
IoTCrawler: Challenges and Solutions for Searching the Internet of Things

 , , , ,
, , , ,  , , , , ,
, , , , ,  ,
, 
 , , ,
, , ,
Abstract
1. Introduction
- R-1
- Scalability: Coming from the issue of Volume, a requirement for scalability arises when designing products for the IoT. The huge amount of available, and often heterogeneous, data sources, which have to be considered for the process of search, leads to a challenge of scalability. All components and solutions in this environment have to be designed to work with large scale data. As a result, the machine initiated search shall be answered within a reasonable time.
- R-2
- Semantics and Context for Machine Initiated Search: Newly emerging search models require to tackle the search problems based on the human- and machine originated users’ contexts and requirements such as location, time, activity, previous records and profile. The search results are targeted to be based on emerging IoT application models, where search can be initiated without human involvement. The generation of higher-level context, such as traffic conditions, e.g., from low-level observations, can enhance the search functionality for applications that require information on trends and profiles about sensory data. Generated data from IoT deployments are largely multivariate, and therefore require aggregation methods that can preserve and represent its key characteristics, while reducing the processing time and storage necessities.
- R-3
- Discovery and Search: To provide a well performing and responsive IoT search framework, the entire process needs to be considered as a two stages approach, namely Discovery and Search. In the first stage, knowledge about available IoT devices and the data streams they provide has to be crawled. The goal is to build up a data repository containing available information about the data streams. In the second stage, while processing a search request, the potential data streams, satisfying the search query, are then extracted from the repository. Before being returned to the requester, the list of candidates needs to be ranked, to allow the application to use the best fitting data streams.
- R-4
- Security and Privacy by Design: It is vital that Privacy and Security are addressed from the beginning in a design phase and through all the development of a project. It requires authentication, access control and privacy mechanisms in order to provide a controlled environment where providers can specify the access policy attached to their data, and even broadcast it in a privacy preserving manner, so that only legitimate consumers are able to access the information.
2. Related Work
2.1. Search over Discovered Metadata
2.2. Semantics, Ontologies and Information Models for Interoperability
2.3. Security and Privacy in IoT
2.4. Reliability in IoT
2.5. Indexing of Discovered Resources
2.6. Ranking of Search Results
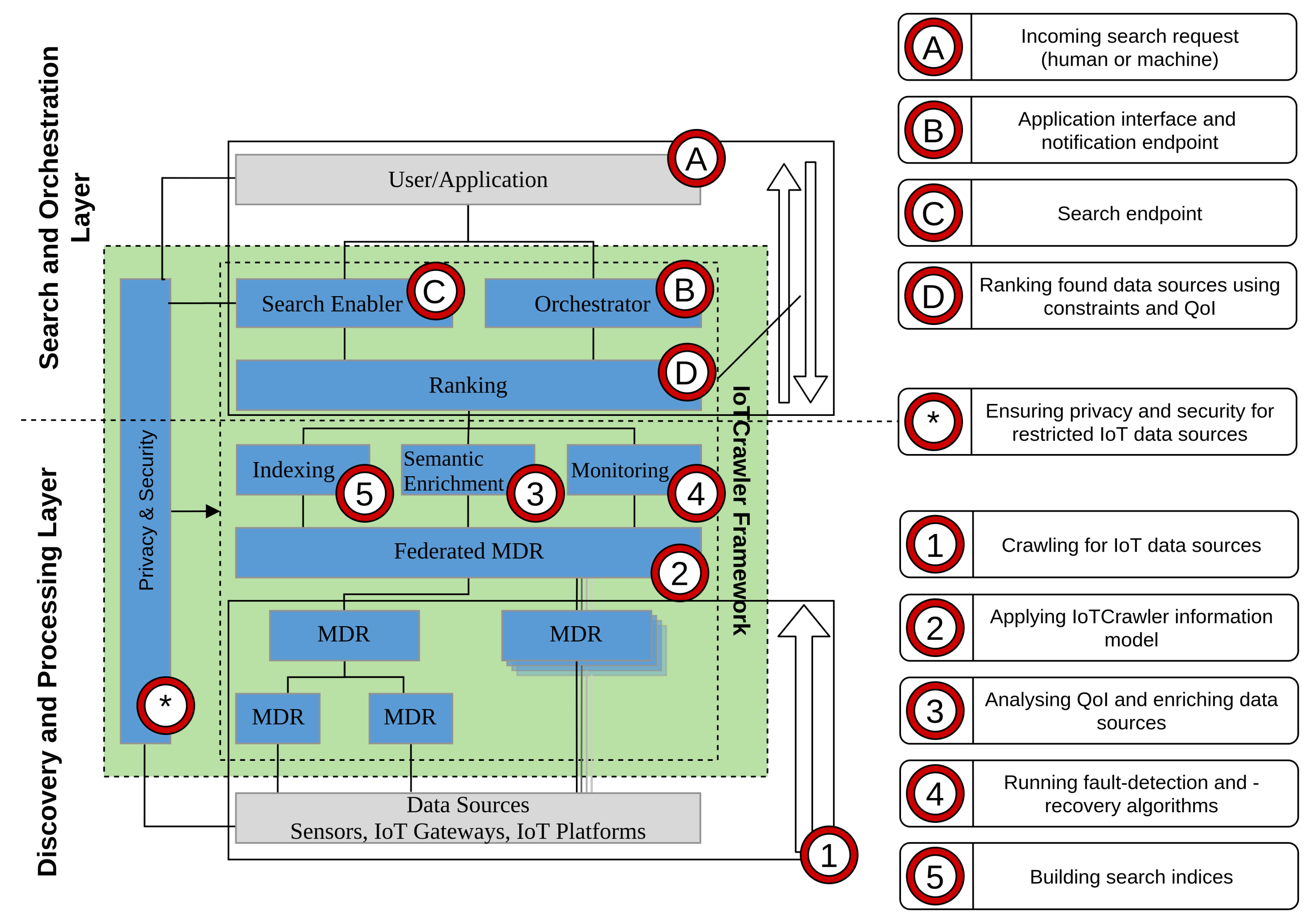
3. Search Framework for IoT
4. Enablers for Discovery and Processing Layer
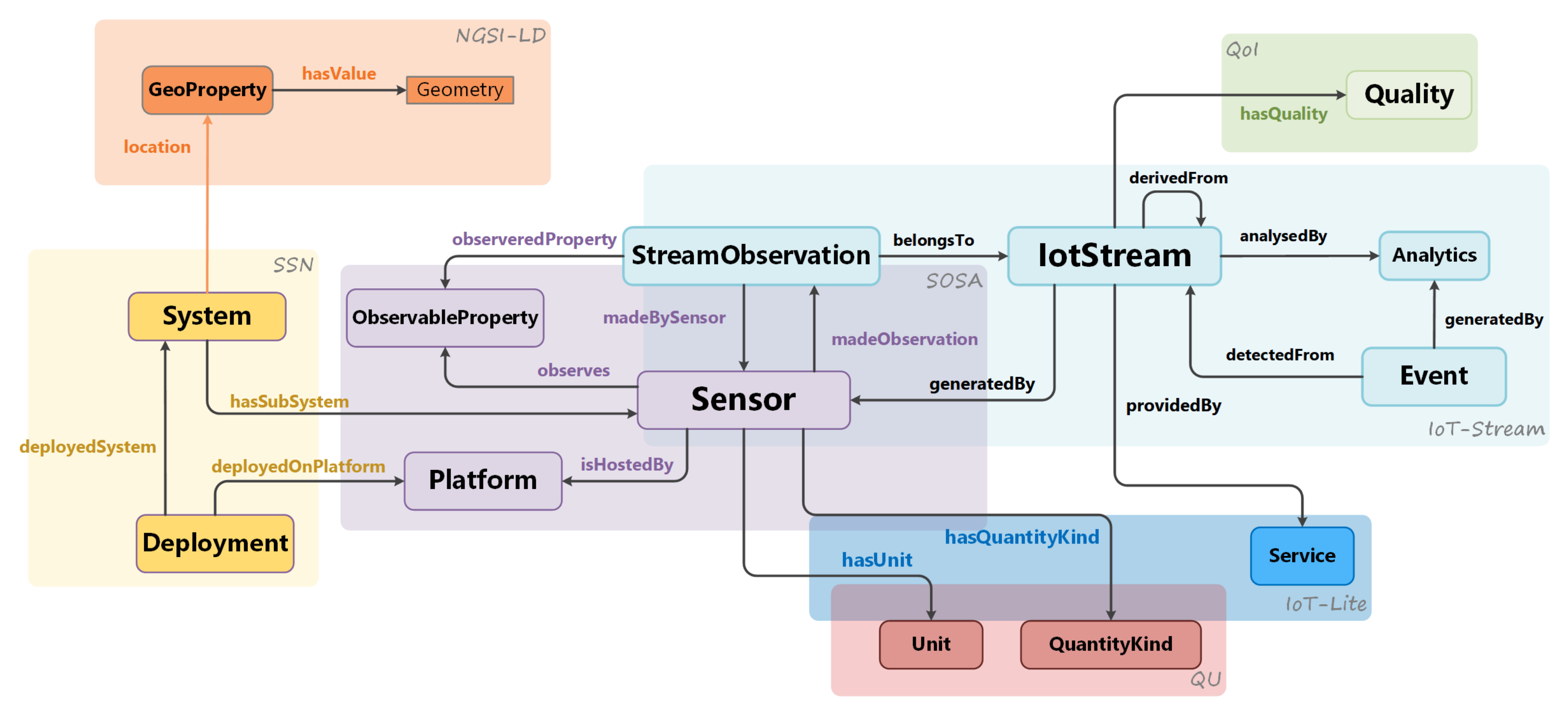
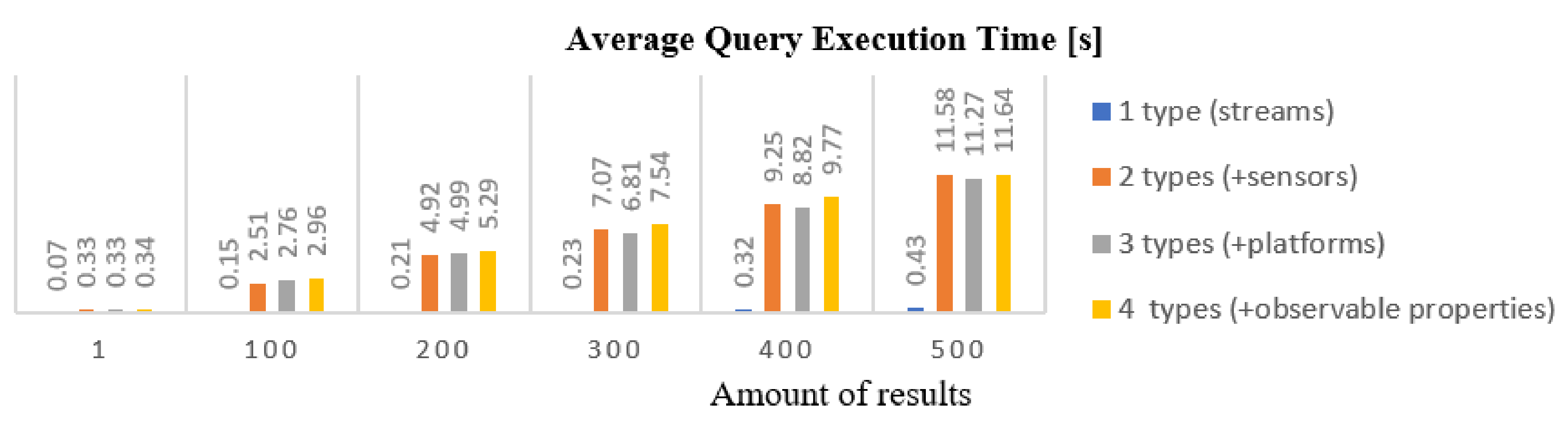
4.1. Information Model
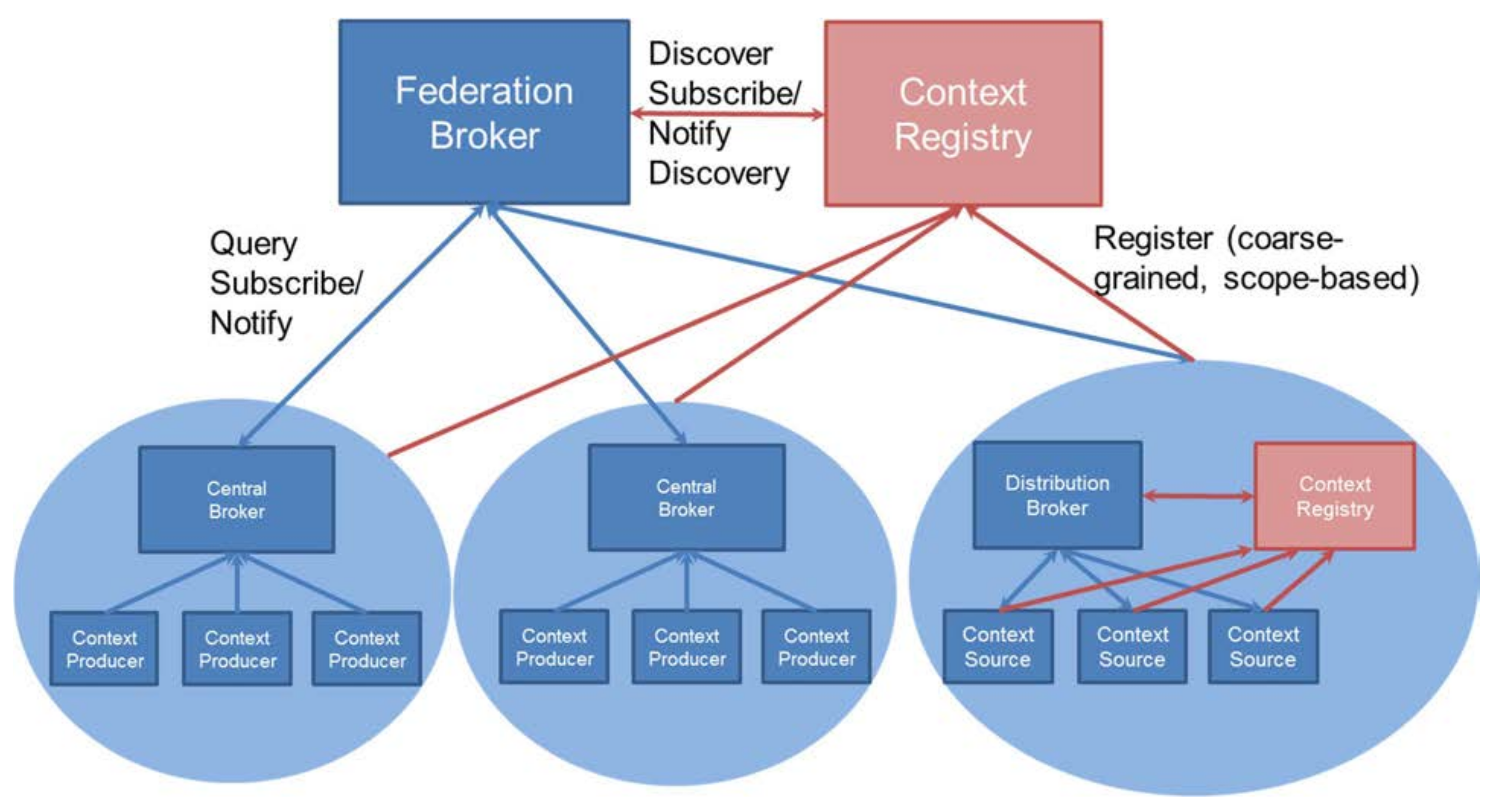
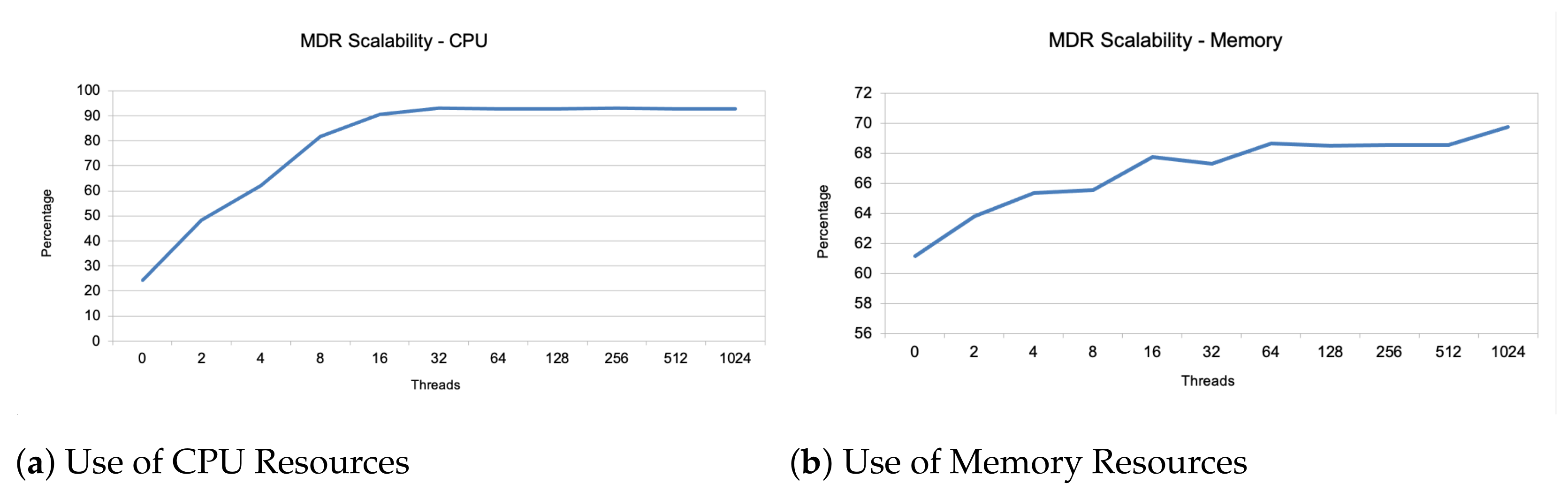
4.2. Federation of Metadata Repositories
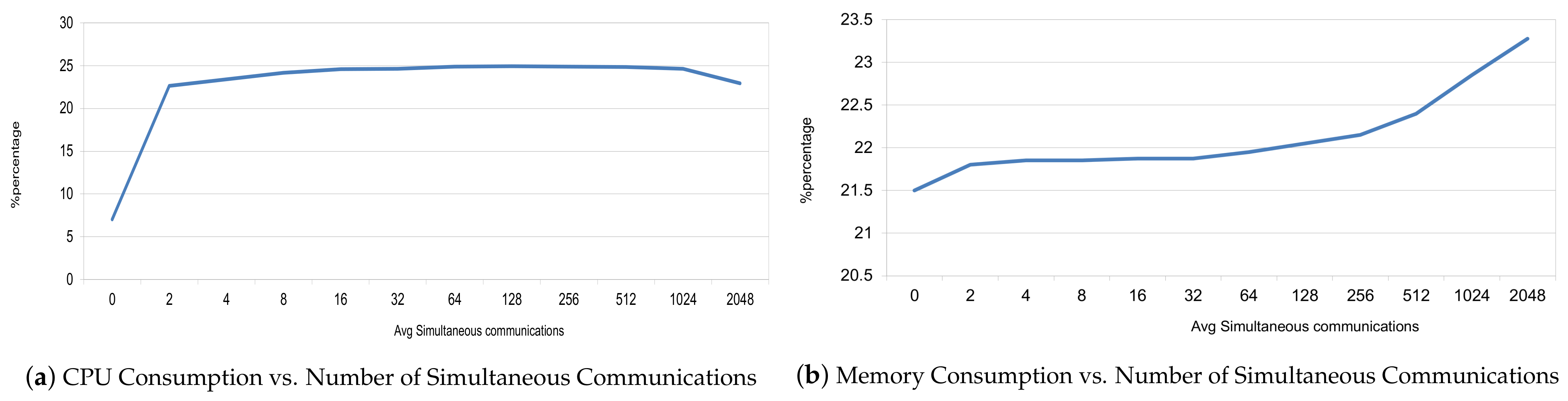
4.3. Monitoring
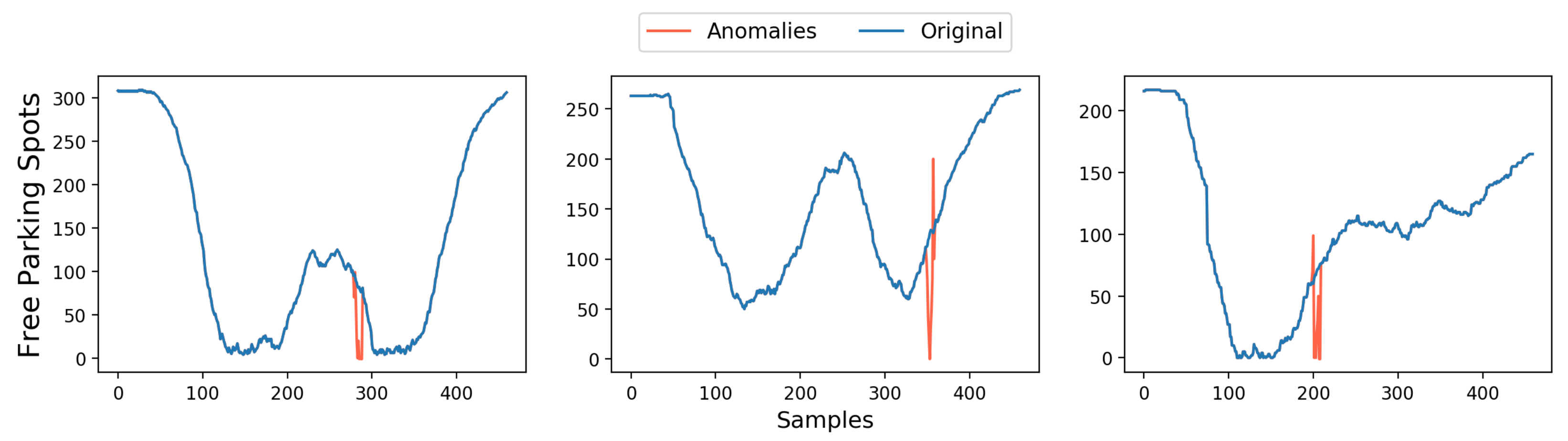
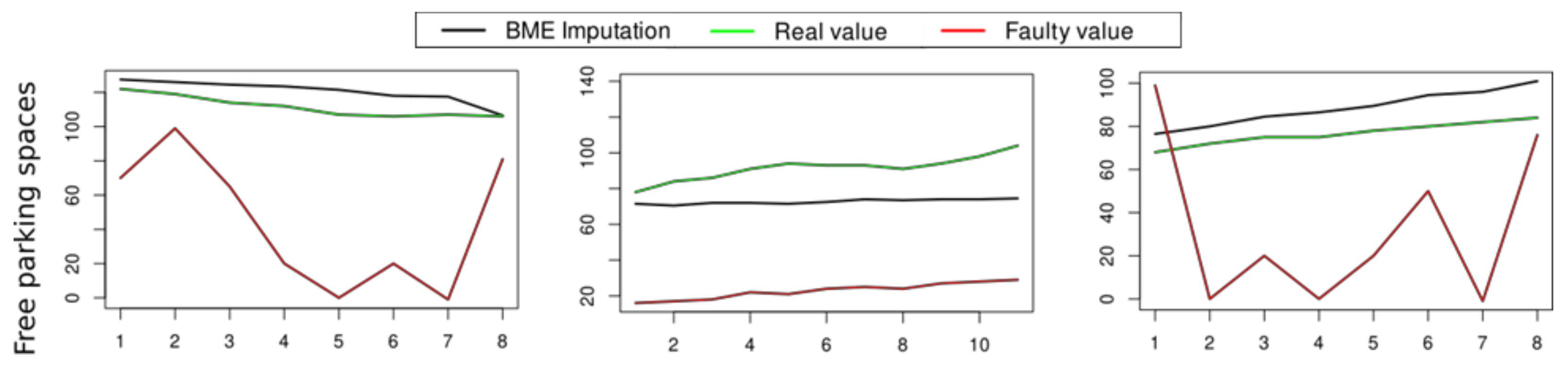
4.3.1. Fault Detection and Fault Recovery
4.3.2. Virtual Sensor
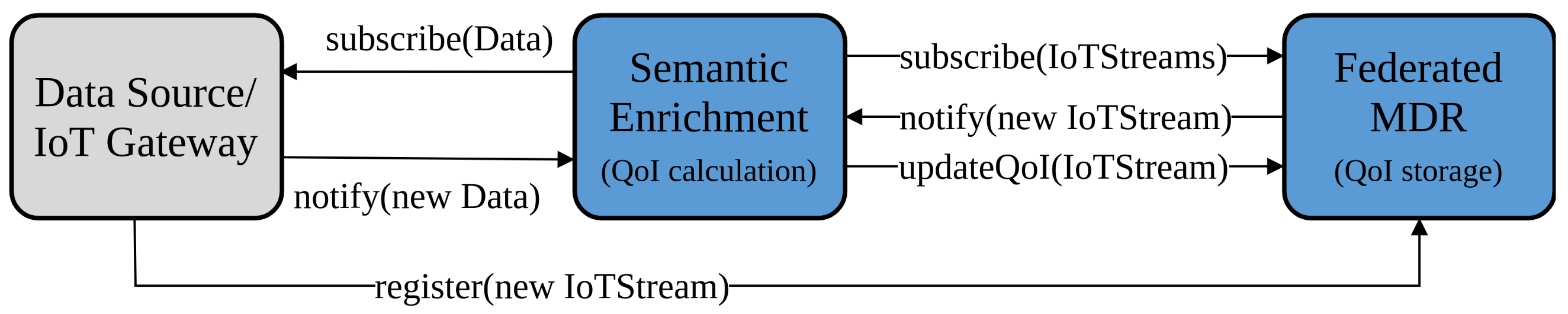
4.4. Semantic Enrichment
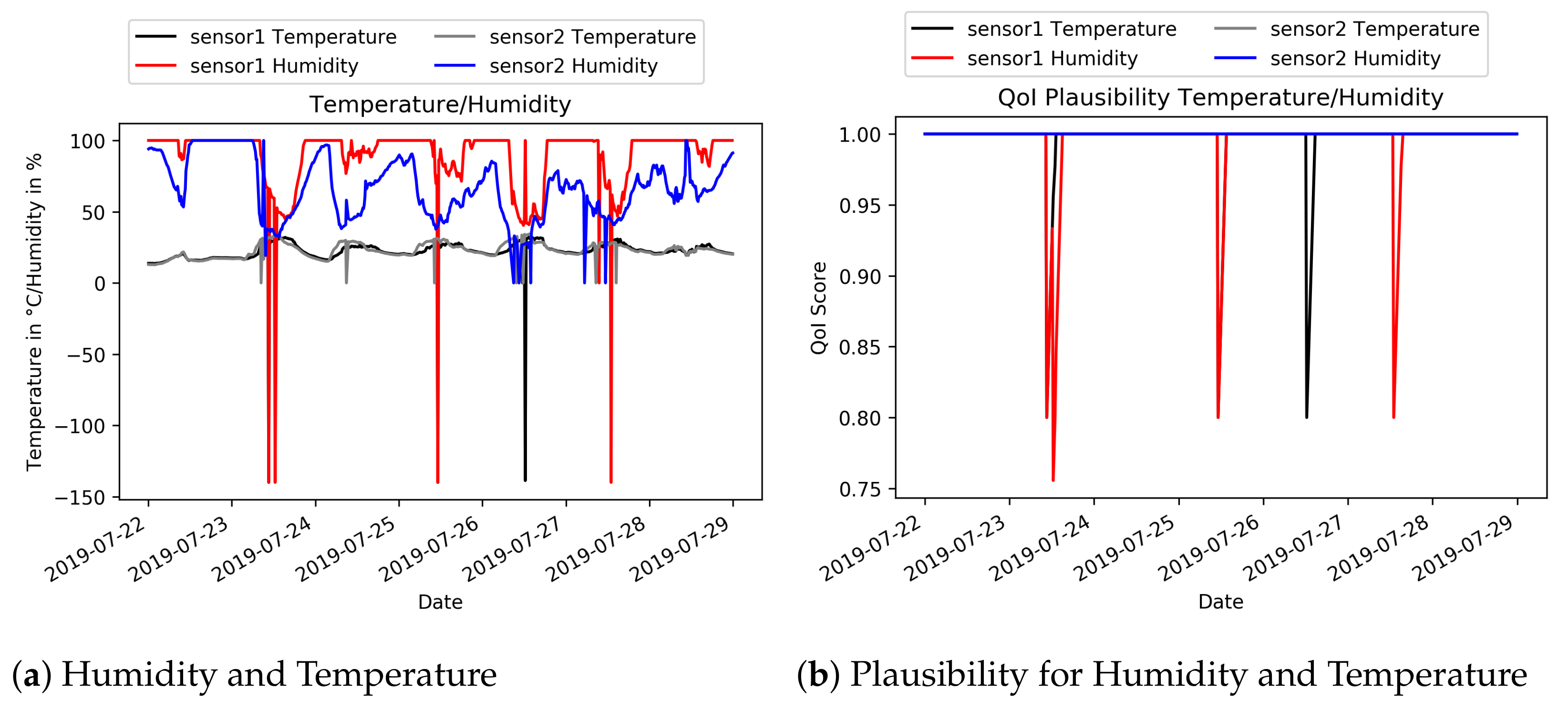
4.4.1. QoI Analyser
4.4.2. Pattern Extractor
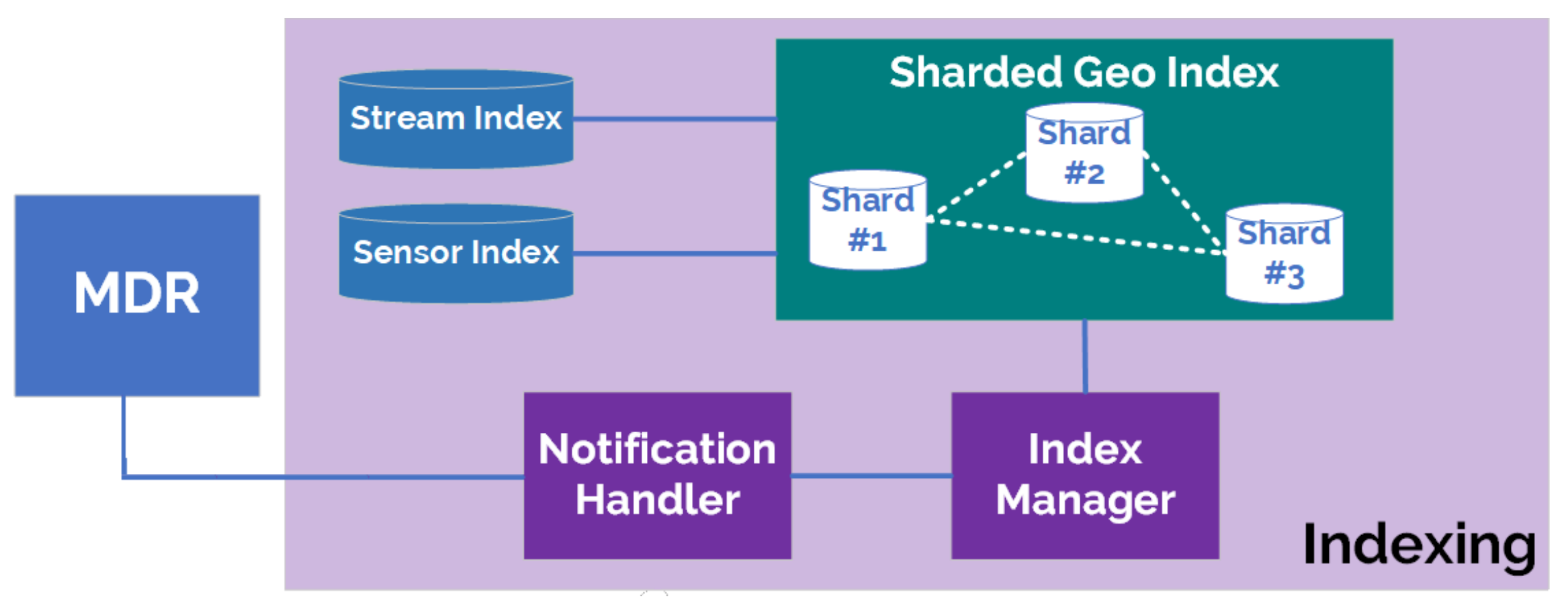
4.5. Indexing
5. Enablers for Search and Orchestration Layer
5.1. Privacy and Security
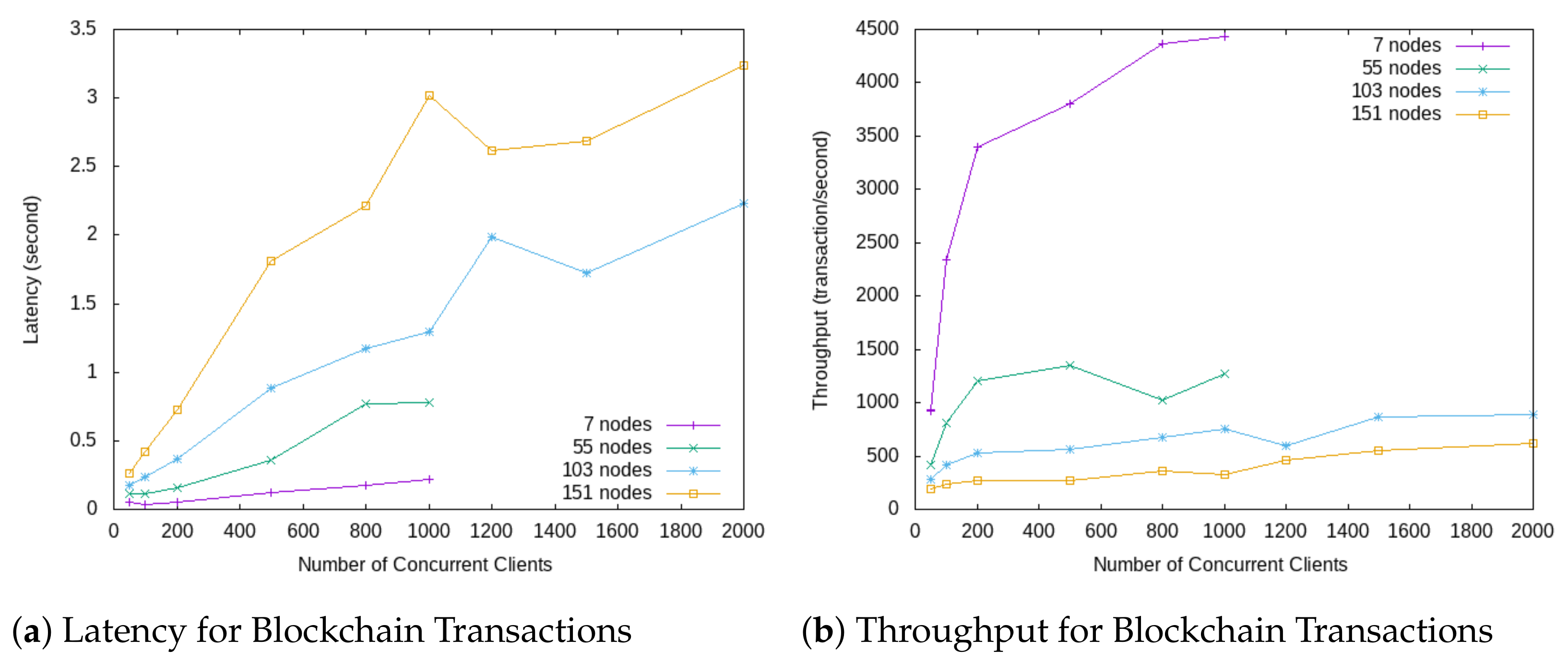
- Untrustworthy entities: First, Policy Administration Point (PAP) might be subject to an attack and perform malicious actions such as updating a policy against the resource owner’s will. Having a Blockchain helps avoid misbehaviour of PAP. The access control policy’s integrity is checked by registering and checking its meta-data, such as the hash value managed by the Blockchain network. Second, policy evaluation done by Policy Decision Point (PDP), which could be manipulated by an untrusted PAP. The Blockchain ensures this misbehaviour to be detectable.
- Auditability: The verifiable property of Blockchain allows detecting if an access control service falsely denied access to a subject that the policy would grant or if the access control service granted a permission while the policy was not satisfied.
- Revocability: The attribute-based access control model that we have in this framework assumes, once a subject has granted an access permission, that the subject will receive an access token. It is challenging to revoke the token once it has been misused or stolen. Blockchain resolves this issue by executing a token smart contract to invalidate the vulnerable token.
- Fault tolerance: Access control components are distributed among peers over the Blockchain network. Such components are PAP, PDP and CM, among others. By having functions executed as smart contracts and invoked by a peer of the network, it avoids becoming a single point of failure as it would be the case with traditional PAP, PDP or CM.
- Integrity: New changes may cause disruption of such services and therefore they should be done cautiously. No single individual can introduce changes. This property is essential in the network where the participants often do not trust each other.
5.1.1. Identity Management and Authentication Evaluation
5.1.2. Authorisation Evaluation
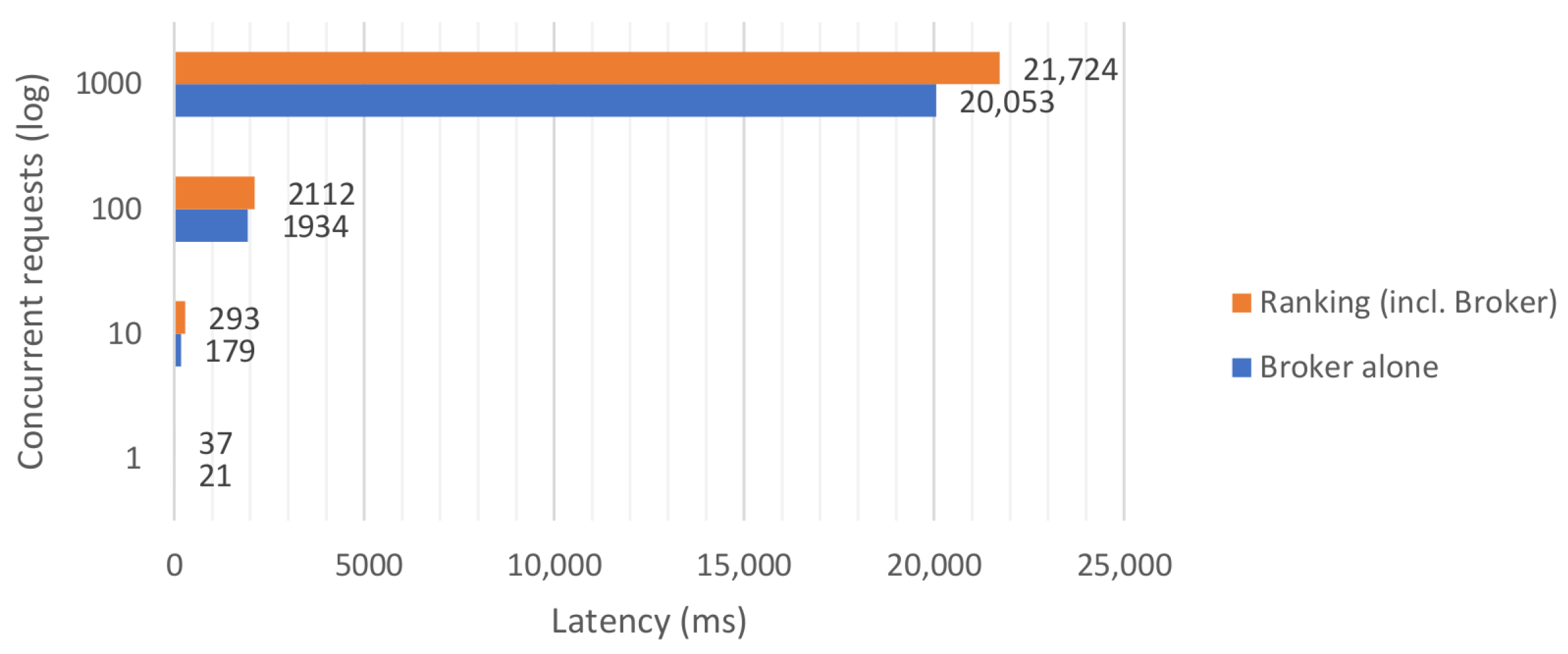
5.2. Ranking
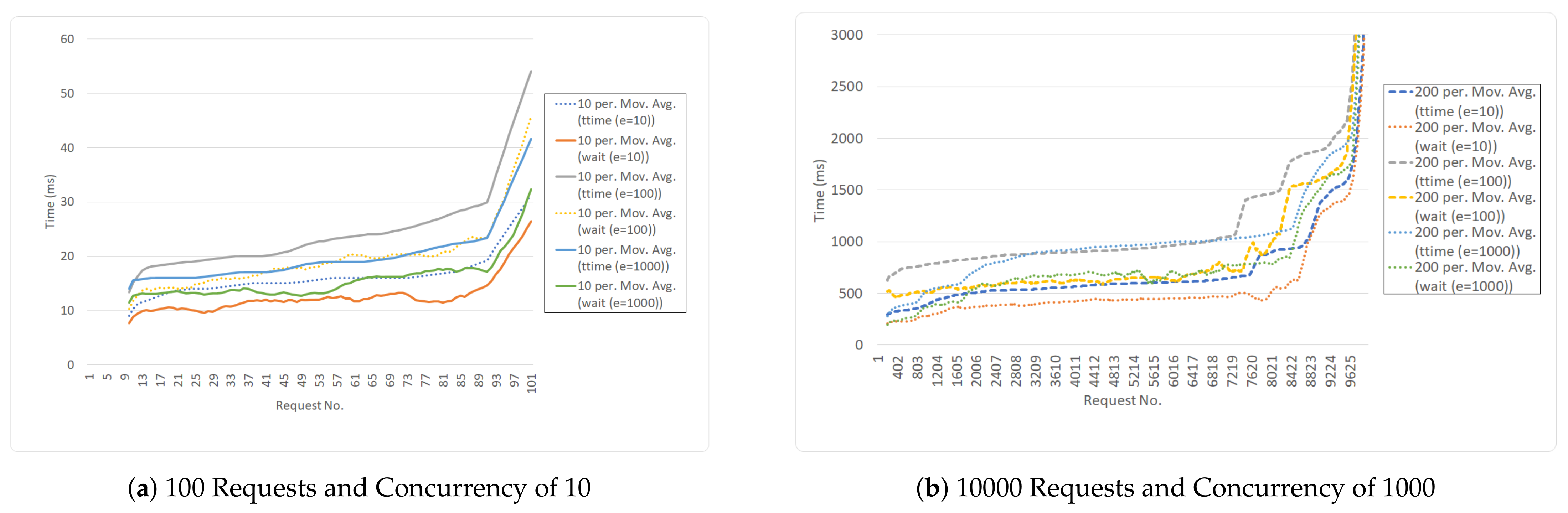
5.3. Search Enabler
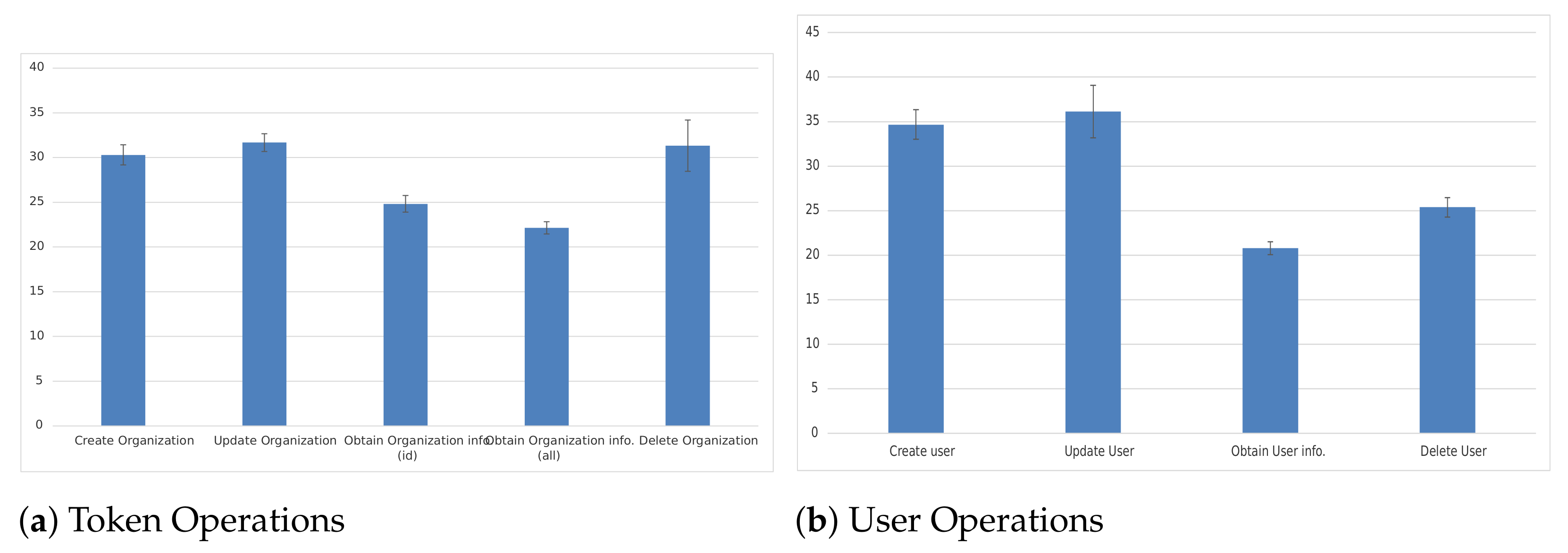
5.4. Orchestrator
6. Application Domain Instantiation
6.1. Smart Home—Semantic Integration Focus
6.2. Smart Parking—Security and Privacy Focus
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ostermaier, B.; Römer, K.; Mattern, F.; Fahrmair, M.; Kellerer, W. A real-time search engine for the web of things. In Proceedings of the 2010 Internet of Things (IOT), Tokyo, Japan, 29 November–1 December 2010; pp. 1–8. [Google Scholar]
- Mayer, S.; Guinard, D. An extensible discovery service for smart things. In Proceedings of the Second International Workshop on Web of Things, San Francisco, CA, USA, 16 June 2011; pp. 1–6. [Google Scholar]
- Le-Phuoc, D.; Quoc, H.N.M.; Parreira, J.X.; Hauswirth, M. The linked sensor middleware–connecting the real world and the semantic web. Proc. Semant. Web Chall. 2011, 152, 22–23. [Google Scholar]
- Le-Phuoc, D.; Dao-Tran, M.; Parreira, J.X.; Hauswirth, M. A native and adaptive approach for unified processing of linked streams and linked data. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2011; pp. 370–388. [Google Scholar]
- Kamilaris, A.; Yumusak, S.; Ali, M.I. WOTS2E: A search engine for a Semantic Web of Things. In Proceedings of the 2016 IEEE 3rd World Forum on Internet of Things (WF-IoT), Reston, VA, USA, 12–14 December 2016; pp. 436–441. [Google Scholar]
- Tran, N.K.; Sheng, Q.Z.; Babar, M.A.; Yao, L.; Zhang, W.E.; Dustdar, S. Internet of Things search engine. Commun. ACM 2019, 62, 66–73. [Google Scholar] [CrossRef]
- Smirnov, P.; Strohbach, M.; Schneider, P.; Gonzalez Gil, P.; Skarmeta, A.F.; Elsaleh, T.; Gonzalez, A.; Rezvani, R.; Truong, H. D5.2 Enablers for Machine Initiated Semantic IoT Search. IoTCrawler 2020. Available online: https://iotcrawler.eu/index.php/project/d5-2-enablers-for-machine-initiated-semantic-iot-search/ (accessed on 24 February 2021).
- Strohbach, M.; Saavedra, L.A.; Smirnov, P.; Legostaieva, S. Smart Home Crawler: Towards a framework for semi-automatic IoT sensor integration. In Proceedings of the 2019 Global IoT Summit (GIoTS), Aarhus, Denmark, 17–21 June 2019; pp. 1–6. [Google Scholar]
- Bonino, D.; Corno, F. Dogont-ontology modeling for intelligent domotic environments. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2008; pp. 790–803. [Google Scholar]
- Compton, M.; Barnaghi, P.; Bermudez, L.; García-Castro, R.; Corcho, Ó.; Cox, S.; Graybeal, J.; Hauswirth, M.; Henson, C.; Herzog, A.; et al. The SSN ontology of the W3C semantic sensor network incubator group. J. Web Semant. 2012, 17, 25–32. [Google Scholar] [CrossRef]
- Janowicz, K.; Haller, A.; Cox, S.J.; Le Phuoc, D.; Lefrançois, M. SOSA: A lightweight ontology for sensors, observations, samples, and actuators. J. Web Semant. 2019, 56, 1–10. [Google Scholar] [CrossRef]
- Bermúdez-Edo, M.; Elsaleh, T.; Barnaghi, P.; Taylor, K. IoT-Lite: A lightweight semantic model for the internet of things and its use with dynamic semantics. Pers. Ubiquitous Comput. 2016, 21, 475–487. [Google Scholar] [CrossRef]
- Kolozali, S.; Bermudez-Edo, M.; Puschmann, D.; Ganz, F.; Barnaghi, P. A knowledge-based approach for real-time iot data stream annotation and processing. In Proceedings of the 2014 IEEE International Conference on Internet of Things (iThings), and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom), Taipei, Taiwan, 1–3 September 2014; pp. 215–222. [Google Scholar]
- Elsaleh, T.; Enshaeifar, S.; Rezvani, R.; Acton, S.T.; Janeiko, V.; Bermudez-Edo, M. IoT-Stream: A Lightweight Ontology for Internet of Things Data Streams and Its Use with Data Analytics and Event Detection Services. Sensors 2020, 20, 953. [Google Scholar] [CrossRef] [PubMed]
- Abomhara, M.; Køien, G.M. Security and privacy in the Internet of Things: Current status and open issues. In Proceedings of the 2014 International Conference on Privacy and Security in Mobile Systems (PRISMS), Aalborg, Denmark, 11–14 May 2014; pp. 1–8. [Google Scholar]
- Riahi, A.; Challal, Y.; Natalizio, E.; Chtourou, Z.; Bouabdallah, A. A systemic approach for IoT security. In Proceedings of the 2013 IEEE International Conference on Distributed Computing in Sensor Systems, Cambridge, MA, USA, 20–23 May 2013; pp. 351–355. [Google Scholar]
- Mahalle, P.; Babar, S.; Prasad, N.R.; Prasad, R. Identity management framework towards internet of things (IoT): Roadmap and key challenges. In International Conference on Network Security and Applications; Springer: Berlin/Heidelberg, Germany, 2010; pp. 430–439. [Google Scholar]
- Bernal Bernabe, J.; Hernandez-Ramos, J.L.; Skarmeta Gomez, A.F. Holistic privacy-preserving identity management system for the internet of things. Mob. Inf. Syst. 2017, 2017. [Google Scholar] [CrossRef]
- Mazzoleni, P.; Crispo, B.; Sivasubramanian, S.; Bertino, E. XACML policy integration algorithms. ACM Trans. Inf. Syst. Secur. (TISSEC) 2008, 11, 1–29. [Google Scholar] [CrossRef]
- Hernández-Ramos, J.L.; Jara, A.J.; Marin, L.; Skarmeta, A.F. Distributed capability-based access control for the internet of things. J. Internet Serv. Inf. Secur. (JISIS) 2013, 3, 1–16. [Google Scholar]
- Pérez, S.; Rotondi, D.; Pedone, D.; Straniero, L.; Núñez, M.J.; Gigante, F. Towards the CP-ABE application for privacy-preserving secure data sharing in IoT contexts. In International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 917–926. [Google Scholar]
- Hwang, Y.H. Iot security & privacy: Threats and challenges. In Proceedings of the 1st ACM Workshop on IoT Privacy, Trust, and Security; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Garcia, N.; Alcaniz, T.; González-Vidal, A.; Bernabe, J.B.; Rivera, D.; Skarmeta, A. Distributed real-time SlowDoS attacks detection over encrypted traffic using Artificial Intelligence. J. Netw. Comput. Appl. 2021, 173, 102871. [Google Scholar] [CrossRef]
- Hernandez-Ramos, J.L.; Martinez, J.A.; Savarino, V.; Angelini, M.; Napolitano, V.; Skarmeta, A.; Baldini, G. Security and Privacy in Internet of Things-Enabled Smart Cities: Challenges and Future Directions. IEEE Secur. Priv. 2020. [Google Scholar] [CrossRef]
- Hernandez-Ramos, J.L.; Geneiatakis, D.; Kounelis, I.; Steri, G.; Fovino, I.N. Toward a Data-Driven Society: A Technological Perspective on the Development of Cybersecurity and Data-Protection Policies. IEEE Secur. Priv. 2019, 18, 28–38. [Google Scholar] [CrossRef]
- Juran, J.; Godfrey, A.B. Quality Handbook, 5th ed.; McGraw-Hill: Irwin, NY, USA, 1999; Volume 173. [Google Scholar]
- Wang, R.Y.; Strong, D.M.; Guarascio, L.M. Beyond accuracy: What data quality means to data consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Mendes, P.N.; Mühleisen, H.; Bizer, C. Sieve: Linked data quality assessment and fusion. In Proceedings of the 2012 Joint EDBT/ICDT Workshops; Association for Computing Machinery: New York, NY, USA, 2012; pp. 116–123. [Google Scholar]
- Sicari, S.; Rizzardi, A.; Grieco, L.; Piro, G.; Coen-Porisini, A. A policy enforcement framework for Internet of Things applications in the smart health. Smart Health 2017, 3, 39–74. [Google Scholar] [CrossRef]
- Klein, A.; Do, H.H.; Hackenbroich, G.; Karnstedt, M.; Lehner, W. Representing data quality for streaming and static data. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering Workshop, Istanbul, Turkey, 17–20 April 2007; pp. 3–10. [Google Scholar]
- Kothari, A.; Boddula, V.; Ramaswamy, L.; Abolhassani, N. DQS-Cloud: A Data Quality-Aware autonomic cloud for sensor services. In Proceedings of the 10th IEEE International Conference on Collaborative Computing: Networking, Applications and Worksharing, Miami, FL, USA, 22–25 October 2014; pp. 295–303. [Google Scholar]
- Puiu, D.; Barnaghi, P.; Toenjes, R.; Kümper, D.; Ali, M.I.; Mileo, A.; Parreira, J.X.; Fischer, M.; Kolozali, S.; Farajidavar, N.; et al. Citypulse: Large scale data analytics framework for smart cities. IEEE Access 2016, 4, 1086–1108. [Google Scholar] [CrossRef]
- Iggena, T.; Fischer, M.; Kuemper, D. Quality Ontology. Available online: http://purl.oclc.org/NET/UASO/qoi (accessed on 8 January 2021).
- Norris, M.; Celik, B.; Venkatesh, P.; Zhao, S.; McDaniel, P.; Sivasubramaniam, A.; Tan, G. IoTRepair: Systematically Addressing Device Faults in Commodity IoT. In Proceedings of the 2020 IEEE/ACM Fifth International Conference on Internet-of-Things Design and Implementation (IoTDI), Sydney, NSW, Australia, 21–24 April 2020; pp. 142–148. [Google Scholar]
- Power, A.; Kotonya, G. A Microservices Architecture for Reactive and Proactive Fault Tolerance in IoT Systems. In Proceedings of the 2018 IEEE 19th International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Chania, Greece, 12–15 June 2018; pp. 588–599. [Google Scholar]
- Izonin, I.; Kryvinska, N.; Tkachenko, R.; Zub, K. An approach towards missing data recovery within IoT smart system. Procedia Comput. Sci. 2019, 155, 11–18. [Google Scholar] [CrossRef]
- Liu, Y.; Dillon, T.; Yu, W.; Rahayu, W.; Mostafa, F. Missing Value Imputation for Industrial IoT Sensor Data With Large Gaps. IEEE Internet Things J. 2020, 7, 6855–6867. [Google Scholar] [CrossRef]
- Al-Milli, N.; Almobaideen, W. Hybrid Neural Network to Impute Missing Data for IoT Applications. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 121–125. [Google Scholar]
- Fathy, Y.; Barnaghi, P.; Tafazolli, R. Large-scale indexing, discovery, and ranking for the Internet of Things (IoT). ACM Comput. Surv. (CSUR) 2018, 51, 1–53. [Google Scholar] [CrossRef]
- Zhou, Y.; De, S.; Wang, W.; Moessner, K. Enabling query of frequently updated data from mobile sensing sources. In Proceedings of the 2014 IEEE 17th International Conference on Computational Science and Engineering, Chengdu, China, 19–21 December 2014; pp. 946–952. [Google Scholar]
- Barnaghi, P.; Wang, W.; Dong, L.; Wang, C. A Linked-Data Model for Semantic Sensor Streams. In Proceedings of the IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013; pp. 468–475. [Google Scholar] [CrossRef]
- Fathy, Y.; Barnaghi, P.; Enshaeifar, S.; Tafazolli, R. A distributed in-network indexing mechanism for the Internet of Things. In Proceedings of the IEEE 3rd World Forum on Internet of Things (WF-IoT), Reston, VA, USA, 12–14 December 2016; pp. 585–590. [Google Scholar] [CrossRef]
- Camerra, A.; Palpanas, T.; Shieh, J.; Keogh, E. iSAX 2.0: Indexing and mining one billion time series. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, NSW, Australia, 13–17 December 2010; pp. 58–67. [Google Scholar]
- Zoumpatianos, K.; Idreos, S.; Palpanas, T. Indexing for Interactive Exploration of Big Data Series. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1555–1566. [Google Scholar] [CrossRef]
- Ganz, F.; Barnaghi, P.; Carrez, F. Information Abstraction for Heterogeneous Real World Internet Data. IEEE Sens. J. 2013, 13, 3793–3805. [Google Scholar] [CrossRef]
- Gonzalez-Vidal, A.; Barnaghi, P.; Skarmeta, A.F. Beats: Blocks of eigenvalues algorithm for time series segmentation. IEEE Trans. Knowl. Data Eng. 2018, 30, 2051–2064. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. Reprint of: The Anatomy of a Large-Scale Hypertextual Web Search Engine. Comput. Netw. 2012, 56, 3825–3833. [Google Scholar] [CrossRef]
- Guinard, D.; Trifa, V.; Karnouskos, S.; Spiess, P.; Savio, D. Interacting with the SOA-Based Internet of Things: Discovery, Query, Selection, and On-Demand Provisioning of Web Services. IEEE Trans. Serv. Comput. 2010, 3, 223–235. [Google Scholar] [CrossRef]
- Yuen, K.K.F.; Wang, W. Towards a ranking approach for sensor services using primitive cognitive network process. In Proceedings of the 4th Annual IEEE International Conference on Cyber Technology in Automation, Control and Intelligent, Hong Kong, China, 4–7 June 2014; pp. 344–348. [Google Scholar] [CrossRef]
- Niu, W.; Lei, J.; Tong, E.; Li, G.; Chang, L.; Shi, Z.; Ci, S. Context-Aware Service Ranking in Wireless Sensor Networks. J. Netw. Syst. Manag. 2014, 22, 50–74. [Google Scholar] [CrossRef]
- Xu, Z.; Martin, P.; Powley, W.; Zulkernine, F. Reputation-Enhanced QoS-based Web Services Discovery. In Proceedings of the IEEE International Conference on Web Services (ICWS 2007), Salt Lake City, UT, USA, 9–13 July 2007; pp. 249–256. [Google Scholar] [CrossRef]
- Noy, N.F.; McGuiness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology; Stanford Knowledge Systems Laboratory Technical Report KSL-01-05 and Stanford Medical Informatics Technical Report SMI-2001-0880; Standford University: Standford, CA, USA, 2001. [Google Scholar]
- Iggena, T.; Kuemper, D. Quality Ontology for IoT Data Sources. Available online: https://w3id.org/iot/qoi (accessed on 8 January 2021).
- Bees, D.; Frost, L.; Bauer, M.; Fisher, M.; Li, W. NGSI-LD API: For Context Information Management; ETSI White Paper No. 31; ETSI: Valbonne, France, 2019. [Google Scholar]
- Taylor, S.; Letham, B. Prophet: Forecasting at Scale; Facebook Research: Menlo Park, CA, USA, 2018. [Google Scholar]
- González-Vidal, A.; Rathore, P.; Rao, A.S.; Mendoza-Bernal, J.; Palaniswami, M.; Skarmeta-Gómez, A.F. Missing Data Imputation with Bayesian Maximum Entropy for Internet of Things Applications. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Christakos, G.; Li, X. Bayesian maximum entropy analysis and mapping: A farewell to kriging estimators? Math. Geol. 1998, 30, 435–462. [Google Scholar] [CrossRef]
- Ilyas, E.B.; Fischer, M.; Iggena, T.; Tönjes, R. Virtual Sensor Creation to Replace Faulty Sensors Using Automated Machine Learning Techniques. In Proceedings of the 2020 Global Internet of Things Summit (GIoTS), Dublin, Ireland, 3 June 2020; pp. 1–6. [Google Scholar]
- Kuemper, D.; Iggena, T.; Toenjes, R.; Pulvermueller, E. Valid.IoT: A framework for sensor data quality analysis and interpolation. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 294–303. [Google Scholar]
- Iggena, T.; Bin Ilyas, E.; Tönjes, R. Quality of Information for IoT-Frameworks. In Proceedings of the 2020 IEEE International Smart Cities Conference (ISC2), Piscataway, NJ, USA, 28 September–1 October 2020; pp. 1–8. [Google Scholar]
- González-Vidal, A.; Alcañiz, T.; Iggena, T.; Ilyas, E.B.; Skarmeta, A.F. Domain Agnostic Quality of Information Metrics in IoT-Based Smart Environments. In Intelligent Environments 2020: Workshop Proceedings of the 16th International Conference on Intelligent Environments, Madrid, Spain; IOS Press: Amsterdam, The Netherlands, 2020; Volume 28, p. 343. [Google Scholar]
- Rezvani, R.; Enshaeifar, S.; Barnaghi, P. Lagrangian-based Pattern Extraction for Edge Computing in the Internet of Things. In Proceedings of the 5th IEEE International Conference on Edge Computing and Scalable Cloud, Paris, France, 21–23 June 2019. [Google Scholar]
- Rezvani, R.; Barnaghi, P.; Enshaeifar, S. A New Pattern Representation Method for Time-series Data. IEEE Trans. Knowl. Data Eng. 2019. [Google Scholar] [CrossRef]
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive. 2015. Available online: www.cs.ucr.edu/~eamonn/time_series_data/ (accessed on 2 January 2021).
- Janeiko, V.; Rezvani, R.; Pourshahrokhi, N.; Enshaeifar, S.; Krogbæk, M.; Christophersen, S.; Elsaleh, T.; Barnaghi, P. Enabling Context-Aware Search using Extracted Insights from IoT Data Streams. In 2020 Global Internet of Things Summit (GIoTS), Dublin, Ireland; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
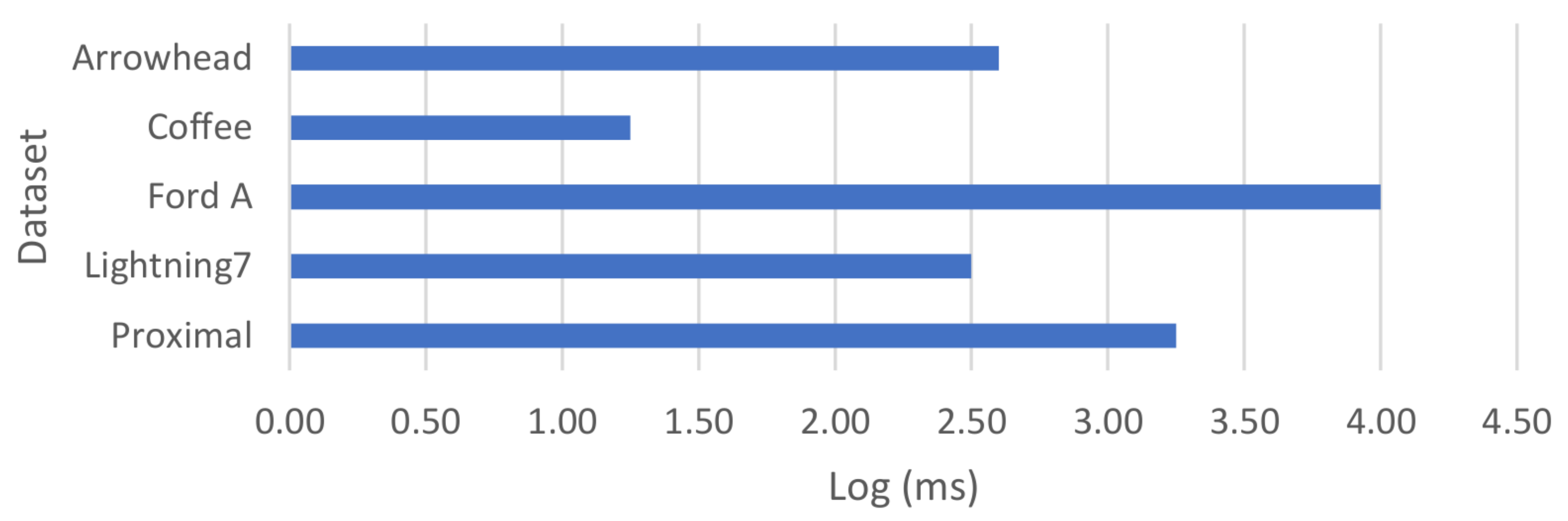
| Model/Data Set | Arrow Head | Lightning 7 | Coffee | Ford A | Proximal |
|---|---|---|---|---|---|
| Raw Data k-means | 0.47 | 0.12 | 0.33 | 0.05 | 0.46 |
| Lagrangian k-means | 0.67 | 0.57 | 0.69 | 0.56 | 0.62 |
| Method | Silhouette Coefficient |
|---|---|
| PCA-Lagrangian + GMM | 0.69 |
| Raw data + GMM | 0.46 |
| Lagrangian scaling + GMM | 0.45 |
| PCA + GMM | 0.39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iggena, T.; Bin Ilyas, E.; Fischer, M.; Tönjes, R.; Elsaleh, T.; Rezvani, R.; Pourshahrokhi, N.; Bischof, S.; Fernbach, A.; Xavier Parreira, J.; et al. IoTCrawler: Challenges and Solutions for Searching the Internet of Things. Sensors 2021, 21, 1559. https://doi.org/10.3390/s21051559
Iggena T, Bin Ilyas E, Fischer M, Tönjes R, Elsaleh T, Rezvani R, Pourshahrokhi N, Bischof S, Fernbach A, Xavier Parreira J, et al. IoTCrawler: Challenges and Solutions for Searching the Internet of Things. Sensors. 2021; 21(5):1559. https://doi.org/10.3390/s21051559
Chicago/Turabian StyleIggena, Thorben, Eushay Bin Ilyas, Marten Fischer, Ralf Tönjes, Tarek Elsaleh, Roonak Rezvani, Narges Pourshahrokhi, Stefan Bischof, Andreas Fernbach, Josiane Xavier Parreira, and et al. 2021. "IoTCrawler: Challenges and Solutions for Searching the Internet of Things" Sensors 21, no. 5: 1559. https://doi.org/10.3390/s21051559
APA StyleIggena, T., Bin Ilyas, E., Fischer, M., Tönjes, R., Elsaleh, T., Rezvani, R., Pourshahrokhi, N., Bischof, S., Fernbach, A., Xavier Parreira, J., Schneider, P., Smirnov, P., Strohbach, M., Truong, H., González-Vidal, A., Skarmeta, A. F., Singh, P., Beliatis, M. J., Presser, M., ... Holmgård Christophersen, S. (2021). IoTCrawler: Challenges and Solutions for Searching the Internet of Things. Sensors, 21(5), 1559. https://doi.org/10.3390/s21051559