1. Introduction
Artificial Intelligence (AI) is rapidly spreading into Internet of Things (IoT) devices, including face recognition for smart security systems [
1,
2,
3], voice assistant with AI speakers [
4,
5,
6], and smart cars [
7,
8]. IoT edge devices, however, do not have sufficient resources to perform inference of complex deep neural networks (DNN) in a timely manner. To satisfy the latency requirement, the inference computation load can be offloaded to high-performance servers in the cloud. This offloading approach started as a full-offloading, and has evolved to a partial offloading. In full offloading, a mobile device transmits input data to a cloud server, which performs inference of the entire DNN and returns a result back to the device. The server, equipped with cutting-edge GPUs and AI accelerators is generally orders of magnitude faster than the mobile device and can meet latency and throughput requirements of real-time inferences.
As IoT edge devices enhance their AI processing capabilities, the offloading mechanism has evolved to partial offloading, called ‘Collaborative Intelligence’ [
9,
10,
11,
12]. Recent mobile devices have AI hardware units inside (e.g., neural processing unit in an application processor) and can perform inference of simple DNNs on-device. However, these units cannot execute complex DNN models by themselves due to limited resources from battery-supplied power and small form factors. Instead, collaborative intelligence utilizes the on-device hardware to keep some computation on-device, and partially offloads the rest of the computation to a server. The motivation behind collaborative intelligence is that most DNNs have intermediate feature spaces smaller than the input feature space. Collaborative intelligence utilizes this characteristic to trade computation time for communication time. It partitions DNN layers and the edge device executes up to the partitioned layer. The output features from the partitioned layer are then transferred to a cloud server, which will continue executing the rest of the network. Executing early layers on the relatively-slow edge device and transferring a smaller amount of features can reduce the end-to-end latency significantly than transferring a large volume of input data and executing the entire layers in the relatively-fast server hardware.
An offloading scheme, either full offloading or collaborative intelligence, incurs significant overheads in transferring a large volume of feature data, especially when the input data is a high-resolution image or video. Compressing the feature data is promising for reducing the communication time. There is a rich literature on compressing input image/video, including Joint Photographic Experts Group (JPEG) and High Efficiency Video Coding (HEVC). These codecs have evolved over decades and can achieve a very high compression ratio on vision data. Compressing intermediate features is relatively new and many studies [
13,
14,
15,
16] extend existing image/video codecs to compress vision-based intermediate features. They add a preprocessing stage before applying an image/video codec to fit intermediate features into the target codec.
Such studies, however, are sub-optimal by poorly processing multiple channels. In most convolutional neural networks (CNN), channel count increases and feature map size decreases as layers deepen. Some studies [
13,
14] individually apply a codec to these many small-sized maps, which suffers from limited redundancy and unamortized header costs. The others [
15,
16] tile multiple maps to build a large frame, which introduces blockiness in the combined frame and degrades the efficiency of natural-image-based codecs.
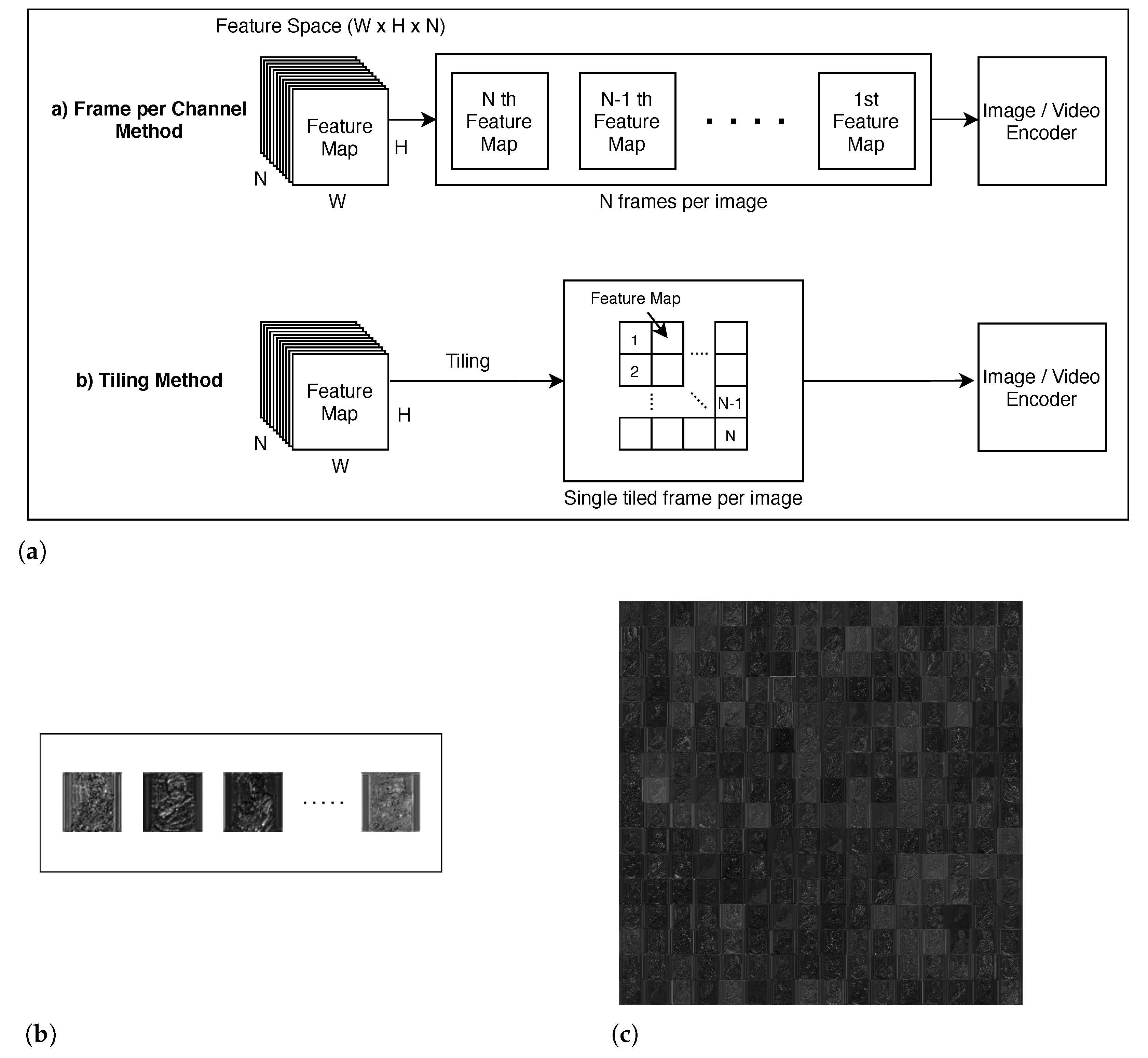
To address these limitations, this paper presents a new preprocessing technique for intermediate compression, called ‘auto-tiler’ (
Figure 1). Auto-tiler is a specially-designed autoencoder that encodes an intermediate feature space (a collection of feature maps) into a single output feature map. Image/video codecs can then be applied to this map without any additional preprocessing. The output map has a smaller dimension than its inputs, and auto-tiler supports multiple output dimensions from a single model to support multiple compression ratios.
Another strength of an auto-tiler is its flexibility in dealing with changes in communication conditions. In a real environment, communication conditions (e.g., latency, throughput, and error rate) can change frequently. Such a change affects communication time and can change the optimal partition layer in collaborative intelligence. The proposed auto-tiler is designed to support multiple partition layers using a single model. The same model can be reused to process intermediate features from different partitioning layers.
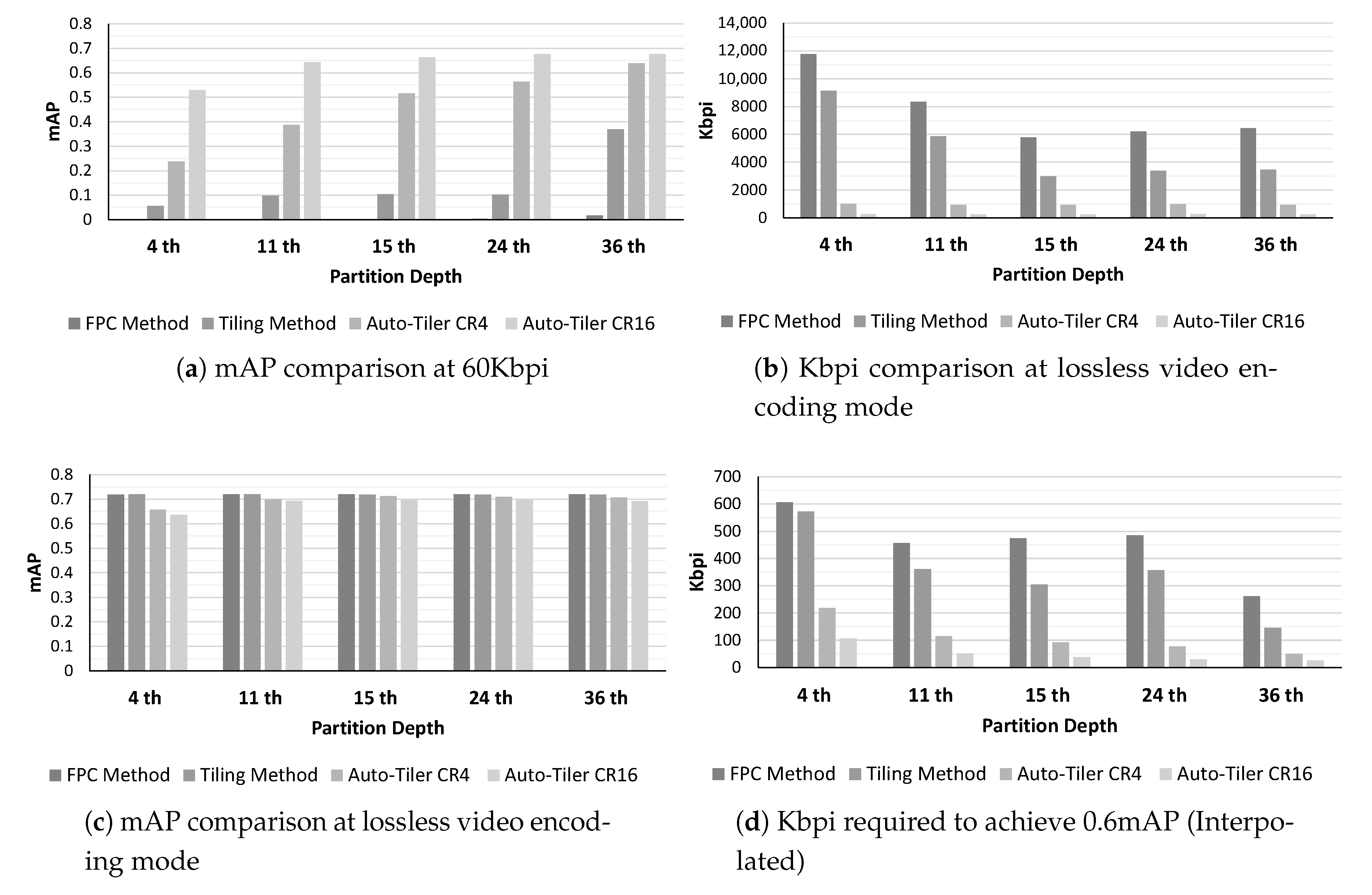
Our evaluation shows that auto-tiler achieves 18% to 67% higher percent point accuracy compared to the existing methods at the same bitrate. Auto-tiler also improved the process latency by 73% to 81% depending on the compression quality. Additionally, by allowing an auto-tiler to support multiple input and output dimensions, we managed to save the storage overhead by 62% with minor accuracy loss.
The rest of the paper is organized as follows—
Section 2 provides backgrounds and motivations for auto-tiler. In
Section 3, we introduce the characteristics of auto-tiler and its unique design choices. In
Section 4, we explain our experimentation settings and compare the performance of auto-tiler with existing methods.
Section 5 provides the summary of our paper and future works.
2. Backgrounds and Related Work
2.1. Collaborative Intelligence
DNN requires billions of operations to infer. Mobile devices, which have limited power supply and computational resources, used to offload the entire computation to clouds. The cloud-only approach fully offloads the computation to the cloud and utilizes high-performance GPUs and AI accelerators to complete the job in a timely manner. As mobile devices introduced AI hardware, this offloading scheme has evolved to Collaborative Intelligence to partially offload computation to servers. With collaborative intelligence, server computation time is traded with on-device computation to reduce transfer time.
There are researches to compress intermediate features in collaborative intelligence in order to reduce the transfer time [
13,
14,
15,
16]. Some suggest preprocessing methods to make feature space easily compressed by conventional image/video codecs such as JPEG and HEVC. They utilize state-of-the-art codecs to achieve high compression efficiency and can be classified into two categories based on how they process multi-channel features.
2.2. Existing Feature Preprocessing Methods and Their Limitations
We organized the existing feature preprocessing methods into two groups—one that applies codecs individually to each feature maps, and another which first tile these feature maps into a large frame before applying codecs. In the following subsections, we will discuss these two methods in detail and analyze their limitations.
2.2.1. Frame per Channel Method
Most CNNs decrease their feature map size but increase feature map count (i.e., channel count) as layers deepen. For example, input features of AlexNet [
17] and VGG16 [
18] have a dimension of 224 × 224 × 3 (width × height × channel). But the third convolutional layer of AlexNet has an intermediate feature space of 13 × 13 × 384 and the conv3_2 layer of VGG16 has an output dimension of 56 × 56 × 256. Some methods [
13,
14] regard each channel as a frame and compress separately (referred to as
Frame Per Channel (FPC) in this paper,
Figure 2). This approach becomes less efficient as the feature map size gets smaller.
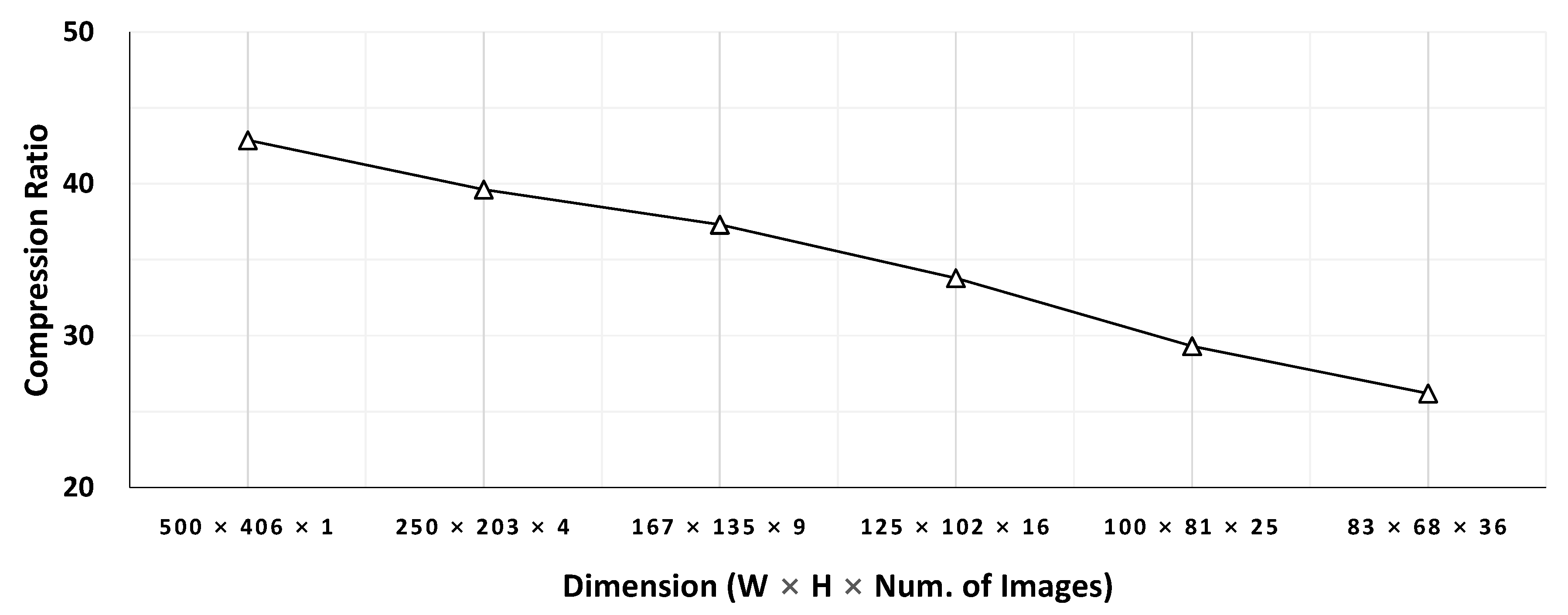
Figure 3 compares JPEG compression ratio of a sample image against ones of different-sized sub-images. Each sub-image is built by slicing the image into smaller sub-images. For example, the four 250 × 203 sub-images are built by splitting 500 × 406 images evenly both horizontally and vertically. The result illustrates that the compression ratio decreases as the feature map size decreases. Our evaluation in
Section 4 also shows FPC-based methods require more bandwidth for a target accuracy or exhibit poor accuracy for a given bandwidth.
2.2.2. Tiling Method
The others [
15,
16] ‘tiles’ many small-sized feature maps into a single large frame and apply a codec to the entire frame (i.e., the entire feature space) (
Figure 2). With increased frame size, tiling-based methods can exploit increased redundancy and amortize costs to achieve a higher compression ratio than FPC-based ones. However, one of the drawbacks of these methods is that it introduces blockiness into the frame. At feature map boundaries, there can be abrupt changes in pixel values. The resulting frame has blocking artifacts at tile boundaries and suffer from sub-optimal compression efficiency with natural-image-based codecs, which rely on a frequency-domain transform to increase data redundancy and reduce the perception of errors [
19,
20].
As explained above, both existing approaches have limitations as a preprocessing method of feature map compression. Furthermore, deep feature space has different spatial characteristics compared to natural images [
15]. To verify this difference in characteristics, we also conducted an experiment on a partitioned YOLO v3 network [
21]. In this experiment, spatial similarity is measured as a percentage of pixels that is within 2% difference with its spatial neighbors (left, top, top-left, bottom-left, top-right). For each neighbors, the similarity is calculated individually and then averaged to determine the overall spatial similarity. As shown in
Figure 4, the overall spatial similarity of the network generally decreases as the layer goes deeper. Therefore the deep feature space should be preprocessed in a way that the spatial similarity can be improved, to effectively use conventional image compression algorithms.
2.3. Autoencoder as a Preprocessor
Autoencoders are a special type of a neural network which is typically used to reduce the dimension of the input feature space using a bottleneck layer. They are trained to learn and approximate the identity function so that the decoding part of the network can reconstruct the input from the compressed bottleneck layer activation.
Deep feature space can be better compressed if we train and use an autoencoder network that is tailored towards compressing the intermediate features. This is because conventional compression algorithms are crafted based on realistic images with human visual system in mind, which the deep feature space differs from. Autoencoder network can then be used as a preprocessor during feature map compression by decreasing the dimension and number of channels of the feature space. This autoencoded feature space is then tiled into a single frame and further compressed by image/video encoders.
We conducted a simple experiment to check the feasibility of autoencoders as the preprocessor.
Figure 4 portrays that a simple autoencoder showed relatively higher spatial similarity in deeper layers, while the spatial similarities of other preprocessing methods decreased. The increased redundancy at deeper layers will allow the video encoders to compress the feature space even further, thus improving the compression ratio.
Although autoencoder can encode the feature space while increasing the spatial similarity, the output feature space is still many small-sized channels, which are not favorable to the conventional encoders. Even though tiling can combine these channels into a single frame, it causes blockiness introduced by different feature maps being adjacent to each other in a tiled frame. The proposed method solves this problem by using an autoencoder with special bottleneck structure while preserving the advantages which autoencoder brings.
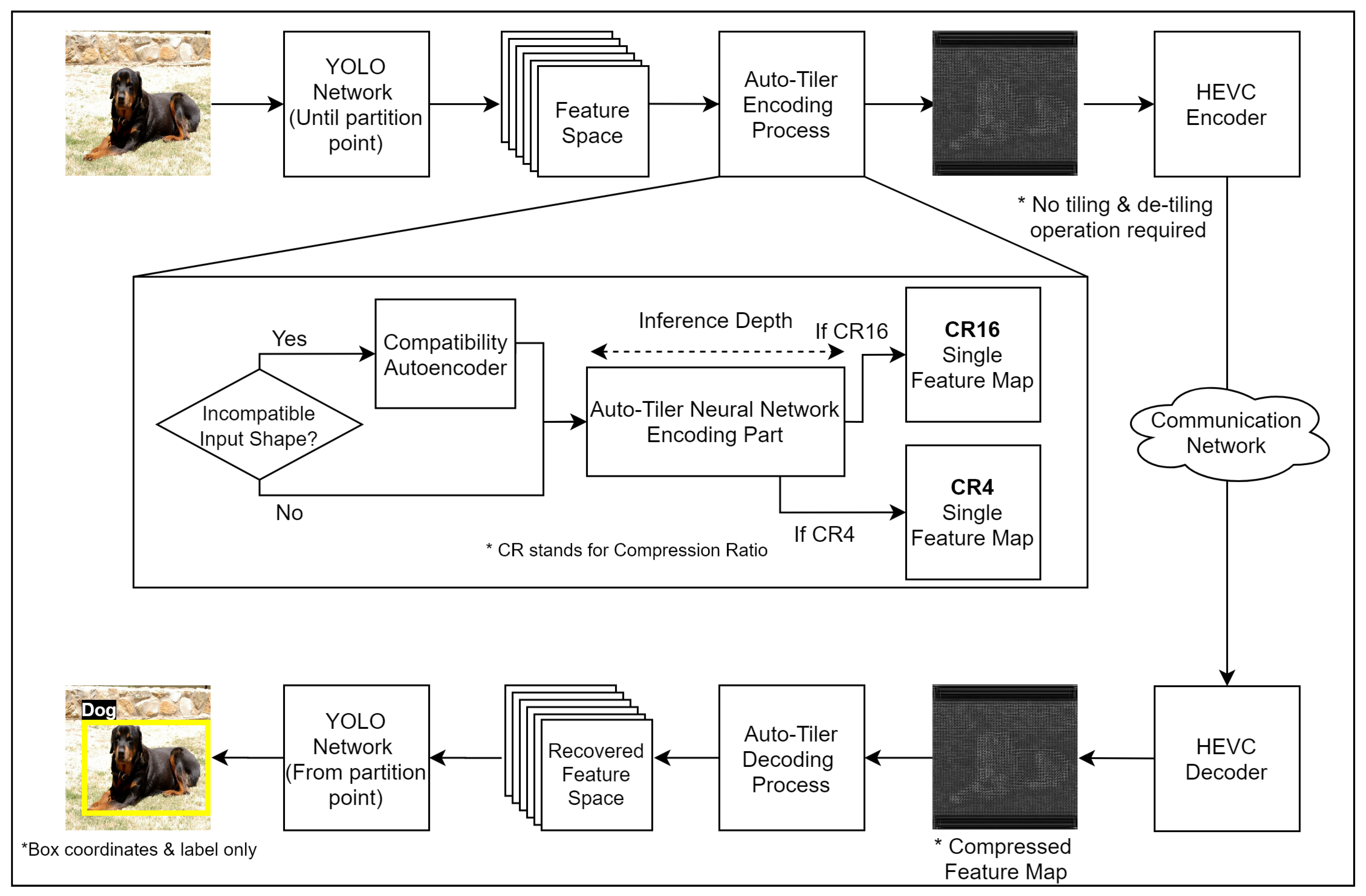
3. Proposed Method
We propose a new preprocessing method called ‘auto-tiler that utilizes a specially-structured autoencoder to encode the feature space into a reduced dimension. The important aspect of the proposed method is that it automatically ‘tiles’ the multi-channel feature space into a single-channel one within its encoding process. By effectively allowing an auto-tiler to learn the optimal tiling process by itself, it eliminates the additional process that was required for better compression by the existing methods. An example of an auto-tiled feature map is illustrated in
Figure 5. This feature map does not have the problems arising from many smaller-sized feature maps in
Figure 2b and also does not show multiple blocky edges as shown in
Figure 2c. The effect of these characteristics are demonstrated in
Section 4.3.1. The result indicates that the proposed method retains noticeably higher structural similarity after compression than the existing methods shown in
Figure 2b,c, allowing for a more efficient compression. In addition, we design an auto-tiler to accept the input feature space with multiple different dimensions, in order to support various partitioned layers of a network. It also allows multiple output dimensions to support quality-compression scalability. The structure of a proposed auto-tiler is shown in
Figure 6, and its core features (auto-tiling, variable input dimensions, and variable output dimensions) are explained in the following subsections.
3.1. Auto-Tiling Autoencoder
The structure of a conventional autoencoder is altered so that it outputs a single, larger feature map at the bottleneck layer. The size of a filter (convolution kernel) in the bottleneck layer is increased to compensate for the low quantity of filters. This eliminates the need to perform tiling/de-tiling operation before the encoding/decoding process. That is, the bottleneck activation of an auto-tiler can be directly encoded by a video encoder, and its decoded frame can also be directly used as an input to the decoding part of an auto-tiler. Furthermore, by using a single, larger filter, the blockiness of a tiled (in this case, auto-tiled) frame can be reduced, which makes room for a video encoder to improve the compression ratio.
3.2. Auto-Tiler with Variable Input/Output Dimensions
During inference, the optimal partitioned layer may change based on available network capacity and compute/memory resource of the edge device [
9]. It implies that the dimension of the intermediate feature space can vary depending on the partitioned layer. However typical autoencoders can only accept the input with one fixed dimension.
Another challenge in partitioned inference is that the required compression ratio can vary depending on the latency requirement or transmission link conditions. However, the output feature dimension of conventional autoencoders is fixed, so the compression ratio cannot be altered on-line. One of the simple solutions to this issue is to train multiple autoencoder models with different input and output dimensions (compression ratios), and store all the models in an edge device. However, this is not an efficient solution as it increases storage overhead proportional to the number of required models. Another approach can be dynamically tuning an autoencoder model depending on the required input/output dimension. However, this method also is limited since training an entire autoencoder network is a costly operation. Therefore, it is advantageous to design an autoencoder (an auto-tiler in the proposed approach) so that it is compatible with variable input and output dimensions.
3.2.1. Variable Input Dimensions
We design an auto-tiler with multiple input dimensions by adding compatibility autoencoders with different structures to a core auto-tiler. A core auto-tiler is a network that is trained on the intermediate layer with the smallest dimension and will be used in conjunction with compatibility autoencoders as needed. Compatibility autoencoders transform the larger input dimension to a smaller one which is compatible with a core auto-tiler. In this way, we can easily support multiple input dimensions while minimizing the storage overhead, since a large portion of the network (core auto-tiler) is shared.
We applied this approach to the YOLO v3 network, which has three partition-able output dimension (Width, Height, Channels): (208, 208, 64) for the 4th layer, (108, 108, 128) for the 11th layer, and (52, 52, 256) for 15th, 24th, and 36th layer. Partitioning beyond the 36th layer is undesirable due to the skip line concatenating the 36th layer with the 96th layer. In order to support these multiple dimensions, we have first trained a core auto-tiler network on activation feature space of 15th, 24th, and 36th layer as they have the same, smallest dimension. Then for the 4th and 11th layer, we trained additional compatibility autoencoders that reduce the dimensions so that it can be compatible with a core auto-tiler.
3.2.2. Variable Output Dimensions
We designed an auto-tiler with variable output dimensions by allowing a core auto-tiler to generate different bottleneck activations in its inference process. Therefore, it will encode the input with different strengths depending on the inference depth. In this way, we can change the compression ratio without having to re-train the network.
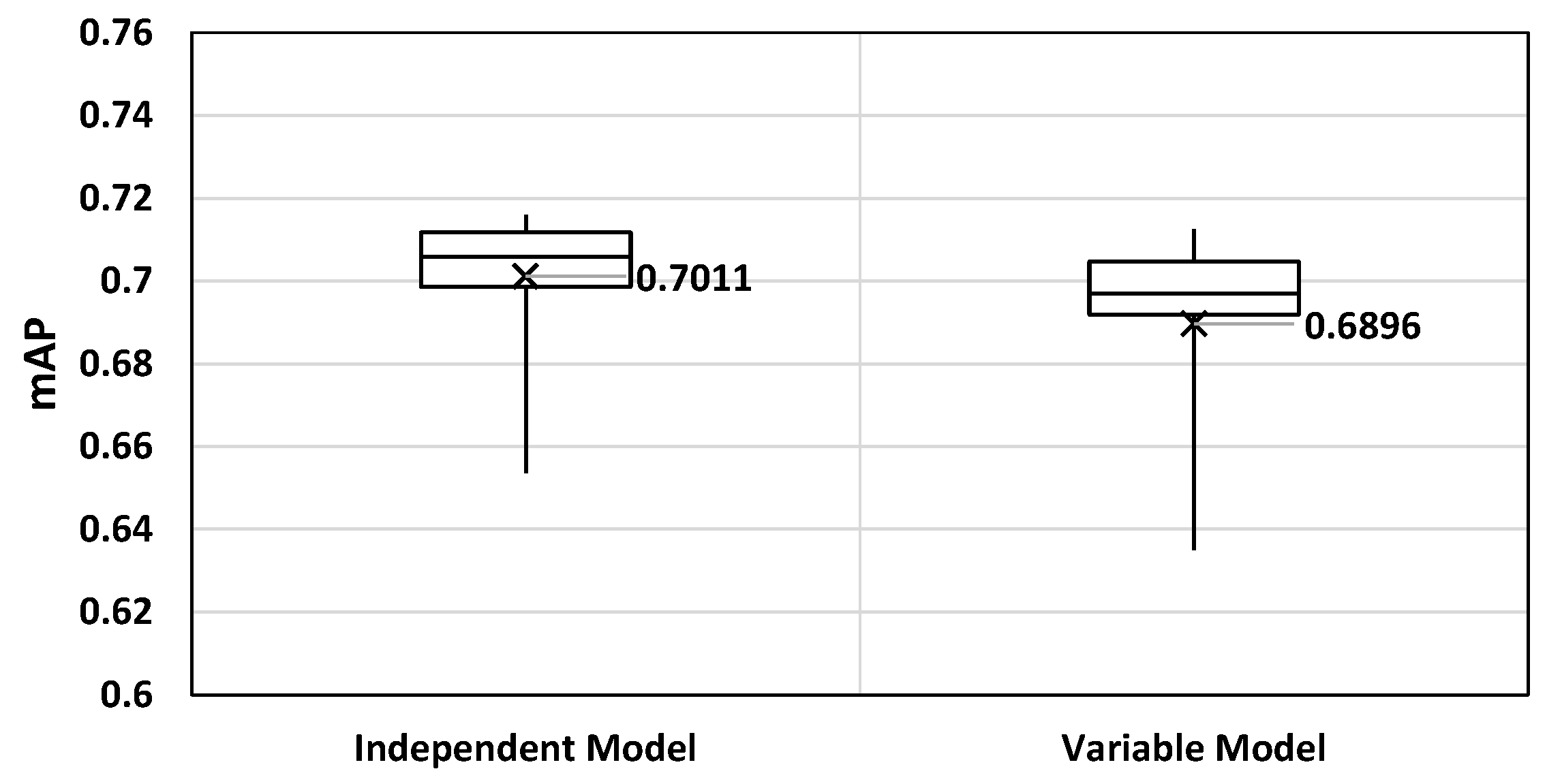
To determine the optimal compression ratio (CR) that an auto-tiler should support, we trained a simple auto-tiler by increasing the CR by 4×, from 4× to 256×. Then, we defined an effective mAP to be 85% of the maximum mAP of the YOLO v3 network. Should an auto-tiler network with a certain CR achieves less mAP than an effective mAP, that CR will be considered ‘too heavy’. Our experiment on
Figure 7 showed that a CR of 4× to 64× was within our effective mAP range, with 64× sitting on the edge of an effective mAP. Thus, we determined that the optimal CR that an auto-tiler network should support is within 4× to 64×.
Based on this approach, we designed an auto-tiler network so that it can compress the input feature space into two different output dimensions. These output dimensions are (416, 416, 1), (208, 208, 1), which compress the feature space of the 15th, 24th, and 36th layers by 4× and 16×, respectively. Its compression ratio is increased by 2× as the partition depth gets shallower. That is, when compressing the 11th layer activation the compression ratio will be 8× and 32×, and when compressing the 4th layer it would be 16× and 64× respectively. This is due to the compatibility autoencoders compressing the 11th and 4th layer activation by 2× and 4× in order to make it compatible with a core auto-tiler. As a result, an auto-tiler network will support a CR from 4× to 64×. The structure of an autoencoder, auto-tiler, and compatibility autoencoders is shown in
Figure 8.
5. Conclusions
In conclusion, we were able to compress the intermediate feature space of deep neural networks more effectively than existing methods by using an auto-tiler as a preprocessor to video encoders. Additionally, by using an auto-tiler we were able to use the bottleneck layer activation by itself without any tiling or de-tiling process during video encoding. This removal of tiling processes allowed us to significantly reduce the total inference latency. Auto-tiler also reduced the blockiness and discontinuity that may be introduced during the existing tiling process, thus reducing accuracy decay at lower bitrates. Furthermore, by supporting variable input and output dimensions we were able to significantly reduce storage space overhead with minimal accuracy loss. Finally, the utilization of an auto-tiler considerably improved the mAP and bitrate overhead during the compression of the intermediate feature space and effectively allowed a much wider range of compression ratio.
In this paper, we illustrated the advantages of AI-based compression in deep intermediate feature space. Our proposed approach, auto-tiler, will allow IoT edge devices in a collaborative intelligence environment to operate more effectively by improving compression efficiency and latency. We however believe that auto-tiler can be further improved on certain points. For one, future works may improve the input and output variability of auto-tiler. Although the proposed auto-tiler in this paper does support multiple input and output dimensions, it is still required to analyze the available dimensions before deployment. Future research may design an omni-dimensional auto-tiler that may support as many dimensions as the conventional codecs. This will allow it to be deployed on any partitioned network without prior dimensional analysis. Another could be to improve the robustness to data losses. Our work is mainly focused on the losses introduced by compression artifacts and assumed no data loss during transmission, as it was beyond the scope of our paper. However, in real-life situations, there may be multiple issues that could result in such losses. Therefore it could be advantageous to consider these issues during the design phase. With these improvements, we speculate that auto-tiler can become an essential technique to be used in IoT devices. To this end, other aspects of auto-tiler must also be explored and need further study.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}