Mobile Robot Localization and Mapping Algorithm Based on the Fusion of Image and Laser Point Cloud


Abstract
:1. Introduction
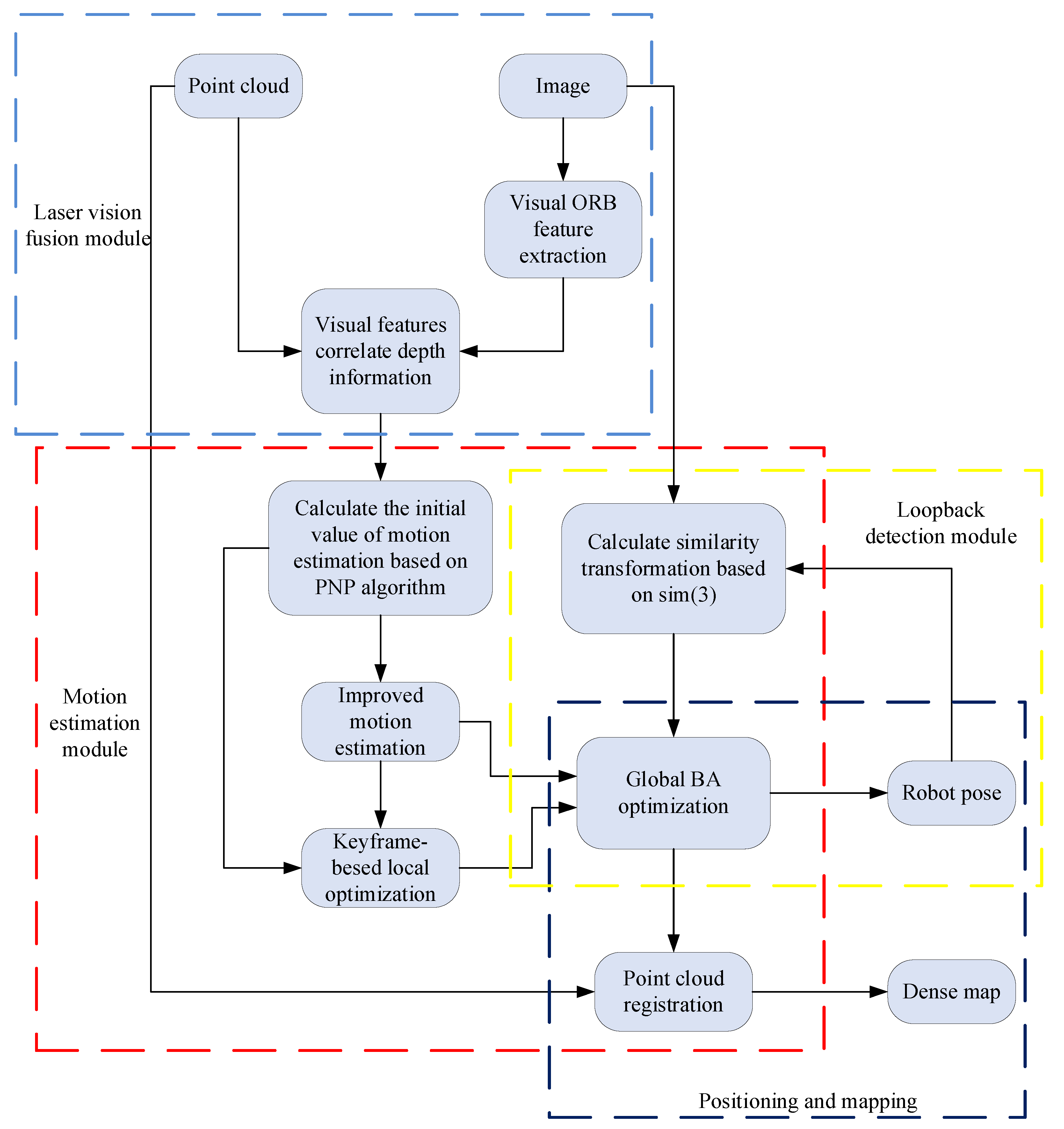
2. Materials and Methods
2.1. BA-Based Back-End Optimized Visual SLAM Algorithm
2.1.1. Visual Odometry
2.1.2. BA-Based Back-End Optimization
- In the motion estimation, the initial value of the pose is obtained by matching frames.
- For K-th iterations, find the Jacobian matrix of the current state and the residual of the objective function . Find the increment , so that the objective function reaches a minimum value until .
- Set the threshold, if is less than the threshold, to stop the iteration and set .
- Otherwise, set , return 2.
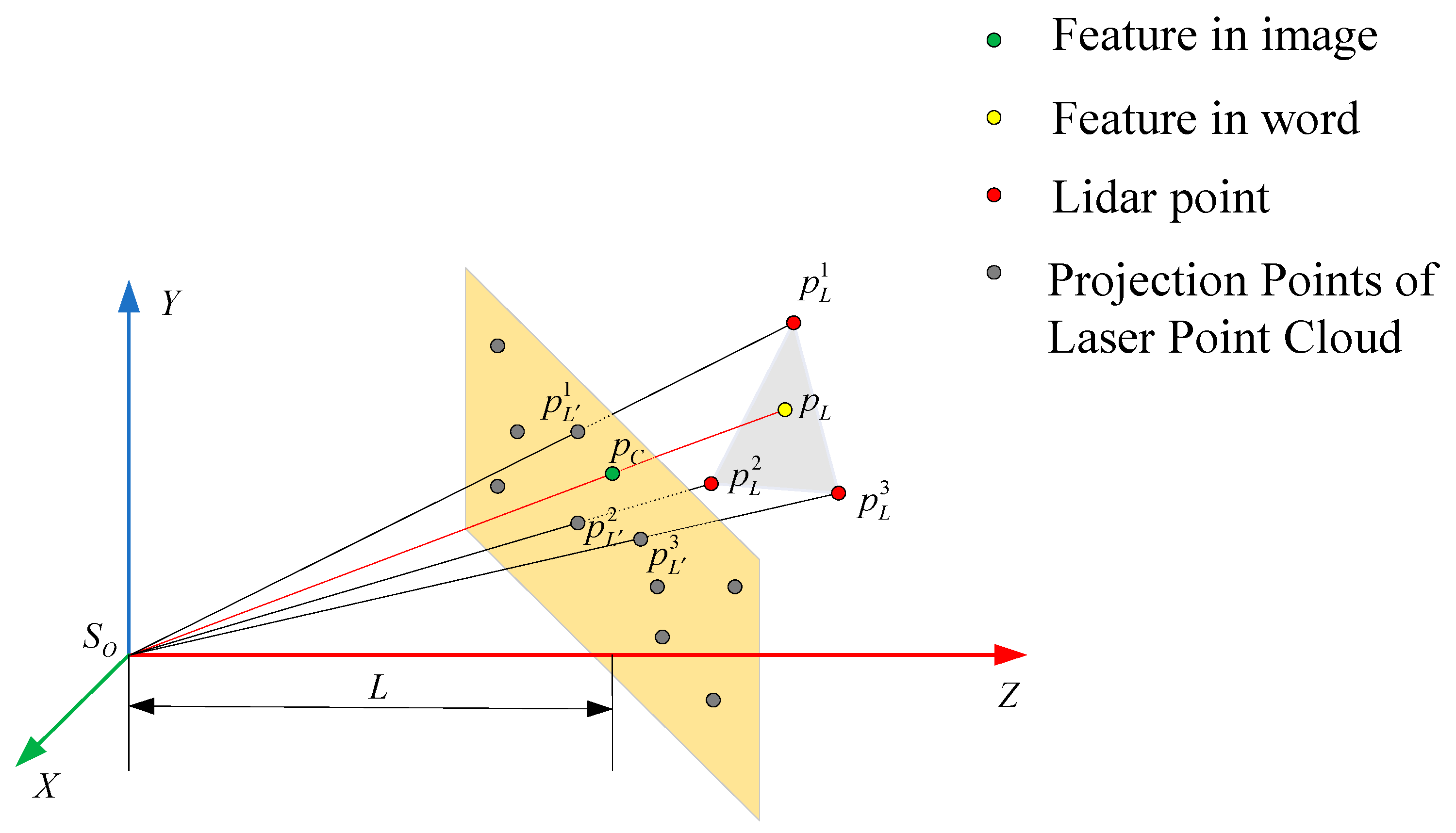
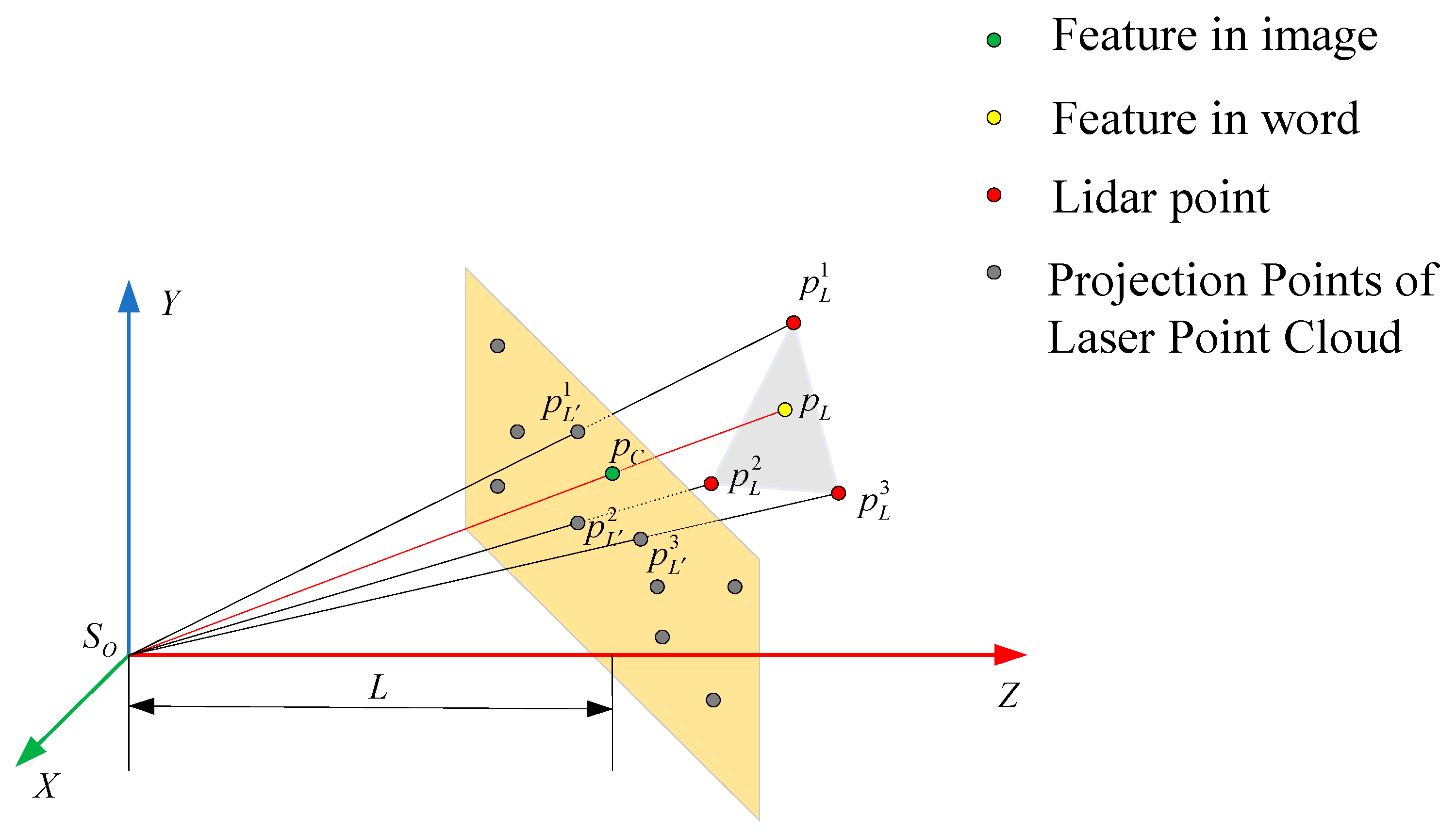
2.2. Pixel-Level Fusion of Images and Point Clouds
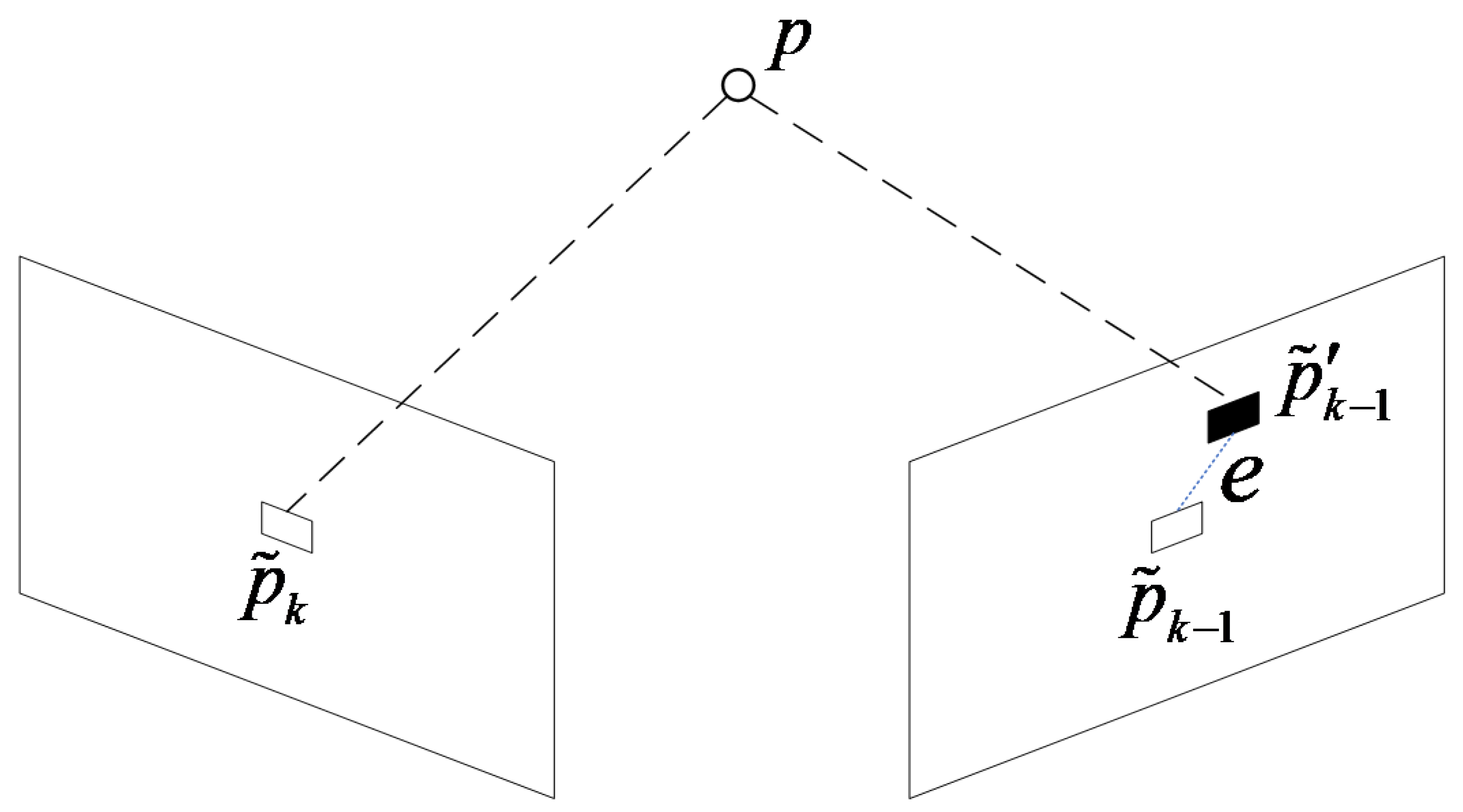
2.3. Pose Estimation Based on the Improved Objective Function
| Algorithm 1: Frame-to-Frame Motion Estimation |
 |
2.4. Keyframe-Based Local Optimization
3. Results
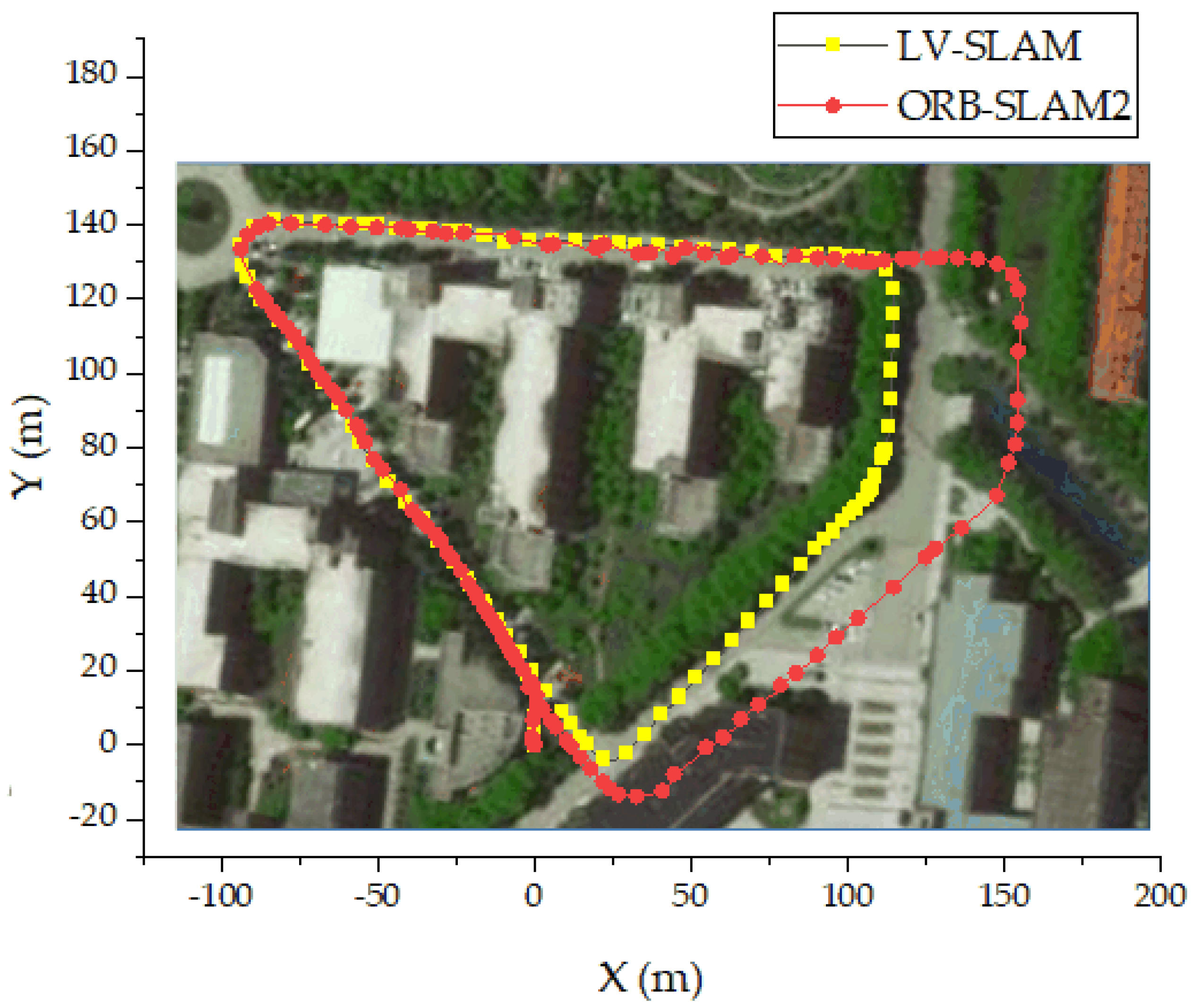
3.1. KITTI Dataset Experiment
3.1.1. Motion Trajectory and Mapping Experiment
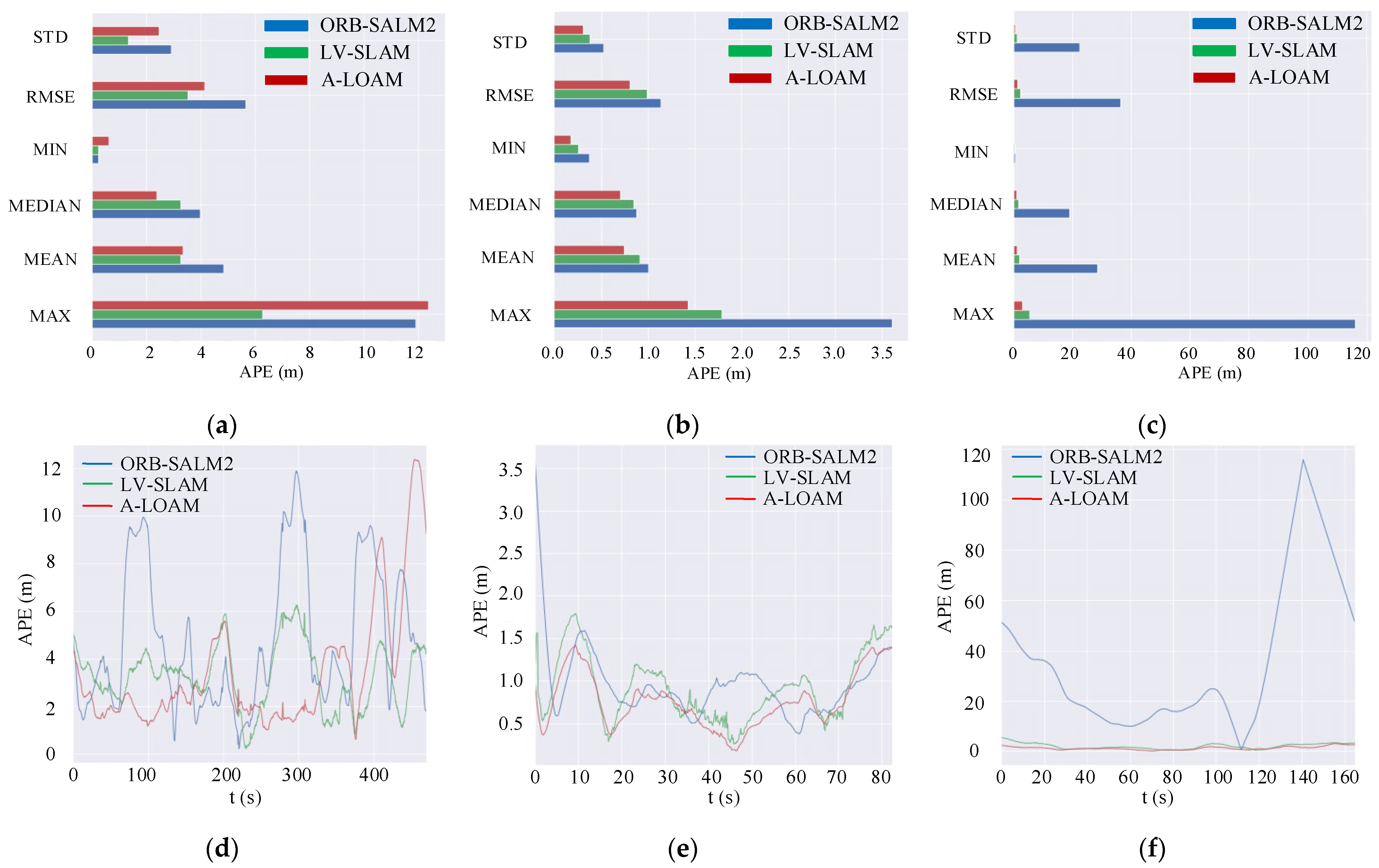
3.1.2. Analysis of Positioning Accuracy
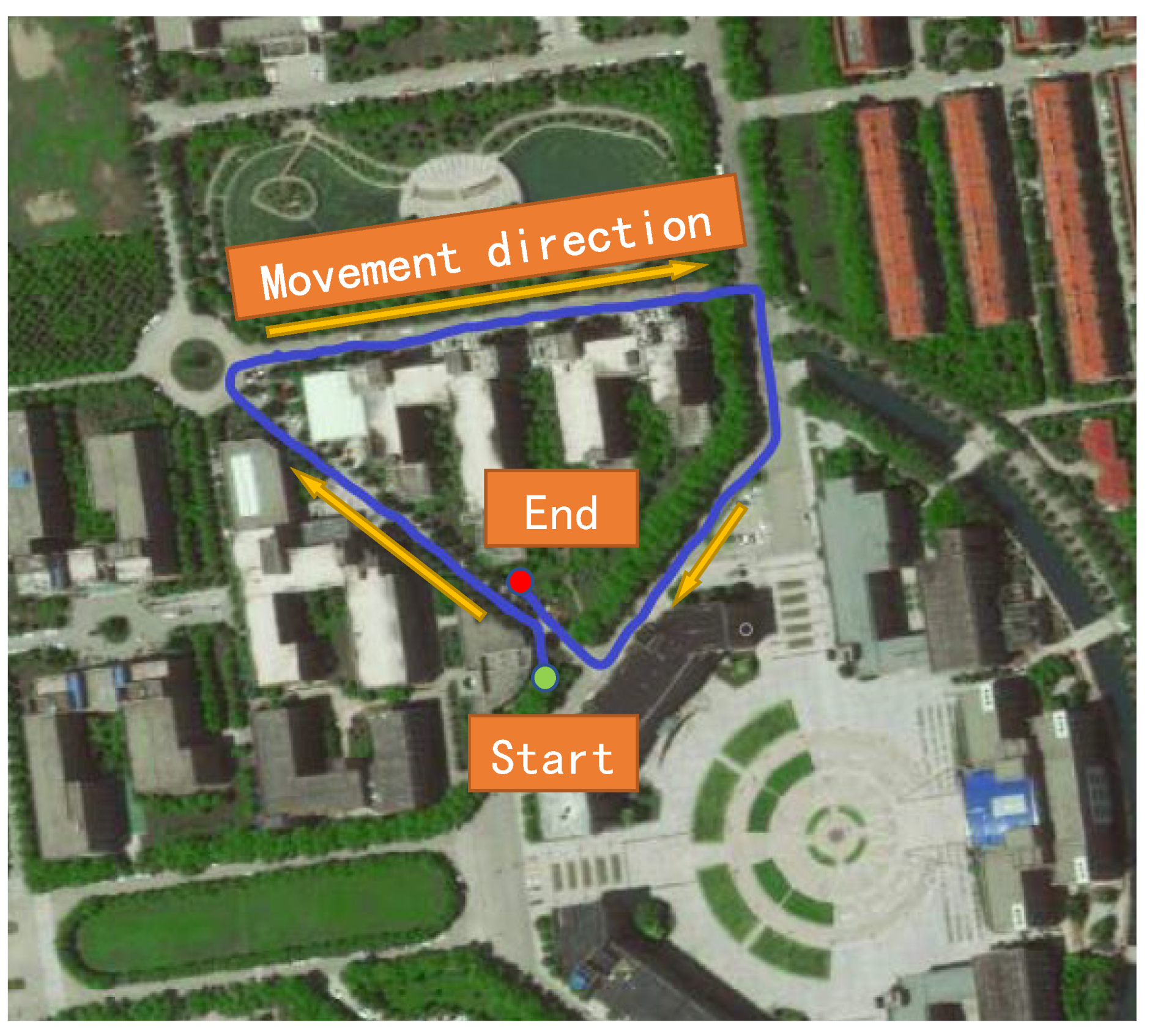
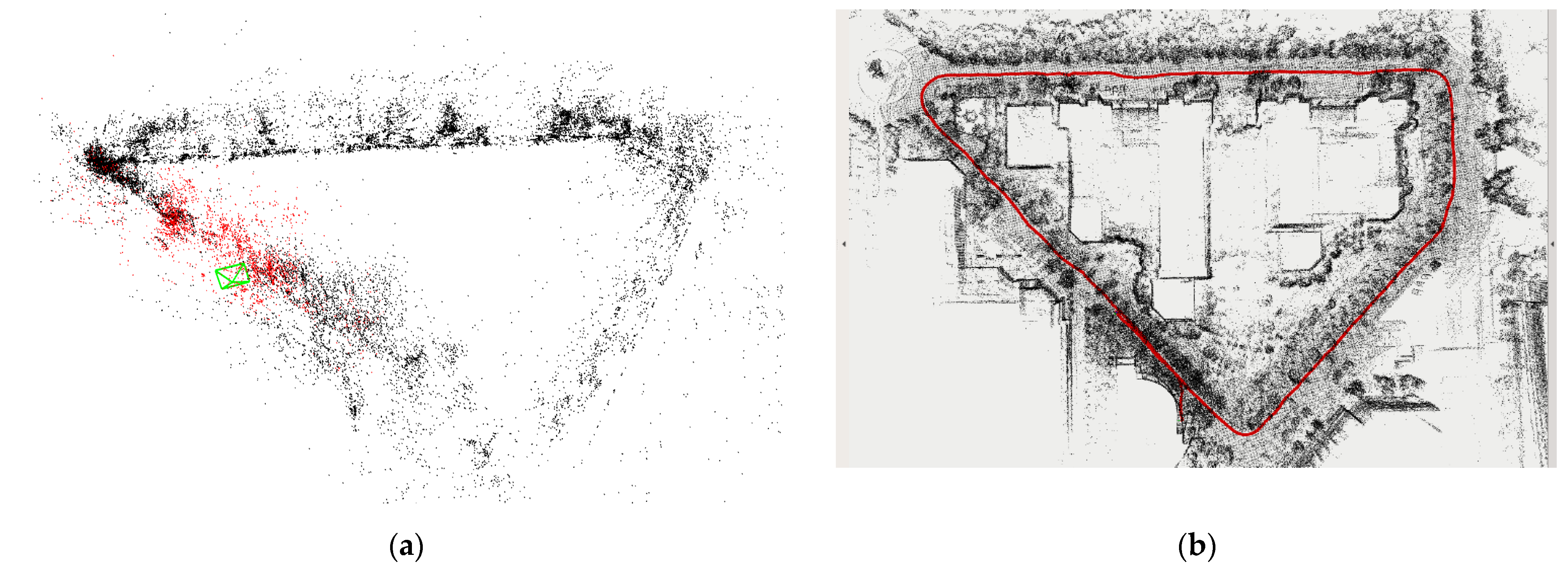
3.2. Outdoor Scene Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, S.; Bangunharcana, A.; Park, J.-M.; Choi, M.; Shin, H.-S. Visual SLAM-Based Robotic Mapping Method for Planetary Construction. Sensors 2021, 21, 7715. [Google Scholar] [CrossRef]
- Shen, D.; Xu, Y.; Li, Q. Research on laser SLAM algorithm based on sparse pose optimization. Prog. Lasers Optoelectron. 2021, 58, 434. [Google Scholar]
- Dai, J.; Li, D.; Zhao, J.W.; Li, Y. Autonomous Navigation of Robots Based on the Improved Informed-RRT Algorithm and DWA. J. Robot. 2022, 2022, 3477265. [Google Scholar] [CrossRef]
- Karlsson, N.; Bernardo, E.D.; Ostrowski, J. The V-SLAM Algorithm for Robust Localization and Mapping. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 611. [Google Scholar] [CrossRef] [PubMed]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation(ICRA), Chicago, IL, USA, 14–18 September 2014. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Y.; Xiong, G.; Zeng, H. Monocular SLAM method for multi-plane point optimization. Foreign Electron. Meas. Technol. 2021, 40, 40. [Google Scholar]
- Jia, Z.; Leng, J. Monocular SLAM Algorithm for Optical Flow Fusion with Line Features. Comput. Eng. Sci. 2018, 40, 2198. [Google Scholar]
- Zhu, D.; Wang, X. Research on binocular vision SLAM based on improved SIFT algorithm. Comput. Eng. Appl. 2011, 40, 170. [Google Scholar]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An Overview to Visual Odometry and Visual SLAM: Applications to Mobile Robotics. Intell. Ind. Syst. 2015, 1, 289. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Graeter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Zhang, Y.; Du, F.; Luo, Y. A SLAM Map Creation Method Fusion Laser and Depth Vision Sensors. Comput. Appl. Res. 2016, 33, 2970. [Google Scholar]
- Qi, J.; He, L.; Yuan, L. SLAM method based on the fusion of monocular camera and lidar. Electro-Opt. Control. 2022, 29, 99. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231. [Google Scholar] [CrossRef] [Green Version]
- Tong, Q.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An Accurate O(n) Solution to the PnP Problem. Int. J. Comput. Vis. 2009, 81, 155. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Chen, X.; Xi, J. Comparative Analysis of Warp Function for Digital Image Correlation-Based Accurate Single-Shot 3D Shape Measurement. Sensors 2018, 18, 1208. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenes | Algorithm | MAX (m) | MIN (m) | RMSE (m) | STD (m) | |
|---|---|---|---|---|---|---|
| 00 Sequence | APE | ORB-SLAM2 | 11.8961 | 0.225525 | 5.65063 | 2.90775 |
| LV-SLAM | 6.2644 | 0.231221 | 3.51915 | 1.32272 | ||
| A-LOAM | 12.3746 | 0.606901 | 4.14547 | 2.45925 | ||
| RPE | ORB-SLAM2 | 4.89548 | 0.00359534 | 0.212906 | 0.180132 | |
| LV-SLAM | 0.872029 | 0.00399336 | 0.0739505 | 0.0443978 | ||
| A-LOAM | 9.62911 | 0.00850367 | 2.87122 | 2.12342 | ||
| 03 Sequence | APE | ORB-SLAM2 | 3.60416 | 0.377288 | 1.13878 | 0.529162 |
| LV-SLAM | 1.79031 | 0.260234 | 0.989652 | 0.382163 | ||
| A-LOAM | 1.42551 | 0.178019 | 0.806478 | 0.30732 | ||
| RPE | ORB-SLAM2 | 0.186905 | 0.00551481 | 0.0588605 | 0.035607 | |
| LV-SLAM | 0.828702 | 0.00223307 | 0.0624783 | 0.0462032 | ||
| A-LOAM | 3.81938 | 0.146385 | 1.82442 | 0.684952 | ||
| 09 Sequence | APE | ORB-SLAM2 | 116.065 | 0.625562 | 36.3116 | 22.5404 |
| LV-SLAM | 5.40621 | 0.335209 | 2.29366 | 1.12238 | ||
| A-LOAM | 3.08308 | 0.107195 | 1.37112 | 0.617775 | ||
| RPE | ORB-SLAM2 | 174.979 | 0.201846 | 6.81681 | 6.79056 | |
| LV-SLAM | 0.32931 | 0.0572069 | 0.0712657 | 0.0315476 | ||
| A-LOAM | 6.41395 | 0.390049 | 2.61259 | 1.04912 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, J.; Li, D.; Li, Y.; Zhao, J.; Li, W.; Liu, G. Mobile Robot Localization and Mapping Algorithm Based on the Fusion of Image and Laser Point Cloud. Sensors 2022, 22, 4114. https://doi.org/10.3390/s22114114
Dai J, Li D, Li Y, Zhao J, Li W, Liu G. Mobile Robot Localization and Mapping Algorithm Based on the Fusion of Image and Laser Point Cloud. Sensors. 2022; 22(11):4114. https://doi.org/10.3390/s22114114
Chicago/Turabian StyleDai, Jun, Dongfang Li, Yanqin Li, Junwei Zhao, Wenbo Li, and Gang Liu. 2022. "Mobile Robot Localization and Mapping Algorithm Based on the Fusion of Image and Laser Point Cloud" Sensors 22, no. 11: 4114. https://doi.org/10.3390/s22114114
APA StyleDai, J., Li, D., Li, Y., Zhao, J., Li, W., & Liu, G. (2022). Mobile Robot Localization and Mapping Algorithm Based on the Fusion of Image and Laser Point Cloud. Sensors, 22(11), 4114. https://doi.org/10.3390/s22114114