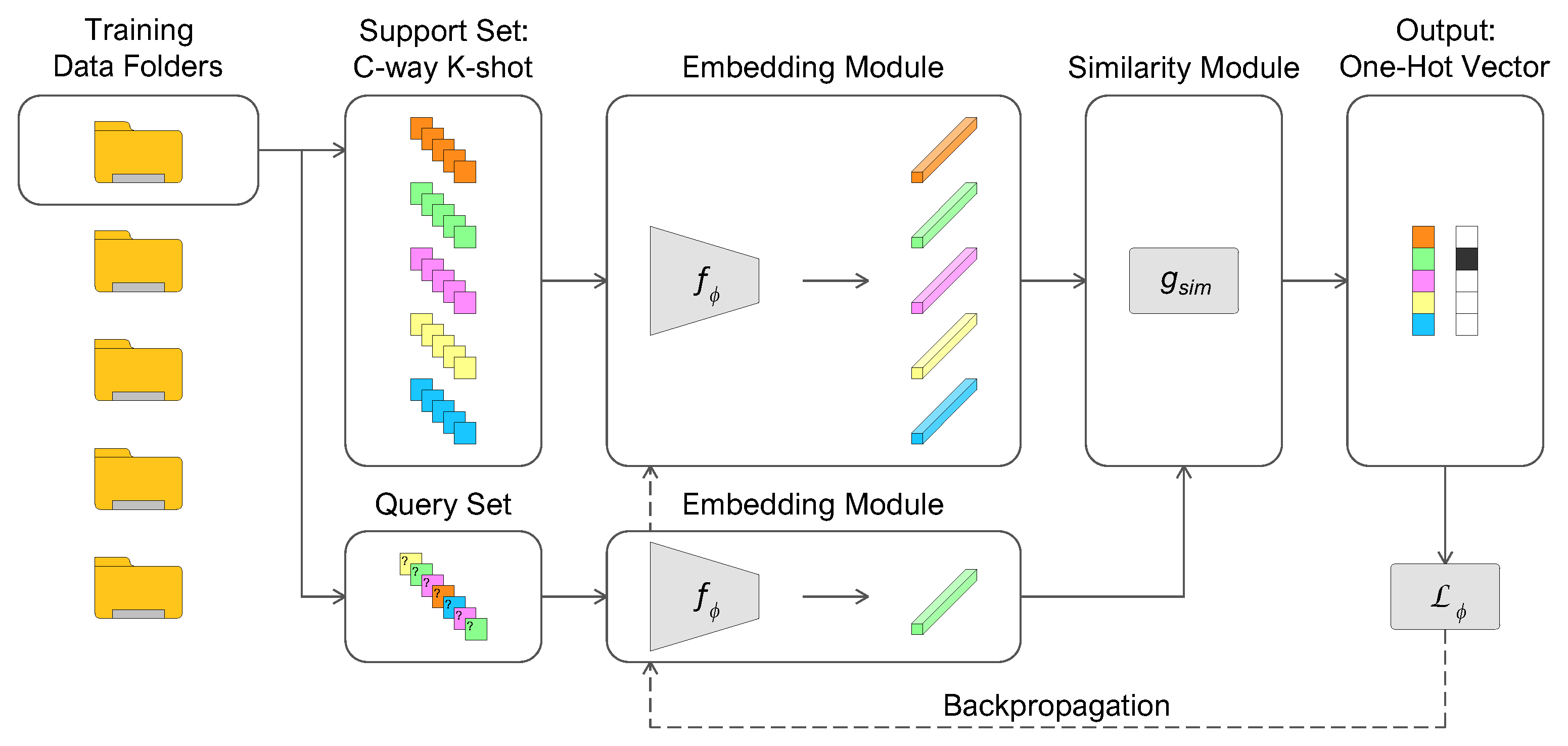
5.1. Few-Shot Models Analysis
The first step of our experiments aims to find the combination that returns the best results in the classification of a target word (SWC), an environmental sound (US8K), and an ambulance siren (A3S-Synth). We train prototypical networks in the configurations with SWC and US8K datasets, while we employ with A3S-Synth. At inference time, all models are evaluated by constructing positive and negative support embeddings in the same combinations with and . The results show the standard deviation across the AUPRC scores computed for each folder and averaged over 10 iterations.
Figure 6 illustrates the performance of prototypical networks with the SWC dataset. The experimental results correlate better scores with higher
. The
10-way 10-shot model returns an AUPRC of 0.83 in the
combination and 0.77 averaged across all the
settings.
Figure 7 exposes the outcomes of prototypical networks using the US8K dataset. Again, the
10-way 10-shot model yields the best results. The AUPRC for
is equal to 0.76, and the average score is 0.72 over all
combinations.
Figure 8 presents the prototypical results with the A3S-Synth dataset. Because
C is fixed and equal to 2, we analyze the performance varying
. Across the examined cases, the
2-way 10-shot model returns the best score with an AUPRC equal to 0.99 employing
and 0.96 averaged over all the
combinations.
We now analyze the experimental results in each dataset varying . Optioning multiple values of C ways is allowed only in multiclass datasets, so we first examine the SWC and US8K experiments by fixing and averaging the AUPRC scores over all the corresponding configurations. In both datasets, we observe that many C ways improve the average scores: multiclass training expands the prior knowledge of the model by increasing the discriminative capability among many classes of sounds and facilitating the discernment between examples belonging to new classes at the inference stage. The 10-way setting returns an average AUPRC equal to 0.76 for the SWC dataset and 0.72 for the US8K. One possible explanation for this lower performance is that the US8K comprises only ten classes, and few classes in training are limiting for constructing a model with high generalization capability.
We proceed to investigate the impact of different K values within the same C-way setting. For the SWC, many K shots return better performance: a higher number of examples creates a prototype that more closely collects the patterns of the original class, so the mean feature vector is more representative and facilitates the mapping between the positive queries and the corresponding support prototype. For the A3S-Synth, we observe that the 1-shot condition is the least effective, and at the same time, there is no substantial improvement between the 5-shot and 10-shot settings. It is probably due to the low inter-class variance of support examples and the significant background noise level in the audio files, which could penalize the prototype generation with many examples. Finally, the dataset that shows the least benefit in using multiple K shots in the training prototype generation is the US8K. Again, the low interclass variability might invalidate the creation of representative prototypes with numerous examples, especially for stationary sounds such as those belonging to the air conditioner, drilling, engine idling, and jackhammer classes. In addition, other sounds might not be adequately represented by a 0.5-s time window, which is too wide for gunshot or too narrow for street music or children playing classes.
The outcomes of individual C-way K-shot cases by varying are now explored. For all datasets and in all the configurations, the performance of prototypical networks with is better than because the prototype created by one example is not always representative of an entire class. On the other hand, increasing n does not provide univocal results for all datasets. With the SWC and A3S-Synth, we notice an improvement in AUPRC scores as n increases, and the case returns the best results in all simulation contexts. Hence, using more examples to create the negative support prototype enhances the capability of the network to classify the positive instances correctly. However, this is not the case with the US8K dataset, which shows a similarity between n at inference time and K in the training phase, where the use of an increasing number of shots does not produce a more robust prototypical representation.
5.2. Siren Detection with Prototypical Networks
5.2.1. Evaluation within Individual Recordings
This first analysis assesses the ESD task within individual recordings composed of audio segments with only traffic noise and others with additional sirens gradually arising from the background. In this way, we test the models to promptly identify the target sound in contexts where the background noise is significant, variable, and unpredictable. In the experiments, we separately analyze the performance of the recording sensors for each microphone position inside and outside the passenger compartment to evaluate which setup provides the best response.
Table 2,
Table 3 and
Table 4 present the results of the best prototypical models trained with the SWC, US8K, and A3S-Synth datasets, respectively, and tested on the single audio tracks of the A3S-Rec dataset for each acquisition sensor. We analyze several
configurations with
and
support examples. AUPRC is the average of the scores calculated for the six individual recordings over 10 iterations with random
support instances. Compared to the previous experiments for selecting the most performing models, we also investigate the combination with
as the three datasets have returned the best results in the
10-shot condition.
The results obtained by varying for each training dataset and audio recording channel are now discussed.
With n fixed and p variable, we observe that the three models provide outcomes with the same trend in all audio channels: offers the worst performance and shows improvements. In most cases, the AUPRC scores increase along with , although there are configurations in which equals or exceeds in performance. The smallest gap between the results with and can be observed in the channels 5–8. The reason is attributable to the noise in the recordings acquired inside the trunk and behind the license plate: using more examples does not always help create a more representative prototype of the target class if the audio segments of the support set are affected by conspicuous background noise.
Similarly, analyzing the results by fixing p and varying n leads to uniform outputs: the AUPRC scores increase as increases, with rare exceptions in the configuration with . This fact confirms that the 1-shot setting, employed for both positive and negative classes or only one of them, is not a suitable approach for classifying sound events with quick fluctuations in intensity and frequency distribution.
As expected, the scores obtained from the A3S-Synth-trained model are better than the SWC ones, followed by the US8K model outcomes. The A3S-Synth dataset provides the best performance in the combination with an AUPRC score of 0.90 at channel 8, and among the several models, it benefits most from multiple support examples.
If we analyze the AUPRC values in each audio channel, there are no substantial differences between microphone positions in the same installation context. The microphones behind the license plate (positions 7–8) achieve the best performance, followed by those inside the passenger compartment (positions 1–4) and finally in the trunk (positions 5–6).
5.2.2. Evaluation with Internal Labeling
In previous simulations, we tested few-shot models on data extracted from recordings acquired by eight microphones outside and inside the cockpit. The audio segments have been annotated by listening to the audio signals recorded by the sensors behind the license plate and applying the same label to all channels. In fact, audio data of microphones 7-8 show the presence of the ambulance sooner than the other positions being installed externally. We have also ascertained that they return the best performance in the ESD task, as illustrated in
Table 2,
Table 3 and
Table 4.
We now investigate the behavior of the sensors inside the passenger compartment, focusing on the influence of cockpit sound attenuation. Because the chassis is made of soundproofing material, it acts as a barrier to the entry of the siren sound when its level is below the enclosure transmission loss at the siren tones frequencies. This fact results in a shorter duration of siren sound events in the internal recordings than in the external ones. To indirectly assess the influence of cockpit attenuation in the ESD task, we have repeated the experiments after revising the annotations only for channels 1, 2, 3, and 4. For this purpose, we have changed the labeling from siren to noise in the audio segments where the siren sound has been fully attenuated. In each audio track, the chassis soundproofing has operated differently, depending on the initial distance between source and receiver, the acquisition scenario, and the traffic noise level.
After the internal labeling operation, siren instances were reduced by about 13%.
Figure 9 shows an example of spectrograms of the same siren occurrence recorded by sensors inside the passenger compartment and behind the license plate. Because the siren sound in the first 5 s of the internal recording is attenuated, we attributed the noise class to this audio segment.
Table 5,
Table 6 and
Table 7 present testing results on channels 1-2-3-4 of the A3S-Rec dataset with internal labeling employing the SWC/US8K/A3S-Synth best prototypical models.
Considering channels 1-2-3-4, the outcomes of the recordings with internal labeling show equal or better AUPRC scores than those with external annotations in all settings. As for the results obtained with external labeling, the few-shot configurations with provide the best performance and generally show greater boosting than the 1-shot setting. We calculated the average relative percentage increment between the external and internal labeling results: the SWC model provides the highest increase in the AUPRC score, at about 7%. This aspect shows that the good generalization capability of a model is related to the matching between the source and target domains. In fact, removing the noisiest instances from the positive class resulted in cleaner siren prototypes, more similar to the SWC ones computed from clean speech recordings.
The performance improvement with the internal labeling is correlated to the noise class attribution of uncertain siren events resulting from cockpit sound attenuation and internal car noise. Whereas the impact of the attribution of not clearly identifiable siren events to the noise class is reflected in higher scores, the algorithm exhibits delayed responsiveness in the siren recognition, as visible in
Figure 9. We thus refer to the external labeling for an unbiased comparison of the effectiveness of the acquisition sensors.
We observe that the internally labeled audio data yield comparable or slightly better AUPRC scores than recordings at positions 7–8 for the experiments conducted with the SWC and US8K models. In contrast, with A3S-Synth, the external channels again outperform the internal ones. This behavior can be attributed to the similarity between the synthetic dataset generated by adding siren sounds to traffic noise recordings in the external environment and the recordings of sensors behind the license plate.
Moreover, in all models, the microphone at position 4 provides the best emergency siren detection scores. One possible reason is that the ambulances often approached the equipped car from the same direction of travel during the acquisition campaign. Thus, the alarm sound first impacted the rear, incurring less reflection from the source to the recording sensors on the back. The better response of the sensor at position 4 compared to the specular one could be due to the operator sitting near position 3, which represented an absorption surface for the incoming sound.
We have not performed tests with different labeling for audio data acquired by the microphones inside the trunk. Recordings at positions 5–6 are simultaneously affected by cabin soundproofing and mechanical component noise, so an internal labeling criterion would have resulted in an excessive reduction of siren instances.
5.2.3. Evaluation across All Recordings
In the next set of experiments, we assess the few-shot techniques across all the recordings. We have identified the siren sound within individual audio tracks, so the classification task is extended over all the recordings performed by a specific sensor. If the detection in individual recordings can be interpreted as identifying the background noise perturbation produced by the siren signal, the detection across all recordings represents a generalization of the previous case. In this way, we rely on the prototypical networks for the more challenging task of discriminating a siren sound from background noise acquired in several contexts and varying both in terms of sound intensity and spectral content.
For this purpose, we have organized the instances of each audio track recorded by a given sensor in a single folder, considering channels 4, 7, and 8 as they provided the best results in the analysis within individual recordings. We construct the support set by employing the most robust combination and evaluate the influence of increasing positive support examples. Consequently, the experiments are conducted with and , computing AUPRC scores averaged over 10 iterations with different random support and query sets.
Table 8 presents the prototypical results across all the recordings acquired by microphones in positions 4-7-8. With a fixed
, a more significant number of
p improves the scores. The best value is equal to 0.86, obtained by the A3S-Synth model in the
combination with data belonging to channel 7.
Despite considering the best performing audio channels and employing more instances to compute the prototypes, the detection across all recordings achieves lower scores than those within the single audio tracks. The reason can be attributed to the variability of the background noise affecting the support and query sets. Prototypes generated from spectrograms with dissimilar frequency distributions might not always enhance the features of a weak target signal, so query samples would not be distinctly associable with the positive or negative class. As confirmation of this aspect, we found that increasing the number of positive examples to in the experiments with individual recordings does not make significant contributions, achieving a maximum improvement of one percentage point. In that case, the use of only instances yields a stable representation that captures the variance of the signal in a single audio track; on the other hand, in the experiments across all recordings, the use of many support examples proves beneficial in almost all combinations. Again, the task-related model computed with the A3S-Synth dataset is the most effective.
In addition, we examine noise reduction effects by applying the harmonic-percussive source separation technique [
59] to the A3S-Rec dataset.
Table 9 presents prototypical results across all the recordings acquired by microphones in position 4-7-8 after harmonic filtering with a separation factor
. We observe an appreciable improvement provided by the filtering operations, especially for the external channels. The best AUPRC scores are attributed to the A3S-Synth model in the
combinations with data belonging to channel 8.
The results show that channels 7–8 yield better performance than channel 4. One possible explanation is that the high noise in the external recordings is easily separated and assigned to the percussive and residual components, emphasizing the harmonic siren sound. On the other hand, filtering operations in cleaner internal recordings do not improve appreciably over unfiltered audio data. We also note that using more positive examples often does not lead to better outcomes. In the filtered condition, spectrograms highlight the harmonic content of the signal, and thus, even few instances can create a representative prototype. Finally, we comment on the better scores of channel 8 compared to 7. Despite being in specular positions, the microphone at position 7 is located on the left side of the license plate. The corresponding recordings may be affected by noises with tonal components from cars in the other direction of travel, which explains the loss of performance with the filtered audio data.
5.3. Siren Detection with Baseline
The last experiments concern classifying the audio files belonging to the A3S-Rec dataset by using the baseline computed by the CNN described in
Section 3.3.2. Training is performed with the A3S-Synth dataset as it provided the best ESD models in the previous experiments. Moreover, the use of synthetic datasets is often an effective strategy to build a representative model in the condition of scarce availability of actual data. We evaluate the CNN performance across all the recordings with and without fine-tuning for domain adaptation. For a comparison with prototypical networks, the
combinations of instances used to construct the support embeddings are employed to update the weights of the two last linear layers, as described in
Section 4.2.3. The AUPRC scores are averaged over 10 different
combinations to account for the variability of the fine-tuning instances.
Table 10 presents the outcomes of the baseline model without fine-tuning tested across all the recordings of A3S-Rec (channels 4-7-8) in unfiltered and harmonic filtered conditions.
Although the results do not differ significantly, we observe the best scores for the external channels in the unfiltered conditions with an AUPRC equal to 0.65. The reason is the affinity between source and target domains, as the synthetic siren audio files have been generated simulating siren alarms immersed in urban traffic noise in the outdoor environment. On the other hand, inference on filtered data shows a slight decrease in performance at channels 7-8. Because the training was conducted on unfiltered data and the filtering accentuates any harmonic components, generic tonal sounds recorded by the external sensors may be confused with the siren alarm.
Table 11 illustrates the results of the baseline model with fine-tuning, again in unfiltered and harmonic filtered conditions.
The analysis of the fine-tuned baseline results mirrors the trend of prototypical AUPRC scores with the A3S-Synth model shown in
Table 8 and
Table 9. In both unfiltered and harmonic filtered conditions, many
instances for the fine-tuning improve the classification performance. Again, the effectiveness of the noise reduction technique is proven by the best results obtained with filtered data belonging to the external channels. For the internal channel, we note that fine-tuning with only 10 positive examples decreases the performance of the baseline without domain adaptation. In this case, few positive examples affected by cockpit attenuation and rapid model overfitting lead to erroneous learning of the siren class. This aspect shows an additional advantage of prototypical networks in the low-data regime. Whereas the convolutional neural network used for the baseline has been trained with few epochs to reduce the problem of overfitting on the fine-tuning data, for prototypical networks, this excessive adaptation does not affect the results due to the distance-based metrics, as investigated in [
26].
In
Table 12, the relative percentage increase of the few-shot achievements with respect to (CNN + fine-tuning) is presented.
In almost all cases, the most significant increments occur in the combination and decrease with higher p values. This fact indicates that by increasing the examples, AUPRC scores of the fine-tuned baseline approximate the few-shot outcomes. However, prototypical networks demonstrate their superior efficacy because they perform equally well with a very limited amount of support instances.
In addition, the improvement with the lowest number of data used in the combination is more evident in the case of the internal microphone, meaning that the few-shot solution performs better than the (CNN + fine-tuning) when the mismatch between training and testing conditions is high.
5.4. Discussion
In light of the results, prototypical networks have shown to be a robust method in emergency siren detection. Similarity learning between instances and prototypes of the same class demonstrates a more effective method than learning single examples that are not always representative of the belonging class. Moreover, adopting a training dataset that matches the target domain facilitates the classification task.
However, not all few-shot techniques are as successful as prototypical networks. We have also performed experiments with relation networks [
33], but they have not equaled the prototypical ones despite obtaining fair results. We attribute the motivation to the embedding generation method, considering the high noise level in our recordings. In the prototypical embedding, the noise and siren feature maps are averaged, so the noise is redistributed among all frequencies. On the other hand, in the relation embedding, the feature maps are summed element-wise, and the sum amplifies the noise representation over the siren.
In this work, our investigations have provided valuable insights for implementing in-car emergency vehicle detection systems, summarized as follows.
The best location for the acquisition sensor is outside the vehicle behind the license plate. This placement is not affected by wind nor cabin attenuation and gives a fast response to siren sound detection. The related disadvantage of the installation is the requirement for weatherproof sensors.
Because the high noise level of external recordings affects the siren detection task, a noise reduction filter such as the one proposed should be included to improve the external sensor performance.
Due to the effectiveness of few-shot techniques compared with traditional methods under conditions of few data and mismatch between training and test sets, the sensors inside the passenger compartment can be employed with significant deployment benefits. Although disadvantages arise from reduced responsiveness resulting from cockpit soundproofing, people talking, or the sound system, internal microphones installed in a weather-protected environment present lower costs and maintenance than the external ones.
The most common and dangerous situation is an ambulance approaching a car in the same direction of travel, so the most suitable microphone placement is at the rear of the vehicle. If the internal installation is chosen, interference with sound-absorbing surfaces should be avoided.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}