
Dual Guided Aggregation Network for Stereo Image Matching


Abstract
:1. Introduction
2. Related Work
2.1. Matching Cost Learning
2.2. End-to-End Disparity Learning
2.3. Left–Right Consistent Learning
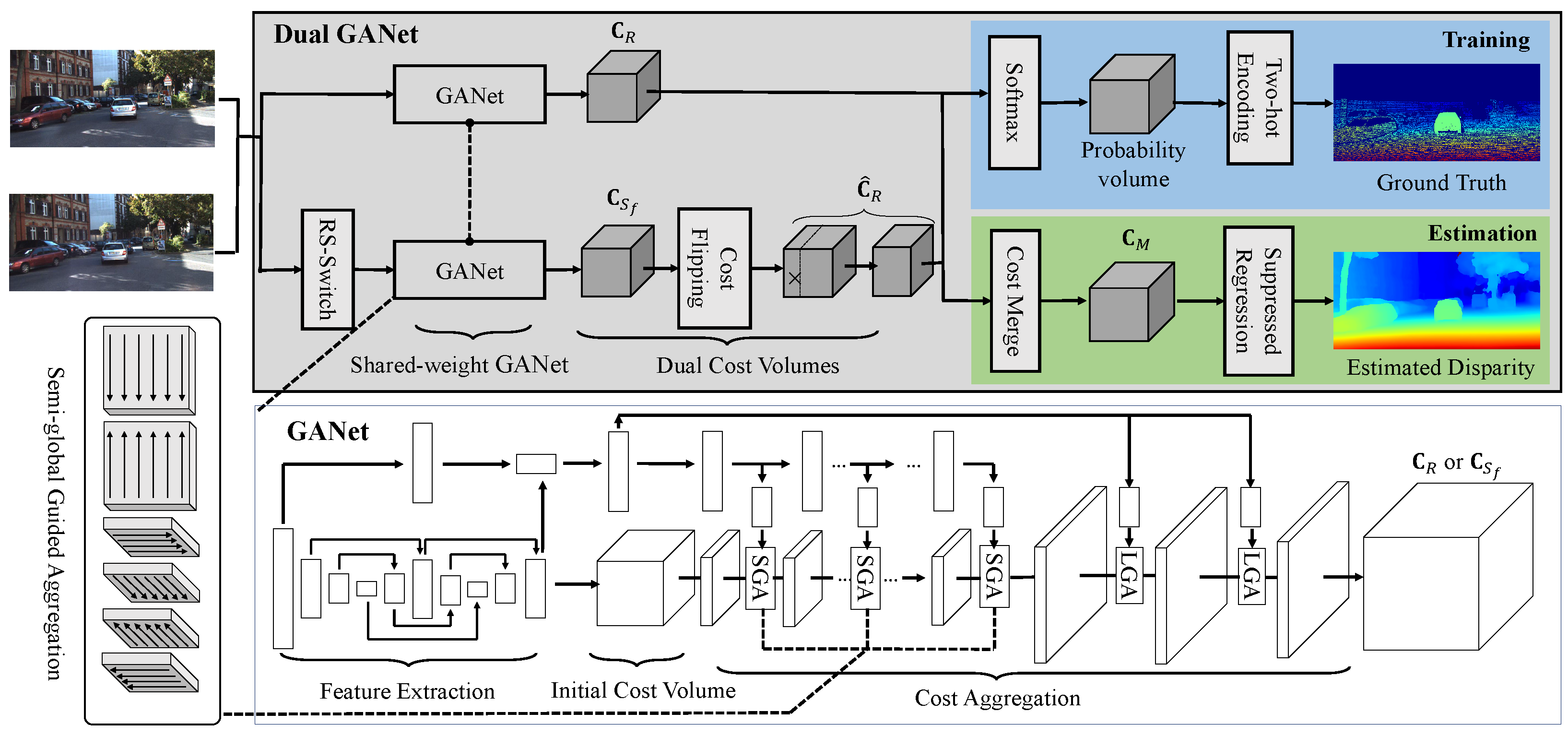
3. Methodology
3.1. GANet
3.2. Cost Volume Consistentization and Flipped Training
3.3. Suppressed Regression
3.4. Loss Function
4. Results and Discussion
4.1. Evaluation Using the Scene Flow Dataset
4.2. Evaluation Using the KITTI2015 Dataset
4.3. Evaluation of Flipped Training
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. In Proceedings of the IEEE Workshop on Stereo and Multi-Baseline Vision, Kauai, HI, USA, 9–10 December 2001; pp. 131–140. [Google Scholar]
- Hirschmüller, H. Stereo processing by semi-global matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Shahbazi, M.; Sohn, G.; Théau, J. High-density stereo image matching using intrinsic curves. ISPRS J. Photogramm. Remote. Sens. 2018, 146, 373–388. [Google Scholar] [CrossRef]
- Choi, E.; Lee, S.; Hong, H. Hierarchical stereo matching in two-scale space for cyber-physical system. Sensors 2017, 17, 1680. [Google Scholar] [CrossRef] [PubMed]
- Jiageng, Z.; Ming, L.; Xuan, L.; Jiangying, Q. A real-time infrared stereo matching algorithm for RGB-D cameras’ indoor 3D perception. ISPRS Int. J. -Geo-Inf. 2020, 9, 472. [Google Scholar]
- Lee, M.-J.; Um, G.-M.; Yun, J.; Cheong, W.-S.; Park, S.-Y. Enhanced soft 3D reconstruction method with an iterative matching cost update using object surface consensus. Sensors 2021, 21, 6680. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Chen, L.; Deng, F.; Heipke, C. Context pyramidal network for stereo matching regularized by disparity gradients. ISPRS J. Photogramm. Remote Sens. 2019, 157, 201–215. [Google Scholar] [CrossRef]
- Žbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Chen, J.; Yuan, C. Convolutional neural network using multi-scale information for stereo matching cost computation. In Proceedings of the International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3424–3428. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient deep learning for stereo matching. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5695–5703. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Mayer, N.; Ilg, E.; Häusser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H. GA-Net: Guided aggregation net for end-to-end stereo matching. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xia, Y.; d’Angelo, P.; Tian, J.; Reinartz, P. Dense matching comparison between classical and deep learning based algorithms for remote sensing data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 521–525. [Google Scholar] [CrossRef]
- Haeusler, R.; Nair, R.; Kondermann, D. Ensemble Learning for Confidence Measures in Stereo Vision. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Gouveia, R.; Spyropoulos, A.; Mordohai, P. Confidence Estimation for Superpixel-Based Stereo Matching. In Proceedings of the International Conference on 3D Vision, Lyon, France, 19–22 October 2015. [Google Scholar]
- Batsos, K.; Cai, C.; Mordohai, P. CBMV: A Coalesced Bidirectional Matching Volume for Disparity Estimation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Park, M.-G.; Yoon, K.-J. Leveraging Stereo Matching with Learning-based Confidence Measures. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Mehltretter, M.; Heipke, C. CNN-based Cost Volume Analysis as Confidence Measure for Dense Matching. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Fischer, P.; Dosovitskiy, A.; Ilg, E.; Häusser, P.; Hazirbas, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning optical flow with convolutional networks. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ilg, E.; Saikia, T.; Keuper, M.; Brox, T. Occlusions, motion and depth boundaries with a generic network for disparity, optical flow or scene flow estimation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 614–630. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Shaked, A.; Wolf, L. Improved stereo matching with constant highway networks and reflective confidence learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cheng, X.; Wang, P.; Yang, R. Learning depth with convolutional spatial propagation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2361–2379. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Manela, J.; Happold, M.; Ramanan, D. Hierarchical Deep Stereo Matching on High-resolution Images. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jie, Z.; Wang, P.; Ling, Y.; Zhao, B.; Wei, Y.; Feng, J.; Liu, W. Left-right comparative recurrent model for stereo matching. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lee, J.; Kim, D.; Ponce, J.; Ham, B. SFNet: Learning Object-aware Semantic Flow. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, S.; De Mello, S.; Gu, J.; Zhong, G.; Yang, M.-H.; Kautz, J. Learning affinity via spatial propagation networks. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Chang, J.-R.; Chen, Y.-S. Pyramid stereo matching network. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Model | # of A.D. | Disparity Regression | Suppressed Regression | 2-Candidate | Average EPE (px) | Average ER > 1px |
|---|---|---|---|---|---|---|---|
| 1 | GANet | 4 | ✓ | 0.780 | 8.7% | ||
| 2 | GANet_small (backbone) | 4 | ✓ | 0.995 | 11.56% | ||
| 3 | GANet_small | 6 | ✓ | 0.895 | 10.31% | ||
| 4 | GANet_small | 6 | ✓ | 0.865 | 7.37% | ||
| 5 | GANet_small | 6 | ✓ | ✓ | 0.440 | 6.56% | |
| 6 | Dual-GANet | 6 | ✓ | 0.862 | 6.65% | ||
| 7 | Dual-GANet | 6 | ✓ | ✓ | 0.418 | 5.81% |
| Model | Average EPE | Average ER > 3 px |
|---|---|---|
| SGM [2] | – | 6.38% |
| GCNet [22] | – | 6.16% |
| PSMNet [30] | – | 2.32% |
| GANet [13] | – | 1.81% |
| CSPN [24] | – | 1.74% |
| GANet_small | 0.790 | 2.32% |
| Dual-GANet (single candidate) | 0.712 | 1.76% |
| Dual-GANet (two candidates) | 0.589 | 0.95% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.-P.; Lin, C.-H. Dual Guided Aggregation Network for Stereo Image Matching. Sensors 2022, 22, 6111. https://doi.org/10.3390/s22166111
Wang R-P, Lin C-H. Dual Guided Aggregation Network for Stereo Image Matching. Sensors. 2022; 22(16):6111. https://doi.org/10.3390/s22166111
Chicago/Turabian StyleWang, Ruei-Ping, and Chao-Hung Lin. 2022. "Dual Guided Aggregation Network for Stereo Image Matching" Sensors 22, no. 16: 6111. https://doi.org/10.3390/s22166111
APA StyleWang, R.-P., & Lin, C.-H. (2022). Dual Guided Aggregation Network for Stereo Image Matching. Sensors, 22(16), 6111. https://doi.org/10.3390/s22166111