Abstract
This work proposes a new approach to improve swarm intelligence algorithms for dynamic optimization problems by promoting a balance between the transfer of knowledge and the diversity of particles. The proposed method was designed to be applied to the problem of video tracking targets in environments with almost constant lighting. This approach also delimits the solution space for a more efficient search. A robust version to outliers of the double exponential smoothing (DES) model is used to predict the target position in the frame delimiting the solution space in a more promising region for target tracking. To assess the quality of the proposed approach, an appropriate tracker for a discrete solution space was implemented using the meta-heuristic Shuffled Frog Leaping Algorithm (SFLA) adapted to dynamic optimization problems, named the Dynamic Shuffled Frog Leaping Algorithm (DSFLA). The DSFLA was compared with other classic and current trackers whose algorithms are based on swarm intelligence. The trackers were compared in terms of the average processing time per frame and the area under curve of the success rate per Pascal metric. For the experiment, we used a random sample of videos obtained from the public Hanyang visual tracker benchmark. The experimental results suggest that the DSFLA has an efficient processing time and higher quality of tracking compared with the other competing trackers analyzed in this work. The success rate of the DSFLA tracker is about 7.2 to 76.6% higher on average when comparing the success rate of its competitors. The average processing time per frame is about at least 10% faster than competing trackers, except one that was about 26% faster than the DSFLA tracker. The results also show that the predictions of the robust DES model are quite accurate.
1. Introduction
The goal in optimization problems is the search for a solution that minimizes (or maximizes) a cost function associated with the problem in a set of possible solutions called solution space.
Evolutionary algorithms (EAs) and swarm intelligence algorithms (SIAs) are two important categories of optimization methods. EAs use a population of agents or particles that explore the solution space in search of the optimal solution inspired by the Darwin’s theory of the evolution of species. SIAs use a population of particles that explore the solution space while interacting with each other and with the environment, resulting from this interaction a coherent global pattern [1]. Both algorithms are called meta-heuristics.
The advantages of the swarm intelligence strategy that make it so popular are the simplicity and flexibility of the algorithms, their derivative-free mechanisms, and their avoidance of the local optimum [2].
Some examples of SIAs are: Particle Swarm Optimization (PSO) [3], Shuffled Frog Leaping Algorithm (SFLA) [4], Salps Search Algorithm (SSA) [5], Cuckoo Search (CS) [6], Ant Colony Optimization (ACO) [7], Firefly Algorithm (FA) [8], and Gray Wolf Optimization (GWO) [2]. For a recent up-to-date list of meta-heuristics, see [2].
The common characteristics of SIAs are that they have search engines inspired by nature, are based on populations, and are interactive. Their main difference, apart from the source that inspires their behavior, is the way that the solution space is globally and locally explored by agents [1].
Originally, SIAs were designed for stationary optimization problems in which the optima do not change within the solution space, and the algorithms efficiently converge to the optimum or near-optimum solution. However, in many real-world situations, optimization problems are subject to dynamic environments in which the optimum can change its position within the solution space. A strategy to address this challenge is to adapt SIAs to work in dynamic optimization problems (DOPs) [1] by considering the optimization environments as a sequence of stationary optimization problems.
Video target tracking is the task of estimating the position and trajectory of one or more targets in a digital video image sequence. A digital video is a sequence of ordered images or frames, and a target can be any object of interest in a scene, e.g., one or more people walking on a sidewalk, cars traveling down an avenue, or animals running in the field.
In the last decades, the increasing popularity of video cameras and digital computers, technological advances, and the great extent to which these products are offered on the market have led to an increased interest in automated video analysis for various real-world applications, e.g., surveillance and security [9], human–machine interfaces [10], and robotics [11]. A more detailed introduction to the subject is provided in [12].
Targets can be represented by their shape and appearance. The appearance of a target is characterized by features (e.g., color, texture, corners) that are extracted from a specific region of the target [12].
According to [13], there are two methods of estimating the target’s trajectory, online and batch. The online method uses the current and previous frames to estimate the state of the target in each time period and the batch method uses the entire sequence of frames to optimize the target estimate in each time using past and future information, however, the batch method cannot be used in applications where it is necessary to track the target in real time. In this work we will only deal with online tracking of a single target.
Tracker models can be classified into two categories according to [14]:
- Category 1 whose models are based on stochastic algorithms. These algorithms are used to predict the position of the target in each frame according to a pattern of movement and observable characteristics of the target. The main examples are the Kalman Filter (KF) [15] and the Particle Filter (PF) [16];
- Category 2 whose models are based on template matching. These models select regions of the current frame and extract certain observable characteristics from these regions, which are then compared with the respective characteristics of one or more templates of the target to be tracked. The most similar region indicates the likely position of the target in the current frame. A classic tracker in this category is the Mean Shift (MS) [17] and other models in this category can be found in [18]. Therefore, there is a class of trackers whose models are based on optimization algorithms since the likely position of the target in a frame is indicated by the position of maximum similarity between the templates and the candidate target [19,20,21,22,23].
It is worth mentioning that many authors have proposed the use of SIA to optimize the trackers based on PF algorithm [14,24,25]. Furthermore, in recent years, great progress and importance have been given to trackers based on Correlation Filter (CF) [26,27,28] and Deep Learning (DL) [29,30,31] due to the good results in visual tracking.
Video target tracking is a challenging task because of the complexity generated by interference from several factors [32], such as: partial or total occlusion of the target; sudden changes in ambient lighting and movement of the target; rotations, deformations and scale changes of the target; blurred and noisy digital images; videos recorded by low-resolution cameras; and image backgrounds with similar aspects to the target. The interference of factors modifies the optimization environment. Therefore, the video target tracking problem is a particular case of a DOP.
The objective of this work is to propose, analyze and discuss a DOP-enhanced SIA approach applied to video target tracking. A tracker based on the meta-heuristic Shuffled Frog Leaping Algorithm (SFLA) [4] is proposed and adapted to DOPs, the Dynamic SFLA tracker (DSFLA).
The proposed method introduces a procedure to select some good solutions from the previous frame and consider them in the next frame, maintaining the diversity of solutions and an adaptive transfer procedure for the selected solutions. Another procedure of the proposed method is the delimitation of the solution space in a promising region of the image by forecasting time series. A version of the double exponential smoothing (DES) [33] model that is robust to outliers is used to forecast the position of the target and delimit the solution space in a promising region for a more efficient search.
The quality of the tracking will be measured by the area under curve (AUC) of the success rate per Pascal metric or One-Pass Evaluation (OPE). The average processing time per frame will also be analyzed.
The quality results of the DSFLA tracker will be compared with the quality results obtained from other SIA-based video target trackers: the PSO tracker whose meta-heuristic is Bare Bones PSO (BBPSO) [34], the Adaptive Discrete Swarm Optimization (ADSO) tracker [22], the SFLA tracker whose meta-heuristic is SFLA [4] and the SSA tracker [23] whose meta-heuristic is SSA [5].
The innovations and contributions presented in this work are:
- A new swarm intelligence algorithm for dynamic optimization problems;
- A new video target tracker;
- An appropriate algorithm for optimization problems with discrete solution space;
- A new and adaptive method of knowledge transfer between two optimization environments and the reduction of the solution spaces based on an efficient time series forecast model;
- A case study in the area of video target tracking showing results compatible with state-of-the-art models based on SIA;
- In situations of controlled ambient light, small occlusions and little camouflage of the target, the DSFLA is fast and stable in tracking any target. Especially, it is robust in situations where there are rotations or fast movements of the target, in low resolution videos corrupted by blurred or noisy interference.
Table 1 presents the summary of characteristics and the strengths and weaknesses of the trackers treated in this work. For all trackers covered in this work, the common characteristics are: they were designed for online tracking of a single target and are based on SIA for optimization problems. They are general propose trackers.

Table 1.
The features of the trackers.
The next section presents a summary of the latest works related to the proposed theme.
2. Related Work
Canalis et al. [19] were one of the first to apply the PSO algorithm to a video target tracking issue. The results were promising, comparable to the results of the traditional Mean Shift (MS) [17] and Particle Filter (PF) Bootstrap [16] trackers. In [20], an improved version of the PSO produced results that outperformed those in [19]. However, both approaches used the meta-heuristic in a stationary optimization environment and there was no delimitation of the solution space in a region of the image.
Gao et al. [21] proposed a tracker based on the Cuckoo Search (CS) [6] algorithm. The CS algorithm mimics the predatory behavior of the cuckoo bird in relation to the laying of eggs during the nesting period. They used six challenging videos and the Bhattacharyya distance [17] from the color histogram based on a space kernel as a measure of similarity between targets. They compared the performance of the CS tracker with the PF, MS, PSO and more four versions of the PSO trackers, and the CS outperformed the other competitors in terms of processing time and tracking quality using the Euclidean distance from the central points of the estimated and true targets. However, similarly to the previously mentioned trackers [19,20], the CS tracker considers only stationary optimization environments.
Bae et al. [22] presented the Adaptive Discrete Swarm Optimization (ADSO) algorithm, a tracker that applies solution space delimitation in a version of the PSO algorithm for the discrete space of solutions. PSO was originally designed for stationary optimization problems with continuous solution space, therefore, when it is applied to discrete optimization problems, the chance of the PSO converging prematurely to local optimum is greater [22]. ADSO was the first video target tracking algorithm that employed the swarm intelligence method in DOPs for discrete solution spaces.
ADSO works in dynamic optimization environments by transferring knowledge from one frame to the other through a probability function that controls the diversity of the particles. This function assigns a probability to each particle according to the degree of occlusion of the target, as defined by two thresholds, and where . These probabilities define whether each particle variable will receive the value of the optimum or if it will receive a random value that covers the entire amplitude of the variable within the solution space.
Bae et al. [22] used seven videos from the public benchmark Pami (http://sites.google.com/site/benchmarkpami/, accessed on 24 November 2020) and the Bhattacharyya distance from the HSV color histogram as a measure of similarity between targets. The results of ADSO outperformed those of PSO trackers and another EA-based tracker in terms of processing time and Euclidean distance and coordinates between estimated and true targets. The results showed that the ADSO is good for tracking fast-moving targets.
Zang et al. [23] presented a tracker based on the Salps Search Algorithm (SSA) [5]. The SSA meta-heuristic mimics the behavior of a group of salps swimming and foraging in the deep ocean. The salp is a member of the Salpidaes family; it has a transparent barrel-shaped body and swims by propulsion, forming long chains. This chain (particles) is formed by a leader who seeks a source of food (the optimal solution) and by followers who follow the movement of the leader. The movement of the leader is responsible for the global exploration of the solution space while the movement of the followers is responsible for the local exploration. The algorithm performs search iterations in the solution space and, at each iteration, the movement of the leader is controlled by a function that makes a balance between local and global exploration.
Zang et al. [23] used 13 videos from the public benchmark (in http://www.visual-tracking.net, accessed on 24 November 2020) and the cross-correlation coefficient of the Histogram Oriented Gradient (HOG) characteristic [35] as a measure of similarity between targets.
The results in [23] outperformed another ten state-of-the-art trackers in terms of performance quality and speed. However, the SSA tracker is based on optimization in stationary environments and does not delimit the solution space in a region of the image.
3. Architecture
3.1. Swarm Intelligence Algorithm in a Dynamic Optimization Problem
Optimization problems entail searching for an optimal (or near-to-optimal) solution among a set of feasible solutions. This search may or may not be subject to one or more restrictions.
Solutions are made up of variables associated with the problem. A solution is feasible if the values assumed by the variables satisfy the restrictions. A feasible solution is optimal if it minimizes or maximizes the objective function (or fitness function or cost function), which measures the quality of solutions.
SIAs reproduce the collective intelligence that emerges from the behavior of a group of agents and are inspired by nature. SIAs were designed for stationary optimization problems in which the parameters, the solution space, and the objective function do not change during the optimization process. However, in many real-world situations, optimization problems are subject to dynamic environments in which the optimum can change its position within the solution space during the optimization process. The optimization environment of a DOP is more challenging than that of a stationary optimization problem since repeated optimization is required in the presence of a changing optimum [1].
A DOP can be defined as a sequence of stationary problems that need to be optimized and can be formally described as follows: Optimize subject to
where is the solution space, is the time, and
is the objective function that associates a real number to each solution . is the set of feasible solutions over time . Each feasible solution consists of a vector of dimensions , where each component of this vector corresponds to a variable of the problem.
Each feasible solution in is associated with a set of neighbors and the feasible solution is a local optimum if and only if
is a minimization or
if it is a maximization.
Similarly, the feasible solution is a global optimum if and only if
is a minimization or
if it is a maximization.
The drawback of the SIAs is that the convergence ability decreases the particle diversity, reducing the ability of the algorithm to adapt to a new optimization scenario. On the other hand, for an SIA to adapt to a DOP, it is necessary to promote the transfer of knowledge. However, if too much knowledge is transferred, then the optimization process in the current environment may begin near a poor location and get trapped in a local optimum [1].
The goal is to promote an ideal balance between knowledge transfer and the diversity of particles since they constitute two conflicting factors [1]. Therefore, enhanced SIAs that promote this balance are suitable for dynamic optimization.
There are a few ways to promote this enhancement, e.g., maintaining a memory scheme of the best particles from previous optimizations and using them in the current optimization or maintaining multiple populations and allocating them to different regions of the solution space [1].
3.2. The Meta-Heuristics SFLA and BBPSO
More details of the SFLA and BBPSO algorithms will be given in this subsection since three of the five trackers were based on them, whereas the ADSO and SSA trackers were reproduced in this work.
3.2.1. The Shuffled Frog Leaping Algorithm
The memetic meta-heuristic SFLA was proposed by Eusuff et al. [4] to solve combinatorial optimization problems. Its solution space exploration mechanism mimics the behavior of a group of frogs (the particles) in a swamp (the solution space) as they vie for the best place to feed. The best places are stones (solutions to the problem), which are located at discrete points of the swamp.
The SFLA starts by randomly generating virtual frogs in the swamp and grouping them into frog communities called memeplexes. Frogs jump within the solution space and are influenced by the positions of the frog with the best fitness in each memeplex and the frog with the best fitness in the swamp.
The position of the worst frog in each memeplex is changed according to
where is the position of the worst memeplex frog in the previous iteration, is the position of the worst memeplex frog and is the jump made by the worst frog in the memeplex in iteration (, where is the maximum number of iterations). The jump is limited by a constant positive predefined and problem-dependent threshold ().
To calculate the worst frog jump, the SFLA calculates a new position adding a random jump towards the best frog in the memeplex as follows
where is the position of the best memeplex frog in the previous iteration and is a pseudo-random number uniformly distributed over a continuous unit interval.
If the fitness of the new position of the worst frog is not improved, the jump calculated by Equation (8) is discarded and another random jump is added to the original position of the worst frog in the memeplex towards the best frog in the swamp as follows
where is the position of the best swamp frog in the previous iteration.
If the new jump does not improve the fitness of the worst frog in the memeplex, then it is replaced by a new frog located at a random point in the swamp.
After performing the jumps and updating the fitness of each frog, they are randomly redistributed among memeplexes before the next iteration of the algorithm. The procedure is repeated until the stop condition is reached.
The algorithm performs simultaneously an independent local search in each memeplex. The global search is guaranteed by the shuffling of frogs and the reorganization of memeplexes. The algorithm also generates random virtual frogs to increase the opportunity for new information in the population [4].
The main advantages of SFLA are that it is more powerful in solving complex combinatorial optimization problems, has a faster search capability, and is more robust in determining the global optimum because of the evolution of several memeplexes (the structure responsible for local exploration) and the scrambling process (the structure responsible for global exploration), which can improve the quality of individuals [36]. The pseudocode and more details are provided in [4].
3.2.2. The Bare Bone Particle Swarm Optimization
The Bare Bone PSO (BBPSO or Gaussian PSO) [34] meta-heuristic, as in the classic PSO, mimics the behavior of a flock of birds (particles) that fly over the solution space while exchanging information with their neighbors, and it has the advantage of working with only two parameters: the number of particles and the neighborhood topology [37].
There are two types of neighborhood topology, the global one in which the particles communicate with each other, and the local where each particle communicates with a subgroup of particles. In this work, we adopted the local neighborhood topology.
The main difference between the two versions of the PSO is that BBPSO uses a Gaussian random variable to update the position of the particles instead of adding a velocity equation, as occurs in the classic PSO.
The equation for updating the position of the particles in the BBPSO is given by
with
where is the element-by-element product between two vectors, is the particle in iteration with dimension ; corresponds to the mean and the variance of the random vector with Gaussian distribution. is the best position visited by the particle until the iteration end is the best position visited by the swarm until the iteration ( and , with the number of iteration and the number of particle).
The pseudocode and more details are provided in [34].
3.3. Target Tracking
Target tracking is a particular case of a DOP since the challenges in the scene modify the solution space, and the optimal solution can vary in each frame.
In this work, to ensure a fair experiment for all trackers, the particles of the meta-heuristics are represented by rectangular bounding boxes and are denoted by four-dimensions vectors , where is the 2D coordinate of the pixel located in the upper left corner of the bounding box, and denotes the horizontal and vertical dimensions, referring to the base and height of the bounding box, respectively. Each particle corresponds to a candidate target.
The appearance and characteristics of the targets are represented by the standardized histogram of the first channel of the YCbCr color model [12]. From previous experience, the inclusion of the second and third YCbCr channel histograms result in an almost zero gain of target discrimination power at the expense of a higher computational cost due to a longer processing time. Therefore, we decided to work only with the first channel for a lower computational cost.
A standardized histogram is a unit area histogram and is an asymptotically unbiased and consistent estimator of the probability density function [38]. The choice of the standardized color histogram is due to its invariance to rotations and scale changes [39], in addition to being a quick approach.
To measure the similarity between the candidate targets and the template, the Bhattacharyya distance [17] is adopted. The equation is given by
where and are the standardized histograms of the template and the candidate target, respectively, indicates the histogram bin, and nBins indicates the total number of bins in the histogram.
The Bhattacharyya distance is a standardized measure that is limited to the continuous unit interval, where zero indicates total similarity and 1 indicates the total lack of similarity between histograms.
Video target trackers in category 2 of the classification given in [14] based on SIAs work as follows: In each frame, particles are scattered at random within the solution space given by
where and are the total pixels of the horizontal and vertical dimensions of the frame, respectively.
Then, the meta-heuristic moves the particles and updates their fitness until a stop condition is reached (e.g., a maximum number of iterations or a minimum quality value of the best solution). When the meta-heuristic reaches the stop condition, the algorithm returns the best quality particle of the swarm, where is or , indicating the target’s position in the current frame. However, it is possible to take advantage of the good solutions of the previous frame to set the initial location of particles in the current frame. It is also possible to spread the particles over a limited region of the solution space since the hypothesis that the target does not move a long distance from one frame to another one is plausible in the vast majority of cases of target tracking in videos.
3.4. Robust Double Exponential Smoothing
One of the proposals of this work is to delimit all dimensions of the solution space. The goal is to surround the target in the next frame in a promising region and increase the chances of detection. A robust version of the DES [33] time series model was used for this purpose.
The exponential smoothing model, also called the Holt and Winters model [33], works on a time series by decomposing it into four factors: level, trend, seasonal factor and an unpredictable residual factor called random noise.
The process of estimating these factors is based on exponential smoothing, i.e., the process eliminates sudden variations in the observed series, and it is then described by its structural components (the four factors). The factor estimation process involves the calculation of weighted arithmetic averages in which the weights decay exponentially over time as it moves to the past values of the time series. More details about the theoretical issues involving Holt and Winters modeling are in [40], and for a review on the subject, see [41,42].
The double exponential smoothing (DES) model decomposes a stochastic process into the level, the trend and a random error term according to
where is the random variable of the stochastic process at time defined in the same sample space, is the smoothing factor that corresponds to the level at time , is the smoothing factor that corresponds to the trend over time , and is a random variable with a zero mean and constant positive variance and is not correlated with and .
Estimates of level, denoted by , and the trend, denoted by , are given by, respectively,
where the coefficients and are called smoothing constants ( ), and the higher the value of the coefficients, the lower the weight that is given to the past values of each factor; is the current value of the observed series; is the current time-smoothing value used to estimate the level; and is the current trend estimate. When , it is necessary to set the starting values of and (in general, but not necessarily) to and .
The time horizon forecasts from the instant are given by
where is the forecast value of the random variable of the generating process of the observed series .
The impact of an outlier on the series forecast can be seen by observing (16) and (17). When an outlier is observed, the values of and are overestimated. However, these values continue to affect future estimates at both the level and the trend, producing persistently skewed forecasts.
In order to mitigate the effects of outliers on predictions, we used a version of the DES model that is robust to outliers. In this case, the observation of the series at time , , is replaced by the lower limit value, , or the upper limit value, , when or , respectively. Limit values are calculated and updated at every time according to, respectively,
where is the average of the observed series, from its update after the first observation until , and calculated according to
and is the variance of the observed series, from its update after the first observation to the observation , and calculated according to
for , and .
Therefore, the robust DES model (RDES) is the model given by Equation (15), the forecast is given by Equation (18), and the estimates of and are given by Equations (16) and (17), respectively. In fact, the RDES model differs from the DES model only when an outlier is observed and the value is replaced by the limit values given by Equation (19) or Equation (20).
To measure the quality of forecasts in time series models, it is common to adopt the square root of the mean squared error of the forecast (RMSE) [43] as a metric. The RMSE is calculated for each point coordinate of according to
where is the maximum number of times (or frames) and is the forecast for time from time ( correspond to of Equation (14)).
The mean squared error measures the variance and squared bias of the forecast for each coordinate [43]. The lower the RMSE, the more homogeneous and less biased the forecast is.
The Euclidian distance of the 2D coordinates between the points in the upper left corner of the and bounding boxes will also be measured to check the quality of the forecasts. The shorter the distance, the more accurate the forecast.
4. The Proposed Method
The video target tracking model proposed in this work, the Dynamic Shuffled Frog Leaping Algorithm tracker, belongs to category 2 of the classification given in [14]. The DSFLA tracker is an enhanced version of the SFLA meta-heuristic [4] for DOPs. The method also involves a scheme for delimiting the space of solution according to the position of the estimated and predicted targets in the previous frames. To predict the target’s position, the RDES [33] is used.
The DSFLA tracker performs the following steps: for the first frame, particles are randomly scattered in the solution space given by Equation (14); for the other frames, the particles are randomly scattered in the delimited solution space by RDES.
Then, the value of the objective function is calculated for all particles, and the SFLA meta-heuristic is executed until a stop condition is reached. In this work, the stop condition is either when the fitness of the best-fit particle of the swarm is less than 0.005 (Bhattacharyya distance) or when the maximum number of iterations is performed.
The solution space (14) is delimited by proposed DSFLA tracker considering the union of two rectangular regions, one around the target estimated by (a region generated by simulating a random walking movement) and another around the predicted target ( correspond to via RDES). The delimitation is given as follows:
- The limits of the coordinates of the solution space are given bywhere and are predefined constants (problem dependent);
- The limits of the coordinates of solution space are given bywhere and are predefined constants (problem dependent).
Figure 1 shows an example of delimiting the solution space obtained from the tenth frame of the video BlurBody (this video was selected from the public Hanyang visual tracker benchmark [44]). The blue bounding box corresponds to the ground truth, and the magenta bounding box corresponds to the estimated target, . The green-filled region corresponds to the delimitation of around the centered in the upper left corner of the blue bounding box, and the yellow-filled region corresponds to the delimitation of around the centered on the coordinates. The area delimited by the red rectangular box corresponds to the delimited region in Equations (24) and (25) of the proposed method for coordinates.

Figure 1.
An example of delimiting the solution space obtained from the tenth frame of the video BlurBody (this video was selected from the public Hanyang visual tracker benchmark [44]).
The new particle selection process selects the particles so that they are distant from each other by a minimum distance, , calculated as follows:
where and are the vertical and horizontal dimensions of the delimited solution space obtained by Equations (24) and (25), respectively, is a predefined maximum percentage of transfer, and is the number of particles.
The choice of particles is made in ascending fitness order starting with .
The new adaptive particle transfer process generates random particles in the bounded solution space and sorts the particles in decreasing order of fitness. Then, the fitness of the selected particles is recalculated and compared with that of the worst generated particles, and the one with the worst fitness is discarded.
The particle transfer process is adaptive since not all particles are selected and that not all selected particles are used (transferred). It varies from frame to frame. In addition, it is possible that some of the transferred and selected particles are positioned outside the delimited solution space but within the solution space (Equation (10)). For a summary of the proposed DSFLA algorithm, see the pseudocode in Algorithm 1.
| Algorithm 1. DSFLA tracker’s pseudocode |
| 1: for f = 1:N % for all N frames |
| 2: Img = readframe(f); |
| 3: for i = 1:n % for all n particles |
| 4: if f == 1 |
| 5: Generate n particles in S using Equation (14); |
| 6: else |
| 7: Generate n particles in reduced S; |
| 8: end |
| 9: Extract the histogram and update the fitness; |
| 10: end |
| 11: if f > 1 |
| 12: Knowledge transfer process; |
| 13: end |
| 14: Update gBest; |
| 15: while <stop condition == false> do |
| 16: Execute SFLA meta-heuristic; |
| 17: end |
| 18: Record gBest and tracker’s performance measures; |
| 19: Particle selection process; |
| 20: Reduce S as a function of gBest: S1; |
| 21: Calculate the forecast pHat via RDES; |
| 22: Reduce S as a function of pHat: S2; |
| 23: Calculate reduced S as a function of S1 and S2 using Equations (24) and (25); |
| 24: end |
5. Experiments and Results
5.1. Experimental Design
To investigate the efficiency of the proposed approach, a random sample of 15 videos was selected from the public Hanyang visual tracker benchmark [44] with the respective ground truth with hand-marked targets. The benchmark focus is on tracking a single target online. The benchmark presents 100 videos with generic scenarios and annotations of ground truth for all frames and annotations of attributes that affect the performance of the tracker in identifying the targets.
The public Hanyang benchmark was designed with a collection of video sequences most commonly used in object tracking. It contains videos from various datasets such as the VIVID [45], CAVIAR (http://homepages.inf.ed.ac.uk/rbf/CAVIARDATA1, accessed on 24 November 2020). Other benchmarks such as PAMI share some public videos in common with the Hanyang benchmark.
Table 2 shows the selected videos with the following information: the video’s size (in number of frames), the resolution of the image (in number of pixels) and the main challenges present in the scene. The challenges are rotation in the image plane (IPR), rotation outside the image plane (OPR), fast movement (FM), blurred movement (BM), low resolution (LR), scale variation (SV), deformation of the target (DEF), confusion between the target and background of the image (BC) and occlusion (OCC).
Table 2.
The features of the videos.
The Hanyang benchmark also includes most of the publicly available codes. The benchmark disseminates performance metrics for in-depth analysis of tracking algorithms. The metrics proposed in [44] are the AUC of the success rate per Pascal metric (success rate) and the Euclidean distance from the central points of the bounding boxes (accuracy).
The Pascal metric [46] is defined according to
where is the bounding box that corresponds to the ground truth, and is the bounding box that corresponds to the candidate target.
The Pascal metric measures the quality of tracking by quantifying the percentage of pixels that are shared between the bounding boxes, i.e., the overlap of the targets. The Pascal metric ranges from 0.0, when there is no overlap between bounding boxes, to 1.0, when there is total overlap between targets. A target is considered to be detected when the Pascal measure of the candidate target is equal to or greater than a predetermined threshold (in this work the Paschal threshold is 0.5).
The success rate per Pascal metric is the curve formed by the percentages of frames in which the target was detected in a given video, with the threshold of the Pascal metric varying from 0.0 to 1.0. The advantage of observing the curve is that the tracker’s performance is visualized for all thresholds of the Pascal measurement. Therefore, calculating the AUC of the success rate per Pascal metric is a more robust and complete measure to assess the quality of the tracker’s performance when compared with a value for a single fixed threshold. The AUC ranges from 0.0 to 1.0, and the closer it is to 1.0, the better the tracker’s performance. More details on the Pascal metric and the success rate per Pascal metric are provided in [44,46].
There are three tests to assess the robustness of the trackers in [44], the OPE (One-Pass Evaluation) which tests the tracker for the success rate and accuracy from the first to the last frame of the video and the template being the ground truth of the first frame; the TRE (Temporal Robust Evaluation) that tests the tracker using a sequence of frames starting from any frame until the last one; and the SRE (Spatial Robust Evaluation) in which the template is modified from 0.8 to 1.2 of its original scale and starting from 12 different locations in the first frame.
In this work, the performance of the trackers will be evaluated by OPE robustness of the AUC of the success rate per Pascal metric and the average processing time per frame.
The overall results will be summarized by the mean, median and coefficient of variation. The coefficient of variation () is the ratio between the sample standard deviation, , and the sample mean, , of an observed variable. The is a dimensionless measure of dispersion and can be expressed as a percentage of variation.
5.2. Configuration of the Tracker’s Parameters
The configuration of the parameters of each tracker was based on previous experience. The average processing time and the AUC of the success rate per Pascal metric were analyzed to determine the configuration of the parameters of each tracker that results in the best performance.
For this purpose, an analysis was conducted by performing the following experiment: (i) four videos were selected at random from [44]; (ii) the values of the processing time and AUC variables were calculated by averaging three executions of each video for each tracker; (iii) the configuration of the parameters for each tracker was chosen according to the best values of the two metrics.
The videos chosen in this stage of the experiment were Couple and Deer (videos 7 and 9 in Table 1, respectively), Bolt2 (frames: 293; resolution: 480 × 270; challenges: IPR, DEF, BC) and Football1 (frames: 74; resolution: 352 × 288; challenges: IPR, OPR, BC).
It is worth mentioning that the chosen values of the parameters were kept fixed throughout the experiment. The final configuration of parameters for each tracker was as follows:
- PSO: 150 particles and 15 local groups with 10 particles;
- ADSO: 40 particles, the thresholds , , , and the probability ;
- SFLA: 50 particles, 10 memeplexes with 5 particles, a maximum number of iterations of 10 and a maximum pixel number for frog leaping of 10;
- DSFLA: The same parameters of SFLA plus , , , , , and ;
- SSA: 80 particles, a maximum number of iterations of 100, and 20 leader salps.
5.3. Analysis of Results
The results of the main experiment are summarized in Table 3 and Table 4. The values presented in the tables correspond to the average of six executions of each video for each of the trackers: PSO, ADSO, SFLA, DSFLA and SSA, always in that order. Replications of all the videos for each tracker were coded in MatLab and executed on the same processor (Intel Pentium Dual-Core, 1.86 GHz, 2 GB DDR2 and 160 GB HDD) to compare the average processing time per frame (it is worth saying that the program codes are not optimized). The average, median, and of the 15 videos are in the last three rows of the tables.
Table 3.
Processing time per frame (s) (the best results are in bold).
Table 4.
AUC of the success rate per Pascal metric (the best results are in bold).
Table 3 shows the performance of the trackers according to the average processing time per frame of each video.
As observed in Table 3, the SSA tracker takes more time for execution, and the ADSO tracker is the fastest, however, the DSFLA tracker is, on average, the second fastest. The values are representative given that the of the trackers is low, except for the PSO tracker.
Figure 2 shows the Whiskers boxplot (output of MatLab’s internal boxplot function) of each tracker for the observed data of the average processing time per frame. Each boxplot segment corresponds to 25% of the observed values, and the small circles correspond to the outliers. The darker part of the central region of the boxplot represents the interquartile range (IQR), , where is the third quartile and is the first quartile. The central point of this region corresponds to the median of the observed values, and the triangles represent the extremes of the 95% confidence interval centered on the median [47], which is calculated according to
where is the second quartile, i.e., the median, and is the size of the observed sample.
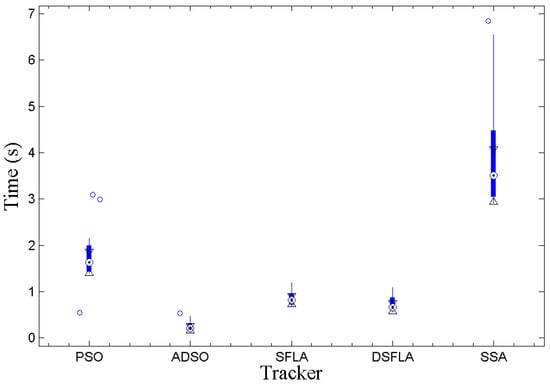
Figure 2.
The boxplot of the variable processing time per frame for all trackers.
If the intervals do not overlap, then we can conclude with 95% confidence that there is a significant difference between the medians, this is equivalent to a statistical test in which the hypothesis that there is no difference between the medians is rejected at 5% significance.
From the graph in Figure 2, all processing times are significantly different except for the those between the SFLA and DSFLA trackers. However, empirically, the proposed DSFLA tracker is systematically about 10% faster than the SFLA tracker.
Table 4 shows the performance of the trackers in relation to the tracking quality according to the AUC of the success rates per Pascal metric. We can see from Table 4 that the of all the trackers indicates a low variation of the results except for the PSO tracker. Therefore, we can say that the trackers are satisfactorily stable. Table 4 also shows that the videos 2, 8, 10 and 15 presented the most difficult challenges for all trackers.
Figure 3 shows the boxplots for the AUC of the success rates per Pascal metric. The DSFLA tracker is significantly superior to the PSO and ADSO trackers since the 95% confidence interval referring to the DSFLA tracker has no overlap with the confidence intervals referring to PSO and ADSO trackers. It is not possible to reject the hypothesis of comparable quality between the DSFLA, SFLA, and SSA trackers. However, Table 4 shows empirically that DSFLA tracker results are consistently better than SFLA and SSA trackers results, at about 7.2% higher AUC on average.
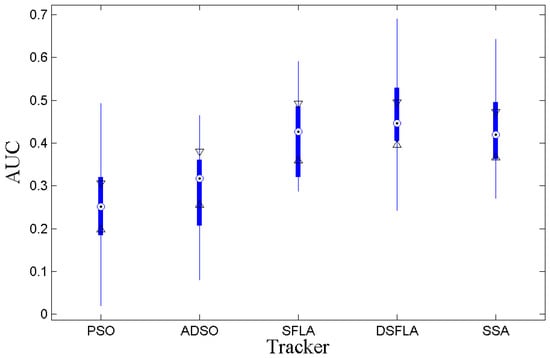
Figure 3.
The boxplot of the AUC variable for all trackers.
Figure 4 and Figure 5 show two examples, chosen at random, of tracking performance given by the success rate per Pascal metric for all trackers for videos 4 and 7, respectively. In Figure 4, the curve that represents the performance of the DSFLA tracker is largely above the other curves. This indicates that DSFLA has higher target detection rates for most of the Pascal metric threshold.
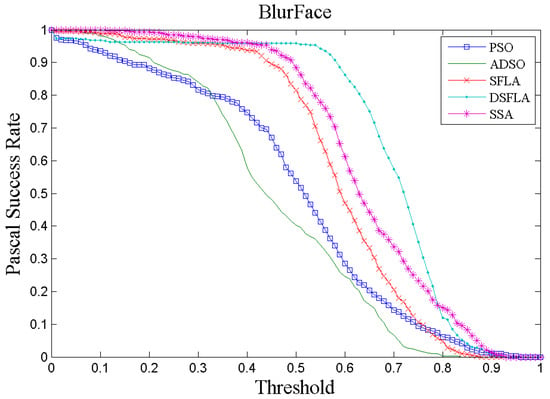
Figure 4.
The success rate curve per Pascal metric of video 4 (BlurFace) for all trackers.
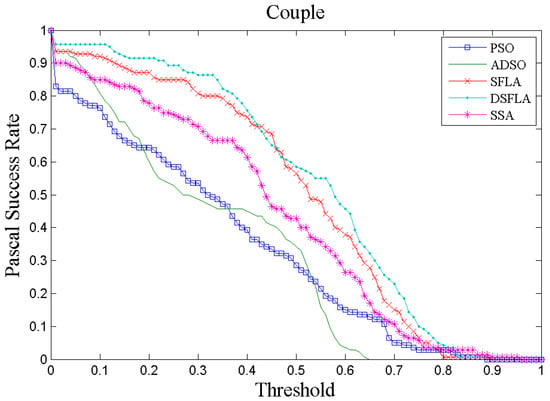
Figure 5.
The success rate curve per Pascal metric of video 7 (Couple) for all trackers.
The graphs of the success rate per Pascal metric for most of the other videos show results that reflect the performance of the trackers shown in Figure 5.
The DSFLA tracker produced the best results with videos 1, 4, 7, 11, and 12. The DSFLA tracker is effective in tracking targets with fast movements or when there are blurred images or rotations of the target.
The videos in which all the trackers performed poorly are those with ambient light variation and when the scale of the target has a wide range, as in the case of video 10 (Dog), or moderate occlusion, as in the case of video 15 (Walking2). A common weakness of all the trackers analyzed in this work is related to the variation in ambient lighting. This is probably due to the use of the standardized color histogram to represent the target characteristics. The color histogram is sensitive to any variation in light in the environment, and it can also easily miss the target when the characteristics of the target and background are similar. The illumination of the target in the scene changes substantially and non-proportionally to the frequencies of the histogram since the change in pixel intensity is not linear.
A possible strategy to overcome this problem is to include a target characteristic based on the shape of the object.
When the target and the background have similar characteristics, bounding boxes of different sizes can contain a similar proportion of pixels of the same intensity, and thus, the histograms are similar in appearance. Therefore, the solution space has several local minima whose objective function values are very close. This case can reduce the quality of tracking since candidate targets of different window sizes have a chance of being the estimated target.
The following analyzes check the quality of the RDES model predictions and how much the delimitation of the solution space is useful for tracking. Table 5 shows the RMSE values (in number of pixels) of the forecasts for the and coordinates and the Euclidean distance between the forecast and .
Table 5.
The RMSE values (in pixels) of the forecasts for the x and y coordinates and the Euclidean distance between the forecast and gBest.
Using the data in Table 5 and Equation (31), the 95% confidence intervals for variable RMSEs of and are and , respectively. Therefore, the prediction error does not exceed 50 pixels of RMSE, that is, the forecasts are reasonably homogeneous and slightly skewed.
Similarly, the 95% confidence interval for the Euclidian distance between the predicted target and is . Thus, we can conclude that the distance between the predicted and estimated target does not exceed 15 pixels. Considering the largest diagonal of the video image, this value varies from 400 to 800 pixels of the videos observed. Therefore, the biggest forecast error made does not exceed 3.8%, that is, we can conclude that the predictions of the RDES model is quite accurate.
The same experimental design used to calibrate the parameters of the trackers was used to investigate whether video target tracking benefits from restricting the solution space by the proposed region.
Table 6 shows the global average and median of the four videos for the variables’ AUC of success rates per Pascal metric and processing time per frame. Two versions of the DSFLA tracker were assessed: version 1 delimits the solution space, as proposed in this work, and version 2 does not delimit the solution space.
Table 6.
AUC of the success rates per Pascal metric and processing time for DSFLA tracker with and without delimitation of the solution space (versions 1 and 2, respectively) (the best results are in bold).
Table 6 shows that the median AUC for version 2 is about 87% of that for version 1 and that the median time to process a frame for version 2 is about 14% longer than that for version 1. Therefore, consistent empirical evidence suggests that the use of the restrictions proposed in this work helps to increase the AUC of the success rate per Pascal metric and improves the processing time.
To conclude, future work to improve the tracker performance involving multiple particle populations acting in different regions of the solution space (in the particle selection process) and an adaptive scheme for quantifying the number of particles to be used in the transfer of knowledge based on the similarity of the frames.
Other representations of the target will also be tested to improve the target recognition ability in environments with varying lighting including the target appearance model with HOG characteristic [35], for instance.
Author Contributions
Conceptualization, E.C.d.C.; methodology, E.C.d.C.; software, E.C.d.C.; formal analysis, E.C.d.C.; investigation, E.C.d.C.; writing—original draft preparation, E.C.d.C.; writing—review and editing, E.O.T.S. and P.M.C.; visualization, E.C.d.C.; supervision, E.O.T.S. and P.M.C.; project administration, E.O.T.S. and P.M.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data was obtained from the public Hanyang visual tracker benchmark [44], an open access CVPR 2013 paper version. site: http://cvlab.hanyang.ac.kr/tracker_benchmark/, accessed on 26 November 2020.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mavrovouniotis, M.; Li, C.; Yang, S. A survey of swarm intelligence for dynamic optimization: Algorithms and applications. Swarm Evol. Comput. 2017, 33, 1–17. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Kennedy, J.K.; Eberhart, R. Particle Swarm Optimization. IEEE Proc. Inter. Conf. Neural Netw. 1995, 4, 1942–1948. [Google Scholar]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Yang, X.-S.; Deb, S. Cuckoo Search via Lévy flights. In Proceedings of the 2009 World Congress Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Yang, X.-S. Firefly Algorithms for Multimodal Optimization. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5792, pp. 169–178. [Google Scholar]
- Yokoyama, M.; Poggio, T. A Contour-Based Moving Object Detection and Tracking. In Proceedings of the IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 271–276. [Google Scholar]
- Ma, Y.; Mao, Z.-H.; Jia, W.; Li, C.; Yang, J.; Sun, M. Magnetic Hand Tracking for Human-Computer Interface. IEEE Trans. Magn. 2011, 47, 970–973. [Google Scholar] [CrossRef]
- Das Sharma, K.; Chatterjee, A.; Rakshit, A. A PSO–Lyapunov Hybrid Stable Adaptive Fuzzy Tracking Control Approach for Vision-Based Robot Navigation. IEEE Trans. Instrum. Meas. 2012, 61, 1908–1914. [Google Scholar] [CrossRef]
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking. ACM Comput. Surv. 2006, 38, 13. [Google Scholar] [CrossRef]
- Rathnayake, T.; Gostar, A.K.; Hoseinnezhad, R.; Tennakoon, R.; Hadiashar, A.B. On-Line Visual tracking with Occlusion Handling. Sensors 2020, 20, 929. [Google Scholar] [CrossRef]
- Sardari, F.; Moghaddam, M.E. A hybrid occlusion free object tracking method using particle filter and modified galaxy based search meta-heuristic algorithm. Appl. Soft Comput. 2017, 50, 280–299. [Google Scholar] [CrossRef]
- Weng, S.-K.; Kuo, C.-M.; Tu, S.-K. Video object tracking using adaptive Kalman filter. J. Vis. Commun. Image Represent. 2006, 17, 1190–1208. [Google Scholar] [CrossRef]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Comaniciu, D.; Ramesh, V.; Meer, P. Kernel-based object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 564–577. [Google Scholar] [CrossRef]
- Watada, J.; Musa, Z.; Jain, L.C.; Fulcher, J. Human Tracking: A State-of-Art Survey. In International Conference on Knowledge-Based and Intelligent Information and Engineering Systems; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6277, pp. 454–463. [Google Scholar] [CrossRef]
- Antón-Canalís, L.; Hernández-Tejera, M.; Sánchez-Nielsen, E. Particle Swarms as Video Sequence Inhabitants for Object Tracking in Computer Vision. In Proceedings of the 6th International Conference on Intelligent Systems Design and Applications, Jinan, China, 16–18 October 2006; Volume 2, pp. 604–609. [Google Scholar] [CrossRef]
- Tawab, A.M.A.; Abdelhalim, M.B.; Habib, S.E.-D. Efficient multi-feature PSO for fast gray level object-tracking. Appl. Soft Comput. 2014, 14, 317–337. [Google Scholar] [CrossRef]
- Gao, M.-L.; Yin, L.-J.; Zou, G.-F.; Li, H.-T.; Liu, W. Visual tracking method based on cuckoo search algorithm. Opt. Eng. 2015, 54, 73105. [Google Scholar] [CrossRef]
- Bae, C.; Kang, K.; Liu, G.; Chung, Y.Y. A novel real time video tracking framework using adaptive discrete swarm optimization. Expert Syst. Appl. 2016, 64, 385–399. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, J.; Nie, Z.; Zhang, J.; Zhang, J. A new visual tracking approach based on salp swarm algorithm for abrupt motion tracking. KSII Trans. Internet Inf. Syst. 2020, 14, 1142–1166. [Google Scholar] [CrossRef]
- Gao, M.-L.; Li, L.-L.; Sun, J.; Yin, L.-J.; Li, H.-T. Firefly Algorithm (FA) Based Particle Filter Method for Visual Tracking. Optik 2015, 126, 1705–1711. [Google Scholar] [CrossRef]
- Li, M.; Pang, B.; He, Y.; Nian, F. Particle Filter Improved by Genetic Algorithm and Particle Swarm Optimization Algorithms. J. Softw. 2013, 8, 666–672. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, J.; Wu, Q.; Qian, X.; Zhou, T.; Hengcheng, F.U. Extented Kernel Correlation Filter for Abrupt Motion Tracking. KSII Transect. Internet Inf. Syst. 2017, 11, 4438–4460. [Google Scholar]
- Li, Y.; Zu, J. A Scale Adaptive Kernel Correlation Filter Tracker. European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 254–265. [Google Scholar]
- Chen, A.Z.; Hong, Z.; Tao, D. An Experiment Survey on Correlation Filter-based Tracking. arXiv 2015, arXiv:1509.05520v1(cs). [Google Scholar]
- Zhai, M.; Chen, L.; Mori, G.; Roshtkhari, M.J. Deep Learning of Apparence Models for Online Object Tracking. In Computer Vision—ECCV 2018 Workshops. ECCV 2018; Springer: Cham, Switzerland, 2018; Available online: http://link.springer.com/conference/eccv (accessed on 23 December 2020).
- Held, D.; Thrun, S.; Savarese, T. Learn to Track at 100 fps with Deep Regression Networks. In Computer Vision—ECCV 2016. ECCV 2016; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 749–765. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Walia, G.S.; Kapoor, R. Recent Advances on Multicue Object Tracking: A Survey. Artif. Intell. Rev. 2016, 46, 1–39. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting Sales by Exponentially weighted moving averages. Maneg. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Kennedy, J. Bare bones particle swarms. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium. SIS’03 (Cat. No.03EX706), Indianapolis, IN, USA, 26 April 2003; pp. 80–87. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Tao, X.; Li, H.; Mao, C.; Wang, C.; Yap, J.B.H.; Sepasgozar, S.; Shirowzhan, S.; Timothy, R. Developing Shuffled Frog-Leaping Algorithm (SFLA) Method to Solve Power Load-Constrained TCRTO Problems in Civil Engineering. Adv. Civ. Eng. 2019, 2019, 1–16. [Google Scholar] [CrossRef]
- Kennedy, J. Small worlds and mega-minds: Effects of neighborhood topology on particle swarm performance. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; Volume 3, p. 1931. [Google Scholar]
- Martinez, W.L.; Martinez, A.R. Computational Statistic Handbook with MatLab, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2002; pp. 125–127. [Google Scholar]
- Yang, H.; Shao, L.; Zheng, F.; Wang, L.; Song, Z. Recent advances and trends in visual tracking: A review. Neurocomputing 2011, 74, 3823–3831. [Google Scholar] [CrossRef]
- Brown, R.G.; Meyer, R.F. The Fundamental Theorem of Exponential Smoothing. Oper. Res. 1961, 9, 673–685. [Google Scholar] [CrossRef]
- Gardner, E.S. Exponential smoothing: The state of the art. J. Forecast. 1985, 4, 1–28. [Google Scholar] [CrossRef]
- Gardner, E.S. Exponential smoothing: The state of the art—Part II. Int. J. Forecast. 2006, 22, 637–666. [Google Scholar] [CrossRef]
- Harvey, A.R. Time Series Models, 2nd ed.; Prentice Hall/Harvester Weatsheaf: Cambridge, UK, 1993. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Online Object Tracking: A Benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Collins, R.T.; Zhou, X.; The, S.K. An Open Access Tracking Testbed and Avaluation Web Site. In Proceedings of the IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS2005), Beijing, China, 15–16 October 2005. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Nelson, L.S. Evaluating Overlapping Confidence Intervals. J. Qual. Technol. 1989, 21, 140–141. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).