
Deep Learning versus Spectral Techniques for Frequency Estimation of Single Tones: Reduced Complexity for Software-Defined Radio and IoT Sensor Communications



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- The performance of the DL approach is compared with the performance of still-active classical techniques that are based on Fourier analysis.
- In many situations, SNR estimation can be inaccurate or unavailable. Hence, system performance is investigated in case of unavailable SNR information.
- The DL approach is SNR-dependent; hence, an investigation of system performance under various SNRs is presented.
- The more the nodes in the DL approach are, the better the accuracy of estimation could be. Hence, this work investigated the effect of changing the number of nodes in the hidden layers of the network.
- The number of input samples (signal length or duration) has significant impact on the complexity and the performance of classical and DL-based methods. This point was fully investigated in this work.
- The effect of different realizations while training was handled in the literature of DL-based approaches, as it is a necessary step in the training process. However, the possibility of different realizations in the working environment (application phase) was not previously handled. In this work, we discuss the effect of different realizations during the application phase.
- The reduced complexity introduced by DL-based FE, in addition to avoiding complex-valued arithmetic operations, makes FE easier and cheaper for IoT communications, sensors, sensor networks, and software-defined radio (SDR). This work presents a discussion on such possibilities.
2. Motivation and Related Work
- The network was trained for a specific SNR. There should be a clarification whether different networks should be present in the case that different SNRs are expected.
- The effect of SNR on estimation error was unclear.
- The number of input nodes was chosen as N = 2000. It is not clear whether this choice of the input samples (nodes) is frequency-, duration-, or network-dependent.
- The division of the frequency range was not clear. The effect of this division on estimation error should be addressed. The relation of this division to the time–frequency uncertainty principle should also be clarified.
- The number of nodes in the hidden layers was 2. The effect of this number on estimation accuracy should be clarified. The possibility that this effect is SNR-dependent should be addressed.
- Classical techniques for frequency estimation have been well-studied for decades. There should be a clear reasoning why one should choose DL-based estimation instead.
3. Problem Statement
- Comparing the performance of DL-based approach with classical techniques.
- Investigating system performance in case of unavailable SNR information.
- Investigating system performance under various SNRs.
- Investigating the effect of changing the number of nodes in the hidden layers of the network.
- Investigating the effect of input signal length (duration) on the performance of both classical and DL-based methods. This factor has significant impact on overall performance and complexity.
- Investigating the effect of different realizations during the application phase (not only during the training phase).
- Investigating the impact of DL-based FE on IoT, sensors, sensor networks, and software-defined radio (SDR).
4. A Brief Overview of Classical FE for Single Tones
4.1. Maximum of DFT Estimator
4.2. Quadratic Interpolator
4.3. Barycentric Estimator
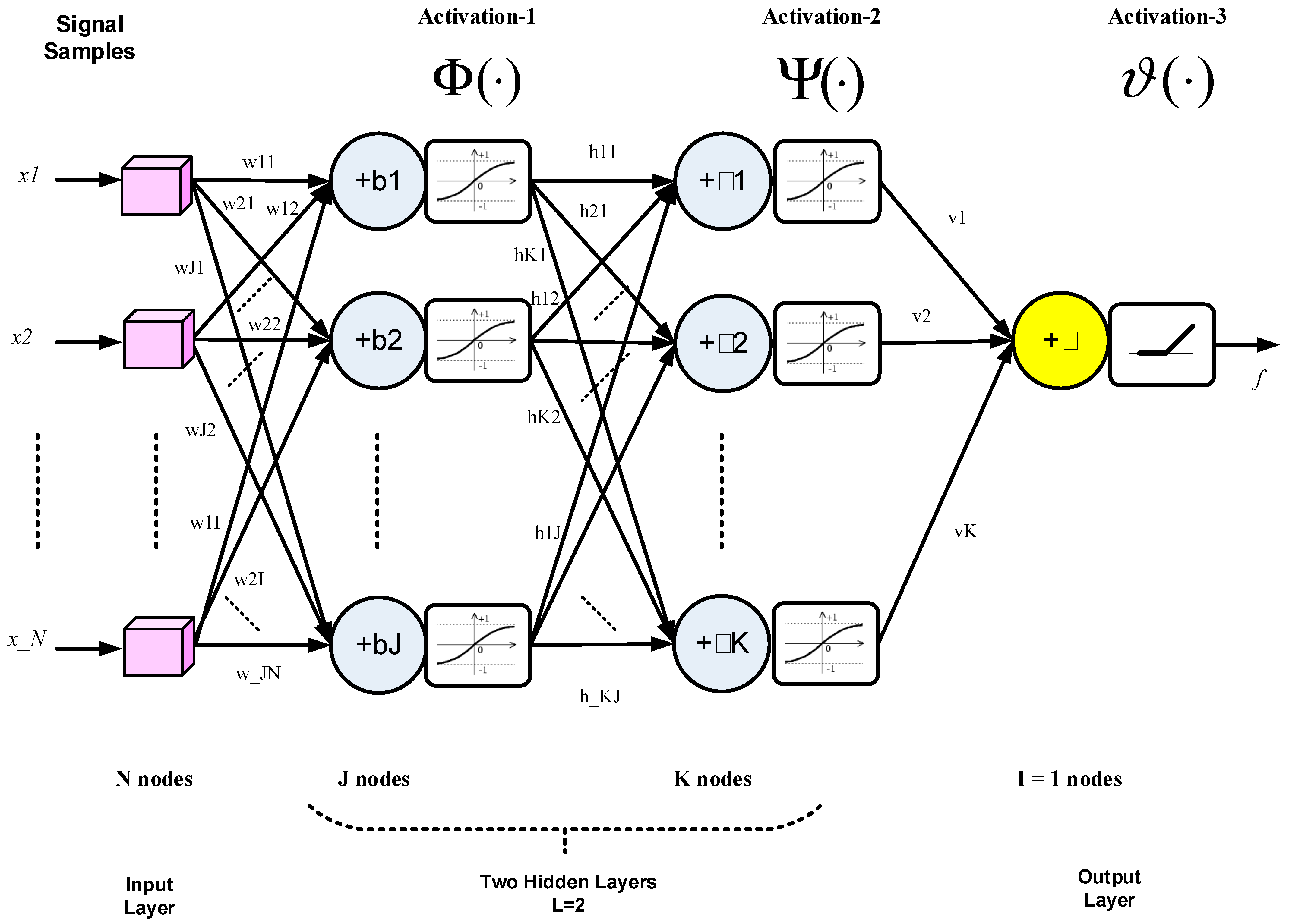
5. Deep Learning for Single-Tone FE: Network Structure and Training
5.1. DL Network Structure
5.2. Training Data
5.3. Training Function: Scaled Conjugate Gradient Backpropagation
6. Results: Deep Learning vs. Classical Single-Tone FE
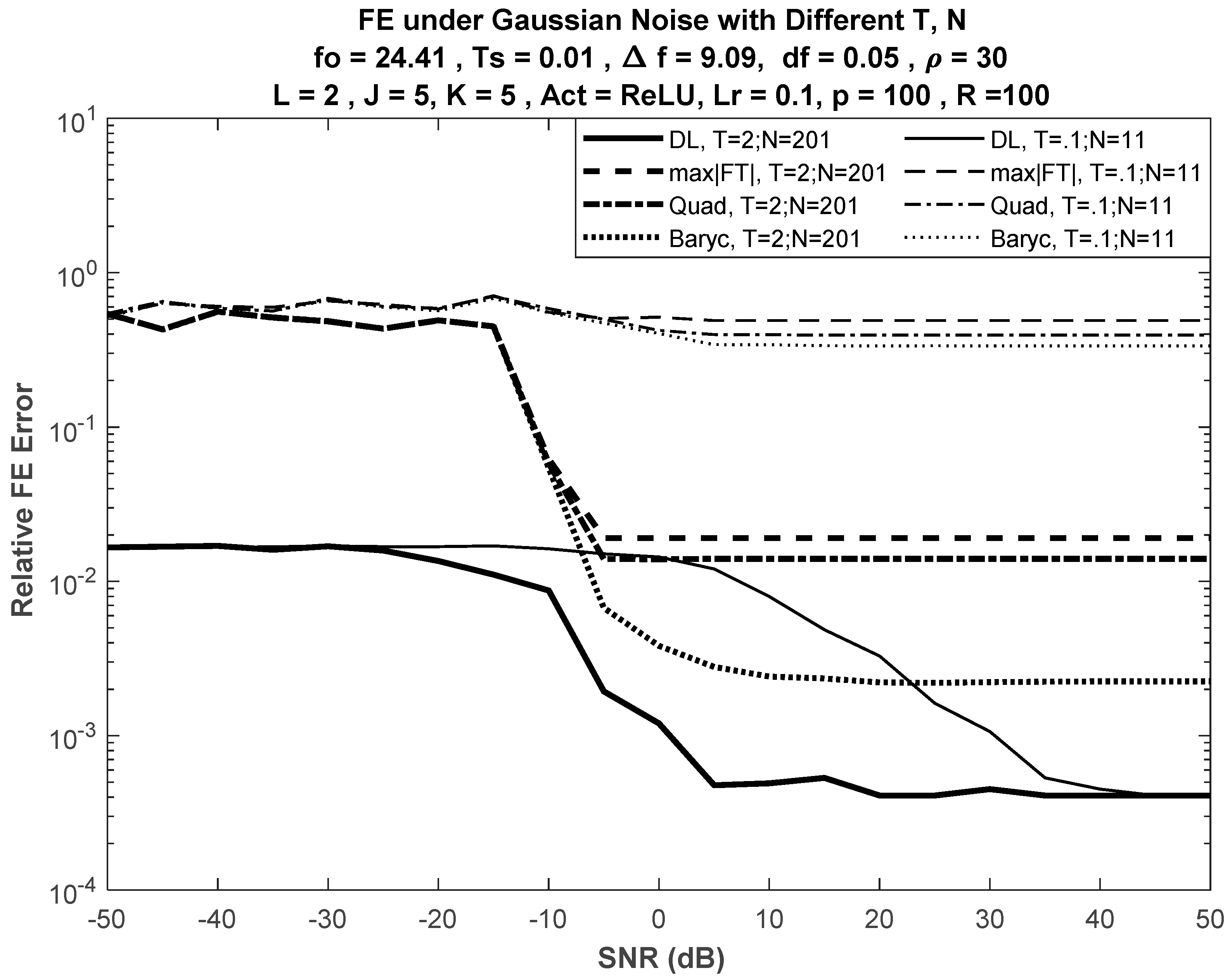
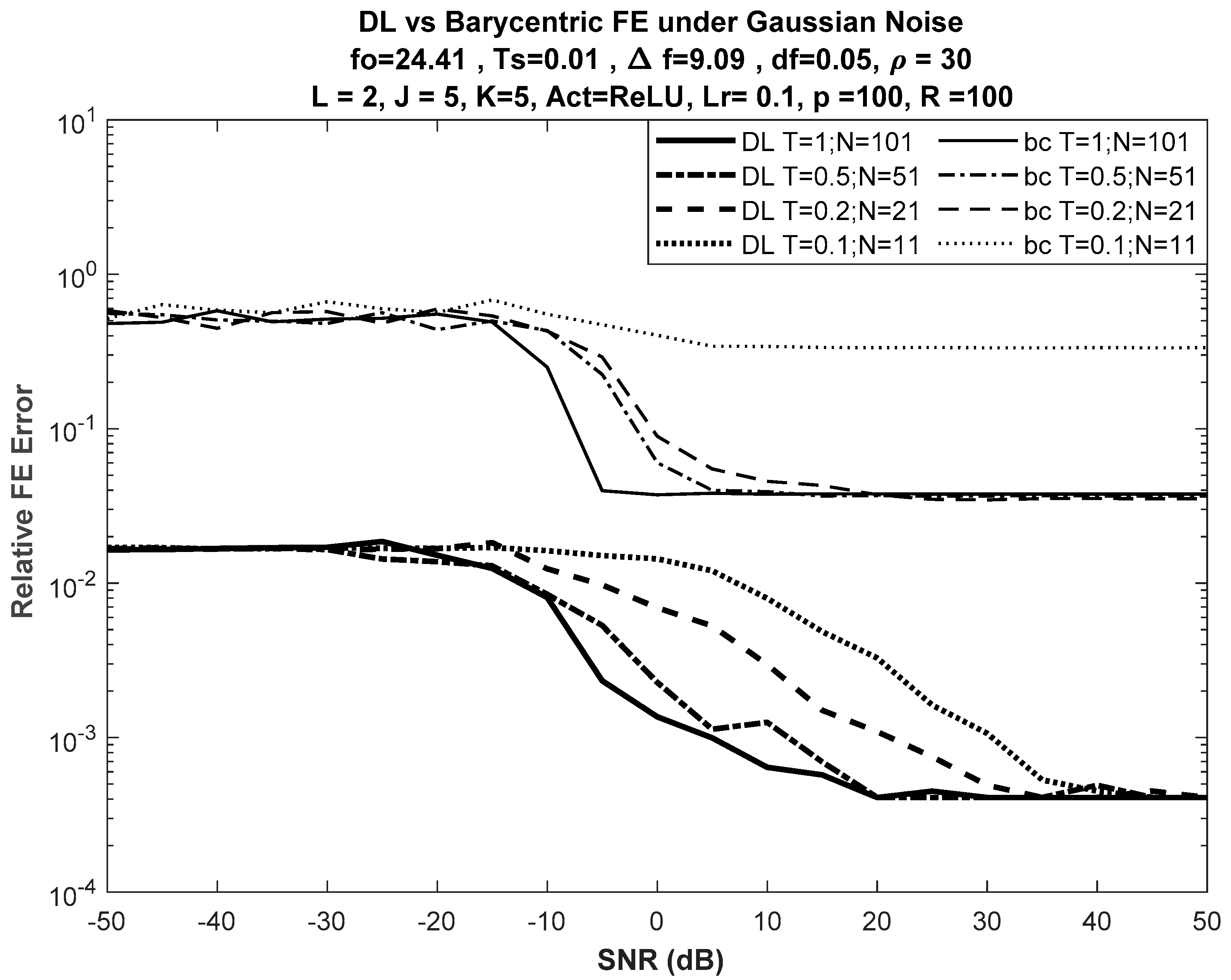
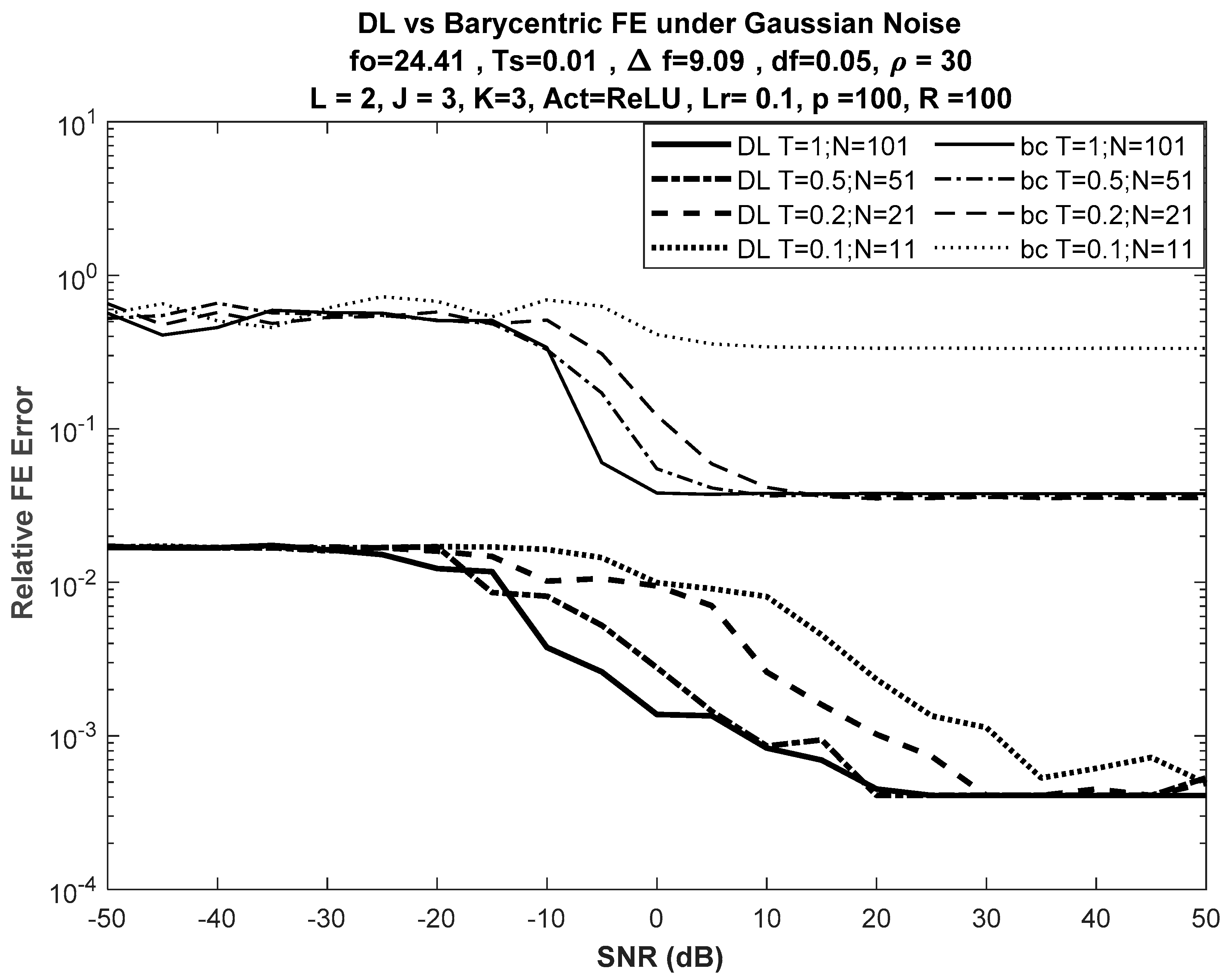
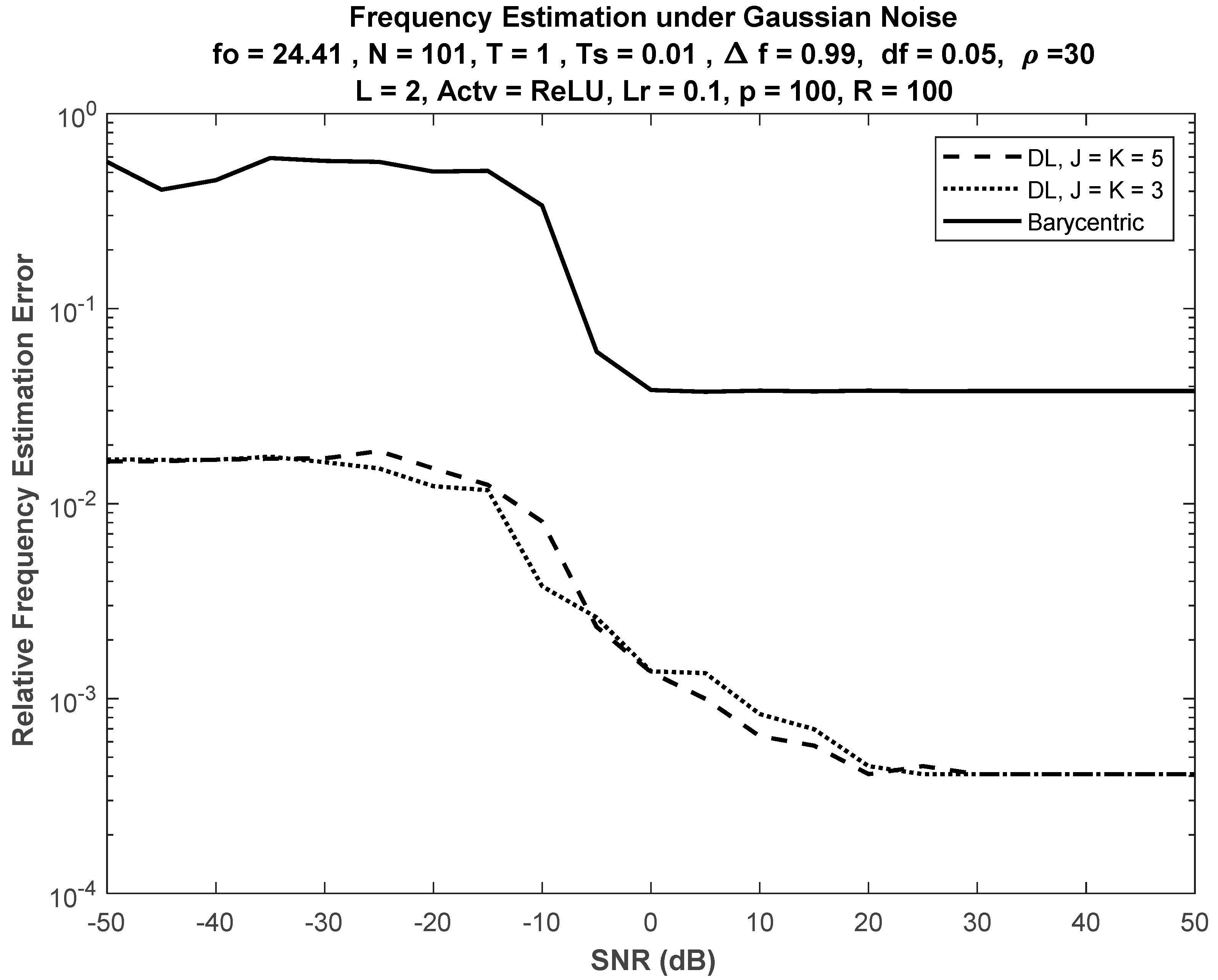
6.1. Performance under Different Input Lengths
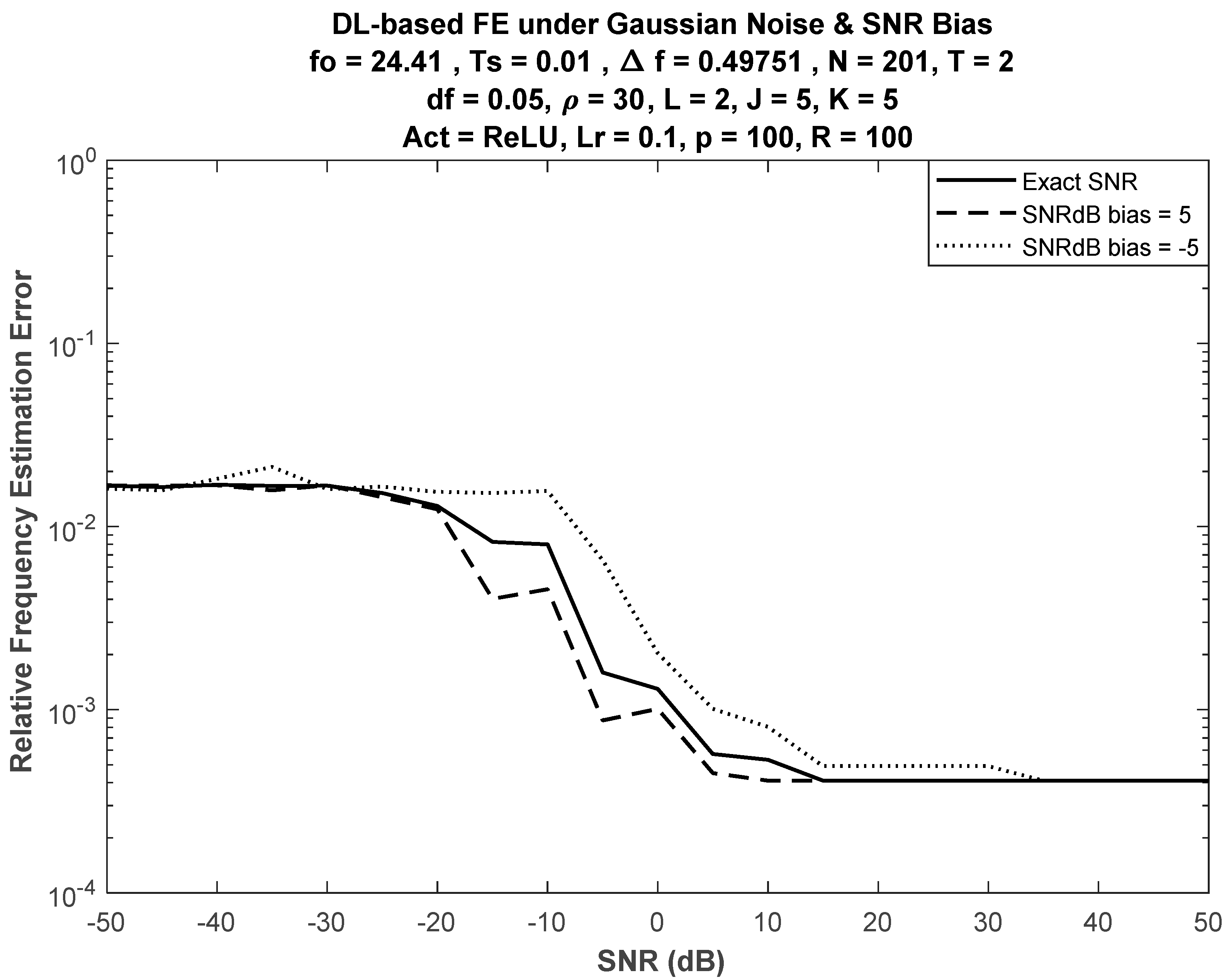
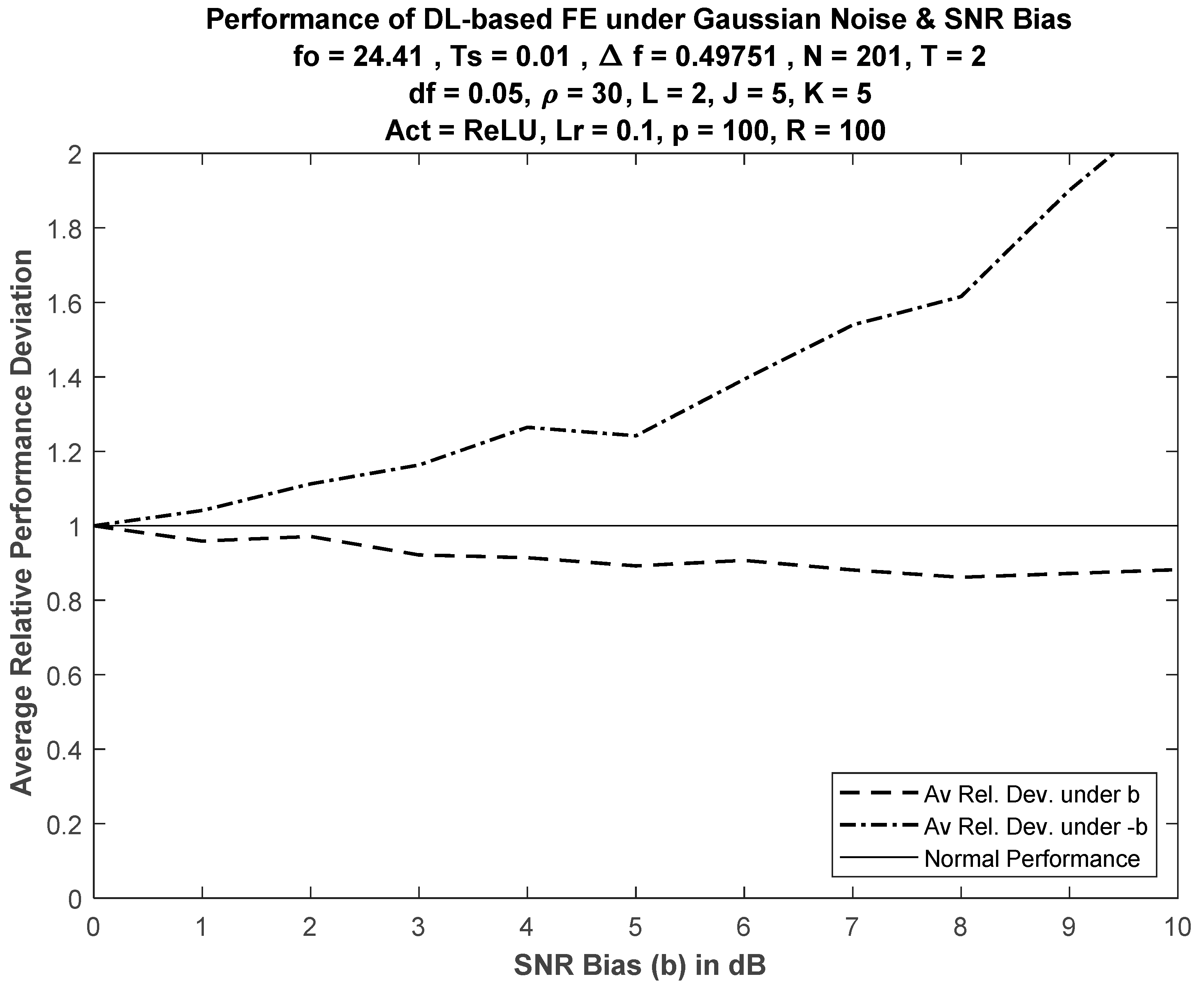
6.2. Performance under Insufficient SNR Information
6.3. Effect of Increasing Nodes at Hidden Layers
6.4. Impact on IoT, Sensors, and SDR
6.5. Future Directions: DL in the SWL Domain
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Serbes, A. Fast and Efficient Sinusoidal Frequency Estimation by Using the DFT Coefficients. IEEE Trans. Commun. 2018, 67, 2333–2342. [Google Scholar] [CrossRef]
- Boashash, B. (Ed.) Time-Frequency Signal Analysis and Processing: A Comprehensive Reference; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Brown, R.D., III; Liao, Y.; Fox, N. Low-Complexity Real-Time Single-Tone Phase and Frequency Estimation. IEEE Mil. Commun. 2010. [Google Scholar]
- Yang, C.; Wei, G.; Chen, F.-J. An Estimation-Range Extended Autocorrelation-Based Frequency Estimator. EURASIP J. Adv. Signal Process. 2009, 961938, 1–7. [Google Scholar] [CrossRef]
- Al-Araji, S.; Hussain, Z.M.; Al-Qutayri, M.A. Digital Phase Lock Loops: Architectures and Applications; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Cao, Y.; Geddes, T.A.; Yang, J.Y.H.; Yang, P. Ensemble deep learning in bioinformatics. Nat. Mach. Intell. 2020, 2, 500–508. [Google Scholar] [CrossRef]
- Kour, H.; Gondhi, N. Machine Learning Techniques: A Survey. In Innovative Data Communication Technologies and Application, ICIDCA 2019, Lecture Notes on Data Engineering and Communications Technologies; Raj, J., Bashar, A., Ramson, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 46. [Google Scholar]
- Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A Comprehensive Survey on Machine Learning for Networking: Evolution, Applications and Research Opportunities. J. Internet Serv. Appl. 2018, 9, 1–99. [Google Scholar] [CrossRef]
- Sajedian, I.; Rho, J. Accurate and Instant Frequency Estimation from Noisy Sinusoidal Waves by Deep Learning. Nano Converg. 2019, 6, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Shimodaira, H. Direct F0 Estimation with Neural-Network-Based Regression. In Proceedings of the 20th Annual Con-ference of the International Speech Communication Association (INTERSPEECH 2019), Graz, Austria, 15–19 September 2019. [Google Scholar]
- Chen, X.; Jiang, Q.; Su, N.; Chen, B.; Guan, J. LFM Signal Detection and Estimation Based on Deep Convolutional Neural Network. In Proceedings of the APSIPA Annual Summit and Conference, Lanzhou, China, 18–21 November 2019. [Google Scholar]
- Hussain, Z.M.; Boashash, B. The T-class of time–frequency distributions: Time-only kernels with amplitude estimation. J. Frankl. Inst. 2006, 343, 661–675. [Google Scholar] [CrossRef]
- Boashash, B. Estimating and Interpreting the Instantaneous Frequency of a Signal-Part 1: Fundamentals. Proc. IEEE 1992, 80, 520–538. [Google Scholar] [CrossRef]
- Almoosawy, A.N.; Hussain, Z.M.; Murad, F.A. Frequency Estimation of Single-Tone Sinusoids under Additive and Phase Noise. Int. J. Adv. Comput. Sci. Appl. 2014. [Google Scholar]
- Bai, G.; Cheng, Y.; Tang, W.; Li, S.; Lu, X. Accurate Frequency Estimation of a Real Sinusoid by Three New Interpolators. IEEE Access 2019, 7, 91696–91702. [Google Scholar] [CrossRef]
- Fan, L.; Qi, G.; Xing, J.; Jin, J.; Liu, J.; Wang, Z. Accurate Frequency Estimator of Sinusoid Based on Interpolation of FFT and DTFT. IEEE Access 2020, 8, 44373–44380. [Google Scholar] [CrossRef]
- Çagatay, C. A Method for Fine Resolution Frequency Estimation from Three DFT Samples. IEEE Signal Process. Lett. 2011, 18, 351–354. [Google Scholar] [CrossRef]
- Hussain, Z.M. Energy-Efficient Systems for Smart Sensor Communications. In Proceedings of the IEEE 30th International Telecommunication Networks and Applications Conference (ITNAC2020), Melbourne, Australia, 25–27 November 2020. [Google Scholar]
- Rice, F.; Cowley, B.; Moran, B.; Rice, M. Cramer-Rao lower bounds for QAM phase and frequency estimation. IEEE Trans. Commun. 2001, 49, 1582–1591. [Google Scholar] [CrossRef]
- So, H.; Chan, F.K.; Sun, W. Efficient frequency estimation of a single real tone based on principal singular value decomposition. Digit. Signal Process. 2012, 22, 1005–1009. [Google Scholar] [CrossRef]
- Escobar, J.J.M.; Matamoros, O.M.; Padilla, R.T.; Hernández, L.C.; Durán, J.P.F.P.; Martínez, A.K.P.; Reyes, I.L.; Espinosa, H.Q. Biomedical Signal Acquisition Using Sensors under the Paradigm of Parallel Computing. Sensors 2020, 20, 6991. [Google Scholar] [CrossRef] [PubMed]
- Xia, Y.; He, Y.; Wang, K.; Pei, W.; Blazic, Z.; Mandic, D.P. A Complex Least Squares Enhanced Smart DFT Technique for Power System Frequency Estimation. IEEE Trans. Power Deliv. 2017, 32, 1270–1278. [Google Scholar] [CrossRef]
- Cohen, L. Time-Frequency Analysis; Prentice Hall: Hoboken, NJ, USA, 1995. [Google Scholar]
- Moller, M.F. A Scaled Conjugate Gradient Algorithm for Fast Supervised Learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- The MathWorks. Trainscg: Scaled Conjugate Gradient Backpropagation, Available from MATLAB Documentation, Also at MathWorks Website. Available online: https://nl.mathworks.com/help/deeplearning/ref/trainscg.html (accessed on 2 April 2021).
- Vanus, J.; Nedoma, J.; Fajkus, M.; Martinek, R. Design of a New Method for Detection of Occupancy in the Smart Home Using an FBG Sensor. Sensors 2020, 20, 398. [Google Scholar] [CrossRef]
- Fletcher, R.; Reeves, C.M. Function Minimization by Conjugate Gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef]
- Takahashi, D. Fast Fourier Transform Algorithms for Parallel Computers; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Sadik, A.; Hussain, Z.; O’Shea, P. Adaptive algorithm for ternary filtering. IET Electron. Lett. 2006, 42, 420. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almayyali, H.R.; Hussain, Z.M. Deep Learning versus Spectral Techniques for Frequency Estimation of Single Tones: Reduced Complexity for Software-Defined Radio and IoT Sensor Communications. Sensors 2021, 21, 2729. https://doi.org/10.3390/s21082729
Almayyali HR, Hussain ZM. Deep Learning versus Spectral Techniques for Frequency Estimation of Single Tones: Reduced Complexity for Software-Defined Radio and IoT Sensor Communications. Sensors. 2021; 21(8):2729. https://doi.org/10.3390/s21082729
Chicago/Turabian StyleAlmayyali, Hind R., and Zahir M. Hussain. 2021. "Deep Learning versus Spectral Techniques for Frequency Estimation of Single Tones: Reduced Complexity for Software-Defined Radio and IoT Sensor Communications" Sensors 21, no. 8: 2729. https://doi.org/10.3390/s21082729
APA StyleAlmayyali, H. R., & Hussain, Z. M. (2021). Deep Learning versus Spectral Techniques for Frequency Estimation of Single Tones: Reduced Complexity for Software-Defined Radio and IoT Sensor Communications. Sensors, 21(8), 2729. https://doi.org/10.3390/s21082729