
Personalized Activity Recognition with Deep Triplet Embeddings


Abstract
:1. Introduction
- Presentation and evaluation of novel personalized embedding approaches to HAR that enable rapid and computationally efficient user-specific data characterization and classification.
- Adaptation of the TNN metric learning methodology into this personalized user-specific HAR classification regime.
- Extension of the proposed approaches to unseen classes and out-of-distribution (OOD) detection. We illustrate how the personalized methodologies presented in this work are easily extensible to the preceding tasks and are able to achieve high accuracy on the experimental datasets.
Related Work
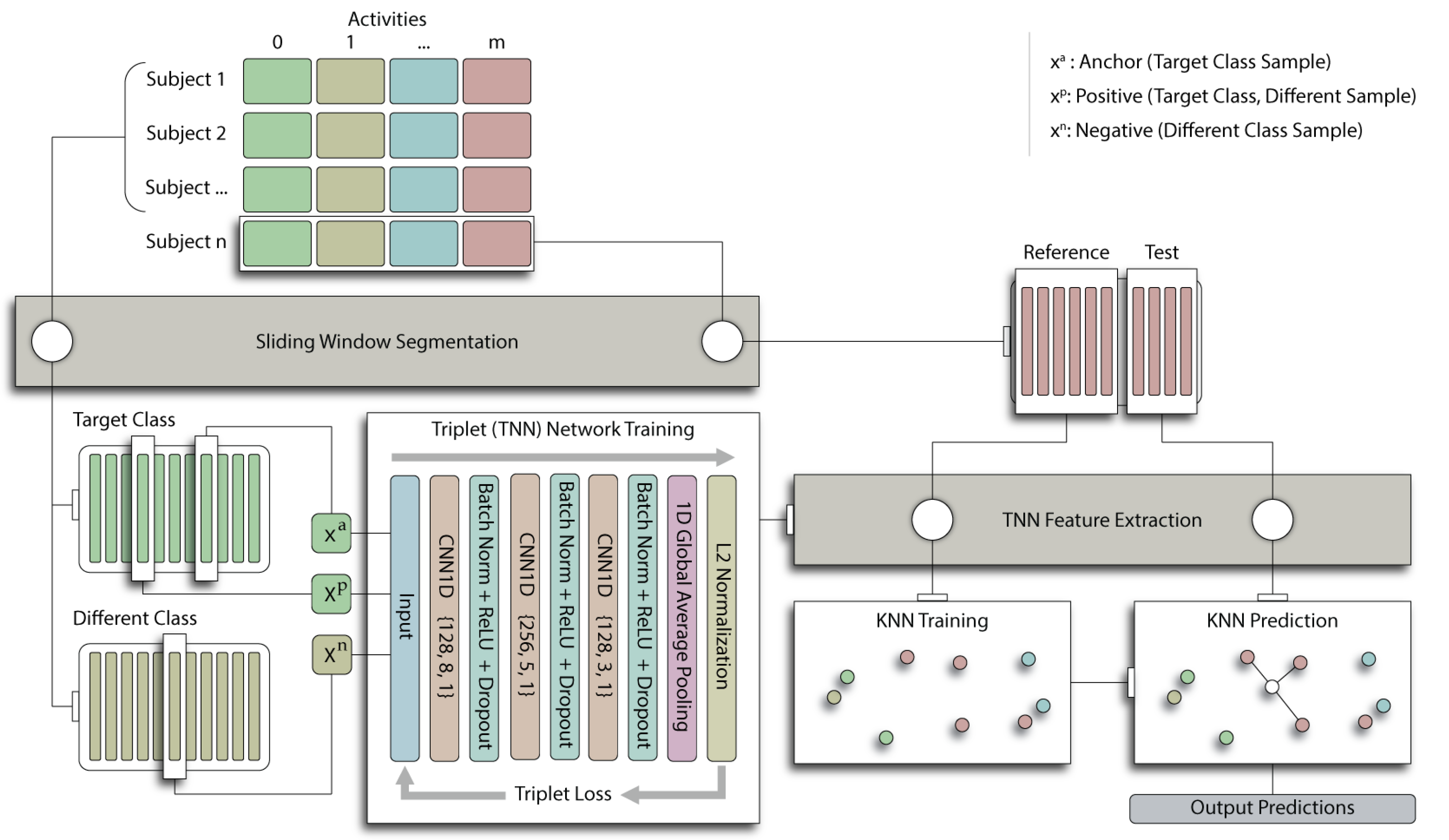
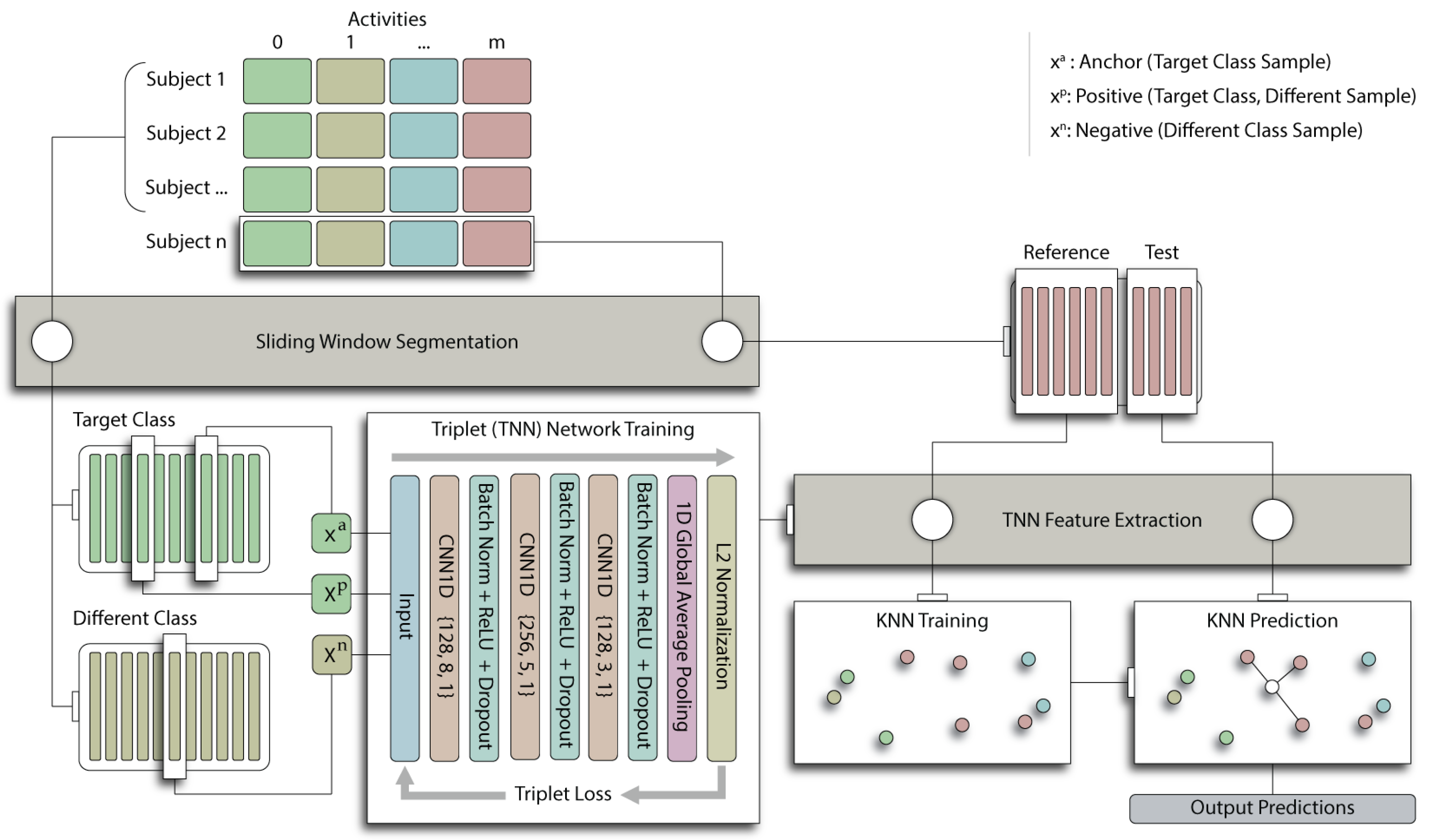
2. Materials and Methods
2.1. Fully Convolutional Neural Network Architecture
2.2. Feature Embedding Methods
2.2.1. Engineered Features
2.2.2. Deep Features
2.2.3. Triplet Network Features
2.3. Data and Preprocessing
2.4. Experiments
2.4.1. Activity Classification
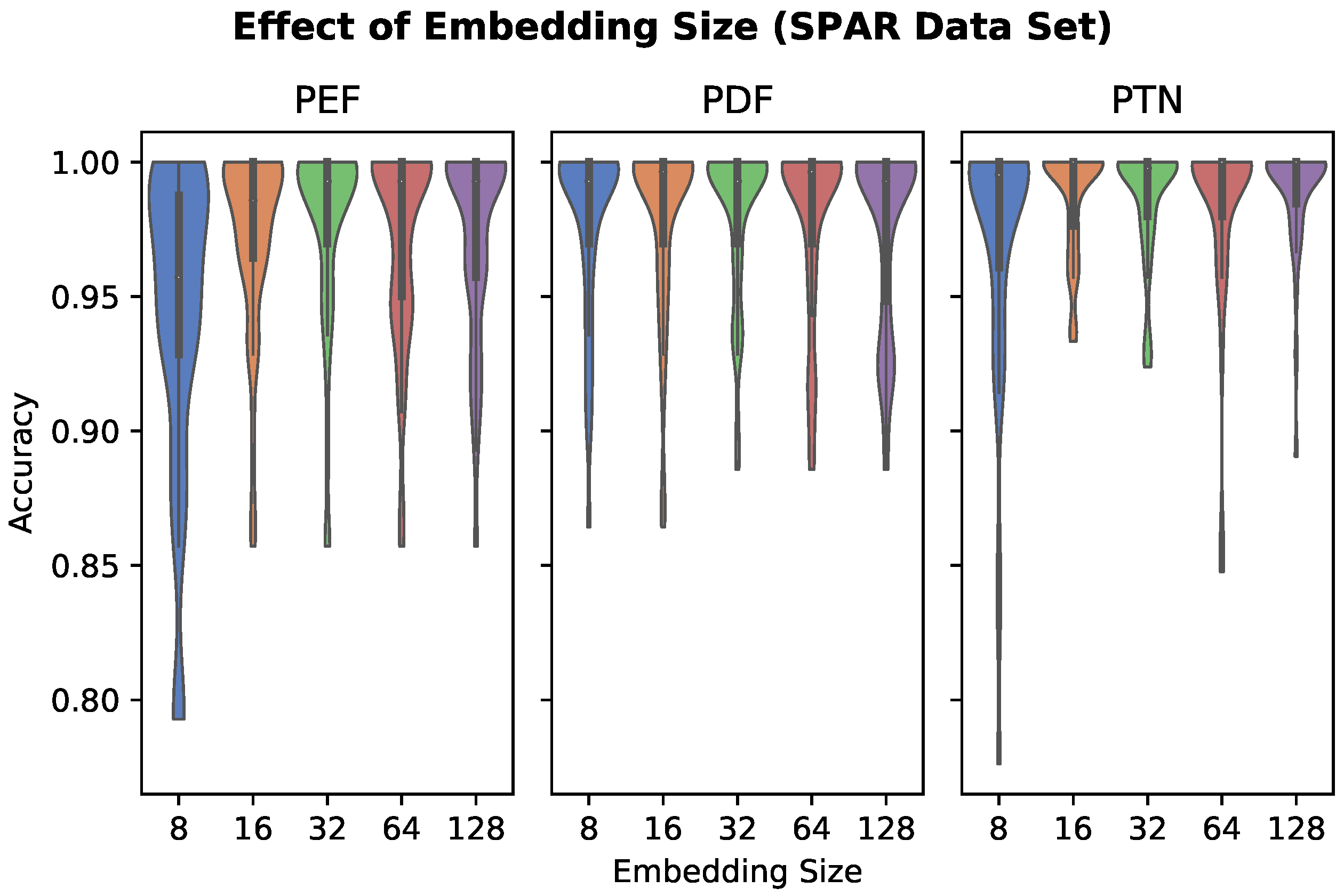
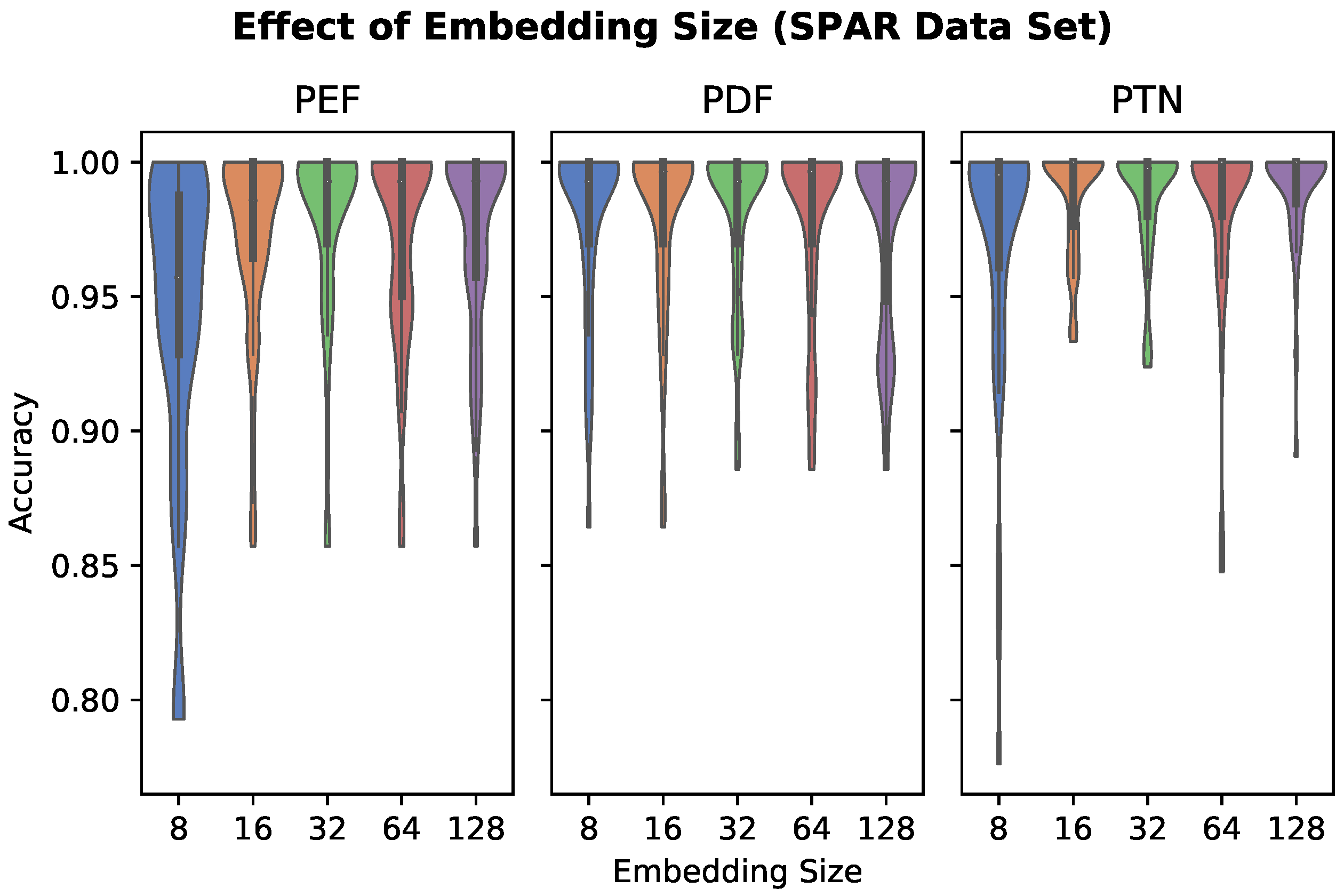
2.4.2. Embedding Size
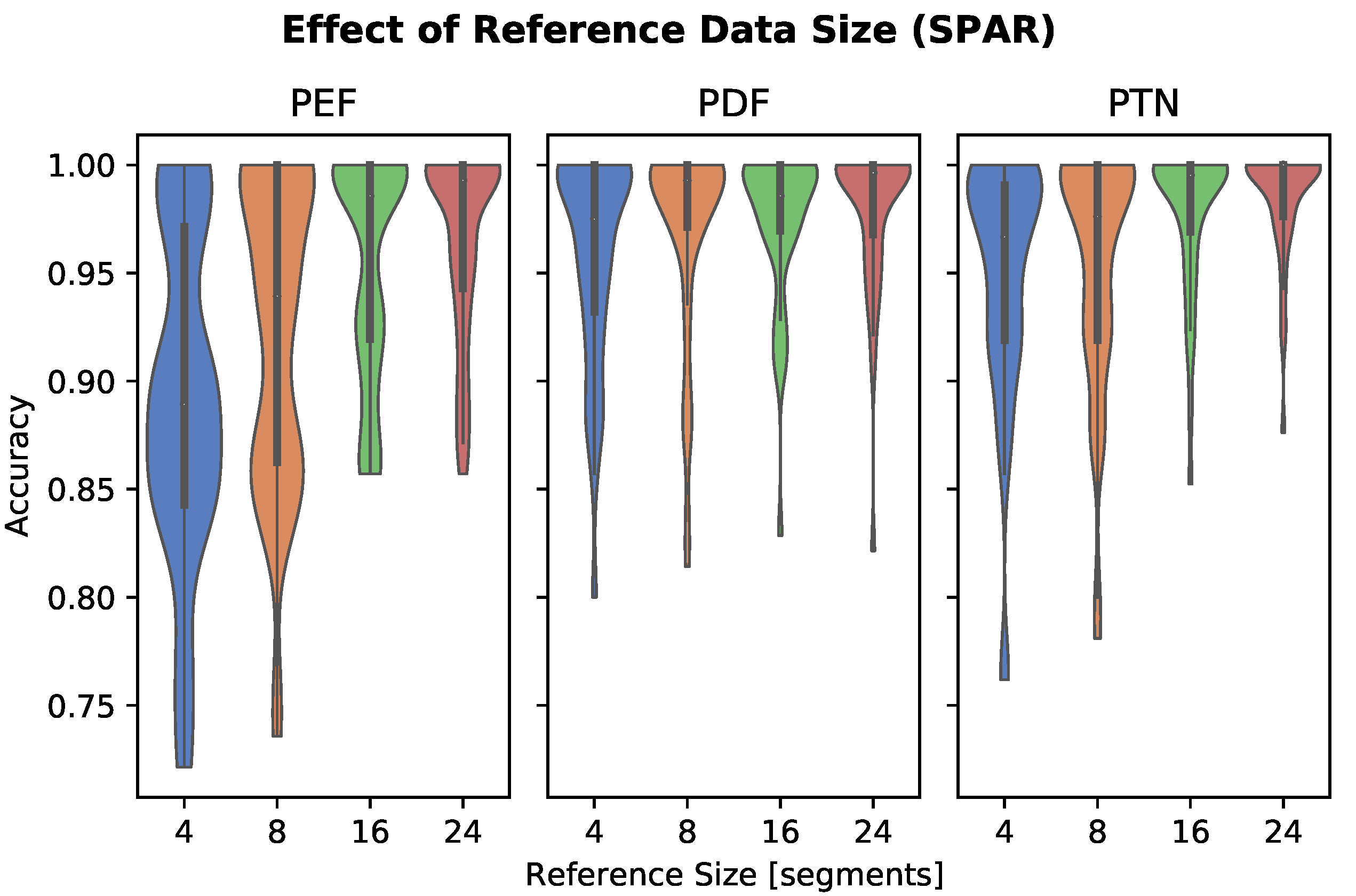
2.4.3. Reference Data Size
2.4.4. Out-of-Distribution Detection
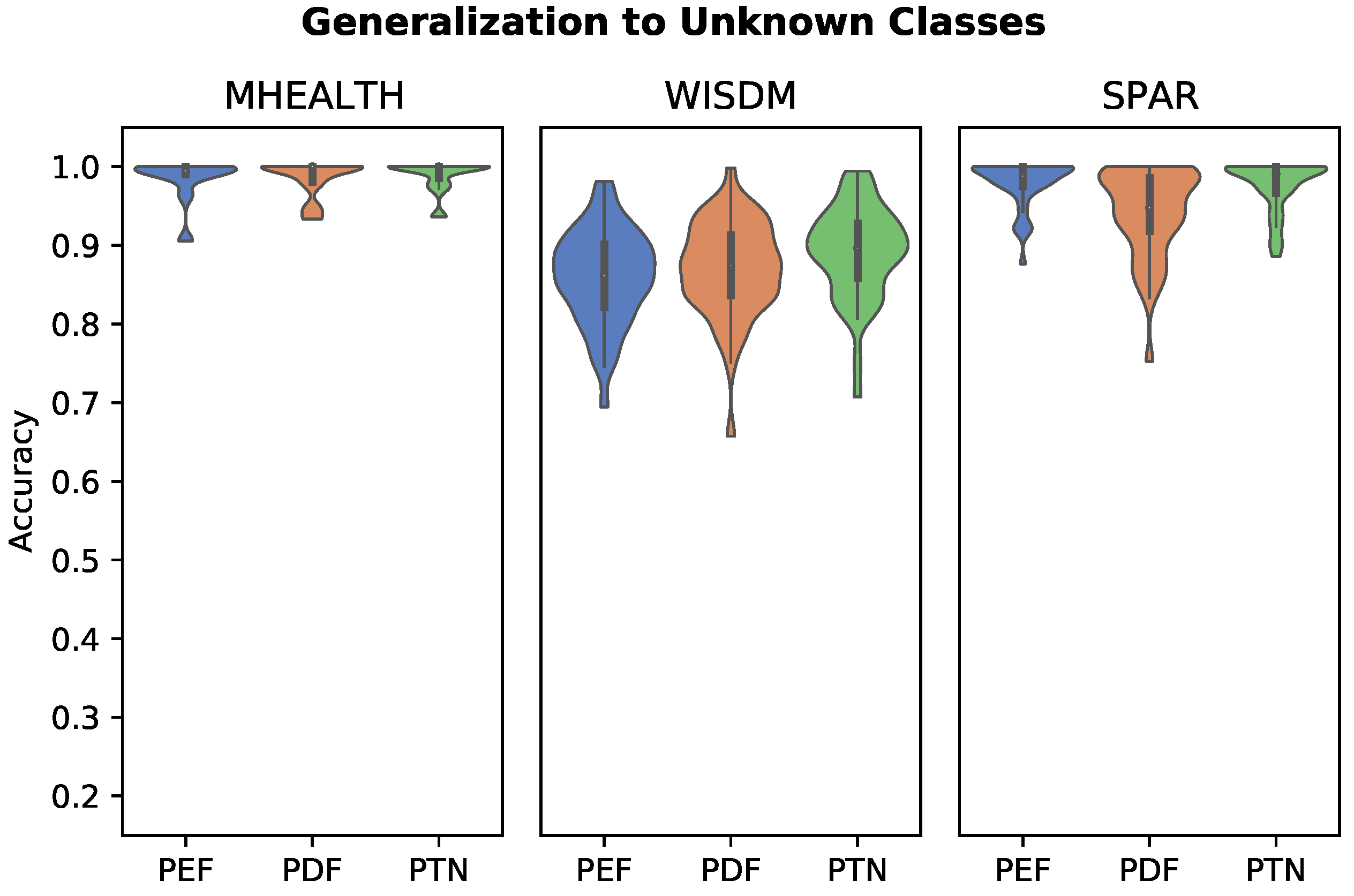
2.4.5. Generalization to New Activity Classes
2.4.6. Computational Expense
3. Results
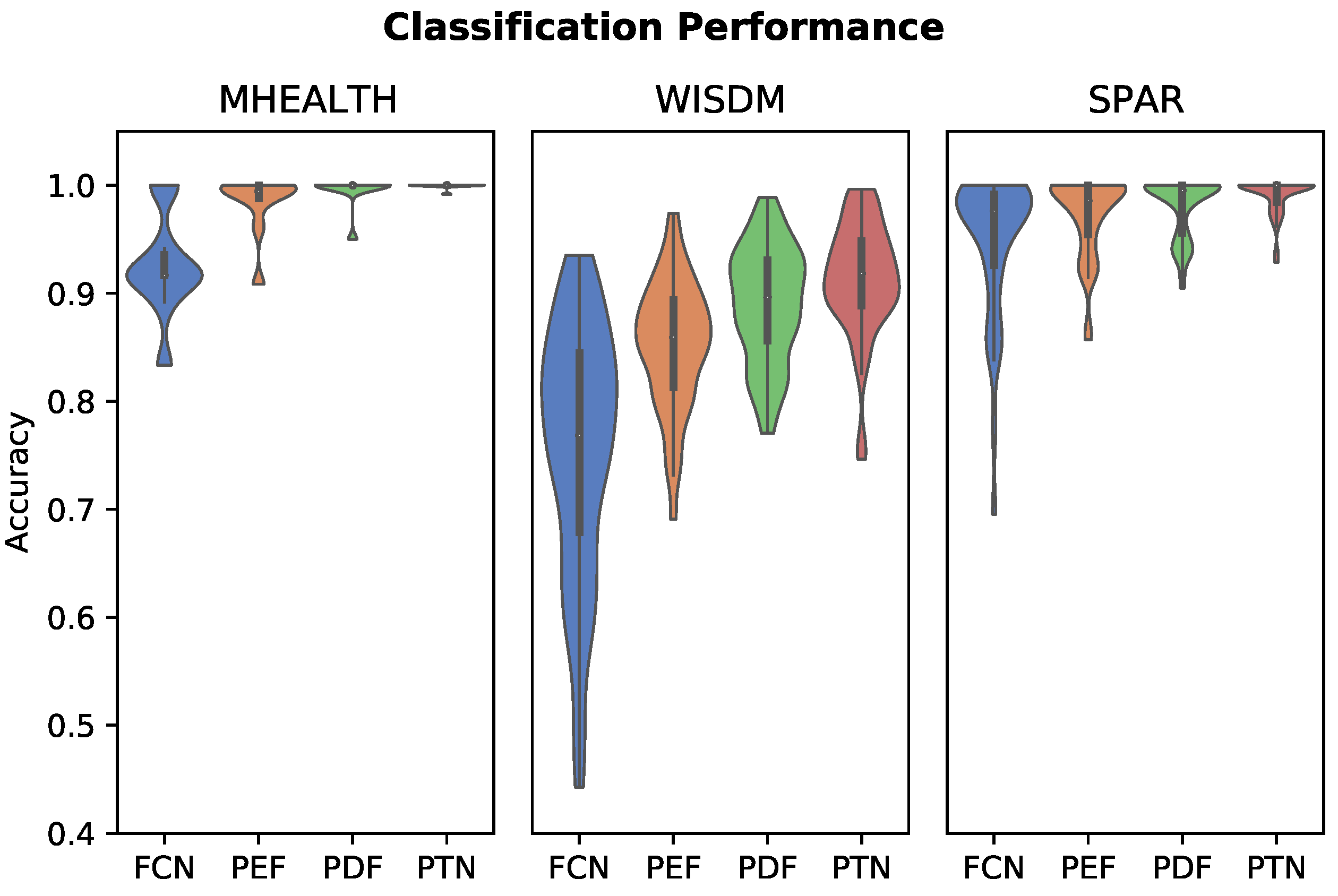
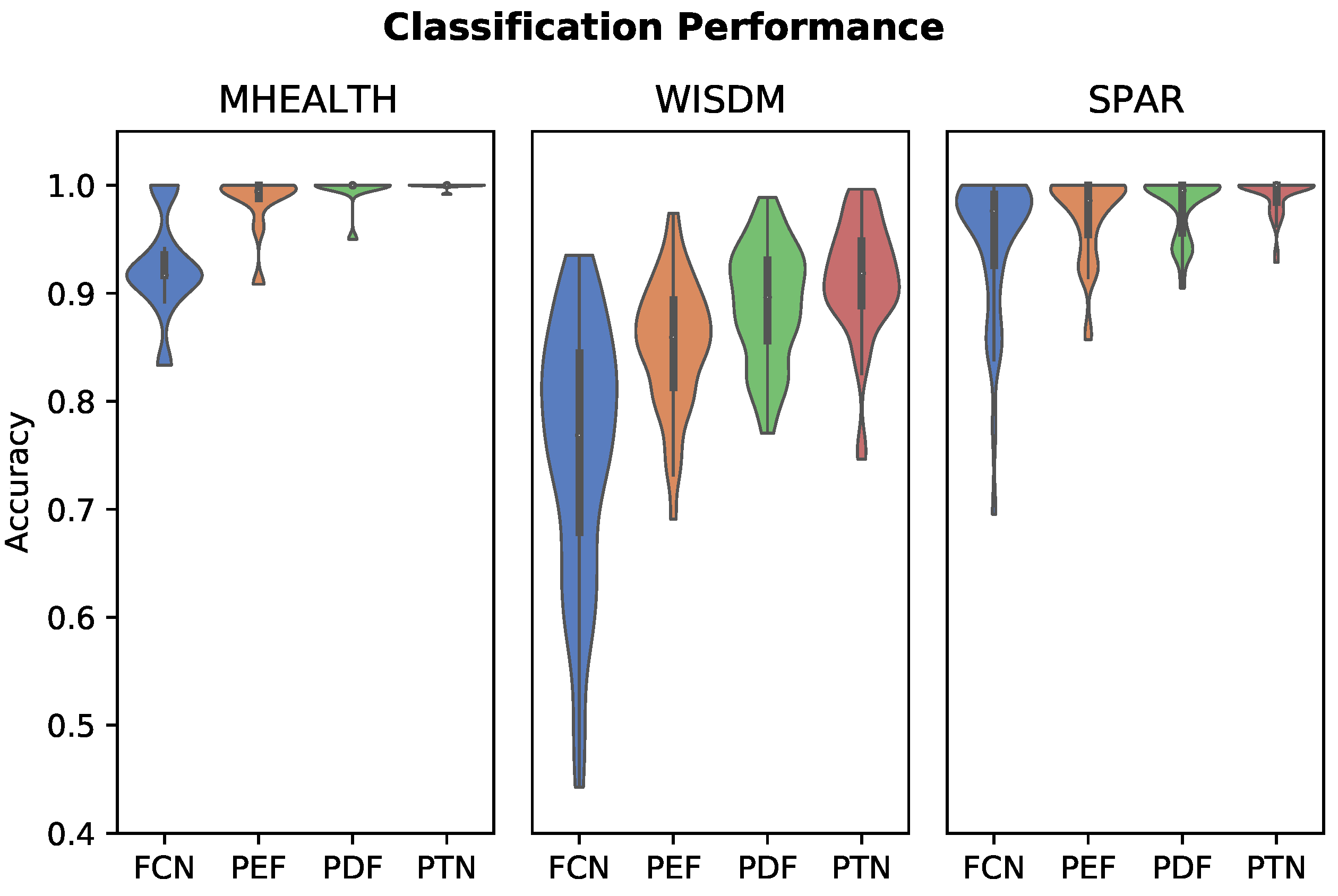
3.1. Activity Classification
3.2. Embedding Size
3.3. Reference Data Size
3.4. Out-of-Distribution Detection
3.5. Generalization to New Activity Classes
3.6. Computational Expense
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| HAR | Human activity recognition |
| TNN | Triplet neural network |
| OOD | Out-of-distribution |
| SNN | Siamese neural network |
| FCN | Fully-convolutional neural network |
| ReLU | Rectified linear unit |
| PEF | Personalized engineered feature |
| Personalized deep feature network | |
| PTN | Personalized triplet network |
| k-NN | k-Nearest Neighbors |
| IMU | Inertial measurement unit |
| ADL | Activities of daily living |
| AUROC | Area under the receiver operator characteristic curve |
References
- Sousa Lima, W.; Souto, E.; El-Khatib, K.; Jalali, R.; Gama, J. Human Activity Recognition Using Inertial Sensors in a Smartphone: An Overview. Sensors 2019, 19, 3213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mertz, L. Convergence Revolution Comes to Wearables: Multiple Advances are Taking Biosensor Networks to the Next Level in Health Care. IEEE Pulse 2016, 7, 13–17. [Google Scholar] [CrossRef] [PubMed]
- Metcalf, D.; Milliard, S.T.J.; Gomez, M.; Schwartz, M. Wearables and the Internet of Things for Health: Wearable, Interconnected Devices Promise More Efficient and Comprehensive Health Care. IEEE Pulse 2016, 7, 35–39. [Google Scholar] [CrossRef] [PubMed]
- Piwek, L.; Ellis, D.A.; Andrews, S.; Joinson, A. The Rise of Consumer Health Wearables: Promises and Barriers. PLoS Med. 2016, 13, e1001953. [Google Scholar] [CrossRef]
- Vargas-Valencia, L.S.; Schneider, F.B.A.; Leal-Junior, A.G.; Caicedo-Rodríguez, P.; Sierra-Arévalo, W.A.; Rodríguez-Cheu, L.E.; Bastos-Filho, T.; Frizera-Neto, A. Sleeve for Knee Angle Monitoring: An IMU-POF Sensor Fusion System. IEEE J. Biomed. Health Inform. 2021, 25, 465–474. [Google Scholar] [CrossRef]
- O’Reilly, M.; Caulfield, B.; Ward, T.; Johnston, W.; Doherty, C. Wearable Inertial Sensor Systems for Lower Limb Exercise Detection and Evaluation: A Systematic Review. Sport. Med. 2018, 48, 1221–1246. [Google Scholar] [CrossRef] [Green Version]
- Porciuncula, F.; Roto, A.V.; Kumar, D.; Davis, I.; Roy, S.; Walsh, C.J.; Awad, L.N. Wearable Movement Sensors for Rehabilitation: A Focused Review of Technological and Clinical Advances. PMR 2018, 10, S220–S232. [Google Scholar] [CrossRef] [Green Version]
- Burns, D.; Boyer, P.; Razmjou, H.; Richards, R.; Whyne, C. Adherence Patterns and Dose Response of Physiotherapy for Rotator Cuff Pathology: Longitudinal Cohort Study. JMIR Rehabil. Assist. Technol. 2021, 8, e21374. [Google Scholar] [CrossRef]
- Modave, F.; Guo, Y.; Bian, J.; Gurka, M.J.; Parish, A.; Smith, M.D.; Lee, A.M.; Buford, T.W. Mobile Device Accuracy for Step Counting Across Age Groups. JMIR mHealth uHealth 2017, 5, e88. [Google Scholar] [CrossRef]
- Robert-Lachaine, X.; Mecheri, H.; Larue, C.; Plamondon, A. Effect of local magnetic field disturbances on inertial measurement units accuracy. Appl. Ergon. 2017, 63, 123–132. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef] [Green Version]
- Hoffer, E.; Ailon, N. Deep metric learning using Triplet network. arXiv 2018, arXiv:1412.6622. [Google Scholar]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tut. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Gonzalez, S.; Sedano, J.; Villar, J.R.; Corchado, E.; Herrero, A.; Baruque, B. Features and models for human activity recognition. Neurocomputing 2015, 167, 52–60. [Google Scholar] [CrossRef] [Green Version]
- San-Segundo, R.; Montero, J.M.; Barra-Chicote, R.; Fernández, F.; Pardo, J.M. Feature extraction from smartphone inertial signals for human activity segmentation. Signal Process. 2016, 120, 359–372. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. arXiv 2016, arXiv:1611.06455. [Google Scholar]
- Guan, Y.; Plötz, T. Ensembles of Deep LSTM Learners for Activity Recognition using Wearables. Proc. ACM Interact. Mobile Wear. Ubiquit. Technol. 2017, 1, 11:1–11:28. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Wang, Y.; Zhang, B.; Ma, J. PSDRNN: An Efficient and Effective HAR Scheme Based on Feature Extraction and Deep Learning. IEEE Trans. Ind. Inform. 2020, 16, 6703–6713. [Google Scholar] [CrossRef]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 103, 1461–1478. [Google Scholar] [CrossRef]
- Weiss, G.M.; Lockhart, J.W. The Impact of Personalization on Smartphone-Based Activity Recognition. In Proceedings of the AAAI 2012, Toronto, ON, USA, 22–26 July 2012. [Google Scholar]
- Sztyler, T.; Stuckenschmidt, H. Online personalization of cross-subjects based activity recognition models on wearable devices. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kona, HI, USA, 13–17 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 180–189. [Google Scholar] [CrossRef]
- Zhao, S.; Li, W.; Cao, J. A User-Adaptive Algorithm for Activity Recognition Based on K-Means Clustering, Local Outlier Factor, and Multivariate Gaussian Distribution. Sensors 2018, 18, 1850. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meng, L.; Miao, C.; Leung, C. Towards online and personalized daily activity recognition, habit modeling, and anomaly detection for the solitary elderly through unobtrusive sensing. Multimed. Tools Appl. 2017, 76, 10779–10799. [Google Scholar] [CrossRef]
- Rokni, S.A.; Nourollahi, M.; Ghasemzadeh, H. Personalized Human Activity Recognition Using Convolutional Neural Networks. arXiv 2018, arXiv:1801.08252. [Google Scholar] [CrossRef]
- Cvetkovic, B.; Lustrek, M.; Kaluza, B.; Gams, M. Semi-supervised Learning for Adaptation of Human Activity Recognition Classifier to the User. In Proceedings of the STAMI 2011: Space, Time and Ambient Intelligence, Barcelona, Spain, 16 July 2011; p. 6. [Google Scholar]
- Hong, J.H.; Ramos, J.; Dey, A.K. Toward Personalized Activity Recognition Systems With a Semipopulation Approach. IEEE Trans.-Hum.-Mach. Syst. 2016, 46, 101–112. [Google Scholar] [CrossRef]
- Bettini, C.; Civitarese, G.; Presotto, R. Personalized Semi-Supervised Federated Learning for Human Activity Recognition. arXiv 2021, arXiv:2104.08094. [Google Scholar]
- Nguyen, H.T.; Kwon, H.; Haresamudram, H.; Peterson, A.F.; Plötz, T. Personalization Models for Human Activity Recognition with Distribution Matching-Based Metrics, Proceedings of the Deep Learning for Human Activity Recognition, Kyoto, Japan, 8 January 2021; Li, X., Wu, M., Chen, Z., Zhang, L., Eds.; Springer Singapore: Singapore, 2021; pp. 43–56. [Google Scholar]
- US Food and Drug Administration. Proposed Regulatory Framework for Mondifications to Artificial Intelligence / Machine Learning - Based Software as a Medical Device; US Food and Drug Administration: Silver Spring, MD, USA, 2019. [Google Scholar]
- Bendale, A.; Boult, T. Towards Open Set Deep Networks. arXiv 2015, arXiv:1511.06233. [Google Scholar]
- Geng, C.; Huang, S.j.; Chen, S. Recent Advances in Open Set Recognition: A Survey. arXiv 2019, arXiv:1811.08581. [Google Scholar] [CrossRef] [Green Version]
- Boyer, P.; Burns, D.; Whyne, C. Out-of-Distribution Detection of Human Activity Recognition with Smartwatch Inertial Sensors. Sensors 2021, 21, 1669. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2014, arXiv:1312.6229. [Google Scholar]
- Sani, S.; Massie, S.; Wiratunga, N.; Cooper, K. Learning Deep and Shallow Features for Human Activity Recognition, Proceedings of the Knowledge Science, Engineering and Management, Melbourne, VIC, Australia, 19–20 August 2017; Lecture Notes in Computer Science; Li, G., Ge, Y., Zhang, Z., Jin, Z., Blumenstein, M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 469–482. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification Using a “Siamese” Time Delay Neural Network. In Proceedings of the 6th International Conference on Neural Information Processing Systems, San Francisco, CA, USA, 6–14 December 1993; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993; pp. 737–744. [Google Scholar]
- Tang, Y.; Zhang, L.; Teng, Q.; Min, F.; Song, A. Triple Cross-Domain Attention on Human Activity Recognition Using Wearable Sensors. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 30, 1–10. [Google Scholar] [CrossRef]
- Khaertdinov, B.; Ghaleb, E.; Asteriadis, S. Deep Triplet Networks with Attention for Sensor-based Human Activity Recognition. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kassel, Germany, 22–26 March 2021; pp. 1–10. [Google Scholar] [CrossRef]
- He, G.; Li, F.; Wang, Q.; Bai, Z.; Xu, Y. A hierarchical sampling based triplet network for fine-grained image classification. Pattern Recognit. 2021, 115, 107889. [Google Scholar] [CrossRef]
- Hao, Y.; Wang, B.; Zheng, R. Invariant Feature Learning for Sensor-based Human Activity Recognition. arXiv 2020, arXiv:2012.07963. [Google Scholar] [CrossRef]
- Banos, O.; Villalonga, C.; Garcia, R.; Saez, A.; Damas, M.; Holgado-Terriza, J.A.; Lee, S.; Pomares, H.; Rojas, I. Design, implementation and validation of a novel open framework for agile development of mobile health applications. Biomed. Eng. Online 2015, 14, S6. [Google Scholar] [CrossRef] [Green Version]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and Smartwatch-Based Biometrics Using Activities of Daily Living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Burns, D.M.; Leung, N.; Hardisty, M.; Whyne, C.M.; Henry, P.; McLachlin, S. Shoulder physiotherapy exercise recognition: Machine learning the inertial signals from a smartwatch. Physiol. Meas. 2018, 39, 075007. [Google Scholar] [CrossRef] [Green Version]
- Jordao, A.; Nazare Jr., A.C.; Sena, J.; Schwartz, W.R. Human Activity Recognition Based on Wearable Sensor Data: A Standardization of the State-of-the-Art. arXiv 2019, arXiv:1806.05226. [Google Scholar]
- Chollet, François Keras. GitHub Repository. 2015. Available online: https://github.com/fchollet/keras (accessed on 29 May 2022).
- Burns, D.M.; Whyne, C.M. Seglearn: A Python Package for Learning Sequences and Time Series. J. Mach. Learn. Res. 2018, 19, 1–7. [Google Scholar]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 1, pp. 431–439. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Hendrycks, D.; Gimpel, K. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. arXiv 2016, arXiv:1610.02136. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning Fine-grained Image Similarity with Deep Ranking. arXiv 2014, arXiv:1404.4661. [Google Scholar]
- Wang, L.; Li, Y.; Lazebnik, S. Learning Deep Structure-Preserving Image-Text Embeddings. arXiv 2016, arXiv:1511.06078. [Google Scholar]
- Yu, B.; Liu, T.; Gong, M.; Ding, C.; Tao, D. Correcting the Triplet Selection Bias for Triplet Loss, Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September2018; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 71–86. [Google Scholar] [CrossRef]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On Calibration of Modern Neural Networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August2017; pp. 1321–1330. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ajerla, D.; Mahfuz, S.; Zulkernine, F. A Real-Time Patient Monitoring Framework for Fall Detection. Wirel. Commun. Mob. Netw. 2019, 2019, 9507938. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sensors | Subjects | Classes | Sampling | Omitted Subjects | Domain | Sensor Placement |
|---|---|---|---|---|---|---|---|
| MHEALTH | 9-axis IMU x3, 2-lead ECG | 10 | 12 | 100 Hz | 0 | Exercise | Chest, left ankle, right arm |
| WISDM | 6-axis IMU x2 | 51 | 18 | 20 Hz | 4 | ADL, Exercise | Right pant pocket, wrist |
| SPAR | 6-axis IMU x1 | 40 | 7 | 50 Hz | 0 | Physiotherapy | Wrist |
| Model | MHEALTH | WISDM | SPAR |
|---|---|---|---|
| FCN | 0.925 ± 0.049 | 0.754 ± 0.012 | 0.947 ± 0.069 |
| PEF | 0.984 ± 0.029 | 0.852 ± 0.060 | 0.971 ± 0.038 |
| 0.995 ± 0.016 | 0.889 ± 0.055 | 0.980 ± 0.028 | |
| PTN | 0.993 ± 0.024 | 0.909 ± 0.054 | 0.978 ± 0.035 |
| PTN | 0.999 ± 0.003 | 0.913 ± 0.053 | 0.990 ± 0.017 |
| Model | Fit Time [s] | Inference Time [s] | Model Size [kB] | Reference Size [kB] |
|---|---|---|---|---|
| FCN | 137 | 0.47 | 4290 | 0 |
| PEF | 3.3 | 0.39 | 3.8 | 112 |
| 129 | 0.94 | 1095 | 112 | |
| PTN | 667 | 1.3 | 1095 | 112 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Burns, D.; Boyer, P.; Arrowsmith, C.; Whyne, C. Personalized Activity Recognition with Deep Triplet Embeddings. Sensors 2022, 22, 5222. https://doi.org/10.3390/s22145222
Burns D, Boyer P, Arrowsmith C, Whyne C. Personalized Activity Recognition with Deep Triplet Embeddings. Sensors. 2022; 22(14):5222. https://doi.org/10.3390/s22145222
Chicago/Turabian StyleBurns, David, Philip Boyer, Colin Arrowsmith, and Cari Whyne. 2022. "Personalized Activity Recognition with Deep Triplet Embeddings" Sensors 22, no. 14: 5222. https://doi.org/10.3390/s22145222
APA StyleBurns, D., Boyer, P., Arrowsmith, C., & Whyne, C. (2022). Personalized Activity Recognition with Deep Triplet Embeddings. Sensors, 22(14), 5222. https://doi.org/10.3390/s22145222