
Two-Step Joint Optimization with Auxiliary Loss Function for Noise-Robust Speech Recognition



Abstract
:
1. Introduction
2. Review of Speech Enhancement and ASR Models
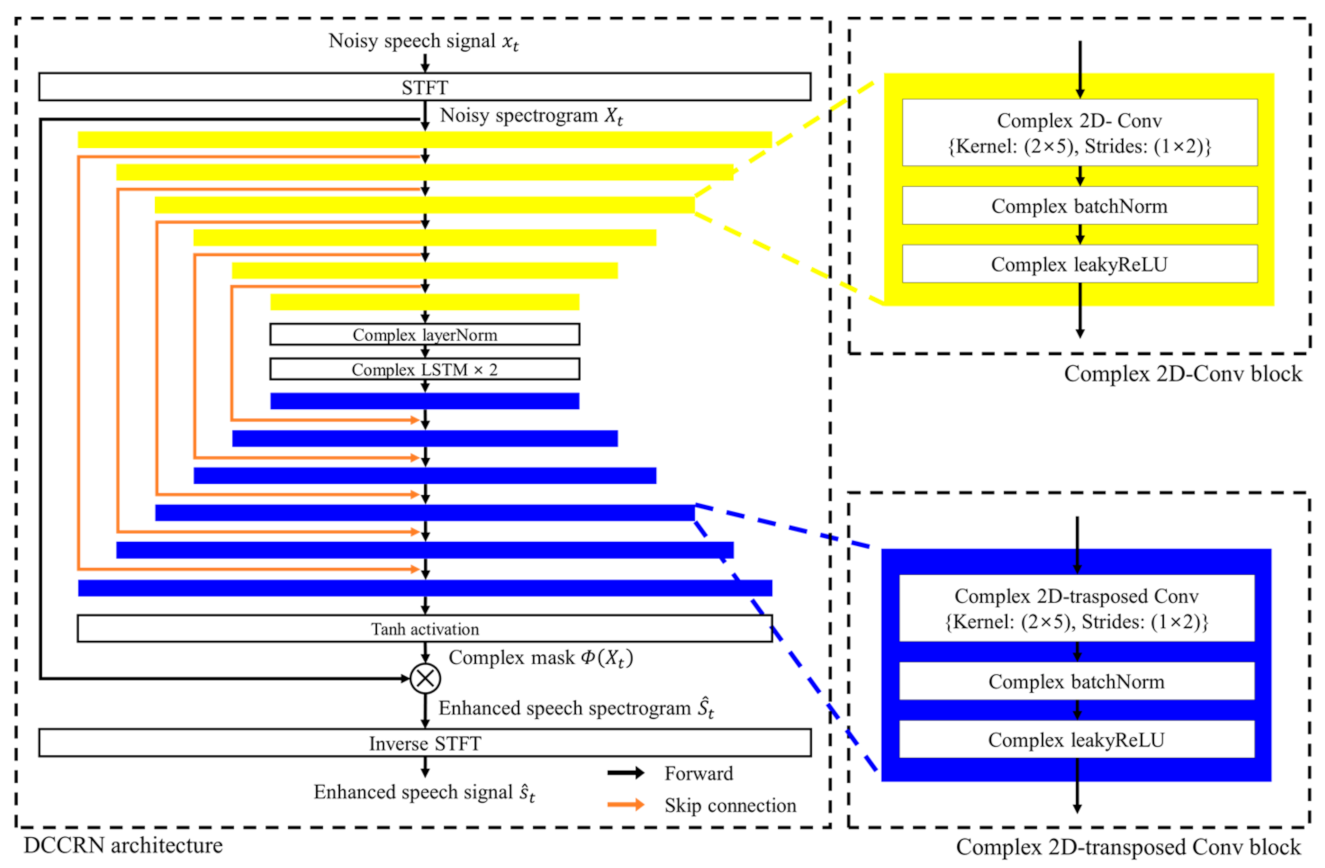
2.1. Deep Complex Convolutional Recurrent Network-Based Speech Enhancement Model
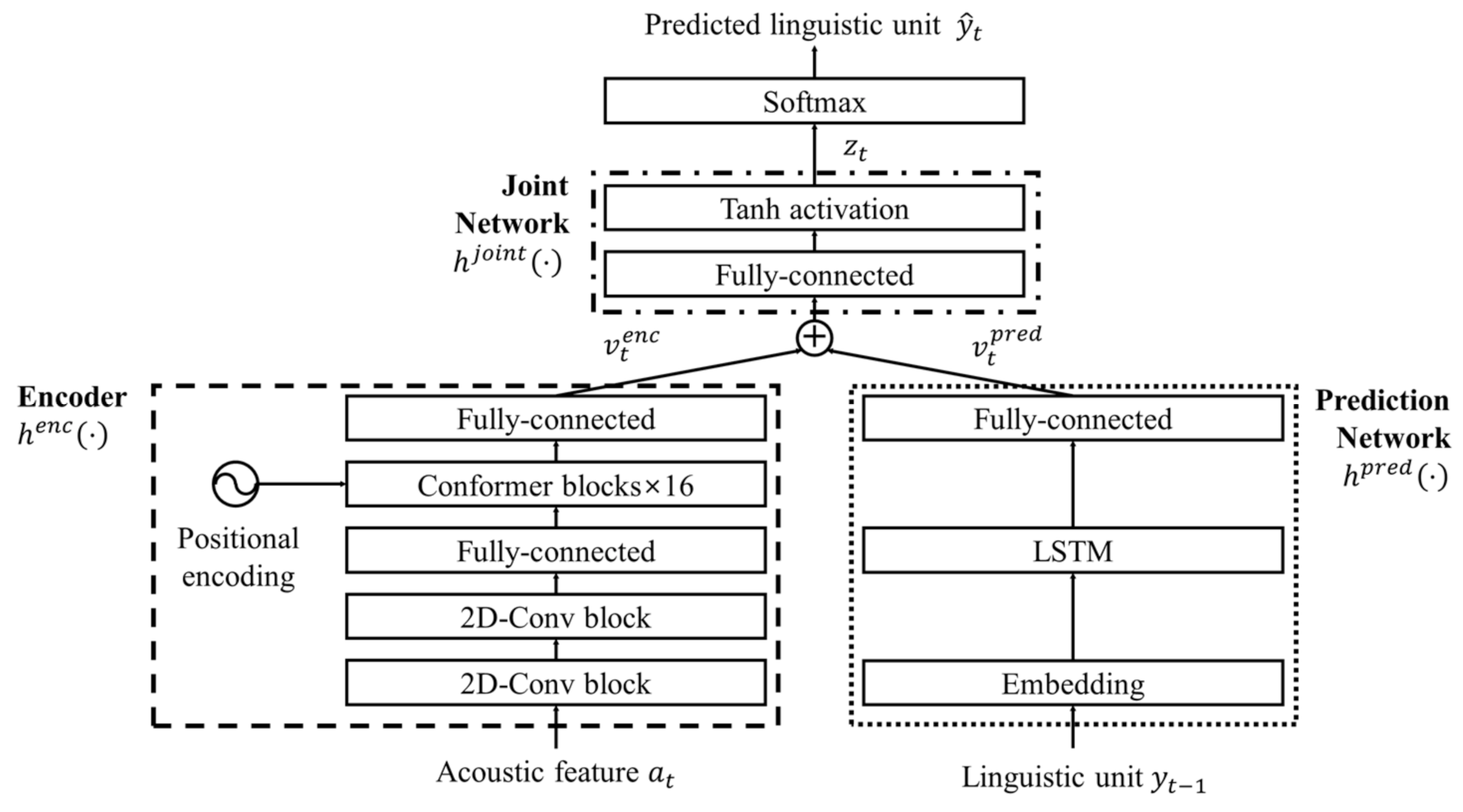
2.2. End-to-End Conformer-Transducer-Based Speech Recognition Model
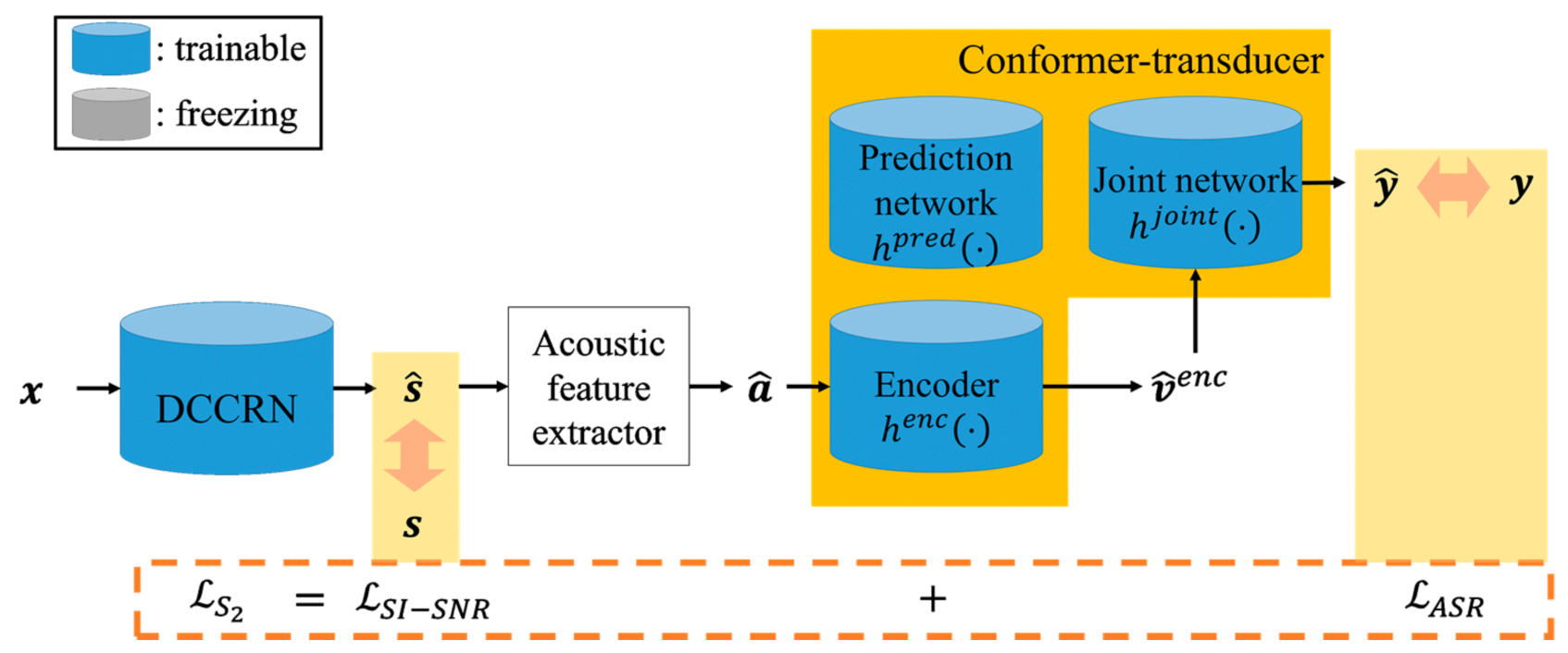
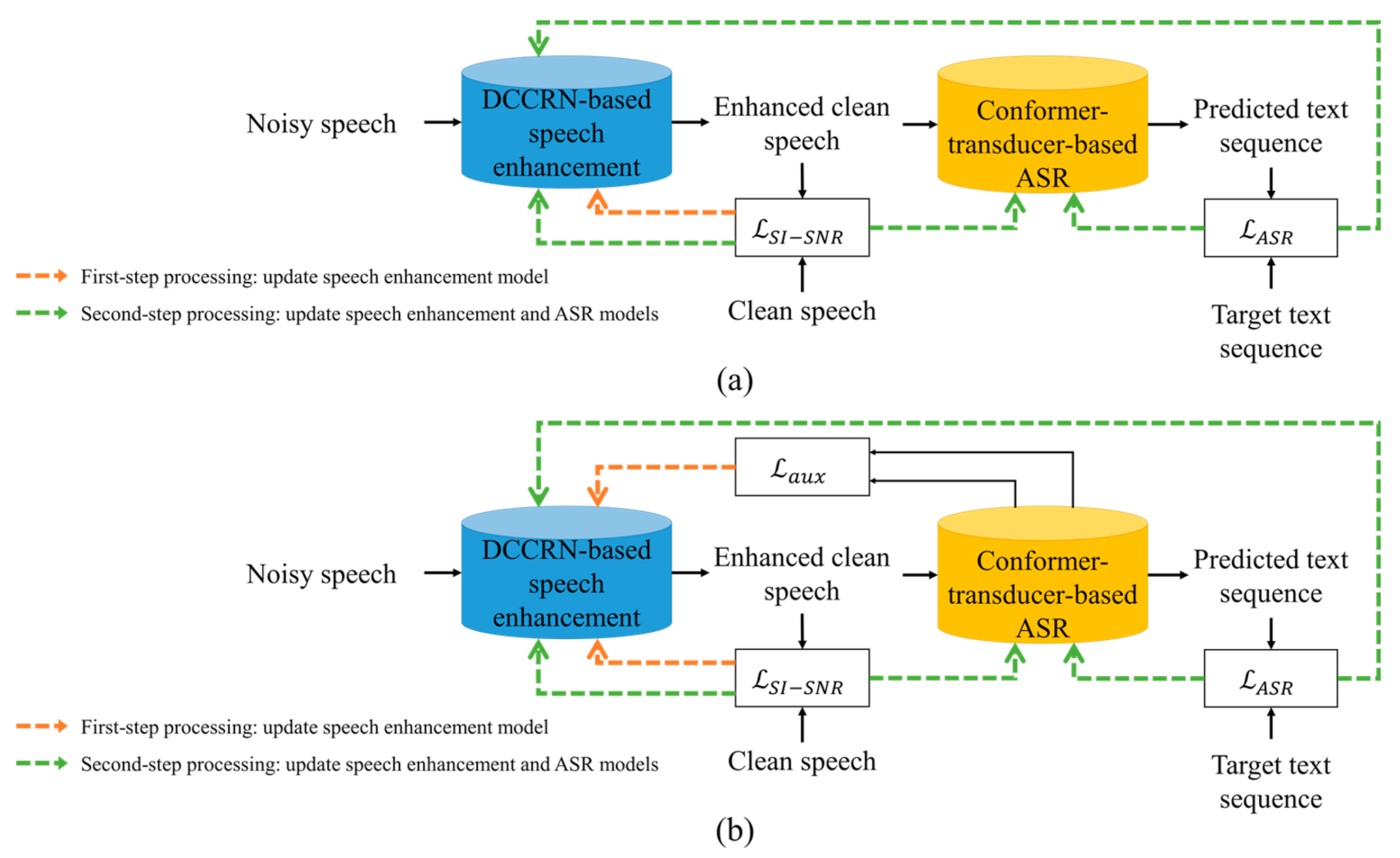
3. Proposed Joint Optimization Approach for Noise-Robust ASR
3.1. First-Step Processing in the Proposed Joint Optimization
3.2. Second-Step Processing in the Proposed Joint Optimization
| Algorithm 1: Two-Step Joint Optimization Procedure with Auxiliary ASR Loss. | |
| Require: , batch size. , the number of iterations. , auxiliary ASR loss weight. , loss weight ratio between speech enhancement and ASR. , speech enhancement learnable parameters. , ASR learnable parameters. | |
| 1: | fordo |
| 2: | Mini-batch of clean speech frames and corresponding acoustic features |
| 3: | Mini-batch of enhanced speech frames and corresponding acoustic features |
| 4: | Mini-batch of linguistic units |
| 5: | First-Step Processing: Update the speech enhancement parameters using SI-SNR and auxiliary ASR loss |
| 6: | Second-Step Processing: Update both speech enhancement and ASR parameters using SI-SNR and ASR loss |
| 7: | end for |
4. Experiments
4.1. Experimental Setup
4.2. Performance Evaluation under Matched Noise Conditions
4.3. Performance Evaluation under Mismatched Noise Conditions
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, C.; Gowda, D.; Lee, D.; Kim, J.; Kumar, A.; Kim, S.; Garg, A.; Han, C. A review of on-device fully neural end-to-end automatic speech recognition algorithms. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems and Computers, Virtual, 1–4 November 2020; pp. 277–283. [Google Scholar] [CrossRef]
- Li, J. Recent advances in end-to-end automatic speech recognition. APSIPA Trans. Signal Inf. Process. 2022, 11, e81. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Nossier, S.A.; Wall, J.; Moniri, M.; Glackin, C.; Cannings, N. An Experimental Analysis of Deep Learning Architectures for Supervised Speech Enhancement. Electronics 2021, 10, 17. [Google Scholar] [CrossRef]
- Soltau, H.; Liao, H.; Sak, H. Neural speech recognizer: Acoustic-to-word LSTM model for large vocabulary speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Stockholm, Sweden, 20–24 August 2017; pp. 3707–3711. [Google Scholar] [CrossRef] [Green Version]
- Chiu, C.-C.; Han, W.; Zhang, Y.; Pang, R.; Kishchenko, S.; Nguyen, P.; Narayanan, A.; Liao, H.; Zhang, S.; Kannan, A.; et al. A comparison of end-to-end models for long-form speech recognition. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 889–896. [Google Scholar] [CrossRef] [Green Version]
- Perero-Codosero, J.M.; Espinoza-Cuadros, F.M.; Hernández-Gómez, L.A. A comparison of hybrid and end-to-end ASR systems for the IberSpeech-RTVE 2020 speech-to-text transcription challenge. Appl. Sci. 2022, 12, 903. [Google Scholar] [CrossRef]
- Caldarini, G.; Jaf, S.; McGarry, K. A literature survey of recent advances in chatbots. Information 2022, 13, 41. [Google Scholar] [CrossRef]
- Liu, D.-R.; Liu, C.; Zhang, F.; Synnaeve, G.; Saraf, Y.; Zweig, G. Contextualizing ASR lattice rescoring with hybrid pointer network language model. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 3650–3654. [Google Scholar] [CrossRef]
- Tanberk, S.; Dağlı, V.; Gürkan, M.K. Deep learning for videoconferencing: A brief examination of speech to text and speech synthesis. In Proceedings of the 2021 International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 506–511. [Google Scholar] [CrossRef]
- Eskimez, S.E.; Yoshioka, T.; Wang, H.; Wang, X.; Chen, Z.; Huang, X. Personalized speech enhancement: New models and comprehensive evaluation. In Proceedings of the 2022 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shenzhen, China, 22–27 May 2022; pp. 356–360. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 30–42. [Google Scholar] [CrossRef] [Green Version]
- Seltzer, M.L.; Yu, D.; Wang, Y. An investigation of deep neural networks for noise robust speech recognition. In Proceedings of the 2013 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7398–7402. [Google Scholar] [CrossRef]
- Amodei, D.; Anubhai, R.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Chen, J.; Chrzanowski, M.; Coates, A.; Diamos, G.; et al. Deep Speech 2: End-to-end speech recognition in English and Mandarin. In Proceedings of the International Conference on Machine Learning (PMLR), New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenge, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar] [CrossRef]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar] [CrossRef]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/attention architecture for end-to-end speech recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X.; et al. A comparative study on transformer vs RNN in speech applications. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Dabre, R.; Lu, X.; Shen, P.; Kawahara, T.; Kawai, H. Improving transformer-based speech recognition systems with compressed structure and speech attributes augmentation. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Graz, Austria, 15–19 September 2019; pp. 4400–4404. [Google Scholar] [CrossRef]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar] [CrossRef]
- Han, W.; Zhang, Z.; Zhang, Y.; Yu, J.; Chiu, C.-C.; Qin, J.; Gulati, A.; Pang, R.; Wu, Y. ContextNet: Improving convolutional neural networks for automatic speech recognition with global context. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 3610–3614. [Google Scholar] [CrossRef]
- Park, D.S.; Zhang, Y.; Jia, Y.; Han, W.; Chiu, C.-C.; Li, B.; Wu, Y.; Le, Q.V. Improved noisy student training for automatic speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 2817–2821. [Google Scholar] [CrossRef]
- Zhang, Y.; Qin, J.; Park, D.S.; Han, W.; Chiu, C.-C.; Pang, R.; Le, Q.V.; Wu, Y. Pushing the limits of semi-supervised learning for automatic speech recognition. arXiv 2017, arXiv:2010.10504. [Google Scholar] [CrossRef]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Droppo, J.; Acero, A. Joint discriminative front end and back end training for improved speech recognition accuracy. In Proceedings of the 2006 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toulouse, France, 14–19 May 2006; pp. 281–284. [Google Scholar] [CrossRef]
- Kinoshita, K.; Ochiai, T.; Delcroix, M.; Nakatani, T. Improving noise robust automatic speech recognition with single-channel time-domain enhancement network. In Proceedings of the 2020 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7009–7013. [Google Scholar] [CrossRef] [Green Version]
- Shimada, K.; Bando, Y.; Mimura, M.; Itoyama, K.; Yoshii, K.; Kawahara, T. Unsupervised speech enhancement based on multichannel NMF-informed beamforming for noise-robust automatic speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 960–971. [Google Scholar] [CrossRef] [Green Version]
- Jeon, K.M.; Lee, G.W.; Kim, N.K.; Kim, H.K. TAU-Net: Temporal activation u-net shared with nonnegative matrix factorization for speech enhancement in unseen noise environments. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 21, 3400–3414. [Google Scholar] [CrossRef]
- Tan, K.; Wang, D. A convolutional recurrent neural network for real-time speech enhancement. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Hyderabad, India, 2–6 September 2018; pp. 3229–3233. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Liu, Y.; Lv, S.; Xing, M.; Zhang, S.; Fu, Y.; Wu, J.; Zhang, B.; Xie, L. DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 2472–2476. [Google Scholar] [CrossRef]
- Schuller, B.; Weninger, F.; Wöllmer, M.; Sun, Y.; Rigoll, G. Non-negative matrix factorization as noise-robust feature extractor for speech recognition. In Proceedings of the 2010 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 4562–4565. [Google Scholar] [CrossRef] [Green Version]
- Narayanan, A.; Wang, D. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of the 2013 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.-Q.; Wang, P.; Wang, D. Complex spectral mapping for single-and multi-channel speech enhancement and robust ASR. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1778–1787. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Kang, Y.; Shi, Y.; Kürzinger, L.; Watzel, T.; Rigoll, G. Adversarial joint training with self-attention mechanism for robust end-to-end speech recognition. EURASIP J. Audio Speech Music Process. 2021, 26, 1–16. [Google Scholar] [CrossRef]
- Pandey, A.; Liu, C.; Wang, Y.; Saraf, Y. Dual application of speech enhancement for automatic speech recognition. In Proceedings of the 2021 Workshop on Spoken Language Technology (SLT), Shenzhen, China, 19–22 January 2021; pp. 223–228. [Google Scholar] [CrossRef]
- Ma, D.; Hou, N.; Xu, H.; Chng, E.S. Multitask-based joint learning approach to robust ASR for radio communication speech. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 497–502. [Google Scholar]
- Noor, M.M.E.; Lu, Y.-J.; Wang, S.-S.; Ghose, S.; Chang, C.-Y.; Zezario, R.E.; Ahmed, S.; Chunh, W.-H.; Tsao, Y.; Wang, H.-M. Investigation of a single-channel frequency-domain speech enhancement network to improve end-to-end Bengali automatic speech recognition under unseen noisy conditions. In Proceedings of the 2021 Conference of the Oriental COCOSDA International Committee for the Coordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), Singapore, 18–20 November 2021; pp. 7–12. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, L.; Lee, K.A.; Liu, M.; Dang, J. Joint feature enhancement and speaker recognition with multi-objective task-oriented network. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Brno, Czech Republic, 30 August–3 September 2021; pp. 1089–1093. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. LibriSpeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Reddy, C.K.A.; Gopal, V.; Cutler, R.; Beyrami, E.; Cheng, R.; Dubey, H.; Matusevych, S.; Aichner, R.; Aazami, A.; Braun, S.; et al. The INTERSPEECH 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, 25–29 October 2020; pp. 2492–2496. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A simple data augmentation method for automatic speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar] [CrossRef] [Green Version]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP), Brussels, Belgium, 2–4 November 2018; pp. 66–71. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Flat minima. Neural Comput. 1997, 9, 1–42. [Google Scholar] [CrossRef] [PubMed]
- Gotmare, A.; Keskar, N.S.; Xiong, C.; Socher, R. A closer look at deep learning heuristics: Learning rate restarts, warmup and distillation. arXiv 2018, arXiv:1810.13243. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 2–5. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1195–1204. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Abadi, M.; Devin, M.; Ghemawat, S.; Irving, G.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar] [CrossRef]
- Sergeev, A.; Del Balso, M. Horovod: Fast and easy distributed deep learning in TensorFlow. arXiv 2018, arXiv:1802.05799. [Google Scholar]
- Heymann, J.; Drude, L.; Boeddeker, C.; Hanebrink, P.; Haeb-Umbach, R. Beamnet: End-to-end training of a beamformer-supported multi-channel ASR system. In Proceedings of the 2020 International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5325–5329. [Google Scholar] [CrossRef]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Freezeout: Accelerate training by progressively freezing layers. arXiv 2017, arXiv:1706.04983. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. Wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 6–12 December 2020; pp. 12449–12460. [Google Scholar]
- Shon, S.; Pasad, A.; Wu, F.; Brusco, P.; Artzi, Y.; Livescu, K.; Han, K.J. Slue: New benchmark tasks for spoken language understanding evaluation on natural speech. In Proceedings of the 2022 International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shenzhen, China, 22–27 May 2022; pp. 7927–7931. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Training Approach | Dev-Clean | Dev-Noisy | Test-Clean | Test-Noisy | ||||
|---|---|---|---|---|---|---|---|---|---|
| CER (%) | WER (%) | CER (%) | WER (%) | CER (%) | WER (%) | CER (%) | WER (%) | ||
| ASR-only | Clean-Condition Training | 3.50 | 8.00 | 28.08 | 39.96 | 3.53 | 8.79 | 25.68 | 37.39 |
| ASR-only | Multi-Condition Training | 3.50 | 8.00 | 9.68 | 16.61 | 3.53 | 8.54 | 9.26 | 16.43 |
| SE-ASR | Separate Optimization | 3.50 | 7.91 | 9.57 | 16.04 | 3.51 | 8.42 | 9.20 | 15.94 |
| SE+ASR | Joint Optimization | 3.48 | 7.98 | 9.61 | 16.23 | 3.51 | 8.41 | 9.21 | 15.98 |
| SE+ASR | Conventional Two-Step Joint Optimization | 3.49 | 7.91 | 9.38 | 15.81 | 3.50 | 8.37 | 9.12 | 15.77 |
| SE+ASR | Proposed Two-Step Joint Optimization | 3.48 | 7.92 | 9.31 | 15.77 | 3.50 | 8.37 | 9.07 | 15.54 |
| Model | Training Approach | Dev-Noisy-Mismatched | Test-Noisy-Mismatched | ||
|---|---|---|---|---|---|
| CER (%) | WER (%) | CER (%) | WER (%) | ||
| ASR-only | Clean-Condition Training | 27.67 | 37.20 | 24.46 | 34.37 |
| ASR-only | Multi-Condition Training | 12.26 | 20.01 | 10.46 | 18.28 |
| SE-ASR | Separate Optimization | 16.42 | 28.67 | 16.39 | 28.44 |
| SE+ASR | Joint Optimization | 12.30 | 20.81 | 10.19 | 17.80 |
| SE+ASR | Conventional Two-Step Joint Optimization | 11.88 | 19.71 | 10.00 | 17.61 |
| SE+ASR | Proposed Two-Step Joint Optimization | 11.57 | 19.68 | 9.87 | 17.37 |
| Speech Enhancement | Speech Recognition Block Trained in Second-Step Processing | Test-Clean | Test-Noisy | Test-Noisy-Mismatched | |||||
|---|---|---|---|---|---|---|---|---|---|
| Encoder | Prediction Network | Joint Network | CER (%) | WER (%) | CER (%) | WER (%) | CER (%) | WER (%) | |
| √ | 3.51 | 8.34 | 9.09 | 16.27 | 9.92 | 17.73 | |||
| √ | √ | 3.53 | 8.60 | 10.85 | 18.14 | 10.27 | 17.92 | ||
| √ | √ | 3.50 | 8.29 | 8.90 | 15.46 | 9.42 | 16.57 | ||
| √ | √ | √ | 3.53 | 8.61 | 10.79 | 17.99 | 10.18 | 17.90 | |
| √ | √ | √ | √ | 3.50 | 8.37 | 9.07 | 15.54 | 9.87 | 17.49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.W.; Kim, H.K. Two-Step Joint Optimization with Auxiliary Loss Function for Noise-Robust Speech Recognition. Sensors 2022, 22, 5381. https://doi.org/10.3390/s22145381
Lee GW, Kim HK. Two-Step Joint Optimization with Auxiliary Loss Function for Noise-Robust Speech Recognition. Sensors. 2022; 22(14):5381. https://doi.org/10.3390/s22145381
Chicago/Turabian StyleLee, Geon Woo, and Hong Kook Kim. 2022. "Two-Step Joint Optimization with Auxiliary Loss Function for Noise-Robust Speech Recognition" Sensors 22, no. 14: 5381. https://doi.org/10.3390/s22145381
APA StyleLee, G. W., & Kim, H. K. (2022). Two-Step Joint Optimization with Auxiliary Loss Function for Noise-Robust Speech Recognition. Sensors, 22(14), 5381. https://doi.org/10.3390/s22145381