
Spatial Attention-Based 3D Graph Convolutional Neural Network for Sign Language Recognition

 , , , , , , and
, , , , , , and
Abstract
:1. Introduction
- Scarcity of large, labeled sign language datasets.
- The representation learning of signs by conventional CNN is inefficient. It involves a lot of non-relevant patterns in the scene, while the relevant patterns are only in the movement field of the signer’s hands.
- A novel graph-based architecture of separable 3DCNN layers is proposed for sign language recognition, with the following characteristics:
- Effective embedding for sign language gesture features with attention-based context enhancement for the spatial representation.
- Ability to avoid the representation over smoothing via minimizing the number of messages passing between the graph nodes.
- Optimum computation cost by reducing the number of layers as well as utilizing an efficient skeletal estimator.
- The performance of the proposed architecture is demonstrated on different datasets with highly varied characteristics.
2. Related Work
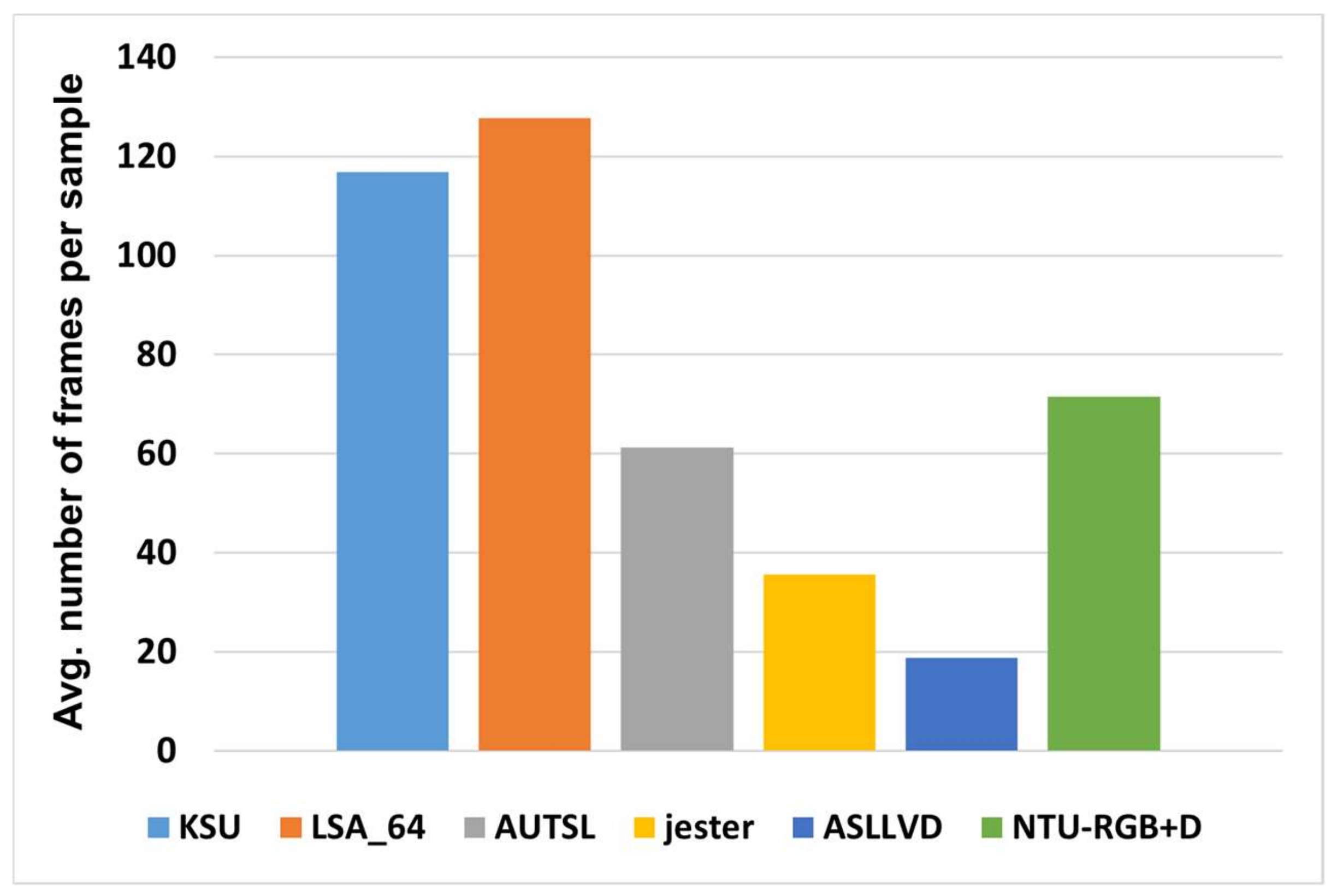
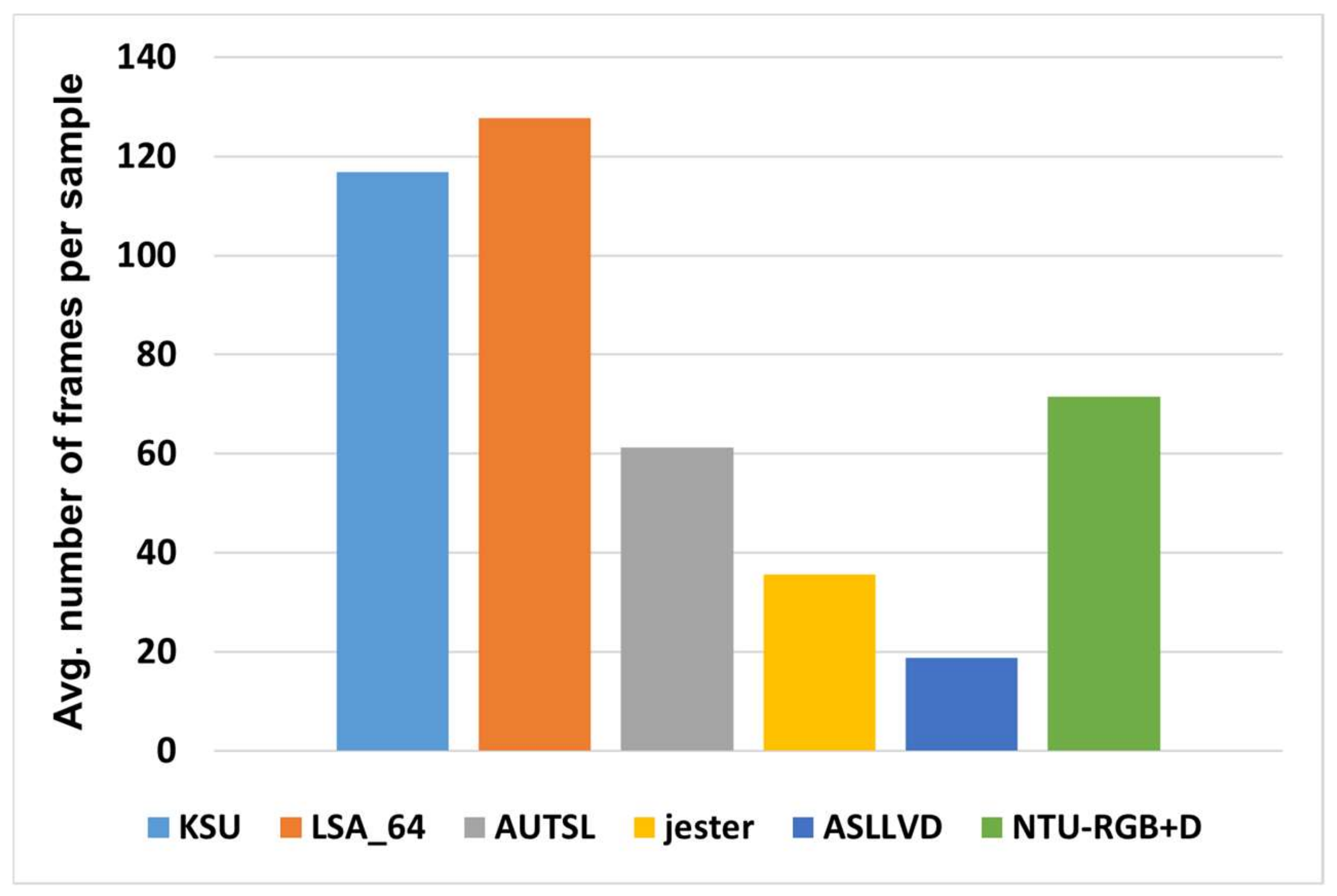
3. Datasets
King Saud University Saudi Sign Language (KSU-SSL) Dataset
4. Methodology
4.1. MediaPipe-Based Graph Construction

4.2. Graph Representation Learning
4.2.1. Basic Separable 3DGCN Implementation
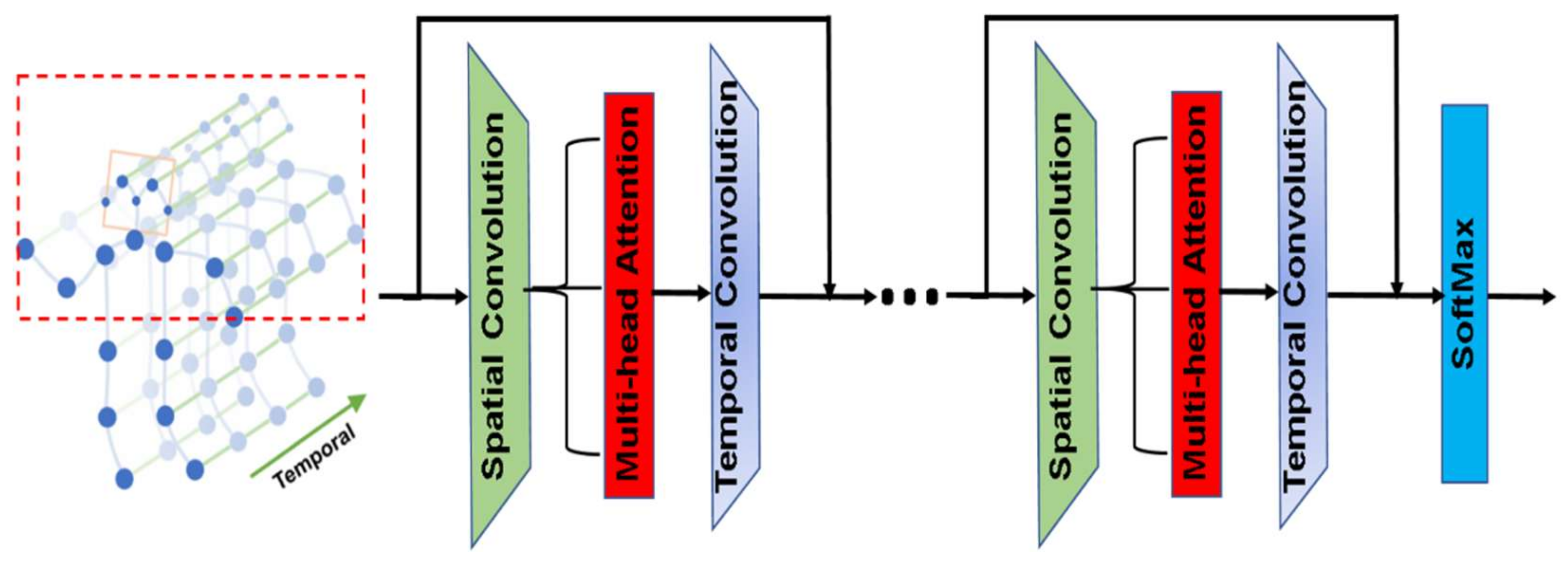
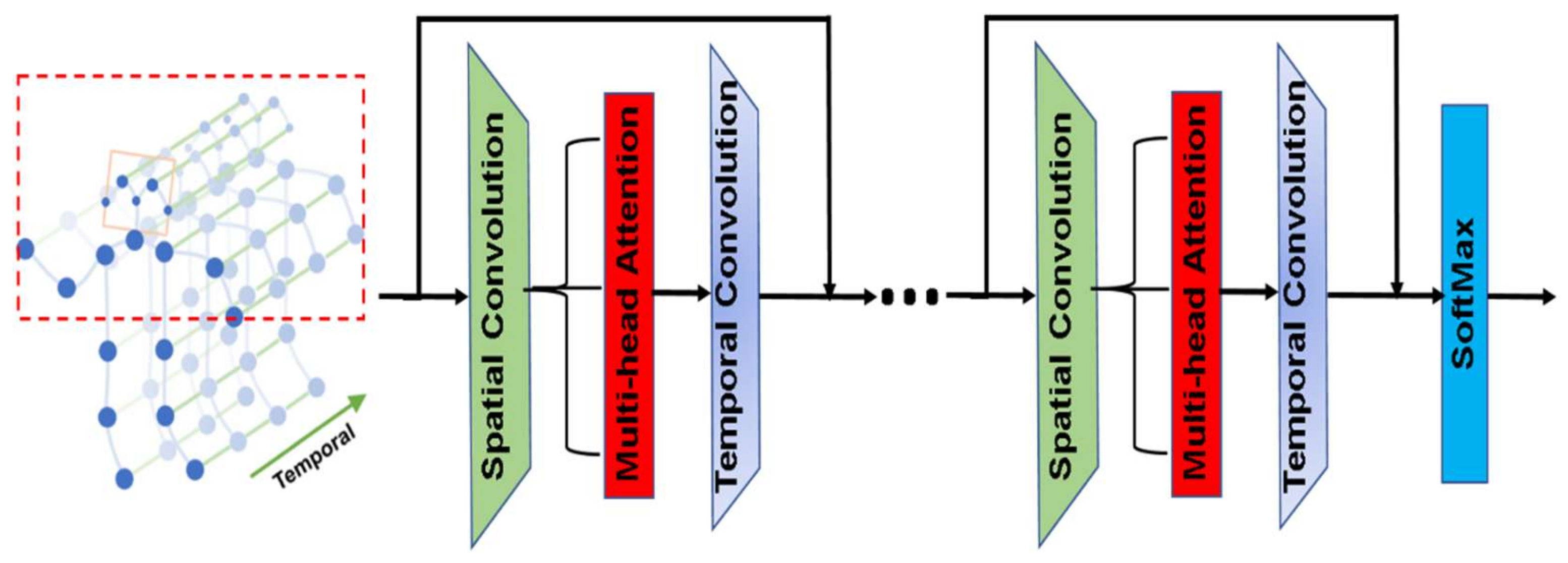
4.2.2. Enhanced Separable 3DGCN Implementation
- 1.
- The node features were transformed through a 2D spatial convolution as in Equation (2).where is the convolution kernel and is the input embedding of nodes.
- 2.
- Unnormalized attention scores were computed between each pair of neighboring nodes as in Equation (3).where is the unnormalized attention score between nodes i and j, is a learnable weight vector, and and are the feature means of nodes i and j on the entire batch.
- 3.
- The attention scores were then normalized via SoftMax as in Equation (4). The normalized attention matrix was then used to scale the adjacency matrix.
- 4.
- Finally, the output of the convolution was multiplied by the scaled adjacency matrix to form the new embedding of the nodes as in Equation (5).
- The uni-labeling partitioning: All the neighboring nodes of a corresponding root node are considered as a single set, including the root node itself. The representations of all nodes are transformed by a single learnable kernel.
- The distance partitioning: The nodes are partitioned into two subsets based on their distance from the root node. The first subset includes the root node with a distance d = 0, and the second subset includes the remaining nodes with d = 1. Two different learnable kernels are utilized to transform the nodes’ representation in the two subsets.
- The spatial partitioning: The neighboring nodes are partitioned into three subsets based on their distance from the root node and the gravity center of the whole skeleton as follows: (1) the root node itself; (2) the centripetal: the set of nodes that are closer to the gravity center of the skeleton than the root node; and (3) the centrifugal: the set of nodes that are closer to the root node than the gravity center of the skeleton. In this work, the nose point was set as a reference point instead of the center of gravity.
5. Experimental Results and Discussion
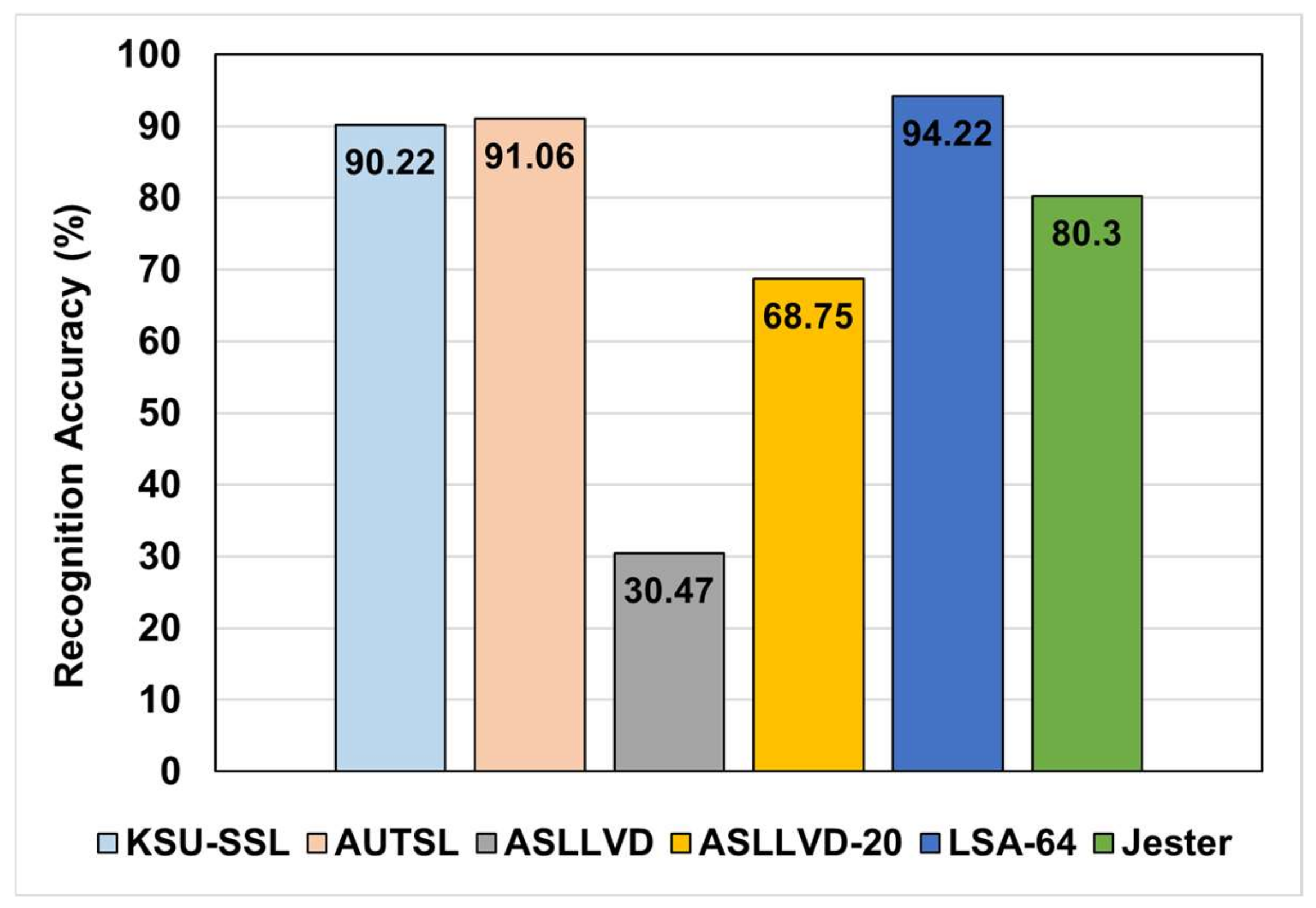
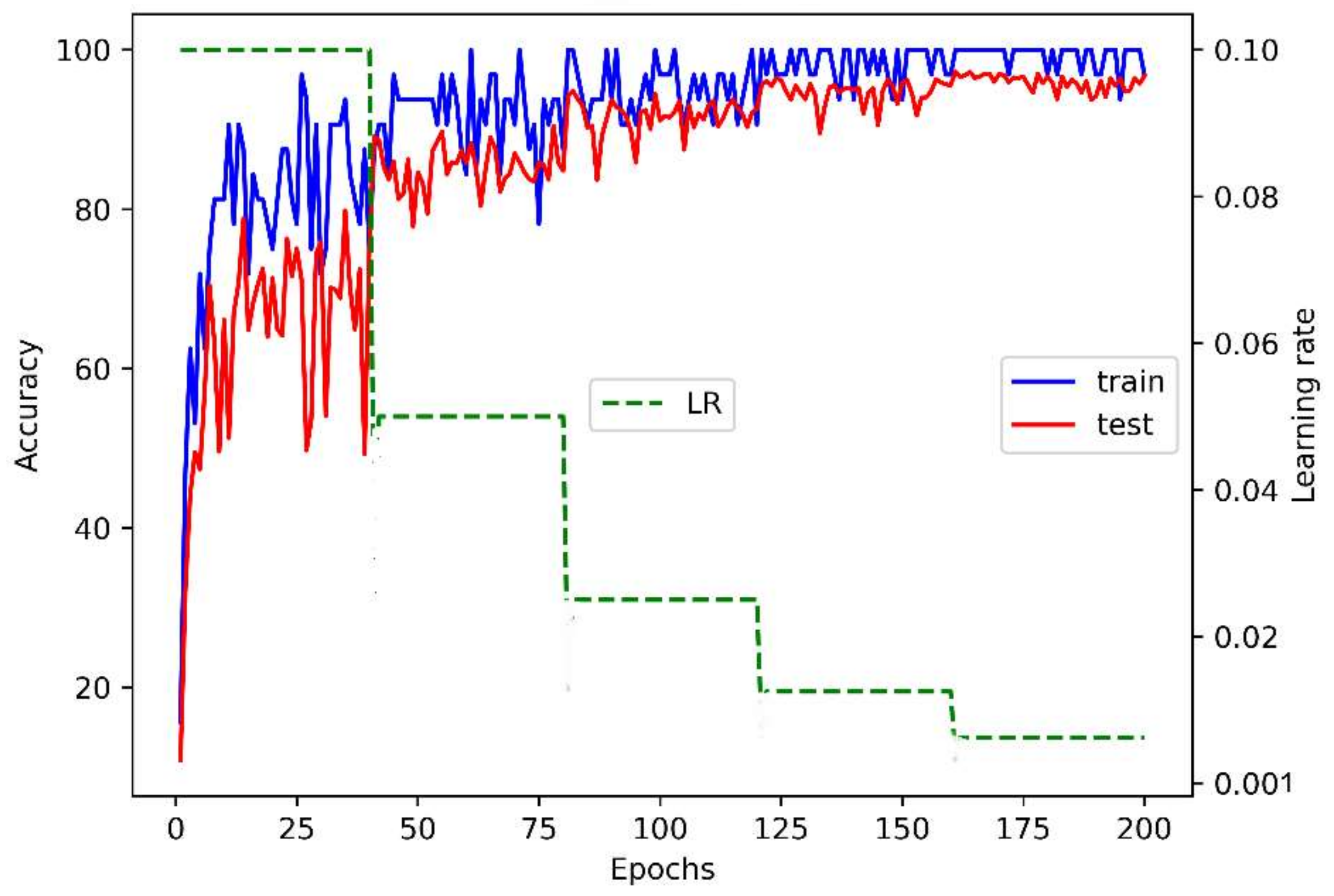
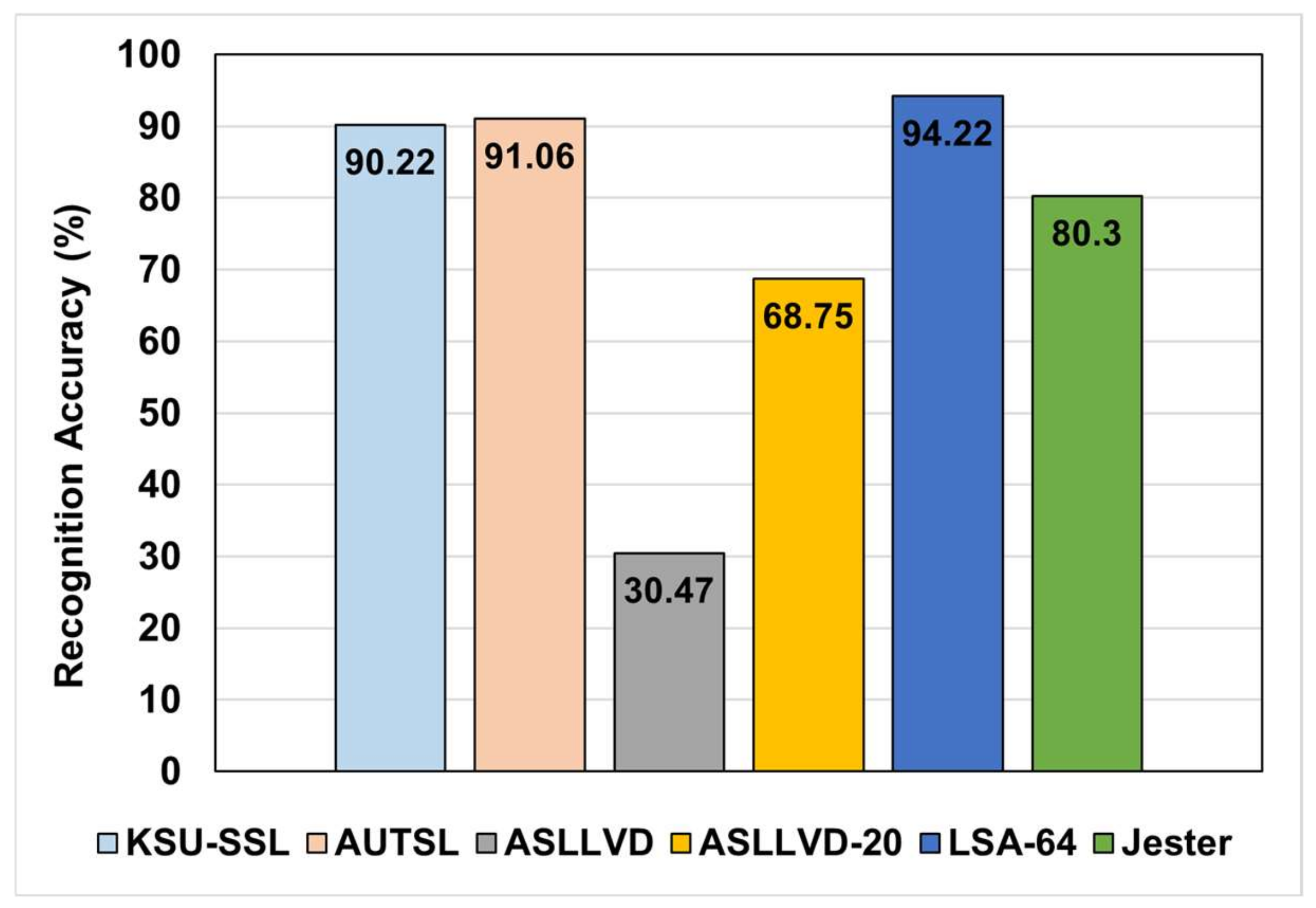
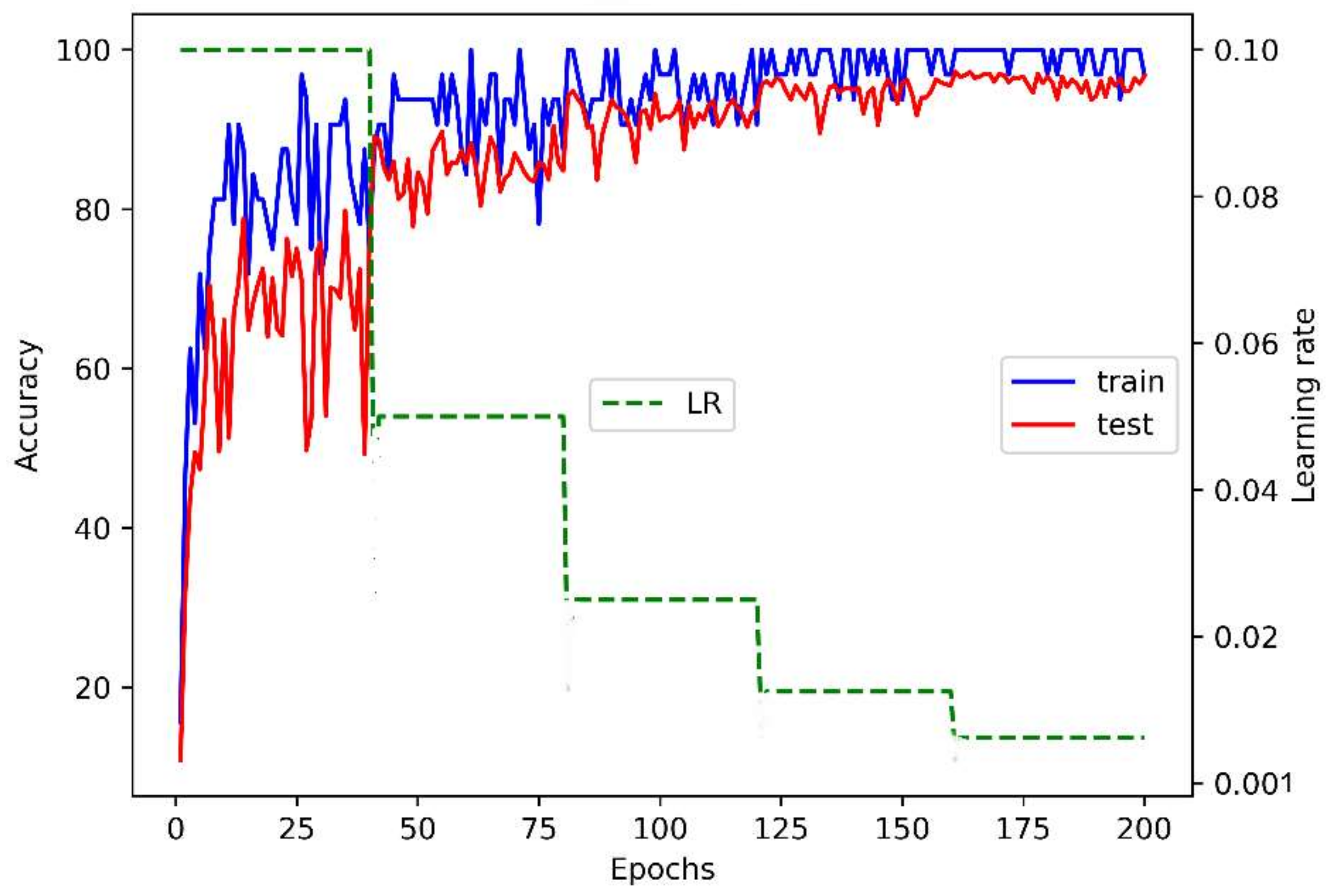
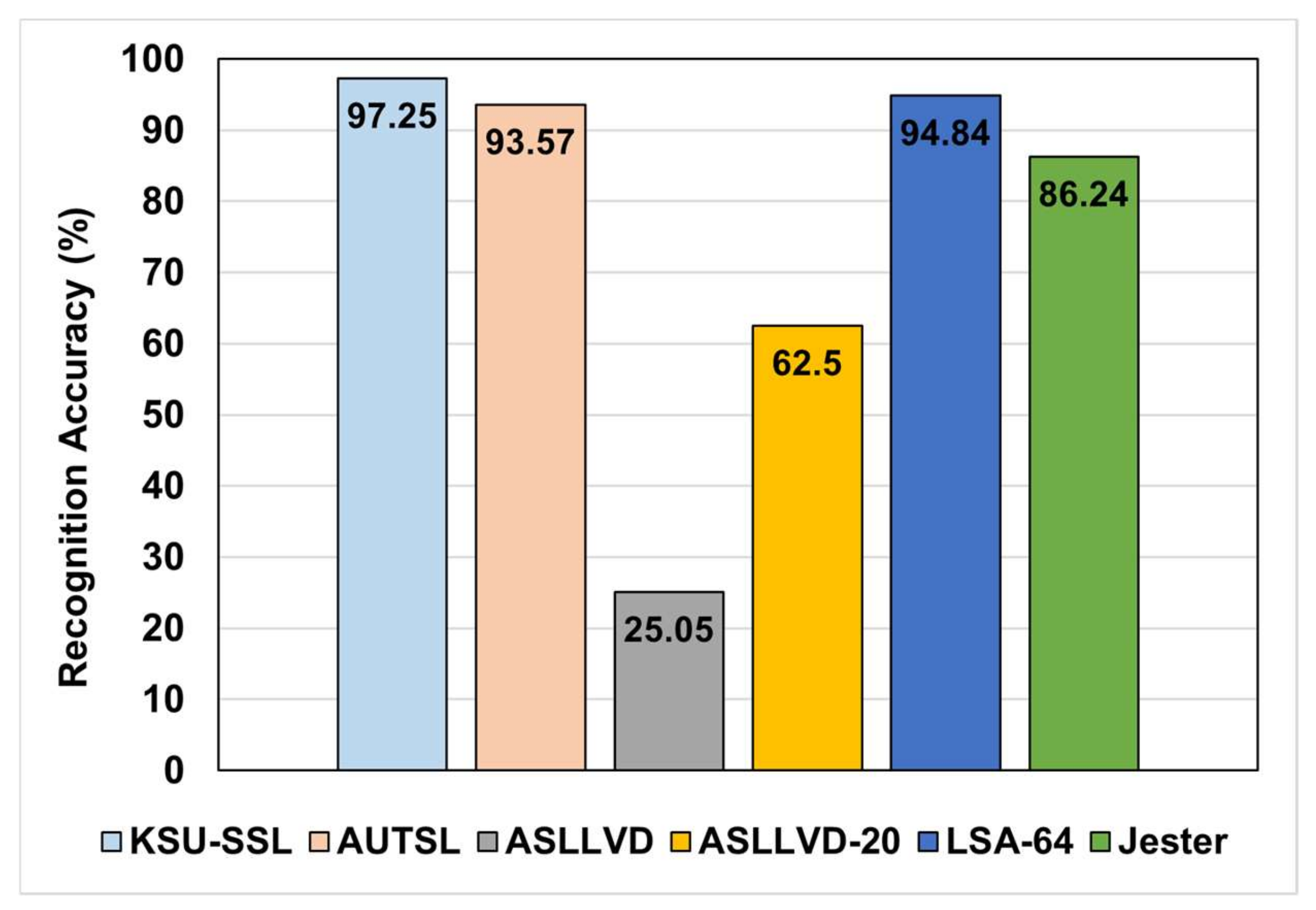
5.1. Evaluation of the Basic 3DGCN-Based Architecture
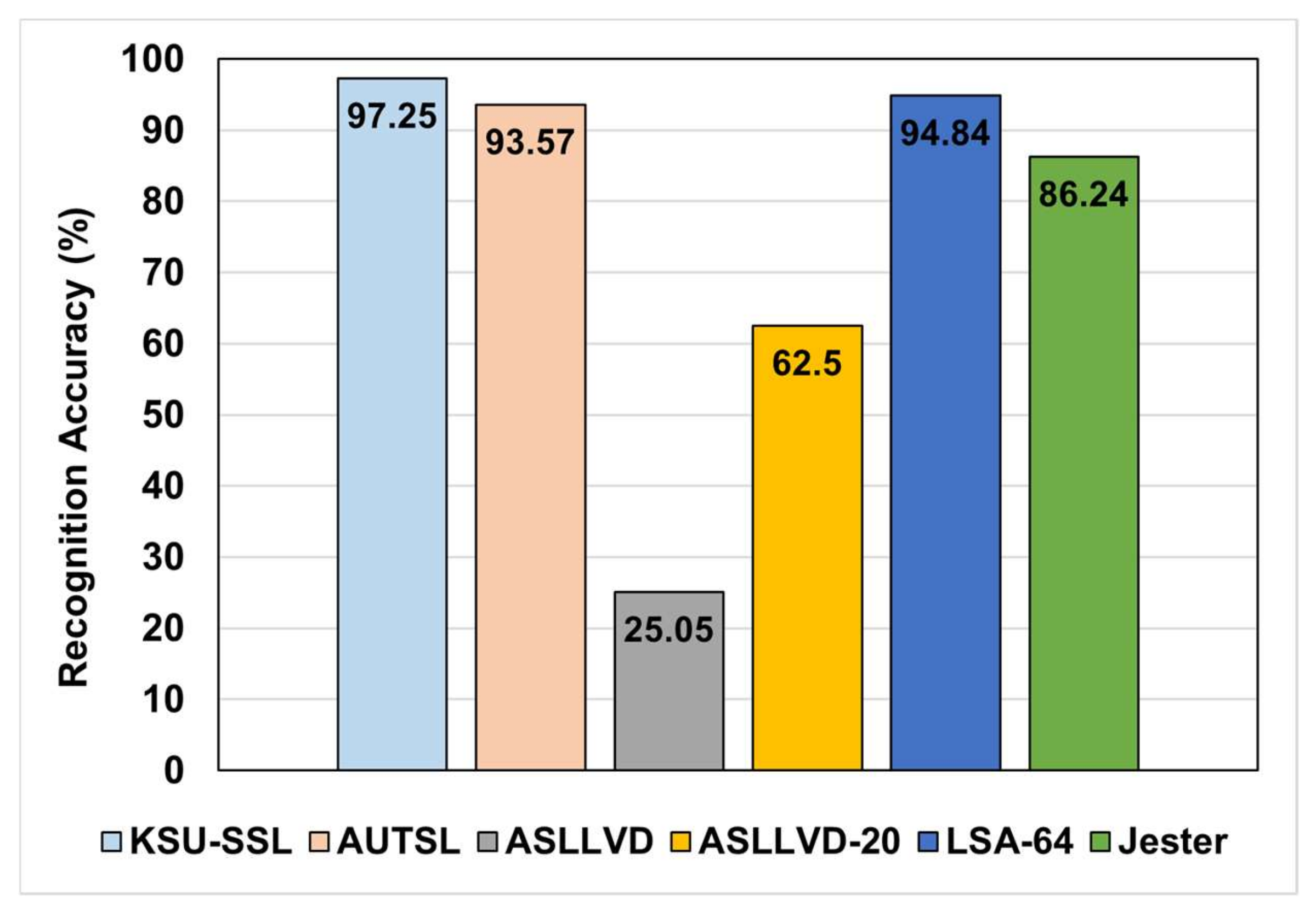
5.2. Evaluation of the Enhanced 3DGCN-Based Architecture
- The partitioning strategy , where these strategies are defined in Section 4.2.2.
- The number of self-attention heads .
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Agrawal, S.; Jalal, A.; Tripathi, R. A survey on manual and non-manual sign language recognition for isolated and continuous sign. Int. J. Appl. Pattern Recognit. 2016, 3, 99–134. [Google Scholar] [CrossRef]
- Rautaray, S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A framework for hand gesture recognition based on accelerometer and EMG sensors. IEEE Trans. Syst. Man Cybern. A Syst. Hum. 2011, 41, 1064–1076. [Google Scholar] [CrossRef]
- Côté-Allard, U.; Fall, C.L.; Drouin, A.; Campeau-Lecours, A.; Gosselin, G.; Glette, K.; Gosselin, B. Deep learning for electromyographic hand gesture signal classification using transfer learning. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 760–771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaiman, M.; Bencherif, M.; Mekhticheand, M.A. Hand gesture recognition for sign language using 3DCNN. IEEE Access 2020, 8, 79491–79509. [Google Scholar] [CrossRef]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2021, 1–42. [Google Scholar] [CrossRef]
- Hossain, M.; Al-Hammadi, M.; Muhammad, G. Automatic fruit classification using deep learning for industrial applications. IEEE Trans. Ind. Inform. 2018, 15, 1027–1034. [Google Scholar] [CrossRef]
- Su, H.; Qi, W.; Hu, Y.; Karimi, H.R.; Ferrigno, G.; Momi, E.D. An incremental learning framework for human-like redundancy optimization of anthropomorphic manipulators. IEEE Trans. Ind. Inform. 2020, 13, 1864–1872. [Google Scholar] [CrossRef]
- Qi, W.; Su, H. A cybertwin based multimodal network for ecg patterns monitoring using deep learning. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Selvaraj, P.; NC, G.; Kumar, P.; Khapra, M. OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages. arXiv 2021, arXiv:2110.05877. [Google Scholar]
- Yasir, F.; Prasad, P.W.C.; Alsadoon, A.; Elchouemi, A. Sift based approach on bangla sign language recognition. In Proceedings of the IEEE 8th International Workshop on Computational Intelligence and Applications (IWCIA), Hiroshima, Japan, 6–7 November 2015. [Google Scholar]
- Thrwat, A.; Gaber, T.; Hassanien, A.E.; Shahin, M.K.; Refaat, B. Sift-based arabic sign language recognition system. Adv. Intell. Syst. Comput. 2015, 334, 359–370. [Google Scholar]
- Liwicki, S.; Everingham, M. Automatic recognition of fingerspelled words in british sign language. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA 20–25 June 2009. [Google Scholar]
- Buehler, P.; Zisserman, A.; Everingham, M. Learning sign language by watching tv (using weakly aligned subtitles). In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Badhe, P.; Kulkarni, V. Indian sign language translator using gesture recognition algorithm. In Proceedings of the IEEE International Conference on Computer Graphics, Bhubaneswar, India, 2–3 November 2015. [Google Scholar]
- Starner, T.; Weaver, J.; Pentland, A. Real-time american sign language recognition using desk and wearable computer based video. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1371–1375. [Google Scholar] [CrossRef]
- Lichtenauer, J.F.; Hendriks, E.A.; Reinders, M.J. Sign language recognition by combining statistical DTW and independent classification. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 2040–2046. [Google Scholar] [CrossRef] [PubMed]
- Nagarajan, S.; Subashini, T.S. Static hand gesture recognition for sign language alphabets using edge oriented histogram and multi class SVM. Int. J. Comput. 2013, 82, 4. [Google Scholar] [CrossRef]
- Tornay, S.; Razavi, M.; Doss, M. Towards multilingual sign language recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Pigou, L.; Oord, A.; Dieleman, S.; Herreweghe, M.V.; Dambre, J. Beyond temporal pooling: Recurrence and temporal convolutions for gesture recognition in video. Int. J. Comput. Vis. 2018, 126, 430–439. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Gao, K. DenseImage network: Video spatial-temporal evolution encoding and understanding. arXiv 2018, arXiv:1805.07550. [Google Scholar]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaman, M.; Hossain, M.S. Hand gesture recognition using 3D-CNN model. IEEE Consum. Electron. Mag. 2019, 9, 95–101. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, D.; Duan, H.; Sun, Y.; Li, G.; Tao, B.; Yun, J.; Liu, Y.; Chen, B. Dynamic gesture recognition algorithm based on 3D convolutional neural network. Comput. Intell. Neurosci. 2021, 2021, 4828102. [Google Scholar] [CrossRef]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaman, M.; Bencherif, M.A.; Alrayes, T.S.; Mekhtiche, M.A. Deep learning-based approach for sign language gesture recognition with efficient hand gesture representation. IEEE Access 2020, 8, 192527–192542. [Google Scholar] [CrossRef]
- Qin, W.; Mei, X.; Chen, Y.; Zhang, Q.; Yao, Y.; Hu, S. Sign Language Recognition and Translation Method based on VTN. In Proceedings of the International Conference on Digital Society and Intelligent Systems, Chengdu, China, 3–4 December 2021. [Google Scholar]
- Wang, Z.; Zhao, T.; Ma, J.; Chen, H.; Liu, K.; Shao, H.; Wang, Q.; Ren, J. Hear sign language: A real-time end-to-end sign language recognition system. IEEE Trans. Mob. Comput. 2022, 21, 2398–2410. [Google Scholar] [CrossRef]
- Qi, W.; Ovur, S.E.; Li, Z.; Marzullo, A.; Song, R. Multi-Sensor Guided Hand Gesture Recognition for a Teleoperated Robot Using a Recurrent Neural Network. IEEE Robot. Autom. Lett. 2021, 6, 6039–6045. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.; Wang, G. Ntu rgb+d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Amorim, C.C.D.; Macêdo, D.; Zanchettin, C. Spatial-temporal graph convolutional networks for sign language recognition. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019. [Google Scholar]
- Jiang, S.; Sun, J.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton aware multi-modal sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–25 June 2021. [Google Scholar]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Sign Language Recognition via Skeleton-Aware Multi-Model Ensemble. arXiv 2021, arXiv:2110.06161. [Google Scholar]
- Coster, M.D.; Herreweghe, M.V.; Dambre, J. Isolated sign recognition from rgb video using pose flow and self-attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–25 June 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, L. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhou, K.; Huang, X.; Li, Y.; Zha, D.; Chen, R.; Hu, X. Towards deeper graph neural networks with differentiable group normalization. arXiv 2020, arXiv:2006.06972. [Google Scholar]
- Muhammad, G.; Alshehri, F.; Karray, F.; Saddik, A.E.; Alsulaiman, M.; Falk, T. A comprehensive survey on multimodal medical signals fusion for smart healthcare systems. Inf. Fusion 2021, 76, 355–375. [Google Scholar] [CrossRef]
- Muhammad, G.; Hossain, M. COVID-19 and non-COVID-19 classification using multi-layers fusion from lung ultrasound images. Inf. Fusion 2021, 72, 80–88. [Google Scholar] [CrossRef]
- Altuwaijri, G.; Muhammad, G.; Altaheri, H.; Alsulaiman, M. A Multi-Branch Convolutional Neural Network with Squeeze-and-Excitation Attention Blocks for EEG-Based Motor Imagery Signals Classification. Diagnostics 2022, 12, 995. [Google Scholar] [CrossRef]
- Amin, S.; Altaheri, H.; Muhammad, G.; Abdul, W.; Alsulaiman, M. Attention-Inception and Long Short-Term Memory-based Electroencephalography Classification for Motor Imagery Tasks in Rehabilitation. IEEE Trans. Ind. Inform. 2022, 18, 5412–5421. [Google Scholar] [CrossRef]
- Sincan, O.M.; Keles, H.Y. Autsl: A large scale multi-modal turkish sign language dataset and baseline methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Ronchetti, F.; Quiroga, F.; Estrebou, C.; Lanzarini, L.; Rosete, A. LSA64: An Argentinian sign language dataset. In Proceedings of the XXII Congreso Argentino de Ciencias de la Computación, San Luis, Argentina, 3–7 October 2016. [Google Scholar]
- Neidle, C.; Thangali, A.; Sclaroff, S. Challenges in Development of the American Sign Language Lexicon Video Dataset (ASLLVD) Corpus. In Proceedings of the Conference Language Resources and Evaluation Conference (LREC), Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Materzynska, J.; Berger, G.; Bax, I.; Memisevic, R. The jester dataset: A large-scale video dataset of human gestures. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.; Yong, M.; Lee, J.; et al. MediaPipe: A Framework for Perceiving and Processing Reality. In Proceedings of the Third Workshop on Computer Vision for AR/VR at IEEE Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Google Research Team. MediaPipe. 2020. Available online: https://google.github.io/mediapipe/solutions/hands.html (accessed on 18 February 2022).
- Kipf, T.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Num. of Classes | Num. of Training Samples | Num. of Validation Samples |
|---|---|---|---|
| KSU-SSL | 293 | 28,021 | 5860 |
| AUTSL | 226 | 28,142 | 4418 |
| ASLLVD-20 | 20 | 85 | 42 |
| ASLLVD | 2745 | 7798 | 1950 |
| SLA-64 | 64 | 2560 | 640 |
| Jester | 27 | 118,558 | 14,786 |
| Partitioning | ||||
|---|---|---|---|---|
| Uni-Labeling | Distance | Spatial | ||
| No. of heads | 1 | 96.62 | 96.77 | 96.79 |
| 2 | 96.7 | 96.82 | 96.52 | |
| 3 | 97.08 | 96.93 | 96.86 | |
| 4 | 96.57 | 97.03 | 97.25 | |
| Architecture | Validation Acc. (%) | Test Acc. (%) | Num. of Params (×106) |
|---|---|---|---|
| VTN | 82.03 | - | ≈29 |
| VTN-HC | 90.13 | - | ≈51 |
| VTN-PF | 91.51 | 92.92 | ≈52 |
| Basic 3DGCN (ours) | 91.06 | 90.27 | ≈0.3 |
| Enhanced 3DGCN (ours) | 93.57 | 93.38 | ≈0.7 |
| Architecture | Dataset | Validation Acc. (%) |
|---|---|---|
| ST-GCN | ASLLVD-20 | 61.04 |
| Basic 3DGCN (ours) | 68.75 | |
| Enhanced 3DGCN (ours) | 62.5 | |
| ST-GCN | ASLLVD | 16.48 |
| Basic 3DGCN (ours) | 30.47 | |
| Enhanced 3DGCN (ours) | 25.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Hammadi, M.; Bencherif, M.A.; Alsulaiman, M.; Muhammad, G.; Mekhtiche, M.A.; Abdul, W.; Alohali, Y.A.; Alrayes, T.S.; Mathkour, H.; Faisal, M.; et al. Spatial Attention-Based 3D Graph Convolutional Neural Network for Sign Language Recognition. Sensors 2022, 22, 4558. https://doi.org/10.3390/s22124558
Al-Hammadi M, Bencherif MA, Alsulaiman M, Muhammad G, Mekhtiche MA, Abdul W, Alohali YA, Alrayes TS, Mathkour H, Faisal M, et al. Spatial Attention-Based 3D Graph Convolutional Neural Network for Sign Language Recognition. Sensors. 2022; 22(12):4558. https://doi.org/10.3390/s22124558
Chicago/Turabian StyleAl-Hammadi, Muneer, Mohamed A. Bencherif, Mansour Alsulaiman, Ghulam Muhammad, Mohamed Amine Mekhtiche, Wadood Abdul, Yousef A. Alohali, Tareq S. Alrayes, Hassan Mathkour, Mohammed Faisal, and et al. 2022. "Spatial Attention-Based 3D Graph Convolutional Neural Network for Sign Language Recognition" Sensors 22, no. 12: 4558. https://doi.org/10.3390/s22124558
APA StyleAl-Hammadi, M., Bencherif, M. A., Alsulaiman, M., Muhammad, G., Mekhtiche, M. A., Abdul, W., Alohali, Y. A., Alrayes, T. S., Mathkour, H., Faisal, M., Algabri, M., Altaheri, H., Alfakih, T., & Ghaleb, H. (2022). Spatial Attention-Based 3D Graph Convolutional Neural Network for Sign Language Recognition. Sensors, 22(12), 4558. https://doi.org/10.3390/s22124558