
Edge-Computing Meshed Wireless Acoustic Sensor Network for Indoor Sound Monitoring

 ,
,  , , ,
, , ,  and
and 
Abstract
1. Introduction
- (1)
- The design of a general-purpose Wireless Acoustic Sensor Network, focusing on the design of the sensing nodes using a commercial computing unit and microphone. Different commercial computing units have been evaluated in terms of cost and capabilities. The selected computing unit is capable of performing edge-computing calculations, which enables acoustic signal processing to be carried out in the sensor without the need to send raw acoustic data to the cloud. Regarding the microphone, three different options have been evaluated in terms of cost, linearity and calibration capabilities. The plug-and-play selected option enables omnidirectional data to be obtained without the need for an external Analogue to Digital Converter.
- (2)
- The conception of a wireless meshed network topology to communicate the sensing devices in a Local Area Network (LAN), maximizing the coverage area of the network without using external hardware such as a router or a range extender. For this purpose, a real-world test has been carried out in a scenario composed of three rooms and one terrace, with a long distance among nodes. A comparison between using a direct connection from nodes to a central unit or a meshed topology has shown that the latter option enables us to drastically reducing the number of frames lost during the experiments.
- (3)
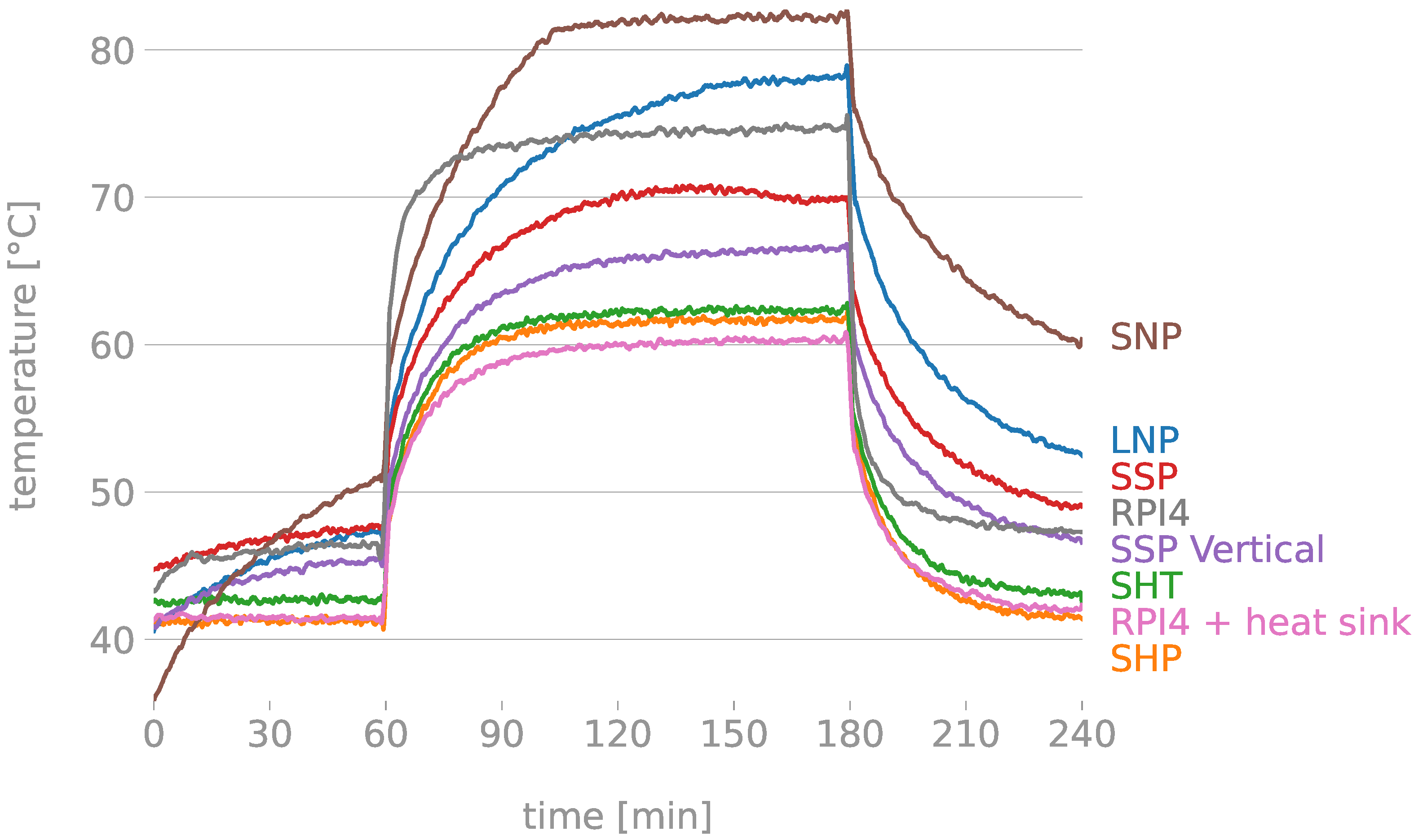
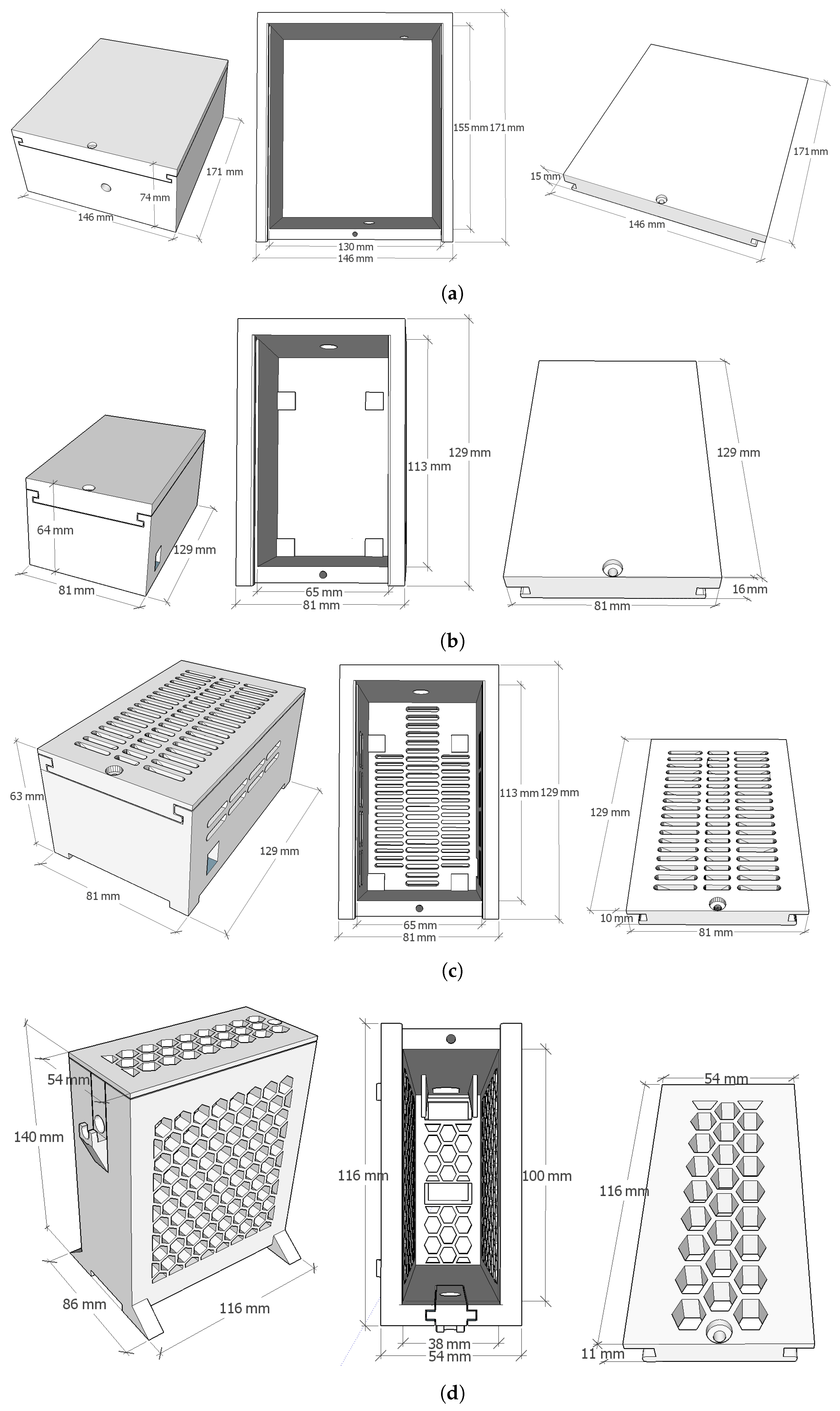
- The design of a coverage (i.e., a protecting 3D-printed box) to protect the hardware and also ensure that such hardware does not overheat, causing the computer unit to stop working in the worst situation. For this purpose, different models of custom 3D-printed boxes of different shapes and materials have been compared. In the experimental evaluation, identical stress tests have been carried out using different models of boxes. The results show that the physical design of the box greatly affects the temperature value reached in the sensor.
2. State of the Art
3. Sensor Design
- Continuous measuring: each sensing node must be capable of measuring continuously and without being interrupted, to avoid sample loss.
- Maximum semblance between devices: To obtain comparable metrics (in terms of measured noise level but also in terms of temperature response, speed and reliability), all the sensing nodes of the network should be as similar as possible among them. Additionally, they should be calibrated prior to their deployment, to ensure that the results that they are supplying are comparable.
- Low cost: The price of each node of the network must be moderate to ensure the deployment of many sensors. This way, a wider area can be covered. For this work, a node is considered as low-cost if its price per unit is around EUR 100 or less, which is considerably low compared to Class-I commercial measuring sensors (which typically have a unitary price higher than EUR 1000 [25]).
- Scalability: It is not only the price that limits the number of sensors that can be deployed over a certain area; other factors must be considered as well. For instance, adding nodes to the network should be as fast as possible, as human resources are usually needed for this task.
- Remote connectivity to access each node: for monitoring purposes, addressing software failure or checking the status of the nodes, each node of the network should be accessible remotely. Occasionally, the physical location in which the sensors are deployed is not easily accessible to the technicians in charge of managing the sensing nodes. For this reason, remote access to the nodes becomes crucial when deploying a wireless network in a real-operation environment. However, it must be taken into account that despite having remote access to the nodes, there are problems that still must be solved physically, such as hardware failure (e.g., the microphone or the computing unit breaks and must be replaced).
3.1. Computing Unit of the Sensor
- Acquires acoustic samples at a rate of 44,100 Hz with a bit depth of 16 bits.
- Every 1 s, it calculates the Equivalent Loudness Level () and calculates the spectrogram of the 1-second window audio.
- After evaluating these two acoustic features, the spectrogram is used as an input of a Convolutional Neural Network (CNN) (i.e., MobileNet V2 [32], which occupies 8.8 MB of RAM) to perform acoustic event classification.
3.2. Microphone Selection and Test
3.3. Sensor Enclosure
- Measuring the temperature for 1 h without stressing the RPi (i.e., relax period).
- Measuring the temperature for 2 h stressing the RPi (i.e., stress period).
- Measuring the temperature for 1 h without stressing the RPi (i.e., second relax period).
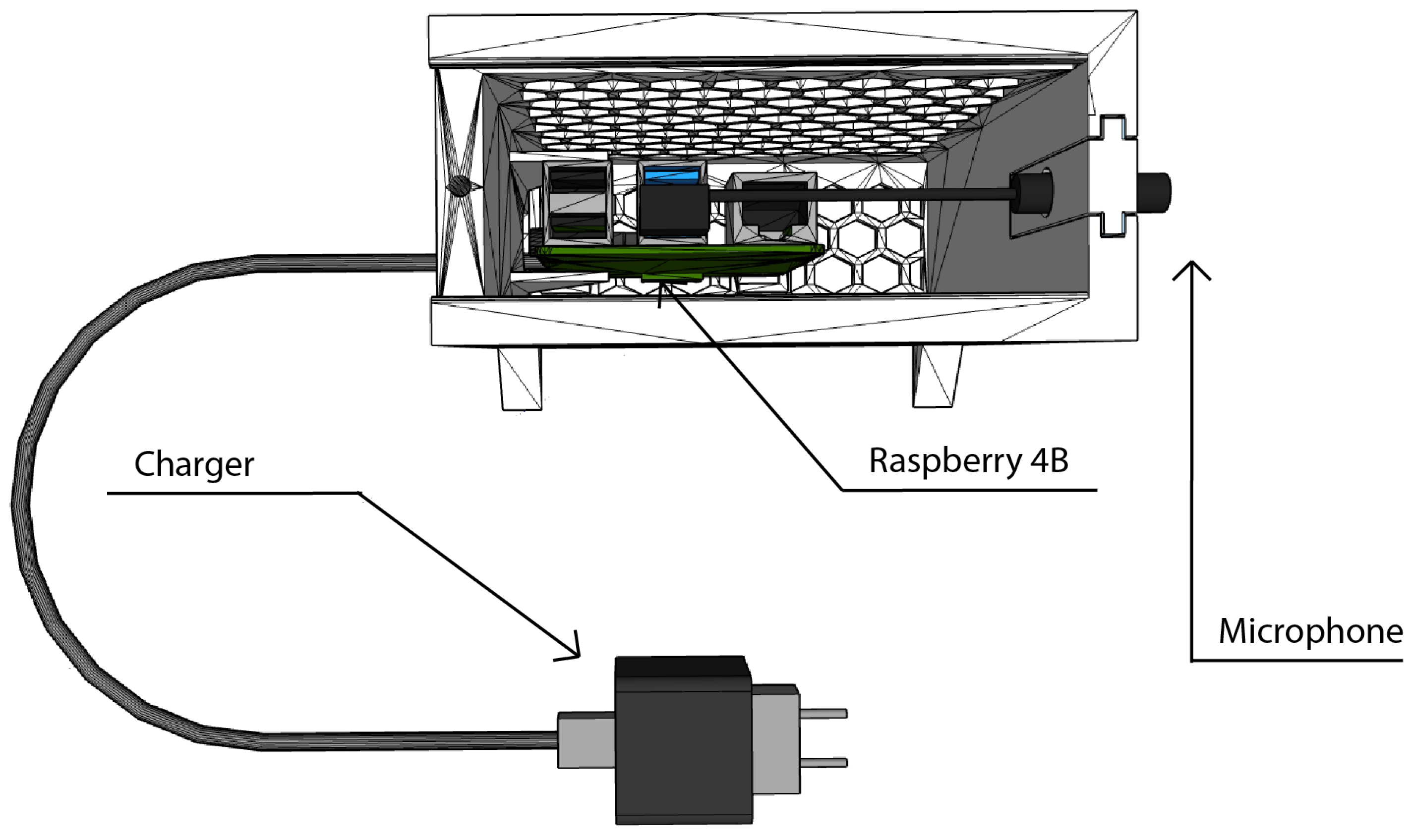
3.4. Assembly of the Nodes
- Single-board Computer: a Raspberry Pi Model 4B of 4 GB RAM with an SD card of 64GB and a heat sink.
- Microphone: An omnidirectional electret condenser microphone [35] with a flat frequency response between 50–18,000 Hz, a maximum sampling rate of 96 kHz/24 bit and a Signal-to-Noise ratio (SNR) of 84 dB. The microphone is connected to the Single-board computer using a USB 3.0 port.
- A 3D-printed designed box: The box integrates the microphone sensor and the computing unit into a single element. Additionally, it offers protection against falls or undesired manual disconnections of the elements that compose the sensor.
- Power supply: a 5V-3A charger with USB-C connector powers the system.
4. WASN Design
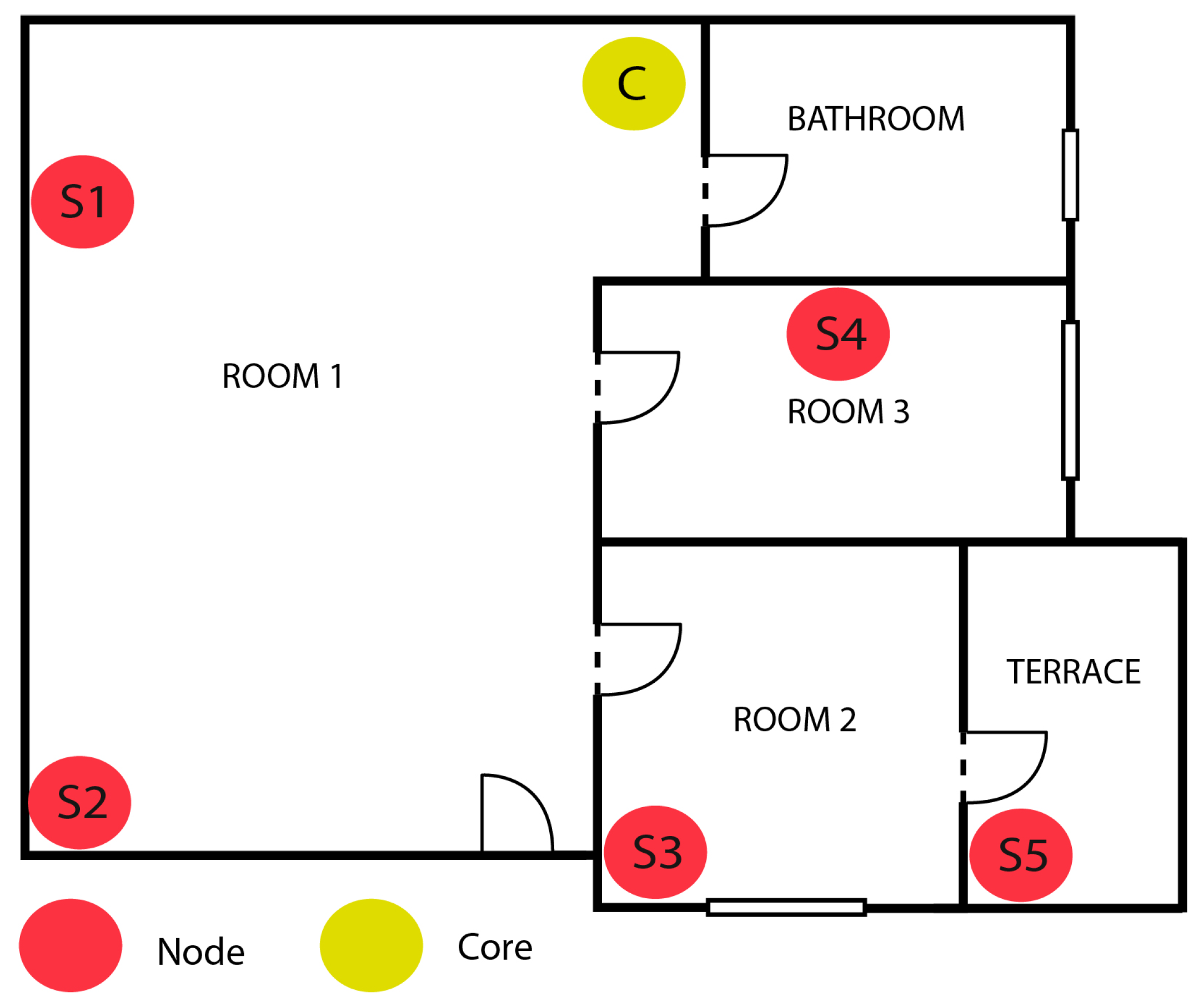
4.1. Physical Topology
- Nodes: N number of sensors identical to the ones described in Section 3.4, located in strategical places to sense the environment. In the proposed prototype, uninterruptedly, each node sends the acoustical level measured over a programmable period of time to the core of the network.
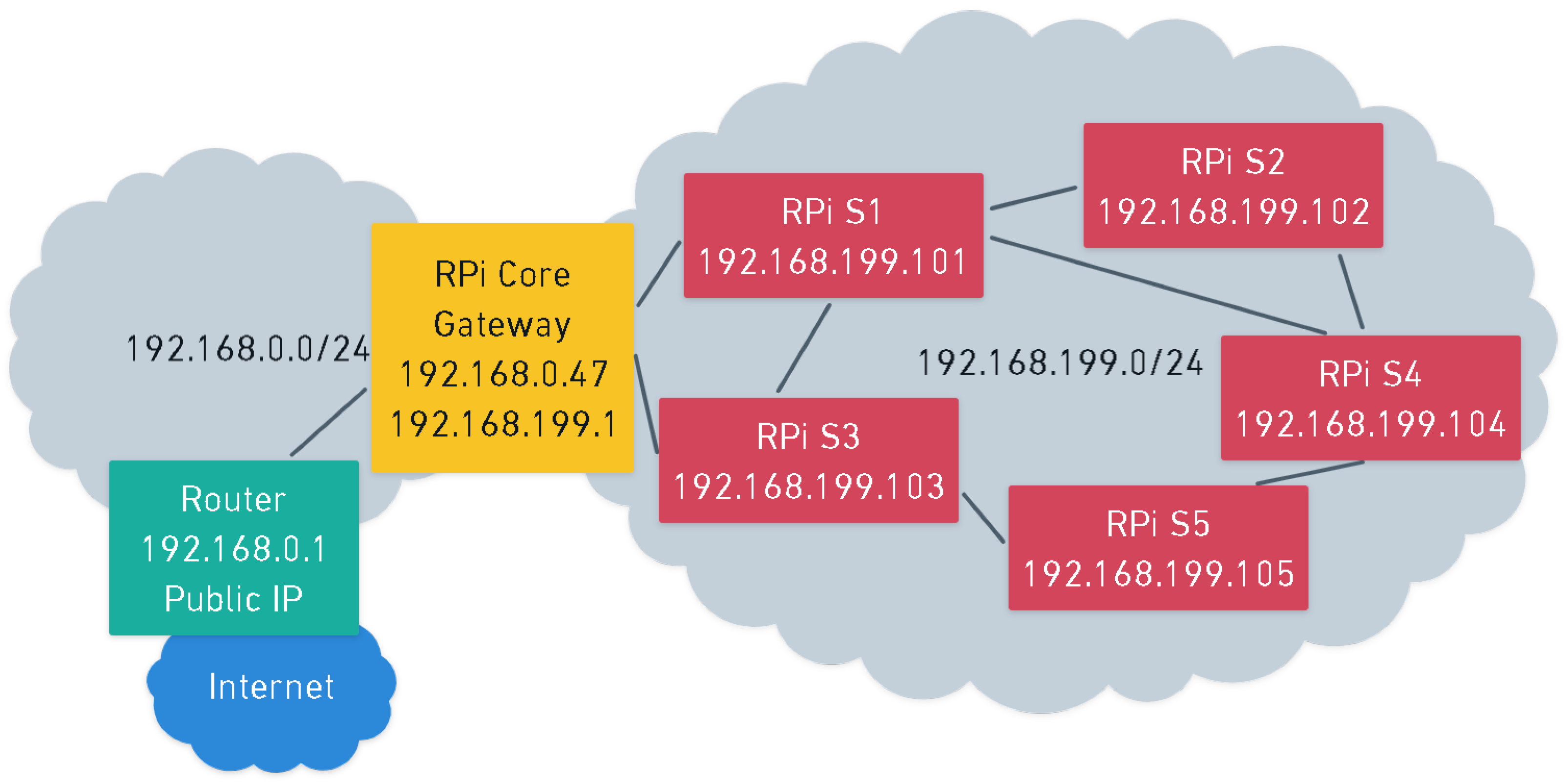
- Core: A single Raspberry Pi 4B per network that acts as a gateway. The purpose of this node is to receive data from all the synchronized nodes and upload them to the cloud, where a graphic representation of the acoustic map could be visualized. Centralizing the nodes allows fast remote management accessing through the core. It is important to place the core next to the router of the indoor space and do a wired connection to it to minimize connectivity problems. This node does not compute any measurement by itself, and it does not need any microphone.
4.2. Logical Topology
- Direct connection: Each node connects directly to the core and sends its data.
- Using other nodes: A node uses the connectivity of another node to send its data. This topology is called a mesh connectivity [44]. With n being the number of devices in a mesh network, then each device must be connected to number of devices. The total number of links can be calculated using the following equation:In such networking, the nodes can create and update their links automatically. Therefore, in case a route to a node becomes disabled, the network will automatically rebuild a new route through another radio node so that the information can still reach its destination [45].
5. WASN Deployment Methodology
5.1. Installation of the Core Node
- Core assembly: First of all, the heat sink must be integrated to the Rpi. Then, the Raspberry must be placed in the designed box. As this is the core node and will only be used as a gateway, this node will not need a microphone.
- Core wiring: the Raspberry should next be plugged into a power source near the router to enable an Ethernet connection between the Raspberry and the router.
- Connection to Ethernet: Once done, an Ethernet wire should be passed through a hole in the cover of the box and, next, must be connected to the RPi. The box can be closed with a M4 screw.
- Connection to the mesh: The core must, then, create a private network and connect to it through WiFi (following the steps of [46]). Additionally, a static IP must be configured, enabling the nodes to send data to it.
- Connection to an external database: The core node must be configured to send processed data to an external database (e.g., Thingspeak). The bytes sent to the cloud would depend on the application. For the proposed project in this paper (i.e., the generation of a noise map), the bytes to be sent would be the levels calculated in the rest of the nodes and a timestamp.
5.2. Installation of New Nodes in an Active System
- Node assembly: Place the heat sink on top of the Raspberry, connect the microphone to the central unit and put both components inside the box. The assembly must look as it does in Figure 5.
- Node wiring: Plug the node to the power source. The box can now be closed with a M4 screw.
- Static IP configuration: connect the running node to a computer using an Ethernet cable to set up the WiFi mesh with an unused IP and static DHCP and obtain the WiFi MAC address (following the steps of [46]).
- Update the core node: add the MAC address of the node to the configuration file of the core so it recognizes the new node as part of the mesh using its MAC.
- Microphone calibration: calibrate the microphone to 1 kHz, 94 dB and set the calibration factor to obtain a referenced sound pressure level.
6. Discussion
6.1. Microphone
6.2. Connectivity
6.3. Computing Unit
6.4. Power
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | Three Dimensional |
| ADC | Analogue-to-Digital Converter |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| DHCP | Dynamic Host Configuration Protocol |
| HWMP | Hybrid Wireless Mesh Protocol |
| IoT | Internet of Things |
| IP | Internet Protocol |
| ISP | Internet Services Providers |
| LAN | Local Area Network |
| Equivalent Loudness level | |
| LoRa | Long Range Modulation |
| M4 | Metric 4 |
| MAC | Media Access Control |
| MEMS | Micro Electro Mechanical systems |
| OLSR | Optimized Link State Routing |
| PDR | Packet Delivery Ratio |
| PLA | Polylactic Acid |
| PSU | Power Supply Unit |
| RPi | Raspberry Pi |
| SD | Secure Digital |
| SNR | Signal-to-Noise Ratio |
| TCPOLY | Thermally Conductive Polymer |
| TPU | Thermoplastic Polyurethane |
| USB | Universal Serial Bus |
| WASN | Wireless Acoustic Sensor Network |
| WiFi | Wireless Fidelity |
References
- Alsina-Pagès, R.M.; Navarro, J.; Alías, F.; Hervás, M. Homesound: Real-time audio event detection based on high performance computing for behaviour and surveillance remote monitoring. Sensors 2017, 17, 854. [Google Scholar] [CrossRef] [PubMed]
- Townsend, D.; Knoefel, F.; Goubran, R. Privacy versus autonomy: A tradeoff model for smart home monitoring technologies. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 4749–4752. [Google Scholar] [CrossRef]
- Hensel, B.K.; Demiris, G.; Courtney, K.L. Defining obtrusiveness in home telehealth technologies: A conceptual framework. J. Am. Med. Inform. Assoc. 2006, 13, 428–431. [Google Scholar] [CrossRef] [PubMed]
- Zheng, S.; Apthorpe, N.; Chetty, M.; Feamster, N. User perceptions of smart home IoT privacy. Proc. ACM Hum.-Comput. Interact. 2018, 2, 1–20. [Google Scholar] [CrossRef]
- Bhushan, B.; Sahoo, G. Requirements, protocols, and security challenges in wireless sensor networks: An industrial perspective. In Handbook of Computer Networks and Cyber Security; Springer: Cham, Switzerland, 2020; pp. 683–713. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Hassan, N.; Gillani, S.; Ahmed, E.; Yaqoob, I.; Imran, M. The role of edge computing in internet of things. IEEE Commun. Mag. 2018, 56, 110–115. [Google Scholar] [CrossRef]
- Bell, M.C.; Galatioto, F. Novel wireless pervasive sensor network to improve the understanding of noise in street canyons. Appl. Acoust. 2013, 74, 169–180. [Google Scholar] [CrossRef]
- Arce, P.; Salvo, D.; Piñero, G.; Gonzalez, A. FIWARE based low-cost wireless acoustic sensor network for monitoring and classification of urban soundscape. Comput. Netw. 2021, 196, 108199. [Google Scholar] [CrossRef]
- Basten, T.; Wessels, P. An overview of sensor networks for environmental noise monitoring. In Proceedings of the ICSV21, International Congress on Sound and Vibration, Beijing, China, 13–17 July 2014. [Google Scholar]
- Vidaña-Vila, E.; Navarro, J.; Alsina-Pagès, R.M.; Ramírez, Á. A two-stage approach to automatically detect and classify woodpecker (Fam. Picidae) sounds. Appl. Acoust. 2020, 166, 107312. [Google Scholar] [CrossRef]
- Navarro, J.; Vidaña-Vila, E.; Alsina-Pagès, R.M.; Hervás, M. Real-time distributed architecture for remote acoustic elderly monitoring in residential-scale ambient assisted living scenarios. Sensors 2018, 18, 2492. [Google Scholar] [CrossRef]
- Sun, Z.; Purohit, A.; Yang, K.; Pattan, N.; Siewiorek, D.; Smailagic, A.; Lane, I.; Zhang, P. Coughloc: Location-aware indoor acoustic sensing for non-intrusive cough detection. In International Workshop on Emerging Mobile Sensing Technologies, Systems, and Applications; Citeseer: San Francisco, CA, USA, 2011. [Google Scholar]
- Botteldooren, D.; De Coensel, B.; Oldoni, D.; Van Renterghem, T.; Dauwe, S. Sound monitoring networks new style. In Proceedings of the Acoustics 2011: Breaking New Ground: Annual Conference of the Australian Acoustical Society, Australian Acoustical Society, Gold Coast, Australia, 2–4 November 2011; pp. 1–5. [Google Scholar]
- Domínguez, F.; Cuong, N.T.; Reinoso, F.; Touhafi, A.; Steenhaut, K. Active self-testing noise measurement sensors for large-scale environmental sensor networks. Sensors 2013, 13, 17241–17264. [Google Scholar] [CrossRef]
- Ginovart-Panisello, G.J.; Vidaña-Vila, E.; Caro-Via, S.; Martínez-Suquía, C.; Freixes, M.; Alsina-Pagès, R.M. Low-Cost WASN for Real-Time Soundmap Generation. Eng. Proc. 2021, 6, 57. [Google Scholar]
- Cobos, M.; Perez-Solano, J.; Berger, L. Acoustic-based technologies for ambient assisted living. In Introduction to Smart eHealth and eCare Technologies; Taylor & Francis Group: Boca Raton, FL, USA, 2016; pp. 159–180. [Google Scholar]
- Quintana-Suárez, M.A.; Sánchez-Rodríguez, D.; Alonso-González, I.; Alonso-Hernández, J.B. A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems. Appl. Sci. 2017, 7, 877. [Google Scholar] [CrossRef]
- Ellis, D. Detecting alarm sounds. In Proceedings of the Workshop on Consistent and Reliable Acoustic Cues CRAC-2000, Aalborg, Denmark, 2 September 2001. [Google Scholar]
- Alías, F.; Alsina-Pagès, R.M. Review of wireless acoustic sensor networks for environmental noise monitoring in smart cities. J. Sens. 2019, 2019, 7634860. [Google Scholar] [CrossRef]
- Mydlarz, C.; Sharma, M.; Lockerman, Y.; Steers, B.; Silva, C.; Bello, J.P. The life of a New York City noise sensor network. Sensors 2019, 19, 1415. [Google Scholar] [CrossRef]
- Bello, J.P.; Silva, C.; Nov, O.; Dubois, R.L.; Arora, A.; Salamon, J.; Mydlarz, C.; Doraiswamy, H. SONYC: A System for Monitoring, Analyzing, and Mitigating Urban Noise Pollution. Commun. ACM 2019, 62, 68–77. [Google Scholar] [CrossRef]
- Mydlarz, C.; Salamon, J.; Bello, J.P. The implementation of low-cost urban acoustic monitoring devices. Appl. Acoust. 2017, 117, 207–218. [Google Scholar] [CrossRef]
- Luo, C.; Hong, Y.; Li, D.; Wang, Y.; Chen, W.; Hu, Q. Maximizing network lifetime using coverage sets scheduling in wireless sensor networks. Ad Hoc Netw. 2020, 98, 102037. [Google Scholar] [CrossRef]
- Vidaña-Vila, E.; Navarro, J.; Stowell, D.; Alsina-Pagès, R.M. Multilabel Acoustic Event Classification Using Real-World Urban Data and Physical Redundancy of Sensors. Sensors 2021, 21, 7470. [Google Scholar] [CrossRef]
- HUMMINGBOARD I.MX6 SBC. Available online: https://www.solid-run.com/embedded-industrial-iot/nxp-i-mx6-family/hummingboard/ (accessed on 10 March 2022).
- CubieBoard. A Series of Open Source Hardware. Available online: http://cubieboard.org/ (accessed on 10 March 2022).
- Jaguar One. Available online: http://www.jaguarboard.org/index.php/com_virtuemart_menu_configuration/products/buy/jaguarboard/207/jaguarboard-detail.html. (accessed on 10 March 2022).
- Banana Pi Open Source Hardware Community. Available online: https://www.banana-pi.org/ (accessed on 10 March 2022).
- pcDuino4 Nano. Available online: https://www.linksprite.com/pcduino4-nano/ (accessed on 10 March 2022).
- BeagleBone Black. Available online: https://beagleboard.org/black (accessed on 10 March 2022).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Wey, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Gyvzala. Gyvzala USB Microphone. Available online: https://igyvazla.com/products/gyvazla-usb-microphone/ (accessed on 9 June 2022).
- Sandberg. Streamer USB Clip Microphone. Available online: https://cdn.sandberg.world/products/pdf/es/126-19es.pdf (accessed on 15 February 2022).
- Saramonic. Saramonic SR-ULM10 USB Microphone. Available online: https://www.saramonic.com/product/sr-ulm10-sr-ulm10l/ (accessed on 9 June 2022).
- ISO 3382-12:2009; Acoustics—Measurement of Room Acoustic Parameters—Part 1: Performance Spaces. International Organization for Standardization: Geneva, Switzerland, 2009.
- Gay, W. DHT11 sensor. In Advanced Raspberry Pi; Springer Science+Business Media New York: New York, NY, USA, 2018; pp. 399–418. [Google Scholar]
- Schlömer, N. Stressberry Github. 2021. Available online: https://github.com/nschloe/stressberry (accessed on 26 February 2022).
- TCPOLY. E-ins Ice9TM Flex Datasheet. 2021. Available online: https://tcpoly.com/wp-content/uploads/2022/03/ice9_Flex_r405.pdf (accessed on 4 February 2022).
- nledevil. Raspberry Pi 4 B. Available online: https://www.tinkercad.com/things/gRJOJb5f6b1 (accessed on 30 March 2022).
- The MathWorks, I. IoT Analytics—ThingSpeak Internet of Things. Available online: https://thingspeak.com/ (accessed on 30 March 2022).
- What’s the Difference between 2.4GHz and 5GHz WiFi? 2020. Available online: https://beambox.com/what-s-the-difference-between-2-4ghz-and-5ghz-wifi (accessed on 10 June 2022).
- Johnson, C.; Curtin, B.; Shyamkumar, N.; David, R.; Dunham, E.; Haney, P.C.; Moore, H.L.; Babbitt, T.A.; Matthews, S.J. A raspberry pi mesh sensor network for portable perimeter security. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 1–7. [Google Scholar]
- Manvi, M.; Maakar, S. A Study on Integrating Wireless Mesh Networking in IoT Systems. Int. Res. J. Eng. Technol. 2020, 7, 1242–1244. [Google Scholar]
- Innes, B.; Walicki, J. WiFiMeshRaspberryPi Github. 2021. Available online: https://github.com/binnes/WiFiMeshRaspberryPi (accessed on 25 January 2022).
- Shah, M.A.; Shah, I.A.; Lee, D.G.; Hur, S. Design approaches of MEMS microphones for enhanced performance. J. Sens. 2019, 2019, 9294528. [Google Scholar] [CrossRef]
- Froiz-Míguez, I.; Fernández-Caramés, T.; Fraga-Lamas, P.; Castedo, L. Design, Implementation and Practical Evaluation of an IoT Home Automation System for Fog Computing Applications Based on MQTT and ZigBee-WiFi Sensor Nodes. Sensors 2018, 18, 2660. [Google Scholar] [CrossRef] [PubMed]
- Fendji, J.L.; Fendji, E.; Samo, S. Energy and Performance Evaluation of Reactive, Proactive, and Hybrid Routing Protocols in Wireless Mesh Network. Int. J. Wirel. Mob. Netw. 2019, 11, 19. [Google Scholar] [CrossRef]
- Alsina-Pagès, R.M.; Navarro, J.; Casals, E. Automated Audio Data Monitoring for a Social Robot in Ambient Assisted Living Environments. In Proceedings of the New Friends: 2nd International Conference on Social Robots in Therapy and Education, Barcelona, Spain, 2 November 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gv1 | Gv2 | Sb1 | Sb2 |
|---|---|---|---|
| 1.922717 | 1.733560 | 2.103515 | 1.911244 |
| Reference Signal Level | Tone at 1 kHz | |||||||
|---|---|---|---|---|---|---|---|---|
| Background Noise | 50 dB | 60 dB | 64 dB | 74 dB | 84 dB | 94 dB | 99.2 dB | |
| Gv1 | 57.2 | 58.3 | 63.0 | 66.2 | 75.7 | 85.6 | 95.6 | 98.2 |
| Gv2 | 57.0 | 57.5 | 61.7 | 64.9 | 74.3 | 84.2 | 94.2 | 97.2 |
| Sb1 | 34.6 | 49.7 | 60.1 | 64.1 | 74.1 | 84.2 | 94.1 | 98.4 |
| Sb2 | 36.0 | 49.5 | 60.0 | 64.0 | 74.0 | 84.0 | 94.0 | 97.8 |
| Box | Material | Dimensions (X × Y × Z) | Acronym | Figure |
|---|---|---|---|---|
| Large Non-holed | PLA | 146 × 171 × 74 mm | LNP | Figure 4a |
| Small Non-holed | PLA | 81 × 129 × 64 mm | SNP | Figure 4b |
| Small Slot-holed | PLA | 81 × 129 × 63 mm | SSP | Figure 4c |
| Small Honeycomb-holed | PLA | 86 × 116 × 140 mm | SHP | Figure 4d |
| Small Honeycomb-holed | TPU | 86 × 116 × 140 mm | SHT | Figure 4d |
| Days | Frames Received in Thingspeak (%) | |||||
|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | S5 | ||
| Direct WiFi | 199 | 98.26 | 97.42 | 99.27 | 86.25 | 76.97 (12 d) |
| WiFi mesh | 90 | 99.37 | 99.22 | 99.95 | 99.95 | 98.28 (9 d) |
| WiFi mesh + reboot S5 | 40 | 99.97 | 99.95 | 99.81 | 99.87 | 99.07 |
| WASN | Microphone | Connectivity | Computing Unit | Power | Price |
|---|---|---|---|---|---|
| MESSAGE | Condenser | ZigBee | Microcontroller | D Battery or | N.A. |
| 2013 [8] | microphone | + GPRS | PIC18F4620 | external power | |
| (around EUR 5) | connection | ||||
| SONYC | Custom | WiFi direct | Tronsmart | 120 V outlet | EUR 81 |
| 2017 [23] | MEMS | connection | MK908ii | + PSU | |
| to router | (EUR 50) | ||||
| P. Arce et al., | miniDSP | WiFi mesh | Raspberry Pi | Battery | EUR 191 |
| 2021 [9] | UMIK-1 | OLSR | 3B | (EUR 20) | |
| (EUR 140) | protocol | (EUR 31) | |||
| Ginovart et al. | LYM00002 | WiFi direct | Raspberry Pi | 5 V–3 A | EUR 78 |
| approach | (EUR 11) | connection | 3B+ | charger | |
| 2021 [16] | to router | (EUR 37) | (EUR 12) | ||
| Proposed | Sandberg | WiFi mesh | Raspberry Pi | 5 V–3 A | EUR 120 |
| approach | 126-19 | HWMP | 4B-4GB | charger | |
| 2022 | (EUR 29) | protocol | (EUR 64) | (EUR 12) |
| WASN | Microphone | Frequency Response | Calibration | Plug and Play |
|---|---|---|---|---|
| MESSAGE 2013 [8] | Condenser | 20 Hz–20 kHz | Yes | No |
| SONYC 2017 [23] | MEMS | 10 Hz–10 kHz | Yes | No |
| P. Arce et al., 2021 [9] | Electret | 20 Hz–20 kHz | No | Yes |
| Ginovart et al., 2021 [16] | Condenser | 20 Hz–16 kHz | Yes | Yes |
| Proposed approach | Electret | 50 Hz–18 kHz | Yes | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caro-Via, S.; Vidaña-Vila, E.; Ginovart-Panisello, G.J.; Martínez-Suquía, C.; Freixes, M.; Alsina-Pagès, R.M. Edge-Computing Meshed Wireless Acoustic Sensor Network for Indoor Sound Monitoring. Sensors 2022, 22, 7032. https://doi.org/10.3390/s22187032
Caro-Via S, Vidaña-Vila E, Ginovart-Panisello GJ, Martínez-Suquía C, Freixes M, Alsina-Pagès RM. Edge-Computing Meshed Wireless Acoustic Sensor Network for Indoor Sound Monitoring. Sensors. 2022; 22(18):7032. https://doi.org/10.3390/s22187032
Chicago/Turabian StyleCaro-Via, Selene, Ester Vidaña-Vila, Gerardo José Ginovart-Panisello, Carme Martínez-Suquía, Marc Freixes, and Rosa Ma Alsina-Pagès. 2022. "Edge-Computing Meshed Wireless Acoustic Sensor Network for Indoor Sound Monitoring" Sensors 22, no. 18: 7032. https://doi.org/10.3390/s22187032
APA StyleCaro-Via, S., Vidaña-Vila, E., Ginovart-Panisello, G. J., Martínez-Suquía, C., Freixes, M., & Alsina-Pagès, R. M. (2022). Edge-Computing Meshed Wireless Acoustic Sensor Network for Indoor Sound Monitoring. Sensors, 22(18), 7032. https://doi.org/10.3390/s22187032