Learning Model Optimization for Image Classification on Edge Device" Sensors 22, no. 19: 7344. https://doi.org/10.3390/s22197344
APA StyleLee, H., Lee, N., & Lee, S. (2022). A Method of Deep Learning Model Optimization for Image Classification on Edge Device. Sensors, 22(19), 7344. https://doi.org/10.3390/s22197344