
Vulnerable Road Users and Connected Autonomous Vehicles Interaction: A Survey



Abstract
:1. Introduction
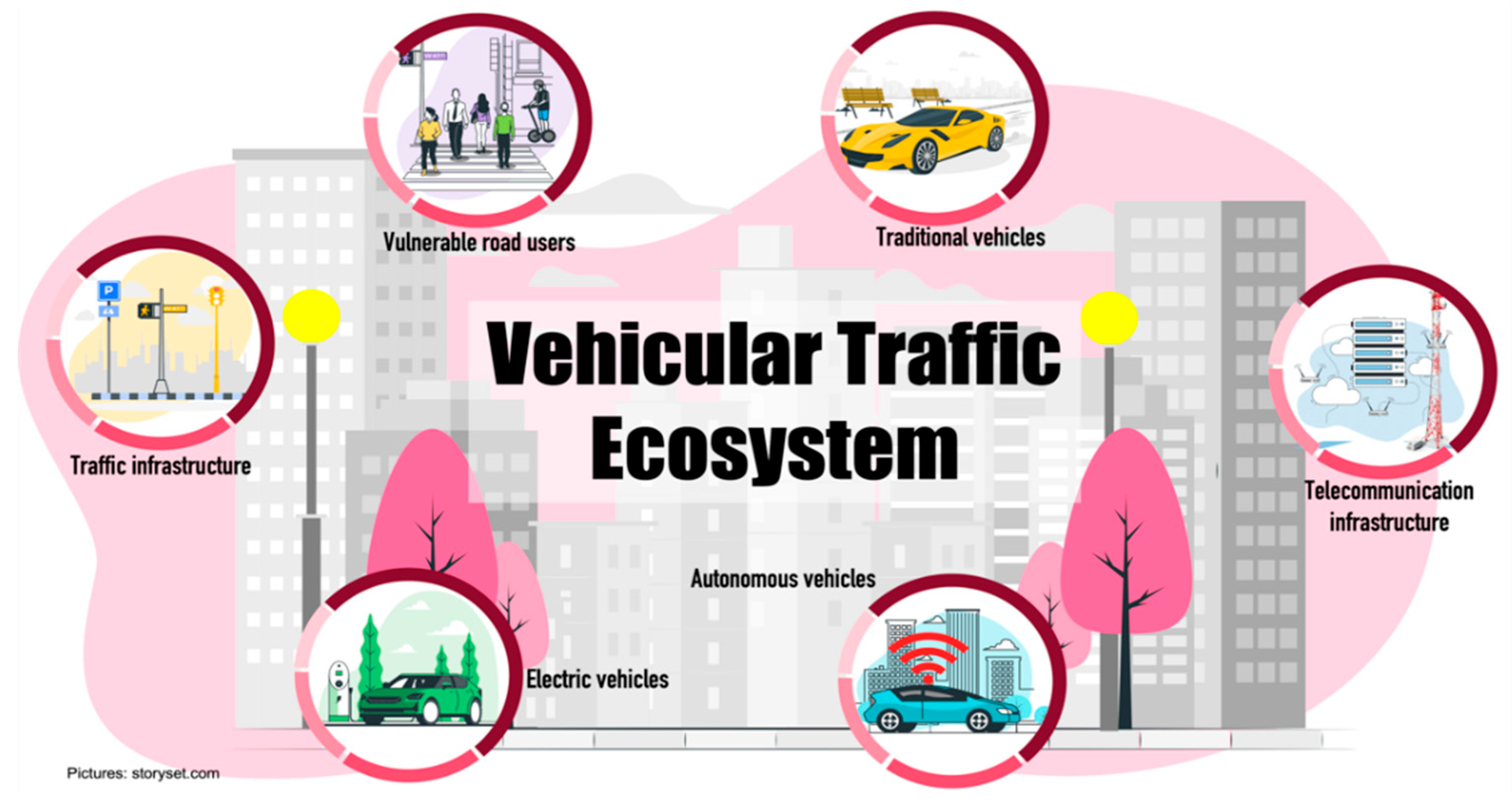
2. Vehicular Traffic Ecosystem
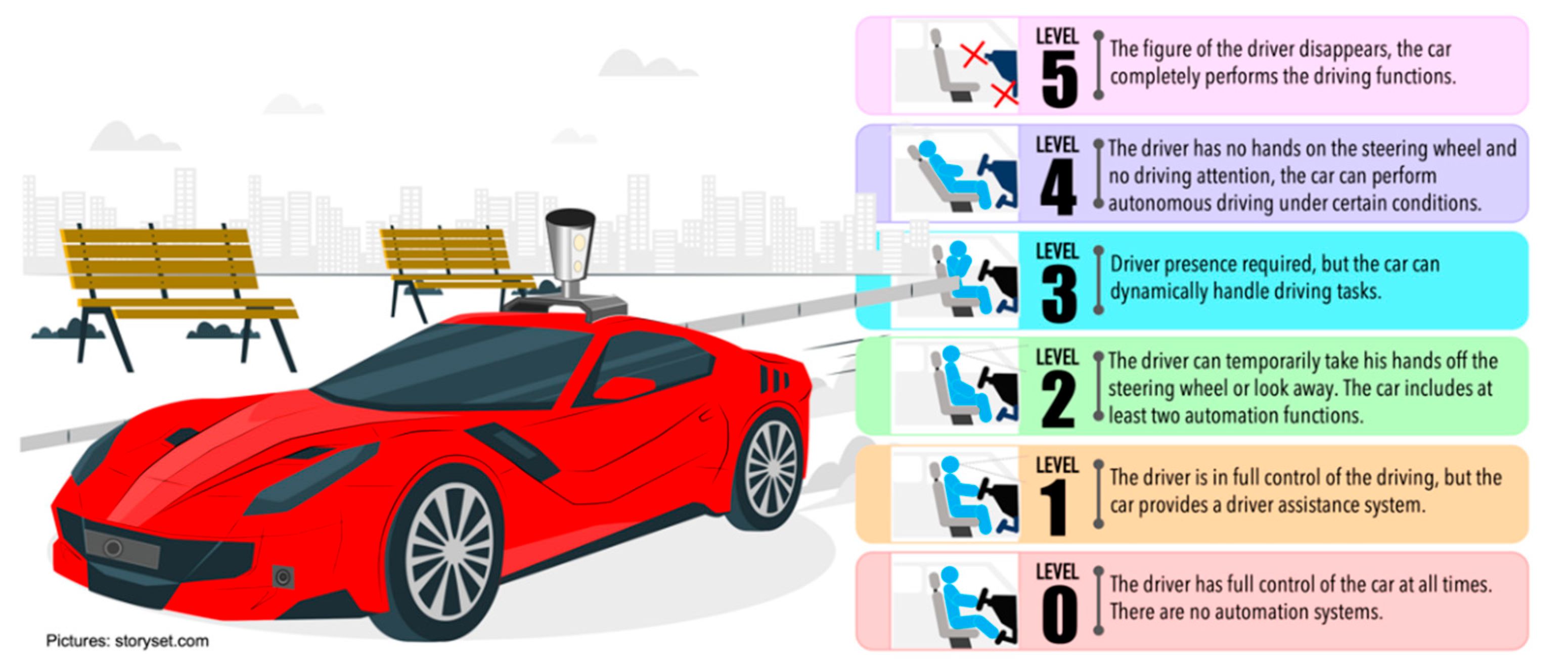
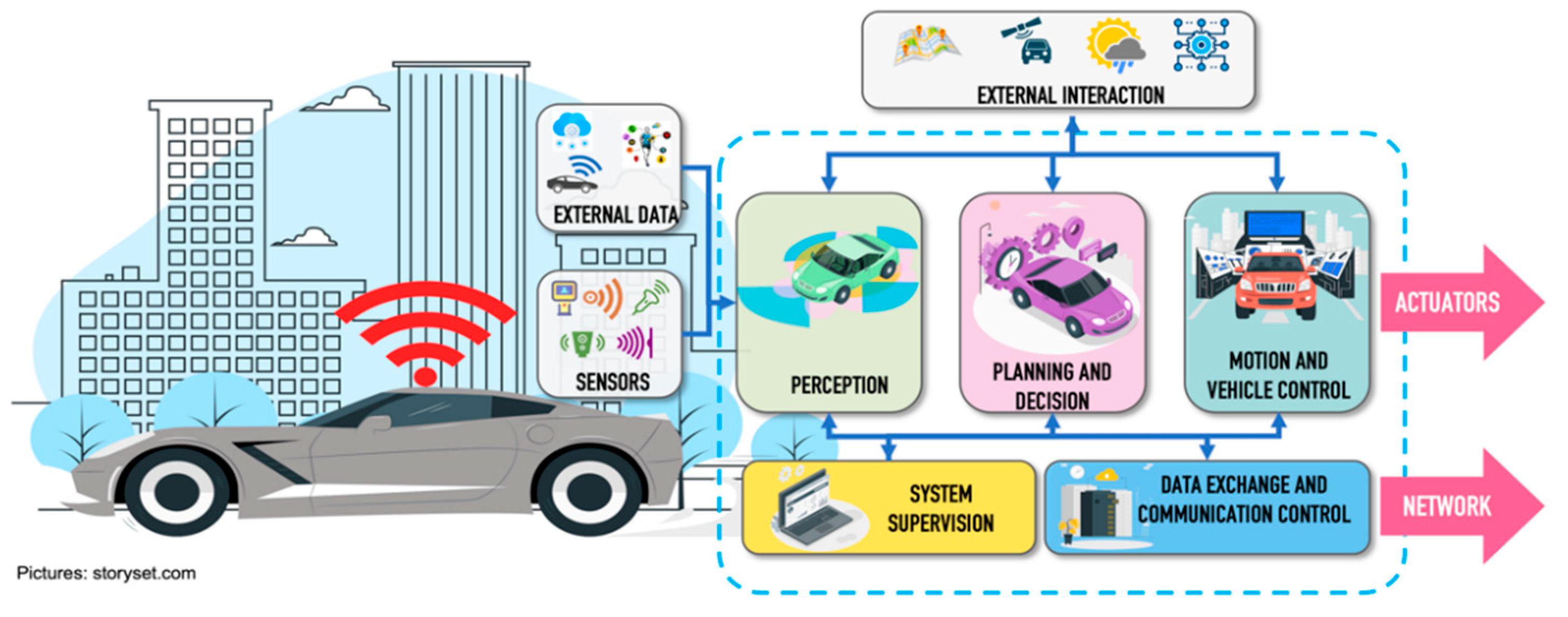
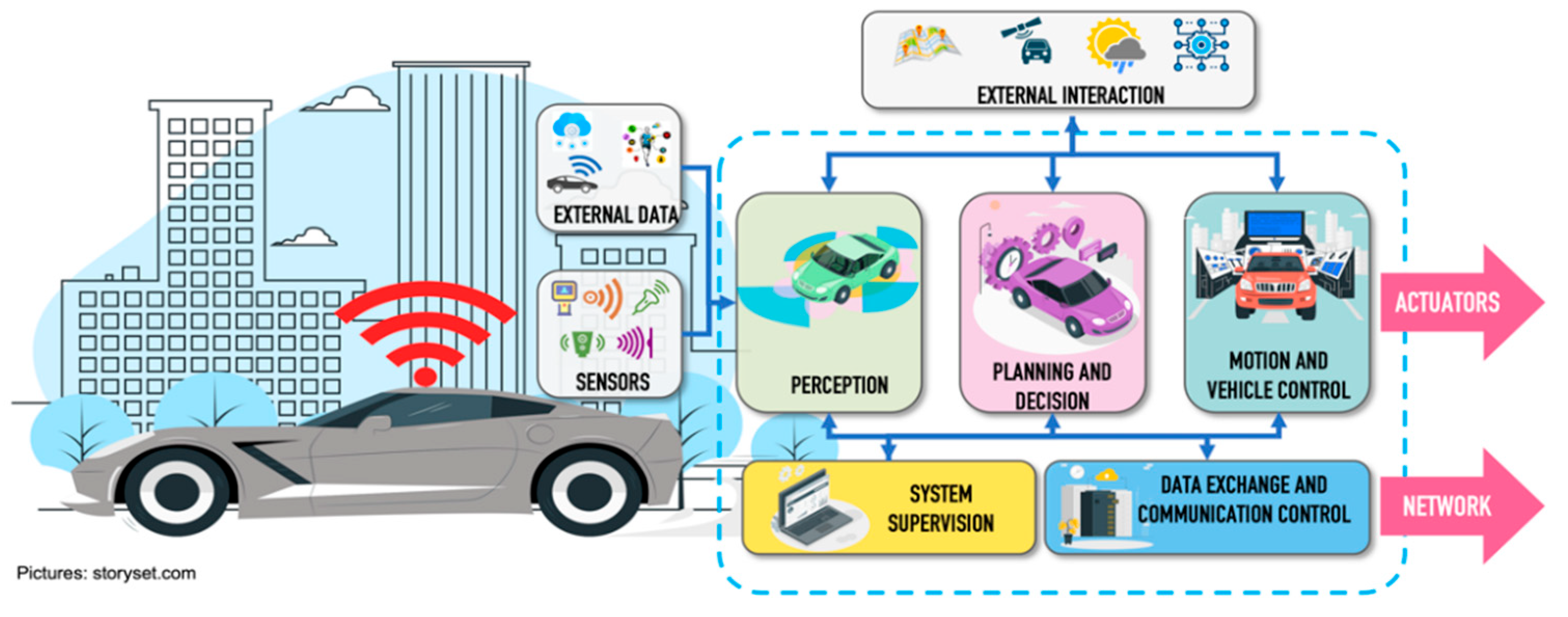
2.1. Connected Autonomous Vehicles (CAVs)
- Perception block. The function of the perception block is to create a representative model of the world surrounding the vehicle through the data received, both by the sensors installed in the vehicle, as well as external data generated by other elements of the ecosystem (pedestrian wearable networks, road side units, infrastructure, data processed in cloud services or fog). It also uses static data from the environment (such as digital maps, rules, routes) or environmental conditions (weather conditions and exact position in real time). The main perception tasks are object detection, localization, and object tracking. Localization integrates data from different sources, such as LiDAR (Light Detection and Ranging), Global Positioning System and Inertial Measurement Unit to increase the accuracy of the result. The implementation of particle filters are widely used for localization systems and have been shown to achieve accuracy levels of up to 10 cm [9,10,11,12]. Object detection consists of identifying and classifying the different objects, through the application of intelligent algorithms, which are detected through the set of sensors implemented in the CAVs. Trajectory tracking consists of identifying and predicting the possible path that an object will follow when it is in motion to avoid a risky situation.
- Planning and decision block. The purpose of this block is to generate the navigation plan for the vehicle, with the representative model of the world created within the perception block, and data information such as destination point, traffic rules, and maps, among others. This system must make a series of decisions to generate a safe and efficient real-time action plan. Its three main tasks are prediction, route planning and obstacle avoidance. Prediction is related to the function that the vehicle must perform to ensure that it can move safely within the driving environment [13]. Route planning focuses on defining the path to be followed by the vehicle within a dynamic traffic environment. To generate the movement plan, there are several context factors such as the state of the vehicle (speed, direction of movement, geo-reference, etc.), information from the vehicle’s travel environment (dynamic and static obstacles, driving spaces, etc.) and traffic regulations. Context factors help to create a safe travel path searching for all possible paths and filter them to select the best movement alternative. However, this type of evaluation and discrimination demands a large number of computational resources, which could affect the response time of the navigation plan. Generally, solutions are based on trajectory optimization through computationally intensive algorithms, trying to find a balance between optimization and computational time [14,15]. Obstacle avoidance refers to avoiding a collision situation with other elements located within the driving environment that endanger the safety of people. Through productive actions based on traffic predictions, measurements of minimum distances or time to collision with the object are used by the obstacle avoidance systems to make appropriate decisions and re-plan the navigation route of the vehicle. Reactive actions can make use of radar sensor data to avoid the detected obstacles.
- Motion and vehicle control. This block is in charge of the execution of the trajectory generated in the previous block through motion commands that control actuators inside the vehicle.
- System supervision. This block oversees checking the correct operation of hardware and software components of the vehicle to maintain the safety of all road users. It is based on the ISO (International Organization for Standardization) 26,262 functional safety standard [16], which is an adaptation of the IEC (International Electrotechnical Commission) 61,508 standard [17].
- Data exchange and communication control. This block is responsible for managing the entire data exchange process with the other elements of the road traffic ecosystem. All information travels over the network using one or more radio interfaces.
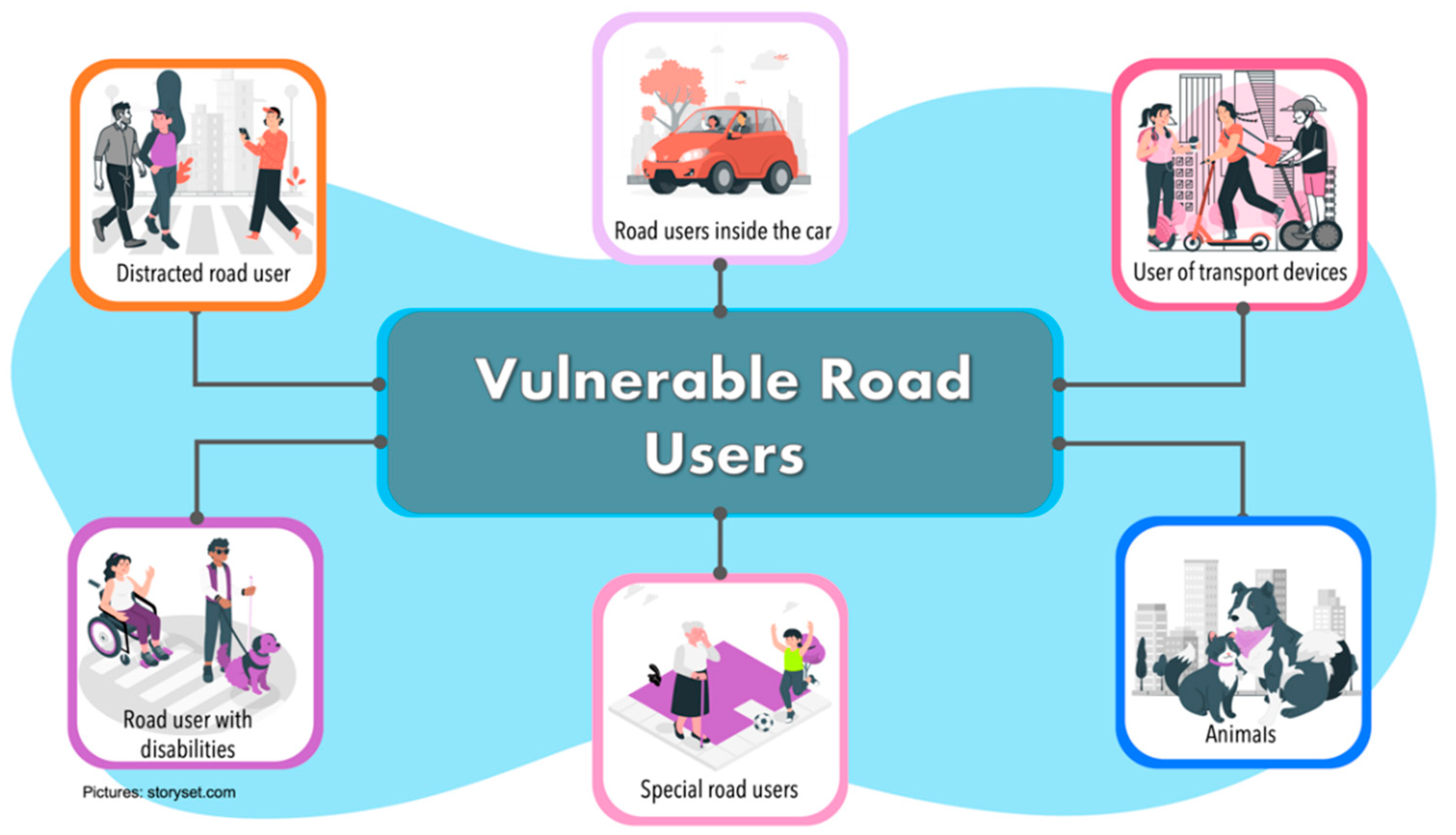
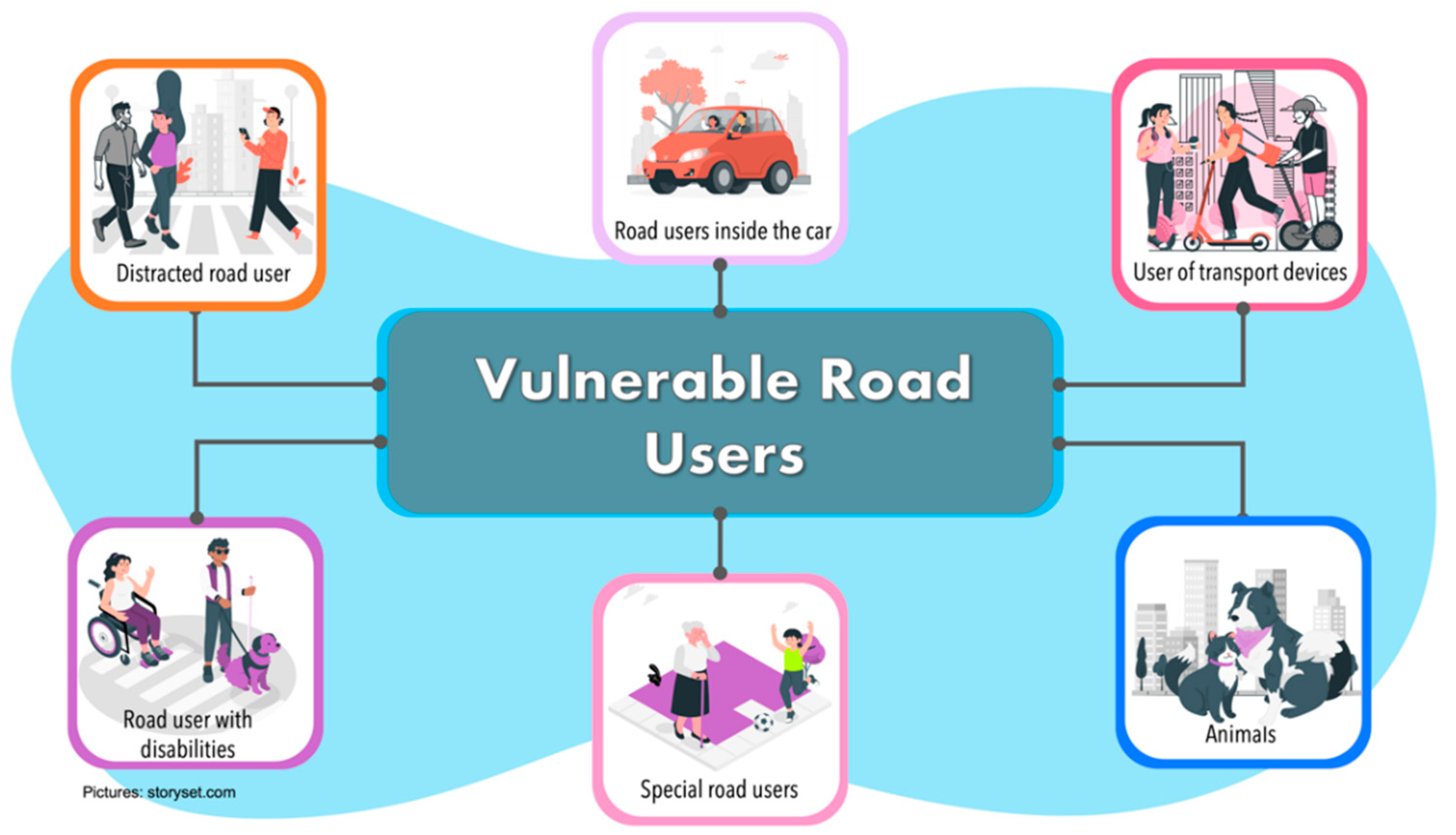
2.2. Vulnerable Road Users (VRUs)
- Distracted road users. They are the type of pedestrians walking in the road traffic ecosystem, who are distracted by some extra activity they are doing. Gen-erally, the activity they are doing may be using a cell phone, conversing with an-other person, or thinking about something else.
- Road users inside the vehicle. We refer to passengers of a CAVs or drivers of a traditional vehicle. People into the car could be elderly or sick people who could suffer an eventuality while traveling. Passengers/drivers can be continuously monitored through Body Sensor Networks or through monitoring devices such as cameras or sensors that are implemented in the steering wheel. These sensors al-ways verify the driver’s conditions and can detect risk situations (fatigue, stress, distraction, among others). On the other hand, passengers in a CAVs can also be monitored through sensors implemented in the seats to detect physiological changes that lead to risky situations.Kjh.
- Special road users. This category refers to people who have a very low travel speed, including elderly and children. They are the most at risk within a road en-vironment. Around half of accident pedestrian occurs at sites remote from cross-ing facilities, with many occurring when parked vehicles obscured driver vision. Children appear suddenly to cross the road while being masked by stationary ve-hicles, failing to look properly, or being careless. Elderly tends to move slowly and are more likely to be less able to judge the path and speed of vehicle.
- Users of transport devices. In recent years, there has been a trend to decrease the usage of cars and use lighter modes of transportation, especially for the last mile. For this reason, this category refers to users in a transport device who are not pro-tected by and external mechanism, such as skates, scooters, roller skis or skates as well as by kick sleds or kick sleds equipped with wheels.
- Animals. They are all types of animals that could be within the road driving zone, such as cats, dogs, horses, among others.
- Road users with disabilities. These are the type of pedestrians moving through the road traffic ecosystem but who have a disability (such as blind people, deaf people, people in wheelchairs or people with assistive devices such as canes, crutches, etc.).
3. CAVs and VRUs Interaction
3.1. CAVs-VRU Interaction Process
3.2. Technologies for Interaction between CAVs-VRUs
3.2.1. Sensing Technology
- Short-range radars are used in functions such as blind-spot monitoring, lane-keep assistance, and parking assistance.
- Medium-range radars are implemented for obstacle detection functions within the range of 100 to 150 m and the beam angle varies between 30° and 160°.
- Long-range radars are used for automatic distance control and brake assistance.
3.2.2. Software Technology
Machine Learning and Deep Learning
Computer Vision
Augmented Reality
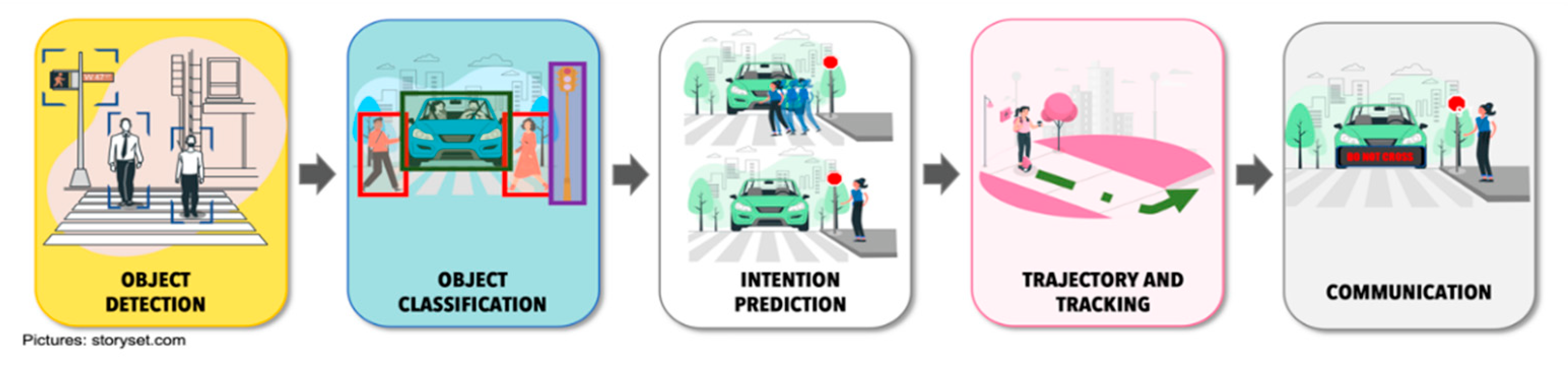
4. Stages for CAVs-VRU Interaction
4.1. Object Detection and Classification
4.2. Intention Prediction
4.3. Trajectory and Tracking
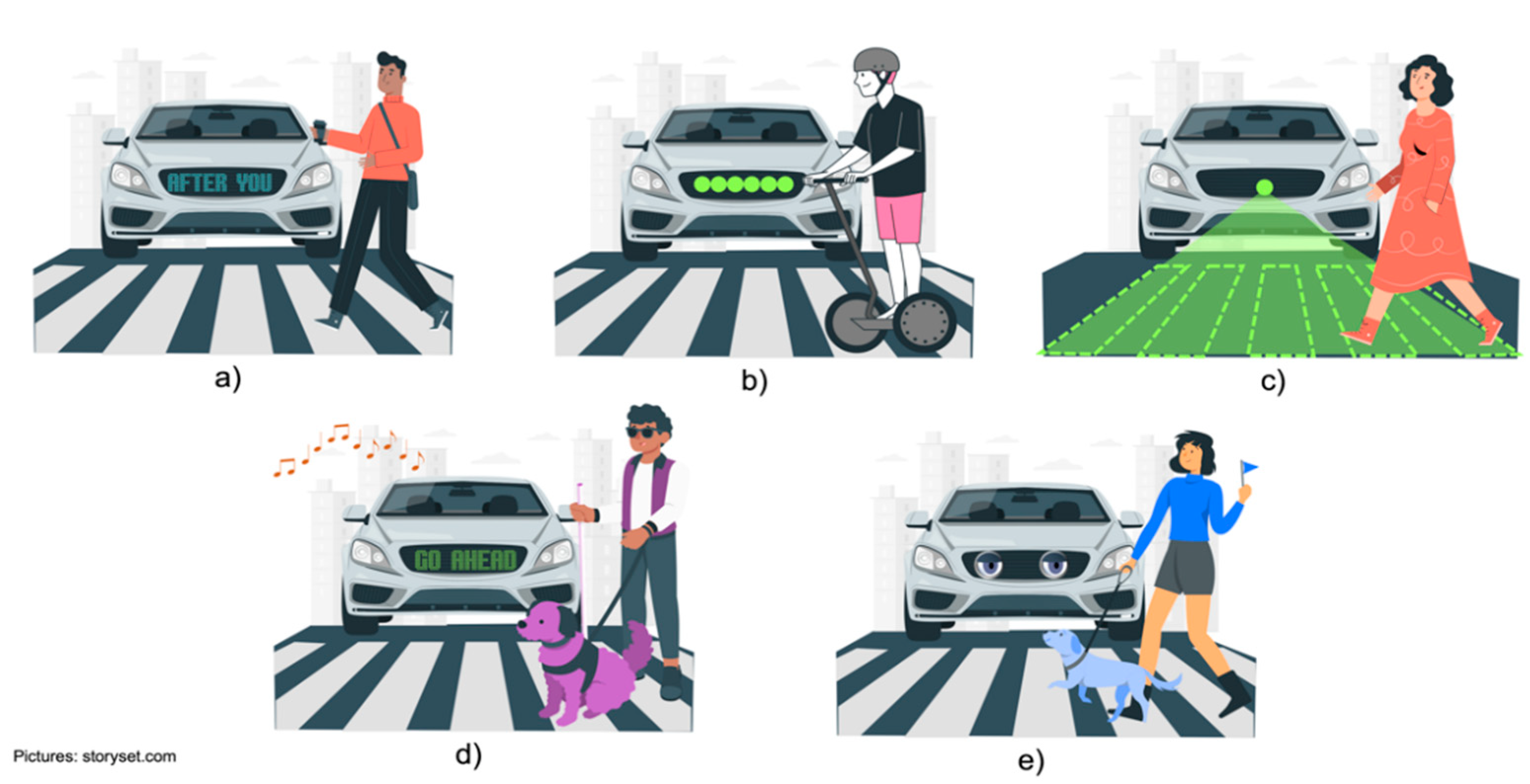
4.4. Intention Communication Interfaces
5. Challenges in the ACs-VRU Interaction
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- The World Bank. Urban Development. 2020. Available online: https://www.worldbank.org/en/topic/urbandevelopment/overview#1 (accessed on 22 April 2022).
- NHTSA. Automated Vehicle for Safety. National Highway Traffic Safety Administration. 2021. Available online: https://www.nhtsa.gov/technology-innovation/automated-vehicles-safety (accessed on 14 June 2022).
- NHTSA. Vehicle Manufactures, Automated Driving Systems. National Highway Traffic Safety Administration. 2021. Available online: https://www.nhtsa.gov/vehicle-manufacturers/automated-driving-systems (accessed on 14 June 2022).
- Thomas, E.; McCrudden, C.; Wharton, Z.; Behera, A. Perception of autonomous vehicles by the modern society: A survey. IET Intell. Transp. Syst. 2020, 14, 1228–1239. [Google Scholar] [CrossRef]
- Precedence Research. Autonomous Vehicle Market (By Application: Defense and Transportation (Commercial and Industrial))-Global Industry Analysis, Size, Share, Growth, Trends, Regional Outlook, and Forecast 2022–2030. Precedence Research, 2022. Available online: https://www.precedenceresearch.com/autonomous-vehicle-market (accessed on 14 May 2022).
- Society of Automotive Engineers. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. 2014. Available online: https://www.sae.org/standards/content/j3016_202104/ (accessed on 14 May 2022).
- Shuttleworth, J. SAE Standards News: J3016 Automated-Driving Graphic Update. 2019. Available online: https://www.sae.org/news/2019/01/sae-updates-j3016-automated-driving-graphic (accessed on 22 April 2022).
- Velasco-Hernandez, G.; Yeong, D.J.; Barry, J.; Walsh, J. Autonomous Driving Architectures, Perception and Data Fusion: A Review. In Proceedings of the IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP 2020), Cluj-Napoca, Romania, 3–5 September 2020. [Google Scholar] [CrossRef]
- Chen, X.; Läbe, T.; Nardi, L.; Behley, J.; Stachniss, C. Learning an Overlap-Based Observation Model for 3D LiDAR Localization. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021. [Google Scholar] [CrossRef]
- Kümmerle, R.; Ruhnke, M.; Steder, B.; Stachniss, C.; Burgard, W. Autonomous Robot Navigation in Highly Populated Pedestrian Zones. J. Field Robot. 2014, 32, 565–589. [Google Scholar] [CrossRef]
- Sun, K.; Adolfsson, D.; Magnusson, M.; Andreasson, H.; Posner, I.; Duckett, T. Localising Faster: Efficient and precise lidar-based robot localisation in large-scale environments. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Yan, F.; Vysotska, O.; Stachniss, C. Global Localization on OpenStreetMap Using 4-bit Semantic Descriptors. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Galceran, E.; Cunningham, A.G.; Eustice, R.M.; Olson, E. Multipolicy decision-making for autonomous driving via changepoint-based behavior prediction: Theory and experiment. Auton. Robot. 2017, 41, 1367–1382. [Google Scholar] [CrossRef]
- Janson, L.; Pavone, M. Fast Marching Trees: A Fast Marching Sampling-Based Method for Optimal Motion Planning in Many Dimensions. In Robotics Research: The 16th International Symposium ISRR; Inaba, M., Corke, P., Eds.; Springer International Publishing: Cham, Germany, 2016; pp. 667–684. [Google Scholar] [CrossRef]
- Artuñedo, A.; Villagra, J.; Godoy, J. Real-Time Motion Planning Approach for Automated Driving in Urban Environments. IEEE Access 2019, 7, 180039–180053. [Google Scholar] [CrossRef]
- ISO 26262-1:2011; Road Vehicles—Functional Safety. International Organization for Standardization, ISO: Geneve, Switzerland, 2018. Available online: https://www.iso.org/standard/68383.html (accessed on 14 May 2022).
- IEC 61508-1 Ed. 2.0 b; 2010 Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems-Part 1: General Requirements. American National Standards Institute (ANSI): New York, NY, USA, 2010; 6p. Available online: https://webstore.ansi.org/standards/iec/iec61508ed2010?gclid=Cj0KCQjw6pOTBhCTARIsAHF23fIpwY8sN37JRD-u3ijpXm67xVbBgxBpVP_cU2pqc4XTWhk2waP0CvsaAoWMEALw_wcB (accessed on 14 May 2022).
- Reyes-Muñoz, A.; Domingo, M.C.; López-Trinidad, M.A.; Delgado, J.L. Integration of Body Sensor Networks and Vehicular Ad-hoc Networks for Traffic Safety. Sensors 2016, 16, 107. [Google Scholar] [CrossRef]
- Reyes, A.; Barrado, C.; Lopez Trinidad, M.; Excelente, C. Vehicle density in VANET applications. J. Ambient. Intell. Smart Environ. 2014, 6, 469. [Google Scholar] [CrossRef] [Green Version]
- Hota, L.; Nayak, B.P.; Kumar, A.; Sahoo, B.; Ali, G.M.N. A Performance Analysis of VANETs Propagation Models and Routing Protocols. Sustainability 2022, 14, 1379. [Google Scholar] [CrossRef]
- Zeadally, S.; Guerrero, J.; Contreras, J. A tutorial survey on vehicle-to-vehicle communications. Telecommun. Syst. 2020, 73, 469–489. [Google Scholar] [CrossRef]
- Guerrero-ibanez, J.A.; Zeadally, S.; Contreras-Castillo, J. Integration challenges of intelligent transportation systems with connected vehicle, cloud computing, and internet of things technologies. IEEE Wirel. Commun. 2015, 22, 122–128. [Google Scholar] [CrossRef]
- Tahir, M.N.; Katz, M.; Rashid, U. Analysis of VANET Wireless Networking Technologies in Realistic Environments. In Proceedings of the 2021 IEEE Radio and Wireless Symposium (RWS), San Diego, CA, USA, 17–22 January 2021; pp. 123–125. [Google Scholar] [CrossRef]
- Tahir, M.N.; Katz, M.; Rashid, U. Analysis of collaborative wireless vehicular technologies under realistic conditions. J. Eng. 2022, 2022, 201–209. [Google Scholar] [CrossRef]
- Ptak, M. Method to Assess and Enhance Vulnerable Road User Safety during Impact Loading. Appl. Sci. 2019, 9, 1000. [Google Scholar] [CrossRef] [Green Version]
- Carsten, O. Road Network Operations & Intelligent Transport Systems; Institute for Transport Studies, University of Leeds: Leeds, UK, 2015; Available online: https://rno-its.piarc.org/sites/rno/files/public/pdf/piarc_road_safety_2016_09_13_v1.pdf (accessed on 14 May 2022).
- European Commission. ITS & Vulnerable Road Users. 2015. Available online: https://transport.ec.europa.eu/transport-themes/intelligent-transport-systems/road/action-plan-and-directive/its-vulnerable-road-users_en (accessed on 14 May 2022).
- OECD. Safety of Vulnerable Road Users. Organisation for Economic Co-operation and Development, DSTI/DOT/RTR/RS7(98)1/FINAL. 1998. Available online: https://www.oecd.org/officialdocuments/publicdisplaydocumentpdf/?cote=DSTI/DOT/RTR/RS7(98)1/FINAL&docLanguage=En (accessed on 14 May 2022).
- Fuest, T.; Sorokin, L.; Bellem, H.; Bengler, K. Taxonomy of Traffic Situations for the Interaction between Automated Vehicles and Human Road Users. In Advances in Human Aspects of Transportation. AHFE 2017. Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2017; Volume 597, pp. 708–719. [Google Scholar]
- Ren, Z.; Jisng, X.; Wang, W. Analysis of the Influence of Pedestrians’ eye Contact on Drivers’ Comfort Boundary During the Crossing Conflict. Procedia Eng. 2016, 137, 399–406. [Google Scholar] [CrossRef] [Green Version]
- Guéguen, N.; Meineri, S.; Eyssartier, C. A pedestrian’s stare and drivers’ stopping behavior: A field experiment at the pedestrian crossing. Saf. Sci. 2015, 75, 87–89. [Google Scholar] [CrossRef]
- Casner, S.M.; Hutchins, E.L.; Norman, D. The Challenges of Partially Automated Driving. Commun. ACM 2016, 59, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Rothenbücher, D.; Li, J.; Sirkin, D.; Mok, B.; Ju, W. Ghost driver: A field study investigating the interaction between pedestrians and driverless vehicles. In Proceedings of the IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016. [Google Scholar] [CrossRef]
- Mahadevan, K.; Somanath, S.; Sharlin, E. Communicating Awareness and Intent in Autonomous Vehicle-Pedestrian Interaction. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Y.; Su, Y. Roadview: A traffic scene simulator for autonomous vehicle simulation testing. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1160–1165. [Google Scholar] [CrossRef]
- Keller, C.; Gavrila, D. Will the Pedestrian Cross? A Study on Pedestrian Path Prediction. IEEE Trans. Intell. Transp. Syst. 2013, 15, 494–506. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Sentouh, C.; Pepieul, J.-C.; Haué, J.-B.; Langlois, S.; Loeillet, J.-J.; Soualmi, B.; Nguyen, T. Cooperation between driver and automated driving system: Implementation and evaluation. Transp. Res. Part F Traffic Psychol. Behav. 2017, 61, 314–325. [Google Scholar] [CrossRef]
- Morris, B. Identifying E/E Architecture Requirements for Autonomous Vehicle Development. EE Times, March 2021. Available online: https://www.eetasia.com/identifying-e-e-architecture-requirements-for-autonomous-vehicle-development/ (accessed on 14 May 2022).
- Ziegler, J.; Bender, P.; Schreiber, M.; Lategahn, H.; Strauss, T.; Stiller, C.; Dang, T. Making Bertha Drive—An Autonomous Journey on a Historic Route. IEEE Intell. Transp. Syst. Mag. 2014, 6, 8–20. [Google Scholar] [CrossRef]
- Hussain, R.; Zeadally, S. Autonomous Cars: Research Results, Issues, and Future Challenges. IEEE Commun. Surv. Tutor. 2018, 21, 1275–1313. [Google Scholar] [CrossRef]
- YOLE Developpement. MEMS and Sensors for Automotive: From Technologies to Market. August 2017. Available online: https://www.systemplus.fr/wp-content/uploads/2017/10/Yole_MEMS_and_sensors_for_automotive_2017-Sample.pdf (accessed on 14 May 2022).
- Zou, G.; He, B.; Zhu, M.; Zhang, L.; Zhang, J. Learning motion field of LiDAR point cloud with convolutional networks. Pattern Recognit. Lett. 2019, 125, 514–520. [Google Scholar] [CrossRef]
- Jung, J.; Che, E.; Olsen, M.J.; Parrish, C. Efficient and robust lane marking extraction from mobile Lidar point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 1–18. [Google Scholar] [CrossRef]
- Wang, H.; Lou, X.; Cai, Y.; Chen, L. A 64-Line Lidar-Based Road Obstacle Sensing Algorithm for Intelligent Vehicles. Sci. Program. 2018, 2018, 6385104. [Google Scholar] [CrossRef]
- Wang, H.; Wang, B.; Liu, B.; Meng, X.; Yang, G. Pedestrian recognition and tracking using 3D LiDAR for autonomous vehicle. Robot. Auton. Syst. 2017, 88, 71–78. [Google Scholar] [CrossRef]
- Sjafrie, H. Introduction to Self-Driving Vehicle Technology; Chapman & Hall/CRC Artificial Intelligence and Robotics; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Buller, W.; Wilson, B.; Garbarino, J.; Kelly, J.; Thelen, B.; Belzowski, B.M. Radar Congestion Study; National Highway Traffic Safety Administration: Washington, DC, USA, 2018; pp. 1–87. [Google Scholar]
- Reina, G.; Johnson, D.; Underwood, J. Radar Sensing for Intelligent Vehicles in Urban Environments. Sensors 2015, 2015, 14661–14678. [Google Scholar] [CrossRef] [Green Version]
- Miller, J.W.; Murphey, Y.L.; Khairallah, F. Camera performance considerations for automotive applications. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 February 2004. [Google Scholar] [CrossRef]
- Wang, W.; Chen, C.; Hung, Y. Tracking by Parts: A Bayesian Approach with Component Collaboration. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 39, 275–388. [Google Scholar] [CrossRef] [Green Version]
- Vatavu, A.; Danescu, R.; Nedevschi, S. Stereovision-based multiple object tracking in traffic scenarios using free-form obstacle delimiters and particle filters. IEEE Trans. Intell. Transp. Syst. 2015, 16, 498–511. [Google Scholar] [CrossRef]
- Bhoi, A. Monocular Depth Estimation: A Survey. arXiv 2019, arXiv:1901.09402. [Google Scholar]
- Garg, R.; Wadhwa, N.; Ansari, S.; Barron, J.T. Learning Single Camera Depth Estimation using Dual-Pixels. arXiv 2019, arXiv:1904.05822. [Google Scholar]
- Cronin, C.; Conway, A.; Walsh, J. State-of-the-Art Review of Autonomous Intelligent Vehicles (AIV) Technologies for the Automotive and Manufacturing Industry. In Proceedings of the 2019 30th Irish Signals and Systems Conference (ISSC), Maynooth, Ireland, 17–18 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Rajeev Thakur ED1-Ruby Srivastava. Infrared Sensors for Autonomous Vehicles. In Recent Development in Optoelectronic Devices; IntechOpen: Rijeka, Yugoslavia, 2017; Chapter 5. [Google Scholar] [CrossRef] [Green Version]
- Gade, R.; Moeslund, T. Thermal cameras and applications: A survey. Mach. Vis. Appl. 2013, 25, 245–262. [Google Scholar] [CrossRef] [Green Version]
- Vargas, J.; Alsweiss, S.; Toker, O.; Razdan, R.; Santos, J. An Overview of Autonomous Vehicles Sensors and Their Vulnerability to Weather Conditions. Sensors 2021, 21, 5397. [Google Scholar] [CrossRef] [PubMed]
- Cotra, M. WTF Is Sensor Fusion? The Good Old Kalman Filter. 2017. Available online: https://towardsdatascience.com/wtf-is-sensor-fusion-part-2-the-good-old-kalman-filter-3642f321440 (accessed on 14 May 2022).
- Banerjee, K.; Notz, D.; Windelen, J.; Gavarraju, S.; He, M. Online Camera LiDAR Fusion and Object Detection on Hybrid Data for Autonomous Driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; p. 1638. [Google Scholar] [CrossRef]
- Udacity Team. Sensor Fusion Algorithms Explained. August 2020. Available online: https://www.udacity.com/blog/2020/08/sensor-fusion-algorithms-explained.html (accessed on 14 May 2022).
- Xue, H.; Zhang, M.; Yu, P.; Zhang, H.; Wu, G.; Li, Y.; Zheng, X. A Novel Multi-Sensor Fusion Algorithm Based on Uncertainty Analysis. Sensors 2021, 21, 2713. [Google Scholar] [CrossRef] [PubMed]
- Conde, M.E.; Cruz, S.; Muñoz, D.; Llanos, C.; Fortaleza, E. An efficient data fusion architecture for infrared and ultrasonic sensors, using FPGA. In Proceedings of the 2013 IEEE 4th Latin American Symposium on Circuits and Systems (LASCAS), Cusco, Peru, 27 February–1 March 2013; p. 4. [Google Scholar] [CrossRef]
- Bertozzi, M.; Broggi, A.; Fascioli, A.; Tibaldi, A.; Chapuis, R.; Chausse, F. Pedestrian localization and tracking system with Kalman filtering. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 584–589. [Google Scholar] [CrossRef]
- Kouskoulis, G.; Antoniou, C.; Spyropoulou, I. A method for the treatment of pedestrian trajectory data noise. Transp. Res. Procedia 2019, 41, 782–798. [Google Scholar] [CrossRef]
- Guo, L.; Li, L.; Zhao, Y.; Zhao, Z. Pedestrian Tracking Based on Camshift with Kalman Prediction for Autonomous Vehicles. Int. J. Adv. Robot. Syst. 2016, 13, 1. [Google Scholar] [CrossRef] [Green Version]
- Smaili, C.; Najjar, M.E.E.; Charpillet, F. Multi-sensor Fusion Method Using Dynamic Bayesian Network for Precise Vehicle Localization and Road Matching. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, 29–31 October 2007; Volume 1, pp. 146–151. [Google Scholar] [CrossRef] [Green Version]
- Věchet, S.; Krejsa, J. Sensors Data Fusion via Bayesian Network. In Recent Advances in Mechatronics; Brezina, T., Jablonski, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 221–226. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Cho, J. An advanced object classification strategy using YOLO through camera and LiDAR sensor fusion. In Proceedings of the 2019 13th International Conference on Signal Processing and Communication Systems (ICSPCS), Gold Coast, QLD, Australia, 16–18 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, D.; Anguelov, D.; Jain, A. PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation. arXiv 2017, arXiv:1711.10871. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. arXiv 2016, arXiv:1612.00593. [Google Scholar]
- Barsce, J.C.; Palombarini, J.A.; Martinez, E.C. Towards autonomous reinforcement learning: Automatic setting of hyper-parameters using Bayesian optimization. In Proceedings of the XLIII Latin American Computer Conference (CLEI), Cordoba, Argentina, 4–8 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Costela, F.M.; Castro-Torres, J.J. Risk prediction model using eye movements during simulated driving with logistic regressions and neural networks. Transp. Res. Part F Traffic Psychol. Behav. 2020, 74, 511–521. [Google Scholar] [CrossRef]
- Völz, B.; Mielenz, R.; Siegwart, R.; Nieto, J. Predicting pedestrian crossing using Quantile Regression forests. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 426–432. [Google Scholar] [CrossRef]
- Bougharriou, S. Linear SVM classifier based HOG car detection. In Proceedings of the 2017 18th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Monastir, Tunisia, 21–23 December 2017; pp. 241–245. [Google Scholar] [CrossRef]
- Ristea, N.-C.; Anghel, A.; Ionescu, R.; Eldar, C. Automotive Radar Interference Mitigation with Unfolded Robust PCA based on Residual Overcomplete Auto-Encoder Blocks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 3203–3208. [Google Scholar] [CrossRef]
- Tabrizi, S.; Cavus, N. A Hybrid KNN-SVM Model for Iranian License Plate Recognition. Procedia Comput. Sci. 2016, 102, 588–594. [Google Scholar] [CrossRef] [Green Version]
- Balavadi, S.S.; Beri, R.; Malik, V. Frontier Exploration Technique for 3D Autonomous SLAM Using K-Means Based Divisive Clustering. In Proceedings of the 2017 Asia Modelling Symposium (AMS), Kota Kinabalu, Malaysia, 4–6 December 2017. [Google Scholar] [CrossRef]
- Wang, W.; Ramesh, A.; Zhu, J.; Li, J.; Zhao, D. Clustering of Driving Encounter Scenarios Using Connected Vehicle Trajectories. IEEE Trans. Intell. Veh. 2020, 5, 485–496. [Google Scholar] [CrossRef] [Green Version]
- Proaño, C.; Villacís, C.; Proaño, V.; Fuertes, W.; Almache, M.; Zambrano, M.; Galárraga, F. Serious 3D Game over a Cluster Computing for Situated Learning of Traffic Signals. In Proceedings of the 2019 IEEE/ACM 23rd International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Cosenza, Italy, 7–9 October 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Bogdal, C.; Schellenberg, R.; Höpli, O.; Bovens, M.; Lory, M. Recognition of gasoline in fire debris using machine learning: Part I, application of random forest, gradient boosting, support vector machine, and naïve bayes. Forensic Sci. Int. 2022, 331, 111146. [Google Scholar] [CrossRef]
- Guo, L.; Ge, P.-S.; Zhang, M.-H.; Li, L.-H.; Zhao, Y.-B. Pedestrian detection for intelligent transportation systems combining AdaBoost algorithm and support vector machine. Expert Syst. Appl. 2012, 39, 4274–4286. [Google Scholar] [CrossRef]
- Yakovlev, S.S.; Borisov, A. A synergy of the Rosenblatt perceptron and the Jordan recurrence principle. Autom. Control Comput. Sci. 2009, 43, 31–39. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Yoon, S.; Kum, D. The multilayer perceptron approach to lateral motion prediction of surrounding vehicles for autonomous vehicles. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1307–1312. [Google Scholar] [CrossRef]
- Heffernan, R.; Paliwal, K.; Lyons, J.; Dehzangi, A.; Sharma, A.; Wang, J.; Sattar, A.; Yang, Y.; Zhou, Y. Improving prediction of secondary structure, local backbone angles and solvent accessible surface area of proteins by iterative deep learning. Sci. Rep. 2015, 5, 11476. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Guo, X.; Wang, Y.; Ma, J.; Jiao, L.; Liu, F.; Liu, X. Region NMS-based deep network for gigapixel level pedestrian detection with two-step cropping. Neurocomputing 2022, 468, 482–491. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Nordhoff, S.; Stapel, J.; van Arem, B.; Happee, R. Passenger opinions of the perceived safety and interaction with automated shuttles: A test ride study with ‘hidden’ safety steward. Transp. Res. Part A Policy Pract. 2020, 138, 508–524. [Google Scholar] [CrossRef]
- Vogelpohl, T.; Kühn, M.; Hummel, T.; Gehlert, T.; Vollrath, M. Transitioning to manual driving requires additional time after automation deactivation. Transp. Res. Part F Traffic Psychol. Behav. 2018, 55, 464–482. [Google Scholar] [CrossRef]
- Heikoop, D.; de Winter, J.; Arem, B.; Stanton, N. Effects of platooning on signal-detection performance, workload, and stress: A driving simulator study. Appl. Ergon. 2016, 60, 116–127. [Google Scholar] [CrossRef] [Green Version]
- Bachute, M.R.; Subhedar, J.M. Autonomous Driving Architectures: Insights of Machine Learning and Deep Learning Algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Li, G.; Zong, C.; Liu, G.; Zhu, T. Application of Convolutional Neural Network (CNN)–AdaBoost Algorithm in Pedestrian Detection. Sens. Mater. 2020, 32, 1997–2006. [Google Scholar] [CrossRef]
- Zhang, Y.; Zou, Y.; Fan, H.; Liu, W.; Cui, Z. Pedestrian detection based on I-HOG feature. In Proceedings of the International Symposium on Artificial Intelligence and Robotics 2021, Fukuoka, Japan, 28 October 2021; Volume 11884, pp. 624–635. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, X. Research on Pedestrian Detection System based on Tripartite Fusion of “HOG + SVM + Median filter”. In Proceedings of the 2020 International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Beijing, China, 23–25 October 2020; pp. 484–488. [Google Scholar] [CrossRef]
- Ma, N.; Chen, L.; Hu, J.; Shang, Q.; Li, J.; Zhang, G. Pedestrian Detection Based on HOG Features and SVM Realizes Vehicle-Human-Environment Interaction. In Proceedings of the 2019 15th International Conference on Computational Intelligence and Security (CIS), Macao, China, 13–16 December 2019; pp. 287–291. [Google Scholar] [CrossRef]
- Li, W.; Su, H.; Pan, F.; Gao, Q.; Quan, B. A fast pedestrian detection via modified HOG feature. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 3870–3873. [Google Scholar] [CrossRef]
- Wang, M.-S.; Zhang, Z.-R. FPGA implementation of HOG based multi-scale pedestrian detection. In Proceedings of the 2018 IEEE International Conference on Applied System Invention (ICASI), Chiba, Japan, 13–17 April 2018; pp. 1099–1102. [Google Scholar] [CrossRef]
- Kim, S.; Cho, K. Trade-off between accuracy and speed for pedestrian detection using HOG feature. In Proceedings of the 2013 IEEE Third International Conference on Consumer Electronics ¿ Berlin (ICCE-Berlin), Berlin, Germany, 9–11 September 2013; pp. 207–209. [Google Scholar] [CrossRef]
- Mihçioğlu, M.E.; Alkar, A.Z. Improving pedestrian safety using combined HOG and Haar partial detection in mobile systems. Traffic Inj. Prev. 2019, 20, 619–623. [Google Scholar] [CrossRef] [PubMed]
- Yao, S.; Pan, S.; Wang, T.; Zheng, C.; Shen, W.; Chong, Y. A new pedestrian detection method based on combined HOG and LSS features. Neurocomputing 2015, 151, 1006–1014. [Google Scholar] [CrossRef]
- Li, J.; Zhao, Y.; Quan, D. The combination of CSLBP and LBP feature for pedestrian detection. In Proceedings of the 2013 3rd International Conference on Computer Science and Network Technology, Dalian, China, 12–13 October 2013; pp. 543–546. [Google Scholar] [CrossRef]
- Cao, J.; Sun, X.; Zhao, S.; Wang, Y.; Gong, S. Algorithm of moving object detection based on multifeature fusion. In Proceedings of the 2017 IEEE International Conference on Information and Automation (ICIA), Macao, China, 18–20 July 2017; pp. 931–935. [Google Scholar] [CrossRef]
- Lestari, R.F.; Nugroho, H.A.; Ardiyanto, I. Liver Detection Based on Iridology using Local Binary Pattern Extraction. In Proceedings of the 2019 2nd International Conference on Bioinformatics, Biotechnology and Biomedical Engineering (BioMIC)-Bioinformatics and Biomedical Engineering, Yogyakarta, Indonesia, 12–13 September 2019; Volume 1, pp. 1–6. [Google Scholar] [CrossRef]
- Liu, Y.-C.; Huang, S.-S.; Lu, C.-H.; Chang, F.-C.; Lin, P.-Y. Thermal pedestrian detection using block LBP with multi-level classifier. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 602–605. [Google Scholar] [CrossRef]
- Gan, G.; Cheng, J. Pedestrian Detection Based on HOG-LBP Feature. In Proceedings of the 2011 Seventh International Conference on Computational Intelligence and Security, Sanya, China, 3–4 December 2011; pp. 1184–1187. [Google Scholar] [CrossRef]
- Park, W.-J.; Kim, D.-H.; Suryanto; Lyuh, C.-G.; Roh, T.M.; Ko, S.-J. Fast human detection using selective block-based HOG-LBP. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 601–604. [Google Scholar] [CrossRef]
- Boudissa, A.; Tan, J.K.; Kim, H.; Ishikawa, S. A simple pedestrian detection using LBP-based patterns of oriented edges. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 469–472. [Google Scholar] [CrossRef]
- Cai, Y.; Liu, Z.; Sun, X.; Chen, L.; Wang, H. Research on pedestrian detection technology based on improved DPM model. In Proceedings of the 2017 IEEE 7th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Honolulu, HI, USA, 31 July–4 August 2017; pp. 216–219. [Google Scholar] [CrossRef]
- Shimbo, Y.; Kawanishi, Y.; Deguchi, D.; Ide, I.; Murase, H. Parts Selective DPM for detection of pedestrians possessing an umbrella. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 972–977. [Google Scholar] [CrossRef]
- Wong, B.-Y.; Hsieh, J.-W.; Hsiao, C.-J.; Chien, S.-C.; Chang, F.-C. Efficient DPM-Based Object Detection Using Shift with Importance Sampling. In Proceedings of the 2016 International Computer Symposium (ICS), Chiayi, Taiwan, 15–17 December 2016; pp. 339–344. [Google Scholar] [CrossRef]
- Mao, X.-J.; Zhao, J.-Y.; Yang, Y.-B.; Li, N. Enhanced deformable part model for pedestrian detection via joint state inference. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 941–945. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Wan, K. Research on Pedestrian Attitude Detection Algorithm from the Perspective of Machine Learning. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; pp. 1350–1356. [Google Scholar] [CrossRef]
- Hua, J.; Shi, Y.; Xie, C.; Zhang, H.; Zhang, J. Pedestrian- and Vehicle-Detection Algorithm Based on Improved Aggregated Channel Features. IEEE Access 2021, 9, 25885–25897. [Google Scholar] [CrossRef]
- Byeon, Y.-H.; Kwak, K.-C. A Performance Comparison of Pedestrian Detection Using Faster RCNN and ACF. In Proceedings of the 2017 6th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Hamamatsu, Japan, 9–13 July 2017; pp. 858–863. [Google Scholar] [CrossRef]
- Verma, A.; Hebbalaguppe, R.; Vig, L.; Kumar, S.; Hassan, E. Pedestrian Detection via Mixture of CNN Experts and Thresholded Aggregated Channel Features. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 555–563. [Google Scholar] [CrossRef]
- Song, H.; Jeong, B.; Choi, H.; Cho, T.; Chung, H. Hardware implementation of aggregated channel features for ADAS. In Proceedings of the 2016 International SoC Design Conference (ISOCC), Jeju, Korea, 23–26 October 2016; pp. 167–168. [Google Scholar] [CrossRef]
- Kokul, T.; Ramanan, A.; Pinidiyaarachchi, U.A.J. Online multi-person tracking-by-detection method using ACF and particle filter. In Proceedings of the 2015 IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 12–14 December 2015; pp. 529–536. [Google Scholar] [CrossRef]
- Kharjul, R.A.; Tungar, V.K.; Kulkarni, Y.P.; Upadhyay, S.K.; Shirsath, R. Real-time pedestrian detection using SVM and AdaBoost. In Proceedings of the 2015 International Conference on Energy Systems and Applications, Pune, India, 30 October–1 November 2015; pp. 740–743. [Google Scholar] [CrossRef]
- Xu, F.; Xu, F. Pedestrian Detection Based on Motion Compensation and HOG/SVM Classifier. In Proceedings of the 2013 5th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2013; Volume 2, pp. 334–337. [Google Scholar] [CrossRef]
- Narayanan, A.; Kumar, R.D.; RoselinKiruba, R.; Sharmila, T.S. Study and Analysis of Pedestrian Detection in Thermal Images Using YOLO and SVM. In Proceedings of the 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 25–27 March 2021; pp. 431–434. [Google Scholar] [CrossRef]
- Xu, Y.; Li, C.; Xu, X.; Jiang, M.; Zhang, J. A two-stage hog feature extraction processor embedded with SVM for pedestrian detection. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3452–3455. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Wang, S. Fast Pedestrian Detection with Attention-Enhanced Multi-Scale RPN and Soft-Cascaded Decision Trees. IEEE Trans. Intell. Transp. Syst. 2020, 21, 5086–5093. [Google Scholar] [CrossRef]
- Li, J.; Wu, Y.; Zhao, J.; Guan, L.; Ye, C.; Yang, T. Pedestrian detection with dilated convolution, region proposal network and boosted decision trees. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 4052–4057. [Google Scholar] [CrossRef]
- Alam, A.; Jaffery, Z.A. Decision Tree Classifier Based Pedestrian Detection for Autonomous Land Vehicle Development. In Proceedings of the 2019 International Conference on Power Electronics, Control and Automation (ICPECA), New Delhi, India, 16–17 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Ohn-Bar, E.; Trivedi, M.M. To boost or not to boost? On the limits of boosted trees for object detection. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3350–3355. [Google Scholar] [CrossRef] [Green Version]
- Correia, A.J.L.; Schwartz, W.R. Oblique random forest based on partial least squares applied to pedestrian detection. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2931–2935. [Google Scholar] [CrossRef]
- Kim, S.; Kwak, S.; Ko, B.C. Fast Pedestrian Detection in Surveillance Video Based on Soft Target Training of Shallow Random Forest. IEEE Access 2019, 7, 12415–12426. [Google Scholar] [CrossRef]
- Li, W.; Xu, Z.; Wang, S.; Ma, G. Pedestrian detection based on improved Random Forest in natural images. In Proceedings of the 2011 3rd International Conference on Computer Research and Development, Shanghai, China, 11–13 March 2011; Volume 4, pp. 468–472. [Google Scholar] [CrossRef]
- Xiang, T.; Li, T.; Ye, M.; Nie, X.; Zhang, C. A hierarchical method for pedestrian detection with random forests. In Proceedings of the 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, China, 19–23 October 2014; pp. 1241–1246. [Google Scholar] [CrossRef]
- Marín, J.; Vázquez, D.; López, A.M.; Amores, J.; Leibe, B. Random Forests of Local Experts for Pedestrian Detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2592–2599. [Google Scholar] [CrossRef]
- Xu, B.; Qiu, G. Crowd density estimation based on rich features and random projection forest. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Cheng, W.-C.; Jhan, D.-M. A self-constructing cascade classifier with AdaBoost and SVM for pedestriandetection. Eng. Appl. Artif. Intell. 2013, 26, 1016–1028. [Google Scholar] [CrossRef]
- Kong, K.-K.; Hong, K.-S. Design of coupled strong classifiers in AdaBoost framework and its application to pedestrian detection. Pattern Recognit. Lett. 2015, 68, 63–69. [Google Scholar] [CrossRef]
- Li, Y.; Cui, F.; Xue, X.; Cheung, W.; Chan, J. Coarse-to-fine salient object detection based on deep convolutional neural networks. Signal Process. Image Commun. 2018, 64, 21–32. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Mahmoudi, N.; Ahadi, S.M.; Mohammad, R. Multi-target tracking using CNN-based features: CNNMTT. Multimed. Tools Appl. 2019, 78, 7077–7096. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Jhong, S.-Y.; Li, G.-Y.; Chen, P.-H. Thermal-Based Pedestrian Detection Using Faster R-CNN and Region Decomposition Branch. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Dong, P.; Wang, W. Better region proposals for pedestrian detection with R-CNN. In Proceedings of the 2016 Visual Communications and Image Processing (VCIP), Chengdu, China, 27–30 November 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, H.; Du, Y.; Ning, S.; Zhang, Y.; Yang, S.; Du, C. Pedestrian Detection Method Based on Faster R-CNN. In Proceedings of the 2017 13th International Conference on Computational Intelligence and Security (CIS), Hong Kong, China, 15–18 December 2017; pp. 427–430. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-Aware Fast R-CNN for Pedestrian Detection. IEEE Trans. Multimed. 2018, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Chen, E.; Tang, X.; Fu, B. A Modified Pedestrian Retrieval Method Based on Faster R-CNN with Integration of Pedestrian Detection and Re-Identification. In Proceedings of the 2018 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 63–66. [Google Scholar] [CrossRef]
- Zhai, S.; Dong, S.; Shang, D.; Wang, S. An Improved Faster R-CNN Pedestrian Detection Algorithm Based on Feature Fusion and Context Analysis. IEEE Access 2020, 8, 138117–138128. [Google Scholar] [CrossRef]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An Improved Faster R-CNN for Small Object Detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 91–99. [Google Scholar]
- Sha, M.; Boukerche, A. Performance evaluation of CNN-based pedestrian detectors for autonomous vehicles. Ad Hoc Netw. 2022, 128, 102784. [Google Scholar] [CrossRef]
- Malbog, M.A. MASK R-CNN for Pedestrian Crosswalk Detection and Instance Segmentation. In Proceedings of the 2019 IEEE 6th International Conference on Engineering Technologies and Applied Sciences (ICETAS), Kuala Lumpur, Malaysia, 20–21 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, S.; Lv, S.; Zhang, H.; Gong, J. Pedestrian Detection Algorithm Based on the Improved SSD. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 3559–3563. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Grishick, R. Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.-Y.; Mark Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kong, Y.; Tao, Z.; Fu, Y. Deep Sequential Context Networks for Action Prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3662–3670. [Google Scholar] [CrossRef]
- Rasouli, A.; Kotseruba, Y.; Kunic, T.; Tsotsos, J. PIE: A Large-Scale Dataset and Models for Pedestrian Intention Estimation and Trajectory Prediction. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; p. 6270. [Google Scholar] [CrossRef]
- Kotseruba, I.; Rasouli, A.; Tsotsos, J.K. Joint Attention in Autonomous Driving (JAAD). arXiv 2016, arXiv:1609.04741. [Google Scholar]
- Razali, H.; Mordan, T.; Alahi, A. Pedestrian intention prediction: A convolutional bottom-up multi-task approach. Transp. Res. Part C Emerg. Technol. 2021, 130, 103259. [Google Scholar] [CrossRef]
- Xu, X. Pedestrian Trajectory Prediction via the Social-Grid LSTM Model. J. Eng. 2018, 2018, 1468–1474. [Google Scholar] [CrossRef]
- Amirian, J.; Hayet, J.-B.; Pettre, J. Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories with GANs. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; p. 2972. [Google Scholar] [CrossRef] [Green Version]
- Völz, B.; Mielenz, H.; Gilitschenski, I.; Siegwart, R.; Nieto, J. Inferring Pedestrian Motions at Urban Crosswalks. IEEE Trans. Intell. Transp. Syst. 2019, 20, 544–555. [Google Scholar] [CrossRef]
- Liu, B.; Adeli, E.; Cao, Z.; Lee, K.-H.; Shenoi, A.; Gaidon, A.; Niebles, J.C. Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction. IEEE Robot. Autom. Lett. 2020, 5, 3485–3492. [Google Scholar] [CrossRef] [Green Version]
- Chaabane, M.; Trabelsi, A.; Blanchard, N.; Beveridge, J. Looking Ahead: Anticipating Pedestrians Crossing with Future Frames Prediction. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; p. 2295. [Google Scholar] [CrossRef]
- Gujjar, P.; Vaughan, R. Classifying Pedestrian Actions in Advance Using Predicted Video of Urban Driving Scenes. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2097–2103. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Y.; Xu, H.; Liu, H. Probabilistic Prediction of Pedestrian Crossing Intention Using Roadside LiDAR Data. IEEE Access 2019, 7, 93781–93790. [Google Scholar] [CrossRef]
- Bertoni, L.; Kreiss, S.; Alahi, A. Perceiving Humans: From Monocular 3D Localization to Social Distancing. IEEE Trans. Intell. Transp. Syst. 2021, 1–18. [Google Scholar] [CrossRef]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.S.; Chandraker, M. DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents. arXiv 2017, arXiv:1704.04394. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar] [CrossRef] [Green Version]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Soft + Hardwired attention: An LSTM framework for human trajectory prediction and abnormal event detection. Neural Netw. 2018, 108, 466–478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar] [CrossRef] [Green Version]
- Saleh, K.; Hossny, M.; Nahavandi, S. Intent prediction of vulnerable road users from motion trajectories using stacked LSTM network. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 327–332. [Google Scholar] [CrossRef]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Are They Going to Cross? A Benchmark Dataset and Baseline for Pedestrian Crosswalk Behavior. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 206–213. [Google Scholar] [CrossRef]
- Agahian, S.; Negin, F.; Köse, C. An efficient human action recognition framework with pose-based spatiotemporal features. Eng. Sci. Technol. Int. J. 2020, 23, 196–203. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. arXiv 2016, arXiv:1604.02808. [Google Scholar]
- Kooij, J.F.P.; Schneider, N.; Flohr, F.; Gavrila, D.M. Context-Based Pedestrian Path Prediction. In Computer Vision–ECCV 2014; Springer: Cham, Germany, 2014; pp. 618–633. [Google Scholar]
- Habibi, G.; Jaipuria, N.; How, J. Context-Aware Pedestrian Motion Prediction in Urban Intersections. arXiv 2018, arXiv:1806.09453. [Google Scholar]
- Li, X.; Liu, Y.; Wang, K.; Yan, Y.; Wang, F.-Y. Multi-Target Tracking with Trajectory Prediction and Re-Identification. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 5028–5033. [Google Scholar] [CrossRef]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. POI: Multiple Object Tracking with High Performance Detection and Appearance Feature. In European Conference on Computer Vision; Springer: Cham, Germany, 2016; Volume 9914, p. 42. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Yang, C.; Yang, F.; Zhuang, Y.; Zhang, Z.; Jia, H.; Xie, X. Trajectory Factory: Tracklet Cleaving and Re-Connection by Deep Siamese Bi-GRU for Multiple Object Tracking. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Milan, A.; Rezatofighi, S.H.; Dick, A.; Reid, I.; Schindler, K. Online Multi-Target Tracking Using Recurrent Neural Networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4225–4232. [Google Scholar]
- Helbing, D.; Molnar, P. Social force model for pedestrian dynamics. Phys. Rev. E 1995, 51, 4282. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. arXiv 2018, arXiv:1803.10892. [Google Scholar]
- Saleh, K.; Hossny, M.; Nahavandi, S. Long-Term Recurrent Predictive Model for Intent Prediction of Pedestrians via Inverse Reinforcement Learning. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, ACT, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Quintero, R.; Parra, I.; Llorca, D.F.; Sotelo, M.A. Pedestrian path prediction based on body language and action classification. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 679–684. [Google Scholar] [CrossRef]
- Jaipuria, N.; Habibi, G.; How, J.P. A Transferable Pedestrian Motion Prediction Model for Intersections with Different Geometries. arXiv 2018, arXiv:1806.09444. [Google Scholar]
- Sighencea, B.I.; Stanciu, R.I.; Căleanu, C.D. A Review of Deep Learning-Based Methods for Pedestrian Trajectory Prediction. Sensors 2021, 21, 7543. [Google Scholar] [CrossRef]
- Sun, L.; Yan, Z.; Mellado, S.M.; Hanheide, M.; Duckett, T. 3DOF Pedestrian Trajectory Prediction Learned from Long-Term Autonomous Mobile Robot Deployment Data. arXiv 2017, arXiv:1710.00126. [Google Scholar]
- Dai, S.; Li, L.; Li, Z. Modeling Vehicle Interactions via Modified LSTM Models for Trajectory Prediction. IEEE Access 2019, 7, 38287–38296. [Google Scholar] [CrossRef]
- Xin, L.; Wang, P.; Chan, C.-Y.; Chen, J.; Li, S.; Cheng, B. Intention-aware Long Horizon Trajectory Prediction of Surrounding Vehicles using Dual LSTM Networks. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; p. 1446. [Google Scholar] [CrossRef] [Green Version]
- Fragkiadaki, K.; Levine, S.; Felsen, P.; Malik, J. Recurrent Network Models for Human Dynamics. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4346–4354. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Cui, Y.; Song, X.; Chen, K.; Fang, H. Multi-information-based convolutional neural network with attention mechanism for pedestrian trajectory prediction. Image Vis. Comput. 2021, 107, 104110. [Google Scholar] [CrossRef]
- Hoermann, S.; Bach, M.; Dietmayer, K. Dynamic Occupancy Grid Prediction for Urban Autonomous Driving: A Deep Learning Approach with Fully Automatic Labeling. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2056–2063. [Google Scholar] [CrossRef] [Green Version]
- Doellinger, J.; Spies, M.; Burgard, W. Predicting Occupancy Distributions of Walking Humans with Convolutional Neural Networks. IEEE Robot. Autom. Lett. 2018, 3, 1522–1528. [Google Scholar] [CrossRef]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Tracking by Prediction: A Deep Generative Model for Mutli-person Localisation and Tracking. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; p. 1132. [Google Scholar] [CrossRef] [Green Version]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, S.H.; Savarese, S. Social-BiGAT: Multimodal Trajectory Forecasting Using Bicycle-GAN and Graph Attention Networks. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 2180–2188. [Google Scholar]
- Kessels, C. The eHMI: How Autonomous Cars Will Communicate with the Outside World. May 2021. Available online: https://www.theturnsignalblog.com/blog/ehmi/ (accessed on 14 May 2022).
- Sucha, M.; Dostal, D.; Risser, R. Pedestrian-driver communication and decision strategies at marked crossings. Accid. Anal. Prev. 2017, 102, 41–50. [Google Scholar] [CrossRef] [Green Version]
- Rasouli, A.; Tsotsos, J.K. Autonomous Vehicles That Interact with Pedestrians: A Survey of Theory and Practice. IEEE Trans. Intell. Transp. Syst. 2020, 21, 900–918. [Google Scholar] [CrossRef] [Green Version]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Understanding Pedestrian Behavior in Complex Traffic Scenes. IEEE Trans. Intell. Veh. 2018, 3, 61–70. [Google Scholar] [CrossRef]
- Choi, J.K.; Ji, Y.G. Investigating the Importance of Trust on Adopting an Autonomous Vehicle. Int. J. Hum.-Comput. Interact. 2015, 31, 692–702. [Google Scholar] [CrossRef]
- Luo, R.; Chu, J.; Yang, X.J. Trust Dynamics in Human-AV (Automated Vehicle) Interaction. In Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems; ACM: New York, NY, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Du, N.; Haspiel, J.; Zhang, Q.; Tilbury, D.; Pradhan, A.K.; Yang, X.J.; Robert, L.P. Look who’s talking now: Implications of AV’s explanations on driver’s trust, AV preference, anxiety and mental workload. Transp. Res. Part C Emerg. Technol. 2019, 104, 428–442. [Google Scholar] [CrossRef]
- Merat, N.; Louw, T.; Madigan, R.; Wilbrink, M.; Schieben, A. What externally presented information do VRUs require when interacting with fully Automated Road Transport Systems in shared space? Accid. Anal. Prev. 2018, 118, 244–252. [Google Scholar] [CrossRef] [PubMed]
- Reig, S.; Norman, S.; Morales, C.G.; Das, S.; Steinfeld, A.; Forlizzi, J. A Field Study of Pedestrians and Autonomous Vehicles. In Proceedings of the 10th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Toronto, ON, Canada, 23–25 September 2018; pp. 198–209. [Google Scholar] [CrossRef]
- Rettenmaier, M.; Albers, D.; Bengler, K. After you?!–Use of external human-machine interfaces in road bottleneck scenarios. Transp. Res. Part F Traffic Psychol. Behav. 2020, 70, 175–190. [Google Scholar] [CrossRef]
- Löcken, A.; Golling, C.; Riener, A. How Should Automated Vehicles Interact with Pedestrians? A Comparative Analysis of Interaction Concepts in Virtual Re-ality. In Proceedings of the 11th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Utrecht, The Netherlands, 21–25 September 2019; pp. 262–274. [Google Scholar] [CrossRef]
- Habibovic, A.; Fabricius, V.; Anderson, J.; Klingegard, M. Communicating Intent of Automated Vehicles to Pedestrians. Front. Psychol. 2018, 9, 1336. [Google Scholar] [CrossRef] [PubMed]
- Strauss, T. Breaking down the Language Barrier between Autonomous Cars and Pedestrians. 2018. Available online: https://uxdesign.cc/wave-breaking-down-the-language-barrier-between-autonomous-cars-and-pedestrians-autonomy-tech-a8ba1f6686 (accessed on 3 May 2022).
- Autocar. The Autonomous Car That Smiles at Pedestrians. 2016. Available online: https://www.autocar.co.uk/car-news/new-cars/autonomous-car-smiles-pedestrians (accessed on 3 May 2022).
- Kitayama, S.; Kondou, T.; Ohyabu, H.; Hirose, M. Display System for Vehicle to Pedestrian Communication. SAE, SAE Technical Paper 2017-01–0075. 2017. Available online: https://www.sae.org/publications/technical-papers/content/2017-01-0075/ (accessed on 14 May 2022).
- Habibovic, A.; Andersson, J.; Lundgren, V.M.; Klingegård, M.; Englund, C.; Larsson, S. External Vehicle Interfaces for Communication with Other Road Users. In Road Vehicle Automation 5; Springer: Cham, Germany, 2019; pp. 91–102. [Google Scholar]
- Woyke, E. A Self-Driving Bus That Can Speak Sign Language. 2017. Available online: https://www.technologyreview.com/2017/04/13/152569/a-self-driving-bus-that-can-speak-sign-language/ (accessed on 14 May 2022).
- Son, S.; Jeong, Y.; Lee, B. An Audification and Visualization System (AVS) of an Autonomous Vehicle for Blind and Deaf People Based on Deep Learning. Sensors 2019, 19, 5035. [Google Scholar] [CrossRef] [Green Version]
- Deb, S.; Strawderman, L.J.; Carruth, D.W. Investigating pedestrian suggestions for external features on fully autonomous vehicles: A virtual reality experiment. Transp. Res. Part F Traffic Psychol. Behav. 2018, 59, 135–149. [Google Scholar] [CrossRef]
- Costa, G. Designing Framework for Human-Autonomous Vehicle Interaction. Master’s Thesis, Keio University Graduate School of Media Design, Yokohama, Japan, 2017. [Google Scholar]
- Ochiai, Y.; Toyoshima, K. Homunculus: The Vehicle as Augmented Clothes. In Proceedings of the 2011 2nd Augmented Human International Conference, Tokyo, Japan, 13 March 2011. [Google Scholar] [CrossRef]
- Chang, C.-M.; Toda, K.; Sakamoto, D.; Igarashi, T. Eyes on a Car: An Interface Design for Communication between an Autonomous Car and a Pedestrian. In Proceedings of the ACM 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Oldenburg, Germany, 24–27 September 2017; p. 73. [Google Scholar] [CrossRef]
- Jaguar Land Rover. The Virtual Eyes Have It. 2018. Available online: https://www.jaguarlandrover.com/2018/virtual-eyes-have-it (accessed on 14 May 2022).
- Hussein, A.; García, F.; Armingol, J.M.; Olaverri-Monreal, C. P2V and V2P communication for Pedestrian warning on the basis of Autonomous Vehicles. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2034–2039. [Google Scholar] [CrossRef]
- Liu, Z.; Pu, L.; Meng, Z.; Yang, X.; Zhu, K.; Zhang, L. POFS: A novel pedestrian-oriented forewarning system for vulnerable pedestrian safety. In Proceedings of the 2015 International Conference on Connected Vehicles and Expo (ICCVE), Shenzhen, China, 19–23 October 2015; pp. 100–105. [Google Scholar] [CrossRef]
- David, K.; Flach, A. CAR-2-X and Pedestrian Safety. IEEE Veh. Technol. Mag. 2010, 5, 70–76. [Google Scholar] [CrossRef]
- Andreone, L.; Visintainer, F.; Wanielik, G. Vulnerable Road Users thoroughly addressed in accident prevention: The WATCH-OVER European project. In Proceedings of the 14th World Congress on Intelligent Transport Systems, Beijing, China, 9–13 October 2007. [Google Scholar]
- García, F.; Jiménez, F.; Anaya, J.J.; Armingol, J.M.; Naranjo, J.E.; de la Escalera, A. Distributed Pedestrian Detection Alerts Based on Data Fusion with Accurate Localization. Sensors 2013, 13, 11687–11708. [Google Scholar] [CrossRef] [Green Version]
- Saleh, K.; Hossny, M.; Nahavandi, S. Towards trusted autonomous vehicles from vulnerable road users perspective. In Proceedings of the 2017 Annual IEEE International Systems Conference (SysCon), Montreal, QC, Canada, 24–27 April 2017; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
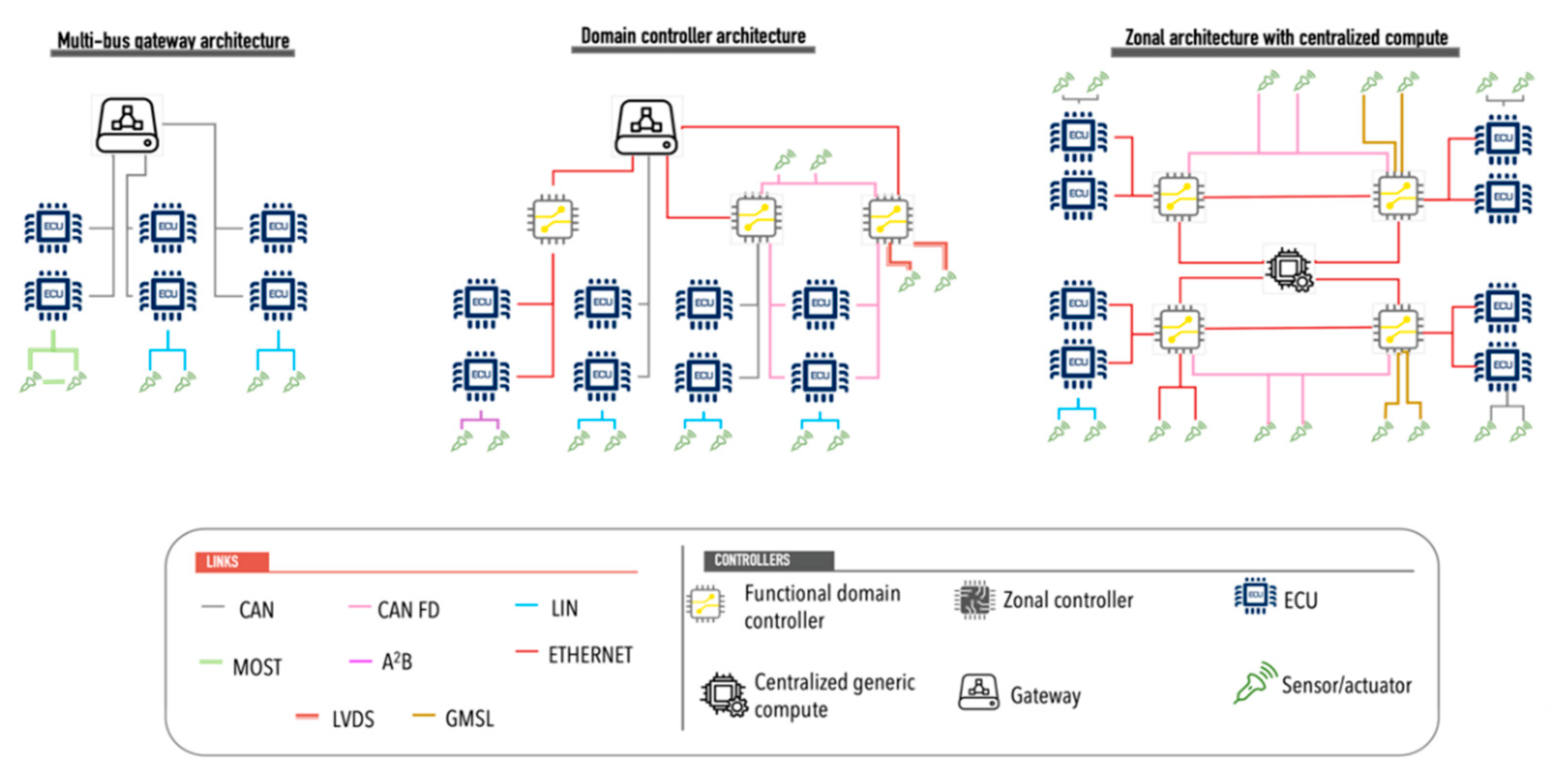
| Media | Description | Transmission Speed | Usage | Distance |
|---|---|---|---|---|
| LIN | Single-wire unidirectional bus | 20 kbps | This media connects sensors and actuators to ECUs. This media is used in applications such as cruise control, position sensor control, temperature control, sunroof, among others. | Up to 40 m |
| CAN | bus based on a message protocol | High speed up to 1 Mbps. Low speed 125 kbps | It is used for controller and device communication without the need for a computer host. | Up to 40 m |
| CAN FD | A variant of CAN that uses flexible data | 8 Mbps | Used in communications with sensors at different transmission rates. | Up to 40 m |
| MOST | A standard used for interconnection of multimedia components that uses a ring topology, performing one-way transfer within the ring and transmits data via light pulses. Up to 64 devices can be connected to the network | From 25 up to 150 Mbps using optical fiber. | Used for audio and video applications in or out of the car. Most is the best transmission and multimedia control network most widely used in automotive electronics. | Up to 40 m |
| LVDS | Transmission system based on twisted pair, that transmits signals at high speeds. | 655 Mbps. | A viable alternative for connecting self-driving vehicle camera systems. | 15–20 m |
| GMSL | High-speed communication interfaces that support high bandwidth requirements, complex interconnections, and data integrity | Up to 6 Gbps | Used for ADAS and infotainment systems. It uses a point-to-point connection with support for 4 K video. | Using shielded twisted pair (STP) or coax cables of up to 15 m |
| Feature | LiDAR | RADAR | Camera |
|---|---|---|---|
| Primary technology | Laser light pulse | Radio wave | Light |
| Range | ∼200 m | ∼250 m | ∼200 m |
| Data rate | 20–100 Mbps | 0.1–15 Mbps | 500 Mbps in high resolution |
| Resolution | Good | Average | Very good |
| Affected by weather conditions | Yes | Yes | Yes |
| Affected by lighting conditions | No | No | Yes |
| Detects speed | Good | Very good | Poor |
| Detects distance | Good | Very good | Poor |
| Category | Usage | Description |
|---|---|---|
| Regression | This type of algorithm is used for autonomous vehicles for event prediction such as collisions, trajectory prediction. | The algorithms focus on establishing a method to define the relationship between a set of variables (which represent the characteristics) and a continuous target variable. Examples of such algorithms being applied in self-driving systems include Bayesian regression [71], neural network regression [72] and decision forest regression [73]. |
| Patter recognition | This type of algorithm is used for CAVs for the object classification such as pedestrians, vehicles, cyclists, traffic signals. | This type of algorithm is used to perform data filtering to recognize instances of a category of objects by discarding irrelevant data points. They focus on reducing the data set through edge detection and fitting line segments and circular arcs to edges. These features are combined to define the object features to be recognized. The most applied recognition algorithms in Advanced Driver Assistance Systems (ADAS) are support vector machines (SVM) with histograms of oriented gradients [74] and principal component analysis (PCA) and Bayes’ decision rule [75] and k-nearest neighbor [76]. |
| Cluster | This type of algorithm is implemented in autonomous vehicles for object classification and detection. | This type of algorithm groups data to discover its characteristics. It is generally used in situations with little data, with discontinuous data or with very low-resolution images. To solve this problem, it generates “center points” and a series of hierarchies that allow it to discover a series of common characteristics. Among the most used algorithms are K-Means [77], K-Medians [78] and Hierarchical clustering [79]. |
| Decision matrix | The main use of this type of algorithms in autonomous vehicles is decision making. | The structure of this model focuses on a set of independently trained decision models, combining their predictions to generate the overall prediction, thus reducing the probability of errors in decision-making. Some examples of this type of algorithms are gradient boosting [80] and AdaBoosting [81]. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reyes-Muñoz, A.; Guerrero-Ibáñez, J. Vulnerable Road Users and Connected Autonomous Vehicles Interaction: A Survey. Sensors 2022, 22, 4614. https://doi.org/10.3390/s22124614
Reyes-Muñoz A, Guerrero-Ibáñez J. Vulnerable Road Users and Connected Autonomous Vehicles Interaction: A Survey. Sensors. 2022; 22(12):4614. https://doi.org/10.3390/s22124614
Chicago/Turabian StyleReyes-Muñoz, Angélica, and Juan Guerrero-Ibáñez. 2022. "Vulnerable Road Users and Connected Autonomous Vehicles Interaction: A Survey" Sensors 22, no. 12: 4614. https://doi.org/10.3390/s22124614
APA StyleReyes-Muñoz, A., & Guerrero-Ibáñez, J. (2022). Vulnerable Road Users and Connected Autonomous Vehicles Interaction: A Survey. Sensors, 22(12), 4614. https://doi.org/10.3390/s22124614