
Distributed Beamforming and Power Allocation for Heterogeneous Networks with MISO Interference Channel


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
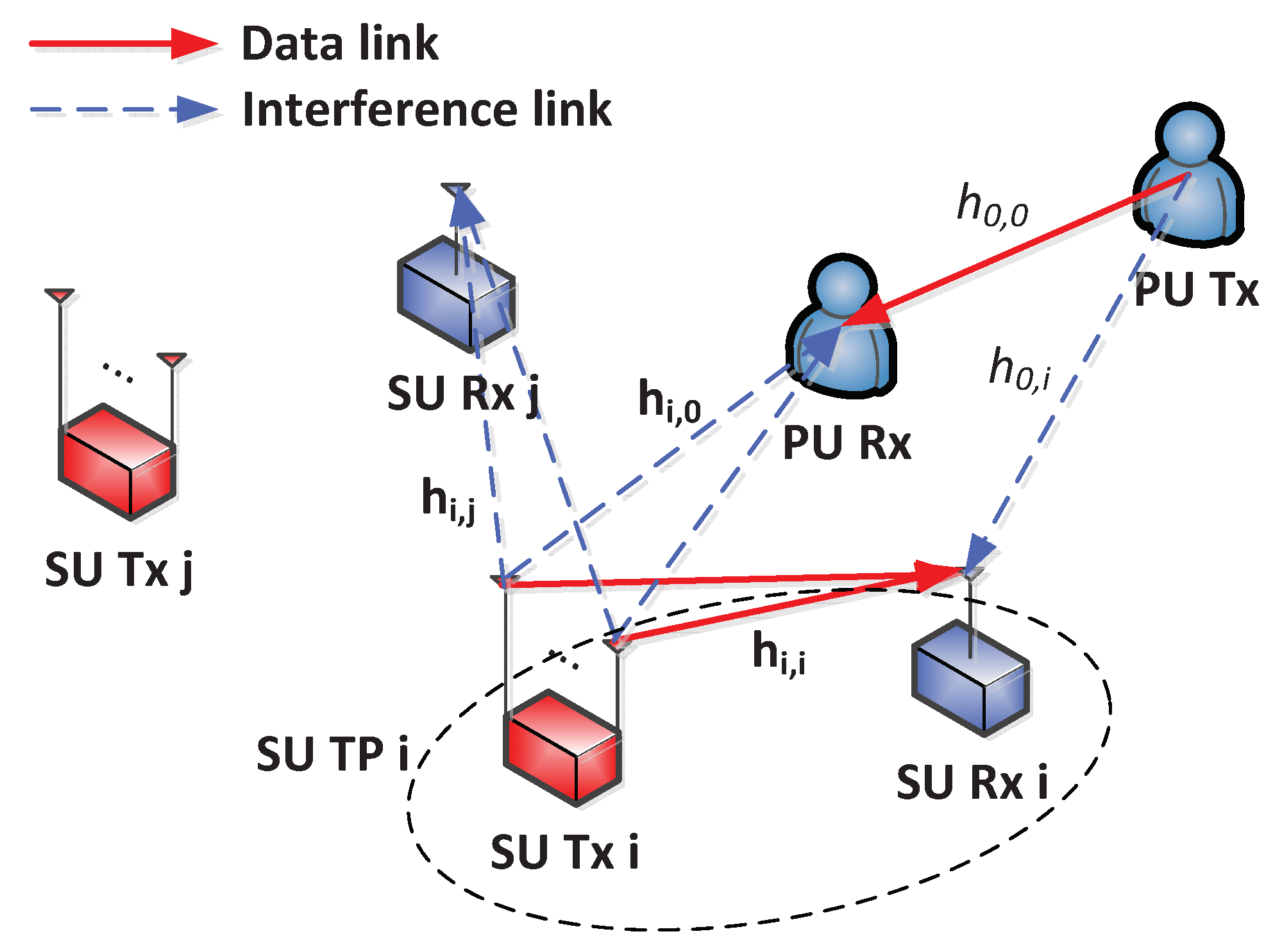
2. System Model and Problem Statement
3. Distributed Beamforming and Power Allocation
| Algorithm 1 Distributed beamforming and power allocation |
| 1: Initialize , , and , randomly |
| 2: Determine , |
| 3: |
| 4: repeat |
| 5: |
| 6: for to N |
| 7: Compute according to (15) |
| 8: Update and according to (16) and (17) |
| 9: end for |
| 10: |
| 11: |
| 12: until |
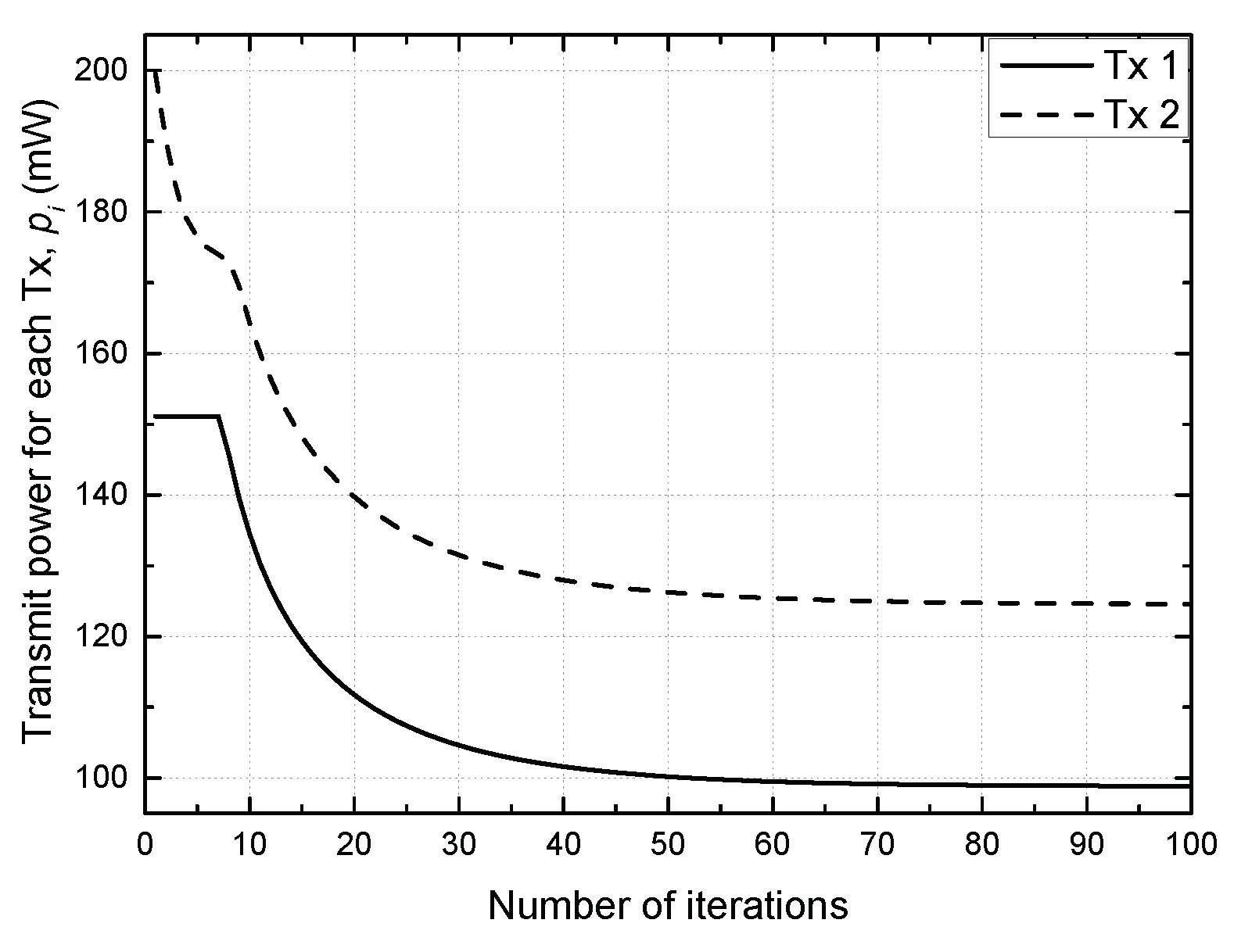
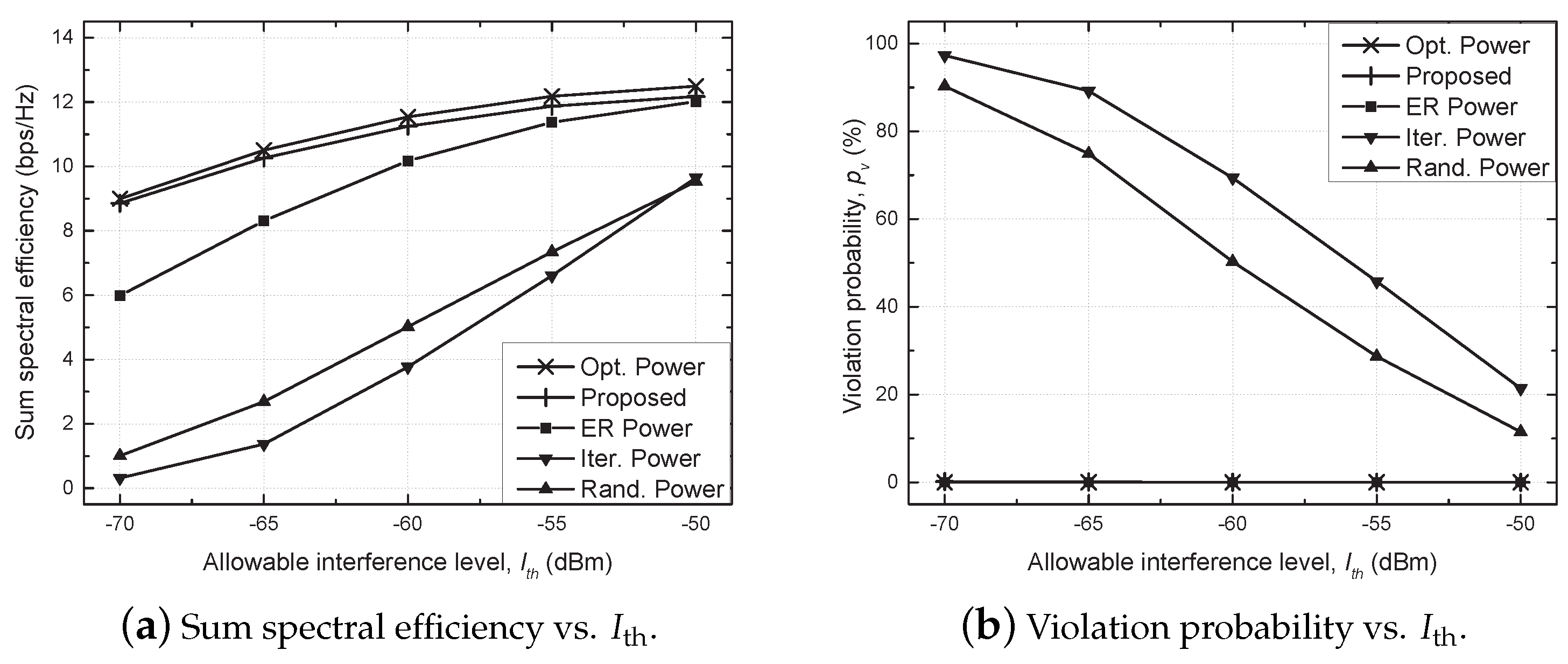
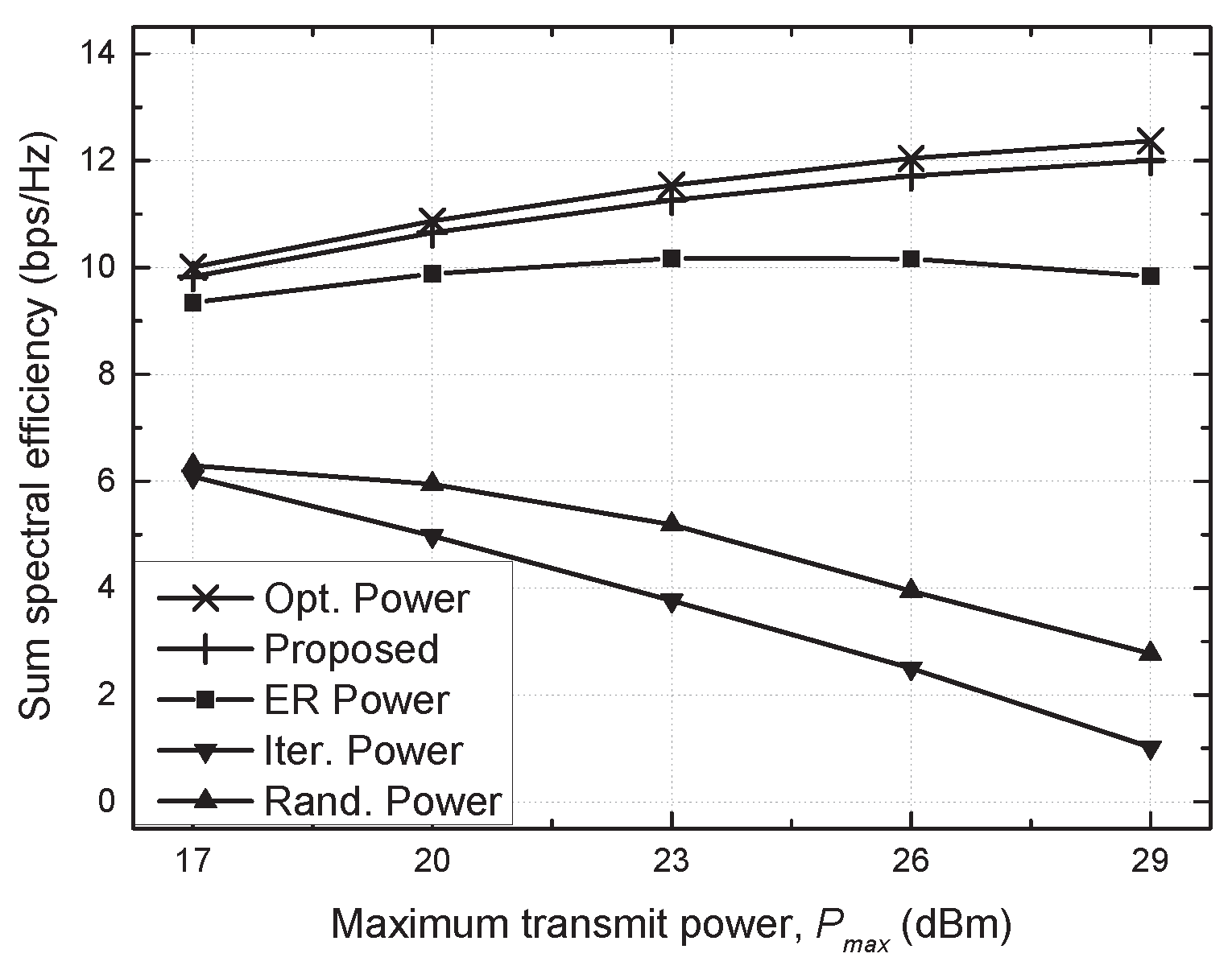
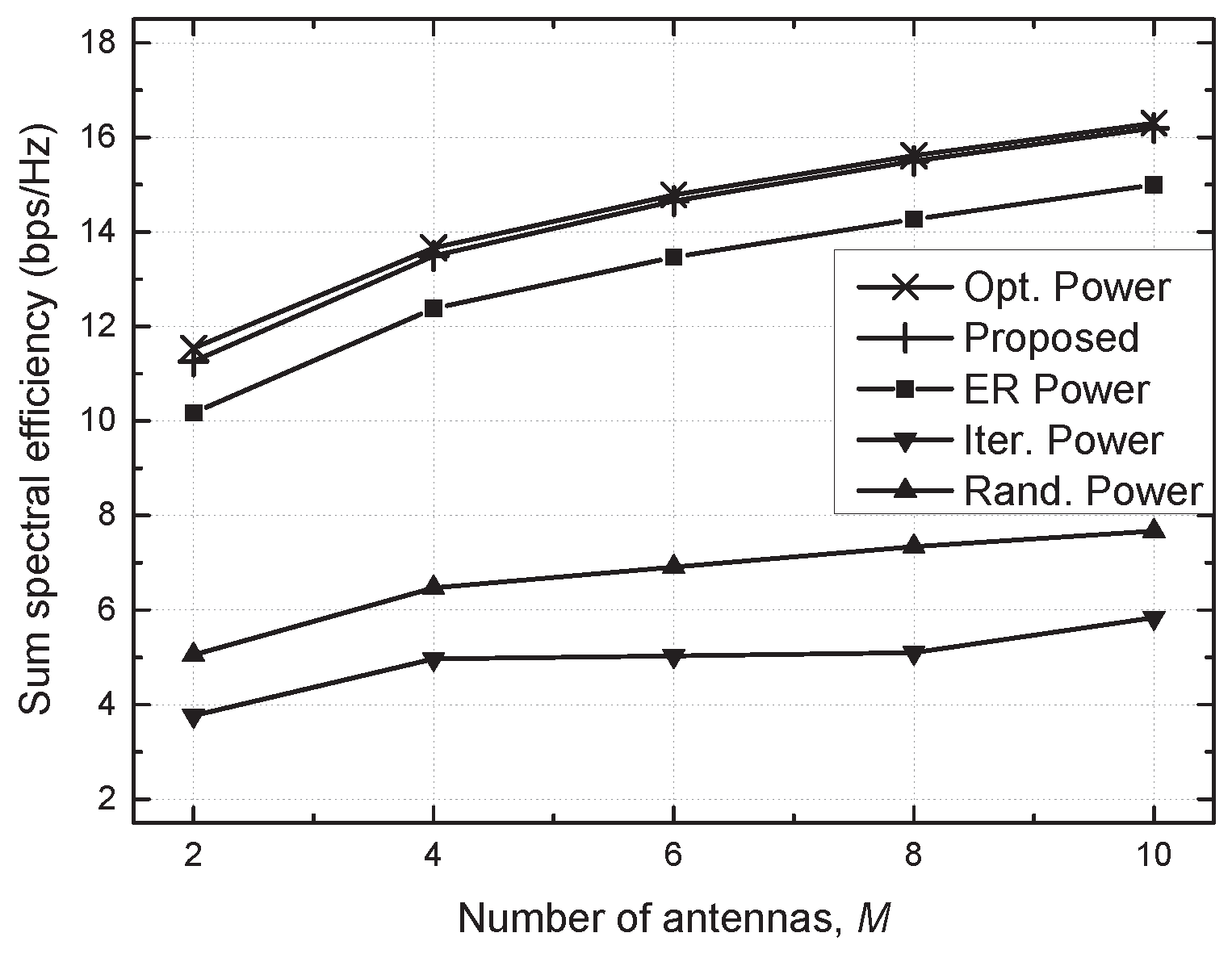
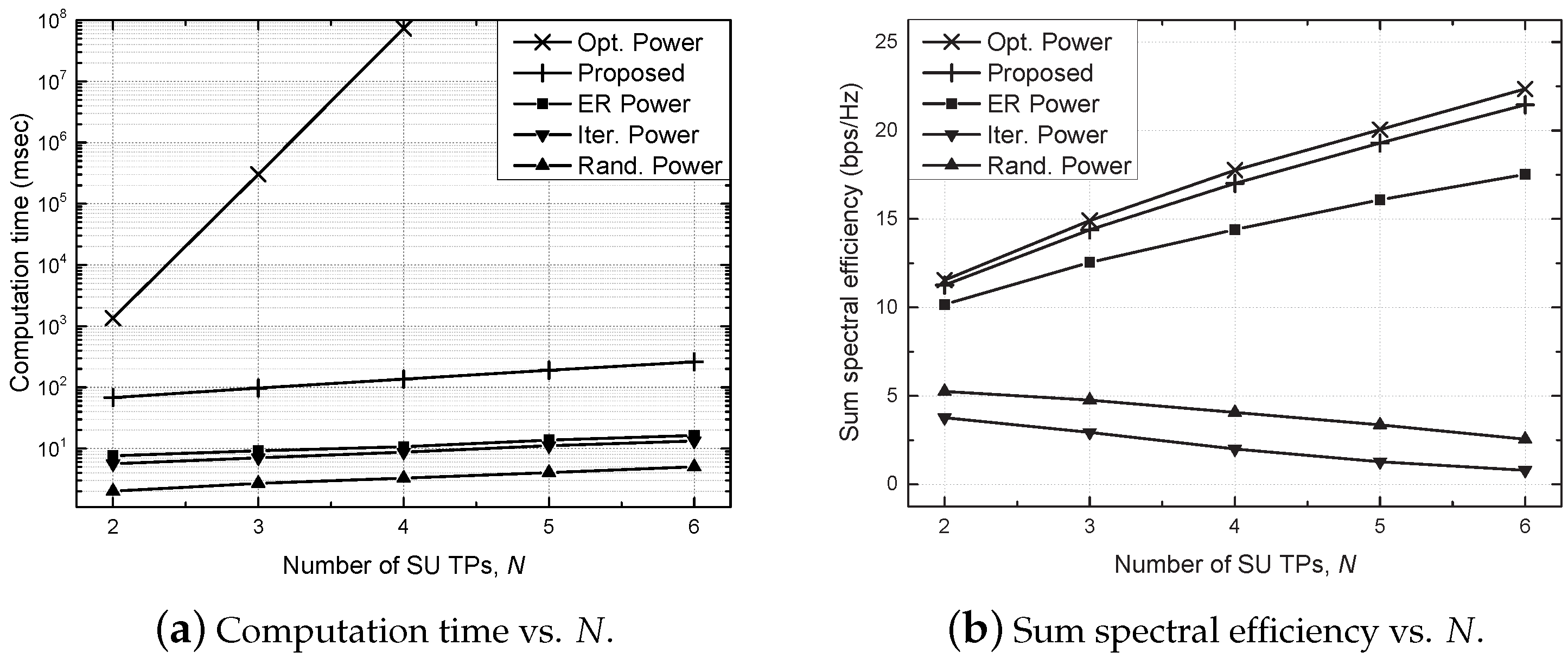
4. Simulation Results and Discussion
- Optimal (Opt.) power scheme: the beamforming vector is determined by the MRT, i.e., , and an optimal power allocation is found via an exhaustive search in which the transmit power is quantized into 100 equispaced values, and all possible combinations are examined;
- Proposed scheme: a distributed power allocation described in Algorithm 1 is utilized with ;
- Equally reduced (ER) power scheme: the same transmit power, , is utilized for each SU TP with , where the optimal value of is found via an exhaustive search [29];
- Iterative (Iter.) power scheme: the beamforming vector and transmit power are determined similarly to the proposed algorithm without considering the constraint of the allowable interference on PU, e.g., C1 of (7), which is a baseline scheme;
- Random (Rand.) power scheme: randomly generated transmit power is utilized for each SU TP with .
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bhushan, N.; Li, J.; Malladi, D.; Gilmore, R.; Brenner, D.; Damnjanovic, A.; Sukhavasi, R.T.; Patel, C.; Geirhofer, S. Network densification: The dominant theme for wireless evolution into 5G. IEEE Commun. Mag. 2014, 52, 82–89. [Google Scholar] [CrossRef]
- Yunas, S.F.; Valkama, M.; Niemela, J. Spectral and energy efficiency of ultra-dense networks under different deployment strategies. IEEE Commun. Mag. 2015, 53, 90–100. [Google Scholar] [CrossRef]
- Khalifa, T.; Abdrabou, A.; Shaban, K.; Gaouda, A.M. Heterogeneous wireless networks for smart grid distribution systems: Advantages and limitations. Sensors 2018, 18, 1517. [Google Scholar] [CrossRef] [PubMed]
- Valenzuela, R.A. Dynamic resource allocation in Line-of-Sight microcells. IEEE J. Sel. Areas Commun. 1993, 11, 941–948. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, S.; Li, X.; Ji, H.; Du, X. Interference management for heterogeneous network with spectral efficiency improvement. IEEE Wirel. Commun. 2015, 22, 101–107. [Google Scholar] [CrossRef]
- Vu, T.K.; Bennis, M.; Samarakoon, S.; Debbah, M.; Latva-aho, M. Joint load balancing and interference mitigation in 5G heterogeneous networks. IEEE Trans. Wirel. Commun. 2017, 16, 6032–6046. [Google Scholar] [CrossRef]
- Coskun, C.C.; Ayanoglu, E. Energy- and spectral-efficient resource allocation algorithm for heterogeneous networks. IEEE Trans. Veh. Technol. 2018, 67, 590–603. [Google Scholar] [CrossRef]
- Gao, H.; Zhang, S.; Su, Y.; Diao, M. Joint resource allocation and power control algorithm for cooperative D2D heterogeneous networks. IEEE Access 2019, 7, 20632–20643. [Google Scholar] [CrossRef]
- Xu, Y.; Hu, Y.; Li, G. Robust rate maximization for heterogeneous wireless networks under channel uncertainties. Sensors 2018, 18, 639. [Google Scholar] [CrossRef]
- Elsherif, A.R.; Ding, Z.; Liu, X. Dynamic MIMO precoding for femtocell interference mitigation. IEEE Trans. Commun. 2014, 62, 648–666. [Google Scholar] [CrossRef]
- Dai, Y.; Jin, S.; Pan, L.; Gao, X.; Jiang, L.; Lei, M. Interference control based on beamforming coordination for heterogeneous network with RRH deployment. IEEE Syst. J. 2015, 9, 58–64. [Google Scholar] [CrossRef]
- de Figueiredo, F.A.P.; Dias, C.F.; de Lima, E.R.; Fraidenraich, G. Capacity bounds for dense massive MIMO in a Line-of-Sight propagation environment. Sensors 2020, 20, 520. [Google Scholar] [CrossRef] [PubMed]
- Althuwayb, A.A. On-chip antenna design using the concepts of metamaterial and SIW principles applicable to terahertz integrated circuits operating over 0.6–0.622 THz. Int. J. Antennas Propag. 2020, 2020, 6653095. [Google Scholar] [CrossRef]
- Althuwayb, A.A. Enhanced radiation gain and efficiency of a metamaterial-inspired wideband microstrip antenna using substrate integrated waveguide technology for sub-6 GHz wireless communication systems. Microw. Opt. Technol. Lett. 2021, 1, 1–7. [Google Scholar]
- Shirkolaei, M.M. Wideband linear microstrip array antenna with high efficiency and low side lobe level. Int. J. RF Microw. Comput. Aided Eng. 2020, 30, e22412. [Google Scholar]
- Alibakhshikenari, M.; Babaeian, F.; Virdee, B.S.; Aïssa, S.; Azpilicueta, L.; See, C.H.; Althuwayb, A.A.; Huynen, I.; Abd-Alhameed, R.A.; Falcone, F.; et al. A comprehensive survey on “Various decoupling mechanisms with focus on metamaterial and metasurface principles applicable to SAR and MIMO antenna systems”. IEEE Access 2020, 8, 192965–193004. [Google Scholar] [CrossRef]
- Shirkolaei, M.M. High efficiency X-band series-fed microstrip array antenna. Prog. Electromagn. Res. C 2020, 105, 35–45. [Google Scholar] [CrossRef]
- Althuwayb, A.A. MTM- and SIW-inspired bowtie antenna loaded with AMC for 5G mm-wave applications. Int. J. Antennas Propag. 2021, 2021, 6658819. [Google Scholar] [CrossRef]
- Nguyen, T.M.; Yadav, A.; Ajib, W.; Assi, C. Resource allocation in two-tier wireless backhaul heterogeneous networks. IEEE Trans. Wirel. Commun. 2016, 15, 6690–6704. [Google Scholar] [CrossRef]
- Cumanan, K.; Krishna, R.; Musavian, L.; Lambotharan, S. Joint beamforming and user maximization techniques for cognitive radio networks based on branch and bound method. IEEE Trans. Wirel. Commun. 2010, 9, 3082–3092. [Google Scholar] [CrossRef]
- Dadallage, S.; Yi, C.; Cai, J. Joint beamforming, power, and channel allocation in multiuser and multichannel underlay MISO cognitive radio networks. IEEE Trans. Veh. Technol. 2016, 65, 3349–3359. [Google Scholar] [CrossRef]
- Ding, Z.; Chin, W.H.; Leung, K.K. Distributed beamforming and power allocation for cooperative networks. IEEE Trans. Wirel. Commun. 2008, 7, 1817–1822. [Google Scholar] [CrossRef]
- KianiHarchehgani, S.; ShahbazPanahi, S.; Dong, M.; Boudreau, G. Joint power allocation and distributed beamforming design for multi-carrier asynchronous two-way relay networks. In Proceedings of the 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Cannes, France, 2–5 July 2019; pp. 1–5. [Google Scholar]
- Feng, Z.; Ren, G.; Chen, J.; Zhang, X.; Luo, Y.; Wang, M.; Xu, Y. Power control in relay-assisted anti-jamming systems: A bayesian three-layer Stackelberg game approach. IEEE Access 2019, 7, 14623–14636. [Google Scholar] [CrossRef]
- Lee, W.; Lee, K. Resource allocation scheme for guarantee of QoS in D2D communications using deep neural network. IEEE Commun. Lett. 2021, 25, 887–891. [Google Scholar] [CrossRef]
- Lee, S.-R.; Moon, S.-H.; Kong, H.-B.; Lee, I. Optimal beamforming schemes and its capacity behavior for downlink distributed antenna systems. IEEE Trans. Wirel. Commun. 2013, 12, 2578–2587. [Google Scholar] [CrossRef]
- Yu, W.; Lui, R. Dual methods for nonconvex spectrum optimization of multicarrier systems. IEEE Trans. Commun. 2006, 54, 1310–1321. [Google Scholar] [CrossRef]
- Zhang, R.; Li, Y.; Wang, C.-X.; Ruan, Y.; Zhang, H. Performance tradeoff in relay aided D2D-cellular networks. IEEE Trans. Veh. Technol. 2018, 67, 10144–10149. [Google Scholar] [CrossRef]
- Shalmashi, S.; Miao, G.; Ben Slimane, S. Interference management for multiple device-to-device communications underlaying cellular networks. In Proceedings of the 2013 IEEE 24th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), London, UK, 8–11 September 2013; pp. 223–227. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K. Distributed Beamforming and Power Allocation for Heterogeneous Networks with MISO Interference Channel. Sensors 2021, 21, 2606. https://doi.org/10.3390/s21082606
Lee K. Distributed Beamforming and Power Allocation for Heterogeneous Networks with MISO Interference Channel. Sensors. 2021; 21(8):2606. https://doi.org/10.3390/s21082606
Chicago/Turabian StyleLee, Kisong. 2021. "Distributed Beamforming and Power Allocation for Heterogeneous Networks with MISO Interference Channel" Sensors 21, no. 8: 2606. https://doi.org/10.3390/s21082606
APA StyleLee, K. (2021). Distributed Beamforming and Power Allocation for Heterogeneous Networks with MISO Interference Channel. Sensors, 21(8), 2606. https://doi.org/10.3390/s21082606