Improving Human Activity Recognition Performance by Data Fusion and Feature Engineering

Abstract
1. Introduction
2. Algorithm Description
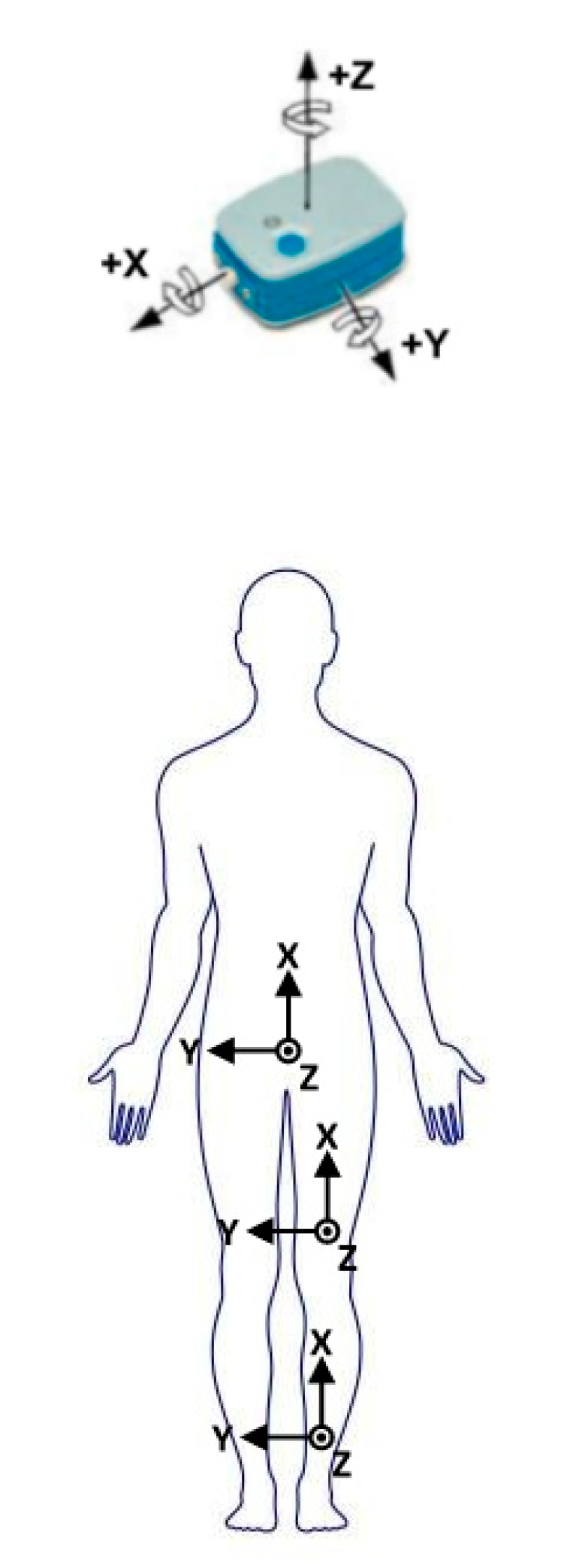
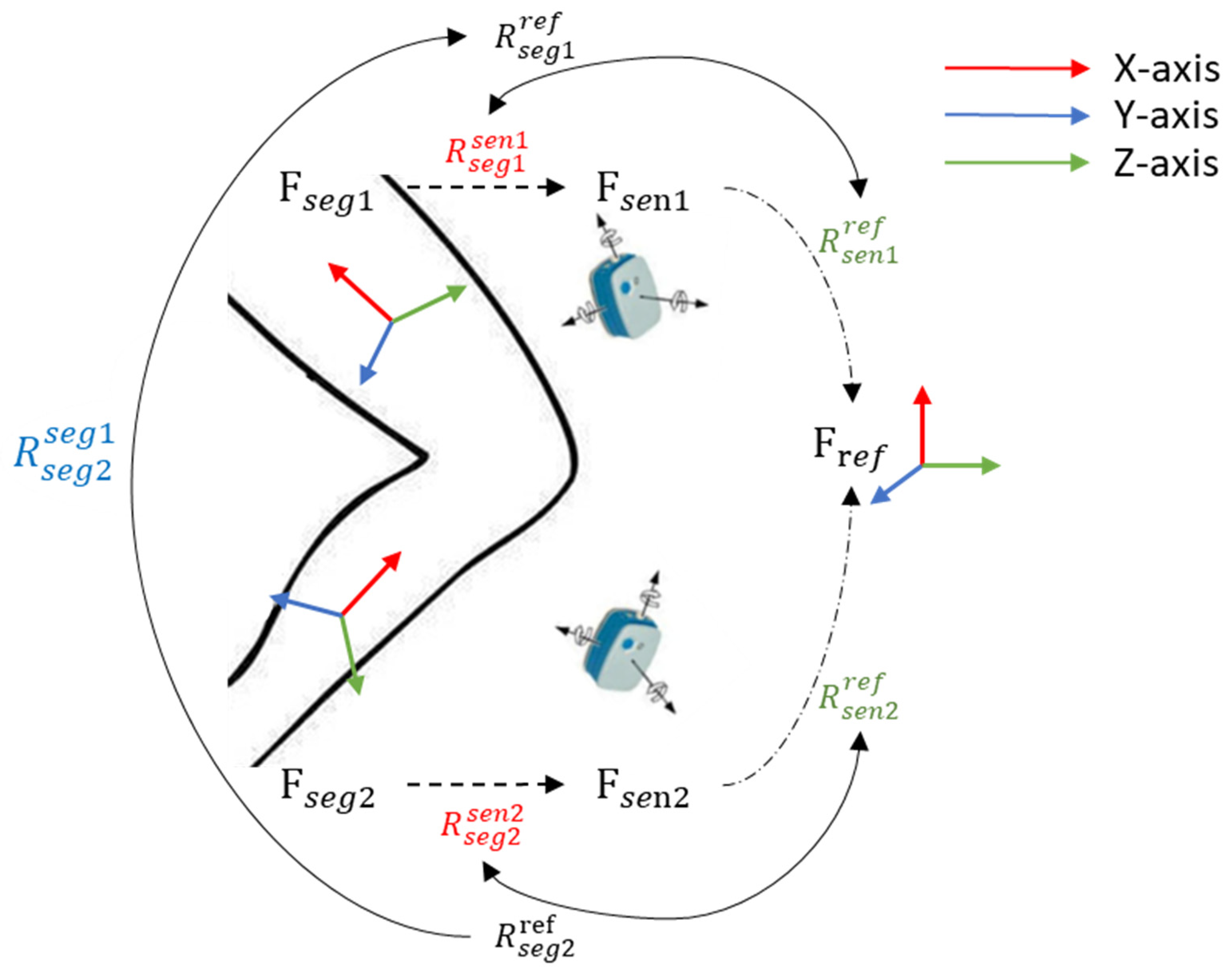
2.1. Calculation of the Joint Angle
2.2. Features
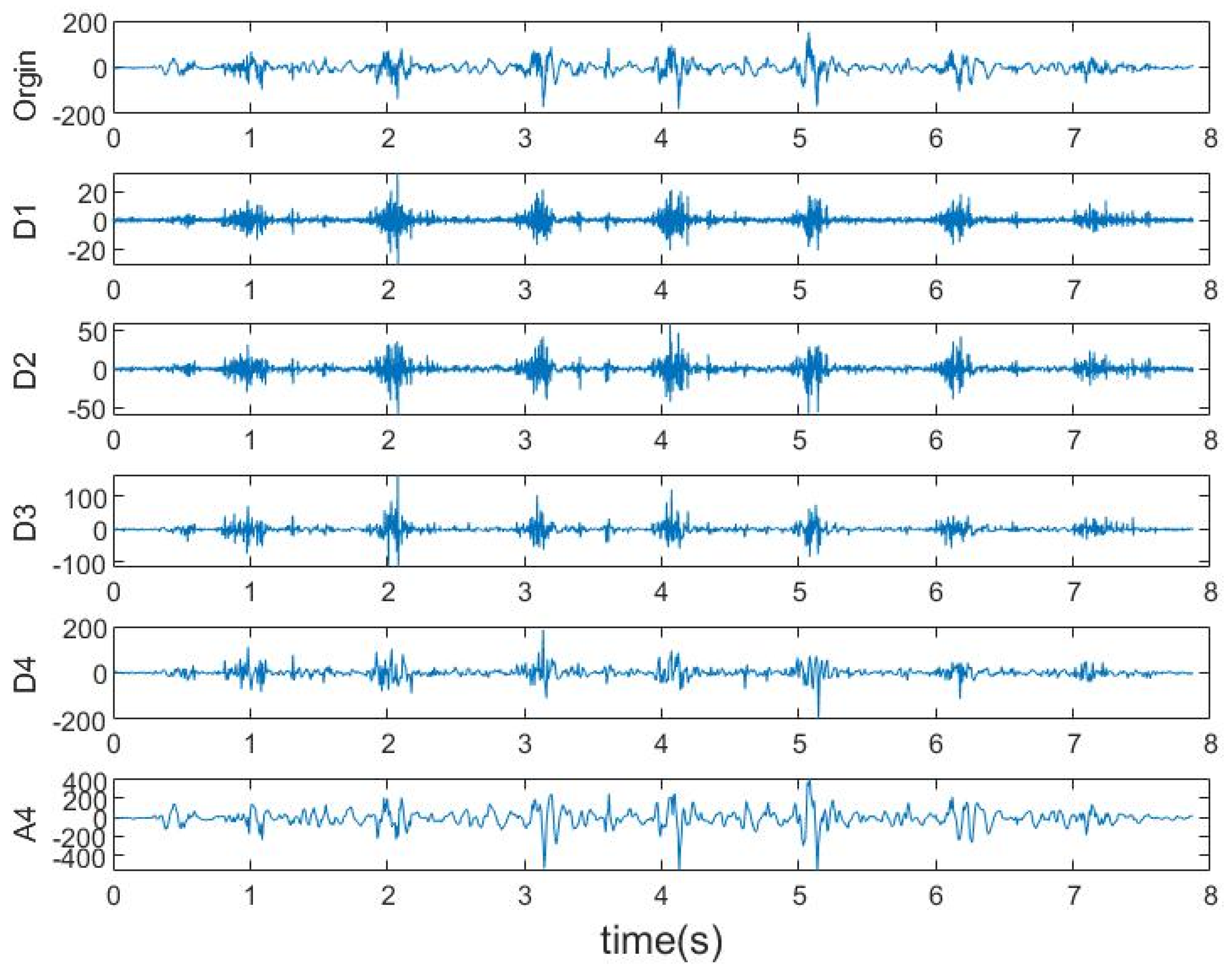
2.2.1. Feature Calculation
- TD Features
- FD Features
- TFD Features
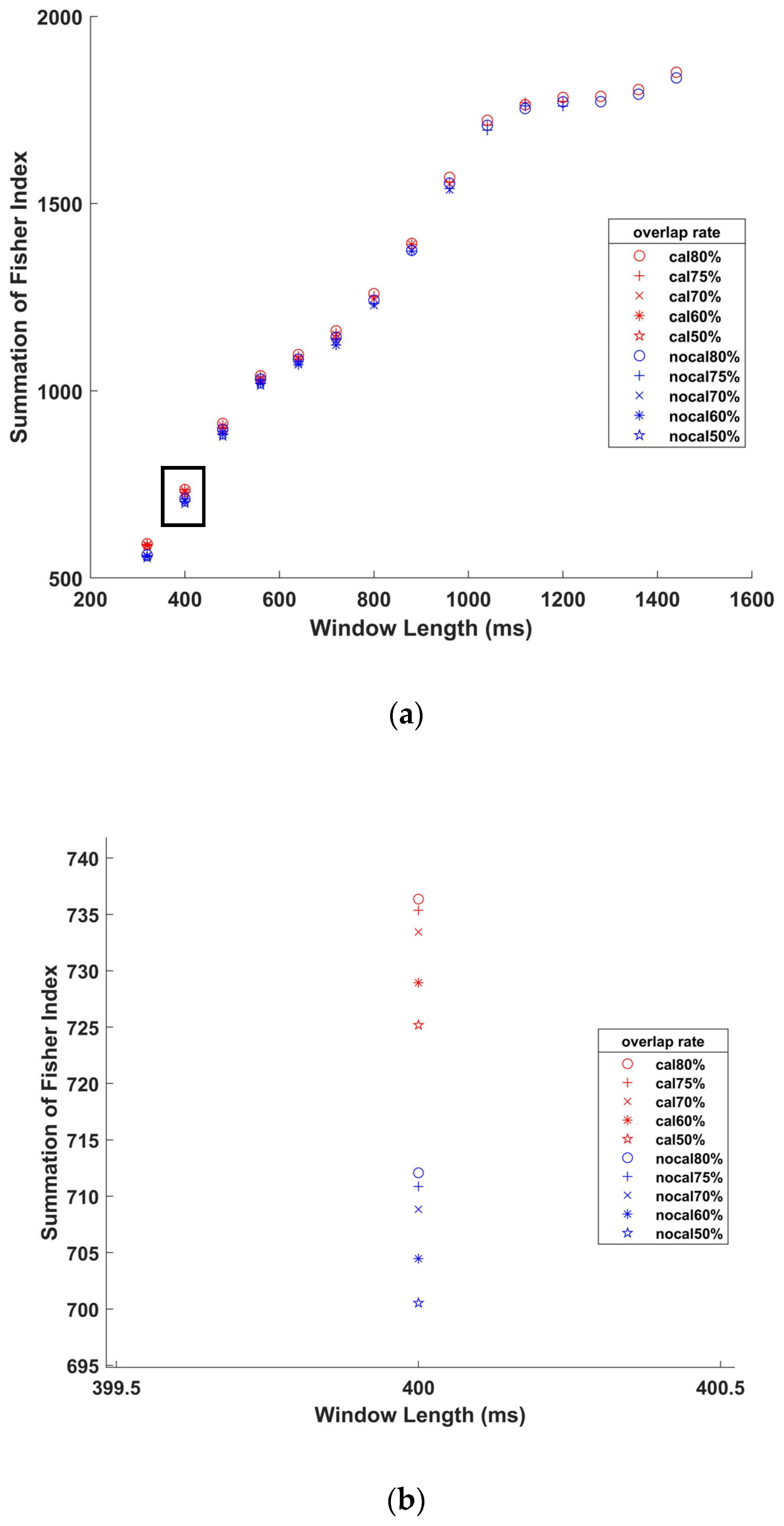
2.2.2. Resampling
2.2.3. Feature Evaluation
2.3. Feature Selection
- Initialization
- 2.
- Fitness evaluation function
- 3.
- Genetic operators
- COFAN: Firstly, the gene bits activated in each parent individual are extracted to form an intermediate individual of length , each of whose gene bits represents the sequence number of an activated gene bits in the parent. Then, the same genes were selected from the intermediate individuals of the two parents to form the homogeneous gene pair, and remaining gens of each intermediate individuals are made into the heterogeneous gene pairs. The two-point crossover operation is performed on the two heterogeneous gene pairs to produce the progeny heterogeneous gene pairs, which are then combined with the homogeneous gene pair to form progeny intermedia individuals. Finally, each of the children is produced by setting the corresponding gene bits of an unactivated individual to “1” according to the progeny intermedia individual.
- MOFAN: Mutation operation is performed on each activated gene bits of the parent individual according to the mutation probability and the actual number of mutations is recorded firstly. Subsequently, the same number of unactivated bits are randomly selected to perform the mutation operation and the child individual is finally generated.
3. Experiments Description
3.1. Participants
3.2. Data Collection
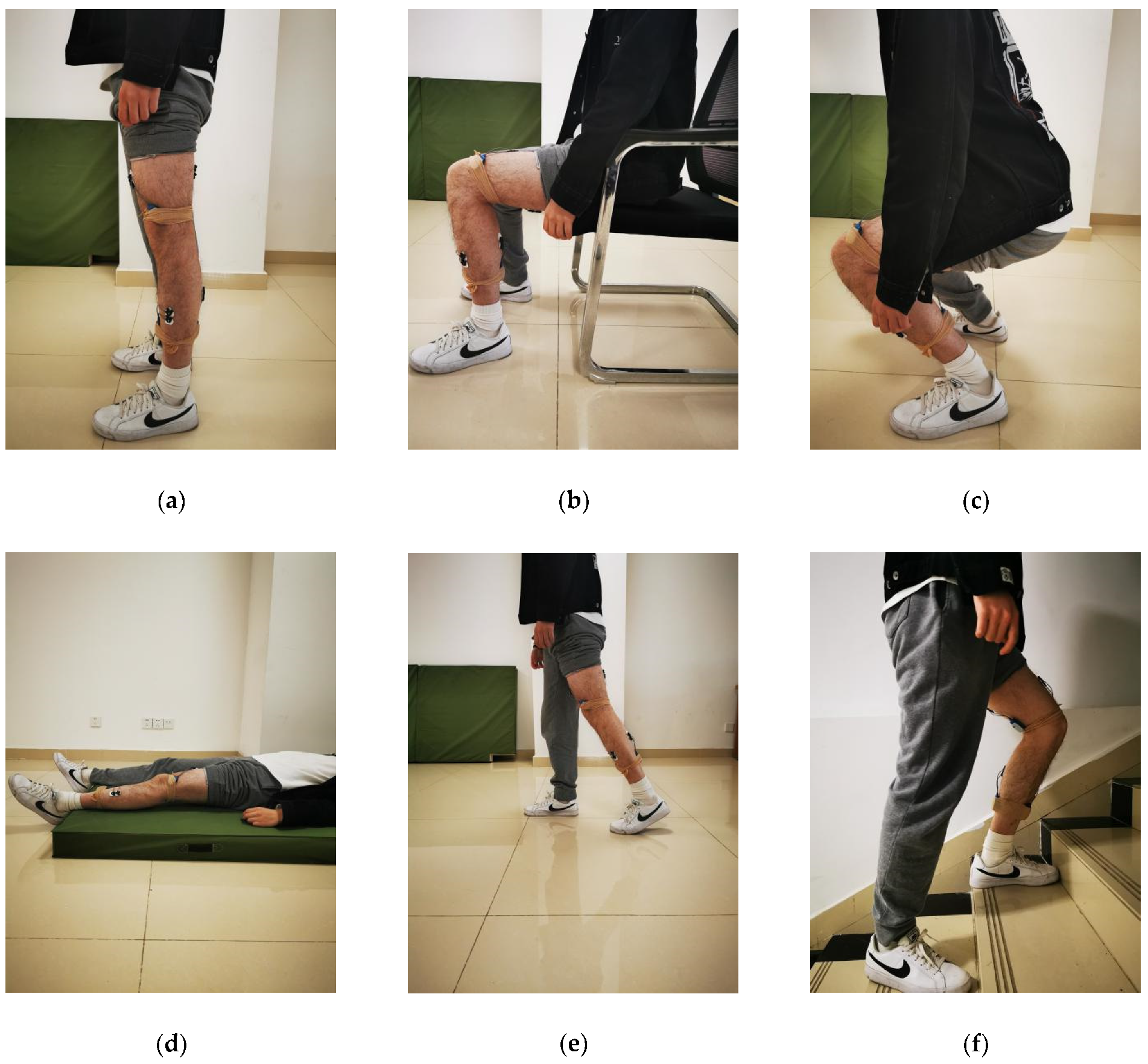
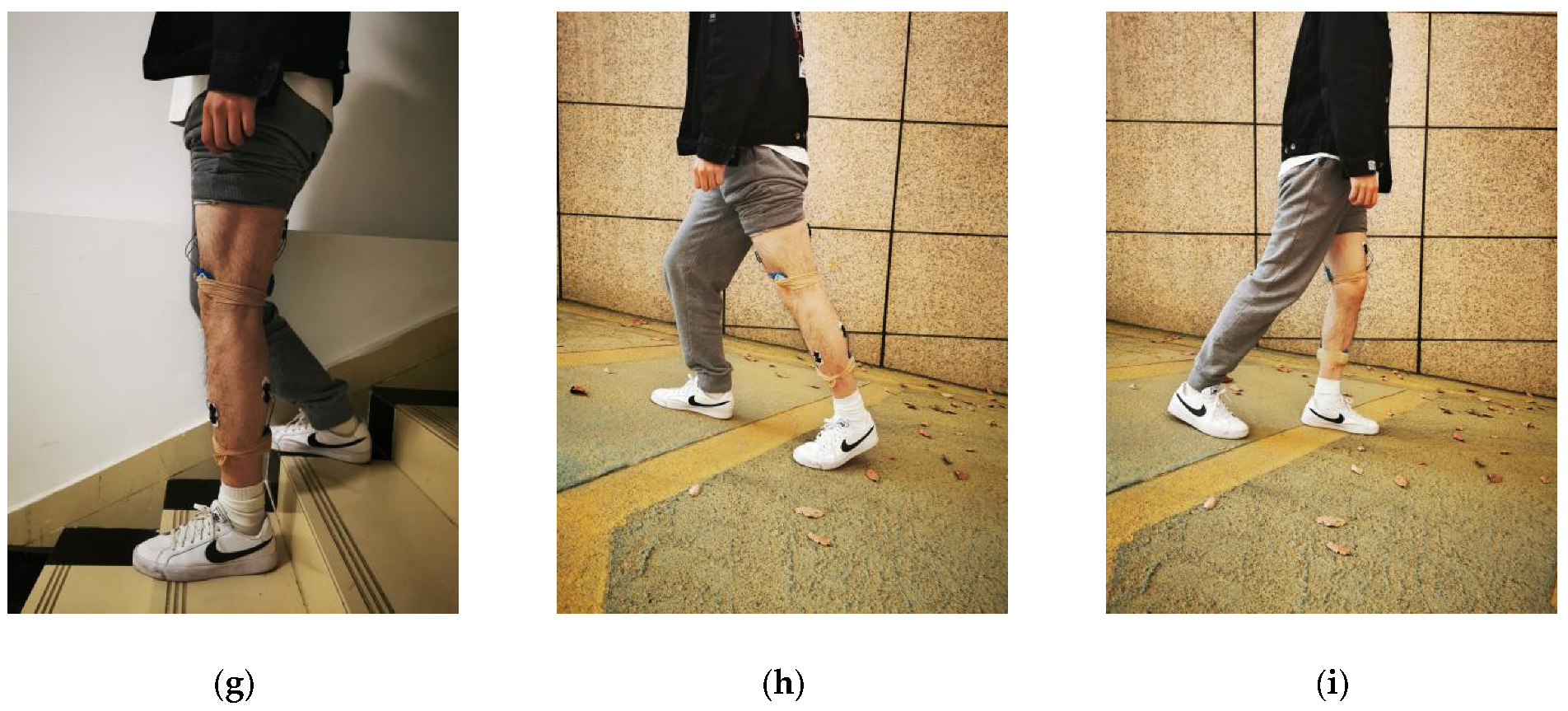
3.2.1. Activities and Procedure
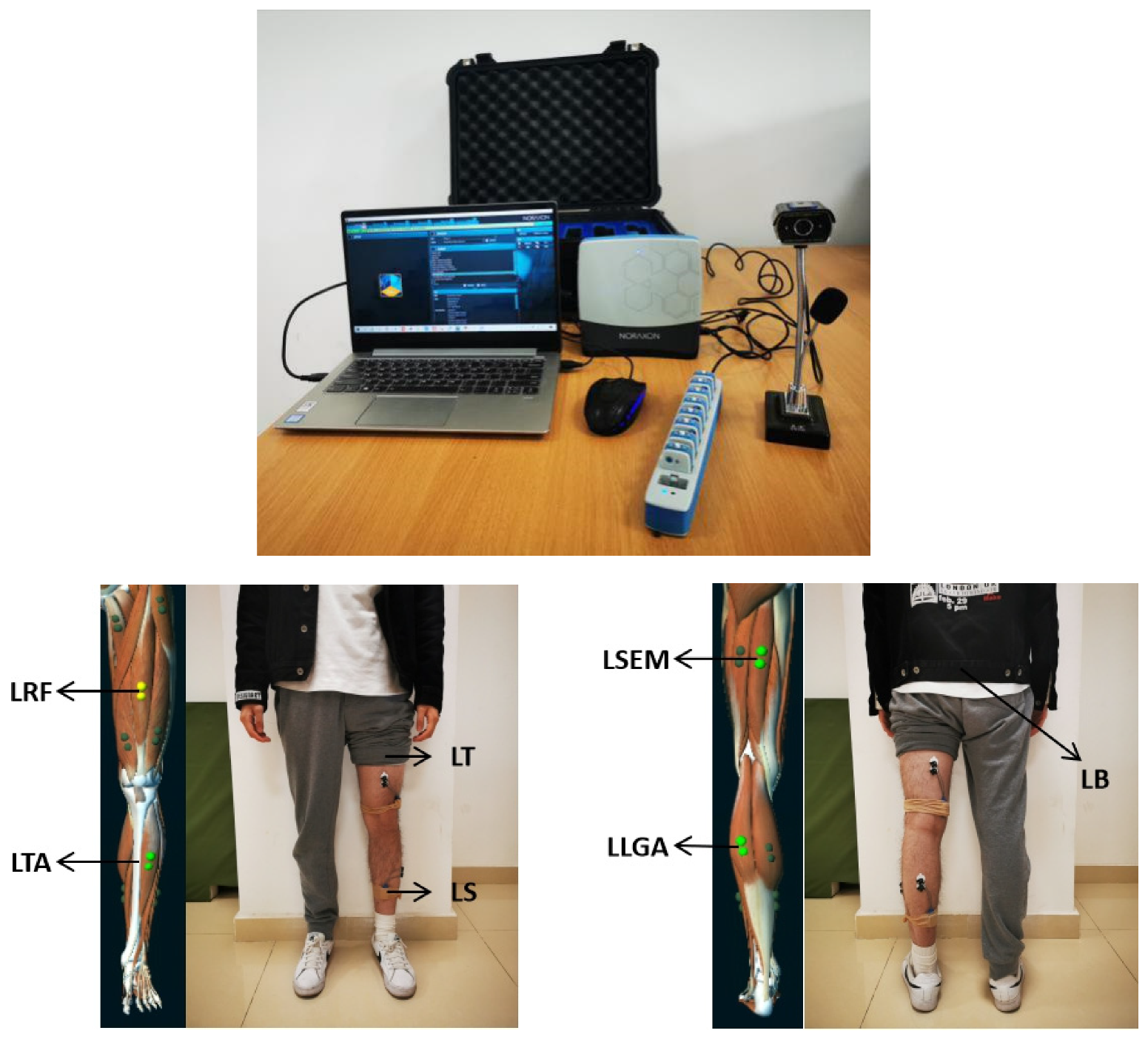
3.2.2. Sensors Configuration and Data Acquisition
3.3. Preprocessing and Segmentation
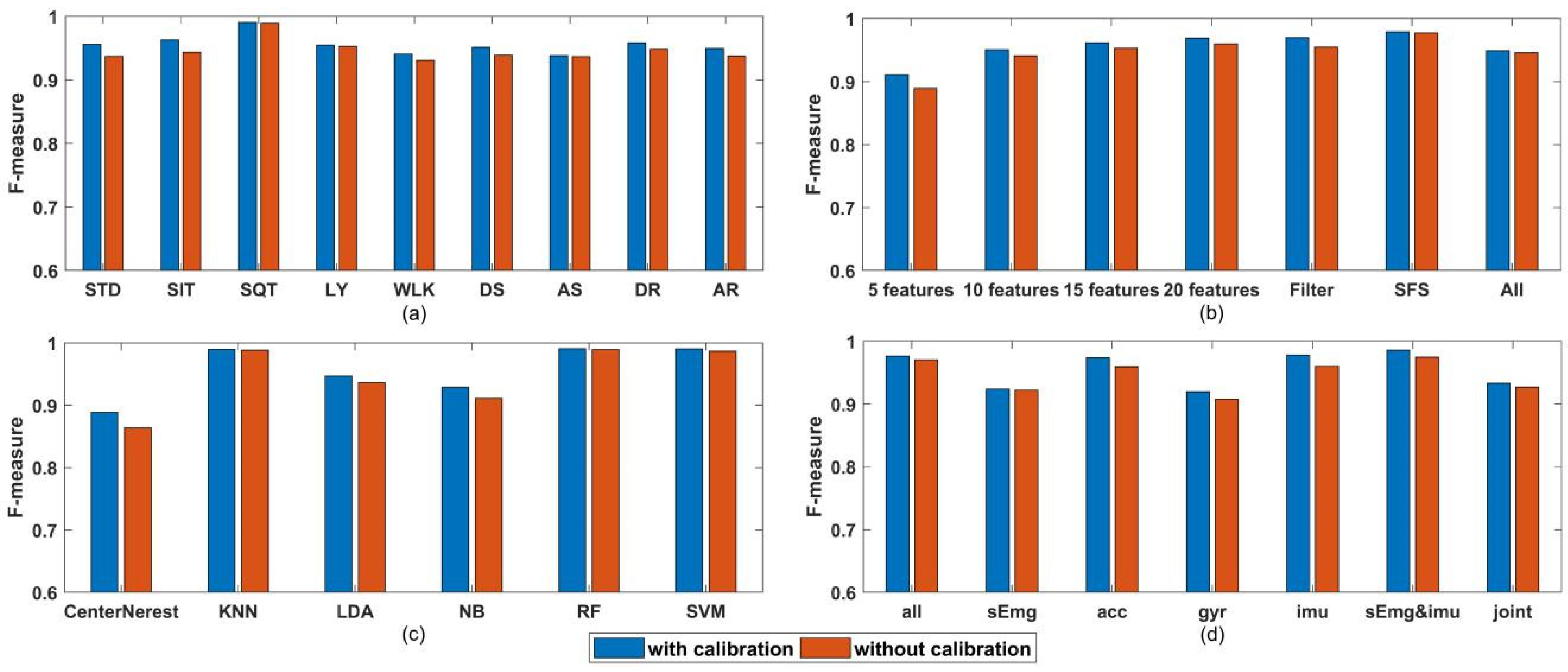
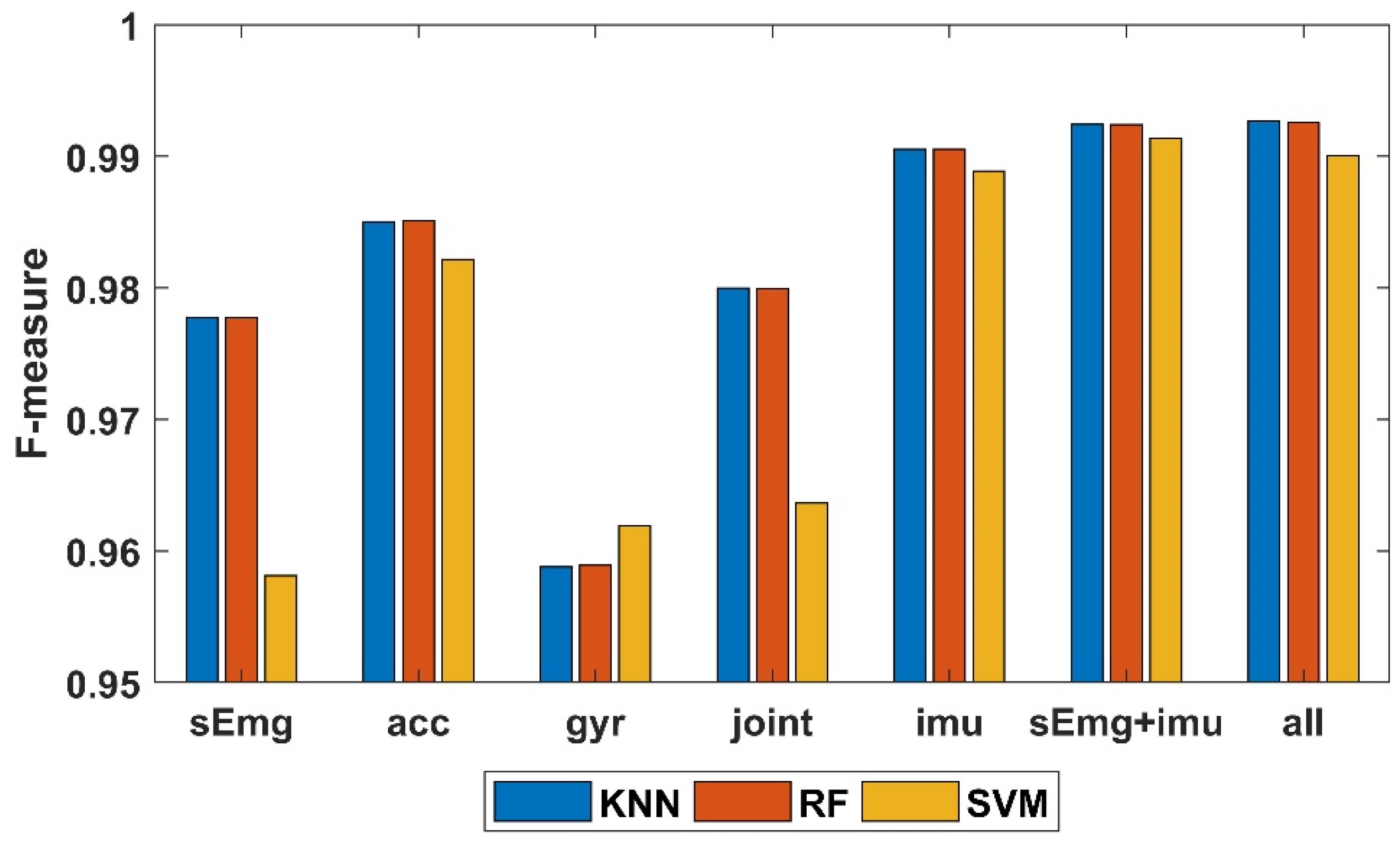
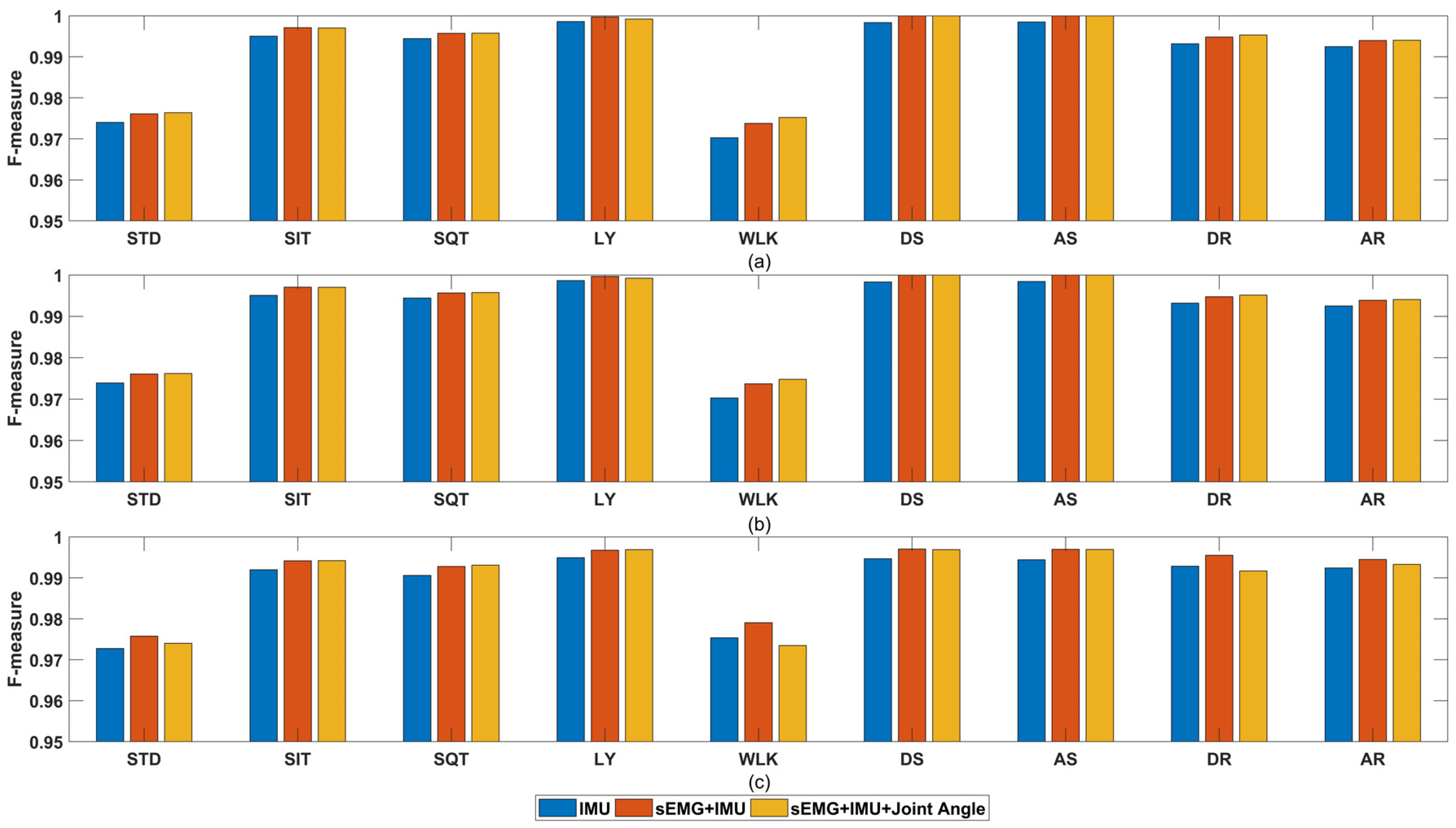
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Martínez-Villaseñor, L.; Ponce, H. Design and Analysis for Fall Detection System Simplification. J. Vis. Exp. 2020, 2020, e60361. [Google Scholar]
- Jackson, K.; Sample, R.; Bigelow, K. Use of an Instrumented Timed Up and Go (iTUG) for Fall Risk Classification. Phys. Occup. Ther. Geriatr. 2018, 36, 354–365. [Google Scholar] [CrossRef]
- Khan, Z.A.; Sohn, W. Abnormal human activity recognition system based on R-transform and independent component features for elderly healthcare. J. Chin. Inst. Eng. 2013, 36, 441–451. [Google Scholar] [CrossRef]
- Mazumder, O.; Kundu, A.S.; Lenka, P.K.; Bhaumik, S. Ambulatory activity classification with dendogram-based support vector machine: Application in lower-limb active exoskeleton. Gait Posture 2016, 50, 53–599. [Google Scholar] [CrossRef] [PubMed]
- Tang, Z.-C.; Sun, S.; Sanyuan, Z.; Chen, Y.; Li, C.; Chen, S. A Brain-Machine Interface Based on ERD/ERS for an Upper-Limb Exoskeleton Control. Sensors 2016, 16, 2050. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Sup, F.C. Activity recognition of the torso based on surface electromyography for exoskeleton control. Biomed. Signal Process. Control. 2014, 10, 281–288. [Google Scholar] [CrossRef]
- Salarian, A.; Horak, F.B.; Zampieri, C.; Carlson-Kuhta, P.; Nutt, J.G.; Aminian, K. iTUG, a Sensitive and Reliable Measure of Mobility. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 303–310. [Google Scholar] [CrossRef]
- Han, Y.; Han, M.; Lee, S.; Sarkar, A.M.J.; Lee, Y.-K. A Framework for Supervising Lifestyle Diseases Using Long-Term Activity Monitoring. Sensors 2012, 12, 5363–5379. [Google Scholar] [CrossRef]
- Kumari, P.; Mathew, L.; Syal, P. Increasing trend of wearables and multimodal interface for human activity monitoring: A review. Biosens. Bioelectron. 2017, 90, 298–307. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Mujtaba, G.; Al-Garadi, M.A. Data fusion and multiple classifier systems for human activity detection and health monitoring: Review and open research directions. Inf. Fusion 2019, 46, 147–170. [Google Scholar] [CrossRef]
- Siu, H.C.; Shah, J.A.; Stirling, L.A. Classification of Anticipatory Signals for Grasp and Release from Surface Electromyography. Sensors 2016, 16, 1782. [Google Scholar] [CrossRef] [PubMed]
- Too, J.; Abdullah, A.R.; Saad, N.M. Classification of Hand Movements Based on Discrete Wavelet Transform and Enhanced Feature Extraction. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 83–89. [Google Scholar] [CrossRef]
- Xue, Y.; Ji, X.; Zhou, D.; Li, J.; Ju, Z. SEMG-Based Human In-Hand Motion Recognition Using Nonlinear Time Series Analysis and Random Forest. IEEE Access 2019, 7, 176448–176457. [Google Scholar] [CrossRef]
- Narayan, Y.; Mathew, L.; Chatterji, S. sEMG signal classification with novel feature extraction using different machine learning approaches. J. Intell. Fuzzy Syst. 2018, 35, 5099–5109. [Google Scholar] [CrossRef]
- Biswas, D.; Cranny, A.; Gupta, N.; Maharatna, K.; Achner, J.; Klemke, J.; Jöbges, M.; Ortmann, S. Recognizing upper limb movements with wrist worn inertial sensors using k-means clustering classification. Hum. Mov. Sci. 2015, 40, 59–76. [Google Scholar] [CrossRef] [PubMed]
- Janidarmian, M.; Roshan Fekr, A.; Radecka, K.; Zilic, Z. A Comprehensive Analysis on Wearable Acceleration Sensors in Human Activity Recognition. Sensors 2017, 17, 529. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor Data Acquisition and Multimodal Sensor Fusion for Human Activity Recognition Using Deep Learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef]
- Ai, Q.; Zhang, Y.; Qi, W.; Liu, Q. Research on Lower Limb Motion Recognition Based on Fusion of sEMG and Accelerometer Signals. Symmetry 2017, 9, 147. [Google Scholar] [CrossRef]
- Jia, R.; Liu, B. Human daily activity recognition by fusing accelerometer and multi-lead ECG data. In Proceedings of the 2013 IEEE International Conference on Signal Processing, Communication and Computing (ICSPCC 2013), KunMing, China, 5–8 August 2013; pp. 1–4. [Google Scholar]
- Al-Amin, M.; Tao, W.; Doell, D.; Lingard, R.; Yin, Z.; Leu, M.C.; Qin, R. Action Recognition in Manufacturing Assembly using Multimodal Sensor Fusion. Procedia Manuf. 2019, 39, 158–167. [Google Scholar] [CrossRef]
- Lara, Ó.D.; Perez, A.; Labrador, M.A.; Posada, J.D. Centinela: A human activity recognition system based on acceleration and vital sign data. Pervasive Mob. Comput. 2012, 8, 717–729. [Google Scholar] [CrossRef]
- Bellos, C.; Papadopoulos, A.; Rosso, R.; Fotiadis, D.I. Heterogeneous data fusion and intelligent techniques embedded in a mobile application for real-time chronic disease man-agement. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011. [Google Scholar]
- Gong, J.; Cui, L.; Xiao, K.; Wang, R. MPD-Model: A Distributed Multipreference-Driven Data Fusion Model and Its Application in a WSNs-Based Healthcare Monitoring System. Int. J. Distrib. Sens. Netw. 2012, 8, 5965–5971. [Google Scholar] [CrossRef]
- Chernbumroong, S.; Cang, S.; Yu, H. A practical multi-sensor activity recognition system for home-based care. Decis. Support Syst. 2014, 66, 61–70. [Google Scholar] [CrossRef]
- Liang, H.; Sun, X.; Sun, Y.; Gao, Y. Text feature extraction based on deep learning: A review. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 1–12. [Google Scholar] [CrossRef]
- Mohammad, Y.; Matsumoto, K.; Hoashi, K. Deep Feature Learning and Selection for Activity Recognition. In Proceedings of the 33rd Annual Acm Symposium on Applied Computing, Pau, France, 9–13 April 2018; Assoc Computing Machinery: New York, NY, USA, 2018; pp. 930–939. [Google Scholar]
- Zdravevski, E.; Lameski, P.; Trajkovik, V.; Kulakov, A.; Chorbev, I.; Goleva, R.; Pombo, N.; Garcia, N. Improving Activity Recognition Accuracy in Ambient Assisted Living Systems by Automated Feature Engineering. IEEE Access 2017, 5, 5262–5280. [Google Scholar] [CrossRef]
- Fang, H.; He, L.; Si, H.; Liu, P.; Xie, X. Human activity recognition based on feature selection in smart home using back-propagation algorithm. ISA Trans. 2014, 53, 1629–1638. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Chen, G.; Wu, X.; Liu, L.; An, N.; Chang, C.-Y. Towards Human Activity Recognition: A Hierarchical Feature Selection Framework. Sensors 2018, 18, 3629. [Google Scholar] [CrossRef] [PubMed]
- Versteyhe, M.; De Vroey, H.; DeBrouwere, F.; Hallez, H.; Claeys, K. A Novel Method to Estimate the Full Knee Joint Kinematics Using Low Cost IMU Sensors for Easy to Implement Low Cost Diagnostics. Sensors 2020, 20, 1683. [Google Scholar] [CrossRef] [PubMed]
- Mohammadzadeh, F.F.; Liu, S.; Bond, K.A.; Nam, C.S. Feasibility of a wearable, sensor-based motion tracking system. In Proceedings of the 6th International Conference on Applied Human Factors and Ergonomics, Las Vegas, NV, USA, 26–30 July 2015; Ahram, T., Karwowski, W., Schmorrow, D., Eds.; 2015; pp. 192–199. [Google Scholar]
- Mahony, R.; Euston, M.; Kim, J.; Coote, P.; Hamel, T. A non-linear observer for attitude estimation of a fixed-wing unmanned aerial vehicle without GPS measurements. Trans. Inst. Meas. Control. 2010, 33, 699–717. [Google Scholar] [CrossRef]
- Wu, G.; Cavanagh, P.R. ISB recommendations for standardization in the reporting of kinematic data. J. Biomech. 1995, 28, 1257–1261. [Google Scholar] [CrossRef]
- Narvaez, F.; Arbito, F.; Proano, R. A Quaternion-Based Method to IMU-to-Body Alignment for Gait Analysis. In Digital Human Modeling: Applications in Health, Safety, Ergonomics, and Risk Management; Duffy, V.G., Ed.; Springer: Cham, Switzerland, 2018; pp. 217–231. [Google Scholar]
- Seel, T.; Raisch, J.; Schauer, T. IMU-Based Joint Angle Measurement for Gait Analysis. Sensors 2014, 14, 6891–6909. [Google Scholar] [CrossRef]
- Müller, P.; Bégin, M.A.; Schauer, T.; Seel, T. Alignment-free, self-calibrating elbow angles measurement using inertial sensors. In Proceedings of the 2016 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), Las Vegas, NV, USA, 24–27 February 2016. [Google Scholar]
- Xi, X.; Yang, C.; Shi, J.; Luo, Z.; Zhao, Y.-B. Surface Electromyography-Based Daily Activity Recognition Using Wavelet Coherence Coefficient and Support Vector Machine. Neural Process. Lett. 2019, 50, 2265–2280. [Google Scholar] [CrossRef]
- Wang, J.; Sun, Y.; Sun, S. Recognition of Muscle Fatigue Status Based on Improved Wavelet Threshold and CNN-SVM. IEEE Access 2020, 8, 207914–207922. [Google Scholar] [CrossRef]
- Jiang, C.; Lin, Y.-C.; Yu, N.-Y. Multi-Scale Surface Electromyography Modeling to Identify Changes in Neuromuscular Activation with Myofascial Pain. EEE Trans. Neural Syst. Rehabil. Eng. 2012, 21, 88–95. [Google Scholar] [CrossRef] [PubMed]
- Phinyomark, A.; Nuidod, A.; Phukpattaranont, P.; Limsakul, C. Feature Extraction and Reduction of Wavelet Transform Coefficients for EMG Pattern Classification. Elektron. Elektrotechnika 2012, 122, 27–32. [Google Scholar] [CrossRef]
- Schimmack, M.; Mercorelli, P. An on-line orthogonal wavelet denoising algorithm for high-resolution surface scans. J. Frankl. Inst. 2018, 355, 9245–9270. [Google Scholar] [CrossRef]
- Phukpattaranont, P.; Thongpanja, S.; Anam, K.; Al-Jumaily, A.; Limsakul, C. Evaluation of feature extraction techniques and classifiers for finger movement recognition using surface electromyography signal. Med. Biol. Eng. Comput. 2018, 56, 2259–2271. [Google Scholar] [CrossRef]
- Xi, X.; Tang, M.; Miran, S.M.; Miran, S.M. Evaluation of Feature Extraction and Recognition for Activity Monitoring and Fall Detection Based on Wearable sEMG Sensors. Sensors 2017, 17, 1229. [Google Scholar] [CrossRef]
- Xi, X.; Yang, C.; Miran, S.M.; Zhao, Y.B.; Lin, S.; Luo, Z. sEMG-MMG State-Space Model for the Continuous Estimation of Multijoint Angle. Complexity 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Cao, H.; Li, X.-L.; Woon, Y.-K.; Ng, S.-K. SPO: Structure Preserving Oversampling for Imbalanced Time Series Classification. In Proceedings of the IEEE International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence) (IJCNN 2008), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Pourpanah, F.; Shi, Y.; Lim, C.P.; Hao, Q.; Tan, C.J. Feature selection based on brain storm optimization for data classification. Appl. Soft Comput. 2019, 80, 761–775. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Kudo, M.; Sklansky, J. Comparison of algorithms that select features for pattern classifiers. Pattern Recognit. 2000, 33, 25–41. [Google Scholar] [CrossRef]
- Efraimidis, P.S.; Spirakis, P.G. Weighted Random Sampling with a Reservoir. Inf. Process. Lett. 2006, 97, 181–185. [Google Scholar] [CrossRef]
- Lixin, Z.; Yannan, Z.; Zehong, Y.; Jiaxin, W.; Shaoqing, C.; Hongyu, L. Classification of traditional Chinese medicine by nearest-neighbour classifier and genetic algorithm. In Proceedings of the Fifth International Conference on Information Fusion (FUSION 2002), Annapolis, MD, USA, 8–11 July 2002. [Google Scholar]
- Pandey, H.M.; Chaudhary, A.; Mehrotra, D. A comparative review of approaches to prevent premature convergence in GA. Appl. Soft Comput. 2014, 24, 1047–1077. [Google Scholar] [CrossRef]
- Altun, K.; Barshan, B. Human Activity Recognition Using Inertial/Magnetic Sensor Units. In Human Behavior Understanding; Gevers, T., Salah, A.A., Sebe, N., Vinciarelli, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 38–51. [Google Scholar]
- Sahin, U.; Sahin, F.; IEEE. Pattern Recognition with surface EMG Signal based Wavelet Transformation. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; IEEE: New York, NY, USA; pp. 303–308. [Google Scholar]
- Englehart, K.; Hudgins, B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003, 50, 848. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Mathematical Definition | Feature | Mathematical Definition |
|---|---|---|---|
| Mean Value (MV) | Standard Deviation (SD) | ||
| Variance (VAR) | Root Mean Square (RMS) | ||
| Skewness (SKE) | Kurtosis (KUR) | ||
| Interquartile Range (IQR) | Peak to Peak(P2P) | ||
| Mean Absolute Value (MAV) | Waveform Length (WL) | ||
| Zero Crossing (ZC) | Slope Sign Change (SSC) | ||
| Wilson Amplitude (WAMP) | Log Detector (LD) | ||
| Auto Regressive Coefficient (ARC) | Energy | ||
| Modified Mean Absolute Value (MMAV) | Correlation Coefficient (CC) | ||
| Jerk | Signal Magnitude Area (SMA) | ||
| Mean Power Frequency (MPF) | Entropy | ||
| Median Frequency (MDF) | One Quarter of Frequency (F25) | ||
| Three Quarters of Frequency (F75) |
| Feature | sEMG | ACC | GYR | Joint |
|---|---|---|---|---|
| MV | ● | ● | ● | ● |
| SD | ● | ● | ● | ● |
| VAR | ● | ● | ● | ● |
| RMS | ● | ● | ● | ● |
| SKE | ● | ● | ● | ● |
| KUR | ● | ● | ● | ● |
| IQR | ● | ● | ● | ● |
| P2P | ● | ● | ● | ● |
| MAV | ● | ● | ● | ● |
| WL | ● | ● | ● | ● |
| ZC | ● | ● | ||
| SSC | ● | ● | ||
| WAMP | ● | ● | ||
| LD | ● | ● | ● | ● |
| ARC | ● | ● | ● | ● |
| Energy | ● | ● | ● | ● |
| MMAV | ● | ● | ● | ● |
| CC | ● | ● | ||
| Jerk | ● | |||
| SMA | ● | ● | ||
| MPF | ● | ● | ● | ● |
| MDF | ● | ● | ● | ● |
| Entropy | ● | ● | ● | ● |
| F25 | ● | ● | ● | ● |
| F75 | ● | ● | ● | ● |
| Top 3 Largest Value of DFT (3LVD) | ● | ● | ● | ● |
| Energy of Wavelet Coefficient (EWC) | ● | ● | ● |
| Gender | Number | Age (Year) | Weight (kg) | Height (cm) |
|---|---|---|---|---|
| Male | 13 | 27.5 2.53 | 69.8 7.65 | 176.5 6.23 |
| Female | 4 | 29.3 4.79 | 59.6 4.03 | 159.8 2.75 |
| All | 17 | 27.6 3.10 | 66.8 7.95 | 172.5 9.17 |
| GFSFAN 10 Features | Filter | SFS | All Features | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Sensor Comb. | Algo. | FN | FM | FN | FM | FN | FM | FN | FM |
| sEMG | KNN | 10 | 0.977 | 59 | 0.98 | 19 | 0.981 | 132 | 0.973 |
| RF | 0.977 | 0.98 | 0.981 | 0.973 | |||||
| SVM | 0.933 | 0.957 | 0.984 | 0.960 | |||||
| ACC | KNN | 10 | 0.985 | 114 | 0.984 | 36 | 0.986 | 285 | 0.985 |
| RF | 0.985 | 0.984 | 0.986 | 0.985 | |||||
| SVM | 0.980 | 0.981 | 0.985 | 0.984 | |||||
| GYR | KNN | 10 | 0.945 | 121 | 0.948 | 55 | 0.965 | 309 | 0.977 |
| RF | 0.946 | 0.948 | 0.965 | 0.977 | |||||
| SVM | 0.943 | 0.949 | 0.978 | 0.977 | |||||
| Joint Ang. | KNN | 10 | 0.993 | 20 | 0.993 | 34 | 0.994 | 50 | 0.934 |
| RF | 0.993 | 0.993 | 0.994 | 0.934 | |||||
| SVM | 0.983 | 0.988 | 0.986 | 0.881 | |||||
| IMU (ACC+GYR) | KNN | 10 | 0.987 | 231 | 0.991 | 31 | 0.992 | 594 | 0.991 |
| RF | 0.989 | 0.991 | 0.992 | 0.991 | |||||
| SVM | 0.987 | 0.988 | 0.991 | 0.989 | |||||
| sEMG+IMU | KNN | 10 | 0.993 | 289 | 0.994 | 37 | 0.994 | 726 | 0.988 |
| RF | 0.993 | 0.994 | 0.994 | 0.988 | |||||
| SVM | 0.989 | 0.991 | 0.993 | 0.992 | |||||
| sEMG+IMU+Joint Ang. | KNN | 10 | 0.994 | 307 | 0.994 | 36 | 0.995 | 776 | 0.988 |
| RF | 0.994 | 0.994 | 0.995 | 0.988 | |||||
| SVM | 0.983 | 0.991 | 0.994 | 0.983 | |||||
| Mean Value | KNN | 10 | 0.982 | 163 | 0.986 | 35.4 | 0.987 | 410 | 0.977 |
| RF | 0.982 | 0.986 | 0.987 | 0.977 | |||||
| SVM | 0.971 | 0.977 | 0.987 | 0.966 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Sun, Y.; Sun, S. Improving Human Activity Recognition Performance by Data Fusion and Feature Engineering. Sensors 2021, 21, 692. https://doi.org/10.3390/s21030692
Chen J, Sun Y, Sun S. Improving Human Activity Recognition Performance by Data Fusion and Feature Engineering. Sensors. 2021; 21(3):692. https://doi.org/10.3390/s21030692
Chicago/Turabian StyleChen, Jingcheng, Yining Sun, and Shaoming Sun. 2021. "Improving Human Activity Recognition Performance by Data Fusion and Feature Engineering" Sensors 21, no. 3: 692. https://doi.org/10.3390/s21030692
APA StyleChen, J., Sun, Y., & Sun, S. (2021). Improving Human Activity Recognition Performance by Data Fusion and Feature Engineering. Sensors, 21(3), 692. https://doi.org/10.3390/s21030692