
Smartwatch-Based Eating Detection: Data Selection for Machine Learning from Imbalanced Data with Imperfect Labels




Abstract
1. Introduction
- A novel ML approach for eating detection using smartwatch, which is robust enough to be used in the wild.
- The approach incorporates virtual sensor streams extracted from DL models that recognize food-intake gestures. This step enables us to transfer knowledge from data with precisely labelled food intake gestures to our dataset.
- To deal with unpredictable nature of data collected in the wild, the approach uses a novel two-step data selection procedure. The first step automatically cleans the eating class from non-eating instances. The second step selects representative non-eating instances that are difficult to distinguish and includes them in the training set.
- A publicly available annotated dataset recorded in the wild without any limitations about the performed activities, meals, or cutlery. The duration of the collected data is 481 h and 10 min and it is collected using off-the-shelf smartwatch providing 3-axis accelerometer and gyroscope.
- An extensive evaluation of the proposed method is carried out, including: (i) A step-by-step evaluation of each part proposed in the method; (ii) a comparison of the method with and without our proposed approach for data selection; (iii) a comparison between our approach and established methods for highly imbalanced problems; (iv) an analysis of the effects of training personalized models; (v) a comparison of the results obtained using feature sets from different combinations of modalities; (vi) an analysis of the results obtained using different types of cutlery for the recorded meals.
2. Related Work
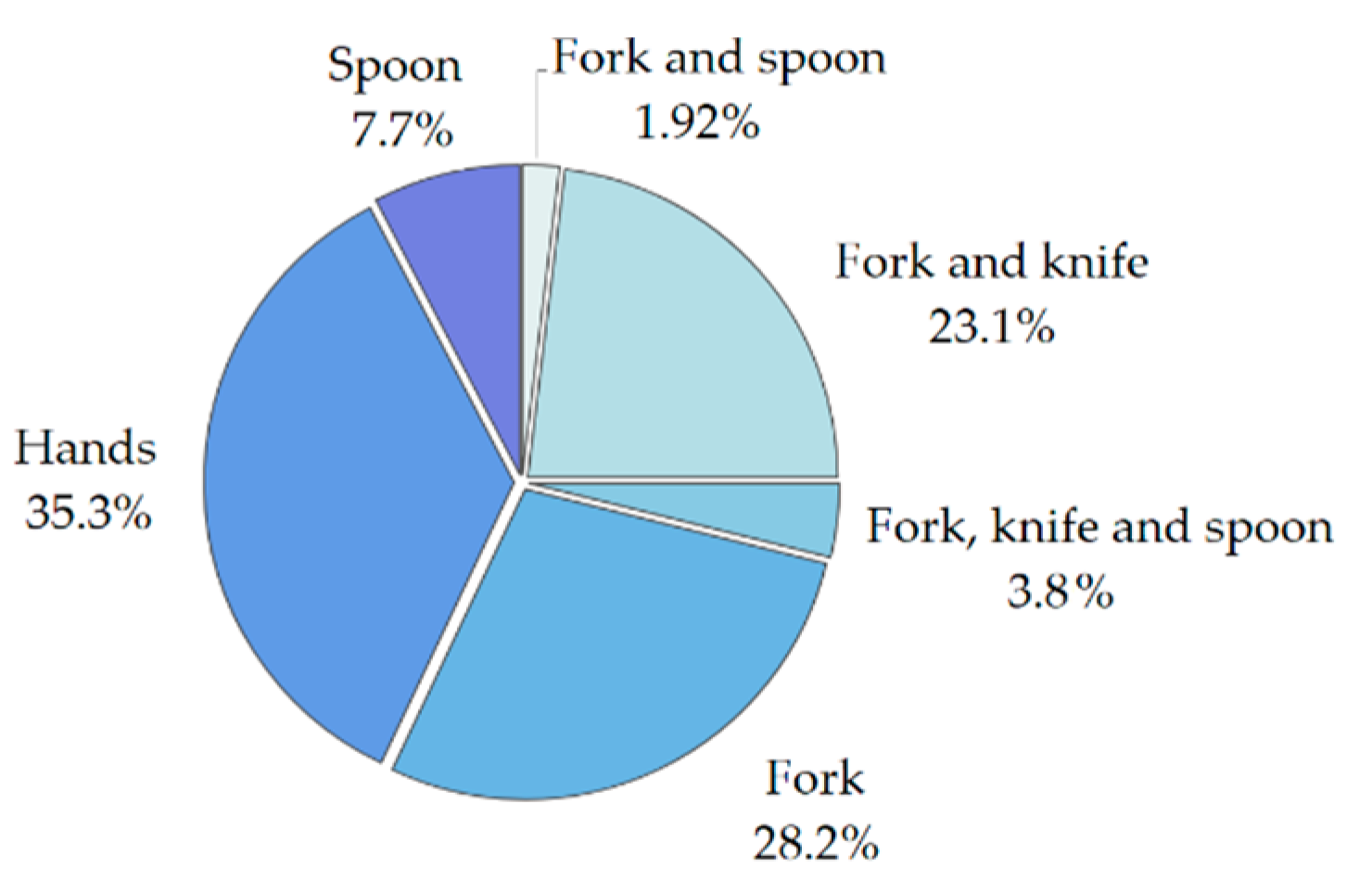
3. Dataset
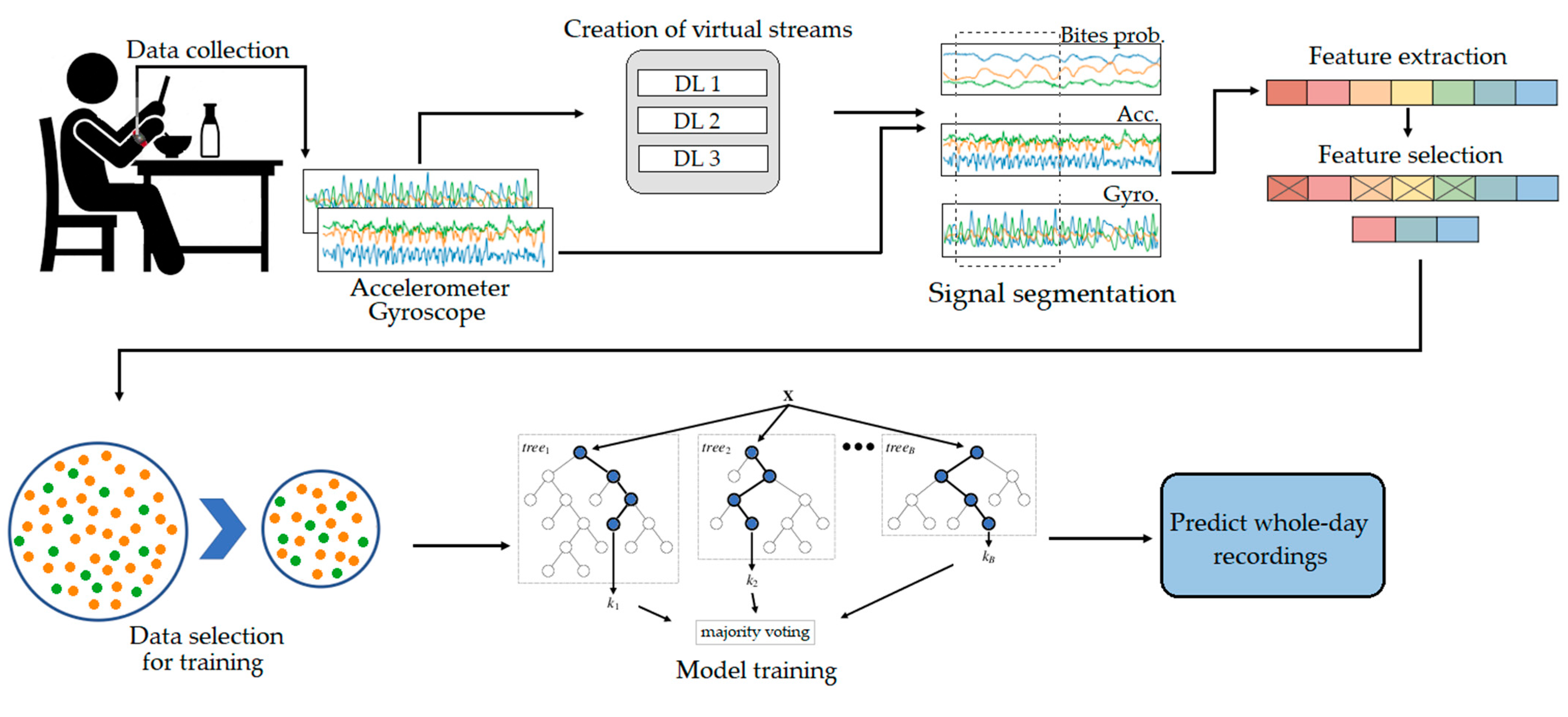
4. Eating Detection Approach
4.1. From Input Data to Features
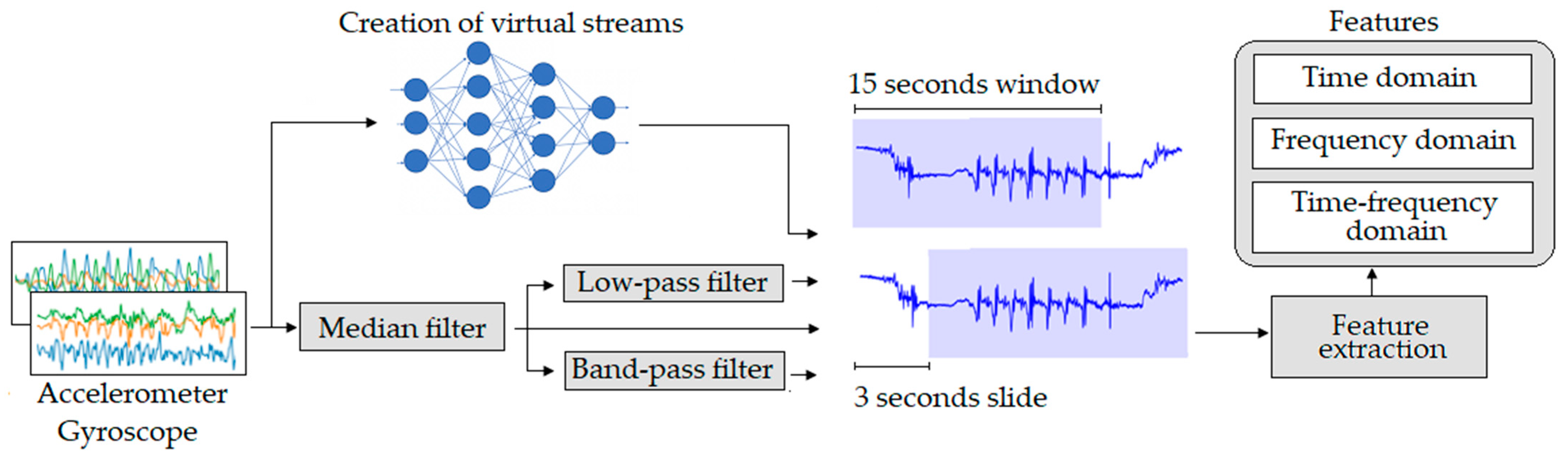
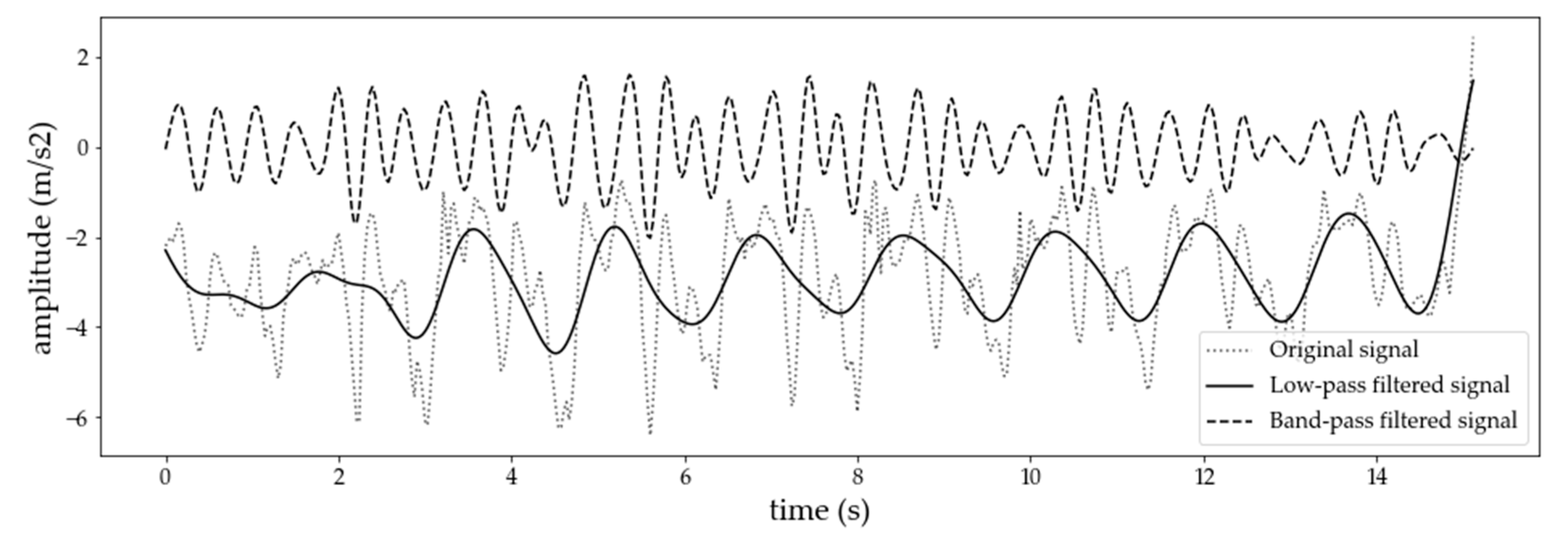
4.1.1. Data Preprocessing and Segmentation
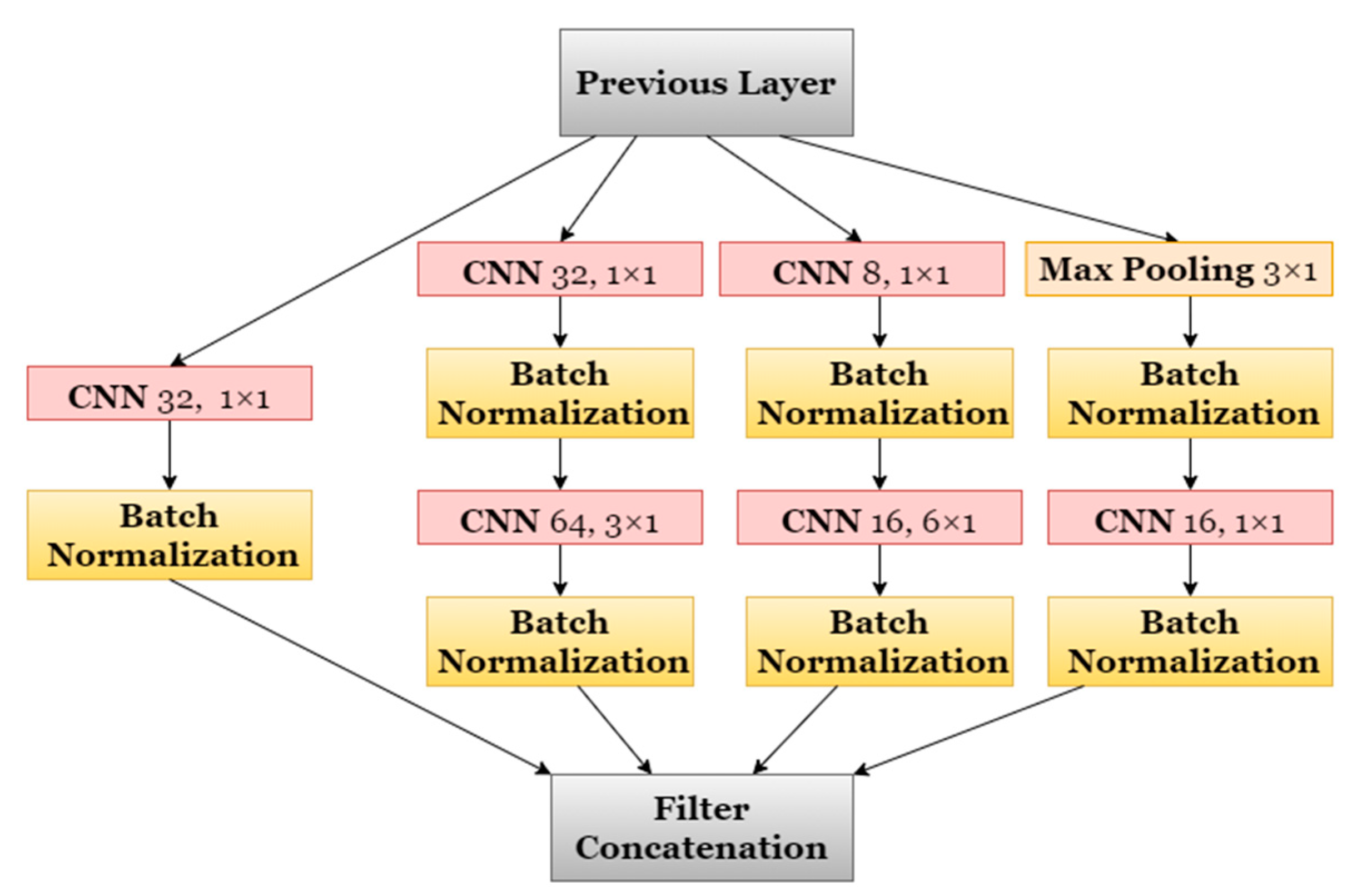
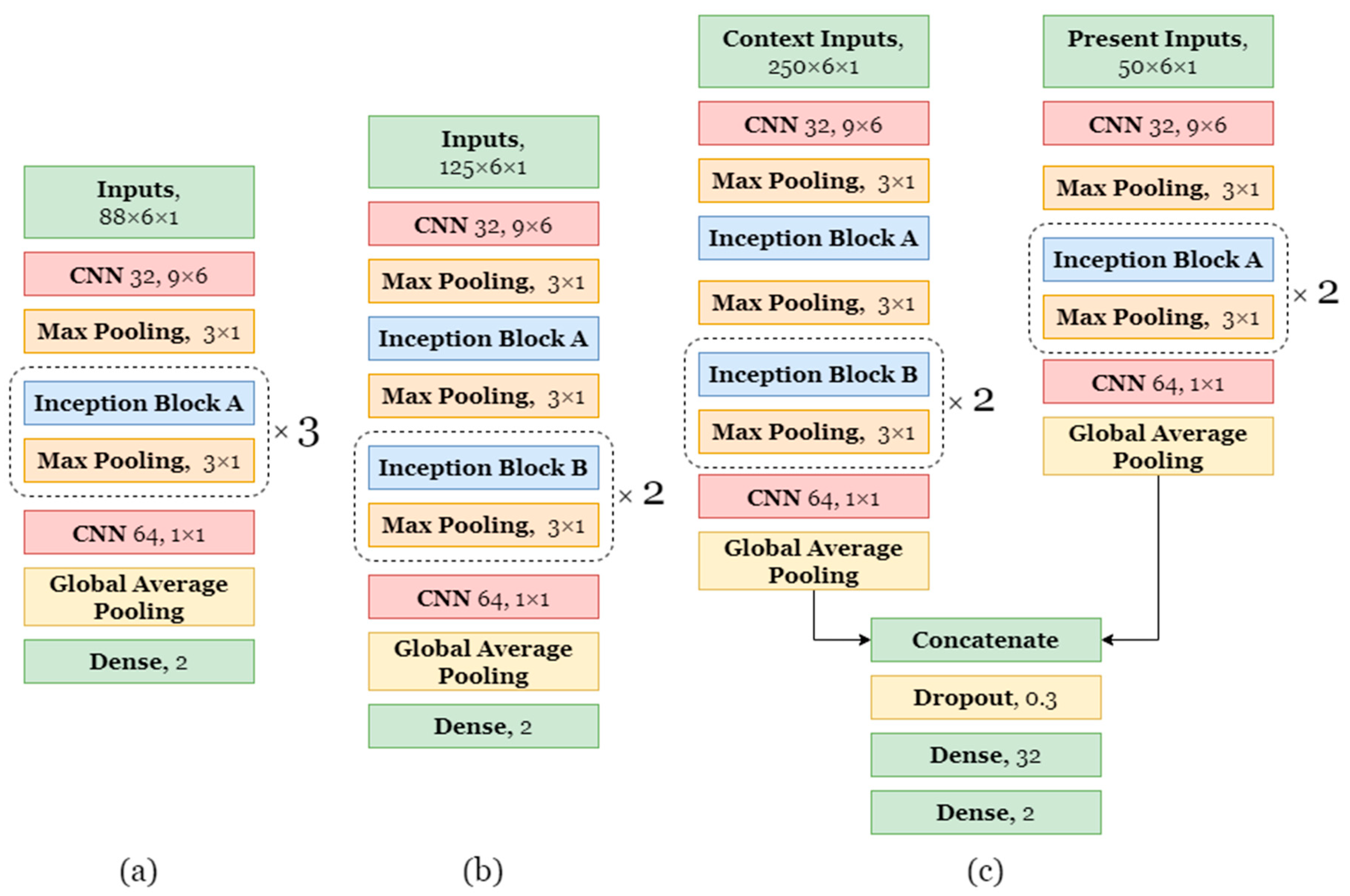
4.1.2. Virtual Sensor Stream Extraction Using DL Models for Detection of Food Intake
- Short architecture: Positivity threshold 0.36, negativity threshold 0.28, bite length bound threshold 5.5, negative ratio 5.
- Medium architecture: Positivity threshold 0.22, negativity threshold 0.28, bite length bound 6.5, negative ratio 5.
- Long architecture: Positivity threshold 0.30, negativity threshold 0.23, bite length bound 7, negative ratio 5.
4.1.3. Feature Extraction
4.1.4. Feature Selection
4.2. Data Selection and Training of the ML Models
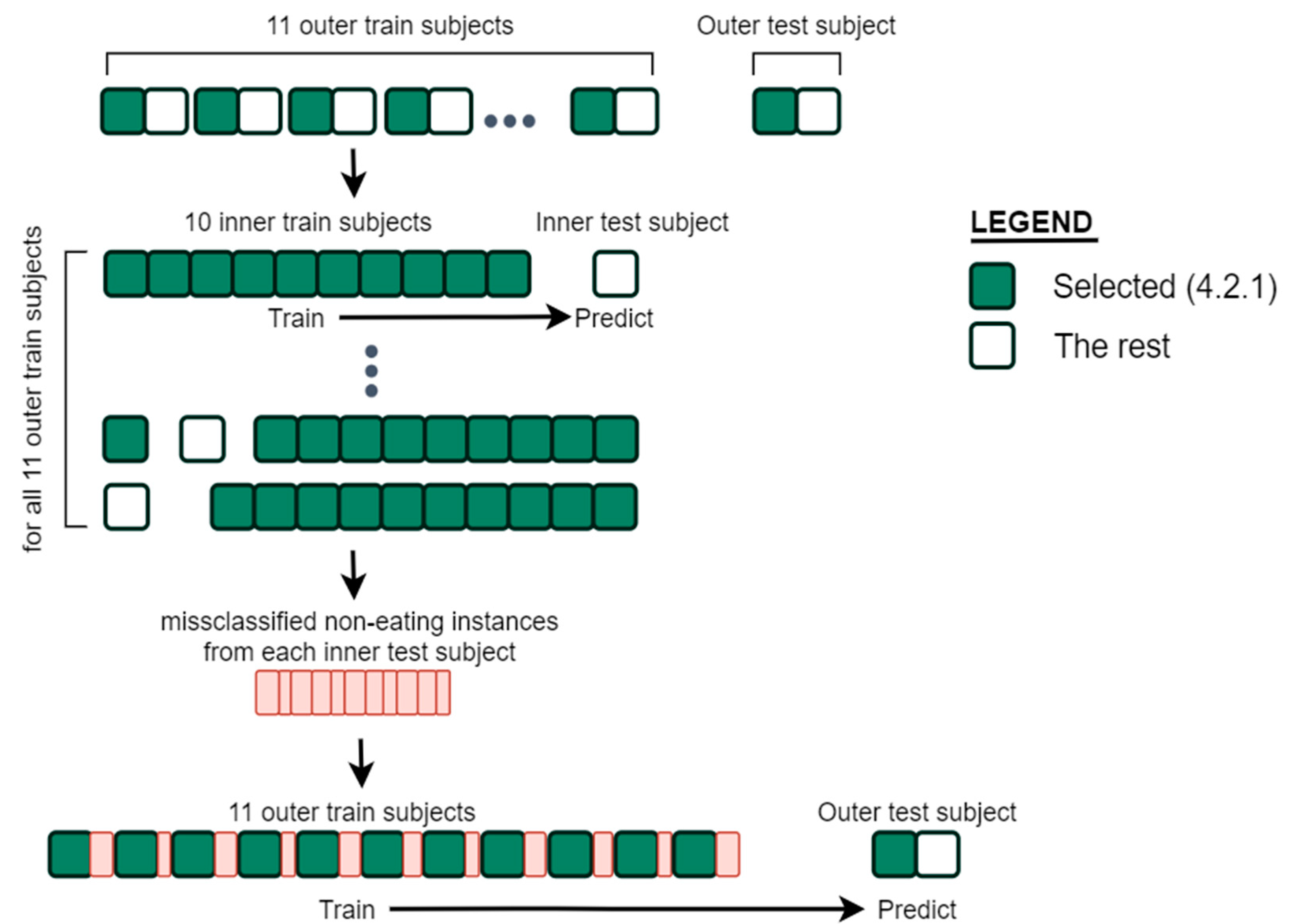
4.2.1. Data Selection Method
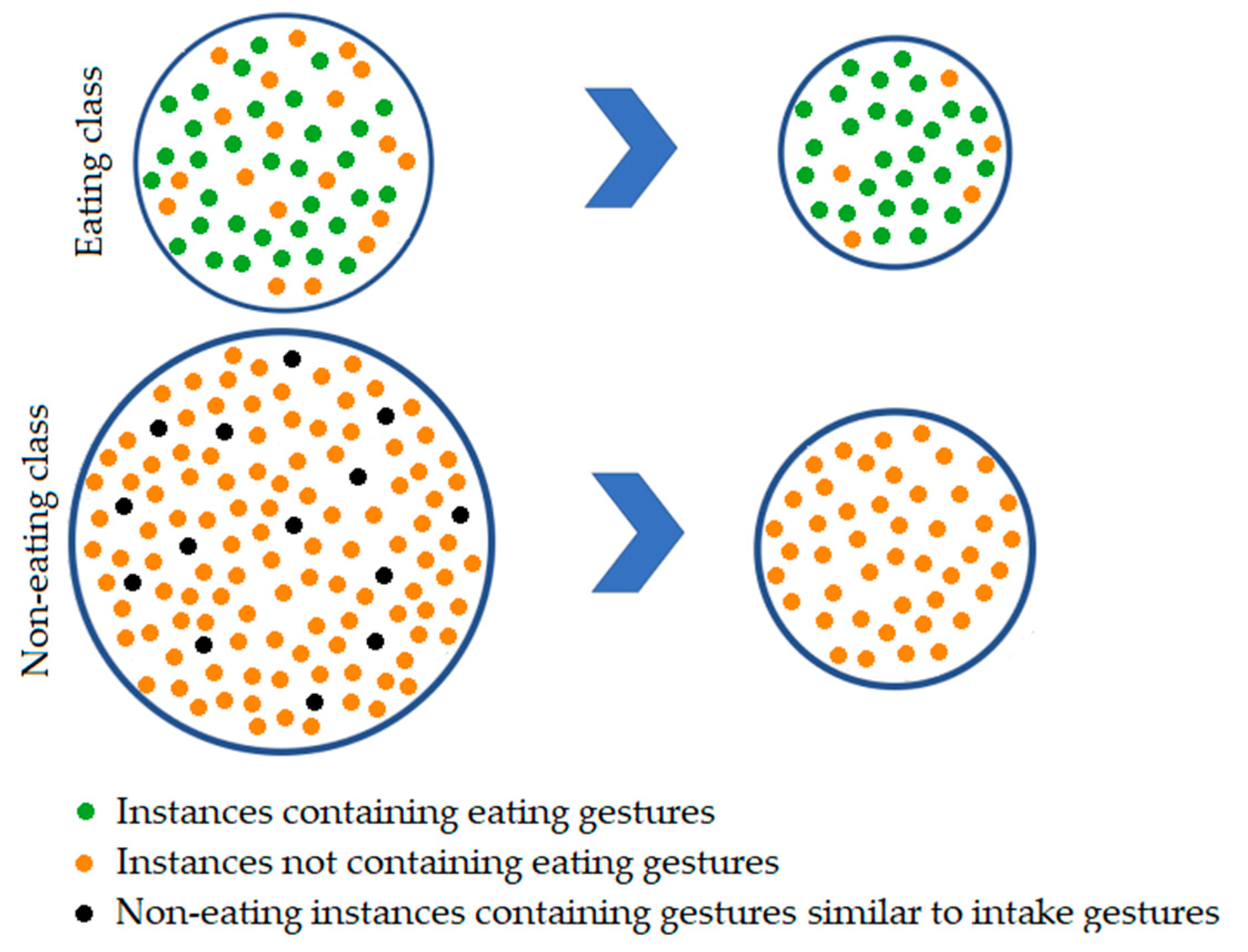
- The first step of the method cleans the non-eating segments. The idea is to eliminate those 10% of the instances that contain gestures that are similar to eating gestures. For this purpose, we used the EditedNearestNeighbors (ENN) method [72]. This method applies a nearest-neighbors algorithm and edits the dataset by removing the samples that do not agree enough with their neighborhood. For each sample in the non-eating class, the N nearest neighbors are computed using Euclidian distance, and if the selection criterion is not fulfilled, the sample is removed. The number of the nearest neighbors that are considered for the selection criterion is 5. The definition of the selection criterion requires that all nearest neighbors have to belong to the opposite class (eating) to drop the inspected sample from the non-eating class. The non-eating samples that do not contain gestures that are similar to eating gestures should not be greatly affected by the used selection criterion. Even though this assumption is a bit weak, the main reason that we rely on it is that the non-eating class is more numerous compared to the eating class, and excluding some non-eating samples, even if they are not very similar to eating samples, is not a problem.
- After the first step of the undersampling technique, we expect that the non-eating class is comprised of instances that contain gestures that are not similar to eating gestures. The idea for the second step is to exclude instances from the eating class that do not contain eating gestures. For this purpose, we clean the eating class. Similar to the previous step, we again used ENN, with a small difference regarding the number of neighbors and the selection criterion. Here, we worked with the 7 nearest neighbors, and the majority vote of the neighbors is used to exclude a sample from the eating class. Due to the large number of non-eating samples that contain gestures that are not similar to eating, using the majority vote criterion most of the samples from the eating class that also do not contain gestures related to eating will be outvoted. Consequently, the eating class should mainly consist of samples that contain eating related gestures.
- The last step of the data selection procedure is to create balanced training dataset. Usually, training a classifier on dataset with unbalanced classes results in poor performance. Therefore, for each daily recording, we undersampled the non-eating class, resulting in 60% non-eating and 40% eating instances. This was done using uniform undersampling of the non-eating class. By keeping more non-eating data, we intended to include more heterogeneous non-eating activities in the training set.
4.2.2. Two-Stage Model Training
5. Experimental Setup
- The TP value shows the number of windows from the eating class correctly classified as eating.
- The FP value shows the number of windows from the non-eating class classified as eating.
- The FN value shows the number of windows from the eating class classified as non-eating class.
6. Experimental Results
6.1. Analysis of the DL Models for Food Intake Detection
6.2. Step-by-Step Evaluation of the Proposed Method
- First step: The first row shows the results obtained using only balanced dataset for the training, without post-processing of the predictions. For those experiments where the data selection step is not used, only the classes are balanced. On the other hand, when data selection is used, as described in Section 4.2.1, the eating segments are undersampled and then we balance the eating and non-eating classes. The results show that the precision for both approaches, with and without the data selection step, is relatively low. This indicates that the method cannot accurately distinguish between activities similar to eating. However, the precision of the approach without data selection is higher compared to the approach where we used data selection. When the data selection step is used the non-eating instances that contain gestures similar to eating are excluded from the training and as a result the models detect them as eating instances.
- First step + HMM: The second row of the table shows the results after smoothing the predictions made in the first stage. Here, both the precision and the recall are significantly improved for both approaches. However, the precision value is again relatively low, indicating that further improvements are needed. The improvement in precision introduced by the smoothing suggests that probably only the short bursts of false positive predictions have been removed. Hence, we developed the second step training, which we expected to deal with this problem.
- Second step: The third row presents the results achieved with our proposed method in Section 4.2.2, excluding the post-processing part performed with HMM. Here our approach uses additional misclassified non-eating instances for training. As a result of this step, we can see that when using data selection, we get an improvement of 0.43 in precision, while the recall decreases by only 0.18. The results show that the second step solves the problem we have in the first step where many false positives are produced. Even though the recall value in the second step is lower when data selection is used, the f1-score, which is interpreted as a weighted average of precision and recall, shows that our method with the data selection step outperforms the same method without the data selection step by 0.03. The explanation for lower recall is that the models do not overfit to the eating class and only those parts of the meal that are related to eating are detected.
- Second step + HMM: The last row shows the results obtained after smoothing the predictions made in the second step. Again, the smoothing improved the results remarkably. For the approach where data selection was used, we can see that the precision is improved by 0.43 if we compare it with the second row of the table, while the recall only decreased by 0.07. This suggests that selecting and training on non-eating instances that are problematic for classification can significantly reduce the number of false-positive predictions, at the expense of a 0.07 reduction in recall, which we find acceptable. Furthermore, the comparison of the f1-score between the approach including data selection and the approach without data selection shows that the former is better by 0.07.
6.3. Comparison to Related Methods for Imbalanced Problems
6.4. Method’s Performance Using Feature Sets from Different Modalities
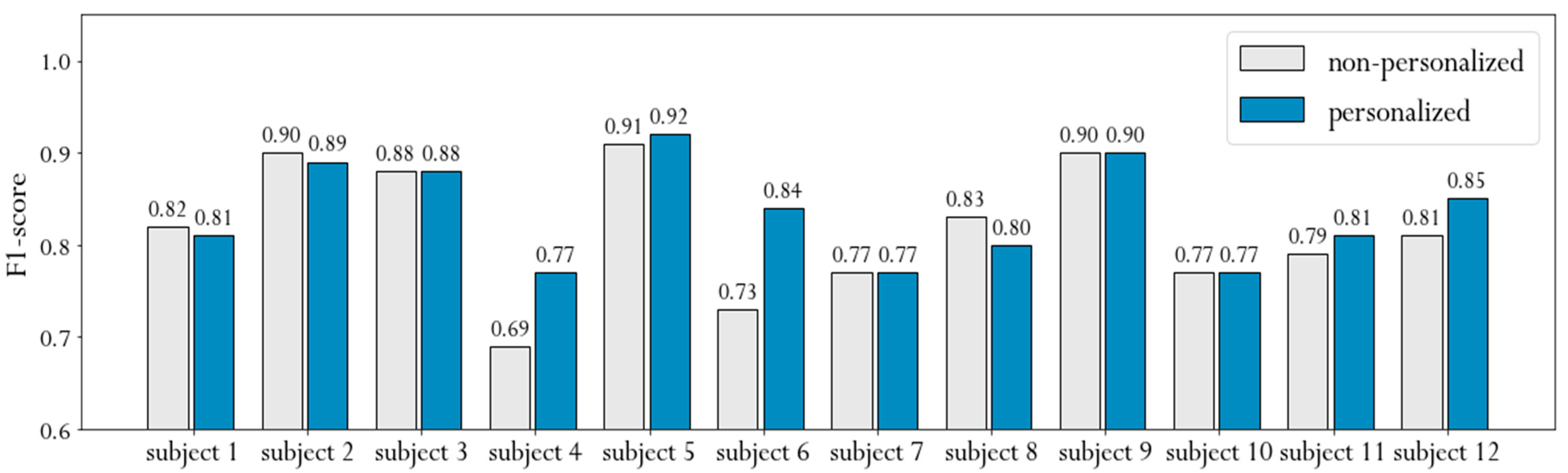
6.5. Personalized Models
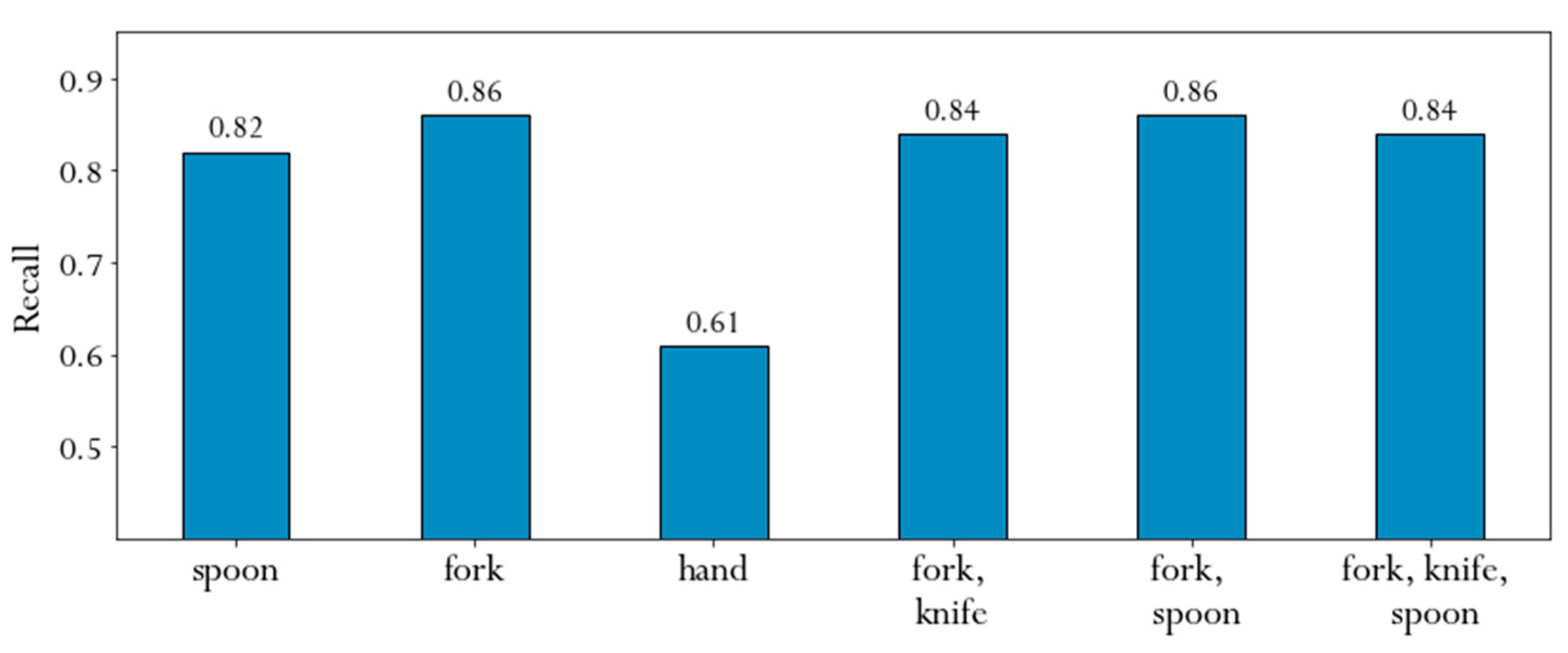
6.6. Method’s Performance by Cutlery Type
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. World Health Statistics–Monitoring Health for the Sdgs; WHO: Geneva, Switzerland, 2016. [Google Scholar]
- TEAM, Lifestyles Statistics. Health and Social Care Information Centre, Statistics on Obesity; Physical Activity and Diet: London, UK, 2015. [Google Scholar]
- GBD 2017 Diet Collaborators. Health effects of dietary risks in 195 countries, 1990–2017: A systematic analysis for the Global Burden of Disease Study. Lancet 2019, 393, 1958–1972. [Google Scholar] [CrossRef]
- Silva, P.; Kergoat, M.J.; Shatenstein, B. Challenges in managing the diet of older adults with early-stage Alzheimer dementia: A caregiver perspective. J. Nutr. Health Aging 2012, 17, 142–147. [Google Scholar] [CrossRef]
- Husain, I.; Spence, D. Can healthy people benefit from health apps? BMJ 2015, 350, h1887. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Karvetti, R.L.; Knuts, L.R. Validity of the 24-hour dietary recall. J. Am. Diet. Assoc. 1985, 85, 1437–1442. [Google Scholar]
- Shim, J.S.; Oh, K.; Kim, H.C. Dietary assessment methods in epidemiologic studies. Epidemiol. Health 2014, 36, 4009. [Google Scholar] [CrossRef] [PubMed]
- Magarey, A.; Watson, J.; Golley, R.K.; Burrows, T.; Sutherland, R.; McNaughton, S.A.; Wilson, D.E.; Campbell, K.; Collins, C.E. Assessing dietary intake in children and adolescents: Considerations and recommendations for obesity research. Pediatric Obes. 2011, 6, 2–11. [Google Scholar] [CrossRef] [PubMed]
- Schoeller, D.A. Limitations in the assessment of dietary energy intake by self-report. Metabolism 1995, 44, 18–22. [Google Scholar] [CrossRef]
- Thompson, F.E.; Subar, A.F.; Loria, C.M.; Reedy, J.L.; Baranowski, T. Need for Technological Innovation in Dietary Assessment. J. Am. Diet. Assoc. 2010, 110, 48–51. [Google Scholar] [CrossRef]
- Amft, O.; Junker, H.; Tröster, G. Detection of eating and drinking arm gestures using inertial body-worn sensors. In Proceedings of the Ninth IEEE International Symposium on Wearable Computers (ISWC’05), Osaka, Japan, 18–21 October 2005. [Google Scholar]
- Amft, O. A wearable earpad sensor for chewing monitoring. In Proceedings of the 2010 IEEE Sensors, Waikoloa, HI, USA, 1–4 November 2010; pp. 222–227. [Google Scholar]
- Farooq, M.; Sazonov, E. Detection of chewing from piezoelectric film sensor signals using ensemble classifiers. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 4929–4932. [Google Scholar]
- Kohyama, K.; Nakayama, Y.; Yamaguchi, I.; Yamaguchi, M.; Hayakawa, F.; Sasaki, T. Mastication efforts on block and finely cut foods studied by electromyography. Food Qual. Prefer. 2007, 18, 313–320. [Google Scholar] [CrossRef]
- Zhu, F.; Bosch, M.; Boushey, C.J.; Delp, E.J. An image analysis system for dietary assessment and evaluation. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1853–1856. [Google Scholar]
- Sun, M.; Burke, L.E.; Mao, Z.H.; Chen, Y.; Chen, H.C.; Bai, Y.; Li, Y.; Li, C.; Jia, W. Ebutton: A wearable computer for health monitoring and personal assistance. In Proceedings of the Design Automation Conference, San Francisco, CA, USA, 1–5 June 2014. [Google Scholar]
- Sazonov, E.; Schuckers, S.; Meyer, L.P.; Makeyev, O.; Sazonova, N.; Melanson, E.L.; Neuman, M. Non-invasive monitoring of chewing and swallowing for objective quantification of ingestive behavior. Physiol. Meas. 2008, 29, 525–541. [Google Scholar] [CrossRef]
- Bedri, A.; Li, R.; Haynes, M.; Kosaraju, R.P.; Grover, I.; Prioleau, T.; Beh, M.Y.; Goel, M.; Starner, T.; Abowd, G.D. EarBit. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, New York, NY, USA, 1 September 2017; Volume 1, pp. 1–20. [Google Scholar]
- Gao, Y.; Zhang, N.; Wang, H.; Ding, X.; Ye, X.; Chen, G.; Cao, Y. iHear Food: Eating Detection Using Commodity Bluetooth Headsets. In Proceedings of the 2016 IEEE First International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Washington, DC, USA, 27–29 June 2016; pp. 163–172. [Google Scholar]
- Zhang, S.; Alharbi, R.; Stogin, W.; Pourhomayoun, M.; Pfammatter, A.; Spring, B.; Alshurafa, N. Food Watch: Detecting and Characterizing Eating Episodes through Feeding Gestures. In Proceedings of the 11th International Conference on Body Area Networks, European Alliance for Innovation, Turin, Italy, 15–16 December 2017. [Google Scholar]
- Zhang, S.; Stogin, W.; Alshurafa, N. I sense overeating: Motif-based machine learning framework to detect overeating using wrist-worn sensing. Inf. Fusion 2018, 41, 37–47. [Google Scholar] [CrossRef]
- Thomaz, E.; Essa, I.; Abowd, G.D. A practical approach for recognizing eating moments with wrist-mounted inertial sensing. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2015 ACM International Symposium on Wearable Computers-UbiComp’15, Osaka, Japan, 7–11 September 2015; Volume 2015, pp. 1029–1040. [Google Scholar]
- Amft, O.; Stäger, M.; Lukowicz, P.; Tröster, G. Analysis of Chewing Sounds for Dietary Monitoring. In Computer Vision; Springer International Publishing: New York, NY, USA, 2005; Volume 3660, pp. 56–72. [Google Scholar]
- Yatani, K.; Truong, K.N. BodyScope: A wearable acoustic sensor for activity recognition. In Proceedings of the UbiComp’12–2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012. [Google Scholar]
- Woda, A.; Mishellany, A.; Peyron, M.A. The regulation of masticatory function and food bolus formation. J. Oral Rehabil. 2006, 33, 840–849. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Amft, O. Monitoring Chewing and Eating in Free-Living Using Smart Eyeglasses. IEEE J. Biomed. Health Inform. 2018, 22, 23–32. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Jia, W.; Mao, Z.H.; Sun, M. Automatic eating detection using a proximity sensor. In Proceedings of the 2014 40th Annual Northeast Bioengineering Conference (NEBEC), Boston, MA, USA, 25–27 April 2014; pp. 1–2. [Google Scholar]
- Bedri, A.; Verlekar, A.; Thomaz, E.; Avva, V.; Starner, T. A wearable system for detecting eating activities with proximity sensors in the outer ear. In Proceedings of the 2015 ACM International Symposium on Wearable Computers–ISWC’15, Osaka, Japan, 7–11 September 2015. [Google Scholar]
- Zhang, S.; Zhao, Y.; Nguyen, D.T.; Xu, R.; Sen, S.; Hester, J.; Alshurafa, N. NeckSense. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Farooq, M.; Sazonov, E. Accelerometer-Based Detection of Food Intake in Free-Living Individuals. IEEE Sens. J. 2018, 18, 3752–3758. [Google Scholar] [CrossRef]
- Kyritsis, K.; Diou, C.; Delopoulos, A. Detecting Meals in the Wild Using the Inertial Data of a Typical Smartwatch. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 4229–4232. [Google Scholar]
- Choe, M.J.; Noh, G.Y. Technology Acceptance of the Smartwatch: Health Consciousness, Self-Efficacy, Innovativeness. Adv. Sci. Lett. 2017, 23, 10152–10155. [Google Scholar] [CrossRef]
- Garcia, R.R.I.; Muth, E.R.; Gowdy, J.N.; Hoover, A.W. Improving the Recognition of Eating Gestures Using Intergesture Sequential Dependencies. IEEE J. Biomed. Health Inform. 2014, 19, 825–831. [Google Scholar] [CrossRef]
- Kim, H.J.; Choi, Y.S. Eating activity recognition for health and wellness: A case study on Asian eating style. In Proceedings of the 2013 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2013; pp. 446–447. [Google Scholar]
- Dong, Y.; Hoover, A.; Muth, E. A Device for Detecting and Counting Bites of Food Taken by a Person during Eating. In Proceedings of the 2009 IEEE International Conference on Bioinformatics and Biomedicine, Washington, DC, USA, 1–4 November 2009; pp. 265–268. [Google Scholar]
- Kim, J.; Lee, M.; Lee, K.J.; Lee, T.; Bae, B.C.; Cho, J.D. An eating speed guide system using a wristband and tabletop unit. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 121–124. [Google Scholar]
- Shen, Y.; Salley, J.; Muth, E.; Hoover, A. Assessing the Accuracy of a Wrist Motion Tracking Method for Counting Bites Across Demographic and Food Variables. IEEE J. Biomed. Health Inform. 2017, 21, 599–606. [Google Scholar] [CrossRef]
- Maramis, C.; Kilintzis, V.; Maglaveras, N. Real-time Bite Detection from Smartwatch Orientation Sensor Data. In Proceedings of the 9th Hellenic Conference on Artificial Intelligence, Thessaloniki, Greece, 18–20 May 2016; pp. 1–4. [Google Scholar]
- Shen, Y.; Muth, E.; Hoover, A. Recognizing Eating Gestures Using Context Dependent Hidden Markov Models. In Proceedings of the 2016 IEEE First International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Washington, DC, USA, 27–29 June 2016; pp. 248–253. [Google Scholar]
- Garcia, R.R.I.; Hoover, A.W. A Study of Temporal Action Sequencing During Consumption of a Meal. In Proceedings of the International Conference on Big Data and Internet of Thing–BDIOT2017, London, UK, 20–22 December 2013; p. 68. [Google Scholar]
- Zhou, Y.; Cheng, Z.; Jing, L.; Hasegawa, T. Towards unobtrusive detection and realistic attribute analysis of daily activity sequences using a finger-worn device. Appl. Intell. 2015, 43, 386–396. [Google Scholar] [CrossRef]
- Sánchez, P.S.; González, G.J.M.; Ortega, I.A.Q.; Novelo, M.B.; García, D.J.; Cruz, M.C.; González, V.A. Recognition of activities of daily living based on the vertical displacement of the wrist. Med. Phys. Fourteenth Mex. Symp. Med. Phys. 2016, 1747, 5. [Google Scholar] [CrossRef]
- Yoneda, K.; Weiss, G.M. Mobile sensor-based biometrics using common daily activities. In Proceedings of the 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, USA, 19–21 October 2017; pp. 584–590. [Google Scholar]
- Bi, C.; Xing, G.; Hao, T.; Huh, J.; Peng, W.; Ma, M. FamilyLog: A Mobile System for Monitoring Family Mealtime Activities. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications, IEEE International Conference on Pervasive Computing and Communications, Kona, HI, USA, 13–17 March 2017; Volume 2017, pp. 21–30. [Google Scholar]
- Kyritsis, K.; Tatli, C.L.; Diou, C.; Delopoulos, A. Automated analysis of in meal eating behavior using a commercial wrist-band IMU sensor. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Jeju, Korea, 11–15 July 2017. [Google Scholar]
- Varkey, J.P.; Pompili, D.; Walls, T.A. Human motion recognition using a wireless sensor-based wearable system. Pers. Ubiquitous Comput. 2011, 16, 897–910. [Google Scholar] [CrossRef]
- Ye, X.; Chen, G.; Cao, Y. Automatic Eating Detection using head-mount and wrist-worn accelerometers. In Proceedings of the 2015 17th International Conference on E-health Networking, Application & Services (HealthCom), Boston, MA, USA, 14–17 October 2015; pp. 578–581. [Google Scholar]
- Schibon, G.; Amft, O. Saving energy on wrist-mounted inertial sensors by motion-adaptive duty-cycling in free-living. In Proceedings of the 2018 IEEE 15th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Las Vegas, NV, USA, 4–7 March 2018; pp. 197–200. [Google Scholar]
- Rahman, T.; Czerwinski, M.; Bachrach, G.R.; Johns, P. Predicting “about-To-eat” moments for just-in-Time eating in-tervention. In Proceedings of the DH 2016 Digital Health Conference, Montreal, QC, Canada, 11–13 April 2016. [Google Scholar]
- Fontana, J.M.; Farooq, M.; Sazonov, E. Estimation of feature importance for food intake detection based on Random Forests classification. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; Volume 2013, pp. 6756–6759. [Google Scholar]
- Mirtchouk, M.; Merck, C.; Kleinberg, S. Automated estimation of food type and amount consumed from body-worn audio and motion sensors. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September; pp. 451–462.
- Dong, B.; Biswas, S. Meal-time and duration monitoring using wearable sensors. Biomed. Signal Process. Control 2017, 32, 97–109. [Google Scholar] [CrossRef]
- Bi, S.; Wang, T.; Davenport, E.; Peterson, R.; Halter, R.; Sorber, J.; Kotz, D. Toward a Wearable Sensor for Eating Detection. In Proceedings of the 2017 Workshop on Moving Target Defense, Dallas, TX, USA, 1–3 November 2017; pp. 17–22. [Google Scholar]
- Zhang, S.; Alharbi, R.; Nicholson, M.; Alshurafa, N. When generalized eating detection machine learning models fail in the field. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 13–15 September 2017; pp. 613–622. [Google Scholar]
- Bell, B.M.; Alam, R.; Alshurafa, N.; Thomaz, E.; Mondol, A.S.; De La Haye, K.; Stankovic, J.A.; Lach, J.; Spruijt-Metz, D. Automatic, wearable-based, in-field eating detection approaches for public health research: A scoping review. NPJ Digit. Med. 2020, 3, 1–14. [Google Scholar] [CrossRef]
- Navarathna, P.; Bequette, B.W.; Cameron, F. Wearable Device Based Activity Recognition and Prediction for Improved Feedforward Control. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018. [Google Scholar]
- Kyritsis, K.; Diou, C.; Delopoulos, A. End-to-end Learning for Measuring in-meal Eating Behavior from a Smartwatch. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; Volume 2018, pp. 5511–5514. [Google Scholar] [CrossRef]
- Dong, Y.; Scisco, J.; Wilson, M.; Muth, E.; Hoover, A. Detecting Periods of Eating During Free-Living by Tracking Wrist Motion. IEEE J. Biomed. Health Inform. 2013, 18, 1253–1260. [Google Scholar] [CrossRef] [PubMed]
- Kyritsis, K.; Diou, C.; Delopoulos, A. A Data Driven End-to-End Approach for In-the-Wild Monitoring of Eating Behavior Using Smartwatches. IEEE J. Biomed. Health Inform. 2021, 25, 22–34. [Google Scholar] [CrossRef] [PubMed]
- Stankoski, S.; Rescic, N. Real-Time Eating Detection Using a Smartwatch Lags; EWSN: Lyon, France, 2020; pp. 247–252. [Google Scholar]
- Gjoreski, M.; Janko, V.; Slapničar, G.; Mlakar, M.; Reščič, N.; Bizjak, J.; Drobnič, V.; Marinko, M.; Mlakar, N.; Luštrek, M.; et al. Classical and deep learning methods for recognizing human activities and modes of transportation with smartphone sensors. Inf. Fusion 2020, 62, 47–62. [Google Scholar] [CrossRef]
- Leng, L.; Zhang, J.; Khan, M.K.; Chen, X.; Alghathbar, K. Dynamic weighted discrimination power analysis: A novel approach for face and palmprint recognition in DCT domain. In Proceedings of the 2010 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 17–19 November 2010. [Google Scholar]
- Selamat, N.A.; Ali, S.H.M. Automatic Food Intake Monitoring Based on Chewing Activity: A Survey. IEEE Access 2020, 8, 48846–48869. [Google Scholar] [CrossRef]
- Kyritsis, K.; Diou, C.; Delopoulos, A. Modeling Wrist Micromovements to Measure In-Meal Eating Behavior From Inertial Sensor Data. IEEE J. Biomed. Health Inform. 2019, 23, 2325–2334. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML); Fürnkranz, J., Joachims, T., Eds.; Omnipress: Haifa, Israel, 2010; pp. 807–814. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D.D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the 30th International Conference on Machine Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 2013. [Google Scholar]
- Gjoreski, H.; Kiprijanovska, I.; Stankoski, S.; Kalabakov, S.; Broulidakis, J.; Nduka, C.; Gjoreski, M. Head-AR: Human Ac-tivity Recognition with Head-Mounted IMU Using Weighted Ensemble Learning. In Activity and Behavior Computing; Springer: Singapore, 2021; pp. 153–167. [Google Scholar]
- Rioul, O.; Duhamel, P. Fast algorithms for discrete and continuous wavelet transforms. IEEE Trans. Inf. Theory 1992, 38, 569–586. [Google Scholar] [CrossRef]
- Li, K.; Yu, M.; Liu, L.; Li, T.; Zhai, J. Feature Selection Method Based on Weighted Mutual Information for Imbalanced Data. Int. J. Softw. Eng. Knowl. Eng. 2018, 28, 1177–1194. [Google Scholar] [CrossRef]
- Wilson, D.L. Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Trans. Syst. Man Cybern. 1972, SMC-2, 408–421. [Google Scholar] [CrossRef]
- Forney, G.D. The viterbi algorithm. Inst. Electr. Electron. Eng. 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Chen, C.; Liaw, A.; Breiman, L. Using Random Forest to Learn Imbalanced Data; Department of Statistics: Berkeley, CA, USA, 2004.
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory Undersampling for Class-Imbalance Learning. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2009, 39, 539–550. [Google Scholar] [CrossRef]
- Hido, S.; Kashima, H.; Takahashi, Y. Roughly balanced bagging for imbalanced data. Stat. Anal. Data Min. ASA Data Sci. J. 2009, 2, 412–426. [Google Scholar] [CrossRef]
- Wongpatikaseree, K.; Ikeda, M.; Buranarach, M.; Supnithi, T.; Lim, A.O.; Tan, Y. Activity Recognition Using Context-Aware Infrastructure Ontology in Smart Home Domain. In Proceedings of the 2012 Seventh International Conference on Knowledge, Information and Creativity Support Systems, Melbourne, Australia, 8–10 November 2012; pp. 50–57. [Google Scholar]
- Leng, L.; Li, M.; Kim, C.; Bi, X. Dual-source discrimination power analysis for multi-instance contactless palmprint recognition. Multimed. Tools Appl. 2017, 76, 333–354. [Google Scholar] [CrossRef]
- Gravina, R.; Alinia, P.; Ghasemzadeh, H.; Fortino, G. Multi-sensor fusion in body sensor networks: State-of-the-art and research challenges. Inf. Fusion 2017, 35, 68–80. [Google Scholar] [CrossRef]
- Stankoski, S.; Lustrek, M. Energy-Efficient Eating Detection Using a Wristband. In Proceedings of the 23th International Multiconference Information Society, Ljubljana, Slovenia, 5–9 October 2020. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FIC Dataset | ISense Dataset | |||||
|---|---|---|---|---|---|---|
| Method | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| Short architecture | 0.73 | 0.82 | 0.77 | 0.68 | 0.78 | 0.72 |
| Medium architecture | 0.75 | 0.77 | 0.75 | 0.73 | 0.78 | 0.75 |
| Long architecture | 0.75 | 0.8 | 0.76 | 0.67 | 0.72 | 0.69 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| Short architecture + HMM | 0.66 | 0.61 | 0.64 |
| Medium architecture + HMM | 0.69 | 0.66 | 0.67 |
| Long architecture + HMM | 0.75 | 0.56 | 0.63 |
| Method | Without Data Selection | With Data Selection | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| 1st step | 0.47 | 0.79 | 0.57 | 0.33 | 0.82 | 0.46 |
| 1st step + HMM | 0.52 | 0.85 | 0.64 | 0.42 | 0.88 | 0.55 |
| 2nd step | 0.61 | 0.74 | 0.65 | 0.76 | 0.65 | 0.68 |
| 2nd step + HMM | 0.7 | 0.85 | 0.75 | 0.85 | 0.81 | 0.82 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| BRF [74] + HMM | 0.41 | 0.9 | 0.54 |
| BB [75] + HMM | 0.52 | 0.89 | 0.64 |
| EE [76] + HMM | 0.38 | 0.92 | 0.53 |
| Ours | 0.85 | 0.81 | 0.82 |
| Metrics | Modality Combination | ||||||
|---|---|---|---|---|---|---|---|
| A | G | D | AG | AD | GD | AGD | |
| Precision | 0.72 | 0.77 | 0.78 | 0.79 | 0.82 | 0.84 | 0.85 |
| Recall | 0.79 | 0.74 | 0.68 | 0.8 | 0.8 | 0.77 | 0.81 |
| F1-score | 0.73 | 0.73 | 0.72 | 0.79 | 0.8 | 0.79 | 0.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stankoski, S.; Jordan, M.; Gjoreski, H.; Luštrek, M. Smartwatch-Based Eating Detection: Data Selection for Machine Learning from Imbalanced Data with Imperfect Labels. Sensors 2021, 21, 1902. https://doi.org/10.3390/s21051902
Stankoski S, Jordan M, Gjoreski H, Luštrek M. Smartwatch-Based Eating Detection: Data Selection for Machine Learning from Imbalanced Data with Imperfect Labels. Sensors. 2021; 21(5):1902. https://doi.org/10.3390/s21051902
Chicago/Turabian StyleStankoski, Simon, Marko Jordan, Hristijan Gjoreski, and Mitja Luštrek. 2021. "Smartwatch-Based Eating Detection: Data Selection for Machine Learning from Imbalanced Data with Imperfect Labels" Sensors 21, no. 5: 1902. https://doi.org/10.3390/s21051902
APA StyleStankoski, S., Jordan, M., Gjoreski, H., & Luštrek, M. (2021). Smartwatch-Based Eating Detection: Data Selection for Machine Learning from Imbalanced Data with Imperfect Labels. Sensors, 21(5), 1902. https://doi.org/10.3390/s21051902