
Clustering Approach for Detecting Multiple Types of Adversarial Examples




Abstract
:1. Introduction
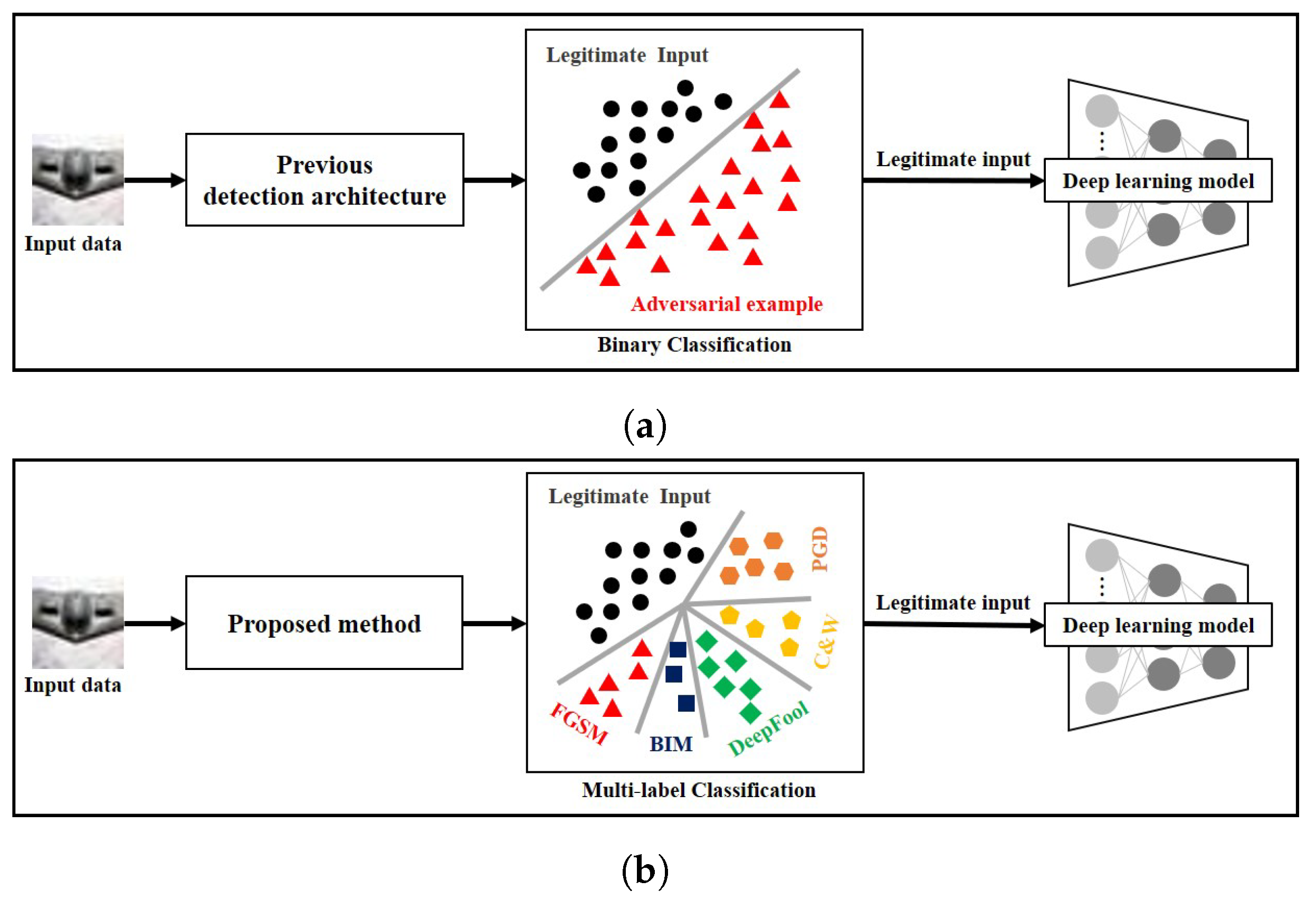
- We propose a novel defense method using adversarial example detection architecture. Different from the current defense methods using adversarial example detection architecture, which can classify the input data into only either legitimate one or adversarial one, the proposed method classifies the input data into multiple classes of data;
- To the best of our knowledge, the existing defense methods including model retraining architecture, input transformation architecture and adversarial example detection architecture use the adversarial example itself for analysis or detection. Thus, this is the first work which approximates the adversarial perturbation of each adversarial example and uses it to detect adversarial examples;
2. Preliminaries and Related Works
2.1. Adversarial Examples
2.2. Defense Methods Using Adversarial Example Detection Architecture
3. Proposed Method
3.1. Overall Operation
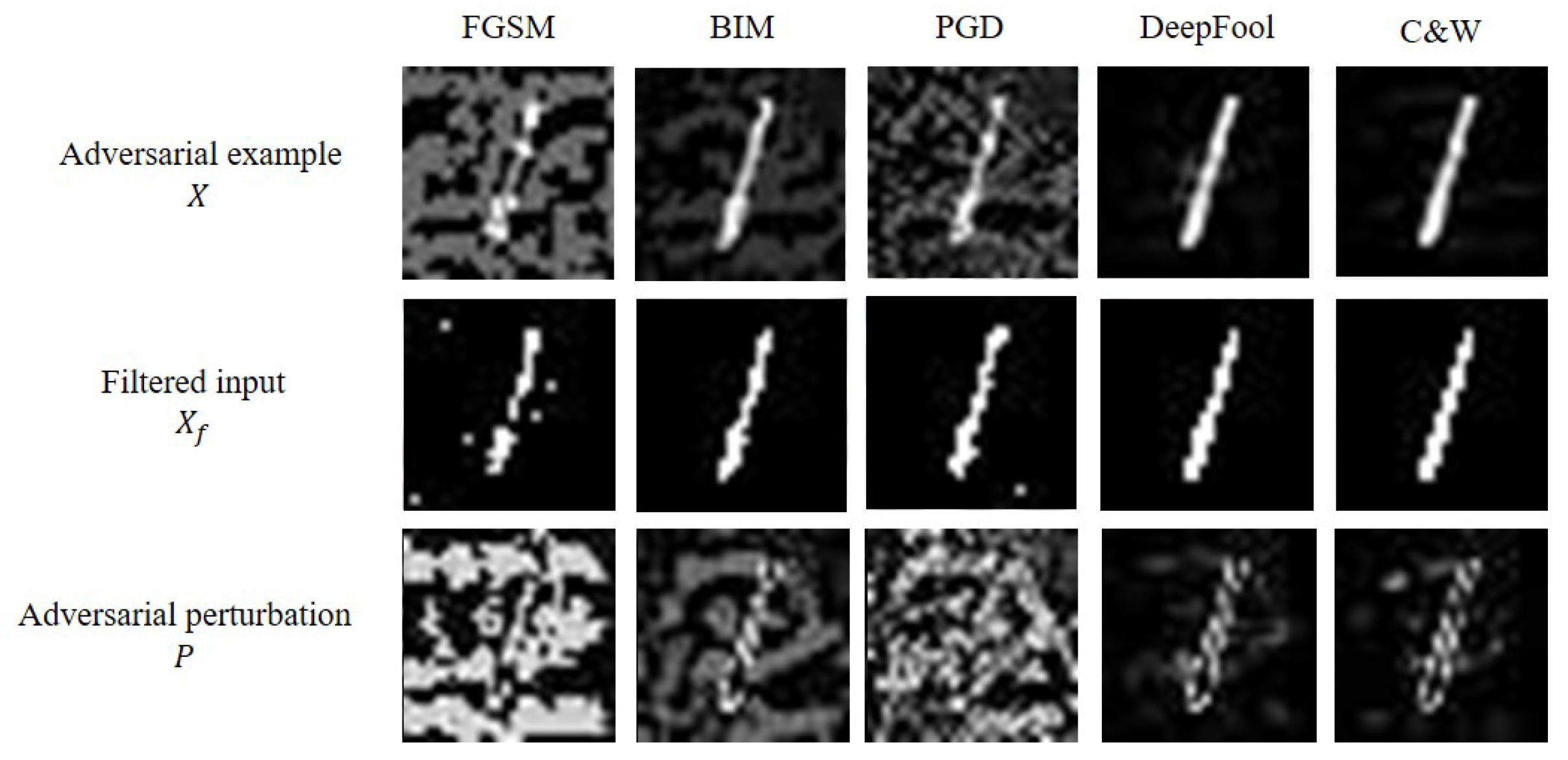
3.2. Adversarial Perturbation Extraction
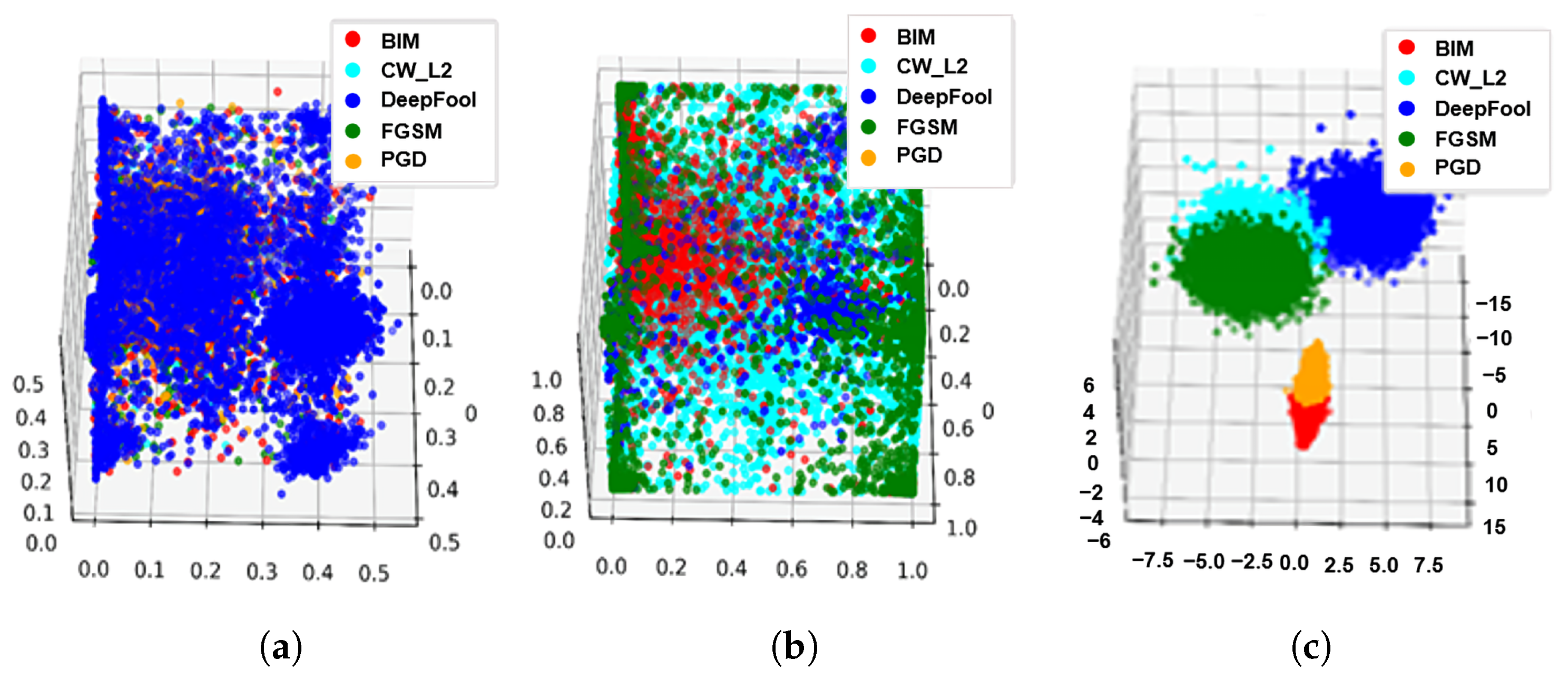
3.3. Dimensionality Reduction
3.4. Clustering
| Algorithm 1 Pseudo code of k-means algorithm |
 |
| Algorithm 2 Pseudo code of the DBSCAN algorithm |
 |
3.5. Operational Example
4. Evaluation Results
4.1. Experimental Setup
4.2. Experimental Analysis
4.2.1. Ablation Analysis
4.2.2. Influence of Dimensionality Reduction and Clustering Methods
4.2.3. Influence of the Number of Adversarial Examples Types
4.2.4. Comparison to Other Defense Methods Using Adversarial Example Detection Architecture
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maqueda, A.I.; Loquercio, A.; Gallego, G.; García, N.; Scaramuzza, D. Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kalash, M.; Rochan, M.; Mohammed, N.; Bruce, N.D.B.; Wang, Y.; Iqbal, F. Malware Classification with Deep Convolutional Neural Networks. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, N. A survey on deep learning based face recognition. Comput. Vis. Image Underst. 2019, 189, 102805. [Google Scholar] [CrossRef]
- Hussain, S.; Neekhara, P.; Jere, M.; Koushanfar, F.; McAuley, J. Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3348–3357. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial Machine Learning at Scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Cui, J.; Liu, S.; Wang, L.; Jia, J. Learnable Boundary Guided Adversarial Training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 15721–15730. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples. arXiv 2017, arXiv:1710.10766. [Google Scholar]
- Guo, C.; Rana, M.; Cissé, M.; van der Maaten, L. Countering Adversarial Images using Input Transformations. arXiv 2017, arXiv:1711.00117. [Google Scholar]
- Wang, J.; Hu, Y.; Qi, Y.; Peng, Z.; Zhou, C. Mitigating Adversarial Attacks Based on Denoising amp; Reconstruction with Finance Authentication System Case Study. IEEE Trans. Comput. 2021. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. arXiv 2015, arXiv:1511.04599. [Google Scholar]
- Choi, S.H.; Shin, J.; Liu, P.; Choi, Y.H. EEJE: Two-Step Input Transformation for Robust DNN Against Adversarial Examples. IEEE Trans. Netw. Sci. Eng. 2020, 8, 908–920. [Google Scholar] [CrossRef]
- Carrara, F.; Becarelli, R.; Caldelli, R.; Falchi, F.; Amato, G. Adversarial examples detection in features distance spaces. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Abusnaina, A.; Wu, Y.; Arora, S.; Wang, Y.; Wang, F.; Yang, H.; Mohaisen, D. Adversarial Example Detection Using Latent Neighborhood Graph. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 10–17 October 2021; pp. 7687–7696. [Google Scholar]
- Wang, Y.; Xie, L.; Liu, X.; Yin, J.L.; Zheng, T. Model-Agnostic Adversarial Example Detection Through Logit Distribution Learning. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3617–3621. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D.A. Towards Evaluating the Robustness of Neural Networks. arXiv 2016, arXiv:1608.04644. [Google Scholar]
- Dathathri, S.; Zheng, S.; Yin, T.; Murray, R.M.; Yue, Y. Detecting Adversarial Examples via Neural Fingerprinting. arXiv 2019, arXiv:1803.03870. [Google Scholar]
- Fidel, G.; Bitton, R.; Shabtai, A. When Explainability Meets Adversarial Learning: Detecting Adversarial Examples using SHAP Signatures. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. arXiv 2017, arXiv:1702.04267. [Google Scholar]
- Lu, J.; Issaranon, T.; Forsyth, D. Safetynet: Detecting and rejecting adversarial examples robustly. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 446–454. [Google Scholar]
- Santhanam, G.K.; Grnarova, P. Defending Against Adversarial Attacks by Leveraging an Entire GAN. arXiv 2018, arXiv:1805.10652. [Google Scholar]
- Yu, F.; Wang, L.; Fang, X.; Zhang, Y. The defense of adversarial example with conditional generative adversarial networks. Secur. Commun. Netw. 2020, 2020, 3932584. [Google Scholar] [CrossRef]
- Zheng, Y.; Velipasalar, S. Part-Based Feature Squeezing To Detect Adversarial Examples in Person Re-Identification Networks. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Online, 19–22 September 2021; pp. 844–848. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 20 March 2022).
- Gu, S.; Yi, P.; Zhu, T.; Yao, Y.; Wang, W. Detecting adversarial examples in deep neural networks using normalizing filters. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence—Volume 1: ICAART, Prague, Czech Republic, 19–21 February 2019. [Google Scholar]
- Krizhevsky, A.; Nair, V.; Hinton, G. CIFAR-10 (Canadian Institute for Advanced Research). 2014. Available online: http://www.cs.toronto.edu/~kriz/cifar.html (accessed on 20 March 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Papernot, N.; Goodfellow, I.; Sheatsley, R.; Feinman, R.; McDaniel, P. Cleverhans v1.0.0: An adversarial machine learning library. arXiv 2016, arXiv:1610.00768. [Google Scholar]
- Akritidis, L.; Alamaniotis, M.; Fevgas, A.; Bozanis, P. Confronting Sparseness and High Dimensionality in Short Text Clustering via Feature Vector Projections. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 813–820. [Google Scholar] [CrossRef]
- Zhang, H.; Zou, Y.; Terry, W.; Karmaus, W.; Arshad, H. Joint clustering with correlated variables. Am. Stat. 2019, 73, 296–306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alahakoon, D.; Halgamuge, S.K.; Srinivasan, B. Dynamic self-organizing maps with controlled growth for knowledge discovery. IEEE Trans. Neural Netw. 2000, 11, 601–614. [Google Scholar] [CrossRef] [PubMed]
- Kaur, S.; Sahambi, J. A framework for improvement in homogeneity of fluorescence and bright field live cell images using fractional derivatives. In Proceedings of the IEEE International Conference on Computing, Communication & Automation, Greater Noida, India, 15–16 May 2015; pp. 1160–1165. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | References | Binary Classification | Multi-Label Classification |
|---|---|---|---|
| Signature-based Detector | S. Dathathri et al.’s method [20] | ✓ | ✗ |
| G. Fidel et al.’s method [21] | ✓ | ✗ | |
| Subnetwork-based Detector | Metzen et al.’s method [22] | ✓ | ✗ |
| Jiajun Lu et al.’s method [23] | ✓ | ✗ | |
| GAN-based Detector | Cowboy [24] | ✓ | ✗ |
| Fangchao Yu et al.’s method [25] | ✓ | ✗ | |
| Squeezer-based Detector | Feature Squeezing [16] | ✓ | ✗ |
| Yu Zheng et al.’s method [26] | ✓ | ✗ | |
| LSTM-based Detector | Carrara et al.’s method [15] | ✓ | ✗ |
| Wang et al.’s method [18] | ✓ | ✗ | |
| GNN-based Detector | Abusnaina et al.’s method [17] | ✓ | ✗ |
| Clustering model-based Detector | Proposed method | ✓ | ✓ |
| Dataset | Method | Homogeneity | Completeness | V-Measure | Average |
|---|---|---|---|---|---|
| MNIST | Adversarial example + k-means (Step 3) | 0.247 | 0.252 | 0.249 | 0.249 |
| Adversarial perturbation + k-means (Step 1 + Step 3) | 0.601 | 0.654 | 0.626 | 0.627 | |
| Adversarial perturbation + LDA + k-means (Step 1 + Step 2 + Step 3) | 0.826 | 0.903 | 0.863 | 0.864 | |
| CIFAR-10 | Adversarial example + k-means (Step 3) | 0.092 | 0.174 | 0.120 | 0.128 |
| Adversarial perturbation + k-means (Step 1 + Step 3) | 0.343 | 0.416 | 0.375 | 0.378 | |
| Adversarial perturbation + LDA + k-means (Step 1 + Step 2 + Step 3) | 0.676 | 0.728 | 0.701 | 0.701 |
| Dataset | Dimensionality Reduction Method | Clustering Method | Homogeneity | Completeness | V-Measure | Average |
|---|---|---|---|---|---|---|
| MNIST | PCA | K-means | 0.734 | 0.809 | 0.770 | 0.771 |
| DBSCAN | 0.783 | 0.745 | 0.764 | 0.764 | ||
| LDA | K-means | 0.826 | 0.903 | 0.863 | 0.864 | |
| DBSCAN | 0.814 | 0.919 | 0.863 | 0.865 | ||
| CIFAR-10 | PCA | K-means | 0.645 | 0.467 | 0.646 | 0.646 |
| DBSCAN | 0.296 | 0.811 | 0.434 | 0.513 | ||
| LDA | K-means | 0.676 | 0.728 | 0.701 | 0.701 | |
| DBSCAN | 0.594 | 0.854 | 0.701 | 0.716 |
| Dataset | Method | Binary Classification | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||
| MNIST | Carrara et al.’s method (LSTM + Euclidean) | 71.67% ± 0.24 | 68.48% ± 0.32 | 79.35% ± 0.28 | 73.52% ± 0.27 |
| Carrara et al.’s method (LSTM + cosine) | 70.50% ± 0.52 | 67.18% ± 0.43 | 78.34% ± 0.48 | 72.28% ± 0.46 | |
| Carrara et al.’s method (MLP + Euclidean) | 70.18% ± 0.37 | 67.29% ± 0.34 | 77.53% ± 0.36 | 72.13% ± 0.32 | |
| Carrara et al.’s method (MLP + cosine) | 69.89% ± 0.64 | 67.02% ± 0.52 | 77.24% ± 0.36 | 71.69% ± 0.36 | |
| Feature Squeezing (Binary filter + distance) | 94.22% ± 0.21 | 95.13% ± 0.21 | 93.20% ± 0.22 | 94.18% ± 0.21 | |
| Feature Squeezing (Binary filter + distance) | 94.21% ± 0.23 | 95.11% ± 0.19 | 93.30% ± 0.27 | 94.20% ± 0.20 | |
| Feature Squeezing (Binary filter + K-L diversity) | 95.14% ± 0.20 | 95.57% ± 0.23 | 94.45% ± 0.24 | 94.22% ± 0.25 | |
| proposed method (LDA + DBSCAN) | 99.99% ± 0.01 | 99.99% ± 0.01 | 99.97% ± 0.05 | 99.98% ± 0.02 | |
| CIFAR-10 | Carrara et al.’s method (LSTM + Euclidean) | 79.62% ± 0.73 | 73.58% ± 0.76 | 91.50% ± 0.67 | 81.64% ± 0.63 |
| Carrara et al.’s method (LSTM + cosine) | 68.65% ± 1.07 | 64.68% ± 1.13 | 78.97% ± 1.11 | 71.33% ± 1.21 | |
| Carrara et al.’s method (MLP + Euclidean) | 77.53% ± 0.86 | 72.68% ± 0.94 | 86.70% ± 0.93 | 79.07% ± 0.87 | |
| Carrara et al.’s method (MLP + cosine) | 79.09% ± 1.38 | 74.99% ± 1.36 | 85.97% ± 1.39 | 80.09% ± 1.39 | |
| Feature Squeezing (Binary filter + distance) | 50.76% ± 0.76 | 50.31% ± 0.77 | 49.45% ± 0.82 | 49.91% ± 0.77 | |
| Feature Squeezing (Binary filter + distance) | 53.41% ± 0.79 | 53.12% ± 0.82 | 51.49% ± 0.87 | 52.29% ± 0.85 | |
| Feature Squeezing (Binary filter + K-L diversity) | 50.85% ± 0.80 | 50.48% ± 0.81 | 49.76% ± 0.84 | 49.93% ± 0.83 | |
| proposed method (LDA + DBSCAN) | 81.32% ± 0.33 | 82.25% ± 0.32 | 83.08% ± 0.39 | 83.17% ± 0.38 | |
| Dataset | Multi-Label Classification | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |
| MNIST | 66.33% ± 2.07 | 66.29% ± 2.13 | 66.66% ± 2.20 | 66.56% ± 2.13 |
| CIFAR-10 | 47.18% ± 4.31 | 46.30% ± 4.37 | 46.23% ± 4.49 | 46.39% ± 4.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, S.-H.; Bahk, T.-u.; Ahn, S.; Choi, Y.-H. Clustering Approach for Detecting Multiple Types of Adversarial Examples. Sensors 2022, 22, 3826. https://doi.org/10.3390/s22103826
Choi S-H, Bahk T-u, Ahn S, Choi Y-H. Clustering Approach for Detecting Multiple Types of Adversarial Examples. Sensors. 2022; 22(10):3826. https://doi.org/10.3390/s22103826
Chicago/Turabian StyleChoi, Seok-Hwan, Tae-u Bahk, Sungyong Ahn, and Yoon-Ho Choi. 2022. "Clustering Approach for Detecting Multiple Types of Adversarial Examples" Sensors 22, no. 10: 3826. https://doi.org/10.3390/s22103826
APA StyleChoi, S.-H., Bahk, T.-u., Ahn, S., & Choi, Y.-H. (2022). Clustering Approach for Detecting Multiple Types of Adversarial Examples. Sensors, 22(10), 3826. https://doi.org/10.3390/s22103826