
Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network

Abstract
1. Introduction
- We propose an approach based on an attentional convolutional network, which can focus on feature-rich areas of the face yet remarkably outperforms recent works in accuracy.
2. Related Works
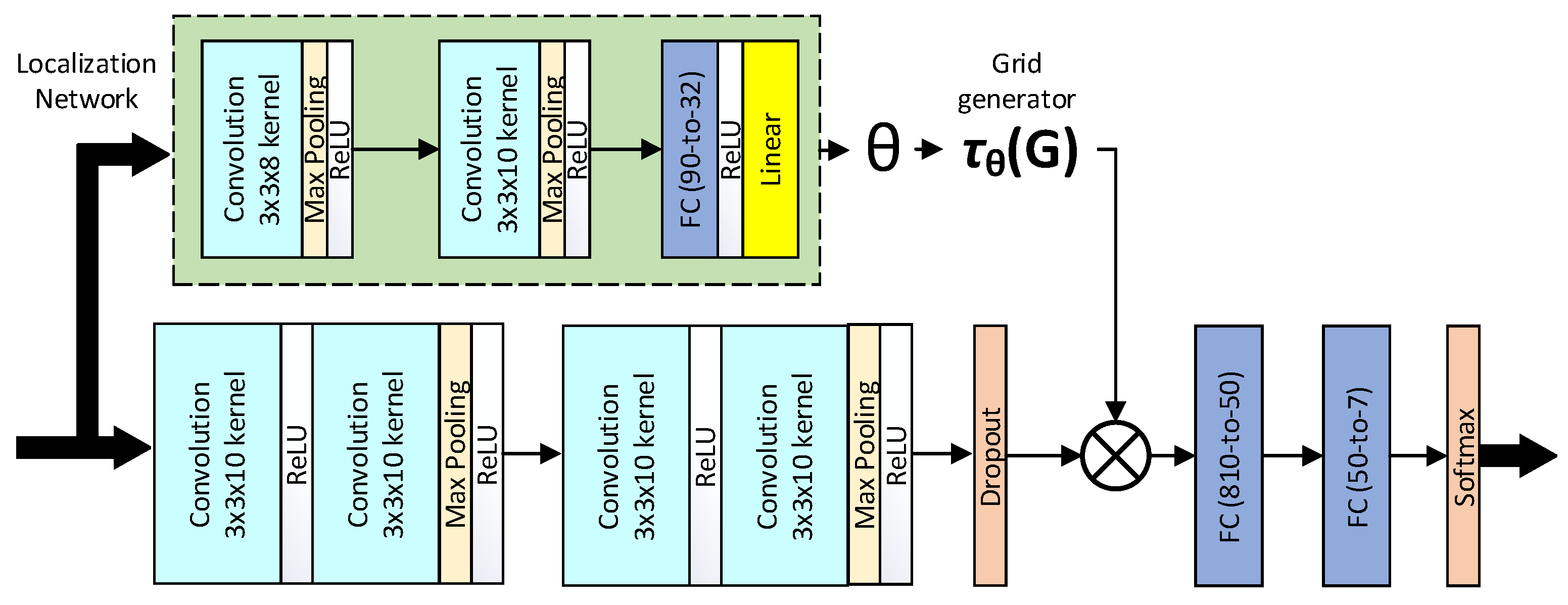
3. The Proposed Framework
4. Experimental Results
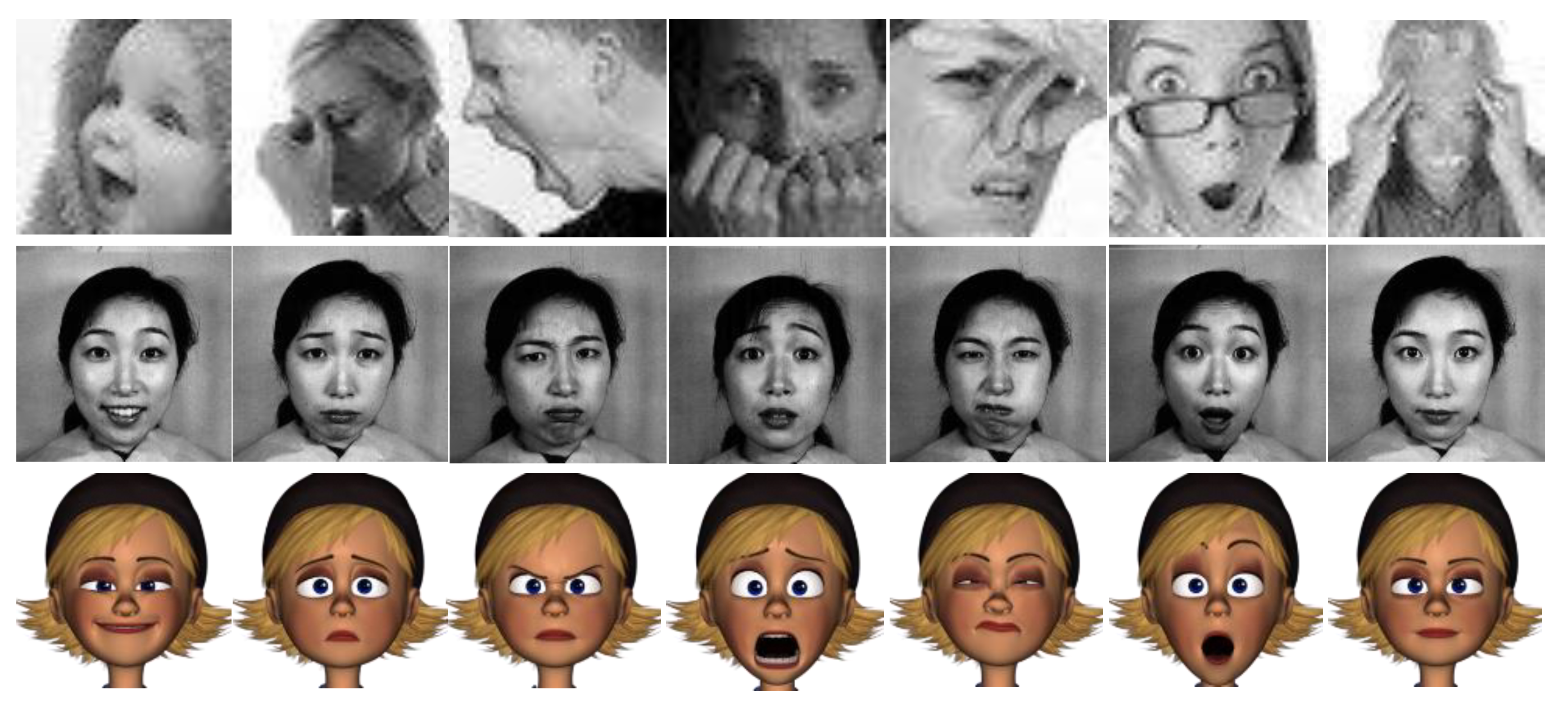
4.1. Databases
4.2. Experimental Analysis and Comparison
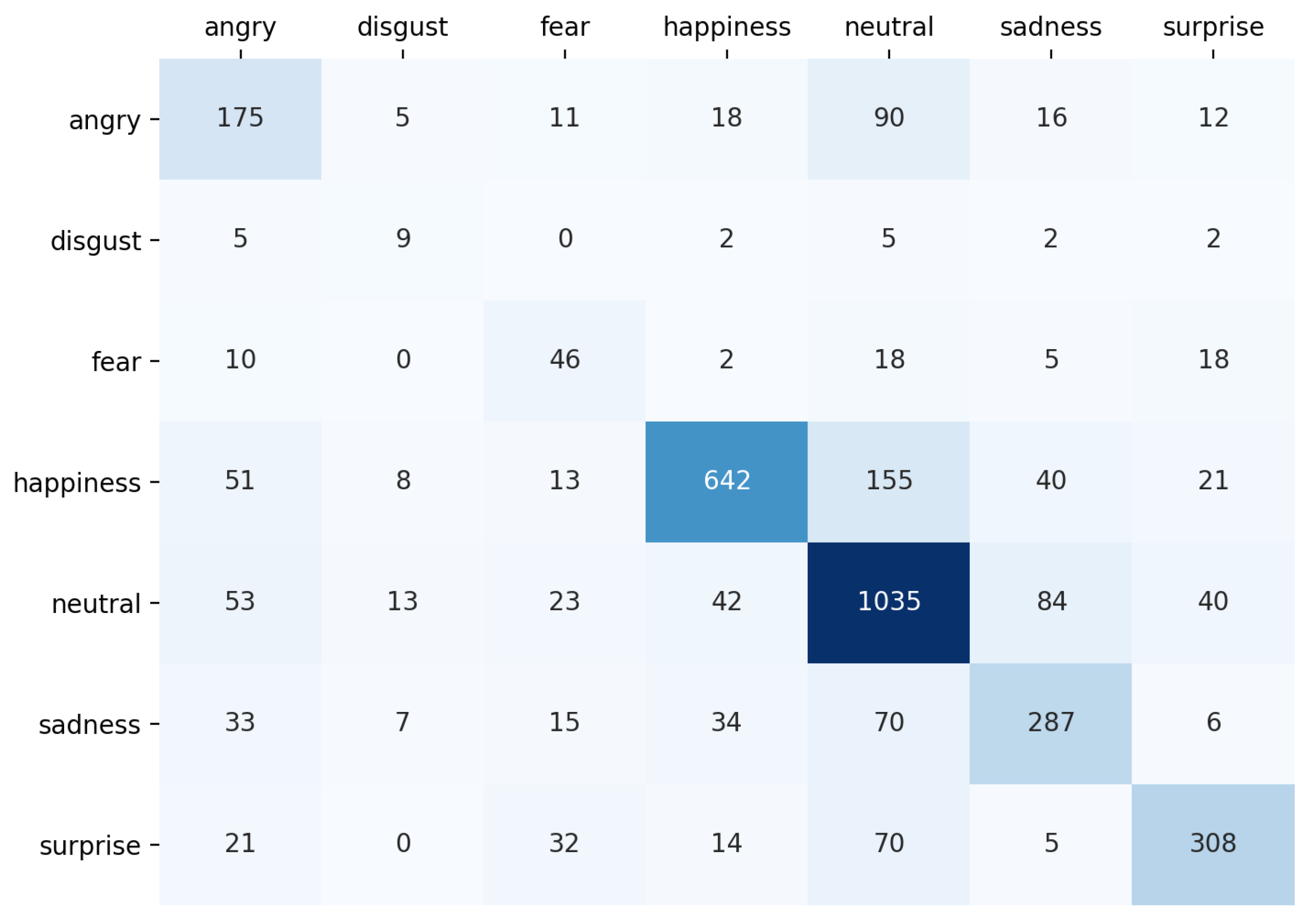
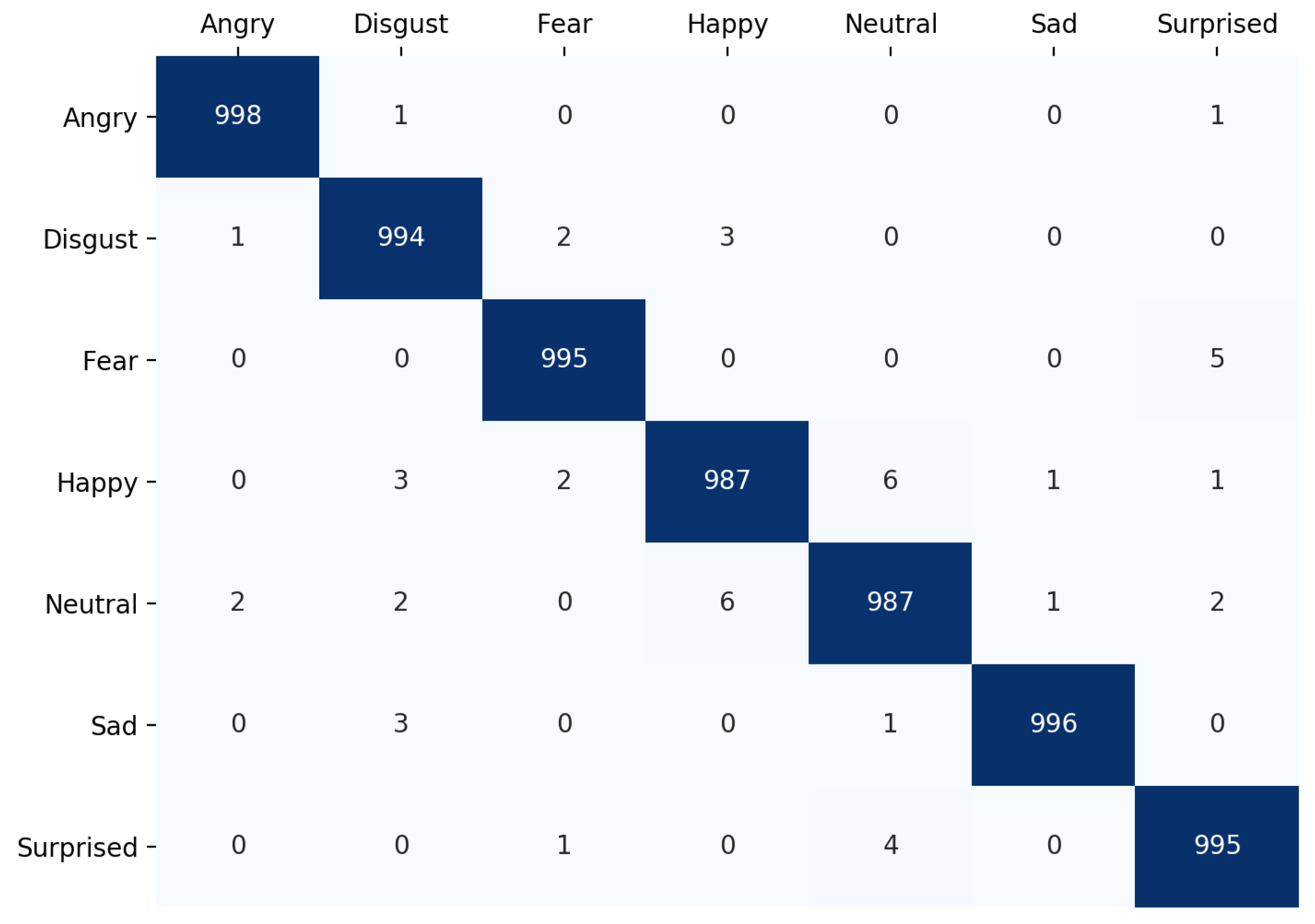
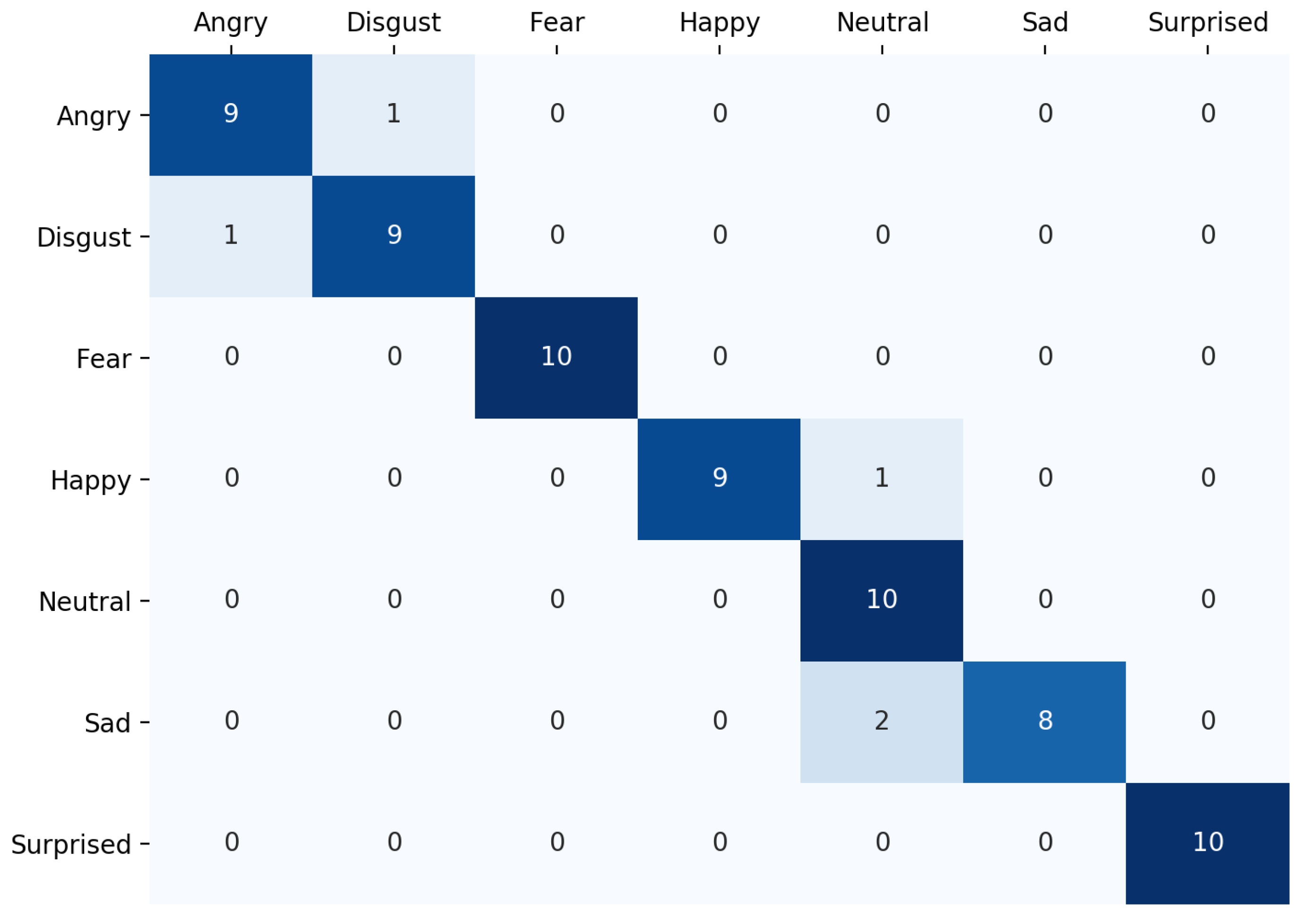
4.3. Confusion Matrix
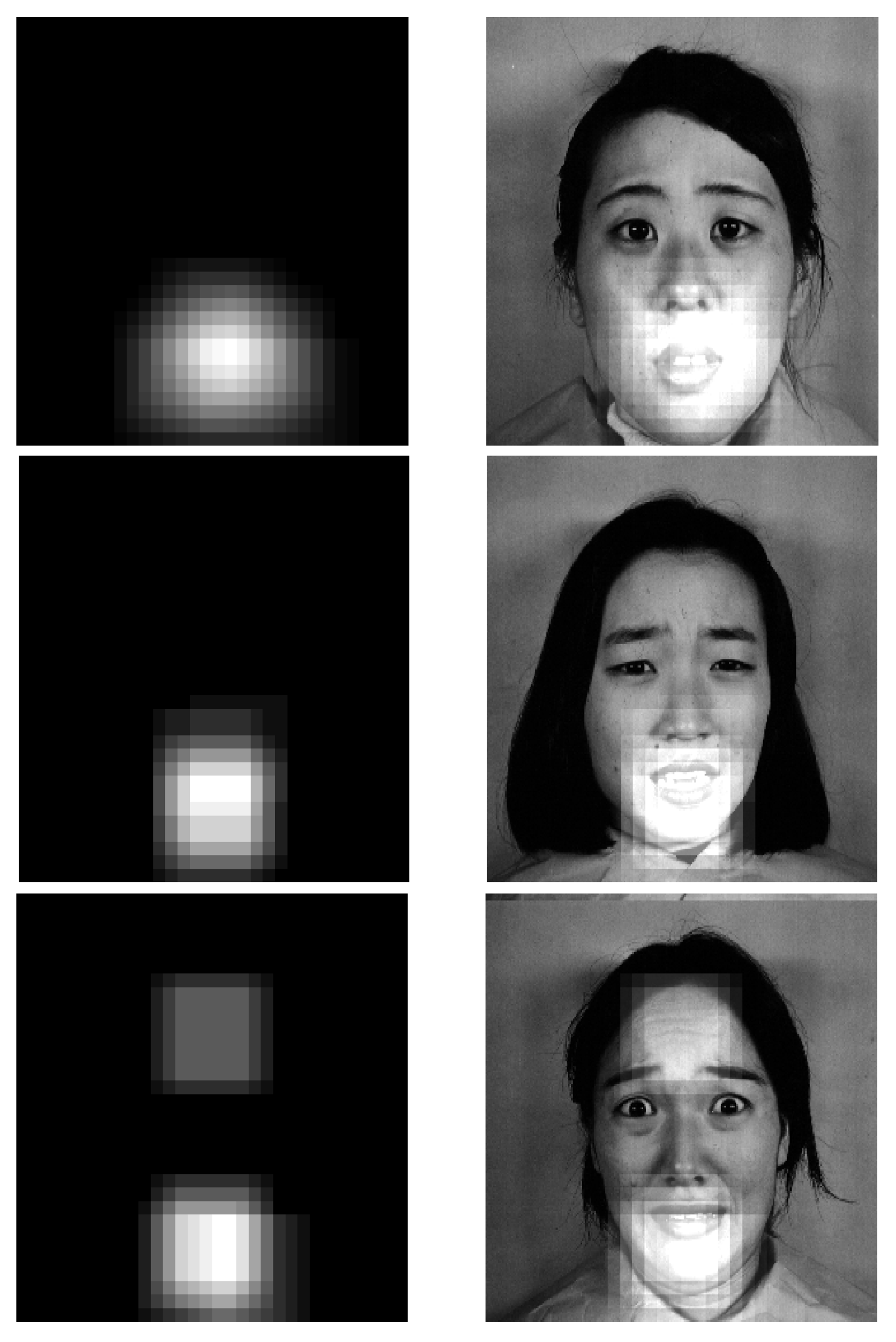
4.4. Model Visualization
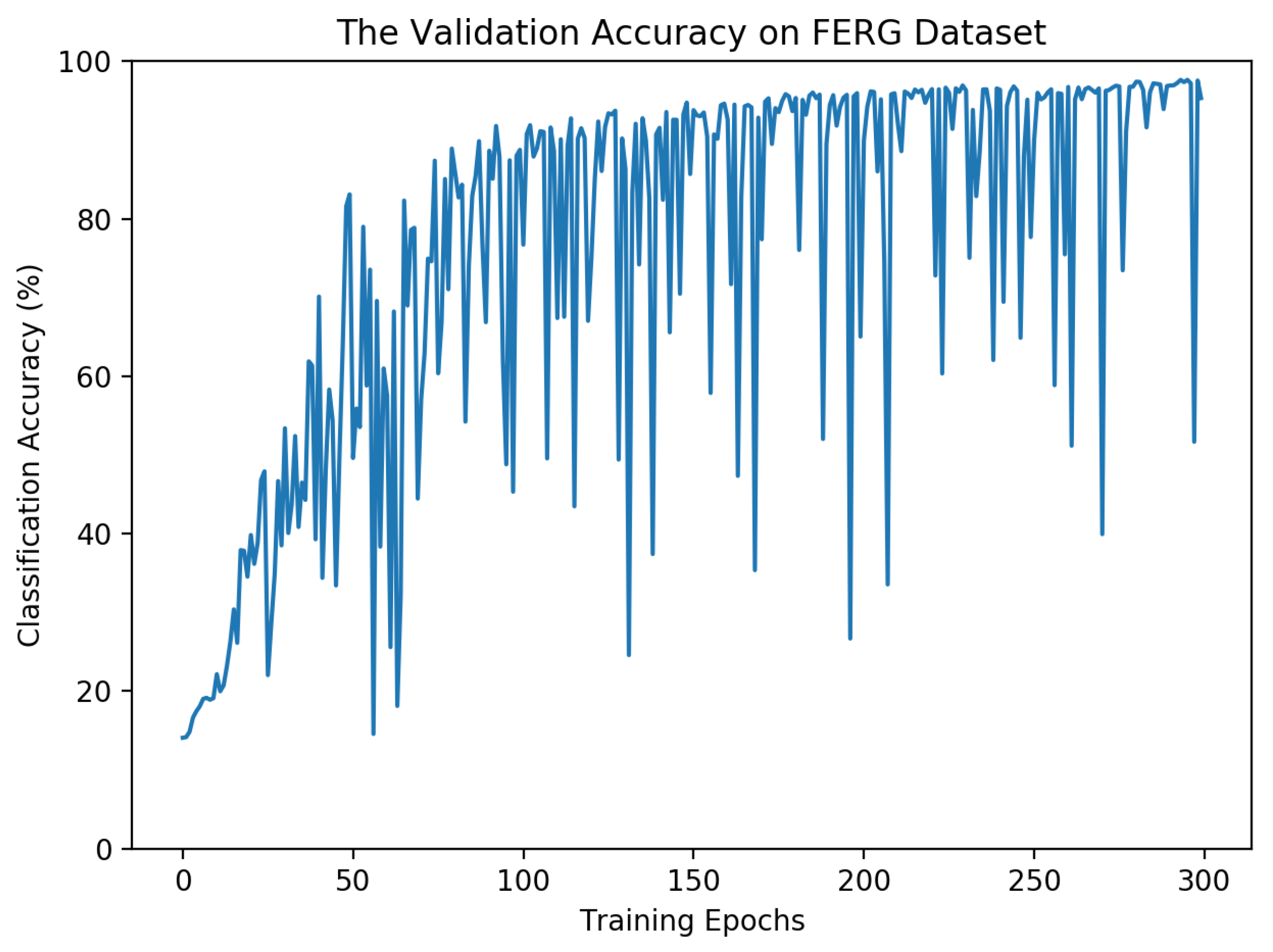
4.5. Model Convergence
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Roddy, C.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar]
- Deepali, A.; Colburn, A.; Faigin, G.; Shapiro, L.; Mones, B. Modeling stylized character expressions via deep learning. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 136–153. [Google Scholar]
- Jane, E.; Jackson, H.J.; Pattison, P.E. Emotion recognition via facial expression and affective prosody in schizophrenia: A methodological review. Clin. Psychol. Rev. 2002, 22, 789–832. [Google Scholar]
- Chu, H.C.; Tsai, W.W.; Liao, M.J.; Chen, Y.M. Facial emotion recognition with transition detection for students with high-functioning autism in adaptive e-learning. Soft Comput. 2017, 22, 2973–2999. [Google Scholar] [CrossRef]
- Chloé, C.; Vasilescu, I.; Devillers, L.; Richard, G.; Ehrette, T. Fear-type emotion recognition for future audio-based surveillance systems. Speech Commun. 2008, 50, 487–503. [Google Scholar]
- Saste, T.S.; Jagdale, S.M. Emotion recognition from speech using MFCC and DWT for security system. In Proceedings of the IEEE 2017 International Conference o fElectronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; pp. 701–704. [Google Scholar]
- Marco, L.; Carcagnì, P.; Distante, C.; Spagnolo, P.; Mazzeo, P.L.; Rosato, A.C.; Petrocchi, S. Computational assessment of facial expression production in ASD children. Sensors 2018, 18, 3993. [Google Scholar]
- Meng, Q.; Hu, X.; Kang, J.; Wu, Y. On the effectiveness of facial expression recognition for evaluation of urban sound perception. Sci. Total Environ. 2020, 710, 135484. [Google Scholar] [CrossRef]
- Ali, M.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the IEEE 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1805–1812. [Google Scholar]
- Kun, H.; Yu, D.; Tashev, I. Speech emotion recognition using deep neural network and extreme learning machine. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Petrantonakis, C.P.; Hadjileontiadis, L.J. Emotion recognition from EEG using higher order crossings. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 186–197. [Google Scholar] [CrossRef]
- Wu, C.-H.; Chuang, Z.-J.; Lin, Y.-C. Emotion recognition from text using semantic labels and separable mixture models. ACM Trans. Asian Lang. Inf. Process. TALIP 2006, 5, 165–183. [Google Scholar]
- Courville, P.L.C.; Goodfellow, A.; Mirza, I.J.M.; Bengio, Y. FER-2013 Face Database; Universit de Montreal: Montréal, QC, Canada, 2013. [Google Scholar]
- Akamatsu, M.J.S.L.; Kamachi, M.; Gyoba, J.; Budynek, J. The Japanese female facial expression (JAFFE) database. In Proceedings of the Third International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 14–16. [Google Scholar]
- LeCun, Y. Generalization and network design strategies. Connect. Perspect. 1989, 119, 143–155. [Google Scholar]
- Pooya, K.; Paine, T.; Huang, T. Do deep neural networks learn facial action units when doing expression recognition? In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Panagiotis, T.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar]
- Cohn, F.J.; Zlochower, A. A computerized analysis of facial expression: Feasibility of automated discrimination. Am. Psychol. Soc. 1995, 2, 6. [Google Scholar]
- Zeiler, D.M.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124. [Google Scholar] [CrossRef]
- Friesen, E.; Ekman, P.; Friesen, W.; Hager, J. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Psychologists Press: Hove, UK, 1978. [Google Scholar]
- Hough, P.V.C. Method and Means for Recognizing Complex Patterns. U.S. Patent 3,069,654, 18 December 1962. [Google Scholar]
- Junkai, C.; Chen, Z.; Chi, Z.; Fu, H. Facial expression recognition based on facial components detection and hog features. In Proceedings of the International Workshops on Electrical and Computer Engineering Subfields, Istanbul, Turkey, 22–23 August 2014; pp. 884–888. [Google Scholar]
- Caifeng, S.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar]
- Stewart, M.B.; Littlewort, G.; Frank, M.; Lainscsek, C.; Fasel, I.; Movellan, J. Recognizing facial expression: Machine learning and application to spontaneous behavior. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 568–573. [Google Scholar]
- Jacob, W.; Omlin, C.W. Haar features for facs au recognition. In Proceedings of the IEEE FGR 2006 7th International Conference on Automatic Face and Gesture Recognition, Southampton, UK, 10–12 April 2006; p. 5. [Google Scholar]
- Alex, K.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Kaiming, H.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Jonathan, L.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Minaee, S.; Abdolrashidiy, A.; Wang, Y. An experimental study of deep convolutional features for iris recognition. In Proceedings of the IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 3 December 2016. [Google Scholar]
- Shervin, M.; Bouazizi, I.; Kolan, P.; Najafzadeh, H. Ad-Net: Audio-Visual Convolutional Neural Network for Advertisement Detection In Videos. arXiv 2018, arXiv:1806.08612. [Google Scholar]
- Ian, G.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Shervin, M.; Wang, Y.; Aygar, A.; Chung, S.; Wang, X.; Lui, Y.W.; Fieremans, E.; Flanagan, S.; Rath, J. MTBI Identification From Diffusion MR Images Using Bag of Adversarial Visual Features. arXiv 2018, arXiv:1806.10419. [Google Scholar]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training deep networks for facial expression recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016. [Google Scholar]
- Han, Z.; Meng, Z.; Khan, A.-S.; Tong, Y. Incremental boosting convolutional neural network for facial action unit recognition. Adv. Neural Inf. Process. Syst. 2016, 29, 109–117. [Google Scholar]
- Meng, Z.; Liu, P.; Cai, J.; Han, S.; Tong, Y. Identity-aware convolutional neural network for facial expression recognition. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 558–565. [Google Scholar]
- Marrero Fernandez, P.D.; Guerrero Pena, F.A.; Ren, T.; Cunha, A. Feratt: Facial expression recognition with attention net. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Peng, K.W.; Yang, X.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar]
- Gan, Y.; Chen, J.; Yang, Z.; Xu, L. Multiple attention network for facial expression recognition. IEEE Access 2020, 8, 7383–7393. [Google Scholar] [CrossRef]
- Arpita, G.; Arunachalam, S.; Balakrishnan, R. Deep self-attention network for facial emotion recognition. Proc. Comput. Sci. 2020, 17, 1527–1534. [Google Scholar]
- Shan, L.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Xiaoqing, W.; Wang, X.; Ni, Y. Unsupervised domain adaptation for facial expression recognition using generative adversarial networks. Comput. Intell. Neurosci. 2018. [Google Scholar] [CrossRef]
- Tudor, R.I.; Popescu, M.; Grozea, C. Local learning to improve bag of visual words model for facial expression recognition. In Proceedings of the ICML Workshop on Challenges in Representation Learning; 2013. Available online: https://www.semanticscholar.org/paper/Local-Learning-to-Improve-Bag-of-Visual-Words-Model-Ionescu-Grozea/97088cbbac03bf8e9a209403f097bc9af46a4ebb?p2df (accessed on 26 April 2021).
- Mariana-Iuliana, G.; Ionescu, R.T.; Popescu, M. Local Learning with Deep and Handcrafted Features for Facial Expression Recognition. arXiv 2018, arXiv:1804.10892. [Google Scholar]
- Panagiotis, G.; Perikos, I.; Hatzilygeroudis, I. Deep Learning Approaches for Facial Emotion Recognition: A Case Study on FER-2013. In Advances in Hybridization of Intelligent Methods; Springer: Cham, Switzerland, 2018; pp. 1–16. [Google Scholar]
- Vin, T.P.; Vinh, T.Q. Facial Expression Recognition System on SoC FPGA. In Proceedings of the IEEE 2019 International Symposium on Electrical and Electronics Engineering (ISEE), Ho Chi Minh City, Vietnam, 10–12 October 2019. [Google Scholar]
- Dimitrios, K.; Zafeiriou, S. Expression, affect, action unit recognition: Aff-wild2, multi-task learning and arcface. arXiv 2019, arXiv:1910.04855. [Google Scholar]
- Hang, Z.; Liu, Q.; Yang, Y. Transfer learning with ensemble of multiple feature representations. In Proceedings of the IEEE 2018 IEEE 16th International Conference on Software Engineering Research, Management and Applications (SERA), Kunming, China, 13–15 June 2018. [Google Scholar]
- Clément, F.; Piantanida, P.; Bengio, Y.; Duhamel, P. Learning Anonymized Representations with Adversarial Neural Networks. arXiv 2018, arXiv:1802.09386. [Google Scholar]
- Ben, N.; Gao, Z.; Guo, B. Facial Expression Recognition with LBP and ORB Features. Comput. Intell. Neurosci. 2021, 2021, 8828245. [Google Scholar] [CrossRef]
- Zaenal, A.; Harjoko, A. A neural network based facial expression recognition using fisherface. Int. J. Comput. Appl. 2012, 59, 3. [Google Scholar]
- Hao, W.; Wei, S.; Fang, B. Facial expression recognition using iterative fusion of MO-HOG and deep features. J. Supercomput. 2020, 76, 3211–3221. [Google Scholar]
- Happy, S.L.; Routray, A. Automatic facial expression recognition using features of salient facial patches. IEEE Trans. Affect. Comput. 2015, 6, 1–12. [Google Scholar] [CrossRef]
- Yoshihiro, S.; Omori, Y. Image Augmentation for Classifying Facial Expression Images by Using Deep Neural Network Pre-trained with Object Image Database. In Proceedings of the ACM 3rd International Conference on Robotics, Control and Automation, Chengdu China, 11–13 August 2018. [Google Scholar]
- Salah, R.; Bengio, Y.; Courville, A.; Vincent, P.; Mirza, M. Disentangling factors of variation for facial expression recognition. In Computer Vision—ECCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 808–822. [Google Scholar]
- Mengyi, L.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply learning deformable facial action parts model for dynamic expression analysis. In Proceedings of the Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 143–157. [Google Scholar]
- Heechul, J.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint fine-tuning in deep neural networks for facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2983–2991. [Google Scholar]
- Zhang, T.; Zheng, W.; Cui, Z.; Zong, Y.; Li, Y. Spatial-temporal recurrent neural network for emotion recognition. IEEE Trans. Cybern. 2018, 99, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-piloted deep network for facial expression recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 425–442. [Google Scholar]
- Eleyan, A.M.A.; Akdemir, B. Facial expression recognition with dynamic cascaded classifier. Neural Comput. Appl. 2020, 32, 6295–6309. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy Rate |
|---|---|
| Unsupervised Domain Adaptation [47] | 65.3% |
| Bag of Words [48] | 67.4% |
| VGG+SVM [49] | 66.31% |
| GoogleNet [50] | 65.2% |
| FER on SoC [51] | 66% |
| Mollahosseini et al. [9] | 66.4% |
| The proposed algorithm | 70.02% |
| Aff-Wild2 (VGG backbone) [52] | 75% |
| Method | Accuracy Rate |
|---|---|
| DeepExpr [2] | 89.02% |
| Ensemble Multi-feature [53] | 97% |
| Adversarial NN [54] | 98.2% |
| The proposed algorithm | 99.3% |
| Method | Accuracy Rate |
|---|---|
| LBP+ORB features [55] | 88.5% |
| Fisherface [56] | 89.2% |
| Deep Features + HOG [57] | 90.58% |
| Salient Facial Patch [58] | 91.8% |
| CNN+SVM [59] | 95.31% |
| The proposed algorithm | 92.8% |
| Method | Accuracy Rate |
|---|---|
| MSR [60] | 91.4% |
| 3DCNN-DAP [61] | 92.4% |
| LBP+ORB features [55] | 93.2% |
| Inception [9] | 93.2% |
| Deep Features + HOG [57] | 94.17% |
| IB-CNN [37] | 95.1% |
| IACNN [38] | 95.37% |
| DTAGN [62] | 97.2% |
| ST-RNN [63] | 97.2% |
| PPDN [64] | 97.3% |
| Dynamic cascaded classifier [65] | 97.8% |
| The proposed algorithm | 98.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors 2021, 21, 3046. https://doi.org/10.3390/s21093046
Minaee S, Minaei M, Abdolrashidi A. Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors. 2021; 21(9):3046. https://doi.org/10.3390/s21093046
Chicago/Turabian StyleMinaee, Shervin, Mehdi Minaei, and Amirali Abdolrashidi. 2021. "Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network" Sensors 21, no. 9: 3046. https://doi.org/10.3390/s21093046
APA StyleMinaee, S., Minaei, M., & Abdolrashidi, A. (2021). Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors, 21(9), 3046. https://doi.org/10.3390/s21093046