
An Open Source Low-Cost Device Coupled with an Adaptative Time-Lag Time-Series Linear Forecasting Modeling for Apple Trentino (Italy) Precision Irrigation

 ,
,  ,
,  , , , ,
, , , , 
Abstract
1. Introduction
2. Materials and Methods
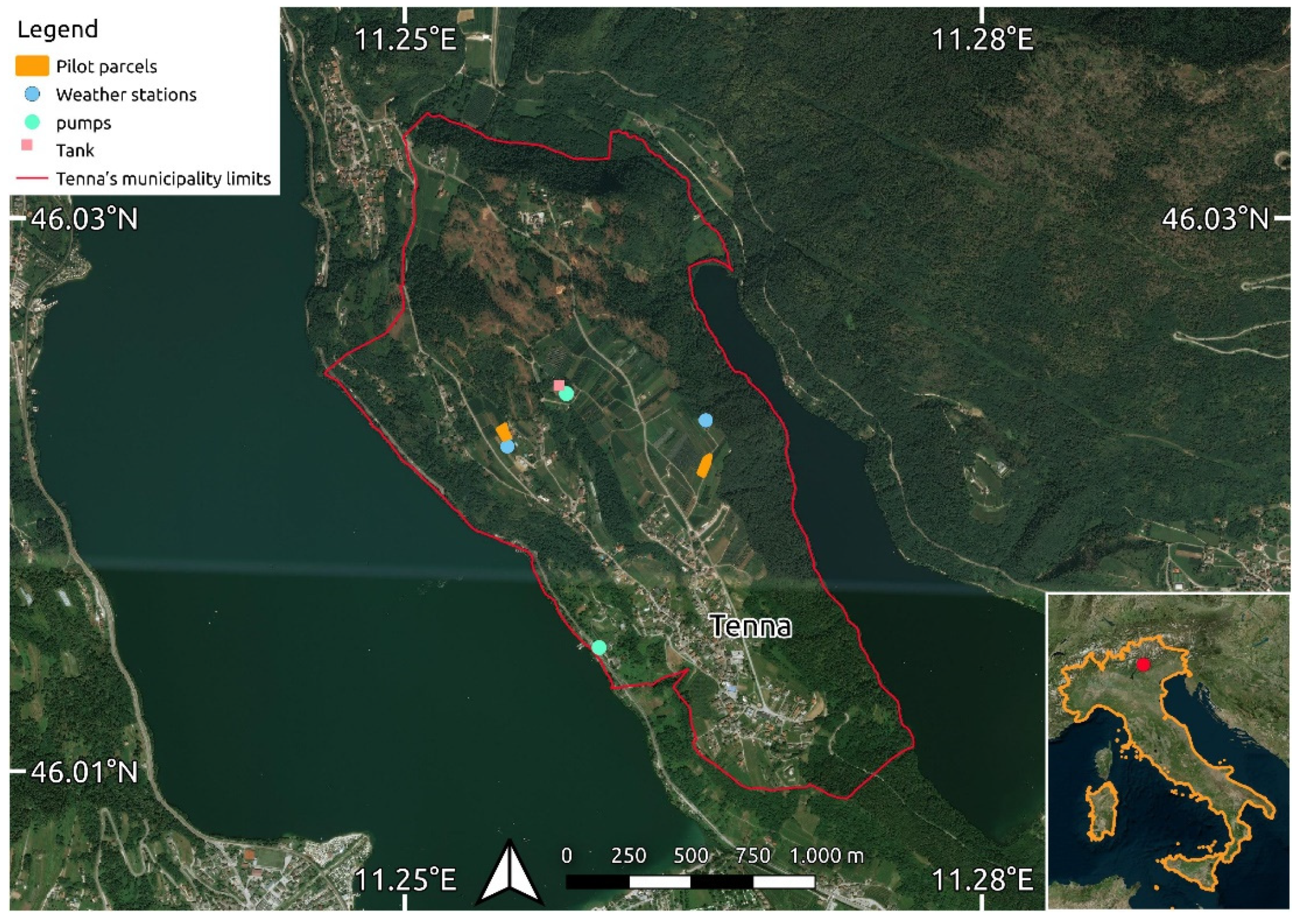
2.1. Experimental Field and Setup
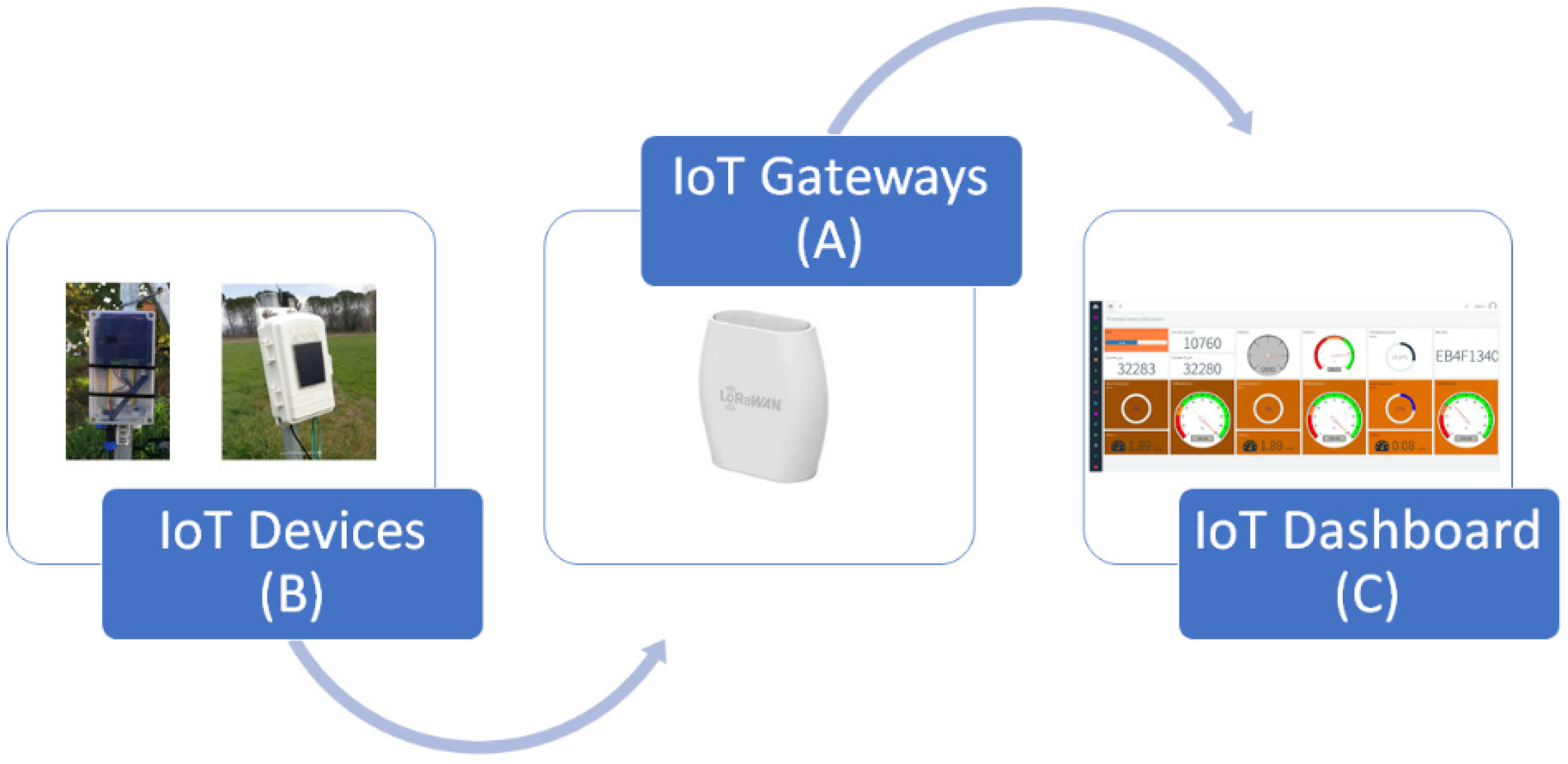
2.2. The Open Source Soil Moisture LoRa Device
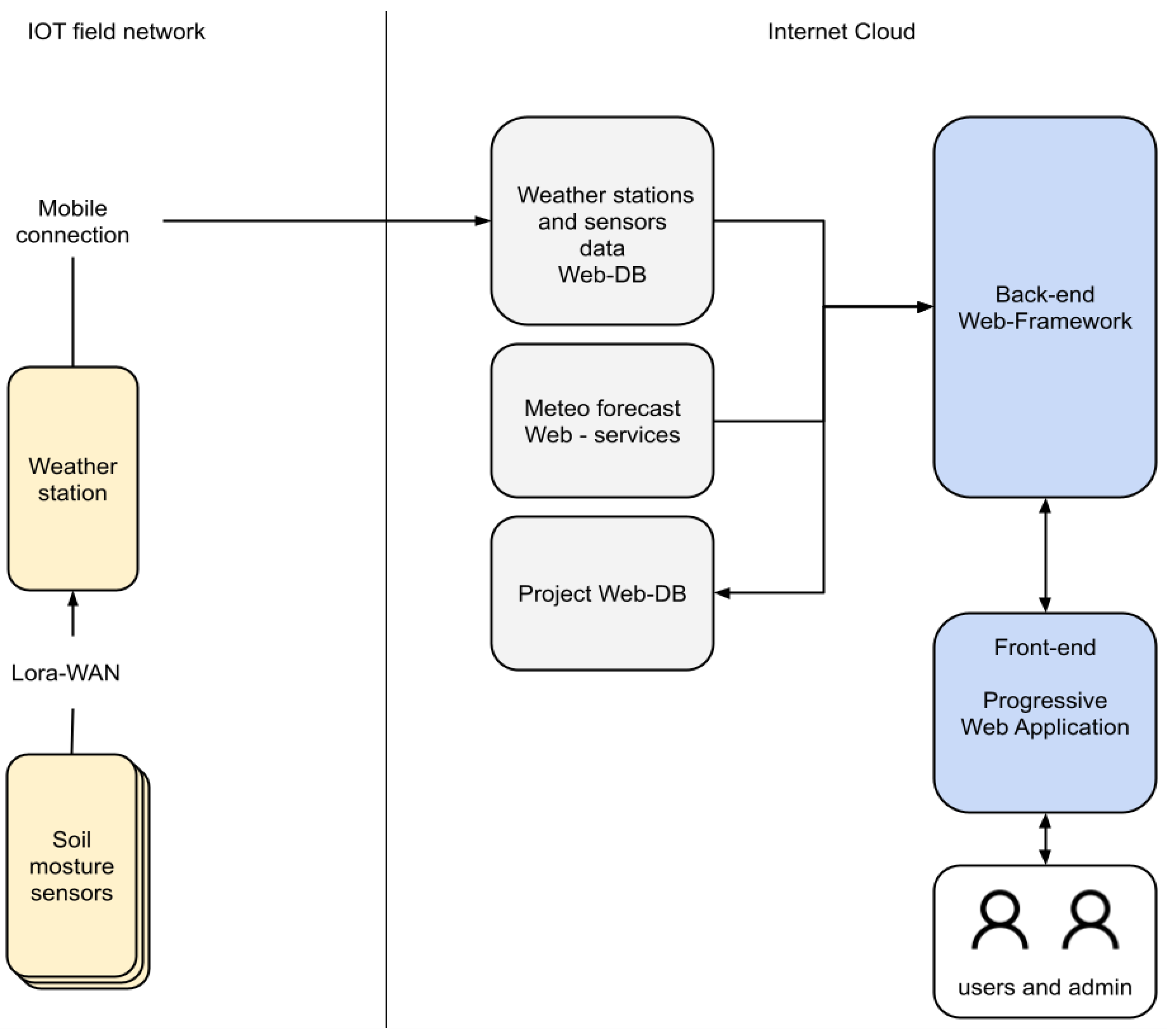
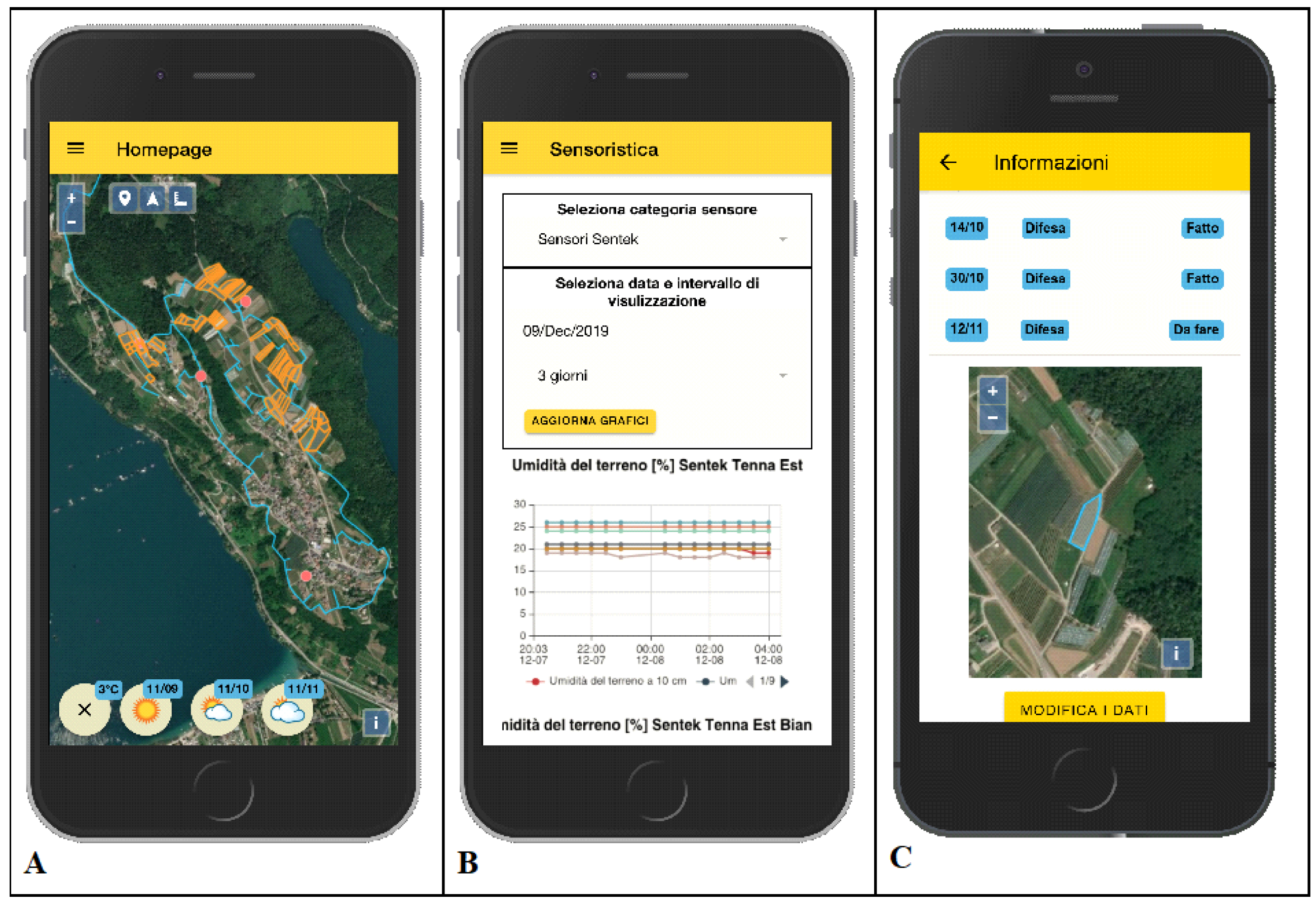
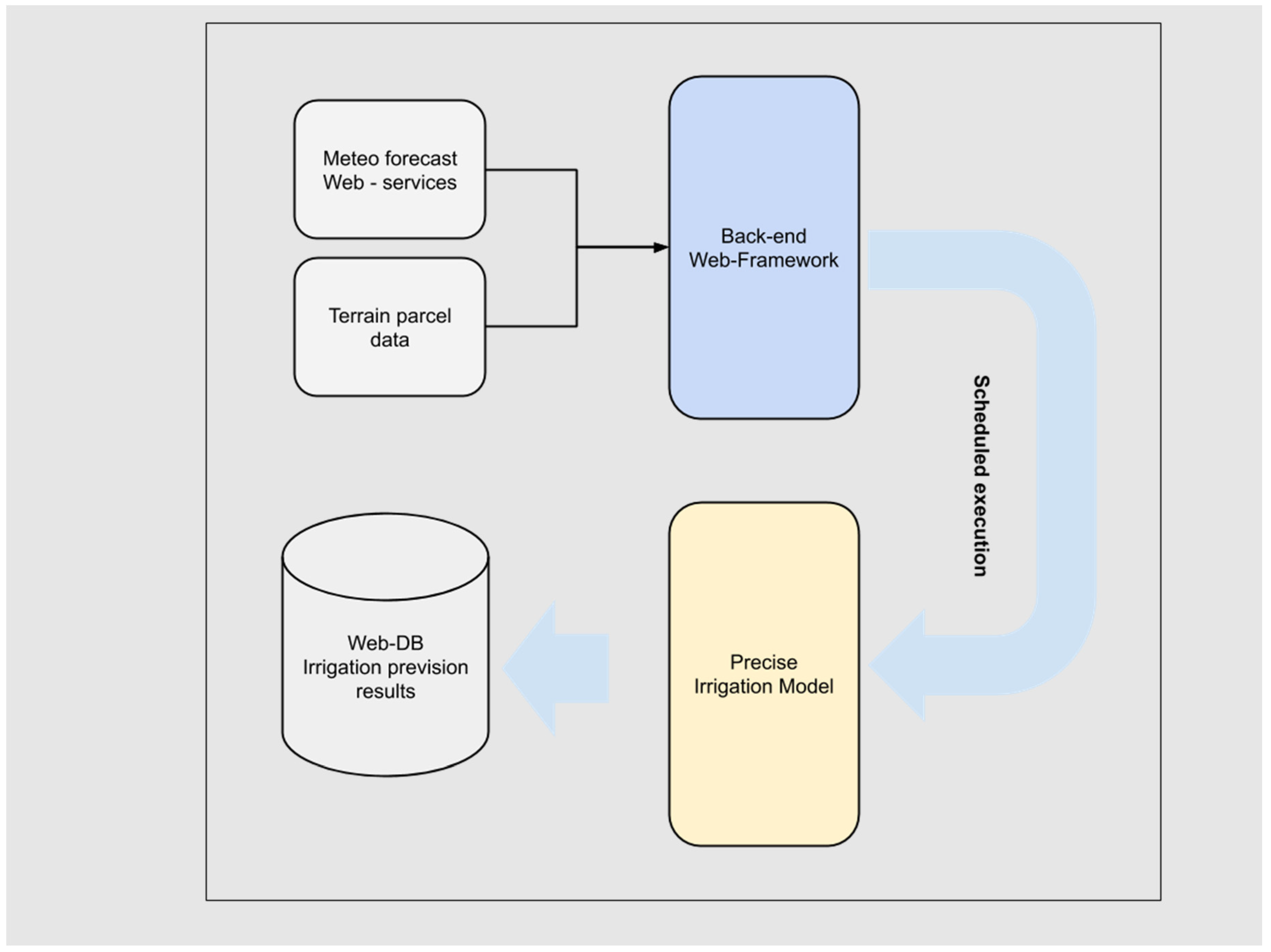
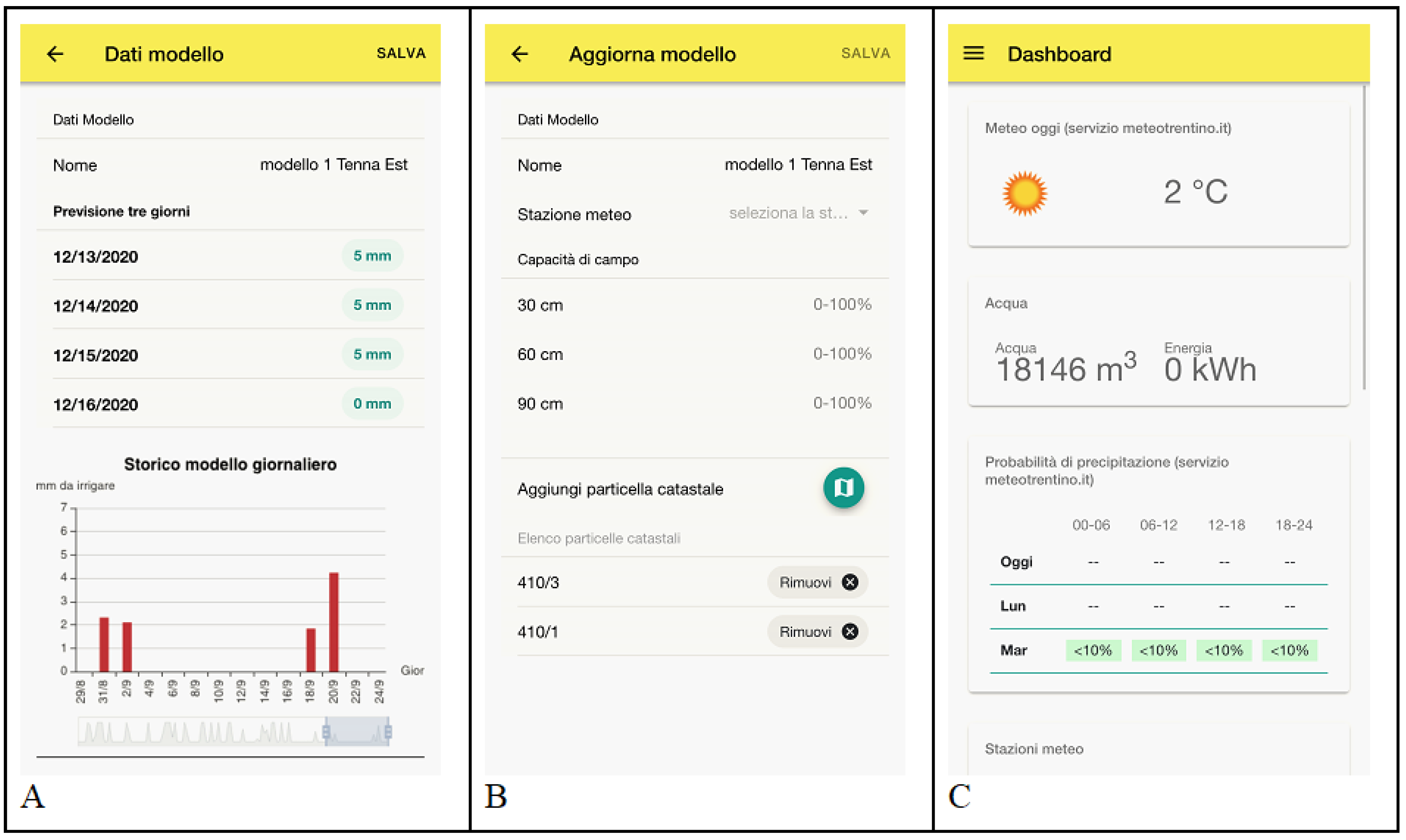
2.3. Data Acquisition and App
2.4. Predictive Modeling
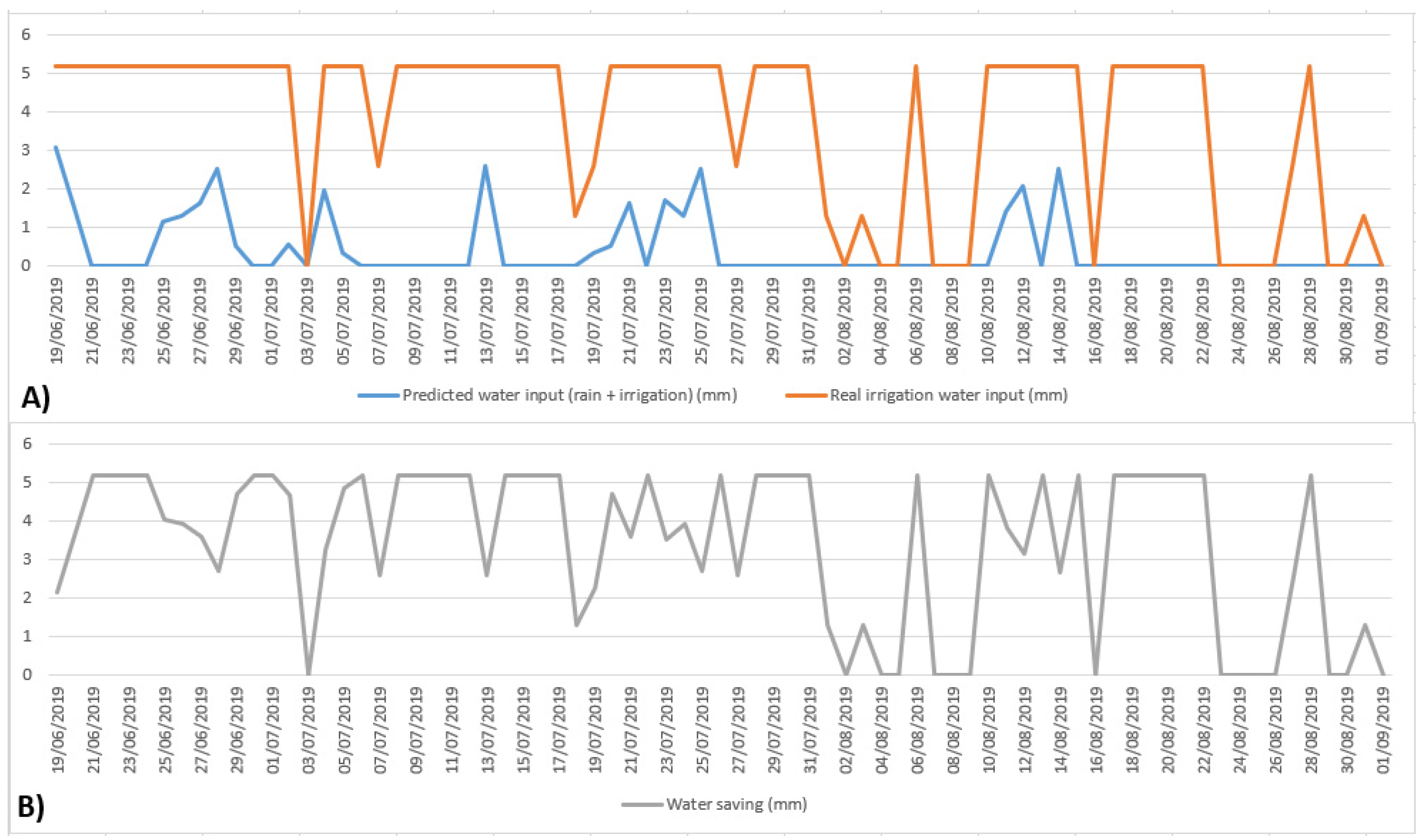
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jamroen, C.; Komkum, P.; Fongkerd, C.; Krongpha, W. An Intelligent Irrigation Scheduling System Using Low-Cost Wireless Sensor Network Toward Sustainable and Precision Agriculture. IEEE Access 2020, 8, 172756–172769. [Google Scholar] [CrossRef]
- Brits, M. Precision planning for precision irrigation: Technology. FarmBiz 2020, 6, 36–37. [Google Scholar]
- Singh, D.; Tilak, D.J. A study on precision irrigation technology in agriculture: Opportunities and challenges in Pune district. Int. J. Disaster Recover. Bus. Contin. 2020, 11, 405–422. [Google Scholar]
- Alt, V.; Isakova, S.; Balushkina, E. Digitalization: Problems of its development in modern agricultural production. In E3S Web of Conferences; EDP Sciences: Les Ulis, France, 2020; Volume 210, p. 10001. [Google Scholar]
- Sharma, R.; Parhi, S.; Shishodia, A. Industry 4.0 Applications in Agriculture: CyberPhysical Agricultural Systems (CPASs). Advances in Mechanical Engineering; Springer: Singapore, 2020; pp. 807–813. [Google Scholar]
- Bodkhe, U.; Tanwar, S.; Bhattacharya, P.; Kumar, N. Blockchain for precision irrigation: Opportunities and challenges. Trans. Emerg. Telecommun. Technol. 2020, e4059. [Google Scholar] [CrossRef]
- Bellvert, J.; Mata, M.; Vallverdú, X.; Paris, C.; Marsal, J. Optimizing precision irrigation of a vineyard to improve water use efficiency and profitability by using a decision-oriented vine water consumption model. Precis. Agric. 2020, 1–23. [Google Scholar] [CrossRef]
- Xu, L.; Chen, L.; Chen, T.; Gao, Y. SOA-based precision irrigation decision support system. Math. Comput. Model. 2011, 54, 944–949. [Google Scholar] [CrossRef]
- Millán, S.; Casadesús, J.; Campillo, C.; Moñino, M.J.; Prieto, M.H. Using Soil Moisture Sensors for Automated Irrigation Scheduling in a Plum Crop. Water 2019, 11, 2061. [Google Scholar] [CrossRef]
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M. Crop evapotranspiration-Guidelines for computing crop water requirements-FAO Irrigation and drainage paper 56. FAO Rome 1998, 300, D05109. [Google Scholar]
- Casadesús, J.; Mata, M.; Marsal, J.; Girona, J. A general algorithm for automated scheduling of drip irrigation in tree crops. Comput. Electron. Agric. 2012, 83, 11–20. [Google Scholar] [CrossRef]
- Ventrella, D.; Di Giacomo, E.; Fiorentino, C.; Giglio, L.; Lopez, R.; Guastaferro, F.; Castrignanò, A. Soil Water Balance and Irrigation Strategies in an Agricultural District of Southern Italy. Ital. J. Agron. 2010, 5, 193–204. [Google Scholar] [CrossRef]
- Farg, E.; Arafat, S.M.; El-Wahed, M.A.; El-Gindy, A. Estimation of Evapotranspiration ETc and Crop Coefficient Kc of Wheat, in south Nile Delta of Egypt Using integrated FAO-56 approach and remote sensing data. Egypt. J. Remote. Sens. Space Sci. 2012, 15, 83–89. [Google Scholar] [CrossRef]
- Peel, M.C.; Finlayson, B.L.; Mcmahon, T.A. Updated world map of the Köppen-Geiger climate classification. Hydrol. Earth Syst. Sci. Discuss. 2007, 4, 439–473. [Google Scholar]
- Hammer, Ø.; Harper, D.A.; Ryan, P.D. PAST: Paleontological statistics software package for education and data analysis. Palaeontol. Electron. 2001, 4, 9. [Google Scholar]
- Brighetti, M.A.; Costa, C.; Menesatti, P.; Antonucci, F.; Tripodi, S.; Travaglini, A. Multivariate statistical forecasting modeling to predict Poaceae pollen critical concentrations by meteoclimatic data. Aerobiologia 2014, 30, 25–33. [Google Scholar] [CrossRef]
- Cecchini, C.; Antonucci, F.; Costa, C.; Marti, A.; Menesatti, P. Application of Near Infrared handheld spectrometers to predict semolina quality. J. Sci. Food Agric. 2021, 101, 151–157. [Google Scholar] [CrossRef]
- Paris, P.; Di Matteo, G.; Tarchi, M.; Tosi, L.; Spaccino, L.; Lauteri, M. Precision subsurface drip irrigation increases yield while sustaining water-use efficiency in Mediterranean poplar bioenergy plantations. For. Ecol. Manag. 2018, 409, 749–756. [Google Scholar] [CrossRef]
- Osroosh, Y.; Peters, R.T.; Campbell, C.S.; Zhang, Q. Comparison of irrigation automation algorithms for drip-irrigated apple trees. Comput. Electron. Agric. 2016, 128, 87–99. [Google Scholar] [CrossRef]
- Domínguez-Niño, J.M.; Oliver-Manera, J.; Girona, J.; Casadesús, J. Differential irrigation scheduling by an automated algorithm of water balance tuned by capacitance-type soil moisture sensors. Agric. Water Manag. 2020, 228, 105880. [Google Scholar] [CrossRef]
- Ortuani, B.; Facchi, A.; Mayer, A.; Brancadoro, L. Assessing the Effectiveness of Variable-Rate Drip Irrigation on Water Use Efficiency in a Vineyard in Northern Italy. Water 2019, 11, 1964. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg T (°C) | −0.6 | 1.9 | 6.2 | 10.8 | 14.7 | 18.3 | 20.7 | 19.9 | 16.9 | 10.5 | 5.1 | 0.8 |
| Min T (°C) | −4.1 | −2.3 | 1.4 | 5.4 | 9.3 | 12.6 | 14.6 | 14.1 | 11.5 | 6 | 1.5 | −2.2 |
| Max T (°C) | 2.9 | 6.2 | 11.1 | 16.2 | 20.1 | 24.1 | 26.8 | 25.7 | 22.3 | 15 | 8.8 | 3.9 |
| Rain (mm) | 40 | 42 | 53 | 69 | 82 | 92 | 84 | 96 | 79 | 85 | 89 | 51 |
| Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min T (°C) | −0.6 | 3.18 | 4.19 | 6.71 | 8.1 | 16.85 | 17.07 | 17.35 | 13.75 | 10.59 | 4.4 | 2.08 |
| Max T (°C) | 6.3 | 11.48 | 14.13 | 13.93 | 15.71 | 29.21 | 28.78 | 28.03 | 22.35 | 17.58 | 8.92 | 7.97 |
| Weather Station | Latitude | Longitude |
|---|---|---|
| East Tenna | 46,022,687 | 11,265,643 |
| West Tenna | 46,021,743 | 11,255,331 |
| Depth Code | Textural Class | OM (%) | FC (%) | WP (%) | AWC (%) | Density (g cm−3) | Total Limestone (g kg−1 CaCO3) |
|---|---|---|---|---|---|---|---|
| T1A30cm | Sandy loam | 1.6 | 17.1 | 6.3 | 10.8 | 20.54 | n.q. (<10) |
| T1B60cm | Sandy loam | 1.4 | 21.6 | 11.8 | 9.8 | 34.56 | n.q. (<10) |
| T1C90cm | Sandy loam | 0.8 | 16.0 | 4.1 | 11.9 | 18.81 | n.q. (<10) |
| Lag | 30 cm | 60 cm | 90 cm | |||
|---|---|---|---|---|---|---|
| Correlation | p | Correlation | p | Correlation | p | |
| 0 | 0.27489 | 0.014864 | 0.078903 | 0.49229 | −0.015345 | 0.89392 |
| 1 | 0.55845 | 1.31 × 10−7− | 0.37812 | 0.00069749 | 0.10545 | 0.36136 |
| 2 | 0.45216 | 4.12 × 10−5 | 0.46996 | 1.84 × 10−5 | 0.13345 | 0.25044 |
| 3 | 0.29893 | 0.0091823 | 0.38455 | 0.0006583 | 0.10924 | 0.35084 |
| 4 | 0.20259 | 0.083435 | 0.31005 | 0.00718 | 0.11708 | 0.3205 |
| 5 | 0.23883 | 0.041858 | 0.31937 | 0.005885 | 0.13446 | 0.25674 |
| No. of Samples | 31 |
| Reprocessing X-block | Autoscale |
| No. of LVs | 8 |
| RMSEC | 2.03 |
| RMSECV | 6.30 |
| Bias | −1.7 |
| SEP-model | 1.12 |
| SEP-test | 1.34 |
| RPDRMSE-model | 1.05 |
| RPDRMSE-test | 1.11 |
| r model (80%) | 0.86 |
| r test (20%) | 0.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Figorilli, S.; Pallottino, F.; Colle, G.; Spada, D.; Beni, C.; Tocci, F.; Vasta, S.; Antonucci, F.; Pagano, M.; Fedrizzi, M.; et al. An Open Source Low-Cost Device Coupled with an Adaptative Time-Lag Time-Series Linear Forecasting Modeling for Apple Trentino (Italy) Precision Irrigation. Sensors 2021, 21, 2656. https://doi.org/10.3390/s21082656
Figorilli S, Pallottino F, Colle G, Spada D, Beni C, Tocci F, Vasta S, Antonucci F, Pagano M, Fedrizzi M, et al. An Open Source Low-Cost Device Coupled with an Adaptative Time-Lag Time-Series Linear Forecasting Modeling for Apple Trentino (Italy) Precision Irrigation. Sensors. 2021; 21(8):2656. https://doi.org/10.3390/s21082656
Chicago/Turabian StyleFigorilli, Simone, Federico Pallottino, Giacomo Colle, Daniele Spada, Claudio Beni, Francesco Tocci, Simone Vasta, Francesca Antonucci, Mauro Pagano, Marco Fedrizzi, and et al. 2021. "An Open Source Low-Cost Device Coupled with an Adaptative Time-Lag Time-Series Linear Forecasting Modeling for Apple Trentino (Italy) Precision Irrigation" Sensors 21, no. 8: 2656. https://doi.org/10.3390/s21082656
APA StyleFigorilli, S., Pallottino, F., Colle, G., Spada, D., Beni, C., Tocci, F., Vasta, S., Antonucci, F., Pagano, M., Fedrizzi, M., & Costa, C. (2021). An Open Source Low-Cost Device Coupled with an Adaptative Time-Lag Time-Series Linear Forecasting Modeling for Apple Trentino (Italy) Precision Irrigation. Sensors, 21(8), 2656. https://doi.org/10.3390/s21082656