
Delicar: A Smart Deep Learning Based Self Driving Product Delivery Car in Perspective of Bangladesh

 , and
, and 
Abstract
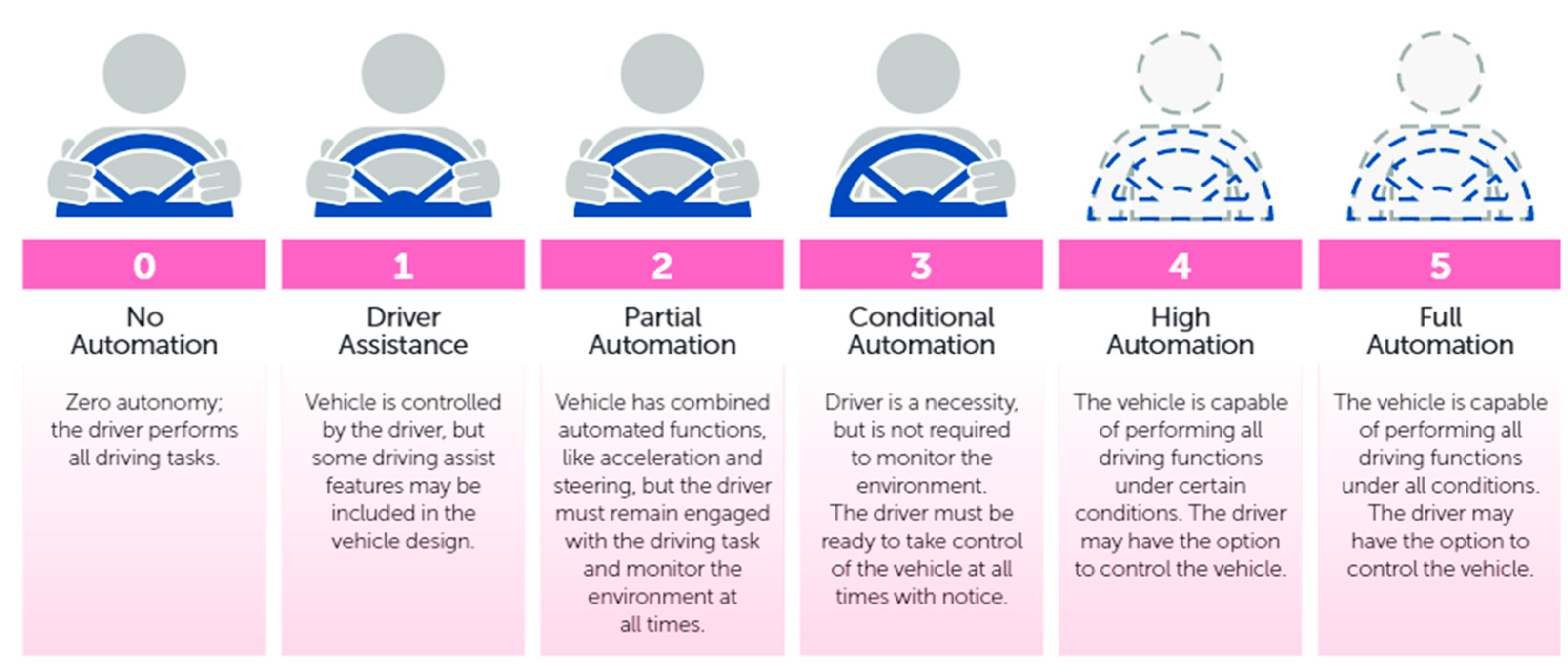
:1. Introduction
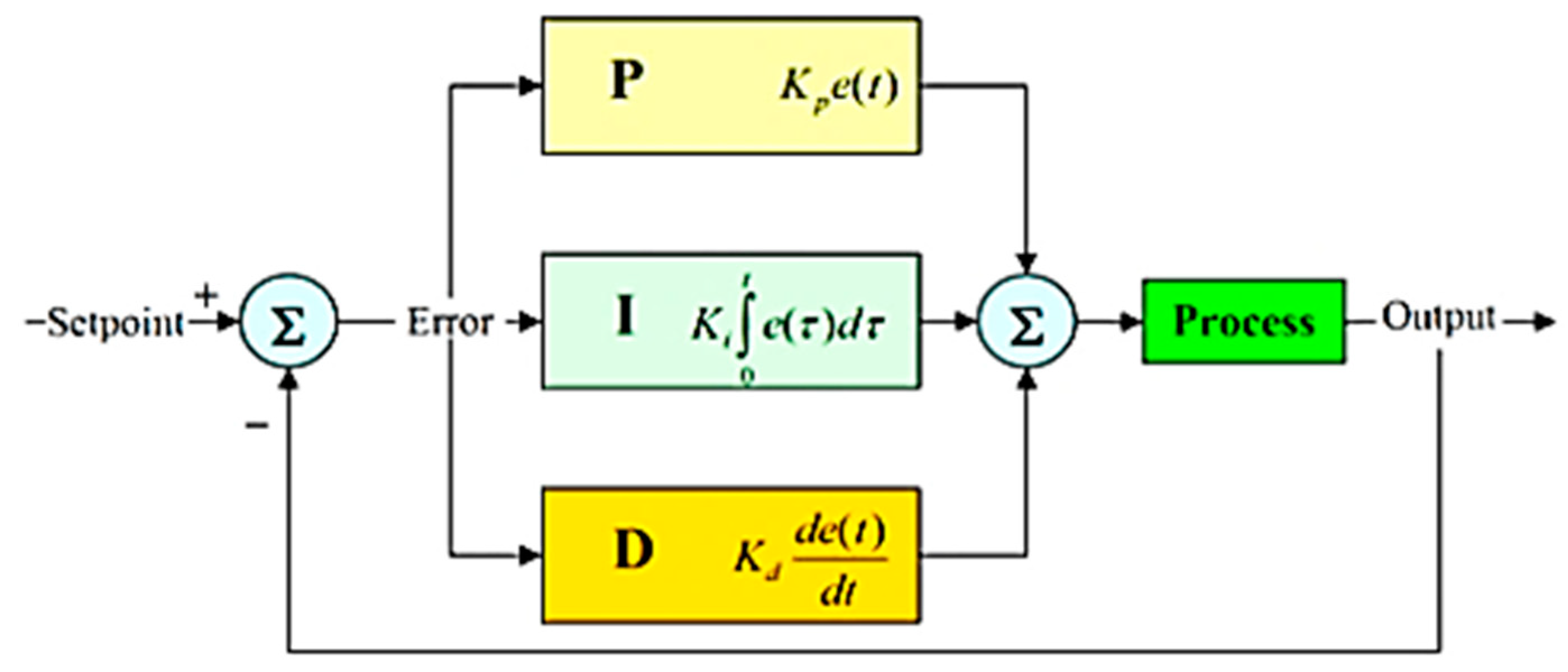
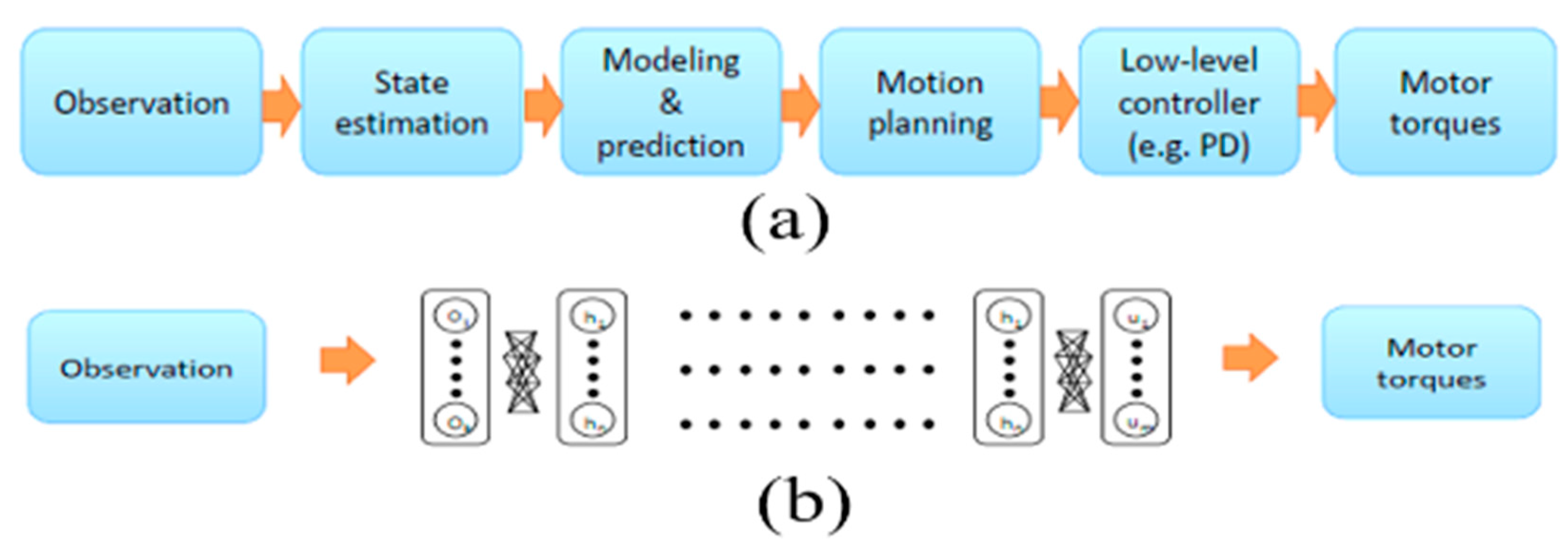
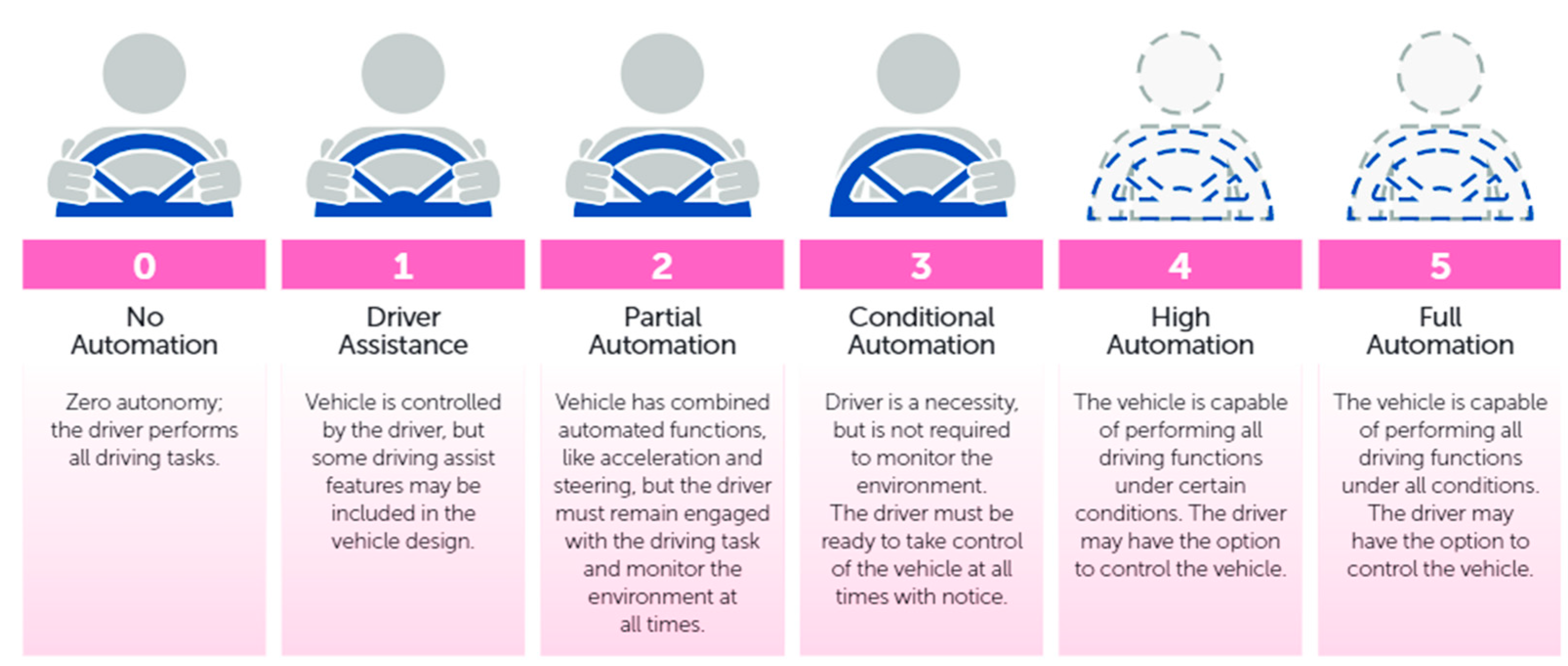
2. Related Works
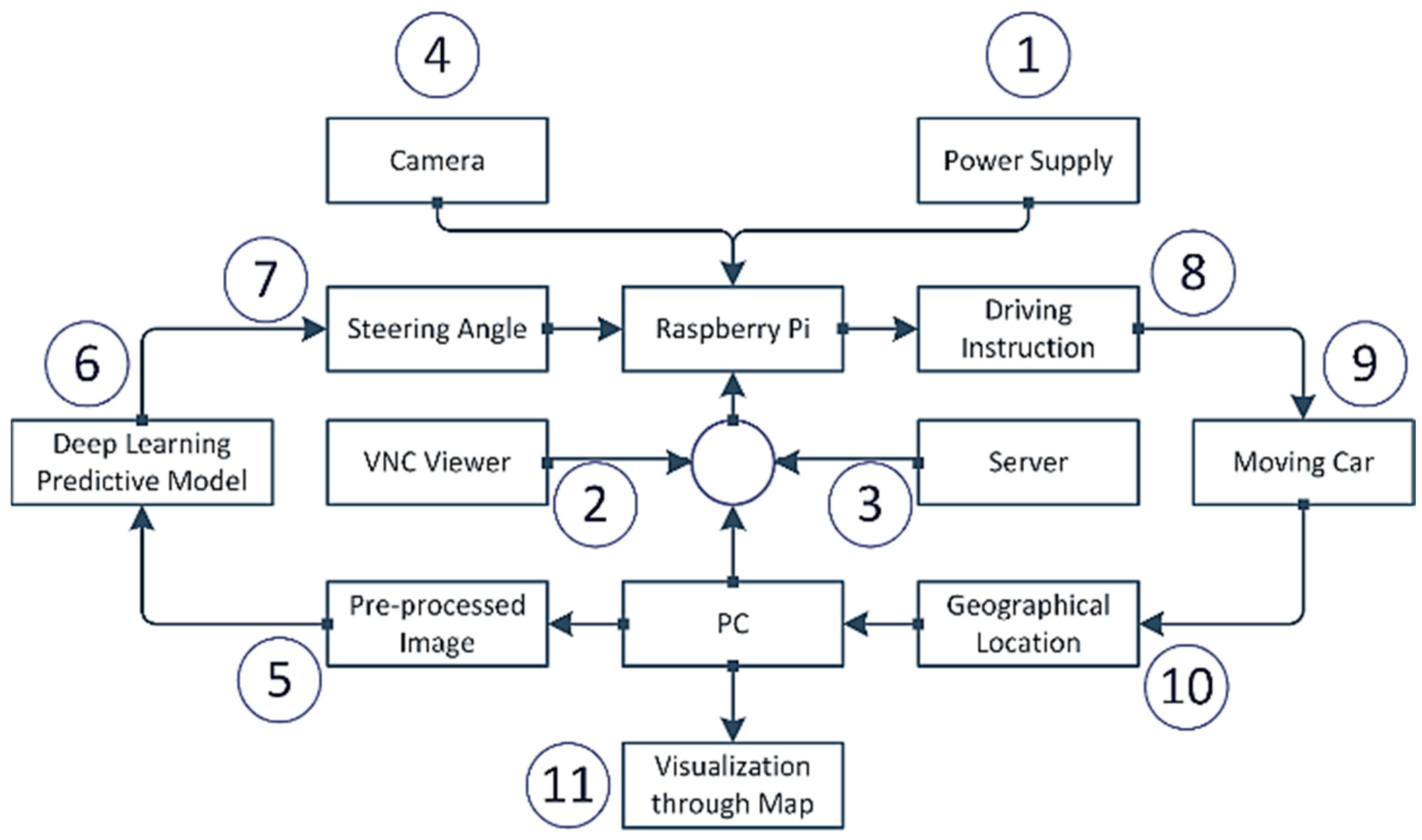
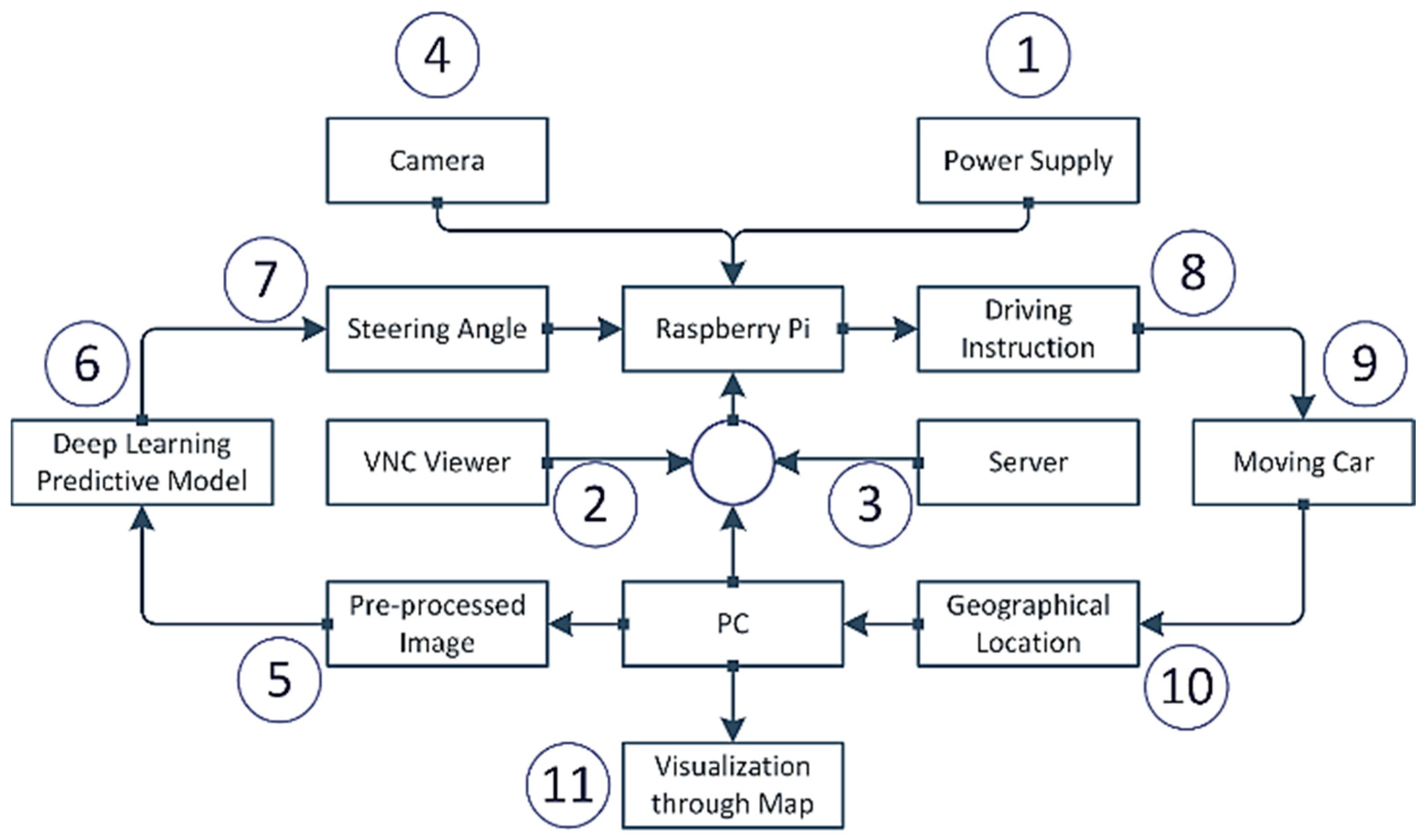
3. Methodology and Implementation
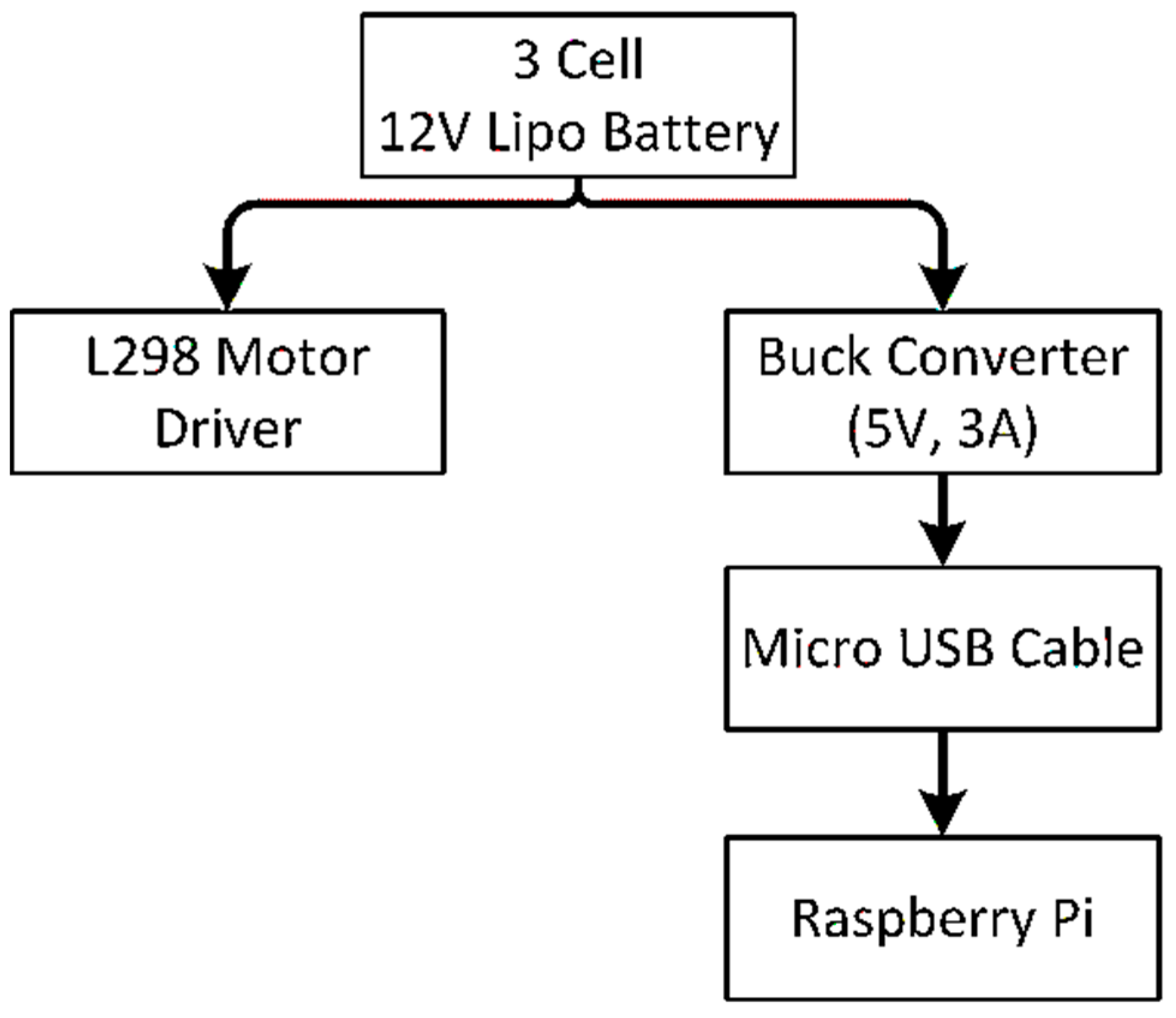
3.1. Functional Hardware Units of the System
- Raspberry Pi 3 Model B+
- NoIR Camera with Night Vision
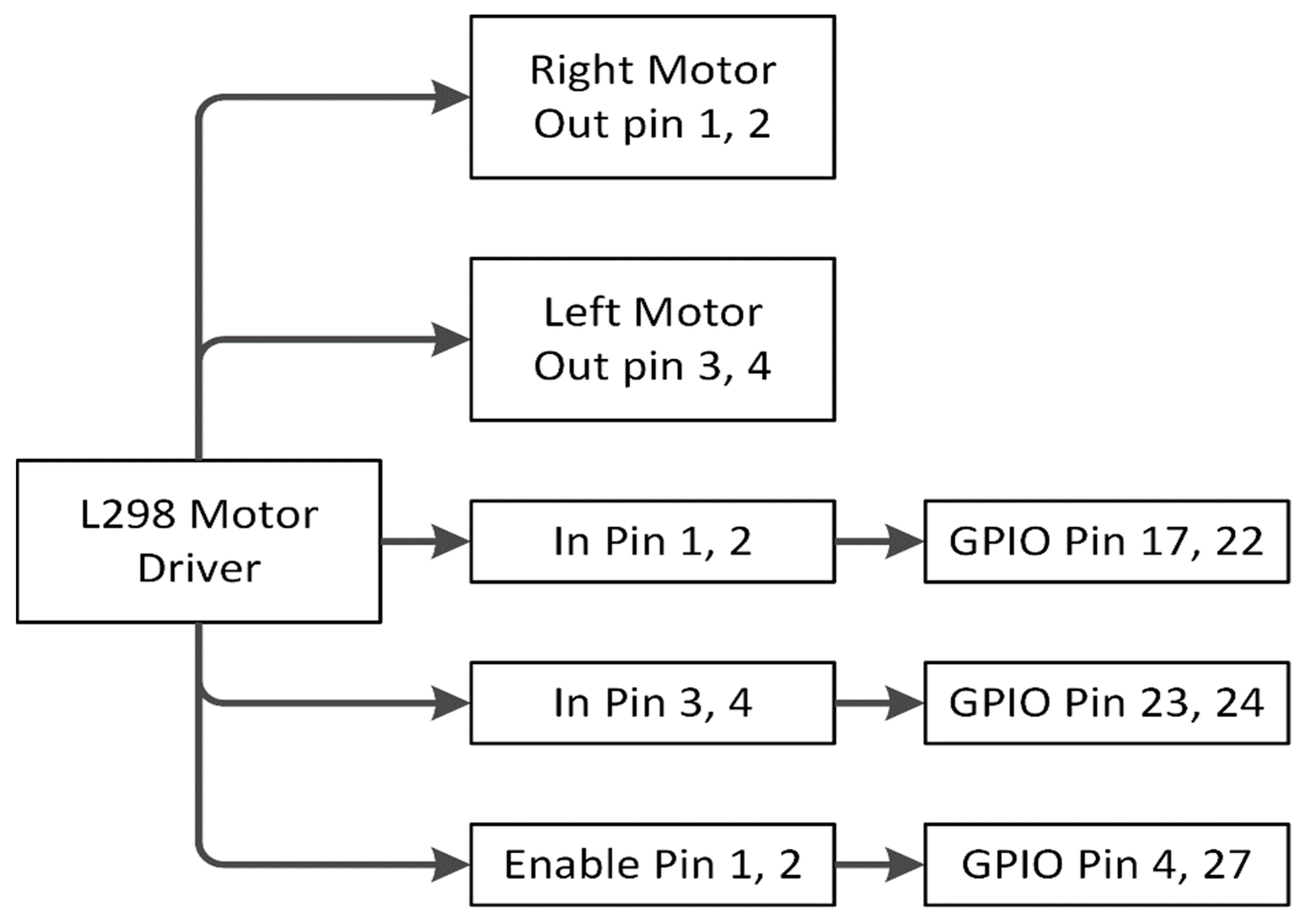
- Motor Driver IC (L298)
- Plastic Gear motor
- 3 cell Lipo Battery (12V)
- Buck Converter
- Acrylic Chassis Board
- Connecting wires
- Switch
3.2. Functional Software Tools of the System
- Python programming language: Python is a high-level, general-purpose programming language.
- Google Colab: Colaboratory (also known as Colab) is a free Jupyter notebook environment running in the cloud and storing on Google Drive notebooks.
- Numpy: NumPy is a library that supports multi-dimensional arrays and matrices.
- Pandas: Pandas is used for data manipulation and analysis.
- Matplotlib: Matplotlib is the Python programming language plotting library.
- Keras: Keras is an open-source neural-network library written in Python. It can run top of TensorFlow, R, Theano or PlaidML, to allow quick experimentation with deep neural networks [61].
- Tensorflow: TensorFlow is an open and free software library for data flow used for machine learning applications like neural networks.
- Imgaug: A library for image augmentation in machine learning experiments, particularly CNN (Convolutional Neural Networks).
- OpenCV: OpenCV-Python is OpenCV’s Python API. It integrates OpenCV C++ API’s best qualities with Python language.
- Scikit-learn: It is a free machine learning library for the Python programming language.
- VNC viewer: VNC Viewer transforms a mobile into a virtual desktop, giving one immediate access from anywhere in the world to one’s Mac, Windows and Linux computers.
- Sublime Text 3: Sublime Text is an advanced script, markup and prose text editor.
- Geoip2
- Folium
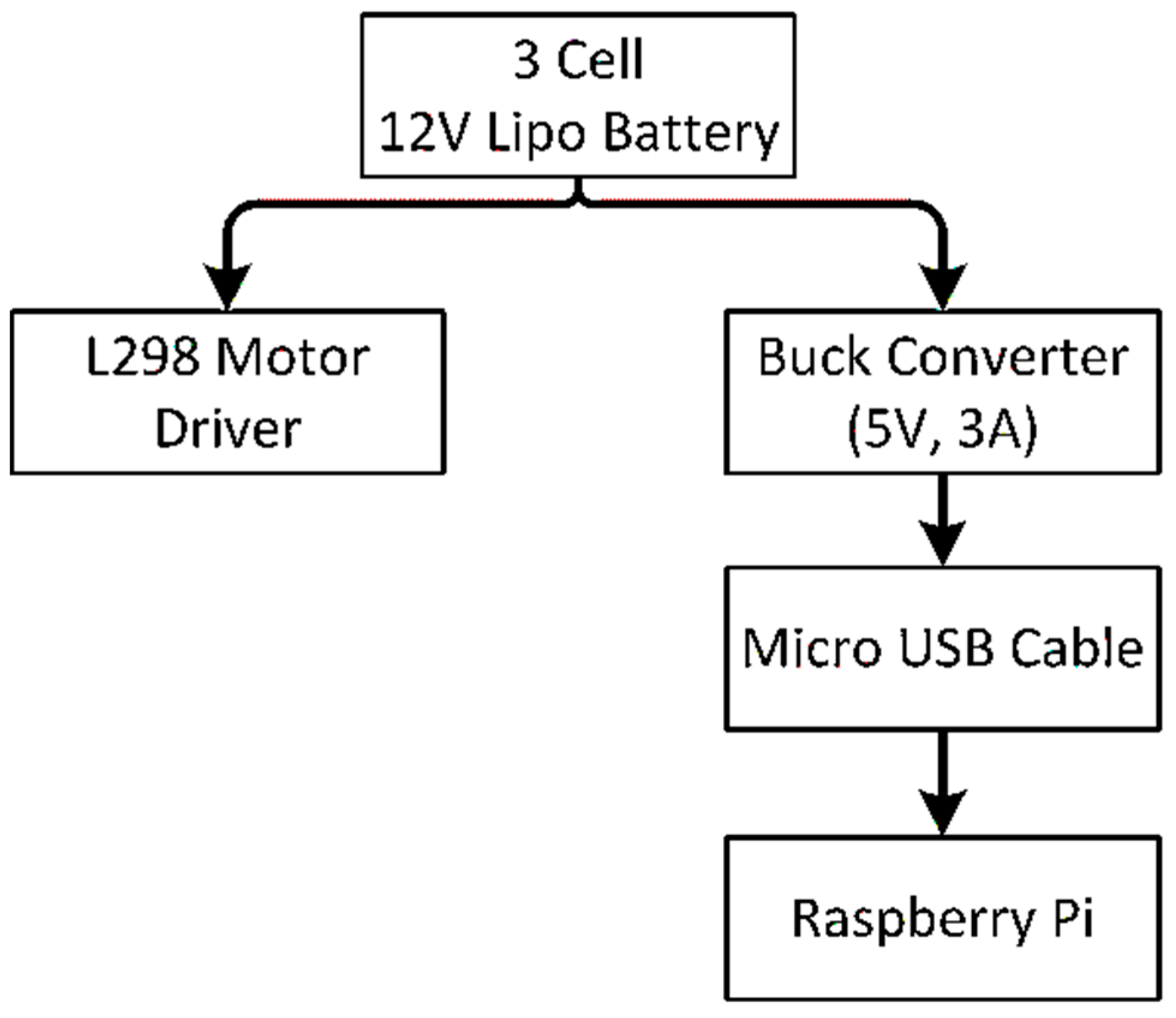
3.3. Power Supply Strategy
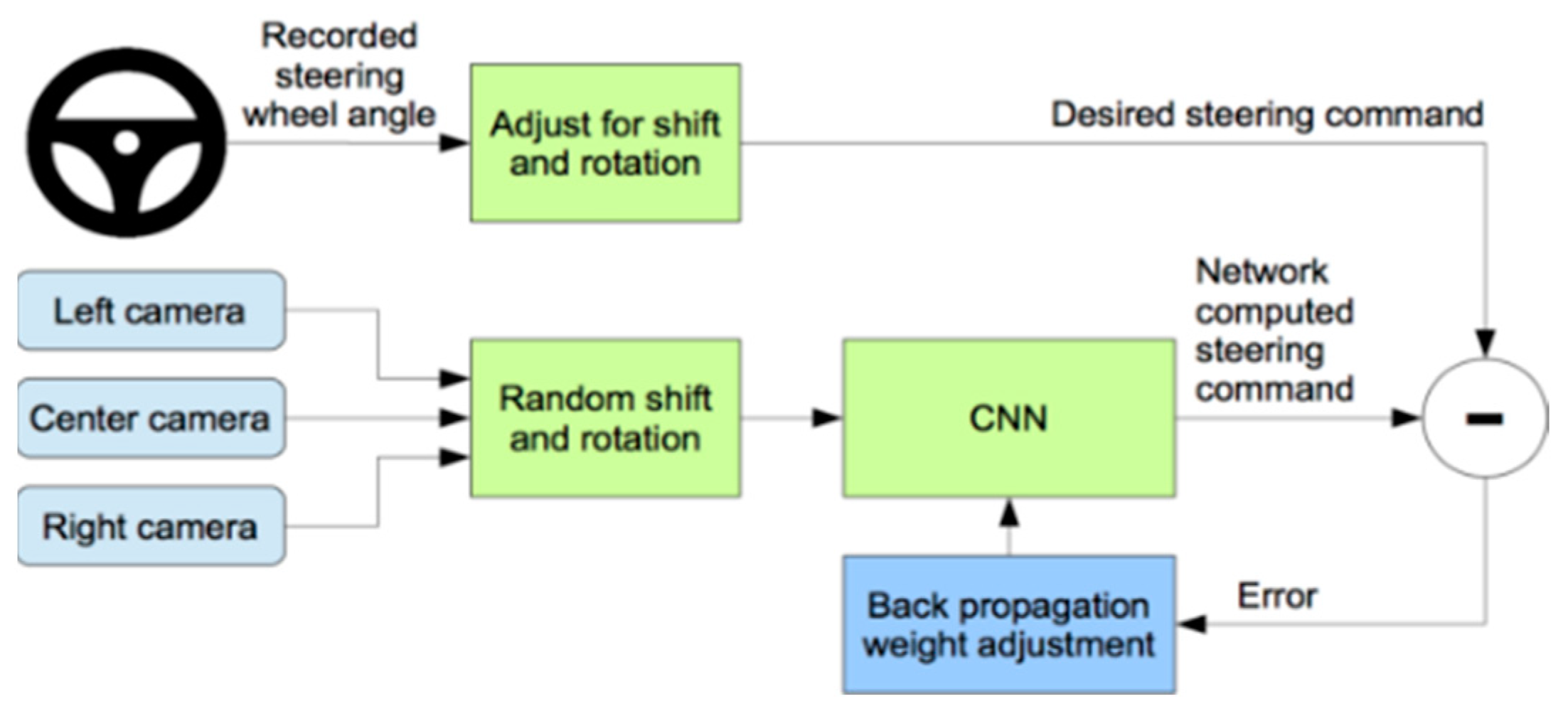
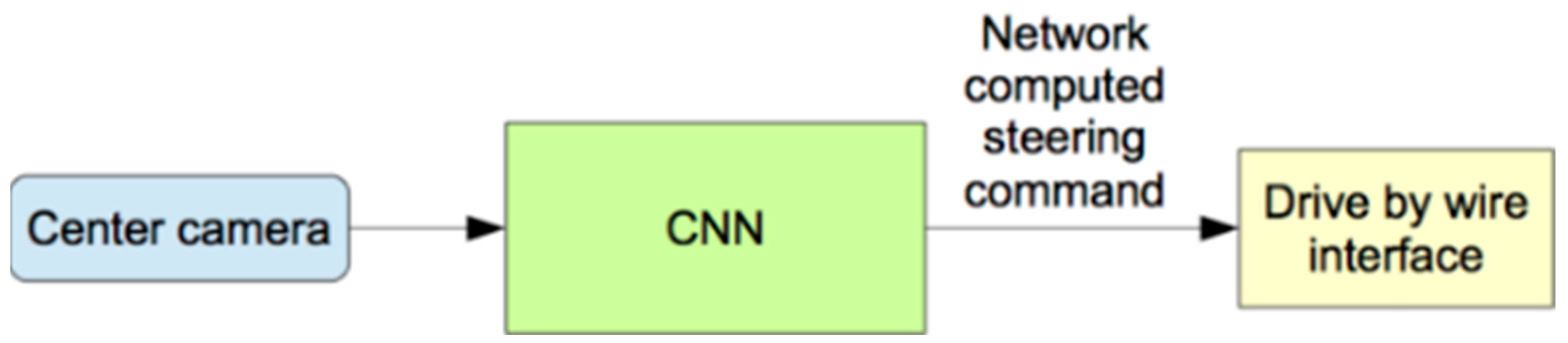
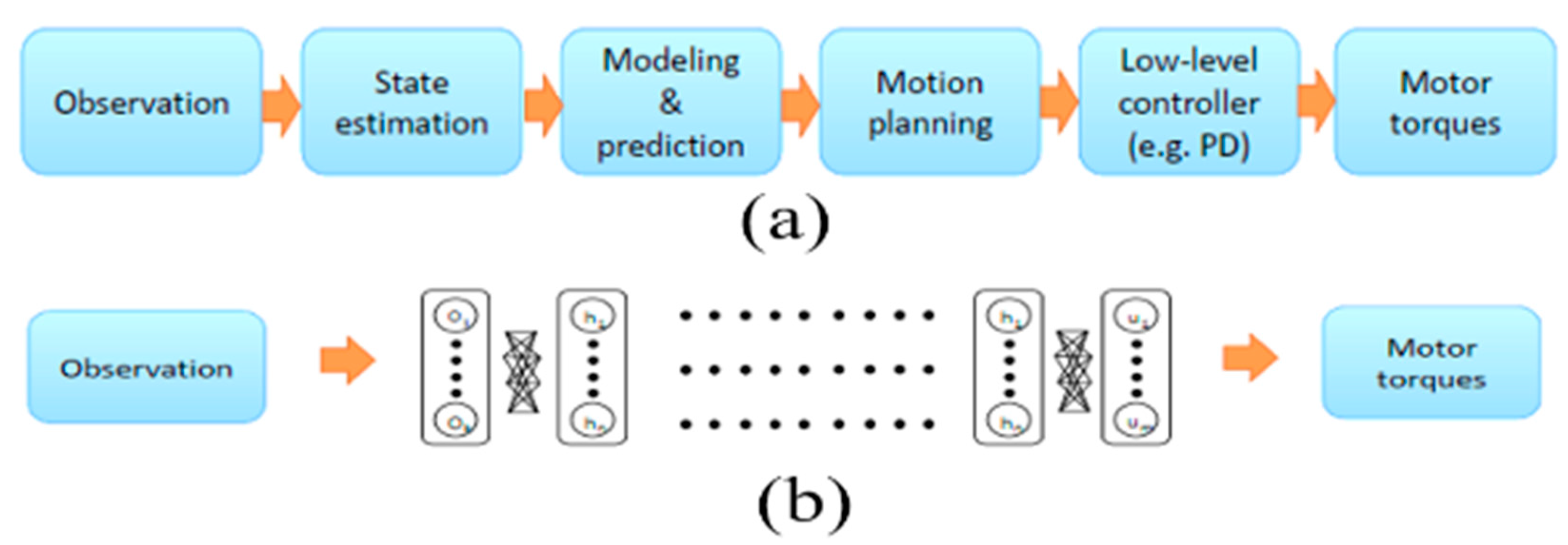
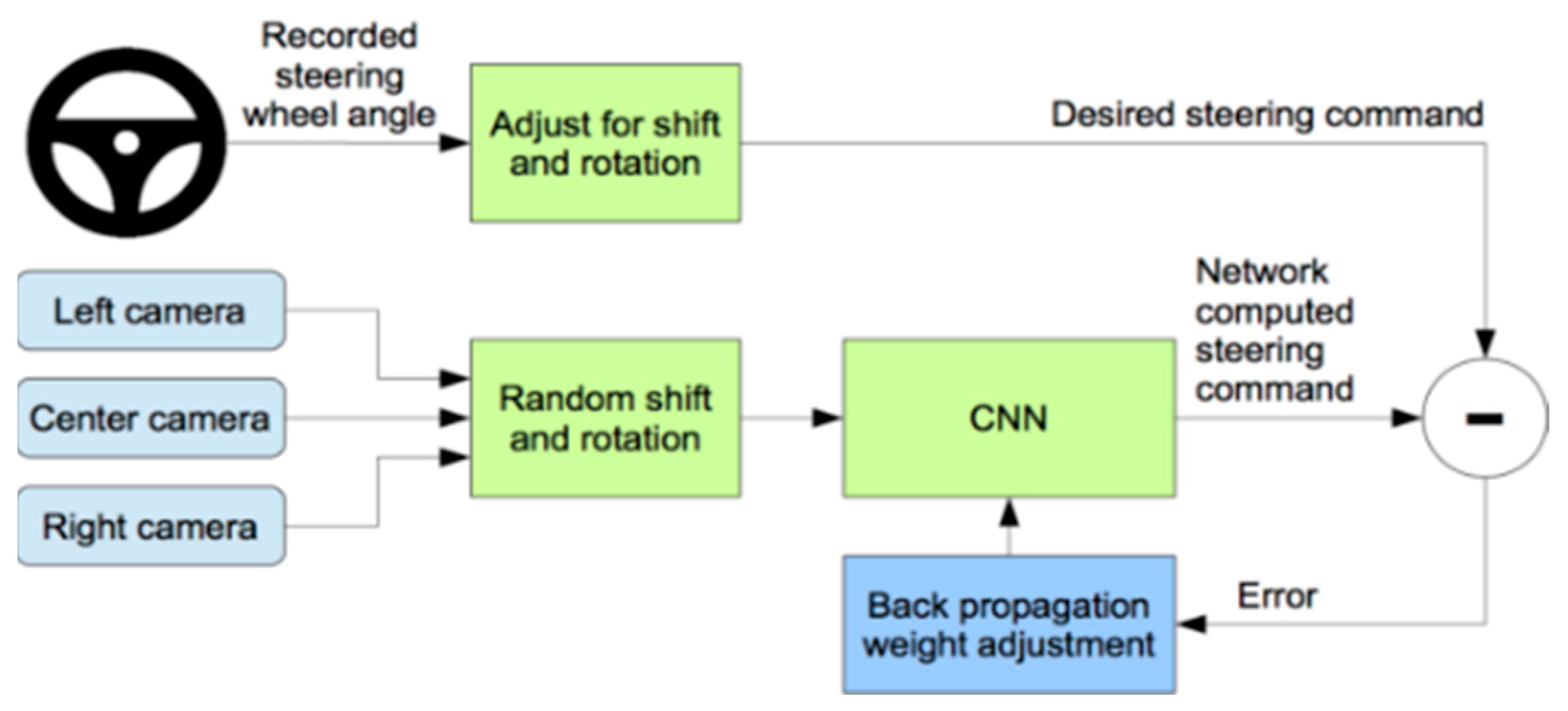
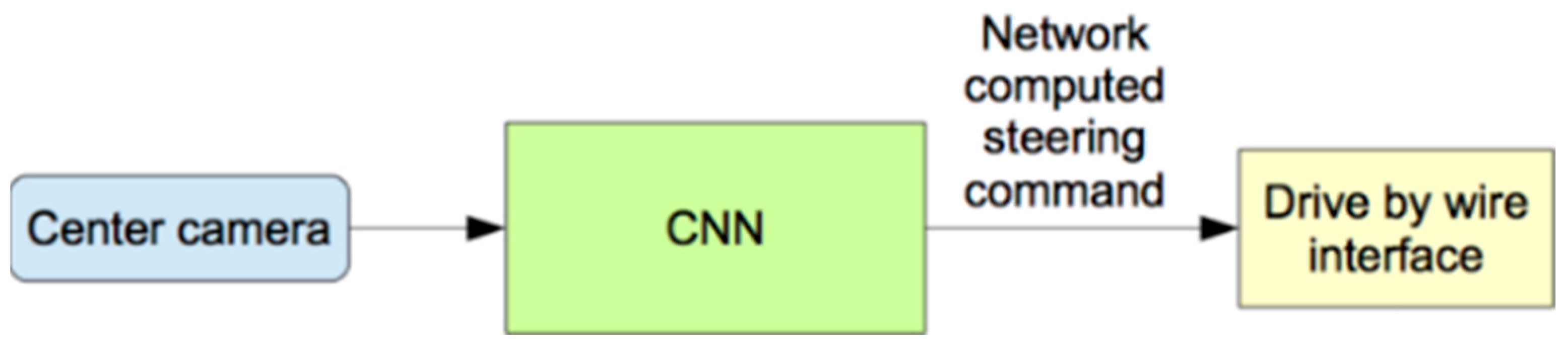
3.4. Deep Learning Predictive Model
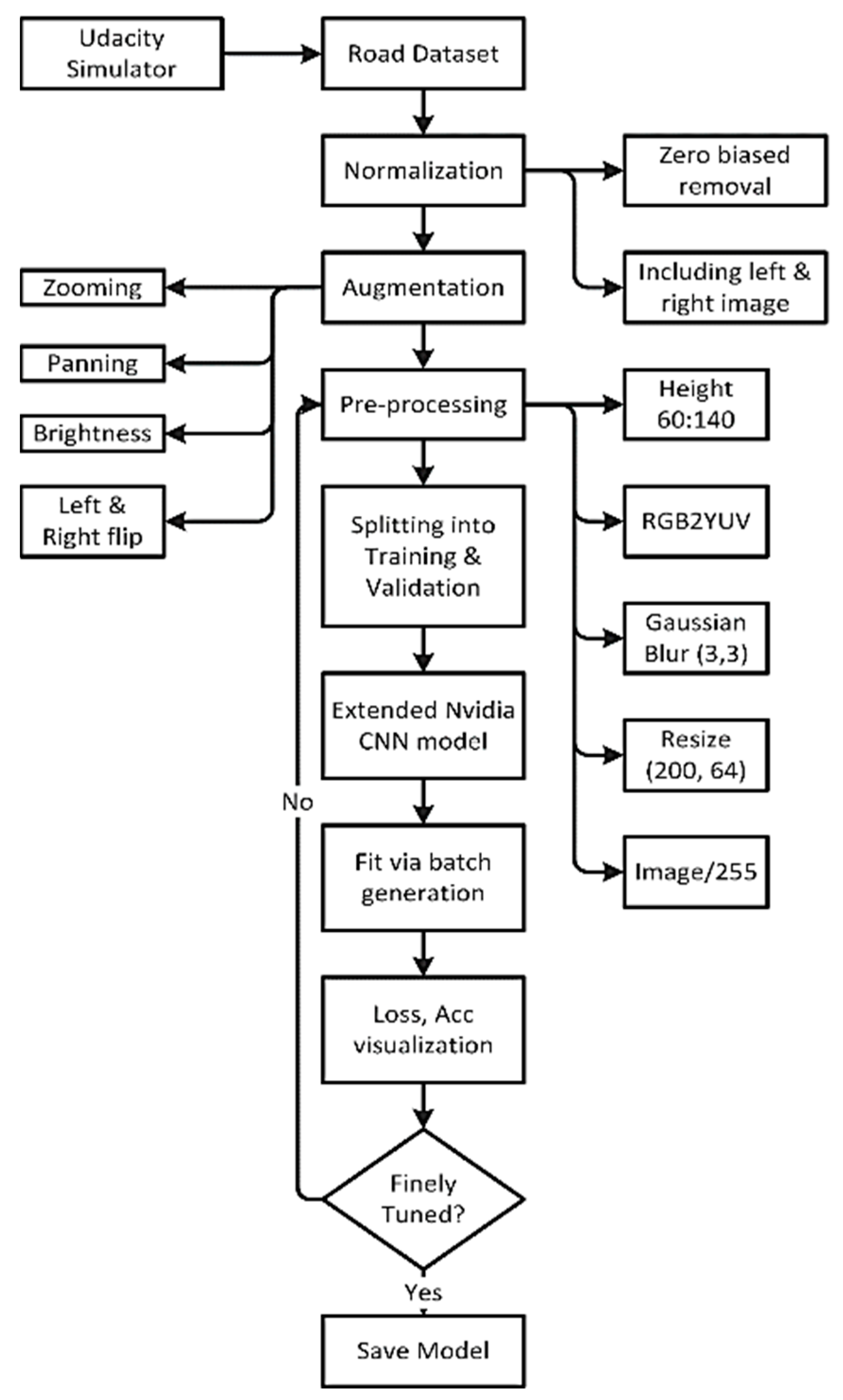
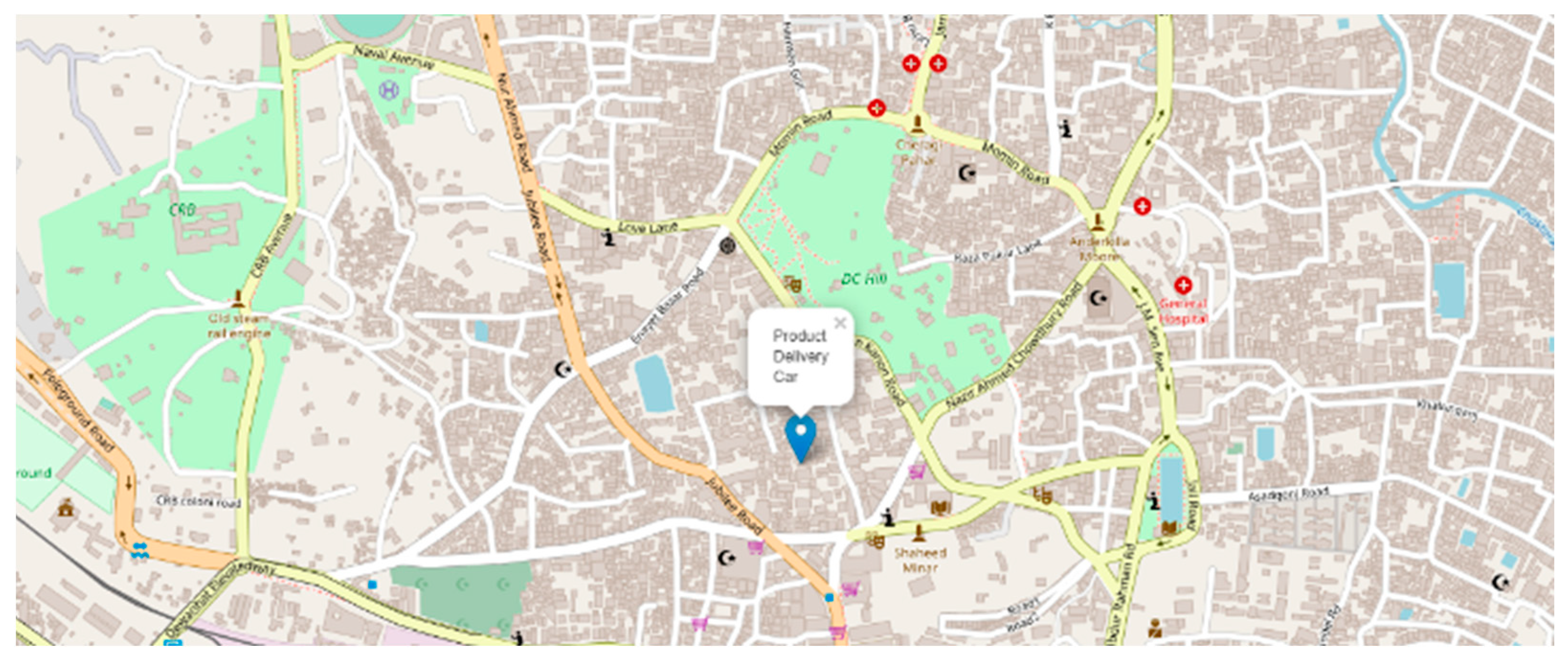
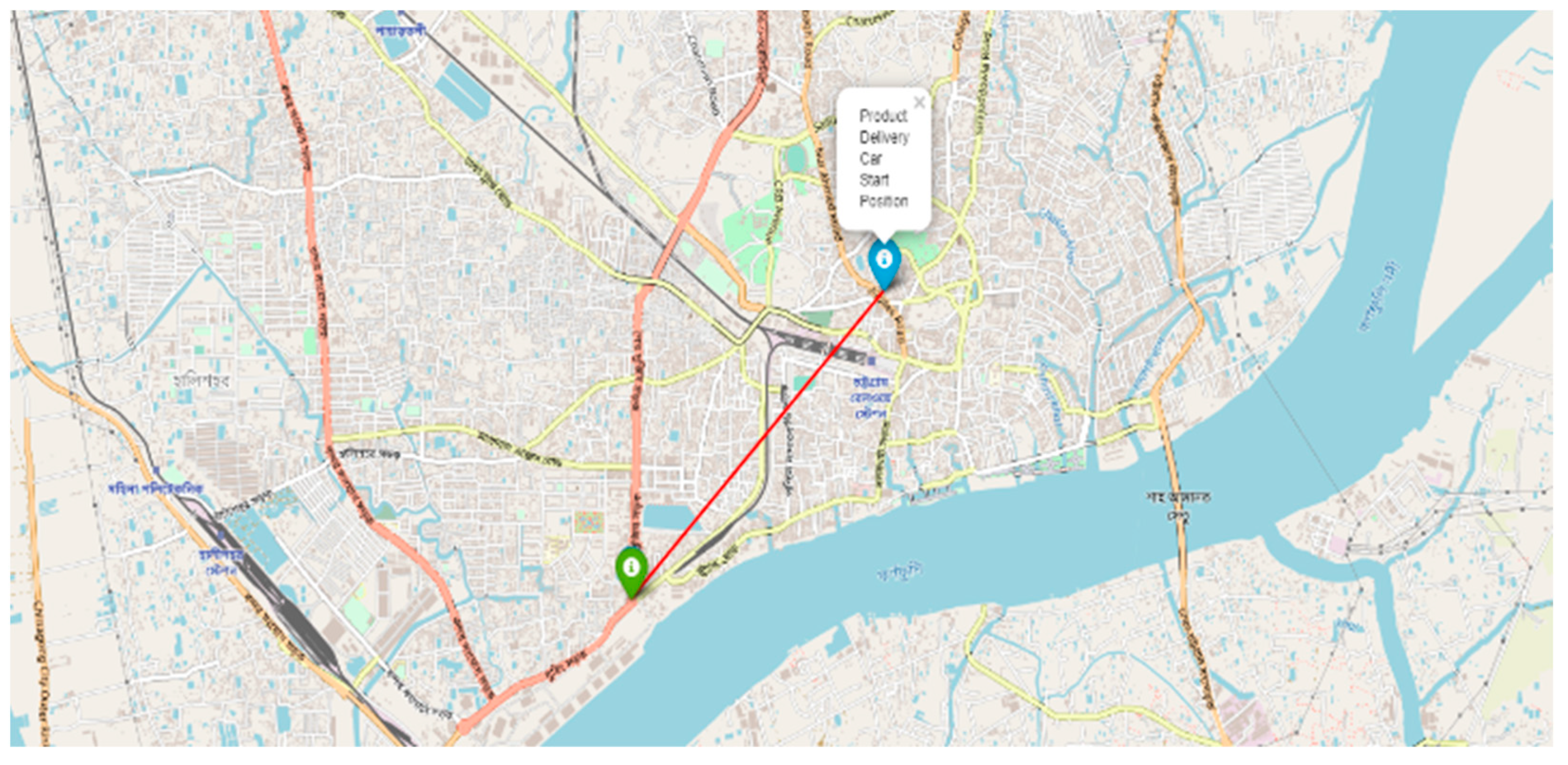
3.5. Dataset Collection
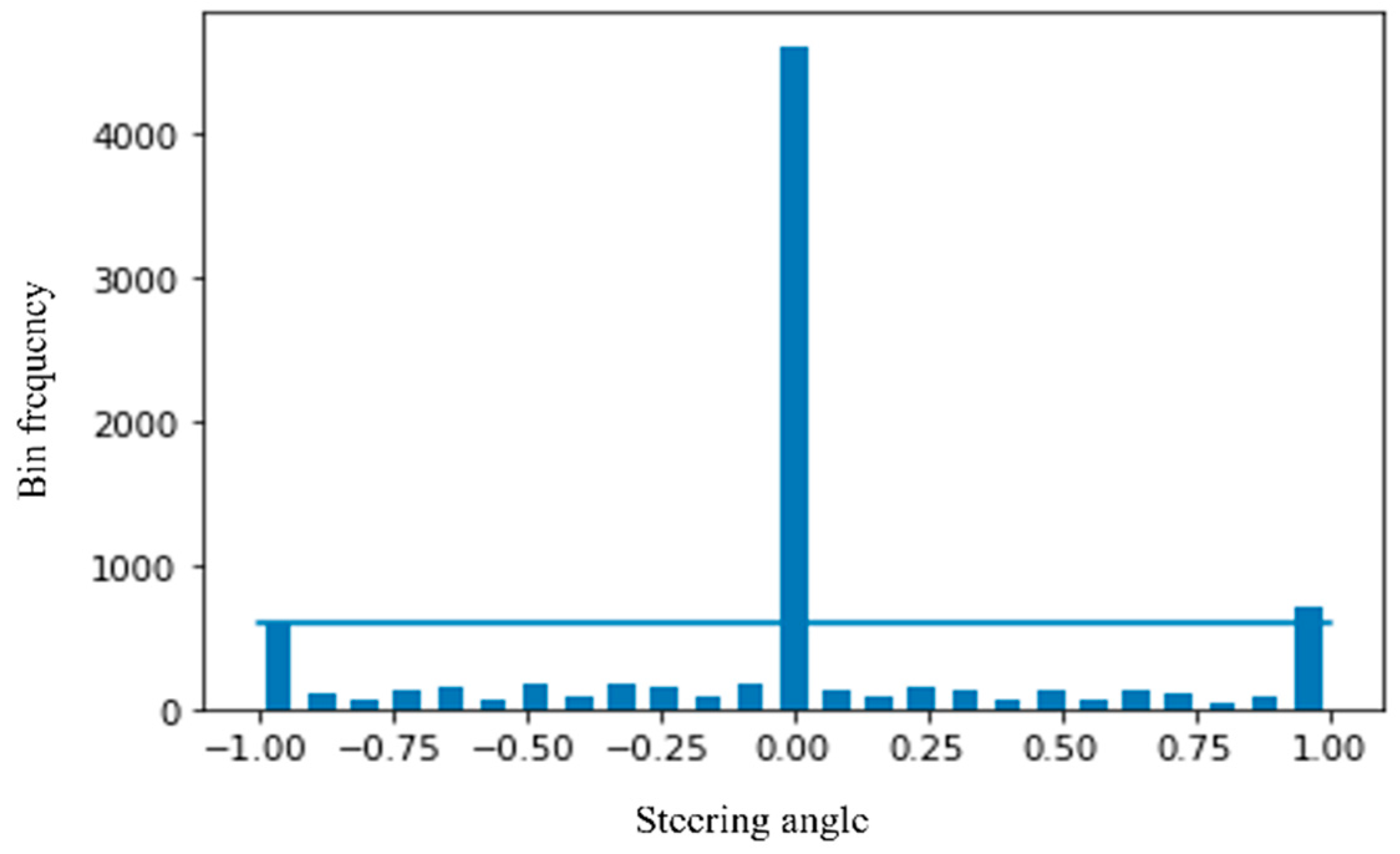
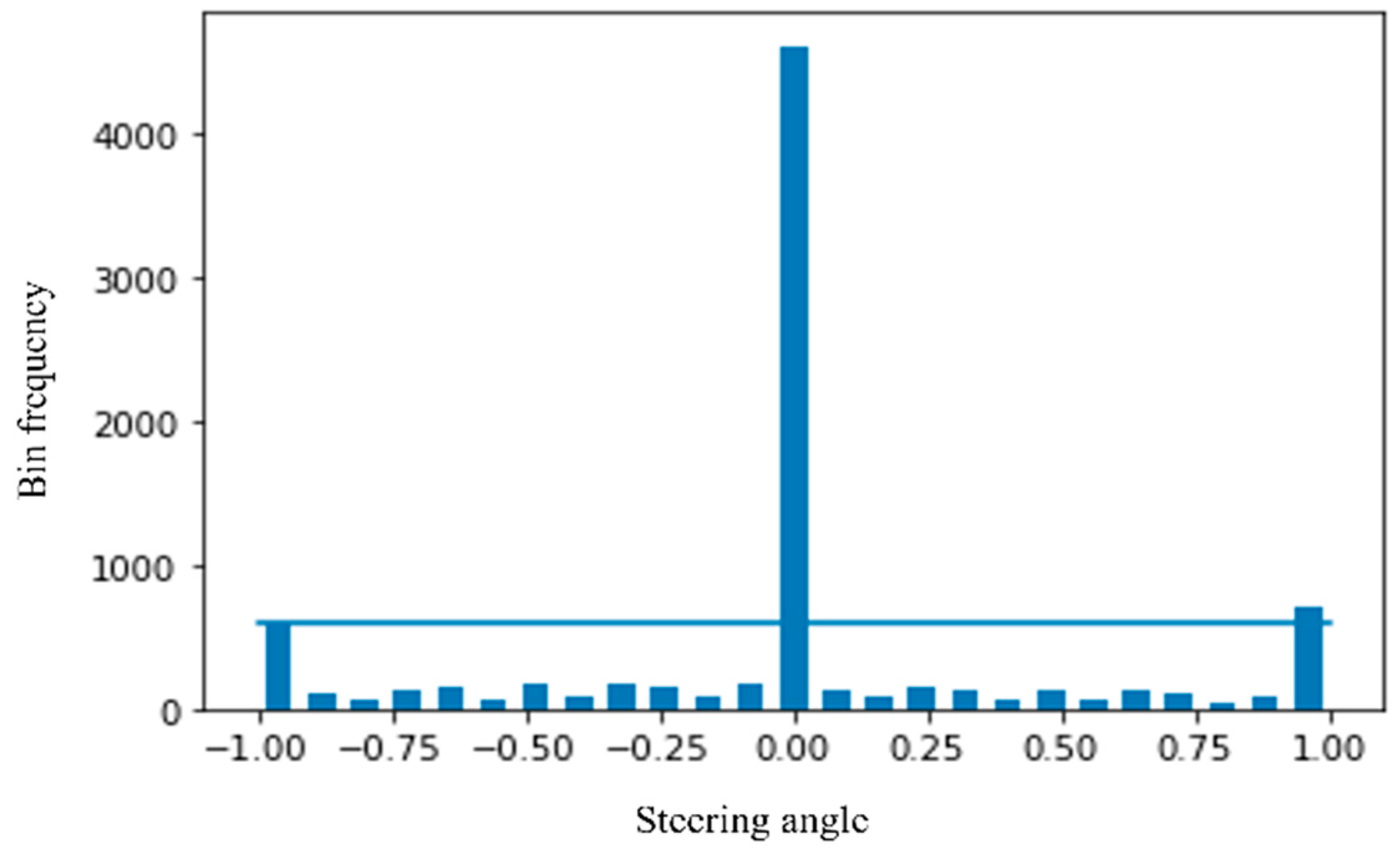
3.6. Normalization
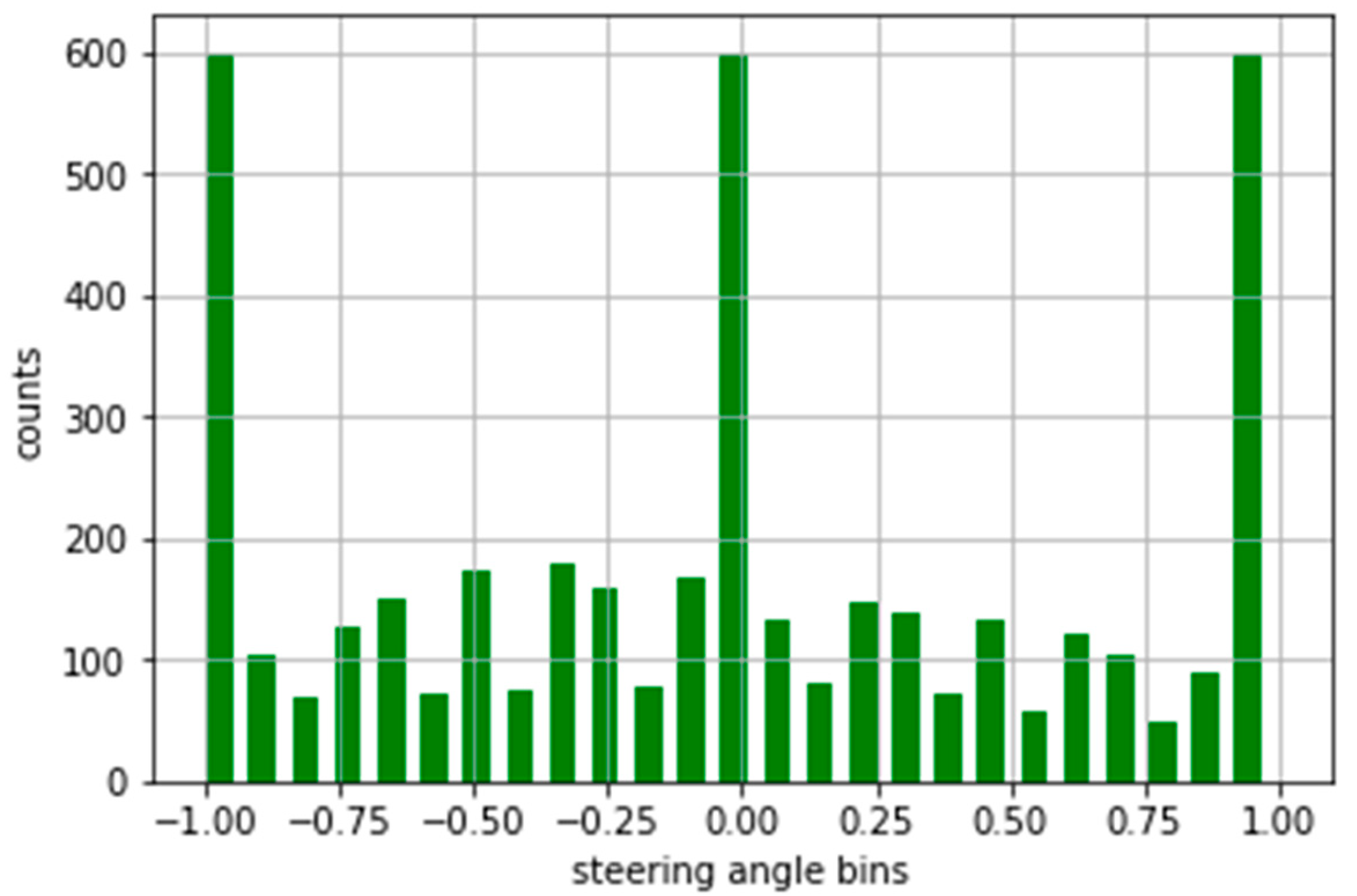
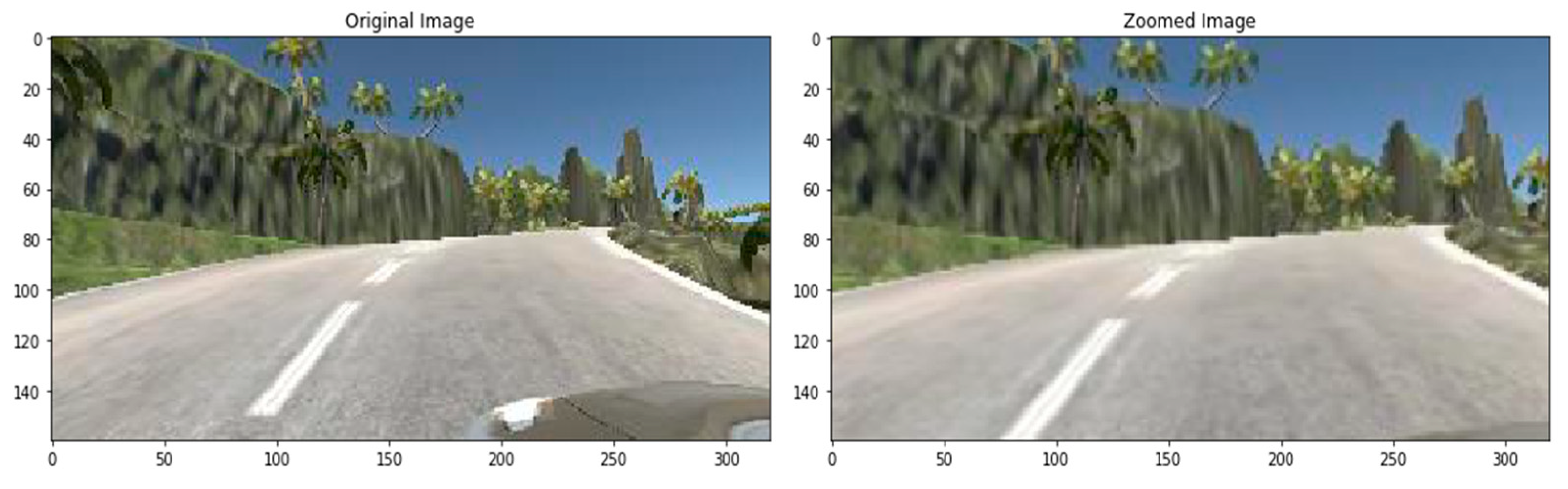
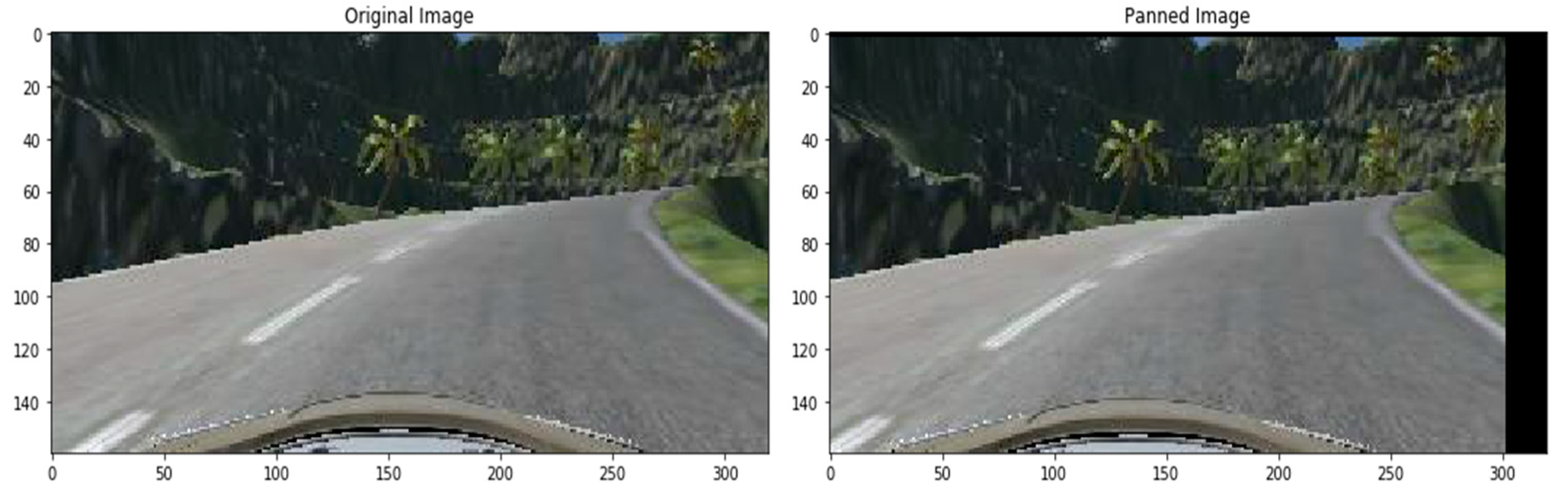
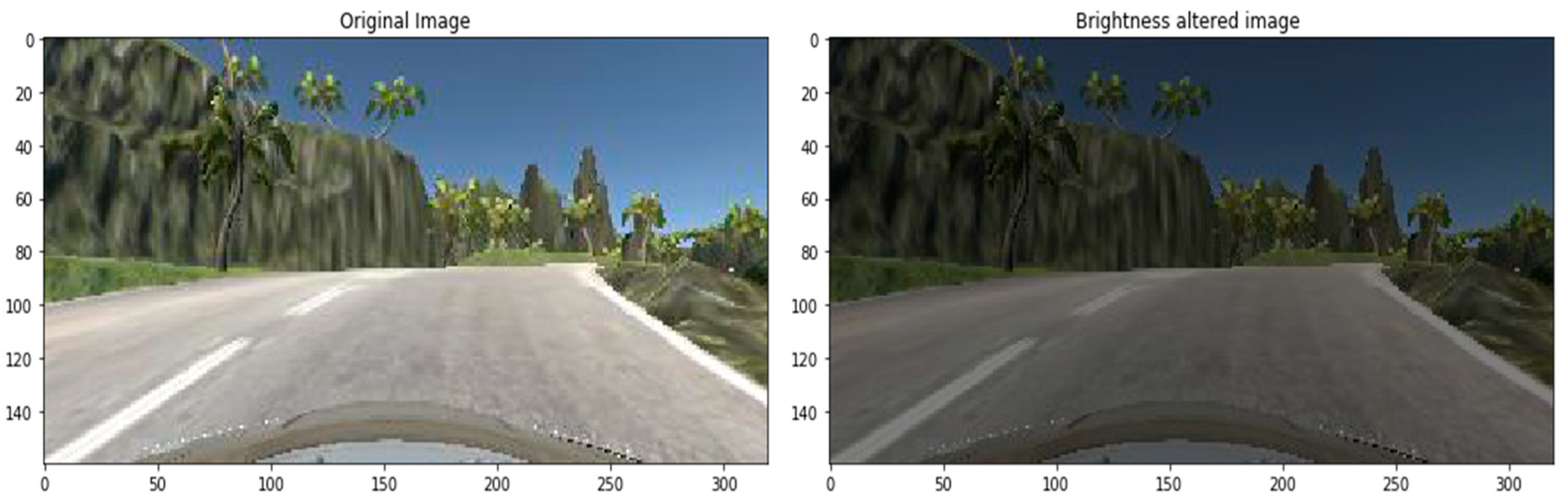
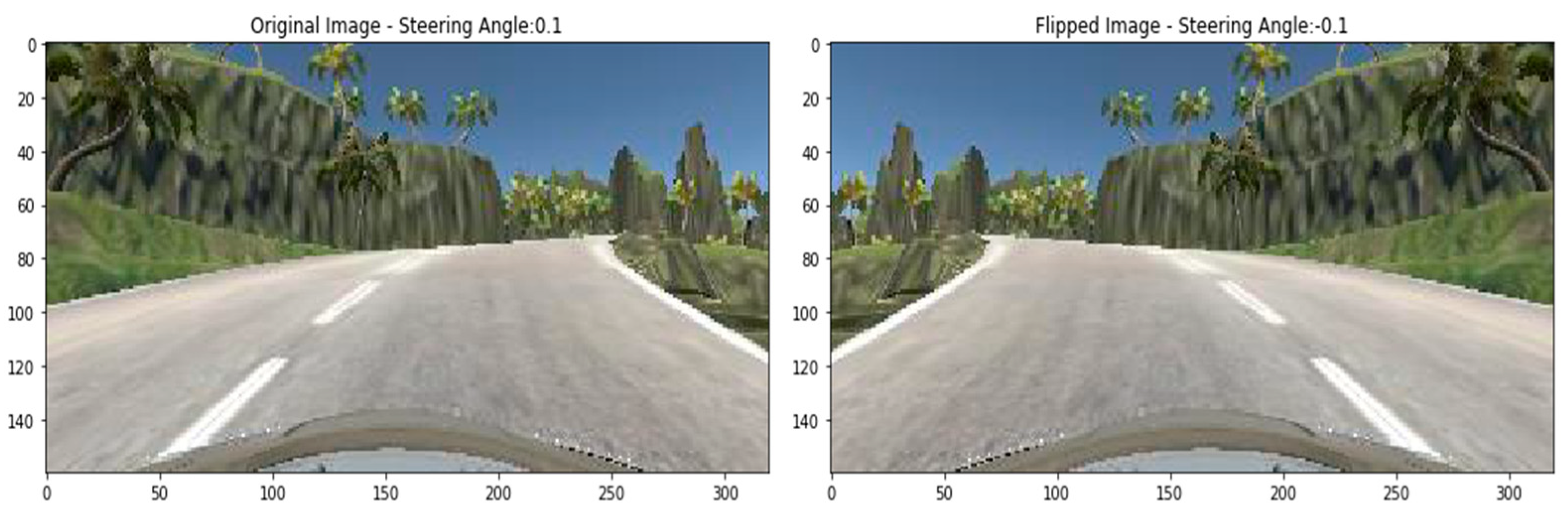
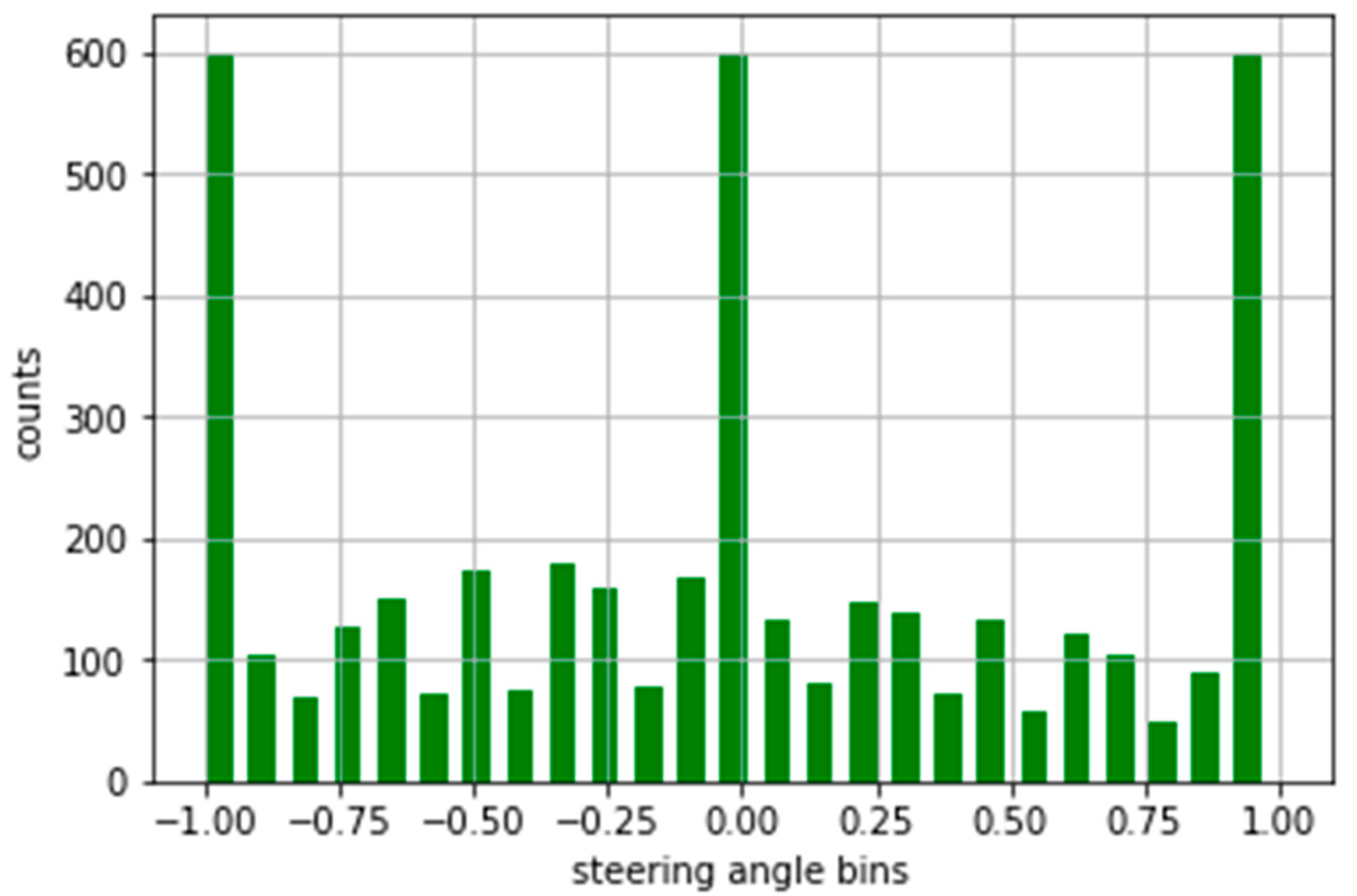
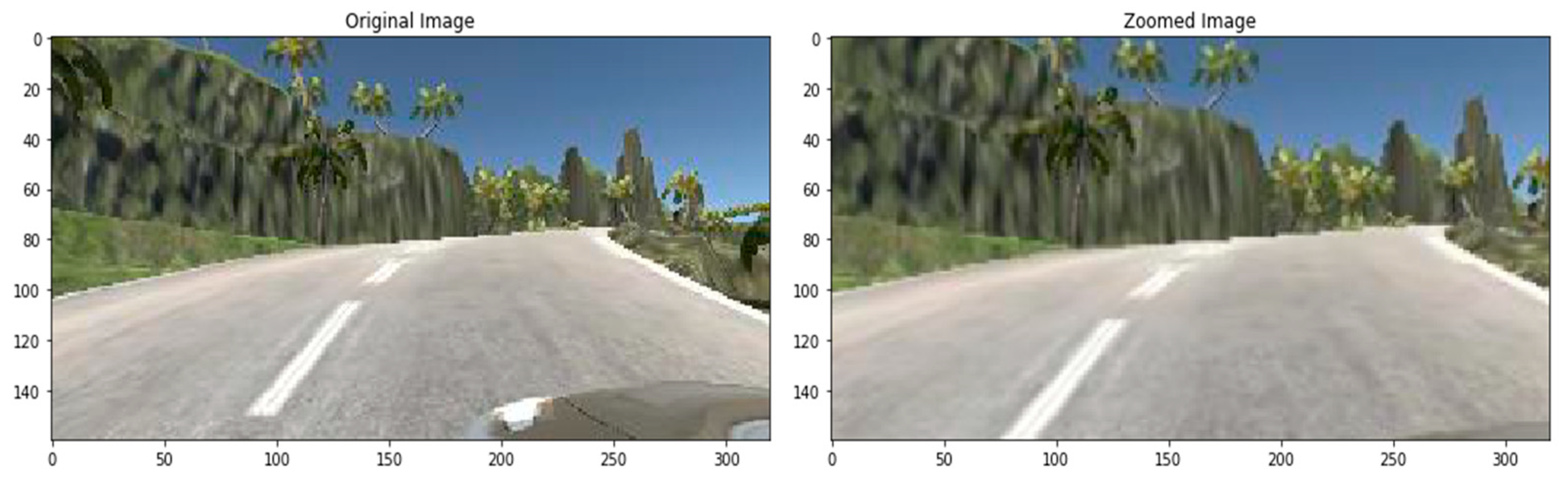
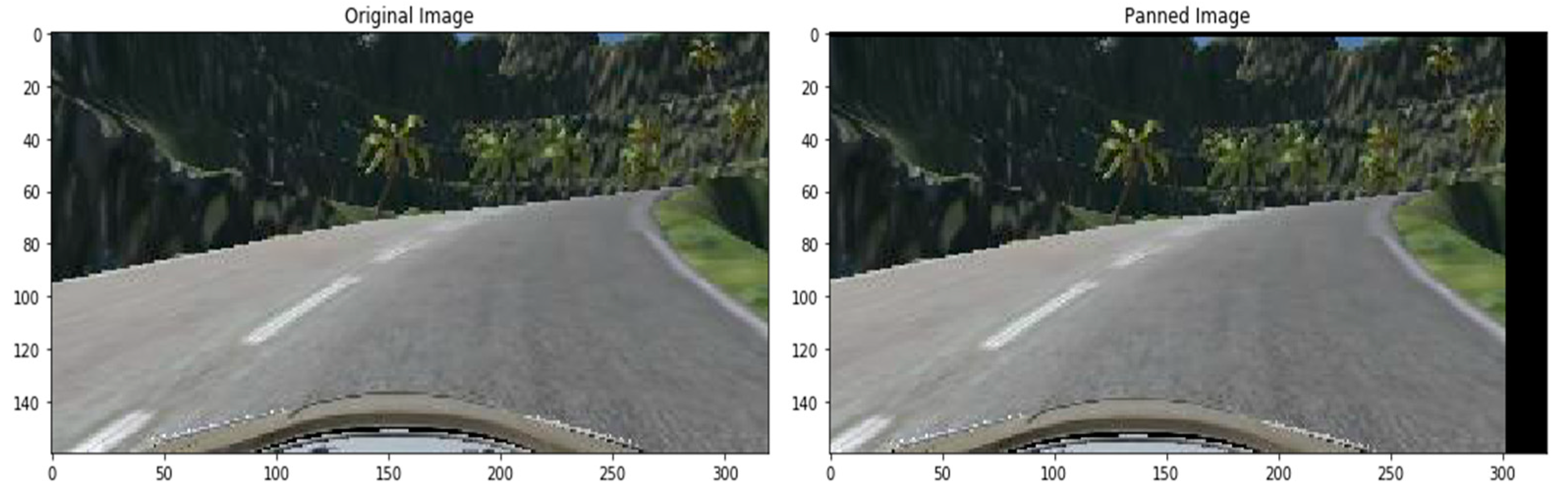
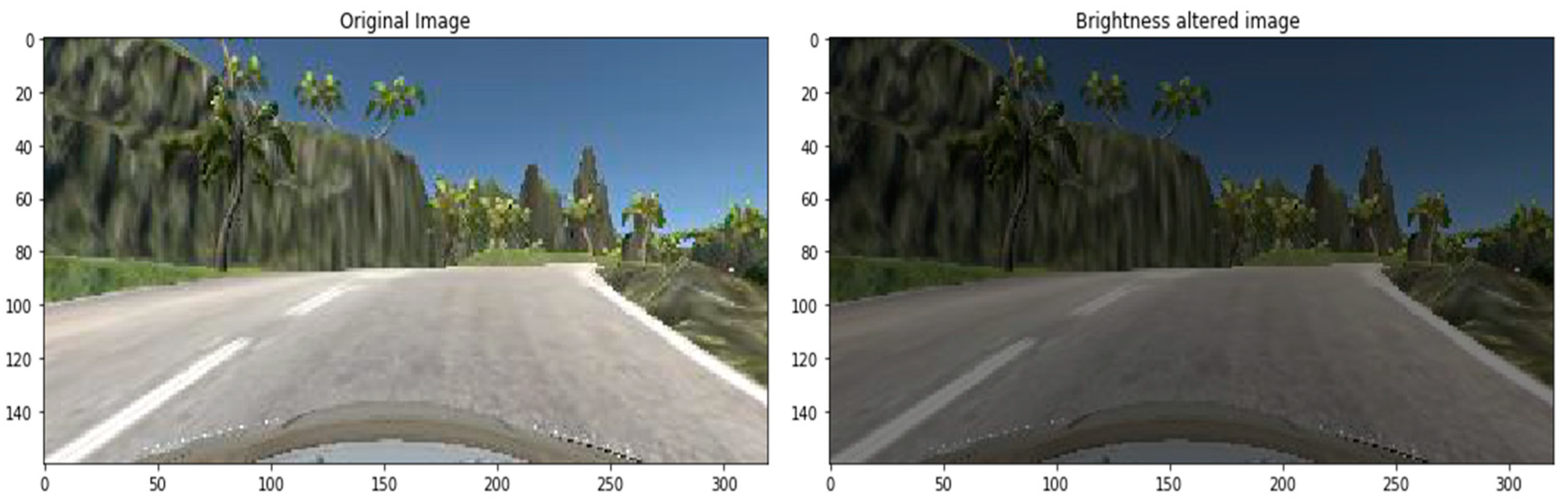
3.7. Augmentation
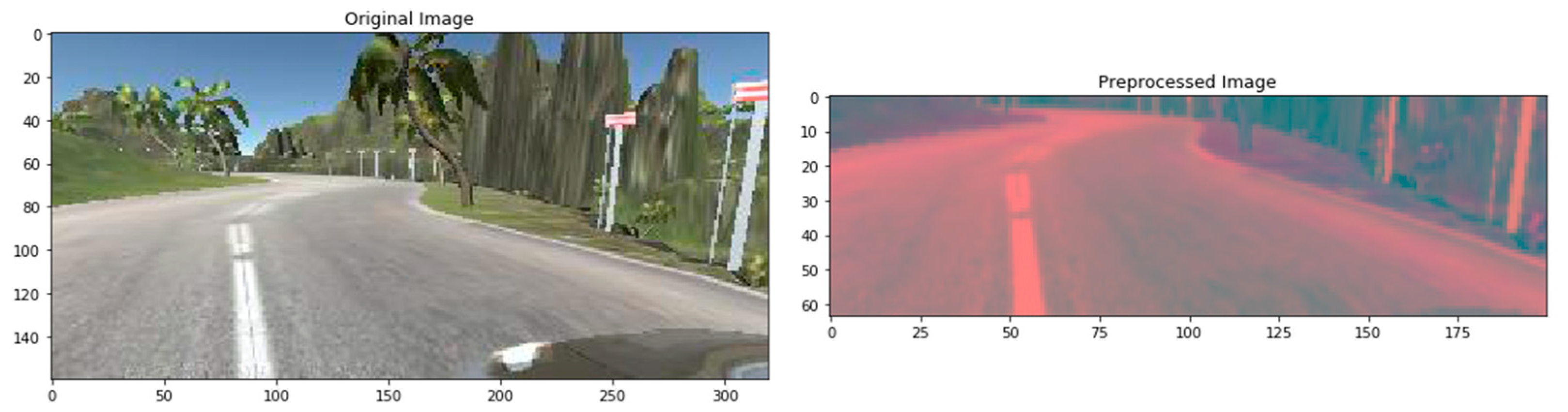
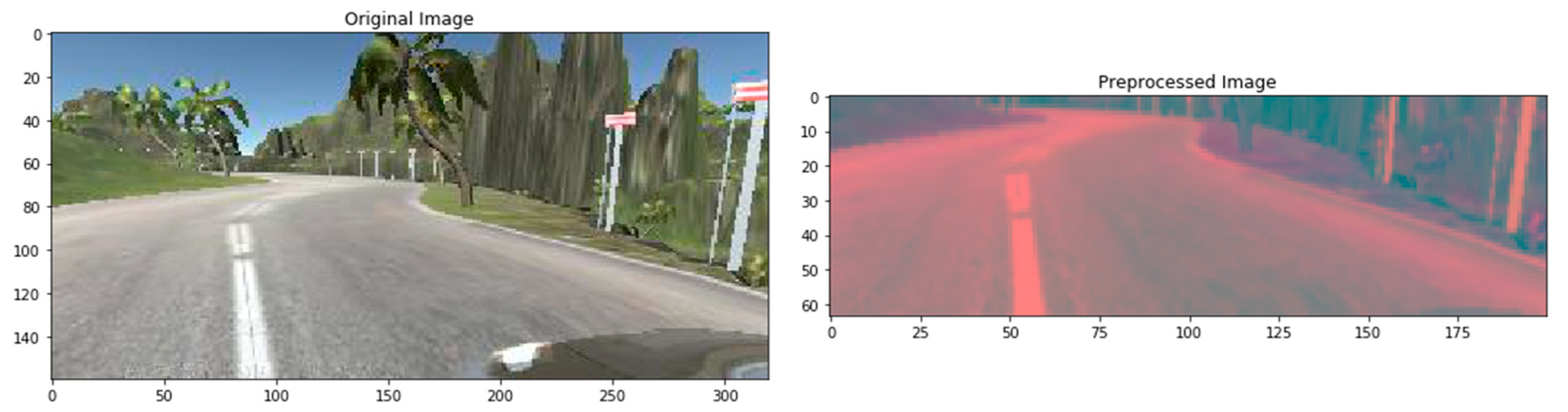
3.8. Pre-Processing of the Dataset
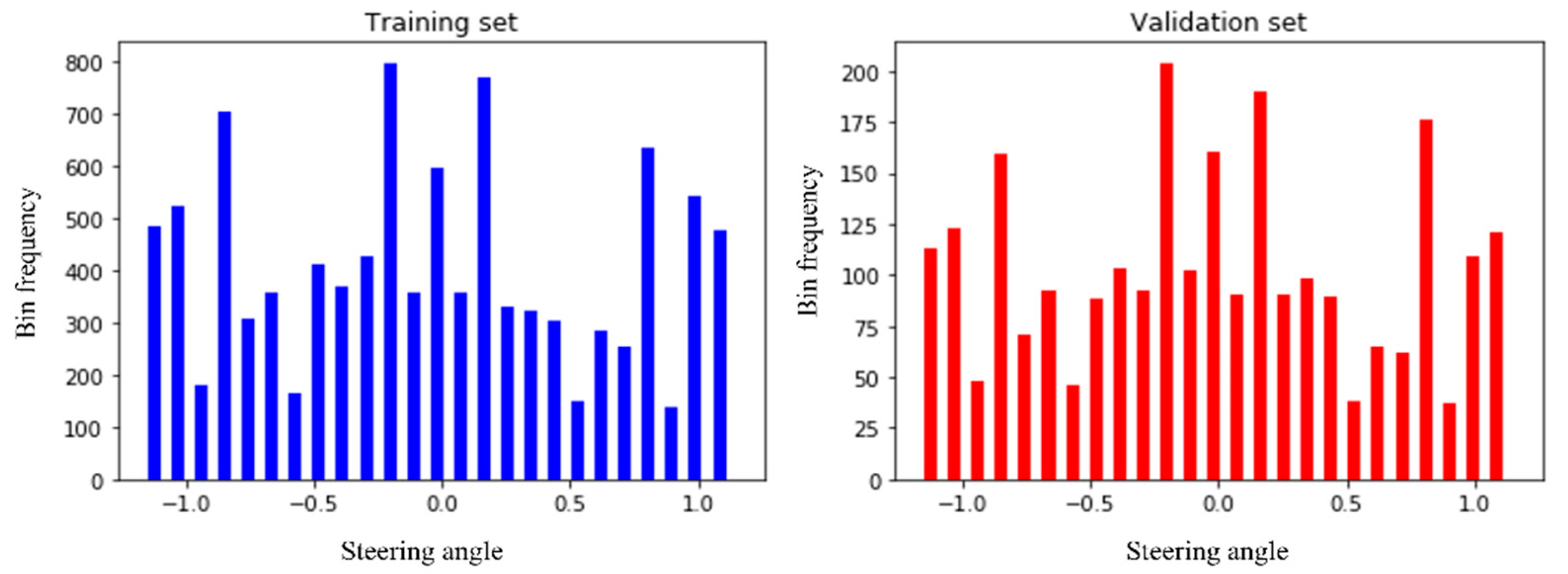
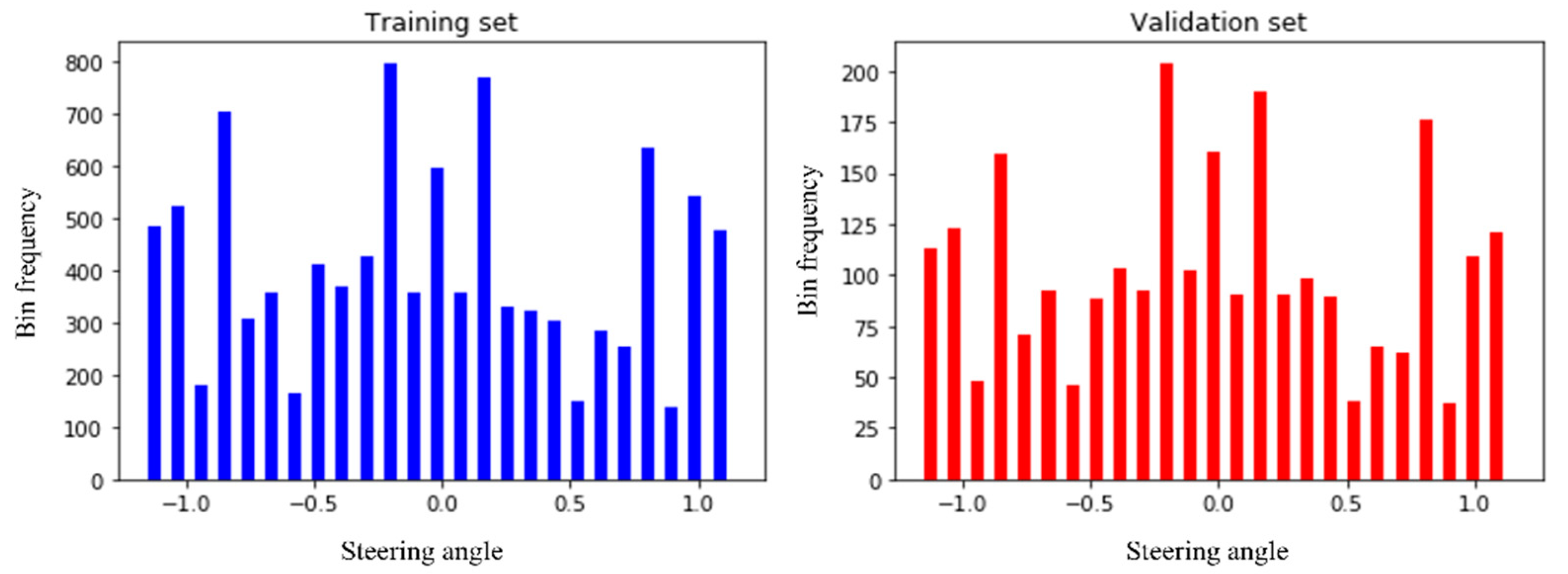
3.9. Splitting of the Dataset
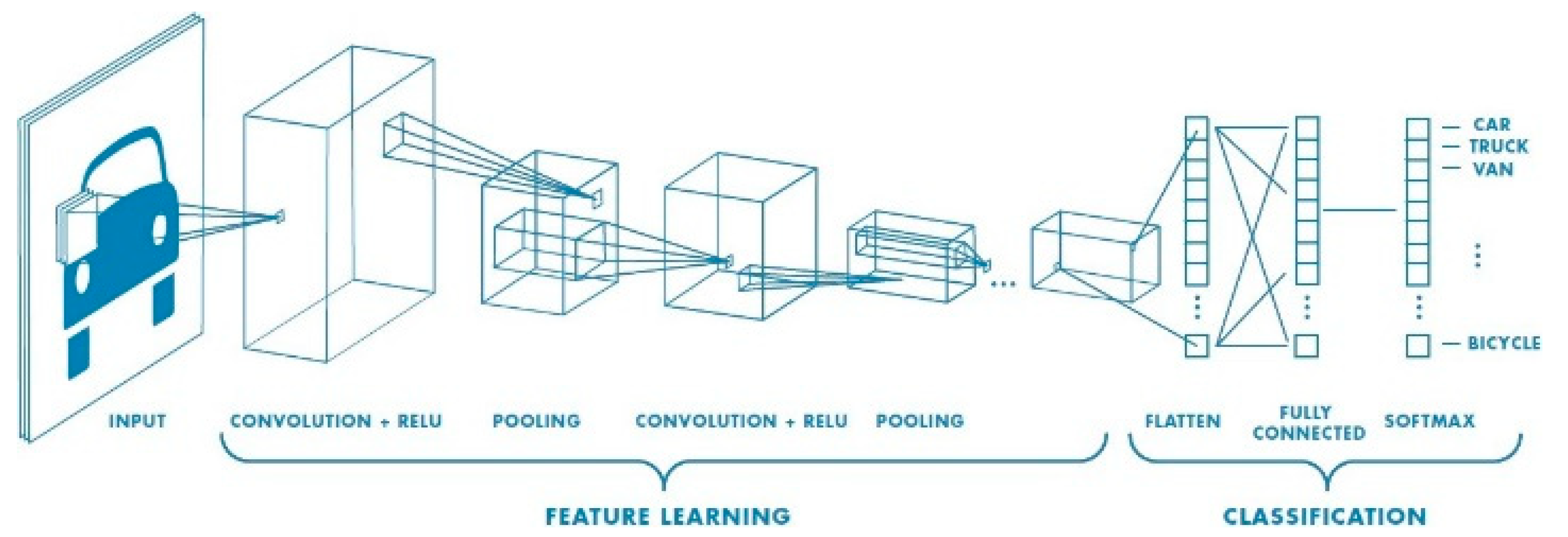
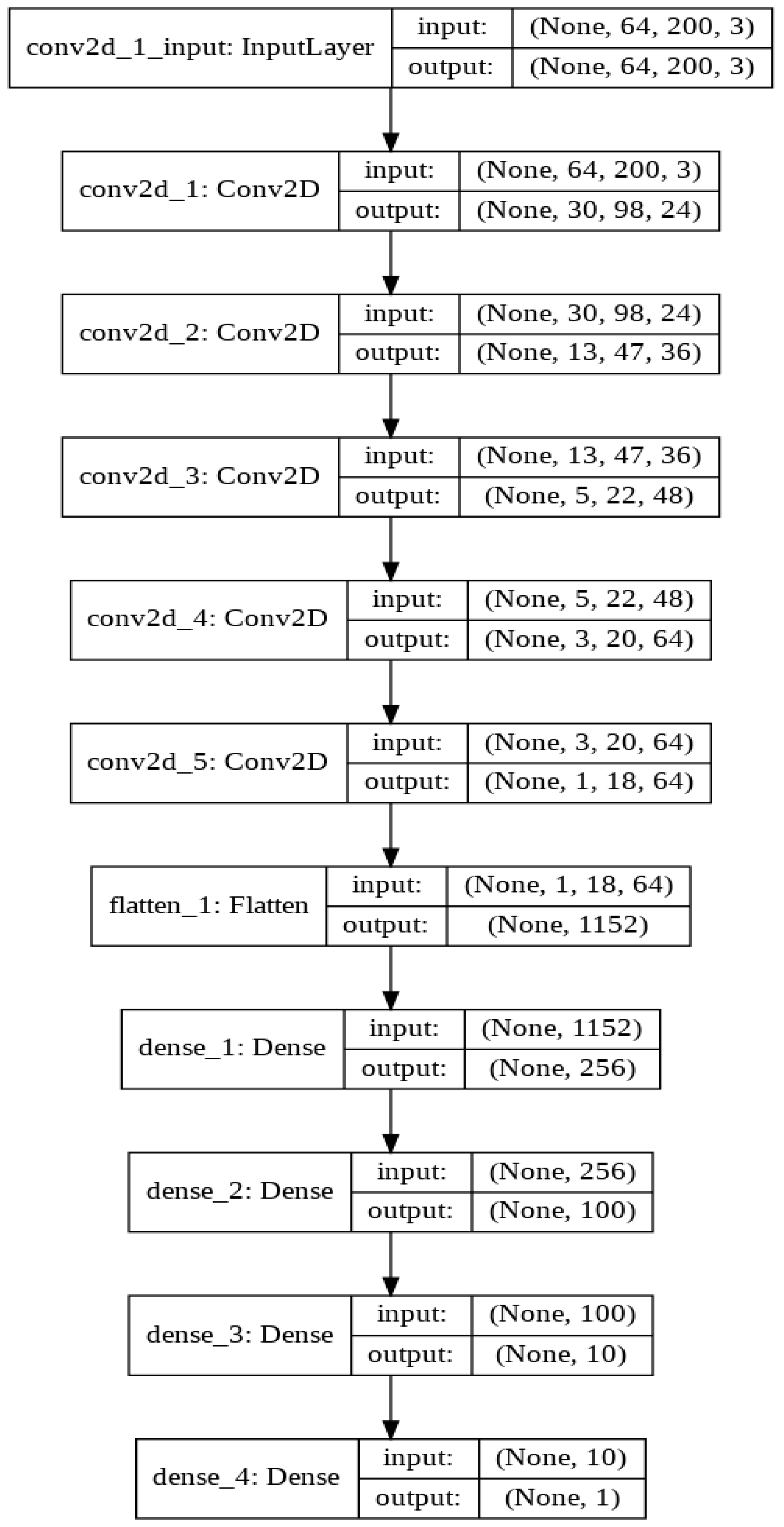
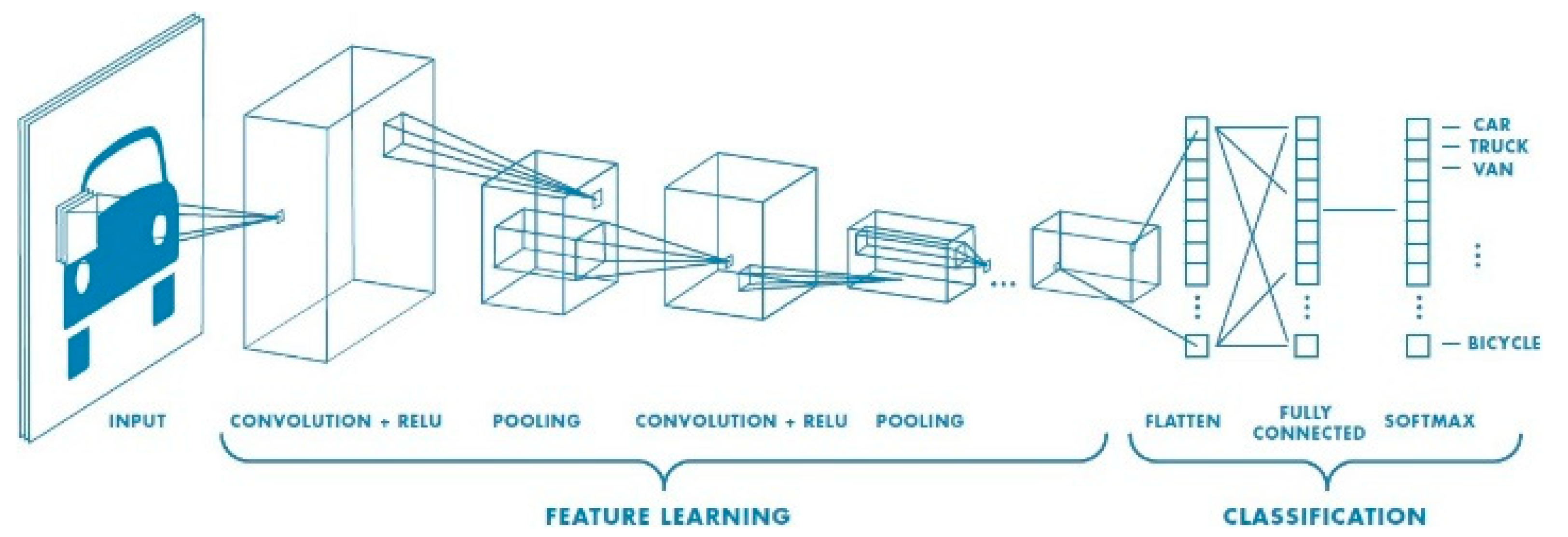
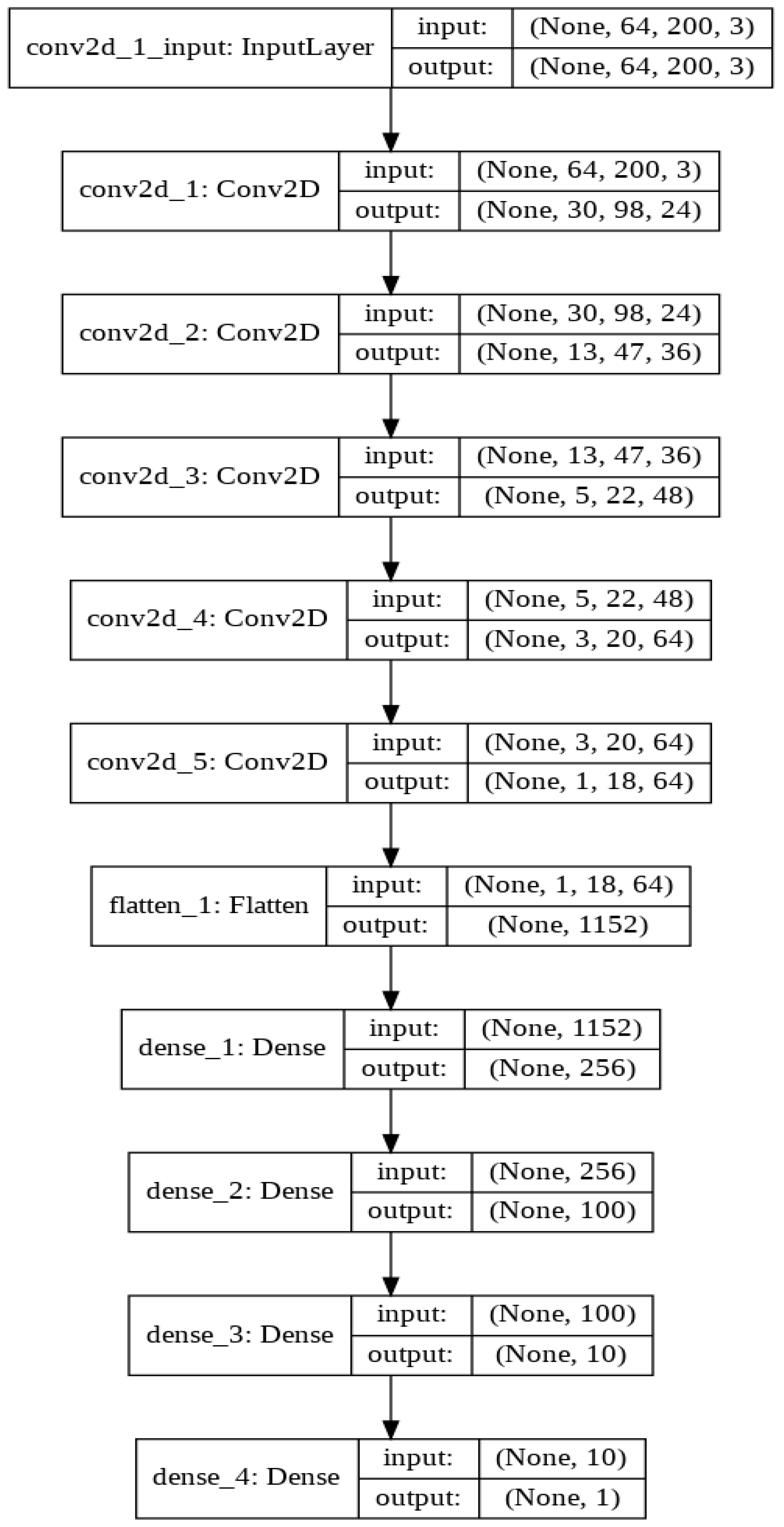
3.10. Convolution Neural Network Architecture
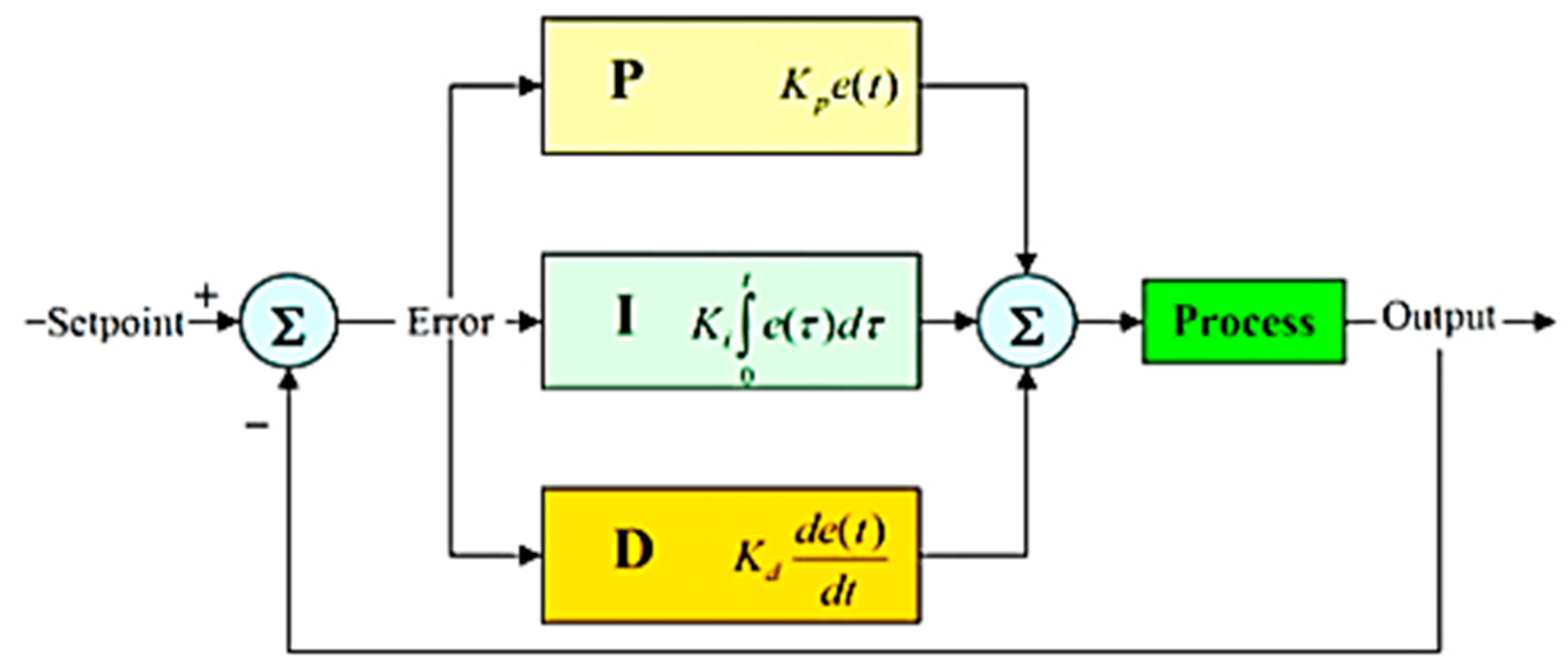
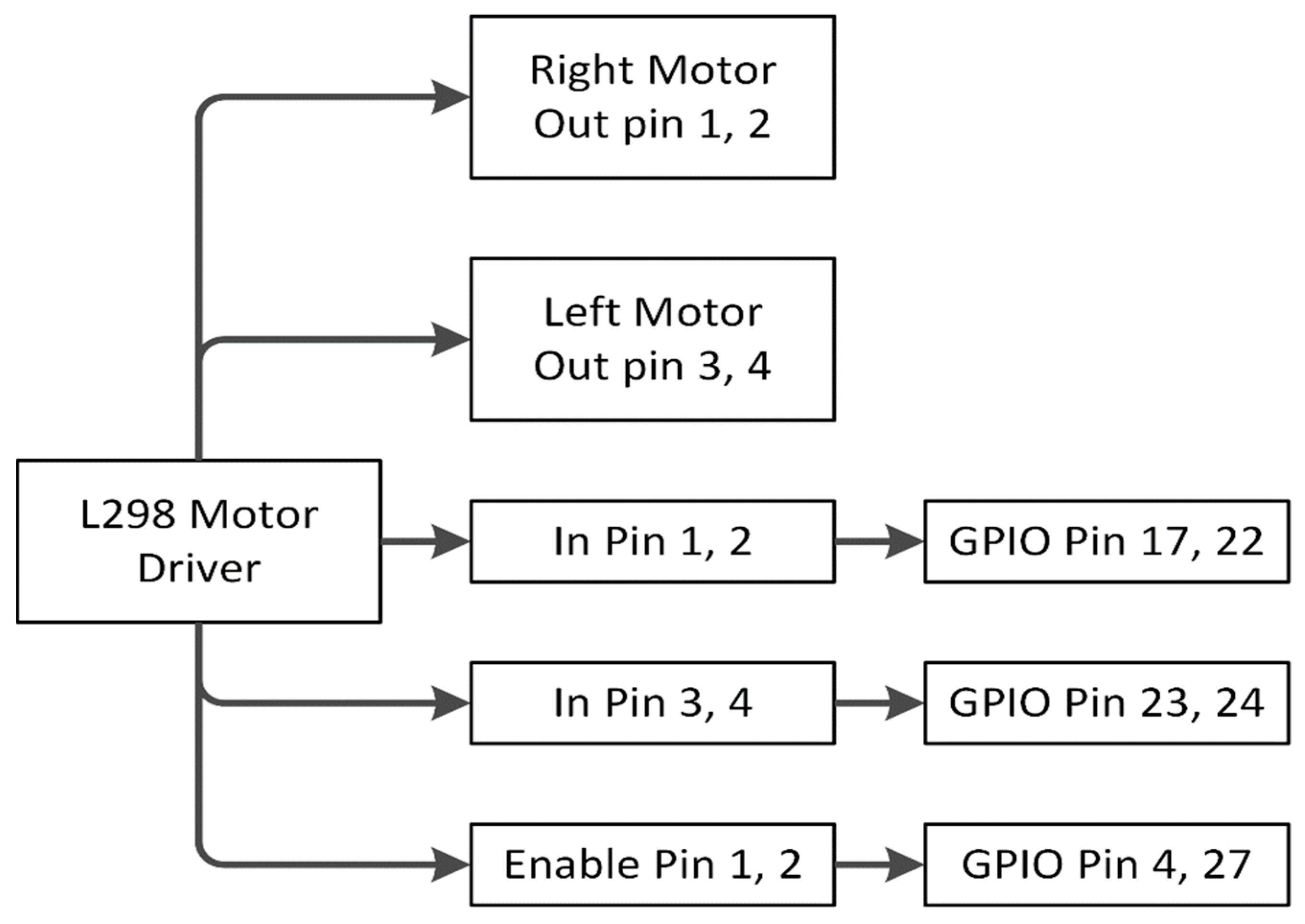
3.11. Driving Instruction through L298 Motor Driver
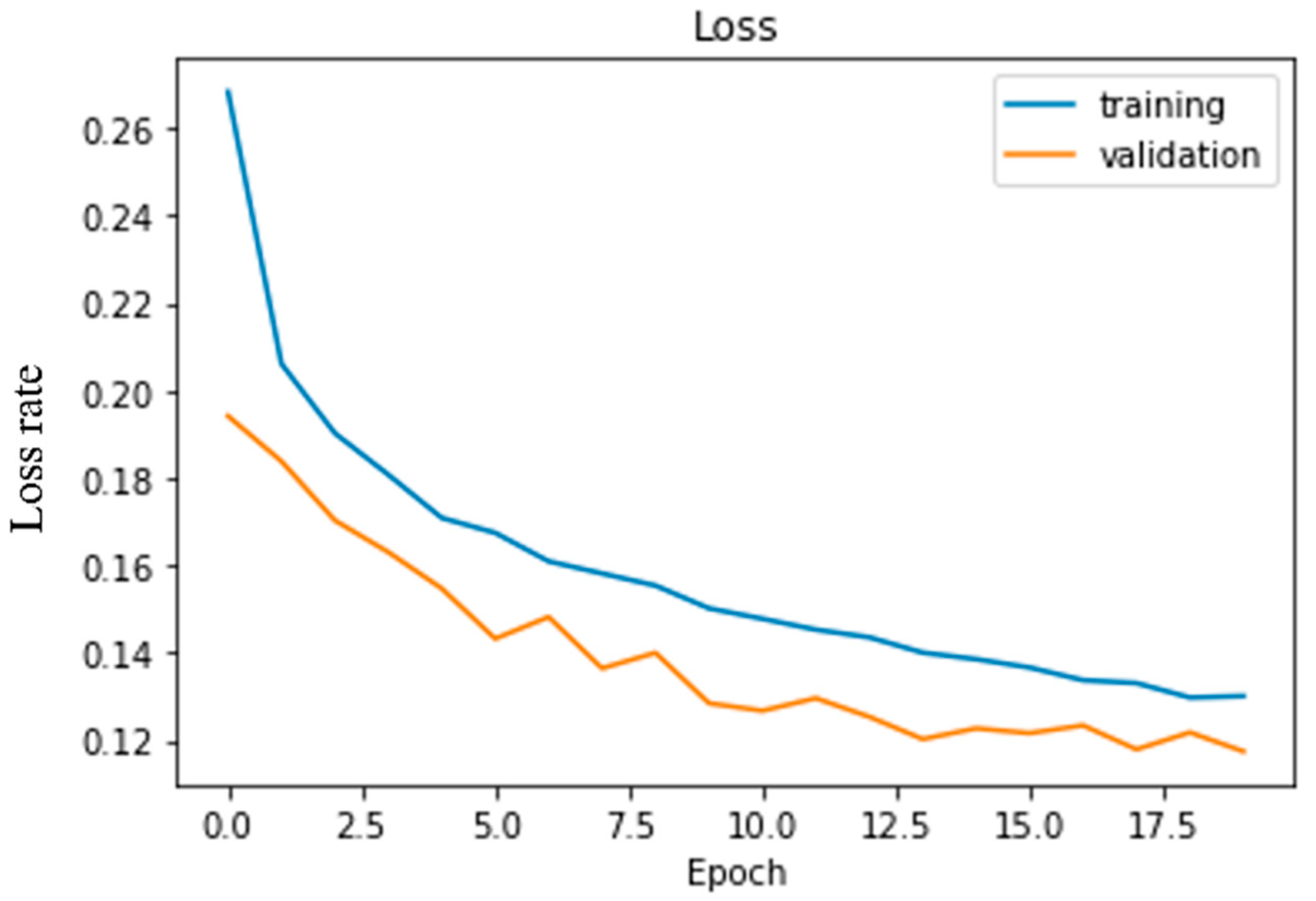
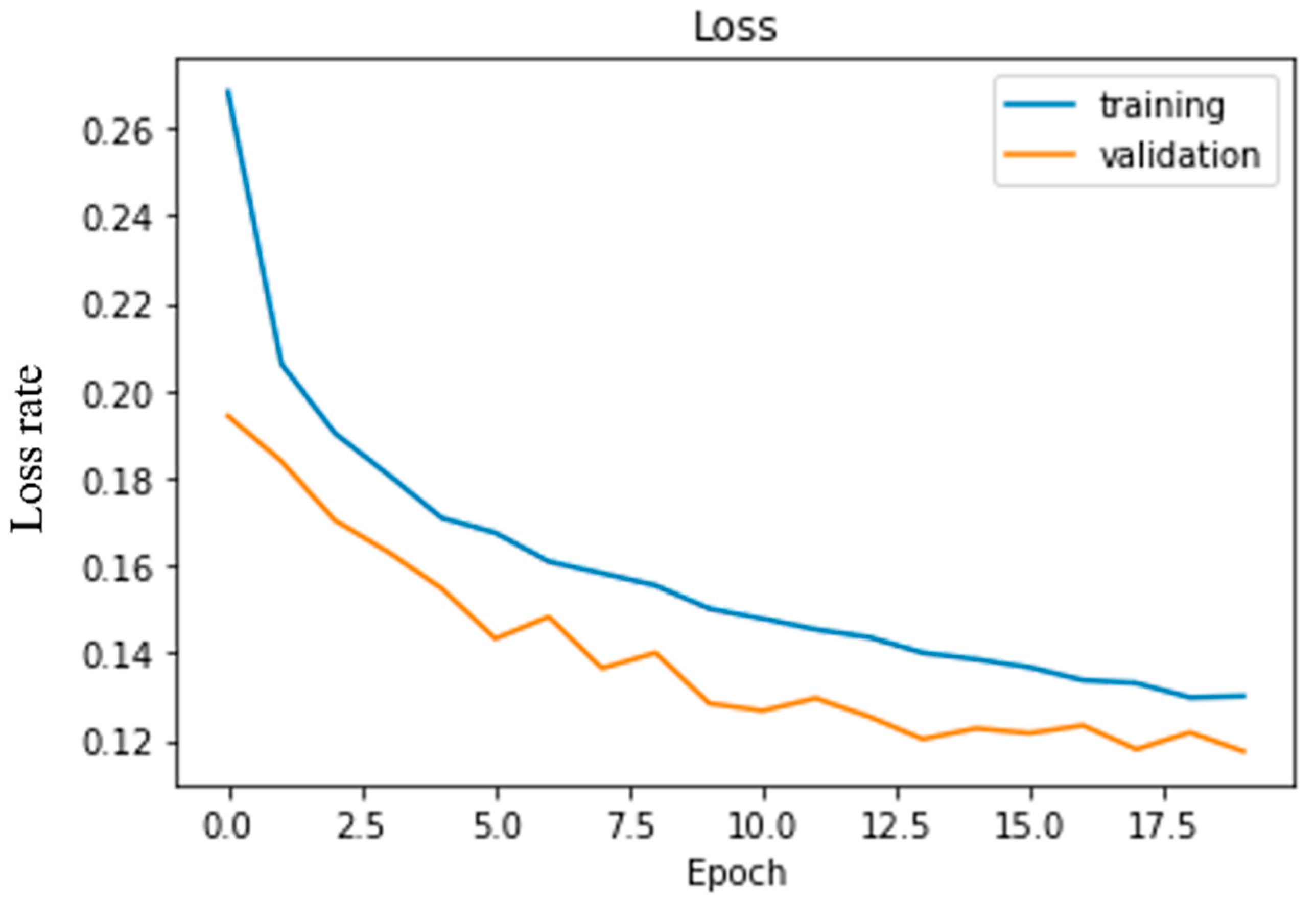
4. Experimental Result
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maasum, A.K.M.; Chy, M.K.A.; Rahman, I.; Uddin, M.N.; Azam, K.I. An Internet of Things (IoT) based smart traffic management system: A context of Bangladesh. In Proceedings of the 2018 International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, 27–28 October 2018; pp. 418–422. [Google Scholar]
- Taj, F.W.; Masum, A.K.M.; Reza, S.T.; Chy, M.K.A.; Mahbub, I. Automatic accident detection and human rescue system: Assistance through communication technologies. In Proceedings of the 2018 International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, 27–28 October 2018; pp. 496–500. [Google Scholar]
- Najafzadeh, M.; Niazmardi, S. A Novel Multiple-Kernel Support Vector Regression Algorithm for Estimation of Water Quality Parameters. Nat. Resour. Res. 2021, 30, 3761–3775. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Homaei, F.; Farhadi, H. Reliability assessment of water quality index based on guidelines of national sanitation foundation in natural streams: Integration of remote sensing and data-driven models. Artif. Intell. Rev. 2021, 54, 4619–4651. [Google Scholar] [CrossRef]
- Amiri-Ardakani, Y.; Najafzadeh, M. Pipe Break Rate Assessment While Considering Physical and Operational Factors: A Methodology Based on Global Positioning System and Data Driven Techniques. Water Resour. Manag. 2021, 35, 3703–3720. [Google Scholar] [CrossRef]
- Saberi-Movahed, F.; Mohammadifard, M.; Mehrpooya, A.; Rezaei-Ravari, M.; Berahmand, K.; Rostami, M.; Karami, S.; Najafzadeh, M.; Hajinezhad, D.; Jamshidi, M. Decoding Clinical Biomarker Space of COVID-19: Exploring Matrix Factorization-based Feature Selection Methods. medRxiv 2021. [Google Scholar] [CrossRef]
- Kong, L. A study on the AI-based online triage model for hospitals in sustainable smart city. Future Gener. Comput. Syst. 2021, 125, 59–70. [Google Scholar] [CrossRef]
- Lv, Z.; Qiao, L.; Kumar Singh, A.; Wang, Q. AI-empowered IoT security for smart cities. ACM Trans. Internet Technol. 2021, 21, 1–21. [Google Scholar] [CrossRef]
- Masum, A.K.M.; Chy, M.K.A.; Hasan, M.T.; Sayeed, M.H.; Reza, S.T. Smart Meter with Load Prediction Feature for Residential Customers in Bangladesh. In Proceedings of the 2019 International Conference on Energy and Power Engineering (ICEPE), Dhaka, Bangladesh, 14–16 March 2019; pp. 1–6. [Google Scholar]
- Masum, A.K.M.; Saveed, M.H.; Chy, M.K.A.; Hasan, M.T.; Reza, S.T. Design and Implementation of Smart Meter with Load Forecasting Feature for Residential Customers. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Bhat, S.A.; Huang, N.-F. Big Data and AI Revolution in Precision Agriculture: Survey and Challenges. IEEE Access 2021, 9, 110209–110222. [Google Scholar] [CrossRef]
- Jung, J.; Maeda, M.; Chang, A.; Bhandari, M.; Ashapure, A.; Landivar-Bowles, J. The potential of remote sensing and artificial intelligence as tools to improve the resilience of agriculture production systems. Curr. Opin. Biotechnol. 2021, 70, 15–22. [Google Scholar] [CrossRef] [PubMed]
- Chy, M.K.A.; Masum, A.K.M.; Hossain, M.E.; Alam, M.G.R.; Khan, S.I.; Alam, M.S. A Low-Cost Ideal Fish Farm Using IoT: In the Context of Bangladesh Aquaculture System. In Inventive Communication and Computational Technologies; Springer: Cham, Switzerland, 2020; pp. 1273–1283. [Google Scholar]
- Zhang, K.; Aslan, A.B. AI technologies for education: Recent research & future directions. Comput. Educ. Artif. Intell. 2021, 2, 100025. [Google Scholar]
- Elshafey, A.E.; Anany, M.R.; Mohamed, A.S.; Sakr, N.; Aly, S.G. Dr. Proctor: A Multi-modal AI-Based Platform for Remote Proctoring in Education. In Artificial Intelligence in Education, Proceedings of the International Conference on Artificial Intelligence in Education, Utrecht, The Netherlands, 14–18 June 2021; Springer: Cham, Switzerland, 2021; pp. 145–150. [Google Scholar]
- Lee, D.; Yoon, S.N. Application of artificial intelligence-based technologies in the healthcare industry: Opportunities and challenges. Int. J. Environ. Res. Public Health 2021, 18, 271. [Google Scholar] [CrossRef] [PubMed]
- Davahli, M.R.; Karwowski, W.; Fiok, K.; Wan, T.; Parsaei, H.R. Controlling Safety of Artificial Intelligence-Based Systems in Healthcare. Symmetry 2021, 13, 102. [Google Scholar] [CrossRef]
- Apell, P.; Eriksson, H. Artificial intelligence (AI) healthcare technology innovations: The current state and challenges from a life science industry perspective. Technol. Anal. Strateg. Manag. 2021, 1–15. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- U.S. Department of Transportation. Automated Driving Systems—A Vision for Safety. Available online: https://www.nhtsa.gov/sites/nhtsa.dot.gov/files/documents/13069a-ads2.0_090617_v9a_tag.pdf (accessed on 3 April 2019).
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixao, T.M.; Mutz, F. Self-driving cars: A survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Daily, M.; Medasani, S.; Behringer, R.; Trivedi, M. Self-driving cars. Computer 2017, 50, 18–23. [Google Scholar] [CrossRef] [Green Version]
- Alam, S.; Sulistyo, S.; Mustika, I.W.; Adrian, R. Review of potential methods for handover decision in v2v vanet. In Proceedings of the 2019 International Conference on Computer Science, Information Technology, and Electrical Engineering (ICOMITEE), Jember, Indonesia, 16–17 October 2019; pp. 237–243. [Google Scholar]
- Baza, M.; Nabil, M.; Mahmoud, M.M.E.A.; Bewermeier, N.; Fidan, K.; Alasmary, W.; Abdallah, M. Detecting sybil attacks using proofs of work and location in vanets. IEEE Trans. Dependable Secur. Comput. 2020. [Google Scholar] [CrossRef]
- Schmittner, C.; Chlup, S.; Fellner, A.; Macher, G.; Brenner, E. ThreatGet: Threat modeling based approach for automated and connected vehicle systems. In Proceedings of the AmE 2020-Automotive meets Electronics; 11th GMM-Symposium, Dortmund, Germany, 10–11 March 2020; pp. 1–3. [Google Scholar]
- Cui, J.; Liew, L.S.; Sabaliauskaite, G.; Zhou, F. A review on safety failures, security attacks, and available countermeasures for autonomous vehicles. Ad Hoc Networks 2019, 90, 101823. [Google Scholar] [CrossRef]
- Dibaei, M.; Zheng, X.; Jiang, K.; Maric, S.; Abbas, R.; Liu, S.; Zhang, Y.; Deng, Y.; Wen, S.; Zhang, J. An overview of attacks and defences on intelligent connected vehicles. arXiv 2019, arXiv:1907.07455. preprint. [Google Scholar]
- Levine, W.S. The Control Handbook; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. preprint. [Google Scholar]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Pomerleau, D.A. Alvinn: An Autonomous Land Vehicle in a Neural Network; Artificial Intelligence And Psychology Project; Carnegie-Mellon University: Pittsburgh, PA, USA, 1989. [Google Scholar]
- Lecun, Y.; Cosatto, E.; Ben, J.; Muller, U.; Flepp, B. Dave: Autonomous Off-Road Vehicle Control Using End-to-End Learning. DARPA-IPTO Final Report. 2004. Available online: https://cs.nyu.edu/~yann/research/dave/ (accessed on 15 February 2019).
- N.T. Report. GPU-Based Deep Learning Inference: A Performance and Power Analysis. Available online: http://developer.download.nvidia.com/embedded/jetson/TX1/docs/jetson_tx1_whitepaper.pdf?autho=1447264273_0fafa14fcc7a1f685769494ec9b0fcad&file=jetson_tx1_whitepaper.pdf (accessed on 23 May 2019).
- Masum, A.K.M.; Rahman, M.A.; Abdullah, M.S.; Chowdhury, S.B.S.; Khan, T.B.F.; Raihan, M.K. A Supervised Learning Approach to An Unmanned Autonomous Vehicle. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1549–1554. [Google Scholar]
- Stavens, D.; Thrun, S. A self-supervised terrain roughness estimator for off-road autonomous driving. arXiv 2012, arXiv:1206.6872. preprint. [Google Scholar]
- Hadsell, R.; Sermanet, P.; Ben, J.; Erkan, A.; Scoffier, M.; Kavukcuoglu, K.; Muller, U.; LeCun, Y. Learning long-range vision for autonomous off-road driving. J. Field Robot. 2009, 26, 120–144. [Google Scholar] [CrossRef] [Green Version]
- Deb, S.; Strawderman, L.; Carruth, D.W.; DuBien, J.; Smith, B.; Garrison, T.M. Development and validation of a questionnaire to assess pedestrian receptivity toward fully autonomous vehicles. Transp. Res. Part C Emerg. Technol. 2017, 84, 178–195. [Google Scholar] [CrossRef]
- Nordhoff, S.; De Winter, J.; Kyriakidis, M.; Van Arem, B.; Happee, R. Acceptance of driverless vehicles: Results from a large cross-national questionnaire study. J. Adv. Transp. 2018, 2018, 5382192. [Google Scholar] [CrossRef] [Green Version]
- Robertson, R.D.; Meister, S.R.; Vanlaar, W.G.; Hing, M.M. Automated vehicles and behavioural adaptation in Canada. Transp. Res. Part A Policy Pract. 2017, 104, 50–57. [Google Scholar] [CrossRef]
- Reke, M.; Peter, D.; Schulte-Tigges, J.; Schiffer, S.; Ferrein, A.; Walter, T.; Matheis, D. A self-driving car architecture in ROS2. In Proceedings of the 2020 International SAUPEC/RobMech/PRASA Conference, Cape Town, South Africa, 29–31 January 2020; pp. 1–6. [Google Scholar]
- Bakioglu, G.; Atahan, A.O. AHP integrated TOPSIS and VIKOR methods with Pythagorean fuzzy sets to prioritize risks in self-driving vehicles. Appl. Soft Comput. 2021, 99, 106948. [Google Scholar] [CrossRef]
- Chen, C.; Demir, E.; Huang, Y.; Qiu, R. The adoption of self-driving delivery robots in last mile logistics. Transp. Res. Part E Logist. Transp. Rev. 2021, 146, 102214. [Google Scholar] [CrossRef]
- Li, L.; Lin, Y.-L.; Zheng, N.-N.; Wang, F.-Y.; Liu, Y.; Cao, D.; Wang, K.; Huang, W.-L. Artificial intelligence test: A case study of intelligent vehicles. Artif. Intell. Rev. 2018, 50, 441–465. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, X.; Yang, Y. Multimodal transport distribution model for autonomous driving vehicles based on improved ALNS. Alex. Eng. J. 2021, 61, 2939–2958. [Google Scholar] [CrossRef]
- Dommès, A.; Merlhiot, G.; Lobjois, R.; Dang, N.-T.; Vienne, F.; Boulo, J.; Oliver, A.-H.; Cretual, A.; Cavallo, V. Young and older adult pedestrians’ behavior when crossing a street in front of conventional and self-driving cars. Accid. Anal. Prev. 2021, 159, 106256. [Google Scholar] [CrossRef]
- Deruyttere, T.; Milewski, V.; Moens, M.-F. Giving commands to a self-driving car: How to deal with uncertain situations? Eng. Appl. Artif. Intell. 2021, 103, 104257. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Gu, Y.; Hashimoto, Y.; Hsu, L.-T.; Iryo-Asano, M.; Kamijo, S. Human-like motion planning model for driving in signalized intersections. IATSS Res. 2017, 41, 129–139. [Google Scholar] [CrossRef] [Green Version]
- Katrakazas, C.; Quddus, M.; Chen, W.-H.; Deka, L. Real-time motion planning methods for autonomous on-road driving: State-of-the-art and future research directions. Transp. Res. Part C Emerg. Technol. 2015, 60, 416–442. [Google Scholar] [CrossRef]
- Mostafa, M.S.B.; Masum, A.K.M.; Uddin, M.S.; Chy, M.K.A.; Reza, S.T. Amphibious Line following Robot for Product Delivery in Context of Bangladesh. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Colak, I.; Yildirim, D. Evolving a Line Following Robot to use in shopping centers for entertainment. In Proceedings of the 2009 35th Annual Conference of IEEE Industrial Electronics, Porto, Portugal, 3–5 November 2009; pp. 3803–3807. [Google Scholar]
- Islam, M.; Rahman, M. Design and fabrication of line follower robot. Asian J. Appl. Sci. Eng. 2013, 2, 27–32. [Google Scholar]
- Punetha, D.; Kumar, N.; Mehta, V. Development and applications of line following robot based health care management system. Int. J. Adv. Res. Comput. Eng. Technol. (IJARCET) 2013, 2, 2446–2450. [Google Scholar]
- Wolcott, R.W.; Eustice, R.M. Robust LIDAR localization using multiresolution Gaussian mixture maps for autonomous driving. Int. J. Robot. Res. 2017, 36, 292–319. [Google Scholar] [CrossRef]
- Ahmad, T.; Ilstrup, D.; Emami, E.; Bebis, G. Symbolic road marking recognition using convolutional neural networks. In Proceedings of the 2017 IEEE intelligent vehicles symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1428–1433. [Google Scholar]
- Greenhalgh, J.; Mirmehdi, M. Detection and Recognition of Painted Road Surface Markings. In Proceedings of the ICPRAM (1), Lisbon, Portugal, 10–12 January 2015; pp. 130–138. [Google Scholar]
- Hyeon, D.; Lee, S.; Jung, S.; Kim, S.-W.; Seo, S.-W. Robust road marking detection using convex grouping method in around-view monitoring system. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1004–1009. [Google Scholar]
- Chollet, F. Keras; Github: San Francisco, CA, USA, 2015; Available online: https://github.com/fchollet/keras (accessed on 17 April 2019).
- Nikitas, A.; Njoya, E.T.; Dani, S. Examining the myths of connected and autonomous vehicles: Analysing the pathway to a driverless mobility paradigm. Int. J. Automot. Technol. Manag. 2019, 19, 10–30. [Google Scholar] [CrossRef] [Green Version]
- Evans, J. Governing cities for sustainability: A research agenda and invitation. Front. Sustain. Cities 2019, 1, 2. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.; Rhee, S.-W. Current status and perspectives on recycling of end-of-life battery of electric vehicle in Korea (Republic of). Waste Manag. 2020, 106, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Bollinger, B.L. The Security and Privacy In Your Car Act: Will It Actually Protect You? North Carol. J. Law Technol. 2017, 18, 214. [Google Scholar]
- Lim, H.S.M.; Taeihagh, A. Autonomous vehicles for smart and sustainable cities: An in-depth exploration of privacy and cybersecurity implications. Energies 2018, 11, 1062. [Google Scholar] [CrossRef] [Green Version]
- Thompson, N.; Mullins, A.; Chongsutakawewong, T. Does high e-government adoption assure stronger security? Results from a cross-country analysis of Australia and Thailand. Gov. Inf. Q. 2020, 37, 101408. [Google Scholar] [CrossRef]
- Feng, S.; Feng, Y.; Yan, X.; Shen, S.; Xu, S.; Liu, H.X. Safety assessment of highly automated driving systems in test tracks: A new framework. Accid. Anal. Prev. 2020, 144, 105664. [Google Scholar] [CrossRef]
- Van Brummelen, J.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part C Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- SullyChen. Autopilot-TensorFlow. Available online: https://github.com/SullyChen/Autopilot-TensorFlow (accessed on 3 April 2019).
- Apollo. Apollo Data Open Platform. Available online: http://data.apollo.auto/?locale=en-us&lang=en (accessed on 3 April 2019).
- Santana, E.; Hotz, G. Learning a driving simulator. arXiv 2016, arXiv:1608.01230. preprint. [Google Scholar]
- Yin, H.; Berger, C. When to use what data set for your self-driving car algorithm: An overview of publicly available driving datasets. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–8. [Google Scholar]
- Udacity. Self-Driving-Car. Available online: https://github.com/udacity/self-driving-car/tree/master/datasets (accessed on 5 May 2019).
- Udacity. Self-Driving-Car-Sim. Available online: https://github.com/udacity/self-driving-car-sim (accessed on 5 May 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
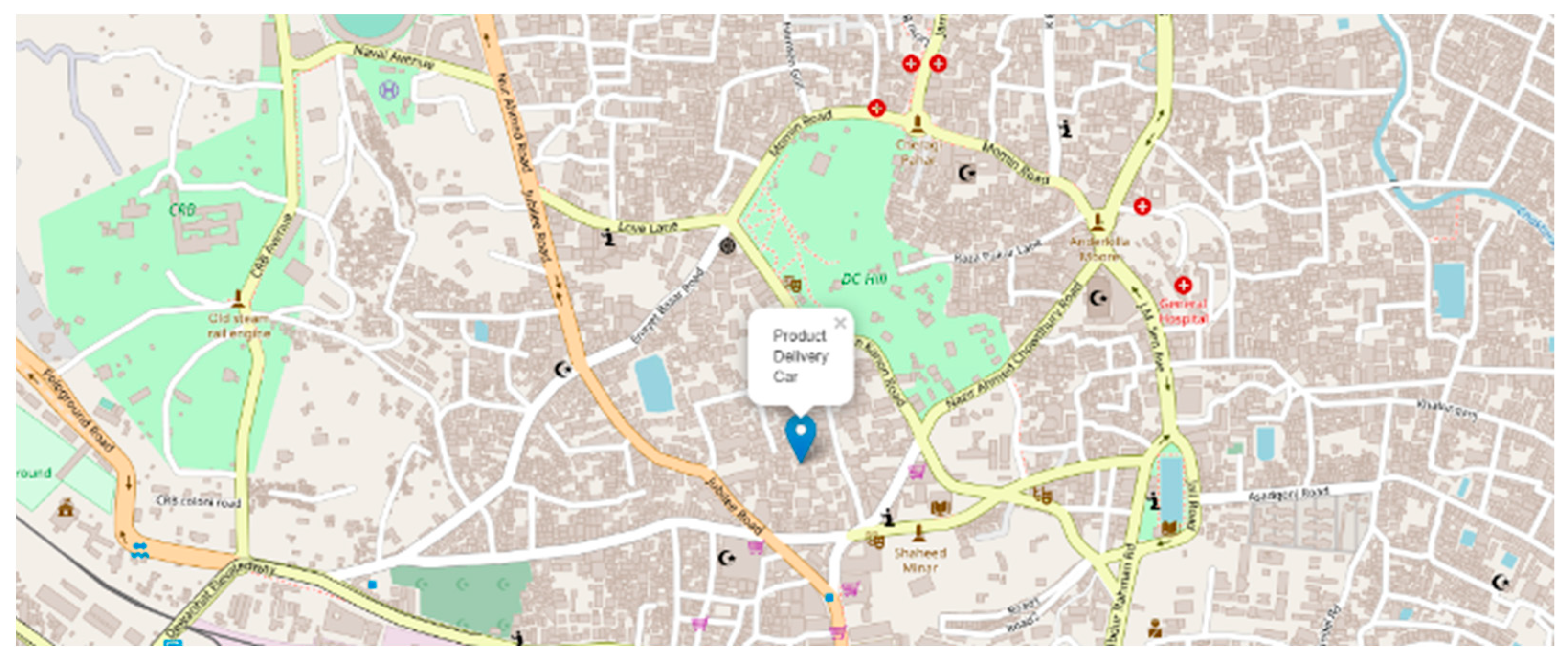{kind=link}
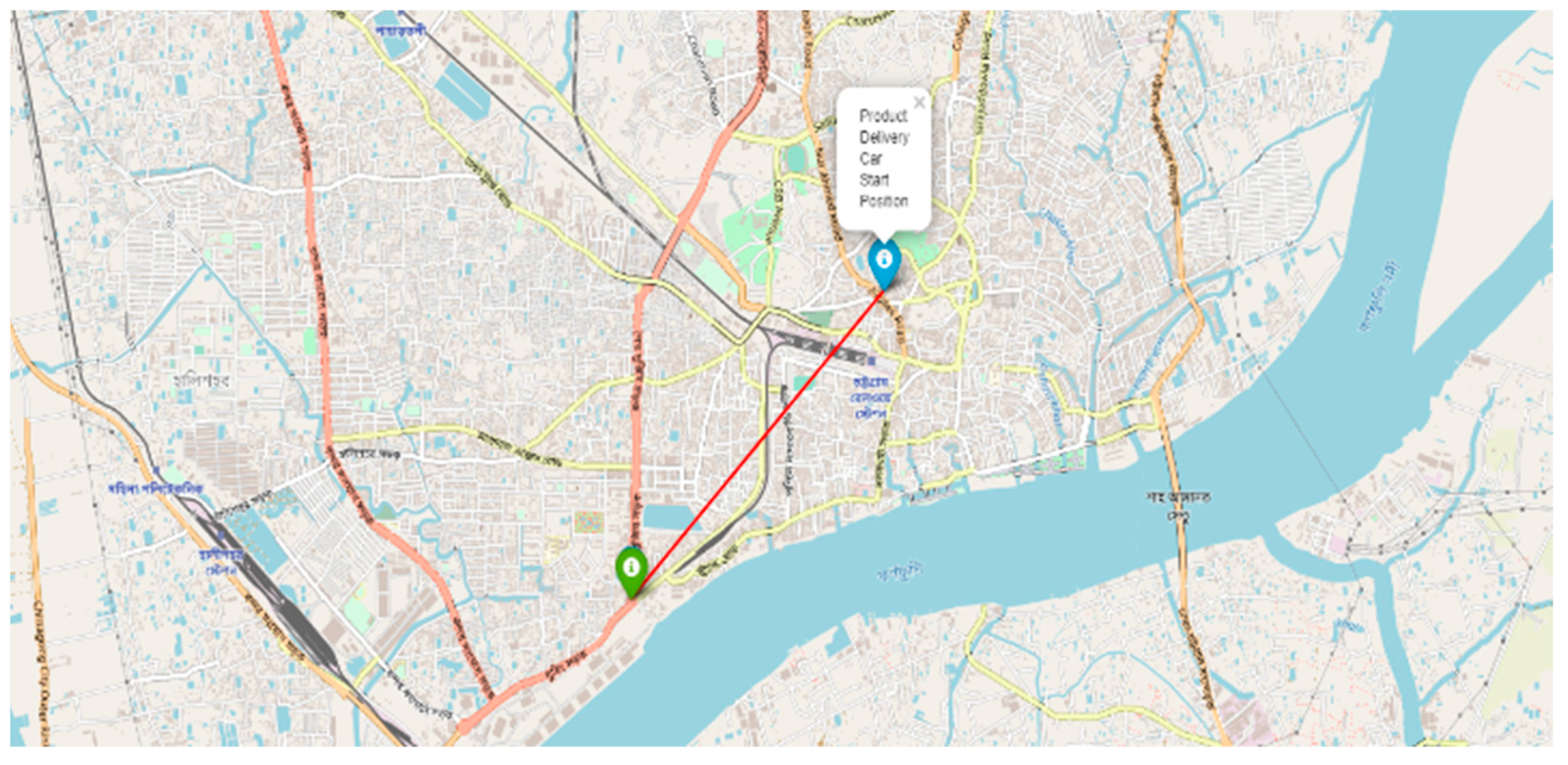{kind=link}
{kind=link}
| Center | Left | Right | Steering | Throttle | Reverse | Speed |
|---|---|---|---|---|---|---|
| E:\android\curly_final\IMG\center_2019_04_12_01_52_50_770.jpg | E:\android\curly_final\IMG\left_2019_04_12_01_52_50_770.jpg | E:\android\curly_final\IMG\right_2019_04_12_01_52_50_770.jpg | 0 | 0 | 0 | 0.00014 |
| E:\android\curly_final\IMG\center_2019_04_12_01_52_50_846.jpg | E:\android\curly_final\IMG\left_2019_04_12_01_52_50_846.jpg | E:\android\curly_final\IMG\right_2019_04_12_01_52_50_846.jpg | 0 | 0 | 0 | 0.000199 |
| E:\android\curly_final\IMG\center_2019_04_12_01_52_50_917.jpg | E:\android\curly_final\IMG\left_2019_04_12_01_52_50_917.jpg | E:\android\curly_final\IMG\right_2019_04_12_01_52_50_917.jpg | 0 | 0 | 0 | 0.00026 |
| Environment/Turning | Accuracy |
|---|---|
| Cloudy | 88.9% |
| Lightening | 89.6% |
| Left | 87.1% |
| Right | 89.3% |
| Straight | 89.0% |
| Configuration | Accuracy |
|---|---|
| TCNN3 | 83.3% |
| TCNN9 | 84.6% |
| CNN-LSTM | 84.5% |
| Nvidia CNN | 89.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chy, M.K.A.; Masum, A.K.M.; Sayeed, K.A.M.; Uddin, M.Z. Delicar: A Smart Deep Learning Based Self Driving Product Delivery Car in Perspective of Bangladesh. Sensors 2022, 22, 126. https://doi.org/10.3390/s22010126
Chy MKA, Masum AKM, Sayeed KAM, Uddin MZ. Delicar: A Smart Deep Learning Based Self Driving Product Delivery Car in Perspective of Bangladesh. Sensors. 2022; 22(1):126. https://doi.org/10.3390/s22010126
Chicago/Turabian StyleChy, Md. Kalim Amzad, Abdul Kadar Muhammad Masum, Kazi Abdullah Mohammad Sayeed, and Md Zia Uddin. 2022. "Delicar: A Smart Deep Learning Based Self Driving Product Delivery Car in Perspective of Bangladesh" Sensors 22, no. 1: 126. https://doi.org/10.3390/s22010126
APA StyleChy, M. K. A., Masum, A. K. M., Sayeed, K. A. M., & Uddin, M. Z. (2022). Delicar: A Smart Deep Learning Based Self Driving Product Delivery Car in Perspective of Bangladesh. Sensors, 22(1), 126. https://doi.org/10.3390/s22010126