1. Introduction
Eye contact is a valuable communicative signal that allows for the extraction of socially relevant information such as state, behavior, intention and emotions [
1]. The human face nonverbally expresses characteristics such as character, emotion and identity [
2].
According to Yoshikawa et al. [
3], the impression a person forms during an interaction is influenced by the feeling of being looked at, which depends on the eye-gaze response from the interlocutor. Yoshikawa et al. [
3] demonstrated that a robot with responsive gaze also provides a strong feeling of being looked at. Similarly, as in a human interaction, mutual gaze also engages human–robot interaction [
4,
5,
6,
7,
8], influences human decision making [
9,
10] and plays a central role in directing attention during communication [
3].
There are many alternative ways to enhance the sense of attention from a robot. Barnes et al. [
11] concluded that users prefer robots that resemble animals or humans over robots that represent imaginary creatures or do not resemble a creature, regardless of the type of interaction with the robot. Mutlu et al. [
12] evaluated the effect of the gaze of a storytelling robot, concluding that participants preferred a robot looking at them during the storytelling. Mutlu et al. [
13,
14] also studied gaze mechanisms in multi-party human–robot conversations, concluding that the gaze allowed the robot to assign and manage the participant roles. Shintani et al. [
15] analyzed role-based gaze conversational behaviors and developed a robot with human-like eye movements, obtaining smoother, more natural and more engaged human–robot interactions. Fukayama et al. [
16] measured the impressions of users interacting with a robot in different social communicating scenarios and concluded that there is a correlation between the impression and the amount of gaze, the mean duration of the gaze and the gaze points. Lee et al. [
17] designed a robotic gaze behavior based on social cueing for users performing quiz sessions in order to overcome in-attentional blindness, with the conclusion that the robotic gaze can improve the quiz scores when participants successfully recognize the gaze-based cues performed by the robot.
Similarly, Ghiglino et al. [
18] verified that endowing artificial agents with human-like eye movements increased attentional engagement and anthropomorphic attribution. The conclusion was that users needed less effort to process and interpret the behavior of an artificial agent when it was human-like, facilitating human–robot interaction. Cid et al. [
19] studied the mechanisms of perception and imitation of human expressions and emotions with a humanoid robotic head designed for human–robot interaction. The use of a robotic head allows for the interaction through speech, facial expressions and body language. Cid et al. [
19] also presented a software architecture that detects, recognizes, classifies and generates facial expressions using the Facial Action Coding System (FACS) [
20,
21] and also compared the scientific literature describing the implementation of different robotic heads according to their appearance, sensors used, degrees of freedom (DOF) and the use of the FACS.
The new contribution of this paper is a proposal to enhance the sense of attention from an assistance mobile robot by improving eye-gaze contact from the face of the robot. This proposal is inspired by the contributions of Velichkovsky et al. [
22] and Belkaid et al. [
10]. Velichkovsky et al. [
22] analyzed the implementation of different social gaze behaviors in a robot in order to generate the impression that a companion robot is a conscious creature. Velichkovsky et al. [
22] evaluated the impression of the gaze behavior on humans in three situations: a robot telling a story, a person telling a story to the robot, and both parties solving a puzzle while talking about objects in the real world. The gaze behavior implemented in the robot consisted of alternating the gaze between the human, the environment and the object of the problem. The conclusion was that social gaze simulated by robots can make the human assign cognitive and emotional properties to the robot. Alternatively, Belkaid et al. [
10] analyzed the effect of mutual gaze and adverted gaze between a robot and a human before making a decision. Belkaid et al. [
10] analyzed a mechatronic (mechanistic mannequin-like) head with big spherical eyes with the conclusion that “robot gaze acts as a strong social signal for humans, modulating response times, decision threshold, neural synchronization, as well as choice strategies and sensitivity to outcomes”. Following these conclusions, the basic gaze implemented in an assistance mobile robot prototype has been revised in order to enhance the sense of attention from its iconic face displayed on a flat screen.
Human ocular motion has been deeply analyzed from an anatomical and physiological point of view; however, thus far, the development of robotic eyes has mainly focused on biomimetic mechatronic implementation [
23,
24,
25] and on movement [
19,
25,
26,
27,
28] rather than on the impression originated by the gaze implemented. The evaluation of the gaze is an open problem, and there is no quantitative method generally proposed to evaluate eye-gaze contact because it is based on subjective human perceptions that are generally influenced by pathologies such as strabismus. For example, eye-trackers are considered valid to estimate the location of the fixation point over a plain screen because they usually interpolate this location from a reduced set of initial eye-gaze calibrations performed at a specific distance [
29]. In the case of using a screen to represent the face of the robot, an additional problem is the difficulty of simulating the effect of spherical eyes in a plain image considering the perspective of the person interacting with the mobile robot. Because of these difficulties, the gaze of a robot is usually mainly implemented only to provide a basic impression of a responsive robot [
19,
25], although there are other implementations such as, for example, the reduction of vision instability by means of the reproduction of the vestibulo–ocular reflex [
27,
28].
This paper proposes enhancing the sense of attention perceived from the iconic face displayed on the screen of an assistance mobile robot during an interaction. In this paper, the sense of attention has been interpreted as the perception of being looked at by the responsive eyes of the iconic face of the robot, which are displayed on a flat screen. This implementation has been validated with five people who work regularly with robots.
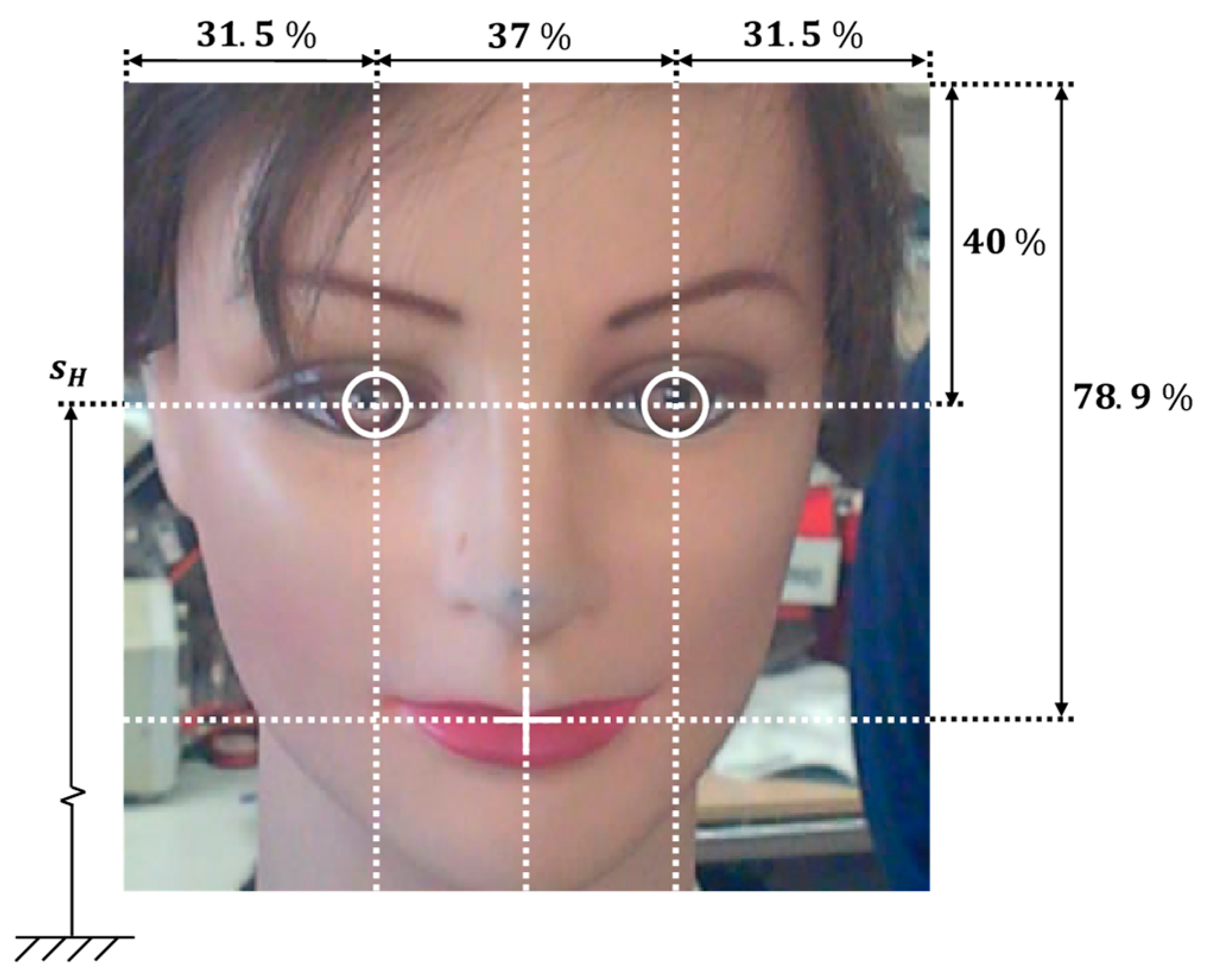
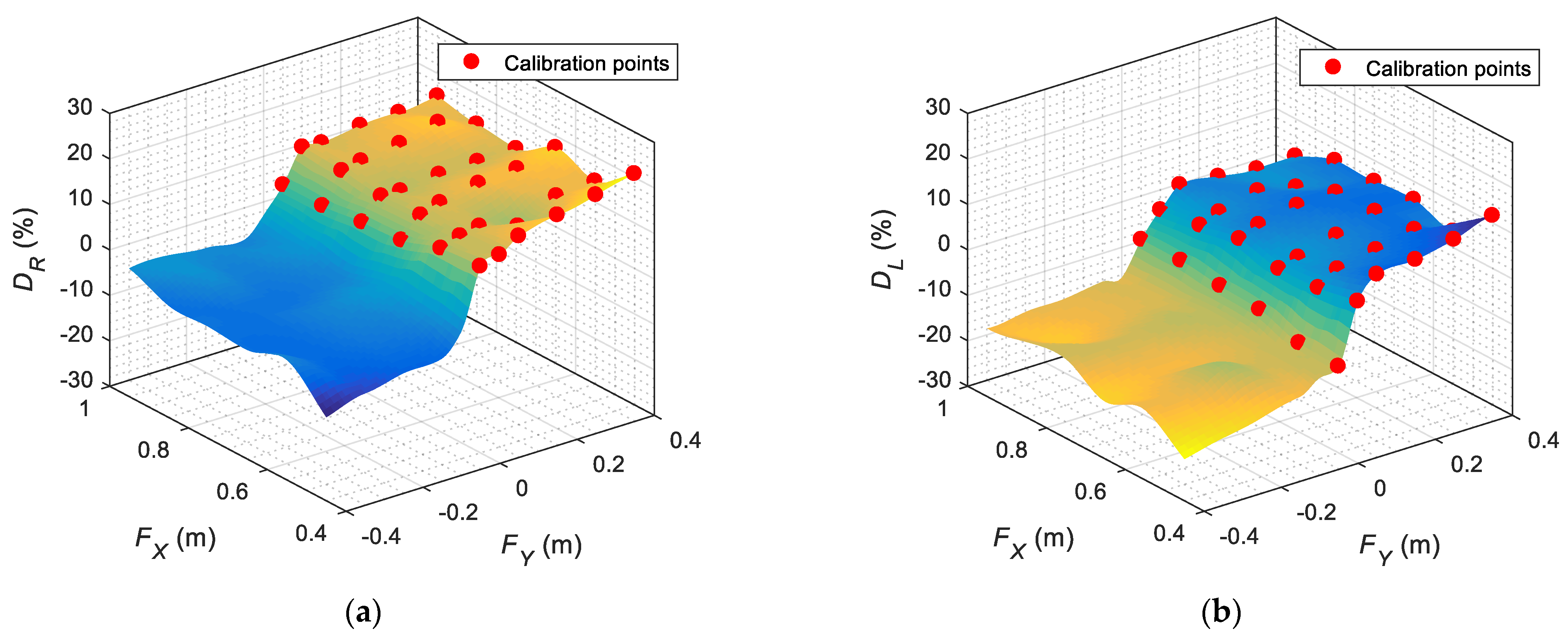
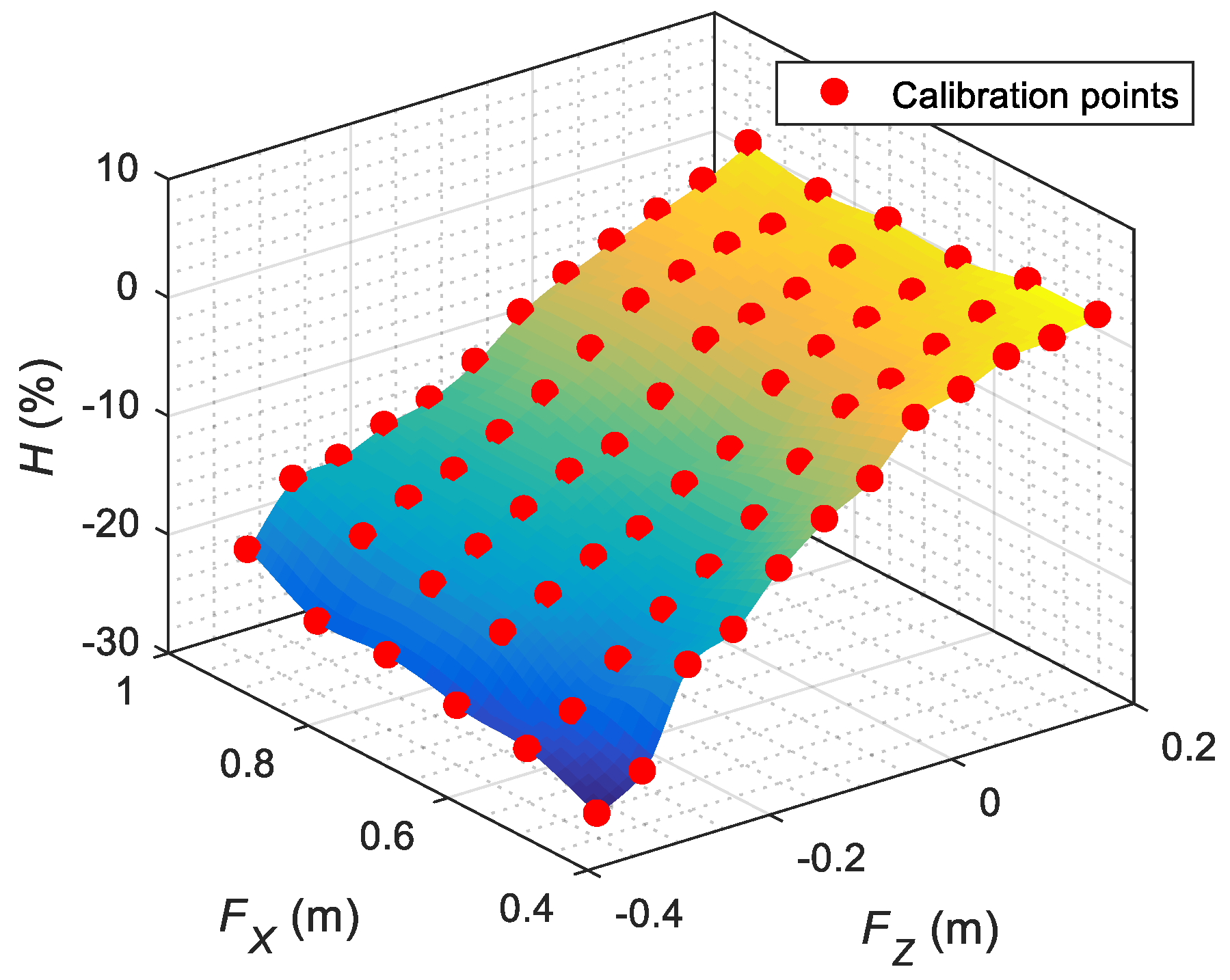
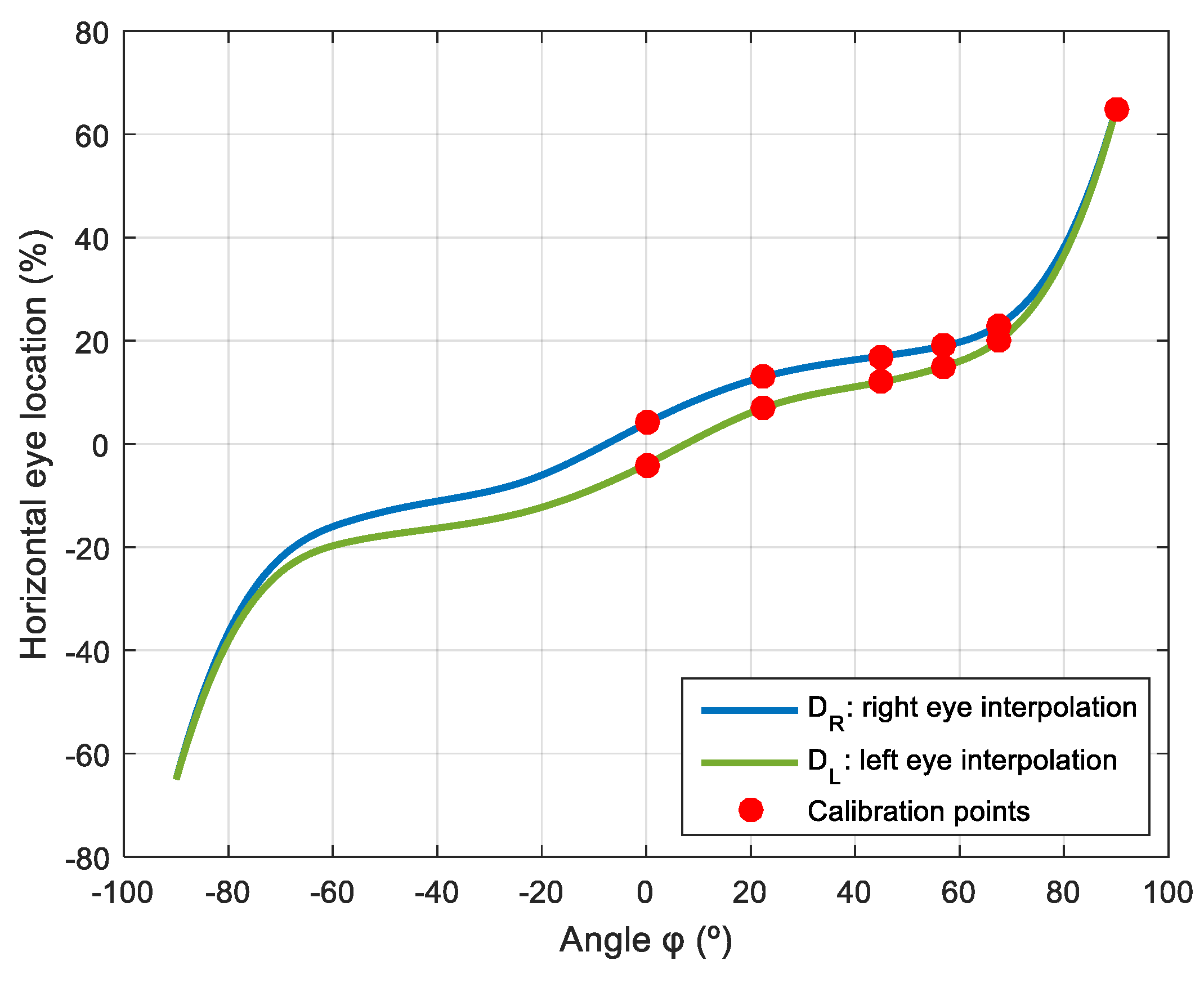
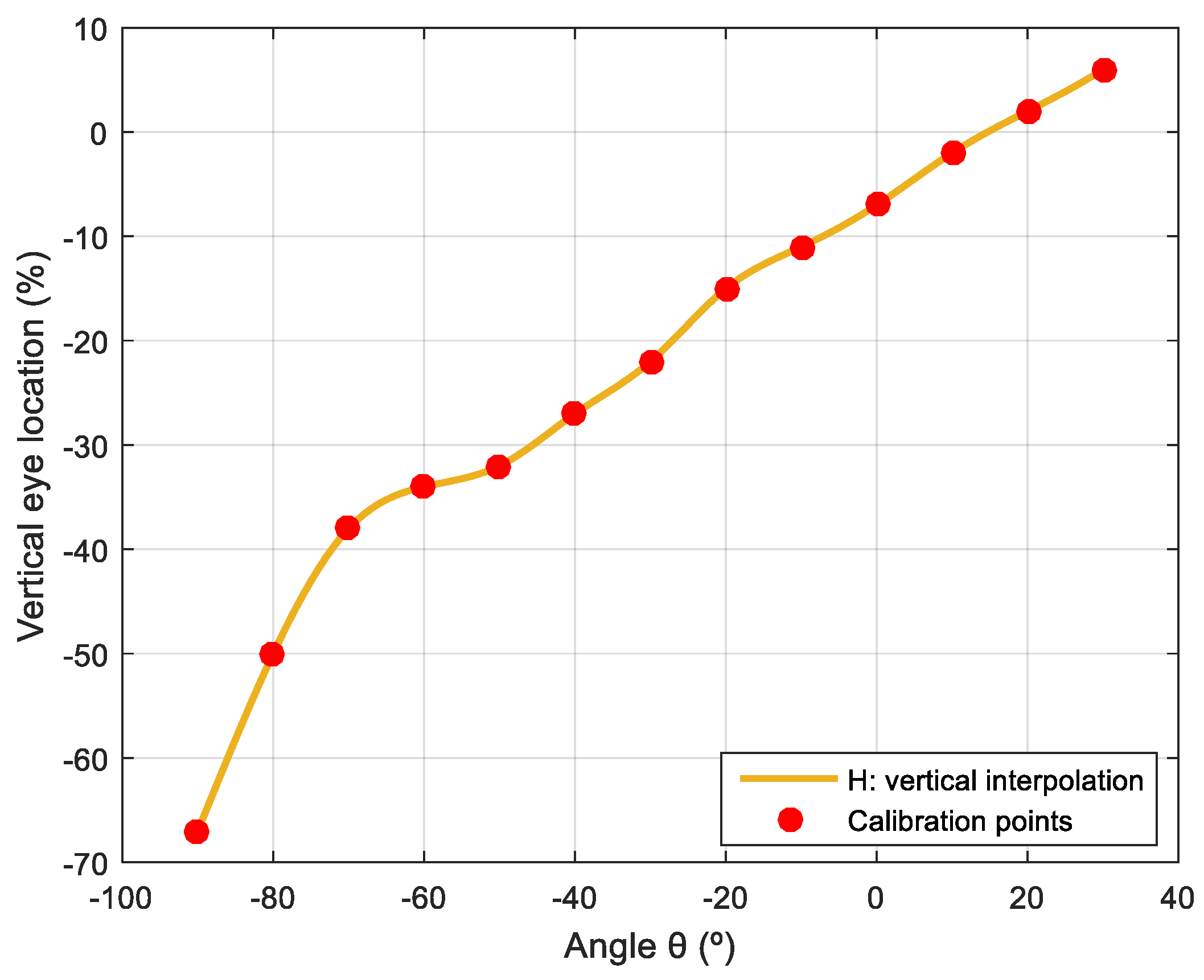
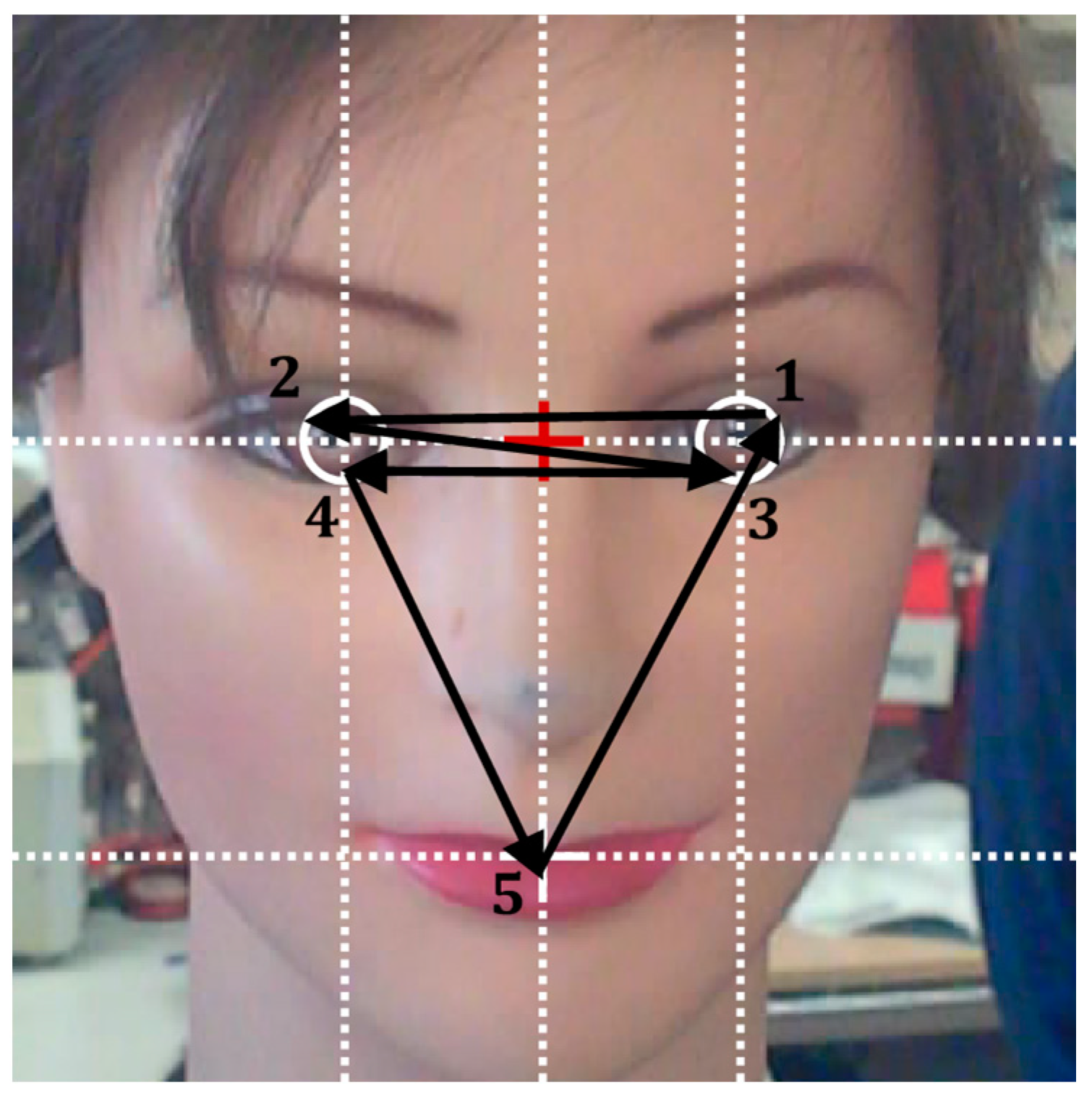
The gaze originally implemented in the assistance mobile robot used in this paper had seven predefined gaze orientations: forward, up, down, half left, half right, left, and right, in all cases with parallel eyes fixed on infinity. The use of these fixed predefined gaze orientations provided the impression of a responsive robot but was not able to generate a sense of attention. As described before, there are no tools to evaluate eye-gaze contact; thus, the perception of eye-gaze contact from the robot has been maximized by manually obtaining 169 eye-gaze calibration points relative to the location of the face of the person interacting with the robot. These calibration results are fully provided for additional evaluation and validation. Finally, the sense of attention has been further enhanced by implementing cyclic face explorations with saccades in the gaze and by performing blinking and small movements of the mouth.
5. Experimental Validation of the Gaze of the Robot
The control of the gaze of the robot is based on the detection of the faces of the people in front of the mobile robot, the estimation of the relative position of these faces, and on pointing the gaze to the face of the nearest person in front of the mobile robot. As described in
Section 3.3, the APR-02 mobile robot has an RGB-D and a panoramic RGB camera placed above the screen of the robot that are used to detect the faces of the people in front of the robot by using the Viola–Jones algorithm [
54]. The distance to the nearest face in front of the mobile robot is estimated from the depth information provided by the RGB-D camera, and the gaze is automatically focused in the nearest frontal face detected. The position of the pupils of the eyes that defines the gaze is based on the empirical calibrations described in
Section 4.2.1 and
Section 4.2.2, and the saccades are automatically implemented when the gaze is focused on a face. This automatic implementation simulates human gaze features such as version and vergence if the person in front of the robot moves laterally or moves closer or farther away.
Additionally, following the conclusions of Velichkovsky et al. [
22], the gaze is complemented with blinks and small movements of the mouth. The objective of all these combined animations is to avoid the Uncanny Valley effect [
62] and assign cognitive and emotional properties to the APR-02 mobile robot in order to enhance the sense of attention from the robot.
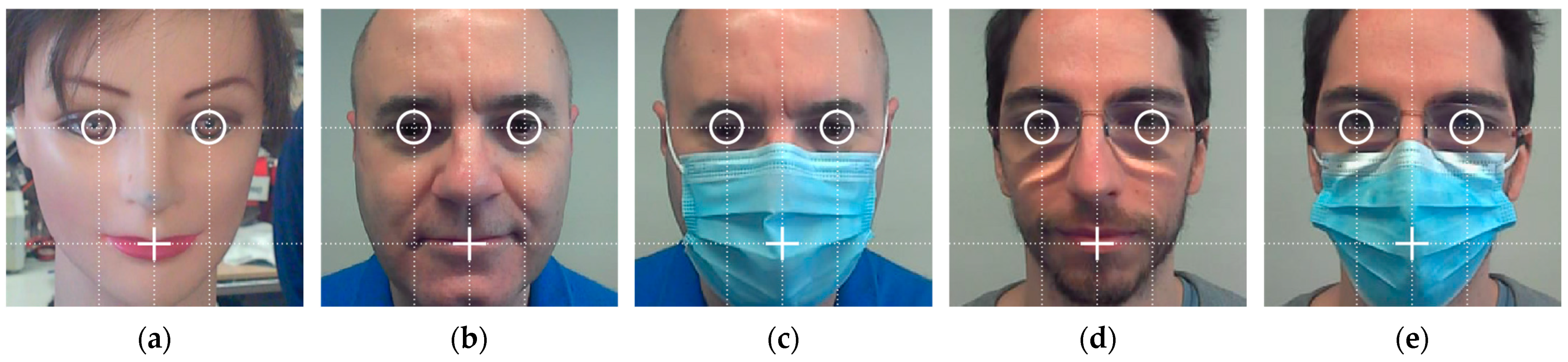
5.1. Effect of Changing the Horizontal Location of a Face in Front of the Robot
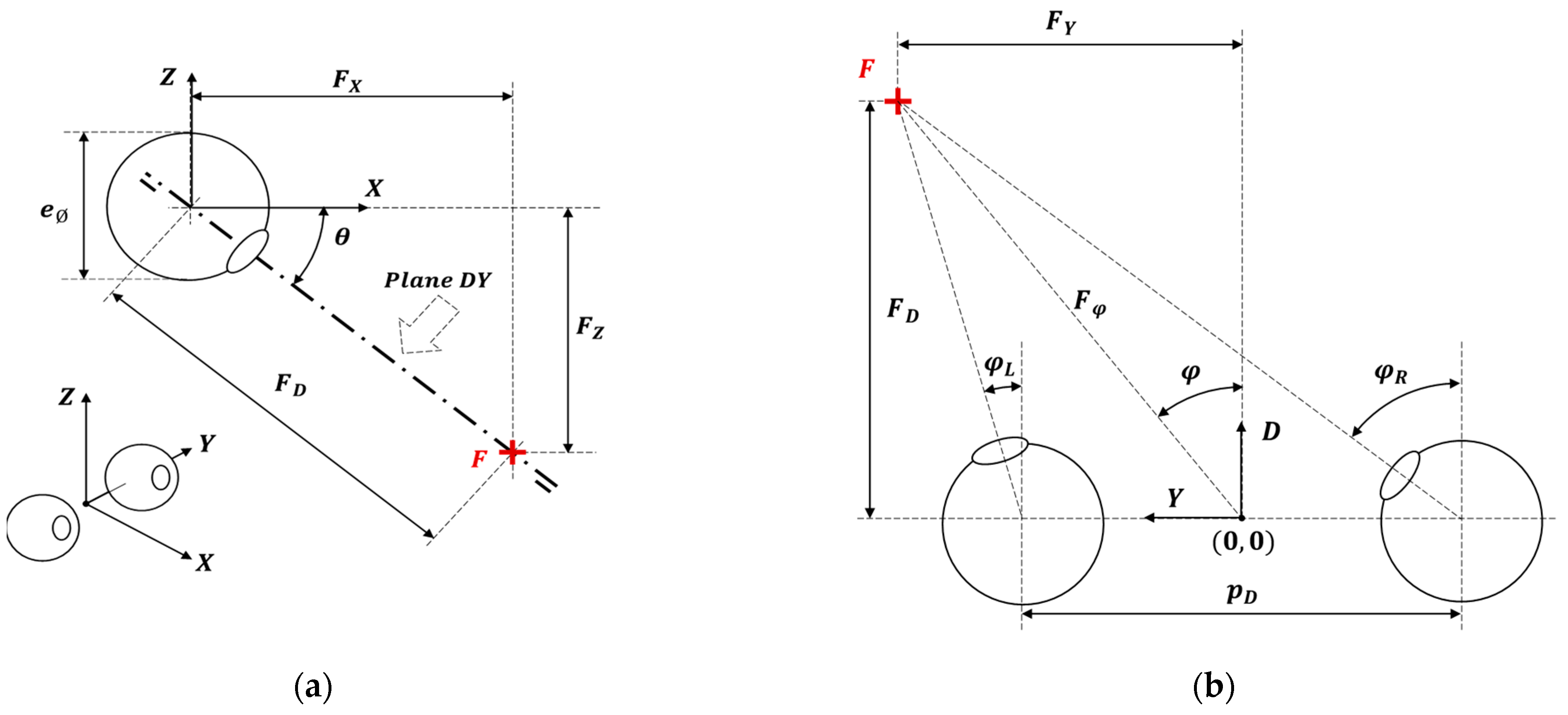
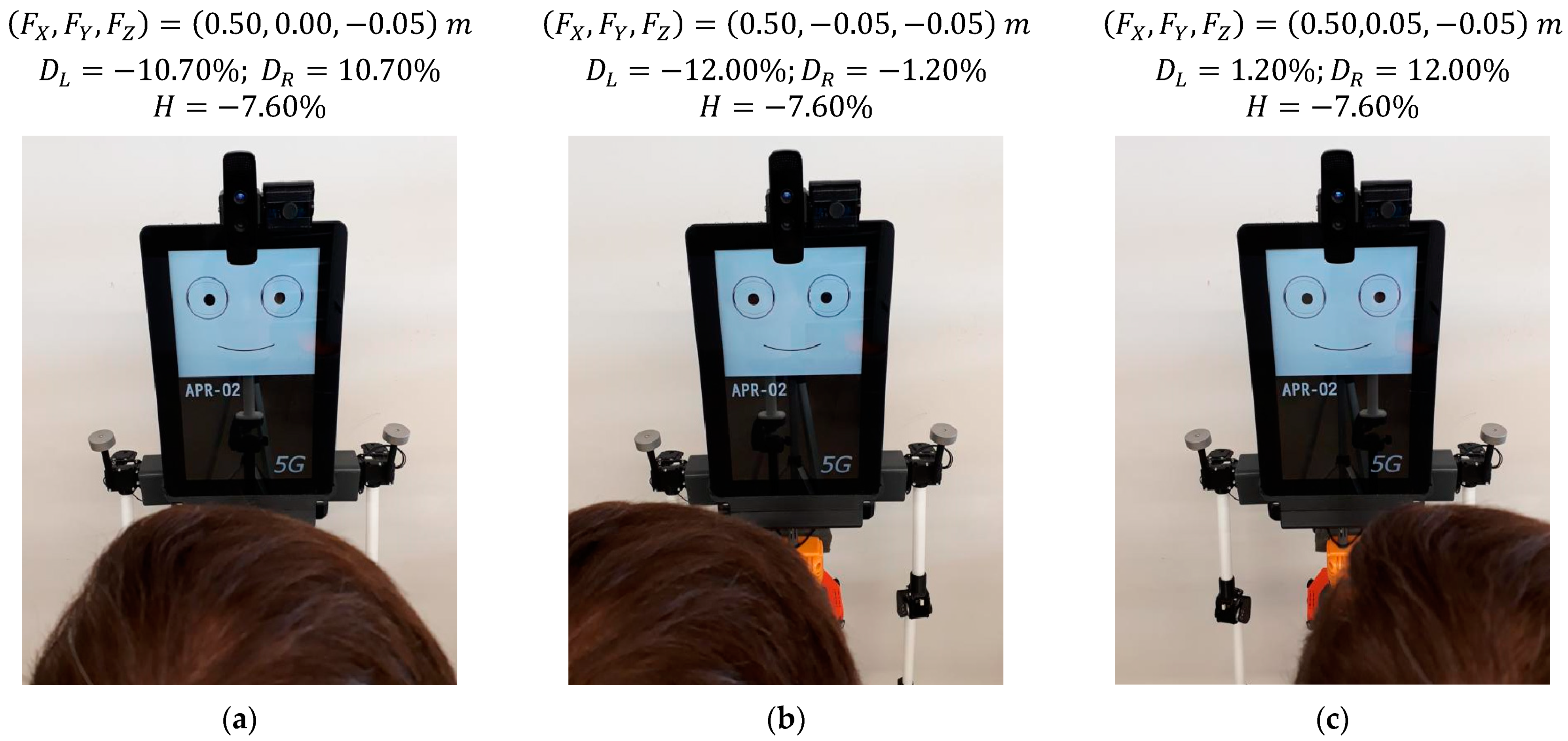
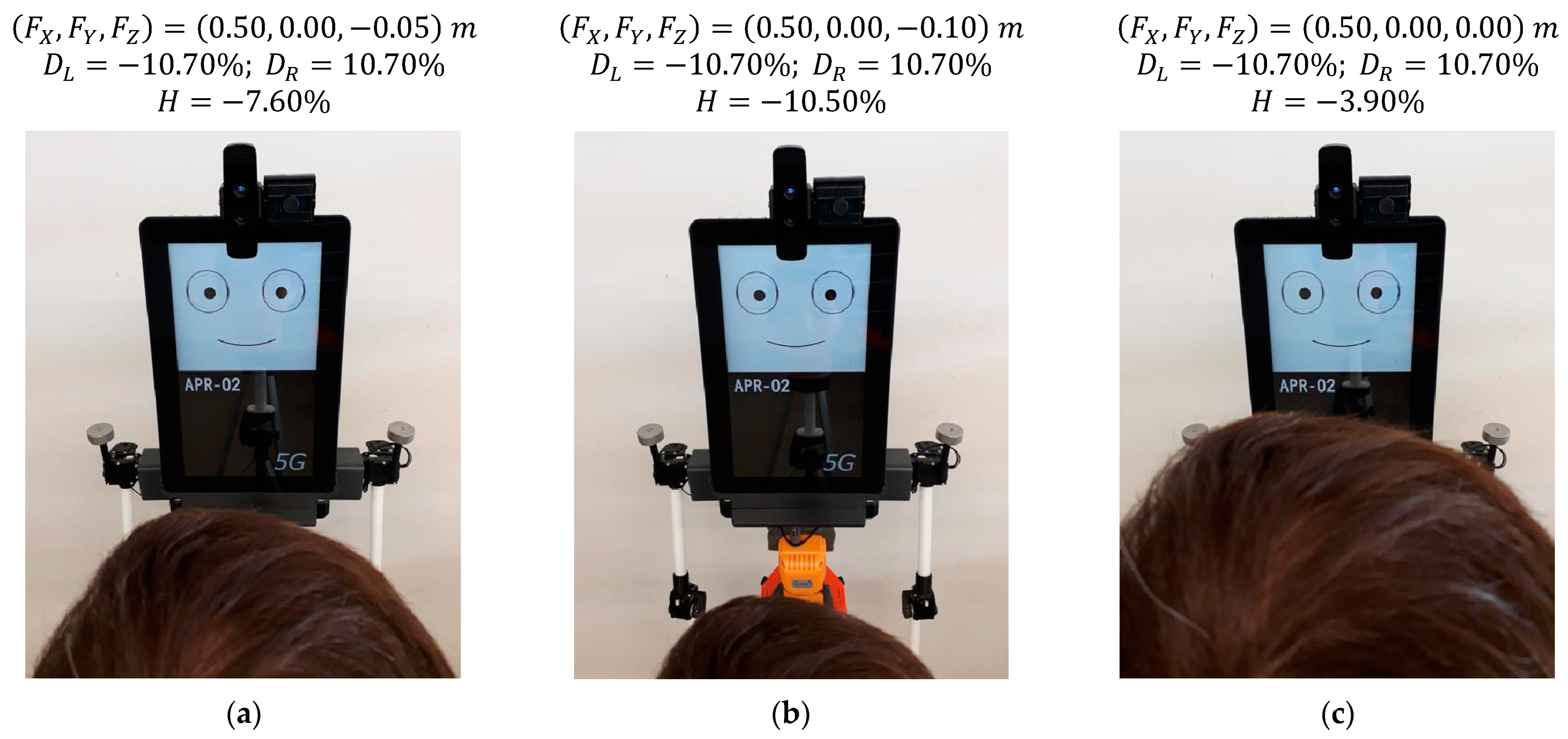
Figure 15 shows the gaze of the robot following a face that is changing its horizontal location in front of the robot (version gaze). The distance from the mannequin to the robot is 0.50 m, the absolute height of the eyes (
) of the mannequin is 1.55 m, and the height of the eyes of the robot (
) is 1.60 m; thus, the eyes are slightly pointing down (
).
Figure 15a shows the gaze looking at a person centered in front of the mobile robot,
Figure 15b shows the person moved 0.05 m to the right of the robot, and
Figure 15c shows the person moved 0.05 m to the left of the robot. The images of
Figure 15 show small gaze variations in response to a total lateral displacement of the face of the mannequin of 0.10 m. As an example, in
Figure 15, the relative horizontal position of the left pupil
slightly changes from −10.70% to −12.00% when the gaze of the left eye follows a face from the center to the right. Alternatively, this gaze changes from −10.70% to 1.20% when following a face from the center to the left. These subtle gaze changes are barely perceived in the images but are clearly perceived by a person in front of the mobile robot.
Figure 15.
Gaze of the robot following a face performing a lateral displacement: (a) face at = 0.00 m; (b) face at = −0.05 m; (c) face at = 0.05 m.
Figure 15.
Gaze of the robot following a face performing a lateral displacement: (a) face at = 0.00 m; (b) face at = −0.05 m; (c) face at = 0.05 m.
5.2. Effect of Changing the Vertical Position of a Face in Front of the Robot
Figure 16 shows the gaze of the robot following a face that changes its vertical position in front of the robot. The distance from the mannequin to the robot is 0.50 m, there is no lateral displacement, and the heights of the eyes (
) are 1.55 m (
Figure 16a), 1.50 m (
Figure 16b) and 1.60 m (
Figure 16c). The images of
Figure 16 show small gaze variations in response to a total vertical displacement of the face of the mannequin of 0.10 m.
Figure 16 shows that the relative vertical position of the pupil
slightly changes from −7.60% to −10.50% when the gaze of the eyes follows a face that goes down. Alternatively, this vertical position changes from −7.60 to −3.90% when following a face that is going up. Again, these subtle gaze changes are barely perceived in the images but are clearly perceived by a person in front of the mobile robot.
Figure 16.
Gaze of the robot following a face at different heights: (a) face at = 1.55 m; (b) face at = 1.50 m; (c) face at = 1.60 m.
Figure 16.
Gaze of the robot following a face at different heights: (a) face at = 1.55 m; (b) face at = 1.50 m; (c) face at = 1.60 m.
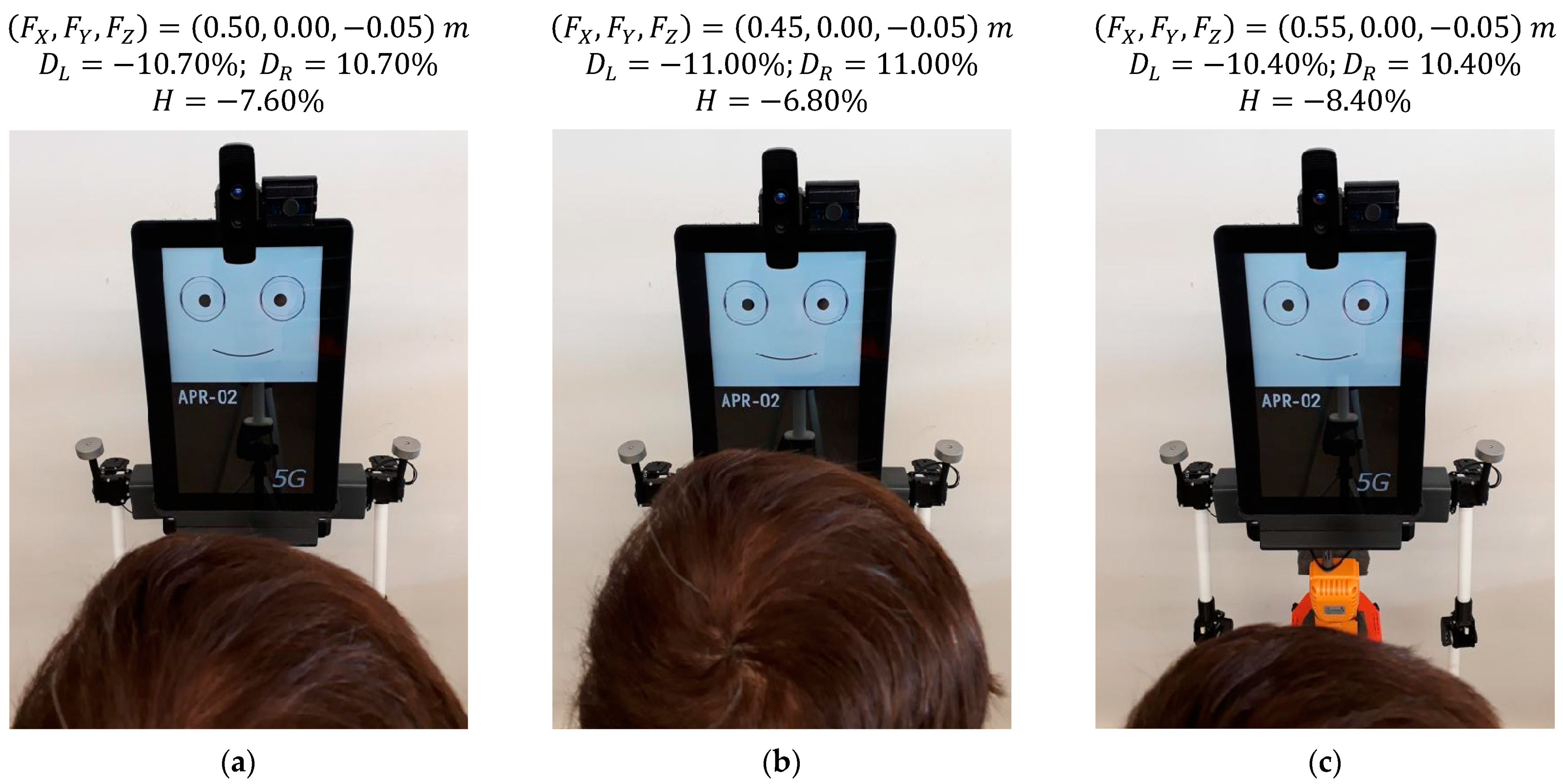
5.3. Effect of Changing the Distance of a Face in Front of the Robot
Figure 17 shows the gaze of the robot following a face that changes its distance in front of the robot (vergence gaze). The distances from the mannequin to the robot are 0.50 m (
Figure 17a), 0.45 m (
Figure 17b) and 0.55 m (
Figure 17c). The images of
Figure 17 show small gaze variations in response to a total change in the distance of the face of the mannequin of 0.10 m.
Figure 17 shows that the relative horizontal positions of the pupils
and
slightly change from |10.70%| to |11.00%| when the face approaches and from |10.70%| to |10.40%| when the face moves away. These subtle gaze changes are barely perceived in the images and are barely perceived by a person attentive to the gaze of the robot.
Figure 17.
Gaze of the robot looking at a face at different distances: (a) face at = 0.50 m; (b) face at = 0.45 m; (c) face at = 0.55 m.
Figure 17.
Gaze of the robot looking at a face at different distances: (a) face at = 0.50 m; (b) face at = 0.45 m; (c) face at = 0.55 m.
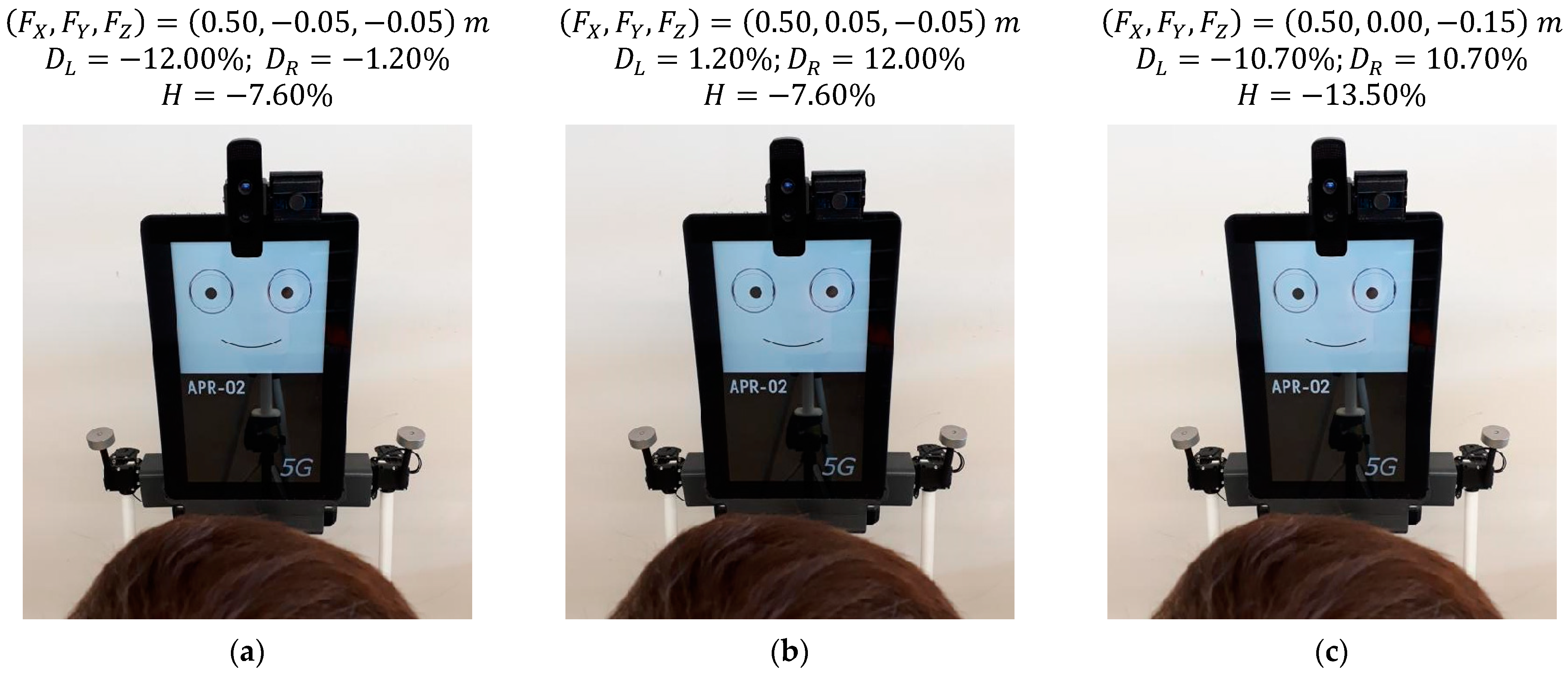
5.4. Effect of Saccades in the Gaze of the Robot
Figure 18 shows three stages of the cyclic fixation behavior proposed to imitate the effect of saccades when looking at a face in front of the robot. The mannequin is centered in front of the robot at a distance of 0.50 m, and the height of the eyes (
) of the mannequin is 1.55 m.
Figure 18a shows the gaze of the robot looking at the left eye of the face as a fixation point,
Figure 18b shows the robot looking at the right eye as a fixation point, and
Figure 18c shows the robot looking at the mouth as a fixation point. In this current implementation, the number of eye shifts can vary randomly from 2 to 4 and the fixation time from 400 to 600 ms in order to avoid the generation of fixed predictable cyclic sequences and intervals. The images of
Figure 18 show slight gaze variations during this cyclic fixation sequence, which are best perceived when they are implemented as jumps instead of soft transitions or soft displacements. As an example,
Figure 18 shows that the relative horizontal position of the pupil of the left eye
changes from −12.0% to 1.2% when the fixation point shifts from the left eye to the right eye of the mannequin. Similarly, the relative vertical position of the pupil
changes from −7.6% to −13.5% when the fixation point shifts from the right eye to the mouth of the mannequin. Finally, this cyclic fixation behavior imitating an exploration of a face provides a dynamic effect, which is perceived as familiar and natural during an interaction, enhancing the sense of attention and increasing the affinity with the mobile robot.
Figure 18.
Gaze of the robot at different stages of the cyclic fixation behavior when looking at a face: (a) on the left eye of the user; (b) on the right eye of the user; (c) on the mouth of the user.
Figure 18.
Gaze of the robot at different stages of the cyclic fixation behavior when looking at a face: (a) on the left eye of the user; (b) on the right eye of the user; (c) on the mouth of the user.
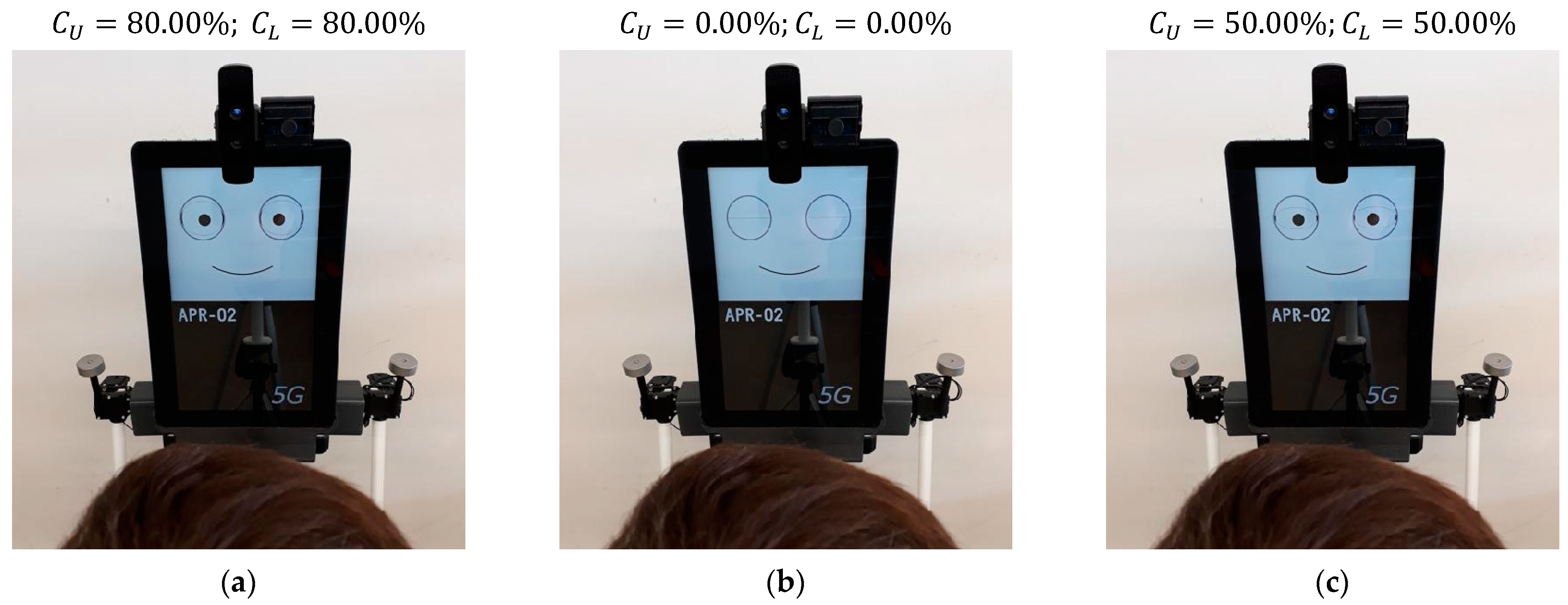
5.5. Effect of Blinking in the Gaze of the Robot
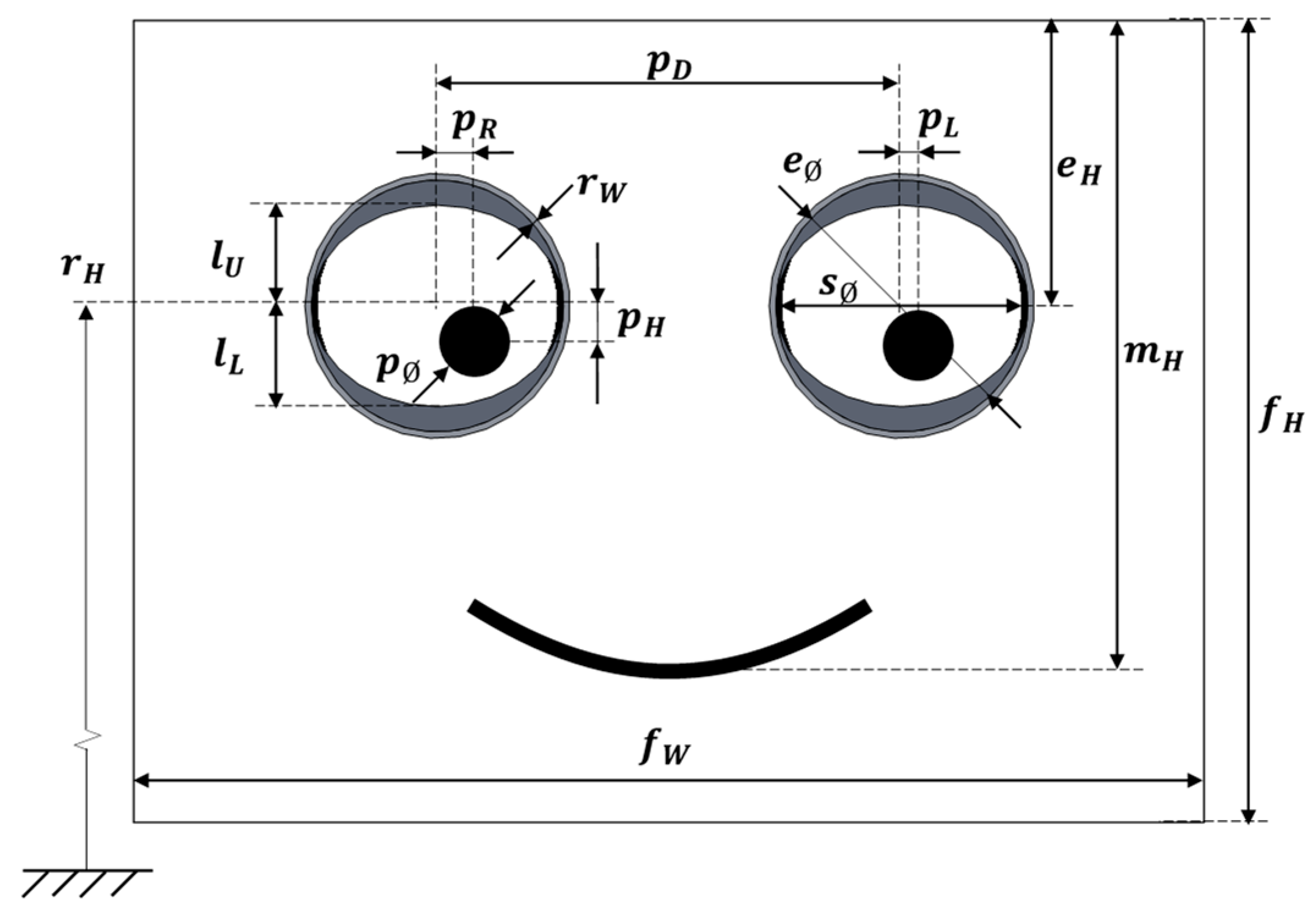
Figure 19 shows the effect of blinking and eyelid control. A blink hides the pupil of the eyes; thus, it has a great effect on the perception of the face. By default, the blink is automatically performed every 1.5 s, as it is perceived as a natural eye reflex.
Figure 19a shows the eyelids at their normal position, both covering 20% of the eyes (apertures
and
).
Figure 19b shows the eyelids totally closed during a blink, both covering 100% of the eyes (apertures
and
).
Figure 19c shows the eyelids half-closed, both covering 50% of the eyes (apertures
and
) as a way to dynamically enhance the gaze of the robot. The implementation of blinks in the gaze of the robot is perceived as familiar and natural during an interaction. The best sense of attention is achieved when eye-blinks are performed as jumps, without smooth transitions. The color of the eyelid and of all the graphic elements of the face can be freely configured, but the use of colors in the face of a mobile robot is a characteristic that requires further analysis by specialized researchers. For example, the image of the iconic face shown in
Figure 3 has been configured with gray eyelids to improve the identification of the different parts of the face.
Figure 19.
Example of blinking: (a) normal gaze; (b) closed eyes; (c) half-closed eyes.
Figure 19.
Example of blinking: (a) normal gaze; (b) closed eyes; (c) half-closed eyes.
5.6. Effect of Subtle Mouth Animations
The implementation of subtle animations in the mouth was initially unplanned, but it is the natural remaining step after the implementation of saccades and blinking in the gaze in order to enhance the sense of attention from the robot.
The animation of the mouth is synchronized (or implemented) with the saccades. The basic parameter that modifies the amplitude of the smile
is randomly increased up to 50% of its fixed value. The objective of the subtle random variation of the amplitude of the smile is to provide a dynamic perception and to enhance the sense of attention from the mobile robot.
Figure 20a shows the mouth used to express a positive-neutral facial expression in the robot, with
, selected in [
47], to encourage interaction.
Figure 20b shows a lower smiling degree achieved with
, and
Figure 20c shows a higher smiling degree achieved with
. Finally, these subtle mouth changes are perceived in the images but are not directly perceived by a person attentive to the gaze of the robot, since they are similar to the subtle micro-emotions expressed by the human smile [
63]. In this case, the best sense of attention is also achieved when the mouth movements are performed as jumps, without smooth transitions.
Figure 20.
Example of the mouth variations: (a) neutral mouth expression; (b) attention variation; (c) smiling variation.
Figure 20.
Example of the mouth variations: (a) neutral mouth expression; (b) attention variation; (c) smiling variation.
6. Discussion and Conclusions
This paper proposes enhancing the sense of attention from an assistance mobile robot prototype by improving eye-gaze contact from its iconic face displayed on a flat screen. This iconic face was implemented with big round eyes and a mouth depicted with a single line. The inclusion of this face was considered a determining factor to develop assistance services, and the gaze and emotion displayed in the face were treated as other actuators of the robot. The implementation of eye-gaze contact from the iconic face is a problem because of the difficulty of simulating real 3D spherical eyes in a 2D image considering the perspective of the person interacting with the mobile robot.
In general, the gaze in a robot is implemented in order to provide the basic impression of a responsive robot [
19,
25]. The gaze implemented originally in the assistance mobile robot used in this paper had seven predefined gaze orientations: forward, up, down, half left, half right, left, and right, in all cases with parallel eyes fixed on infinity. In this case, the use of a deterministic computation of the angular orientation of the spherical eyes was not convincing because the eyes of this iconic face were perceived as 2D objects, and the geometric projection of 3D spherical eyes did not provide a convincing eye-gaze effect. The method implemented in this paper to maximize the perception of eye-gaze contact from the face of the robot is based on a manual calibration of the location of the pupils relative to the distance and orientation of the face of the user interacting with the robot. The method implemented provides a total of 169 eye-gaze calibration points and interpolation recommendations. Two basic eye-gaze calibration procedures have been implemented. A detailed short-distance eye-gaze calibration enables an accurate imitation of the looking-at-face gaze in the case of a user placed in front of the mobile robot, while a long-distance eye-gaze calibration enables a rough imitation of the look-at-face gaze in the case of a user away from the robot. The difference between these two calibrations is that in the short-distance calibration, the user interacting with the robot must accurately and precisely perceive eye-gaze contact from the robot, while in the long-distance calibration, the user perception is less precise. The implementation of this robotic gaze has been validated with five people who work regularly with robots. The limitation of this method proposed to maximize the perception of eye-gaze contact is that it has been optimized for the eye dimensions implemented in the iconic face used in the assistant mobile robot APR-02. The general application of this methodology remains an open question that will require the development of further analyses with other robotic face designs, for example, evaluating the use of the pupillary distance as a reference to normalize the calibration data provided.
The direct use of calibration data as a strategy to improve eye-gaze contact from the face of the robot has provided an optimal gaze in a short-range interaction and the best perception that the robot is attentive to the user. Further enhancements regarding sense of attention have been achieved with the implementation of a cyclic face exploration sequence based on the holistic location of the eyes and mouth in the image of the user placed in front of the robot. This cyclic face exploration is implemented with saccades, using a deterministic eye-gaze sequence shifting from the left to the right eye several times and then shifting to the mouth and starting again. This exploration sequence can be adapted depending on the cultural background of the user interacting with the robot or depending on the objective of the eye-gaze contact [
44].
The practical application of this responsive gaze in the assistant mobile robot APR-02 is based on the information provided by two frontal onboard cameras and on the application of the Viola–Jones face detection algorithm [
54]. The use of a face detection algorithm provides a valuable indication of the existence of a person looking at or oriented to the mobile robot. In this case, the frontal depth camera also provides an estimate of the distance of the faces detected in a short distance range in front of the mobile robot for precise gaze control, while the location of the faces of the most distant people is roughly estimated from the information gathered by the onboard LIDAR.
Finally, the sense of attention has been maximized by simulating eye-blinks and small mouth movements. The best sense of attention has been achieved when the saccades, eye-blinks and mouth movements have been performed as jumps, without smooth transitions. The familiar human-like behavior achieved with the combination of all these dynamic face effects has contributed to the assignation of cognitive and emotional properties to an assistance mobile robot prototype displaying an iconic face in a flat screen and has improved the affinity with the robot. The development of this perception agrees with Yoshikawa et al. [
3], who concluded that a responsive gaze provides a strong feeling of being looked at, with Fukayama et al. [
16], who concluded that there is a correlation between user impression and the gaze of a robot, with Velichkovsky et al. [
22], who also concluded that the simulation of a human gaze can provoke the assignation of cognitive and emotional properties to a robot, and with Mori et al. [
62], who proposed the Uncanny Valley effect to model the affinity with a human-like robot, suggesting that the worst affinity is obtained in the case of a static robot.
The complete procedure proposed in this paper to improve the sense of attention can be applied to robots with mechatronic faces, although then the limitation will be the continuous mechanical implementation of instantaneous saccades, eye-blinks and small mouth movements. Alternatively, the implementation of a precise eye-gaze contact may also have promising applications in virtual reality [
64] and in future applications of augmented reality [
65].
As a future work, the implementation of eye-gaze contact from the robot will include an estimation of the gaze of the user in front of the robot [
66,
67] in order to evaluate the implementation of new mutual-gaze features such as sharing the focus of attention or redirecting the focus of attention. Additionally, the expressivity of the mobile robot will be implemented as a specific agent combining gaze control, face control and arms control in order to adequately imitate human behaviors in complex humanoid robots.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}