1. Introduction
Due to the known adverse effects of air pollution, cities consider monitoring relevant air quality indices a necessity [
1,
2,
3]. Studies report that many premature deaths could be prevented by complying with air quality guidelines such as the ones provided by the World Health Organization [
4]. To satisfy the desire for higher spatial and temporal resolution due to differences in individual exposure [
5], a lot of research on affordable air quality monitoring devices has been performed [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. Such devices consist of gas and/or particulate matter sensors in the low-cost range, and they are supposed to be connected to the internet of things, thus forming a network and being part of the smart city vision [
16]. More often than not, these low-cost systems contain data-derived models obtained from machine learning (ML) algorithms, a subfield of artificial intelligence, to compensate for cross-sensitivities and/or interferences with environmental factors (temperature, humidity, pressure) of the sensors, with the aim to decrease the uncertainty of measurement results and increase the value of the product.
While low-cost particulate matter sensors immediately provide interpretable output, this is generally not the case for gas sensors, as they only deliver raw sensor signal intensity—e.g., voltage or current, thereby requiring calibration [
17,
18,
19]. As mentioned above, change in raw signal
s is not only caused by the target gas
r1, but also by other gases or environmental factors
r2, …
rn, which motivated use of a multivariate approach via sensor fusion [
11]. The amount by which each variable affects the sensor signal is described by its parameters
αk belonging to the individual factors. Therefore, a gas sensor generates signals according to a sensing model
f (Equation (1)). Note that Equation (1) is usually inverted to compute the fractions of the target compounds.
In reality, every low-cost sensor has a different baseline (zero), responds differently to the gases and environmental factors, and adds noise to the signal, thereby requiring individual calibration [
20,
21,
22,
23]. Due to this high unit-to-unit variability (in combination with drift due to aging, i.e., time-dependent parameters
αk), laboratory calibration is currently considered too expensive [
11]. Hence, most low-cost sensor systems are characterized with field data obtained by collocating devices next to reference stations [
6,
7,
13]. This data can contain many nonlinear relationships, partly due to the sensor responses, but also due to the complex relationships between the interfering variables [
13].
Newer studies have shown that these models do not generalize well due to strong correlations within the field data, and the devices suffer from spatial and temporal relocation problems [
24,
25]. The underlying cause is the difference in probability distributions of the factors across different locations and times, known as concept drift. It is debatable if such systems could ever be certified under these circumstances, since they “replay” seen relationships and perform only quasi-measurements. In particular, the measurement uncertainty can change over time and space, thus results can become unreliable under changing atmospheric conditions. Ideally, the data acquisition process should be designed in a way to yield independent (orthogonal) variables using some design of experiments [
26]. This is particularly relevant if the data quality objective of legislators should be met, as air quality data could not be used for decision-making otherwise. Nonetheless, it boils down to the role of low-cost sensor systems and what purpose they should fulfill in the future [
27].
A recent publication suggested to proceed with field calibration and to compare multivariate distributions of pollutants and environmental conditions (i.e., the atmosphere) across locations in order to decide the suitability of a field-calibrated device for a specific location [
25]. In this case, the comparison of distributions is achieved by using similarity metrics for probability distributions, one of them being the Kullback–Leibler divergence
DKL (Equation (2)), which is a measure of how one probability distribution
p(
x) is different from a reference probability distribution
q(
x) [
28,
29].
More precisely,
q(
x) is the distribution from the calibration data, and
p(
x) is the operation distribution at a new location. Furthermore, the authors mention that such metrics could serve for dynamic recalibration procedures, so that low-cost air quality monitors will require service if metrics exceed some threshold. This methodology is known as predictive maintenance (PD) [
30]. Nonetheless, it is worth noting that different drift components, e.g., aging and concept drift, will overlap with field calibration, and it cannot be known whether a sensor has aged, or the temporally or spatially local atmosphere has changed (e.g., all points that are measured during a certain period at a certain place). Thus, recalibration intervals can be shorter with field calibration due to this additional drift component.
Unfortunately, the proposed approach lacks practicability, as in most cases the atmospheric composition of a specific location will not be known in advance in order to decide whether a performed calibration is suitable or not. Therefore, it would be more reasonable to focus on a method that relies only on the calibration data. Additionally, choosing a threshold of the Kullback–Leibler divergence is not an intuitive task, since it is bound between zero and infinity and hard to interpret. Theoretically, it is also necessary to refit the distribution p(x) with every newly acquired data point, followed by numerical computation of the integral (unless the data come from a generic distribution, e.g., standard normal, for which closed-form solutions exist).
Nonetheless, PD has been applied on several occasions and bears enormous potential [
30]. For low-cost sensors, the interest usually revolved around the removal/autocorrection of drift components instead [
31,
32,
33]. In the context of metrology, it enables dynamic service of devices as opposed to fixed predefined maintenance intervals. This is particularly relevant, as the unit-to-unit variability of low-cost sensors is significant and a fixed recalibration interval, e.g., with transfer standards, for all devices cannot be considered a satisfying solution [
34]. Therefore, the reliability of measurement results can be increased. Furthermore, remote devices can call for service autonomously as soon as some of their parameters show a trend towards malfunction. In addition, it can balance workload, as devices with similar needs for maintenance can be grouped together for parallel recalibration. For networks of such instruments, any optimization of operation cost leads to cost reduction.
Detecting unusual behavior, e.g., system malfunction, is a common ML task in which normal and non-normal operation states have to be distinguished—a problem known as anomaly detection [
35,
36]. In contrast to the proposed approach using the Kullback–Leibler divergence, there is a subset of techniques that requires only data from the calibration procedure (which is available anyway), but not from the location where the device would be placed at [
37,
38,
39,
40]. Low-cost sensors are consumables and degrade over time due to aging. Therefore, one could hypothesize that sensors move away from their reference states that are defined by the fresh sample. The reference state can be thought of as a multivariate probability distribution (“generated” by the set of sensor signals of a brand-new system that is exposed to different conditions); over time, this distribution changes its parameters, i.e., mean and/or covariance, due to aging.
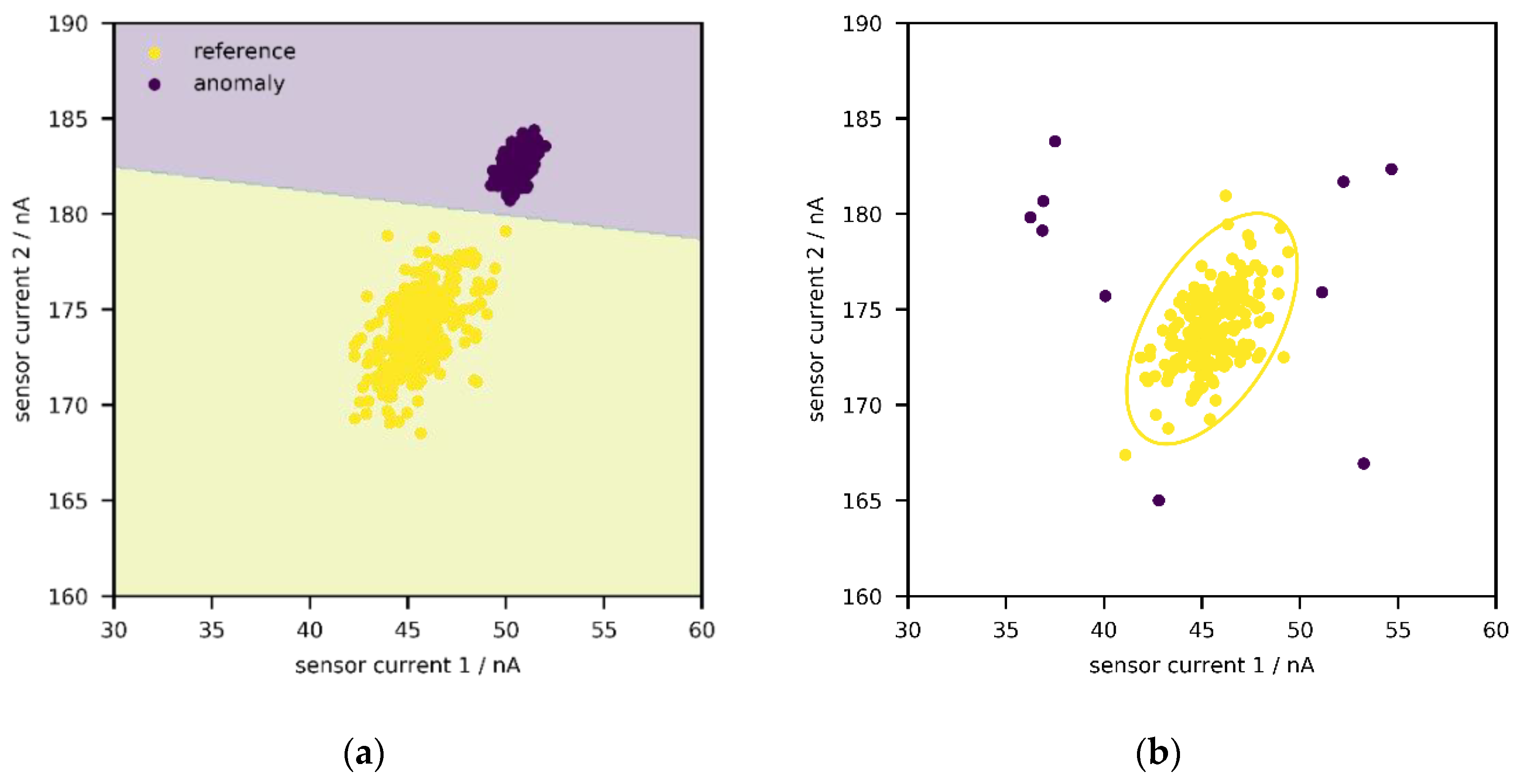
In the following, two general approaches shall briefly be sketched. First, with supervised anomaly detection (
Figure 1a), one or more classes of anomalies can be directly targeted as long as labelled data are available [
30,
35,
36]. In some cases, such data can be obtained by performing stress tests—e.g., by exposing a machine/device to extreme environments or operating under unusual conditions for some time in laboratory environments. In
Figure 1a, the reference state and one anomaly class are depicted; a support-vector machine with linear kernel is used to describe the decision boundary between the two states, but any other classification algorithm works just as well—e.g., logistic regression, random forest, neural network.
Unfortunately, it is rarely known in advance what non-normal (or aged) states look like; even if historical data from stress testing might be available, it is likely incomplete so that not every possible defect has been captured. Therefore, it could be more interesting to just identify every point outside a reference state, independent of its direction (
Figure 1b) [
30,
35,
36]. This is known as unsupervised anomaly detection, and this publication will explore the suitability of such an approach. One archetype of methods among the plethora of algorithms aims to construct an envelope around the data, i.e., the set of points from the reference state, so that points outside of it can be identified (
Figure 1b). Such an envelope can be interpreted as a confidence region, and newly generated points are regarded as “acceptable” if they lie within said region. As implied above, the reference state is generated during the calibration procedure according to Equation (1), by exposing a system to different concentrations of gases and environmental conditions. Due to aging or concept drift, one could expect that, over time, more and more sensor signals would fall outside the envelope. In this manner, the need for recalibration (or the suitability of a calibration) could be identified during operation.
As an example, one could fit a normal distribution to the data set, and in a second step, compute the Mahalanobis distance (the extension of the
Z-score to more than one dimension) of points to estimate their regularity [
37]. However, the actual distribution of the data does not need to be normal, and in that case, other techniques can be applied with the same idea—e.g., local-outlier factor [
38], one-class support vector machine [
39], or isolation forest [
40]. The common concept is to identify regions in the feature/signal space where the probability distribution “lives” or resides. Note that the regions do not need to be contiguous—e.g., in the presence of multiple clusters. Such methods do not necessarily compute a distance metric but rely on either an anomaly score or the position relative to the envelope (inside/outside); moreover, they allow defining an initial amount of outliers/contamination
ν to control the shape/tightness of the volume, which is a hyperparameter. Furthermore, if there are already some outliers in the training set, the algorithms will try to identify them by itself.
Nonetheless, there are several aspects to keep in mind in such applications. Differences in available algorithms have to be investigated on a standardized data set in order to compare them. Moreover, the physics of aging drift and unit-to-unit variability have to be studied, since they might affect the viability of the methodology. Besides, if calibration occurs on the field, additional drift components can interfere with aging drift, and the recalibration intervals can end up being rather short. This work aimed to address these points by expanding the PD approach with an emphasis on electrochemical gas sensors and unsupervised anomaly detection. To study the suitability of the methodology, a sensing and aging drift model was developed. The benefit of having such a model is that Monte Carlo simulations of laboratory calibration followed by aging can be performed and compared with published experimental (field) data, thus accounting for the unit-to-unit variability of sensors and different drift components.
3. Results and Discussion
In a first step, the four algorithms were tested on the published field experiments, thereby modelling field calibration, with three values of
ν (0.01, 0.05, and 0.10). In
Figure 2, results from device 1 (which has the fewest missing values) and reference data are presented. More precisely, the average fraction of anomalies (weekly moving average, centered on every time point) has been computed and a few interesting observations are made. First, the output of the four algorithms is consistent and the curves are overlapping, thereby suggesting (close to) normally distributed data, as otherwise the RC model would deviate from the nonparametric methods; this is true for both sensor (
Figure 2a) and reference data (
Figure 2b). Moreover, the curves of the reference data match with the one of the sensor data, which suggests that the generated anomalies are a result from concept drift and a change in the underlying distribution, i.e., conditions that have not been observed during the calibration phase, as the references would not contain any anomalies otherwise. Such “anomalous” conditions include higher or lower values of either pollutant(s) but also different combinations compared to the ones in during the calibration phase. Thus, the measurement results can be completely unreliable during these periods—for instance, if the calibration function is extrapolated (e.g., random forests cannot extrapolate at all) [
24]. Something that is not necessarily captured is the rotation of the probability distribution (i.e., changing entries in the covariance matrix) of the current atmosphere due to varying relationships between the pollutants [
24]. Unfortunately, devices 2 and 3 have more missing information compared to device 1, but the aforementioned trends appear to be the same (
Figure S2). The average fraction of anomalies increases with increasing values of
ν, mostly between 0.01 and 0.05, but halts after that. The smaller the value of
ν, the larger the envelope, as less initial anomalies/outliers are removed during the construction of the envelopes. Hence, for very low values, almost no anomalies will be detected, and hyperparameter
ν should be increased unless the profile stops changing (quasi-convergence).
Interestingly, there are only few anomalies at the end of the four months of operation, both in the sensor and reference data, suggesting that the aging process might not yet be significant over this period. It would have been more intuitive if the frequency of anomalies would increase over time, and it is remarkable that the average fraction of anomalies only increases and decreases periodically, which can be attributed to the field calibration as explained above. Therefore, such anomaly scores disclose the reliability of the measurement results generated by field calibrated air quality monitors, which could be considered as safety measure in future applications.
To understand which pollutants are responsible for the anomalies, the quantiles of the calibration reference data inside the envelope (c) were compared against the quantiles of the monitoring data outside the envelope (m), summarized in
Table 2. The analysis shows that, during operation, the gas levels are either higher (CO, NO
2) or lower (O
3), which then causes the increase in anomalies in
Figure 2. This concept drift is a consequence of field calibration [
24], as more combustion for heating in the winter leads to higher levels of CO and NO
2, while less radiation leads to a decrease in O
3 levels. Nonetheless, these spikes in the anomaly score can be prevented by extending the calibration range in a laboratory setting.
The measurement period can be considered comparably short, so a longer study might be needed. For this reason, the data set from De Vito et al. [
6], which has been characterized in an earlier publication [
24], was also tested under the same procedure (two weeks of field calibration with sensors for CO, NO
2, and O
3 from a different manufacturer); the results are depicted in
Figure S3. Note that the values for
ν had to be increased to reach “convergence”. With these data, the parametric method diverges from the nonparametric methods. While the nonparametric techniques agree in most scenarios, they disagree in the sensor data at moderate to high values of
ν.
Figure S3a,b demonstrate the increase in the fraction of anomalies over time, both in the sensor and reference data. This illustrates a late starting concept drift, as the atmosphere changes continuously over time. Nonetheless, the increase in the sensor data appears steeper, hinting at an additional drift component (e.g., resulting from aging).
Thus far, these results seem promising, but they are obtained only from a few field-calibrated devices. To examine the performance on the population without concept drift, Monte Carlo experiments were performed. In a first step, the implemented population model was inspected to prove its correctness. For this purpose, 10,000 randomly sampled devices were exposed to 200 evenly spaced gas fractions (CO: 0–1000 ppb, NO
2: 0–200 ppb, O
3: 0–200 ppb) without mixing, and
Figure 3 depicts the results of the calibration simulation (q
0.50, q
0.25–0.75, q
0.05–0.95) of the three sensors as function of the fractions. The computed median baselines (CO-B4: −110.45 nA, NO
2-B4: 0.41 nA, OX-B4: −0.79 nA) match approximately the median baselines in
Table 1, which is also true for the median sensitivities (CO-B4: 0.53 nA/ppb, NO
2-B4: −0.43 nA/ppb, OX-B4: −0.49 nA/ppb), and deviations result from the Monte Carlo error.
In
Figure S4, a randomly sampled device was calibrated (with 10,000 randomly sampled values) in two different settings, once with lower fractions of NO
2 (
Figure S4a, CO: 0–400 ppb, NO
2: 0–15 ppb, O
3: 0–150 ppb) and once with higher fractions of NO
2 (
Figure S4b, CO: 0–400 ppb, NO
2: 0–150 ppb, O
3: 0–150 ppb). Recall that the generated fractions were sampled from uniform distributions. Due to the linearity of the model, the signal distributions are uniform as well, with two exceptions. The NO
2-B4 sensor shows mainly noise for low fractions and is therefore close to normally distributed (
Figure S4a), which becomes uniform for higher fractions once the signal-to-noise ratio increases (
Figure S4b). The opposite is true for the OX-B4 sensor, but the reason is different. For low fractions of NO
2, the sensor signal is mainly generated by O
3. If higher amounts of NO
2 are used, moderate sensor signals are generated in three different ways: low O
3 and high NO
2 values, high O
3 and low NO
2 values, or intermediate values of both gases. These three scenarios are more likely than the extremes responsible for the lowest and highest sensor signal intensities, i.e., very low and very high fractions of O
3/NO
2, leading to a triangular distribution.
In a second step, 10,000 Monte Carlo experiments of sensor sampling, followed by monitoring over two years at moderate but constant fractions, were performed (
Figure 4a, CO: 50 ppb, NO
2: 50 ppb, O
3: 50 ppb).
Figure 4a depicts the population distribution (q
0.50, q
0.25–0.75, q
0.05–0.95) of the three sensor signals over time; the zero drift is mildly visible, especially for CO-B4. The same procedure is repeated at higher fractions (
Figure 4b, CO: 600 ppb, NO
2: 600 ppb, O
3: 600 ppb). The signals have the tendency to converge towards the baseline (especially NO
2-B4 and OX-B4), which can be attributed to the exponential decay of the sensitivity. In
Figure S5a,b, one randomly sample device is examined, depicting noise, zero, and sensitivity drift. The trajectories show baseline drift at fractions of zero (
Figure S5a), and the decay of sensitivity is pronounced at increased fractions of gases (
Figure S5b). Overall, the zero drift appears to play a major role at low fractions, while the opposite is true for the sensitivity drift. The results are consistent with the data in
Table 1.
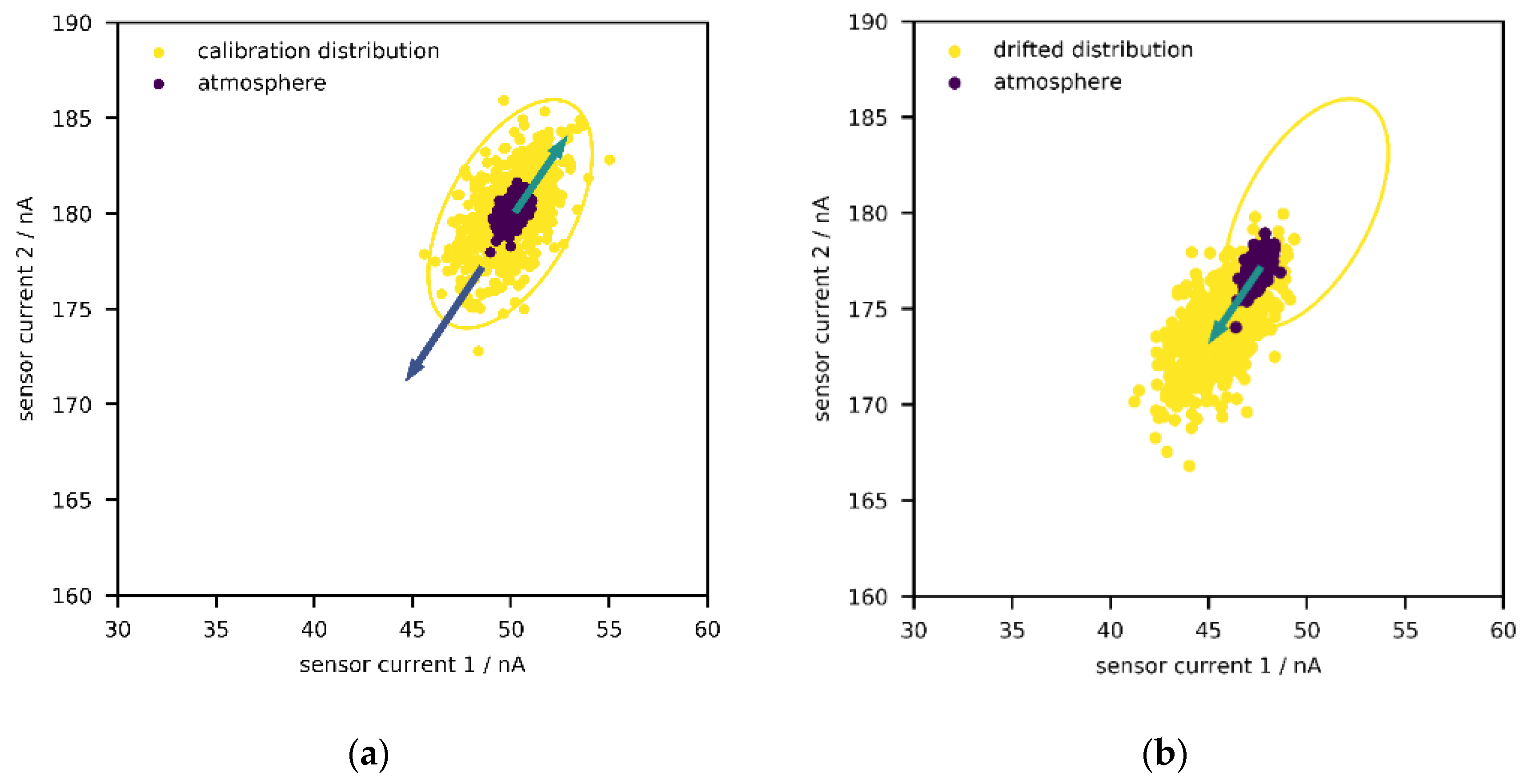
Before moving onto the results of the population model, it is worth mentioning that establishing PD for low-cost sensors will also require studying the dynamics of the atmosphere, i.e., trajectories and time constants of changes in fractions of the measured pollutants, and comparing it with the dynamics of aging over the whole population of sensors. As discussed above, field calibration captures only a (random) subset of the complete atmosphere at a specific location, and the relationships between the compounds change over time. Consequently, the current atmosphere can be interpreted as a smaller distribution within the field calibration distribution (
Figure 5a). Depending on “how much” of the complete distribution has been captured during calibration, the current atmosphere might leave the envelope, which then causes anomalies, as seen in
Figure 2.
Moreover, depending on the direction of the largest expansion of the envelope around the field data, the direction of drift in the signal space, and the trajectory of the atmosphere, the aging drift can be “masked” for some time. Such masking happens, for example, when the temporally local atmosphere, e.g., the collection of data points from the last week, moves towards higher levels (e.g., due to seasonality), thereby generating higher sensor signal intensities, while the aging drift leads to lower signal intensities, a scenario illustrated in
Figure 5a. To elaborate this with a hypothetical example, suppose that the CO level was monotonically increasing over the course of a year, which would lead to a higher signal intensity; in addition, the sensor aging process was lowering the signal intensity over time. This would be interpreted as increasing gas levels at decreased speed (in comparison with reliable reference devices). Depending on the time constants of both processes, the signal distribution would shift a lot, although this would not be recognized, since the atmosphere would move in the opposite direction and would be still within the confidence region—i.e., inside the envelope. If aging drift carried on and the atmospheric gas levels finally decreased, the generated sensor signals would be low enough to be outside the envelope, thereby being detected by the ML algorithms at this point (
Figure 5b).
Although such peculiarities delay the necessary maintenance, they are unlikely to happen on a regular basis. Another event is more probable and not limited to field calibration but can also occur with laboratory calibration. More precisely, if drift caused higher signal intensities over time, but the calibration limits are set much higher than what was observed in the atmosphere, the signal distribution could shift inside the envelope and no anomalies would be recognized over time, since the highest possible signal intensities would be always within the envelope.
Even if the upper calibration limits were not excessively high, the aging process can be hidden. Under the assumption that the population model reflects the real-word physics, the simulations above show that the existence of sensitivity drift leads to a compression of the distribution towards the baseline, i.e., the lowest possible value, while the baseline drift causes the baseline to move in any direction. Therefore, zero drift can be interpreted as a random vector with independent components acting on the baseline. As for sensitivity drift, another random vector acts on the maximum possible sensor signal and points towards the baseline, thus compressing the whole sensor signal distribution.
With two sensors, the confidence region can be thought of as square-like region in two dimensions due to the uniform calibration distributions, and the baseline becomes the lowest possible value, given that fraction of zero is included in the calibration (
Figure 6a). As mentioned above, issues might occur if the (shrinking) signal distribution shifts/drifts inside the envelope (
Figure 6b), which might happen for a non-negligible portion of low-cost sensor systems. From geometrical interpretation, one could assume that the probability to drift inside the confidence region should be around 25% (one out of four squares). With three sensors, this probability then reduces to 12.5%, since there are eight cubes and the envelope is one of them, and the probability decrease further with the inclusion of further sensors. Hence, for a device with
p sensors, this probability would be around 2
−p. The outcome of such a process is that, over time, all incoming measurement results will be accepted and no anomalies detected anymore. Thus, there might be a subpopulation of devices failing to perform PD with the presented algorithms.
Finally, to evaluate the performance of the four algorithms on the whole population of low-cost sensor systems with laboratory calibration, Monte Carlo experiments were combined with unsupervised anomaly detection (
ν was fixed to 0.10 for consistency). In total, 1000 random devices were sampled and calibrated with 10,000 randomly sampled fractions (CO: 0–1000 ppb, NO
2: 0–100 ppb, O
3: 0–100 ppb), whereas the resulting signal distribution was used to train the algorithms. For drift monitoring, the data set of collected references values by Zimmerman et al. was iterated five times (i.e., repeating the four months of observations), thereby simulating pseudo-seasonality. These reference values were used to generate sensor signals and the devices underwent aging with increasing time index (according to Equations (4)–(6)), whereas the generated sensor signals were assessed according to their position relative to the envelopes.
Figure 7 shows anomalies for the four algorithms (monthly moving average) over the whole population of low-cost sensor systems (q
0.50, q
0.25–0.75, q
0.05–0.95).
In the initial phase, the spread is small and becomes larger over time, as the influence of drift (i.e., its direction relative to the envelope) starts playing a role. The dynamics of the atmosphere are visible, as the fraction of anomalies increases and decreases periodically, although the median trend is to increase over time. In contrast to field calibration (
Figure 2a and
Figure S2), the recalibration frequency appears smaller when lab calibration is performed, which comes from the fact that the average fraction of anomalies peaks much later (
Figure 2a and
Figure 7), which can be explained by the extended calibration range. The differences between the four algorithms seems negligible; OCSVM and IF detect an anomaly peak in the half-time of the first 150 days, which is not the case for RC and LOF. However, this first anomaly peak has a much lower magnitude and occurs later in time compared with this hypothetical laboratory calibration, which is natural as no concept drift is possible. In this example, sensor aging becomes visible after five months as the four algorithms depict the increase in anomalies, though with a diverging anomaly fraction over the population.
While the PD approach with the presented algorithms appears to work for at least 50% of all devices (in 50% of all cases, the fraction of anomalies increases over time), it seems not to be true for at least some other 25% of the devices. This might support the aforementioned hypothesis since the trajectories of the lower quantiles indicate breakdown of the anomaly detectors. Remarkably, the probability of failing appears to be at least twice as high compared to what is calculated above (for a device with three sensors). On one hand, there is certainly a small portion of devices with little to no drift at all. On the other hand, even if the baseline does not move strictly inside the envelope but passes close to it, some part of the drifted signal distribution will overlap with the envelope, and depending on the dynamics of the atmospheric gas levels, signal drift can be masked again. The underlying issue is that drifts and changes in fractions are often indistinguishable without knowing any further information, thus it is of importance to engineer solutions that deal with this problem while still only having need of calibration data. Nonetheless, there is a chance that breakdown occurs less frequently in real-world scenarios, e.g., as some of the assumptions might not be fulfilled, thus field experiments would be needed to verify the results.
In addition to cost effectiveness, this also explains the preference towards preventive maintenance such as drift compensation using the combined knowledge of the whole sensor network. For example, a class of statistical methods have been developed that aim to detect and remove sensor drift components during operation (blind calibration), although this requires dense deployment of the network and an initial model learning phase [
44,
45,
46]. Due to the reconstruction of the original signals, one initial laboratory calibration would be sufficient and no further recalibration would be needed. However, these methods are not necessarily dedicated to low-cost electrochemical sensors, as they assume random walk behavior of zero drift (which is more realistic) but tend to neglect sensitivity drift. Moreover, the approach becomes unstable if many sensors express drift, but also if the underlying pollution phenomena change over the year.
If mobile sensor systems (e.g., on public transport or drones) with high measurement accuracy are deployed as well, frequently exchanged measurement results can also be used to perform cheap recalibrations without explicitly having to recognize drifts or the optimal moment for recalibration [
47,
48,
49]. Similar approaches have been explored with stationary reference stations as recalibration seeds, although so far only for particulate matter [
50]. Nonetheless, a handful of well-characterized low-cost sensor systems distributed across a city might do a similar job. On a final note, the question arises to what extent the different procedures could be superimposed to obtain even more reliable measurement results.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}