
Horizontal Review on Video Surveillance for Smart Cities: Edge Devices, Applications, Datasets, and Future Trends

 , , and
, , and
Abstract
1. Introduction
2. Background
2.1. Smart Cities
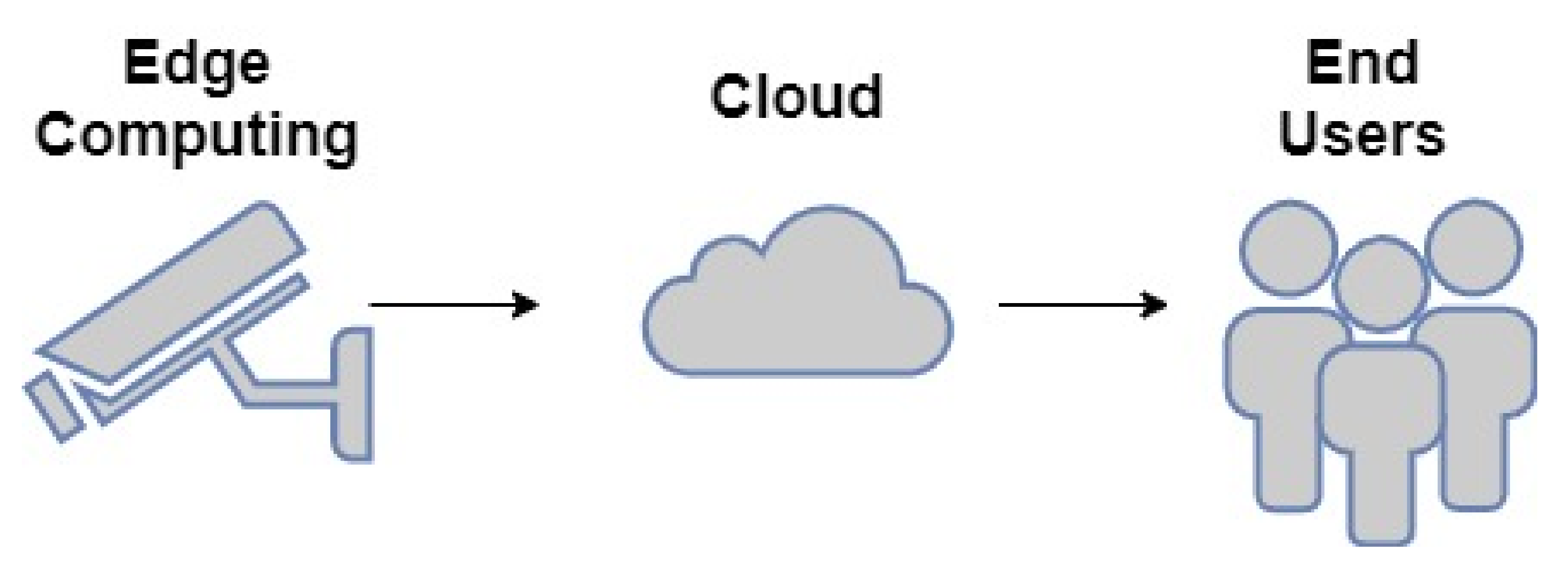
2.2. Video Surveillance
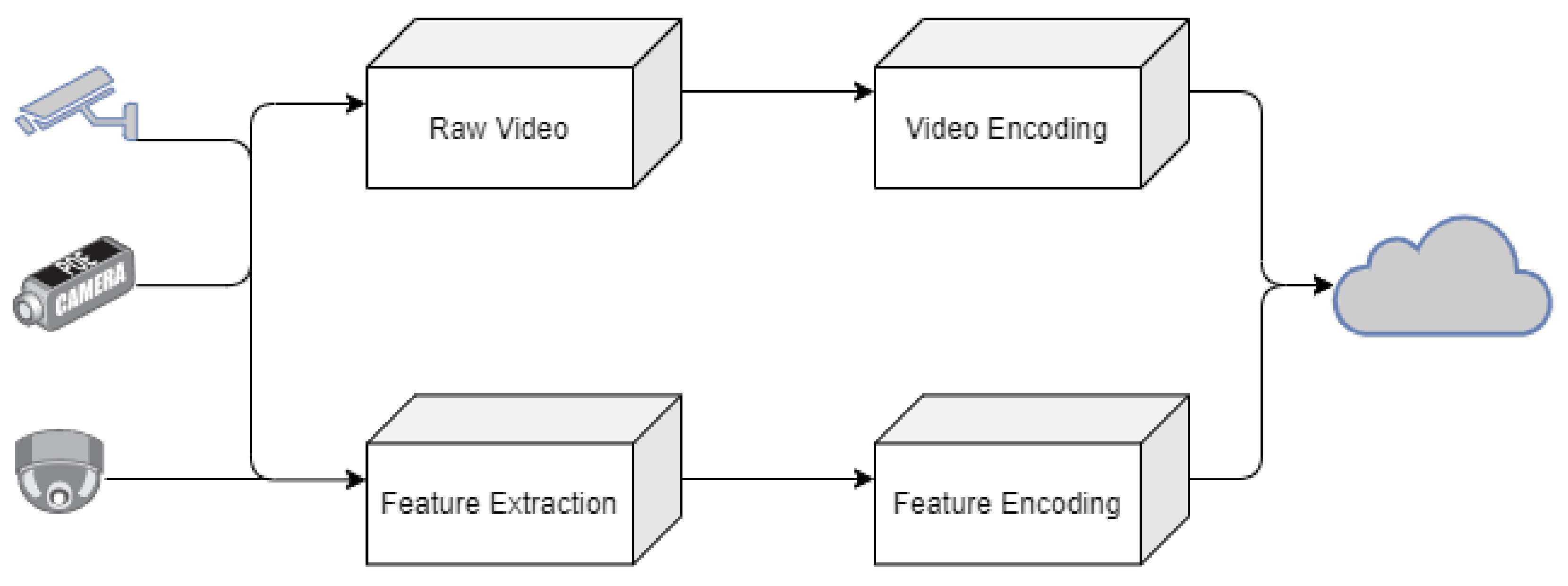
2.2.1. Edge Computing Component
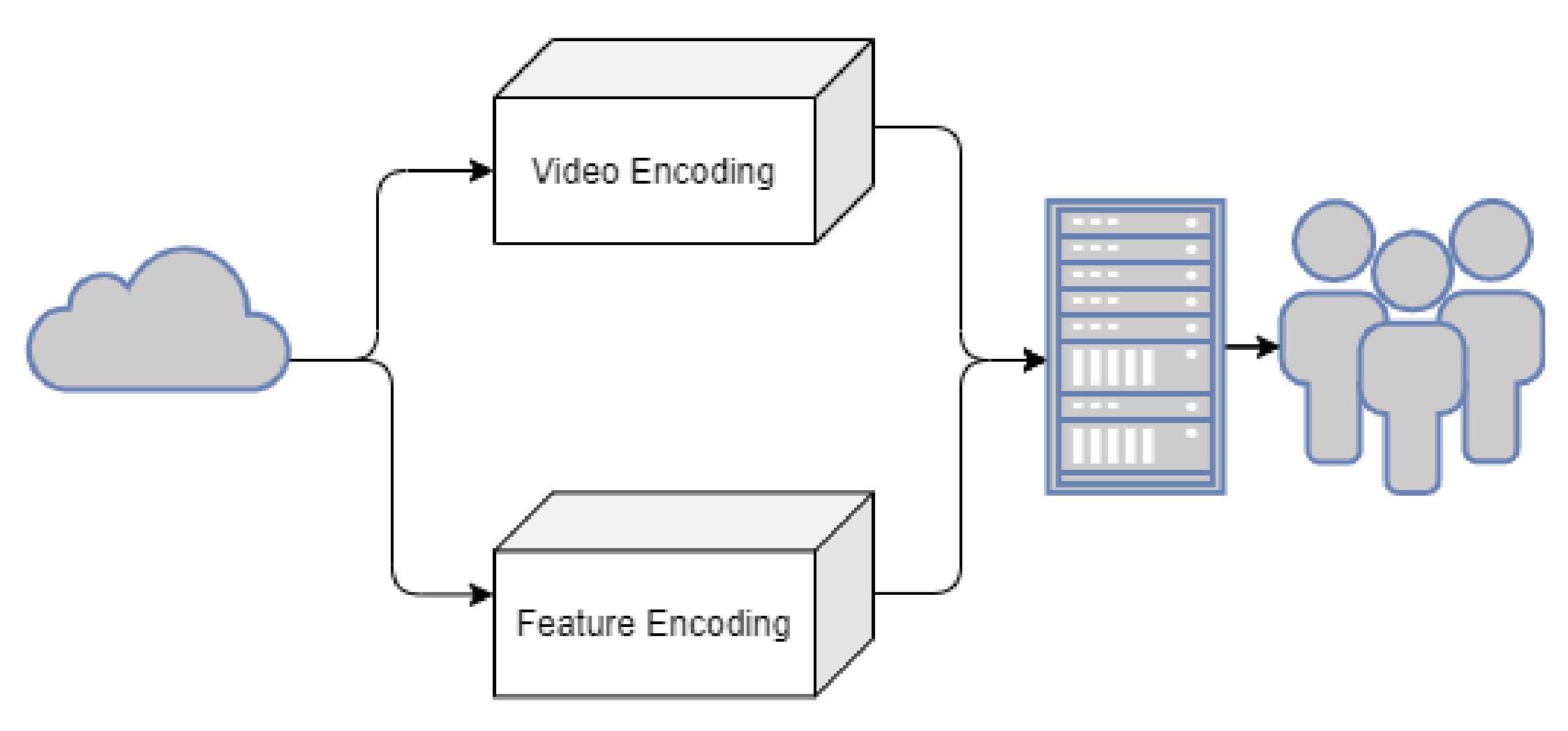
2.2.2. Smart City Inhabitant Management (Cloud)
2.2.3. End Users
2.3. Edge Computing Video Surveillance
2.4. IOT and Edge-Computing Surveillance
2.5. Surveillance Technologies in Smart Cities Digest
3. Embedded Systems in Computer Vision
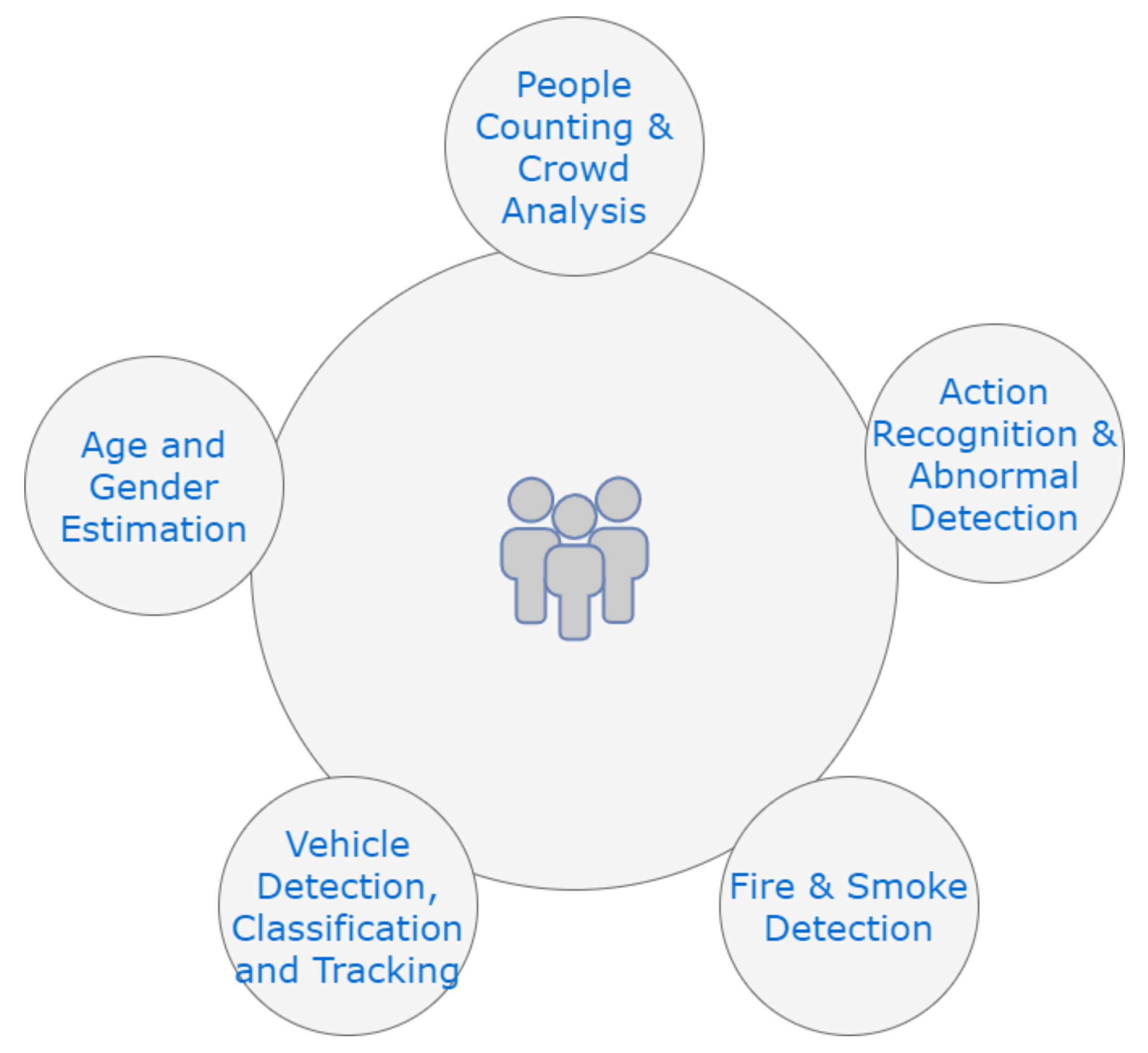
4. Computer Vision Applications
4.1. People Counting and Crowd Analysis
4.2. Age and Gender Estimation
4.3. Action Recognition and Abnormality Detection
4.4. Fire and Smoke Detection
4.5. Vehicle Detection, Classification and Tracking
5. Discussion and Future Trends
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Washburn, D.; Sindhu, U.; Balaouras, S.; Dines, R.A.; Hayes, N.; Nelson, L.E. Helping CIOs understand “smart city” initiatives. Growth 2009, 17, 1–17. [Google Scholar]
- Giffinger, R.; Gudrun, H. Smart cities ranking: An effective instrument for the positioning of the cities? ACE Archit. City Environ. 2010, 4, 7–26. [Google Scholar]
- Hall, R.E.; Bowerman, B.; Braverman, J.; Taylor, J.; Todosow, H.; Von Wimmersperg, U. The Vision of a Smart City; Technical Report; Brookhaven National Lab.: Upton, NY, USA, 2000. [Google Scholar]
- Duan, L.; Lou, Y.; Wang, S.; Gao, W.; Rui, Y. AI-Oriented Large-Scale Video Management for Smart City: Technologies, Standards, and Beyond. IEEE MultiMedia 2018, 26, 8–20. [Google Scholar] [CrossRef]
- Ren, J.; Guo, Y.; Zhang, D.; Liu, Q.; Zhang, Y. Distributed and Efficient Object Detection in Edge Computing: Challenges and Solutions. IEEE Netw. 2018, 32, 137–143. [Google Scholar] [CrossRef]
- Alshammari, A.; Rawat, D.B. Intelligent multi-camera video surveillance system for smart city applications. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 317–323. [Google Scholar]
- Wang, R.; Tsai, W.T.; He, J.; Liu, C.; Li, Q.; Deng, E. A Video Surveillance System Based on Permissioned Blockchains and Edge Computing. In Proceedings of the 2019 IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 February–2 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Acharya, D.; Khoshelham, K.; Winter, S. Real-time detection and tracking of pedestrians in CCTV images using a deep convolutional neural network. In Proceedings of the 4th Annual Conference of Research@ Locate, Sydney, Australia, 3–6 April 2017; Volume 1913, pp. 31–36. [Google Scholar]
- Fu, X.; Yang, Y. Modeling and analyzing cascading failures for Internet of Things. Inf. Sci. 2021, 545, 753–770. [Google Scholar] [CrossRef]
- Fu, X.; Yang, Y. Modeling and analysis of cascading node-link failures in multi-sink wireless sensor networks. Reliab. Eng. Syst. Saf. 2020, 197, 106815. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhou, Y.; Sun, Y.; Wang, Z.; Liu, B.; Li, K. Federated Learning in Smart Cities: A Comprehensive Survey. arXiv 2021, arXiv:2102.01375. [Google Scholar]
- Dlodlo, N.; Gcaba, O.; Smith, A. Internet of things technologies in smart cities. In Proceedings of the 2016 IST-Africa Week Conference, Durban, South Africa, 11–13 May 2016; pp. 1–7. [Google Scholar]
- Gharaibeh, A.; Salahuddin, M.A.; Hussini, S.J.; Khreishah, A.; Khalil, I.; Guizani, M.; Al-Fuqaha, A. Smart cities: A survey on data management, security, and enabling technologies. IEEE Commun. Surv. Tutor. 2017, 19, 2456–2501. [Google Scholar] [CrossRef]
- Roman, R.; Lopez, J.; Mambo, M. Mobile edge computing, fog et al.: A survey and analysis of security threats and challenges. Future Gener. Comput. Syst. 2018, 78, 680–698. [Google Scholar] [CrossRef]
- Hu, P.; Dhelim, S.; Ning, H.; Qiu, T. Survey on fog computing: Architecture, key technologies, applications and open issues. J. Netw. Comput. Appl. 2017, 98, 27–42. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A survey on the edge computing for the Internet of Things. IEEE Access 2017, 6, 6900–6919. [Google Scholar] [CrossRef]
- Hassan, N.; Gillani, S.; Ahmed, E.; Yaqoob, I.; Imran, M. The role of edge computing in internet of things. IEEE Commun. Mag. 2018, 56, 110–115. [Google Scholar] [CrossRef]
- Eigenraam, D.; Rothkrantz, L. A smart surveillance system of distributed smart multi cameras modelled as agents. In Proceedings of the 2016 Smart Cities Symposium Prague (SCSP), Prague, Czech Republic, 26–27 May 2016; pp. 1–6. [Google Scholar]
- Bilal, K.; Khalid, O.; Erbad, A.; Khan, S.U. Potentials, trends, and prospects in edge technologies: Fog, cloudlet, mobile edge, and micro data centers. Comput. Netw. 2018, 130, 94–120. [Google Scholar] [CrossRef]
- Ai, Y.; Peng, M.; Zhang, K. Edge computing technologies for Internet of Things: A primer. Digit. Commun. Netw. 2018, 4, 77–86. [Google Scholar] [CrossRef]
- Achmad, K.A.; Nugroho, L.E.; Djunaedi, A.; Widyawan, W. Smart City Model: A Literature Review. In Proceedings of the 2018 10th International Conference on Information Technology and Electrical Engineering (ICITEE), Bali, Indonesia, 24–26 July 2018; pp. 488–493. [Google Scholar]
- Lim, C.; Kim, K.J.; Maglio, P.P. Smart cities with big data: Reference models, challenges, and considerations. Cities 2018, 82, 86–99. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, W.; Wu, F.; De, S.; Wang, R.; Zhang, B.; Huang, X. A survey on an emerging area: Deep learning for smart city data. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 392–410. [Google Scholar] [CrossRef]
- Ke, R.; Zhuang, Y.; Pu, Z.; Wang, Y. A smart, efficient, and reliable parking surveillance system with edge artificial intelligence on IoT devices. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Jameel, T.; Ali, R.; Ali, S. Security in modern smart cities: An information technology perspective. In Proceedings of the 2019 2nd International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 6–7 March 2019; pp. 293–298. [Google Scholar]
- Balsamo, D.; Weddell, A.S.; Das, A.; Arreola, A.R.; Brunelli, D.; Al-Hashimi, B.M.; Merrett, G.V.; Benini, L. Hibernus++: A self-calibrating and adaptive system for transiently-powered embedded devices. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2016, 35, 1968–1980. [Google Scholar] [CrossRef]
- Piyare, R.; Lee, S.R. Smart home-control and monitoring system using smart phone. ICCA ASTL 2013, 24, 83–86. [Google Scholar]
- Rodrigues, C.F.; Riley, G.; Luján, M. Fine-grained energy profiling for deep convolutional neural networks on the Jetson TX1. In Proceedings of the 2017 IEEE International Symposium on Workload Characterization (IISWC), Seattle, WA, USA, 1–3 October 2017; pp. 114–115. [Google Scholar]
- Natarov, R.; Dyka, Z.; Bohovyk, R.; Fedoriuk, M.; Isaev, D.; Sudakov, O.; Maksymyuk, O.; Krishtal, O.; Langendörfer, P. Artefacts in EEG Signals Epileptic Seizure Prediction using Edge Devices. In Proceedings of the 2020 9th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 8–11 June 2020; pp. 1–3. [Google Scholar]
- Babu, R.G.; Karthika, P.; Rajan, V.A. Secure IoT systems using raspberry Pi machine learning artificial intelligence. In Proceedings of the International Conference on Computer Networks and Inventive Communication Technologies, Coimbatore, India, 23–24 May 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 797–805. [Google Scholar]
- Wang, Y.; Balmos, A.D.; Layton, A.W.; Noel, S.; Ault, A.; Krogmeier, J.V.; Buckmaster, D.R. An Open-Source Infrastructure for Real-Time Automatic Agricultural Machine Data Processing. In Proceedings of the 2017 ASABE American Society of Agricultural and Biological Engineers Annual International Meeting, Spokane, WA, USA, 16–19 July 2017. [Google Scholar]
- Ohta, A.; Isshiki, T.; Kunieda, H. New FPGA architecture for bit-serial pipeline datapath. In Proceedings of the IEEE Symposium on FPGAs for Custom Computing Machines (Cat. No. 98TB100251), Napa Valley, CA, USA, 17 April 1998; pp. 58–67. [Google Scholar]
- Ancarani, F.; De Gloria, D.; Olivieri, M.; Stazzone, C. Design of an ASIC architecture for high speed fractal image compression. In Proceedings of the Ninth Annual IEEE international ASIC Conference and Exhibit, Rochester, NY, USA, 23–27 September 1996; pp. 223–226. [Google Scholar]
- Basterretxea, K.; Echanobe, J.; del Campo, I. A wearable human activity recognition system on a chip. In Proceedings of the 2014 Conference on Design and Architectures for Signal and Image Processing, Madrid, Spain, 8–10 October 2014; pp. 1–8. [Google Scholar]
- Bahoura, M. FPGA implementation of blue whale calls classifier using high-level programming tool. Electronics 2016, 5, 8. [Google Scholar] [CrossRef]
- Zhai, X.; Ali, A.A.S.; Amira, A.; Bensaali, F. MLP neural network based gas classification system on Zynq SoC. IEEE Access 2016, 4, 8138–8146. [Google Scholar] [CrossRef]
- Alilat, F.; Yahiaoui, R. MLP on FPGA: Optimal Coding of Data and Activation Function. In Proceedings of the 2019 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Metz, France, 18–21 September 2019; Volume 1, pp. 525–529. [Google Scholar]
- Akbar, M.A.; Ali, A.A.S.; Amira, A.; Bensaali, F.; Benammar, M.; Hassan, M.; Bermak, A. An empirical study for PCA-and LDA-based feature reduction for gas identification. IEEE Sensors J. 2016, 16, 5734–5746. [Google Scholar] [CrossRef]
- Lin, Y.S.; Chen, W.C.; Chien, S.Y. MERIT: Tensor Transform for Memory-Efficient Vision Processing on Parallel Architectures. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 28, 791–804. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing fpga-based accelerator design for deep convolutional neural networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar]
- Zhao, R.; Niu, X.; Wu, Y.; Luk, W.; Liu, Q. Optimizing CNN-based object detection algorithms on embedded FPGA platforms. In Proceedings of the International Symposium on Applied Reconfigurable Computing, Delft, The Netherlands, 3–7 April 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 255–267. [Google Scholar]
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating binarized neural networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 77–84. [Google Scholar]
- Kim, J.W.; Choi, K.S.; Choi, B.D.; Ko, S.J. Real-time vision-based people counting system for the security door. In Proceedings of the International Technical Conference on Circuits/Systems Computers and Communications, Phuket, Thailand, 16–19 July 2002; Volume 2002, pp. 1416–1419. [Google Scholar]
- Laptev, I.; Pérez, P. Retrieving actions in movies. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Tao, C.; Zhang, J.; Wang, P. Smoke detection based on deep convolutional neural networks. In Proceedings of the 2016 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016; pp. 150–153. [Google Scholar]
- Zhang, K.; Gao, C.; Guo, L.; Sun, M.; Yuan, X.; Han, T.X.; Zhao, Z.; Li, B. Age group and gender estimation in the wild with deep RoR architecture. IEEE Access 2017, 5, 22492–22503. [Google Scholar] [CrossRef]
- Cutler, R.; Davis, L.S. Robust real-time periodic motion detection, analysis, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 781–796. [Google Scholar] [CrossRef]
- Hoffman, D.; Flinchbaugh, B. The interpretation of biological motion. Biol. Cybern. 1982, 42, 195–204. [Google Scholar] [PubMed]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; pp. 555–562. [Google Scholar]
- Wu, X.; Liang, G.; Lee, K.K.; Xu, Y. Crowd density estimation using texture analysis and learning. In Proceedings of the 2006 IEEE International Conference on Robotics and Biomimetics, Kunming, China, 17–20 December 2006; pp. 214–219. [Google Scholar]
- An, S.; Liu, W.; Venkatesh, S. Face recognition using kernel ridge regression. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. Adv. Neural Inf. Process. Syst. 2010, 23, 1324–1332. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012; Volume 1. [Google Scholar]
- Chen, K.; Gong, S.; Xiang, T.; Change Loy, C. Cumulative attribute space for age and crowd density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2467–2474. [Google Scholar]
- Zhan, B.; Monekosso, D.N.; Remagnino, P.; Velastin, S.A.; Xu, L.Q. Crowd analysis: A survey. Mach. Vis. Appl. 2008, 19, 345–357. [Google Scholar] [CrossRef]
- Chen, K.; Kämäräinen, J.K. Pedestrian density analysis in public scenes with spatiotemporal tensor features. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1968–1977. [Google Scholar] [CrossRef]
- Wang, G.; Zou, Y.; Li, Z.; Yang, D. SMCA-CNN: Learning a Semantic Mask and Cross-Scale Adaptive Feature for Robust Crowd Counting. IEEE Access 2019, 7, 168495–168506. [Google Scholar] [CrossRef]
- Xiong, H.; Lu, H.; Liu, C.; Liu, L.; Cao, Z.; Shen, C. From open set to closed set: Counting objects by spatial divide-and-conquer. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 8362–8371. [Google Scholar]
- Tian, Q.; Zhou, B.; Zhao, W.H.; Wei, Y.; Fei, W.W. Human Detection using HOG Features of Head and Shoulder Based on Depth Map. JSW 2013, 8, 2223–2230. [Google Scholar] [CrossRef][Green Version]
- Fradi, H.; Dugelay, J.L. Towards crowd density-aware video surveillance applications. Inf. Fusion 2015, 24, 3–15. [Google Scholar] [CrossRef]
- Lebanoff, L.; Idrees, H. Counting in Dense Crowds Using Deep Learning; University of Central California: Upland, CA, USA, 2015. [Google Scholar]
- Gao, B.B.; Xing, C.; Xie, C.W.; Wu, J.; Geng, X. Deep label distribution learning with label ambiguity. IEEE Trans. Image Process. 2017, 26, 2825–2838. [Google Scholar] [CrossRef] [PubMed]
- Demirkus, M.; Toews, M.; Clark, J.J.; Arbel, T. Gender classification from unconstrained video sequences. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 55–62. [Google Scholar]
- Shah, M.; Javed, O.; Shafique, K. Automated visual surveillance in realistic scenarios. IEEE MultiMedia 2007, 14, 30–39. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Kim, K.W.; Hong, H.G.; Koo, J.H.; Kim, M.C.; Park, K.R. Gender recognition from human-body images using visible-light and thermal camera videos based on a convolutional neural network for image feature extraction. Sensors 2017, 17, 637. [Google Scholar] [CrossRef] [PubMed]
- Arigbabu, O.A.; Ahmad, S.M.S.; Adnan, W.A.W.; Yussof, S.; Mahmood, S. Soft biometrics: Gender recognition from unconstrained face images using local feature descriptor. arXiv 2017, arXiv:1702.02537. [Google Scholar]
- Bosch, A.; Zisserman, A.; Munoz, X. Representing shape with a spatial pyramid kernel. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 401–408. [Google Scholar]
- Setty, S.; Husain, M.; Beham, P.; Gudavalli, J.; Kandasamy, M.; Vaddi, R.; Hemadri, V.; Karure, J.; Raju, R.; Rajan, B.; et al. Indian movie face database: A benchmark for face recognition under wide variations. In Proceedings of the 2013 Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing And Graphics (NCVPRIPG), Jodhpur, India, 18–21 December 2013; pp. 1–5. [Google Scholar]
- Assaleh, K.; Shanableh, T.; Abuqaaud, K. Face recognition using different surveillance cameras. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–5. [Google Scholar]
- Fariza, A.; Mu’arifin; Arifin, A.Z. Age Estimation System Using Deep Residual Network Classification Method. In Proceedings of the 2019 International Electronics Symposium (IES), Surabaya, Indonesia, 27–28 September 2019; pp. 607–611. [Google Scholar]
- Fu, Y.; Guo, G.; Huang, T.S. Age synthesis and estimation via faces: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1955–1976. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [PubMed]
- Guo, G.; Mu, G.; Fu, Y.; Huang, T.S. Human age estimation using bio-inspired features. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 112–119. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Kläser, A.; Marszalek, M.; Schmid, C. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Proceedings of the British Machine Vision Conference, Leeds, UK, 1 September 2008. [Google Scholar] [CrossRef]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Action recognition by dense trajectories. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3169–3176. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Work Stat Learn Comput Vision, ECCV, Prague, Czech Republic, 11–14 May 2004; Volume 1. [Google Scholar]
- Perronnin, F.; Dance, C. Fisher kernels on visual vocabularies for image categorization. In Proceedings of the 2007 IEEE Conference on Computer Vision And Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 568–576. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 20–36. [Google Scholar]
- Ma, S.; Sigal, L.; Sclaroff, S. Learning activity progression in lstms for activity detection and early detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1942–1950. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4597–4605. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1510–1517. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Paluri, M.; Gall, J.; Stiefelhagen, R.; Van Gool, L. Holistic large scale video understanding. arXiv 2019, arXiv:1904.11451. [Google Scholar]
- Gaidon, A.; Harchaoui, Z.; Schmid, C. Temporal localization of actions with actoms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2782–2795. [Google Scholar] [CrossRef]
- Tian, Y.; Sukthankar, R.; Shah, M. Spatiotemporal deformable part models for action detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2642–2649. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal action localization in untrimmed videos via multi-stage cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1049–1058. [Google Scholar]
- Yeung, S.; Russakovsky, O.; Mori, G.; Fei-Fei, L. End-to-end learning of action detection from frame glimpses in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2678–2687. [Google Scholar]
- Escorcia, V.; Heilbron, F.C.; Niebles, J.C.; Ghanem, B. Daps: Deep action proposals for action understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 768–784. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal action detection with structured segment networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2914–2923. [Google Scholar]
- Nguyen, T.N.; Meunier, J. Anomaly detection in video sequence with appearance-motion correspondence. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1273–1283. [Google Scholar]
- Xu, Z.; Zhu, S.; Fu, B.; Cheng, Y.; Fang, F. Motion coherence based abnormal behavior detection. In Proceedings of the 2017 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 214–218. [Google Scholar]
- Patron-Perez, A.; Marszalek, M.; Reid, I.; Zisserman, A. Structured learning of human interactions in TV shows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2441–2453. [Google Scholar] [CrossRef]
- Köpüklü, O.; Kose, N.; Gunduz, A.; Rigoll, G. Resource efficient 3d convolutional neural networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27 October–2 November 2019; pp. 1910–1919. [Google Scholar]
- Monfort, M.; Andonian, A.; Zhou, B.; Ramakrishnan, K.; Bargal, S.A.; Yan, T.; Brown, L.; Fan, Q.; Gutfreund, D.; Vondrick, C.; et al. Moments in time dataset: One million videos for event understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 502–508. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Yan, Z.; Wang, H.; Torresani, L.; Torralba, A. SLAC: A sparsely labeled dataset for action classification and localization. arXiv 2017, arXiv:1712.093742. [Google Scholar]
- Goyal, R.; Kahou, S.E.; Michalski, V.; Materzyńska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The "something something" video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 510–526. [Google Scholar]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Luo, X.; Ye, O.; Zhou, B. An Modified Video Stream Classification Method Which Fuses Three-Dimensional Convolutional Neural Network. In Proceedings of the 2019 International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 8–10 November 2019; pp. 105–108. [Google Scholar]
- Xiang, Y.; Okada, Y.; Kaneko, K. Action recognition for videos by long-term point trajectory analysis with background removal. In Proceedings of the 2016 12th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Naples, Italy, 28 November–1 December 2016; pp. 23–30. [Google Scholar]
- Al-Berry, M.; Salem, M.A.M.; Ebeid, H.; Hussein, A.; Tolba, M.F. Directional Multi-Scale Stationary Wavelet-Based Representation for Human Action Classification. In Handbook of Research on Machine Learning Innovations and Trends; IGI Global: Hershey, PA, USA, 2017; pp. 295–319. [Google Scholar]
- Al-Berry, M.; Salem, M.M.; Hussein, A.; Tolba, M. Spatio-temporal motion detection for intelligent surveillance applications. Int. J. Comput. Methods 2015, 12, 1350097. [Google Scholar] [CrossRef]
- Wang, D.; Shao, Q.; Li, X. A new unsupervised model of action recognition. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 1160–1164. [Google Scholar]
- Yin, Z.; Wan, B.; Yuan, F.; Xia, X.; Shi, J. A deep normalization and convolutional neural network for image smoke detection. IEEE Access 2017, 5, 18429–18438. [Google Scholar] [CrossRef]
- Yang, Z.; Shi, W.; Huang, Z.; Yin, Z.; Yang, F.; Wang, M. Combining Gaussian mixture model and HSV model with deep convolution neural network for detecting smoke in videos. In Proceedings of the 2018 IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 8–11 October 2018; pp. 1266–1270. [Google Scholar]
- Filonenko, A.; Kurnianggoro, L.; Jo, K.H. Smoke detection on video sequences using convolutional and recurrent neural networks. In Proceedings of the International Conference on Computational Collective Intelligence, Nicosia, Cyprus, 27 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 558–566. [Google Scholar]
- Salhi, L.; Silverston, T.; Yamazaki, T.; Miyoshi, T. Early Detection System for Gas Leakage and Fire in Smart Home Using Machine Learning. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; pp. 1–6. [Google Scholar]
- Pérez-Chust, R.; Fernández-Moreno, M.; García, D.F. Detection of atmospheric emissions by classifying images with convolutional neural networks. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 1523–1527. [Google Scholar]
- Li, X.; Chen, Z.; Wu, Q.J.; Liu, C. 3D parallel fully convolutional networks for real-time video wildfire smoke detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 30, 89–103. [Google Scholar] [CrossRef]
- Greco, A.; Petkov, N.; Saggese, A.; Vento, M. AReN: A Deep Learning Approach for Sound Event Recognition using a Brain inspired Representation. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3610–3624. [Google Scholar] [CrossRef]
- Avgerinakis, K.; Briassouli, A.; Kompatsiaris, I. Smoke detection using temporal HOGHOF descriptors and energy colour statistics from video. In Proceedings of the International Workshop on Multi-Sensor Systems and Networks for Fire Detection and Management, Antalya, Turkey, 8–9 November 2012. [Google Scholar]
- Petrovic, V.S.; Cootes, T.F. Analysis of Features for Rigid Structure Vehicle Type Recognition. In Proceedings of the BMVC, London, UK, 7–9 September 2004; Volume 2, pp. 587–596. [Google Scholar]
- Boyle, J.; Ferryman, J. Vehicle subtype, make and model classification from side profile video. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Sochor, J.; Herout, A.; Havel, J. Boxcars: 3d boxes as cnn input for improved fine-grained vehicle recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3006–3015. [Google Scholar]
- Laroca, R.; Severo, E.; Zanlorensi, L.A.; Oliveira, L.S.; Gonçalves, G.R.; Schwartz, W.R.; Menotti, D. A robust real-time automatic license plate recognition based on the YOLO detector. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–10. [Google Scholar]
- Bas, E.; Tekalp, A.M.; Salman, F.S. Automatic vehicle counting from video for traffic flow analysis. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 392–397. [Google Scholar]
- Sina, I.; Wibisono, A.; Nurhadiyatna, A.; Hardjono, B.; Jatmiko, W.; Mursanto, P. Vehicle counting and speed measurement using headlight detection. In Proceedings of the 2013 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Sanur Bali, Indonesia, 28–29 September 2013; pp. 149–154. [Google Scholar]
- Kim, H. Multiple vehicle tracking and classification system with a convolutional neural network. J. Ambient. Intell. Humaniz. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, X.; Story, B.; Rajan, D. Accurate vehicle detection using multi-camera data fusion and machine learning. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3767–3771. [Google Scholar]
- Abdillah, B.; Jati, G.; Jatmiko, W. Improvement CNN Performance by Edge Detection Preprocessing for Vehicle Classification Problem. In Proceedings of the 2018 International Symposium on Micro-NanoMechatronics and Human Science (MHS), Nagoya, Japan, 9–12 December 2018; pp. 1–7. [Google Scholar]
- Priyadharshini, R.A.; Arivazhagan, S.; Sangeetha, L. Vehicle recognition based on Gabor and Log-Gabor transforms. In Proceedings of the 2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies, Ramanathapuram, India, 8–10 May 2014; pp. 1268–1272. [Google Scholar]
- Lu, K.; Li, J.; Zhou, L.; Hu, X.; An, X.; He, H. Generalized haar filter-based object detection for car sharing services. IEEE Trans. Autom. Sci. Eng. 2018, 15, 1448–1458. [Google Scholar] [CrossRef]
- Kellner, D.; Barjenbruch, M.; Klappstein, J.; Dickmann, J.; Dietmayer, K. Tracking of extended objects with high-resolution Doppler radar. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1341–1353. [Google Scholar] [CrossRef]
- Bhaskar, H.; Dwivedi, K.; Dogra, D.P.; Al-Mualla, M.; Mihaylova, L. Autonomous detection and tracking under illumination changes, occlusions and moving camera. Signal Process. 2015, 117, 343–354. [Google Scholar] [CrossRef]
- Lee, K.; Yim, K.; Mikki, M.A. A secure framework of the surveillance video network integrating heterogeneous video formats and protocols. Comput. Math. Appl. 2012, 63, 525–535. [Google Scholar] [CrossRef][Green Version]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the First Edition of the MCC Workshop on Mobile cloud Computing, Helsinki, Finland, 13–17 August 2012; pp. 13–16. [Google Scholar]
- Stergiou, C.; Psannis, K.E.; Kim, B.G.; Gupta, B. Secure integration of IoT and cloud computing. Future Gener. Comput. Syst. 2018, 78, 964–975. [Google Scholar] [CrossRef]
- Sterbenz, J.P. Drones in the smart city and iot: Protocols, resilience, benefits, and risks. In Proceedings of the 2nd Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use, Singapore, 26 June 2016; p. 3. [Google Scholar]
- Niforatos, E.; Vourvopoulos, A.; Langheinrich, M. Understanding the potential of human–machine crowdsourcing for weather data. Int. J. Hum.-Comput. Stud. 2017, 102, 54–68. [Google Scholar] [CrossRef]
- Lee, G.; Mallipeddi, R.; Lee, M. Trajectory-based vehicle tracking at low frame rates. Expert Syst. Appl. 2017, 80, 46–57. [Google Scholar] [CrossRef]
- Zhang, F.; Kang, L.; Xu, X.; Shen, J.; Zhou, L. Power Controlled and Stability-based Routing Protocol for Wireless Ad Hoc Networks. J. Inf. Sci. Eng. 2017, 33, 979–992. [Google Scholar]
- Polenghi-Gross, I.; Sabol, S.A.; Ritchie, S.R.; Norton, M.R. Water storage and gravity for urban sustainability and climate readiness. J. Am. Water Work. Assoc. 2014, 106, E539–E549. [Google Scholar] [CrossRef]
- Loghin, D.; Cai, S.; Chen, G.; Dinh, T.T.A.; Fan, F.; Lin, Q.; Ng, J.; Ooi, B.C.; Sun, X.; Ta, Q.T.; et al. The disruptions of 5G on data-driven technologies and applications. IEEE Trans. Knowl. Data Eng. 2020, 32, 1179–1198. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Smart City | Surveillance | Internet of Things | Artificial Intelligence | Edge Computing |
|---|---|---|---|---|---|
| Dlodlo et al. [12] | 🗸 | × | 🗸 | × | × |
| Eigenraam et al. [18] | 🗸 | 🗸 | 🗸 | × | × |
| Roman et al. [14] | × | 🗸 | × | × | 🗸 |
| Bilal et al. [19] | × | × | 🗸 | × | 🗸 |
| Ai et al. [20] | × | × | 🗸 | × | 🗸 |
| Hu et al. [15] | × | 🗸 | × | × | 🗸 |
| Achmad et al. [21] | 🗸 | × | × | × | × |
| Yu et al. [16] | × | 🗸 | × | × | 🗸 |
| Gharaibeh et al. [13] | 🗸 | × | × | × | × |
| Lim et al. [22] | 🗸 | 🗸 | × | × | × |
| Zhaohua et al. [11] | 🗸 | × | 🗸 | 🗸 | × |
| Chen et al. [23] | 🗸 | × | 🗸 | 🗸 | × |
| Ke et al. [24] | 🗸 | 🗸 | 🗸 | × | × |
| Jameel et al. [25] | 🗸 | 🗸 | 🗸 | × | × |
| Hassan et al. [17] | × | 🗸 | × | × | 🗸 |
| Our review paper | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 |
| Embedded System | Advantages | Disadvantages |
|---|---|---|
| NVIDIA Jetson COMs [28] | Used mainly in running TensorFlow models Used for images and video processing | More expensive than the usual COM Excessive power to work |
| Google Coral AI [29] | Small in Size Easily integrated with Google cloud services | Smaller version of TensorFlow models COM Steeper learning curve |
| Raspberry PI [30] | Excellent prototyping Easy for high production | Used for classification for small dataset COM Not the best when it comes to Computer Vision |
| Toradex iMX series [31] | Mainly manufacturers use it Easily programmed | Used for classification for small dataset COM Not the best when it comes to Computer Vision |
| Inforce 6601 SoM | Adapted for general- purpose applications | High cost |
| Algorithm | Hardware Type | Frequency | Latency | Power |
|---|---|---|---|---|
| MLP [34] | FPGA spartan-6 | - | 800 ns | 294 mW |
| MLP [35] | FPGA Artix-7 | - | 19,968 ns | 123 mW |
| MLP [36] | FPGA zynq-7000 | - | 540 ns | 1776 mW |
| MLP [36] | FPGA Artix-7 | 100 MHz | 270 ns | 240 mW |
| MLP [37] | FPGA Virtex-6 | 577 MHz | μs | 372 mW |
| MLP [37] | FPGA Virtex-7 | 577 MHz | μs | 216 mW |
| PCA(DT) [38] | Zynq SoC ZC702 | - | 795 ns | - |
| PCA(DT) [38] | Zynq SoC ZC702 | - | 746 ns | - |
| PCA(KNN) [38] | Zynq SoC ZC702 | - | 3073 ns | - |
| DNN [39] | ASIC ACCELERATORS Systolic | 200 MHz | - | 168 mW |
| DNN [39] | ASIC ACCELERATORS Eyeriss | 200 MHz | - | 304 mW |
| DNN [39] | ASIC ACCELERATORS MAERI | 200 MHz | - | 379 mW |
| DNN [40] | ASIC ACCELERATORS MERIT-z | 400 MHz | - | 386 mW |
| YOLO (Tiny) [41] | x86 CPU Intel Core i7 | 3.07 GHz | 1.12 s | - |
| YOLO (Tiny) [41] | ARM CPU ARMv7-A | Upto 1 GHz | 36.92 s | - |
| YOLO (GoogLeNet) [40] | x86 CPU Intel Core i7 | 3.07 GHz | 13.54 s | - |
| YOLO (GoogLeNet) [41] | ARM CPU ARMv7-A | Upto 1 GHz | 0.744 s | - |
| Faster RCNN (VGG16) [40] | ARM CPU ARMv7-A | Upto 1 GHz | Failed | - |
| YOLO (Tiny) [40] | GPU GeForce Titan X | 1531 MHz | 0.0037 s | 178 W |
| SVM [41] | GeForce 840 M GPU | 1.124 MHz | 0.03 ms | - |
| SVM [41] | Kepler GPU Tegra TK1 | 0.852 MHz | 1.23 ms | - |
| Markov Chain [41] | Intel i73770 CPU | 1600 MHz | 33.4 ns | - |
| Markov Chain [41] | GPUGTX690 GTX 690 | 1.25 GHz | Na | - |
| Markov Chain [41] | GPUGTX650 GTX 650 | 2500 MHz | Na | - |
| Faster RCNN (ZF) [40] | x86 CPU Intel Core i7 | 3.07 GHz | 2.547 s | - |
| Faster RCNN (ZF) [40] | ARM CPU ARMv7-A | 1 t GHz | 71.53 s | - |
| Faster RCNN (ZF) [40] | FPGA Zynq (zc706) | 0.2 GHz | - | - |
| CNN Size 2.74 GMAC [41] | Virtex6 VLX240T | 150 MHz | - | - |
| YOLO (GoogLeNet) [40] | GPU GeForce Titan X | 1531 MHz | 0.010 s | 230 W |
| Faster RCNN (ZF) [40] | GPU GeForce Titan X | 1531 MHz | 0.043 s | 69 W |
| F-RCNN (VGG16) [40] | GPU GeForce Titan X | 1531 MHz | 0.062 s | 81 W |
| MLP [41] | Xilinx Zynq-7000 XC7Z010T-1CLG400 | - | 540 ns | 1.556 W |
| STFT and MLP [41] | FPGA Xilinx Artix-7 XC7A100T | 25.237 MHz | - | 0.123 W |
| STFT and MLP [41] | Nexys-4 Artix-7 Virtex-6 XC6VLX240T | 27.889 MHz | - | 3.456 W |
| ANN [41] | VIRTEX -E 14.5 ISE | 5.332 MHz | μs | - |
| SVM [41] | GPU-based Tegra TK1 System-on-Chip | 875 MHz | 1.23 ms | - |
| SVM [41] | TESLA P100 GPU | 1480 MHz | 0.047 ms | - |
| TABLA [42] | Kepler GPU Tegra TK1 | 852 MHz | - | 5 W |
| Applications | Name | Description | Type | Size and Resolution | Paper |
|---|---|---|---|---|---|
| UCSD | - Includes a ROI and the perspective map of the scene - Contain two Ped1 and Ped2 | Videos | - It is a 2000-frames video dataset from a surveillance camera of a single scene. - Ped1 contain 34 training videos and 36 testing videos while Ped2 contain 16 training videos and 12 testing videos | [57] | |
| People Counting | UCFCC50 | - Dataset contains images of extremely dense crowds - The images are collected mainly from the FLICKR | Images | - The counts of persons range between 94 and 4543 - with an average of 1280 individuals per image | [58] |
| TRANCOS | - consists of 1244 images, with a total of 46,796 ve- hicles annotated - captured using the publicly available video surveillance cameras of the Direccion General de Trafico of Spain | Images | - It is a 2000-frames video dataset from a surveillance camera of a single scene | [59] |
| Application | Method Used | Advantages | Disadvantages |
|---|---|---|---|
| People Counting | Conventional Techniques [60] | - Multiple features combined - Overcome overlap | - Count can be performed on still images only - Should be connected to a camera of kinect |
| Machine Learning [61] | - Count in heavily crowded places - Detect partial human beings | - Difficult in low resolution cameras - Cannot work in dim light | |
| Deep Learning [62] | - Novel loss function introduced | - Time consuming when coming to training |
| Applications | Name | Description | Type | Size and Resolution | Paper |
|---|---|---|---|---|---|
| Age and Gender Estimation | Age Detection of Actors | - 19,906 images in the training set - 6636 in the test set | Images | - Size: 48 MB (Compressed) | [69] |
| SCFace | - Color images of faces at various angles. 4160 static images (in visible and infrared spectrum) of 130 subjects | Images | - different quality cameras mimic the real-world conditions | [70] | |
| UTKFace | - 21,000 frontal face images of all ages, ethnicity’s and genders | Images | - 500–600 per class | [71] | |
| IMDB-WIKI | - face images from 20,284 celebrities from IMDb and 62,328 from Wikipedia. List of the most popular | Images | - 523,051 Images - 27 GB for IMDB - 3 GB for WIKI - ranges of resolutions - JPEG format - 460,723 face images from IMDb and - 62,328 face images from Wikipedia | [46] |
| Application | Method Used | Advantages | Disadvantages |
|---|---|---|---|
| Age and Gender Estimation | Conventional Techniques [72] | - Fast calculation speed - Simple to compute | - Large feature dimension - Sensitive to noise |
| Machine Learning [73] | - Capture low redundancy colors - Tolerant to noise | - Works in unsupervised way - Classes are randomly chosen by the machine | |
| Deep Learning [74] | - the age estimation task is split into several comparative stages - very good object recognition rate | - Time consuming when coming to training - Large in dimension and could take time to train |
| Applications | Name | Description | Type | Size and Resolution | Paper |
|---|---|---|---|---|---|
| Avenue | - The videos are captured in CUHK campus avenue | Videos | - Contains 16 training and 21 testing video clips | [104] | |
| UMN | - Scenes are taken from inside the University of Minnesota | Videos | - 1st scene consists of 1450 frames with 320 × 240 resolution - 2nd scene consists of 4415 frames with 320 × 240 resolution - 3rd scene consists of 2145 frames with 320 × 240 resolution | [105] | |
| TV Human Interaction Dataset | - Videos from 20 different TV shows for prediction social actions: handshake, high five, hug, kiss and none | Videos | - 6766 video clips - 156 MB. | [106] | |
| Action Recognition | KINETICS-600 | - 500,000 videos with 600 classes | Videos | - 10 s duration - 604 GB - 392k clips | [107] |
| Moments in Time Dataset | - One million labeled 3 s videos, involving people, animals, objects or natural phenomena, that capture the collected gist of a dynamic scene | Videos | - 399 classes - 1757 labeled videos per class - 3 s video duration | [108] | |
| SLAC | -520K untrimmed videos retrieved from YouTube | Videos | - an average length of 2.6 min- utes - 1.75 M clips, including 755K positive samples 993 K negative samples | [109] | |
| 20-BNsometh- ingsomething Dataset V2 | - a large collection of densely- labeled video clips that show humans performing pre-defined basic actions with everyday objects | Videos | - 220,847 videos - 19.4 GB - 174 classes | [110] | |
| Charades | - A dataset which guides our research into unstructured video activity recognition and commonsense reasoning for daily human activities. labeled video clips that show humans | Videos | - 157 action classes - 41,104 labels - 46 object classes - 27,847 textual descriptions of the videos - 76 GB - 24 fps - 480 p | [111] | |
| A Large-Scale Video Ben- chmark for Human Activity Underst- anding | - a wide range of complex human activities that are of interest to people in their daily living - Illustrating three scenarios in which ActivityNet can be used to compare algorithms for human activity understanding: global video classification, trimmed activity classification and activity detection | Videos | - 200 classes - 684 video hours - 10,024 training videos (15,410 instances) - 4926 validation videos (7654 instances) - 5044 testing videos (labels withheld) | [112] | |
| UCF101 | - diversity in terms of actions and with the presence of large variations in pose, object scale, viewpoint, cluttered background, illumination condition | Videos | - action categories can be divided into five types: (1)Human-Object Interaction (2) Body-Motion Only (3) Human-Human Interaction (4) Playing Musical Instruments (5) Sports | [113] |
| Application | Method Used | Advantages | Disadvantages |
|---|---|---|---|
| Action Detection | Trajectory analysis [114] Handcrafted features [115] | - Efficient in non-jammed scenes - Efficient for basic actions | - Can’t detect irregular shapes in jammed scenes - Not efficient for abnormal events |
| Deep Learning: Supervised [116] Deep Learning: Unsupervised [117] | - Works well in understanding the behaviour - Works well in understanding the behaviour | - Both normal and abnormal events should be there - Less accurate than supervised models |
| Fire Detection | Mivia | - It is composed by 149 videos | Videos | - Contains smoke and fire videos, no smoke and fire videos | [124] |
| Bilkent | - Seven smoke videos and ten nonsmoke videos | Videos | - cover indoor and outdoor with different illumination, short or long distance surveillance scenes | [125] | |
| Cetin | - Early fire and smoke detection based on color features and motion analysis - Smoke detection sample clips | Videos | [125] |
| Fire and Smoke detection | Conventional Techniques [72] | - Train the model to classify regions | - Low Accuracy |
| Machine Learning [73] | - Classification of fire/smoke pixels using Region Segmentation | - Detection delay of about 15 s by the machine | |
| Deep Learning [74] | - adaptive background subtraction for movement detection | - False alarms |
| Vehicle Detection /Traffic Estimation | BIT Vehicle | From the Beijing Laboratory of Intelligent Information Technology, this dataset includes 9850 vehicle images condition | Images | - six categories by vehicle type: bus, microbus, minivan, sedan, SUV, and truck | [134] |
| GTI Vehicle Image Database | - 3425 rear-angle images of avehicles on the road, as well as 3900 images of roads absent of any vehicles | Images | - 360 × 256 pixels recorded in highways of Madrid, Brussels and Turin | [135] |
| Application | Method Used | Advantages | Disadvantages |
|---|---|---|---|
| Vehicle Detection, Classification and Tracking | Conventional Techniques [136] | - Motion detection problem - Less computational time | - Background noise - Segmenting the objects from foreground nature |
| Machine Learning [137] | - Provides better perf- ormance of single moving object detection based on scenario | - In multiple objects moving doesn’t work probably | |
| Deep Learning [138] | - Detect small objects better than multiple objects | - Restricted with the functionality of similarities |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ezzat, M.A.; Abd El Ghany, M.A.; Almotairi, S.; Salem, M.A.-M. Horizontal Review on Video Surveillance for Smart Cities: Edge Devices, Applications, Datasets, and Future Trends. Sensors 2021, 21, 3222. https://doi.org/10.3390/s21093222
Ezzat MA, Abd El Ghany MA, Almotairi S, Salem MA-M. Horizontal Review on Video Surveillance for Smart Cities: Edge Devices, Applications, Datasets, and Future Trends. Sensors. 2021; 21(9):3222. https://doi.org/10.3390/s21093222
Chicago/Turabian StyleEzzat, Mostafa Ahmed, Mohamed A. Abd El Ghany, Sultan Almotairi, and Mohammed A.-M. Salem. 2021. "Horizontal Review on Video Surveillance for Smart Cities: Edge Devices, Applications, Datasets, and Future Trends" Sensors 21, no. 9: 3222. https://doi.org/10.3390/s21093222
APA StyleEzzat, M. A., Abd El Ghany, M. A., Almotairi, S., & Salem, M. A.-M. (2021). Horizontal Review on Video Surveillance for Smart Cities: Edge Devices, Applications, Datasets, and Future Trends. Sensors, 21(9), 3222. https://doi.org/10.3390/s21093222