
Multi-Scale Safety Helmet Detection Based on RSSE-YOLOv3


Abstract
:1. Introduction
2. Related Work
3. Methodology
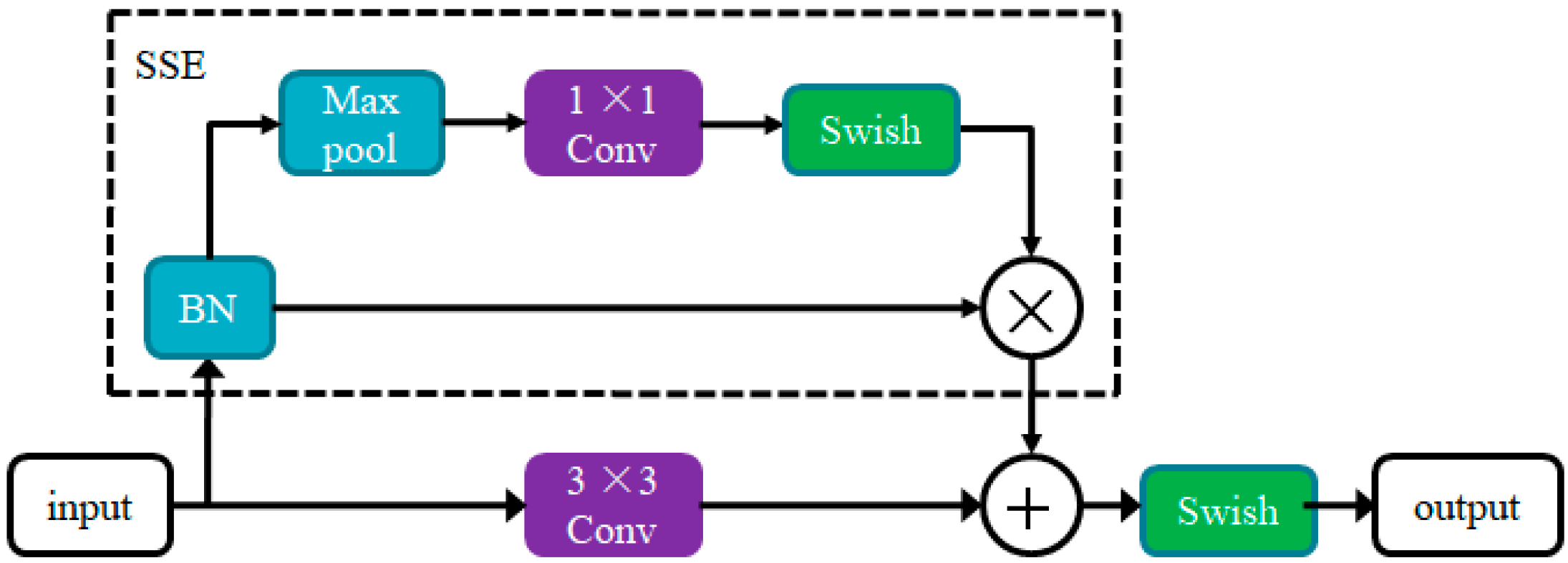
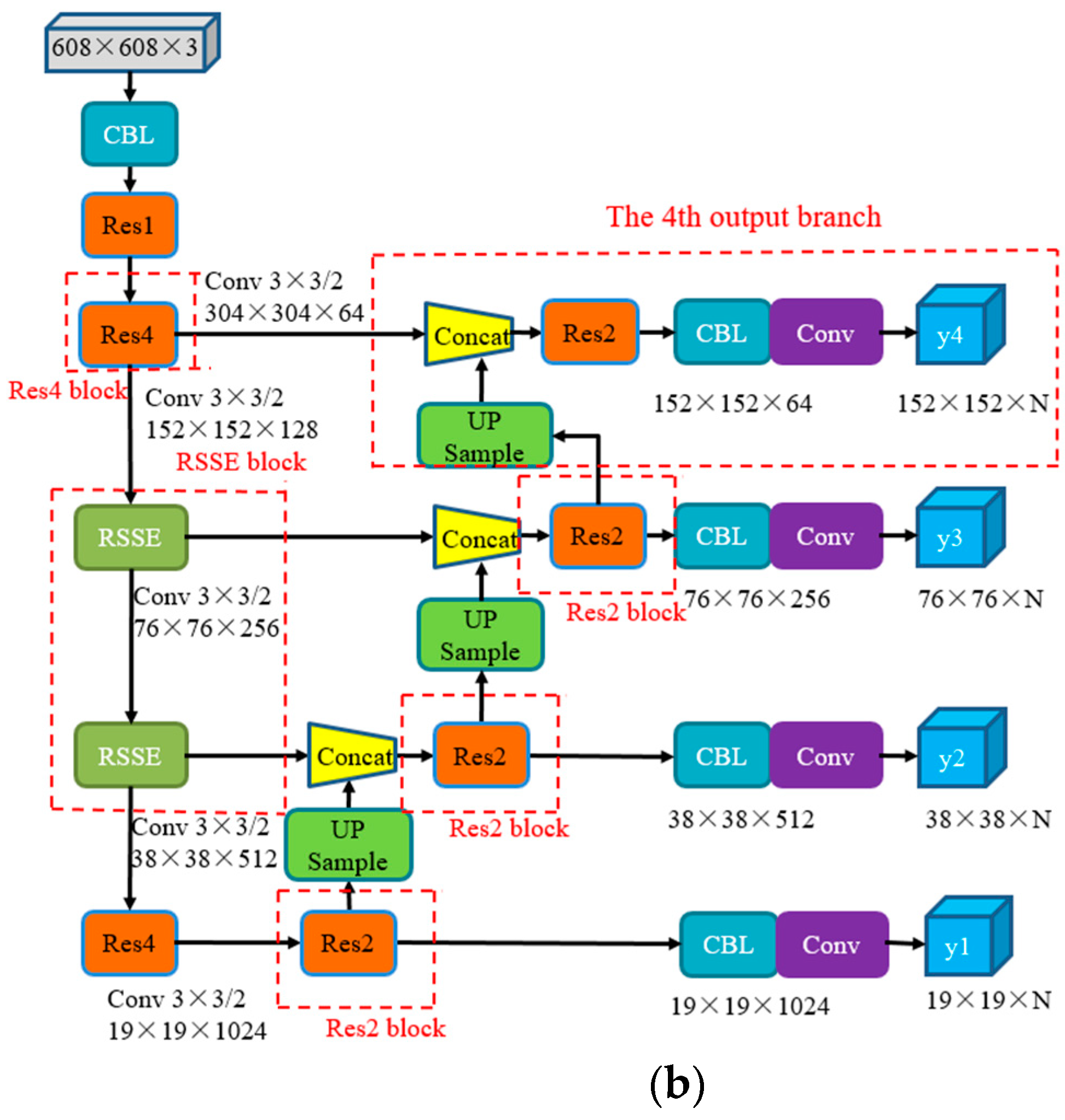
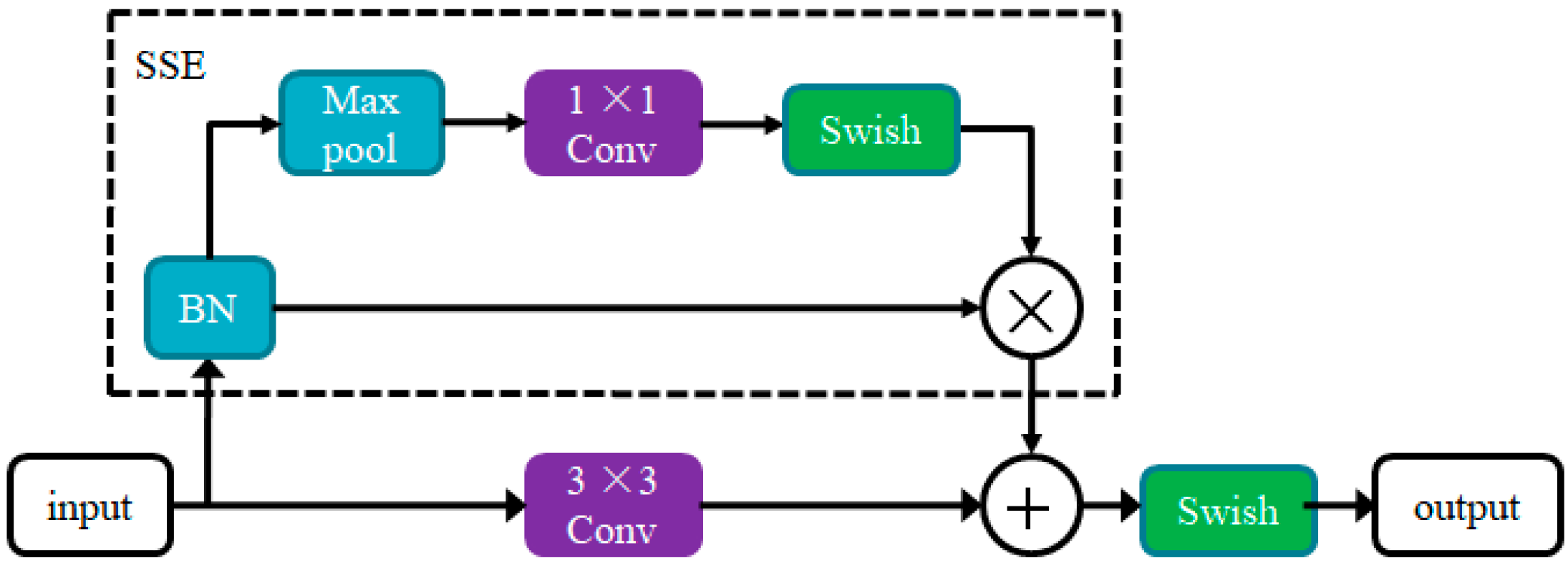
3.1. RSSE Block Design
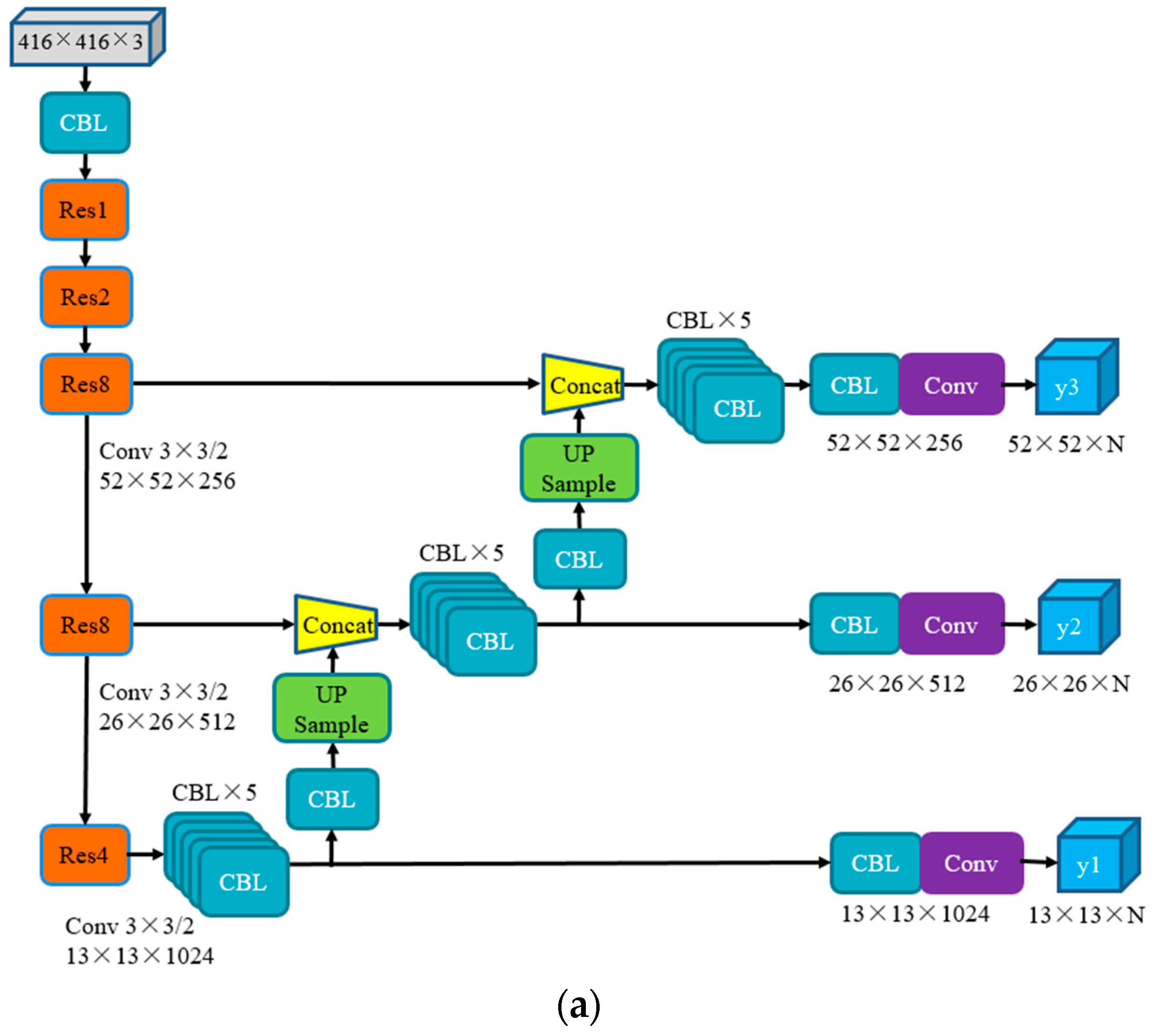
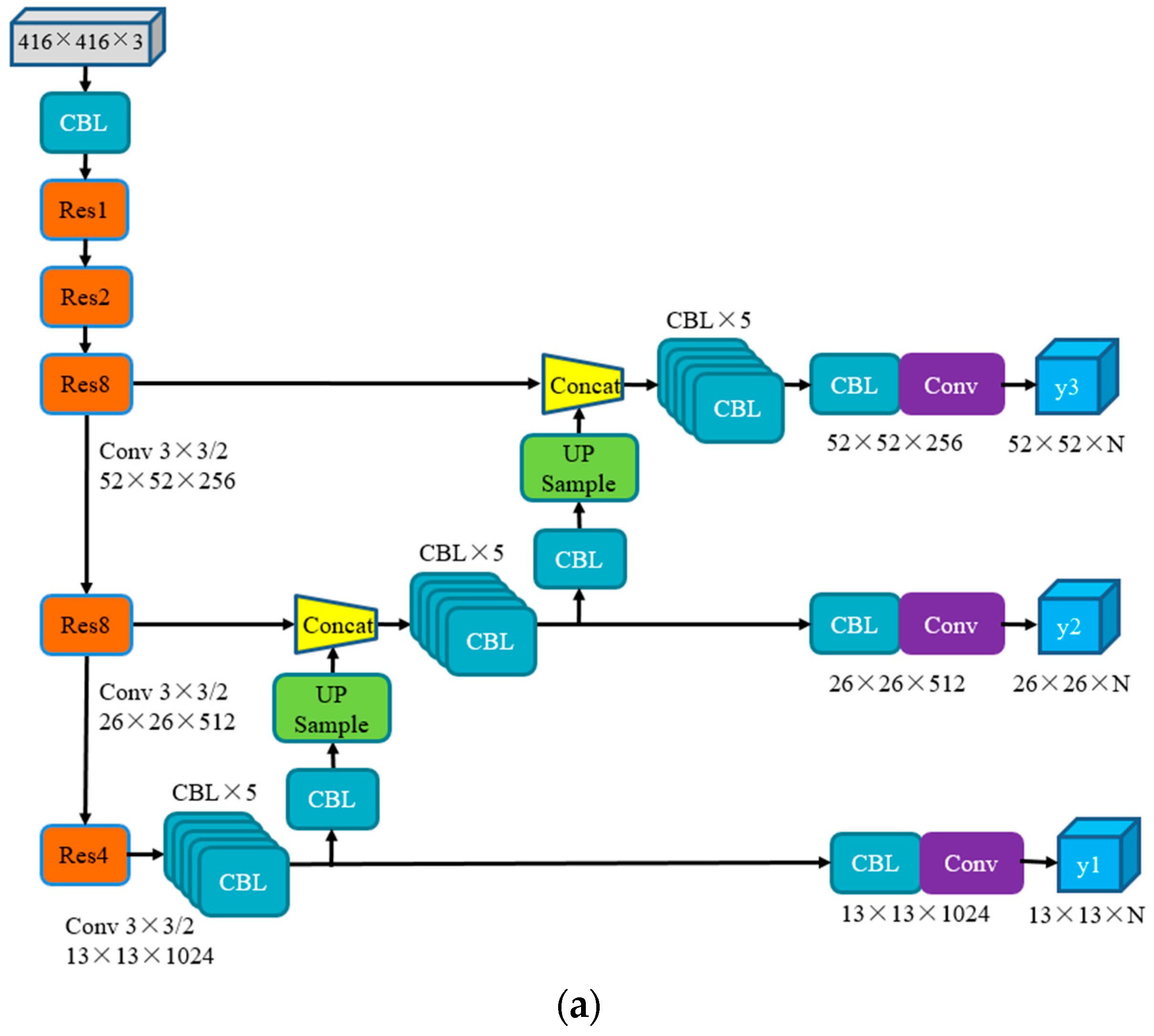
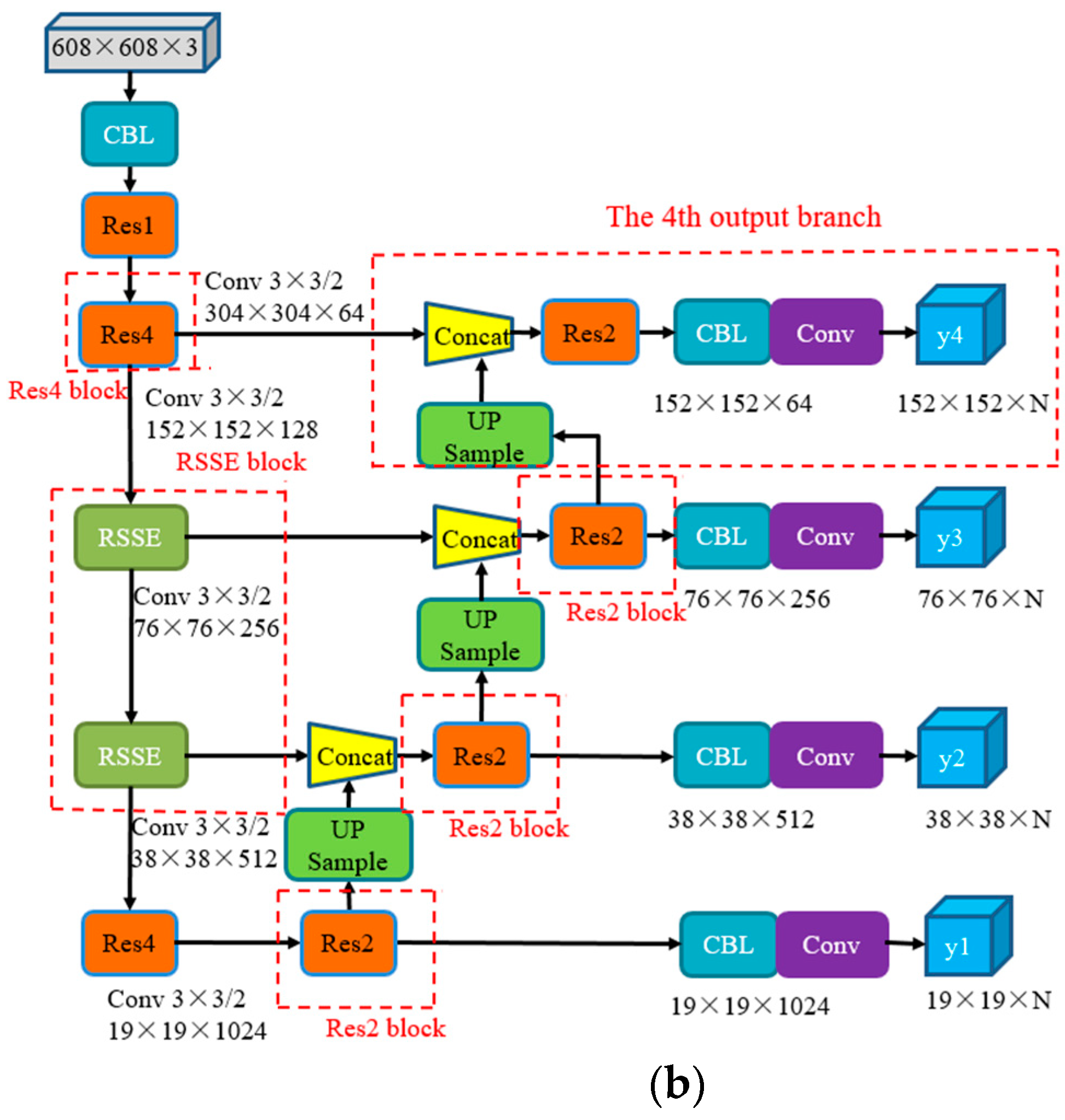
3.2. Multi-Scale Detection Algorithm
3.3. K-Means for Anchor Boxes
3.4. Loss Function
4. Experiments
4.1. Datasets
4.2. Evaluation Criteria
5. Results and Discussions
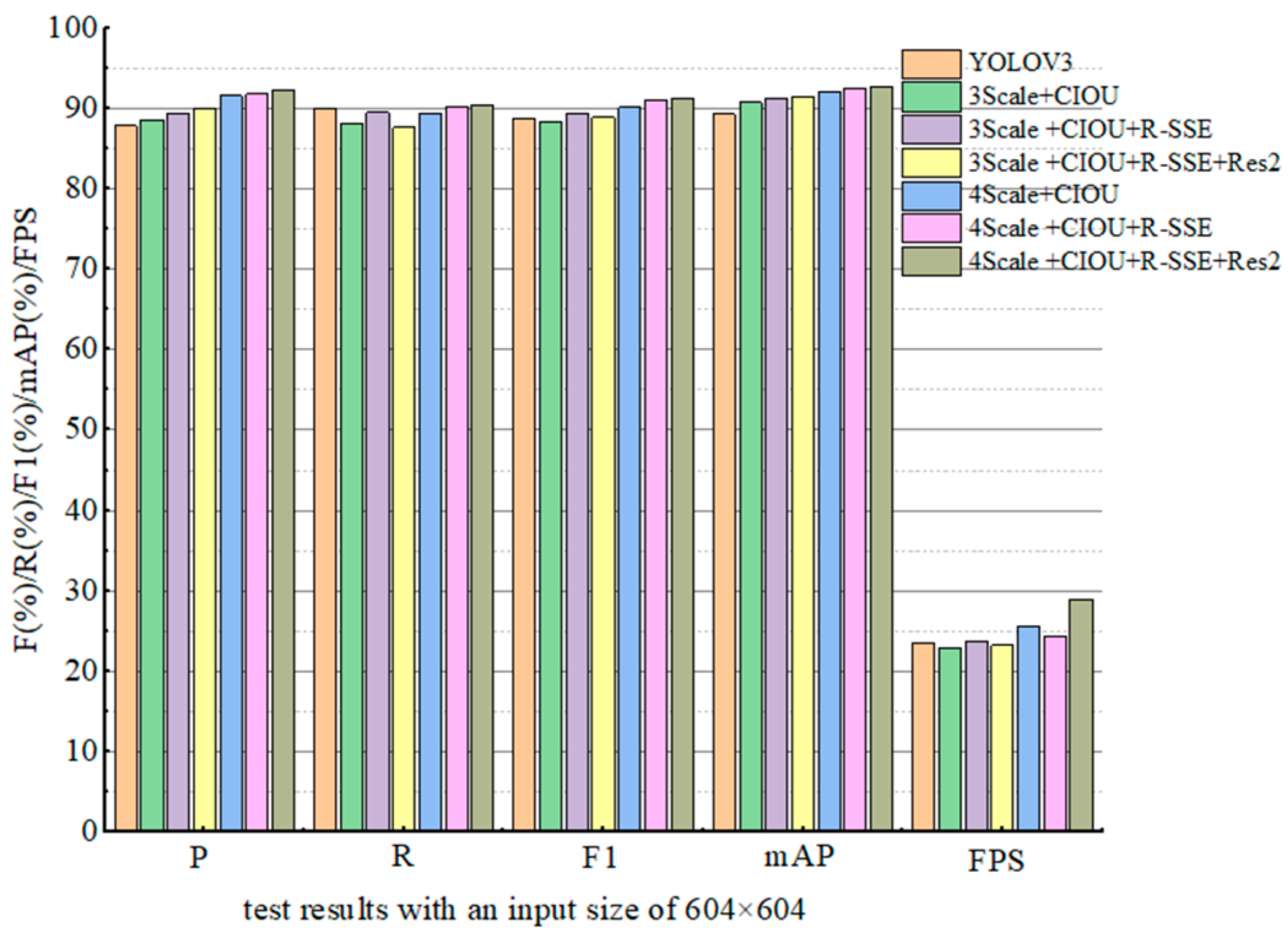
5.1. Ablation Experiment
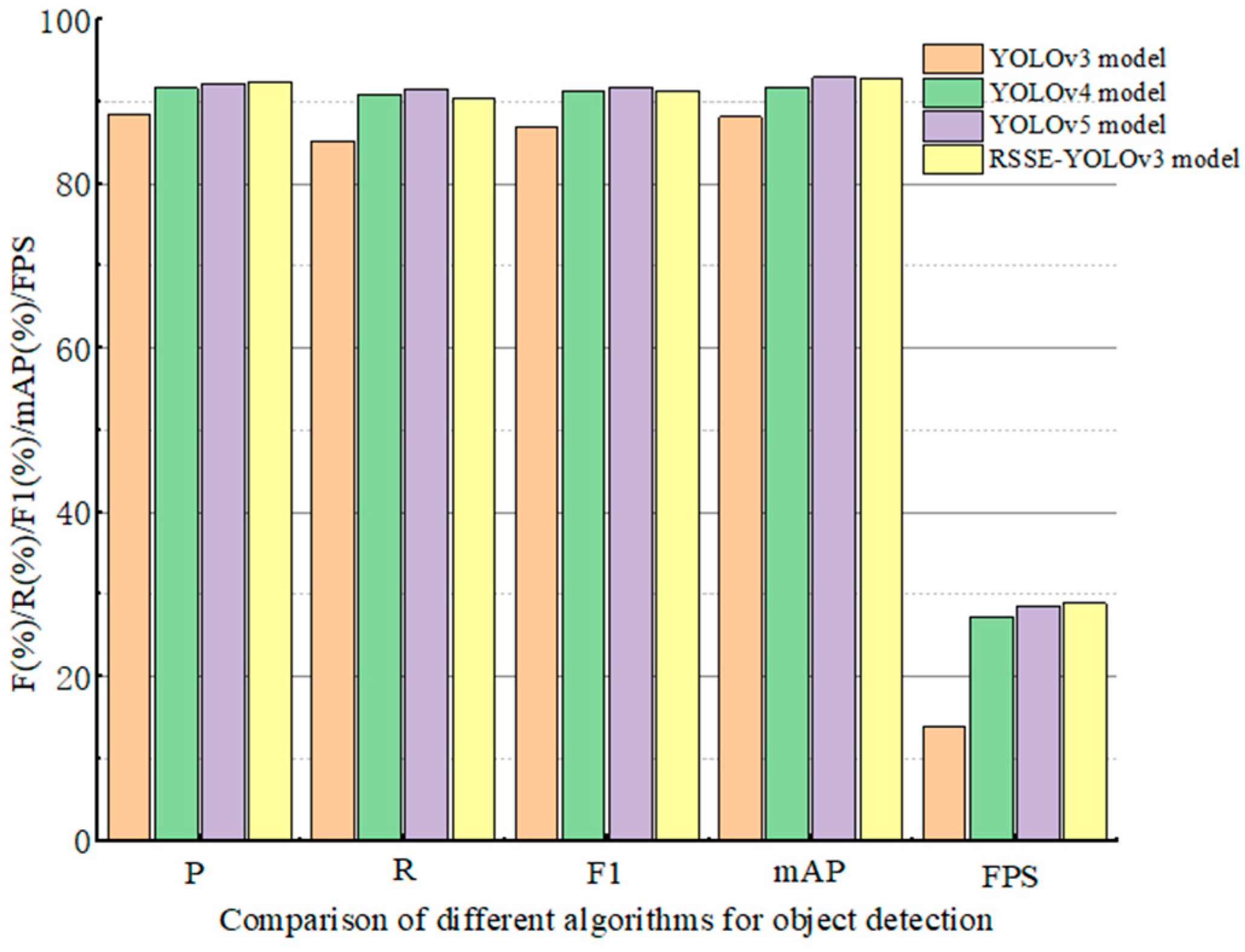
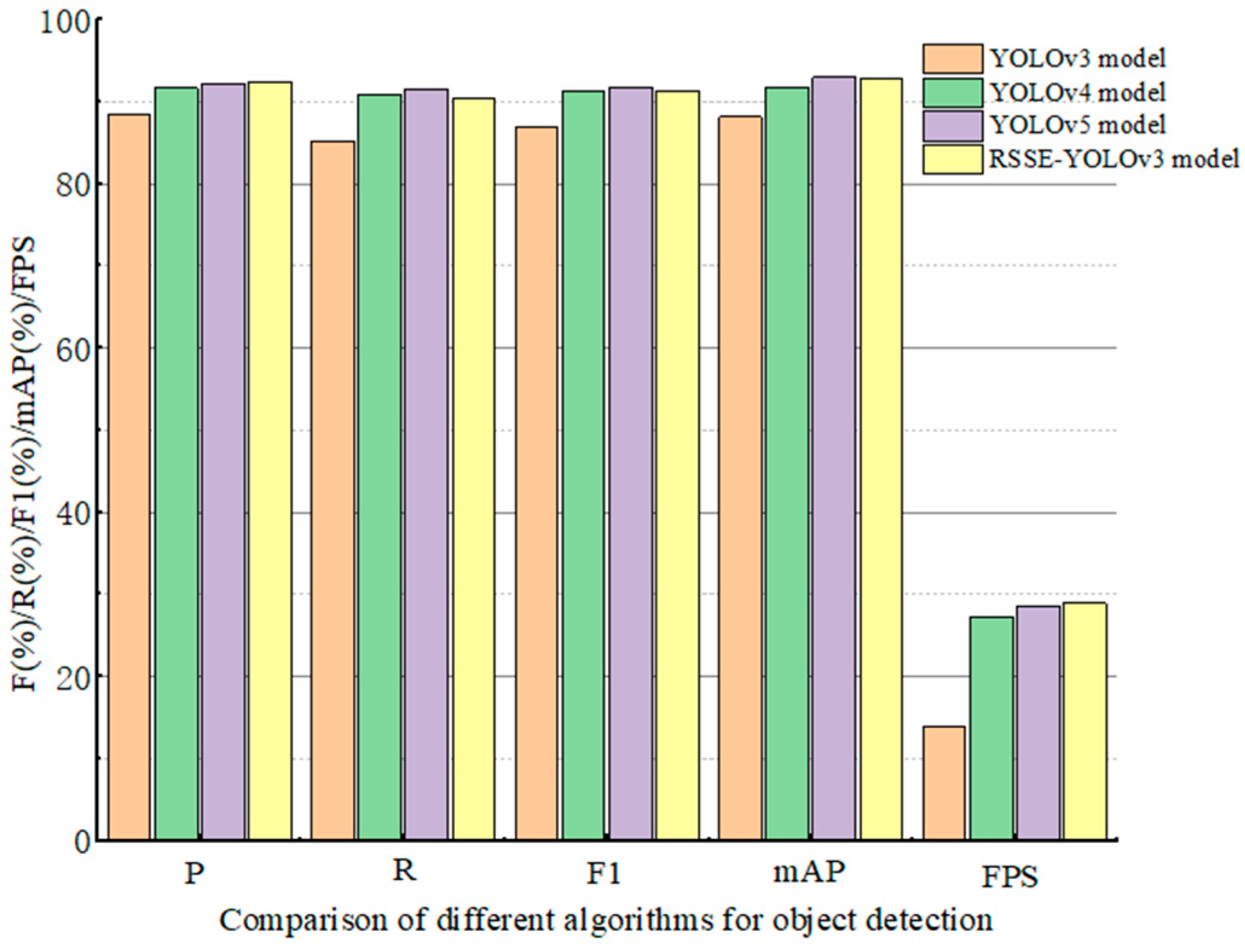
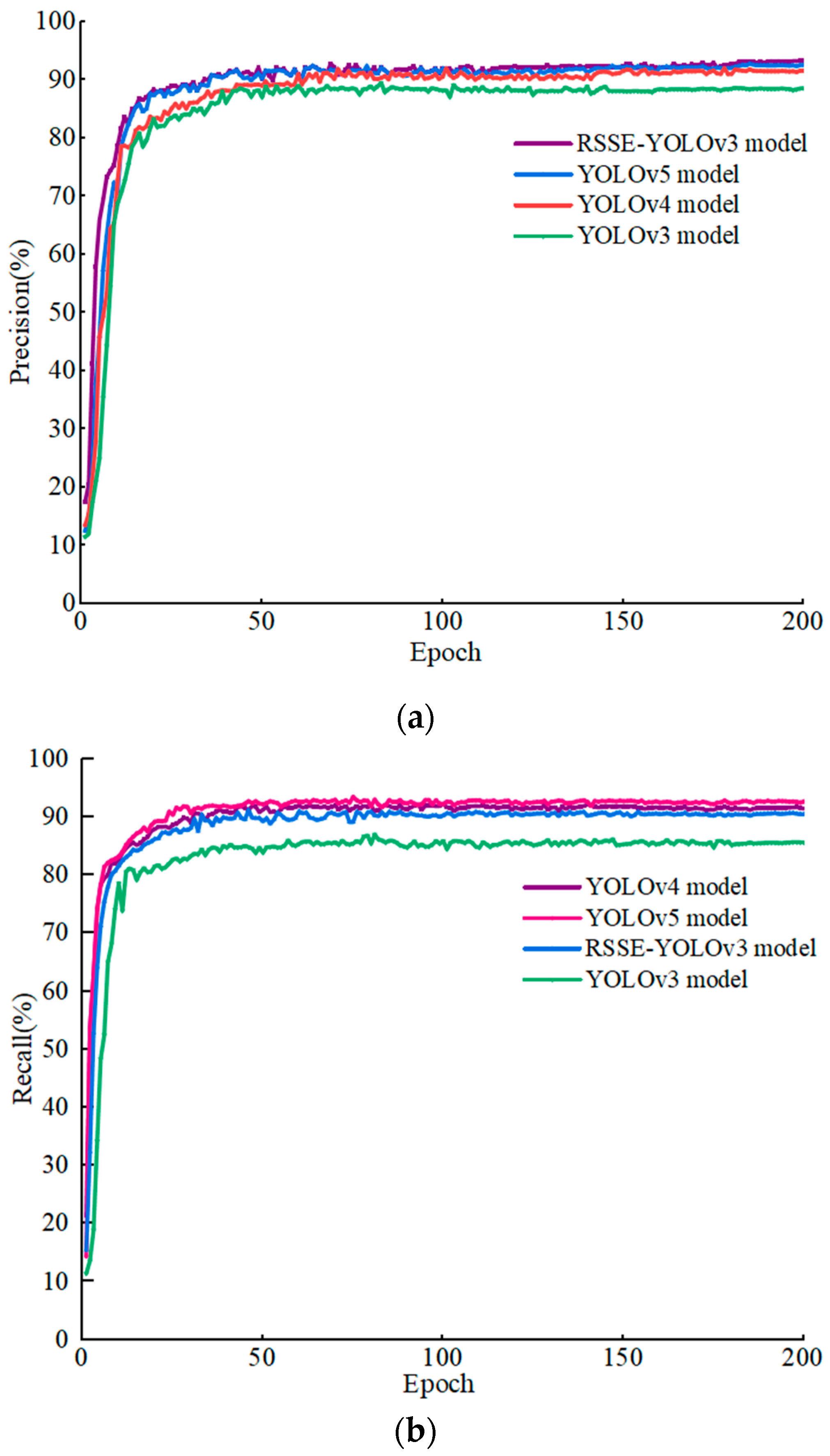
5.2. Result Comparison with Other Detection Models
5.3. Detection Results under Application Scenarios
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jin, Y.; Wu, X.; Domg, H.; Yu, L.; Zhang, W. Improved YOLOv4 Algorithm for Safety Helmet Detection. Comput. Sci. 2021, 48, 268–275. [Google Scholar]
- Wang, Y.; Wang, Z.; Wu, B.; Yang, G. Research Review of Safety Helmet Wearing Detection Algorithm in Intelligent Construction Site. J. Wuhan Univ. Technol. 2021, 43, 56–62. [Google Scholar]
- Xu, K.; Deng, C. Research on Helmet Wear Identification Based on Improved YOLOv3. Prog. Laser Optoelectron. 2021, 58, 0615002. [Google Scholar]
- Lin, T.-Y.; Doll´ar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Kaiming, H.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, Part I; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale deconvolutional single shot detector for small objects. Sci. China Inf. Sci. 2020, 63, 120113. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, X.; Qiu, Z.; Huang, P.; Hu, J.; Luo, J. Application Research of YOLO v2 Combined with Color Identification. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Zhengzhou, China, 18 October 2018; pp. 138–141. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.027672018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Adibhatla, V.A.; Chih, H.C.; Hsu, C.C.; Cheng, J.; Abbod, M.F.; Shieh, J.S. Applying deep learning to defect detection in printed circuit boards via a newest model of you-only-look-once. Math. Biosci. Eng. 2021, 18, 4411–4428. [Google Scholar] [CrossRef] [PubMed]
- Li, N.; Lyu, X.; Xu, S.; Wang, Y.; Wang, Y.; Gu, Y. Incorporate OHEM and Multi-Part Combination Into Automatic Safety Helmet Wearing Detection. IEEE Access 2020, 9, 139536–139543. [Google Scholar] [CrossRef]
- Fang, M.; Sun, T.; Shao, Z. Fast helmet-wearing-condition detection based on improved YOLOv2. Opt. Precis. Eng. 2019, 27, 1196–1205. [Google Scholar] [CrossRef]
- Chao, H. Research on Helmet Detection System Based on Improved YOLOv3; Huazhong University of Science and Technology: Wuhan, China, 2019. [Google Scholar] [CrossRef]
- Cheng, R.; He, X.; Zheng, Z.; Wang, Z. Multi-Scale Safety Helmet Detection Based on SAS-YOLOv3-Tiny. Appl. Sci. 2021, 11, 3652. [Google Scholar] [CrossRef]
- Yan, D. Improved YOLOv3 Helmet Detection Algorithm. In Proceedings of the IEEE 2021 4th International Conference on Robotics, Control and Automation Engineering (RCAE), Wuhan, China, 4–6 November 2021. [Google Scholar]
- Han, K.; Zeng, X. Deep Learning-Based Workers Safety Helmet Wearing Detection on Construction Sites Using Multi-Scale Features. IEEE Access 2022, 10, 718–729. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural net-works. Int. Conf. Mach. Learn. 2019, 97, 6105–6114. [Google Scholar]
- Goyal, A.; Bochkovskiy, A.; Deng, J.; Koltun, V. Non-deep Networks. arXiv 2021, arXiv:2110.07641v1. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. arXiv 2021, arXiv:2101.03697. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 2016 ACM Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287v1. [Google Scholar] [CrossRef]
- Benyang, D.; Xiaochun, L.; Miao, Y. Safety helmet detection method based on YOLOv4. In Proceedings of the 2020 16th International Conference on Computational Intelligence and Security (CIS), Guangxi, China, 27–30 November 2020; pp. 155–158. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| K | Feature Map Size | Anchors | ||
|---|---|---|---|---|
| K = 9 | 19 × 19 | 143, 273 | 229, 340 | 379, 445 |
| 38 × 38 | 74, 120 | 99, 194 | 167, 162 | |
| 76 × 76 | 11, 18 | 25, 43 | 44, 78 | |
| K = 12 | 19 × 19 | 129, 229 | 188, 247 | 291, 113 |
| 38 × 38 | 67, 130 | 89, 180 | 125, 129 | |
| 76 × 76 | 35, 58 | 47, 89 | 80, 82 | |
| 152 × 52 | 6, 10 | 14, 23 | 22, 41 | |
| Scheme | 3Scale | 4Scale | CIOU | RSSE | Res2 |
|---|---|---|---|---|---|
| 3Scale + CIOU | √ | √ | |||
| 3Scale + CIOU + RSSE | √ | √ | √ | ||
| 3Scale + CIOU + RSSE + Res2 | √ | √ | √ | √ | |
| 4Scale + CIOU | √ | √ | |||
| 4Scale + CIOU + RSSE | √ | √ | √ | ||
| 4Scale + CIOU + RSSE + Res2 | √ | √ | √ | √ |
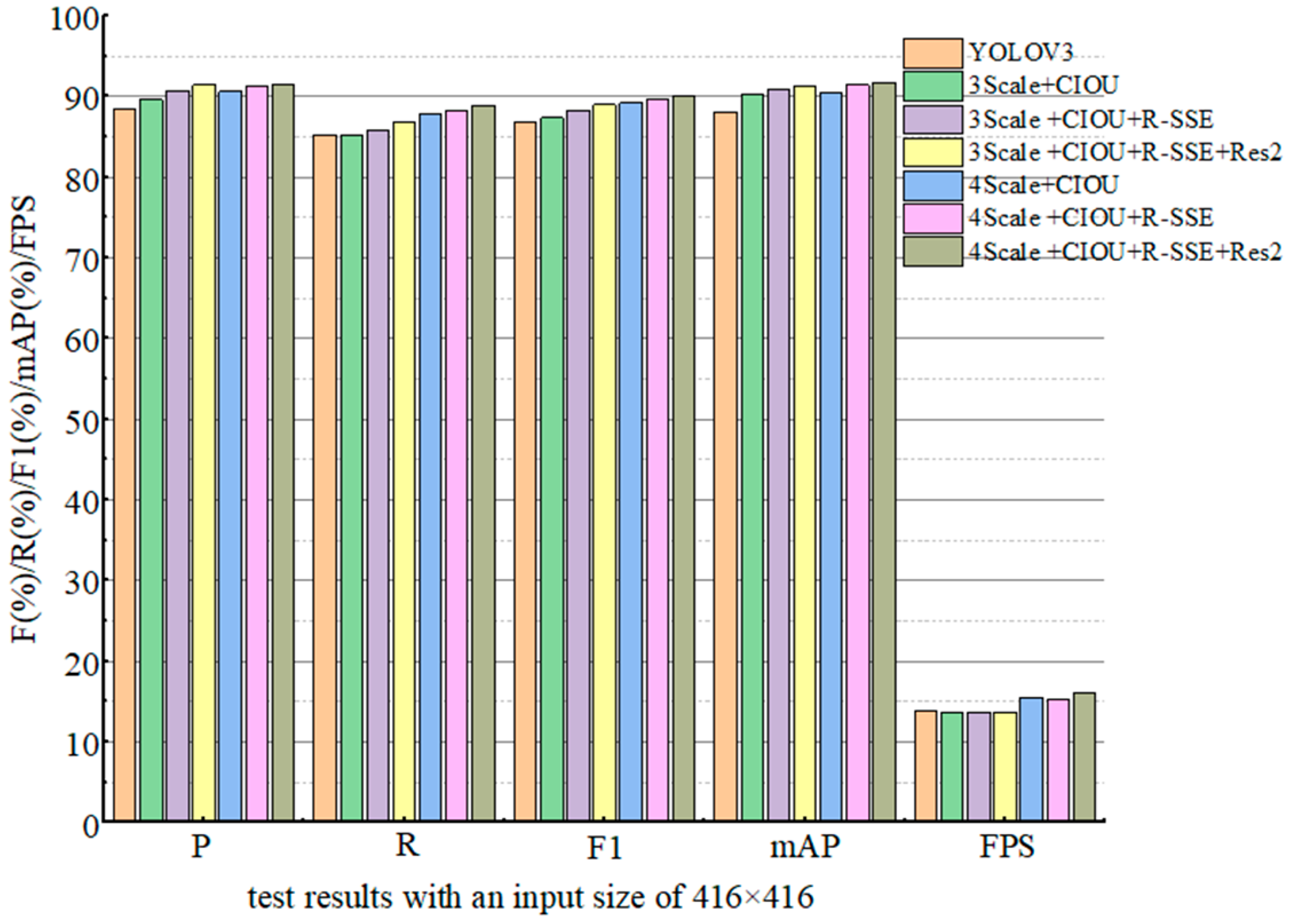
| Model | P (%) | R (%) | F1 (%) | mAP (%) | FPS |
|---|---|---|---|---|---|
| YOLOV3 | 88.4 | 85.2 | 86.8 | 88.1 | 13.8 |
| 3Scale + CIOU | 89.6 | 85.2 | 87.3 | 90.3 | 13.7 |
| 3Scale + CIOU + RSSE | 90.7 | 85.8 | 88.2 | 90.8 | 13.6 |
| 3Scale + CIOU + RSSE + Res2 | 91.4 | 86.7 | 88.9 | 91.2 | 13.6 |
| 4Scale + CIOU | 90.6 | 87.8 | 89.2 | 90.5 | 15.5 |
| 4Scale + CIOU + RSSE | 91.3 | 88.2 | 89.7 | 91.4 | 15.3 |
| 4Scale + CIOU + RSSE + Res2 | 91.5 | 88.8 | 90.1 | 91.7 | 16.1 |
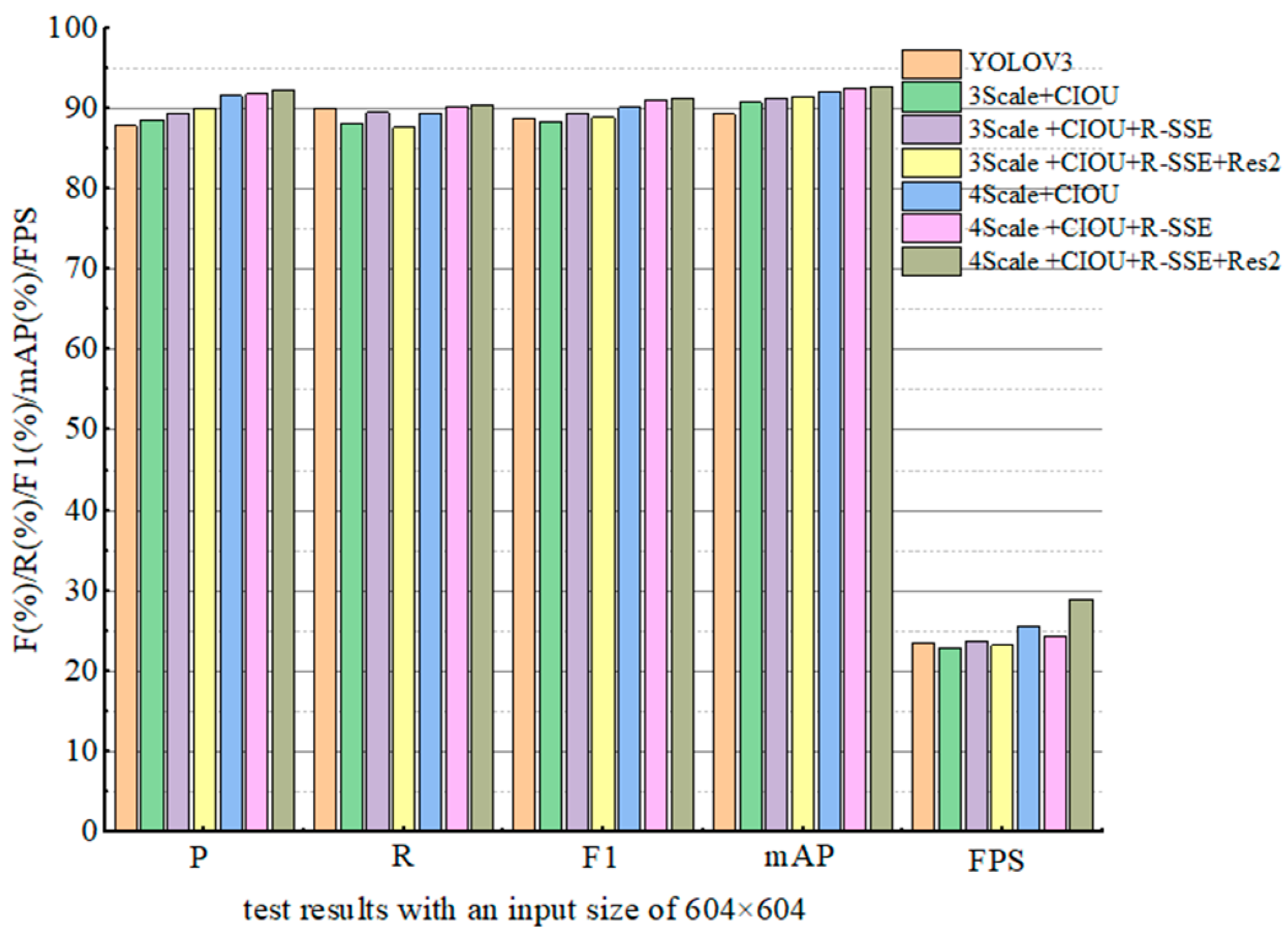
| Model | P (%) | R (%) | F1 (%) | mAP (%) | FPS |
|---|---|---|---|---|---|
| YOLOV3 | 87.8 | 89.9 | 88.8 | 89.3 | 23.5 |
| 3Scale + CIOU | 88.6 | 88.2 | 88.4 | 90.8 | 22.9 |
| 3Scale + CIOU + RSSE | 89.3 | 89.5 | 89.4 | 91.2 | 23.7 |
| 3Scale + CIOU + RSSE + Res2 | 90 | 87.6 | 88.9 | 91.5 | 23.2 |
| 4Scale + CIOU | 91.6 | 89.3 | 90.1 | 92.1 | 25.6 |
| 4Scale + CIOU+RSSE | 91.8 | 90.2 | 91 | 92.5 | 24.3 |
| 4Scale + CIOU + RSSE + Res2 | 92.3 | 90.4 | 91.3 | 92.8 | 28.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H. Multi-Scale Safety Helmet Detection Based on RSSE-YOLOv3. Sensors 2022, 22, 6061. https://doi.org/10.3390/s22166061
Song H. Multi-Scale Safety Helmet Detection Based on RSSE-YOLOv3. Sensors. 2022; 22(16):6061. https://doi.org/10.3390/s22166061
Chicago/Turabian StyleSong, Hongru. 2022. "Multi-Scale Safety Helmet Detection Based on RSSE-YOLOv3" Sensors 22, no. 16: 6061. https://doi.org/10.3390/s22166061
APA StyleSong, H. (2022). Multi-Scale Safety Helmet Detection Based on RSSE-YOLOv3. Sensors, 22(16), 6061. https://doi.org/10.3390/s22166061