
A Navigation and Augmented Reality System for Visually Impaired People †

 , , , ,
, , , ,  and
and 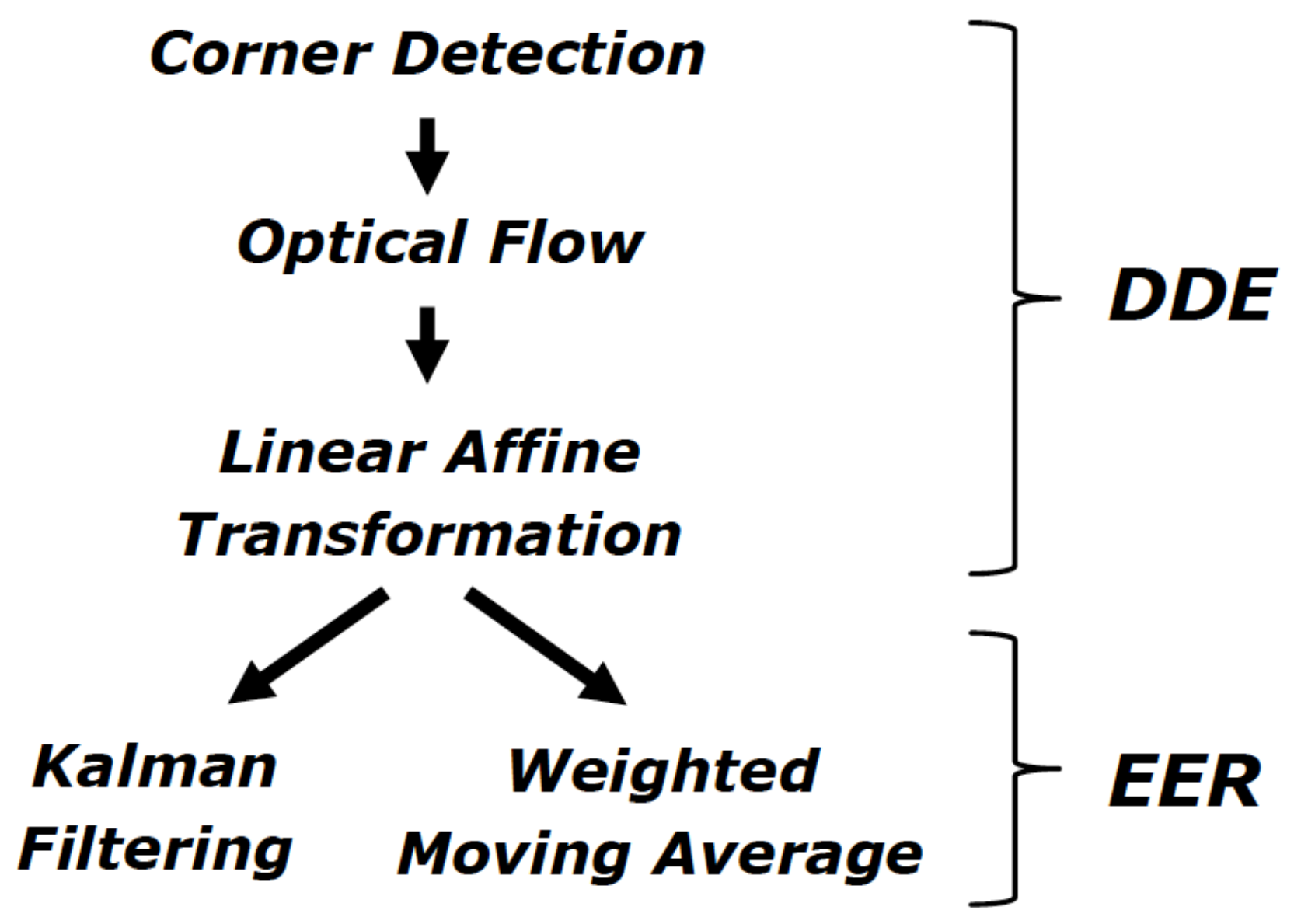{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- a new localization system based on ARKit, responsible for guiding the user along pre-defined virtual paths;
- a machine learning identification mechanism, responsible for facilitating access to the digital contents associated with specific sites of interest.
2. Related Work
2.1. Indoor Positioning System
2.2. Machine Learning for Image and Object Recognition
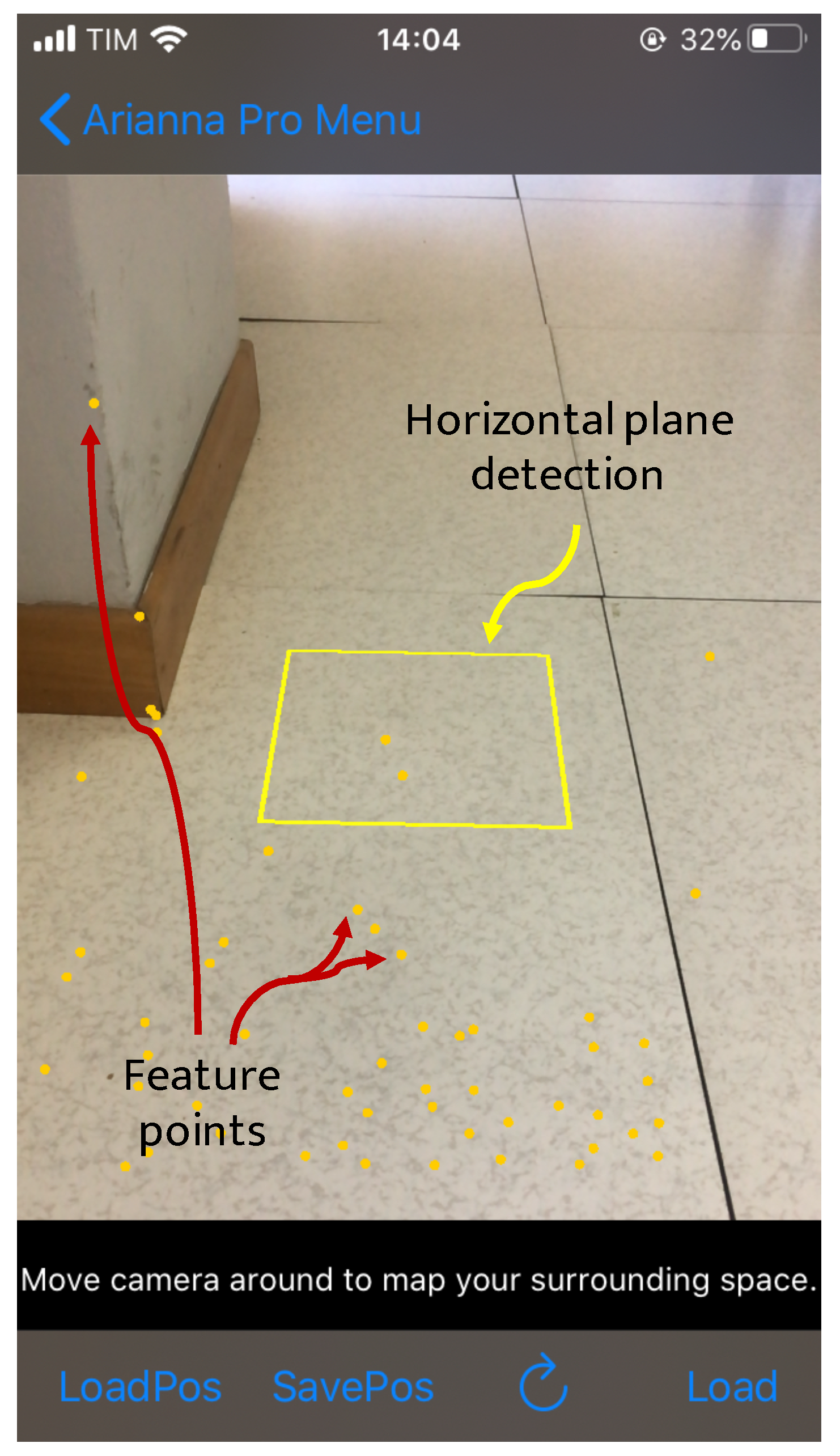
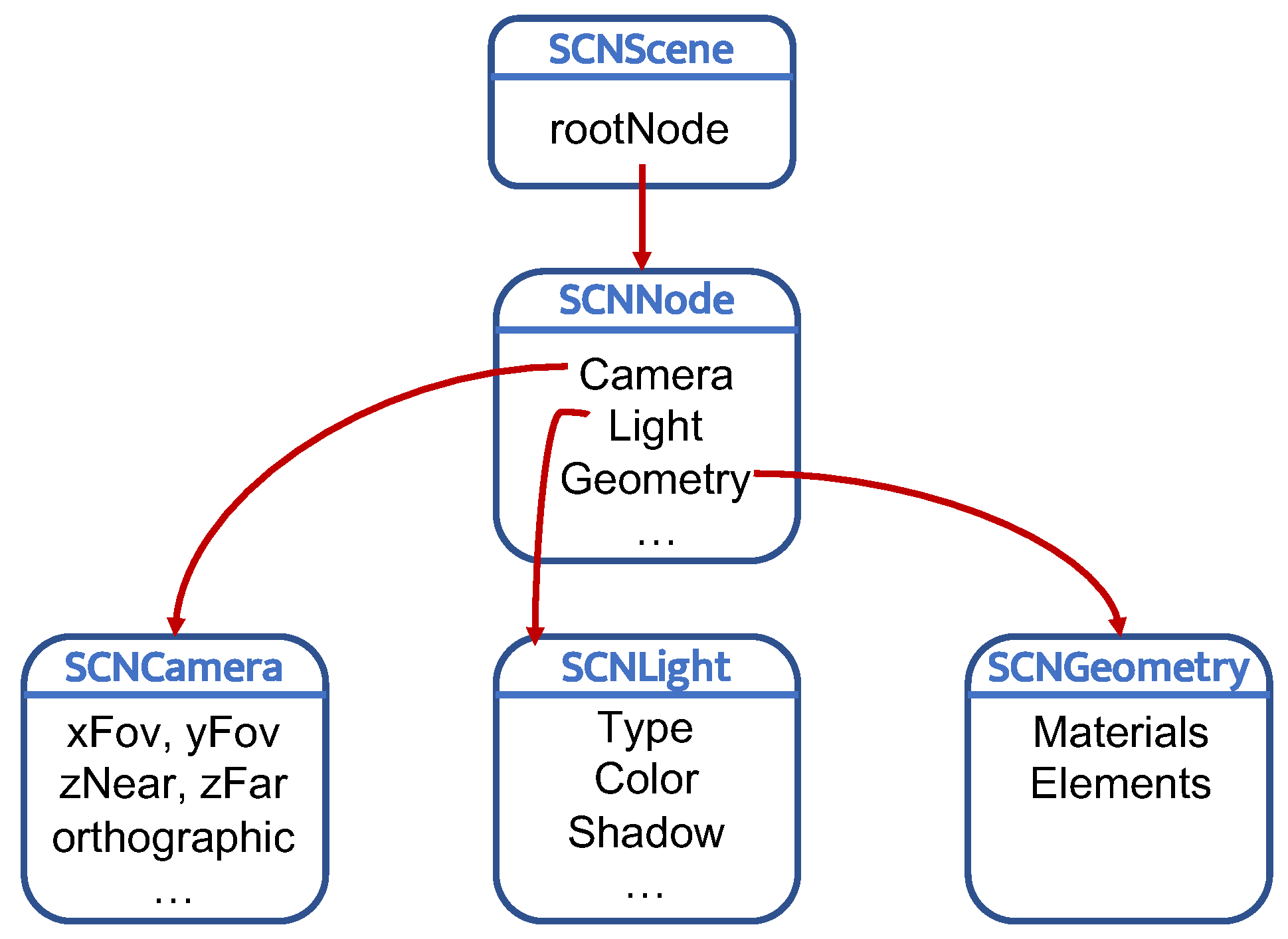
3. The ARIANNA System
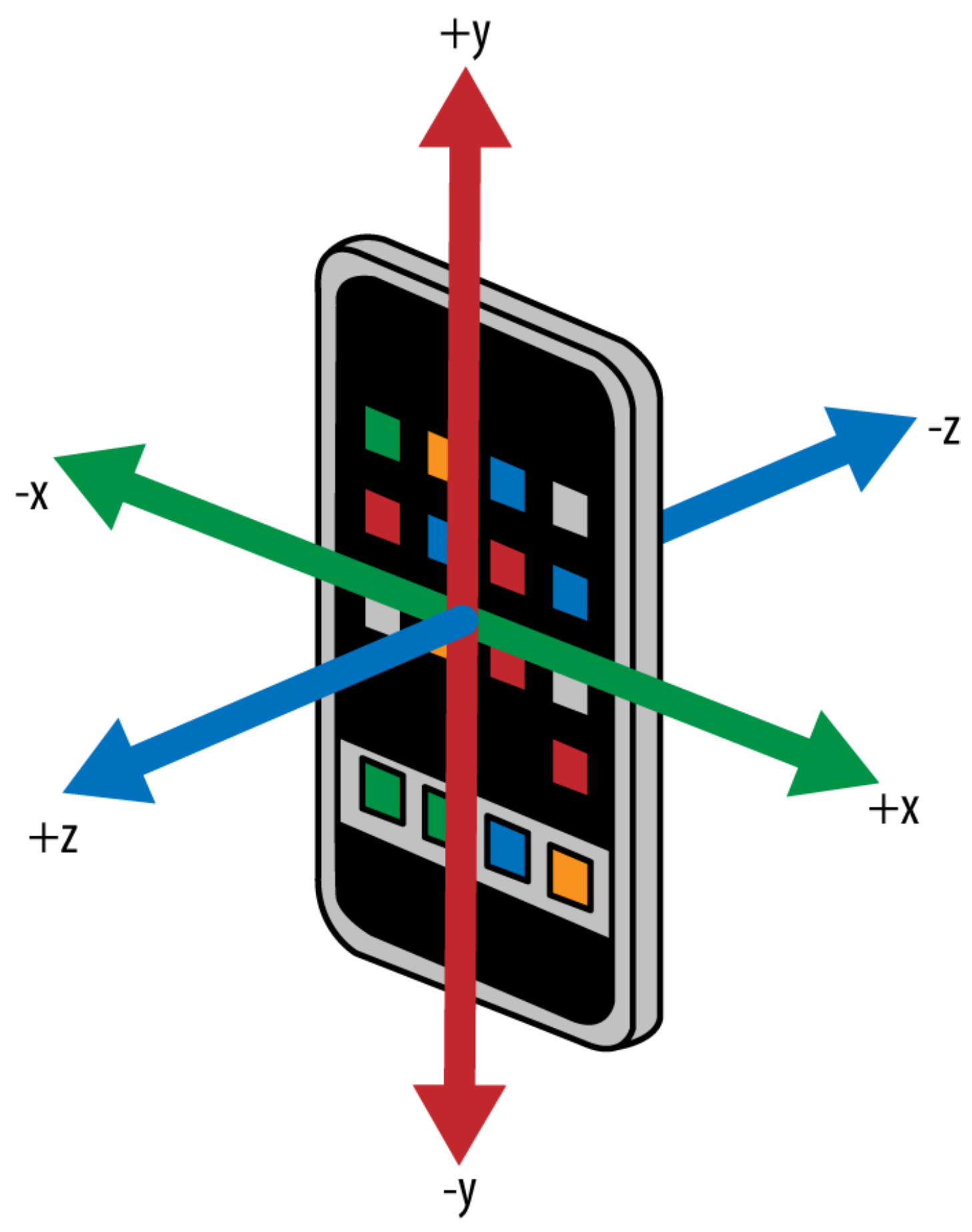
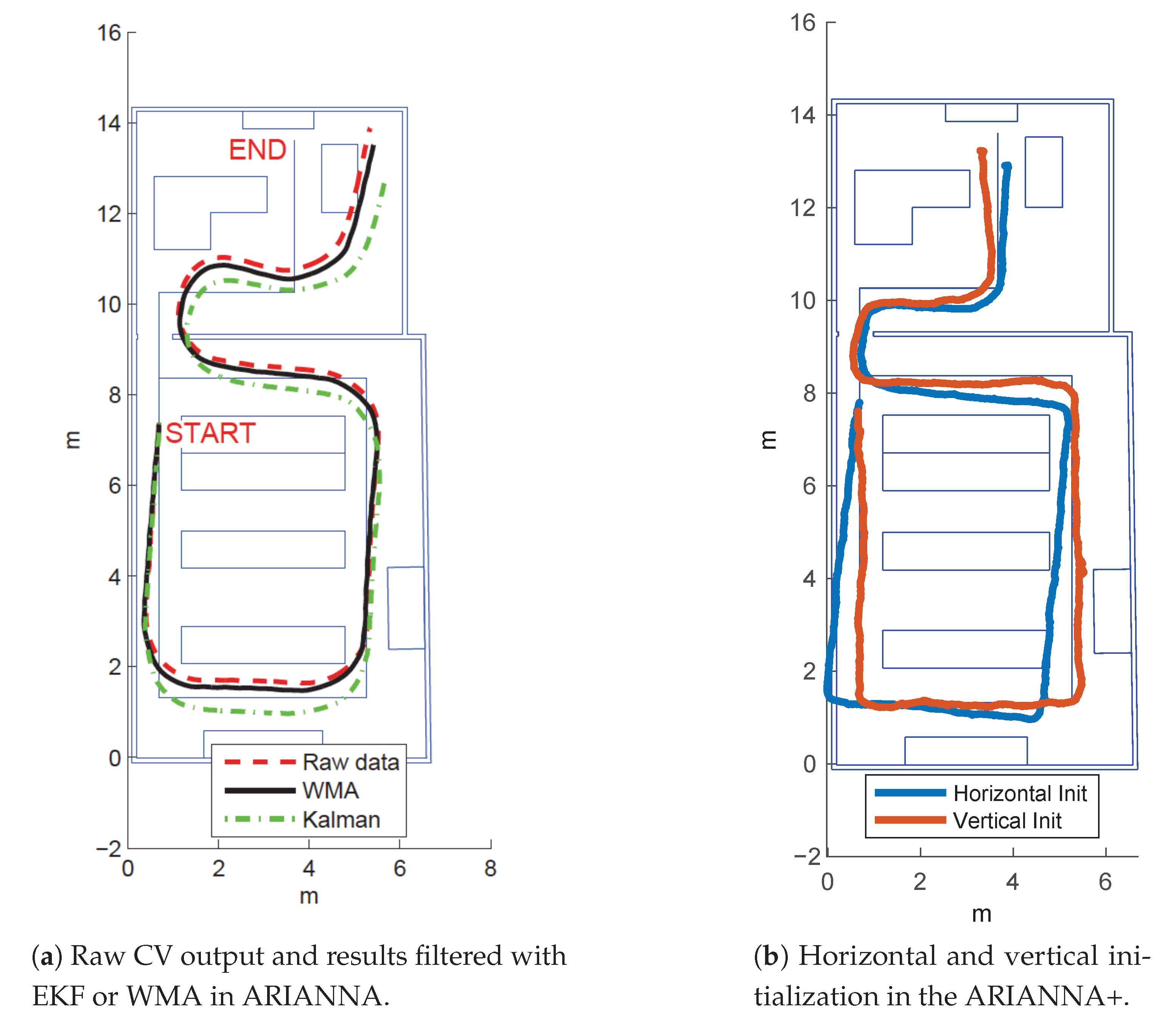
3.1. Navigation Service
3.2. Tracking Service
- distance and direction estimation (DDE);
- estimation error reduction (EER).
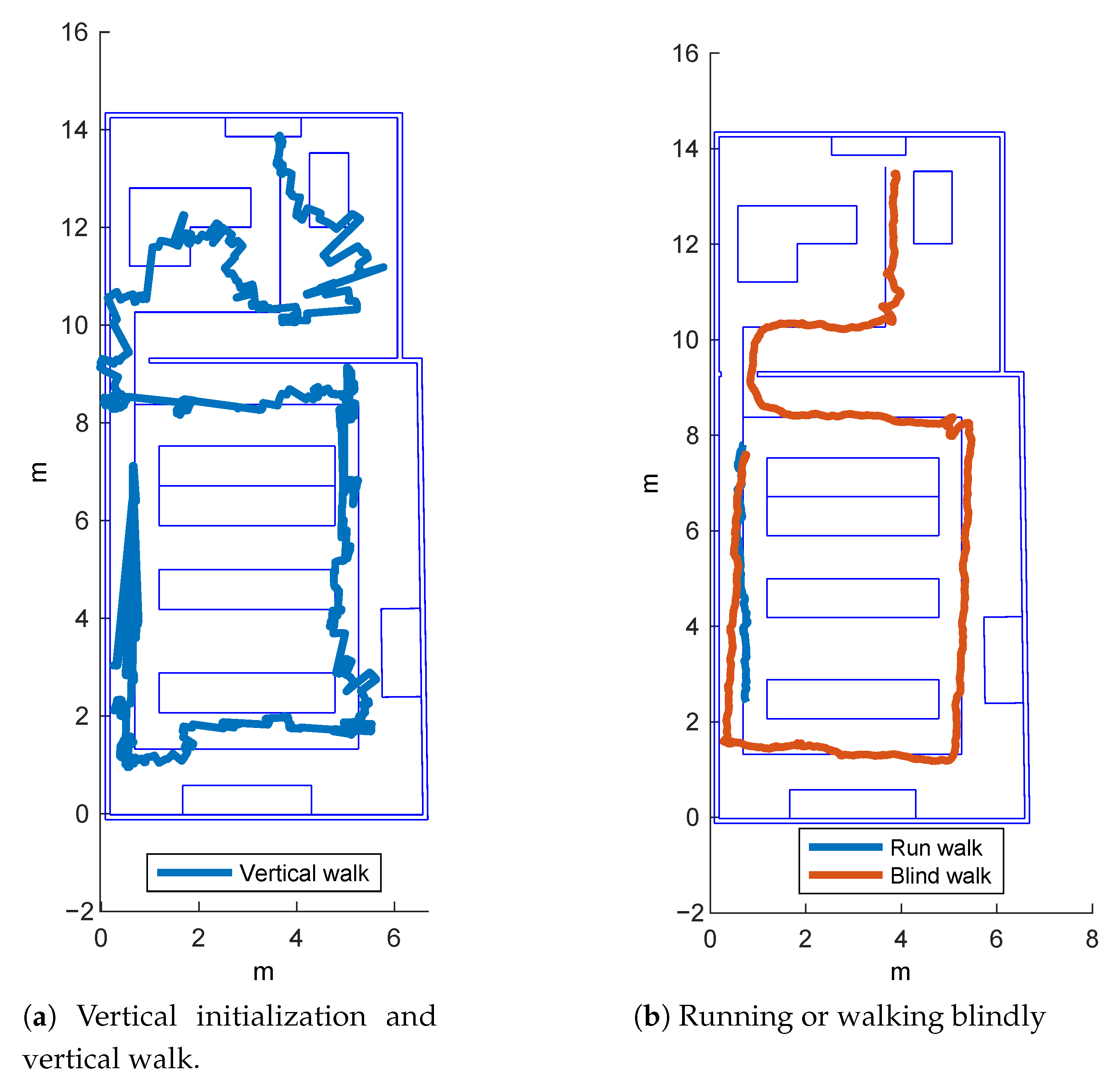
4. The ARIANNA+ System
4.1. Methodology: The Virtual Path
4.1.1. Navigation Service
4.1.2. Tracking Service
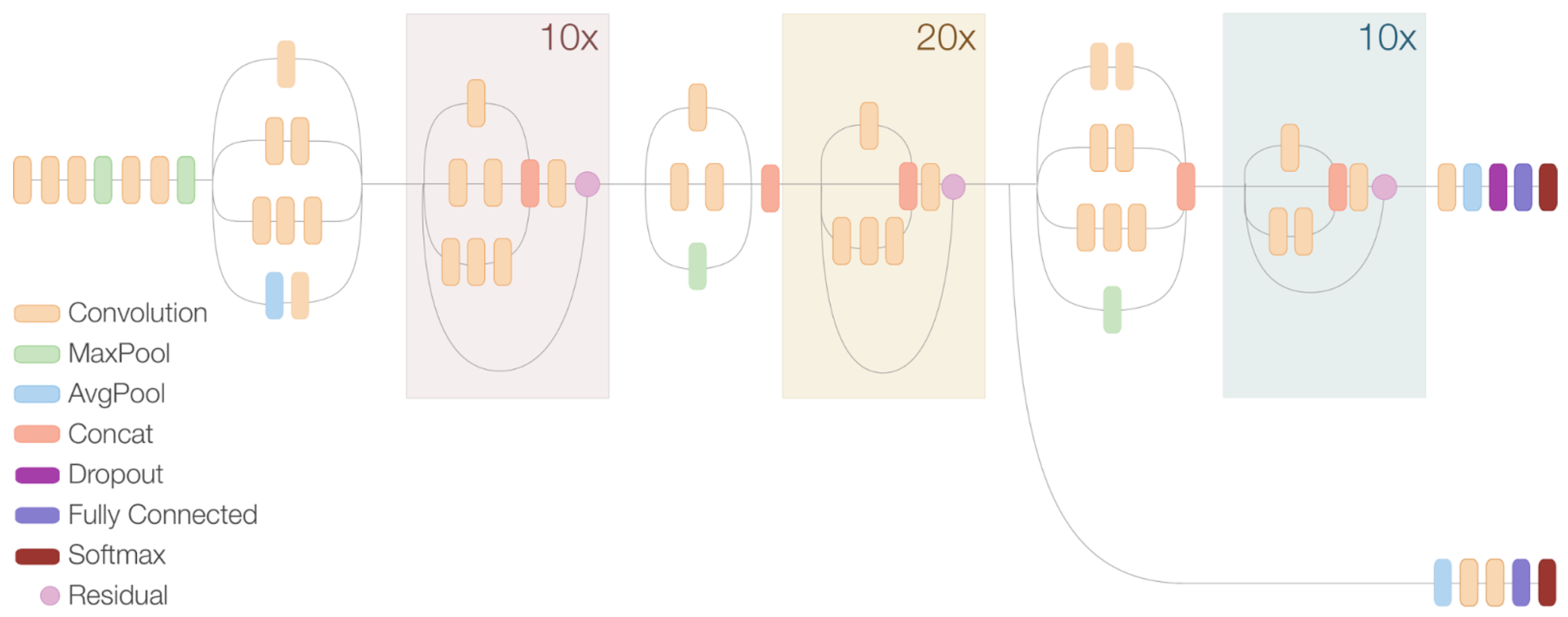
4.2. Environment Recognition: The Case of Cultural Heritage
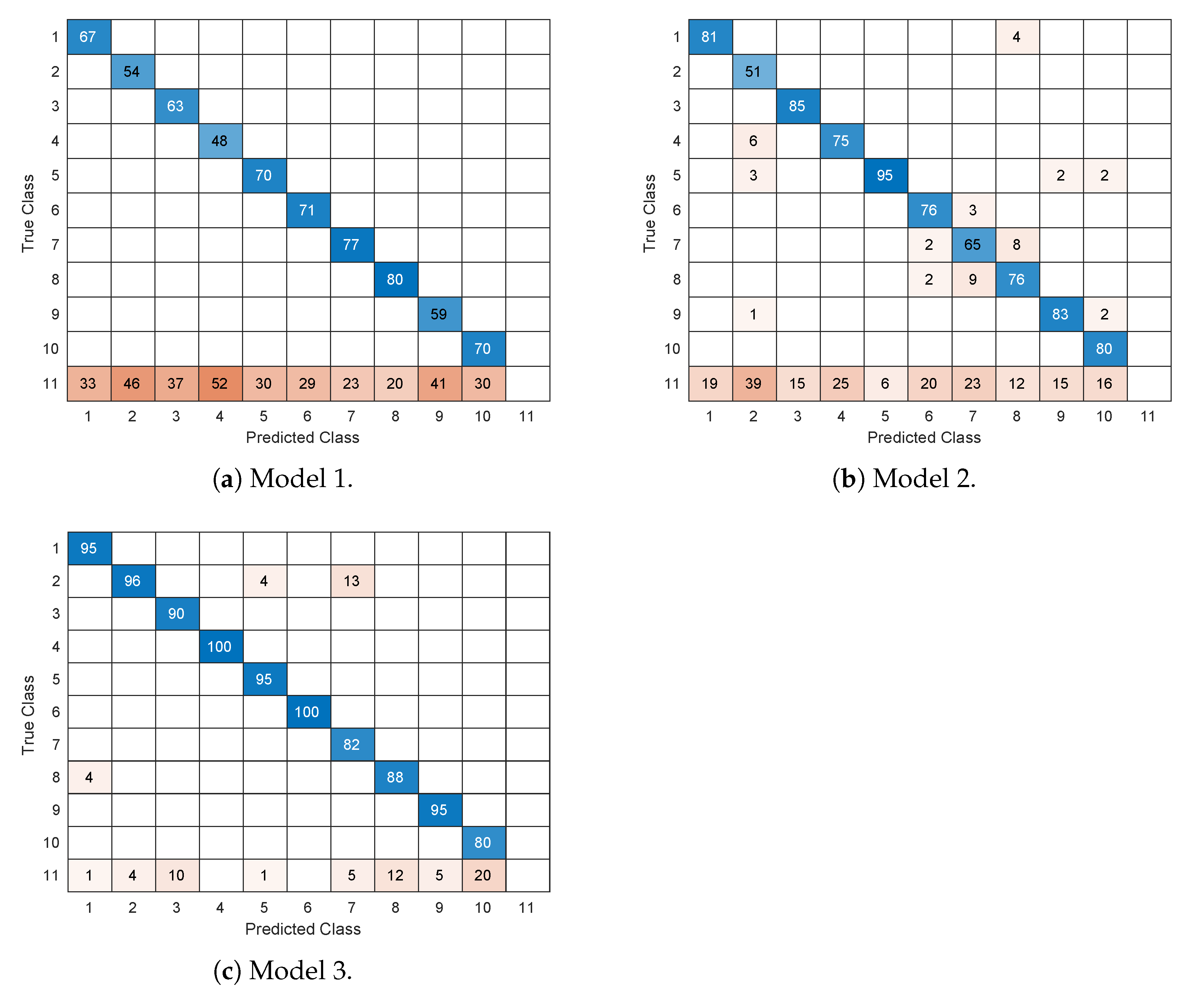
- Model 1: faster R-CNN, Inception v2;
- Model 2: faster R-CNN, Inception v2, ResNet;
- Model 3: SSD, Inception v2.
5. Experimental Results
5.1. Navigation and Tracking
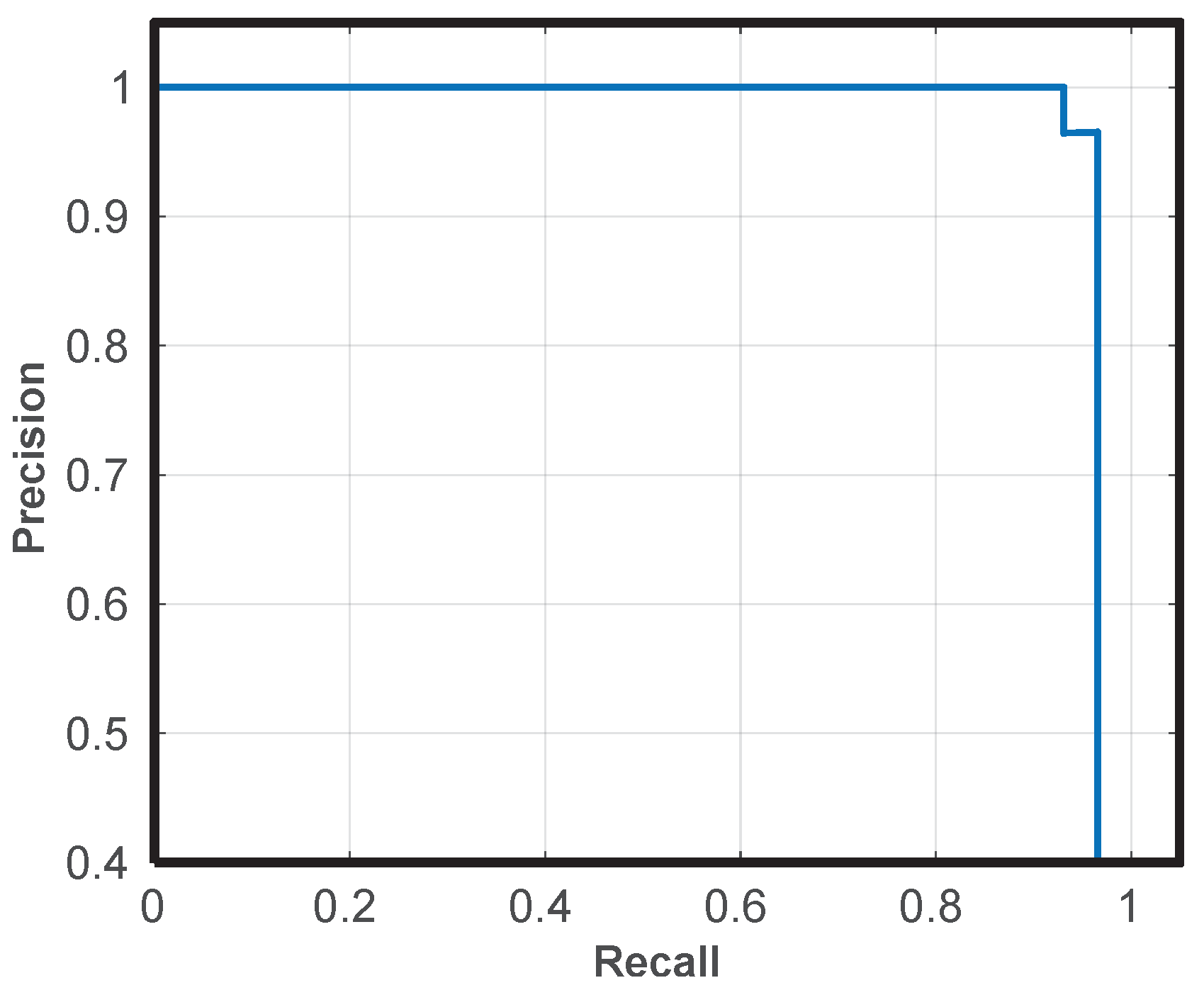
5.2. Monument Recognition
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bahl, P.; Padmanabhan, V.N. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the IEEE INFOCOM 2000, Conference on Computer Communications, Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No. 00CH37064), Tel Aviv, Israel, 26–30 March 2000; pp. 775–784. [Google Scholar]
- Gustafsson, F.; Gunnarsson, F. Positioning using time-difference of arrival measurements. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003 (ICASSP ’03), Hong Kong, China, 6–10 April 2003; p. VI-553. [Google Scholar]
- Montorsi, F.; Pancaldi, F.; Vitetta, G.M. Design and implementation of an inertial navigation system for pedestrians based on a low-cost MEMS IMU. In Proceedings of the 2013 IEEE International Conference on Communications Workshops (ICC), Budapest, Hungary, 9–13 June 2013; pp. 57–61. [Google Scholar]
- Filardo, L.; Inderst, F.; Pascucci, F. C-IPS: A smartphone based indoor positioning system. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016; pp. 1–7. [Google Scholar]
- Cutolo, F.; Mamone, V.; Carbonaro, N.; Ferrari, V.; Tognetti, A. Ambiguity-Free Optical–Inertial Tracking for Augmented Reality Headsets. Sensors 2020, 20, 1444. [Google Scholar] [CrossRef]
- Croce, D.; Giarré, L.; La Rosa, F.G.; Montana, E.; Tinnirello, I. Enhancing tracking performance in a smartphone-based navigation system for visually impaired people. In Proceedings of the 2016 24th Mediterranean Conference on Control and Automation (MED), Athens, Greece, 21–24 June 2016; pp. 1355–1360. [Google Scholar]
- Kot, T.; Novák, P.; Bajak, J. Using HoloLens to create a virtual operator station for mobile robots. In Proceedings of the 2018 19th International Carpathian Control Conference (ICCC), Szilvasvarad, Hungary, 28–31 May 2018; pp. 422–427. [Google Scholar]
- Szajna, A.; Stryjski, R.; Woźniak, W.; Chamier-Gliszczyński, N.; Kostrzewski, M. Assessment of Augmented Reality in Manual Wiring Production Process with Use of Mobile AR Glasses. Sensors 2020, 20, 4755. [Google Scholar] [CrossRef] [PubMed]
- Croce, D.; Giarré, L.; Pascucci, F.; Tinnirello, I.; Galioto, G.E.; Garlisi, D.; Lo Valvo, A. An Indoor and Outdoor Navigation System for Visually Impaired People. IEEE Access 2019, 7, 170406–170418. [Google Scholar] [CrossRef]
- Lo Valvo, A.; Garlisi, D.; Giarré, L.; Croce, D.; Giuliano, F.; Tinnirello, I. A Cultural Heritage Experience for Visually Impaired People. IOP Conf. Ser. Mater. Sci. Eng. 2020, 949, 012034. [Google Scholar] [CrossRef]
- Real, S.; Araujo, A. Navigation Systems for the Blind and Visually Impaired: Past Work, Challenges, and Open Problems. Sensors 2019, 19, 3404. [Google Scholar] [CrossRef] [PubMed]
- Danalet, A.; Farooq, B.; Bierlaire, M. A Bayesian Approach to Detect Pedestrian Destination-Sequences from WiFi Signatures. Transp. Res. Part C Emerg. Technol. 2014, 44, 146–170. [Google Scholar] [CrossRef]
- Youssef, M.A.; Agrawala, A.; Udaya Shankar, A. WLAN location determination via clustering and probability distributions. In Proceedings of the First IEEE International Conference on Pervasive Computing and Communications, 2003 (PerCom 2003), Fort Worth, TX, USA, 26 March 2003; pp. 143–150. [Google Scholar]
- Ijaz, F.; Yang, H.K.; Ahmad, A.W.; Lee, C. Indoor positioning: A review of indoor ultrasonic positioning systems. In Proceedings of the 2013 15th International Conference on Advanced Communications Technology (ICACT), PyeongChang, Korea, 27–30 January 2013; pp. 1146–1150. [Google Scholar]
- Willis, S.; Helal, S. RFID information grid for blind navigation and wayfinding In Proceedings of the IEEE International Symposium on Wearable Computers. Osaka, Japan, 18–21 October 2005; pp. 1–8. [Google Scholar]
- Simões, W.C.S.S.; de Lucena, V.F. Hybrid Indoor Navigation as sistant for visually impaired people based on fusion of proximity method and pattern recognition algorithm. In Proceedings of the IEEE 6th International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 5–7 September 2016; pp. 108–111. [Google Scholar]
- Jiménez, A.R.; Seco, F.; Prieto, J.C.; Guevara, J. Indoor pedestrian navigation using an INS/EKF framework for yaw drift reduction and a foot-mounted IMU. In Proceedings of the Workshop on Positioning, Navigation and Communication, Dresden, Germany, 11–12 March 2010; pp. 135–143. [Google Scholar]
- Jiménez, A.R.; Seco, F.; Zampella, F.; Prieto, J.C.; Guevara, J. Improved Heuristic Drift Elimination (iHDE) for pedestrian navigation in complex buildings. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation, Guimaraes, Portugal, 21–23 September 2011; pp. 1–8. [Google Scholar]
- Fallah, N.; Apostolopoulos, I.; Bekris, K.; Folmer, E. Indoor human navigation systems: A survey. Interact. Comput. 2013, 25, 21–33. [Google Scholar]
- Fallah, N.; Apostolopoulos, I.; Bekris, K.; Folmer, E. The user as a sensor: Navigating users with visual impairments in indoor spaces using tactile landmarks. In Proceedings of the ACM Annual Conference on Human Factors in Computing Systems (CHI), Austin, TX, USA, 5–10 May 2012; pp. 425–432. [Google Scholar]
- Kaemarungsi, K.; Krishnamurthy, P. Properties of indoor received signal strength for WLAN location fingerprinting. In Proceedings of the First Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services (MobiQuitous), Boston, MA, USA, 26 August 2004; pp. 14–23. [Google Scholar]
- Ladd, A.M.; Bekris, K.E.; Rudys, A.P.; Wallach, D.S.; Kavraki, L.E. On the feasibility of using wireless Ethernet for indoor localization. IEEE Trans. Robot. Autom. 2004, 20, 555–559. [Google Scholar] [CrossRef]
- Wang, H.C.; Katzschmann, R.K.; Teng, S.; Araki, B.; Giarré, L.; Rus, D. Enabling independent navigation for visually impaired people through a wearable vision-based feedback system. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 6533–6540. [Google Scholar]
- Tapu, R.; Mocanu, B.; Zaharia, T. A computer vision system that ensure the autonomous navigation of blind people. In Proceedings of the E-Health and Bioengineering Conference (EHB), Iasi, Romania, 21–23 November 2013; pp. 1–4. [Google Scholar]
- Chuang, T.K.; Lin, N.C.; Chen, J.S.; Hung, C.H.; Huang, Y.W.; Tengl, C.; Huang, H.; Yu, L.F.; Giarre, L.; Wang, H.C. Deep trail-following robotic guide dog in pedestrian environments for people who are blind and visually impaired—Learning from virtual and real worlds. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–7. [Google Scholar]
- Yoon, C.; Louie, R.; Ryan, J.; Vu, M.; Bang, H.; Derksen, W.; Ruvolo, P. Leveraging Augmented Reality to Create Apps for People with Visual Disabilities: A Case Study in Indoor Navigation. In Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility, Pittsburgh, PA, USA, 28–30 October 2019. [Google Scholar]
- Saini, A.; Gupta, T.; Kumar, R.; Gupta, A.K.; Panwar, M.; Mittal, A. Image based Indian monument recognition using convoluted neural networks. In Proceedings of the International Conference on Big Data, IoT and Data Science (BID), Pune, India, 20–22 December 2017; pp. 138–142. [Google Scholar]
- Amato, G.; Falchi, F.; Gennaro, C. Fast image classification for monument recognition. J. Comput. Cult. Herit. (JOCCH) 2015, 8, 1–25. [Google Scholar] [CrossRef]
- Gada, S.; Mehta, V.; Kanchan, K.; Jain, C.; Raut, P. Monument Recognition Using Deep Neural Networks. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Coimbatore, India, 14–16 December 2017; pp. 1–6. [Google Scholar]
- Palma, V. Towards deep learning for architecture: A monument recognition mobile app. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W9, 551–556. [Google Scholar] [CrossRef]
- Pielot, M.; Oliveira, R. Peripheral Vibro-Tactile Displays. In Proceedings of the 15th International Conference on Human-Computer Interaction with Mobile Devices and Services, Munich, Germany, 27–30 August 2013; pp. 1–10. [Google Scholar]
- Pielot, M. How the Phone’s Vibration Alarm Can Help to Save Battery. Blog Post. Available online: http://pielot.org/2012/12/how-the-phones-vibration-alarm-can-help-to-save-battery/ (accessed on 27 April 2021).
- Hide, C.; Botterill, T.; Andreotti, M. Low cost vision-aided IMU for pedestrian navigation. In Proceedings of the 2010 Ubiquitous Positioning Indoor Navigation and Location Based Service, Kirkkonummi, Finland, 14–15 October 2010; pp. 1–7. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Croce, D.; Galioto, G.; Galioto, N.; Garlisi, D.; Giarré, L.; Inderst, F.; Pascucci, F.; Tinnirello, I. Supporting Autonomous Navigation of Visually Impaired People for Experiencing Cultural Heritage. In Rediscovering Heritage Through Technology: A Collection of Innovative Research Case Studies That Are Reworking the Way We Experience Heritage; Seychell, D., Dingli, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 25–46. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo Valvo, A.; Croce, D.; Garlisi, D.; Giuliano, F.; Giarré, L.; Tinnirello, I. A Navigation and Augmented Reality System for Visually Impaired People. Sensors 2021, 21, 3061. https://doi.org/10.3390/s21093061
Lo Valvo A, Croce D, Garlisi D, Giuliano F, Giarré L, Tinnirello I. A Navigation and Augmented Reality System for Visually Impaired People. Sensors. 2021; 21(9):3061. https://doi.org/10.3390/s21093061
Chicago/Turabian StyleLo Valvo, Alice, Daniele Croce, Domenico Garlisi, Fabrizio Giuliano, Laura Giarré, and Ilenia Tinnirello. 2021. "A Navigation and Augmented Reality System for Visually Impaired People" Sensors 21, no. 9: 3061. https://doi.org/10.3390/s21093061
APA StyleLo Valvo, A., Croce, D., Garlisi, D., Giuliano, F., Giarré, L., & Tinnirello, I. (2021). A Navigation and Augmented Reality System for Visually Impaired People. Sensors, 21(9), 3061. https://doi.org/10.3390/s21093061