
Multi-Modal Vehicle Trajectory Prediction by Collaborative Learning of Lane Orientation, Vehicle Interaction, and Intention



Abstract
:1. Introduction
- We explore the embedding efficiency of various interaction models under the Long Short-Term Memory (LSTM) encoder–decoder prediction framework and integrate both interaction and lane orientation information in a lightweight encoding module to improve environment interpretation.
- We propose an approach to effectively learn the driving uncertainty, which conforms to the lane orientation and considers multiple modes of the vehicle trajectory in a dual-level mode paradigm.
- We perform extensive validation on both high-speed scenarios and urban road scenarios, including the NGSIM, HighD, and Argoverse benchmarks. Experimental results show that the proposed method significantly improves the prediction accuracy compared with the baselines while maintaining a fast runtime speed.
2. Related Work
2.1. Trajectory Prediction Based on the Interaction Model
2.2. Trajectory Prediction Based on Road Map Information
2.3. Multi-Modal Trajectory Prediction
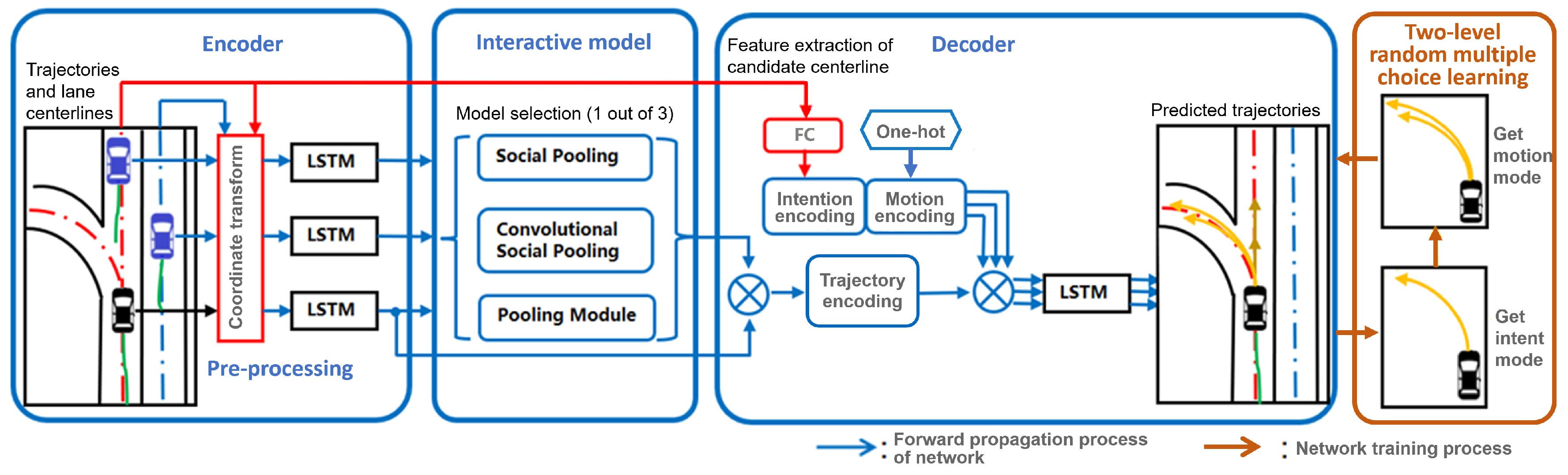
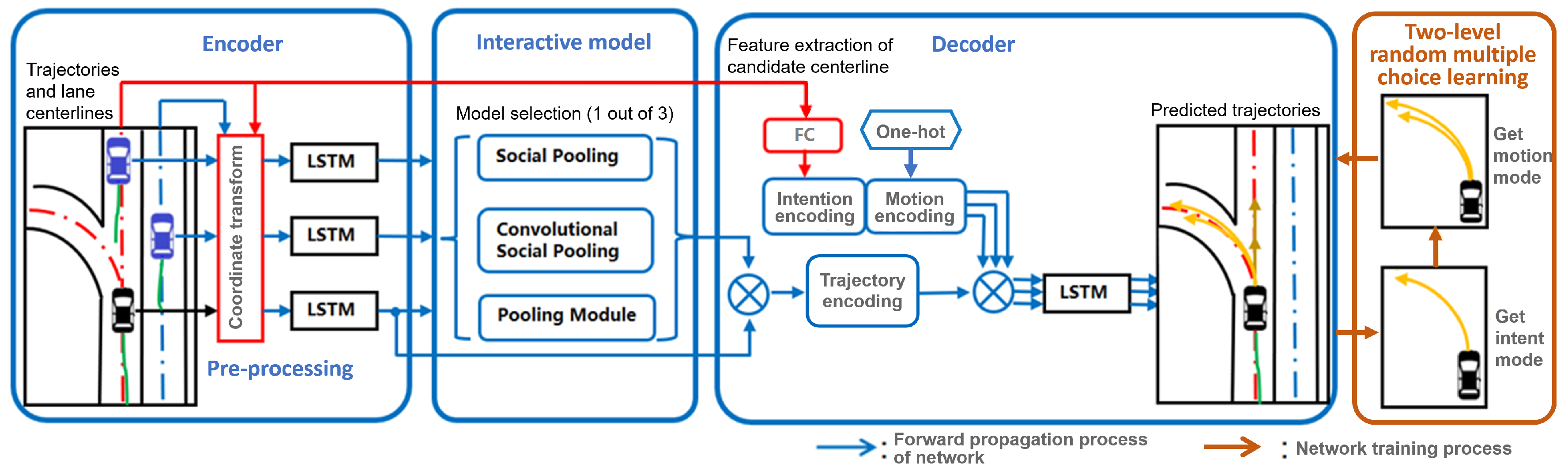
3. Multi-Modal Trajectory Prediction by Joint Learning Interaction and Lane Orientation Information
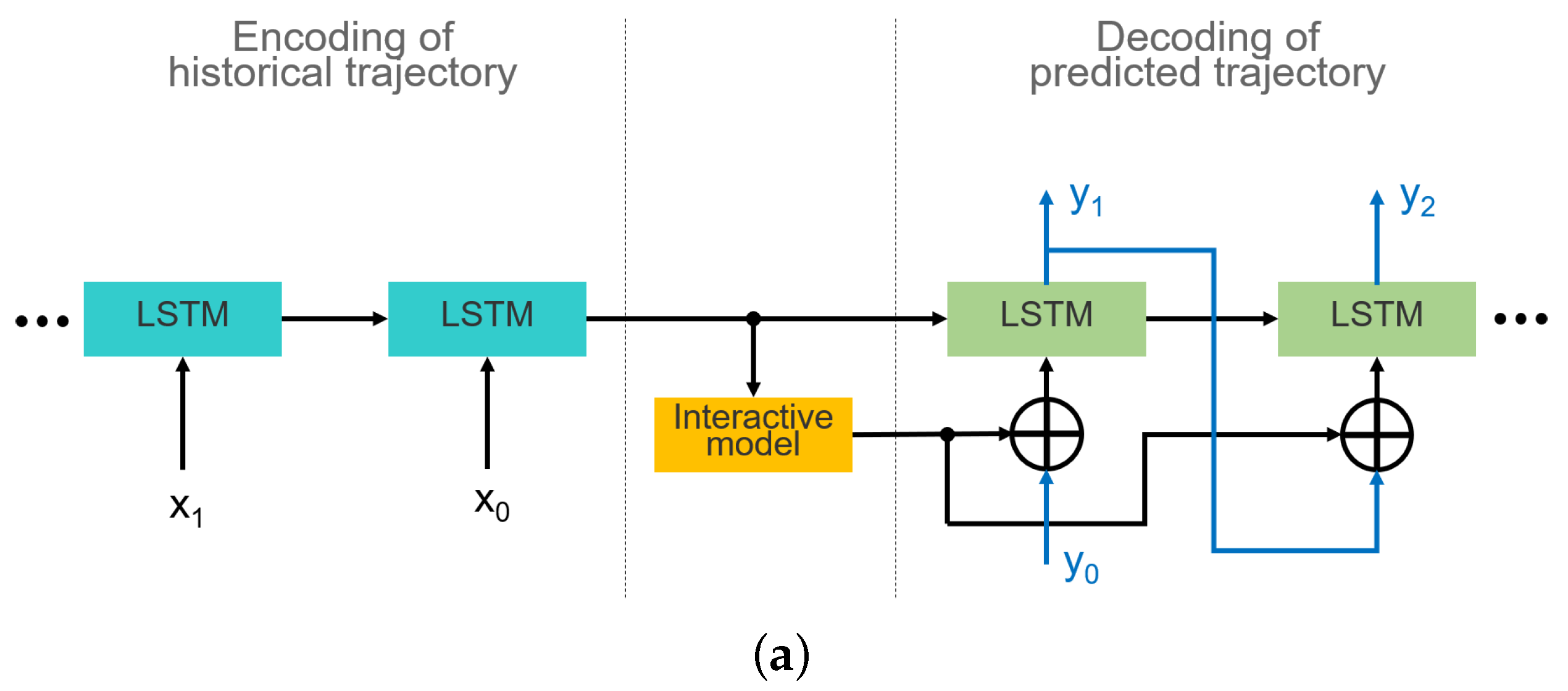
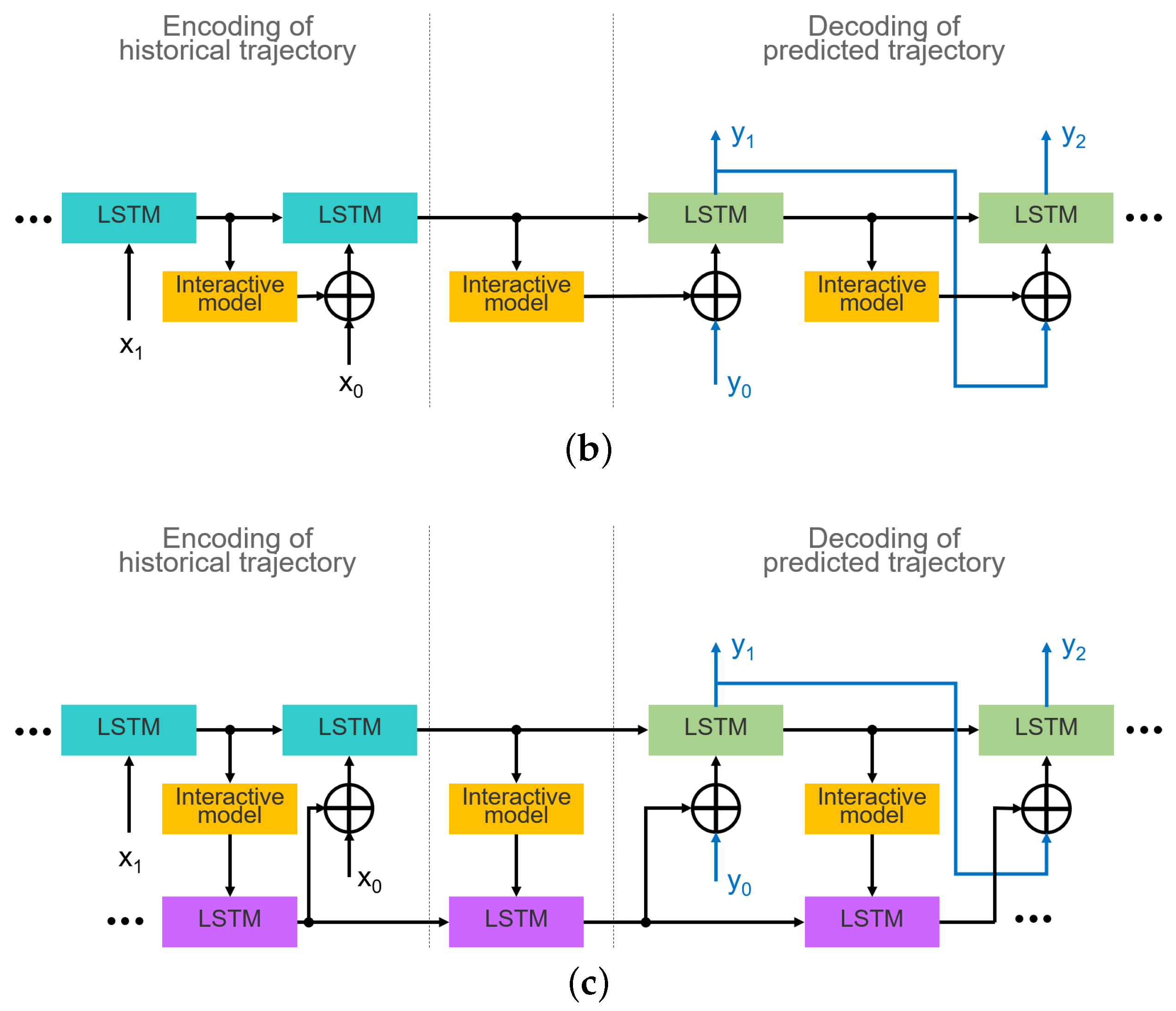
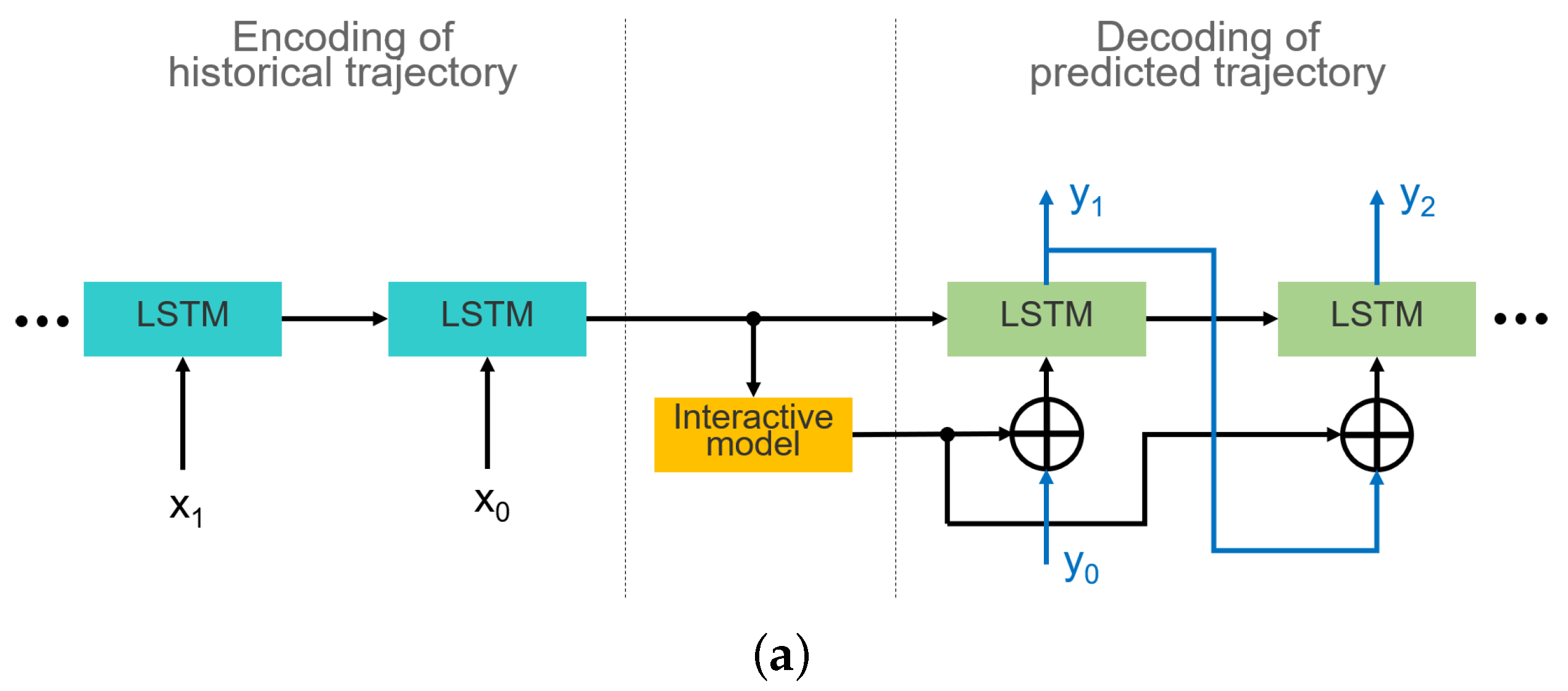
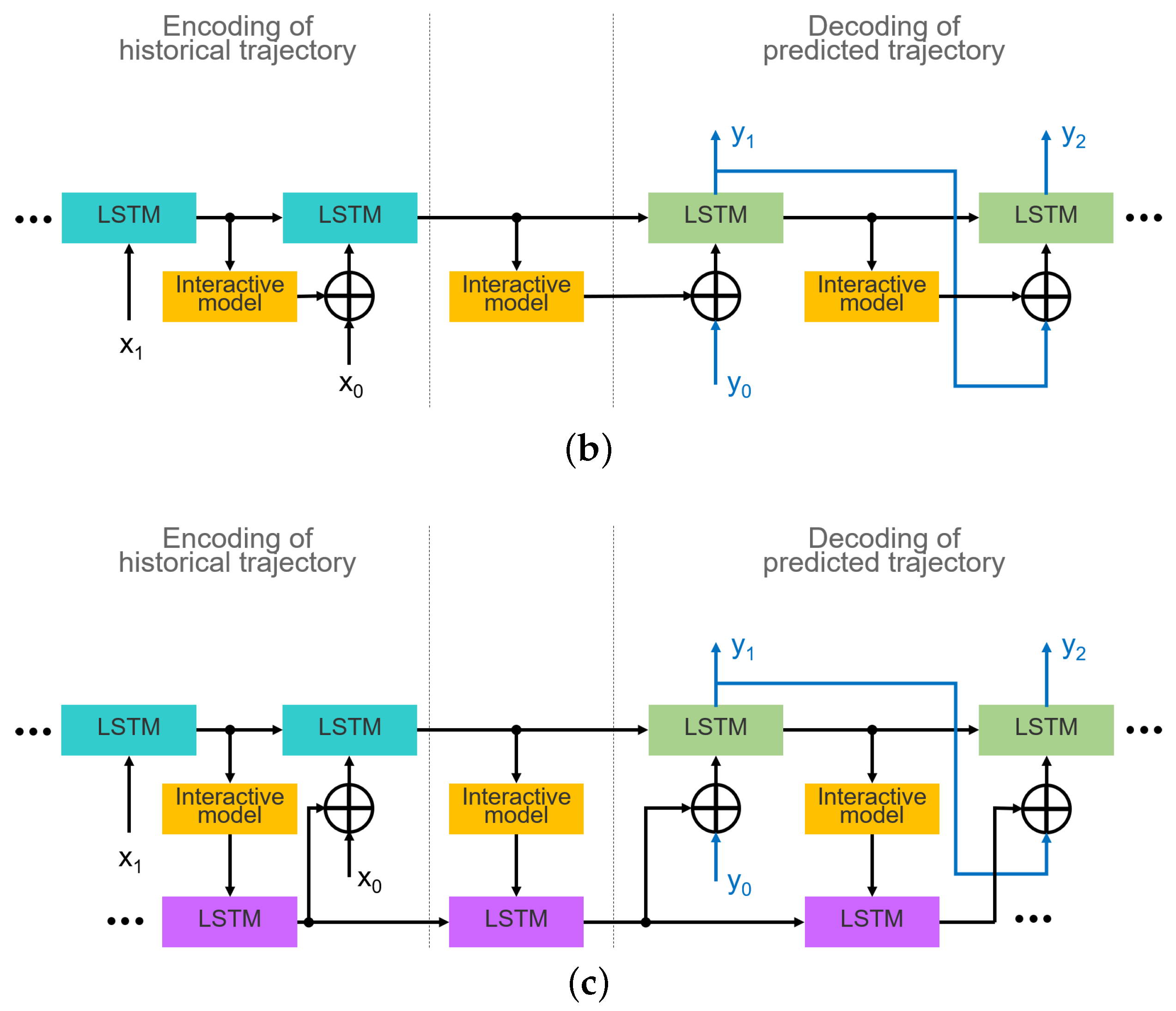
3.1. Embedding of Interaction Model
3.2. Integration of Lane Orientation Information
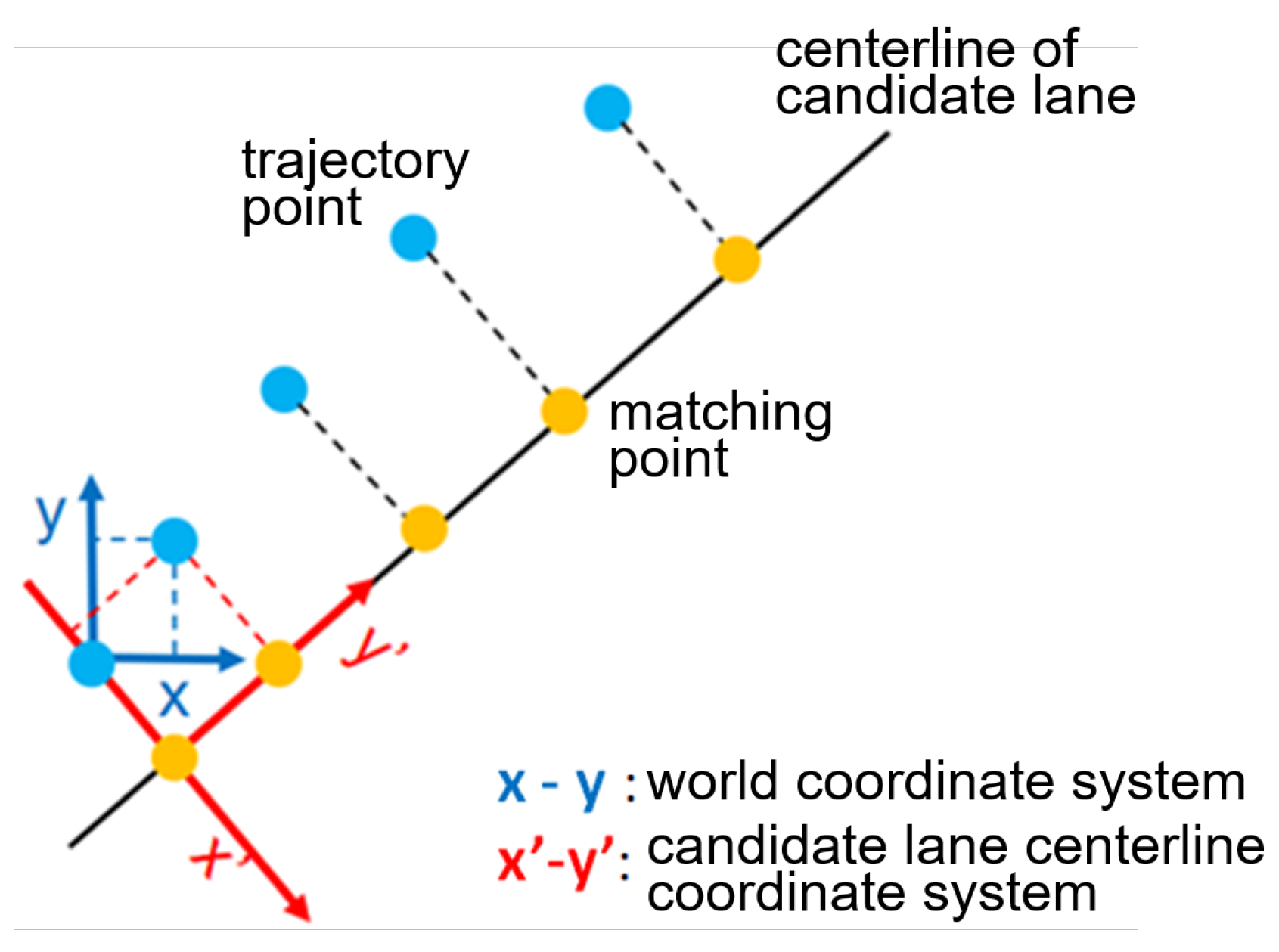
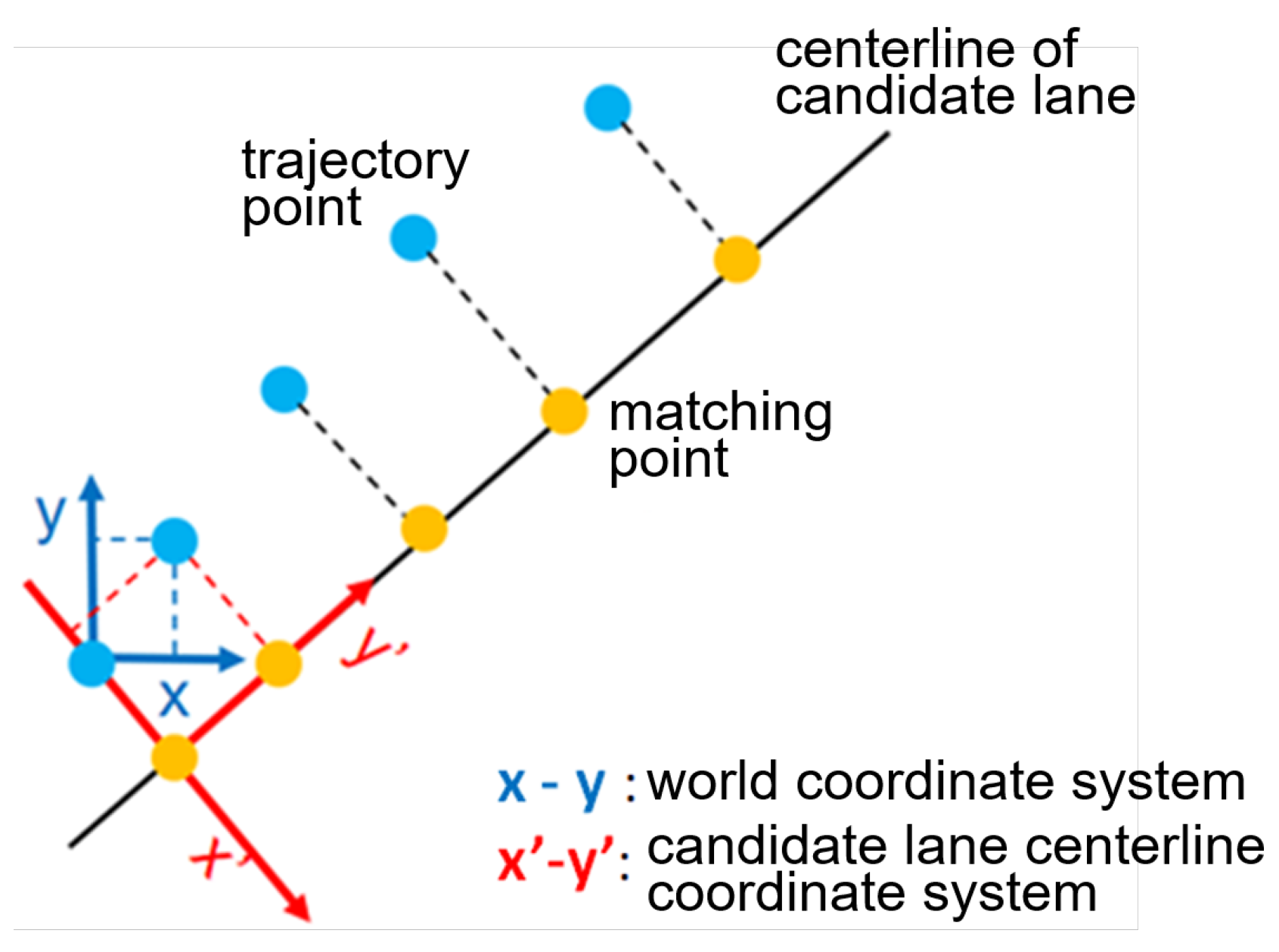
3.2.1. Selection of Candidate Lane Centerline
3.2.2. Motion Trajectory Coordinate Transform
3.3. Multi-Modal Prediction
3.3.1. Modality Interpretation
3.3.2. Learning Strategy
4. Experiments
4.1. Experimental Setting
4.2. Exploration of Interaction Integration
4.2.1. Exploration of Interaction Model
4.2.2. Exploration on Interaction Embedding
4.3. Evaluation of Lane Orientation Information Integration
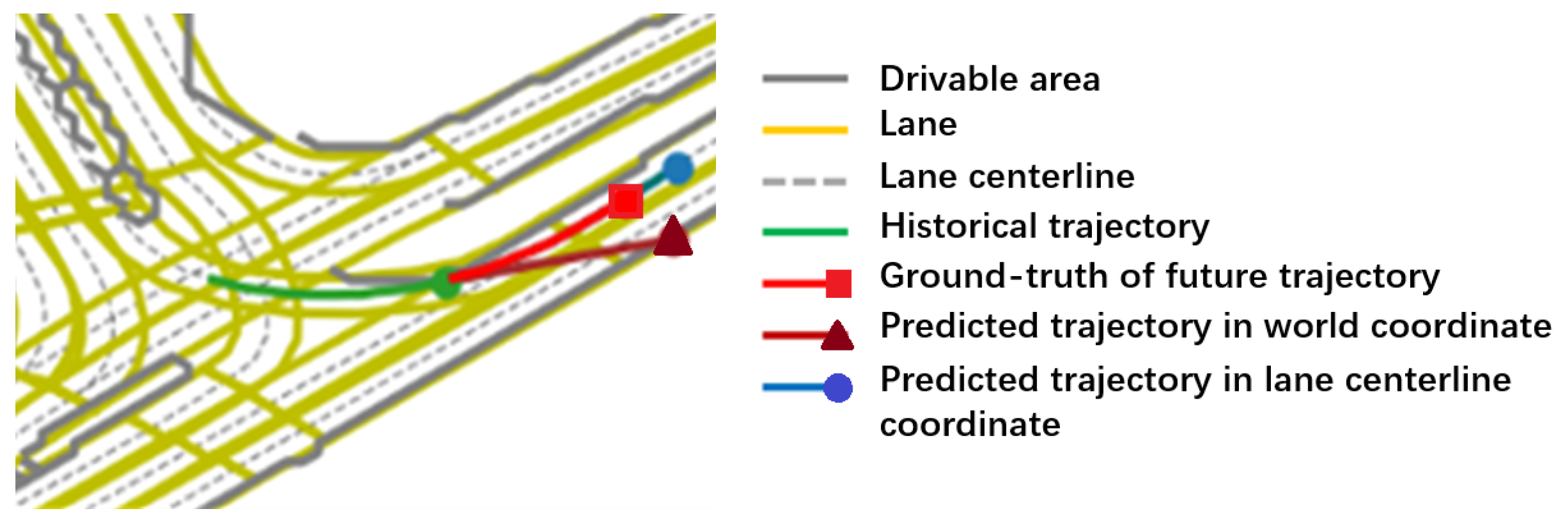
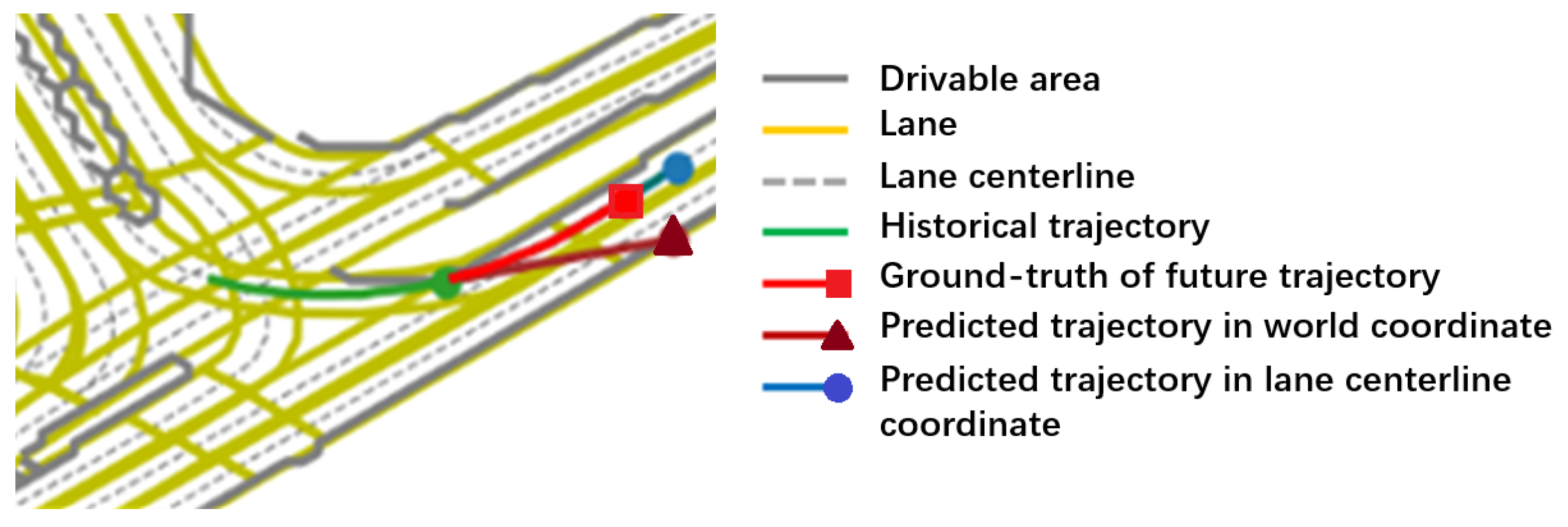
4.3.1. Qualitative Analysis
4.3.2. Quantitative Analysis
4.4. Evaluation of Multi-Modal Prediction
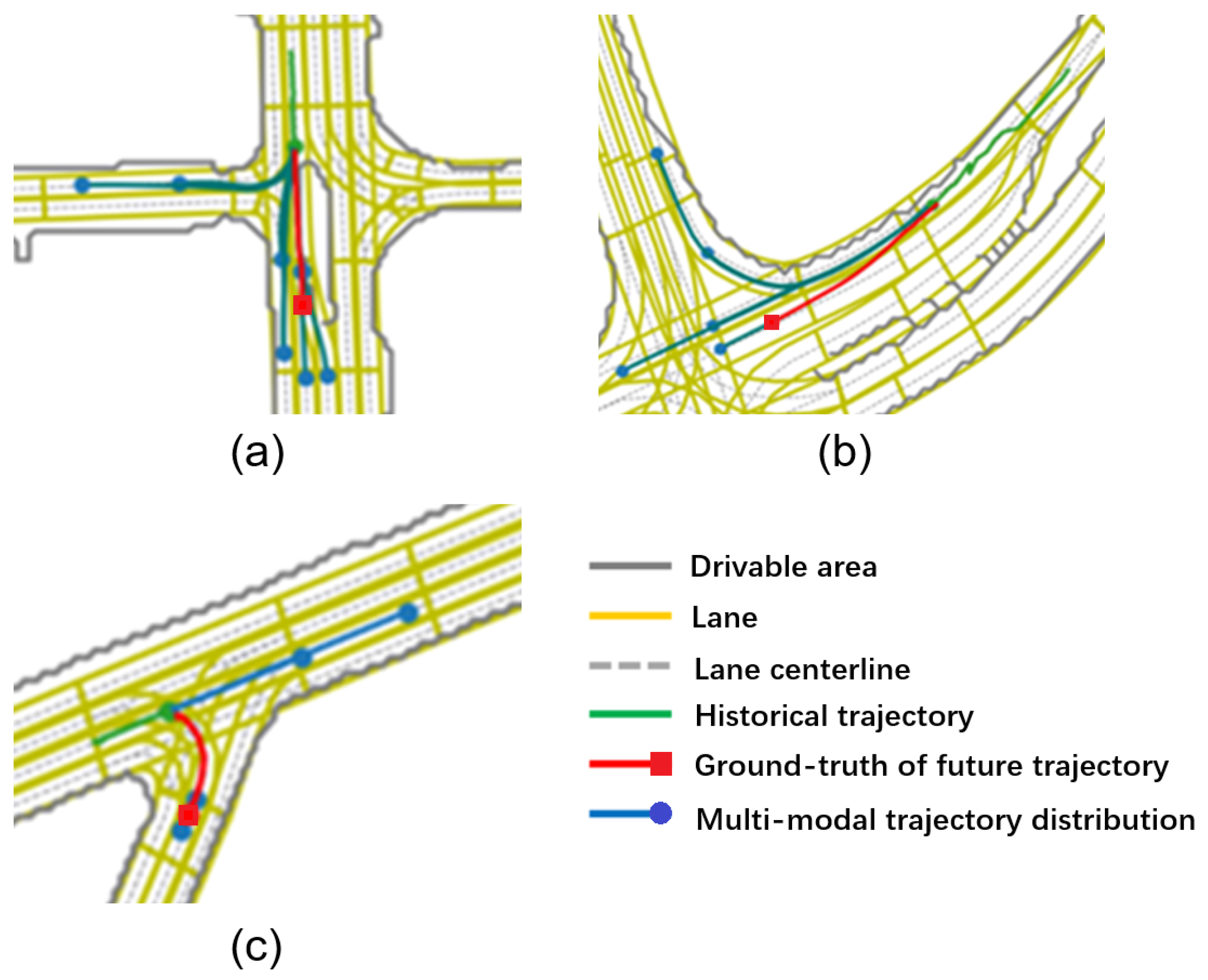
4.4.1. Qualitative Analysis
4.4.2. Quantitative Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LSTM | Long Short-Term Memory |
| NN | Neural Network |
| CNN | Convolutional Neural Network |
| GNN | Graph Neural Network |
| GAN | Generative Adversarial Network |
| FC | Fully Connected |
References
- Trabelsi, R.; Khemmar, R.; Decoux, B.; Ertaud, J.-Y.; Butteau, R. Recent Advances in Vision-Based On-Road Behaviors Understanding: A Critical Survey. Sensors 2022, 22, 2654. [Google Scholar] [CrossRef] [PubMed]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Gupta, A.; Johnson, J.; Li, F.F.; Savarese, S.; Alahi, A. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qin, Z.; Chen, L.; Fan, J.; Xu, B.; Hu, M.; Chen, X. An improved real-time slip model identification method for autonomous tracked vehicles using forward trajectory prediction compensation. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Gao, J.; Sun, C.; Zhao, H.; Shen, Y.; Anguelov, D.; Li, C.; Schmid, C. Vectornet: Encoding hd maps and agent dynamics from vectorized representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11525–11533. [Google Scholar]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-agent tensor fusion for contextual trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Vemula, A.; Muelling, K.; Oh, J. Social attention: Modeling attention in human crowds. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4601–4607. [Google Scholar]
- Zhang, P.; Ouyang, W.; Zhang, P.; Xue, J.; Zheng, N. Sr-lstm: State refinement for lstm towards pedestrian trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12085–12094. [Google Scholar]
- Zhou, L.; Zhao, Y.; Yang, D.; Liu, J. Gchgat: Pedestrian trajectory prediction using group constrained hierarchical graph attention networks. Appl. Intell. 2022, 1573–7497. [Google Scholar] [CrossRef]
- Saeed, T.U. Road infrastructure readiness for autonomous vehicles. Ph.D. Thesis, Purdue University Graduate School, West Lafayette, IN, USA, 2019. [Google Scholar]
- Saeed, T.U.; Alabi, B.N.T.; Labi, S. Preparing road infrastructure to accommodate connected and automated vehicles: System-level perspective. J. Infrastruct. Syst. 2020, 27, 06020003. [Google Scholar] [CrossRef]
- Park, S.H.; Lee, G.; Seo, J.; Bhat, M.; Kang, M.; Francis, J.; Jadhav, A.; Liang, P.P.; Morency, L.P. Diverse and admissible trajectory forecasting through multimodal context understanding. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2020; pp. 282–298. [Google Scholar]
- Cui, H.; Nguyen, T.; Chou, F.C.; Lin, T.H.; Schneider, J.; Bradley, D.; Djuric, N. Deep kinematic models for physically realistic prediction of vehicle trajectories. arXiv 2019, arXiv:abs/1908.00219. [Google Scholar]
- Cui, H.; Radosavljevic, V.; Chou, F.C.; Lin, T.H.; Nguyen, T.; Huang, T.K.; Schneider, J.; Djuric, N. Multimodal trajectory predictions for autonomous driving using deep convolutional networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2090–2096. [Google Scholar]
- Djuric, N.; Radosavljevic, V.; Cui, H.; Nguyen, T.; Chou, F.C.; Lin, T.H.; Singh, N.; Schneider, J. Uncertainty-aware short-term motion prediction of traffic actors for autonomous driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2095–2104. [Google Scholar]
- Yalamanchi, S.; Huang, T.K.; Haynes, G.C.; Djuric, N. Long-term prediction of vehicle behavior using short-term uncertaintyaware trajectories and high-definition maps. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Luo, C.; Sun, L.; Dabiri, D.; Yuille, A. Probabilistic multi-modal trajectory prediction with lane attention for autonomous vehicles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 2370–2376. [Google Scholar]
- Greer, R.; Deo, N.; Trivedi, M. Trajectory prediction in autonomous driving with a lane heading auxiliary loss. IEEE Robot. Autom. Lett. 2021, 6, 4907–4914. [Google Scholar] [CrossRef]
- Hu, Y.; Zhan, W.; Tomizuka, M. A framework for probabilistic generic traffic scene prediction. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2790–2796. [Google Scholar]
- Huang, X.; McGill, S.G.; DeCastro, J.A.; Fletcher, L.; Leonard, J.J.; Williams, B.C.; Rosman, G. Diversitygan: Diversity-aware vehicle motion prediction via latent semantic sampling. IEEE Robot. Autom. Lett. 2020, 5, 5089–5096. [Google Scholar] [CrossRef]
- Lee, S.; Prakash, S.P.S.; Cogswell, M.; Ranjan, V.; Crandall, D.; Batra, D. Stochastic multiple choice learning for training diverse deep ensembles. Adv. Neural Inf. Process. Syst. 2016, 29, 2119–2127. [Google Scholar]
- Wang, Z.; Zhou, S.; Huang, Y.; Tian, W. Dsmcl: Dual-level stochastic multiple choice learning for multi-modal trajectory prediction. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Park, S.H.; Kim, B.D.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM encoder–decoder Architecture. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar]
- Coifman, B.; Li, L. A critical evaluation of the Next Generation Simulation (NGSIM) vehicle trajectory dataset. Transp. Part B-Methodol. 2017, 105, 362–377. [Google Scholar] [CrossRef]
- Krajewski, R.; Bock, J.; Kloeker, L.; Eckstein, L. The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2118–2125. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8740–8749. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested traffic states in empirical observations and microscopic simulations. Phys. Rev. E 2000, 62, 1805. [Google Scholar] [CrossRef] [Green Version]
- Tang, C.; Salakhutdinov, R.R. Multiple futures prediction. Adv. Neural Inf. Process. Syst. 2019, 32, 15424–15434. [Google Scholar]
- Zeng, W.; Liang, M.; Liao, R.; Urtasun, R. LaneRCNN: Distributed Representations for Graph-Centric Motion Forecasting. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Gilles, T.; Sabatini, S.; Tsishkou, D.; Stanciulescu, B.; Moutarde, F. HOME: Heatmap Output for future Motion Estimation. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Khandelwal, S.; Qi, W.; Singh, J.; Hartnett, A.; Ramanan, D. What-if motion prediction for autonomous driving. arXiv 2020, arXiv:2008.10587. [Google Scholar]
- Ngiam, J.; Caine, B.; Vasudevan, V.; Zhang, Z.; Chiang, H.-T.L.; Ling, J.; Roelofs, R.; Bewley, A.; Liu, C.; Venugopal, A.; et al. Scene Transformer: A unified multi-task model for behavior prediction and planning. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | NGSIM | HighD | ||
|---|---|---|---|---|
| Methods | ADE (m)↓ | FDE (m)↓ | ADE (m)↓ | FDE (m)↓ |
| CV | 3.42 | 6.68 | 1.49 | 2.83 |
| IDM | 3.40 | 6.60 | 1.52 | 2.86 |
| LSTM (baseline) | 3.19 | 6.27 | 1.43 | 2.76 |
| S-LSTM | 2.24 | 4.18 | 1.30 | 2.55 |
| CS-LSTM | 2.20 | 4.11 | 1.28 | 2.54 |
| P-LSTM | 2.21 | 4.17 | 1.25 | 2.52 |
| Embedding Style | ADE (m) ↓ | FDE (m) ↓ | Runtime (Hz) ↑ |
|---|---|---|---|
| Current frame | 2.21 | 4.17 | 98 |
| Each frame | 2.21 | 4.15 | 12 |
| Space–time coupling | 2.20 | 4.14 | 8 |
| Methods | ADE (m) ↓ | FDE (m) ↓ |
|---|---|---|
| CV | 3.95 | 8.56 |
| CV-map | 3.72 | 7.19 |
| LSTM (baseline) | 2.77 | 5.67 |
| LSTM-map | 1.67 | 3.58 |
| P-LSTM-map | 1.58 | 3.37 |
| VectorNet | 1.66 | 3.67 |
| Rasterized Map | 1.60 | 3.64 |
| Methods | minADE (m) ↓ | minFDE (m) ↓ |
|---|---|---|
| CV | 3.95 | 8.56 |
| CV-map | 3.72 | 7.19 |
| LSTM (baseline) | 2.53 | 5.04 |
| LSTM-map | 1.67 | 3.58 |
| P-LSTM-map | 1.58 | 3.37 |
| LSTM-M-map | 0.88 | 1.74 |
| P-LSTM-M-map | 0.85 | 1.66 |
| Methods | minADE (m) ↓ | minFDE (m) ↓ |
|---|---|---|
| P-LSTM-M-map | 0.85 | 1.66 |
| MFP-k | 1.40 | - |
| P-LSTM-map-k | 1.40 | 3.15 |
| LaneRCNN | 0.90 | 1.45 |
| LaneRCNN-M | 0.86 | 1.35 |
| WIMP | 0.90 | 1.42 |
| HOME | 0.94 | 1.45 |
| SceneTransformer | 0.80 | 1.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, W.; Wang, S.; Wang, Z.; Wu, M.; Zhou, S.; Bi, X. Multi-Modal Vehicle Trajectory Prediction by Collaborative Learning of Lane Orientation, Vehicle Interaction, and Intention. Sensors 2022, 22, 4295. https://doi.org/10.3390/s22114295
Tian W, Wang S, Wang Z, Wu M, Zhou S, Bi X. Multi-Modal Vehicle Trajectory Prediction by Collaborative Learning of Lane Orientation, Vehicle Interaction, and Intention. Sensors. 2022; 22(11):4295. https://doi.org/10.3390/s22114295
Chicago/Turabian StyleTian, Wei, Songtao Wang, Zehan Wang, Mingzhi Wu, Sihong Zhou, and Xin Bi. 2022. "Multi-Modal Vehicle Trajectory Prediction by Collaborative Learning of Lane Orientation, Vehicle Interaction, and Intention" Sensors 22, no. 11: 4295. https://doi.org/10.3390/s22114295
APA StyleTian, W., Wang, S., Wang, Z., Wu, M., Zhou, S., & Bi, X. (2022). Multi-Modal Vehicle Trajectory Prediction by Collaborative Learning of Lane Orientation, Vehicle Interaction, and Intention. Sensors, 22(11), 4295. https://doi.org/10.3390/s22114295