
RF eigenfingerprints, an Efficient RF Fingerprinting Method in IoT Context

 ,
,
Abstract
:1. Introduction
- We adapt the eigenfaces principles to RF fingerprinting domain. Furthermore, we develop a strong theoretical background of our approach.
- We propose a novel baseband model for emitter impairments simulation, taking into account I/Q offset, I/Q imbalance, and power amplifier nonlinearity.
- We develop a lightweight FPGA implementation of our features projection step on Digilent Zedboard (Xilinx Zynq-7000).
- We present a methodology to interpret the features learned by our algorithm.
2. State of the Art
2.1. Eigenfaces
2.2. RF Fingerprinting
2.3. Feature-Learning for RF Fingerprinting
3. Methodology
3.1. Preprocessing
- : The emitted preamble.
- : The signal complex amplitude.
- : The signal delay between emitter and receiver.
- : The frequency offset between emitter and receiver.
- : An additive white Gaussian complex noise with power .
- Preprocessing process n°1: This preprocessing process is presented in Figure 3 and consists of correcting the frequency offset, the signal delay, and the complex amplitude.
- Preprocessing process n°2: This preprocessing process is presented in Figure 4 and consists of correcting the signal delay and the complex amplitude.
3.2. Feature Learning
3.3. Features Selection
| Algorithm 1: Feature eigenvectors selection algorithm |
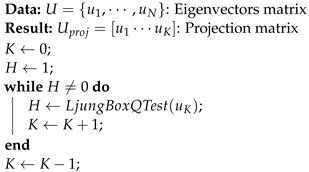 |
3.4. Decision
3.4.1. Projection
3.4.2. Statistical Modeling
- : The mean vector of class c.
- : The variance–covariance matrix of class c.
- : The distribution parameters of class c.
- : The probability of receiving a signal. In this paper, we consider that the emission probability of a certain emitter is equal to . Another possibility is to consider in a multinoulli distribution and estimate it using frequentist approach) for class k (here, ).
- : The mixture parameters.
3.4.3. Class Parameters Learning
- : The projection of in the subspace.
- : The corresponding class of .
- : The Dirac function.
- : The threshold corresponding to (with ).
- : The confidence interval size.
3.4.4. Outlier Detection
- T: The outlier tolerance threshold (the outlier tolerance threshold can be determined using the method presented in [9]).
- : The indicator function.
3.4.5. Classification
- : The threshold corresponding to with ).
- : The normalized noise power of class c.
3.4.6. Clustering
4. Experiments
4.1. Impairments Simulation
- IQ offset (U is an uniform distribution):
- -
- : Real part.
- -
- : Imaginary part.
- IQ imbalance:
- -
- : Gain imbalance.
- -
- : Phase skew.
- Power amplifier (AM/AM) ( ans are negative and produce amplitude clipping (compression)):
- -
- .
- -
- .
- -
- .
- -
- .
4.2. Real-World Performance Evaluation
- Classifier 1: RF eigenfingerprints using preprocessing process n°2 (Figure 4).
- Classifier 2: RF eigenfingerprints using preprocessing process n°1 (Figure 3).
- Classifier 3: Naive Bayes classifier composed of RF eigenfingerprints statistical model (Equation (9)) using preprocessing process n°1 and Gaussian distribution for frequency offset.
4.3. FPGA Implementation
| Algorithm 2: Pseudocode of FPGA implementation |
 |
5. Interesting Properties in IoT Context
5.1. Integration in IoT Networks
5.1.1. Three-Steps Decision
5.1.2. Interactions with Upper Layers
5.2. IoT Properties
5.2.1. Scalability
- Few-shot learning: This property consists of requiring few data to learn a specific class. Generally, the deep learning model requires at least a thousand data for learning a class. On the contrary, our method requires fewer data per class (35 examples per class).
- Partial retrainability: This property consists of adding or removing a wireless device simply. It is possible because feature learning and feature class parameters learning are independent and classification is not based on a common classifier.
5.2.2. Complexity
- Memory: This property requires that features projection and 2-steps decision (projection, classification) have low memory impact. The memory complexity of RF eigenfingerprints are summarized in Table 2.
5.3. Explainability
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Noise Projection on Orthonormal Basis
- Demonstrating that allows us to prove that noise projection on different axes are statistically independent.
- Demonstrating that and and (using Lindenberg conditions) prove that .
- Demonstrating that and prove the statistical distribution of noise vector projection of complex Gaussian noise vector can be described by (with ):
Appendix B. Class Centroid Sampling
Appendix B.1. Determining Sample Size
- : The projection of an aligned signal belonging to class c in the subspace.
- : The samples number used to estimate the class centroid .
Appendix B.2. Determining Confidence Interval Size
Appendix C. Class Threshold Computing
References
- Patel, K.K.; Patel, S.M. Internet of Things-IOT: Definition, Characteristics, Architecture, Enabling Technologies, Application and Future Challenges. Int. J. Eng. Sci. Comput. 2016, 6, 6122–6131. [Google Scholar]
- Shah, S.H.; Yaqoob, I. A survey: Internet of Things (IOT) technologies, applications and challenges. In Proceedings of the 2016 IEEE Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 21–24 August 2016; pp. 381–385. [Google Scholar]
- Sankhe, K.; Belgiovine, M.; Zhou, F.; Angioloni, L.; Restuccia, F.; D’Oro, S.; Melodia, T.; Ioannidis, S.; Chowdhury, K. No Radio Left Behind: Radio Fingerprinting Through Deep Learning of Physical-Layer Hardware Impairments. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 165–178. [Google Scholar] [CrossRef]
- Zeng, K.; Govindan, K.; Mohapatra, P. Non-cryptographic authentication and identification in wireless networks [Security and Privacy in Emerging Wireless Networks]. IEEE Wirel. Commun. 2010, 17, 56–62. [Google Scholar] [CrossRef]
- Morge-Rollet, L.; Le Roy, F.; Le Jeune, D.; Gautier, R. Siamese Network on I/Q Signals for RF fingerprinting. In Actes de la Conférence CAID 2020; Hindustan Aeronautics Limited: Bengaluru, India, 2020; pp. 152–159. [Google Scholar]
- Mattei, E.; Dalton, C.; Draganov, A.; Marin, B.; Tinston, M.; Harrison, G.; Smarrelli, B.; Harlacher, M. Feature Learning for Enhanced Security in the Internet of Things. In Proceedings of the 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Ottawa, ON, Canada, 11–14 November 2019. [Google Scholar]
- Sirovich, L.; Kirby, M. Low-dimensional procedure for the characterization of human faces. J. Opt. Soc. Am. A Opt. Image Sci. 1987, 4, 519–524. [Google Scholar] [CrossRef]
- Kirby, M.; Sirovich, L. Application of the Karhunen-Loeve Procedure for the Characterization of Human Faces. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 103–108. [Google Scholar] [CrossRef] [Green Version]
- Aurélien, G. Hands-On Machine Learning with Scikit-Learn, Keras and TensorFlow; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Brunton, S.L.; Kutz, J.N. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Turk, M.A.; Pentl, A.P. Face recognition using eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, USA, 3–6 June 1991. [Google Scholar]
- Turk, M.A.; Pentl, A.P. Eigenfaces for Recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef]
- Georghiades, A.S.; Belhumeur, P.N.; Kriegman, D.J. From Few to Many: Illumination Cone Models for Face Recognition under Variable Lighting and Pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.C.; Ho, J.; Kriegman, D.J. Acquiring linear subspaces for face recognition under variable lighting. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 684–698. [Google Scholar]
- Yang, S.; Qin, H.; Liang, X.; Gulliver, T.A. An Improved Unauthorized Unmanned Aerial Vehicle Detection Algorithm Using Radiofrequency-Based Statistical Fingerprint Analysis. Sensors 2019, 19, 274. [Google Scholar] [CrossRef] [Green Version]
- Aneja, S.; Aneja, N.; Bhargava, B.; Chowdhury, R.R. Device fingerprinting using deep convolutional neural networks. Int. Commun. Netw. Distrib. Syst. 2022, 28, 171–198. [Google Scholar] [CrossRef]
- Soltanieh, N.; Norouzi, Y.; Yang, Y.; Karmakar, N.C. A Review of Radio Frequency Fingerprinting Techniques. IEEE J. Radio Freq. Identif. 2020, 4, 222–233. [Google Scholar] [CrossRef]
- Robyns, P.; Marin, E.; Lamotte, W.; Quax, P.; Singelée, D.; Preneel, B. Physical-layer fingerprinting of LoRa devices using supervised and zero-shot learning. In Proceedings of the 10th ACM Conference on Security and Privacy in Wireless and Mobile Networks, Boston, MA, USA, 18 July 2017. [Google Scholar]
- Guo, X.; Zhang, Z.; Chang, J. Survey of Mobile Device Authentication Methods Based on RF fingerprint. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April 2019. [Google Scholar]
- Brik, V.; Banerjee, S.; Gruteser, M.; Oh, S. Wireless device identification with radiometric signatures. In Proceedings of the 14th ACM International Conference on Mobile Computing and Networking, San Francisco, CA, USA, 14–19 September 2008. [Google Scholar]
- Riyaz, S.; Sankhe, K.; Ioannidis, S.; Chowdhury, K. Deep Learning Convolutional Neural Networks for Radio Identification. IEEE Commun. Mag. 2018, 56, 146–152. [Google Scholar] [CrossRef]
- Tian, Q.; Lin, Y.; Guo, X.; Wang, J.; AlFarraj, O.; Tolba, A. An Identity Authentication Method of a MIoT Device Based on Radio Frequency (RF) Fingerprint Technology. Sensors 2020, 20, 1213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohamed, I.; Dalveren, Y.; Catak, F.O.; Kara, A. On the Performance of Energy Criterion Method in Wi-Fi Transient Signal Detection. Electronics 2022, 11, 269. [Google Scholar] [CrossRef]
- Aghnaiya, A.; Dalveren, Y.; Kara, A. On the Performance of Variational Mode Decomposition-Based Radio Frequency Fingerprinting of Bluetooth Devices. Sensors 2020, 20, 1704. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y. Yuanling Huang and Jian Chen. Radio Frequency Fingerprint Extraction of Radio Emitter Based on I/Q Imbalance. Procedia Comput. Sci. 2017, 107, 472–477. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Yoshua Bengin and Aaron Courville. In Deep Learning; The MIT Press: Cambridge, MA. USA, 2018. [Google Scholar]
- John, D. Radio Frequency Machine Learning Systems (RFMLS). Available online: https://www.darpa.mil/program/radio-frequency-machine-learning-systems (accessed on 15 April 2022).
- The Radio Frequency Spectrum + Machine Learning = A New Wave in Radio Technology. Available online: https://www.darpa.mil/news-events/2017-08-11a (accessed on 15 April 2022).
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016; pp. 213–226. [Google Scholar]
- Chen, X.; Hao, X. Feature Reduction Method for Cognition and Classification of IoT Devices Based on Artificial Intelligence. IEEE Access 2019, 7, 103291–103298. [Google Scholar] [CrossRef]
- Peng, L.; Hu, A.; Zhang, J.; Jiang, Y.; Yu, J.; Yan, Y. Design of a Hybrid RF fingerprint Extraction and Device Classification Scheme. IEEE Int. Things J. 2019, 6, 349–360. [Google Scholar] [CrossRef]
- Chen, S.; Wen, H.; Wu, J.; Xu, A.; Jiang, Y.; Song, H.; Chen, Y. Radio Frequency Fingerprint-Based Intelligent Mobile Edge Computing for Internet of Things Authentication. Sensors 2019, 19, 3610. [Google Scholar] [CrossRef] [Green Version]
- Gutierrez del Arroyo, J.A.; Borghetti, B.J.; Temple, M.A. Considerations for Radio Frequency Fingerprinting across Multiple Frequency Channels. Sensors 2022, 22, 2111. [Google Scholar] [CrossRef]
- Qing, G.; Wang, H.; Zhang, T. Radio frequency fingerprinting identification for Zigbee via lightweight CNN. Phys. Commun. 2021, 44, 101250. [Google Scholar] [CrossRef]
- Jian, T.; Rendon, B.C.; Ojuba, E.; Soltani, N.; Wang, Z.; Sankhe, K.; Gritsenko, A.; Dy, J.; Chowdhury, K.; Ioannidis, S. Deep Learning for RF Fingerprinting: A Massive Experimental Study. IEEE Internet Things Mag. 2020, 3, 50–57. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer: New York, NY, USA, 1996. [Google Scholar]
- Stoica, P.; Moses, R.L. Spectral Analysis of Signals; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Hankin, R.K.S. The Complex Multivariate Gaussian Distribution. R J. 2015, 7, 73–80. [Google Scholar] [CrossRef] [Green Version]
- Goodman, N.R. Statistical analysis based on a certain multivariate complex Gaussian distribution. Proc. IEEE 1963, 34, 152–177. [Google Scholar] [CrossRef]
- Nguyen, N.T.; Zheng, G.; Han, Z.; Zheng, R. Device fingerprinting to enhance wireless security using nonparametric Bayesian method. In Proceedings of the 2011 Proceedings IEEE INFOCOM (2011), Shanghai, China, 11–15 April 2011. [Google Scholar]
- Scott, I. Analogue IQ Error Correction For Transmitters—Off Line Method. Available online: http://vaedrah.angelfire.com (accessed on 15 April 2022).
- Isaksson, M.; Wisell, D.; Ronnow, D. A comparative analysis of behavioral models for RF power amplifiers. IEEE Trans. Microw. Theory Tech. 2006, 54, 348–359. [Google Scholar] [CrossRef]
- Ozturk, E.; Erden, F.; Guvenc, I. RF-Based Low-SNR Classification of UAVs Using Convolutional Neural Networks. arXiv 2020, arXiv:2009.05519. [Google Scholar]
- Sharif, M.U.; Shahid, R.; Gaj, K.; Rogawski, M. Hardware-software codesign of RSA for optimal performance vs. flexibility trade-off. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016. [Google Scholar]
- Xie, N.; Li, Z.; Tan, H. A Survey of Physical-Layer Authentication in Wireless Communications. IEEE Commun. Surv. Tutorials 2021, 23, 282–310. [Google Scholar] [CrossRef]
- He, Y.; Meng, G.; Chen, K.; Hu, X.; He, J. Towards Security Threats of Deep Learning Systems: A Survey. IEEE Trans. Softw. Eng. 2021, 48, 1743–1770. [Google Scholar] [CrossRef]
- West, N.E.; O’Shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6 March 2017. [Google Scholar]
- Kuzdeba, S.; Carmack, J.; Robinson, J. RF Fingerprinting with Dilated Causal Convolutions–An Inherently Explainable Architecture. In Proceedings of the 2021 55th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–3 November 2021. [Google Scholar]
- Tse, D.; Viswanath, P. Fundamentals of Wireless Communication; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Rice, M.D. Digital Communications: A Discrete-Time Approach; Pearson Education India: Chennai, India, 2008. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Version | opti1 | opti2 | BRAM18K | DSP48E | FF | LUTs | Cycles | Latency |
|---|---|---|---|---|---|---|---|---|
| apfixed162_v1 | No | No | 6 | 4 | 224 | 363 | 6009 | 75.11 s |
| apfixed162_v2 | Yes | No | 6 | 4 | 223 | 417 | 6004 | 75.05 s |
| apfixed162_v3 | No | Yes | 6 | 5 | 266 | 446 | 1762 | 22.03 s |
| apfixed162_v4 | Yes | Yes | 6 | 5 | 265 | 547 | 1757 | 21.96 s |
| Type | Computation | Memory |
|---|---|---|
| Projection | O(NxK) | O(NxK) |
| Classification | O(KxC) | O(KxC) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morge-Rollet, L.; Le Roy, F.; Le Jeune, D.; Canaff, C.; Gautier, R. RF eigenfingerprints, an Efficient RF Fingerprinting Method in IoT Context. Sensors 2022, 22, 4291. https://doi.org/10.3390/s22114291
Morge-Rollet L, Le Roy F, Le Jeune D, Canaff C, Gautier R. RF eigenfingerprints, an Efficient RF Fingerprinting Method in IoT Context. Sensors. 2022; 22(11):4291. https://doi.org/10.3390/s22114291
Chicago/Turabian StyleMorge-Rollet, Louis, Frédéric Le Roy, Denis Le Jeune, Charles Canaff, and Roland Gautier. 2022. "RF eigenfingerprints, an Efficient RF Fingerprinting Method in IoT Context" Sensors 22, no. 11: 4291. https://doi.org/10.3390/s22114291
APA StyleMorge-Rollet, L., Le Roy, F., Le Jeune, D., Canaff, C., & Gautier, R. (2022). RF eigenfingerprints, an Efficient RF Fingerprinting Method in IoT Context. Sensors, 22(11), 4291. https://doi.org/10.3390/s22114291