
Computer Vision-Based Bridge Damage Detection Using Deep Convolutional Networks with Expectation Maximum Attention Module


Abstract
1. Introduction
- (1)
- A novel bridge damage detection method based on densely connected convolutional networks with expectation maximum attention module (EMA-DenseNet) is proposed, which can detect cracks and exposed steel bars efficiently in the complex environment at the bottom of the bridge.
- (2)
- The structure of the advanced DenseNet was redesigned and the EMA module was added in the last pooling layer of the DenseNet, which is obviously helpful for the damage feature extraction.
- (3)
- Experiments were carried out on a public crack dataset and a bridge damage dataset respectively and the results were compared with the most advanced algorithms, showing the superiority of the proposed method.
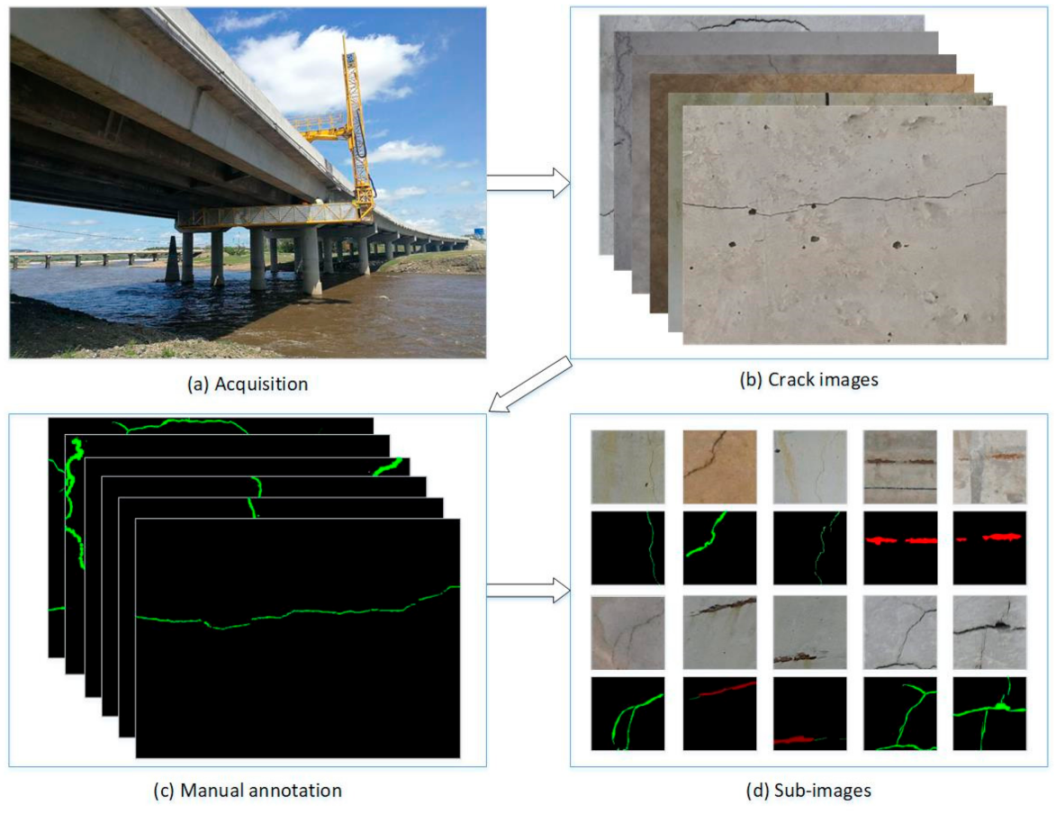
2. Data Collection
2.1. Public Crack Dataset
2.2. The Established Bridge Damage Dataset
3. Methodology
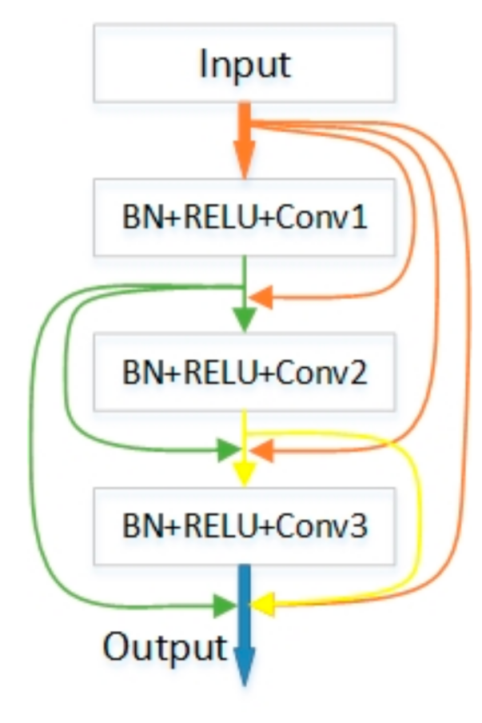
3.1. The DenseNet Backbone
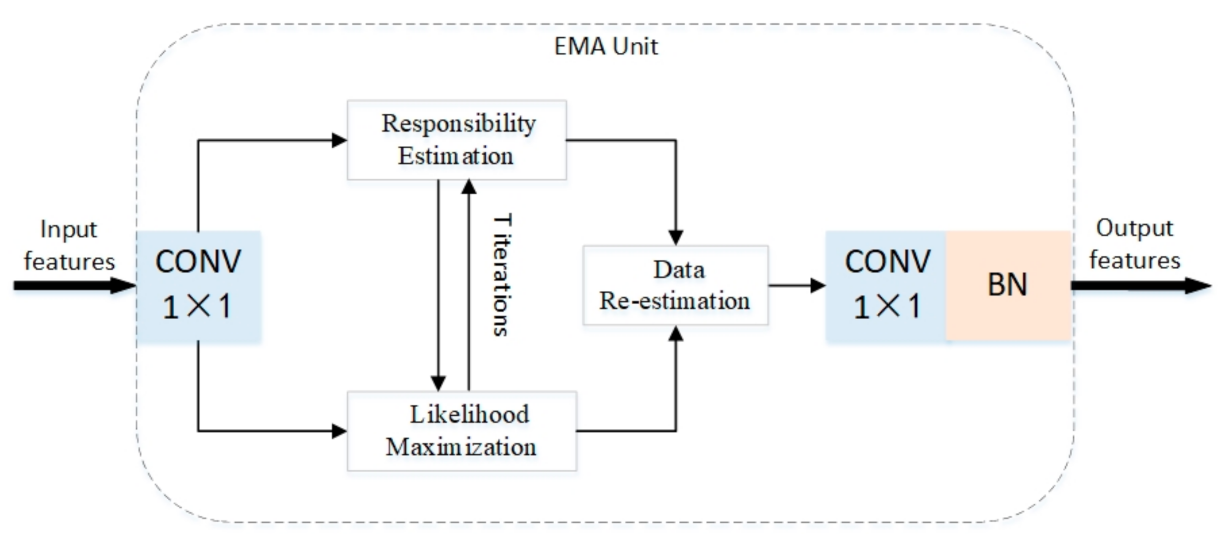
3.2. Expectation-Maximization Attention Module
3.3. Loss Function
4. Results and Analysis
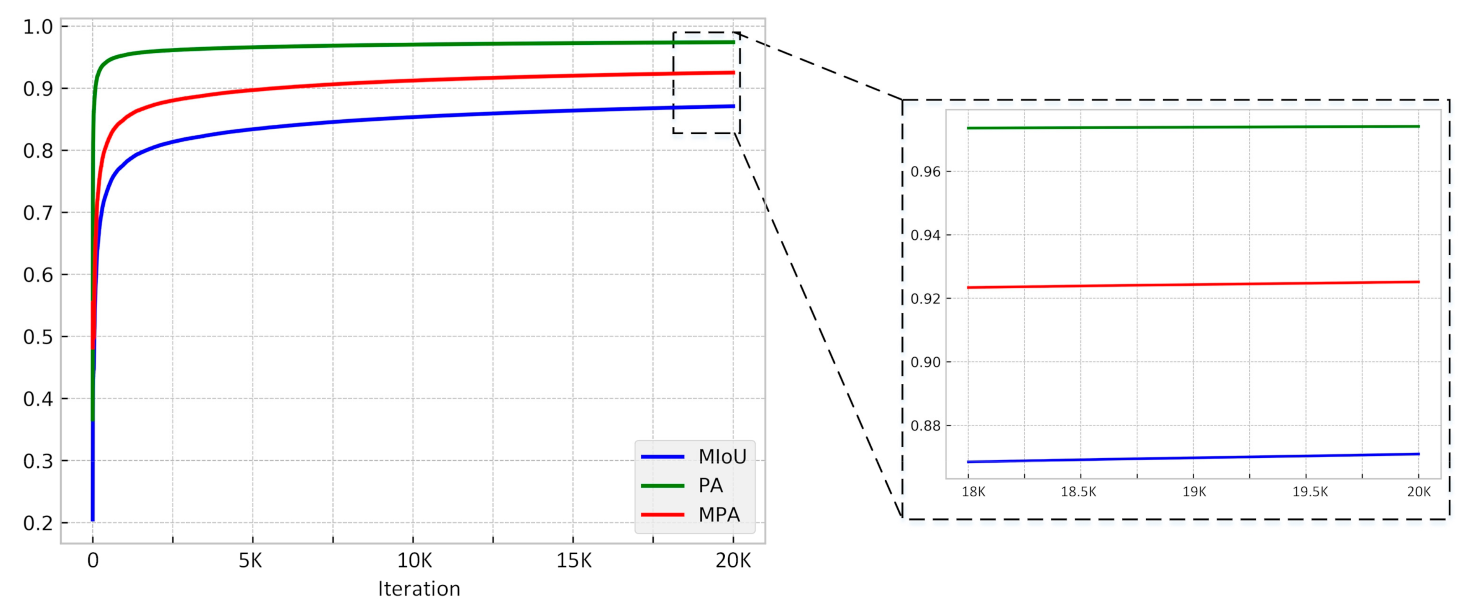
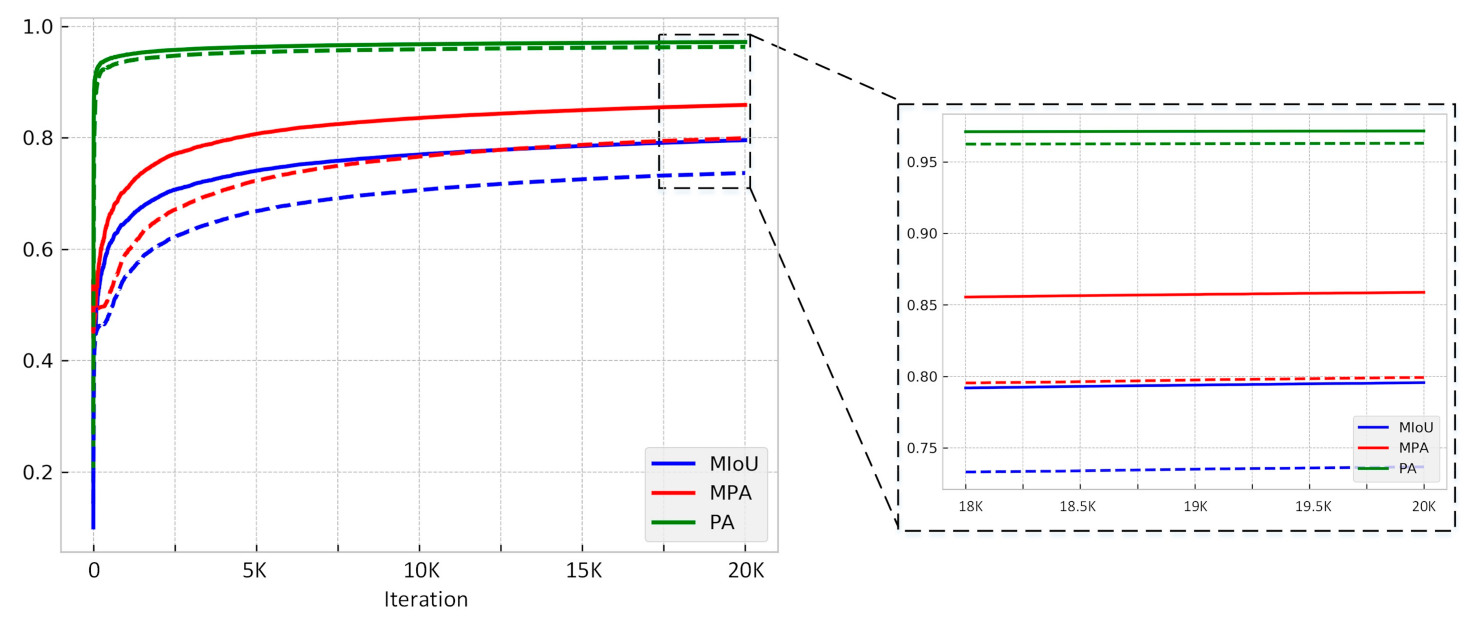
4.1. Model Training
4.2. Evaluation Metrics
4.3. Results on the Public Crack Dataset
4.4. Results on the Bridge Damage Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- La, H.M.; Gucunski, N.; Dana, K.; Kee, S.-H. Development of an autonomous bridge deck inspection robotic system. J. Field Robot. 2017, 34, 1489–1504. [Google Scholar] [CrossRef]
- Jeong, S.; Hou, R.; Lynch, J.P.; Sohn, H.; Law, K.H. An information modeling framework for bridge monitoring. Adv. Eng. Softw. 2017, 114, 11–31. [Google Scholar] [CrossRef]
- Worden, K.; Cross, E. On switching response surface models, with applications to the structural health monitoring of bridges. Mech. Syst. Signal. Process. 2018, 98, 139–156. [Google Scholar] [CrossRef]
- Zhou, G.; Li, A.; Li, J.; Duan, M. Structural Health Monitoring and Time-Dependent Effects Analysis of Self-Anchored Suspension Bridge with Extra-Wide Concrete Girder. Appl. Sci. 2018, 8, 115. [Google Scholar] [CrossRef]
- Guo, A.; Jiang, A.; Lin, J.; Li, X. Data mining algorithms for bridge health monitoring: Kohonen clustering and LSTM pre-diction approaches. J. Supercomput. 2020, 76, 932–947. [Google Scholar] [CrossRef]
- Mutlib, N.K.; Baharom, S.; El-Shafie, A.; Nuawi, M.Z. Ultrasonic health monitoring in structural engineering: Buildings and bridges. Struct. Control Health Monit. 2015, 23, 409–422. [Google Scholar] [CrossRef]
- Han, Q.; Xu, J.; Carpinteri, A.; Lacidogna, G. Localization of acoustic emission sources in structural health monitoring of masonry bridge. Struct. Control Health Monit. 2014, 22, 314–329. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast crack detection method for large-size concrete surface images using percolation-based image processing. Mach. Vis. Appl. 2010, 21, 797–809. [Google Scholar] [CrossRef]
- Tung, P.-C.; Hwang, Y.-R.; Wu, M.-C. The development of a mobile manipulator imaging system for bridge crack inspection. Autom. Constr. 2002, 11, 717–729. [Google Scholar] [CrossRef]
- Akagic, A.; Buza, E.; Omanovic, S.; Karabegovic, A. Pavement crack detection using Otsu thresholding for image segmentation. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 1092–1097. [Google Scholar]
- Tang, J.; Gu, Y. Automatic crack detection and segmentation using a hybrid algorithm for road distress analysis. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 3026–3030. [Google Scholar]
- Ronny Salim, L.; La, H.M.; Zeyong, S.; Weihua, S. Developing a crack inspection robot for bridge maintenance. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 6288–6293. [Google Scholar]
- Kim, J.-W.; Kim, S.-B.; Park, J.-C.; Nam, J.-W. Development of crack detection system with unmanned aerial vehicles and digital image processing. In Proceedings of the 2015 World Congress on Advances in Structural Engineering and Mechanics (ASEM15), Incheon, Korea, 25–29 August 2015. [Google Scholar]
- Chen, Z.; Li, H.; Bao, Y.; Li, N.; Jin, Y. Identification of spatio-temporal distribution of vehicle loads on long-span bridges using computer vision technology. Struct. Control Health Monit. 2015, 23, 517–534. [Google Scholar] [CrossRef]
- Ho, H.-N.; Kim, K.-D.; Park, Y.-S.; Lee, J.-J. An efficient image-based damage detection for cable surface in cable-stayed bridges. NDT E Int. 2013, 58, 18–23. [Google Scholar] [CrossRef]
- Chan, B.; Guan, H.; Jo, J.; Blumenstein, M. Tuwards UAV-based bridge inspection systems: A reivew and an application perspective. Struct. Monit. Maint. 2015, 2, 283–300. [Google Scholar]
- Yang, C.H.; Wen, M.C.; Chen, Y.C.; Kang, S.C. An optimized unmanned aeiral system for bridge inspection. In Proceedings of the Insternational Symposium on Automation and Robotics in Construction; IAARC Publications: Vilnius, Lithuania, 2015. [Google Scholar]
- Dorafshan, S.; Maguire, M.; Hoffer, N.; Coopmans, C. Fatigue Crack Detection Using Unmanned Aerial Systems in Un-der-Bridge Inspection; Idaho Transportation Department: Boise, ID, USA, 2017. [Google Scholar]
- Yang, Y.-S.; Yang, C.-M.; Huang, C.-W. Thin crack observation in a reinforced concrete bridge pier test using image processing and analysis. Adv. Eng. Softw. 2015, 83, 99–108. [Google Scholar] [CrossRef]
- Song, L.; Wang, X. Faster region convolutional neural network for automated pavement distress detection. Road Mater. Pavement Des. 2021, 22, 23–41. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Harrahs and Harveys, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for im-age-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput. Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep Learning–Based Fully Automated Pavement Crack Detection on 3D Asphalt Surfaces with an Improved CrackNet. J. Comput. Civ. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Xu, Y.; Bao, Y.; Chen, J.; Zuo, W.; Li, H. Surface fatigue crack identification in steel box girder of bridges by a deep fusion convolutional neural network based on consumer-grade camera images. Struct. Health Monit. 2018, 18, 653–674. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NY, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the CVPR 2017, IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 4700–4708. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmen-tation. IEEE Trans. Pattern Anal. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput. Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional net-works. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Li, G.; Ma, B.; He, S.; Ren, X.; Liu, Q. Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique. Sensors 2020, 20, 717. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Song, W.; Jia, G.; Zhu, H.; Jia, D.; Gao, L. Automated Pavement Crack Damage Detection Using Deep Multiscale Convolutional Features. J. Adv. Transp. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Los Angeles, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–decoder network for pixel-level road crack detection in black-box images. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M.; Azim, R. Densely connected deep neural network considering connectivity of pixels for automatic crack detection. Autom. Constr. 2020, 110, 103018. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference Learn. Represent (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Piscataway, NJ, USA, 8–10 June 2015; pp. 1026–1034. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Choi, W.; Cha, Y.-J. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2019, 67, 8016–8025. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MIoU (%) | PA (%) | MPA (%) | Precision (%) | FPS (f/s) |
|---|---|---|---|---|---|
| FCN | 85.77 | 97.96 | 90.12 | 81.73 | 15.6 |
| SegNet | 85.35 | 96.58 | 88.30 | 78.55 | 18.5 |
| DeepLab v3+ | 86.50 | 97.29 | 91.57 | 81.08 | 12.8 |
| SDDNet | 85.27 | 96.91 | 91.01 | 81.50 | 33.2 |
| Ours | 87.42 | 97.58 | 92.59 | 81.97 | 25.4 |
| Image | FCN | SegNet | DeepLab v3+ | SDDNet | Ours |
|---|---|---|---|---|---|
| (a) | 87.0% | 83.1% | 87.3% | 85.8% | 87.3% |
| (b) | 84.2% | 85.2% | 85.2% | 84.3% | 85.9% |
| (c) | 82.2% | 86.5% | 85.9% | 85.1% | 86.8% |
| (d) | 84.7% | 83.1% | 87.0% | 84.5% | 87.8% |
| (e) | 83.6% | 83.0% | 87.3% | 86.0% | 88.1% |
| Method | MIoU (%) | PA (%) | MPA (%) | Precision (%) | FPS (f/s) |
|---|---|---|---|---|---|
| FCN | 74.75 | 94.05 | 81.72 | 71.54 | 8.1 |
| SegNet | 75.03 | 93.28 | 82.15 | 71.67 | 9.0 |
| DeepLab v3+ | 78.86 | 95.78 | 85.33 | 74.71 | 7.4 |
| SDDNet | 77.10 | 94.08 | 83.92 | 73.78 | 18.5 |
| Ours | 79.87 | 97.31 | 86.35 | 74.70 | 14.6 |
| Image | FCN | SegNet | DeepLab v3+ | SDDNet | Ours |
|---|---|---|---|---|---|
| (a) | 75.7% | 75.9% | 78.8% | 77.0% | 80.5% |
| (b) | 61.6% | 75.2% | 79.8% | 77.1% | 81.9% |
| (c) | 73.2% | 74.9% | 79.5% | 74.4% | 80.3% |
| (d) | 78.7% | 80.1% | 80.5% | 80.6% | 81.8% |
| (e) | 74.6% | 72.9% | 77.0% | 77.2% | 78.3% |
| (f) | 78.7% | 79.3% | 78.4% | 78.1% | 79.3% |
| mean | 73.8% | 76.4% | 79.0% | 77.4% | 80.4% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, W.; Ma, B.; Liu, Q.; Wu, X.; Li, G. Computer Vision-Based Bridge Damage Detection Using Deep Convolutional Networks with Expectation Maximum Attention Module. Sensors 2021, 21, 824. https://doi.org/10.3390/s21030824
Qiao W, Ma B, Liu Q, Wu X, Li G. Computer Vision-Based Bridge Damage Detection Using Deep Convolutional Networks with Expectation Maximum Attention Module. Sensors. 2021; 21(3):824. https://doi.org/10.3390/s21030824
Chicago/Turabian StyleQiao, Wenting, Biao Ma, Qiangwei Liu, Xiaoguang Wu, and Gang Li. 2021. "Computer Vision-Based Bridge Damage Detection Using Deep Convolutional Networks with Expectation Maximum Attention Module" Sensors 21, no. 3: 824. https://doi.org/10.3390/s21030824
APA StyleQiao, W., Ma, B., Liu, Q., Wu, X., & Li, G. (2021). Computer Vision-Based Bridge Damage Detection Using Deep Convolutional Networks with Expectation Maximum Attention Module. Sensors, 21(3), 824. https://doi.org/10.3390/s21030824