
Facial Expression Recognition Based on Squeeze Vision Transformer




Abstract
:1. Introduction
- (1)
- We combine existing visual tokens and landmark heatmap-based local tokens allowing the ViT to maintain the global and local features at the same time;
- (2)
- To reduce the excessive number of computations of the ViT, we propose a squeeze module to reduce the number of feature dimensions and parameters for each encoder layer;
- (3)
- To prove that the proposed Squeeze ViT is robust to FER under various environments, we measure the performance not only on lab-controlled FER datasets but also on a wild FER dataset;
- (4)
- Through various ablation studies, we prove that the FER performance increases when visual and landmark tokens are used together and demonstrate that Squeeze ViT can significantly reduce the numbers of parameters and computations in comparison to pure ViTs;
- (5)
- The remainder of this paper is structured as follows: In Section 2, we present a review of the related studies on FER based on conventional approaches, a CNN, and a ViT. Section 3 provides the details of our proposed Squeeze ViT method. Section 4 provides a comprehensive evaluation of the proposed method based on various experiments. Finally, some concluding remarks are given in Section 5.
2. Related Studies
2.1. FER Based on Conventional Approaches
2.2. FER Based on CNN
2.3. FER Based on ViT
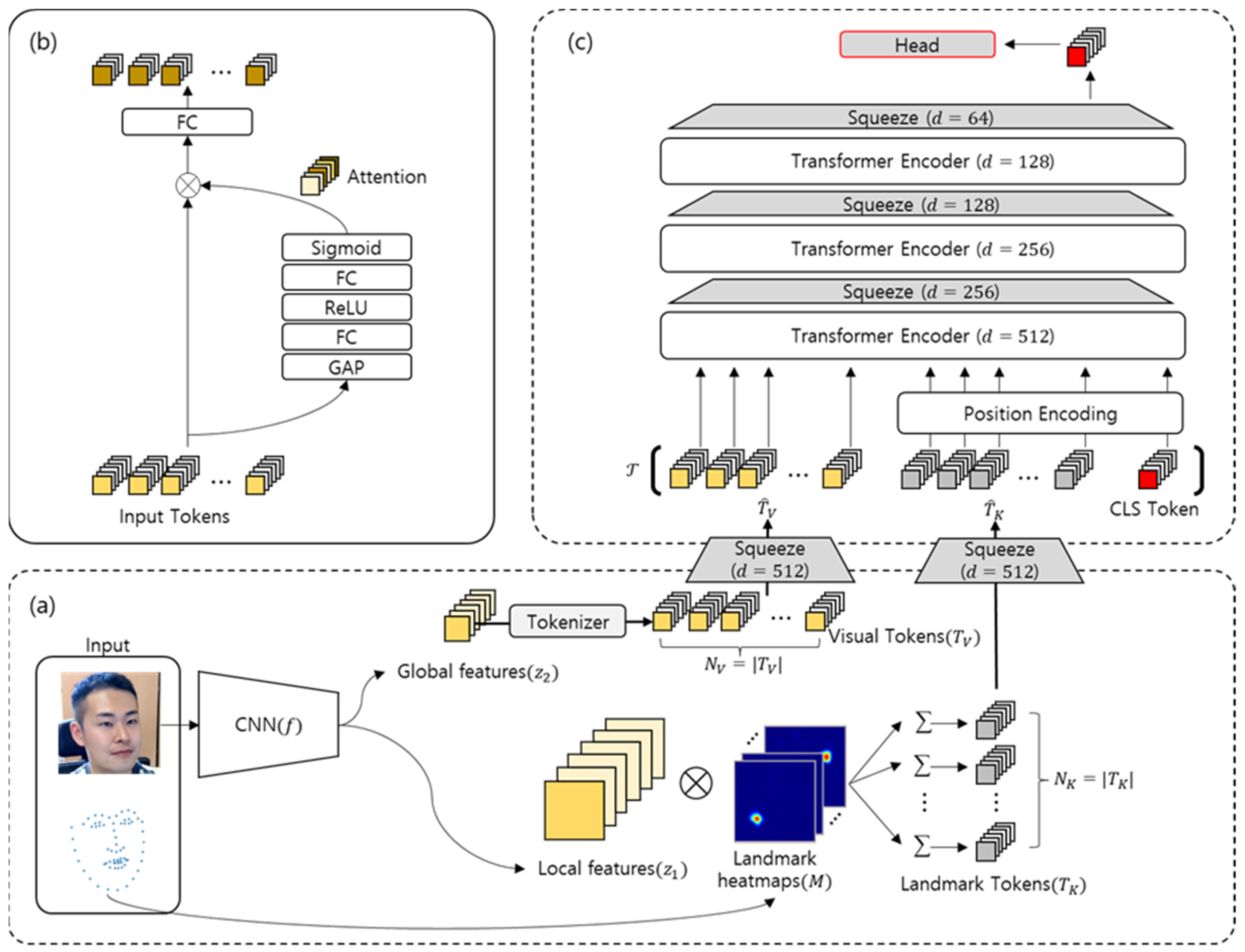
3. Proposed Method
3.1. Overview of Squeeze ViT
3.2. Review of ViT
3.3. Refined Representation of Tokens
3.4. Squeeze ViT
- (1)
- ViT can learn the global expressions more easily than a CNN by using self-attention for all tokens; however, this characteristic is rather disadvantageous for tasks in which local representation is important, such as FER. To alleviate this limitation, we allow the transformer encoder to interact between mixed (global + local) representation tokens;
- (2)
- Existing ViT [18]—based transformers [29,30] encode tokens with the same transformer layer stack under the same network settings. Therefore, the input and output tokens share characteristics with the same number of tokens. Although these methods are simple and effective, to achieve good performance, they are computationally expensive. The squeeze module can also reduce the parameters and operations of subsequent transformer layers by progressively reducing the number of feature dimensions of the token. In this process, although a feature loss may occur as the feature dimension of the token is reduced, such a loss can be overcome using feature-wise attention in the squeeze module;
- (3)
- With the ViT, the output of the last transformer encoder is used for classification, whereas with Squeeze ViT, the output of the last squeeze module is used for classification. The class token of the final output is applied to the MLP to finally classify the facial expressions.
| Algorithm 1: Training of Pytorch-like Squeeze ViT Structure |
| # f: backbone returning intermediate layer outputs (third and fourth) # s: squeeze module # pos: absolute position encoding # layers: list of tuples (e, transformer encoder; s, squeeze module) # h: prediction head cls = Parameter() for (x, y, M) in loader: z1, z2 = f(x) # z1, local feature map; z2, global feature map t1, t2 = K(z1, M), G(z2) # t1, landmark tokens; t2, visual tokens t1, t2 = s(pos(t1)), s(t2) # projections, -by- and -by-, respectively t = cat(t1, t2, cls) for (e, s) in layers: # processing of transformer encoder (e), squeeze module (s) t = e(t) # embedding tokens t = s(t) # projection, -by- p = h(t.cls) # projection head, only for the CLS token L = LabelSmoothingCrossEntropy(p, y) # loss function L.backward() # back-propagate update(f, layers, h) # AdamW update def K(z, M): # generation of landmark tokens z = z.expand() # reshape, -by- M = M.expand() # reshape, -by- t = zTM # dot prod, -by- t = sum(t) # reduce sum, -by- return t def G(z): # generation of visual tokens t = z.flatten() # flatten, -by-() return t |
4. Experimental Results
4.1. Dataset
4.2. Implementation Details
4.3. Ablation Studies
4.4. Performance Comparison with Previous State-of-the-Art Methods
4.5. Confusion Matrix Comparison
- i.
- CK+: The proposed model showed a degraded performance on a surprise (SU) expression, which is difficult to distinguish from disgust (DI) and neutral (NE). Regardless, it showed a perfect probe performance on disgust (DI), happy (HA), and sad (SA) expressions;
- ii.
- MMI: The overall performance is good except for angry (AN), fear (FE), and sadness (SA). In the case of fear (FE), a lower accuracy was demonstrated because fear (FE), angry (AN), and surprise (SU) share relatively similar muscle movements as the other expressions;
- iii.
- RAF-DB: Similar to the other datasets, the proposed model showed a relatively good performance for happy (HA) and sad (SA). By contrast, disgust (DI) seemed to be easily misclassified as sadness (SA) or anger (AN). Finally, neutral (NE) was also confused with sadness (SA).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gannouni, S.; Aledaily, A.; Belwafi, K.; Aboalsamh, H. Emotion detection using electroencephalography signals and a zero-time windowing-based epoch estimation and relevant electrode identification. Sci. Rep. 2021, 11, 7071. [Google Scholar] [CrossRef] [PubMed]
- Hasnul, M.A.; Aziz, N.A.A.; Alelyani, S.; Mohana, M.; Aziz, A.A. Electrocardiogram-Based Emotion Recognition Systems and Their Applications in Healthcare—A Review. Sensors 2021, 21, 5015. [Google Scholar] [CrossRef] [PubMed]
- Kulke, L.; Feyerabend, D.; Schacht, A. A Comparison of the Affectiva iMotions Facial Expression Analysis Software with EMG for Identifying Facial Expressions of Emotion. Front. Psychol. 2020, 11, 329. [Google Scholar] [CrossRef] [PubMed]
- Du, S.; Tao, Y.; Martinez, A.M. Compound facial expressions of emotion. Proc. Natl. Acad. Sci. USA 2014, 111, 1454–1462. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, L.; Lang, C.; Li, Y.; Feng, S.; Zhao, J. Fine-Grained Facial Expression Recognition in the Wild. IEEE Trans. Inf. Forensics Secur. 2020, 16, 482–494. [Google Scholar] [CrossRef]
- Ghimire, D.; Jeong, S.; Lee, J.; Park, S.H. Facial expression recognition based on local region specific features and support vector machines. Multimed. Tools Appl. 2017, 76, 7803–7821. [Google Scholar] [CrossRef] [Green Version]
- Ghimire, D.; Lee, J. Geometric feature-based facial expression recognition in image sequences using multi-class AdaBoost and support vector machines. Sensors 2013, 13, 7714–7734. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jeong, M.; Ko, B.C. Driver’s Facial Expression Recognition in Real-Time for Safe Driving. Sensors 2018, 18, 4270. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Cai, H.; Liu, H.; Zhang, J.; Chen, S. Feature Selection Mechanism in CNNs for Facial Expression Recognition. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–12. [Google Scholar]
- Fan, Y.; Li, V.; Lam, J.C. Facial Expression Recognition with Deeply-Supervised Attention Network. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Xu, T.; White, J.; Kalkan, S.; Gunes, H. Investigating bias and fairness in facial expression recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020; pp. 506–523. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 6897–6906. [Google Scholar]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Ko, B.C. A Brief Review of Facial Emotion Recognition Based on Visual Information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Greche, L.; Es-Sbai, N. Automatic System for Facial Expression Recognition Based Histogram of Oriented Gradient and Normalized Cross Correlation. In Proceedings of the 2016 International Conference on Information Technology for Organizations Development (IT4OD), Fez, Morocco, 30 March–1 April 2016; pp. 1–5. [Google Scholar]
- Lee, S.H.; Plataniotis, K.N.; Ro, Y.M. Intra-class variation reduction using training expression images for sparse representation based facial expression recognition. IEEE Trans. Affect. Comput. 2014, 5, 340–351. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1–9. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the Ninth International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021; pp. 1–12. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised Pre-Training for Object Detection With Transformers. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–28 June 2021; pp. 1601–1610. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–28 June 2021; pp. 8126–8135. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–28 June 2021; pp. 12873–12883. [Google Scholar]
- Xue, F.; Wang, Q.; Guo, G. TransFER: Learning Relation-aware Facial Expression Representations with Transformers. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 3601–3610. [Google Scholar]
- Aouayeb, M.; Hamidouche, W.; Soladie, C.; Kpalma, K.; Seguier, R. Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition. arXiv 2021, arXiv:2107.03107. [Google Scholar]
- Wang, C.; Wang, Z. Progressive Multi-Scale Vision Transformer for Facial Action Unit Detection. Front. Neurorobot. 2022, 12, 824592. [Google Scholar] [CrossRef] [PubMed]
- Ma, F.; Sun, B.; Li, S. Facial Expression Recognition with Visual Transformers and Attentional Selective Fusion. IEEE Trans. Affect. Comput. 2022. [Google Scholar] [CrossRef]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–15. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–28 June 2021; pp. 10012–10022. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Valstar, M.; Pantic, M. Induced disgust, happiness and surprise: An addition to the mmi facial expression database. In Proceedings of the 3rd International Workshop on EMOTION (Satellite of LREC): Corpora for Research on Emotion and Affect, Valletta, Malta, 17–23 May 2010; pp. 65–70. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Hawaii, HO, USA, 21–26 July 2017; pp. 2584–2593. [Google Scholar]
- Zeng, J.; Shan, S.; Chen, X. Facial expression recognition with inconsistently annotated datasets. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 222–237. [Google Scholar]
- Chen, Y.; Wang, J.; Chen, S.; Shi, Z.; Cai, J. Facial Motion Prior Networks for Facial Expression Recognition. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Chen, S.; Wang, J.; Chen, Y.; Shi, Z.; Geng, X.; Rui, Y. Label distribution learning on auxiliary label space graphs for facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 4321–4330. [Google Scholar]
- Ruan, D.; Yan, Y.; Lai, S.; Chai, Z.; Shen, C.; Wang, H. Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–28 June 2021; pp. 7660–7668. [Google Scholar]
- Mao, S.; Shi, G.; Gou, S.; Yan, D.; Jiao, L.; Xiong, L. Adaptively Lighting up Facial Expression Crucial Regions via Local Non-Local Joint Network. arXiv 2022, arXiv:2203.14045. [Google Scholar]
- She, J.; Hu, Y.; Shi, H.; Wang, J.; Shen, Q.; Mei, T. Dive into Ambiguity: Latent Distribution Mining and Pairwise Uncertainty Estimation for Facial Expression Recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–28 June 2021; pp. 6248–6257. [Google Scholar]
- Zhang, Y.; Wang, C.; Deng, W. Relative Uncertainty Learning for Facial Expression Recognition. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021; pp. 1–12. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 87–102. [Google Scholar]


{kind=link}
{kind=link}
| Visual Token | Landmark Token | Accuracy (%) |
|---|---|---|
| ✔ | ✘ | 88.0 |
| ✔ | ✔ | 88.9 |
| Methods | Params (M) | FLOPs (G) | Accuracy (%) |
|---|---|---|---|
| ViT [18] | 86.86 | 33.03 | 98.75 |
| Squeeze ViT | 11.96 | 1.84 | 99.54 |
| Methods | Accuracy (%) | ||
|---|---|---|---|
| CK+ | MMI | RAF-DB | |
| WRF [8] | 92.6 | 76.7 | - |
| IPA2LT [34] | 91.67 | 65.61 | 86.77 |
| FMPN [35] | 98.06 | 82.74 | - |
| ALSG [36] | 93.08 | 70.49 | 85.53 |
| FDRL [37] | 99.54 | 85.23 | 89.47 |
| LNLAttenNet [38] | 98.18 | 68.75 | 86.15 |
| ViT-SE * [23] | 99.49 | - | 87.22 |
| DMUE [39] | - | - | 88.76 |
| RUL [40] | - | - | 88.98 |
| Squeeze ViT | 99.54 | 89.89 | 88.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Nam, J.; Ko, B.C. Facial Expression Recognition Based on Squeeze Vision Transformer. Sensors 2022, 22, 3729. https://doi.org/10.3390/s22103729
Kim S, Nam J, Ko BC. Facial Expression Recognition Based on Squeeze Vision Transformer. Sensors. 2022; 22(10):3729. https://doi.org/10.3390/s22103729
Chicago/Turabian StyleKim, Sangwon, Jaeyeal Nam, and Byoung Chul Ko. 2022. "Facial Expression Recognition Based on Squeeze Vision Transformer" Sensors 22, no. 10: 3729. https://doi.org/10.3390/s22103729
APA StyleKim, S., Nam, J., & Ko, B. C. (2022). Facial Expression Recognition Based on Squeeze Vision Transformer. Sensors, 22(10), 3729. https://doi.org/10.3390/s22103729