
A Novel Focal Phi Loss for Power Line Segmentation with Auxiliary Classifier U-Net



Abstract
1. Introduction
Contributions
- A novel focal Phi loss (FPL) function for highly imbalanced data and thin RoI segmentation, where we modulate the Phi coefficient (also known as MCC) [26] to achieve an optimal trade-off between the evaluation parameters with minimal hyperparameter tuning.
- Validation of the proposed novel FPL function in terms of characteristic evaluation parameters (accuracy, sensitivity, specificity, false detection rate (FDR), class-wise dice scores and precision) on two PL detection benchmark datasets with varying levels of class imbalance.
- Empirical analysis of the choice of loss function for PL detection and evaluation of the proposed novel FPL function with state-of-the-art loss functions for handling class imbalance.
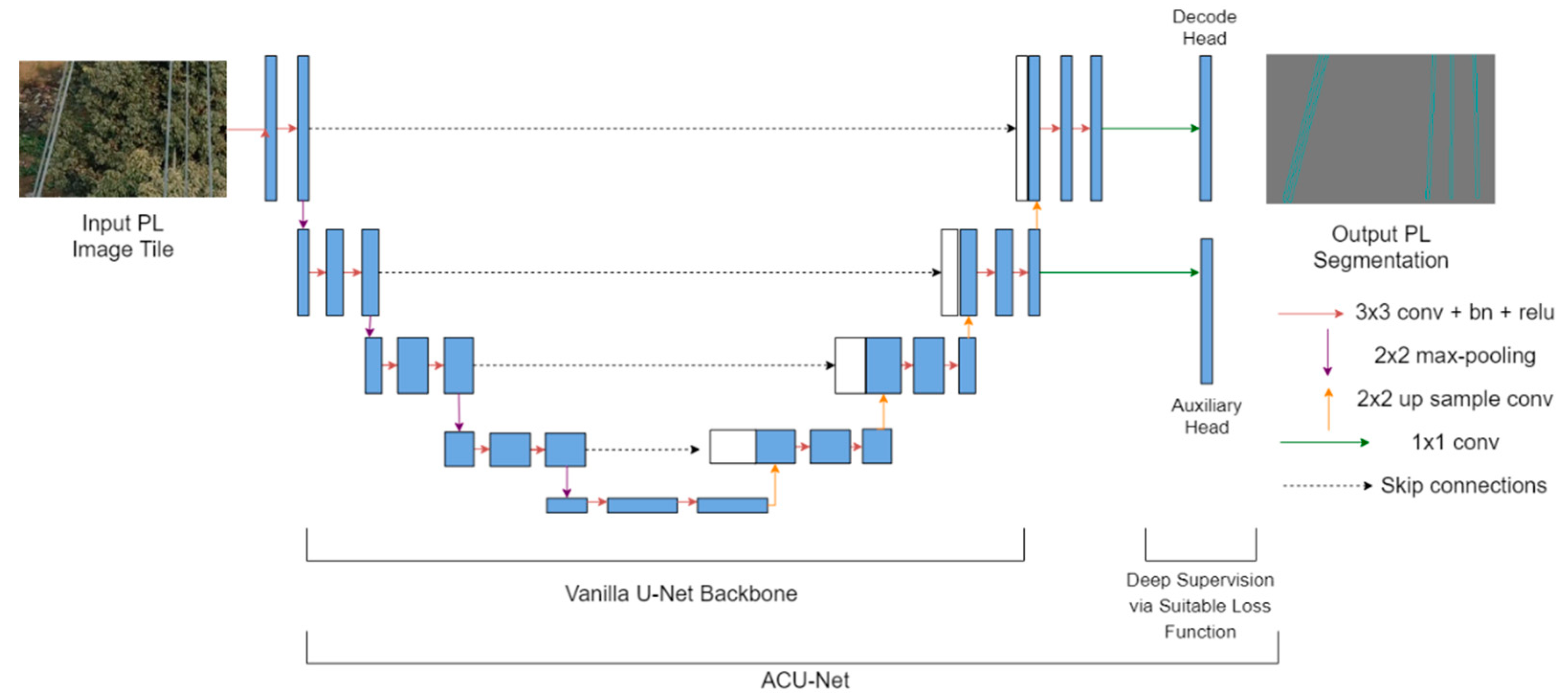
- A deeply supervised U-Net, named the auxiliary classifier U-Net (ACU-Net), improved with the simple addition of a convolutional auxiliary classifier for faster model convergence and better feature representations.
2. Related Work and Theoretical Foundation
2.1. Distribution Based Loss Functions
2.2. Region Based Loss Functions
2.3. Compound Loss Functions
3. Method
3.1. Focal Phi Loss
3.2. Network Architecture
4. Experiments
4.1. Dataset
- Scaling the images for a ratio range of (0.5, 1.5);
- Random rotation in the range of (45.0, 315.0) with a probability of 50%;
- Horizontal flipping with a probability of 50%;
- Resizing the images to 256 × 256;
- Random brightness with a delta of 32;
- Random contrast in the range of (0.5, 1.5);
- Random saturation in the range of (0.5, 1.5);
- Random hue with a delta of 0.5;
- Image padding for the resized images with size 256 × 256.
- PL class pixels with a color of (6, 230, 230);
- Bg class pixels with a color of (120, 120, 120).
4.2. Evaluation Parameters
4.3. Experimental Results
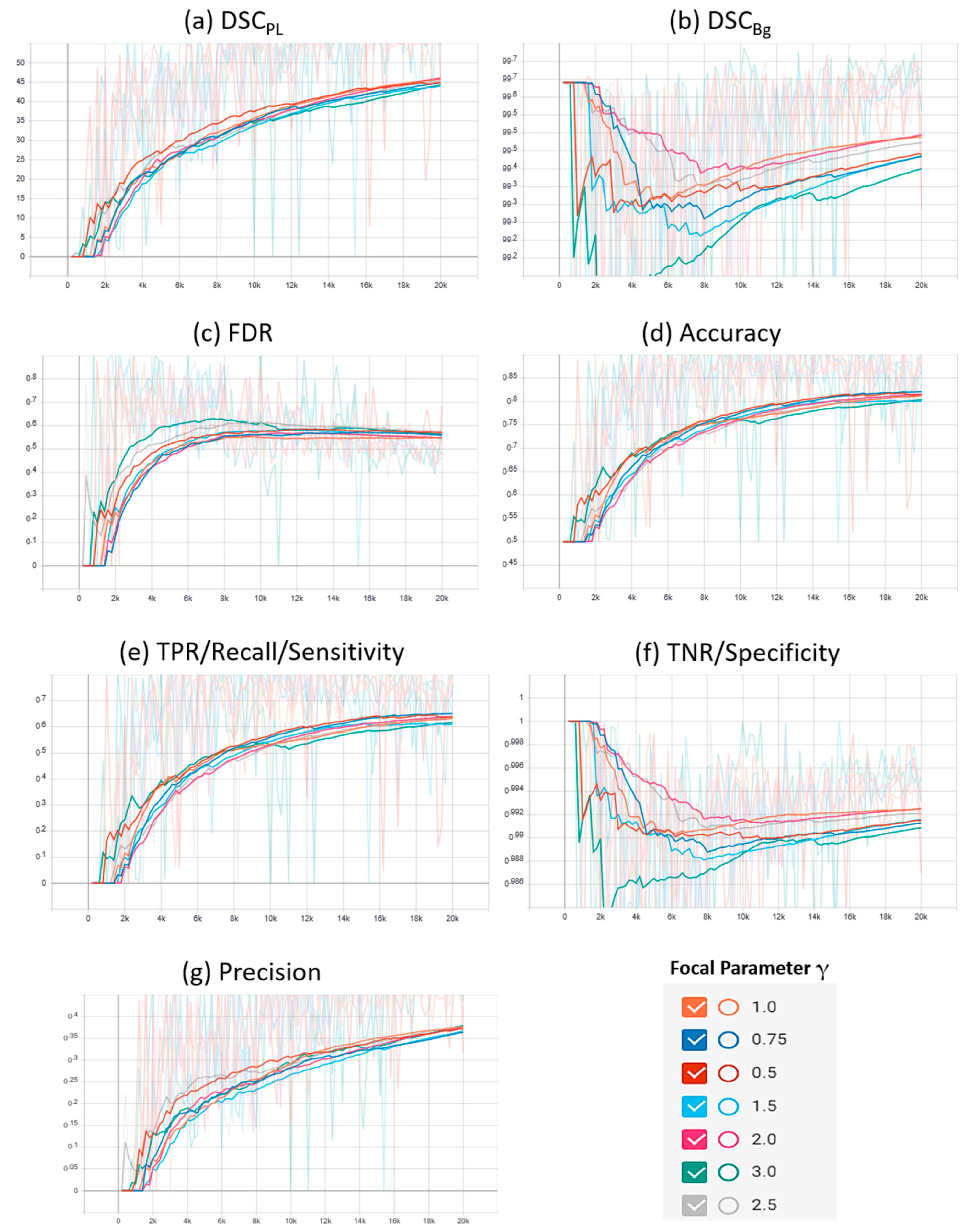
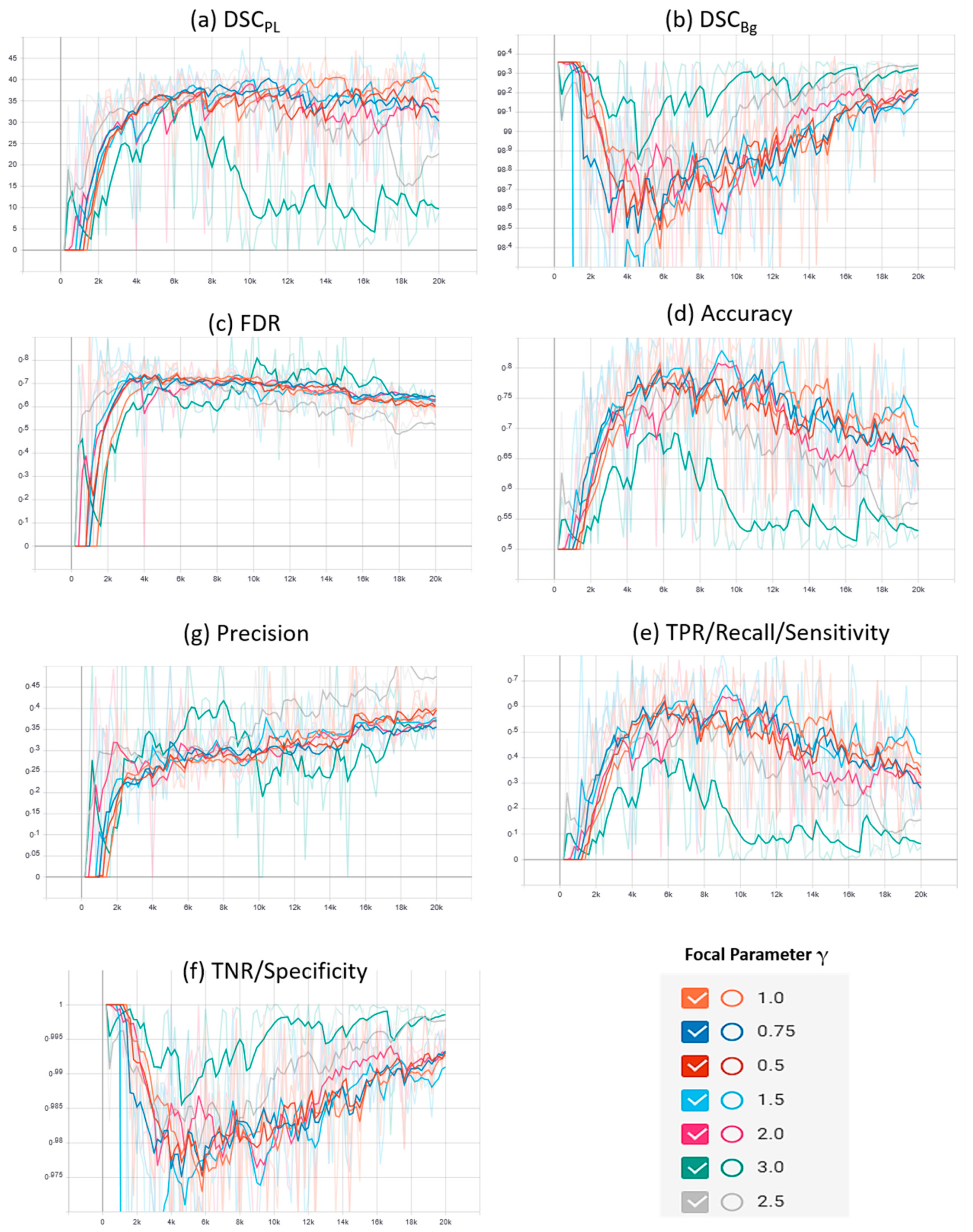
4.3.1. Focal Phi Loss (FPL) Results
4.3.2. Investigation of Various State-of-the-Art Loss Functions for PL Detection
4.3.3. Ablation Study
4.3.4. Analysis and Discussion
Comparison of FPL with MCC Loss
Comparative Analysis of FPL with State-of-the-Art Loss Functions
Comparative Analysis of Vanilla U-Net with ACU-Net
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACU-Net | Auxiliary Classifier U-Net |
| Bg | Background |
| BCE | Binary Cross Entropy |
| BBCE | Balanced Binary Cross Entropy |
| DL | Dice Loss |
| DSC | Dice Score |
| FDR | False Detection Rate |
| FL | Focal Loss |
| FN | False Negative |
| FP | False Positive |
| FPL | Focal Phi Loss |
| FTL | Focal Tversky Loss |
| GT | Ground Truth |
| LR | Learning Rate |
| PL | Power Line |
| PLDU | Power Line Dataset of Urban Scenes |
| RoI | Region of Interest |
| TN | True Negative |
| TNR | True Negative Rate |
| TP | True Positive |
| TPR | True Positive Rate |
| TL | Tversky Loss |
| UAV | Unmanned Aerial Vehicles |
| WBCE | Weighted Binary Cross Entropy |
Notations
| A | Majority class |
| B | Minority class |
| (y,ŷ) | y as the actual probabilities and ŷ as the predicted probabilities |
| pt | Predicted probabilities in Focal Loss |
| LBCE | BCE Loss |
| LWBCE | Weighted BCE Loss |
| LBBCE | Balanced BCE Loss |
| LFOCAL | Focal Loss |
| LDICE | Dice Loss |
| LTVERSKY | Tversky Loss |
| LMCC | MCC Loss |
| α,β | Class-wise weights |
| γ F | ocal parameter |
| ε | Smoothing factor for loss functions |
| ρ | Class imbalance level |
| Ci | is a set of examples in class i for calculating ρ |
| Sα | Smoothing parameter for exponential moving average |
| DSCBg | Dice score for background class |
| DSCPL | Dice score for power line class |
References
- Li, Z.; Liu, Y.; Walker, R.; Hayward, R.; Zhang, J. Towards automatic power line detection for a UAV surveillance system using pulse coupled neural filter and an improved Hough transform. Mach. Vis. Appl. 2010, 21, 677–686. [Google Scholar] [CrossRef]
- Miao, X.; Liu, X.; Chen, J.; Zhuang, S.; Fan, J.; Jiang, H. Insulator detection in aerial images for transmission line inspection using single shot multibox detector. IEEE Access 2019, 7, 9945–9956. [Google Scholar] [CrossRef]
- Yan, G.; Li, C.; Zhou, G.; Zhang, W.; Li, X. Automatic extraction of power lines from aerial images. IEEE Geosci. Remote Sens. Lett. 2007, 4, 387–391. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, W.; Yu, H.; Zhang, H.; Xia, G.-S. Detecting power lines in UAV images with convolutional features and structured constraints. Remote Sens. 2019, 11, 1342. [Google Scholar] [CrossRef]
- Zhou, G.; Yuan, J.; Yen, I.-L.; Bastani, F. Robust real-time UAV based power line detection and tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 744–748. [Google Scholar]
- Choi, H.; Koo, G.; Kim, B.J.; Kim, S.W. Weakly supervised power line detection algorithm using a recursive noisy label update with refined broken line segments. Expert Syst. Appl. 2021, 165, 113895. [Google Scholar] [CrossRef]
- Madaan, R.; Maturana, D.; Scherer, S. Wire detection using synthetic data and dilated convolutional networks for unmanned aerial vehicles. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3487–3494. [Google Scholar]
- Choi, H.; Koo, G.; Kim, B.J.; Kim, S.W. Real-time Power Line Detection Network using Visible Light and Infrared Images. In Proceedings of the 2019 International Conference on Image and Vision Computing New Zealand (IVCNZ), Dunedin, New Zealand, 2–4 December 2019; pp. 1–6. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed]
- Mazurowski, M.A.; Habas, P.A.; Zurada, J.M.; Lo, J.Y.; Baker, J.A.; Tourassi, G.D. Training neural network classifiers for medical decision making: The effects of imbalanced datasets on classification performance. Neural Netw. 2008, 21, 427–436. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 1–54. [Google Scholar] [CrossRef]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Ls-net: Fast single-shot line-segment detector. arXiv 2019, arXiv:1912.09532. [Google Scholar] [CrossRef]
- Li, Y.; Xiao, Z.; Zhen, X.; Cao, X. Attentional information fusion networks for cross-scene power line detection. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1635–1639. [Google Scholar] [CrossRef]
- Dai, Z.; Yi, J.; Zhang, Y.; Zhou, B.; He, L. Fast and accurate cable detection using CNN. Appl. Intell. 2020, 50, 4688–4707. [Google Scholar] [CrossRef]
- Yetgin, Ö.E.; Benligiray, B.; Gerek, Ö.N. Power line recognition from aerial images with deep learning. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 2241–2252. [Google Scholar] [CrossRef]
- Abdelfattah, R.; Wang, X.; Wang, S. TTPLA: An Aerial-Image Dataset for Detection and Segmentation of Transmission Towers and Power Lines. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Tang, Y. Deep learning using linear support vector machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. Artif. Intell. Stat. 2015, 562–570. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; pp. 379–387. [Google Scholar]
- Abraham, N.; Khan, N.M. A novel focal tversky loss function with improved attention u-net for lesion segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 683–687. [Google Scholar]
- Wang, L.; Wang, C.; Sun, Z.; Chen, S. An Improved Dice Loss for Pneumothorax Segmentation by Mining the Information of Negative Areas. IEEE Access 2020, 8, 167939–167949. [Google Scholar] [CrossRef]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin, Germany, 2017; pp. 240–248. [Google Scholar]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4413–4421. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Abhishek, K.; Hamarneh, G. Matthews Correlation Coefficient Loss for Deep Convolutional Networks: Application to Skin Lesion Segmentation. arXiv 2020, arXiv:2010.13454. [Google Scholar]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar]
- Yi-de, M.; Qing, L.; Zhi-Bai, Q. Automated image segmentation using improved PCNN model based on cross-entropy. In Proceedings of the 2004 International Symposium on Intelligent Multimedia, Video and Speech Processing (ISIMP), Hong Kong, China, 20–22 October 2004; pp. 743–746. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Pihur, V.; Datta, S.; Datta, S. Weighted rank aggregation of cluster validation measures: A monte carlo cross-entropy approach. Bioinformatics 2007, 23, 1607–1615. [Google Scholar] [CrossRef] [PubMed]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. EL-GAN: Embedding loss driven generative adversarial networks for lane detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 256–272. [Google Scholar]
- Taghanaki, S.A.; Zheng, Y.; Zhou, S.K.; Georgescu, B.; Sharma, P.; Xu, D.; Comaniciu, D.; Hamarneh, G. Combo loss: Handling input and output imbalance in multi-organ segmentation. Comput. Med Imaging Graph. 2019, 75, 24–33. [Google Scholar] [CrossRef] [PubMed]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Zhu, Q. On the performance of Matthews correlation coefficient (MCC) for imbalanced dataset. Pattern Recognit. Lett. 2020, 136, 71–80. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ade20k dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Yetgin, Ö.E.G.; Gerek, Ö.N. Ground Truth of Powerline Dataset (Infrared-IR and Visible Light-VL), 9th ed.; Mendeley Ltd.: Amsterdam, The Netherlands, 2019; Available online: http://dx.doi.org/10.17632/twxp8xccsw.9 (accessed on 28 January 2021).
- Zhang, W.Y.H.; Yu, H.; Zhang, H.; Xia, G. Powerline Dataset for Urban Scenes (PLDU). 2019. Available online: https://drive.google.com/drive/folders/1XjoWvHm2I8Y4RVi9gEd93ZP-KryjJlm (accessed on 17 December 2020).
- Contributors, M. MMSegmentation, an Open Source Semantic Segmentation Toolbox. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 20 January 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S.# | Dataset | Train | Val | Image Size | Annotation Type | Class Imbalance Level (ρ) |
|---|---|---|---|---|---|---|
| 1 | Mendeley PL Dataset [39] | 320 | 80 | 512 × 512 | Pixel | 0.073:99.92 |
| 2 | Power line Dataset of Urban Scenes (PLDU) [40] | 453 | 120 | 560 × 360 or 360 × 560 | Pixel | 1.18:98.82 |
| SN | Dataset | Focal Parameter | DSCPL | DSCBg | TPR | TNR | FDR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Mendeley PL Dataset | γ = 0.5 | 63.025 | 99.65 | 81.33 | 99.435 | 47.965 | 52.035 | 90.385 |
| γ = 0.75 | 58.38 | 99.57 | 81.775 | 99.28 | 54.275 | 45.725 | 90.525 | ||
| γ = 1.0 | 58.145 | 99.56 | 82.97 | 99.25 | 54.855 | 45.145 | 91.11 | ||
| γ = 1.5 | 59.55 | 99.595 | 81.615 | 99.32 | 52.67 | 47.33 | 90.47 | ||
| γ = 2.0 | 60.045 | 99.61 | 79.45 | 99.37 | 51.235 | 48.765 | 89.41 | ||
| γ = 2.5 | 60.865 | 99.63 | 78.78 | 99.41 | 49.8 | 50.2 | 89.1 | ||
| γ = 3.0 | 60.6 | 99.61 | 80.88 | 99.36 | 50.835 | 49.165 | 90.12 | ||
| 2 | Power line Dataset of Urban Scenes (PLDU) | γ = 0.5 | 41.35 | 98.735 | 65.72 | 97.935 | 68.08 | 31.92 | 81.83 |
| γ = 0.75 | 41.635 | 98.675 | 70.325 | 97.76 | 69.765 | 30.235 | 84.045 | ||
| γ = 1.0 | 42.46 | 98.725 | 68.905 | 97.88 | 68.03 | 31.97 | 83.39 | ||
| γ = 1.5 | 43.065 | 98.705 | 73.615 | 97.78 | 69.165 | 30.835 | 85.695 | ||
| γ = 2.0 | 38.52 | 98.455 | 68.435 | 97.36 | 71.785 | 28.21 | 82.9 | ||
| γ = 2.5 | 38.215 | 98.55 | 64.035 | 97.595 | 70.595 | 29.40 | 80.815 | ||
| γ = 3.0 | 41.47 | 99.06 | 50.97 | 98.76 | 62.075 | 37.925 | 74.865 |
| SN | Loss Function | Parameters | Learning Rate | DSCPL | DSCBg | TPR | TNR | FDR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Balanced Cross Entropy (BBCE) Loss (baseline) [29] | β = 0.98 (PL class), 1 − β = 0.02 (Bg) | 1 × 10−3 | 46.785 | 99.23 | 84.605 | 98.67 | 67.48 | 32.52 | 91.655 |
| 2 | Matthews Correlation Coefficient (MCC) Loss [26] | γ = 1.0 | 1 × 10−3 | 58.145 | 99.56 | 82.97 | 99.25 | 54.855 | 45.145 | 91.11 |
| 3 | Focal Phi Loss (FPL) (Ours) | γ = 0.5 | 1 × 10−3 | 63.025 | 99.65 | 81.33 | 99.435 | 47.965 | 52.035 | 90.385 |
| 4 | Tversky Loss (TL) [20] | α = 0.3, β = 0.7 | 5 × 10−5 | 72.78 | 99.81 | 70.60 | 99.83 | 24.90 | 75.10 | 85.22 |
| 5 | Dice Loss (DL) [23] | α = 0.5, β = 0.5 | 5 × 10−5 | 71.37 | 99.81 | 66.325 | 99.85 | 22.69 | 77.31 | 83.09 |
| 6 | Focal Tversky Loss (FTL) [21] | α = 0.3, β = 0.7, γ = 0.75 | 5 × 10−5 | 52.67 | 99.755 | 37.94 | 99.955 | 13.875 | 86.125 | 68.945 |
| SN | Loss Function | Parameters | Learning Rate | DSCPL | DSCBg | TPR | TNR | FDR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Balanced Cross Entropy (BBCE) Loss (baseline) [29] | β = 0.98 (PL class), 1 − β = 0.02 (Bg) | 1 × 10−3 | 27.145 | 96.715 | 91.485 | 93.745 | 84.05 | 15.95 | 92.615 |
| 2 | Matthews Correlation Coefficient (MCC) Loss [26] | γ = 1.0 | 1 × 10−3 | 42.46 | 98.725 | 68.905 | 97.88 | 68.03 | 31.97 | 83.39 |
| 3 | Focal Phi Loss (FPL) (Ours) | γ = 1.5 | 1 × 10−3 | 43.065 | 98.705 | 73.615 | 97.78 | 69.165 | 30.835 | 85.695 |
| 4 | Tversky Loss (TL) [20] | α = 0.3, β = 0.7 | 1 × 10−7 | 3.52 | 88.47 | 29.42 | 80.05 | 98.13 | 1.87 | 54.74 |
| 5 | Dice Loss (DL) [23] | α = 0.5, β = 0.5 | 1 × 10−7 | 3.89 | 93.23 | 20.06 | 88.22 | 97.85 | 2.15 | 54.14 |
| 6 | Focal Tversky Loss (FTL) [21] | α = 0.3, β = 0.7, γ = 0.75 | 1 × 10−7 | 3.62 | 89.31 | 28.35 | 81.43 | 98.07 | 1.93 | 54.89 |
| SN | Loss Function | Parameters | Learning Rate | Model | DSCPL | DSCBg | TPR | TNR | FDR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Balanced Cross Entropy (BBCE) Loss (baseline) [29] | β = 0.98 (PL class), 1 − β = 0.02 (Bg) | 1 × 10−3 | ACU-Net (Ours) | 46.785 | 99.23 | 84.60 | 98.67 | 67.48 | 32.52 | 91.655 |
| Vanilla U-Net | 50.555 | 99.38 | 86.38 | 98.86 | 64.1 | 35.9 | 92.62 | ||||
| 2 | Matthews Correlation Coefficient (MCC) Loss [26] | γ = 1.0 | 1 × 10−3 | ACU-Net (Ours) | 58.145 | 99.56 | 82.97 | 99.25 | 54.85 | 45.145 | 91.11 |
| Vanilla U-Net | 56.975 | 99.585 | 73.87 | 99.36 | 51.67 | 48.33 | 86.62 | ||||
| 3 | Focal Phi Loss (FPL) (Ours) | γ = 0.5 | 1 × 10−3 | ACU-Net (Ours) | 63.025 | 99.65 | 81.33 | 99.43 | 47.965 | 52.035 | 90.385 |
| Vanilla U-Net | 56.240 | 99.525 | 83.320 | 99.170 | 57.250 | 42.750 | 91.245 | ||||
| 4 | Tversky Loss (TL) [20] | α = 0.3, β = 0.7 | 5 × 10−5 | ACU-Net (Ours) | 72.78 | 99.81 | 70.60 | 99.83 | 24.90 | 75.10 | 85.22 |
| Vanilla U-Net | 71.815 | 99.805 | 68.510 | 99.840 | 24.555 | 75.445 | 84.175 | ||||
| 5 | Dice Loss (DL) [23] | α = 0.5, β = 0.5 | 5 × 10−5 | ACU-Net (Ours) | 71.37 | 99.81 | 66.325 | 99.85 | 22.69 | 77.31 | 83.09 |
| Vanilla U-Net | 70.720 | 99.805 | 65.31 | 99.860 | 22.890 | 77.110 | 82.590 | ||||
| 6 | Focal Tversky Loss (FTL) [21] | α = 0.3, β = 0.7, γ = 0.75 | 5 × 10−5 | ACU-Net (Ours) | 52.67 | 99.755 | 37.94 | 99.955 | 13.875 | 86.125 | 68.945 |
| Vanilla U-Net | 40.110 | 99.720 | 26.070 | 99.975 | 13.060 | 86.940 | 63.020 |
| SN | Loss Function | Parameters | Learning Rate | Model | DSCPL | DSCBg | TPR | TNR | FDR | Precision | Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Balanced Cross Entropy (BBCE) (baseline) [29] | β = 0.98 (PL class), 1 − β = 0.02 (Bg) | 1 × 10−3 | ACU-Net (Ours) | 27.145 | 96.715 | 91.485 | 93.745 | 84.05 | 15.95 | 92.615 |
| Vanilla U-Net | 23.245 | 96.315 | 82.41 | 93.115 | 86.400 | 13.60 | 87.76 | ||||
| 2 | Matthews Correlation Coefficient (MCC) Loss [26] | γ = 1.0 | 1 × 10−3 | ACU-Net (Ours) | 42.46 | 98.725 | 68.905 | 97.88 | 68.03 | 31.97 | 83.39 |
| Vanilla U-Net | 38.340 | 98.410 | 72.905 | 97.215 | 73.555 | 26.445 | 85.055 | ||||
| 3 | Focal Phi Loss (FPL) (Ours) | γ = 1.5 | 1 × 10−3 | ACU-Net (Ours) | 43.065 | 98.705 | 73.615 | 97.78 | 69.165 | 30.835 | 85.695 |
| Vanilla U-Net | 41.625 | 98.760 | 66.720 | 97.980 | 69.280 | 30.720 | 82.345 | ||||
| 4 | Tversky Loss (TL) [20] | α = 0.3, β = 0.7 | 1 × 10−7 | ACU-Net (Ours) | 3.52 | 88.47 | 29.42 | 80.05 | 98.13 | 1.87 | 54.74 |
| Vanilla U-Net | 2.905 | 90.865 | 19.615 | 84.130 | 98.430 | 1.570 | 51.875 | ||||
| 5 | Dice Loss (DL) [23] | α = 0.5, β = 0.5 | 1 × 10−7 | ACU-Net (Ours) | 3.89 | 93.23 | 20.06 | 88.22 | 97.85 | 2.15 | 54.14 |
| Vanilla U-Net | 3.07 | 89.64 | 23.29 | 82.03 | 98.35 | 1.65 | 52.66 | ||||
| 6 | Focal Tversky Loss (FTL) [21] | α = 0.3, β = 0.7, γ = 0.75 | 1 × 10−7 | ACU-Net (Ours) | 3.62 | 89.31 | 28.35 | 81.43 | 98.07 | 1.93 | 54.89 |
| Vanilla U-Net | 2.905 | 90.865 | 19.620 | 84.125 | 98.430 | 1.570 | 51.870 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaffari, R.; Hashmani, M.A.; Reyes-Aldasoro, C.C. A Novel Focal Phi Loss for Power Line Segmentation with Auxiliary Classifier U-Net. Sensors 2021, 21, 2803. https://doi.org/10.3390/s21082803
Jaffari R, Hashmani MA, Reyes-Aldasoro CC. A Novel Focal Phi Loss for Power Line Segmentation with Auxiliary Classifier U-Net. Sensors. 2021; 21(8):2803. https://doi.org/10.3390/s21082803
Chicago/Turabian StyleJaffari, Rabeea, Manzoor Ahmed Hashmani, and Constantino Carlos Reyes-Aldasoro. 2021. "A Novel Focal Phi Loss for Power Line Segmentation with Auxiliary Classifier U-Net" Sensors 21, no. 8: 2803. https://doi.org/10.3390/s21082803
APA StyleJaffari, R., Hashmani, M. A., & Reyes-Aldasoro, C. C. (2021). A Novel Focal Phi Loss for Power Line Segmentation with Auxiliary Classifier U-Net. Sensors, 21(8), 2803. https://doi.org/10.3390/s21082803