1. Introduction
With the development of information technology, scientific text information has increased dramatically. It is estimated that the growth rate of the new scientific publications is about 9% each year, leading to a doubling of the global scientific output roughly every nine years [
1]. Researchers need to explore a domain according to their own questions to identify the specific knowledge information. For researchers interested in cancer diagnosis, the interests could be cancer-related genes and the corresponding proteins [
2]. Researchers in the microbiology field may be interested in the microbial habitat and phenotypic information [
3]. The information of interest often appears as knowledge pairs, which are also commonly seen in many real-world scenarios, like the pairs of readers and books, actors and movies, audiences and music. These pairs can be effectively represented by a bipartite network, the patterns of which can be computed in a shorter time than that of a general complex network. Therefore, a bipartite network can used as an important type of network for pattern extraction, further data mining and visualization. This network is a special type of the complex network, with only two sets of specific nodes. In our case, the specific knowledge pairs like “genes and proteins”, “microbial habitat and phenotypic information”, and other pairs can be well modeled and visualized as the two sets of nodes in a bipartite network. Thus, the overwhelming amount of information can be reduced and the specific knowledge information can be highlighted.
However, in bibliometric or scientometric theory, co-word networks [
4] or co-citation networks [
5] are more often seen. These networks provide the theory foundations for representing and analyzing the knowledge landscape. They can be regarded as a general type of complex network, which is less effective for computing or finding patterns than a bipartite network. Transforming the complex network into a bipartite network may provide a way to effectively explore the knowledge of interest. This is because co-word networks are built based on the keyword list for each of the articles. Some of the keywords are even suggested by the rough keyword classification tree of the journal submission systems. Therefore, detailed information about the conducted research may be missing. In addition, the chaotic terms in the co-word network may confuse researchers, because of the inclusion of very different types of words like real-world datasets, technical notions, academic concepts, or names of hardware. Moreover, the results may not be ideal due to a lack of consideration of the preferences or tendencies of the researchers in a specific field. Co-word networks often provide researchers with over-general concepts. This could be a waste of time for an experienced expert.
Experienced researchers often want to know more specific information, like the pairs of entities. Taking the “remote sensing” field as an example, an important question for “remote sensing” researchers may be “what sensors have been studied in what applications” since studies in the remote sensing field are often highly related to the sensors used. Sensors determine the resolution, the spatial-temporal precision, and other attributes of the acquired data. High-resolution sensors can provide urban planners with background images, helping road network construction. Data acquired by night-time light sensors can help evaluate human economical activities [
6]. Moreover, data from several different sensors can sometimes be used simultaneously. High-spatial-resolution sensed data can cover the shortage of the high-temporal-resolution but low-spatial-resolution data [
7]. Two sensed data can be combined to generate new information [
8]. Co-word networks from traditional scientometric methodology can offer a macro view of the remote sensing-related field [
9] and other scientific fields [
10,
11,
12]. However, co-words are often based on keywords which are often too general without enough details. How to extract the specific and concrete pairs of “sensors” and “applications” thus becomes an open question.
Mining the valuable literature to generate very specific and concrete knowledge pairs is not a new topic. Scholars have treated this topic as a serious science and put forward the corresponding theory, namely the theory of the solution of inventive problems or TRIZ [
13]. Several very useful principles for innovation have been proposed by manually organizing and analyzing the high-quality patent and literature like 50 years ago [
14], but nowadays, this work may be able to be reproduced by the modern text mining technologies. Methods of text mining nowadays can be roughly grouped into four categories: statistical approaches, linguistic approaches, machine learning approaches, and other approaches [
15]. Some studies have applied the text mining techniques to model more abundant and accurate semantic meanings [
16]. Several feature extraction methods from text mining have been used to identify problems and solutions [
17] or more representative domain keywords [
18]. Using text mining, it is possible to extract knowledge pairs, further building the bipartite network. As the knowledge pairs reflect the specific interests of researchers, we call this network consisting of knowledge pairs the bipartite network of interest (BNOI).
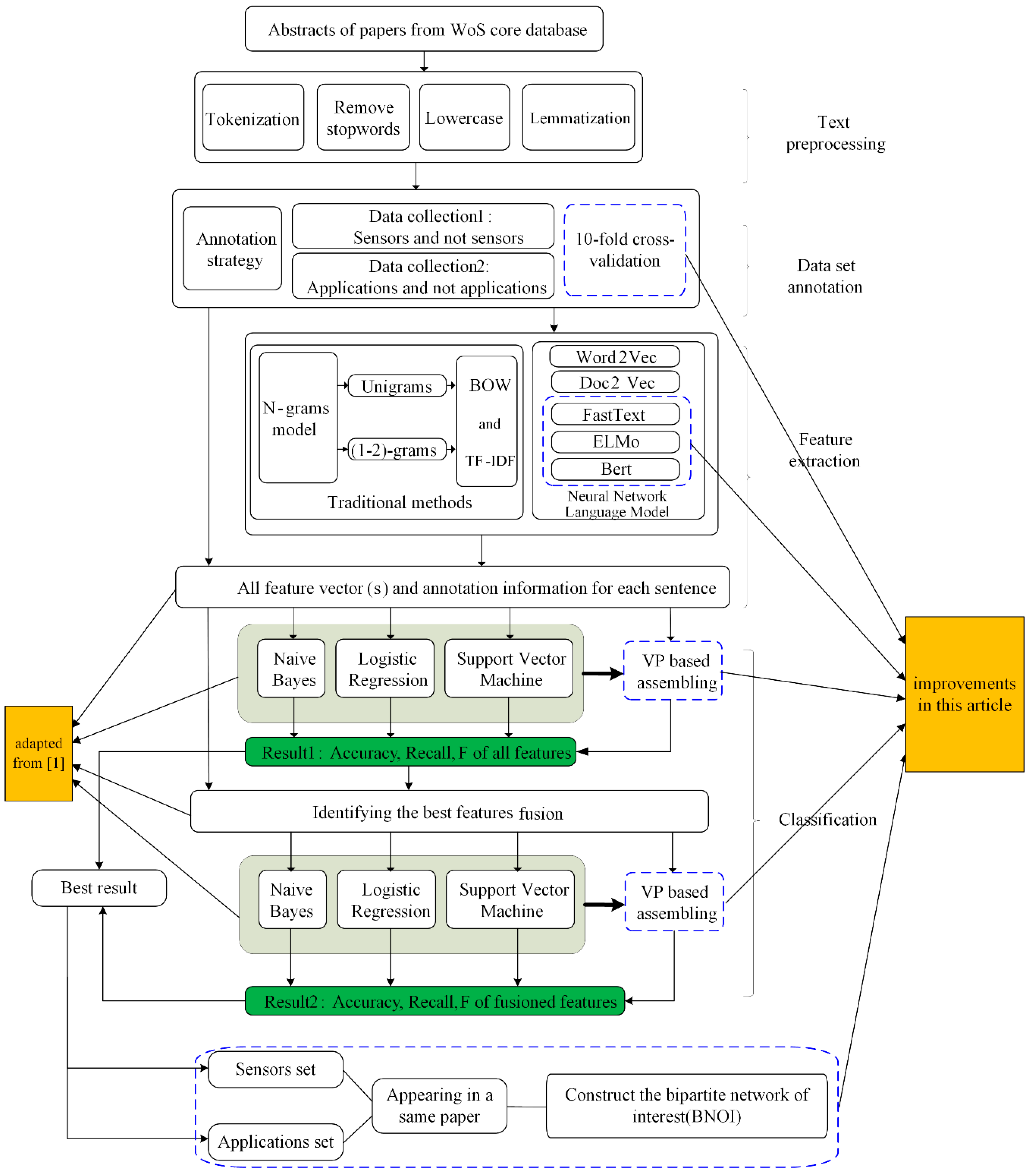
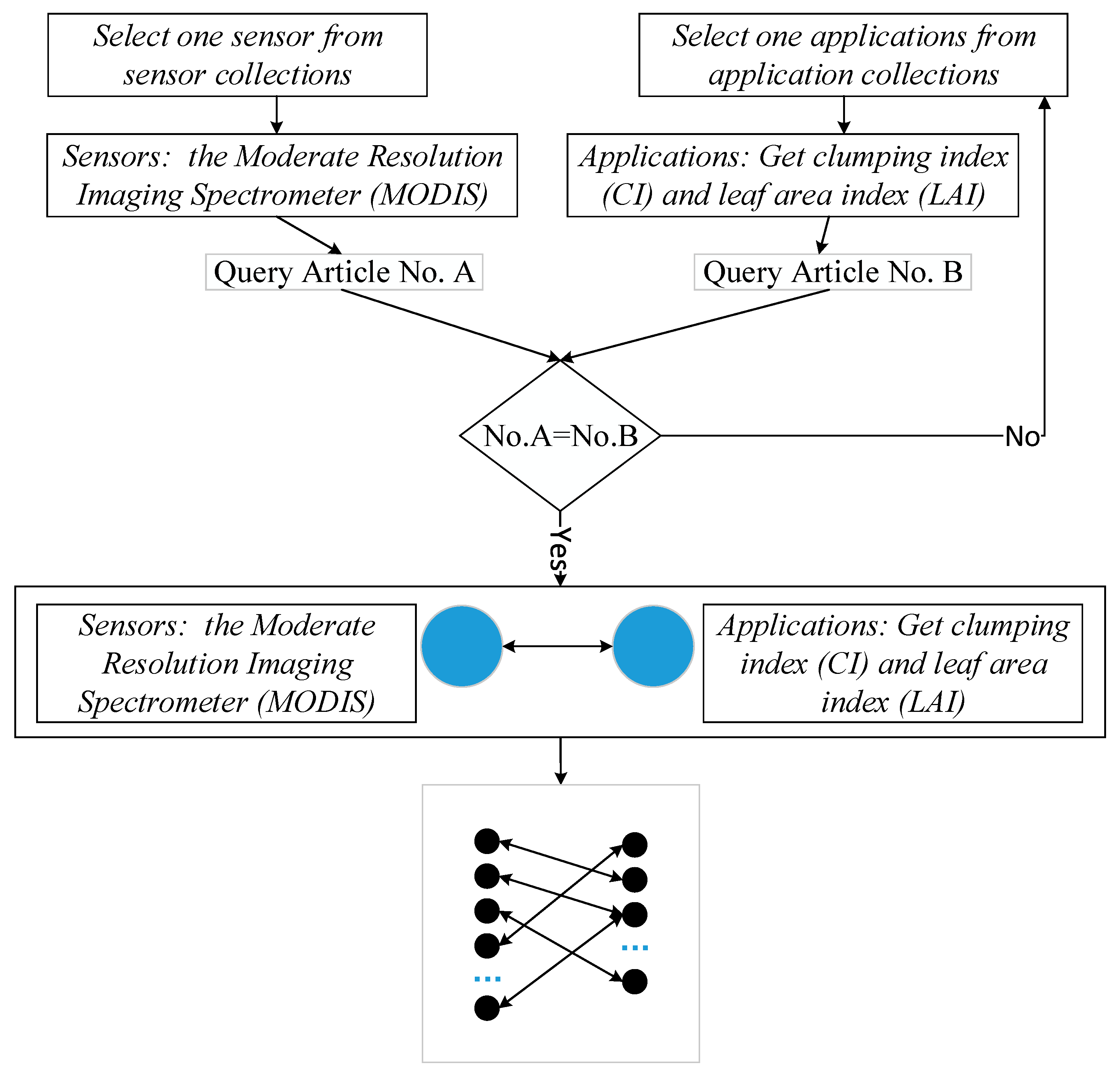
As we are familiar with the field of the remote sensing, we build the BNOI using the literature from the remote sensing field, answering the typical question “what sensors can be used for what applications”. With manual annotation, we determine whether a sentence belongs to the category “sensors” or not and we also determine whether a sentence belongs to the “application” type or not. These sentences with annotations will be used to build the training datasets and the testing datasets. If a “sensors”-containing sentence and sentence with the word “application” appear in a same paper, then the bipartite network relation can be built. When the words “sensors” and “applications” are visualized in a bipartite network, the experts can get more concrete information for questions of interest rather than the over-general information available in a co-word network. Thus, a lot of time and energy of the experts will be saved. Consider the following examples:
“Both the clumping index (CI) and leaf area index (LAI) can be obtained from global Earth Observation data from sensors such as the Moderate Resolution Imaging Spectrometer (MODIS).” [
19]
“The Operational Land Imager (OLI) onboard Landsat-8 satellite can provide remote sensing reflectance (R-rs) of aquatic environments with high spatial resolution (30 m), allowing for benthic habitat mapping and monitoring of bathymetry and water column optical properties.” [
20]
These two example sentences are identified as both “sensors” type and “applications” type. From the first sentence, we know that the Moderate Resolution Imaging Spectrometer (MODIS) can observe the clumping index (CI) and leaf area index (LAI). From the second sentence, we know that Landsat-8 satellite can map the benthic habitat and monitor the bathymetry and the water column optical properties. However, this is concluded by human readers through reading and interpretation. To automatically understand the linkages of “sensors” and “applications”, text mining techniques will help. Nine feature extraction methods (traditional models and neural network language models (NNLM) [
21]) and three classical classifiers (SVM, NB, and LR) are employed. By comparing different feature combination and classification assembly methods, classification models are obtained.
To be more clear, feature-level fusion (fusing nine features) and the best classifiers identification are adopted in our paper, which has been also adopted in reference [
17], but differently from the former work, in order to increase the classification performance, the concept of multi-attribute group decision-making is borrowed by using the voting principle (VP) [
22,
23]. After identifying the classifiers with the best performance the VP method is used for the classifier-level fusion. “Sensors” and “applications” are then automatically identified through the classification process. Based on the best classification results, the BNOI for “sensors” and “applications” is built and compared with the traditional co-word network results.
The contribution of our research is to fill the gap of not considering the interests of researchers in traditional scientometric analysis. The approach can be used to enhance the visual and analytical scientometric software like VoSviewer [
24] or CiteSpace [
25]. Armed with the interests and domain preferences of researchers, the visualization of the domain knowledge can become more of interest to experienced domain experts. The following sections are organized as follows: how the work related to our task is done is described in
Section 2.
Section 3 describes the methodology and the workflow that we will use for experiments, including experimental design, classification techniques, and corpus creation.
Section 4 provides our experimental results and analyses.
Section 5 discusses the results and draws the conclusions.
2. Related Work
Mining the patents and literature to help find the rules of innovation thus helping better innovation process in the scientific field is an important topic [
13]. TRIZ, known as the theory of the solution of inventive problems, has been developed by analyzing over two million references and patent files in a early period [
14] without advanced text mining techniques, and many useful invention principles were proposed. Nowadays, the innovation happens more frequently and a larger amount of patents and literature are available for mining. Therefore, mining the literature for concrete innovations with proper text mining techniques become a new challenge.
Text mining is greatly developed under the urgent demands of mining of open-domain text nowadays [
26]. Online social media platforms such as Facebook, Twitter, and Weibo generate a large amount of text contianing public opinion data every day, and machine learning models can be used to analyze these data to understand the social phenomena of public concerns [
27]. Text mining is also used to mine quality information for helping extract useful knowledge [
28], sentiment classification for film reviews [
29], and multilingual sentiment analysis [
30]. However, these methods all deal with the text from the open domain, which is a different problem than text processing in scientific papers that are often in a very specific domain because, scientific text from scientific papers is often more standardized, having very professional vocabularies, and being more objective from the emotion perspective.
Therefore, the famous text mining methods cannot be directly applied for this mining task, or at least, the text mining methods should be adjusted thus better serving the mining task in scientific texts. For example, for open domain, extracting the knowledge pairs can be undertaken by the name entity recognition (NER) task and the entities are often very concrete objects like people, locations and dates [
31]. However, such entity types are usually not sufficient for the machine to understand the facts contained in a scientific text, which often contain more abstract and complex meanings.
Currently, these text mining methods have been selected or adapted accordingly for dealing mining task of scientific texts. Several approaches have used text mining methods to classify articles, whereby classifiers are adjusted or features selected for fitting the classifying scenario. For example, neural networks and SVM are adjusted for classifying publications from the fields of life science, resource and environment science, and basic science [
32]. Besides classifiers, features are also vital for classification performance. Several traditional features are extended or adapted for analyzing literature text. For example, the methods considering the weights of words for documents are applied to divide scientific documents into art, biology, literature, and so on [
33,
34]. Other traditional methods such as the bag of words (BOW) and term frequency (TF) are also frequently applied. For example, by using supervised machine learning to classify text based on TF [
35], documents are classified using improved term frequency–inverse document frequency (TF-IDF) results [
18,
36].
These adaptations provide meaningful insights for us to automatically understand scientific papers. Recently, a work classified the knowledge pair of “problems” and “solutions” from scientific research papers; Different linguistic features and NNLM features were tested for finding the best combinations [
17]. Their work offered an insight for exploring the interests of researchers. “Problems” and “solutions” are apparently the most frequently mentioned knowledge pairs. Similar to the TRIZ theory [
13,
14], the problems and solutions are the key research targets in their work. Differently, their work provides a practical solution for how modern text mining technologies can be used for extracting the interested knowledge pairs, so this work can be regarded as the modern approximation version of the TRIZ process, providing intelligent suggestions for problems and solutions.
In addition, there is still space for improving the classification accuracy, because only single classifiers are used in that work [
17]. A combination of these classifiers using the voting principle (VP) may be a direct solution for improving the accuracy, which has been mentioned by many previous works. For example, Duan et al. proposed an extreme learning machine based on voting principles to determine the hidden layer in the neural network and reduce randomness [
37]. Hull et al. considered the simple probability average strategy of four text filtering methods [
38]. It is found that this strategy can improve the best classifier for sorting documents and is always better than the best single algorithm in filtering applications, but Li and Jaen found that a simple average combination of multiple classifiers does not always improve classification accuracy compared to the best single classifier [
39]. Uren pointed out that voting systems with different features will perform better than voting systems with a single feature [
40]. Therefore, VP methods could be promising in the classification task.
Inspired by these works, in our paper, we proposed to mine the knowledge of interest pair of “sensors” and “applications”. Our work can be regarded as an extensional work of [
17] because we also use a similar solution, with traditional and NNLM feature extraction methods to identify the terms “sensors” and “applications”. We aim at a different knowledge pair of “sensors” and “applications”, which can be representative for a large type of data-dependent research activities. With the method adapted from [
17] and the new introduced NNLM features like FastText, ELMo, and Bert, the classification results are generated. Finally, based on the classification results, information of interest visualization of BNOI is provided for researchers.
4. Results
4.1. Middle Results of Text Preprocessing
Text preprocessing usually includes tokenization, case conversion, removing stop words. In addition, the number of selected features (words) can be often reduced by transforming the words to their generic form (lemmatization) [
64]. The lemmatization is to restore a formal vocabulary of any kind to a general form (expresses complete semantics), for example, ‘ate’ can be restored ‘eat’. The semantic information of some words will be lost after lemmatization. For this operation, in the “sensors” experiment, we compared the impact of unigrams (BOW) and Word2Vec’s classification accuracy as shown in
Table 4.
It can be seen from
Table 4 that lemmatization and non-lemmatization changes have little effect on classification accuracy. In methods 1, and 2, the NB and SVM classifiers are less effective, and the LR classifier achieved the highest F-measure of 85.9%. For methods 3 and 4, the accuracy of non-lemmatization is 0.6% higher than that of lemmatization. On the other hand, from the two sets of comparative experiments, it is found that the recall rate of lemmatization is usually higher than that of non-lemmatization. This means that lemmatization allows more sentences to be recognized as positive samples, which will inevitably lead to a decrease in precision. However, the purpose of this article is to provide researchers with as much useful information as possible. In summary, lemmatization does lose part of the semantic information and reduce the accuracy rate. Even so, it is acceptable to adopt lemmatization in this experiment, because this method can not only reduce resource consumption, but also provide more positive sample.
However, using only the feature extraction method of lemmatization, the number of features is still huge (≈5000). A huge number of features will decrease the computing efficiency. Feature reduction is usually the next work during the feature extraction engineering. In this article, we use chi-square statistic (CHI) to select features to reduce the complexity.
Table 5 shows the comparison of the number of features using feature selection for BOW feature extraction methods.
From
Table 5, after feature selection, the number of features is greatly reduced, and the reduction rate reaches more than 80%. For the “sSensors” or not “sensors” task, the number of features is changed from 5293 to 879, and for the “applications” or not “applications” task, the number of features is changed from 5293 to 970. Redundant features are greatly reduced, and program execution efficiency can be further improved.
4.2. Classification Results and BNOI Network Building
The classification is conducted for determining whether a sentence belongs to “sensors” type or not, “applications” type or not. For sensors, the terms of sensors are often just composed of nouns, but for applications, the determination of positive samples often depends on a relatively complete verb-object construct. We used the Stanford CoreNLP analysis tool to obtain related phrases about “sensors” and “applications”. After summary of the statistics, there are about 2269 “sensors”. There are about 4181 “applications”. For the data set, there are 0.67 “sensors” and 1.26 “applications” per sentence.
4.2.1. “Sensors” or Not “Sensors” Classification
As seen from
Table 6 and
Table 7, we were able to achieve good results in distinguishing whether a single sentence belongs to the “sensors” class in remote sensing. The VP classifier achieved quite good results in the nine feature extraction methods, six of which had the highest F-measure. The main reason is that the VP classifier can fuse information from multiple “decision makers” (classifiers). For example: “
Ground-based radiometers appeared to be highly sensitive to F/T conditions of the very surface of the soil and indicated normalized polarization index (NPR) values that were below the defined freezing values during the morning sampling period on all sampling dates” [
65], obviously, the sentence belongs to the field of remote sensing. The classifiers {LR, NB, SVM} have the probabilities of classifying a positive sample as {30%, 99%, 32%}, and the F-measures are {86%, 82%, 89%}. Calculated by Equations (1) and (2), the weights are {0.3342, 0.2863, 0.3795} respectively. The final result of the VP classifier is 0.501, which is a positive sample. In the traditional feature extraction method (No. 1–4), the (1-2)-grams (BOW) achieves a good performance of 92.9% for the VP classifier. In the NNLM method (No. 5–9), the ELMo method achieves the highest F-measure in the SVM classifier, which is 85.9%.
Since the corpus used in this work is an ultra-short text of a single sentence, the available features are relatively few. For the determination of whether it belongs to the sensor in remote sensing, the useful feature words are mostly single nouns (such as the name of the Remote Sensing satellite) and these words are neutral and not emotional. Using a traditional BOW model may have a good effect.
Table 8 shows the chi-square statistic score and P_value for the top lemmas from the unigrams (BOW) in previous binary classification of “sensors” and “non-sensors”.
For the chi-square statistic, the higher the score, the smaller the
p-value, the higher correlation of the feature will be [
66,
67].
Table 5 shows the top 10 highly correlation words we selected. The terms “Resolution”, “Image” and “MODIS”, all belong to “Moderate resolution imaging spectrometer (MODIS)”. The next few words are related to spectral imagers. The terms “Landsat” and “Radar” also play a very important role in the classification results. “Landsat” and “Sentinel” are important satellites in the remote sensing field. The results show that these feature words have enough information to build the classification model, and also indicates that the corpus we created is valid. However, it was found that the scores of “remote” and “sense” were too high, which may bias the classification. Therefore, we deleted similar words and the classification results are shown in
Table 9 and
Table 10.
From the comparison of
Table 9 and
Table 10, and
Table 6 and
Table 7, it can be concluded that by deleting some words that cause bias, the classification F-measure of the first nine methods is reduced to some degrees, from 92.9% (Method 3, VP) decreased to 89.3% (Method 3, VP). In this experiment, many language models are introduced, but these models are often used for open-domain text modeling, therefore, these models cannot guarantee the models can still work well in the scientific text scenario. Also, we are also inspired by the work of problem and solution identification [
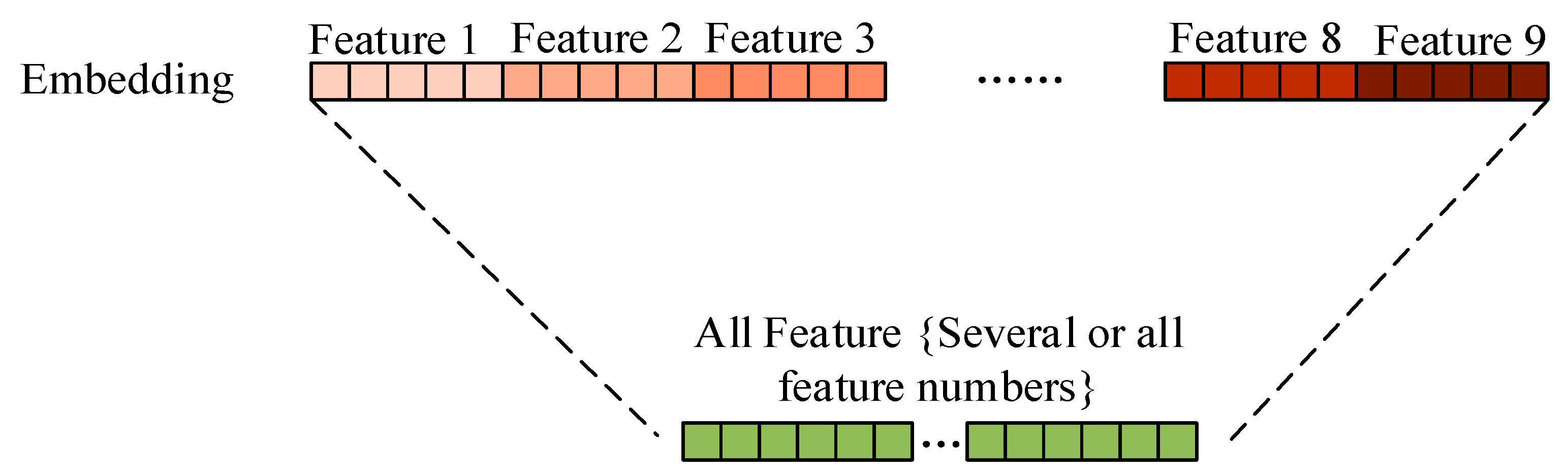
17]. Thus, we used the method of combining multiple features. Its purpose is to fuse word frequency information and semantic information, which can improve each single feature, thus enhancing the classification result. The methods 10 and 11 of
Table 6,
Table 7,
Table 9 and
Table 10 use the method, as shown in
Figure 4. For the method 10, all the feature methods were combined. The F-measure is higher than all single methods. For the method 11, several high-precision feature methods {1, 3, 7, 8} have been selected, and the final classification F-measure is the highest, which is 94.0% (
Table 7) and 93.2% (
Table 10).
For the method 11 in
Table 10, the confusion matrix of VP classifier is shown in
Table 11. For sensor classification, the precision, recall and F-measure are 93.1%, 93.3%, and 93.2%, respectively. From the above three evaluation indicators, we can tell the VP classifier can improve the performance of the sensor classification.
4.2.2. “Applications” or Not “Applications” Classification
The results for disambiguation of applications from non-applications can be seen in
Table 12 and
Table 13. Among the first nine methods, as well as the classification results of “applications” in remote sensing, the SVM classifier achieved the best results, and the five feature methods had the highest F-measure.
By analyzing
Table 12 and
Table 13, when combining features (method 10 and method 11), the VP achieved the best classification result of 86.4%. This shows that the combined features and VP classifier are effective for “applications”. Unlike sensors, application features are more in the form of phrases, so (1-2)-grams (BOW) are used to extract the lemma.
Table 14 shows these lemmas.
We selected the top ten highly correlation lemmas. The representative keyword for “applications” are expected to be “monitoring” and “observation”. However, there are also sensors in remote sensing, such as MODIS, Lidar. This is because application is often expressed as the scenarios with concrete actions. Similarly, we also delete biased words, and the classification results obtained are shown in the
Table 15 and
Table 16 below.
In comparison, after deleting bias words that may cause prejudice, the classification result also appears to be slightly reduced. For method 10, the classification F-measures of combining all features ranges from 84.9% (VP,
Table 13) to 84.5% (VP,
Table 16). For the method 11, four feature methods {1, 3, 6, 9} were combined and the classification F-measures is reduced from 86.4% (VP,
Table 13) to 85.5% (VP,
Table 16). It can be seen that although the accuracy is reduced, the best result is always obtained by combining all the features through the VP classifier. This also shows that this method still has a good effect on application classification. Its confusion matrix is shown in
Table 17.
4.2.3. Knowledge Visualization Analysis by BNOI Versus Co-Word Network
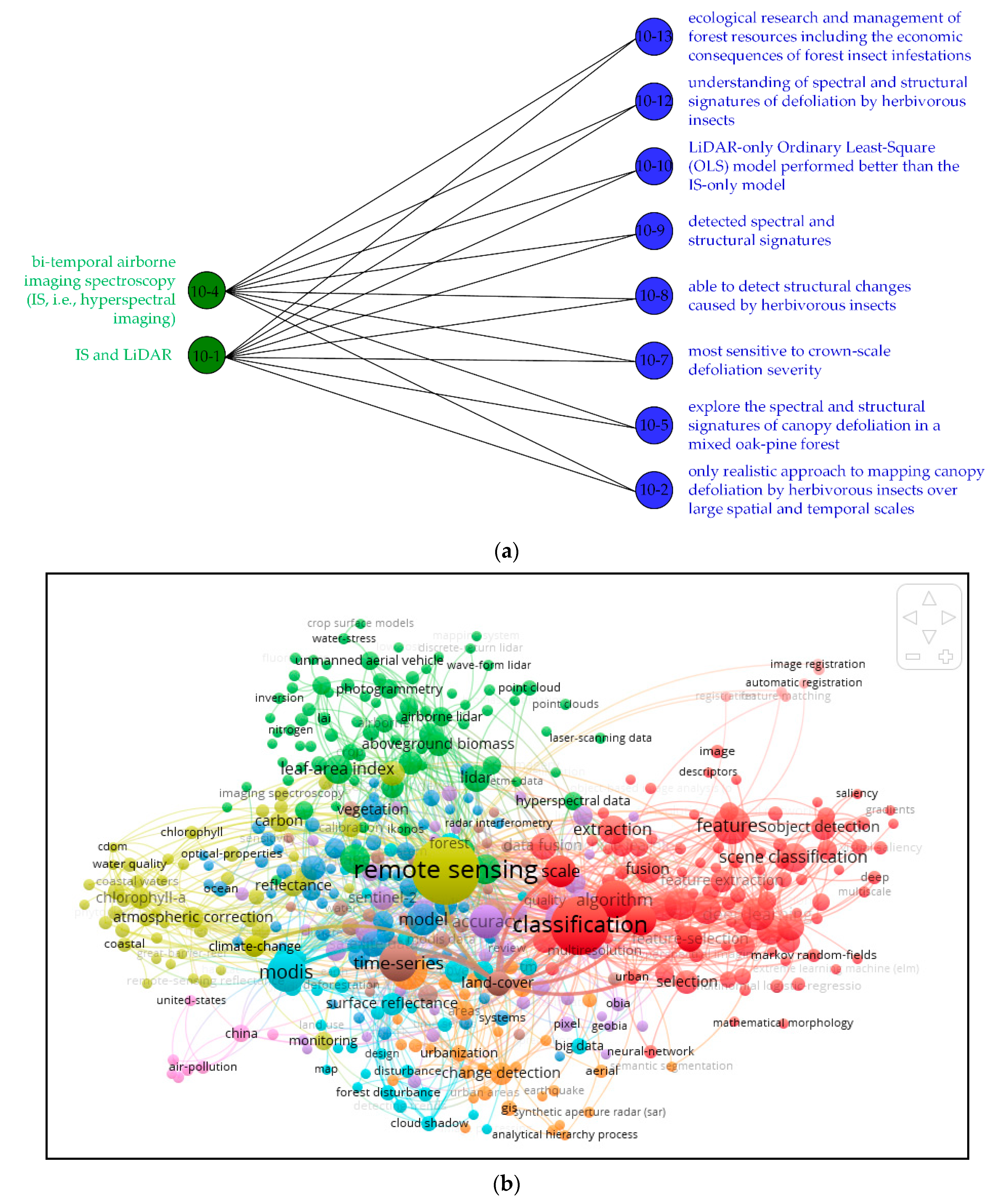
Figure 5 shows the BNOI visualization of interested knowledge pair of “sensors” and “applications” and the traditional co-word network generated by VoSviewer. Note that VoSviewer is a powerful bibliometric software for visualizing the bibliometric information. Besides co-word network, other types of network like our BNOI can also be visualized by VoSviewer.
In
Figure 5a, the left side is the specific sensors, and the applications corresponding to the sensors are on the right. We have counted the paired information of sensors and applications in the data set. There are about 4500 pairs of information in total, which is similar to the information we used before using the Stanford CoreNLP analysis tool. For the data of 350 articles in this experiment, approximately 12 pairs of information appear in the same article. This work is a further expansion of this experiment, readers can add knowledge quickly, conveniently, and intuitively. The classification results with highest accuracy will be the input of building a BNOI graph (that is, sensors result classified using index 1, 3, 5, 7 and applications results classified using index 1, 3, 6, 9). Also, the lemmas are used to index terms in the articles. Nowadays, technology is changing with each passing day, “sensors” and “applications” are also constantly evolving to new combinations, which are important for inspiring researchers to design their research workflow. From this figure, we can easily understand some applications of some sensors. Bipartite network is widely deployed in modeling the complex network because it brings the computational efficiency. In term of visualization readability, they also bring improvements by comparing the general network like the co-word network in
Figure 5b.
Scientometric or bibliometric tools should be furtherly deployed in widely spreading and active evolving disciplines. However, there are problems for domain experts to understand the bibliometric studies for limited depth of the analysis. For domain experts, the needed knowledge is often specific and displays certain tendencies. BNOI presented in
Figure 5a conveys more specific information for the bipartite connection part between “sensors” and “applications”, thus is more informative than the co-word network. The general co-word network can be improved by previous classification process in our work. We need to note that the process taken in our approach will inevitably take much more time for the previous classifications. For many scenarios, VoSviewer is enough for the displaying for the domain hotspots and suitable for newcomers in the field. Only the experts, who already know much about the field, will need the BNOI reported in our work.
4.3. Result Analysis and Discussion
In this work, classical classifiers (NB, SVM, and LR) and a total of nine feature extraction methods (traditional and NNLM) are employed. Then two experiments use different feature combinations and a VP method based on multi-attribute group decision-making theory. The experimental results demonstrate that our approach have provided a useful way to identify the bipartite knowledge pairs of “sensors” and “applications”.
From the perspective of feature selection, combinations of the features are efficient way to increase the classification performance. For the classification of “sensors”, the text content is mostly a proper noun and the entity boundary is clear; for the classification of “applications”, the entity boundary is not clear, and it is difficult to effectively classify it from the perspective of a single keyword. For these two classification tasks, there are some biased phrases. Therefore, we delete some biased words, and combine traditional models and NNLM for feature fusion. The results of ten-fold cross-validation show that the F-measure of “sensors” is 93.2%, and the F-measure of “applications” is 85.5%.
From the perspective of the classifier, the highest F-measure of the LR, NB, and SVM classifiers for the classification of “sensors” is 88.6%, 87.4% and 88.7%, respectively. The VP classifier obtained the highest F-measure of 93.2% in the multi-feature fusion method. For the classification of “applications”, the highest F-measure of the LR, NB, and SVM classifiers is 75.6%, 83.4% and 82.3%, respectively. The VP classifier also obtained the highest F-measure of 85.5% in the multi-feature fusion method. This shows that the VP classifier proposed in this paper can improve the classification performance.
From the perspective of comprehensive use, the main purpose of researchers to search the literature is to get more content of interest. For the classification of “sensors”, the better solution is “ {1, 3, 7, 8} + VP”(1 for Unigrams(BOW), 3 for (1-2)-grams(BOW), 7 for FastText, and 8 for ELMo), which has the highest recognition performance; for the classification of “applications”, the optimal solution is “ {1, 3, 6, 9} + VP “ (1 for Unigrams (BOW), 3 for (1-2)-grams (BOW), 6 for Doc2Vec, and 9 for BERT), which can more comprehensively identify the “applications” in the article. It can be seen from
Table 11 and
Table 17 of the confusion matrix that the VP classifier can obtain more positive samples, and has higher accuracy, recall rate and F-measure, which can meet the needs of researchers.
Finally, the BNOI visualization is built and compared with the co-word network. We can tell the BNOI visualization show the knowledge pair of “sensors” and “applications”, which is more specific than general co-word network visualization. Considering the domain experts, mapping of the BNOI type are surely more suitable and interesting. Thus, the approach proposed in our paper can be regarded as being superior in qualitative readability for domain experts. With the literature explosion, the readers from expert groupings should be highly emphasized, our work can thus fulfill this demand.
The BNOI also has the disadvantages because of its nature for additional classification processes. BNOI always takes more time than the traditional co-word network construction. And the BNOI mapping should not be prepared for the newcomer in the field. Because concrete knowledge entities in a BNOI may be too concrete, newcomers without enough background knowledge may feel it is hard to follow.
5. Conclusions
Mining the literature for finding the innovations have been proposed in TRIZ theory. With the current advanced text mining methodology, more innovation rules may be revealed. Our work used the hybrid feature extraction and classification approach to provide a bipartite network of interest (BNOI), expected to better serve researchers to identify new innovations more effectively. Through the quantitative performance evaluation and qualitative visualization, we demonstrated that our approach can help find concrete knowledge of interest to experienced researchers.
To be specific, our proposed approach extracts the bipartite knowledge pairs automatically with relatively high F-measure and the BNOI is obtained based on the classification results. The automatic process is verified by the classification F-measure obtained by the ten-fold cross-validation of the collected “remote sensing” field articles. The increase of the quantitative performance is due to the feature selection process and the classifier assembling process. Feature selection identifying features and the voting principle to assemble the classifiers are important. In this article, the comprehensive model significantly improves both tasks. In addition, biased phrases such as “remote”, “sense”, and “application” have been removed from the text. Although these features can be identified as positive samples, they are meaningless to researchers. Lastly, the classification-results based BNOI is built. The qualitative characteristics of the BNOI like readability and informative towards domain readers are also discussed by comparing with the co-word network. A classification-results based BNOI is built and demonstrated to be effective for domain knowledge understanding.
Compared with the work Heffernan and Teufel [
17], they have the problems and solutions tagged, which is different from our targets of “sensors” and “applications”, so we cannot directly apply their method. In the feature extraction and classification model part, we conducted similar classification with newer methods like FastText, Bert models. Moreover, we put this one step further by applying the VP to combine different classifiers to achieve better classification results. The classification F-measure using our proposed VP classifier increases from 88.7% (sensors) and 83.4% (applications) by methods in Heffernan and Teufel [
17] to 93.2% (sensors) and 85.5% (applications), respectively. Thus, our proposed method is demonstrated to be efficient.
In the future, we plan to create a larger corpus that contains more sensors and applications. In one aspect, the classification performance can be improved. The increase of amount of data may help build a better classification model. Also, both academic and industrial fields studying feature extraction and classification models. Thus, updating the classification model with the state of the art will also be necessary. In another aspect, the object of this experiment is mainly about scientific text in the remote sensing field, and applying the approach to other scientific fields will be a topic in our next work. “Sensors” and “applications” stand for the type of “data” and “applications” research, should be applied to other similar questions. The follow-up research is how to learn and applied the obtained patterns to another field. Transfer learning seems promising to help solve the problem and it is also an important research hotspot. Therefore, our next work will deal with how to transfer the knowledge of “sensors” and “applications” pairs to other similar knowledge pairs. We will explore the approach in this paper to other fields, such as extracting knowledge pairs of the “nature of proteins” and “their applications in medicine”, the “natural pests in agriculture” and “their solutions”.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}