

Multi-Fault Detection and Classification of Wind Turbines Using Stacking Classifier



Abstract
:1. Introduction
1.1. Contributions
- An AdaBoost, K-nearest neighbors, and logistic regression-based stacking ensemble (AKL-SE) classifier is introduced.
- We integrated SCADA data with status data for fault detection and employed data and predictive analytics techniques for data obtained from wind turbines.
- We performed a comparison with state-of-the-art ML models and different combinations of ensemble models.
1.2. Article Organization
2. Literature Review
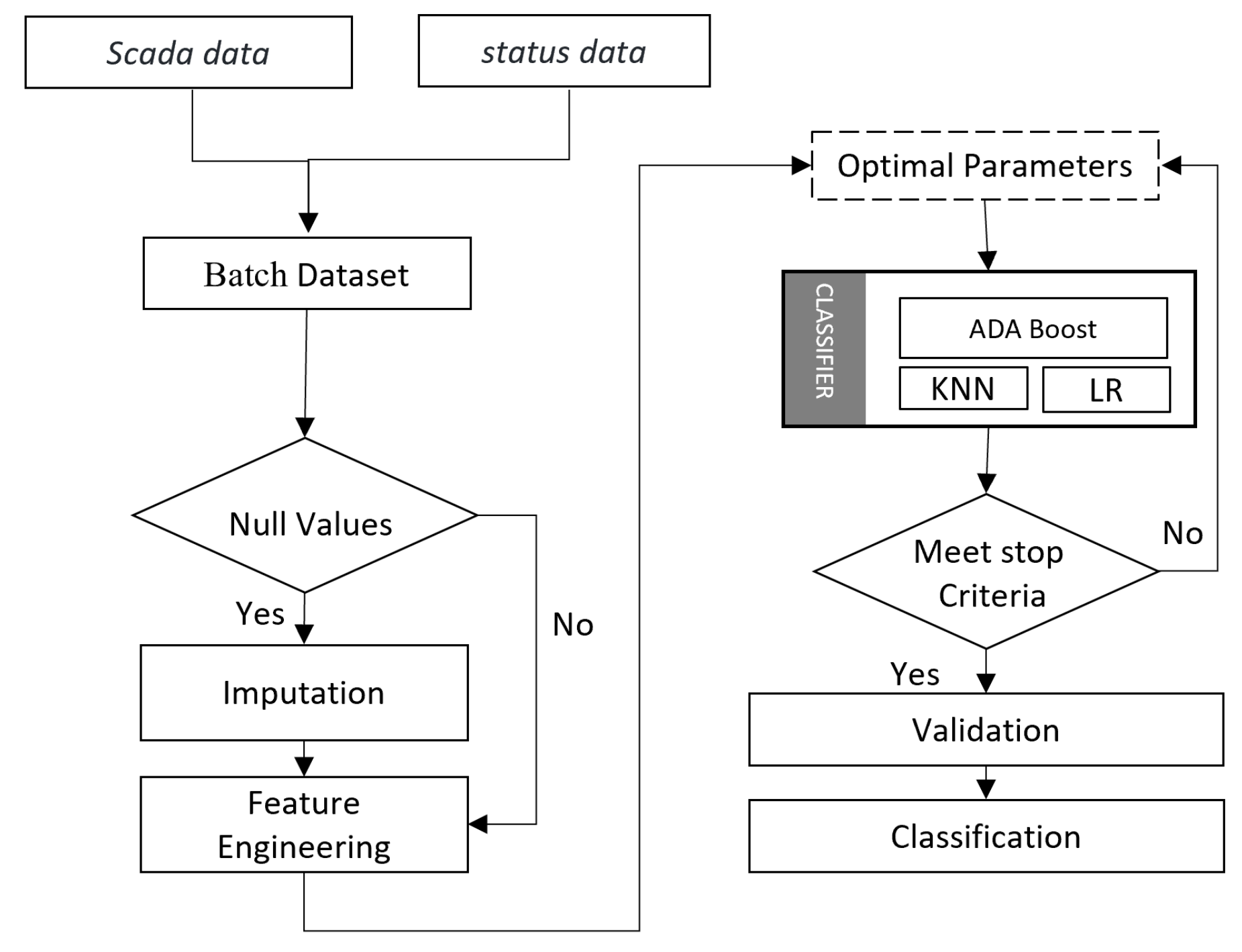
3. Methodology
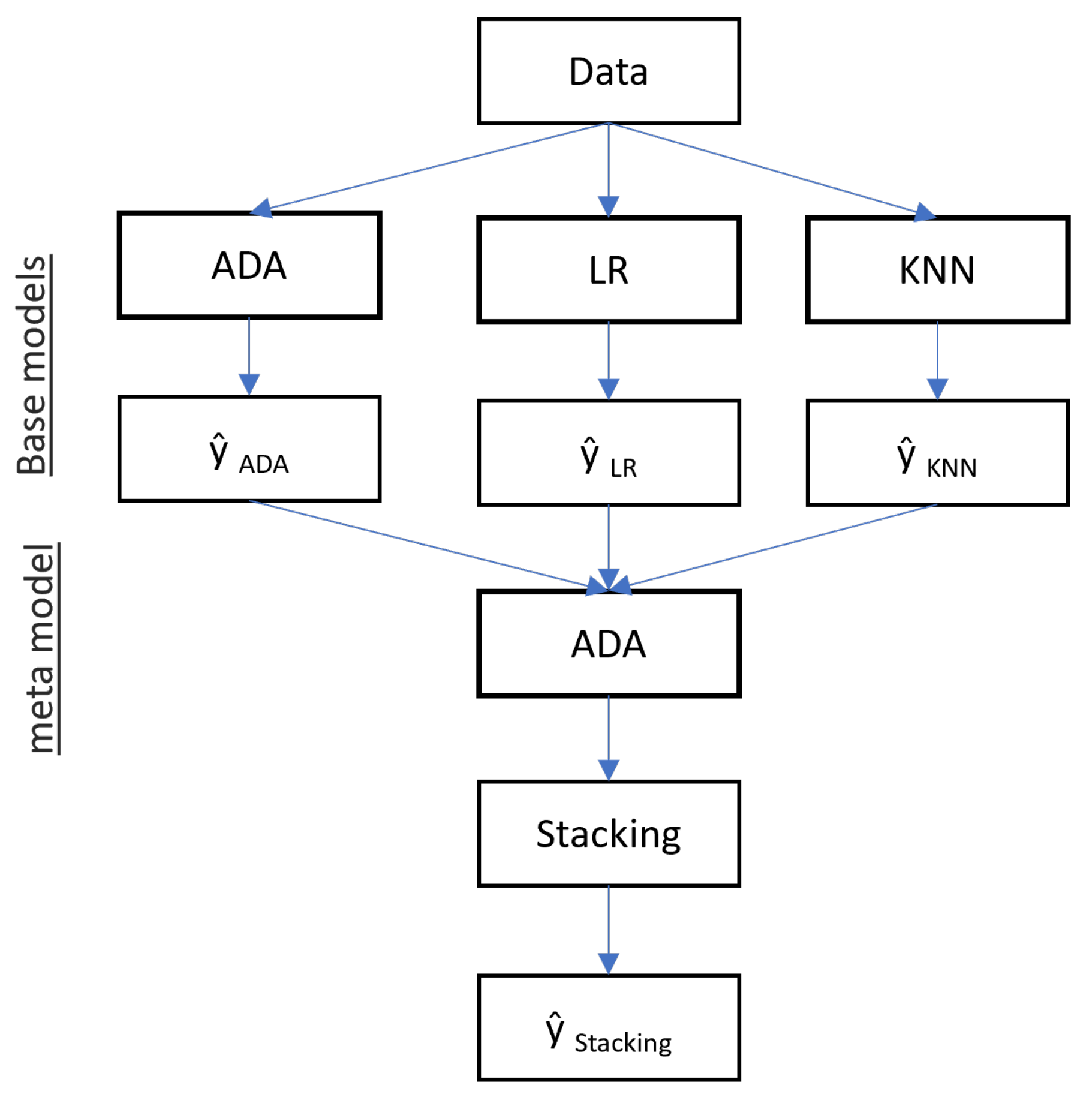
3.1. Stacking Ensemble Classification
3.2. AdaBoost
| Algorithm 1 Pseudo code for AdaBoost training |
| Require: Initialize weight to Require: Initialize Train first weak decision tree model for Each observation do if pred ≠ correct then else end if end for Train second weak model with greater weights return pred |
3.3. Logistic Regression
3.4. K-Nearest Neighbor
| Algorithm 2 Pseudo code for K-nearest neighbors training |
| Require: Initialize Require: Initialize =[] Train first weak decision tree model for Each observation do = euclidean distance calculate euclidean distance append neighbors end for pick the top-K closest training data take the most common label of these labels return labels |
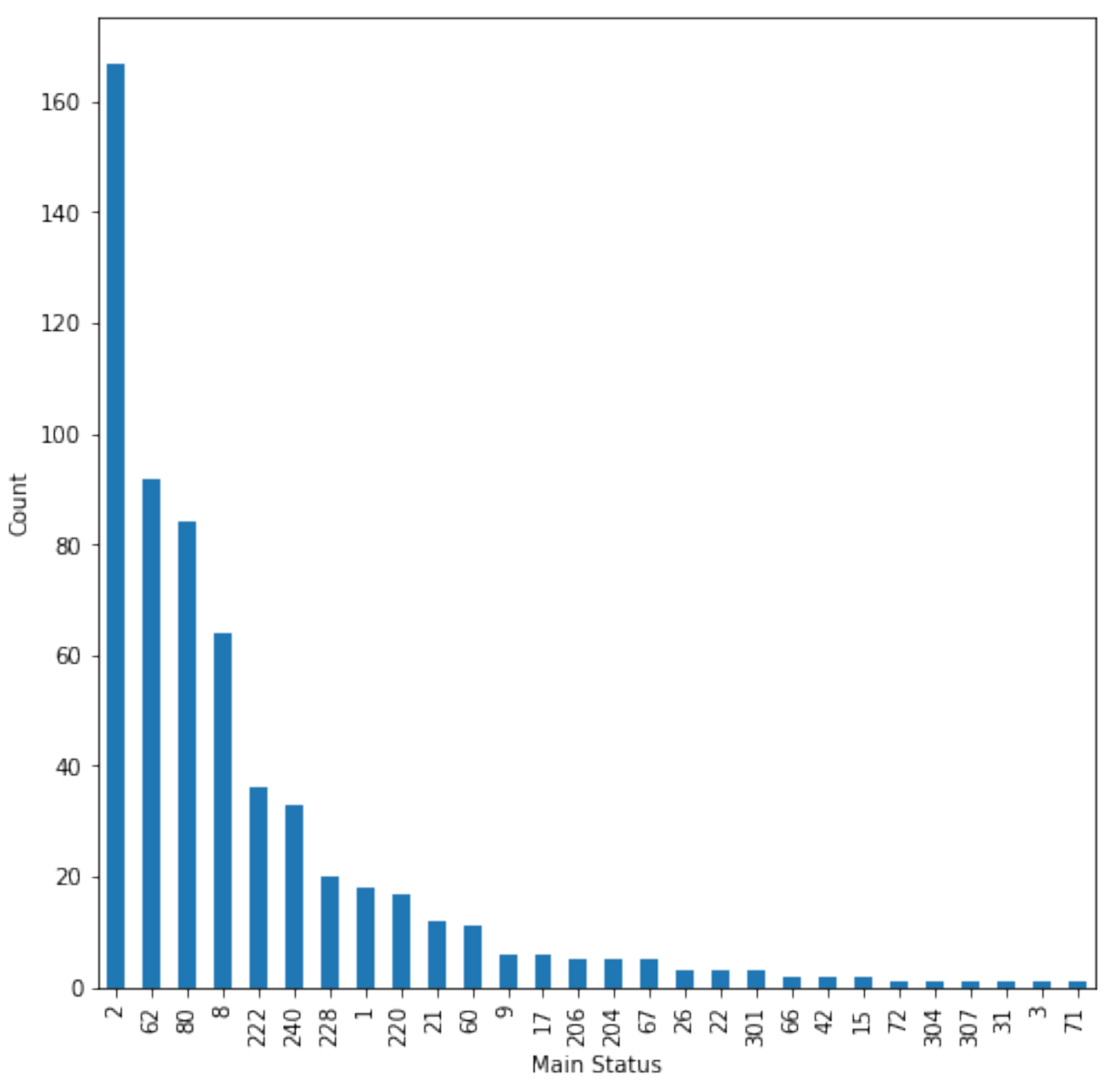
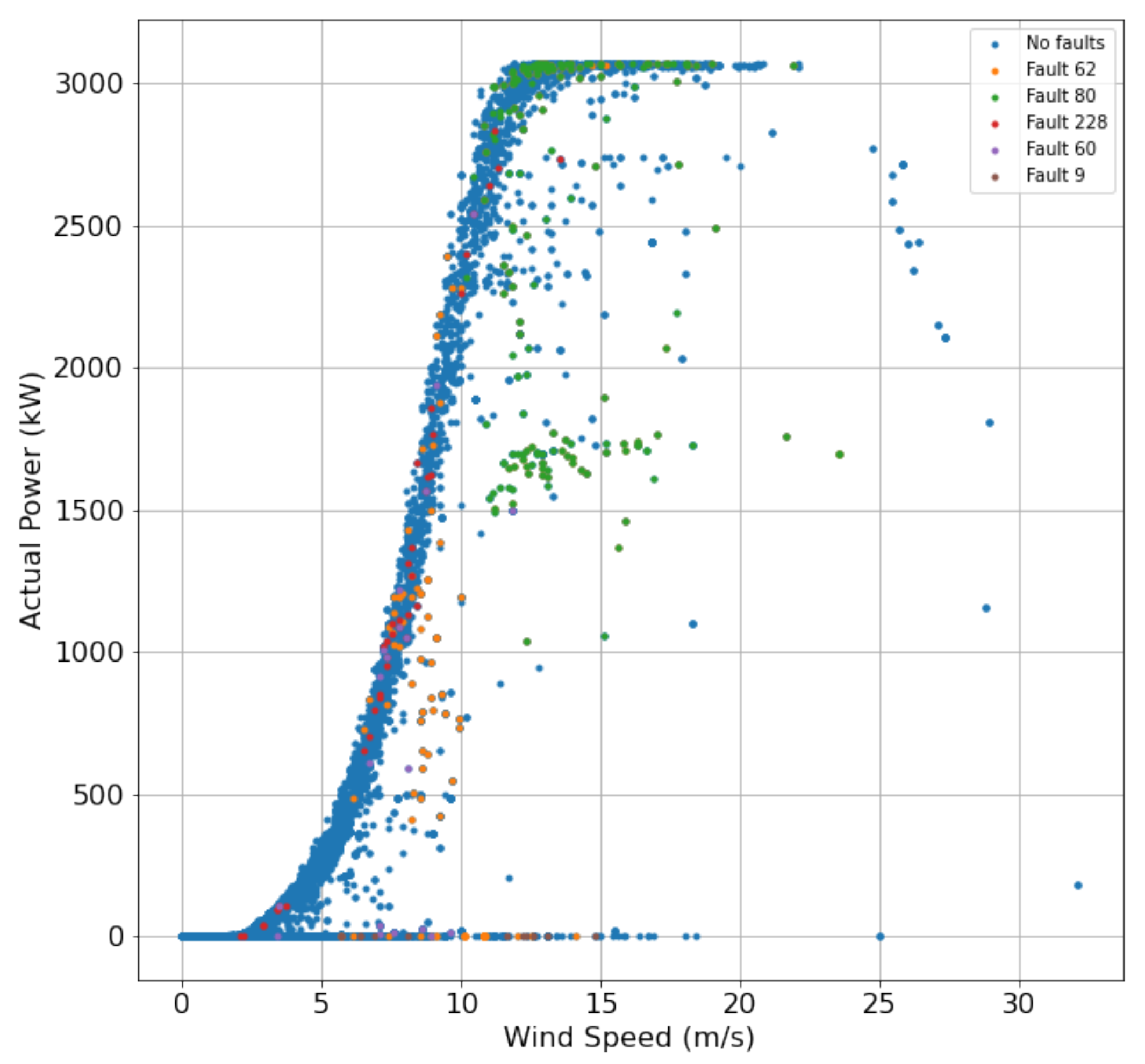
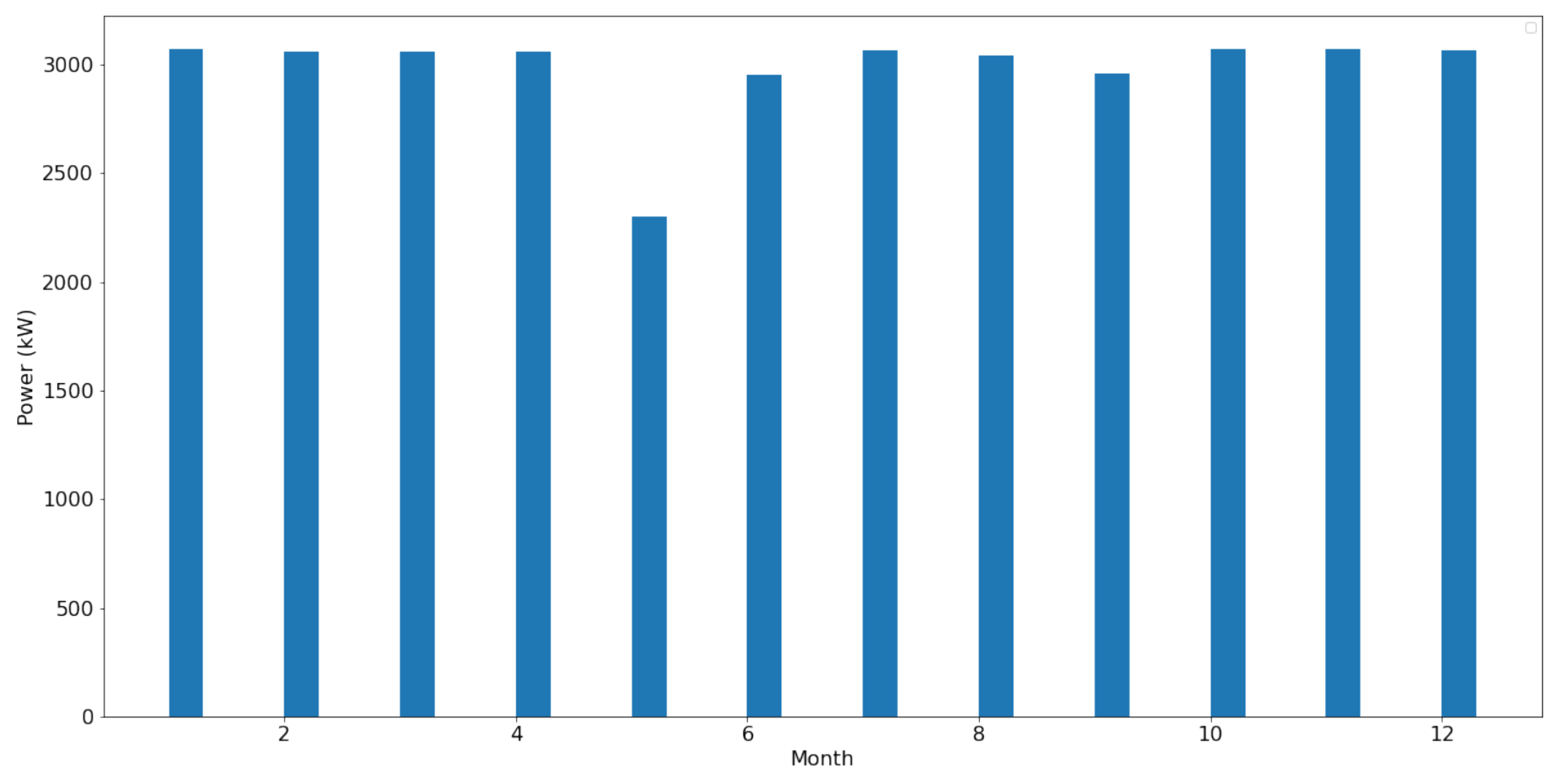
4. Data Analysis
5. Results
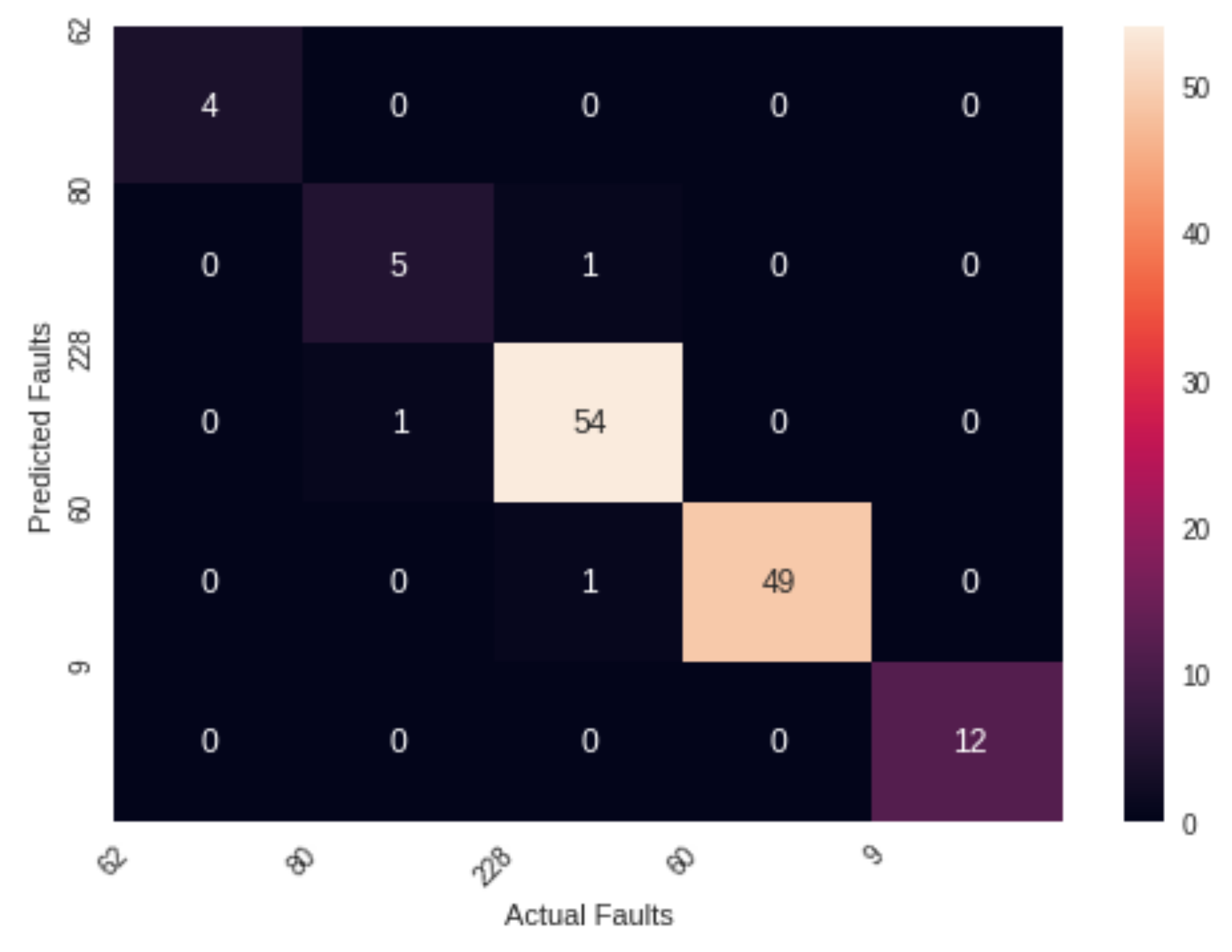
5.1. Confusion Matrix
5.2. Receiver Operating Characteristics
5.3. Precision
5.4. Recall
5.5. Accuracy
5.6. F1 Score
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SCADA | Supervisory control and data acquisition |
| O&M | Operation and maintenance |
| ML | Machine learning |
| WT | Wind turbines |
| RES | Renewable energy sources |
| LR | Logistic regression |
| MLP | Multi-layer perceptron |
| SVM | Support-vector machine |
| LSTM | Long short-term memory |
| CMS | Condition monitoring system |
| WEC | Wind energy converter |
| KNN | K-nearest neighbors |
| AUC | Area under the curve |
| ROC | Receiver operating characteristics |
Appendix A

References
- Xiang, L.; Yang, X.; Hu, A.; Su, H.; Wang, P. Condition monitoring and anomaly detection of wind turbine based on cascaded and bidirectional deep learning networks. Appl. Energy 2022, 305, 117925. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhu, C.; Tan, J.; Tan, Y.; Rao, L. Anomaly detection and condition monitoring of wind turbine gearbox based on LSTM-FS and transfer learning. Renew. Energy 2022, 189, 90–103. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, H.; Liu, J.; Zhao, J.; Sun, P. An anomaly identification model for wind turbine state parameters. J. Clean. Prod. 2018, 195, 1214–1227. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.C. Adaptive error curve learning ensemble model for improving energy consumption forecasting. Comput. Mater. Contin 2021, 69, 1893–1913. [Google Scholar] [CrossRef]
- Li, H.; Chen, Z. Overview of different wind generator systems and their comparisons. IET Renew. Power Gener. 2008, 2, 123–138. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, X.; Qian, P. Wind turbine fault detection and identification through PCA-based optimal variable selection. IEEE Trans. Sustain. Energy 2018, 9, 1627–1635. [Google Scholar] [CrossRef]
- Chen, X.; Yang, Y.; Cui, Z.; Shen, J. Vibration fault diagnosis of wind turbines based on variational mode decomposition and energy entropy. Energy 2019, 174, 1100–1109. [Google Scholar] [CrossRef]
- Bodla, M.K.; Malik, S.M.; Rasheed, M.T.; Numan, M.; Ali, M.Z.; Brima, J.B. Logistic regression and feature extraction based fault diagnosis of main bearing of wind turbines. In Proceedings of the 2016 IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), Hefei, China, 5–7 June 2016; pp. 1628–1633. [Google Scholar]
- Malik, H. Wavelet and Hilbert Huang transform based wind turbine imbalance fault classification model using k-nearest neighbour algorithm. Int. J. Renew. Energy Technol. 2018, 9, 66–83. [Google Scholar] [CrossRef]
- Lima, L.; Blatt, A.; Fujise, J. Wind turbine failure prediction using SCADA data. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1618, p. 022017. [Google Scholar]
- Chatterjee, J.; Dethlefs, N. Deep learning with knowledge transfer for explainable anomaly prediction in wind turbines. Wind Energy 2020, 23, 1693–1710. [Google Scholar] [CrossRef]
- Zheng, X.X.; Peng, P. Fault diagnosis of wind power converters based on compressed sensing theory and weight constrained Adaboost-SVM. J. Power Electron. 2019, 19, 443–453. [Google Scholar]
- Wu, Z.; Wang, X.; Jiang, B. Fault diagnosis for wind turbines based on ReliefF and eXtreme gradient boosting. Appl. Sci. 2020, 10, 3258. [Google Scholar] [CrossRef]
- Downey, A.; Ubertini, F.; Laflamme, S. Algorithm for damage detection in wind turbine blades using a hybrid dense sensor network with feature level data fusion. J. Wind. Eng. Ind. Aerodyn. 2017, 168, 288–296. [Google Scholar] [CrossRef]
- Kushwah, K.; Sahoo, S.; Joshuva, A. Health Monitoring of Wind Turbine Blades Through Vibration Signal Using Machine Learning Techniques. In Proceedings of the International Conference on Computing and Communication Systems, Vellore, India, 9–11 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 239–247. [Google Scholar]
- Joshuva, A.; Deenadayalan, G.; Sivakumar, S.; Sathishkumar, R.; Vishnuvardhan, R. Logistic model tree classifier for condition monitoring of wind turbine blades. Int. J. Recent Technol. Eng. 2019, 8, 202–209. [Google Scholar]
- Wenyi, L.; Zhenfeng, W.; Jiguang, H.; Guangfeng, W. Wind turbine fault diagnosis method based on diagonal spectrum and clustering binary tree SVM. Renew. Energy 2013, 50, 1–6. [Google Scholar] [CrossRef]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale convolutional neural networks for fault diagnosis of wind turbine gearbox. IEEE Trans. Ind. Electron. 2018, 66, 3196–3207. [Google Scholar] [CrossRef]
- Rahimilarki, R.; Gao, Z.; Jin, N.; Zhang, A. Convolutional neural network fault classification based on time-series analysis for benchmark wind turbine machine. Renew. Energy 2022, 185, 916–931. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Tee, K.F.; Li, Q.; Wu, X.P. Comparative study of onshore and offshore wind characteristics and wind energy potentials: A case study for southeast coastal region of China. Sustain. Energy Technol. Assess. 2020, 39, 100711. [Google Scholar] [CrossRef]
- Vidal, Y.; Pozo, F.; Tutivén, C. Wind turbine multi-fault detection and classification based on SCADA data. Energies 2018, 11, 3018. [Google Scholar] [CrossRef]
- Miele, E.S.; Bonacina, F.; Corsini, A. Deep anomaly detection in horizontal axis wind turbines using Graph Convolutional Autoencoders for Multivariate Time series. Energy AI 2022, 8, 100145. [Google Scholar] [CrossRef]
- Lei, J.; Liu, C.; Jiang, D. Fault diagnosis of wind turbine based on Long Short-term memory networks. Renew. Energy 2019, 133, 422–432. [Google Scholar] [CrossRef]
- He, X.; Zhou, X.; Yu, W.; Hou, Y.; Mechefske, C.K. Adaptive variational mode decomposition and its application to multi-fault detection using mechanical vibration signals. ISA Trans. 2021, 111, 360–375. [Google Scholar] [CrossRef] [PubMed]
- Joshuva, A.; Kumar, R.S.; Sivakumar, S.; Deenadayalan, G.; Vishnuvardhan, R. An insight on VMD for diagnosing wind turbine blade faults using C4. 5 as feature selection and discriminating through multilayer perceptron. Alex. Eng. J. 2020, 59, 3863–3879. [Google Scholar] [CrossRef]
- Teng, W.; Ding, X.; Zhang, X.; Liu, Y.; Ma, Z. Multi-fault detection and failure analysis of wind turbine gearbox using complex wavelet transform. Renew. Energy 2016, 93, 591–598. [Google Scholar] [CrossRef]
- Mishnaevsky, L., Jr.; Thomsen, K. Costs of repair of wind turbine blades: Influence of technology aspects. Wind Energy 2020, 23, 2247–2255. [Google Scholar] [CrossRef]
- Ou, Y.; Tatsis, K.E.; Dertimanis, V.K.; Spiridonakos, M.D.; Chatzi, E.N. Vibration-based monitoring of a small-scale wind turbine blade under varying climate conditions. Part I: An experimental benchmark. Struct. Control. Health Monit. 2021, 28, e2660. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Hutchinson, P.; Lieven, N.A.; Nunez-Yanez, J. Adaptive event-triggered anomaly detection in compressed vibration data. Mech. Syst. Signal Process. 2019, 122, 480–501. [Google Scholar] [CrossRef]
- Coronado, D.; Wenske, J. Monitoring the oil of wind-turbine gearboxes: Main degradation indicators and detection methods. Machines 2018, 6, 25. [Google Scholar] [CrossRef]
- Bie, Y.; Liu, X.; Xu, T.; Zhu, Z.; Li, Z. A review of the application of oil analysis in condition monitoring and life prediction of wind turbine gearboxes. Insight-Non-Destr. Test. Cond. Monit. 2021, 63, 289–301. [Google Scholar] [CrossRef]
- Leahy, K.; Hu, R.L.; Konstantakopoulos, I.C.; Spanos, C.J.; Agogino, A.M. Diagnosing wind turbine faults using machine learning techniques applied to operational data. In Proceedings of the 2016 IEEE International Conference on Prognostics and Health Management (Icphm), Ottawa, ON, Canada, 20–22 June 2016; pp. 1–8. [Google Scholar]
- Khan, P.W.; Kim, Y.; Byun, Y.C.; Lee, S.J. Influencing Factors Evaluation of Machine Learning-Based Energy Consumption Prediction. Energies 2021, 14, 7167. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.C. Analysis of factors affecting machine learning-based energy prediction. In Proceedings of the KIIT Conference; 2021; pp. 33–35. [Google Scholar]
- Pang, Y.; He, Q.; Jiang, G.; Xie, P. Spatio-temporal fusion neural network for multi-class fault diagnosis of wind turbines based on SCADA data. Renew. Energy 2020, 161, 510–524. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.C.; Lee, S.J. Optimal Photovoltaic Panel Direction and Tilt Angle Prediction Using Stacking Ensemble Learning. Front. Energy Res. 2022, 10, 865413. [Google Scholar] [CrossRef]
- Lu, W.; Liu, J.; Fu, X.; Yang, J.; Jones, S. Integrating machine learning into path analysis for quantifying behavioral pathways in bicycle-motor vehicle crashes. Accid. Anal. Prev. 2022, 168, 106622. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Li, Y.; Li, Y.; Liu, X.; Li, J. BPSO-Adaboost-KNN ensemble learning algorithm for multi-class imbalanced data classification. Eng. Appl. Artif. Intell. 2016, 49, 176–193. [Google Scholar]
- Piech, C. Logistic Regression. 2017. Available online: https://pdfs.semanticscholar.org/8a27/7cf63806ee25977bb8a59fa511e5918d2cfe.pdf (accessed on 7 May 2022).
- Jiang, Y.; Hamer, J.; Wang, C.; Jiang, X.; Kim, M.; Song, Y.; Xia, Y.; Mohammed, N.; Sadat, M.N.; Wang, S. SecureLR: Secure logistic regression model via a hybrid cryptographic protocol. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 16, 113–123. [Google Scholar] [CrossRef]
- Niño-Adan, I.; Landa-Torres, I.; Portillo, E.; Manjarres, D. Influence of statistical feature normalisation methods on K-Nearest Neighbours and K-Means in the context of industry 4.0. Eng. Appl. Artif. Intell. 2022, 111, 104807. [Google Scholar] [CrossRef]
- Leahy, K.; Hu, R.L.; Konstantakopoulos, I.C.; Spanos, C.J.; Agogino, A.M.; O’Sullivan, D.T. Diagnosing and predicting wind turbine faults from SCADA data using support vector machines. Int. J. Progn. Health Manag. 2018, 9. [Google Scholar] [CrossRef]
- Yansari, R.T.; Mirzarezaee, M.; Sadeghi, M.; Araabi, B.N. A new survival analysis model in adjuvant Tamoxifen-treated breast cancer patients using manifold-based semi-supervised learning. J. Comput. Sci. 2022, 61, 101645. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr # | Parameter | AdaBoost | Logistic Regression | KNN |
|---|---|---|---|---|
| 1 | base estimators | none | - | - |
| 2 | learning rate | 1.0 | - | - |
| 3 | n estimators/jobs | 50 | none | −1 |
| 4 | random state | none | none | - |
| 5 | leaf size | - | - | 30 |
| 6 | max iter | - | 100 | - |
| 7 | n neighbors | - | - | 5 |
| 8 | c/p | - | 1.0 | 2 |
| 9 | weights | none | none | uniform |
| 10 | penalty | - | 12 | - |
| Sr # | Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| 1 | AdaBoost | 0.95 | 0.91 | 0.95 | 0.93 |
| 2 | K-Nearest Neighbors | 0.97 | 0.97 | 0.96 | 0.96 |
| 3 | Logistic Regression | 0.96 | 0.97 | 0.96 | 0.96 |
| 4 | Quadratic Discriminant Analysis | 0.88 | 0.88 | 0.88 | 0.87 |
| 5 | Naive Bayes | 0.68 | 0.77 | 0.68 | 0.65 |
| 6 | Decision Tree Classifier | 0.65 | 0.66 | 0.65 | 0.62 |
| 7 | Recurrent Neural Network | 0.72 | 0.74 | 0.71 | 0.72 |
| 8 | Stacking Classifier | 0.98 | 0.98 | 0.98 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waqas Khan, P.; Byun, Y.-C. Multi-Fault Detection and Classification of Wind Turbines Using Stacking Classifier. Sensors 2022, 22, 6955. https://doi.org/10.3390/s22186955
Waqas Khan P, Byun Y-C. Multi-Fault Detection and Classification of Wind Turbines Using Stacking Classifier. Sensors. 2022; 22(18):6955. https://doi.org/10.3390/s22186955
Chicago/Turabian StyleWaqas Khan, Prince, and Yung-Cheol Byun. 2022. "Multi-Fault Detection and Classification of Wind Turbines Using Stacking Classifier" Sensors 22, no. 18: 6955. https://doi.org/10.3390/s22186955
APA StyleWaqas Khan, P., & Byun, Y.-C. (2022). Multi-Fault Detection and Classification of Wind Turbines Using Stacking Classifier. Sensors, 22(18), 6955. https://doi.org/10.3390/s22186955