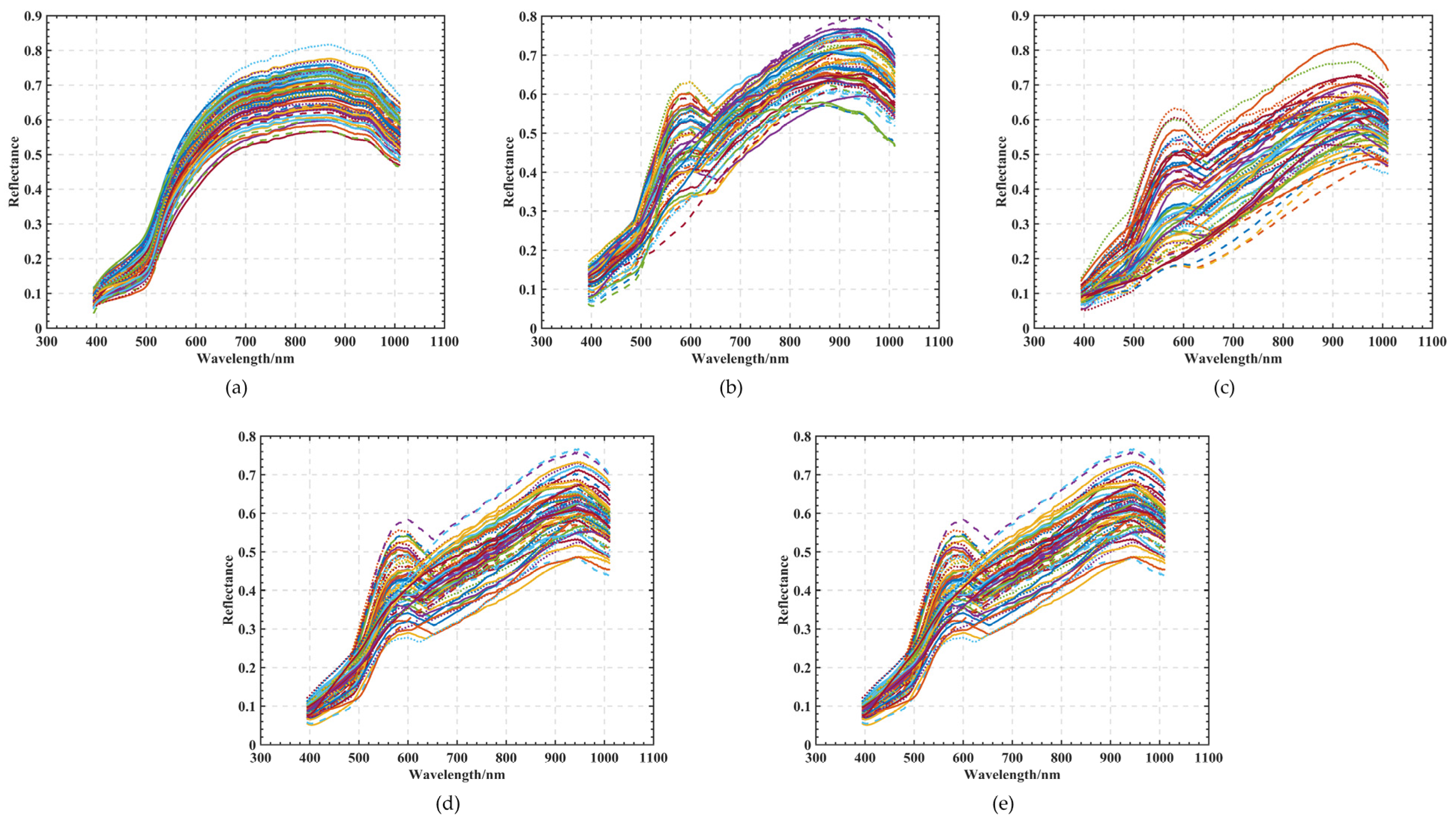
Corn has a reputation as a “golden crop”; even though the seed is small, the crop is vital to China and plays a major role in the international trade in corn seeds. It is of great significance that there are independent and controllable seed sources in the seed industry. High temperature and humidity cause mold to grow on seeds, reducing their germination rates, as well as their quality and nutritional value [
1,
2]. Over the past few decades, crop diseases have been a frequent cause of crop yield reduction, and their cause must be determined by studying the diseased seeds [
3,
4]. The seed industry must speed up the promotion of corn seed science, perform efficient seed discrimination, achieve independent self-improvement, and be able to control seed quality independently. Chemical composition analysis is the approach that provides the most precise indication of the level of mold present [
5]; however, there is inevitably some damage to the sample, as well as subjective considerations, in the process of analysis [
6]. A new and innovative technological tool has emerged in recent years for the nondestructive testing of seeds, known as hyperspectral imaging [
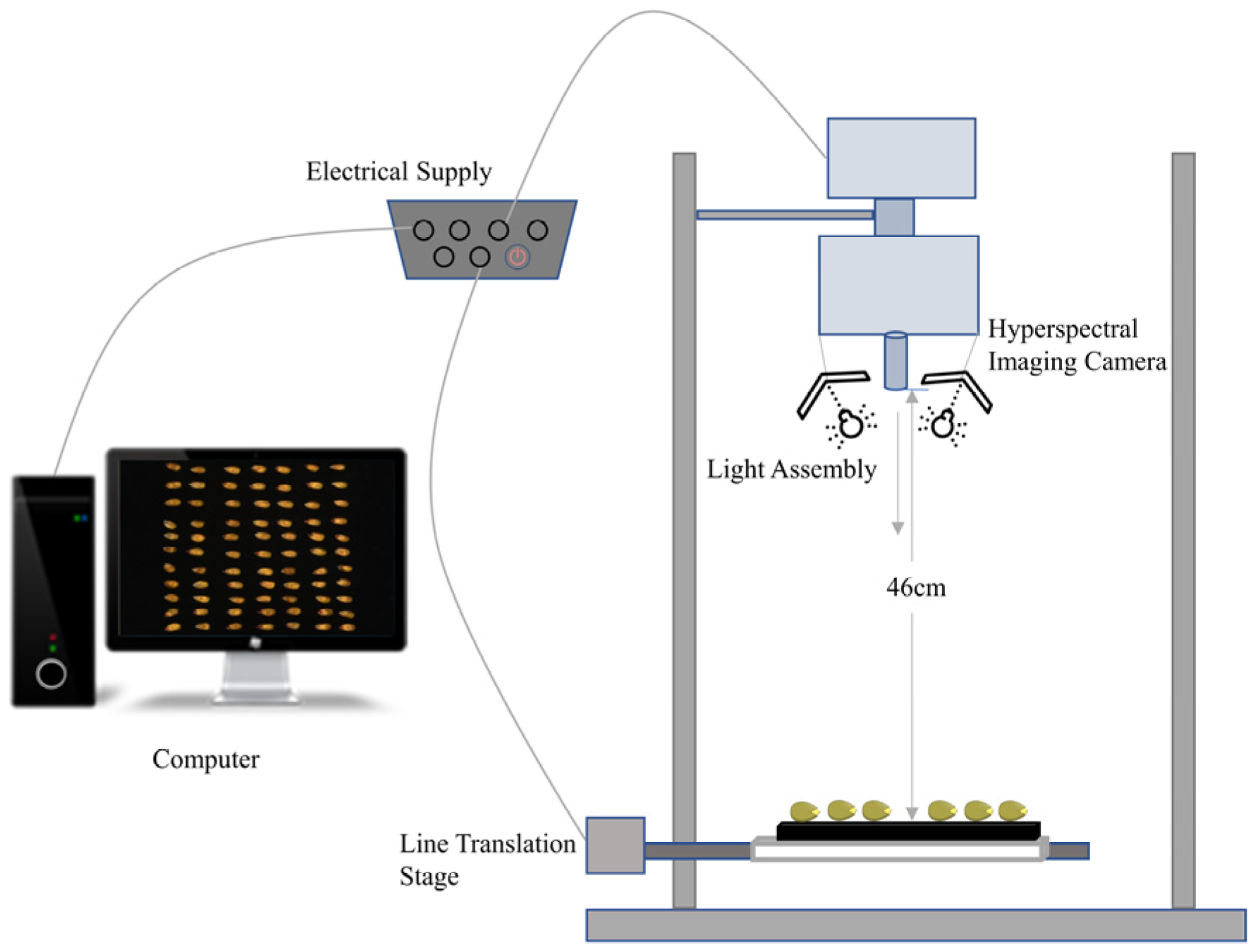
7,
8,
9,
10]. Hyperspectral remote sensing imaging (HRSI) uses spectral signatures to identify, detect, and discriminate between objects of varying spectral characteristics [
11]. The results are directly proportional to the spectral resolution of the sensor and how much information is stored in each band [
12]. Sensors with high resolution tend to have bands that are much tighter than those with low resolution. HRSI is based on a narrow band that combines spatial information and hundreds of channels of spectral information so that the chemical and structural information of seeds may be combined using this technology, which can be used for both extracting aberrant information and determining its spatial distribution [
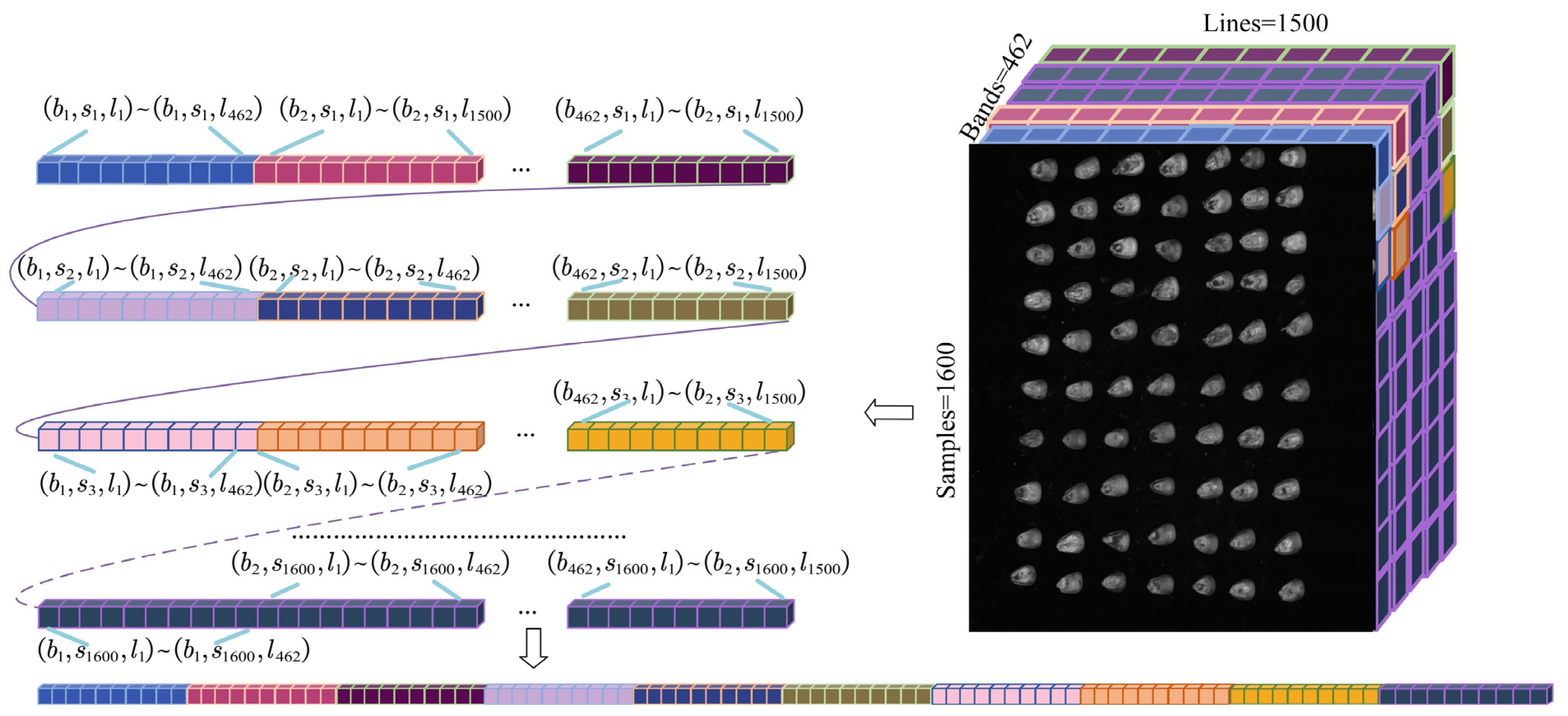
13,
14]. A machine learning algorithm can be constructed to categorize crops by using multispectral and multi-temporal images. Both anomalous information and spatial distribution may be obtained if one takes the initiative. On the one hand, the sample does not have to be destroyed during the experiment, so the method is both efficient and nondestructive. On the other hand, the image information from the imaging spectrometer offers research assistance for computer vision. The first consideration is the choice of the featured wavelength. Yang Sai et al. [
15], to identify corn seeds, employed a joint skewness technique to select feature wavelengths, and when this was paired with a support vector machine, the model’s classification accuracy increased to 96.28%. However, the value of the skewness distribution is more affected by symmetrical distributions on both sides of the distribution. A one-way tailspin is a tail that spins in one direction. Positive (negative) skewness indicates the tail’s direction of rotation more than its tendency to spin [
16]. The second consideration is the selection of the classification algorithm. The hyperspectral imaging distinction and linear discriminant analysis performed by Ali Mohammadi F et al. [
17] correctly classified three different types of maize kernels with an accuracy of 95%. After using the watershed technique to partially segment moldy peanuts, Jiang et al. [
18] determined the classification impact from their data. Yuan et al. [
19] used a support vector machine (SVM), partial least squares discriminant analysis (PLS-DA), and a cluster-independent pattern classifier (SIMCA). Both used dimensionality reduction data and then directly applied machine learning models for classification.
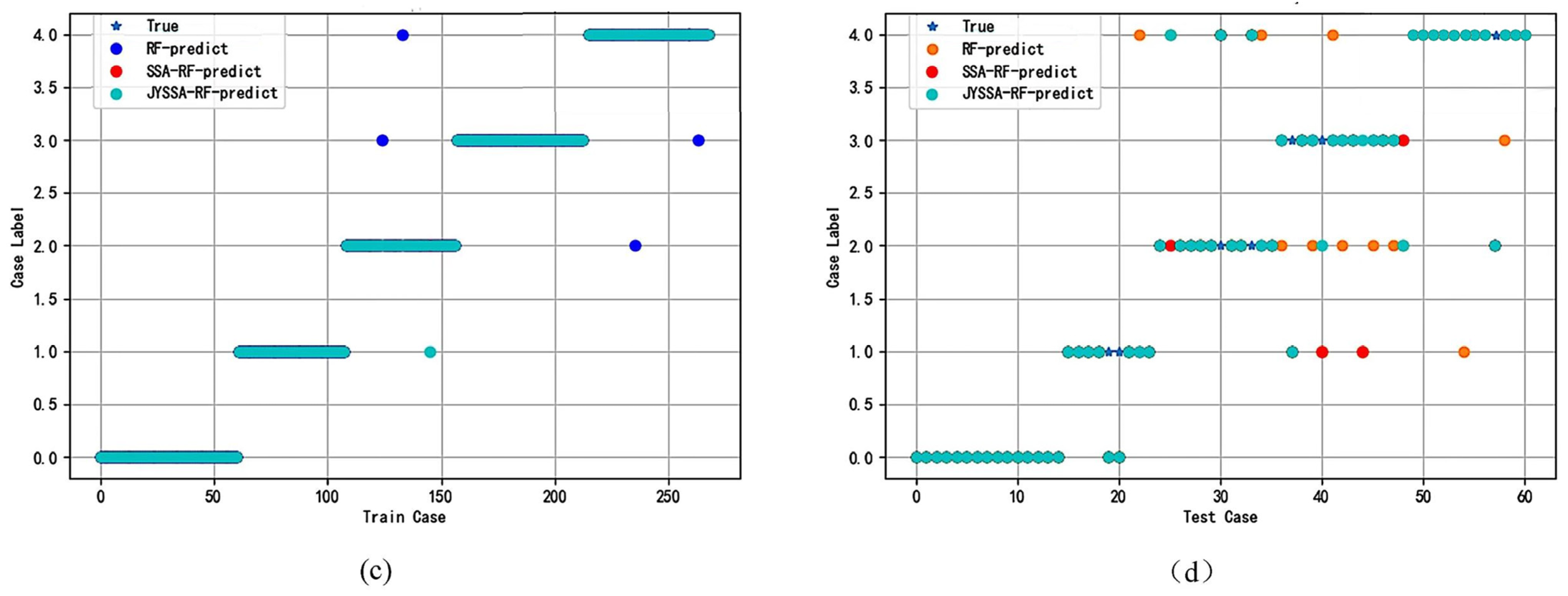
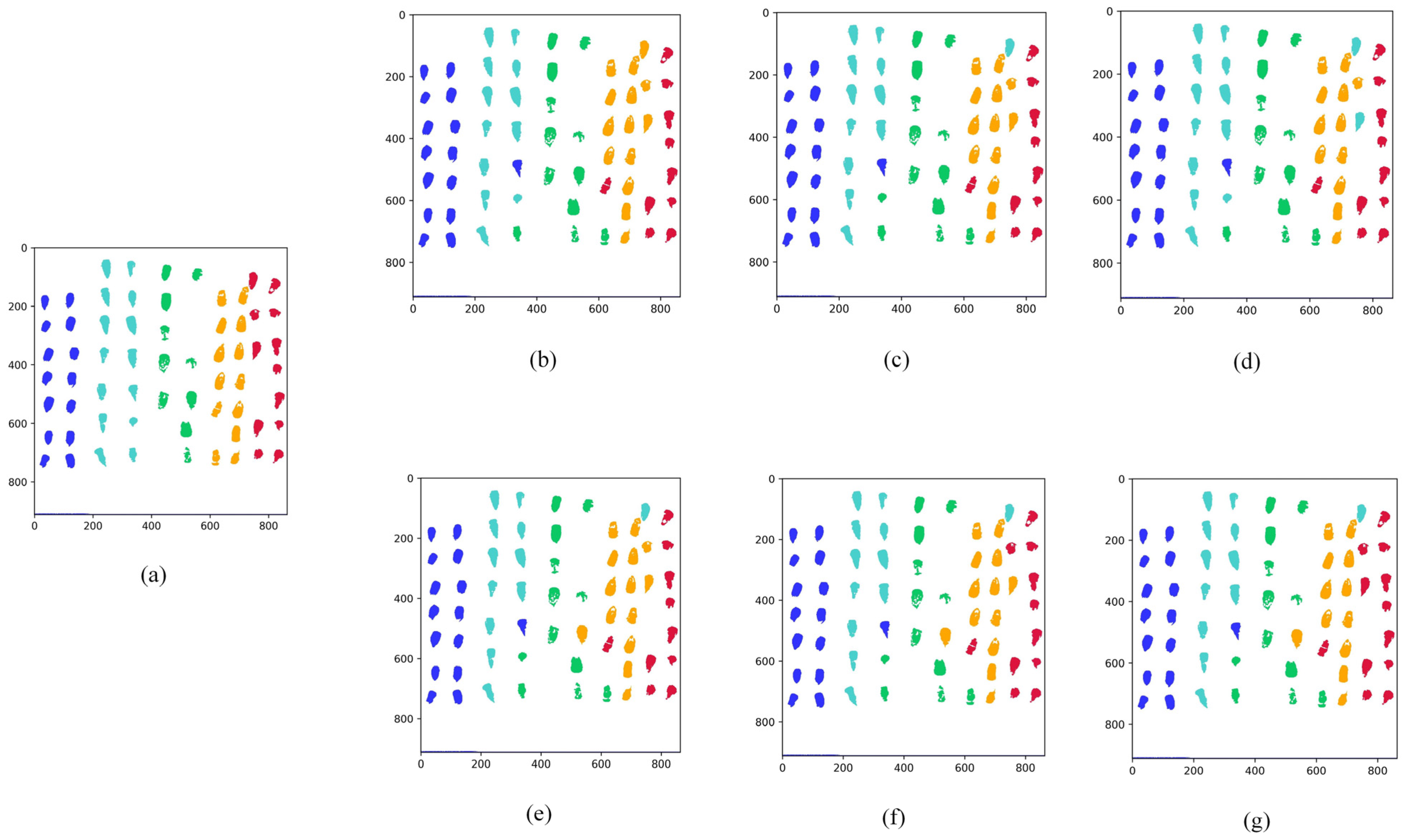
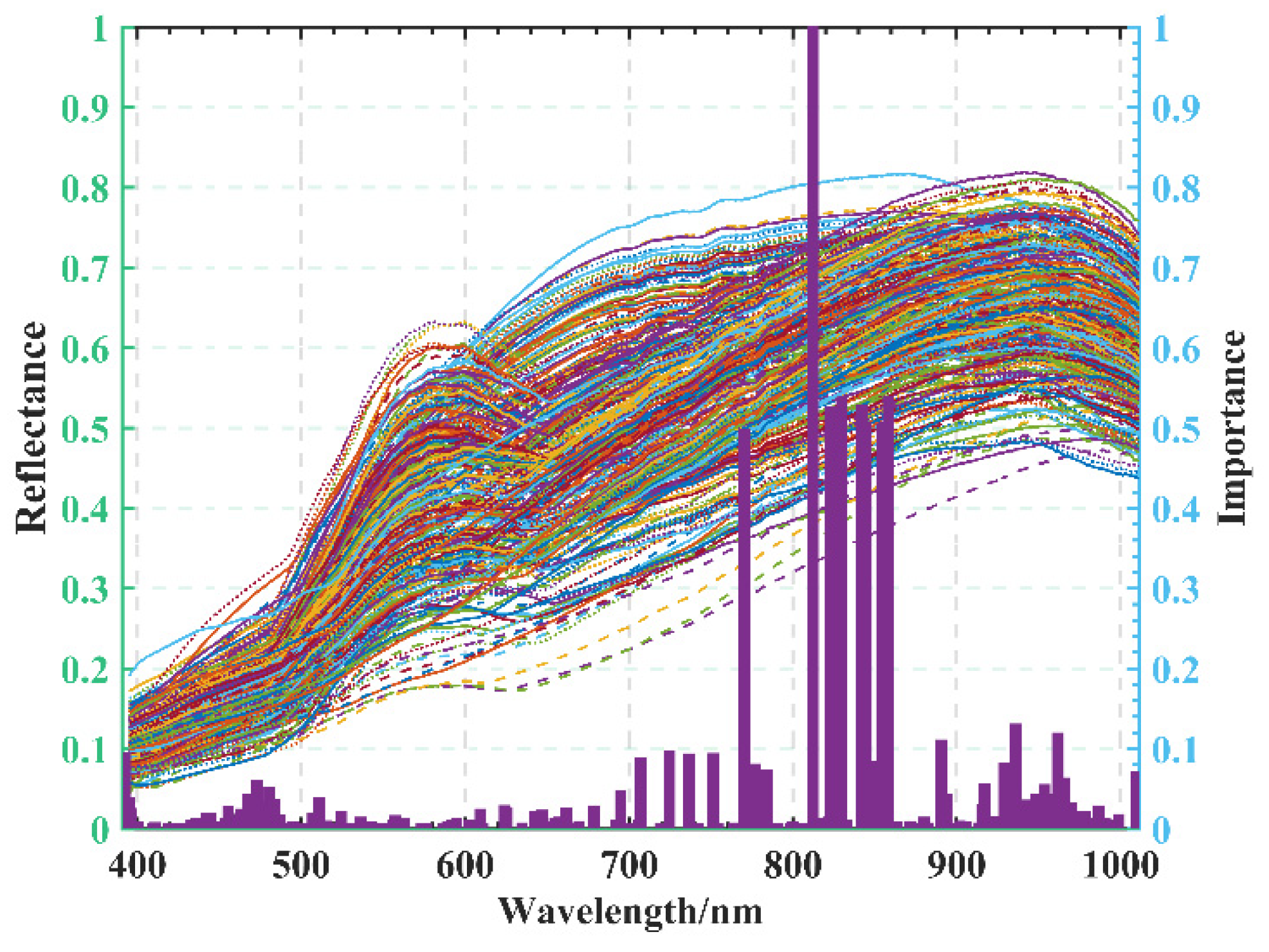
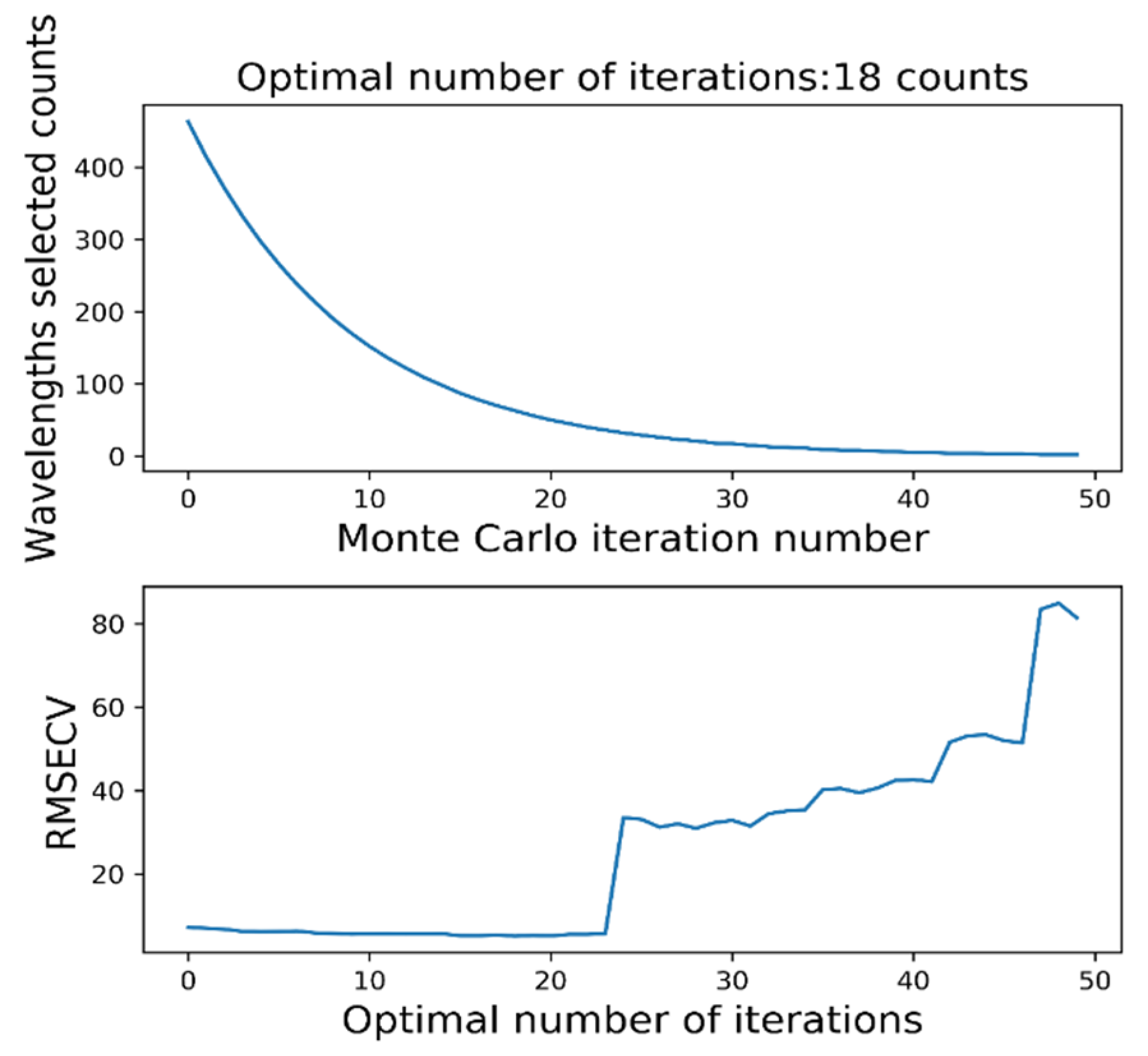
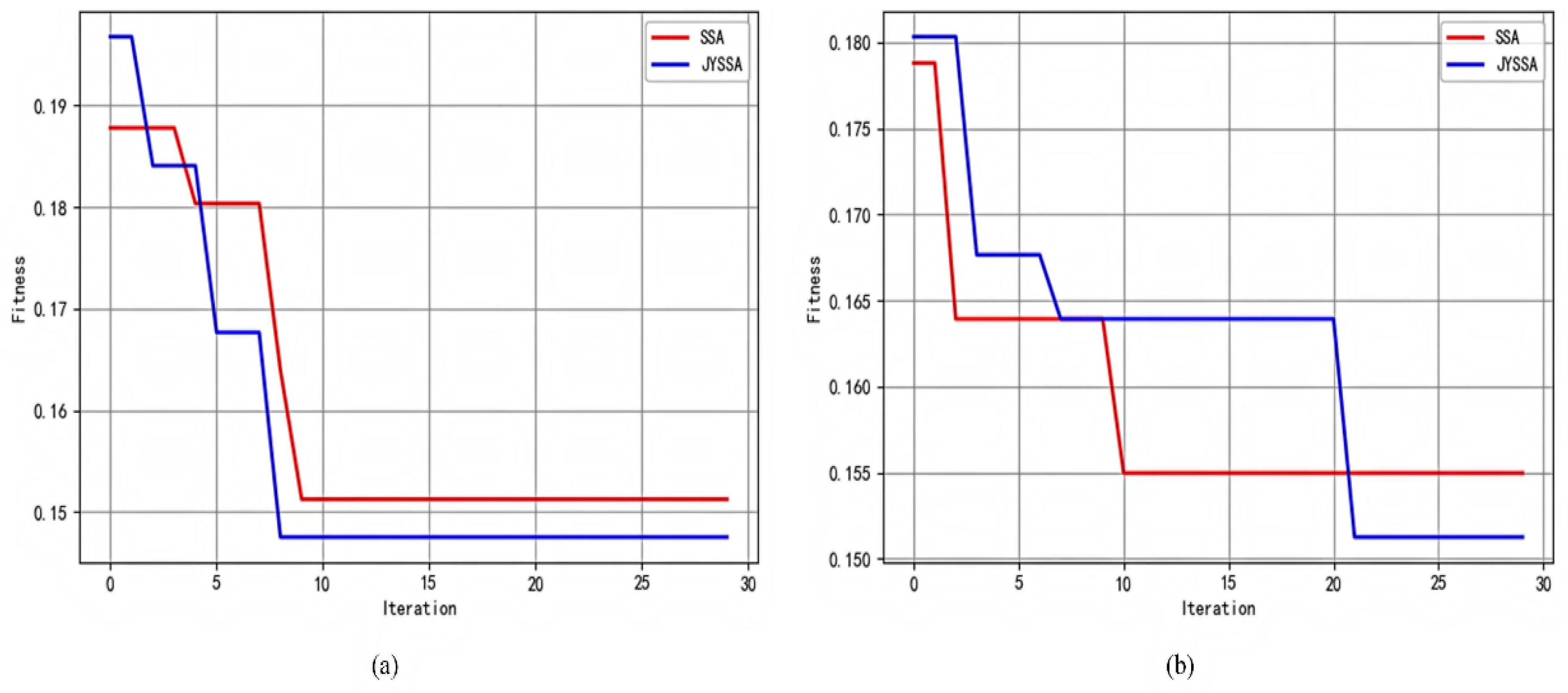
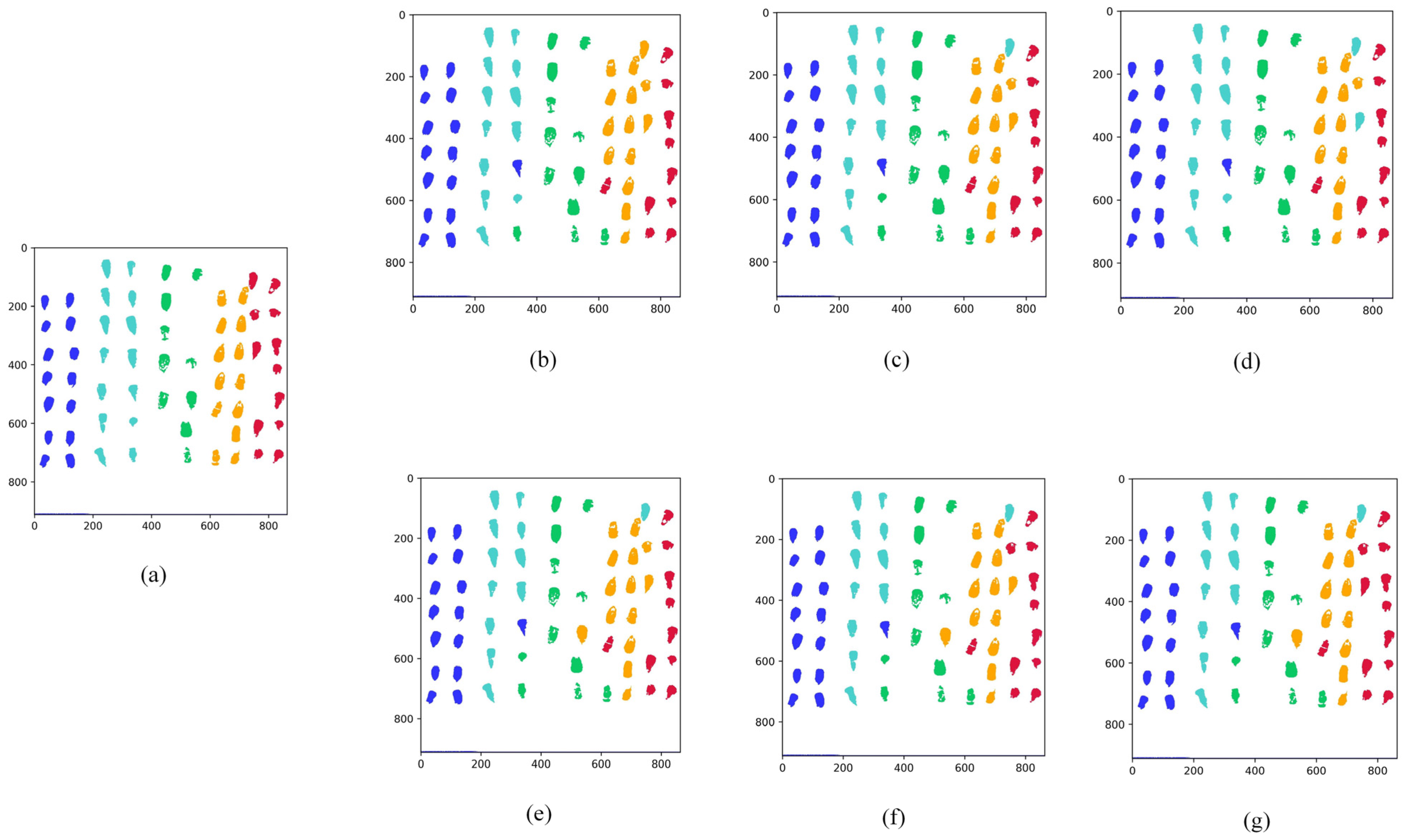
Nevertheless, an RF classification model becomes an optimization problem when the wavelengths of hyperspectral light are divided by a large number. The grid search is straightforward to use, and all combinations of discrete parameter spaces can be evaluated as quickly as possible. It is necessary to discretize continuous parameters before using them [
20]. However, the general simulated annealing algorithm is used by other researchers for its ability to search iteratively for optimal parameters. Compared to the initial value, generally simulated annealing (GSA) has a slower convergence speed [
21]. The advantage of the swarm intelligence algorithm in the optimization model is highlighted due to the outstanding flexibility of sparrow (sparrow, S) established by Xue et al. [
22], who developed a novel swarm intelligence optimization algorithm based on its discovery and contention strategy. In order to simplify the search procedure and avoid anomalies caused by discrete data, the SSA was adopted. The normal distribution was directly used in the search algorithm to ensure continuity. Taking advantage of the SSA simplifies search procedures and eliminates anomalies caused by discrete data. The search algorithm is directly based on normal distributions to maintain continuity. However, the SSA algorithm is prone to judging the local optimum as the optimal global solution [
23]. The SSA algorithm continues to be discussed and improved by researchers to improve its performance. As an extension of the basis and model of the SSA, Tang et al. implemented a fusion of the SSA and bird swarm algorithm [
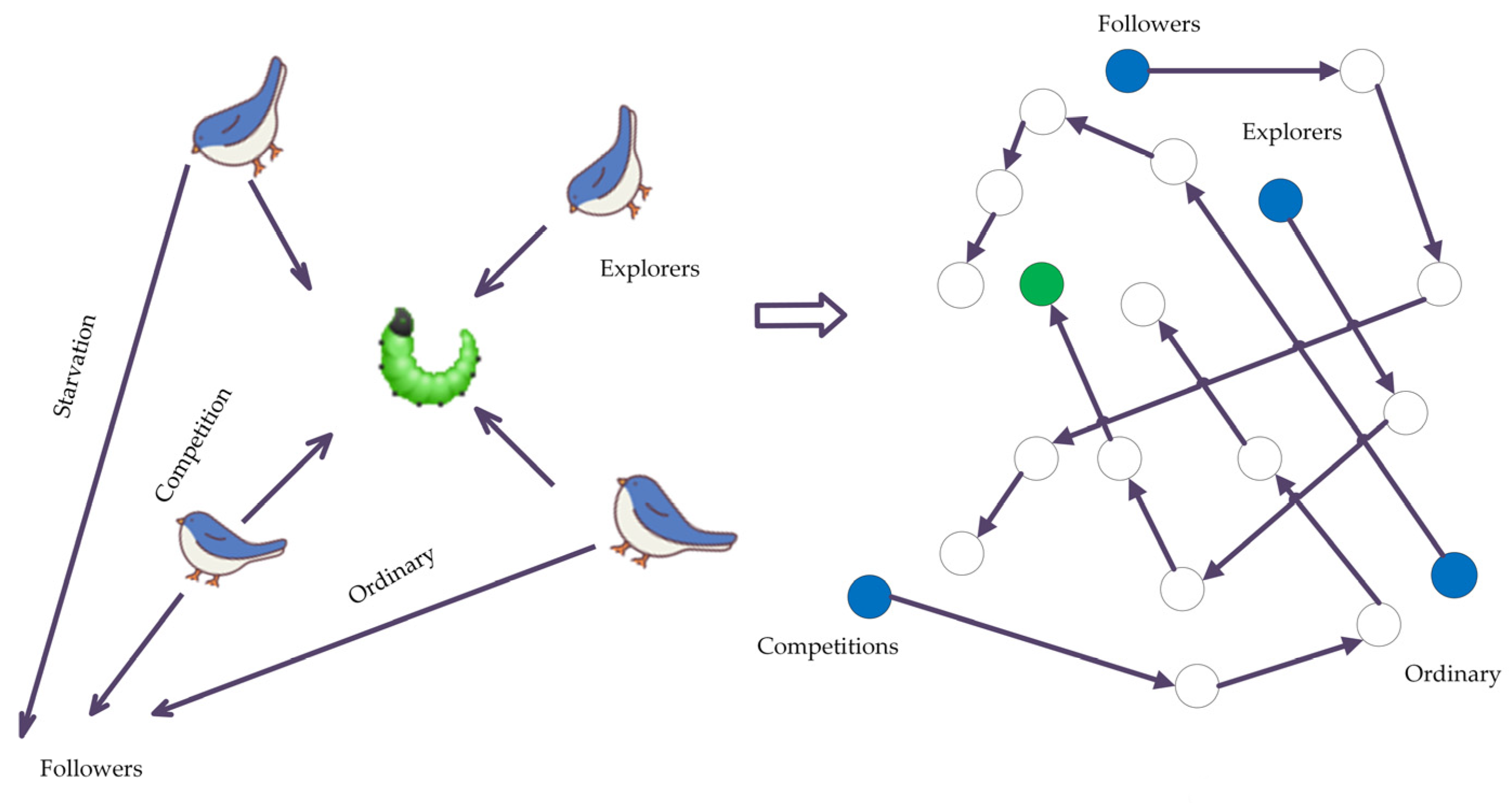
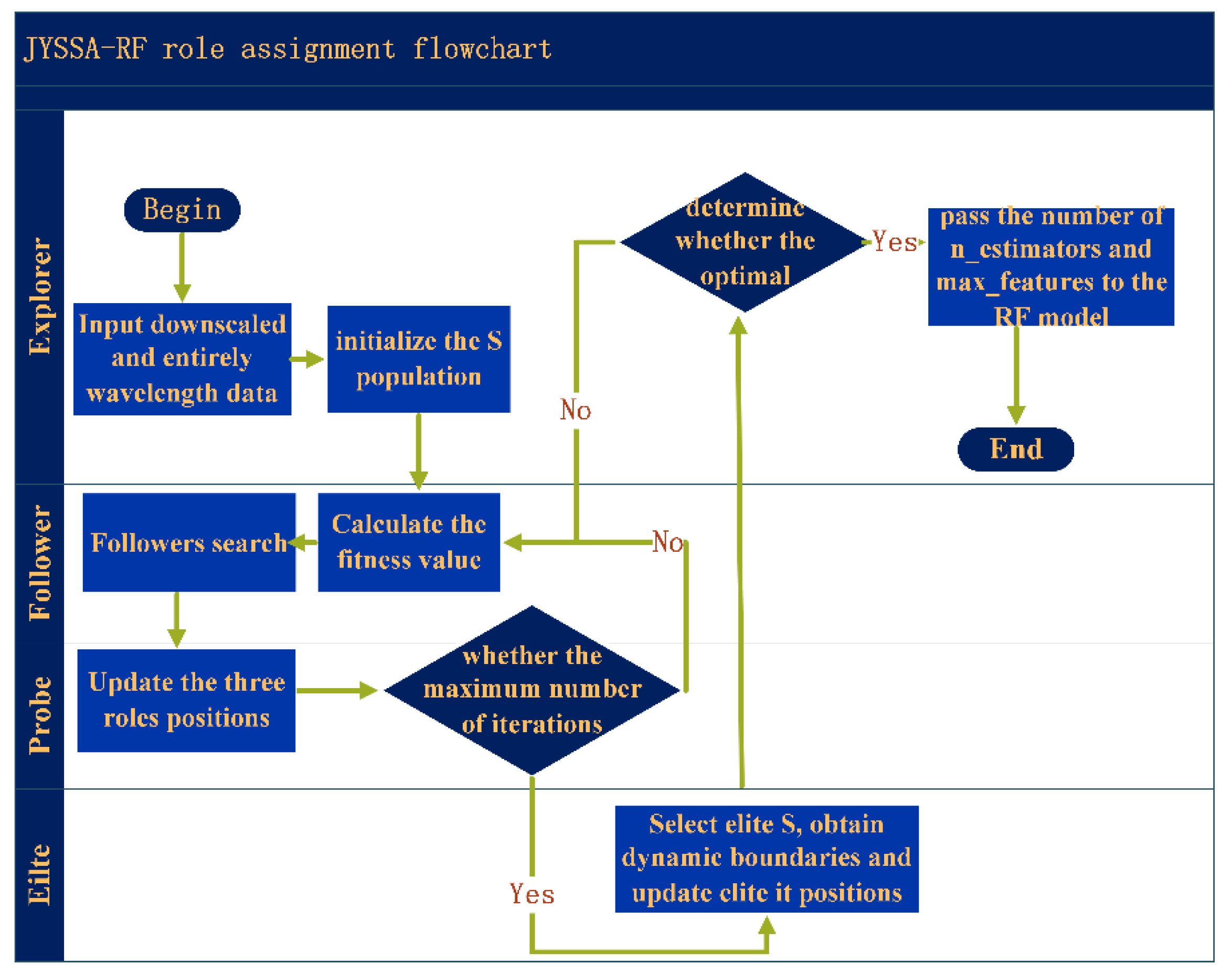
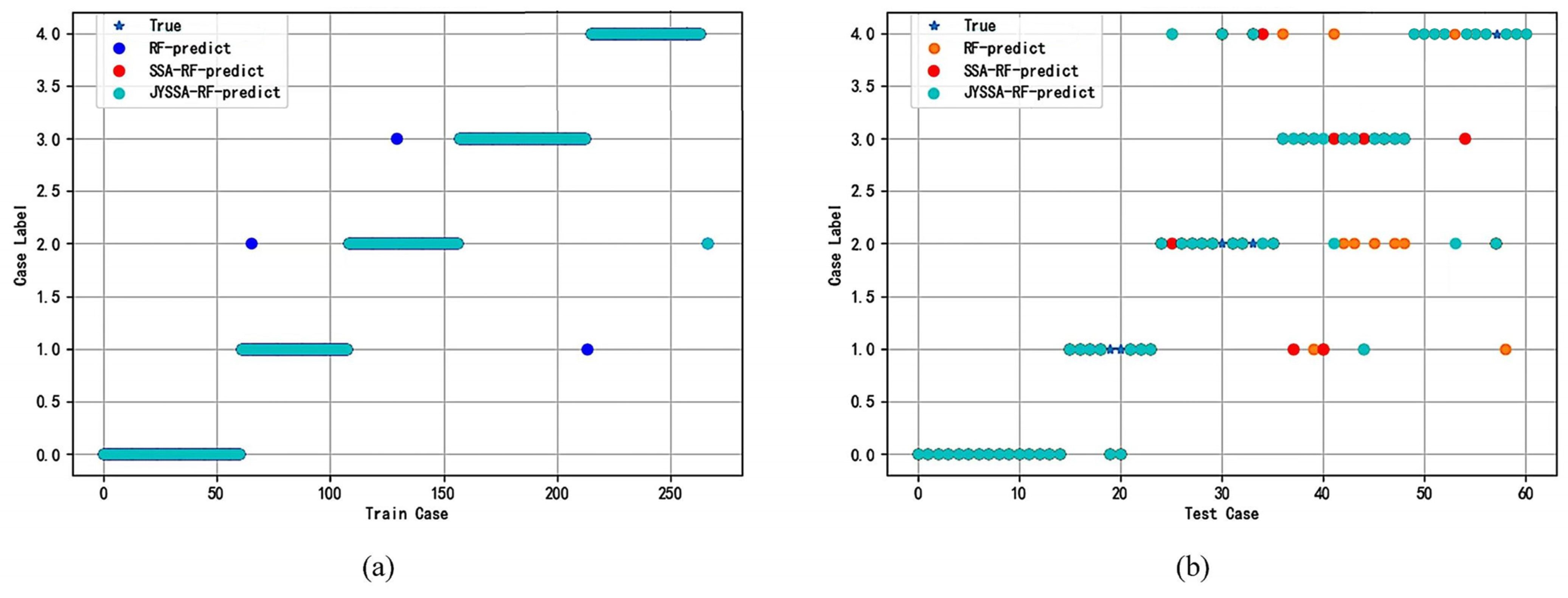
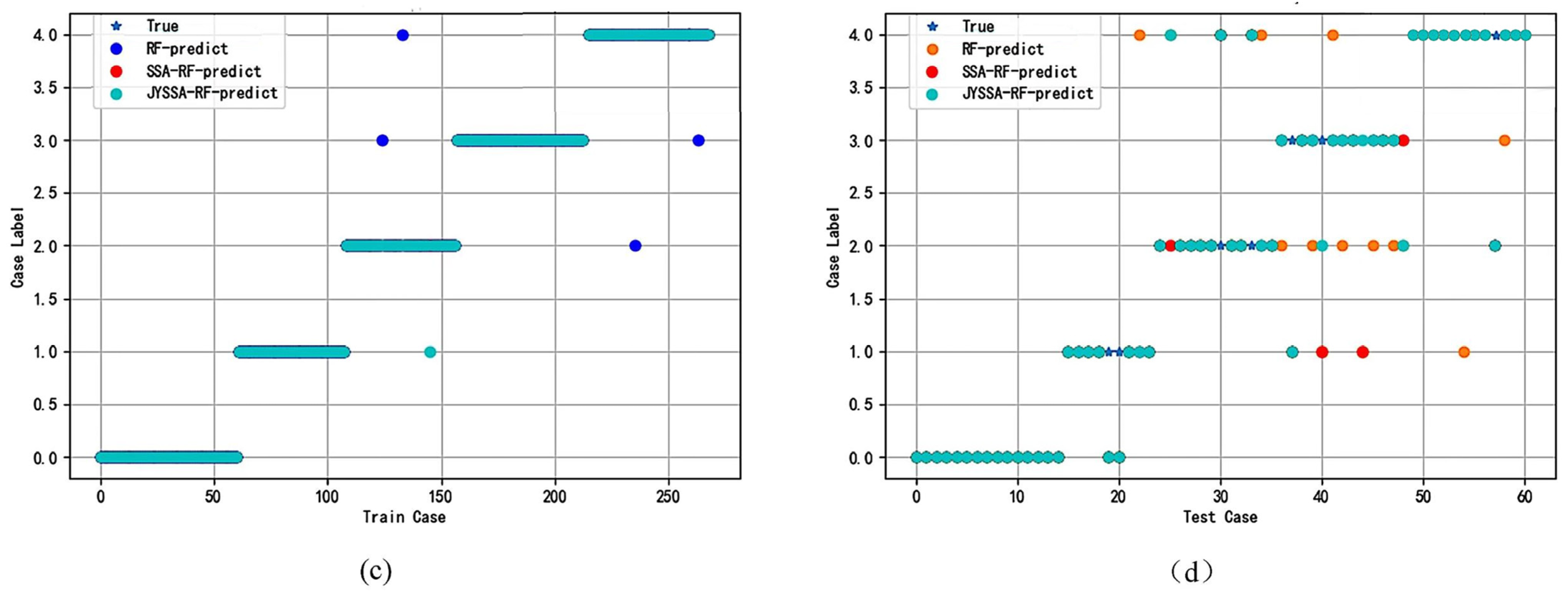
24]. The introduction of updated algorithms resulted in the need to update too many position formulae. This paper uses the random forest (RF) model for hyperspectral wavelength importance analysis to extract feature wavelengths. These wavelengths were input into the RF model to create classification models for maize seeds with different degrees of mold. Last but not least, the SSA was used to optimize a machine learning classifier to process hyperspectral data from the perspective of a model. The elite inverse-strategy-enhanced sparrow search algorithm (JYSSA) was used to broaden the search range, maximize the number of forests and feature subsets in the random forest classifier, and search for each of their optimal solutions. This is the first time that a novel approach has been used in the area of nondestructive testing to address the issue of choosing RF model parameters from a large variety of wavelengths, an issue that plays a significant role in the exploration of efficient and comprehensive methods of detecting mold in maize seeds of various ages.





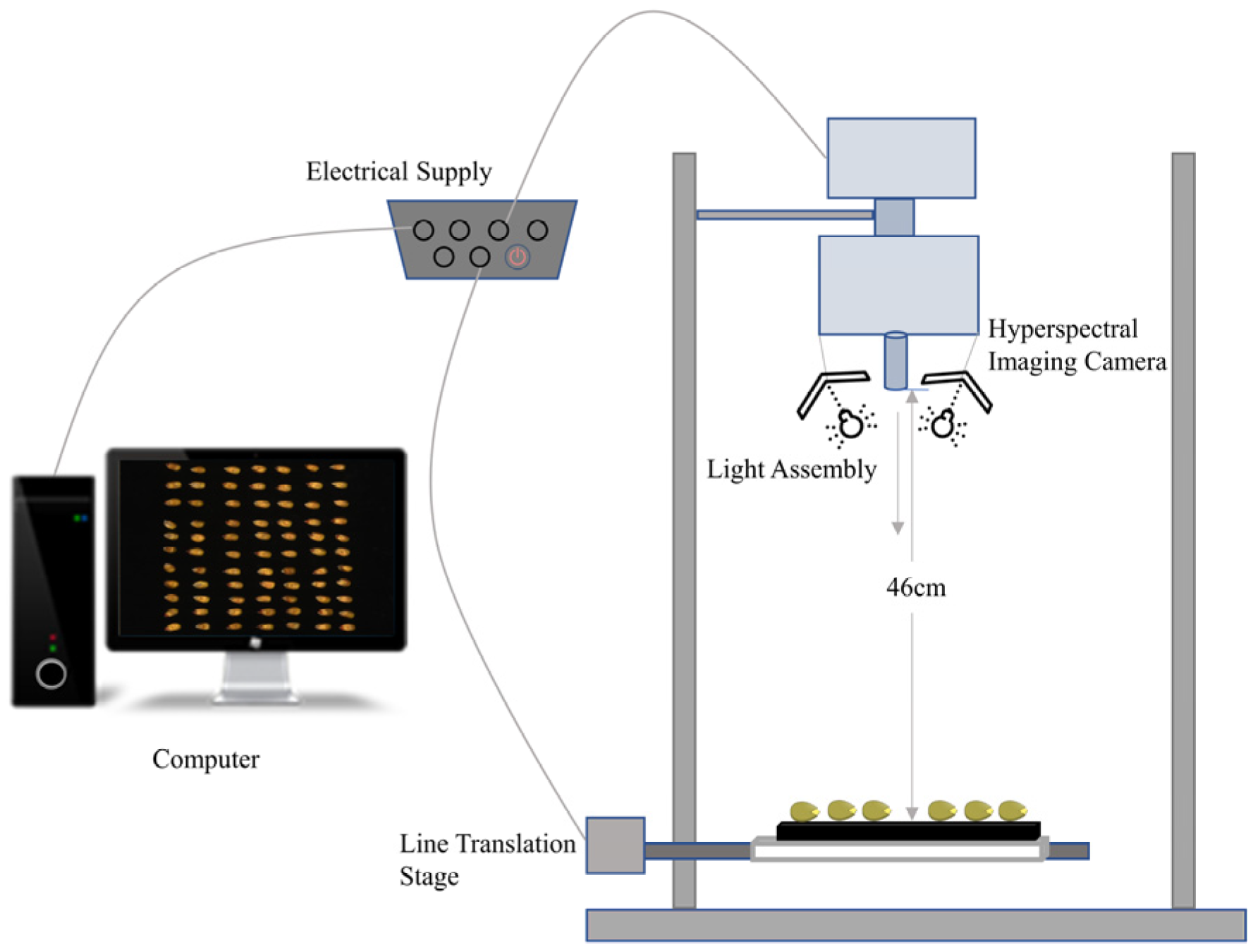
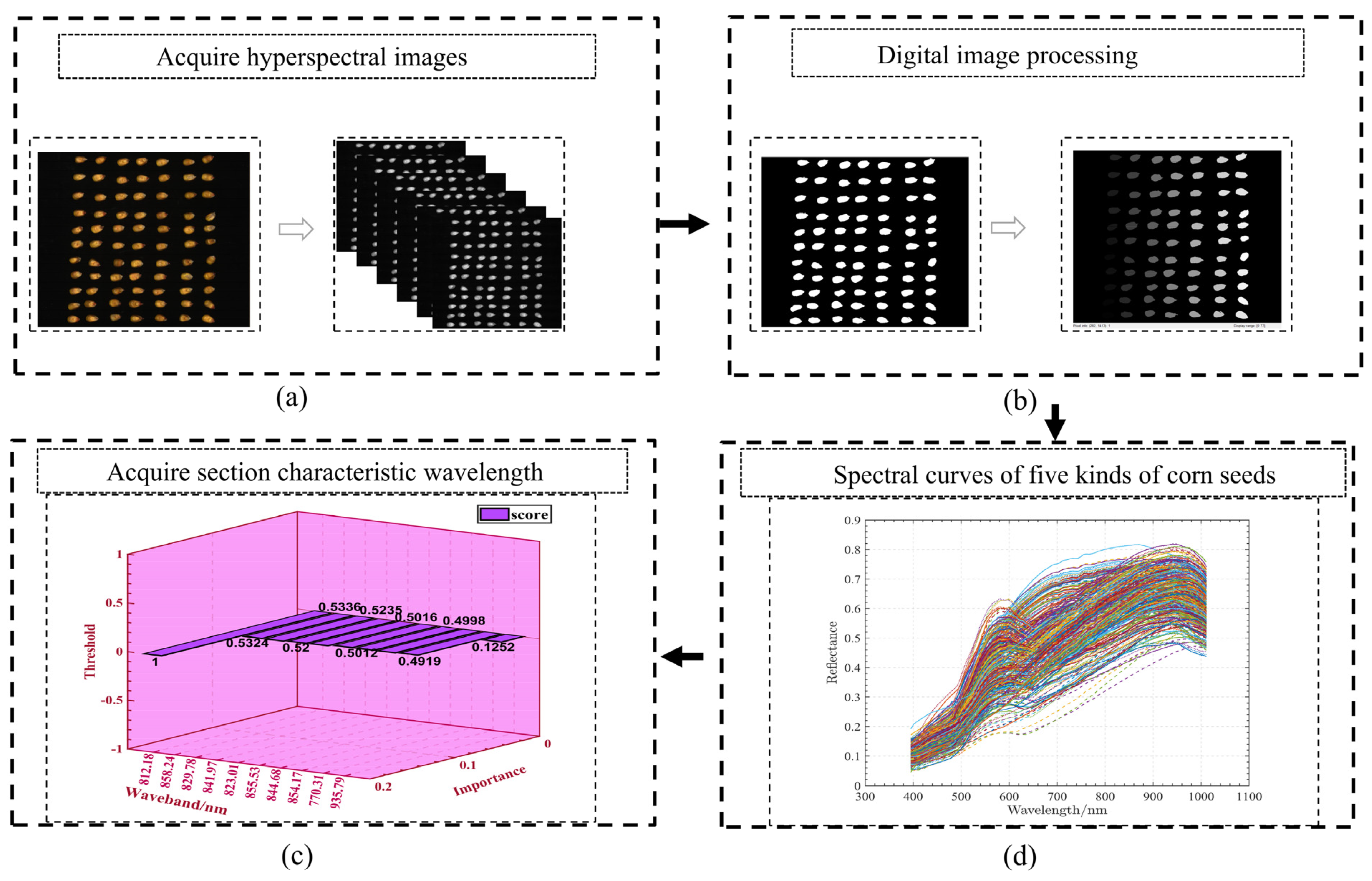
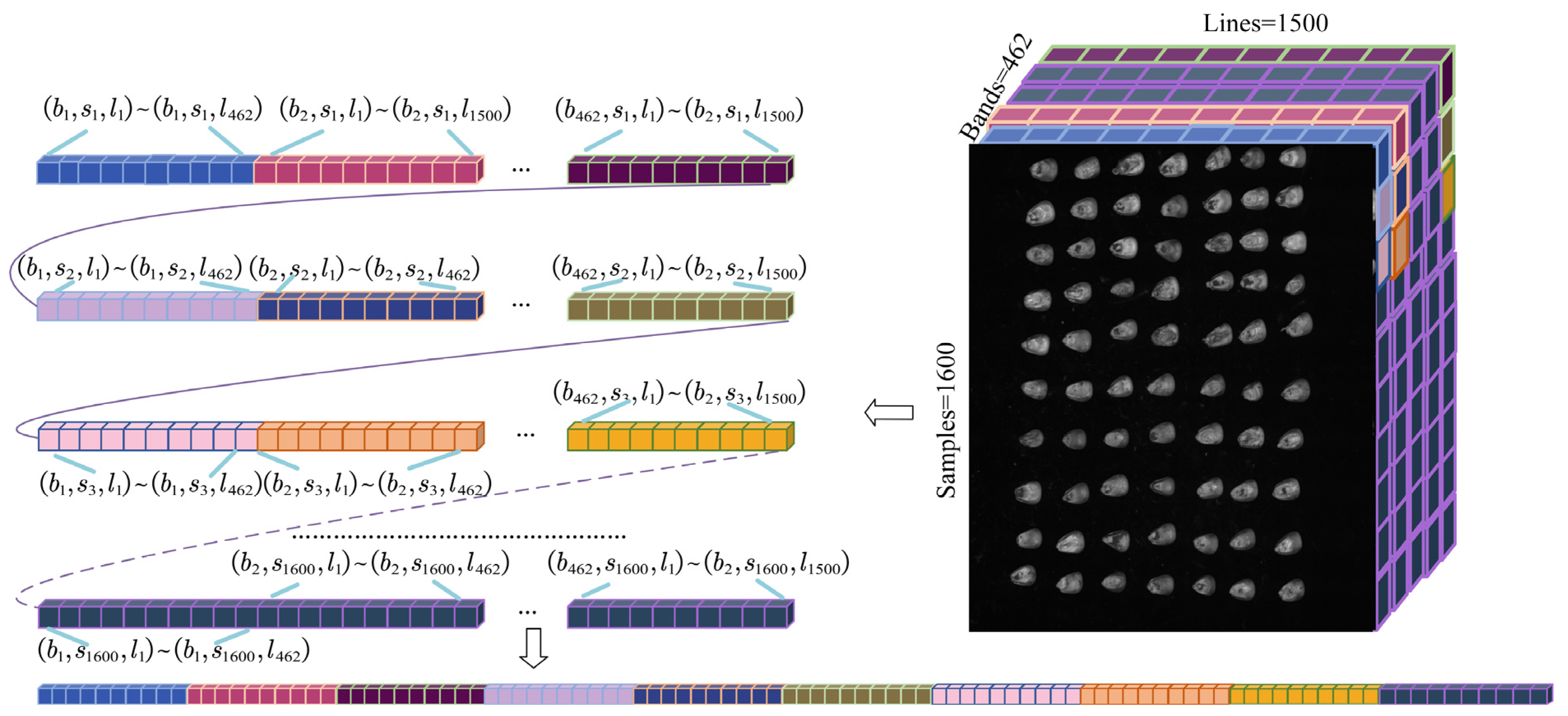


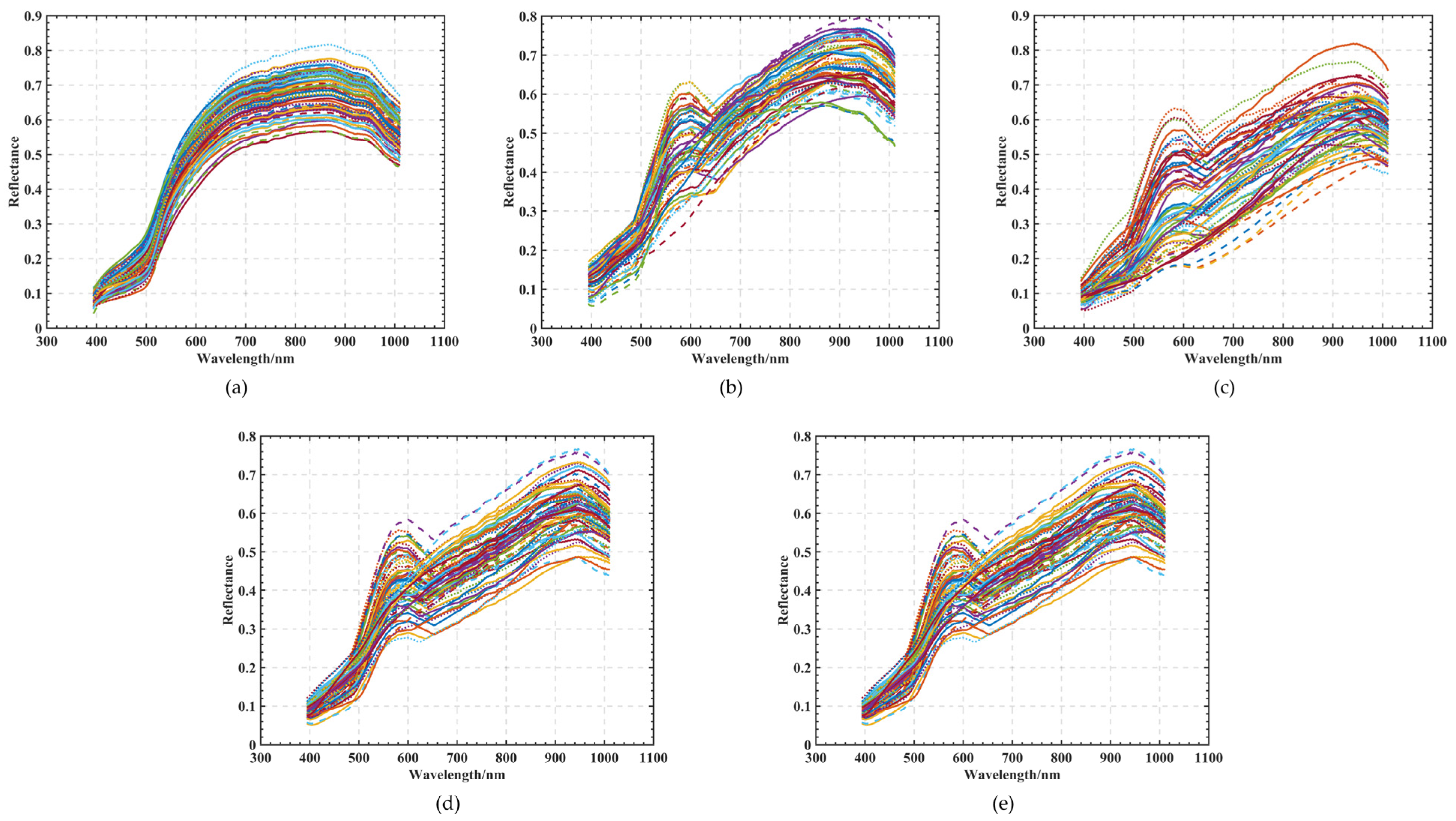
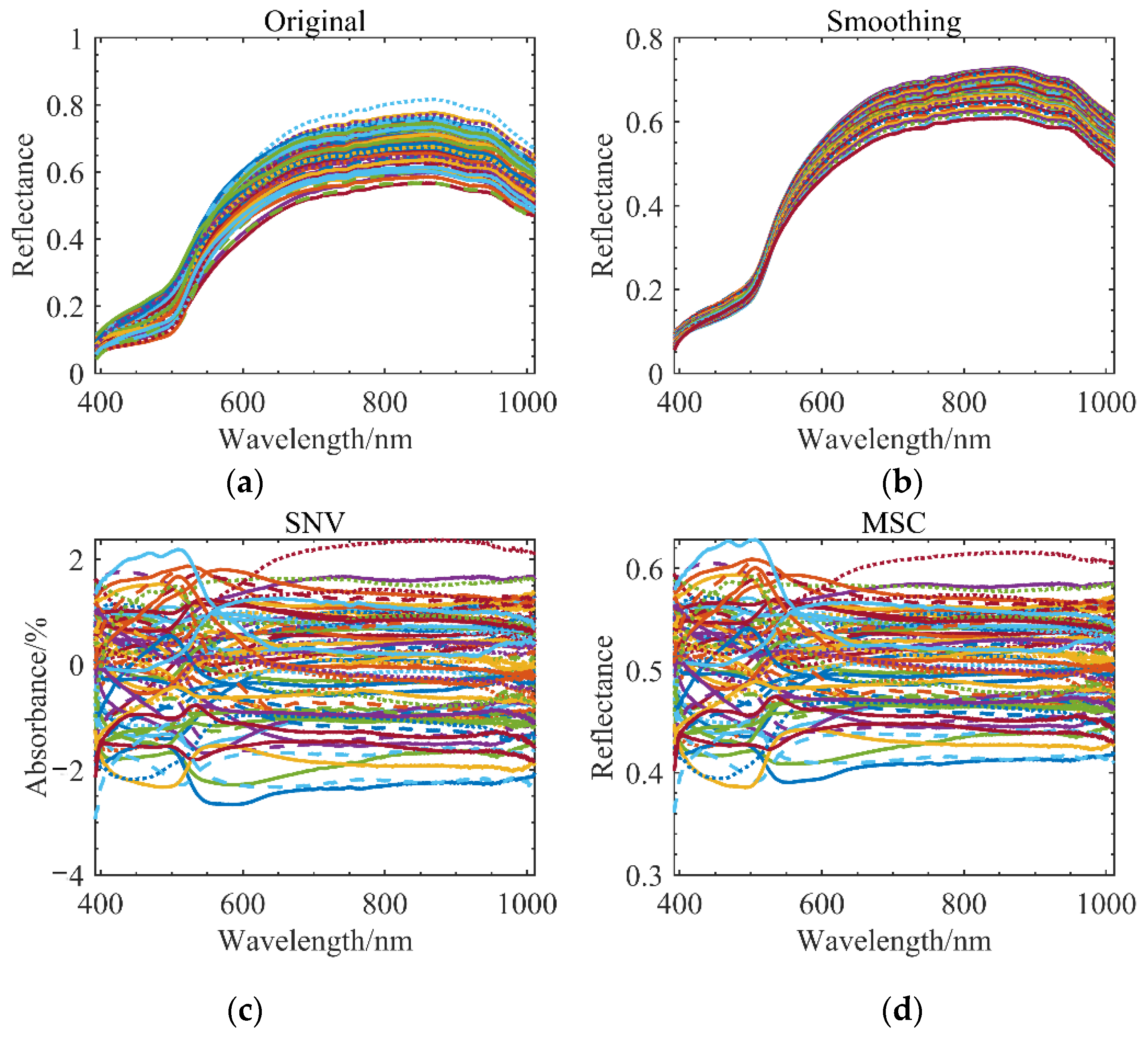

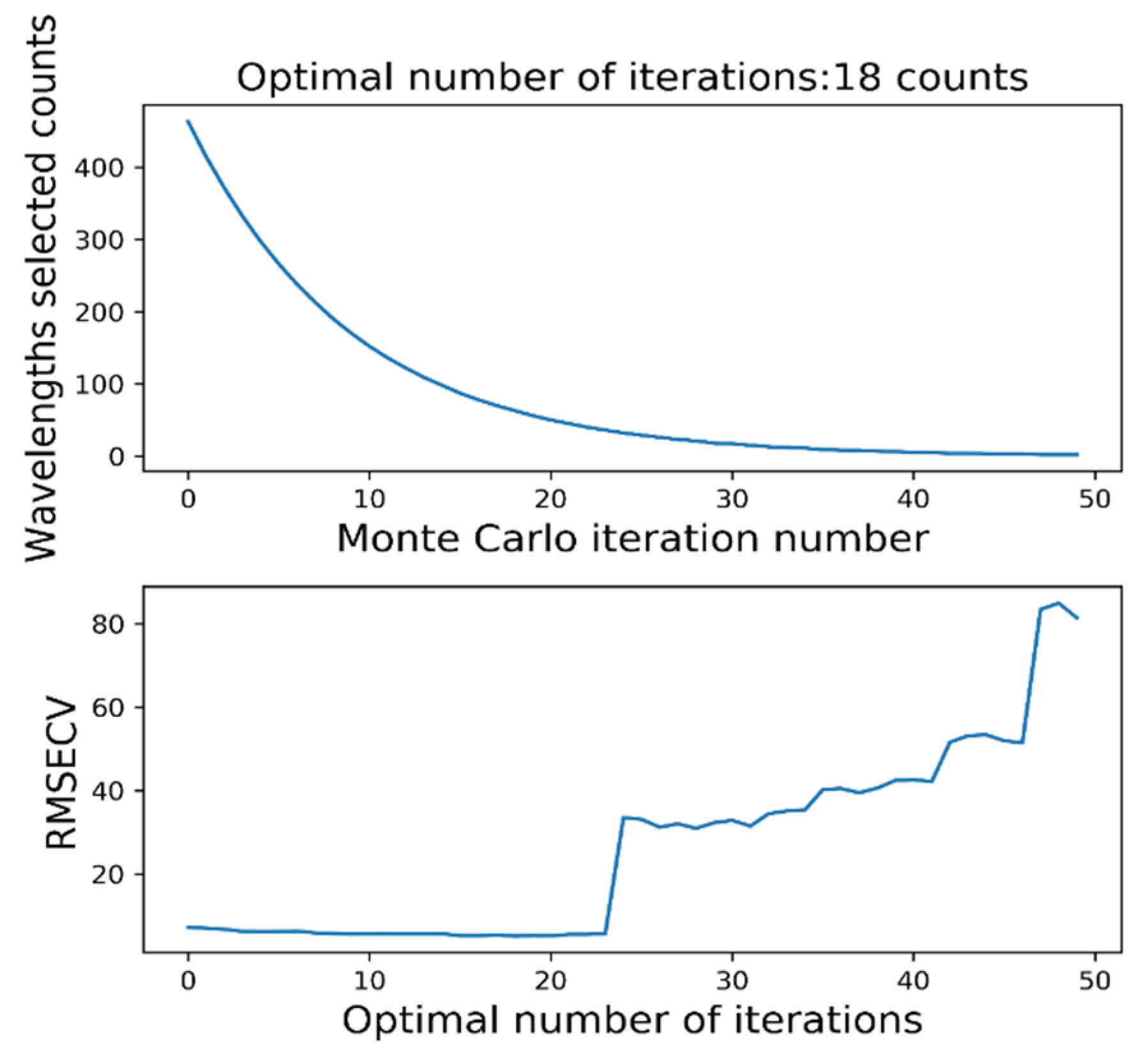
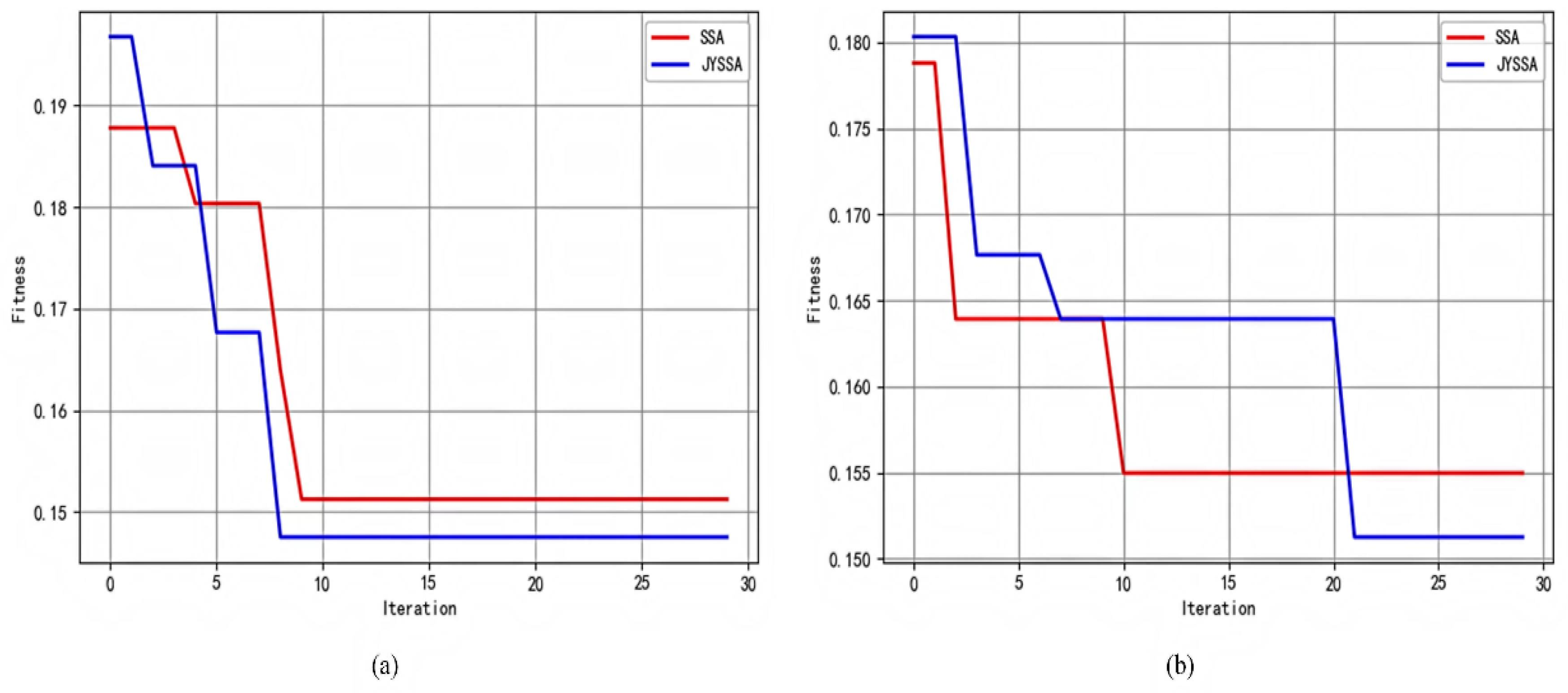
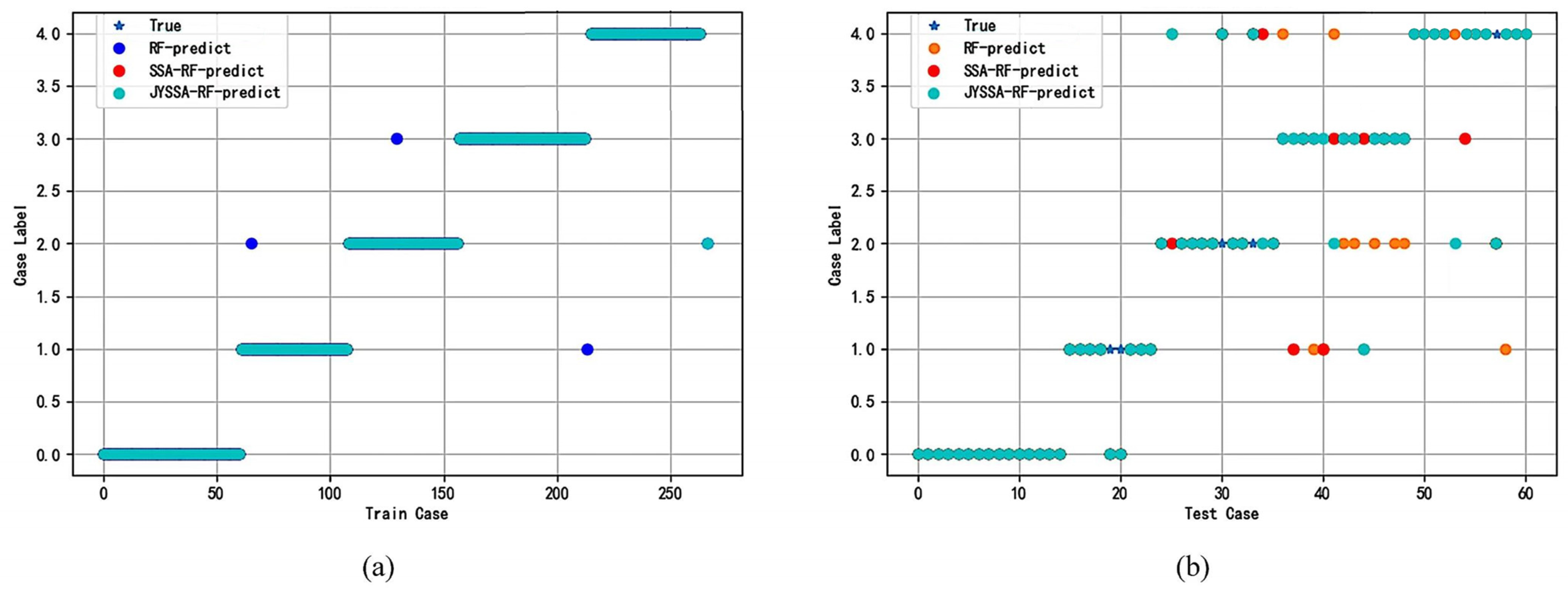

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}