
Optimization-Based Online Initialization and Calibration of Monocular Visual-Inertial Odometry Considering Spatial-Temporal Constraints



Abstract
1. Introduction
- We propose an online method for bootstrapping the optimization-based monocular VIO system, which can simultaneously estimate the initial states and calibrate the spatial and temporal parameters between the camera and IMU sensors.
- The time offset is modeled, and two short-term motion interpolation algorithms considering both the temporal parameter and the unknown metric-scale are proposed to interpolate the camera and IMU pose at an arbitrary intermediate time, which enable us to align the camera poses and IMU poses.
- A three-step incremental estimator is introduced to estimate the initial states and the spatial-temporal parameters using the aligned poses.
- A tightly-coupled nonlinear optimization algorithm is additionally included to improve the accuracy of the estimated results.
2. Related Work
3. Short-Term Sensor Motion Interpolation
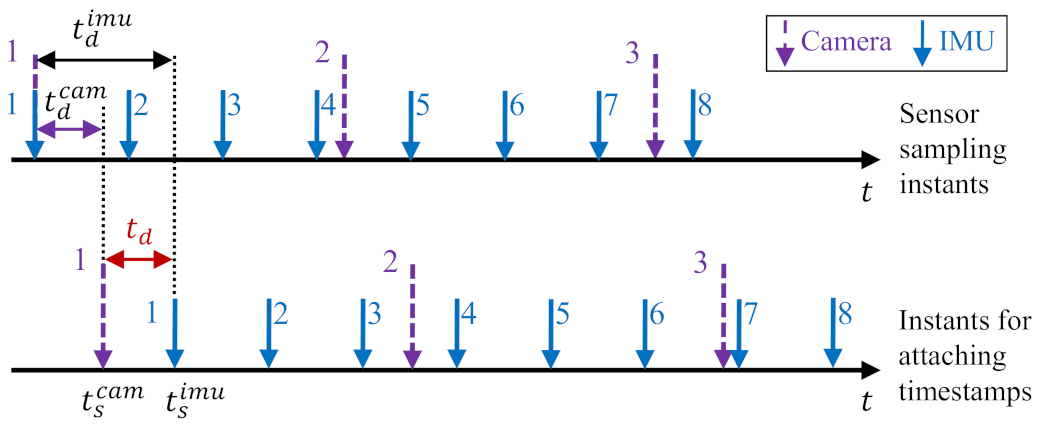
3.1. Time Offset Model
3.2. Sensor Motion Interpolation
3.2.1. Camera Motion Interpolation
3.2.2. IMU Motion Interpolation
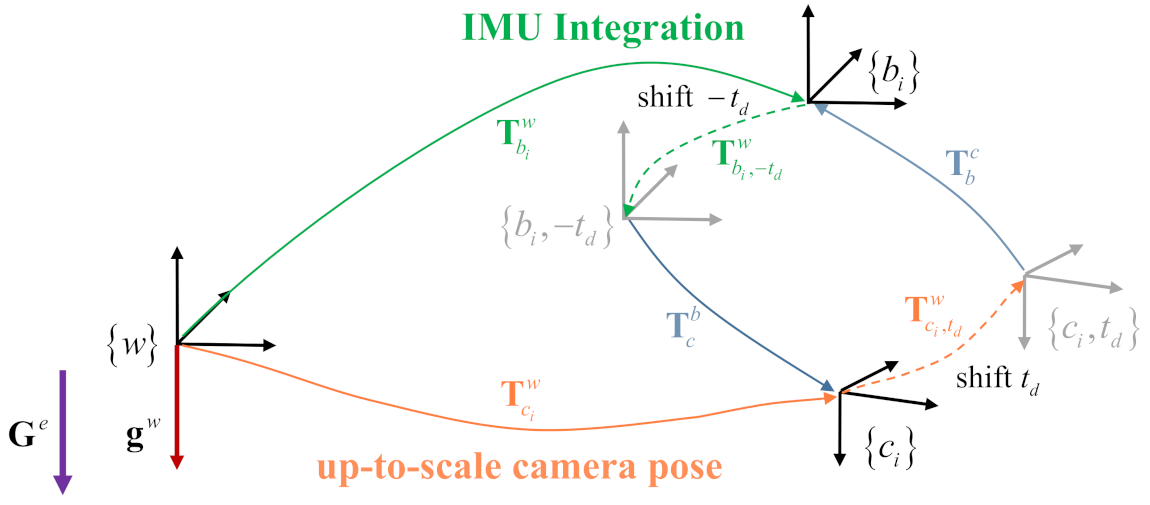
3.3. Spatial Relationships between Camera and IMU
4. Online Initialization and Extrinsic Spatial-Temporal Calibration
4.1. IMU Preintegration
4.2. Incremental Estimation
4.2.1. Estimating Gyroscope Bias, and Calibrating Extrinsic Rotation and Time Offset
4.2.2. Approximating Scale, Gravity, and Extrinsic Translation
4.2.3. Estimating Accelerometer Bias, and Refining Scale, Gravity, and Extrinsic Translation
4.3. Updates, Termination, and Velocity Estimation
5. Visual-Inertial Bundle Adjustment
5.1. Feature Reprojection Error
5.2. IMU Preintegration Error
6. Experiments Furthermore, Discussions
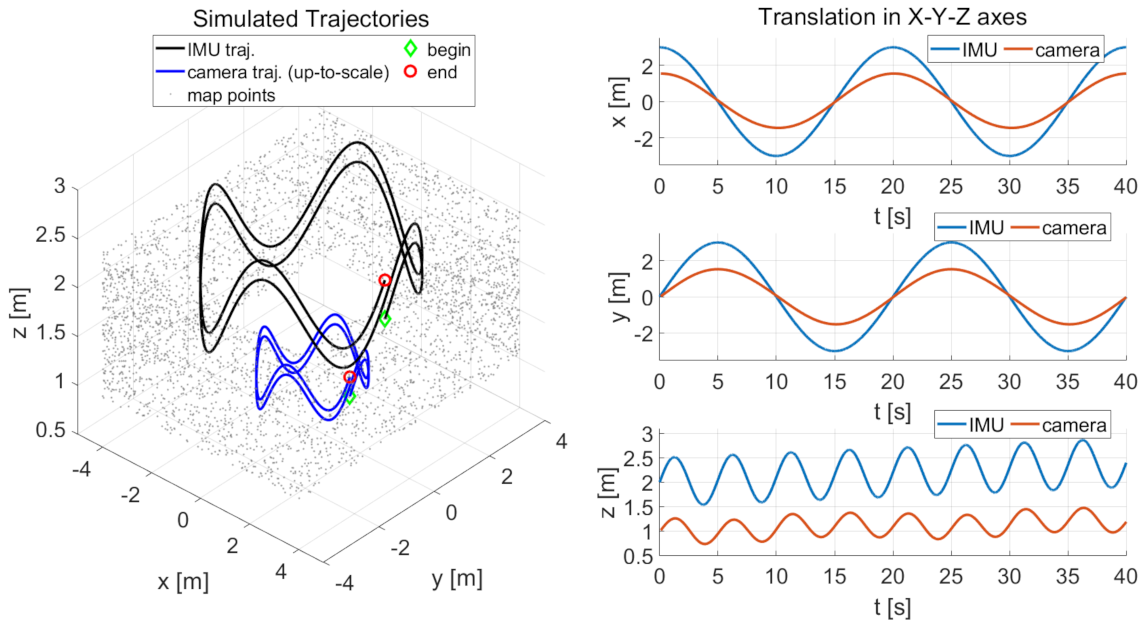
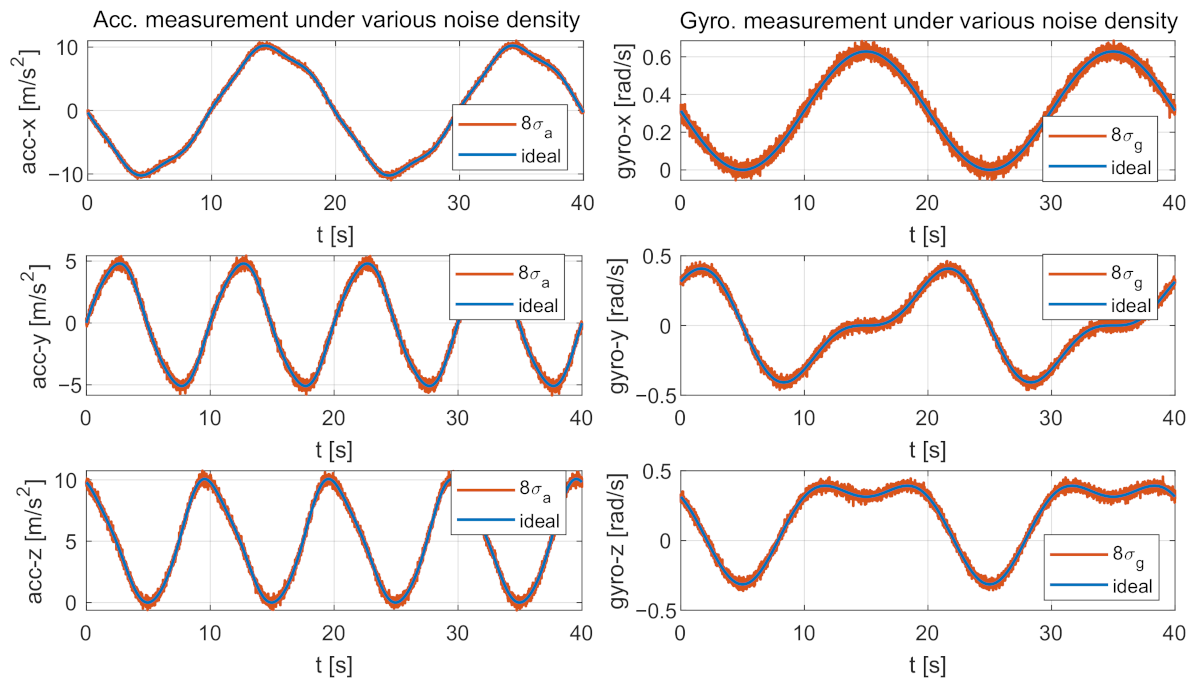
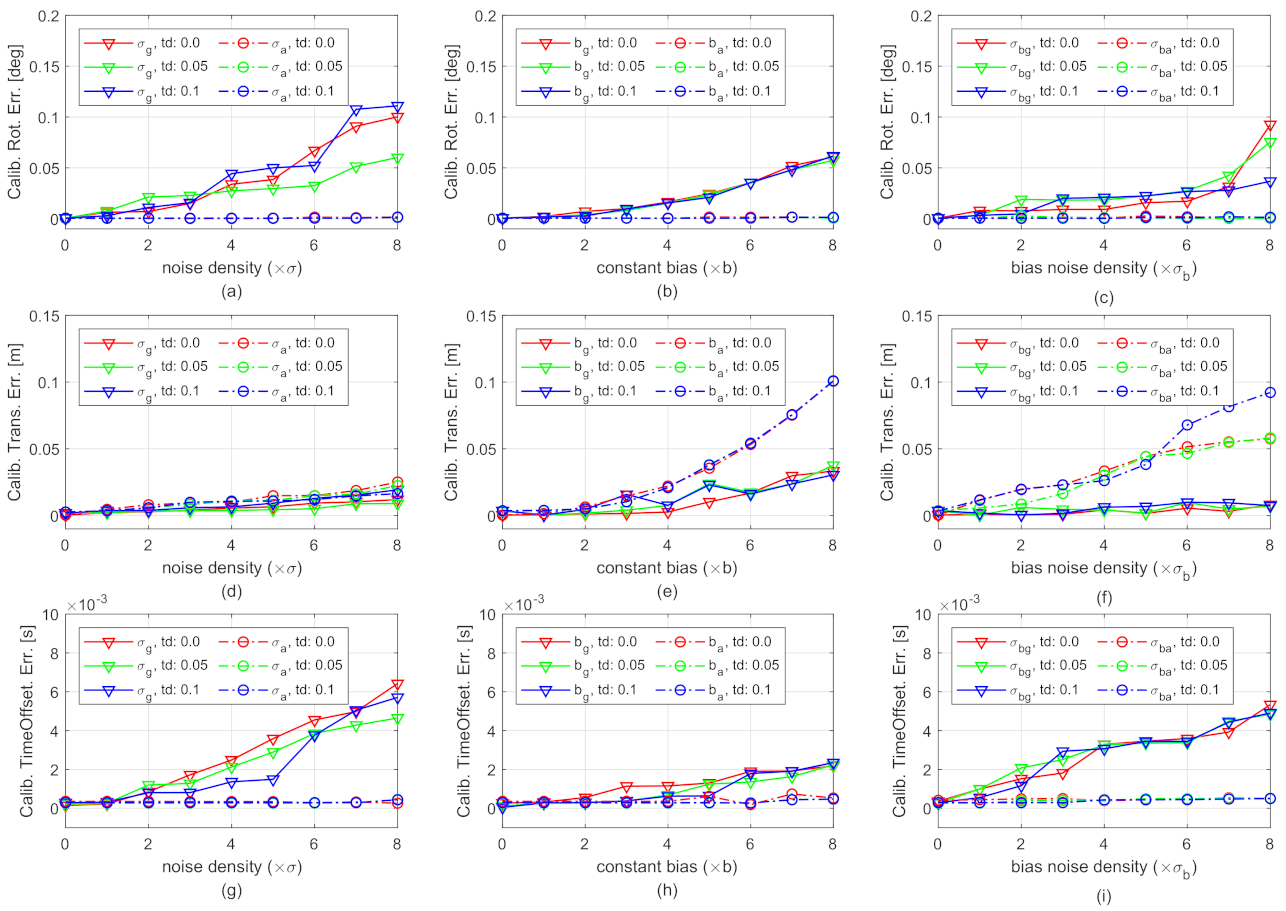
6.1. Robustness Performance against Various IMU Noises
6.2. Overall Performance of Both the Incremental Estimation and the Bundle Adjustment on Public Dataset
6.2.1. Dataset
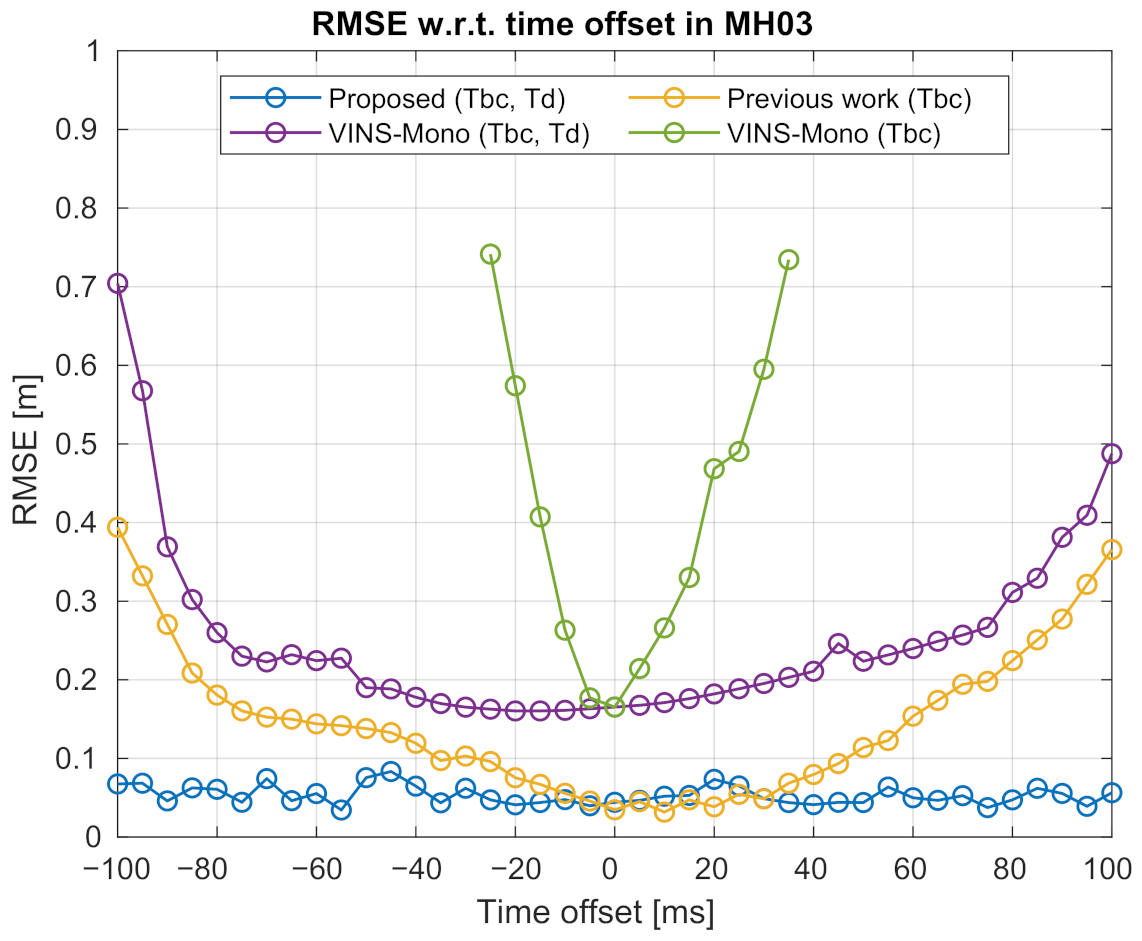
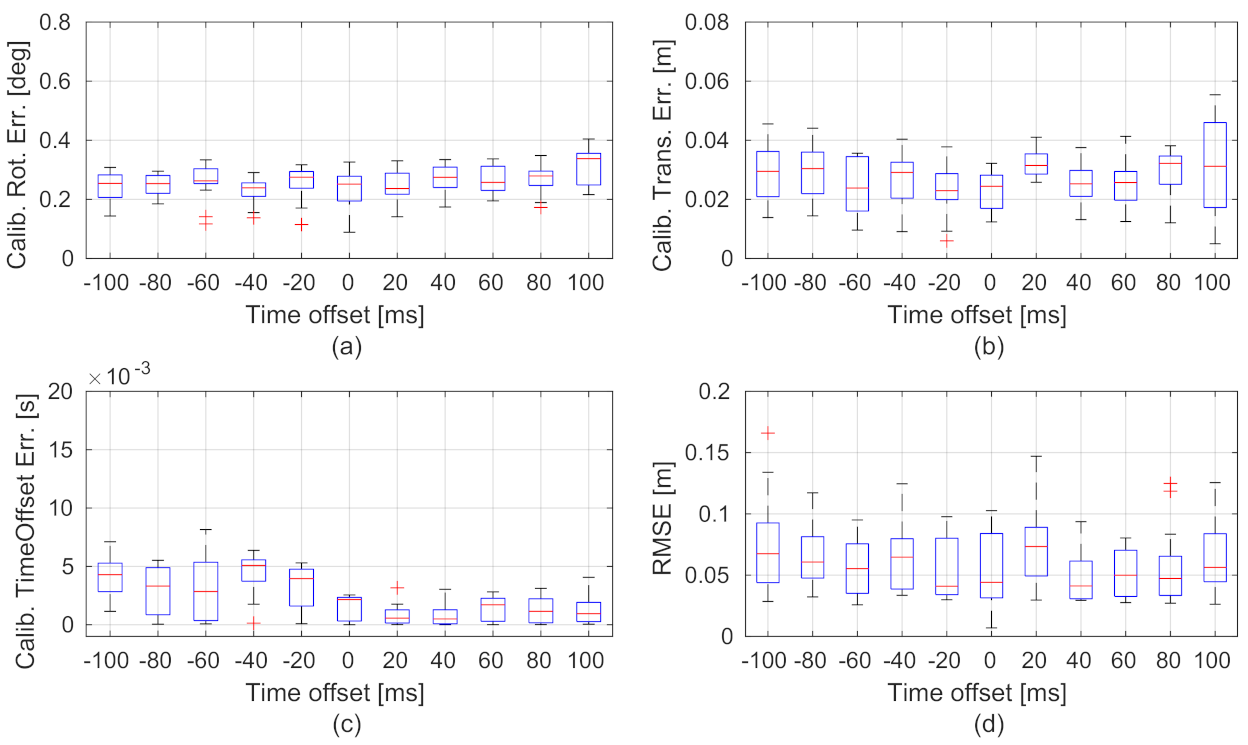
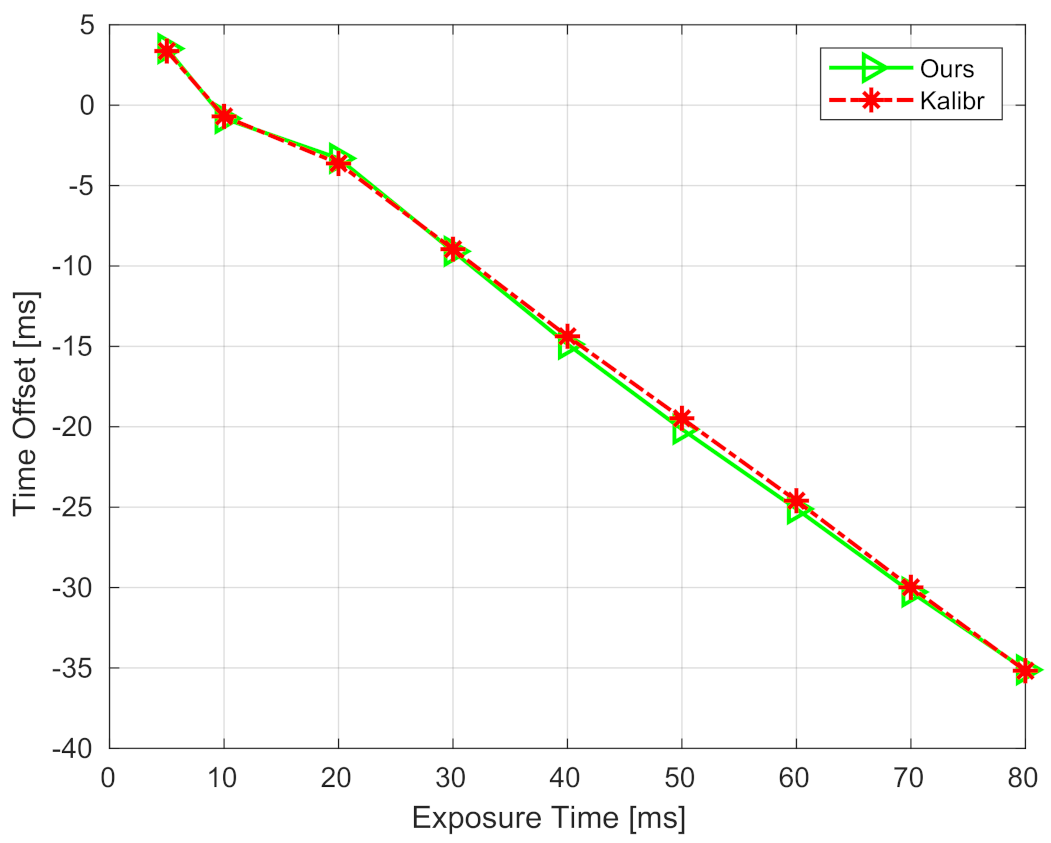
6.2.2. Robustness Performance Concerning Various Time Offsets
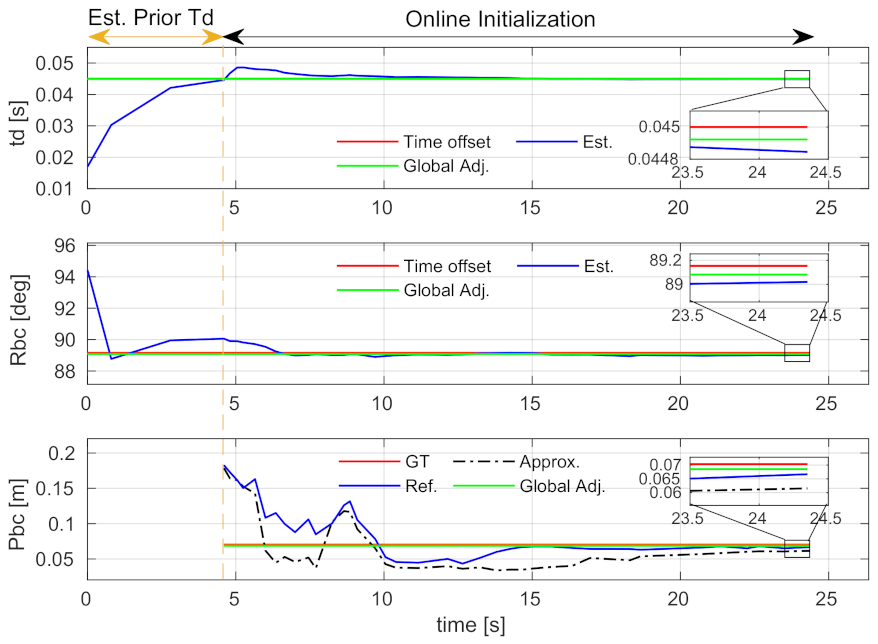
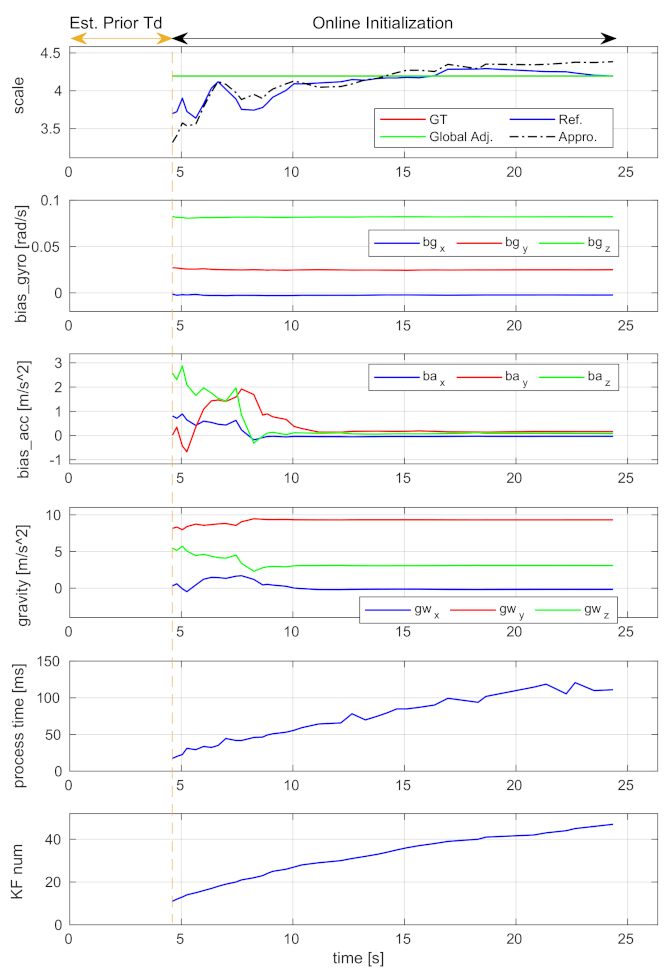
6.2.3. Convergence Performance
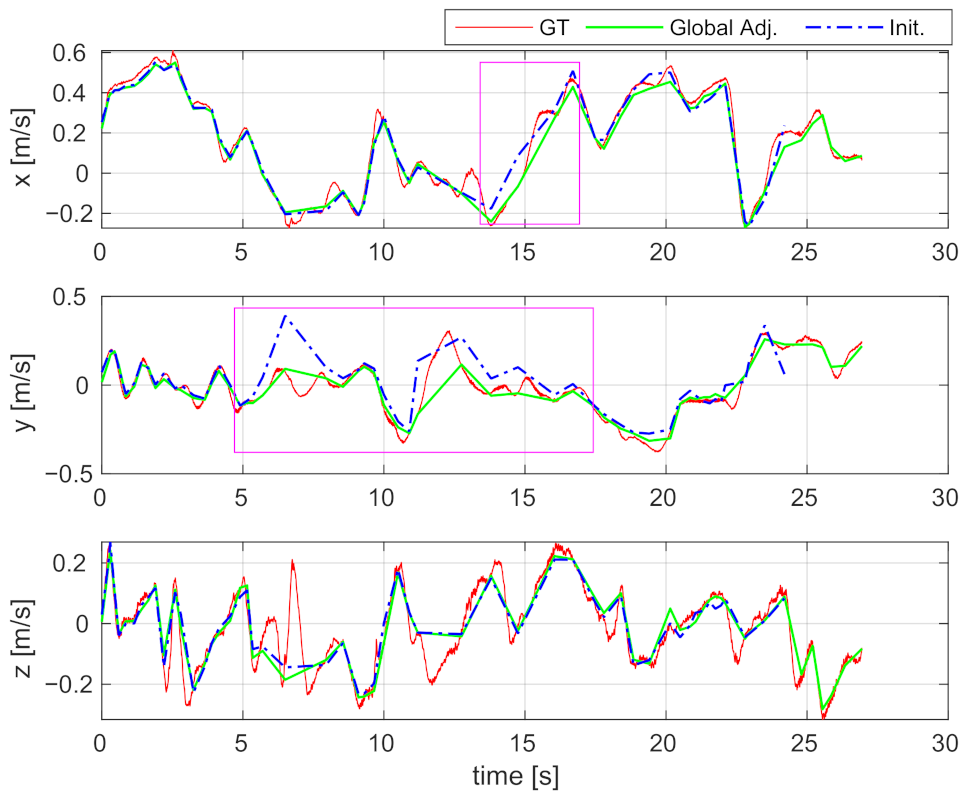
6.2.4. Velocity Estimation
6.2.5. Computational Complexity Analysis
6.2.6. Accuracy on the Whole Dataset
6.3. Real Sensor Experiments
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. Preliminaries
Appendix A.1.1. First-Order Approximation
Appendix A.1.2. Adjoint Property
Appendix A.1.3. BCH Linear Approximation
Appendix A.2. Gauss–Newton Algorithm
Appendix A.3. State Update
Appendix A.4. Jacobians of Rotation Errors
Appendix A.5. Jacobians of Feature Residual Errors
References
- Lin, Y.; Gao, F.; Qin, T.; Gao, W.; Liu, T.; Wu, W.; Yang, Z.; Shen, S. Autonomous aerial navigation using monocular visual-inertial fusion. J. Field Robot. 2018, 35, 23–51. [Google Scholar] [CrossRef]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Jones, E.; Soatto, S. Visual-inertial navigation, mapping and localization: A scalable real-time causal approach. Int. J. Robot. Res. 2011, 30, 407–430. [Google Scholar] [CrossRef]
- Huai, Z.; Huang, G. Robocentric visual-inertial odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6319–6326. [Google Scholar]
- Dong, J.; Fei, X.; Soatto, S. Visual-Inertial-Semantic Scene Representation for 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 960–970. [Google Scholar]
- Yang, Z.; Gao, F.; Shen, S. Real-time monocular dense mapping on aerial robots using visual-inertial fusion. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4552–4559. [Google Scholar]
- Oskiper, T.; Samarasekera, S.; Kumar, R. Multi-sensor navigation algorithm using monocular camera, IMU and GPS for large scale augmented reality. In Proceedings of the 2012 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Atlanta, GA, USA, 5–8 November 2012; pp. 71–80. [Google Scholar]
- Li, P.; Qin, T.; Hu, B.; Zhu, F.; Shen, S. Monocular visual-inertial state estimation for mobile augmented reality. In Proceedings of the 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Nantes, France, 9–13 October 2017; pp. 11–21. [Google Scholar]
- Furgale, P.; Barfoot, T.D.; Sibley, G. Continuous-time batch estimation using temporal basis functions. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 2088–2095. [Google Scholar]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar]
- Maye, J.; Furgale, P.; Siegwart, R. Self-supervised calibration for robotic systems. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, QLD, Australia, 23–26 June 2013; pp. 473–480. [Google Scholar]
- Rehder, J.; Nikolic, J.; Schneider, T.; Hinzmann, T.; Siegwart, R. Extending kalibr: Calibrating the extrinsics of multiple IMUs and of individual axes. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4304–4311. [Google Scholar]
- Rehder, J.; Siegwart, R.; Furgale, P. A general approach to spatiotemporal calibration in multisensor systems. IEEE Trans. Robot. 2016, 32, 383–398. [Google Scholar] [CrossRef]
- Weiss, S.; Achtelik, M.; Lynen, S.; Chli, M.; Siegwart, R. Real-time onboard visual-inertial state estimation and self-calibration of mavs in unknown environments. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 957–964. [Google Scholar]
- Kelly, J.; Sukhatme, G.S. Visual-inertial sensor fusion: Localization, mapping and sensor-to-sensor self-calibration. Int. J. Robot. Res. 2011, 30, 56–79. [Google Scholar] [CrossRef]
- Li, M.; Mourikis, A. High-precision, consistent EKF-based visual-inertial odometry. Int. J. Robot. Res. 2013, 32, 690–711. [Google Scholar] [CrossRef]
- Li, M.; Yu, H.; Zheng, X.; Mourikis, A. High-fidelity sensor modeling and self-calibration in vision-aided inertial navigation. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 409–416. [Google Scholar]
- Yang, Z.; Shen, S. Monocular visual-inertial state estimation with online initialization and camera-IMU extrinsic calibration. IEEE Trans. Autom. Sci. Eng. 2017, 14, 39–51. [Google Scholar] [CrossRef]
- Huang, W.; Liu, H.; Wan, W. An Online Initialization and Self-Calibration Method for Stereo Visual-Inertial Odometry. IEEE Trans. Robot. 2020, 36, 1153–1170. [Google Scholar] [CrossRef]
- Kelly, J.; Sukhatme, G.S. A general framework for temporal calibration of multiple proprioceptive and exteroceptive sensors. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 195–209. [Google Scholar]
- Ling, Y.; Bao, L.; Jie, Z.; Zhu, F.; Li, Z.; Tang, S.; Liu, Y.; Liu, W.; Zhang, T. Modeling Varying Camera-IMU Time Offset in Optimization-Based Visual-Inertial Odometry. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 484–500. [Google Scholar]
- Qin, T.; Shen, S. Online temporal calibration for monocular visual-inertial systems. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3662–3669. [Google Scholar]
- Mur-Artal, R.; Tardós, J. Visual-inertial monocular SLAM with map reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Campos, C.; Montiel, J.; Tardós, J. Fast and Robust Initialization for Visual-Inertial SLAM. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 1288–1294. [Google Scholar]
- Campos, C.; Montiel, J.; Tardós, J. Inertial-Only Optimization for Visual-Inertial Initialization. arXiv 2020, arXiv:2003.05766. [Google Scholar]
- Martinelli, A. Closed-form solution of visual-inertial structure from motion. Int. J. Comput. Vision 2014, 106, 138–152. [Google Scholar] [CrossRef]
- Kaiser, J.; Martinelli, A.; Fontana, F.; Scaramuzza, D. Simultaneous state initialization and gyroscope bias calibration in visual inertial aided navigation. IEEE Robot. Autom. Lett. 2016, 2, 18–25. [Google Scholar] [CrossRef]
- Li, J.; Yang, B.; Huang, K.; Zhang, G.; Bao, H. Robust and Efficient Visual-Inertial Odometry with Multi-plane Priors. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV); Springer: Berlin/Heidelberg, Germany, 2019; pp. 283–295. [Google Scholar]
- Li, M.; Mourikis, A. 3-D motion estimation and online temporal calibration for camera-IMU systems. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 5709–5716. [Google Scholar]
- Li, M.; Mourikis, A. Online temporal calibration for camera–IMU systems: Theory and algorithms. Int. J. Robot. Res. 2014, 33, 947–964. [Google Scholar] [CrossRef]
- Zuo, X.; Geneva, P.; Lee, W.; Liu, Y.; Huang, G. LIC-Fusion: LiDAR-Inertial-Camera Odometry. arXiv 2019, arXiv:1909.04102. [Google Scholar]
- Yang, Y.; Geneva, P.; Eckenhoff, K.; Huang, G. Degenerate motion analysis for aided INS with online spatial and temporal sensor calibration. IEEE Robot. Autom. Lett. 2019, 4, 2070–2077. [Google Scholar] [CrossRef]
- Eckenhoff, K.; Geneva, P.; Bloecker, J.; Huang, G. Multi-Camera Visual-Inertial Navigation with Online Intrinsic and Extrinsic Calibration. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3158–3164. [Google Scholar]
- Liu, Y.; Meng, Z. Online Temporal Calibration Based on Modified Projection Model for Visual-Inertial Odometry. IEEE Trans. Instrum. Meas. 2020, 69, 5197–5207. [Google Scholar] [CrossRef]
- Mourikis, A.I.; Roumeliotis, S.I. A multi-state constraint Kalman filter for vision-aided inertial navigation. In Proceedings of the Proceedings 2007 IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Huang, W.; Liu, H. Online Initialization and Automatic Camera-IMU Extrinsic Calibration for Monocular Visual-Inertial SLAM. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 5182–5189. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Mirzaei, F.M.; Roumeliotis, S.I. A Kalman filter-based algorithm for IMU-camera calibration: Observability analysis and performance evaluation. IEEE Trans. Robot. 2008, 24, 1143–1156. [Google Scholar] [CrossRef]
- Furgale, P.; Tong, C.H.; Barfoot, T.D.; Sibley, G. Continuous-time batch trajectory estimation using temporal basis functions. Int. J. Robot. Res. 2015, 34, 1688–1710. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Schneider, T.; Li, M.; Cadena, C.; Nieto, J.; Siegwart, R. Observability-Aware Self-Calibration of Visual and Inertial Sensors for Ego-Motion Estimation. IEEE Sens. J. 2019, 19, 3846–3860. [Google Scholar] [CrossRef]
- Mair, E.; Fleps, M.; Suppa, M.; Burschka, D. Spatio-temporal initialization for IMU to camera registration. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics, Karon Beach, Thailand, 7–11 December 2011; pp. 557–564. [Google Scholar]
- Sun, K.; Mohta, K.; Pfrommer, B.; Watterson, M.; Liu, S.; Mulgaonkar, Y.; Taylor, C.J.; Kumar, V. Robust stereo visual inertial odometry for fast autonomous flight. IEEE Robot. Autom. Lett. 2018, 3, 965–972. [Google Scholar] [CrossRef]
- Feng, Z.; Li, J.; Zhang, L.; Chen, C. Online Spatial and Temporal Calibration for Monocular Direct Visual-Inertial Odometry. Sensors 2019, 19, 2273. [Google Scholar] [CrossRef] [PubMed]
- Qin, T.; Shen, S. Robust initialization of monocular visual-inertial estimation on aerial robots. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4225–4232. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 834–849. [Google Scholar]
- Mur-Artal, R.; Montiel, J.; Tardós, J. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.; Tardós, J. ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM. arXiv 2020, arXiv:2007.11898. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2016, 33, 249–265. [Google Scholar] [CrossRef]
- Lupton, T.; Sukkarieh, S. Visual-inertial-aided navigation for high-dynamic motion in built environments without initial conditions. IEEE Trans. Robot. 2012, 28, 61–76. [Google Scholar] [CrossRef]
- Forster, C.; Carlone, L.; Dellaert, F.; Scaramuzza, D. On-Manifold Preintegration for Real-Time Visual-Inertial Odometry. IEEE Trans. Robot. 2017, 33, 1–21. [Google Scholar] [CrossRef]
- Kelley, C.T. Iterative Methods for Optimization; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1999. [Google Scholar]
- Hartley, R.I.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004; pp. 153–177. ISBN 0521540518. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Gilmore, R. Baker-Campbell-Hausdorff formulas. J. Math. Phys. 1974, 15, 2090–2092. [Google Scholar] [CrossRef]
Short Biography of Authors
 | Weibo Huang received the B.Eng. degree in automation and electrical engineering from University of Science and Technology Beijing, Beijing, China, in 2015. He is currently working toward the Ph.D. degree with the Key Laboratory of Machine Perception, Peking University, Beijing, under the supervision of Prof. H. Liu. His research interests include online multi-sensor self-calibration, and visual-inertial fusion and localization. |
 | Weiwei Wan received a Ph.D. degree in Robotics from the Department of Mechano-Informatics, the University of Tokyo, Japan, in 2013. From 2013 to 2015, he was a Post-Doctoral Research Fellow of the Japanese Society for the Promotion of Science, Japan, and a Visiting Researcher with Carnegie Mellon University, Pittsburgh, PA, USA. He is currently an Associate Professor working at the School of Engineering Science, Osaka University, Toyonaka, Osaka, Japan. His major interest is smart manufacturing using dual-arm robots, specifically, developing and deploying grasping planning, motion planning, and other low level and high level task planning algorithms for next-generation factories. He is also studying visual perception, force control, and learning approaches to make up for the inherent shortages of planning algorithms. His current research interests include robotic grasping and manipulation planning for next-generation manufacturing. |
 | Hong Liu received a Ph.D. degree in mechanical electronics and automation in 1996 and serves as a full professor in the School of EECS, Peking University (PKU), China. He is also the Director of Open Lab on Human Robot Interaction, PKU. He has published more than 150 papers. His research interests include computer vision and robotics, image processing, and pattern recognition. He received the Chinese National Aero-space Award, the Wu Wenjun Award on Artificial Intelligence, the Excellence Teaching Award, and Candidates of Top Ten Outstanding Professors in PKU. He has been selected as Chinese Innovation Leading Talent supported by National High-level Talents Special Support Plan since 2013. He is the Vice President of Chinese Association for Artificial Intelligent (CAAI), and the Vice Chair of Intelligent Robotics Society, CAAI. He has served as a Keynote Speaker, Co-chair, Session Chairs, and PC Member of many important international conferences, such as IEEE/RSJ IROS, IEEE ROBIO, IEEE SMC, and IIHMSP, and recently serves as a Reviewer for many international journals such as Pattern Recognition, IEEE Transactions on Signal Processing, and IEEE Transactions on Pattern Analysis and Machine Intelligence. |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Offset | |||||
|---|---|---|---|---|---|
| (ms) | (deg) | (m) | (ms) | (rad/s) | (m/s) |
| 0 | 0.010 | 0.014 | 1.170 | 0.836 × 10 | 0.853 × 10 |
| 50 | 0.015 | 0.011 | 1.303 | 1.026 × 10 | 0.941 × 10 |
| 100 | 0.021 | 0.012 | 1.503 | 1.024 × 10 | 1.012 × 10 |
| Global Adj. with Ext. Opt. (s) | Global Adj. without Ext. Opt. (s) | Local Adj. with Ext. Opt. (s) | Local Adj. without Ext. Opt. (s) |
|---|---|---|---|
| 11.834 | 9.125 | 1.514 | 1.427 |
| VINS-Mono [40] | Feng et al. | Ours | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| time offset | RMSE | RMSE | RMSE | ||||||||||
| (ms) | (deg) | (m) | (ms) | (m) | (deg) | (m) | (ms) | (m) | (deg) | (m) | (ms) | (m) | |
| *V1_01 | 0 | 0.285 | 0.018 | 0.291 | 0.071 | 0.583 | 0.022 | 0.150 | 0.073 | 0.099 | 0.008 | 0.001 | 0.047 |
| 50 | 0.286 | 0.019 | 0.284 | 0.075 | 0.588 | 0.023 | 0.210 | 0.073 | 0.136 | 0.008 | 0.836 | 0.043 | |
| 100 | 0.235 | 0.019 | 0.220 | 0.103 | 0.577 | 0.022 | 0.150 | 0.077 | 0.247 | 0.033 | 0.244 | 0.064 | |
| *V1_02 | 0 | 0.327 | 0.018 | 0.059 | 0.095 | 0.563 | 0.019 | 0.090 | 0.118 | 0.128 | 0.011 | 0.026 | 0.025 |
| 50 | 0.312 | 0.013 | 0.034 | 0.092 | 0.559 | 0.019 | 0.100 | 0.116 | 0.086 | 0.003 | 0.082 | 0.022 | |
| 100 | 0.363 | 0.011 | 0.053 | 0.192 | 0.569 | 0.021 | 0.100 | 0.143 | 0.154 | 0.015 | 2.372 | 0.047 | |
| *V1_03 | 0 | 0.220 | 0.012 | 0.095 | 0.141 | 0.507 | 0.013 | 0.330 | 0.118 | 0.165 | 0.012 | 0.340 | 0.012 |
| 50 | 0.180 | 0.014 | 0.005 | 0.153 | 0.508 | 0.016 | 0.330 | 0.121 | 0.276 | 0.018 | 3.194 | 0.046 | |
| 100 | 0.229 | 0.016 | 0.008 | 0.192 | 0.513 | 0.014 | 0.390 | 0.093 | 0.194 | 0.023 | 2.695 | 0.053 | |
| *V2_01 | 0 | 0.295 | 0.020 | 0.152 | 0.065 | 0.491 | 0.023 | 0.330 | 0.099 | 0.183 | 0.017 | 1.009 | 0.019 |
| 50 | 0.259 | 0.020 | 0.174 | 0.068 | 0.457 | 0.025 | 0.290 | 0.088 | 0.145 | 0.002 | 0.297 | 0.014 | |
| 100 | 0.291 | 0.020 | 0.029 | 0.070 | 0.513 | 0.022 | 0.360 | 0.082 | 0.132 | 0.012 | 0.279 | 0.034 | |
| *V2_02 | 0 | 0.353 | 0.012 | 0.123 | 0.134 | 0.553 | 0.020 | 0.090 | 0.099 | 0.065 | 0.010 | 0.016 | 0.028 |
| 50 | 0.344 | 0.012 | 0.135 | 0.120 | 0.558 | 0.020 | 0.090 | 0.089 | 0.116 | 0.010 | 0.174 | 0.041 | |
| 100 | 0.329 | 0.012 | 0.031 | 0.140 | 0.558 | 0.020 | 0.090 | 0.100 | 0.220 | 0.014 | 1.751 | 0.059 | |
| *V2_03 | 0 | 0.429 | 0.011 | 0.271 | 0.150 | 0.633 | 0.015 | 0.090 | 0.135 | 0.177 | 0.027 | 0.403 | 0.091 |
| 50 | 0.455 | 0.011 | 0.262 | 0.337 | 0.626 | 0.015 | 0.040 | 0.234 | 0.203 | 0.012 | 0.459 | 0.079 | |
| 100 | 0.409 | 0.041 | 0.010 | 0.252 | 0.633 | 0.014 | 0.040 | 0.233 | 0.206 | 0.011 | 1.368 | 0.096 | |
| *MH_01 | 0 | 0.168 | 0.021 | 0.068 | 0.134 | 0.501 | 0.018 | 0.160 | 0.080 | 0.203 | 0.009 | 1.842 | 0.022 |
| 50 | 0.184 | 0.021 | 0.014 | 0.152 | 0.505 | 0.015 | 0.120 | 0.119 | 0.143 | 0.011 | 0.125 | 0.054 | |
| 100 | 0.168 | 0.023 | 0.155 | 0.158 | 0.481 | 0.014 | 0.120 | 0.111 | 0.082 | 0.019 | 0.107 | 0.027 | |
| *MH_02 | 0 | 0.193 | 0.016 | 0.042 | 0.297 | 0.621 | 0.014 | 0.290 | 0.082 | 0.125 | 0.028 | 0.596 | 0.021 |
| 50 | 0.256 | 0.018 | 0.020 | 0.253 | 0.624 | 0.014 | 0.340 | 0.086 | 0.280 | 0.016 | 0.225 | 0.029 | |
| 100 | 0.306 | 0.023 | 0.054 | 0.220 | 0.634 | 0.015 | 0.210 | 0.074 | 0.316 | 0.013 | 0.010 | 0.033 | |
| *MH_03 | 0 | 0.323 | 0.024 | 0.184 | 0.165 | 0.619 | 0.022 | 0.010 | 0.161 | 0.251 | 0.024 | 2.158 | 0.030 |
| 50 | 0.325 | 0.025 | 0.168 | 0.224 | 0.627 | 0.024 | 0.050 | 0.133 | 0.034 | 0.011 | 2.357 | 0.038 | |
| 100 | 0.340 | 0.022 | 0.054 | 0.488 | 0.607 | 0.020 | 0.090 | 0.173 | 0.338 | 0.031 | 0.948 | 0.046 | |
| *MH_04 | 0 | 0.211 | 0.076 | 0.113 | 0.239 | 0.554 | 0.019 | 0.110 | 0.197 | 0.044 | 0.019 | 0.002 | 0.153 |
| 50 | 0.198 | 0.033 | 0.052 | 0.285 | 0.521 | 0.013 | 0.170 | 0.178 | 0.109 | 0.029 | 0.313 | 0.240 | |
| 100 | 0.218 | 0.025 | 0.347 | 0.316 | 0.512 | 0.018 | 0.030 | 0.143 | 0.090 | 0.023 | 1.279 | 0.215 | |
| *MH_05 | 0 | 0.187 | 0.029 | 0.237 | 0.184 | 0.605 | 0.013 | 0.090 | 0.162 | 0.107 | 0.016 | 0.472 | 0.204 |
| 50 | 0.201 | 0.029 | 0.211 | 0.248 | 0.509 | 0.010 | 0.200 | 0.207 | 0.118 | 0.012 | 0.437 | 0.254 | |
| 100 | 0.236 | 0.028 | 0.101 | 0.296 | 0.552 | 0.017 | 0.170 | 0.205 | 0.104 | 0.026 | 0.616 | 0.214 | |
| Bias_Gyro (Rad/s) | Bias_acc (/) | Velocity (m/s) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | StaDev | Max | Mean | StaDev | Max | Mean | StaDev | Max | |
| V1_01 | 0.56 | 0.09 | 0.66 | 4.19 | 0.77 | 4.30 | 3.33 | 1.26 | 5.97 |
| V1_02 | 0.52 | 0.21 | 1.09 | 3.48 | 0.96 | 5.16 | 3.35 | 1.74 | 6.29 |
| V1_03 | 1.26 | 0.10 | 1.44 | 6.90 | 1.18 | 10.33 | 5.76 | 1.08 | 7.42 |
| V2_01 | 0.50 | 0.16 | 0.84 | 3.95 | 1.43 | 5.85 | 1.34 | 0.69 | 3.46 |
| V2_02 | 1.16 | 0.25 | 1.58 | 7.17 | 2.32 | 12.19 | 2.01 | 1.07 | 8.04 |
| V2_03 | 0.78 | 0.12 | 1.02 | 6.35 | 1.20 | 10.47 | 2.54 | 1.32 | 7.64 |
| MH_01 | 0.70 | 0.26 | 1.30 | 4.34 | 1.46 | 6.19 | 3.05 | 1.47 | 6.72 |
| MH_02 | 0.32 | 0.15 | 0.51 | 3.81 | 1.46 | 5.98 | 2.17 | 1.07 | 4.42 |
| MH_03 | 0.60 | 0.18 | 0.83 | 3.04 | 0.85 | 4.99 | 4.72 | 2.23 | 6.47 |
| MH_04 | 0.44 | 0.05 | 0.50 | 4.08 | 0.75 | 6.04 | 5.20 | 1.39 | 8.61 |
| MH_05 | 0.33 | 0.07 | 0.44 | 4.57 | 1.27 | 7.44 | 4.27 | 2.04 | 8.03 |
| Exp. Time | 5 ms | 10 ms | 20 ms | 30 ms | 40 ms | 50 ms | 60 ms | 70 ms | 80 ms |
|---|---|---|---|---|---|---|---|---|---|
| /deg | 0.355 | 0.429 | 0.418 | 0.402 | 0.383 | 0.378 | 0.242 | 0.388 | 0.308 |
| /m | 0.012 | 0.006 | 0.003 | 0.013 | 0.012 | 0.016 | 0.015 | 0.008 | 0.017 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Wan, W.; Liu, H. Optimization-Based Online Initialization and Calibration of Monocular Visual-Inertial Odometry Considering Spatial-Temporal Constraints. Sensors 2021, 21, 2673. https://doi.org/10.3390/s21082673
Huang W, Wan W, Liu H. Optimization-Based Online Initialization and Calibration of Monocular Visual-Inertial Odometry Considering Spatial-Temporal Constraints. Sensors. 2021; 21(8):2673. https://doi.org/10.3390/s21082673
Chicago/Turabian StyleHuang, Weibo, Weiwei Wan, and Hong Liu. 2021. "Optimization-Based Online Initialization and Calibration of Monocular Visual-Inertial Odometry Considering Spatial-Temporal Constraints" Sensors 21, no. 8: 2673. https://doi.org/10.3390/s21082673
APA StyleHuang, W., Wan, W., & Liu, H. (2021). Optimization-Based Online Initialization and Calibration of Monocular Visual-Inertial Odometry Considering Spatial-Temporal Constraints. Sensors, 21(8), 2673. https://doi.org/10.3390/s21082673