
Performance Study of Distance-Weighting Approach with Loopy Sum-Product Algorithm for Multi-Object Tracking in Clutter


Abstract
1. Introduction
2. Target Tracking Dynamic System Model and Assumptions
3. Algorithm Description
3.1. Probabilistic Data Association Filter
3.1.1. Prediction
3.1.2. Measurement Validation
3.1.3. Data Association Probabilities
3.1.4. State Estimation
3.2. Distance-Weighting Probabilistic Data Association Filter
3.3. Joint Probabilistic Data Association Filter
3.3.1. Measurement Validation
3.3.2. The Validation Matrix
3.3.3. The Feasible Joint Events
- A measurement can have only one source, i.e.,
- Each target can generate at most one measurement, i.e.,in Equation (31), called the target detection indicator, indicates if a measurement is associated with target t in event . Similarly, we define the measurement association indicator to indicate if measurement j is associated with a target in event .
3.3.4. Joint Data Association Probabilities
3.4. Loopy Sum-Product Algorithm
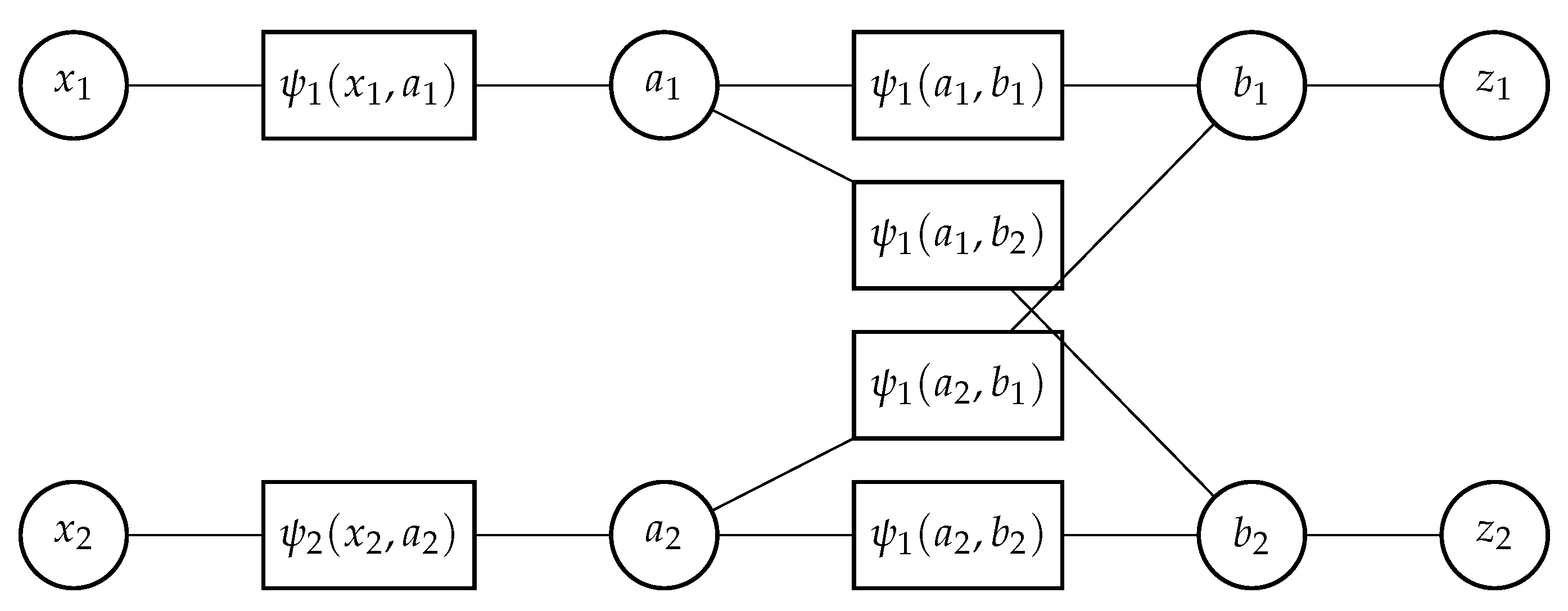
3.4.1. Belief Propagation in Factor Graphs
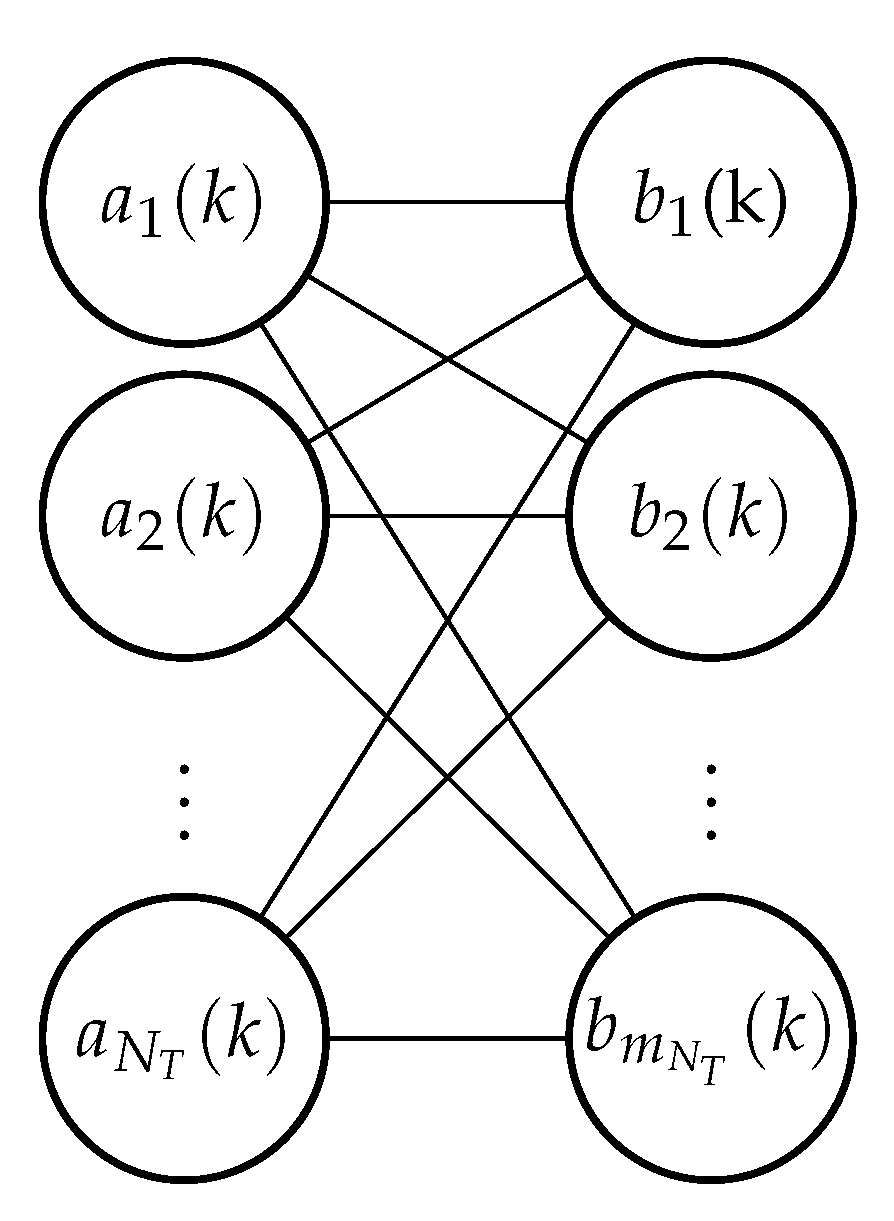
3.4.2. Factor Graphs for Data Association
- Target oriented association variable (a): Create an association variable for each target . The value assigned to is an index to the measurement with which target i is hypothesized to be associated at time k (zero if the target is hypothesized to not have been detected). The complete set of target oriented association variables at time k is denoted by .
- Measurement oriented association variable (b): Create an association variable for each measurement . The value assigned to is an index to the target with which measurement j is hypothesized to be associated at time k (zero if the measurement is hypothesized to be clutter). The complete set of measurement oriented association variables at time k is denoted by .
3.4.3. Joint Data Association Probabilities
3.5. Distance-Weighting Loopy Sum-Product Algorithm
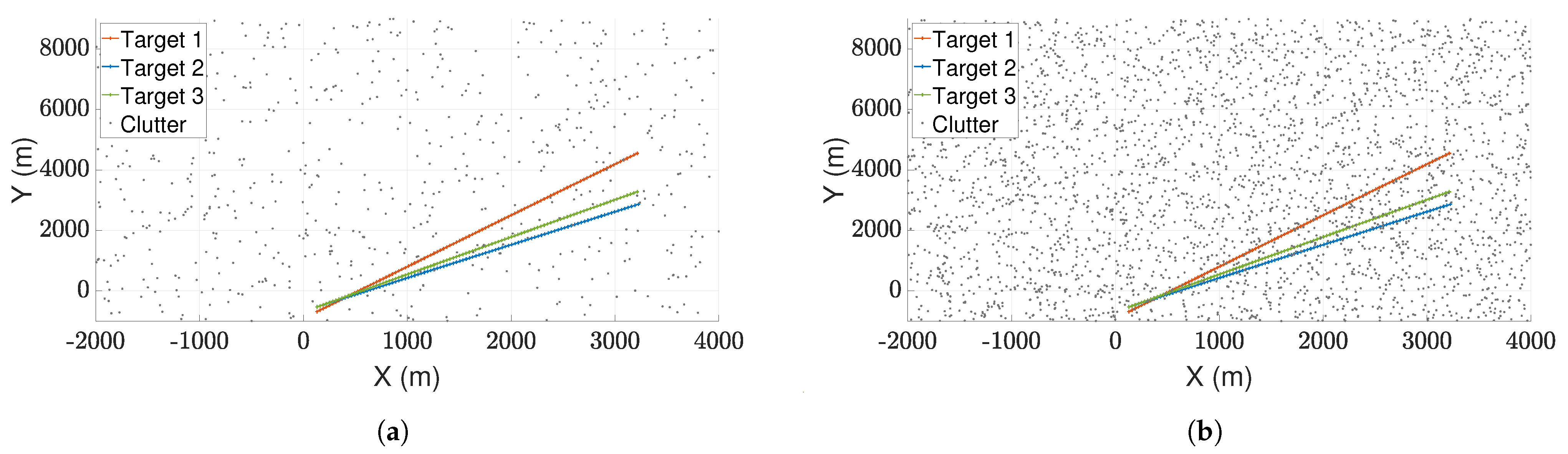
4. Simulation and Analysis
4.1. The Dynamic Model
4.2. Simulation Parameters
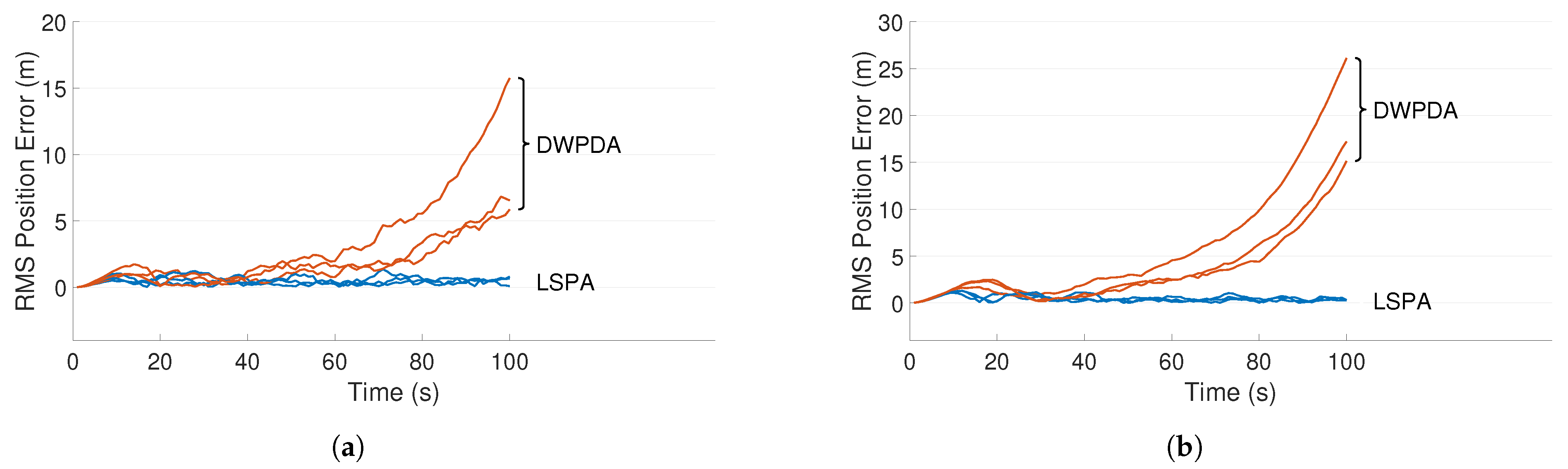
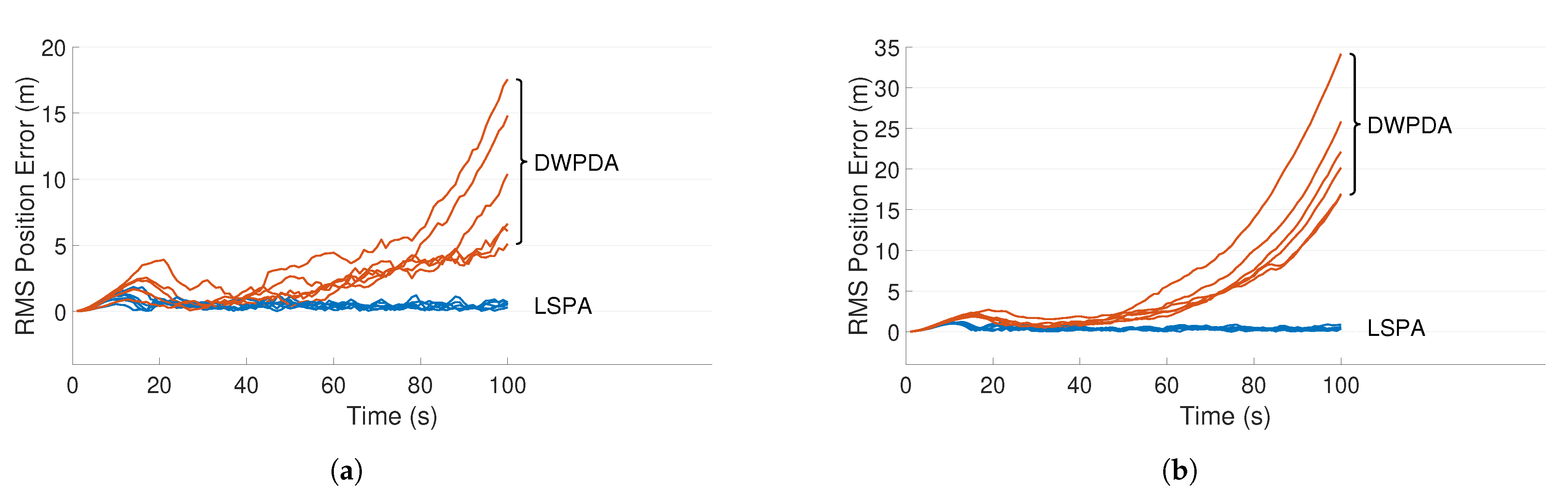
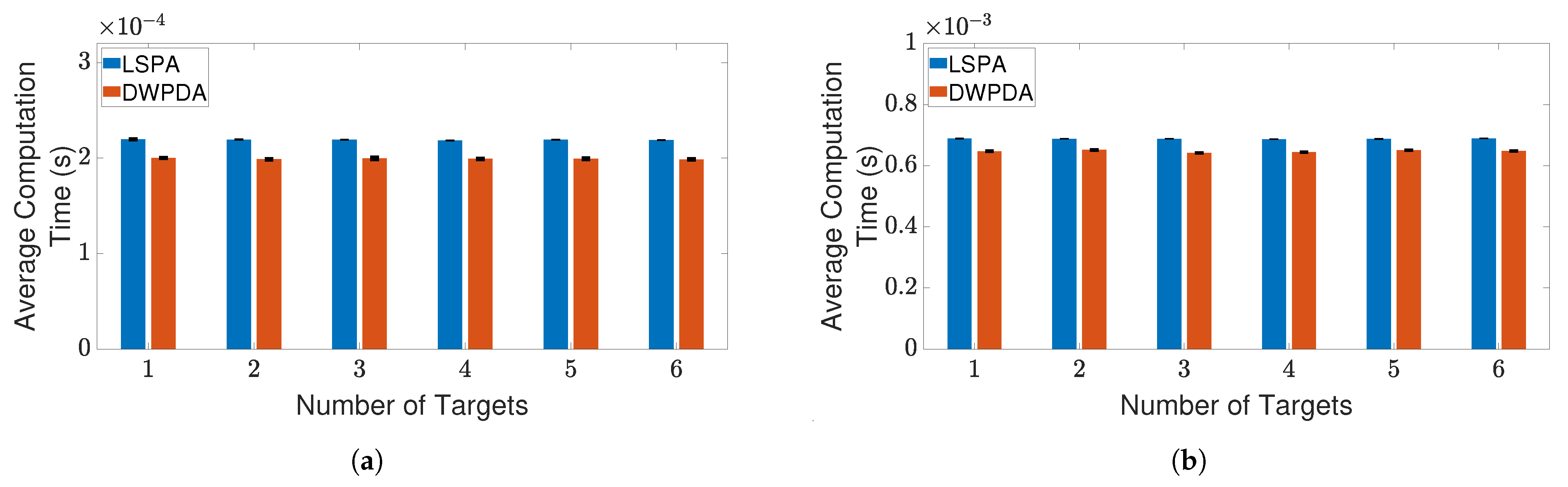
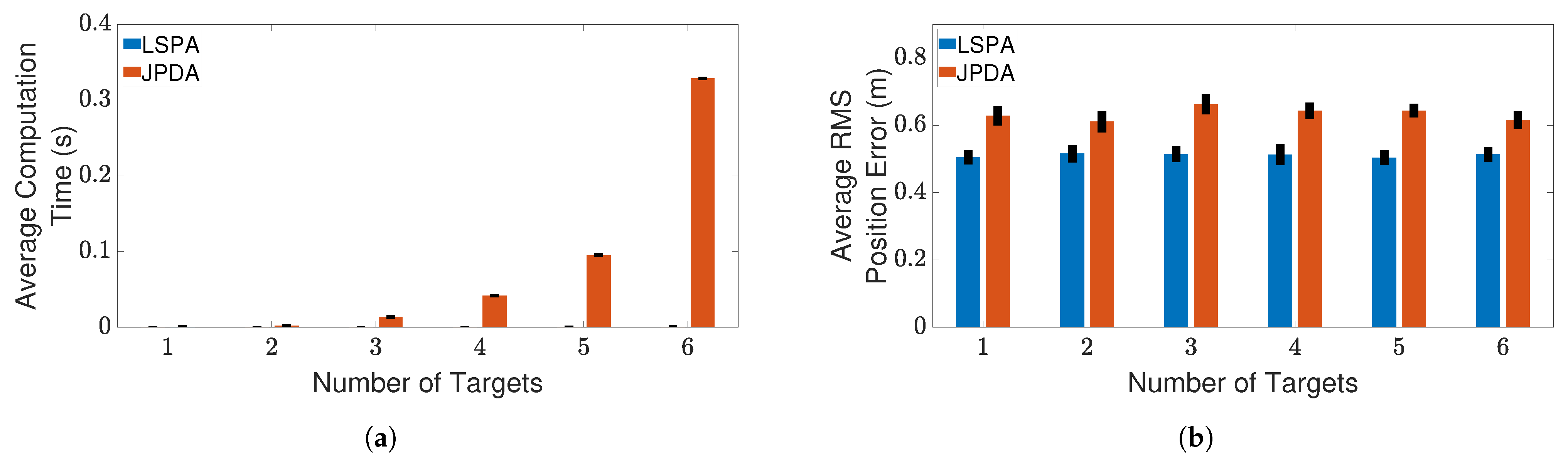
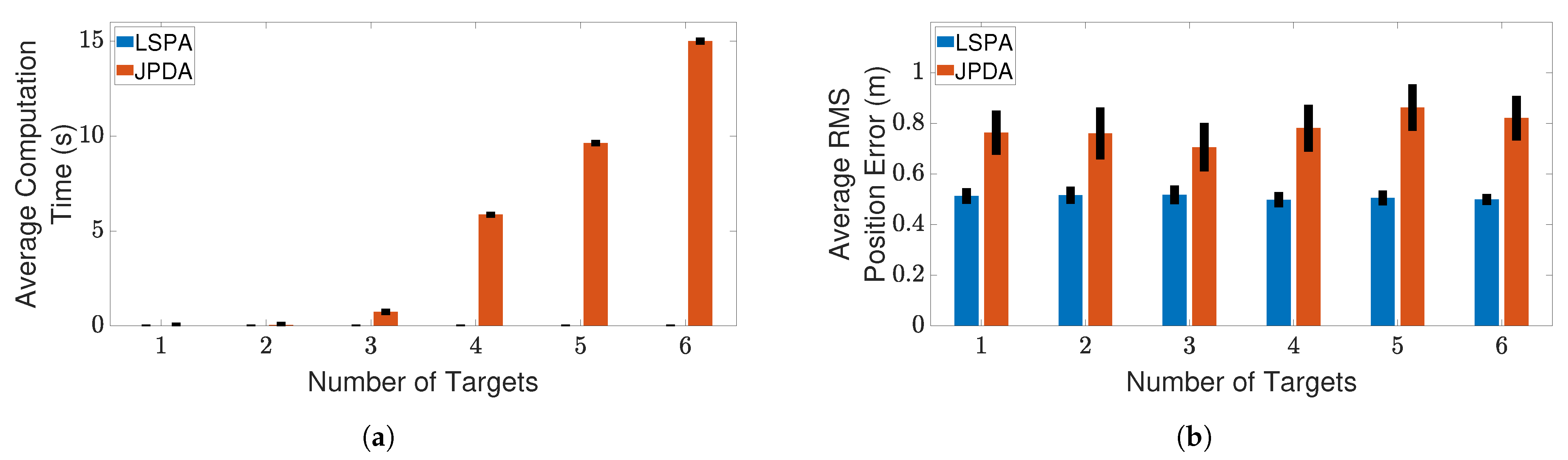
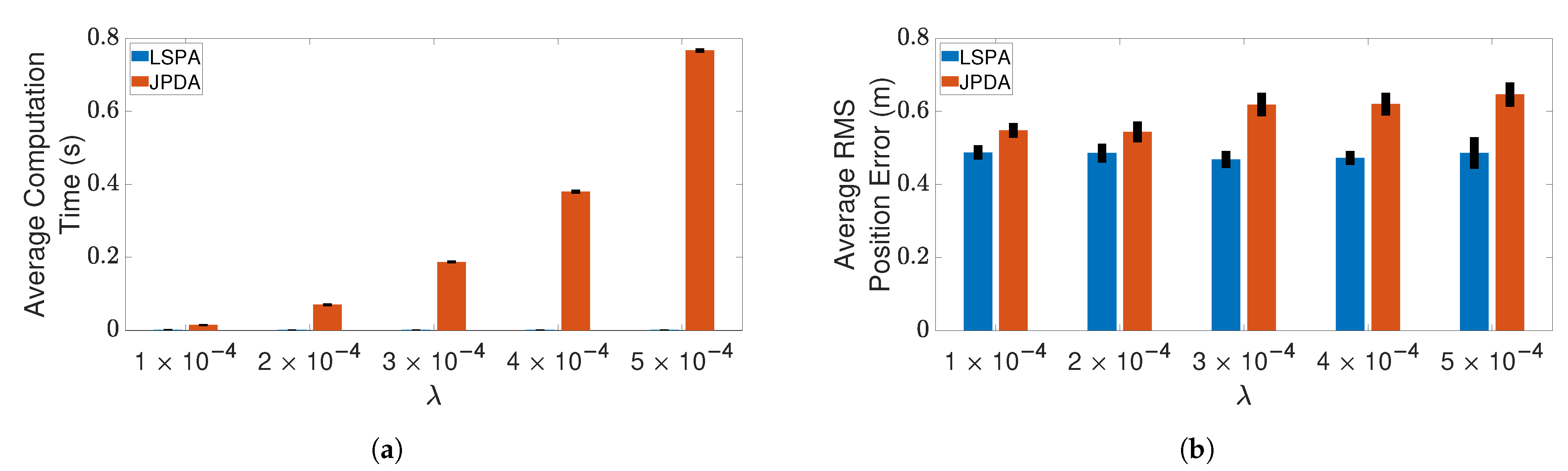
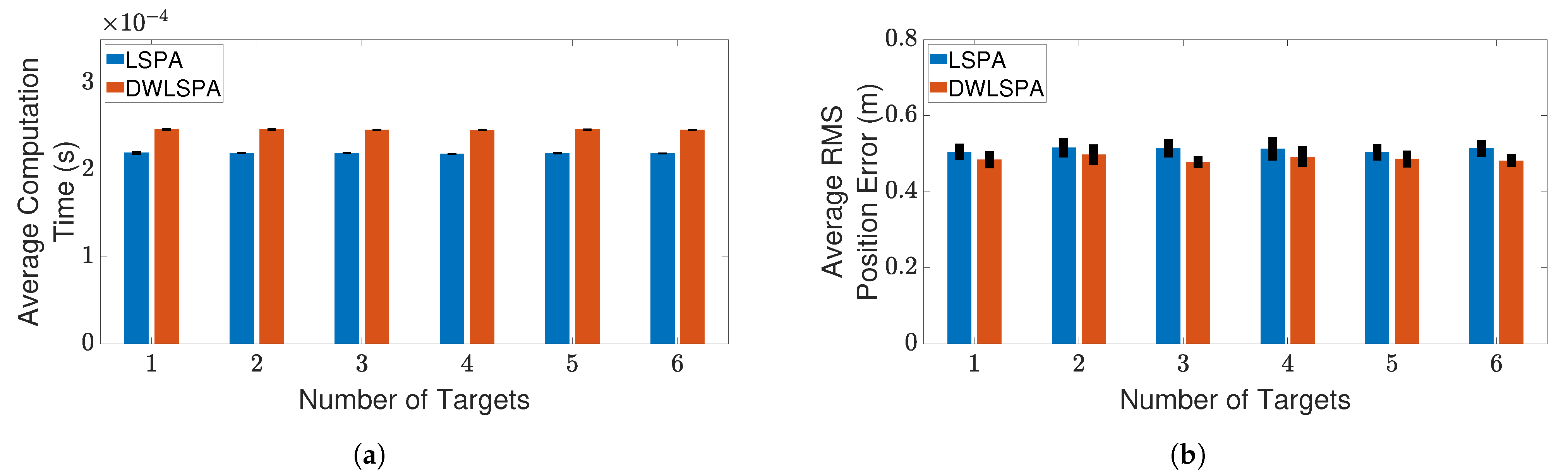
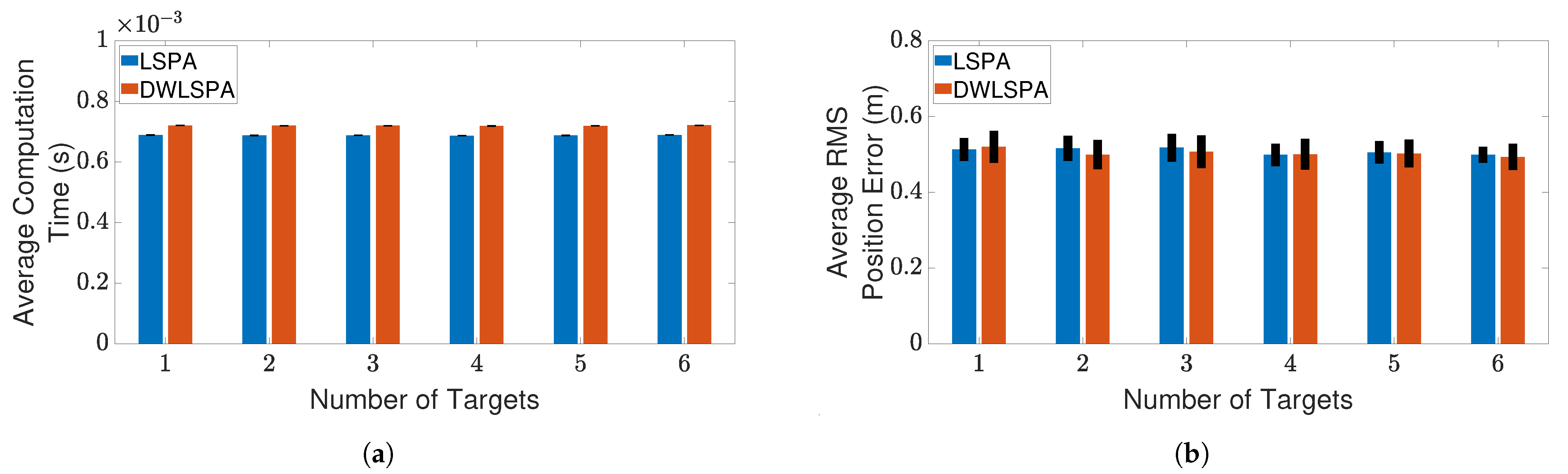
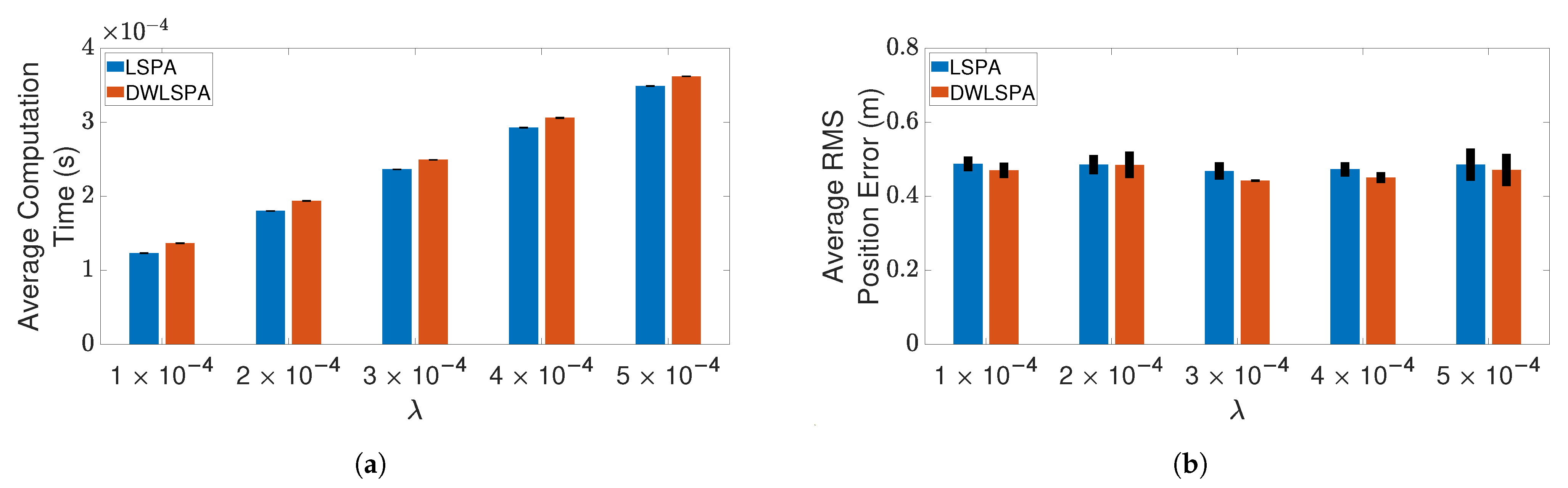
4.3. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DA | Data Association |
| MTT | Multiple Target Tracking |
| KF | Linear Kalman Filter |
| NN | Nearest Neighbor |
| PDA | Probabilistic Data Association |
| DWPDA | Distance-Weighting Probabilistic Data Association |
| PDAF | Probabilistic Data Association Filter |
| JPDA | Joint Probabilistic Data Association |
| JPDAF | Joint Probabilistic Data Association Filter |
| MHT | Multiple Hypothesis Tracking |
| SPA | Sum-Product Algorithm |
| LSPA | Loopy Sum-Product Algorithm |
| DWLSPA | Distance-Weighting Loopy Sum-Product Algorithm |
| LR | Likelihood Ratio |
| Probability Distribution Function | |
| PMF | Probability Mass Function |
| NCV | Nearly Constant Velocity |
| RMS | Root Mean Square |
| GOSPA | Generalized Optimal Sub-Pattern Assignment |
References
- Bar-Shalom, Y.; Tse, E. Tracking in a Cluttered Environment With Probabilistic Data Association. Automatica 1975, 11, 451–460. [Google Scholar] [CrossRef]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; Technical Report; University of North Carolina at Chapel Hill: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Kschischang, F.R.; Brendan, J.F.; Loeliger, H.-A. Factor Graphs and the Sum-Product Algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Li, Y.; Yu, J.; Li, X. A Novel Probabilistic Data Association for Target Tracking in a Cluttered Environment. Sensors 2016, 16, 2180. [Google Scholar] [CrossRef] [PubMed]
- Williams, J.L.; Lau, R.A. Data Association by Loopy Belief Propagation. In Proceedings of the 13th International Conference on Information Fusion, Edinburgh, SA, Australia, 26–29 July 2010; pp. 1–8. [Google Scholar]
- Li, X.; Bar-Shalom, Y. Tracking in Clutter With Nearest Neighbor Filters: Analysis and Performance. IEEE Trans. Aerosp. Electron. Syst. 1996, 32, 995–1010. [Google Scholar]
- Fortmann, T.E.; Bar-Shalom, Y.; Scheffe, M. Sonar Tracking of Multiple Targets Using Joint Probabilistic Data Association. IEEE J. Ocean. Eng. 1983, 8, 173–184. [Google Scholar] [CrossRef]
- Rezatofighi, S.H.; Milan, A.; Zhang, Z.; Shi, Q.; Dick, A.; Reid, I. Joint Probabilistic Data Association Revisited. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 3047–3055. [Google Scholar]
- Blackman, S. Multiple Hypothesis Tracking for Multiple Target Tracking. IEEE Trans. Aerosp. Electron. Syst. 2004, 19, 5–18. [Google Scholar] [CrossRef]
- Roecker, J.A.; Phillis, G.L. Suboptimal Joint Probabilistic Data Association. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 510–517. [Google Scholar] [CrossRef]
- Reid, D.B. An Algorithm for Tracking Multiple Targets. IEEE Trans. Automat. Cont. 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Willett, P.; Tian, X. Tracking and Data Fusion: A Handbook of Algorithms; YBS Publishing: Storrs, CT, USA, 2011. [Google Scholar]
- Wiberg, N.; Loeliger, H.-A.; Kotter, R. Codes and Iterative Decoding on General Graphs. Eur. Trans. Telecomm. 1996, 6, 513–525. [Google Scholar]
- Williams, J.L.; Lau, R.A. Convergence of Loopy Belief Propagation for Data Association. In Proceedings of the Sixth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Brisbane, QLD, Australia, 7–10 December 2010; pp. 175–180. [Google Scholar]
- Williams, J.L.; Lau, R.A. Approximate Evaluation of Marginal Association Probabilities with Belief Propagation. IEEE Trans. Aerosp. Electron. Syst. 2014, 4, 2942–2959. [Google Scholar] [CrossRef]
- Meyer, F.; Braca, P.; Willett, P.; Hlawatsch, F. Scalable multitarget tracking using multiple sensors: A belief propagation approach. In Proceedings of the 18th International Conference on Information Fusion (Fusion), Washington, DC, USA, 6–9 July 2015; pp. 1778–1785. [Google Scholar]
- Meyer, F.; Braca, P.; Willett, P.; Hlawatsch, F. Tracking an unknown number of targets using multiple sensors: A belief propagation method. In Proceedings of the 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 719–726. [Google Scholar]
- Meyer, F.; Braca, P.; Willett, P.; Hlawatsch, F. A scalable algorithm for tracking an unknown number of targets using multiple sensors. IEEE Trans. Signal Process. 2017, 65, 3478–3493. [Google Scholar] [CrossRef]
- Meyer, F.; Kropfreiter, T.; Williams, J.L.; Lau, R.; Hlawatsch, F.; Braca, P.; Win, M.Z. Message passing algorithms for scalable multitarget tracking. Proc. IEEE 2018, 106, 221–259. [Google Scholar] [CrossRef]
- Gaglione, D.; Soldi, G.; Braca, P.; De Magistris, G.; Meyer, F.; Hlawatsch, F. Classification-aided multitarget tracking using the sum-product algorithm. IEEE Signal Process. Lett. 2020, 27, 1710–1714. [Google Scholar] [CrossRef]
- MATLAB. Version 9.9.0.1467703 (R2020b); MATLAB: Natick, MA, USA, 2020. [Google Scholar]
- Rahmathullah, A.S.; García-Fernández, Á.F.; Svensson, L. Generalized optimal sub-pattern assignment metric. In Proceedings of the 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–8. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Targets | ||||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| LSPA | 0.4571 | 0.9103 | 1.5033 | 1.9659 | 2.3441 | 2.9000 |
| DWLSPA | 0.4435 | 0.8787 | 1.5243 | 1.8601 | 2.2664 | 2.8253 |
| JPDA | 0.6751 | 2.5626 | 4.6425 | 6.1505 | 9.3851 | 11.5240 |
| DWPDA | 4.7454 | 9.1838 | 14.2879 | 18.5087 | 23.3401 | 27.4684 |
| LSPA | 1.4280 | 1.6058 | 1.4056 | 1.6628 | 1.7690 |
| DWLSPA | 1.3718 | 1.5652 | 1.3388 | 1.5289 | 1.6257 |
| JPDA | 3.5367 | 4.2030 | 4.3475 | 4.4828 | 5.2677 |
| DWPDA | 7.4128 | 11.8464 | 14.4591 | 15.0590 | 15.8318 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Damale, P.U.; Chong, E.K.P.; Ma, T.J. Performance Study of Distance-Weighting Approach with Loopy Sum-Product Algorithm for Multi-Object Tracking in Clutter. Sensors 2021, 21, 2544. https://doi.org/10.3390/s21072544
Damale PU, Chong EKP, Ma TJ. Performance Study of Distance-Weighting Approach with Loopy Sum-Product Algorithm for Multi-Object Tracking in Clutter. Sensors. 2021; 21(7):2544. https://doi.org/10.3390/s21072544
Chicago/Turabian StyleDamale, Pranav U., Edwin K. P. Chong, and Tian J. Ma. 2021. "Performance Study of Distance-Weighting Approach with Loopy Sum-Product Algorithm for Multi-Object Tracking in Clutter" Sensors 21, no. 7: 2544. https://doi.org/10.3390/s21072544
APA StyleDamale, P. U., Chong, E. K. P., & Ma, T. J. (2021). Performance Study of Distance-Weighting Approach with Loopy Sum-Product Algorithm for Multi-Object Tracking in Clutter. Sensors, 21(7), 2544. https://doi.org/10.3390/s21072544