
ULMR: An Unsupervised Learning Framework for Mismatch Removal




Abstract
:1. Introduction
2. Methodology
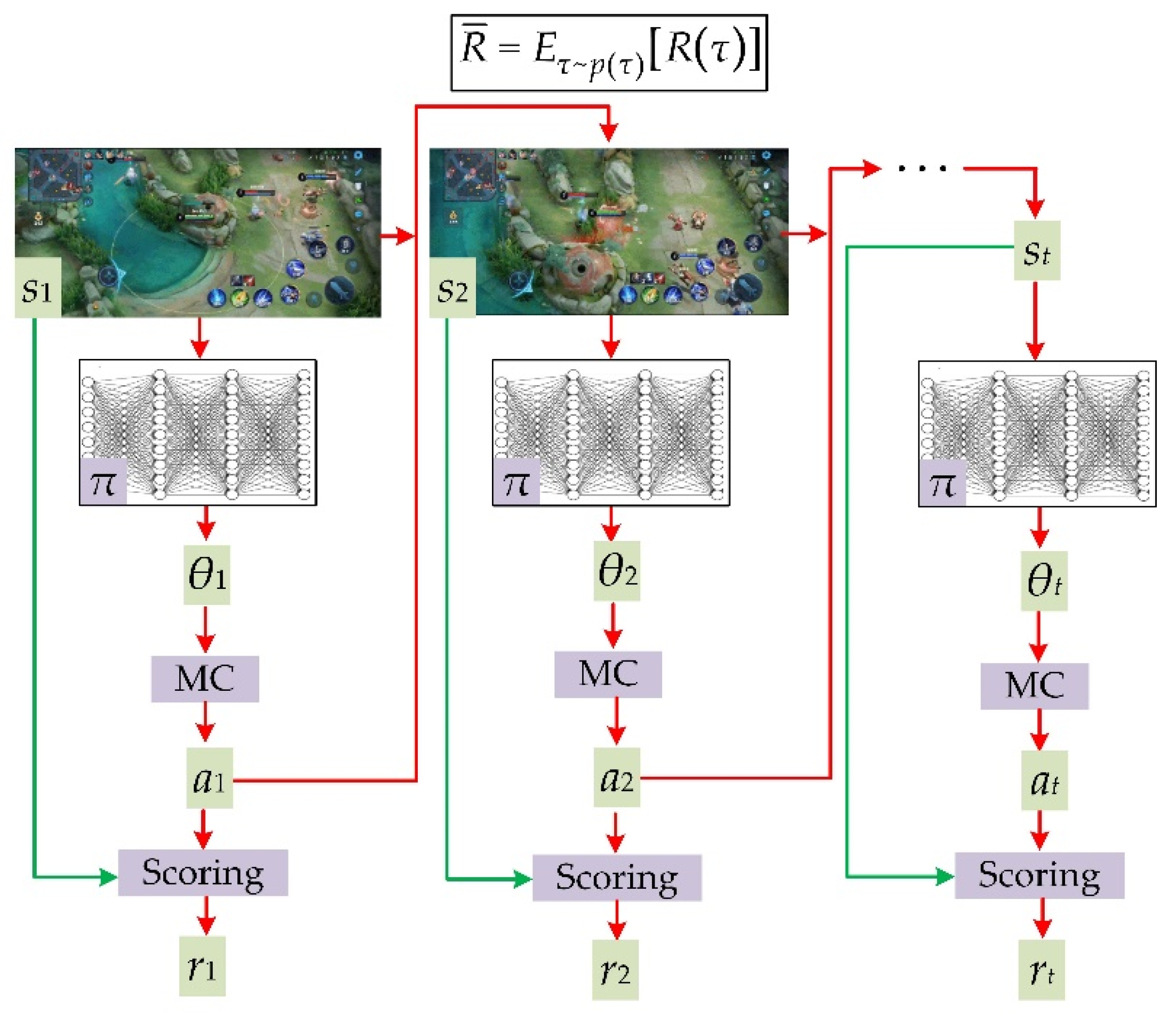
2.1. Basic Framework of DRL
2.2. Learning to Remove Mismatches
2.3. Sampling Subsets by Monte Carlo
| Algorithm 1: Sampling a minimal subset Ω containing m pairs of matched points |
| Input: A point pair set s containing n pairs of points, and the RMPs θ (Equation (7)) Output: A sampled subset with the PDF pθ (Equation (8)) 1 Initialize Ω as an empty list for j = 1 to m 2 Draw independent random variables u1,…,un from uniform distribution U(0,1) 3 Select one point pair yj with index i in set s, where 4 If yj is already in Ω, repeat step 2 and 3 until a new point pair is selected 5 Append yj to Ω End |
| 6 Return Ω |
2.4. Scoring a Sampled Subset
3. Experiments
3.1. Implementation Details
3.1.1. Network Architecture
3.1.2. Training and Predicting Pipelines
3.1.3. Training Settings
3.2. Benchmark Algorithms and Training Data
3.2.1. Benchmark Algorithms
3.2.2. Training Data
3.3. Test Experiments of Real Scenario Images
3.4. Application Experiments of Real Tasks
3.5. Ablation Experiments
3.5.1. Effect of Sampling Number
3.5.2. Compatibility with Other Classification Networks
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jin, Y.; Mishkin, D.; Mishchuk, A.; Matas, J.; Fua, P.; Yi, K.; Trulls, E. Image Matching Across Wide Baselines: From Paper to Practice. Int. J. Comput. Vis. 2021, 129, 517–547. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A review of multimodal image matching: Methods and applications. Inf. Fusion. 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, S.; Yuan, W.; Cai, Y. Poor textural image tie point matching via graph theory. ISPRS-J. Photogramm. Remote Sens. 2017, 129, 21–31. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image Matching from Handcrafted to Deep Features: A Survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Longuet-Higgins, H.C. A computer algorithm for reconstructing a scene from two projections. Nature 1981, 293, 133–135. [Google Scholar] [CrossRef]
- Hartley, R.I. In defense of the eight-point algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 580–593. [Google Scholar] [CrossRef]
- Torr, P.H.S.; Zisserman, A. MLESAC: A New Robust Estimator with Application to Estimating Image Geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef]
- Chum, O.; Matas, J. Matching with PROSAC-progressive sample consensus. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 220–226. [Google Scholar]
- Brachmann, E.; Krull, A.; Nowozin, S.; Shotton, J.; Michel, F.; Gumhold, S.; Rother, C. DSAC-differentiable ransac for camera localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6684–6692. [Google Scholar]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a fast, reliable and accurate robust estimator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1304–1312. [Google Scholar]
- Barath, D.; Matas, J. Graph-Cut RANSAC. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6733–6741. [Google Scholar]
- Brachmann, E.; Rother, C. Neural-guided RANSAC: Learning where to sample model hypotheses. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4322–4331. [Google Scholar]
- Ma, J.; Zhao, J.; Tian, J.; Bai, X.; Tu, Z. Regularized vector field learning with sparse approximation for mismatch removal. Pattern Recognit. 2013, 46, 3519–3532. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. LAM: Locality affine-invariant feature matching. ISPRS-J. Photogramm. Remote Sens. 2019, 154, 28–40. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality preserving matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Bian, J.; Lin, W.; Matsushita, Y.; Yeung, S.; Nguyen, T.; Cheng, M. GMS: Grid-based motion statistics for fast, ultra-robust feature correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4181–4190. [Google Scholar]
- Ma, J.; Li, Z.; Zhang, K.; Shao, Z.; Xiao, G. Robust feature matching via neighborhood manifold representation consensus. ISPRS-J. Photogramm. Remote Sens. 2022, 183, 196–209. [Google Scholar] [CrossRef]
- Chen, J.; Yang, M.; Peng, C.; Luo, L.; Gong, W. Robust feature matching via local consensus. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Mousavi, V.; Varshosaz, M.; Remondino, F.; Pirasteh, S.; Li, J. A Two-Step Descriptor-Based Keypoint Filtering Algorithm for Robust Image Matching. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–21. [Google Scholar] [CrossRef]
- Yi, K.M.; Trulls, E.; Ono, Y.; Lepetit, V.; Salzmann, M.; Fua, P. Learning to Find Good Correspondences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2666–2674. [Google Scholar]
- Zhao, C.; Cao, Z.; Li, C.; Li, X.; Yang, J. NM-Net: Mining Reliable Neighbors for Robust Feature Correspondences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 215–224. [Google Scholar]
- Chen, S.; Niu, J.; Deng, C.; Zhang, Y.; Chen, F.; Xu, F. CE-Net: A Coordinate Embedding Network for Mismatching Removal. IEEE Access 2021, 9, 147634–147648. [Google Scholar] [CrossRef]
- Cavalli, L.; Larsson, V.; Oswald, M.; Sattler, T.; Pollefeys, M. AdaLAM: Revisiting Handcrafted Outlier Detection. arXiv 2020, arXiv:2006.04250v1. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guiba, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–10. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Moradi, R.; Berangi, R.; Minaei, B. A survey of regularization strategies for deep models. Artif. Intell. Rev. 2020, 53, 3947–3986. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Tian, X.; Jiang, N.; Wang, D. A Full Stage Data Augmentation Method in Deep Convolutional Neural Network for Natural Image Classification. Discret. Dyn. Nat. Soc. 2020, 2, 1–11. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Goncalves, N. Deep Facial Diagnosis: Deep Transfer Learning from Face Recognition to Facial Diagnosis. IEEE Access 2020, 8, 123649–123661. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762v5. [Google Scholar]
- Sun, W.; Jiang, W.; Trulls, E.; Tagliasacchi, A.; Yi, K. ACNe: Attentive Context Normalization for Robust Permutation Equivariant Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11283–11292. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012; pp. 71–72. [Google Scholar]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 845–869. [Google Scholar] [CrossRef] [PubMed]
- Sukhbaatar, S.; Fergus, R. Learning from noisy labels with deep neural networks. arXiv 2014, arXiv:1406.2080. [Google Scholar]
- Probst, T.; Paudel, D.P.; Chhatkuli, A.; Gool, L.V. Unsupervised learning of consensus maximization for 3D vision problems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 929–938. [Google Scholar]
- Schulman, J.; Heess, N.; Weber, T.; Abbeel, P. Gradient estimation using stochastic computation graphs. In Proceedings of the Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 1–9. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Hassabis, D. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Jaderberg, M.; Mnih, V.; Czarnecki, W.M.; Schaul, T.; Leibo, J.Z.; Silver, D.; Kavukcuoglu, K. Reinforcement learning with unsupervised auxiliary tasks. arXiv 2016, arXiv:1611.05397. [Google Scholar]
- Truong, G.; Le, H.; Suter, D.; Zhang, E.; Gilani, S.Z. Unsupervised learning for robust fitting: A reinforcement learning approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 10348–10357. [Google Scholar]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018; pp. 47–70. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 1–9. [Google Scholar]
- Johnson, N.L.; Kemp, A.W.; Kotz, S. Univariate Discrete Distributions, 3rd ed.; Wiley: Hoboken, NJ, USA, 2005; pp. 108–151. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 1–12. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the International Conference on Computational Statistics (COMPSTAT), Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004; pp. 239–257. [Google Scholar]
- Xiao, J.; Owens, A.; Torralba, A. SUN3D: A database of big spaces reconstructed using SfM and object labels. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 1625–1632. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Luo, Z.; Shen, T.; Zhou, L.; Zhu, S.; Zhang, R.; Yao, Y.; Fang, T.; Quan, L. GeoDesc: Learning Local Descriptors by Integrating Geometry Constraints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 170–185. [Google Scholar]
- Ramírez, J.; Yu, W.; Perrusquía, A. Model-free reinforcement learning from expert demonstrations: A survey. Artif. Intell. Rev. 2022, 55, 3213–3241. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Code Resource (Accessed on 1 June 2022) | Key Parameter Setting |
|---|---|---|
| RANSAC | https://github.com/opencv/opencv/blob/4.x/modules/calib3d/src/fundam.cpp | Epipolar error threshold: 3.0 pixels; Maximum number of iterations: 2000 |
| GC-RANSAC | https://github.com/danini/graph-cut-ransac | As above |
| GMS | https://github.com/JiawangBian/GMS-Feature-Matcher | Grid size: 20 × 20; Number of neighbors: 9; with rotation: true; With scale: true |
| LFGC | https://github.com/vcg-uvic/learned-correspondence-release | Default as in [21] |
| NM-Net | https://github.com/sailor-z/NM-Net | Default as in [22] |
| ULCM | https://bitbucket.org/probstt/ulcm-public/src/master/ | Default as in [37] |
| ACNe | https://github.com/vcg-uvic/acne | Inlier clustering type: combined |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, C.; Chen, S.; Zhang, Y.; Zhang, Q.; Chen, F. ULMR: An Unsupervised Learning Framework for Mismatch Removal. Sensors 2022, 22, 6110. https://doi.org/10.3390/s22166110
Deng C, Chen S, Zhang Y, Zhang Q, Chen F. ULMR: An Unsupervised Learning Framework for Mismatch Removal. Sensors. 2022; 22(16):6110. https://doi.org/10.3390/s22166110
Chicago/Turabian StyleDeng, Cailong, Shiyu Chen, Yong Zhang, Qixin Zhang, and Feiyan Chen. 2022. "ULMR: An Unsupervised Learning Framework for Mismatch Removal" Sensors 22, no. 16: 6110. https://doi.org/10.3390/s22166110
APA StyleDeng, C., Chen, S., Zhang, Y., Zhang, Q., & Chen, F. (2022). ULMR: An Unsupervised Learning Framework for Mismatch Removal. Sensors, 22(16), 6110. https://doi.org/10.3390/s22166110