
Permutation-Based Block Code for Short Packet Communication Systems

 ,
, 


Abstract
:1. Introduction
1.1. Related Literature
1.2. Main Contributions
- A statistical algorithm to generate codewords for a -code must be developed and implemented.
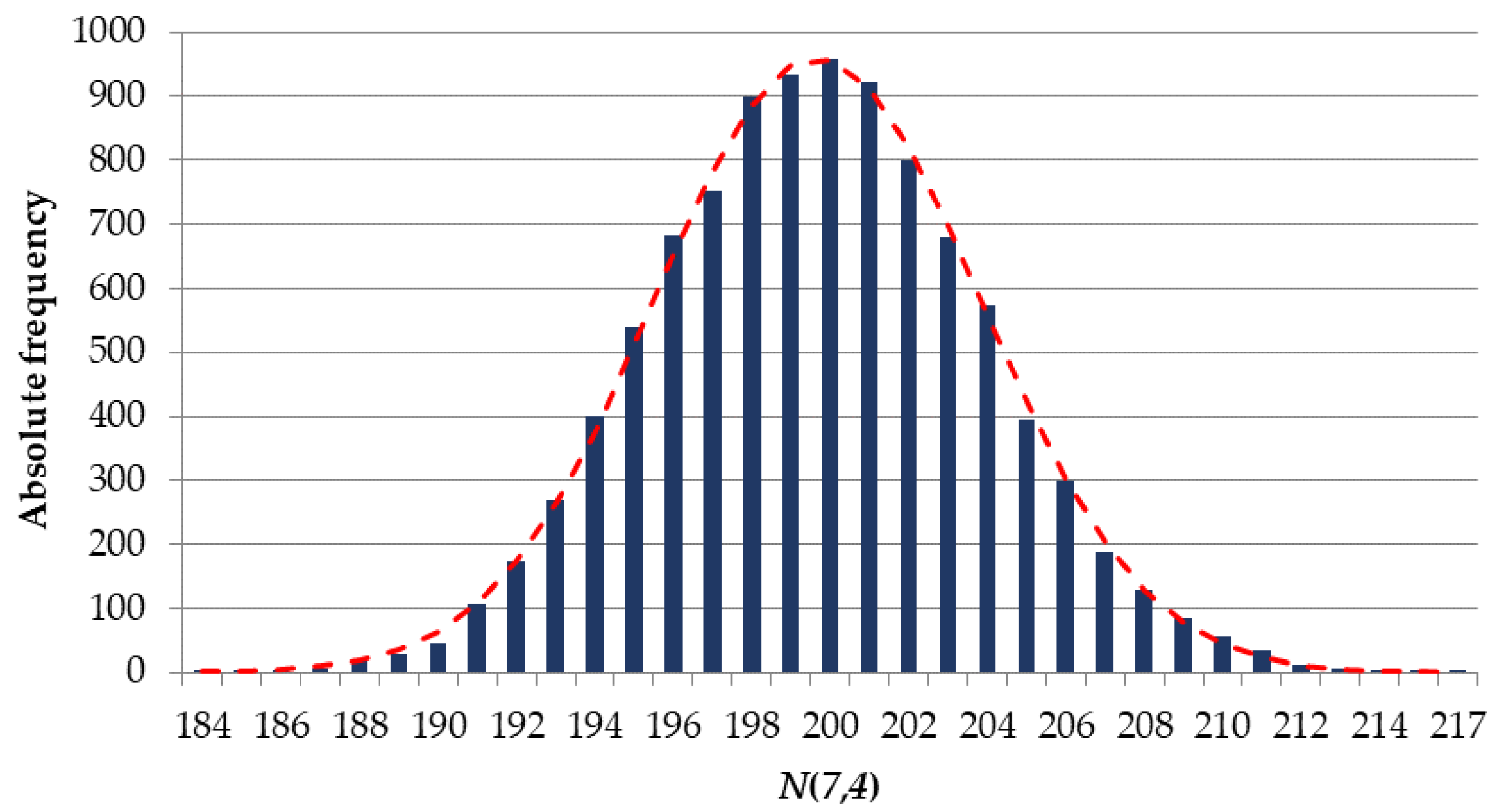
- An analysis of the distribution frequency of a random value for a given number of implementations of the codeword generating algorithm must be performed. The distribution law for must be determined.
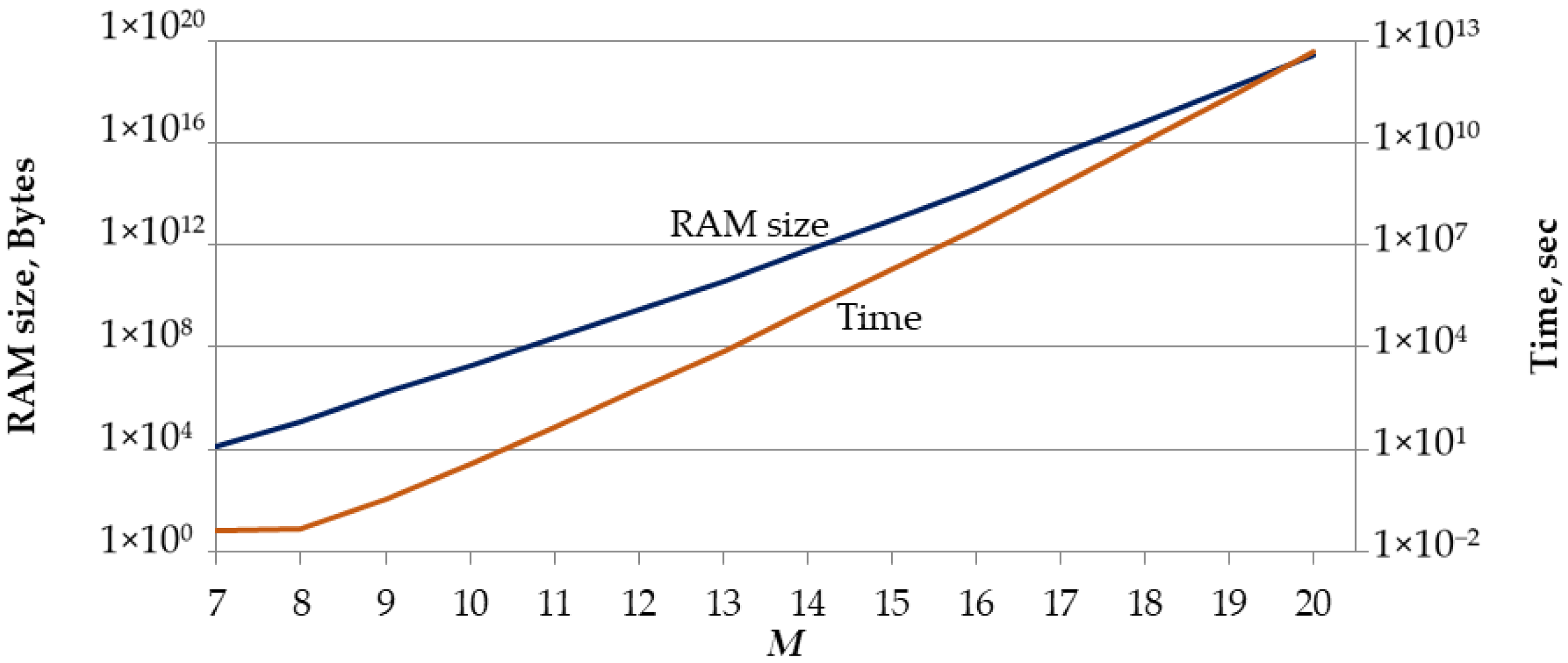
- The dependences of the average and the maximum -code size, its standard deviation from the parameters and must be explored.
- A technique to estimate a -code size depending on parameters and must be developed and applied.
1.3. Paper Structure
2. Materials and Methods
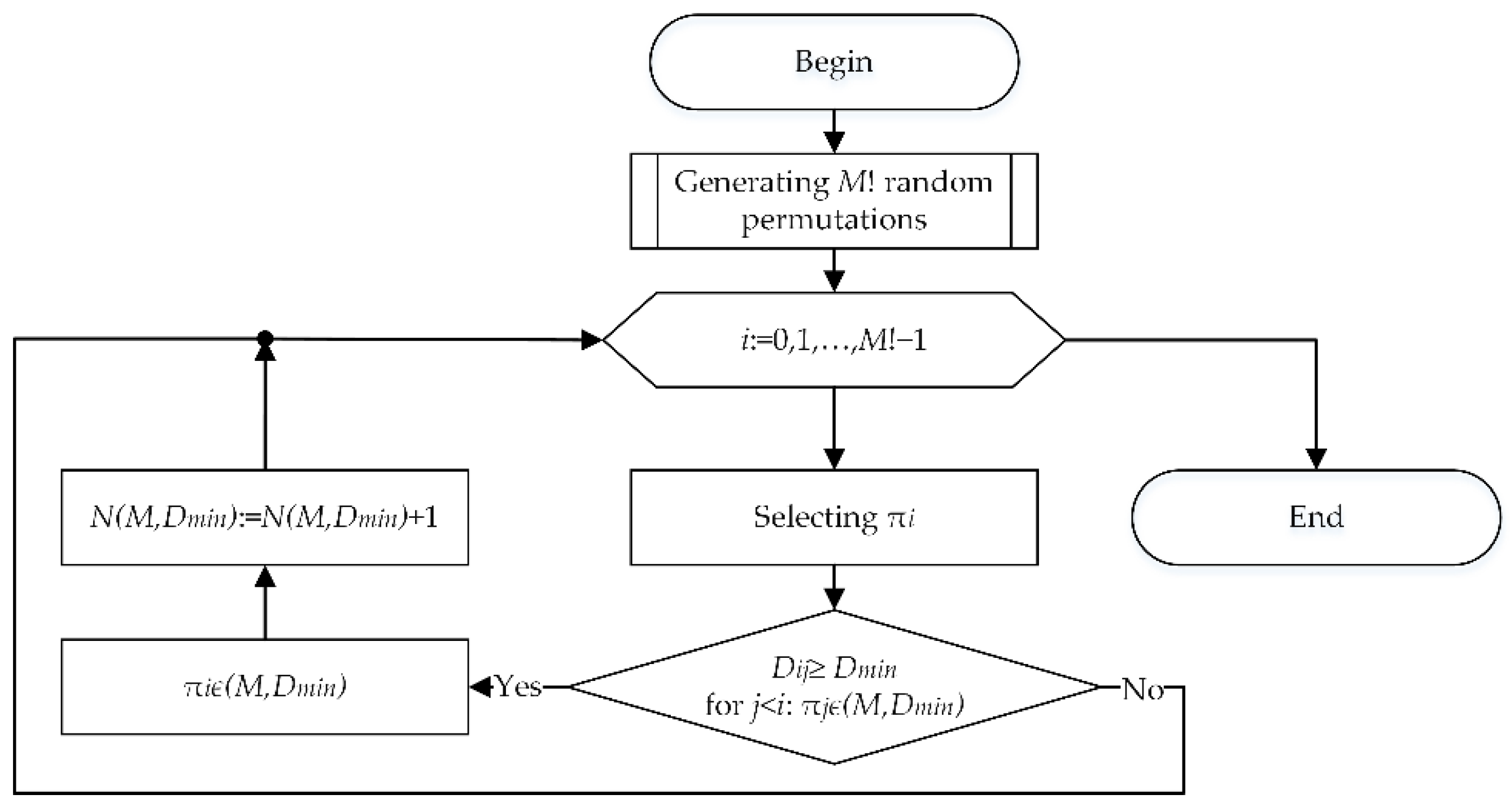
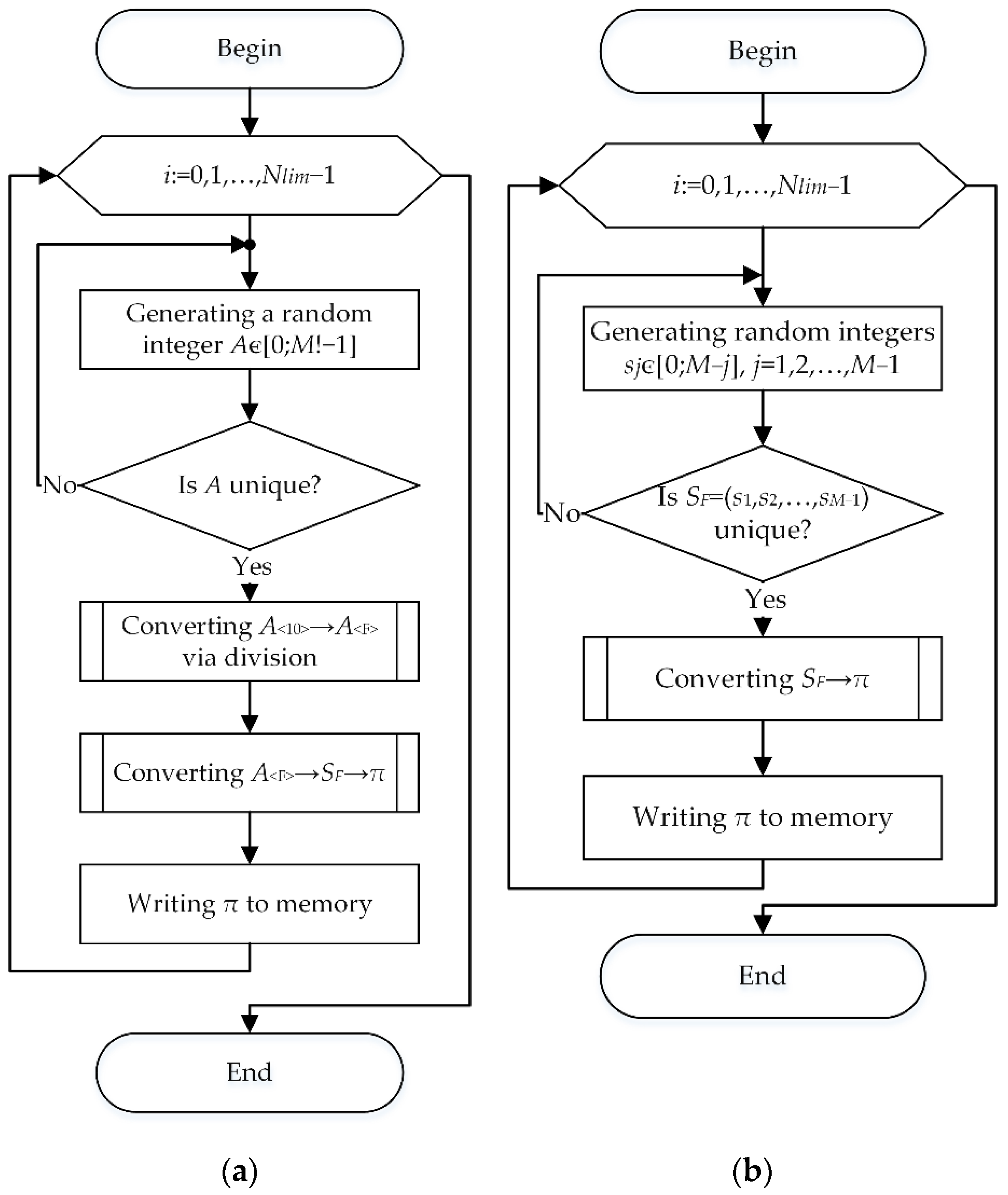
2.1. Algorithm to Generate Codewords
- OS—Windows 10
- CPU—Intel Core i5-10400F
- RAM 32Gb (2x16Gb dual channel 3200Mhz)
- GPU—GeForce GTX 1650 4Gb
- Hard Drive—SSD M.2 2280 1TB Samsung
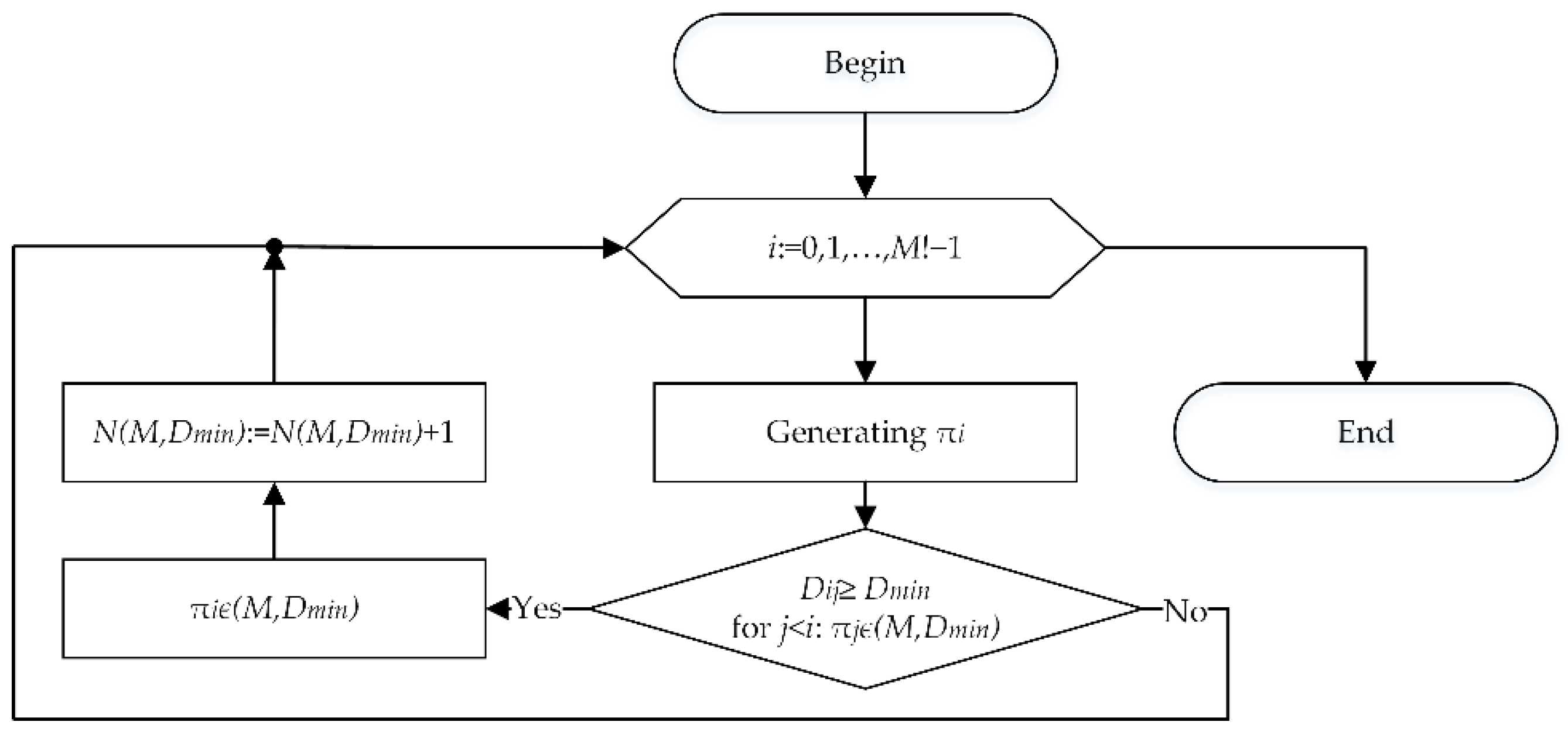
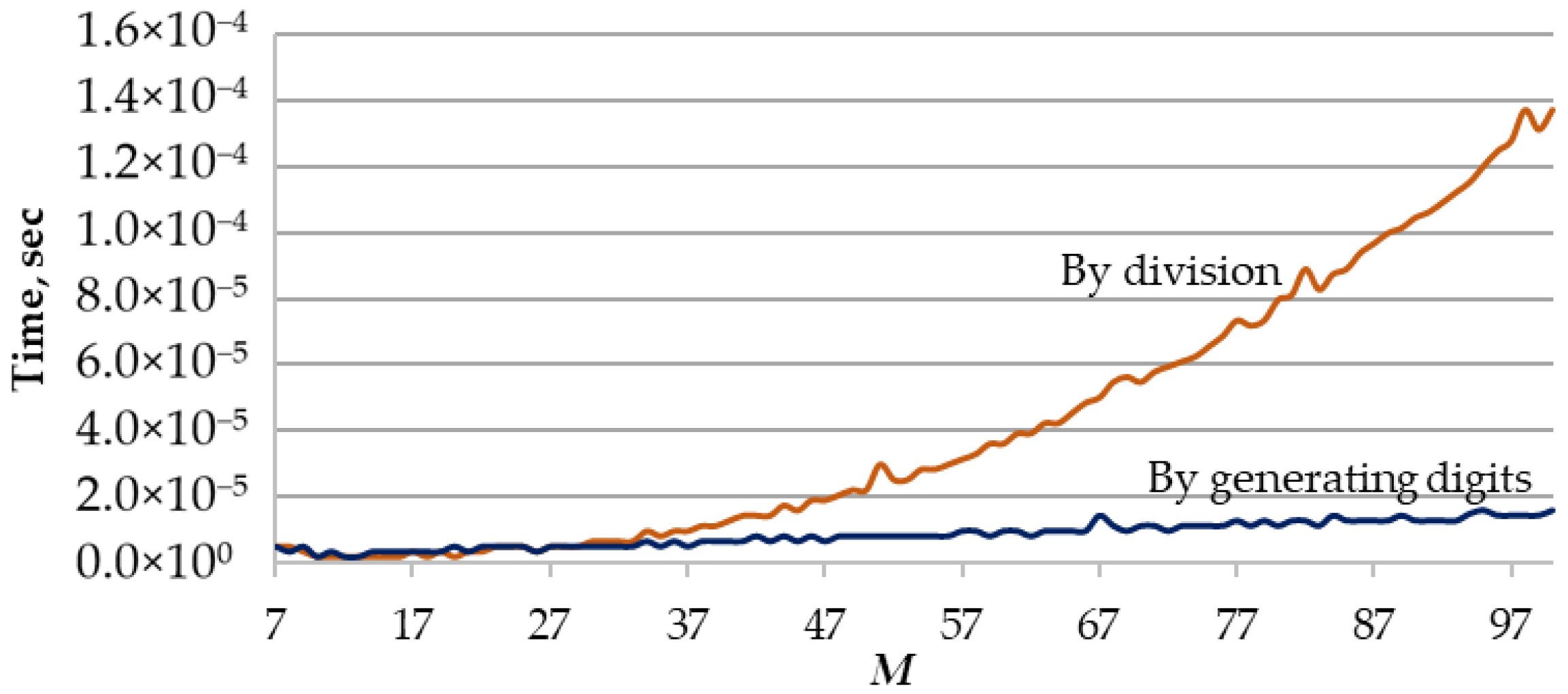
2.2. Algorithms to Generate the Initial Set of Random Permutations
- Randomly generating individual digits of a factorial number and converting the factorial number into a permutation.
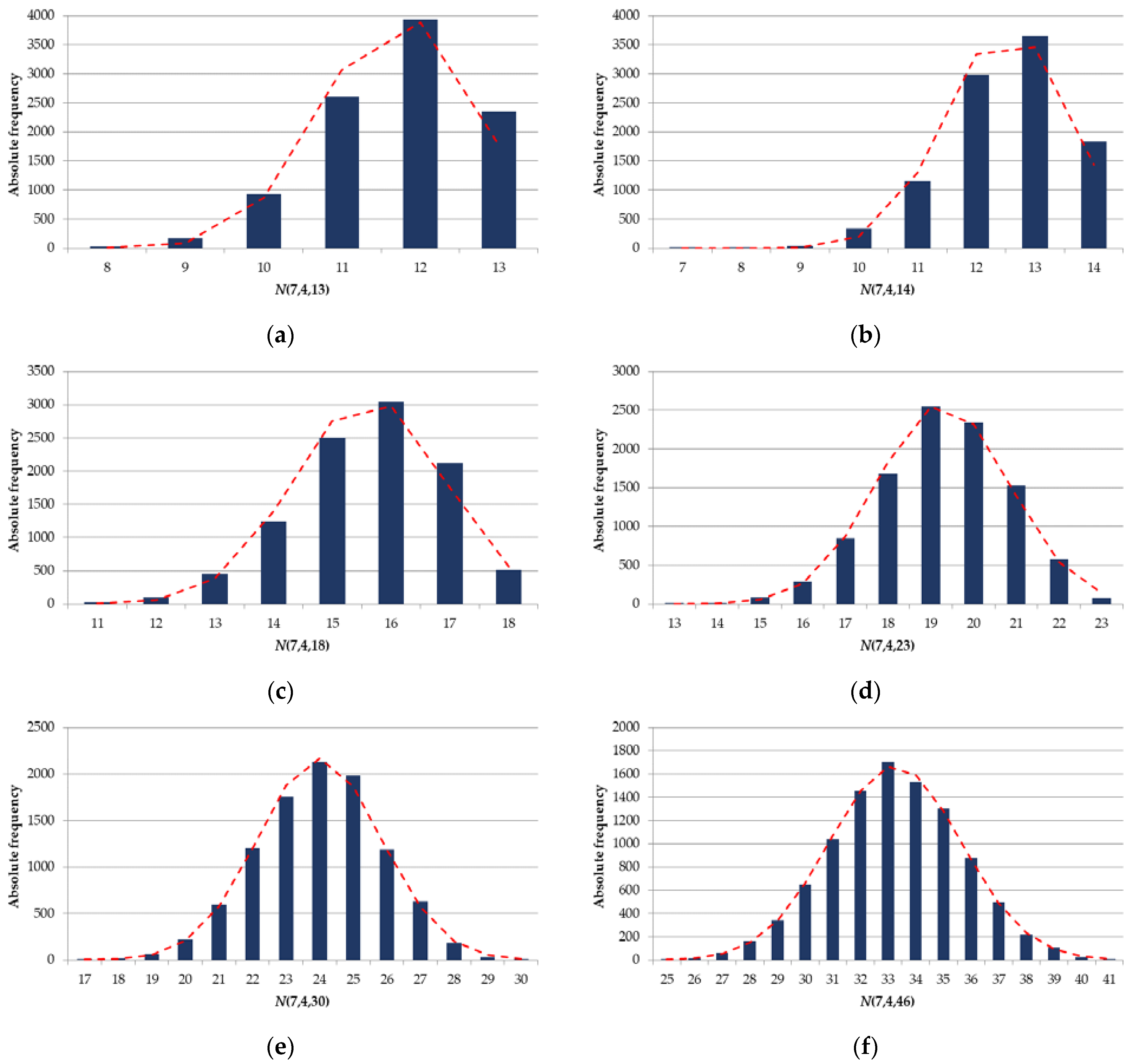
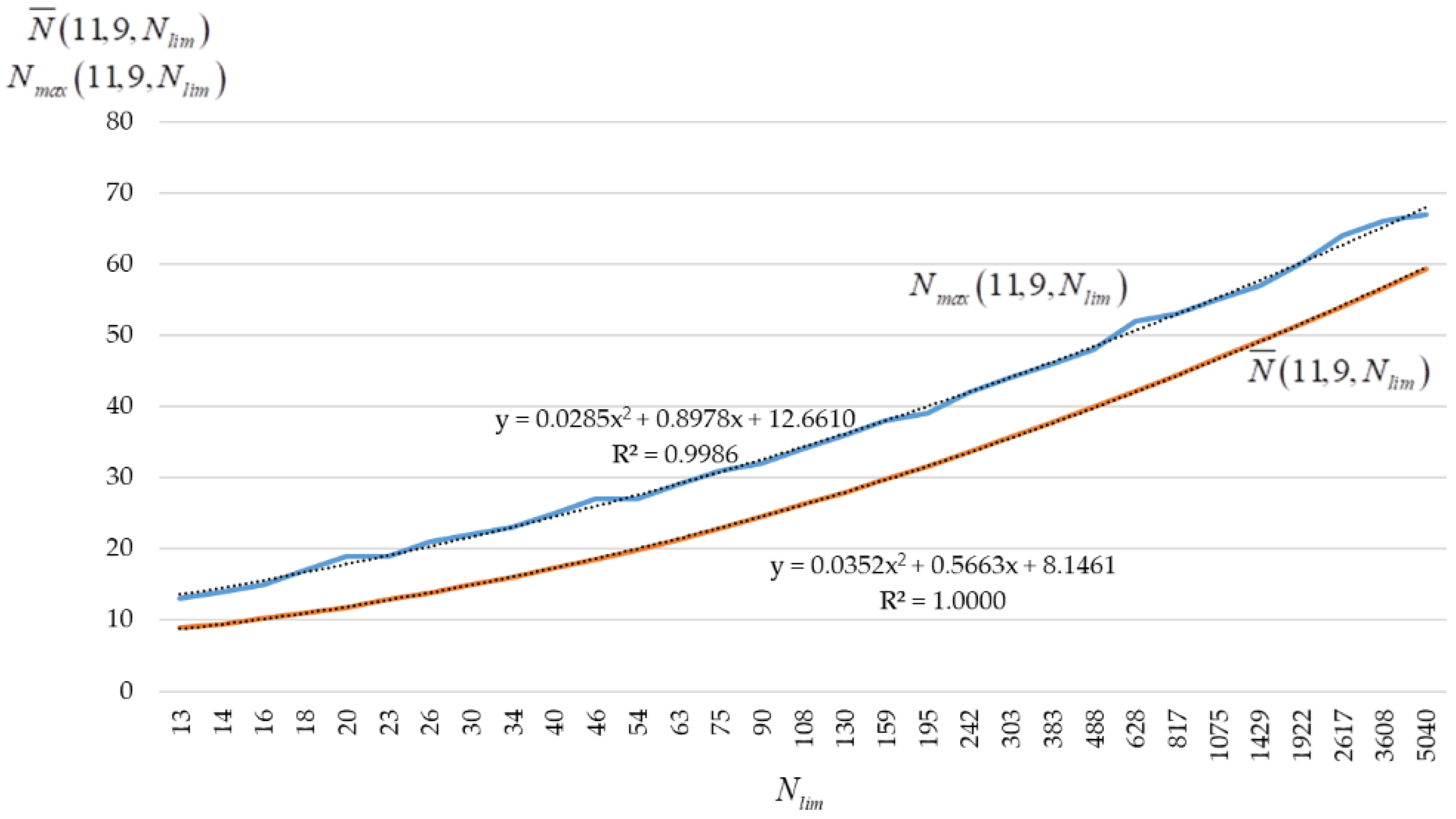
2.3. Dependence of the -Code Size on the Values of , , and
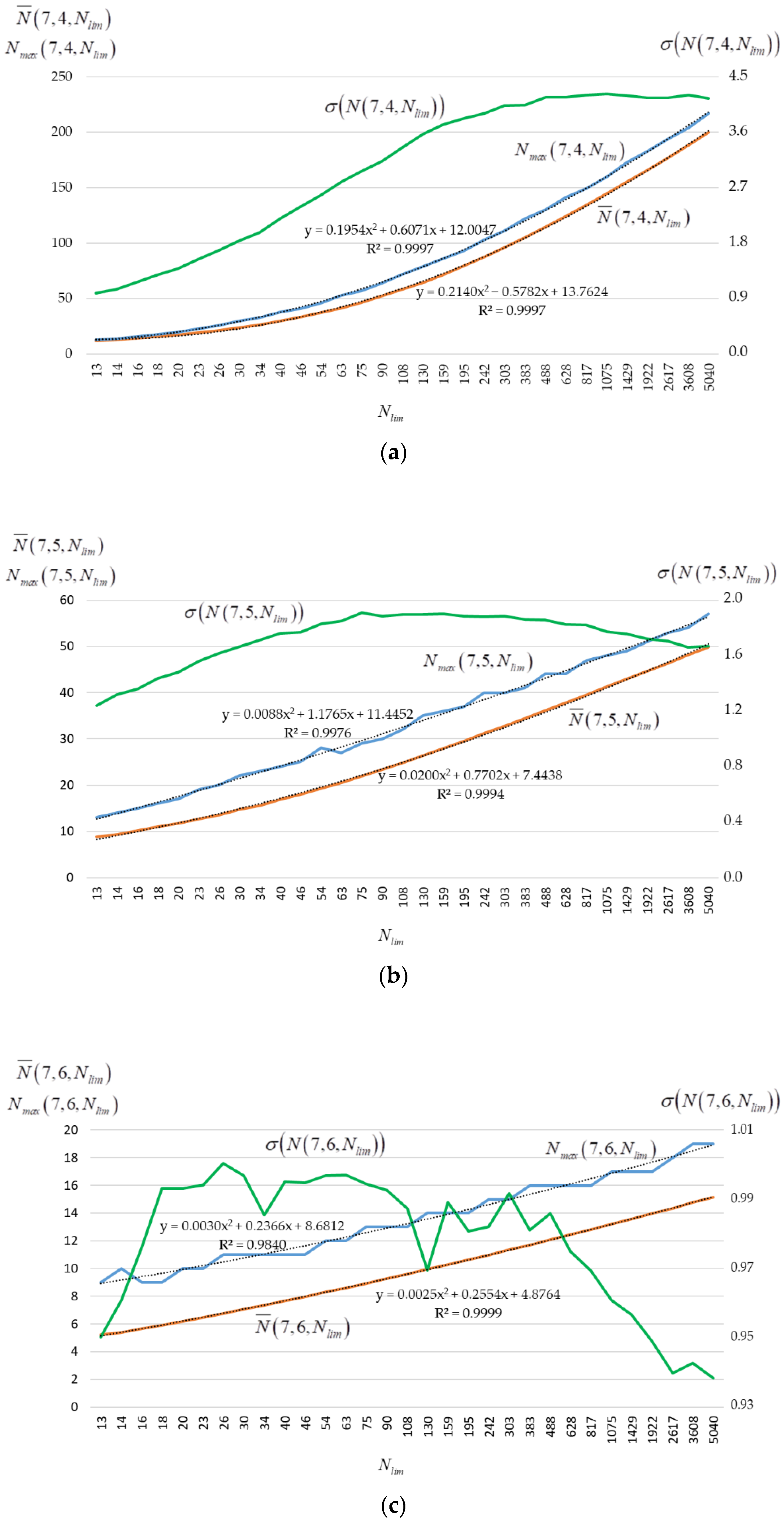
2.4. Technique for Constructing an Approximation Polynomial
- To calculate , to set and values, and to calculate ;
- To generate dependencies and for the range of values determined in accordance with (2);
- To determine approximation polynomials for and .
- Values of , , and are chosen. Values of are calculated using an expressionwhere . It’s obvious that ;
- Dependences and are also formed for the range of values determined in accordance with (3);
- Quadratic approximation polynomials are calculated for and .
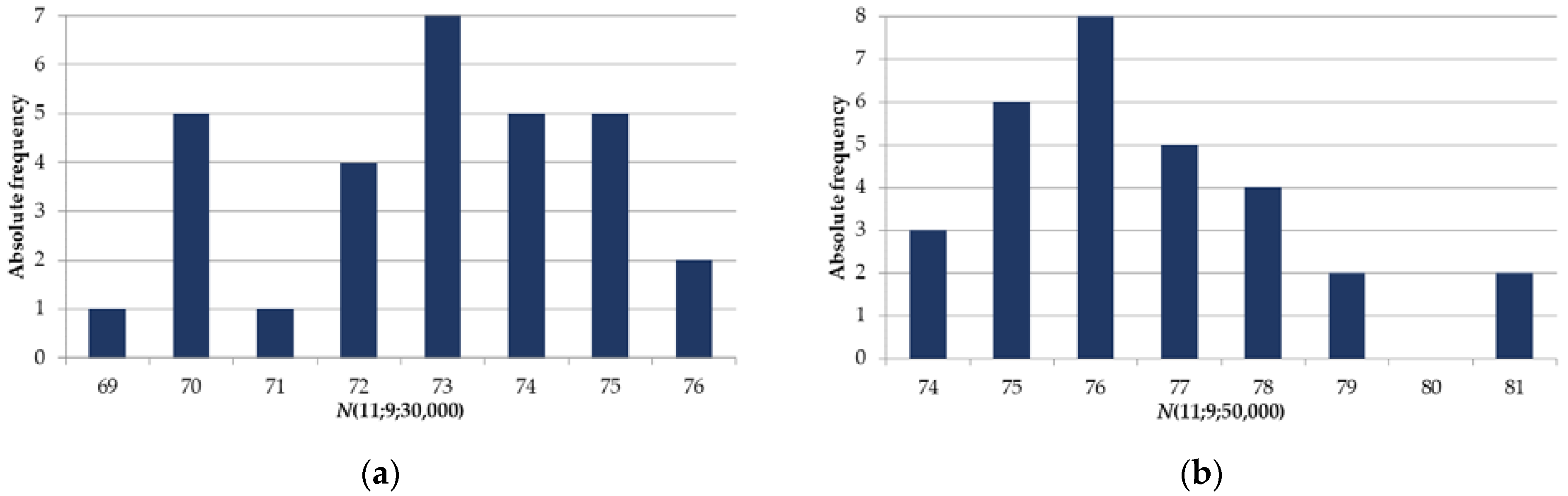
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Statista Research Department. Volume of Data/Information Created, Captured, Copied, and Consumed Worldwide from 2010 to 2025. Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed on 22 June 2022).
- Avizienis, A.; Laprie, J.-C.; Randell, B. Fundamental Concepts of Dependability; Department of Computing Science Technical Report Series; Department of Computing Science, University of Newcastle upon Tyne: Newcastle upon Tyne, UK, 2001; p. 21. [Google Scholar]
- Durisi, D.; Liva, G.; Polyanskiy, Y. Short-Packet Transmission. In Information Theoretic Perspectives on 5G Systems and Beyond; Marić, I., Shamai (Shitz), S., Simeone, O., Eds.; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Mahmood, N.H.; Böcker, S.; Moerman, I.; López, O.A.; Munari, A.; Mikhaylov, K.; Clazzer, F.; Bartz, H.; Park, O.-S.; Mercier, E.; et al. Machine Type Communications: Key Drivers and Enablers towards the 6G Era. J. Wirel. Com. Netw. 2021, 2021, 134. [Google Scholar] [CrossRef]
- Elhoseny, M.; Hassanien, A.E. Dynamic Wireless Sensor Networks: New Directions for Smart Technologies. In Studies in Systems, Decision and Control, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2019; ISBN 978-3-319-92807-4. [Google Scholar]
- McEliece, R.J. A Public-Key Criptosystem Based on Algebraic Theory; Jet Propulsi on Lab: Pasadena, CA, USA, 1978; pp. 114–116. [Google Scholar]
- Rao, T.R.N. Joint Encryption and Error Correction Schemes. In Proceedings of the 11th Annual International Symposium on Computer Architecture—ISCA ’84, Ann Arbor, MI, USA, 5–7 June 1984; ACM Press: New York, NY, USA, 1984; pp. 240–241. [Google Scholar]
- Niederreiter, H. Knapsack-Type Cryptosystems and Algebraic Coding Theory. Prob. Control Inf. Theory 1986, 15, 159–166. [Google Scholar]
- Rao, T.R.N.; Nam, K.-H. Private-Key Algebraic-Coded Cryptosystems. In Advances in Cryptology—CRYPTO’ 86; Odlyzko, A.M., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1987; Volume 263, pp. 35–48. ISBN 978-3-540-18047-0. [Google Scholar]
- Kløve, T.; Korzhik, V.I. Error Detecting Codes: General Theory and Their Application in Feedback Communication Systems; Kluwer Academic Publishers: Boston, MA, USA, 1995; ISBN 978-0-7923-9629-1. [Google Scholar]
- Kløve, T. Codes for Error Detection; Series on Coding Theory and Cryptology; World Scientific: Singapore, 2007; Volume 2, ISBN 978-981-270-586-0. [Google Scholar]
- Stakhov, A.P. The “Golden” Matrices and a New Kind of Cryptography. Chaos Solitons Fractals 2007, 32, 1138–1146. [Google Scholar] [CrossRef]
- Stakhov, A.P. The Golden Section, Fibonacci Numbers, Mathematics of Harmony and “Golden” Scientific Revolution. Comput. Sci. Cybersecur. 2016, 2016, 31–68. [Google Scholar]
- Mazurkov, M.I.; Chechel’nitskii, V.Y.; Murr, P. Information Security Method Based on Perfect Binary Arrays. Radioelectron. Commun. Syst. 2008, 51, 612–614. [Google Scholar] [CrossRef]
- Mazurkov, M.I.; Chechelnytskyi, V.Y.; Nekrasov, K.K. Three-Level Cryptographic System for Block Data Encryption. Radioelectron. Commun. Syst. 2010, 53, 376–379. [Google Scholar] [CrossRef]
- Borisenko, A.A.; Kalashnikov, V.V.; Kulik, I.A.; Goryachev, A.E. Generation of Permutations Based Upon Factorial Numbers. In Proceedings of the Eighth International Conference on Intelligent Systems Design and Applications, Kaohiung, Taiwan, 26 November 2008; IEEE Computer Society: Washington, DC, USA, 2008; pp. 57–61. [Google Scholar]
- Borysenko, A.A.; Horiachev, O.Y.; Matsenko, S.M.; Kobiakov, O.M. Noise-Immune Codes Based on Permutations. In Proceedings of the 2018 IEEE 9th International Conference on Dependable Systems, Services and Technologies (DESSERT), Kiev, Ukraine, 24–27 May 2018; IEEE: Washington, DC, USA, 2018; pp. 609–612. [Google Scholar]
- Al-Azzeh, J.S.; Ayyoub, B.; Faure, E.; Shvydkyi, V.; Kharin, O.; Lavdanskyi, A. Telecommunication Systems with Multiple Access Based on Data Factorial Coding. Int. J. Commun. Antenna Propag. 2020, 10, 102–113. [Google Scholar] [CrossRef]
- Faure, E.; Shcherba, A.; Vasiliu, Y.; Fesenko, A. Cryptographic Key Exchange Method for Data Factorial Coding. CEUR Workshop Proc. 2020, 2654, 643–653. [Google Scholar]
- Durisi, G.; Koch, T.; Popovski, P. Toward Massive, Ultrareliable, and Low-Latency Wireless Communication With Short Packets. Proc. IEEE 2016, 104, 1711–1726. [Google Scholar] [CrossRef] [Green Version]
- Lee, B.; Park, S.; Love, D.J.; Ji, H.; Shim, B. Packet Structure and Receiver Design for Low Latency Wireless Communications With Ultra-Short Packets. IEEE Trans. Commun. 2018, 66, 796–807. [Google Scholar] [CrossRef]
- Bana, A.-S.; Trillingsgaard, K.F.; Popovski, P.; de Carvalho, E. Short Packet Structure for Ultra-Reliable Machine-Type Communication: Tradeoff between Detection and Decoding. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Washington, DC, USA, 2018; pp. 6608–6612. [Google Scholar]
- Salamat Ullah, S.; Liew, S.C.; Liva, G.; Wang, T. Short-Packet Physical-Layer Network Coding. IEEE Trans. Commun. 2020, 68, 737–751. [Google Scholar] [CrossRef]
- Salamat Ullah, S.; Liew, S.C.; Liva, G.; Wang, T. Implementation of Short-Packet Physical-Layer Network Coding. IEEE Trans. Mob. Comput. 2021, 20, 1. [Google Scholar] [CrossRef]
- Wu, J.; Kim, W.; Shim, B. Pilot-Less One-Shot Sparse Coding for Short Packet-Based Machine-Type Communications. IEEE Trans. Veh. Technol. 2020, 69, 9117–9120. [Google Scholar] [CrossRef]
- Feng, C.; Wang, H. Secure Short-Packet Communications at the Physical Layer for 5G and Beyond. arXiv 2021, arXiv:2107.05966. [Google Scholar] [CrossRef]
- Feng, C.; Wang, H.-M.; Poor, H.V. Reliable and Secure Short-Packet Communications. IEEE Trans. Wirel. Commun. 2022, 21, 1913–1926. [Google Scholar] [CrossRef]
- Nguyen, A.T.P.; Le Bidan, R.; Guilloud, F. Superimposed Frame Synchronization Optimization for Finite Blocklength Regime. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference Workshop (WCNCW), Marrakech, Morocco, 15–19 April 2019; IEEE: Washington, DC, USA, 2019; pp. 1–6. [Google Scholar]
- Nguyen, A.T.P.; Le Bidan, R.; Guilloud, F. Trade-Off Between Frame Synchronization and Channel Decoding for Short Packets. IEEE Commun. Lett. 2019, 23, 979–982. [Google Scholar] [CrossRef]
- Nguyen, A.T.P.; Guilloud, F.; Le Bidan, R. On the Optimization of Resources for Short Frame Synchronization. Ann. Telecommun. 2020, 75, 635–640. [Google Scholar] [CrossRef]
- Faure, E.; Shcherba, A.; Stupka, B. Permutation-Based Frame Synchronisation Method for Short Packet Communication Systems. In Proceedings of the 2021 11th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Cracow, Poland, 22 September 2021; IEEE: Washington, DC, USA, 2021; pp. 1073–1077. [Google Scholar]
- Al-Azzeh, J.; Faure, E.; Shcherba, A.; Stupka, B. Permutation-Based Frame Synchronization Method for Data Transmission Systems with Short Packets. Egypt. Inform. J. 2022, in press. [Google Scholar] [CrossRef]
- Faure, E.V. Factorial coding with data recovery. Visnyk Cherkaskogo Derzhavnogo Tehnol. Univ. 2016, 2, 33–39. [Google Scholar]
- Faure, E.V. Factorial Coding with Error Correction. Radio Electron. Comput. Sci. Control. 2017, 3, 130–138. [Google Scholar] [CrossRef] [Green Version]
- Reed, I.S.; Solomon, G. Polynomial Codes Over Certain Finite Fields. J. Soc. Ind. Appl. Math. 1960, 8, 300–304. [Google Scholar] [CrossRef]
- Shcherba, A.; Faure, E.; Lavdanska, O. Three-Pass Cryptographic Protocol Based on Permutations. In Proceedings of the 2020 IEEE 2nd International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 25 November 2020; IEEE: Washington, DC, USA, 2020; pp. 281–284. [Google Scholar]
- Conway, J.H.; Sloane, N.J.A. Sphere Packings, Lattices, and Groups, 3rd ed.; Springer: New York, NY, USA, 1999; ISBN 978-1-4757-6568-7. [Google Scholar]
- MacWilliams, F.J.; Sloane, N.J.A. The Theory of Error Correcting Codes; North Holland Mathematical Library; North Holland Publishing Co.: Amsterdam, The Netherlands, 1977; ISBN 978-0-444-85193-2. [Google Scholar]
- Smith, D.H.; Montemanni, R. A New Table of Permutation Codes. Des. Codes Cryptogr. 2012, 63, 241–253. [Google Scholar] [CrossRef]
- Vinck, A.J.H. Coded Modulation for Power Line Communications. arXiv 2011, arXiv:1104.1528. [Google Scholar] [CrossRef]
- Frankl, P.; Deza, M. On the Maximum Number of Permutations with given Maximal or Minimal Distance. J. Comb. Theory Ser. A 1977, 22, 352–360. [Google Scholar] [CrossRef] [Green Version]
- Dixon, J.D.; Mortimer, B. Permutation Groups; Springer: New York, NY, USA, 1996; ISBN 978-1-4612-0731-3. [Google Scholar]
- Chu, W.; Colbourn, C.J.; Dukes, P. Constructions for Permutation Codes in Powerline Communications. Des. Codes Cryptogr. 2004, 32, 51–64. [Google Scholar] [CrossRef]
- Janiszczak, I.; Lempken, W.; Östergård, P.R.J.; Staszewski, R. Permutation Codes Invariant under Isometries. Des. Codes Cryptogr. 2015, 75, 497–507. [Google Scholar] [CrossRef]
- Bereg, S.; Mojica, L.G.; Morales, L.; Sudborough, H. Kronecker Product and Tiling of Permutation Arrays for Hamming Distances. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; IEEE: Washington, DC, USA; pp. 2198–2202. [Google Scholar]
- Bereg, S.; Mojica, L.G.; Morales, L.; Sudborough, H. Constructing Permutation Arrays Using Partition and Extension. Des. Codes Cryptogr. 2020, 88, 311–339. [Google Scholar] [CrossRef] [Green Version]
- Bereg, S.; Malouf, B.; Morales, L.; Stanley, T.; Sudborough, I.H. Using Permutation Rational Functions to Obtain Permutation Arrays with Large Hamming Distance. Des. Codes Cryptogr. 2022, 90, 1659–1677. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference: Part I. Biometrika 1928, 20A, 175. [Google Scholar] [CrossRef]
- Python 3.10.5 Documentation. Available online: https://docs.python.org/3/ (accessed on 2 June 2022).
- Other Versions—PyCharm Edu. Available online: https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows&code=PCC (accessed on 2 June 2022).
- Borysenko, O.; Kulyk, I.; Horiachev, O. Electronic system for generating permutations based on factorial numbers. Her. Sumy State Univ. 2007, 1, 183–188. [Google Scholar]
- Faure, E.; Shvydkyi, V.; Shcherba, A. Method for Generating Reproducible and Unpredictable Sequence of Permutations. Bezpeka ìnf. 2014, 20, 253–258. [Google Scholar] [CrossRef]
- Celant, G.; Broniatowski, M. Interpolation and Extrapolation Optimal Designs 1: Polynomial Regression and Approximation Theory; Mathematics and Statistics; John Wiley: London, UK; Hoboken, NJ, USA, 2016; ISBN 978-1-84821-995-3. [Google Scholar]
- Meeker, W.Q.; Hahn, G.J.; Escobar, L.A. Statistical Intervals: A Guide for Practitioners and Researchers, 2nd ed.; Wiley series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2017; ISBN 978-0-471-68717-7. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 4 | 5 | 6 | |
|---|---|---|---|
| 199.6787 | 49.8305 | 15.1698 | |
| 4.1532 | 1.6693 | 0.9384 | |
| 217 | 57 | 19 |
| 0 | 5040 | 6 | 817 | 12 | 195 | 18 | 63 | 24 | 26 | 30 | 13 |
| 1 | 3608 | 7 | 628 | 13 | 159 | 19 | 54 | 25 | 23 | ||
| 2 | 2617 | 8 | 488 | 14 | 130 | 20 | 46 | 26 | 20 | ||
| 3 | 1922 | 9 | 383 | 15 | 108 | 21 | 40 | 27 | 18 | ||
| 4 | 1429 | 10 | 303 | 16 | 90 | 22 | 34 | 28 | 16 | ||
| 5 | 1075 | 11 | 242 | 17 | 75 | 23 | 30 | 29 | 74 |
| 4 | 5 | 6 | |
|---|---|---|---|
| 13 | 0.000000 | 0.193433 | 0.000002 |
| 14 | 0.000000 | 0.367169 | 0.000000 |
| 16 | 0.000000 | 0.380055 | 0.000090 |
| 18 | 0.000000 | 0.589350 | 0.000028 |
| 20 | 0.000000 | 0.288059 | 0.000000 |
| 23 | 0.000000 | 0.755697 | 0.000000 |
| 26 | 0.000000 | 0.000328 | 0.337444 |
| 30 | 0.000012 | 0.000049 | 0.000011 |
| 34 | 0.299914 | 0.000002 | 0.013646 |
| 40 | 0.035342 | 0.002416 | 0.000689 |
| 46 | 0.421327 | 0.008021 | 0.000055 |
| 54 | 0.622645 | 0.000000 | 0.000001 |
| 63 | 0.755772 | 0.000324 | 0.000297 |
| 75 | 0.832253 | 0.000087 | 0.000013 |
| 90 | 0.104076 | 0.713204 | 0.018065 |
| 108 | 0.653265 | 0.647142 | 0.001913 |
| 130 | 0.978050 | 0.010121 | 0.000001 |
| 159 | 0.076289 | 0.000081 | 0.000449 |
| 195 | 0.061514 | 0.003801 | 0.000813 |
| 242 | 0.427242 | 0.066269 | 0.026604 |
| 303 | 0.489814 | 0.410349 | 0.025393 |
| 383 | 0.044070 | 0.053179 | 0.020188 |
| 488 | 0.527648 | 0.076959 | 0.031807 |
| 628 | 0.000791 | 0.594741 | 0.336770 |
| 817 | 0.242391 | 0.926065 | 0.037511 |
| 1075 | 0.949684 | 0.470563 | 0.932577 |
| 1429 | 0.019384 | 0.038698 | 0.093501 |
| 1922 | 0.912574 | 0.428931 | 0.177253 |
| 2617 | 0.085210 | 0.085414 | 0.000893 |
| 3608 | 0.545212 | 0.143008 | 0.000000 |
| 5040 | 0.276788 | 0.631289 | 0.000000 |
| 4 | 0.2140 | −0.5782 | 13.7624 | 0.1954 | 0.6071 | 12.0047 |
| 5 | 0.0200 | 0.7702 | 7.4438 | 0.0088 | 1.1765 | 11.4452 |
| 6 | 0.0025 | 0.2554 | 4.8764 | 0.0030 | 0.2366 | 8.6812 |
| Expected | Expected | ||||
|---|---|---|---|---|---|
| 0.04 | 30 | 73.3836 | 77.1631 | 81.2250 | 84.8191 |
| 0.08 | 15 | 73.3922 | 77.1775 | 80.8342 | 84.3992 |
| 0.12 | 10 | 73.3180 | 77.0940 | 80.1974 | 83.6976 |
| 0.16 | 7 | 73.2486 | 77.0101 | 79.6796 | 83.1427 |
| 0.20 | 6 | 73.2849 | 77.0551 | 79.4527 | 82.8157 |
| 0.24 | 5 | 73.2955 | 77.0786 | 79.9968 | 83.4801 |
| 0.28 | 4 | 73.1316 | 76.8810 | 79.6330 | 82.9191 |
| 0.32 | 3 | 72.9731 | 76.6821 | 80.5106 | 84.1495 |
| 0.36 | 3 | 73.1561 | 76.9123 | 80.0525 | 83.5624 |
| 0.4 | 3 | 73.1844 | 76.9536 | 79.0658 | 82.3375 |
| 0.44 | 2 | 72.9079 | 76.6054 | 79.6497 | 83.0483 |
| Expected | |||
|---|---|---|---|
| 0.04 | 30 | 0.00 | 0.00 |
| 0.08 | 15 | 0.01 | 0.02 |
| 0.12 | 10 | 0.09 | 0.09 |
| 0.16 | 7 | 0.18 | 0.20 |
| 0.20 | 6 | 0.13 | 0.14 |
| 0.24 | 5 | 0.12 | 0.11 |
| 0.28 | 4 | 0.34 | 0.37 |
| 0.32 | 3 | 0.56 | 0.62 |
| 0.36 | 3 | 0.31 | 0.33 |
| 0.4 | 3 | 0.27 | 0.27 |
| 0.44 | 2 | 0.65 | 0.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faure, E.; Shcherba, A.; Makhynko, M.; Stupka, B.; Nikodem, J.; Shevchuk, R. Permutation-Based Block Code for Short Packet Communication Systems. Sensors 2022, 22, 5391. https://doi.org/10.3390/s22145391
Faure E, Shcherba A, Makhynko M, Stupka B, Nikodem J, Shevchuk R. Permutation-Based Block Code for Short Packet Communication Systems. Sensors. 2022; 22(14):5391. https://doi.org/10.3390/s22145391
Chicago/Turabian StyleFaure, Emil, Anatoly Shcherba, Mykola Makhynko, Bohdan Stupka, Joanna Nikodem, and Ruslan Shevchuk. 2022. "Permutation-Based Block Code for Short Packet Communication Systems" Sensors 22, no. 14: 5391. https://doi.org/10.3390/s22145391
APA StyleFaure, E., Shcherba, A., Makhynko, M., Stupka, B., Nikodem, J., & Shevchuk, R. (2022). Permutation-Based Block Code for Short Packet Communication Systems. Sensors, 22(14), 5391. https://doi.org/10.3390/s22145391