

A Monitoring Method Based on FDALM and Its Application in the Sintering Process of Ternary Cathode Material



Abstract
:1. Introduction
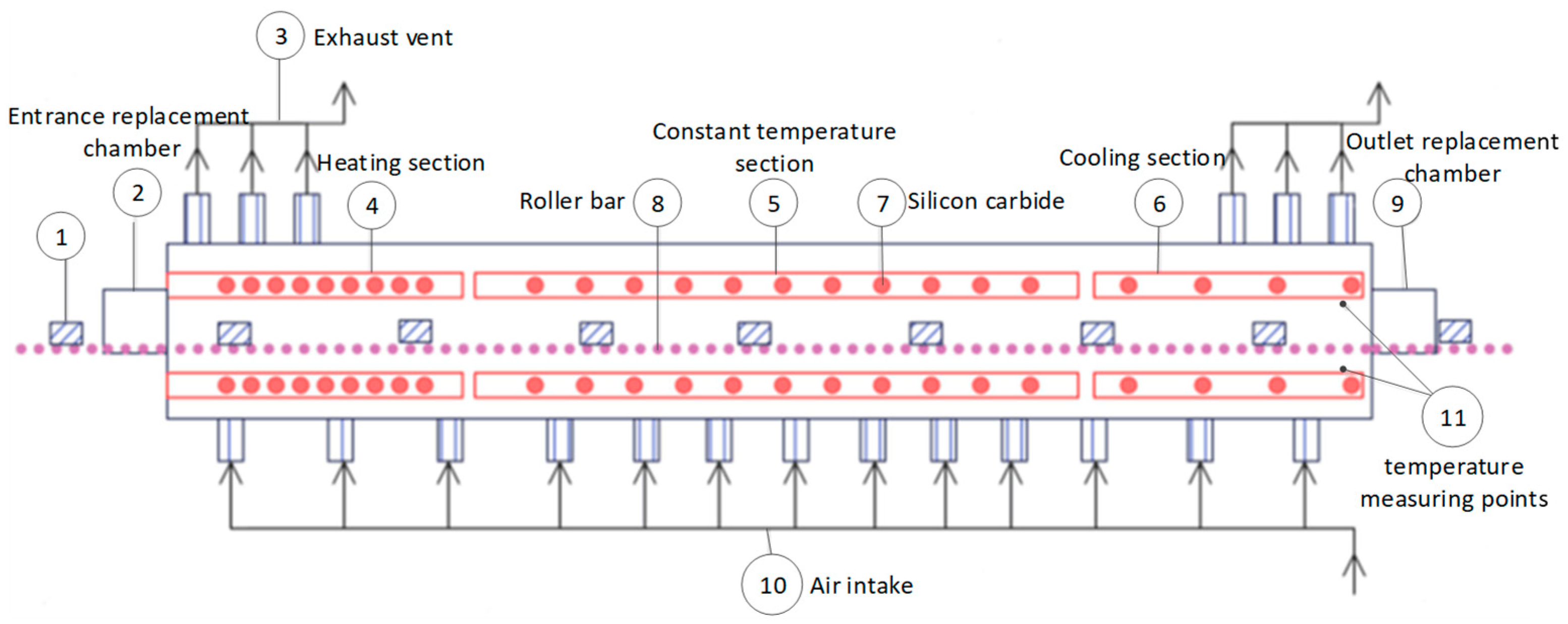
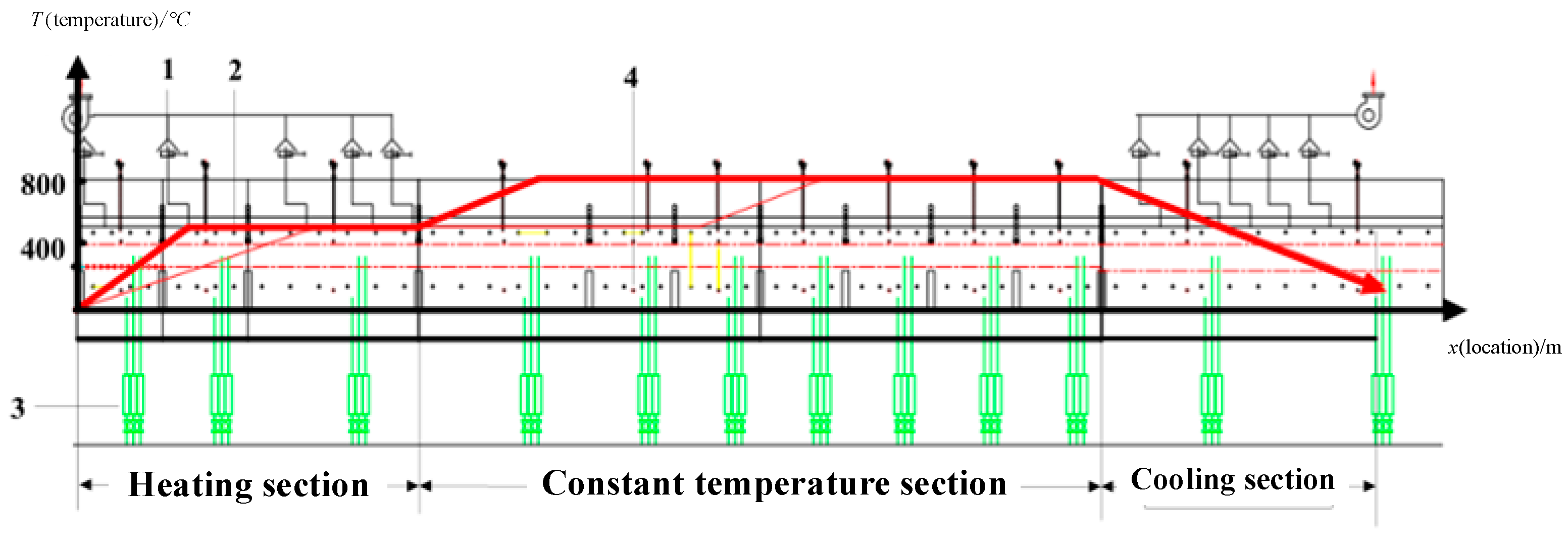
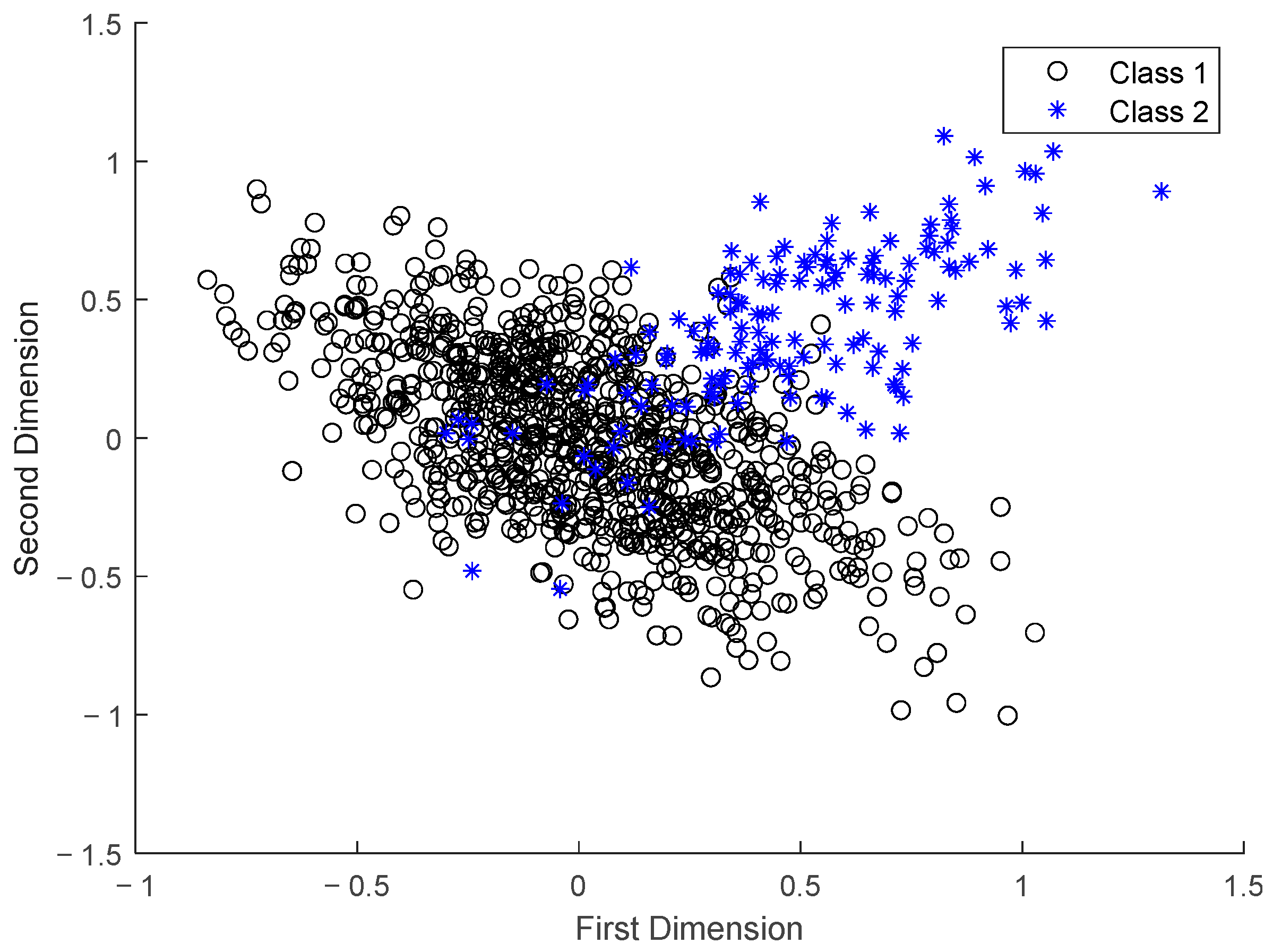
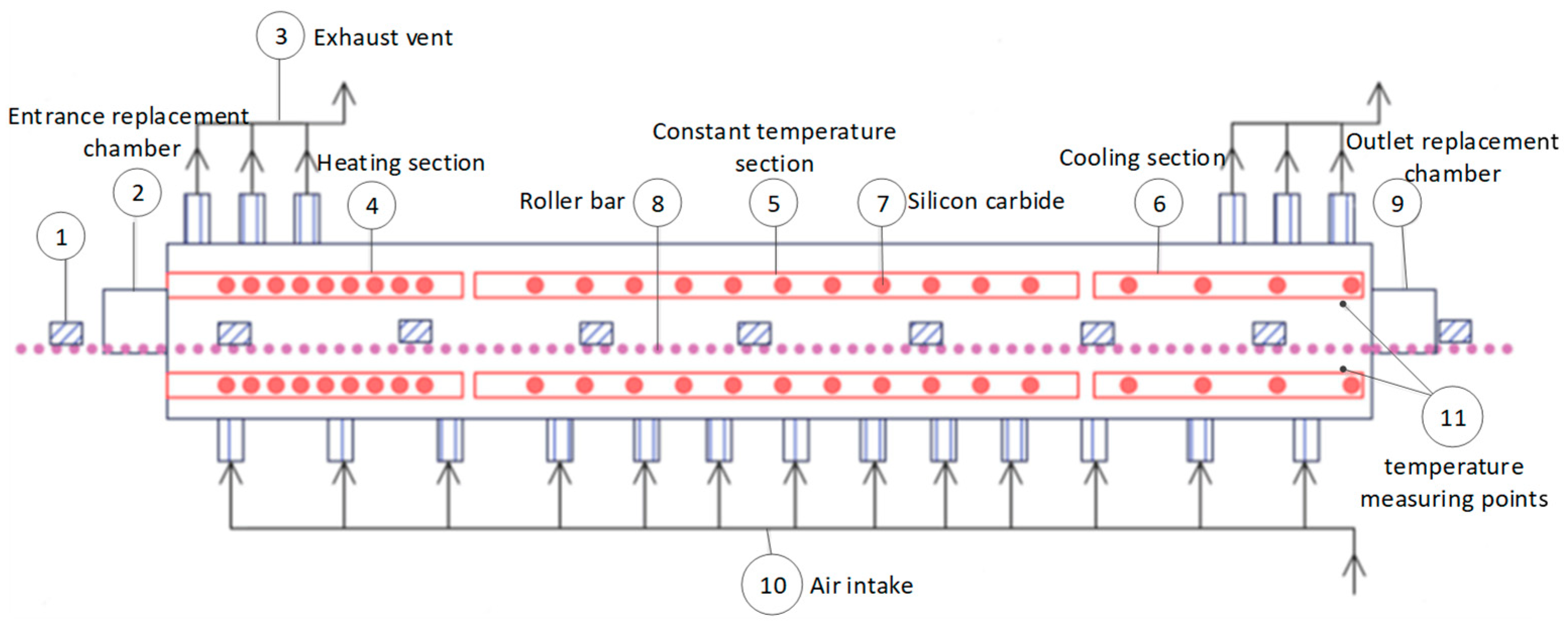
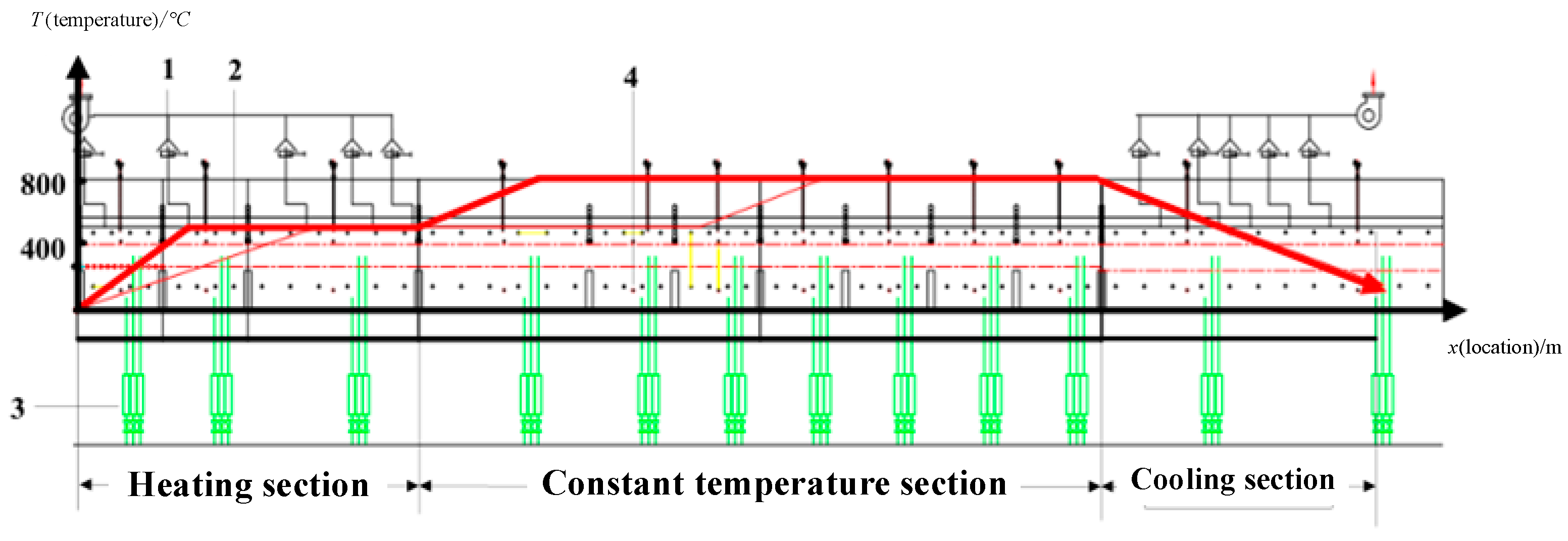
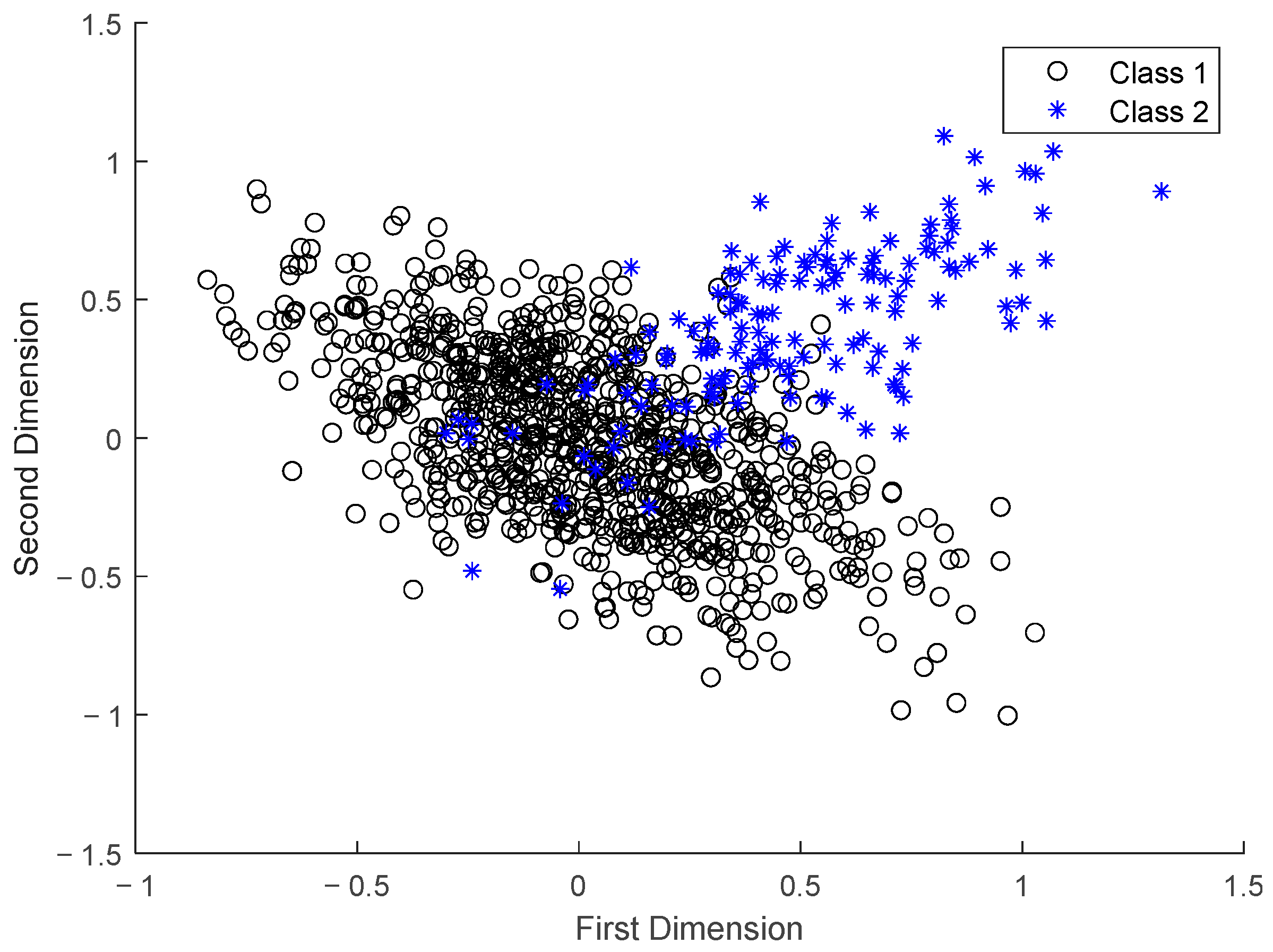
2. Description of the Problem in Monitoring the Preparation Process of Ternary Cathode Material
3. Factor Dynamic Autoregressive Latent Variable Model
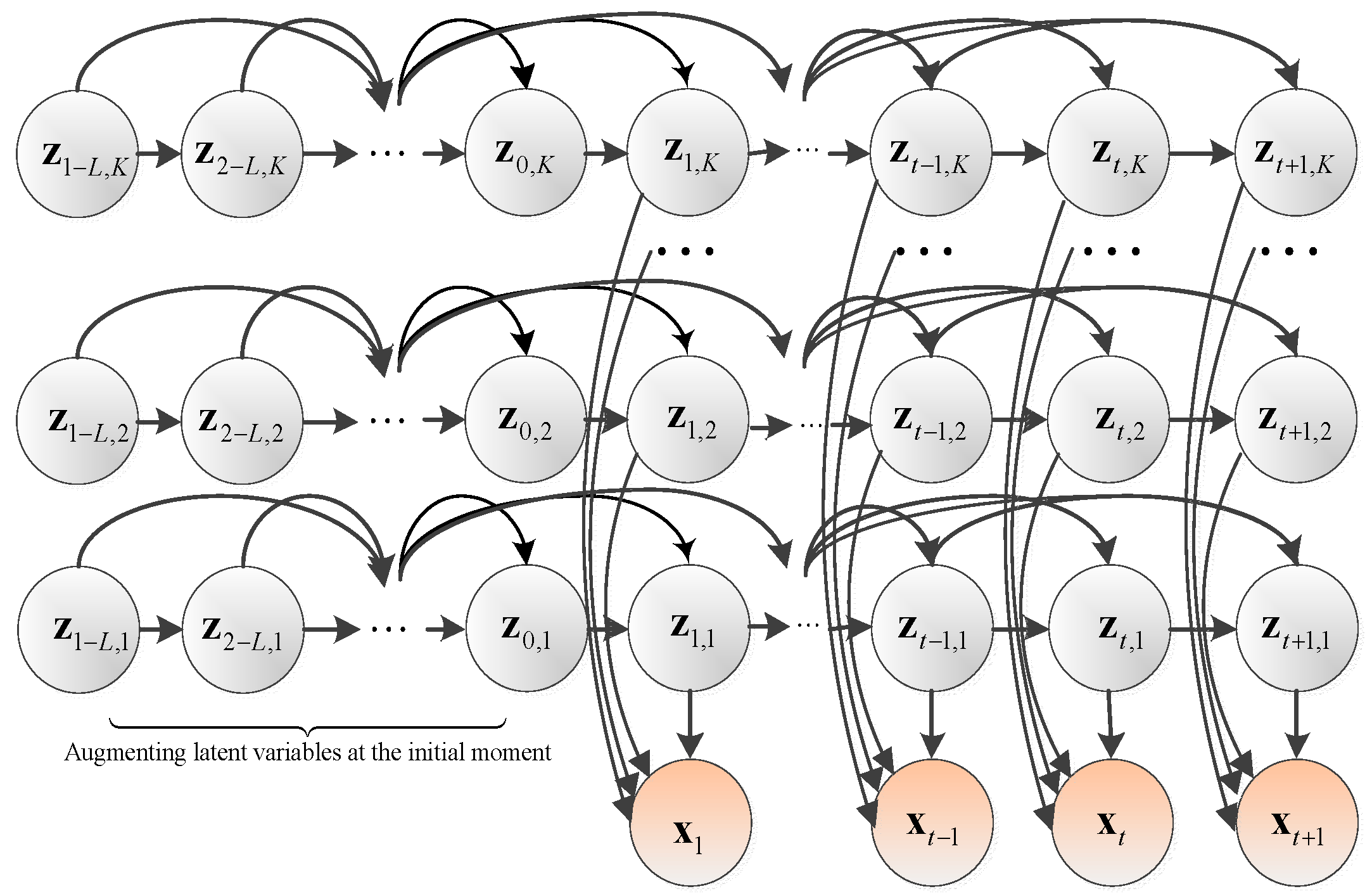
3.1. Model Structure
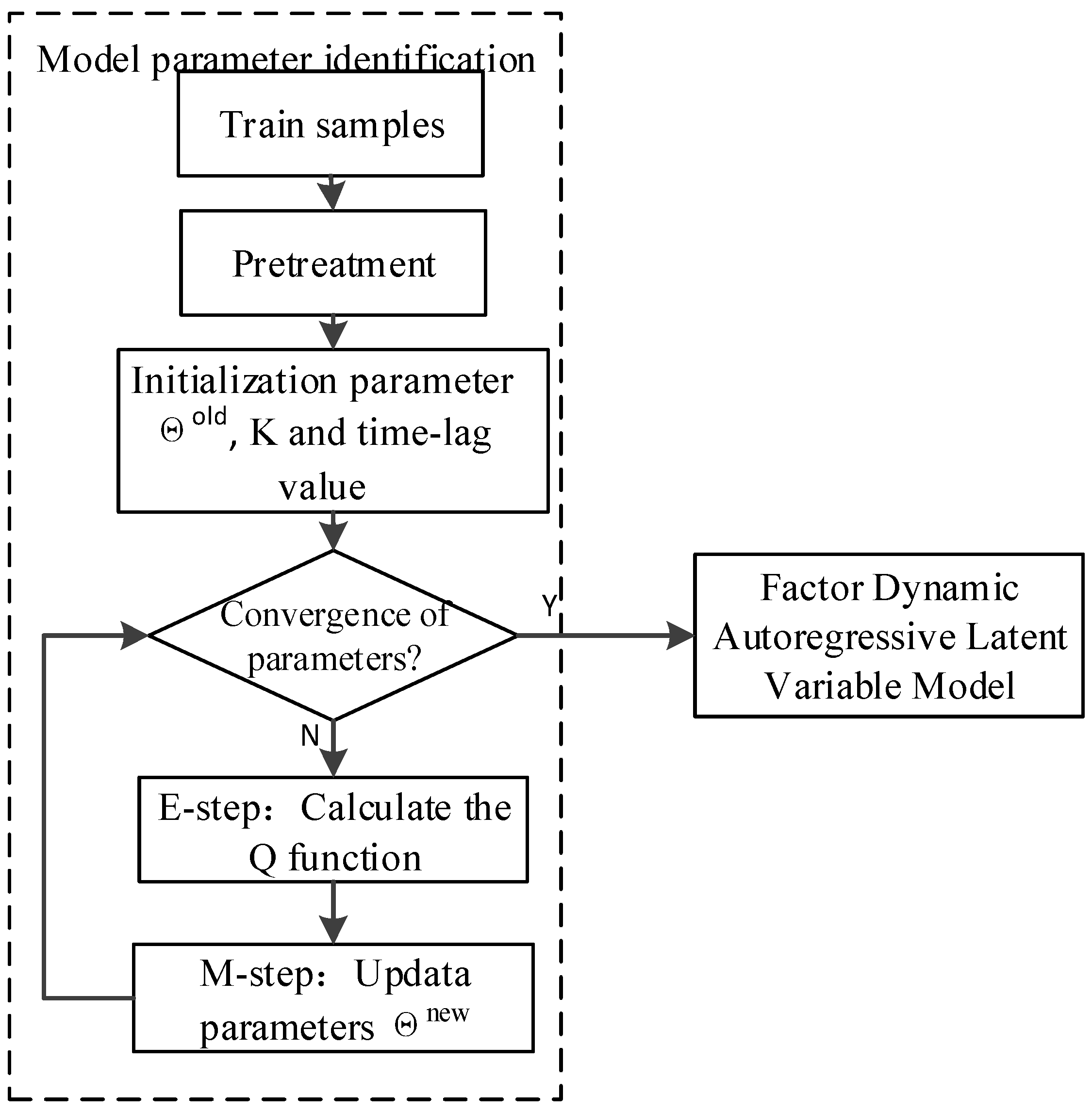
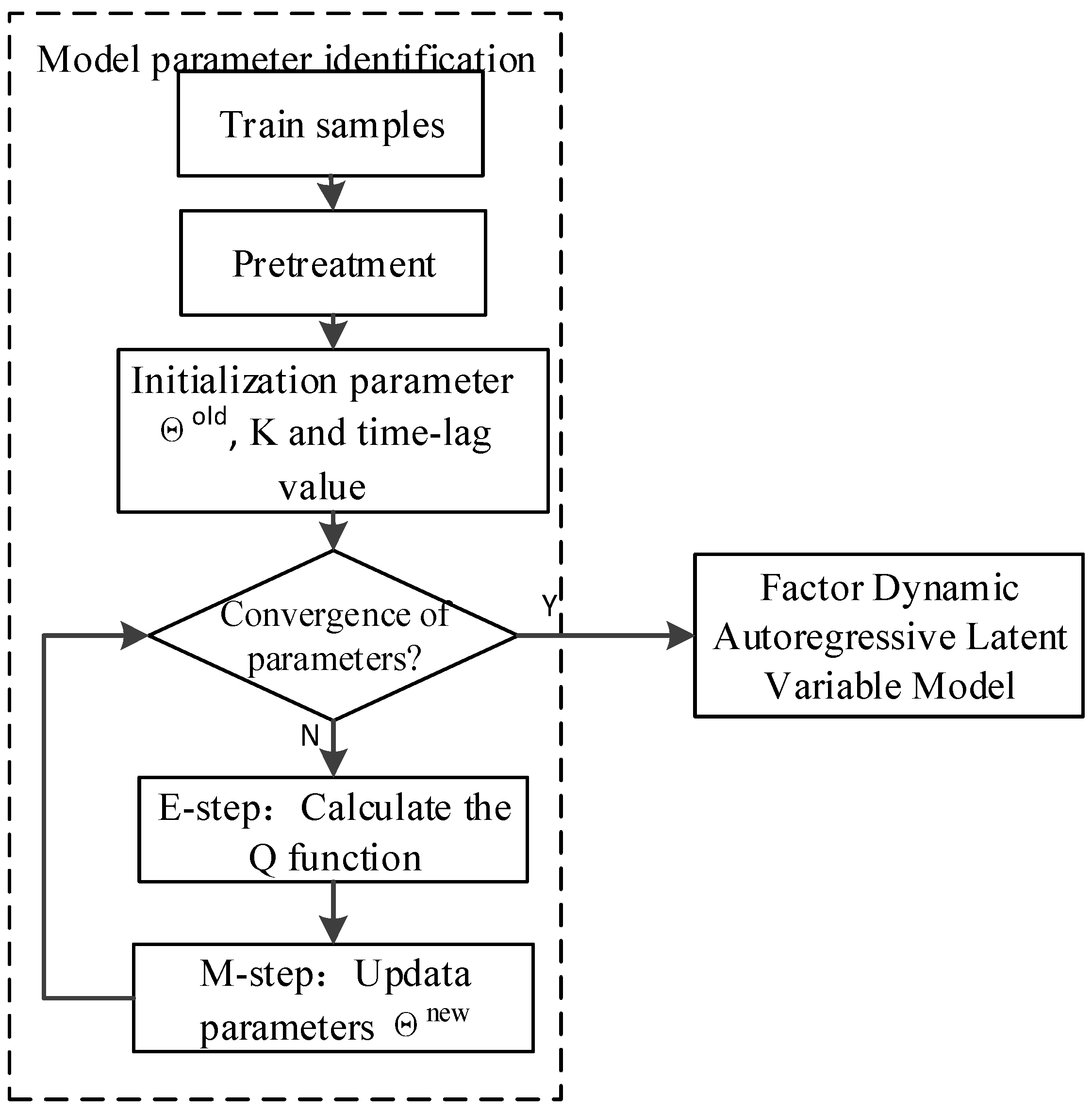
3.2. FDALM Parameter Identification
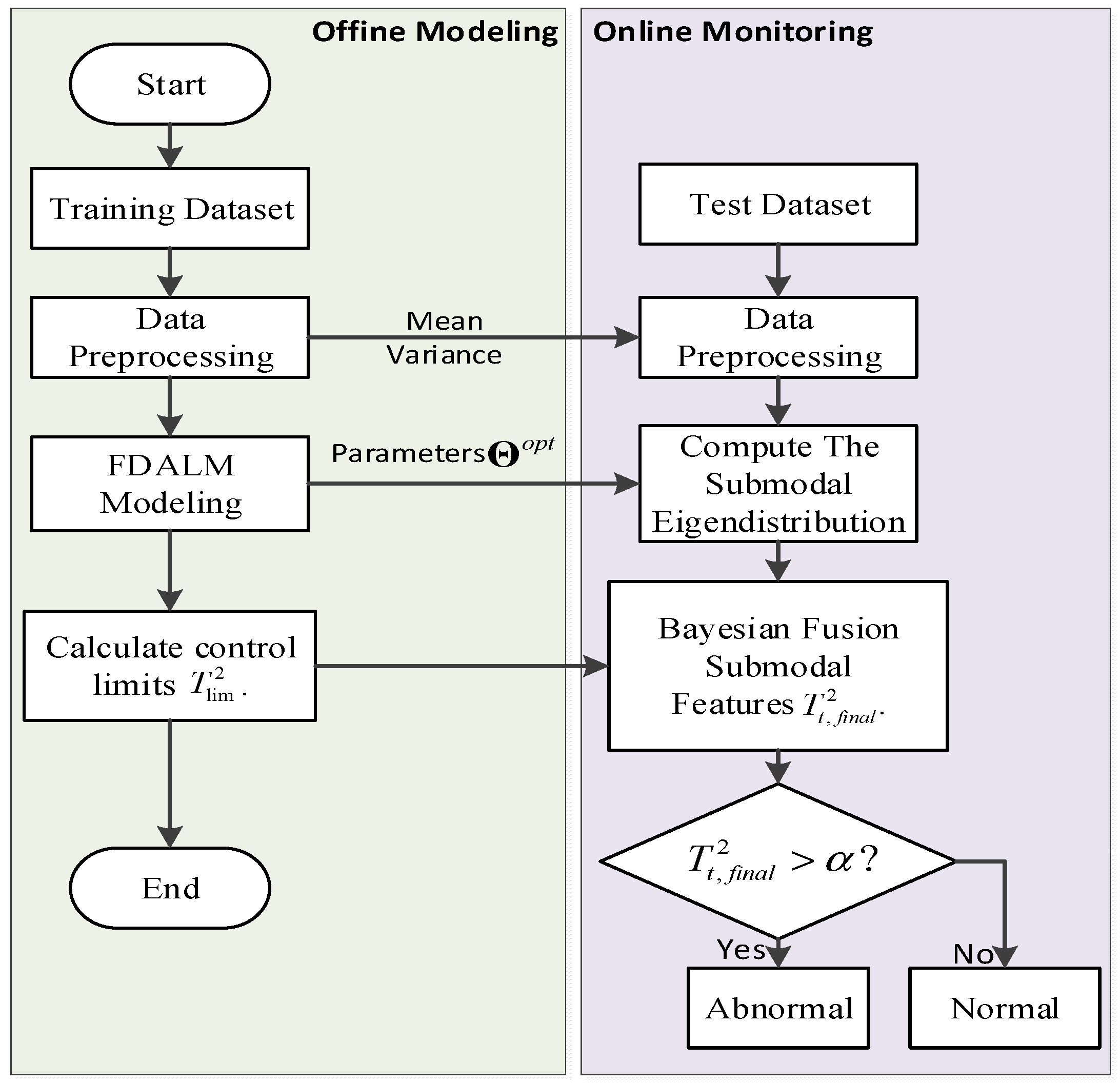
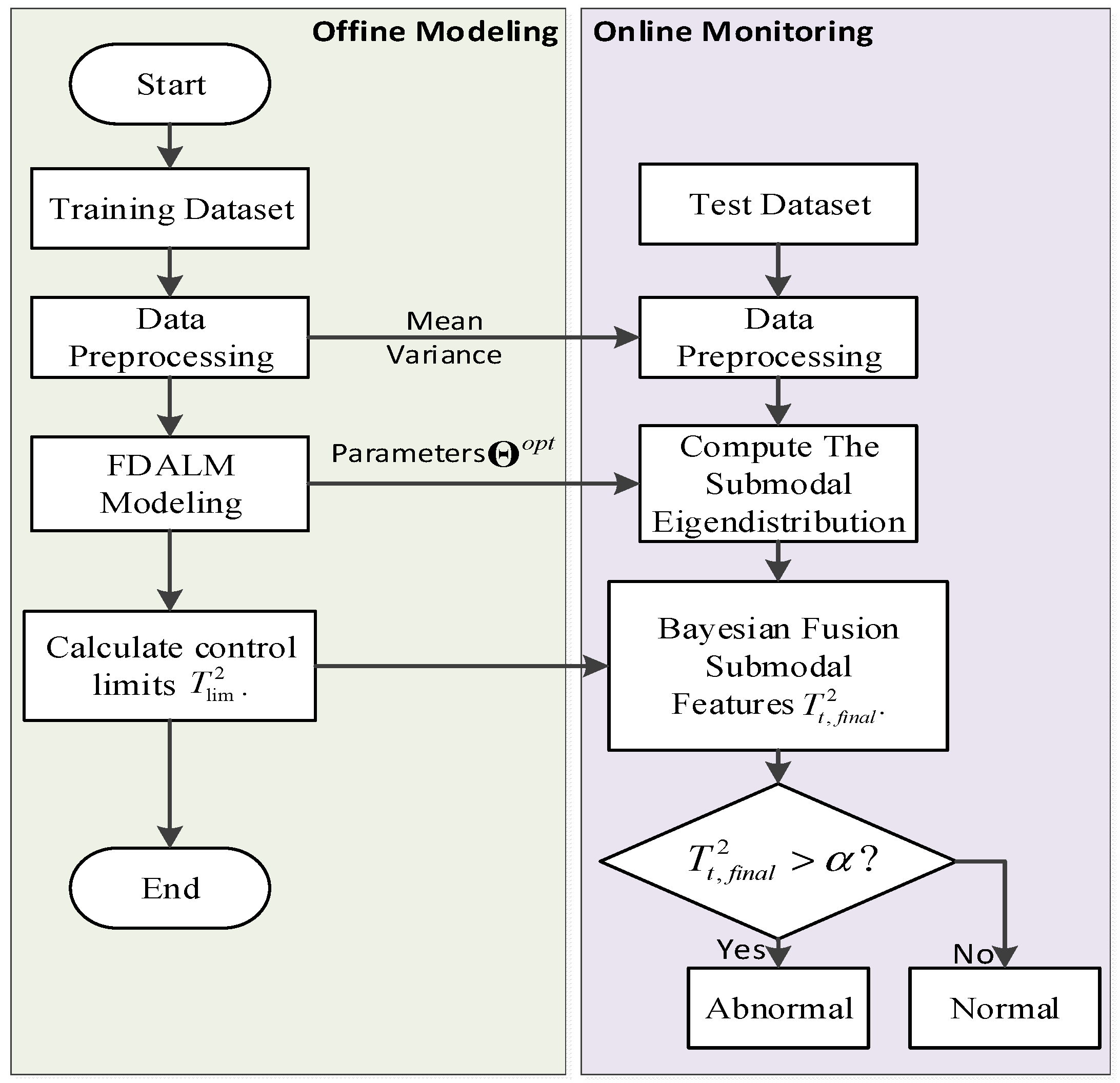
4. FDALM-Based Multimodal Process Monitoring Method
| Algorithm 1: Steps of an FDALM-based Process Monitoring Method |
| Input: In order to train the model parameters, the observation variables are selected from the process variables and quality variables, and the sampling sequence of T consecutive moments is selected as the training data set, denoted as ; in order to test the monitoring performance, the sampling sequence of N consecutive moments is selected online as the Test data set, denoted as . Step 1: The training and testing data sets are preprocessed by a normalization method. Step 2: Use the dynamic order identification algorithm and clustering algorithm to identify the order coefficient L and factor K of the model, determine the structure of FDALM, and initialize the model parameters . Step 3: Identification of FDALM Parameters Using Improved EM Algorithm. Step 4: Determine the control threshold and significance level of the sub-model, calculate the latent variable distribution of each observation sample under each sub-model online, and use the Bayesian inference technology to fuse the output of each sub-mode into the sample posterior failure probability . Step 5: Compare with the significance level to judge the state of the process. Output: Output system operating status. |
5. Application Research on the Preparation Process of Ternary Cathode Material
5.1. Model Building
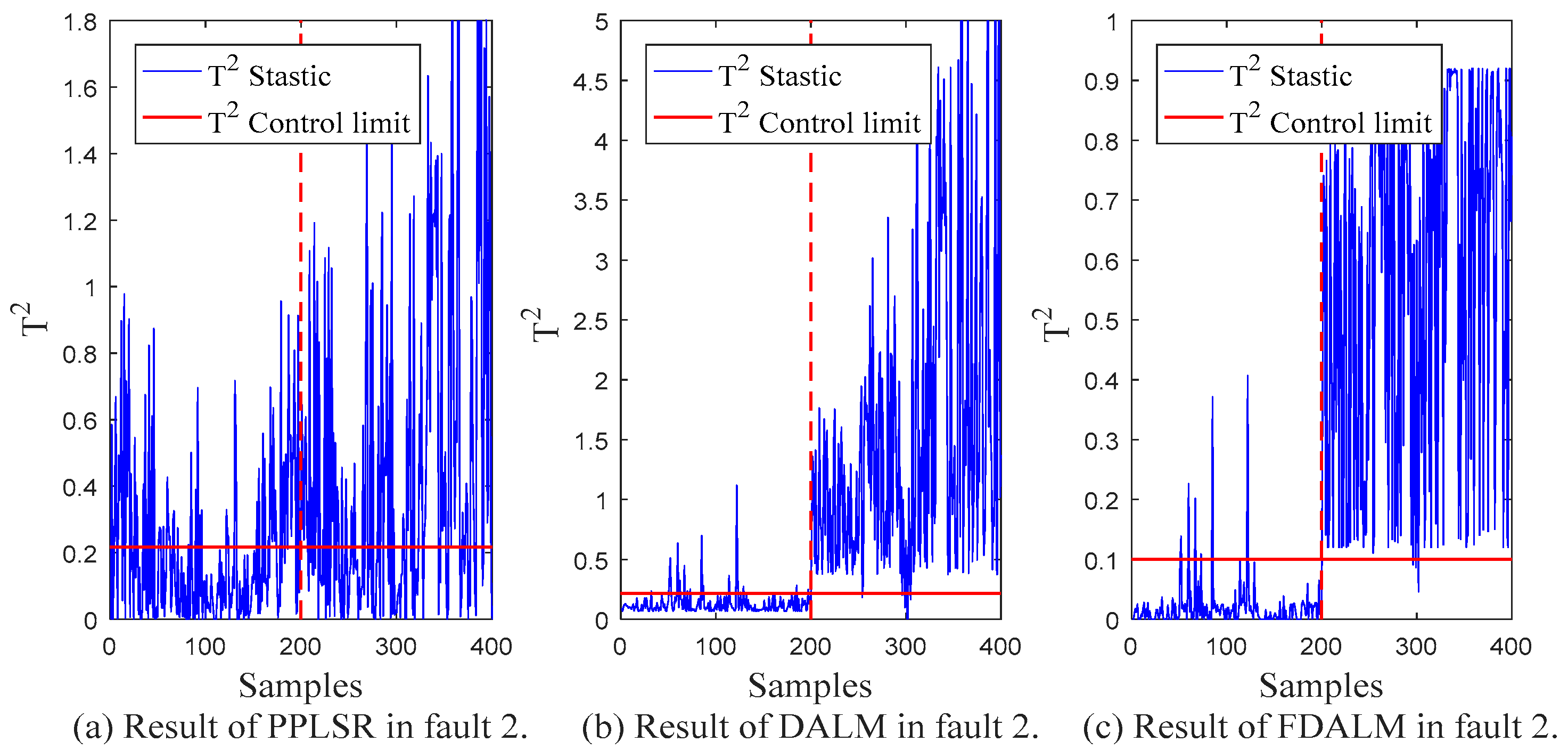
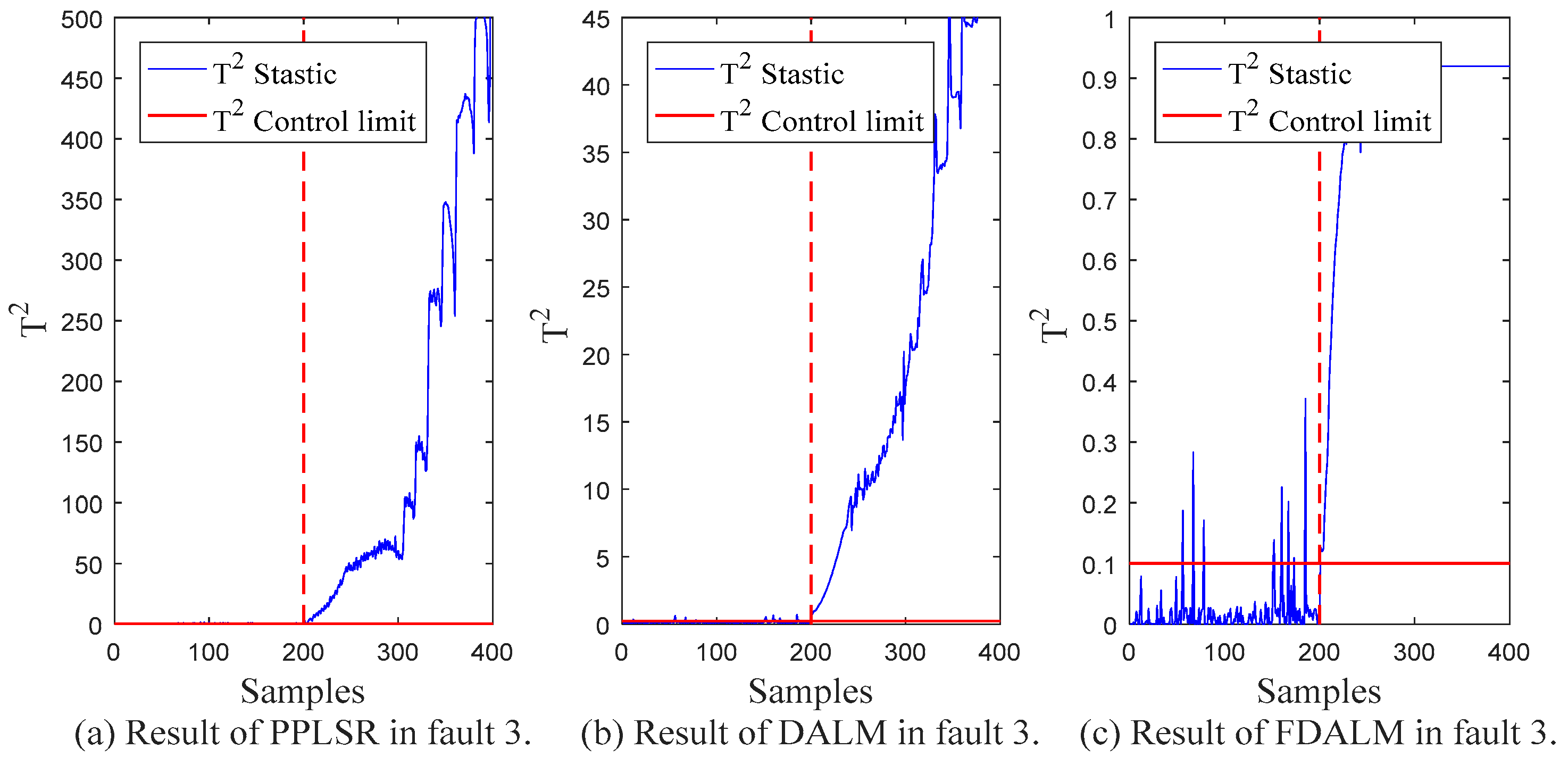
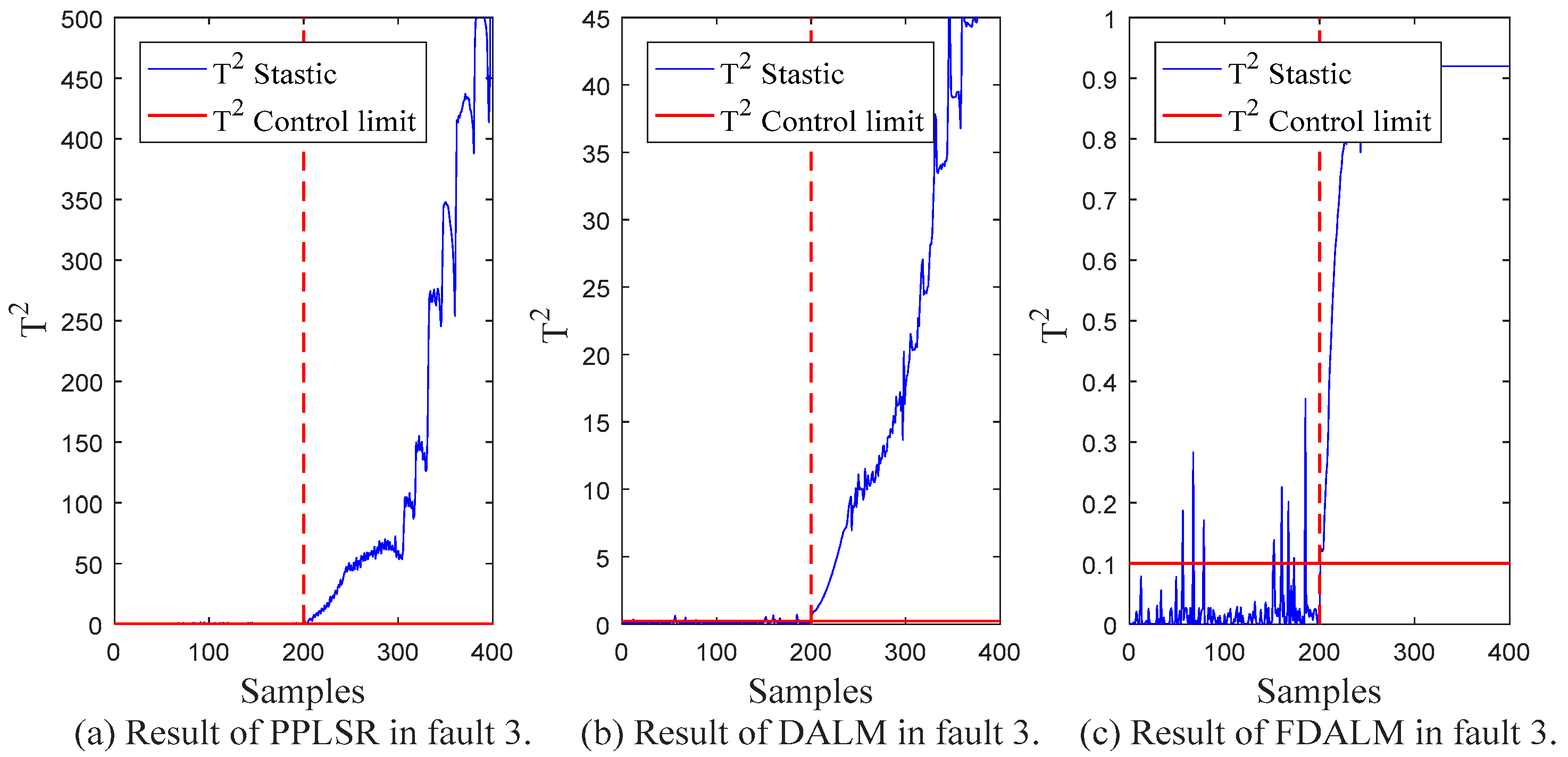
5.2. Process Monitoring
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N. A review of process fault detection and diagnosis Part II: Quantitative model and search strategies. Comput. Chem. Eng. 2003, 27, 313–326. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N.; Yin, K. A review of process fault detection and diagnosis: Part III: Process history based methods. Comput. Chem. Eng. 2003, 27, 327–346. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quantitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–311. [Google Scholar] [CrossRef]
- Qin, S.J. Statistical process monitoring: Basics and beyond. J. Chemom. 2003, 17, 480–502. [Google Scholar] [CrossRef]
- Kano, M.; Hasebe, S.; Hashimoto, I.; Ohno, H. A new multivariate statistical process monitoring method using principal component analysis. Comput. Chem. Eng. 2001, 25, 1103–1113. [Google Scholar] [CrossRef]
- Wang, X.; Kruger, U.; Lennox, B. Recursive partial least squares algorithms for monitoring complex industrial processes. Control Eng. Pract. 2003, 11, 613–632. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Ding, S.X.; Huang, B. Data-Driven Fault Diagnosis for Traction Systems in High-Speed Trains: A Survey, Challenges, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1700–1716. [Google Scholar] [CrossRef]
- Kruger, U.; Zhou, Y.; Irwin, G.W. Improved principal component monitoring of large-scale processes. J. Process Control 2004, 14, 879–888. [Google Scholar] [CrossRef]
- Kruger, U.; Kumar, S.; Littler, T. Improved principal component monitoring using the local approach. Automatica 2007, 43, 1532–1542. [Google Scholar] [CrossRef]
- Foka, Y.; Prosper, H.B.; Brambilla, N.; Kovalenko, V. Deep Learning and Bayesian Methods. EPJ Web Conf. 2017, 137, 11007. [Google Scholar]
- Ge, Z.; Chen, X. Dynamic Probabilistic Latent Variable Model for Process Data Modeling and Regression Application. IEEE Trans. Control. Syst. Technol. 2019, 27, 323–331. [Google Scholar] [CrossRef]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Chen, N.; Hu, F.H.; Chen, J.Y.; Chen, Z.W.; Gui, W.H.; Li, X. A Process Monitoring Method Based on Dynamic Autoregressive Latent Variable Model and Its Application in the Sintering Process of Ternary Cathode Materials. Machines 2021, 9, 229. [Google Scholar] [CrossRef]
- Ng, Y.S.; Srinivasan, R. An adjoined multi-model approach for monitoring batch and transient operations. Comput. Chem. Eng. 2009, 33, 887–902. [Google Scholar] [CrossRef]
- Yoo, C.K.; Villez, K.; Lee, I.-B.; Rosén, C.; Vanrolleghem, P. Multi-model statistical process monitoring and diagnosis of a sequencing batch reactor. Biotechnol. Bioeng. 2007, 96, 687–701. [Google Scholar] [CrossRef]
- Ben Khediri, I.; Weihs, C.; Limam, M. Kernel k-means clustering based local support vector domain description fault detection of multimodal processes. Expert Syst. Appl. 2012, 39, 2166–2171. [Google Scholar] [CrossRef]
- Zhao, Z.G.; Liu, F. A new method for process monitoring based on mixture probabilistic principal component analysis models. In Proceedings of the Third International Symposium on Neural Networks, Chengdu, China, 28–31 May 2006; pp. 939–944. [Google Scholar]
- Zhao, S.J.; Zhang, J.; Xu, Y.M. Monitoring of processes with multiple operating modes through multiple principle component analysis models. Ind. Eng. Chem. Res. 2004, 43, 7025–7035. [Google Scholar] [CrossRef]
- Zhao, S.J.; Zhang, J.; Xu, Y.M. Performance monitoring of processes with multiple operating modes through multiple PLS models. J. Process Control 2006, 16, 763–772. [Google Scholar] [CrossRef]
- Yu, J. A new fault diagnosis method of multimode processes using Bayesian inference based Gaussian mixture contribution decomposition. Eng. Appl. Artif. Intell. 2013, 26, 456–466. [Google Scholar] [CrossRef]
- Yu, J.; Qin, S.J. Multimode process monitoring with Bayesian inference-based finite Gaussian mixture models. AIChE J. 2008, 54, 1811–1829. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z. Mixture Bayesian regularization method of PPCA for multimode process monitoring. AIChE J. 2010, 56, 2838–2849. [Google Scholar] [CrossRef]
- Wang, F.; Tan, S.; Yang, Y.; Shi, H. Hidden Markov Model-Based Fault Detection Approach for a Multimode Process. Ind. Eng. Chem. Res. 2016, 55, 4613–4621. [Google Scholar] [CrossRef]
- Wang, J.; Shao, W.; Song, Z. Student’s-t Mixture Regression-Based Robust Soft Sensor Development for Multimode Industrial Processes. Sensors 2018, 18, 3968. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.-K.; Tian, X.-Y.; Zhong, Q.; He, S.-W.; Huo, C.-B.; Cao, Y.; Tong, Z.-Q.; Li, D.-C. Real-time process control of powder bed fusion by monitoring dynamic temperature field. Adv. Manuf. 2020, 8, 380–391. [Google Scholar] [CrossRef]
- Chen, J.; Gui, W.; Dai, J.; Jiang, Z.; Chen, N.; Li, X. A hybrid model combining mechanism with semi-supervised learning and its application for temperature prediction in roller hearth kiln. J. Process. Control. 2021, 98, 18–29. [Google Scholar] [CrossRef]
- Egorova, E.; Rudakova, I.; Rusinov, L.; Vorobjev, N. Diagnostics of sintering processes on the basis of PCA and two-level neural network model. J. Chemom. 2018, 32, e2959. [Google Scholar] [CrossRef]
- Panić, B.; Klemenc, J.; Nagode, M. Improved Initialization of the EM Algorithm for Mixture Model Parameter Estimation. Mathematics 2020, 8, 373. [Google Scholar] [CrossRef]
- Fu, X.; Yu, Z. Multiple models soft-sensing method based on improved adapt affinity propagation. Comput. Appl. Chem. 2016, 33, 111–116. [Google Scholar]
- Wang, Z.Y.; Liang, J. A JITL-Based Probabilistic Principal Component Analysis for Online Monitoring of Nonlinear Processes. J. Chem. Eng. Jpn. 2018, 51, 874–889. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Data Description | Sampling Number |
|---|---|---|
| Normal | This interval is normal data | 1st−1000th |
| Fault 1 | 1001st–1200th is normal data; 1201st–1400th is the abnormal temperature increase in the third temperature zone | 1001st−1400th |
| Fault 2 | 1401st–1600th is normal data; 1601st–1800th is the abnormal temperature drop in the third temperature zone | 1401st−1800th |
| Fault 3 | 1801st–2000th is normal data; 2001st–2200th is shutdown fault | 1801st−2200th |
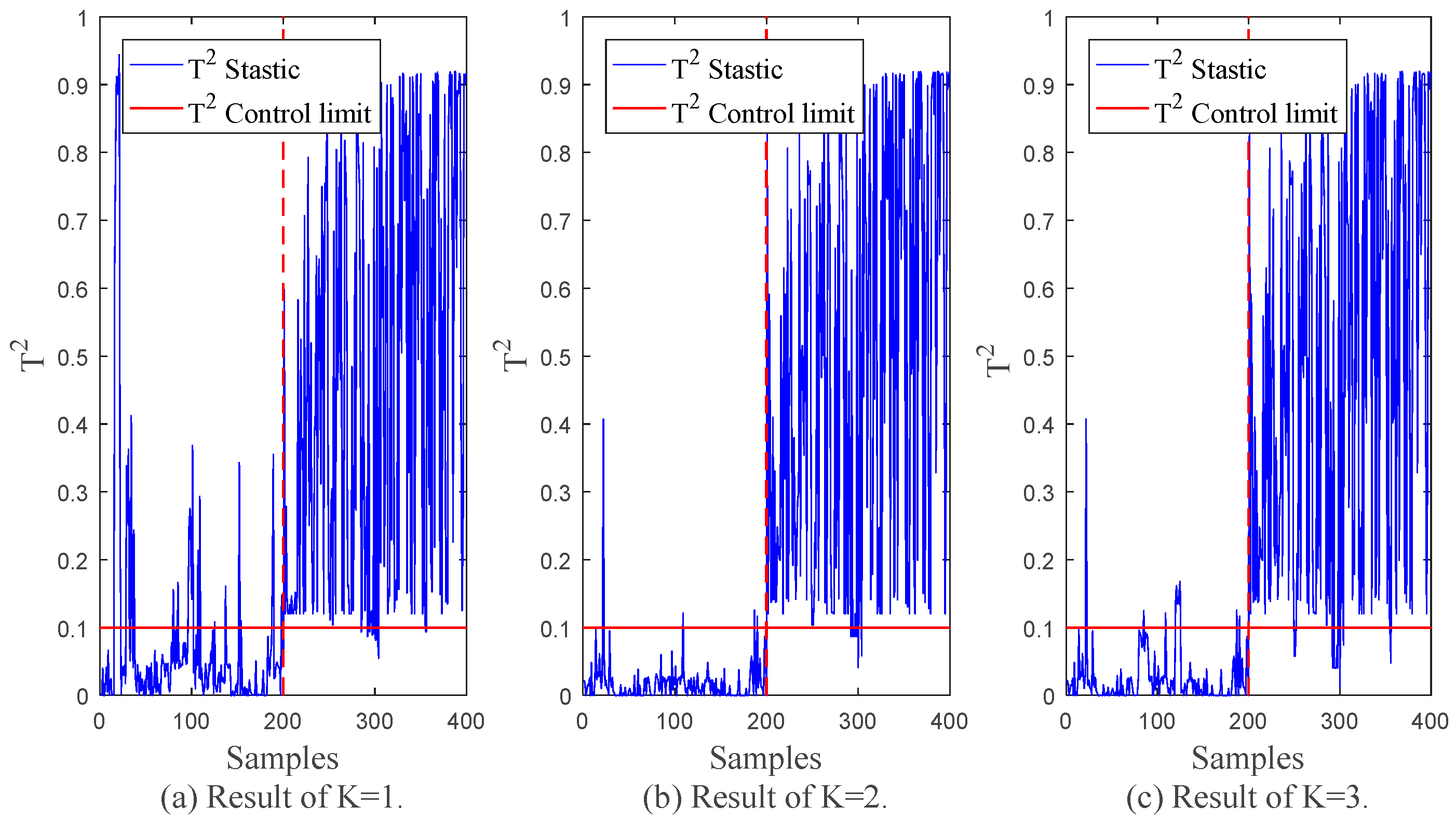
| K | 1 | 2 | 3 |
|---|---|---|---|
| FAR | 0.150 | 0.020 | 0.055 |
| FDR | 0.945 | 0.965 | 0.940 |
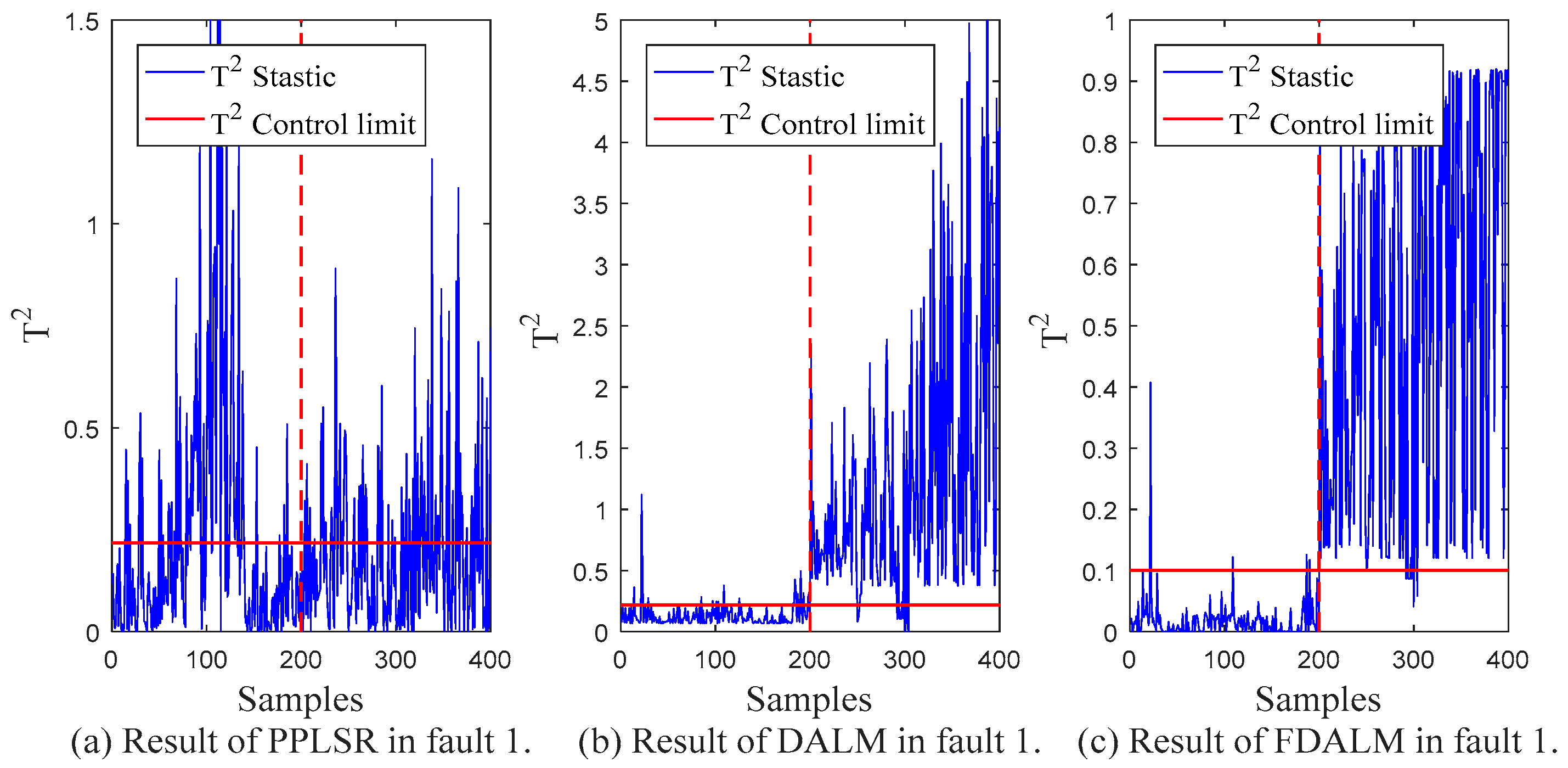
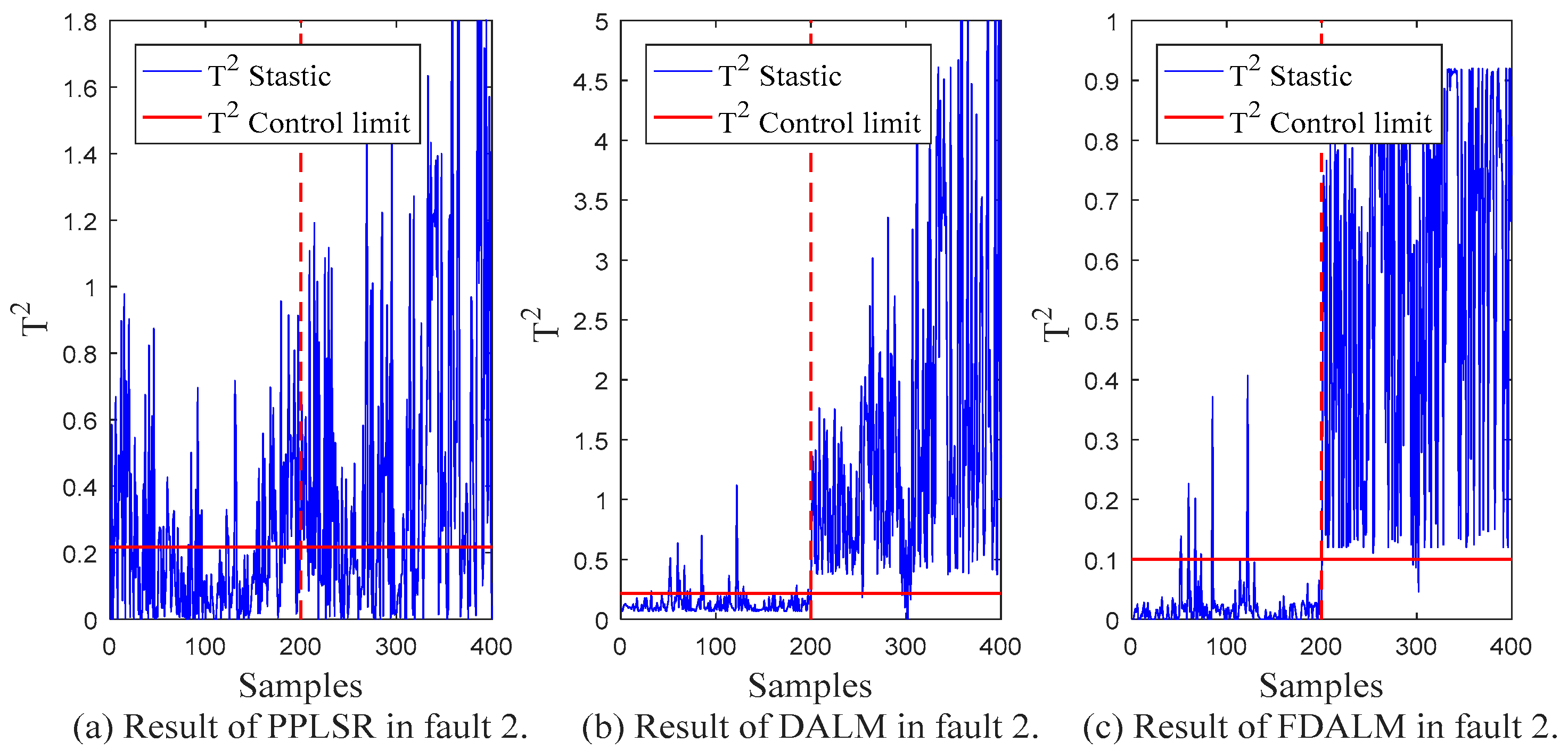
| Type | PPLSR | DALM | FDALM | |||
|---|---|---|---|---|---|---|
| FAR | FDR | FAR | FDR | FAR | FDR | |
| Fault 1 | 0.240 | 0.120 | 0.120 | 0.925 | 0.020 | 0.965 |
| Fault 2 | 0.100 | 0.350 | 0.090 | 0.970 | 0.045 | 0.985 |
| Fault 3 | 0.315 | 0.980 | 0.085 | 1.000 | 0.040 | 1.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, N.; Hu, F.; Chen, J.; Wang, K.; Yang, C.; Gui, W. A Monitoring Method Based on FDALM and Its Application in the Sintering Process of Ternary Cathode Material. Sensors 2022, 22, 7203. https://doi.org/10.3390/s22197203
Chen N, Hu F, Chen J, Wang K, Yang C, Gui W. A Monitoring Method Based on FDALM and Its Application in the Sintering Process of Ternary Cathode Material. Sensors. 2022; 22(19):7203. https://doi.org/10.3390/s22197203
Chicago/Turabian StyleChen, Ning, Fuhai Hu, Jiayao Chen, Kai Wang, Chunhua Yang, and Weihua Gui. 2022. "A Monitoring Method Based on FDALM and Its Application in the Sintering Process of Ternary Cathode Material" Sensors 22, no. 19: 7203. https://doi.org/10.3390/s22197203
APA StyleChen, N., Hu, F., Chen, J., Wang, K., Yang, C., & Gui, W. (2022). A Monitoring Method Based on FDALM and Its Application in the Sintering Process of Ternary Cathode Material. Sensors, 22(19), 7203. https://doi.org/10.3390/s22197203