1. Introduction
Autonomous driving is expected to help reduce traffic accidents, reduce the workload of drivers, and improve the quality of transportation, which has become a research hotspot in recent years [
1]. However, the majority of people are skeptical regarding self-driving cars. A poll conducted in Germany found that roughly 25% of respondents were hesitant to utilize self-driving cars because their set driving patterns made them feel psychologically constrained and uneasy [
2]. According to studies, in addition to legal and safety considerations, fulfilling user expectations, user acceptability, and accessibility to functional implementation are the fundamental requirements for the effective deployment of autonomous cars [
3]. Therefore, enabling autonomous vehicles to have more accurate, comfortable, and personalized behavioral decisions is the key to improving autonomous driving technology.
The LCD problem is one of the more complicated and demanding challenges in autonomous driving technology, and has been intensively investigated by researchers at home and abroad [
4]. Existing LCD methods can roughly be divided into two categories: rule-based methods and learning-based methods. Rule-based decision-making methods plan the behavior of autonomous vehicles, and establish a decision-making behavior library based on driving rules, knowledge, experience, and traffic rules [
5]. The Gipps [
6] model and the CORSIM [
7] model are examples of traditional rule-based LCD models. Finite state machines have also frequently been employed in autonomous driving LCD systems, providing an example of rule-based decision-making techniques. Wang et al. [
8] proposed a driving LCD model based on the finite state machine, which output the best driving behavior in the current scene by means of a benefit evaluation model. Qi et al. [
9] designed a hierarchical finite state machine behavioral decision-making model. Rule-based decision-making methods can handle the general driving environment well, but they are designed in a fixed way, and their mode cannot be adjusted for drivers with different driving styles.
The monitors and sensors of autonomous cars are now able to record the motion state parameters of both the vehicle in front and other nearby vehicles thanks to advancements in autonomous driving decision-making technology. As a result, it is possible to study how vehicles make decisions by mining historical vehicle motion data [
10], which is one of the key causes for the progressive rise in popularity of learning-based methodologies. Liu et al. [
11] built an autonomous LCD model based on benefit, safety, and tolerance using a Bayesian parameter-optimized support vector machine method. Ma et al. [
12] constructed a driving agent model based on a Bayesian network, which integrated vision and decision making. Tang et al. [
13] proposed a lane change prediction method based on an adaptive fuzzy neural network. Xie et al. [
14] utilized random forests to simulate LC maneuvers from the standpoint of traffic incidents. Díaz-Álvarez et al. [
15] employed artificial neural networks to model the behavior of drivers performing LC tasks. Human driving behaviors are typically extremely nonlinear and complicated movements that are challenging to adequately simulate using traditional shallow machine learning models.
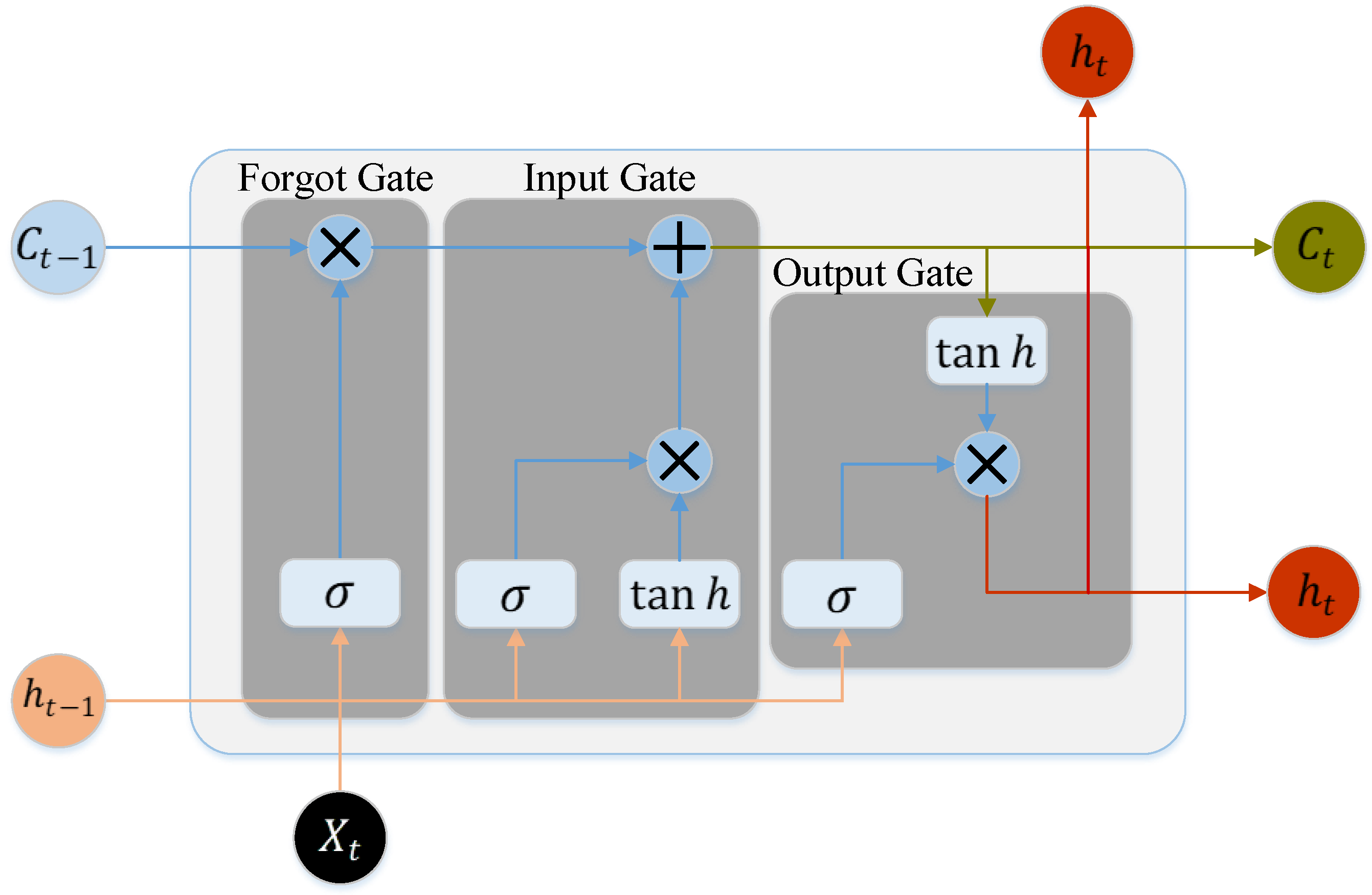
Deep neural networks (DNNs) are able to mimic discretionary lane changing (DLC) operations on roads more accurately, and may implicitly include memory effects in their structures [
16]. DNNs have been shown to possess excellent application potential for behavioral decision making in complicated settings, such as urban roadways and crossroads [
17]. On the basis of NGSIM data, Zhang et al. [
18] established a vehicle following and LC simulation model using an LSTM model optimized by the Hybrid Retraining Constraint (HRC) training method. Zhang et al. [
19] utilized XGBoost to construct an LC prediction model on the basis of the NGSIM dataset with selected high-dimensional driving feature data. Fang [
20] used a deep belief network (DBN) to build an LCD model, and trained the network using NGSIM data, and the results showed that the network outperformed the BP neural network. Although these methods can achieve good LC predictions in driving scenarios, they have limitations with respect to modeling interactions with each other.
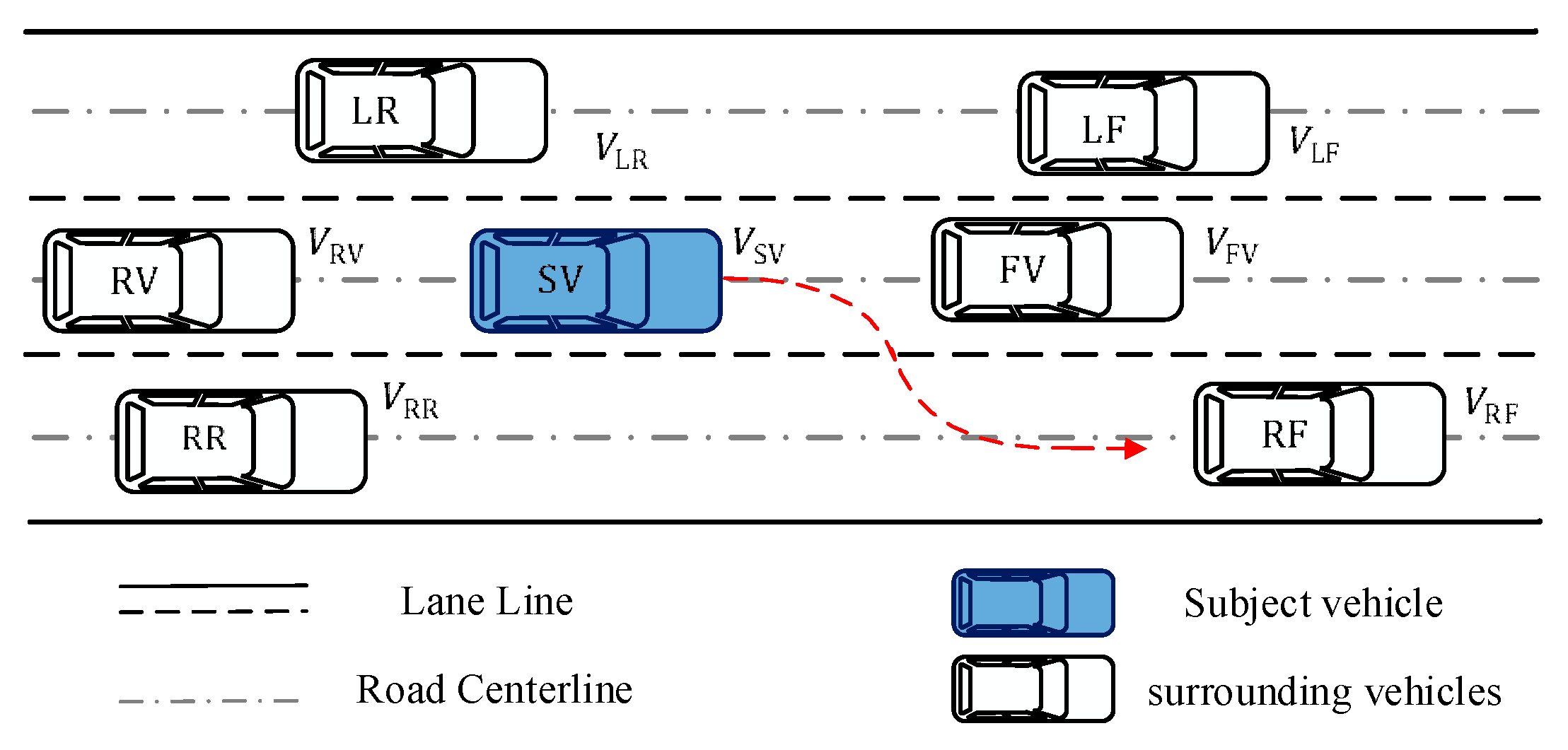
The analysis of the above decision-making approaches reveals that less study has been performed on personalized behavioral decision making and more emphasis has been placed on security and scene coverage in current LCD methods. At present, most of the personalized driving research focuses on the design of assisted driving systems and the identification of driving style. In fact, different drivers show different personal preferences in terms of risk perception, ride comfort and travel efficiency. Therefore, from a driving style perspective, enabling autonomous driving to capture human decision-making behavior is expected to provide drivers and occupants with personalized choices. In addition, the above methods only consider the feature quantities (e.g., speed, acceleration and distance) related to the motion state of the subject vehicle when modeling behavioral decisions. However, when an autonomous vehicle is operating in the driving environment, it forms a whole in which both it and the surrounding vehicles affect each other. Autonomous vehicles cannot make precise behavioral decisions by only considering the characteristics of the motion state of the subject vehicle.
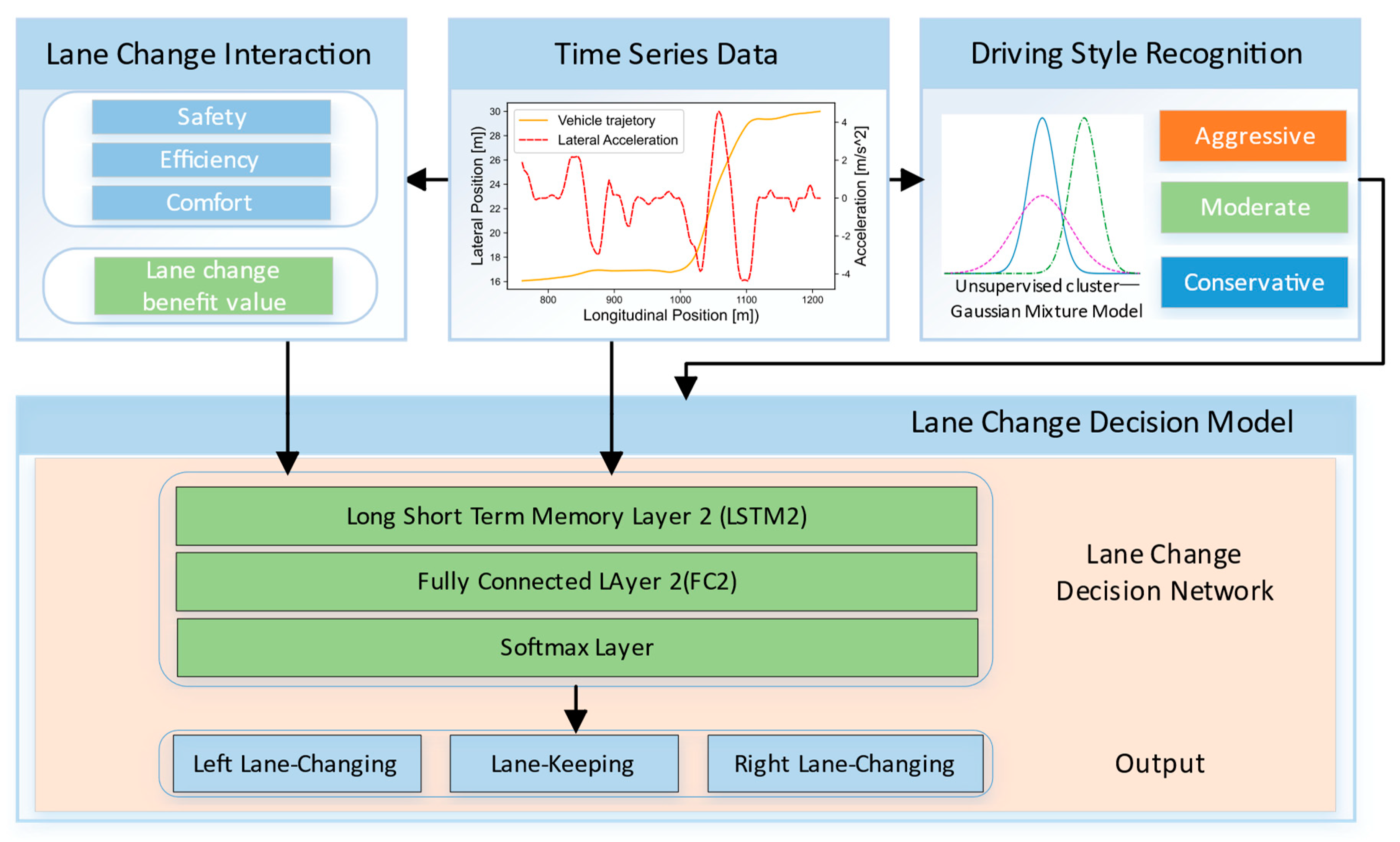
To address these issues, on the basis of the LSTM recurrent neural network model, this paper establishes an LCD model that considers the driving style of the SV and includes interactions. Firstly, personalization factors (driving characteristics and driving style) are introduced into the algorithm model, enabling autonomous vehicles to capture individual characteristics and human decision making, with the aim of achieving personalized driving, while also improving the adaptability of automated driving systems to human drivers. Then, the interaction between the autonomous vehicle and surrounding vehicles is modeled by constructing a gain function to improve the accuracy of the decision-making method. At the same time, the driving environment is extended to three lanes, with the autonomous vehicle being able to perform lane keeping and left–right LC, which is more general. The contributions of this study can be summarized as follows:
(1) A driving style recognition method for autonomous vehicles on highways is proposed, and characteristic variables such as speed, acceleration and headway are selected for quantitative analysis.
(2) The interaction between the main vehicle and the surrounding vehicles is modeled through the gain function, which enhances the understanding of the scenario by the autonomous vehicle.
(3) A personalized decision-making model with interaction is established. The behavioral feature data and LC gain values of different driving styles are used as the input of the LSTM model, and then the time series relationship of various states in the process of lane change is learned.
The rest of this paper is organized as follows:
Section 2 briefly describes the overall framework and data processing modules of the paper;
Section 3 describes the scheme for driving style identification;
Section 4 constructs a personalized LCD model;
Section 5 describes the model evaluation and analysis of the results; and
Section 6 presents the conclusions.
3. Driving Style Recognition Based on GMM
In this section, the Gaussian mixture model (GMM) is used to generate a unique driving style for each vehicle. The Gaussian mixture model is an extension of the Gaussian model, and it is also a linear combination of multiple Gaussian distribution functions. GMM is the fastest−learning probability model. Its principle is to construct the most suitable mixed multi-dimensional Gaussian distribution model by fitting the input dataset [
22]. The Gaussian mixture model GMM can be described as follows:
Here,
denotes multidimensional feature data.
θ is the parameter of the Gaussian mixture model, which can be expressed as
.
is the weight of each Gaussian distribution, meaning the probability of each cluster class being selected, and
, where
and
Σ are the mean and covariance parameters of the multivariate Gaussian function, and K is the number of models.
is the univariate Gaussian distribution function in this case, and its form is as follows, where
,
represents the standard deviation of the kth class:
When clustering datasets, the Gaussian mixture model for unknown parameters is not able to determine which potential components each data point originates from, so it is necessary to estimate the parameters of the Gaussian mixture model. The expectation maximization algorithm (EM) is a commonly used algorithm for GMM parameter estimation. EM is a maximum likelihood estimation algorithm that iteratively computes the maximum value of the cost function [
23].
(1) Selection of the Number of Clusters: GMM−based clustering requires the number of clusters
k to be pre−specified, and finding the optimal value of
k is a challenge. To obtain the optimal number of clusters, this paper adopts the Akaike Information Criterion (
AIC) and Bayesian Information Criterion (
BIC) to evaluate the performance of GMM clustering, where
k is the number of clusters,
N is the number of data points, and
L is the maximum likelihood of the objective function. The formulas for calculating
AIC and
BIC are as follows:
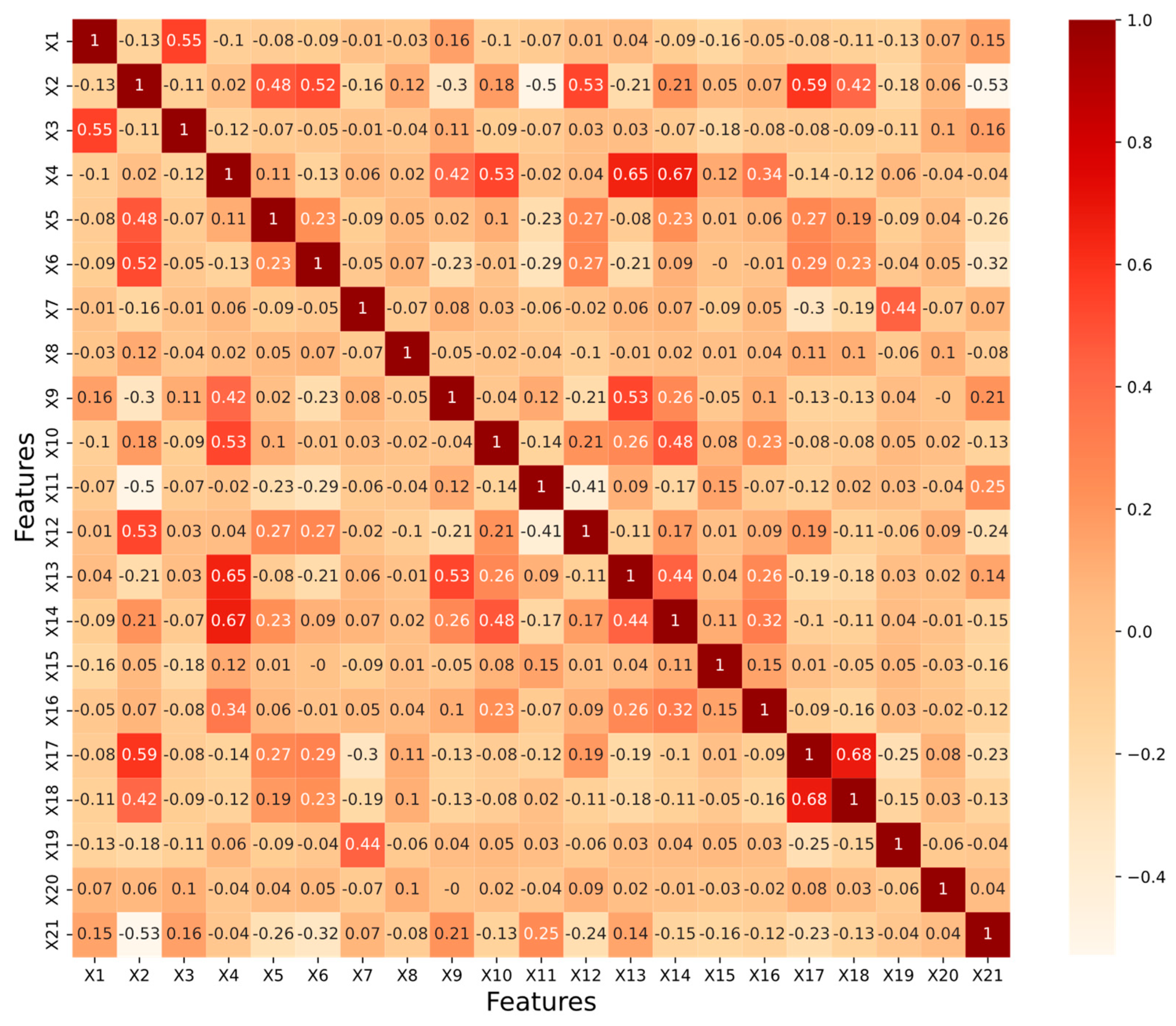
(2) Feature Selection: Different drivers have distinct driving styles when they drive. This paper classifies drivers by analyzing the identification parameters of each driver’s driving characteristics. There is no uniform standard for the selection of driving style characterization parameters, and different scholars choose different indicators. The driving style index parameters selected in this paper are shown in
Table 1, in order to fully characterize the driving style of the driver.
In this research, the influence of GMM on driving style recognition is investigated. The GMM−based driving style identification algorithm is able to determine the driving style of the SV on the basis of few driving behavior data. From
Table 1, it can be seen that feature information such as speed, acceleration, lateral speed, and spatial headway time distance of the SV are extracted. At the same time, statistics such as standard deviation, mean and maximum values are introduced to strengthen the robustness of the GMM clustering method recognition.
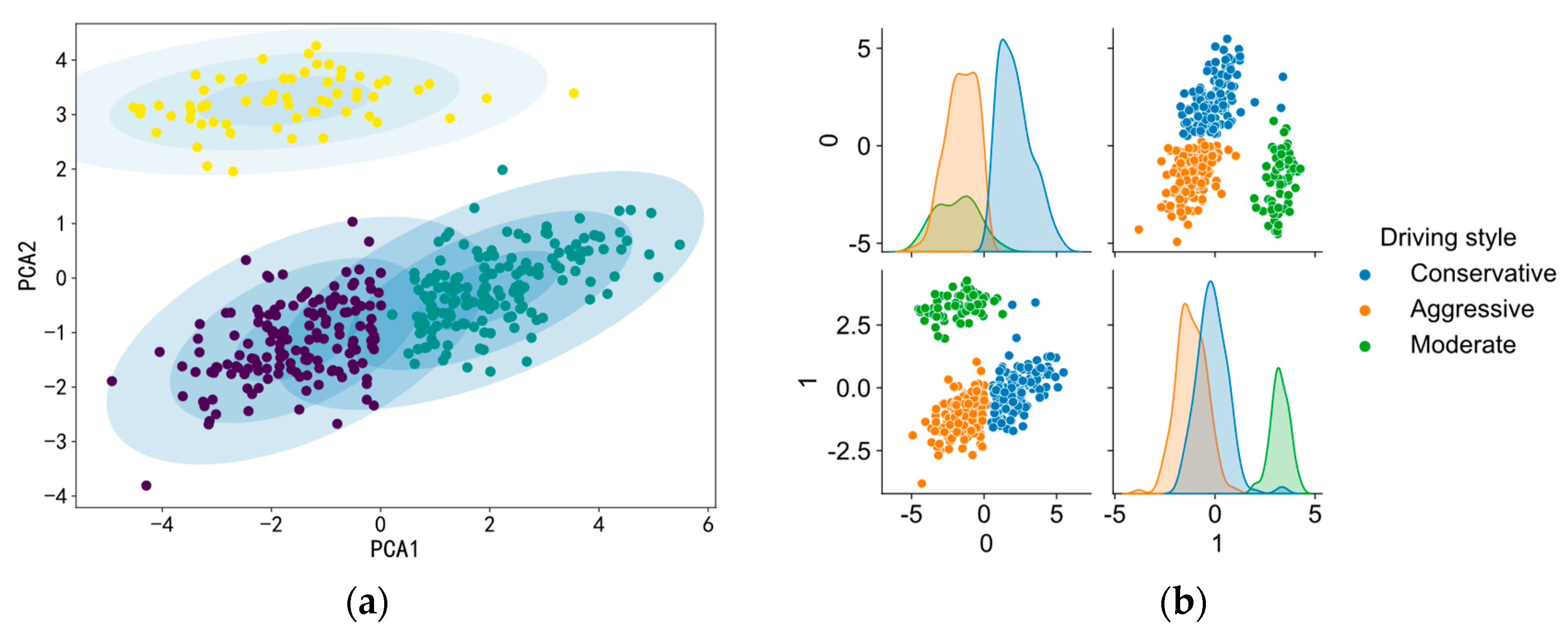
Here, it is assumed that the driving style of each vehicle does not change at a particular time. The data for the statistical characteristics of the three SV driving styles are shown in
Table 2. The driving styles can be defined as aggressive, moderate, and conservative on the basis of the characteristic quantities of lateral speed maximum, acceleration mean, and headway time distance. The definition of these three groups of names is only a reflection of the clustering of the SV driving styles and does not affect the further analysis of personalized LCD.
Using the built GMM clustering algorithm, 481 driving behaviors were classed as aggressive, 1286 were classed as moderate, and the remainder (1204) were classed as conservative. It can be seen from
Table 2 that drivers with different driving styles exhibit significantly different driving behaviors. Aggressive drivers tend to drive at faster speeds, with shorter following distance and smaller headway. However, conservative drivers chose lower speeds, longer following distances and larger headway distances in order to drive carefully.
Figure 2 presents a visualization of the three clusters of driving styles. As shown in the figure, the data for the three driving styles also exhibit varied significant distributions in the feature space.
6. Conclusions
This research proposes an LCD model that considers SV driving styles as well as interactions. Feature variables such as speed, acceleration and headway time distance are selected, and the style type is identified for each vehicle sample on the basis of the unsupervised clustering algorithm GMM. The interaction between the SV and the surrounding vehicles is described by constructing a gain function, which takes into account the safety, driving efficiency, and comfort of the SV. The LC feature variables with different driving styles and the LC gain values are used as model inputs to construct an LSTM−based personalized LCD model.
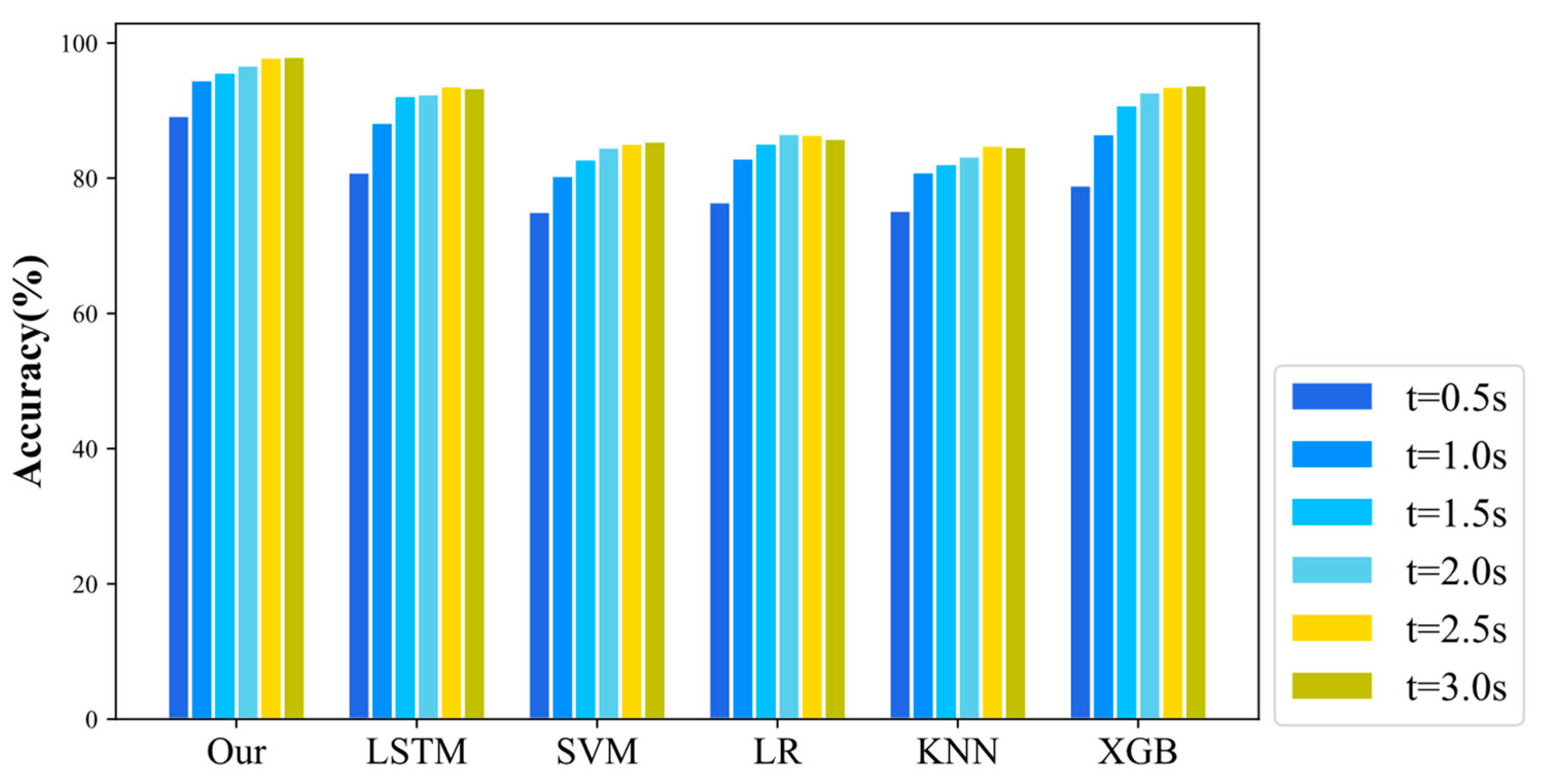
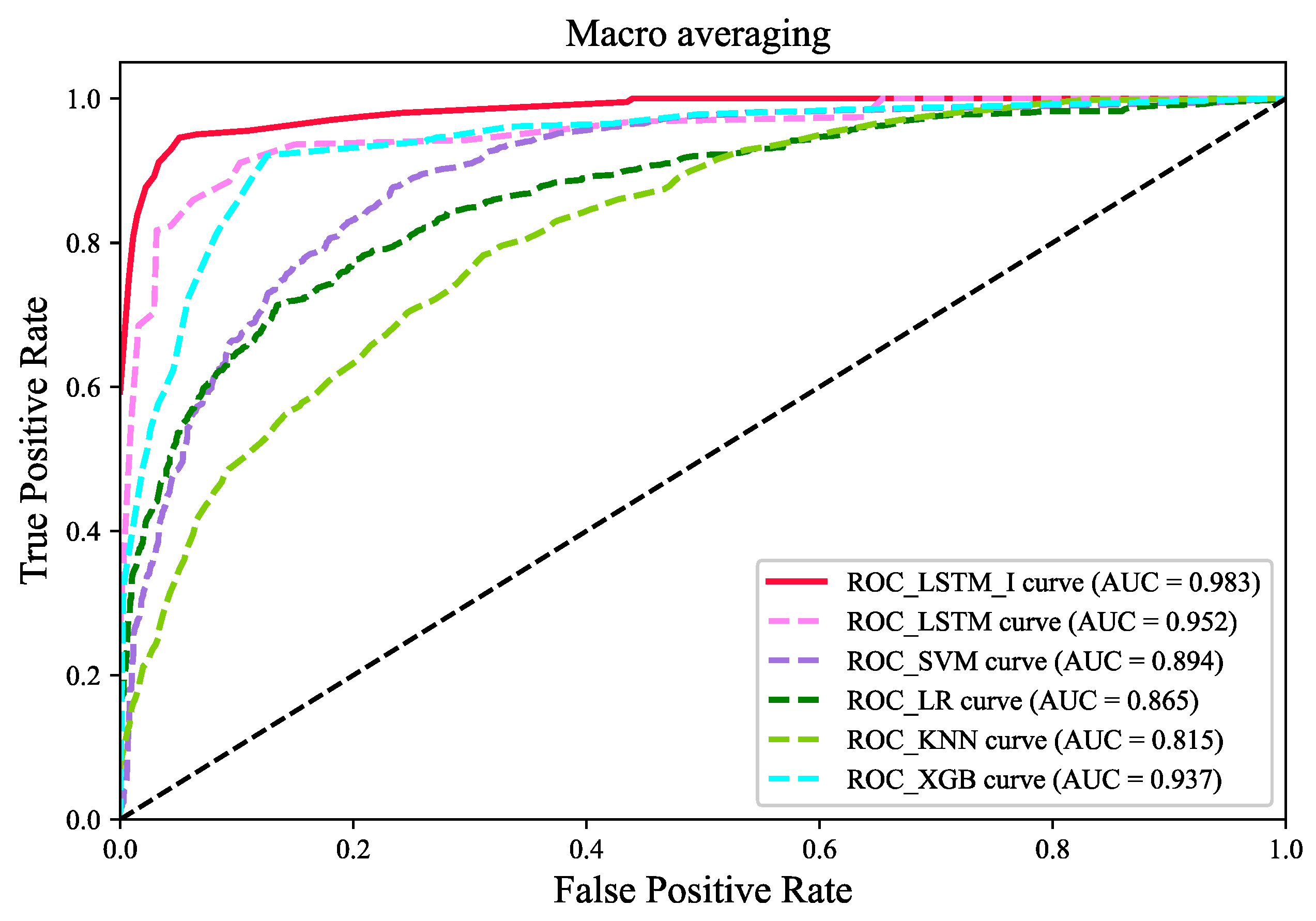
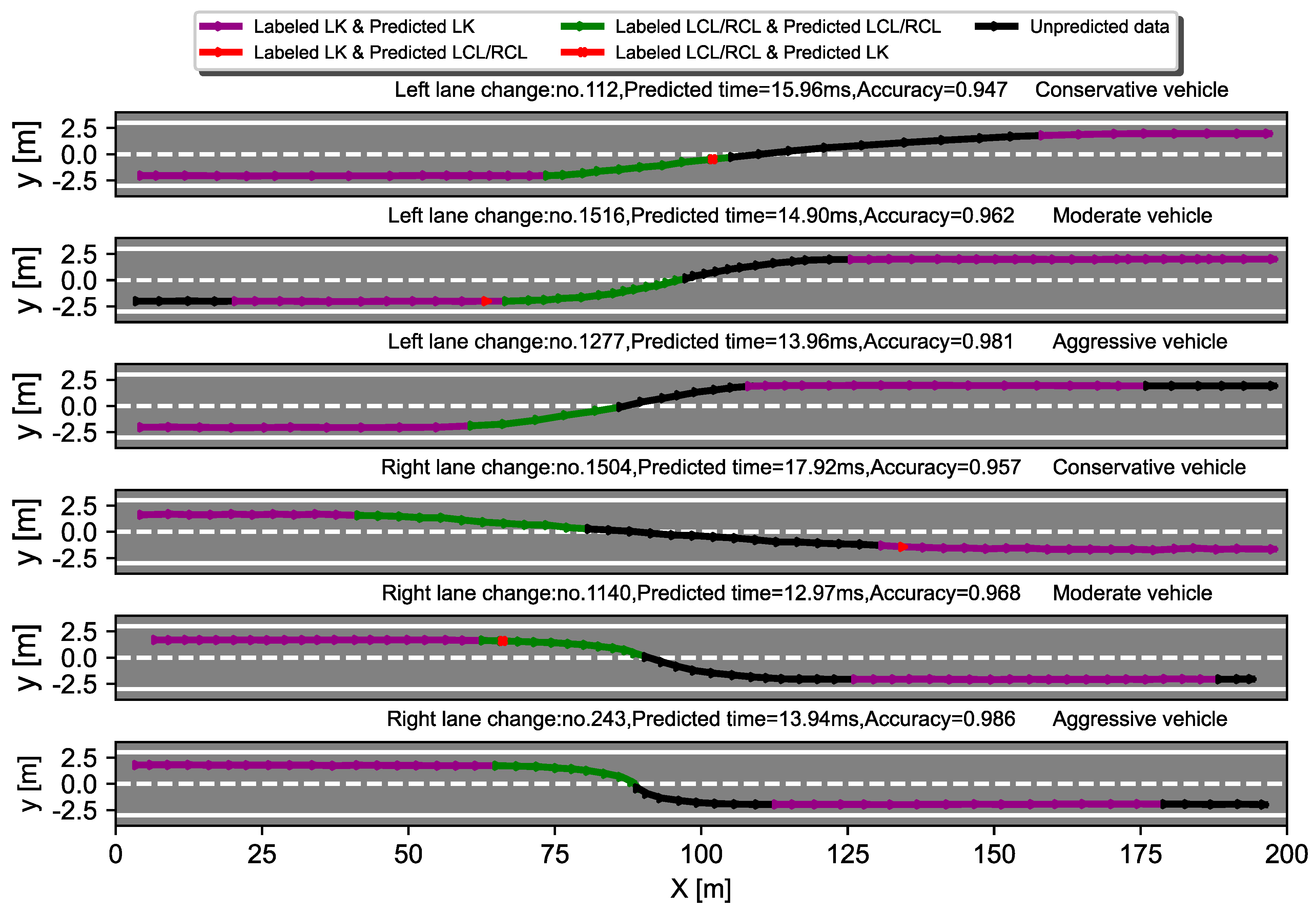
To verify the effectiveness of the model, real vehicle trajectory data, MGSIM, were used to evaluate the model. The model was also compared with other models, and the results showed that the model outperformed the other models in terms of accuracy, F1 score, and macro−AUC value. This indicates that the model is able to make more accurate behavioral decisions on the basis of the state of its own vehicle and information regarding the surrounding vehicles. Behavioral decisions were also evaluated for different driving styles. The test results showed that the personalized LCD framework is able to make sound decisions on the basis of different driving styles, and it can provide personalized options for different drivers.
Future work will focus on the improvement of the proposed model algorithms and the application of real−time on−board hardware systems for algorithm validation. Additionally, other traffic participants (e.g., pedestrians, non-motorized vehicles) will be taken into consideration in the driving environment in order to further improve the decision−making capability of autonomous vehicles.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}