1. Introduction
The signal propagation over the airborne space contains the spatial information of delivery. The sound source localization (SSL) system interprets the received signal to estimate the angle of arrival (AoA) for the signal source. Understanding the spatial information usually requires the extensive processing over the multi-channel signals. The dominant methods utilize the phase differences between the receivers for beamforming [
1,
2] which can be employed for various applications such as underwater warfare systems. Along with processing power, the number of receivers determines the beamforming performance equivalent to the AoA estimation resolution. The beamforming limitations are confronted with the biomimetics methods. Certain animals including humans can precisely localize sound sources in three-dimensional (3D) space by using the binaural correlation and structure profile [
3]. Numerous monaural [
4] and binaural [
5] sound localization systems have been suggested to mimic the human-like hearing system. Recently, researchers are performing studies to comprehend the propagation on the practical structure with single or dual receivers for precise and feasible SSL systems [
6,
7,
8,
9,
10,
11,
12,
13,
14].
The acoustic information can be used for improving the safety of future autonomous transport systems. The acoustic reception with a single channel can classify the sound source to identify the obstacles and hazards. Beyond the identification, the SSL system provides the further information on the sound source in conjunction with a vision system. The sound propagates the information over the non-line-of-sight (NLOS) locations via diffraction property; hence, the system safety is significantly enhanced by the sound identification and localization on the extended ranges and directions. The system may recognize the direct or indirect endangerment to activate the pre-emptive safety devices which reduce or remove the impact of the imminent collisions. Therefore, the sound is the complementary to vision for navigating mobile objects. This paper extends the SSL methods toward the novel, feasible, and deployable structure to realize them on mobile systems such as vehicles, robots, etc. Observe that the intricate shape of the mobile system produces the complex propagation pathway which requires the complex mathematical model in the SSL algorithms. The proposed SSL system should contain the high scalability and low complexity to meet the objective. The goal of this paper is that the SSL designer can place the receivers on anywhere in the installation system without concern about the hardware and algorithm complexity for optimal performance.
The SSL system for mobile vehicle requires the additional hardware and algorithm complexity compared to the simple sound classifier. The beamforming, monaural, and binaural approach can be used for the SSL system. Note that the arrival level- and time-based methods are not considered for SSL system due to the substantial performance limitations. The beamforming for SSL system provides the accurate localization once the acoustic propagation model is precisely built [
2]. The localization resolution is proportional to the receiver number; therefore, the decent number of microphones demonstrate the pinpoint accuracy for AoA finding. In contrast, the beamforming method requires the significant computational power to realize the algorithm with numerous receivers [
15]. The non-flat surface of the SSL system creates the extra difficulty to derive the sound propagation model which is the essential components for beamforming realization. The system-wide synchronized sampling of individual signal is necessary to employ the phase information between the receivers. Occasionally, the synchronized sampling causes the realization problem for distributed system in centralized beamforming processing [
16].
The monaural and binaural SSL system utilizes the inter-aural level and time differences with frequency variation induced by receiver structure [
4,
17]. The structure related transfer function generates the variety variation on magnitude, time, and frequency of received signals. The isotropic single or dual receiver without the structure cannot implement the monaural or binaural SSL system due to the absence of variation over the AoA. The head and pinna shape can be adopted as the structure for the SSL system [
18,
19]. The precise transfer function for the structure exceeds the conventional SSL performance via using the structure produced information [
3]. The low number of receivers present the low-profile SSL system as well. However, the structure for the monaural and binaural SSL system may provide the installation limitations on aerodynamic or artistic figure. The placement of the SSL system requires the transfer function analysis again due to the mutual relation by attachment. No explicit parameters are observed for performance scalability in the monaural and binaural SSL system which is not suitable for the super-resolution localization. Numerous research articles [
6,
7,
8,
9,
10,
11,
12,
13,
14] have proposed the improvement methods for a monaural and binaural SSL system by employing the novel algorithm and combining approach; however, the scalability is barely observed without the saturation.
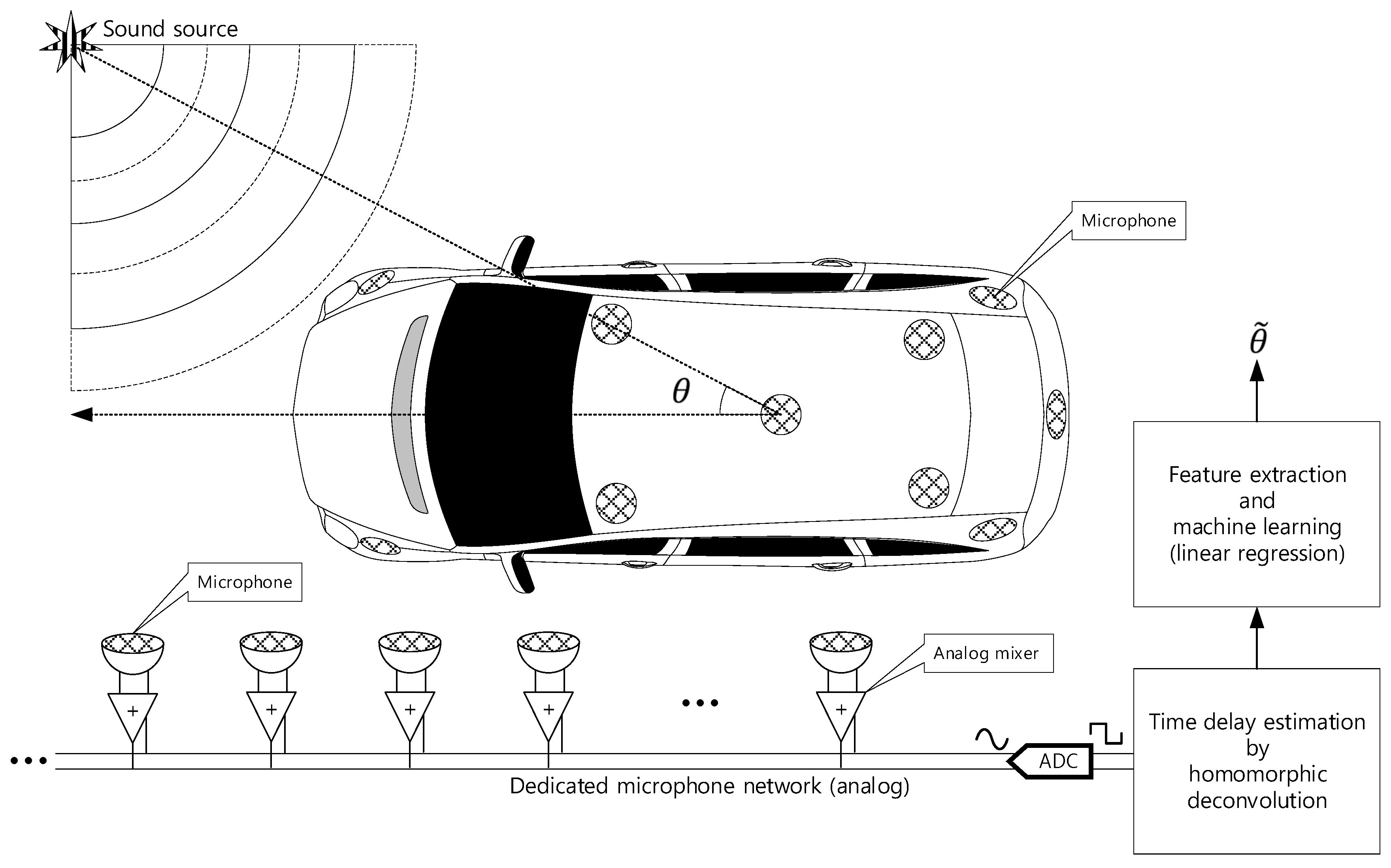
This paper proposes the single analog-to-digital converter (ADC) channel SSL system for transport with multiple receivers. The proposed SSL system does not involve any physical structure for localization and the in-situ receivers are placed within the target system. The individual receivers are connected by the analog microphone network which provides the simple communication and connectivity based on asynchronized analog adder circuit [
20]. On the microphone network bus, the various time delay data on the mixed signal represents the time of flight (ToF) between microphones. The homomorphic deconvolution (HD) algorithm estimates the implicit ToF distribution based on the homomorphic system. The HD algorithm can produce the output in terms of non-parametric and parametric configurations for the feature extraction which is used for machine learning to derive the AoA. The distribution of the non-parametric method as well as coefficients of the parametric model are important clues to compute AoA information. The proposed vehicle SSL system is extensive to present the complete proposition in single article. Hence, the previous paper [
21] demonstrated the ToF estimation for two microphones with non-parametric and parametric HD algorithms. Observe that
Figure 1 is parallel to the previous article illustration except the receiver number and machine learning stage. This article describes the SSL system with machine learning based on the findings in previous paper.
The proposed single-channel multiple-receiver (SCMR) SSL system consists of two computational stages as homomorphic deconvolution and machine learning stage indicated in
Figure 1. The previous paper verified the performance of ToF estimation by utilizing the non-parametric and parametric HD algorithms [
21]. The machine learning trains the algorithm to recognize the AoA from the output of HD algorithms. This paper employs the linear regression with supervised learning for AoA prediction. The SCMR SSL system demonstrates the consistent computational requirement for any problem size in terms of receiver number. The single channel HD computation shows the constant computational burden for any receiver configuration. The extracted features (in non-parametric or parametric distribution) from HD are delivered to the linear regression which establish the uniform computational order for fixed regression degree. Once the receiver configuration presents the proper ToF between microphones to distinguish the AoA distribution, the linear regression estimates the arrival angle accurately with constant computational requirement. The surface and numerical profile of receiver installation hardly affect the SCMR SSL performance when the linear regression is trained deeply with extensive featured dataset. The mathematical model of the sound propagation is not mandatory for SCMR SSL system for 2D or 3D surface, and extensive or reduced number of receivers. However, the dense and considerable dataset should follow the massive computational power for learning process in linear regression.
Recently numerous investigations have been conducted for SSL systems with machine/deep learning and are organized as below. Sun et al. [
23] suggests the indoor SSL system based on the generalized cross correlation feature and probabilistic neural network to tolerate the high reverberation and low signal-to-noise ratio (SNR) situation. The convolutional recurrent neural network is developed for joint sound event localization and detection of multiple overlapping sound events in 3D space from a sequence of consecutive spectrogram time frames [
24]. Ma, Gonzalez, and Brown present the novel binaural sound localization that combines the model-based information about the spectral characteristics of sound sources and deep neural networks [
25]. In underwater ocean waveguides, the generalized regression neural network localizes the sound source based on the normalized sample covariance matrix of input signal [
26]. The AoA estimation is performed by the input inter-channel phase differences from the deep neural network-based phase difference enhancement [
27]. In the mismatched head-related transfer function condition, the data-efficient and clustering method based on deep neural network is provided to improve binaural localization performance [
28].
This paper accomplishes the goals proposed by the authors’ previous SSL publications. The ToFs between microphones were estimated by non-parametric and parametric homomorphic deconvolutions which are served as the fundamental ground for this paper [
21]. The asymmetric horizontal pyramidal horns were organized for the far-field monaural SSL system by utilizing cepstral parameters induced by fundamental frequencies [
13]. The asymmetric vertical cylindrical pipes around a single microphone realized the small-profile near-field monaural SSL system [
12]. To be estimated by homomorphic deconvolution, the direction-wise time delays from the multiple plate structure were designed for the reflective monaural SSL system [
11]. The binaural system detected the azimuthal movement of the sound source [
10] and the low-power acoustic sensor network localized the target in the distributed field [
29] as the efforts for the SSL subject by the authors. Observe that the identical anechoic chamber [
30] has been operated for the acoustic experiments and evaluations of the prior works.
2. Non-Parametric and Parametric Homomorphic Deconvolution
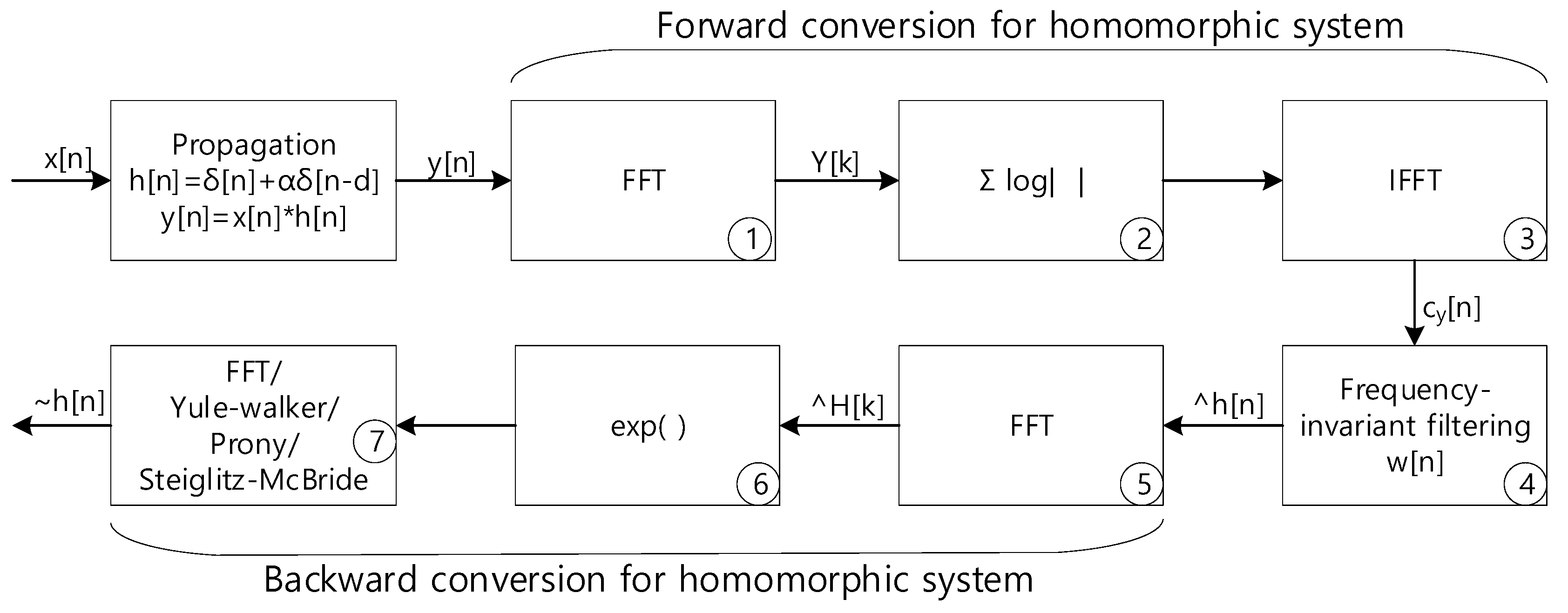
This section is provided by editing and modifying the previous paper [
21] to improve readability of the overall presentation. For further information, the readers are recommended to pursue the article for discovering the detail description on non-parametric and parameter HD. In the paper, the HD utilizes the homomorphic systems in cascade to derive the propagation function which represents ToFs between the receivers. The real cepstrum of the received signal as the geometric series form realizes the forward conversion of the homomorphic system. The robust method to extract the propagation function from the received signal is delivered by the distinct geometric series rates in cepstrum domain. The actual separation in the cepstrum domain is performed by the simple window known as frequency-invariant linear filtering (FILF). Finally, the propagation function for ToF is derived by the backward conversion of the homomorphic system in inverse cepstrum. For non-parametric estimation, the discrete Fourier transform (DFT) or fast Fourier transform (FFT) is extensively used for the real cepstrum. The propagation function model implements the parametric ToF estimation in last stage of HD via applying Yule–Walker [
31,
32], Prony [
32,
33], and Steiglitz–McBride [
32,
34]. Observe that the parametric method calculates model coefficients and the non-parametric technique generates the numerical distribution.
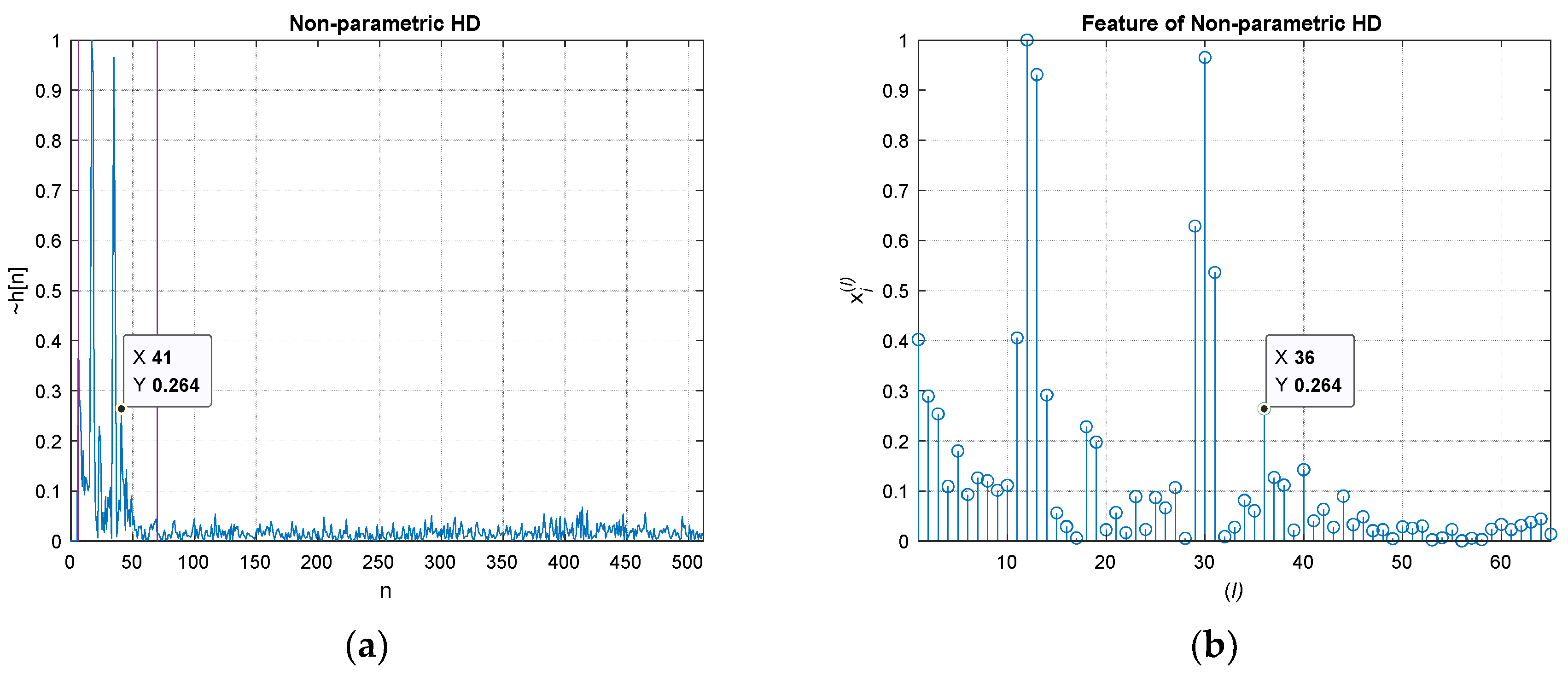
Figure 2 illustrates the overall computational procedure for non-parametric and parametric HD algorithm.
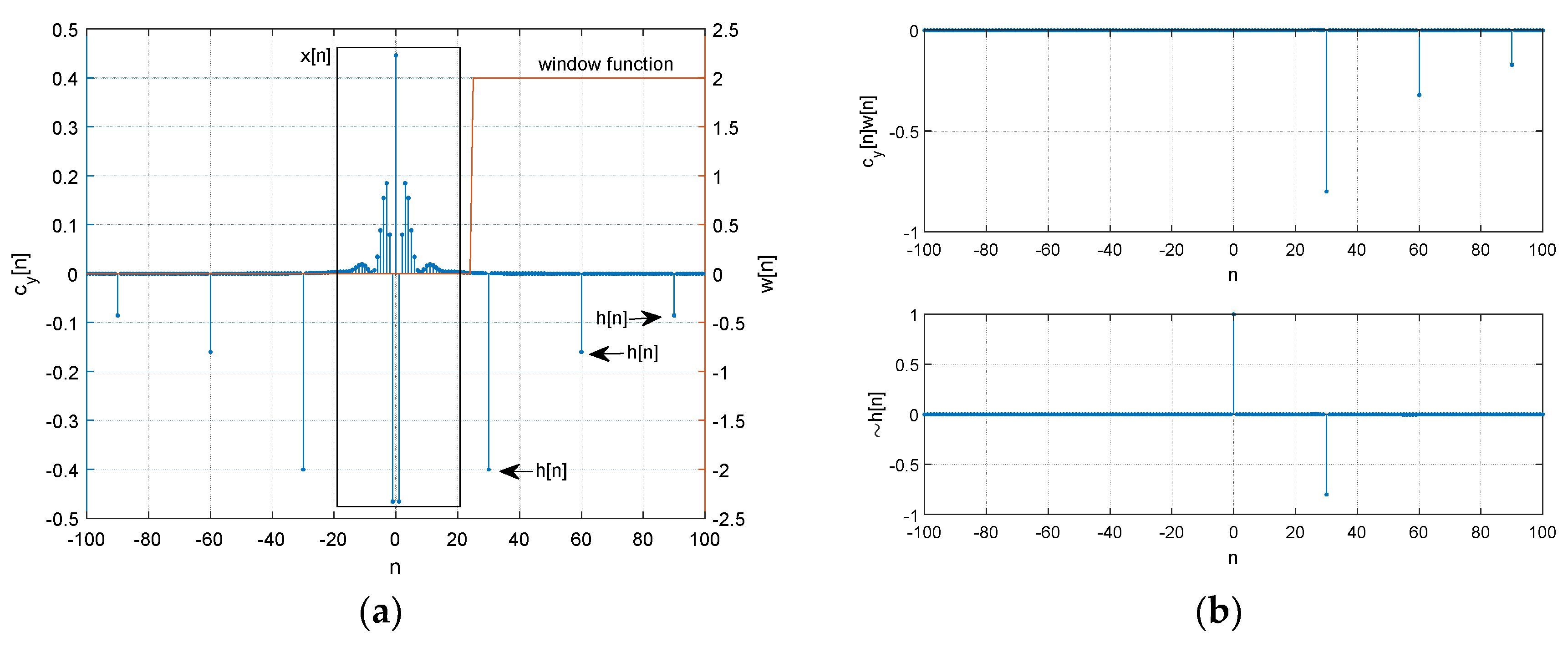
Figure 3 demonstrates the estimation procedure for two receivers with numerical examples. Both microphones receive the signal
with
time difference. The corresponding propagation function
is represented by
with sampling period
, Kronecker delta function
, and attenuation rate
. The received signal
is the convolution sum as
. The first FFT (stage ① in
Figure 2) and IFFT (stage ③) pair with absolute logarithm (stage ②) presents the real cepstrum
to divide the signal and propagation distribution.
Figure 3a shows the numerical example of forward conversion with marked areas for contributions. The window function
extracts the propagation function. The other FFT (stage ⑤) and IFFT (stage ⑦) pair with exponential function (stage ⑥) reestablishes and estimates the non-parametric propagation impulse response
.
Figure 3b presents the example for windowed
in upper and derived
in lower. The original
is
which is identical to the estimated
as
.
The regressive model is utilized for the parametric estimation to define the peaky distribution in propagation function
. The Yule–Walker, Prony, and Steiglitz–McBride method are devised to provide the signal spectral property. The conventional regressive signal models in time and
z domain are below.
The Yule–Walker algorithm estimates the model parameters below to describe the propagation function
of a given time signal.
The Prony and Steiglitz–McBride algorithm computes the model coefficients below to represent
.
The last computational stage (⑦ in
Figure 2) of the non-parametric and parametric HD algorithms performs the inverse transformation from frequency to time domain. The Yule–Walker, Prony, and Steiglitz–McBride algorithms are originally devised for forward transformation from time to frequency domain. The conjugated frequency domain distribution to the Yule–Walker, Prony, and Steiglitz–McBride algorithms generate the conjugated parameters for estimation according to Equation (3).
and
is the frequency and time domain data, respectively with FFT in
length.
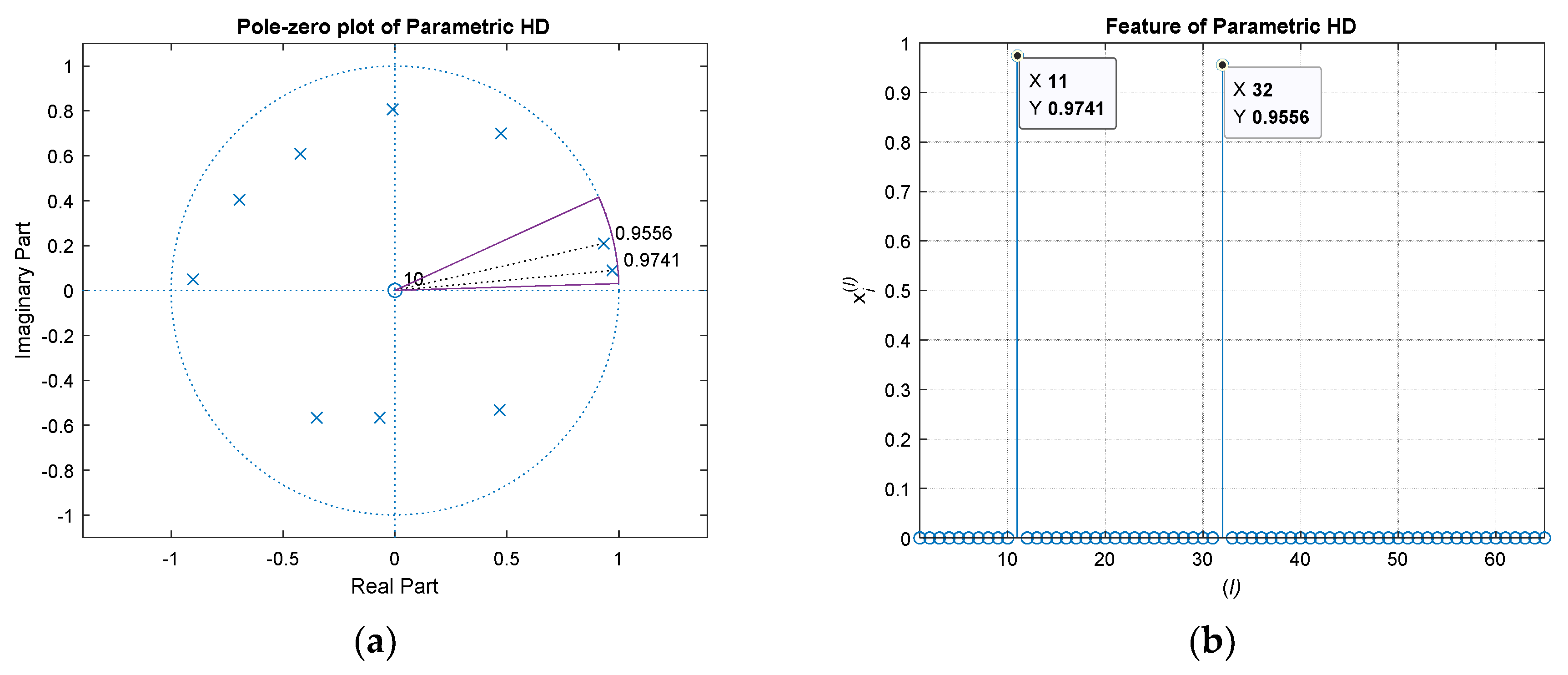
Between the microphones, the likelihood of ToF information is produced by the numerical distribution of non-parametric HD. Hence, the time positions standing for the maximum values specify the propagation function estimation. The last inverse Fourier transform (⑦ in
Figure 2) of non-parametric HD is replaced for the parametric methods by Yule–Walker, Prony, and Steiglitz–McBride. The ToF positions by maximum values from following regressive model is properly indicated by the derived complex number coefficients for the parametric method.
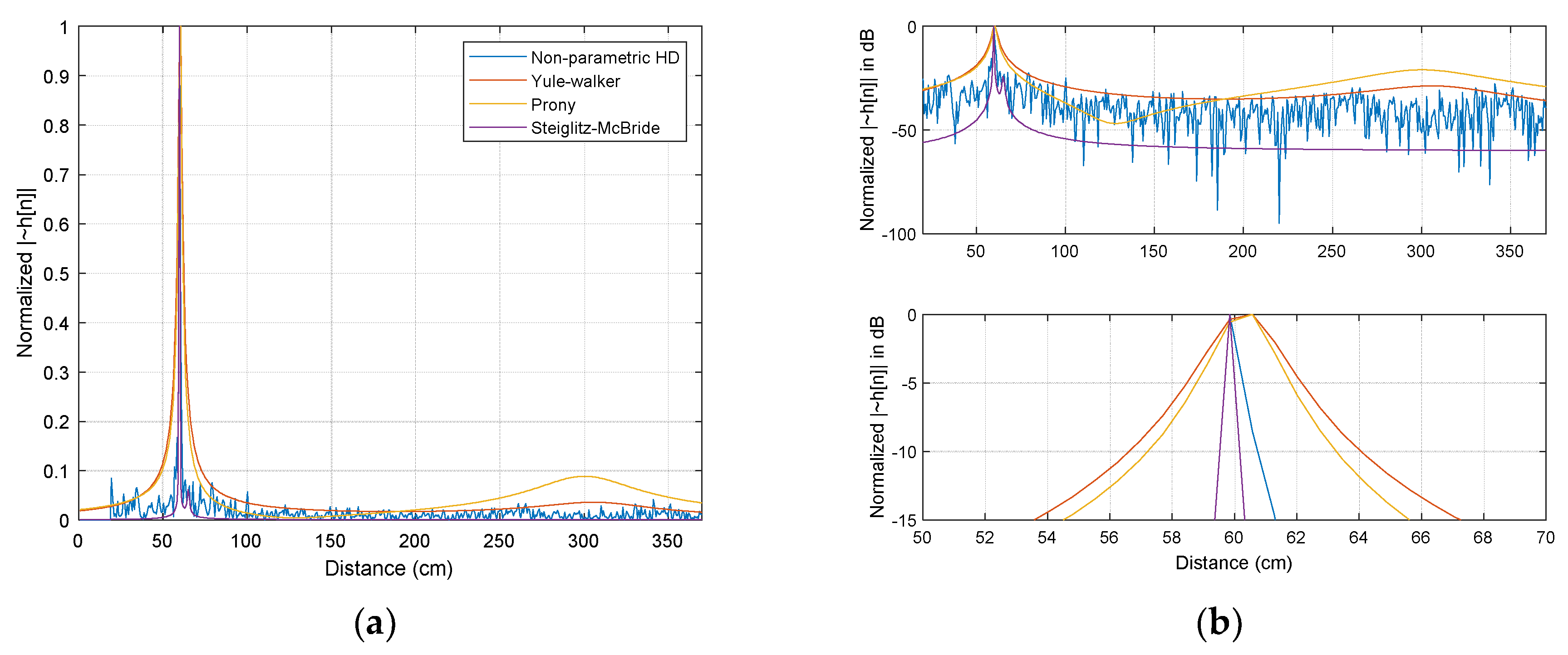
The simulations for various SNR and ensemble average length (after logarithm stage in ②) present statistical performance outcomes [
21]. The Steiglitz–McBride and non-parametric HD method demonstrate the consistent distribution with low variance and bias in general. The Prony and Yule–Walker methods are subject to the simulation conditions. In both methods, the better statistical performance is produced by the high SNR and long ensemble length overall. The experiments in anechoic chamber similarly provides the equivalent outcomes as the simulation. In the Steiglitz–McBride and non-parametric HD method, near zero bias and variance are shown for the increased ensemble length. The Prony and Yule–Walker method illustrate the performance enhancement in terms of bias and variance for longer ensemble length situations. The FILF window
is determined to remove the 25 sample (18 cm in equivalence) underneath with maximum phase realization in the experiments.
Figure 4 indicates the normalized
with 100 ensemble average length and 60 cm distance situations for non-parametric and parametric HD algorithms.
4. Simulations
Prior to discuss the SCMR SSL system simulation, the overall algorithmic procedures are required to summarize for fluent readability. The sound source is propagated over the medium with multiple arrivals on single-channel multiple-receiver configuration. The AoA determines the time delays between the arrivals and establishes the corresponding propagation function h[n]. The HD algorithms decompose the received signal y[n] for h[n] by non-parametric and parametric methods. The features for the linear regression are prepared with direct feature extraction (non-parametric HD) and radial projection (parametric HD). Using the labeled datasets, the linear regression based on the QR decomposition performs the least square solution for optimal coefficients to predict the AoA. The linear regression provides the accurate estimations for unlabeled received signal y[n].
The first step in simulation is to decide the receiver locations for the proposed SSL system. Note that the SSL system understands the datasets for prediction by calculating the coefficients of the linear model. Unlike the conventional beamforming algorithms [
1,
2], the SCMR SSL system does not involve the sophisticated mathematical model to place the receivers and to derive the direction. However, the optimal placements should be found by using the brute force method which consists of systematically enumerating all possible receiver configurations for the least prediction error. The extensive simulation datasets are necessary for searching the best receiver positions. The SSL system performance is numerated by root mean square error (RMSE) as below.
The
yi is the real output (label) of the given input features
. The estimated output
is the output of the linear regression based on the calculated coefficients
in Equation (23).
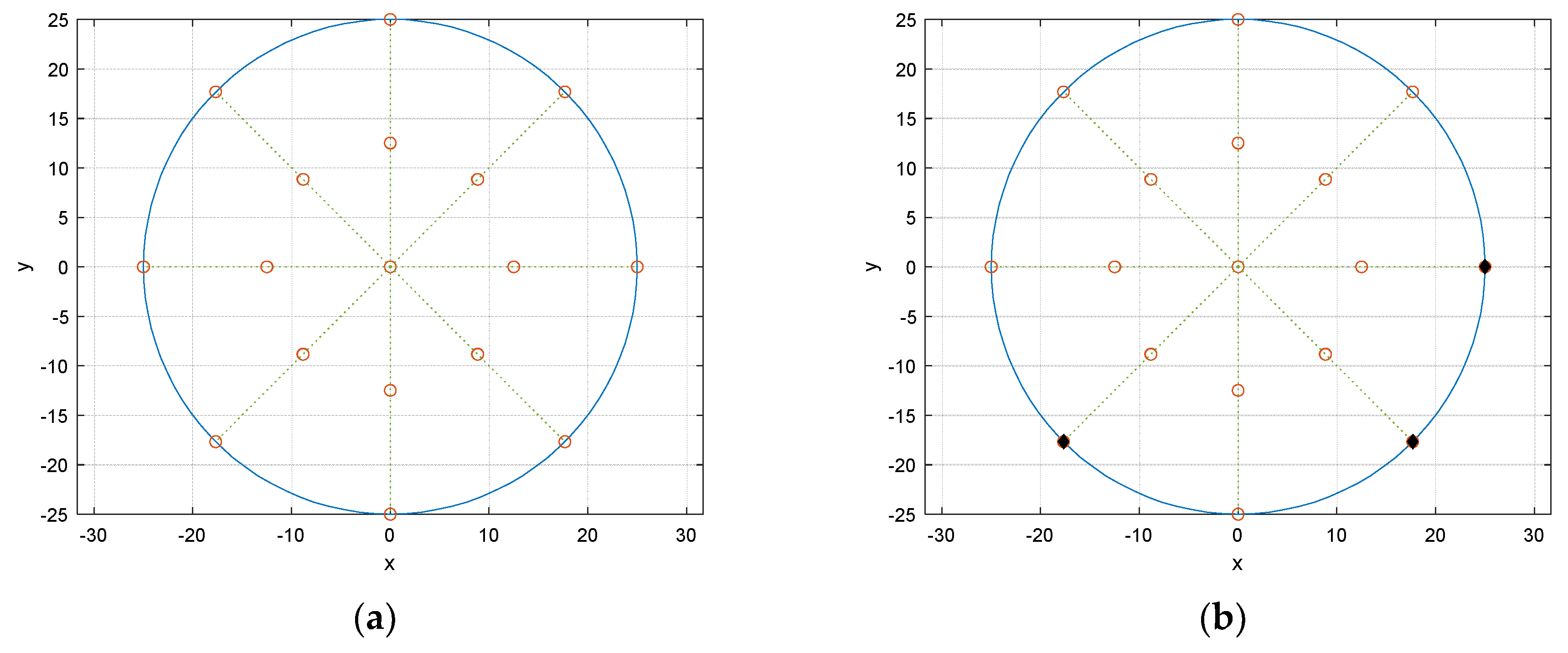
The receiver configuration presents the circular fashion in receiver placement. From the origin, two concentric circles are located with 25 cm and 50 cm diameter, respectively. The circular angle is divided by 8 directions and individual angular distance between the adjacent directions is
. The receiver grid is the overlap between the concentric circles and radial directions as shown in
Figure 7a which demonstrates the possible receiver locations as blank circles.
Figure 7b exhibits the example of the receiver locations with 3 sensors. The number of selections for placing receivers in the given grid can be calculated by simple binomial coefficient. For instance, 17 grid points are available in
Figure 7 and 3 receivers are accessible the 680 possibilities for the combination.
With given receiver locations, the arrival times can be computed by direct distance from the sound source. Additionally, the distance provides the attenuation based on the inverse square law which describes the magnitude of propagation signal over the distance. The equation for inverse square law is shown in below.
The
Lp(
ri) is the sound pressure level in decibels at the distance
ri. The terms
a and
r0 are model parameter for amplitude and distance, correspondingly. The acoustic anechoic chamber used in the experiments records the signal with various distance to measure and compute the parameters for precise simulation. The derived values are
a = 36.1438 and
r0 = 0.0043 cm for the given anechoic chamber [
29]. For the sensor configuration, the inverse square law equation calculates the relative magnitude difference between the receivers in numerical simulation.
The simulation parameters are presented in
Table 1. The input data is generated by the numbers such as SNR, angle range, sound speed, receiver count, and etc. The non-parametric and parametric HD are performed by the values for instance ensemble length, frame length, etc. Some parameters show the certain proportionality over the performance; however, the purpose of the pilot simulation is to deliver the optimal receiver configuration by RMSE outcome with fixed parameter values. Further analysis determines the ensemble length and parametric order based on the optimal receiver configuration.
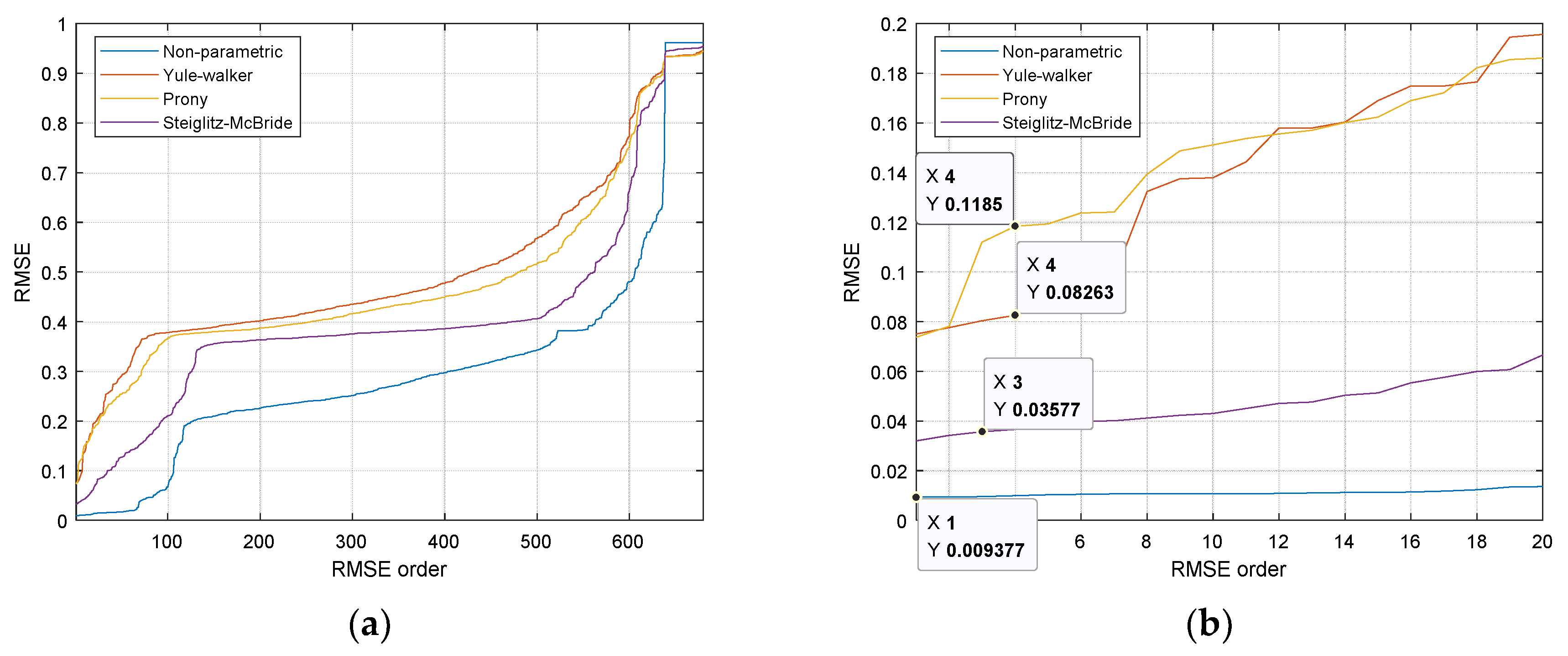
The RMSE performances for all 680 possible receiver configurations are demonstrated in
Figure 8 with ascending order from left to right. The simulation was performed by the 14 computers with intel i7-7700 processor and DDR4 32GB memory for 25-h execution time. The MATLAB parallel processing toolbox provides the coarse-grained parallelism by dividing the for-loop iterations over the multi-core processor.
Figure 8b magnifies the left-bottom corner of
Figure 8a to select the optimal configuration. The highlighted numbers in each HD algorithms represent the particular receiver configuration which indicates the overall best performance. Note that the
x numbers in
Figure 8b specify the performance rank. The chosen configuration shows the 1, 3, 4, and 4 rank in non-parametric, Steiglitz–McBride, Yule–Walker, and Prony HD, respectively.
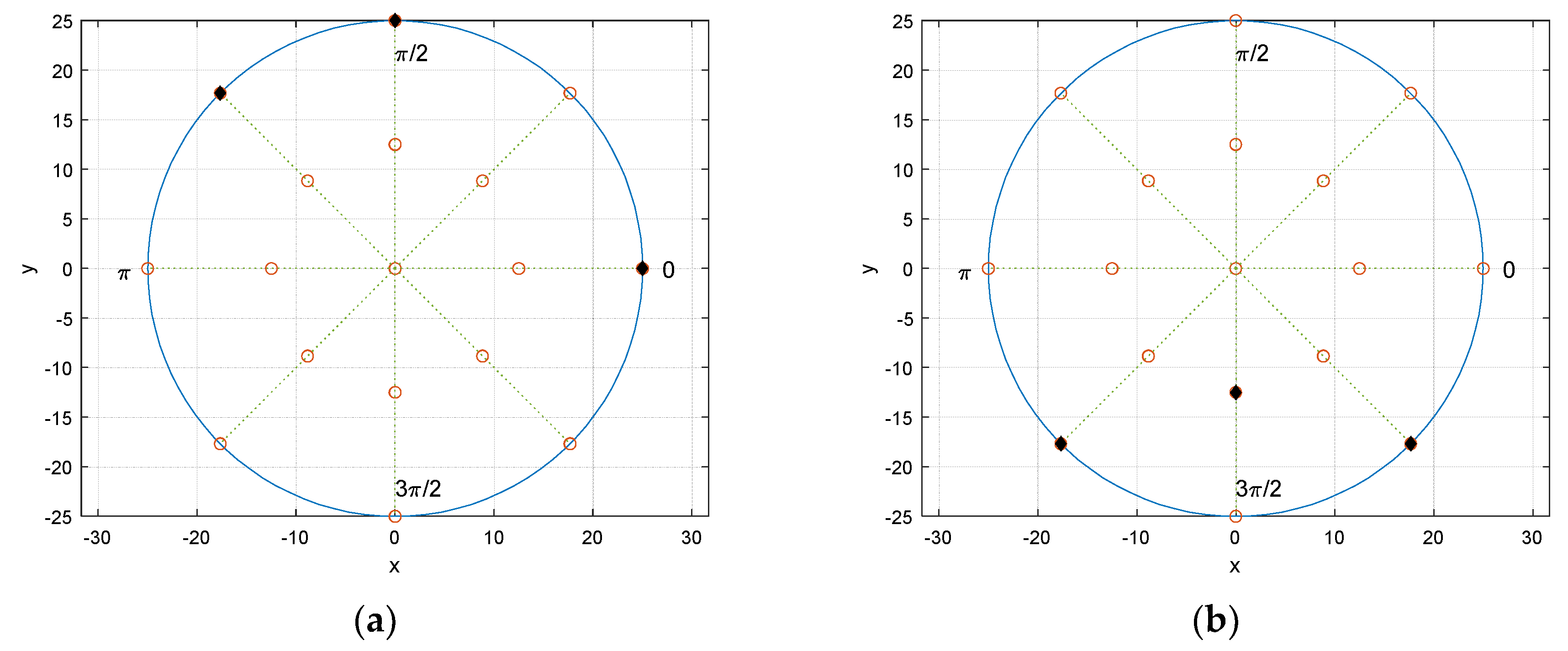
The selected receiver configuration is presented in
Figure 9a. The black filled dots represent the receiver locations over the potential blank positions. The asymmetricity with wide distribution in locations provides the prominent and distinctive arrival time distribution for linear regression. One of the worst performance configurations is depicted in
Figure 9b. Contrary to the best receiver distribution, the configuration demonstrates the symmetricity and tight spreading which delivers the significant ambiguity for linear regression. The higher number of receivers expects the better performance and the three-receiver configuration is the minimum requirement to predict the half circular angle.
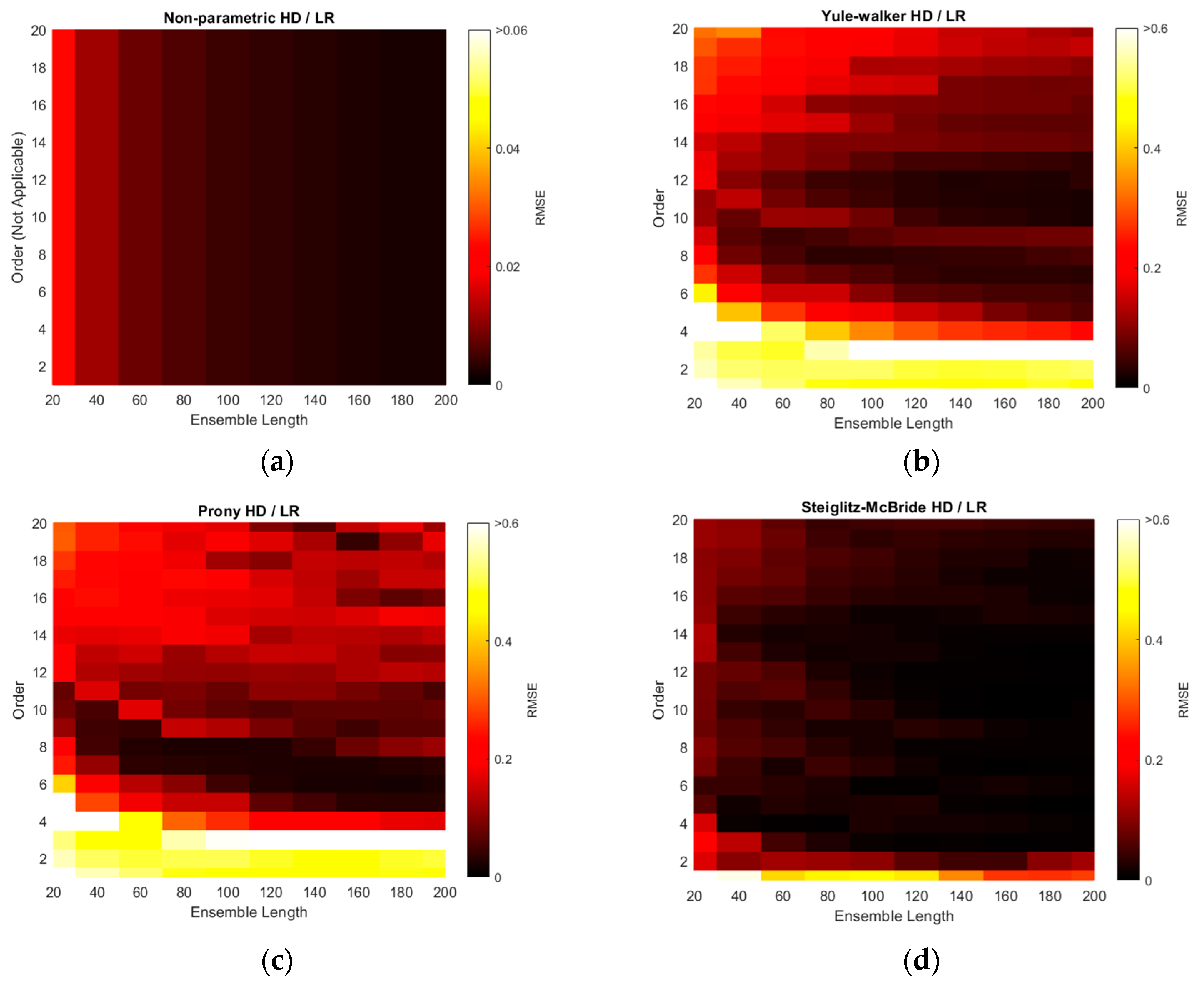
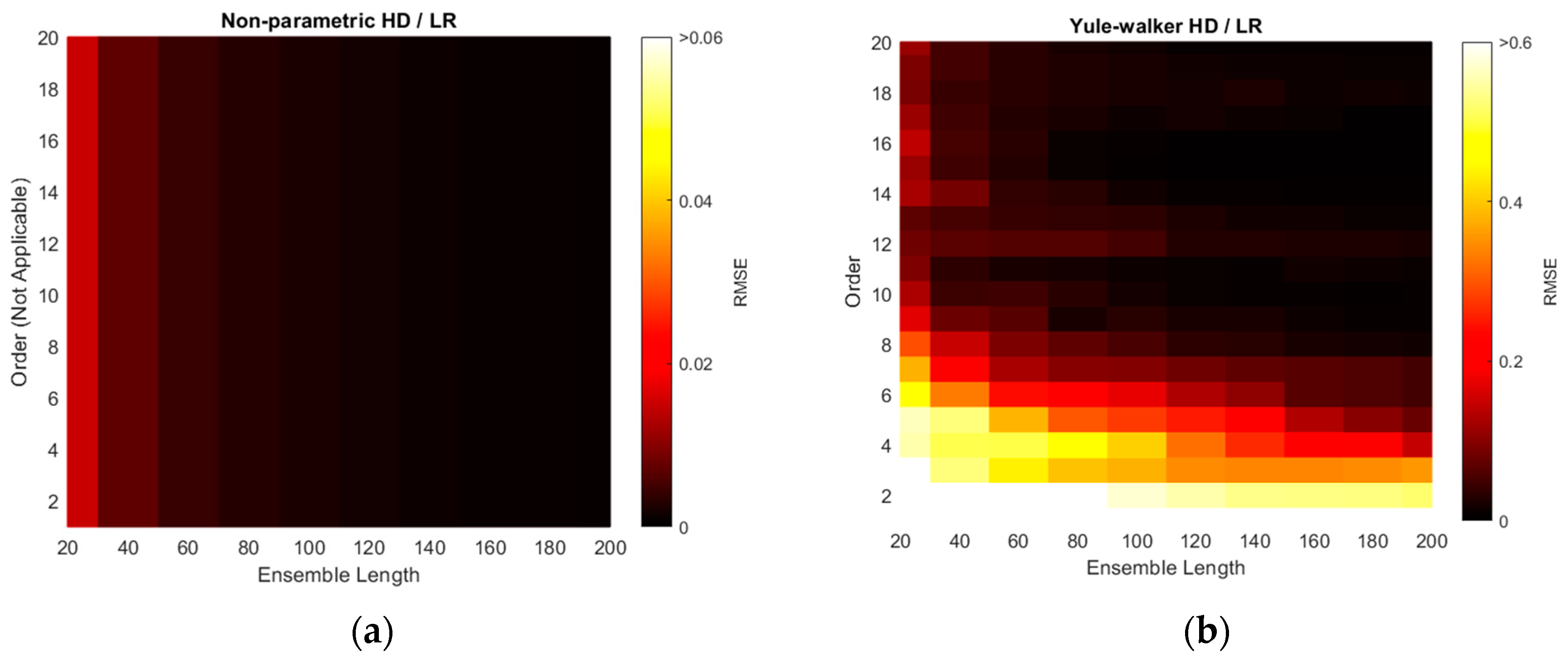
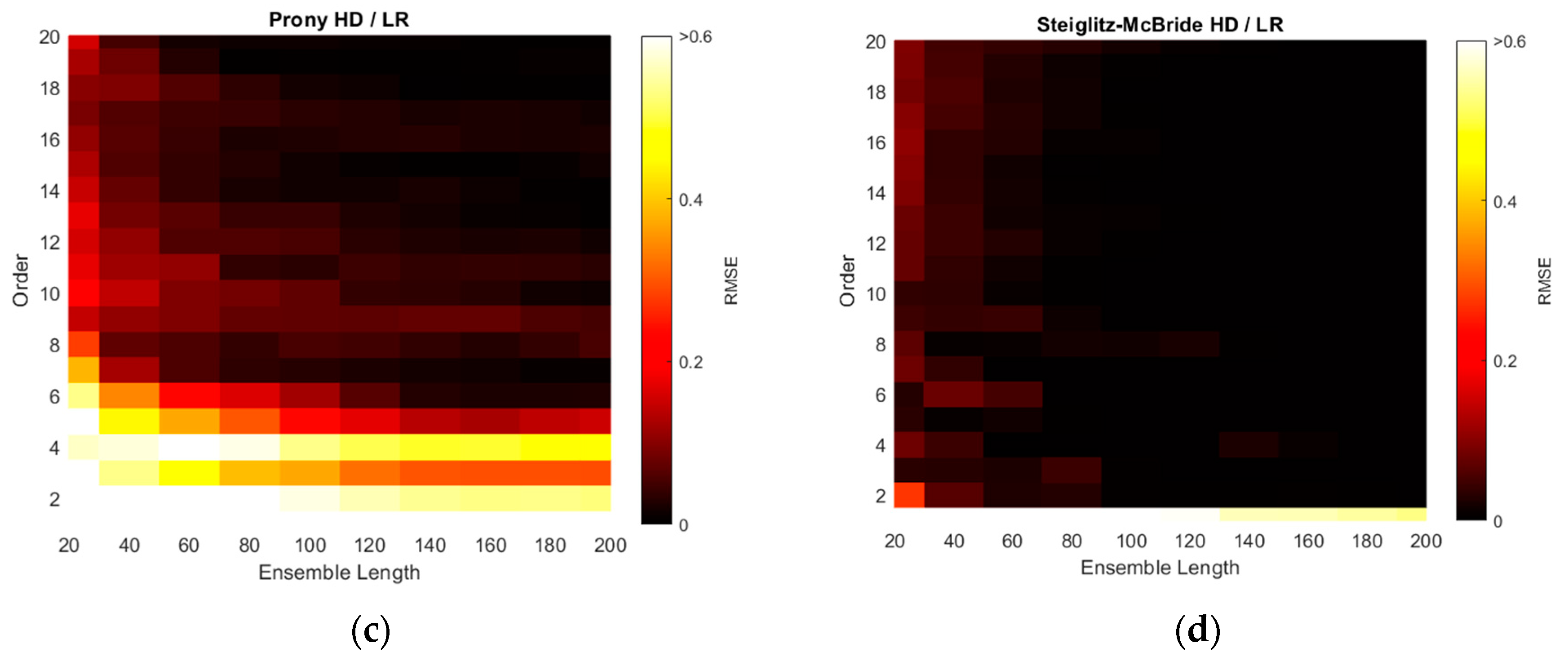
The RMSEs of non-parametric and parametric HD with linear regression (LR) are illustrated with various ensemble lengths and model orders in
Figure 10. The model order is changed from 1 to 20 in every 1 step and the ensemble length is modified from 20 to 200 in every 20 interval. Note that the non-parametric HD/LR contains the parameter of ensemble length only. The order in the non-parametric HD/LR in
Figure 10a is dummy variable to compare with the performance of the other HD/LR algorithms. Additionally, the color scale for non-parametric HD/LR in
Figure 10a indicates the reduced range because of the high consistent and low variance RMSE distribution. The longer ensemble length in non-parametric HD/LR presents the daker shade in the RMSE figure on right. The Yule–Walker HD/LR shows the daker lake and river around the order 11/length 160 and order 10 ~ order 7, respectively. The Prony HD/LR demonstrates the darker river similar to the Yule–Walker HD/LR distribution. The Steiglitz–McBride HD/LR displays the darker district above the order 2 and length 160 boundary. The non-parametric HD/LR and Steiglitz–McBride HD/LR establish the best overall performance in
Figure 10.
The minimum RMSE values for HD/LR algorithms are organized with corresponding ensemble length and model order in
Table 2. In general, the longer ensemble length presents the improved performance in prediction. The parametric HDs with linear regression do not demonstrate the performance proportionality in terms of model order due to the under- and over-determined parameter. The Yule–Walker HD/LR and Prony HD/LR show the similar performance in order 11 and 6, respectively. The Steiglitz–McBride HD/LR indicates around 70 times better performance than the other parametric HDs in order 10. The non-parametric HD/LR RMSE is located between two performance levels. Note that the worst minimum RMSE in
Table 2 is 1.2514 degree.
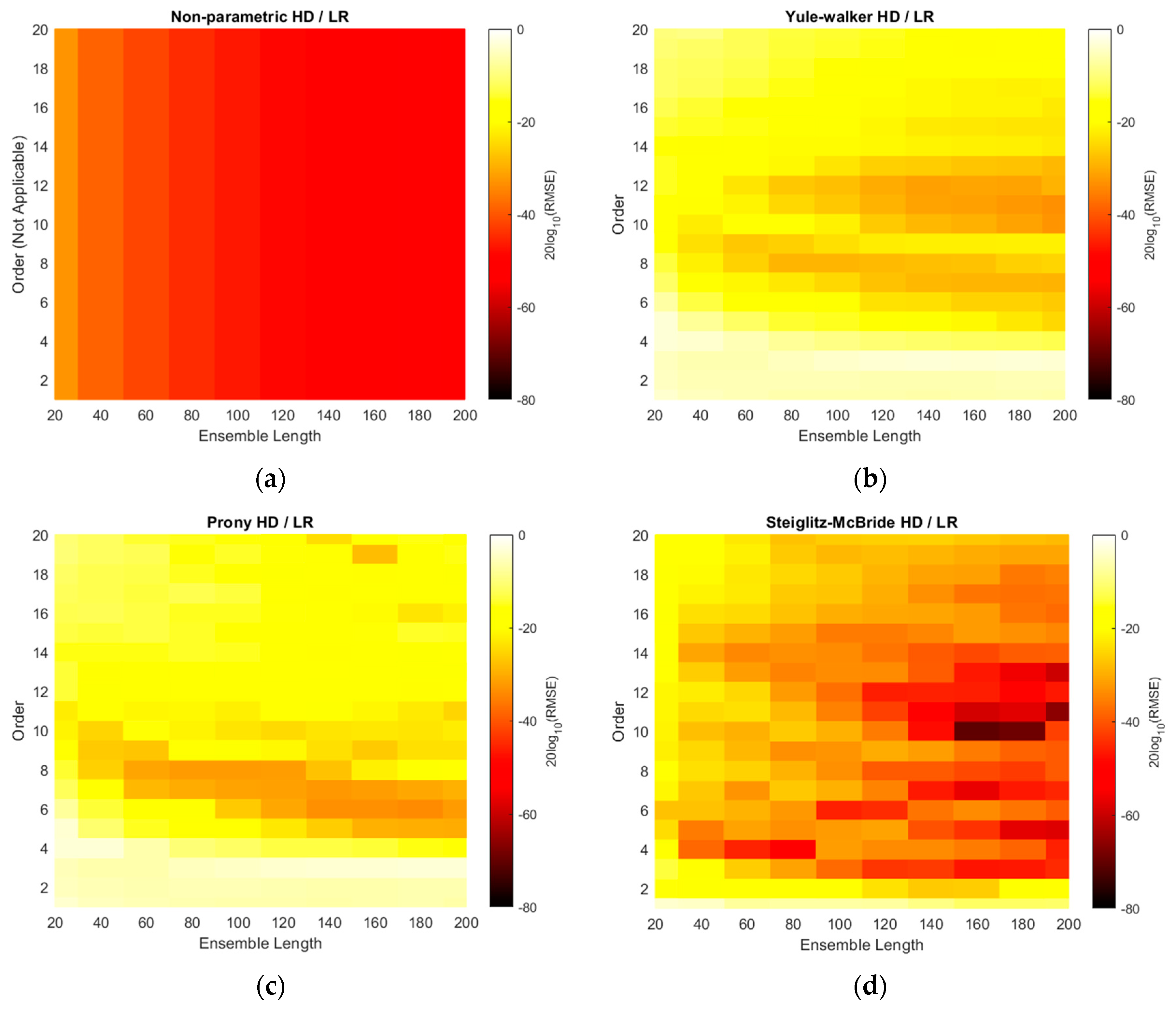
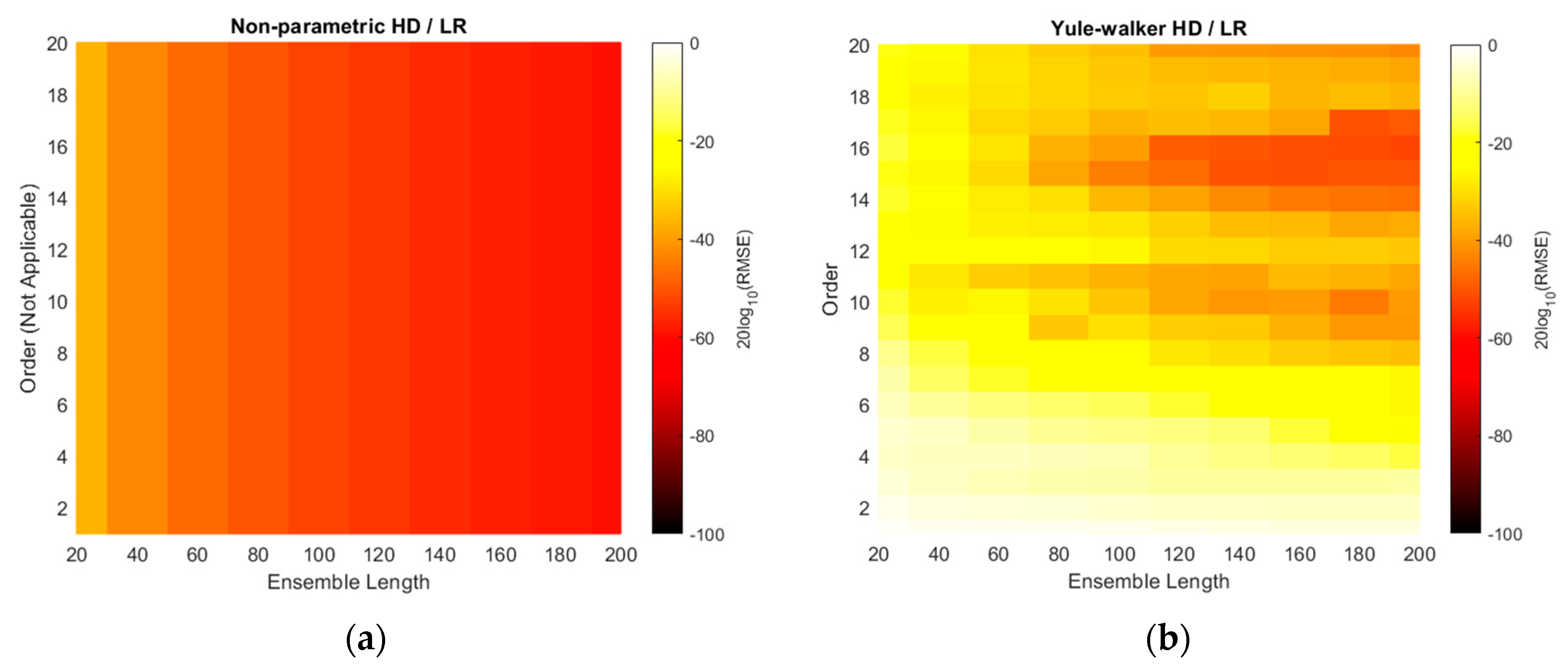
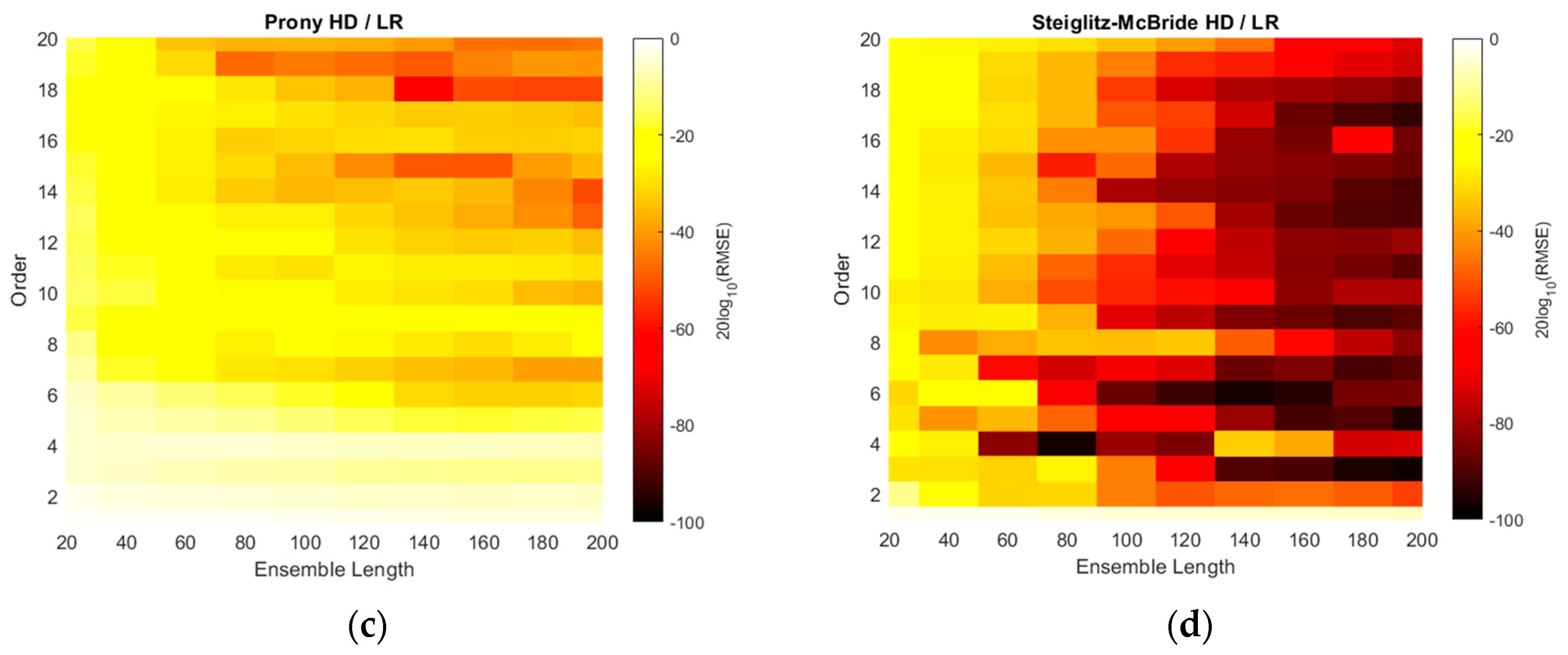
The RMSE distributions of
Figure 10 are recharted in
Figure 11 with the decibel scale. Observe that all plots in
Figure 11 are coded with single color scale. Hence, the RMSE performances can be sorted as Yule–Walker, Prony, non-parametric, and Steiglitz–McBride HD/LR in ascending order by examining the color shade. The Yule–Walker HD/LR shows the sweet spot around the model order 11 and 12 with ensemble length 120 and above. The Prony HD/LR demonstrates the sweet belt along with model order 6 and 7 for ensemble length 60 and above. The Steiglitz–McBride HD/LR presents the deeper and narrower sweet spot in model order 10 and ensemble length 160. As expected, the non-parametric HD/LR delivers the consistent and proportional performance improvement for longer ensemble length.
The simulation above is performed to find the optimal receiver locations for three-sensor configuration. Among the radial configuration, the asymmetric and wide distribution is selected over the 680 possibilities. The RMSE is used for evaluation and the error is defined as the difference between the real and predicted angle. Over the optimal receiver configuration, the range of model orders and ensemble lengths were placed to calculate the RMSEs for the non-parametric and parametric HD with linear regression. The RMSE distributions represent that the longer ensemble length and particular model order provide the least RMSE value. The Steiglitz–McBride HD/LR shows the best performance and Yule–Walker HD/LR demonstrates the least accuracy in this simulation.
5. Results
The field experiments are realized and evaluated in an anechoic chamber which is verified to show the limited conformance with ISO 3745 [
41] for the 1 kHz–16 kHz 1/3 octave band in a hemi-free-field mode and for the 250 Hz–16 kHz 1/3 octave band in a free-field mode [
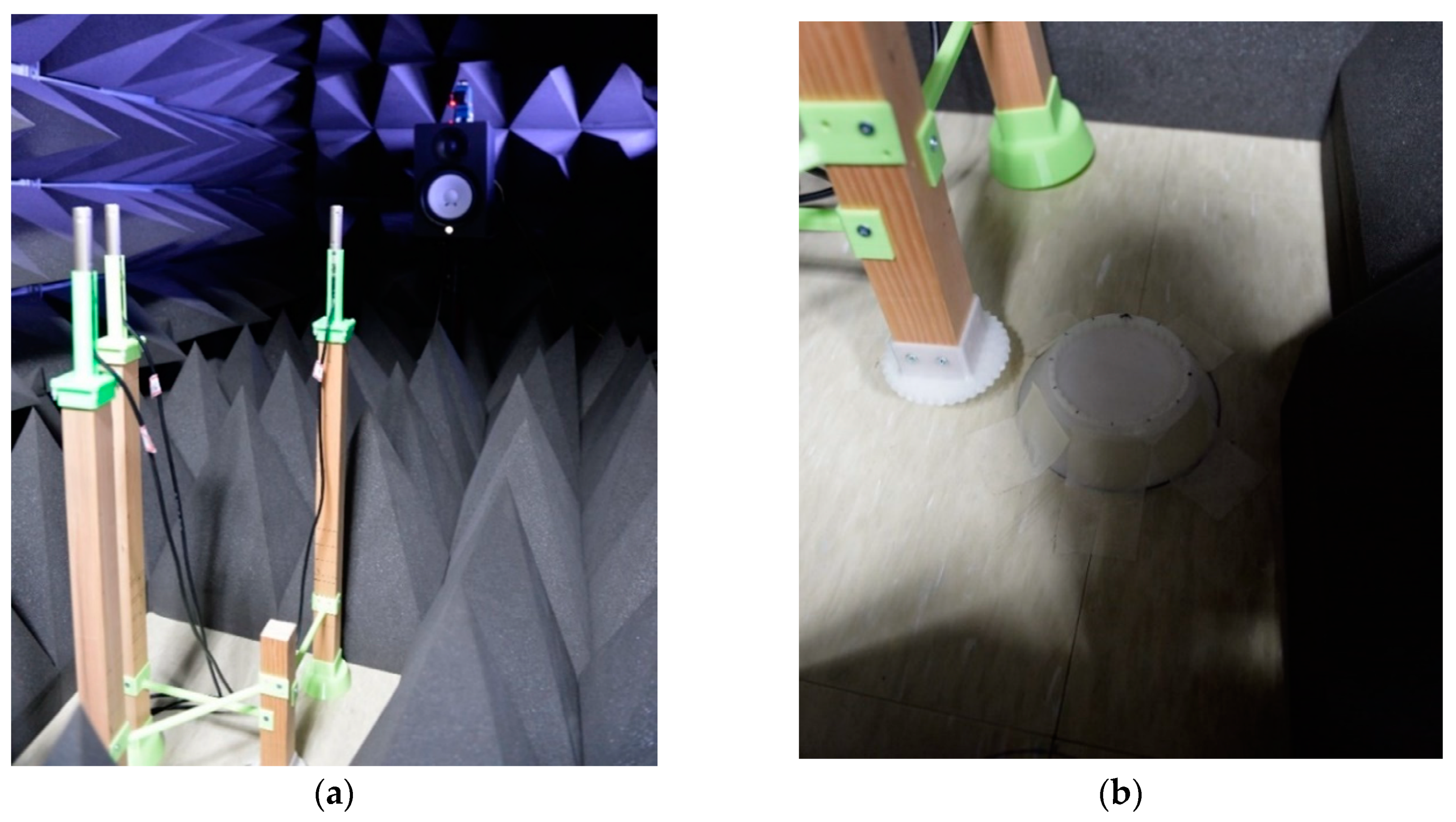
30]. The proposed SCMR SSL methods are evaluated with the free-field mode which involves entirely covered surfaces for all directions with acoustic pyramids. The experiment configuration consists of three microphones with given locations and one speaker with far-field provision. The direction and angle between receivers and transmitter are guided by the line laser (GLL 3–80 P, Bosch, Gerlingen, Germany) placed above the sound source speaker. The far-field provision is maintained by keeping one meter the minimum distance for signal propagation.
The microphones are located on the frames made of lumbers with plastic connectors. The structure sustains the microphone height and receiver shape for angular movements. Observe that the sound source and receiver level should be identical for horizontal propagation. The angle movement for AoA is engaged by the pair of saw-toothed wheels with engraved and intagliated shape for 10° rotation. As shown in
Figure 9a, the three receivers are located on the radial pattern with concentric circles; therefore, the center of the circles provides the angular movement center which is dedicated for saw-toothed wheel pair. The overall experiment configuration is illustrated in
Figure 12a and the receiver center is shown in
Figure 12b for the angular movement engager. The plastic parts are realized by the 3D printer (Replicator 2, MakerBot, Brooklyn, NY, USA) from the polylactic acid (PLA) filament.
The analog mixer (MX-1020, MPA Tech, Seoul, Korea) connects to the microphones (C-2, Behringer, Tortola, British Virgin Islands) for single channel signal which is digitized by the computer-connected audio device (Quad-Capture, Roland, Hamamatsu, Japan). The speaker (HS80M, Yamaha, Hamamatsu, Japan) is also wired to the audio device to generate the wideband signal. The real-time audio for generation, reception, and execution is processed by the MATLAB system object with the audio stream input/output (ASIO) driver. With 48 kHz sampling rate, the audio is recorded for 20 s in every designated angles. In order to reduce the interruption by transition conditions, the first and last one second data is eliminated. Therefore, the distinct angle experiments employ the overall 18 s of recorded data. Each data frame is established by 1024 samples and the new ensemble average process is begun after the 10 frames later. For data consistency, the rest of the frames are overlapped with given parameter. The experiment parameters are presented in the
Table 3.
Similar to the simulation results, the RMSEs of non-parametric and parametric HD with linear regression are demonstrated with ensemble lengths and model orders in
Figure 13. Note that the model order and color scale in the non-parametric HD/LR in
Figure 13a is inconsistent with the other RMSE figures as discussed in simulation section. Compare to the simulation
Figure 10, the RMSE colors are represented by the darker shade overall which indicates the improved performance in predictions. The longer ensemble length provides the reduced RMSE in all HD/LR algorithms. Additionally, the higher model order delivers the better prediction performance in marginal manner because of the shade gradation in vertical direction. The performance glitches can be observed in order 12 and 9 in Yule–Walker and Prony HD/LR method, respectively. The Steiglitz–McBride HD/LR shows darkest RMSE shade which is below 0.1 radian for most of area except 20 and 40 frames for ensemble length.
The RMSE plots are changed to the decibel scale in
Figure 14. The consistent and wide scale is used for non-parametric and parametric HD/LRs. Note that the RMSE approaches down to the −100 dB in Steiglitz–McBride HD/LR method. The non-parametric HD/LR presents the coherent and proportional performance enhancement for longer ensemble length. The Yule–Walker and Prony HD/LR show the similar performance with distinct areas and patterns for darker shade. Compare to the simulation result in
Figure 11, higher model order produces the lower RMSE overall for Yule–Walker and Prony HD/LR. The Steiglitz–McBride HD/LR method indicates the extensive area for below −60 dB RMSE with uneven boundary of ensemble length 80 above and model order 3 higher. The deep dark shade can be perceived in the low model order as below as 3.
Table 4 establishes the minimum RMSE values for HD/LR algorithms with corresponding ensemble length and model order. The experiments produce the performance in terms of minimum RMSE with 2, 9, 40, and 21 times better than the simulation counterparts for
Table 2 listing order. Therefore, the non-parametric and Steiglitz–McBride HD/LR method show 2 and 21 times lower RMSE than the simulation minimum values, correspondingly. Note that the experiments are performed with identical parameters indicated in simulation specifications except SNR and angle resolution. Overall, the longer ensemble length delivers the higher prediction performance for all HD/LR algorithms. The minimum RMSEs are located in the higher model order than the simulation outcomes for Yule–Walker and Prony HD/LR. The Steiglitz–McBride HD/LR method presents the best performance in low model order 3 since the Steiglitz–McBride algorithm accurately describes the propagation function as shown in previous paper [
21]. Note that the worst minimum RMSE in
Table 4 is 0.1411 degree.
The actual predictions are demonstrated in
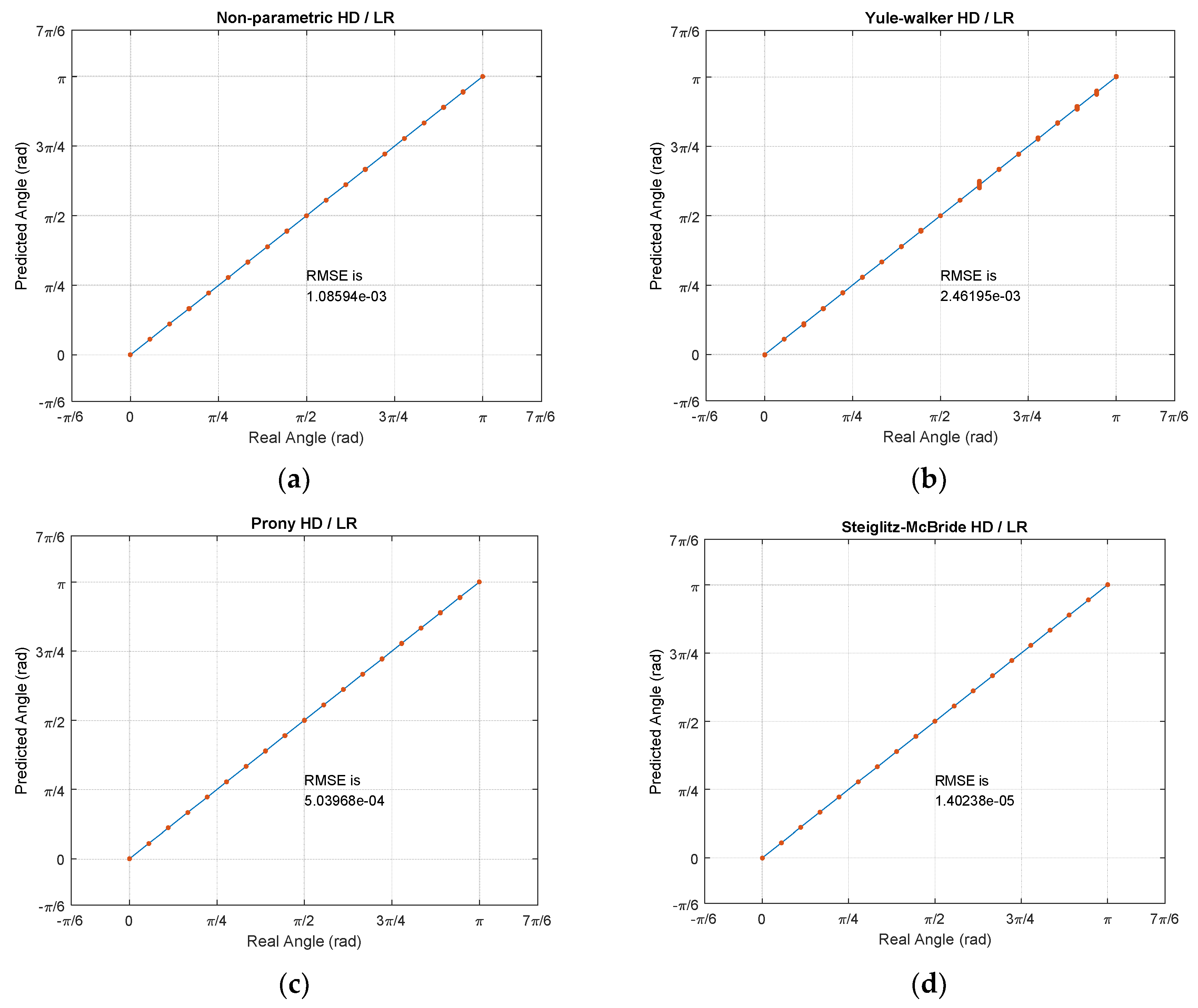
Figure 15. The simulations and experiments are performed by two datasets which include the training set and test set for 1000 iterations each. The training set is annotated by the labels and test set is classified as hold-out set for blind test. All RMSEs in this paper are computed by the test set over the linear regression model which is built by training set. Note that the given frame size, overlap size, and sampling frequency provide the approximately 6.5 s for 1000 iterations.
Figure 15 illustrates the individual coordinate by
x axis with real angle and
y axis with predicted angle. Therefore, the solid diagonal line in the figures indicates the perfect prediction. The 19 angular points are separated by
radian with equiprobable chance for all iterations. The single point in the plot is the cumulated spots with highly accurate predictions. The non-parametric, Prony, and Steiglitz–McBride HD/LR show the high precision predictions with distinct points in
Figure 15. The Yule–Walker HD/LR presents the spread distribution for certain angular points; therefore, the Yule–Walker HD/LR produces the least performance.
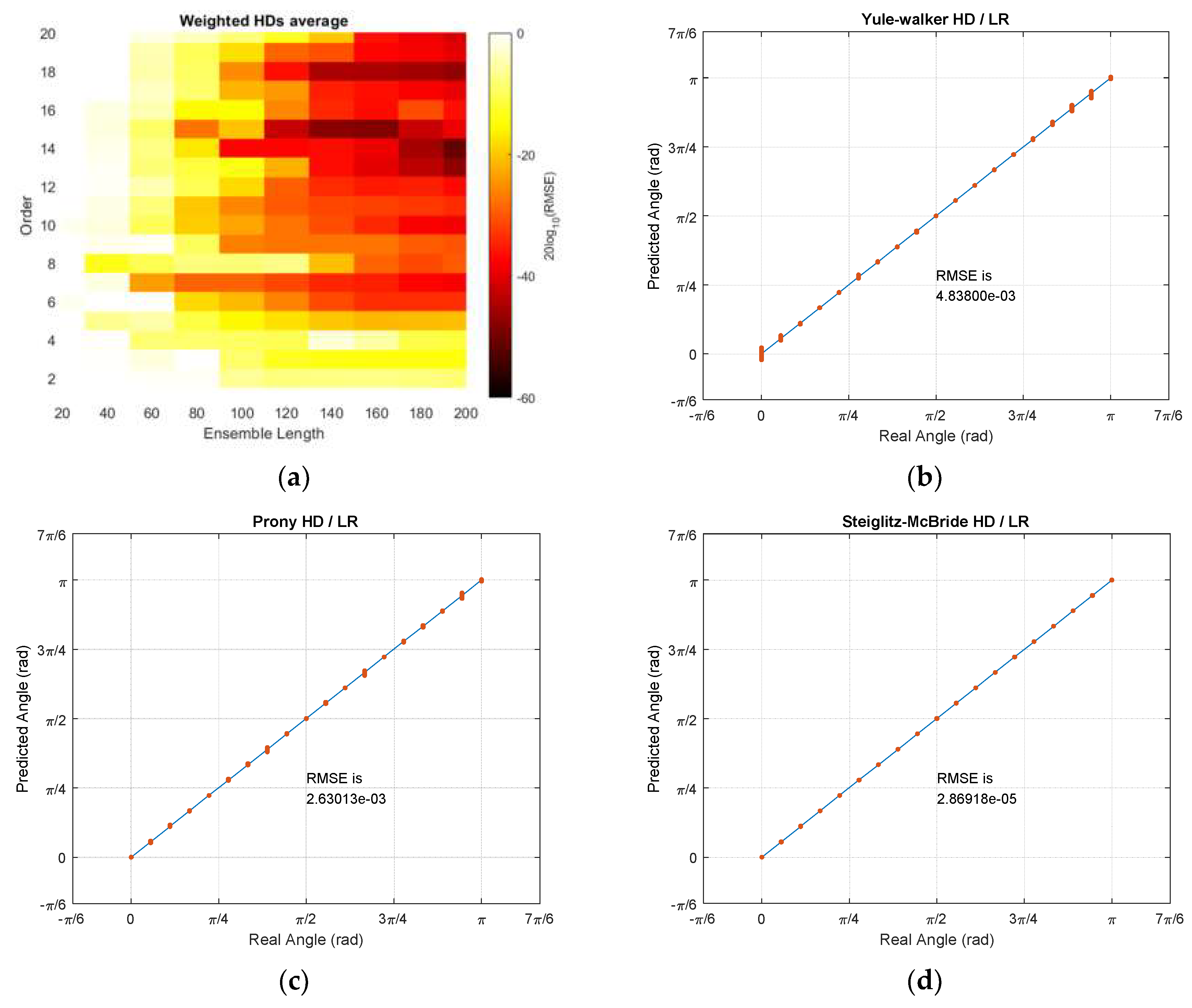
The combined RMSE distribution derives the optimal parameters for all HDs with LR. In order to reduce the bias of certain outcome, the weighted RMSE distributions are averaged for final result. The minimum RMSE of each HD/LR is normalized to the non-parametric HD/LR minimum by constant weight for individual algorithm output. The weighted HD/LR average RMSE distribution indicates the optimal parameters as ensemble length 200 and model order 14. With derived values,
Table 5 demonstrates the minimum RMSE values for all HD/LR algorithms. Observe that no model order is applied to the non-parametric HD/LR algorithm. The Steiglitz–McBride HD/LR provides the best performance followed by non-parametric, Prony, and Yule–Walker HD/LR. Except the non-parametric HD/LR, the parametric HD/LRs deliver the minor performance degradation due to the quantity shift for length and order. The highest performance glitch is the Prony HD/LR RMSE with 5.2 times lower than own minimum.
The weighted average HD/LR RMSE distribution and individual prediction plots are shown in
Figure 16. The average RMSE distribution presents the precise accuracy on longer ensemble length and higher model order in general. Especially, the model order 14, 15, and 18 provide the darkest shade in performance gradation on
Figure 16a. The Yule–Walker and Prony HD/LR estimate the individual angle with minor variance in certain points as shown in prediction plots in
Figure 16b,c, respectively. The Steiglitz–McBride HD/LR still produces very accurate prediction in
Figure 16d. The non-parametric HD/LR prediction is identical to the
Figure 15a since the ensemble length is 200 frames. Note that the worst minimum RMSE in
Table 5 and
Figure 16 is 0.2772 degree.
The experiments in the anechoic chamber demonstrate the performance of non-parametric and parametric HDs with LR. The designed angles with apart are blindly provided to estimate the AoA with individual HD algorithms with LR. Overall, the accurate predictions are expected in proper ensemble length and model order. The optimal parameter values for each HD/LR produce the pinpoint accuracy for prediction in the descending performance order of Steiglitz–McBride, Prony, non-parametric, and Yule–Walker HD/LR. The weighted RMSE distribution derives the overall RMSE minimum at ensemble length 200 and model order 14. The obtained parameter value generates accurate estimations with minor variance. The performance can be sorted in the descending order as Steiglitz–McBride, non-parametric, Prony, and Yule–Walker HD/LR. The non-parametric HD/LR presents the consistent performance and Yule–Walker HD/LR indicates the least accuracy in simulation as well as experiments. The worst minimum RMSE in simulation and experiments are 1.2514 and 0.2772 degree, respectively. Hence, the proposed HD/LR algorithms deliver the highly accurate predictions in overall.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}