A CNN-Based Length-Aware Cascade Road Damage Detection Approach


Abstract
1. Introduction
- A CrdNet for precise location and classification of road damage is proposed. This proposed model fully considers weak semantic information and abnormal geometric properties of road damage.
- LrNet outputs fused diversified feature representation from high-to-low level feature representations, across every stage. The fusion of multi-scale convolutional features can meet the feature requirements for detecting road damage.
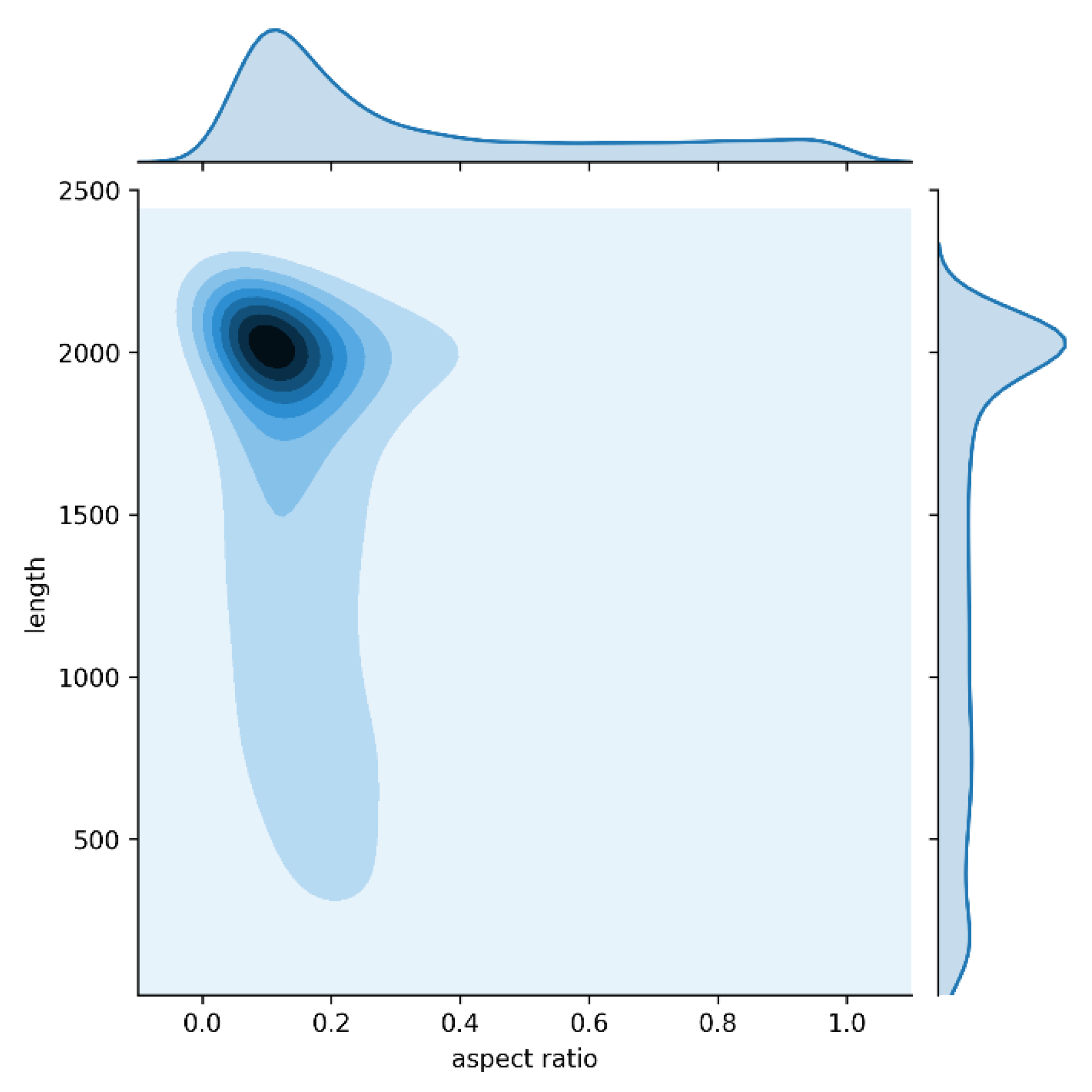
- Considering the abnormal geometric properties of road damage, CrdNet utilizes MSARM to generate high-quality positive samples and predict damage of different lengths on three parallel branches.
- A full labeled dataset containing seven types of damage and 7282 high-resolution images are constructed for performance evaluation, where 6550 road images are used for training the proposed network, and the remaining images are used for testing. The dataset was manually labeled by human experts and contains seven usual types of road damage: longitudinal crack (LC), transverse crack (TC), repair (R), poor repair (PR), pothole (P), crazing (C), and block repair (BR), which can meet the daily basic needs of MRDI. For the uncommon P and C, we use spatial-level transform to augment these two type of less images, which avoids the imbalance of training data. Extensive comparative experiments between the proposed method and several classical generic object detectors are conduced, and the results demonstrate the effectiveness of the proposed method.
2. Proposed Method
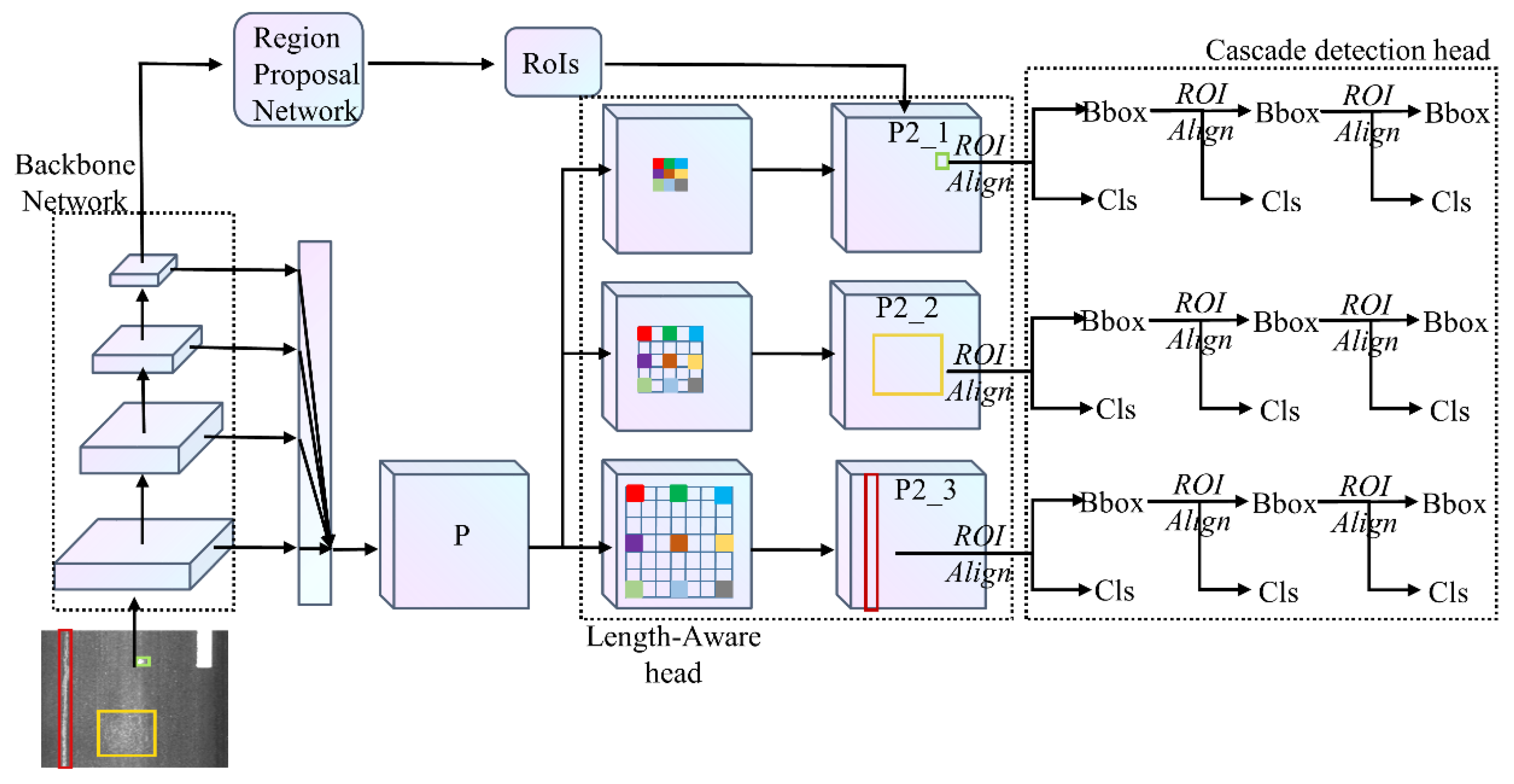
2.1. Overview of CrdNet
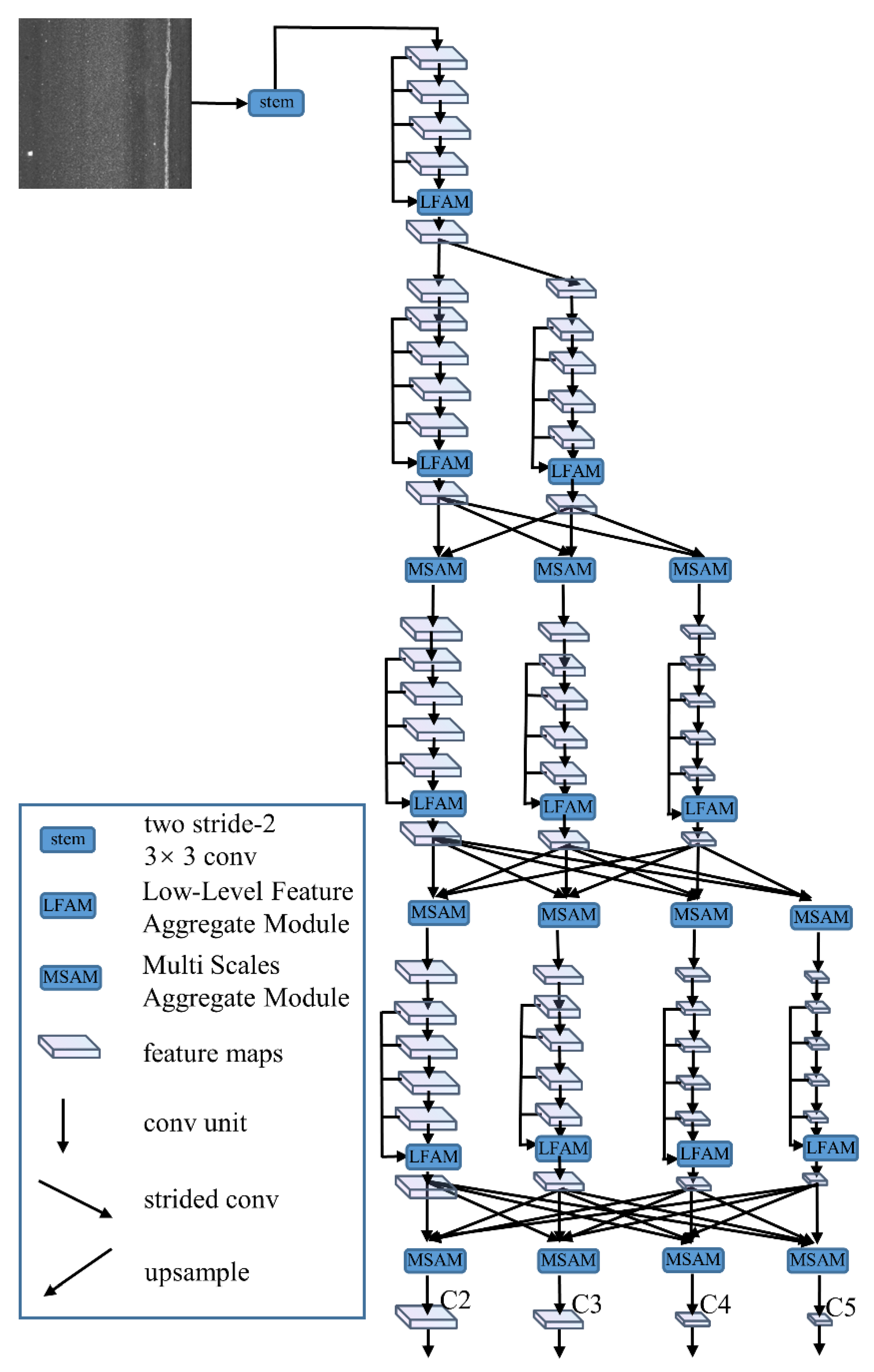
2.2. LrNet Backbone Network
2.2.1. Parallel Branches of LrNet
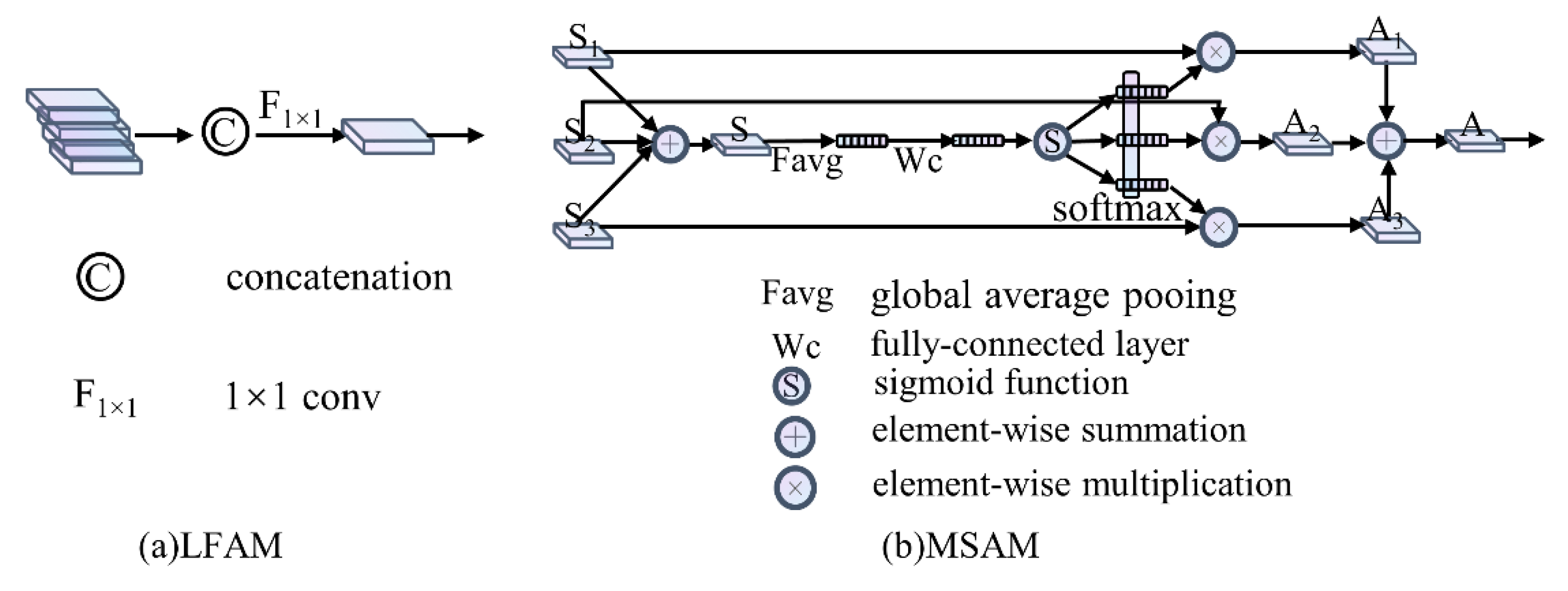
2.2.2. LFAM
2.2.3. MSAM
2.3. Length-Aware Head
2.3.1. Length-Aware Branches
2.3.2. Adaptive ROI Assignment Function Based on Length
3. Experiments
3.1. Experimental Setup
3.1.1. Dataset Description
3.1.2. Evaluation Metrics
3.1.3. Data Preprocessing
3.1.4. Network Setup
3.1.5. Methods to Compare
3.2. Results and Analysis
- (1)
- For light and dark images, the mAP_B and mAP_D of all experiments are very similar, indicating that CNNs and two-stage detectors can effectively address the illumination problem of the images and achieve robust damage detection under imperfect imaging conditions. The classic Faster RCNN has the worst performance, especially for elongated types (LC, TC, and PR) and small object types (P), but it effectively detects block repair with regular shapes. Under the same backbone network, Cascade RCNN performs better than Faster RCNN for all categories. The mAP values of Faster RCNN+ and Cascade RCNN+ are both higher than those of Faster RCNN and Cascade RCNN, since MSARM generates high-quality positive samples to cover elongated damage. For CrdNet− without MSARM, the performance over Cascade RCNN+ shows that the information loss of high-level FPN greatly harms the performance.
- (2)
- The backbone networks, which extract diversified feature, are very important for damage detection. ResNet-101, which only extracts features establishing long-range dependency, do not perform well under four two-stage detectors. VoVNetV2-57, based on ResNet-101, which aggregates low-level features and extracts diversified feature, boosts detection performance. HRNetV2-W32, which repeatedly integrates feature maps with different resolutions, far exceeds the performance of the previous two backbone networks. Under the four detectors, LrNet perform better than the above three backbone networks with equivalent calculations and parameters. Roughly speaking, LrNet has the merits of ResNet-101, Vovnet57, and HRNetV2-W32: it extracts large receptive field features to establish long-range dependency, effectively retains the low-level features extracted by CNNs and integrates suitable receptive field features with the use of multi-scale attention mechanism. The experimental results show that the above three aspects of the backbone network are important to improve damage detection.
- (3)
- Finally, we compared the proposed CrdNet with the baseline. Obviously, compared with the other three two-stage detectors, CrdNet consistently performed better with the four backbone networks. This result demonstrates that prediction on high-resolution feature maps based on the length of damage is superior to prediction on multi-level feature maps of FPN. Under the same baseline backbone network LrNet, the mAP values of faster RCNN+ and Cascade RCNN+ are 80.08 and 82.09%, respectively. The mAP of CrdNet is 90.92%, 9.84% higher than faster RCNN+ and 8.83% higher than Cascade RCNN+. Cascade RCNN+ is a detector based on cascade prediction. But our method can adaptively perform cascade prediction on high-resolution feature maps, which effectively reserves information for elongated and small damages and can see the entire extent of damage by large receptive field features. The benefit of CrdNet over the baseline is that the detection results are highly accurate, and the detection results on HL 2019 are shown in Section 3.4.
3.3. Detailed Analysis of Proposed Method
3.3.1. Ablation Study
3.3.2. LrNet
3.3.3. Length-Aware Branches and Length-Adaptive ROIs Assignment Function
3.3.4. Cascade Detection Head
3.4. Qualitative Analysis of CrdNet
3.4.1. Visualization of High-Resolution Feature Maps of Backbone Networks
3.4.2. MSARM
3.4.3. Analysis Results of CrdNet
4. Conclusions
- (1)
- Predicting damage instances with a bounding box is a relatively rough location method. It is not able to pick up more concrete geometric properties of damage, which makes it difficult to provide more useful damage indicators for assessment in practice.
- (2)
- To minimize the information loss of shrinking high-resolution images, the resized image and patches of the image should both be considered as the input of CNNs.
- (3)
- CNNs that extract features in an automatic learning fashion may neglect the key features of certain damage, leading to failure to predict the damage. In the future, explicitly adding prior knowledge of road damage to the feature extraction process of CNNs addresses the failure prediction.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 60, pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ghosh, S.; Das, N.; Das, I.; Maulik, U. Understanding deep learning techniques for image segmentation. ACM Comput. Surv. (CSUR) 2019, 52, 1–35. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, S.; Qi, L.; Coleman, S.; Kerr, D.; Shi, W. Multi-level and multi-scale horizontal pooling network for person re-identification. Multimed. Tools Appl. 2020, 79, 28603–28619. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Zhang, S.; Xie, Y.; Wan, J.; Xia, H.; Li, S.Z.; Guo, G. Widerperson: A diverse dataset for dense pedestrian detection in the wild. IEEE Trans. Multimed. 2019, 22, 380–393. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Yi, J.; Wu, P.; Metaxas, D.N. ASSD: Attentive single shot multibox detector. Comput. Vis. Image Underst. 2019, 189, 102827. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 24–27 June 2017; pp. 936–944. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P.H. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection and classification using deep neural networks with smartphone images. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Wang, W.; Wu, B.; Yang, S.; Wang, Z. Road Damage Detection and Classification with Faster R-CNN. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–18 December 2018; pp. 5220–5223. [Google Scholar]
- Anand, S.; Gupta, S.; Darbari, V.; Kohli, S. Crack-pot: Autonomous Road Crack and Pothole Detection. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–6. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Cao, M.T.; Tran, Q.V.; Nguyen, N.M.; Chang, K.T. Survey on performance of deep learning models for detecting road damages using multiple dashcam image resources. Adv. Eng. Inform. 2020, 46, 101182. [Google Scholar] [CrossRef]
- Zhou, Z.; Lu, Q.; Wang, Z.; Huang, H. Detection of Micro-Defects on Irregular Reflective Surfaces Based on Improved Faster R-CNN. Sensors 2019, 19, 5000. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: Design backbone for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–350. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13903–13912. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 558–567. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Image Number |
|---|---|
| LC | 1054 |
| TC | 1047 |
| R | 1059 |
| PR | 1046 |
| C | 1003 |
| P | 1007 |
| BR | 1066 |
| Method | Scales | Aspect Ratios |
|---|---|---|
| FPN | [32, 64, 128, 256, 512] | [0.5, 1.0, 2.0] |
| MSARM | [32, 48, 64, 96, 128,192, 384, 512, 768] | [0.1, 0.5, 1.0, 2.0, 10] |
| Method | Average Precision (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Backbone | LC | TC | R | PR | C | P | BR | mAP (%) | mAP_B (%) | mAP_D (%) | |
| FasterRCNN | Resnet101 | 42.33 | 47.26 | 66.32 | 49.94 | 59.26 | 43.67 | 81.02 | 55.69 | 56.23 | 55.14 |
| CascadeRCNN | Resnet101 | 45.63 | 49.52 | 68.37 | 53.45 | 63.52 | 48.26 | 83.56 | 58.90 | 59.62 | 58.18 |
| CrdNet − | Resnet101 | 50.34 | 51.63 | 70.28 | 58.24 | 67.97 | 53.29 | 84.68 | 62.35 | 63.21 | 61.48 |
| Faster RCNN + | Resnet101 | 44.36 | 48.33 | 67.66 | 52.67 | 60.12 | 46.38 | 81.26 | 57.25 | 57.78 | 56.72 |
| Cascade RCNN + | Resnet101 | 46.28 | 49.54 | 68.14 | 54.21 | 64.26 | 51.29 | 84.65 | 59.77 | 59.92 | 59.62 |
| CrdNet | Resnet101 | 51.68 | 52.42 | 72.35 | 60.81 | 68.33 | 55.86 | 85.12 | 63.80 | 64.47 | 63.12 |
| Faster RCNN | VoVNetV2-57 | 43.56 | 48.85 | 67.25 | 51.26 | 62.44 | 46.89 | 82.05 | 57.47 | 58.43 | 56.51 |
| CascadeRCNN | VoVNetV2-57 | 46.58 | 50.67 | 68.51 | 53.41 | 64.26 | 48.83 | 83.98 | 59.46 | 59.96 | 58.97 |
| CrdNet − | VoVNetV2-57 | 51.29 | 52.04 | 71.56 | 60.08 | 68.26 | 54.18 | 84.97 | 63.20 | 63.36 | 63.03 |
| Faster RCNN + | VoVNetV2-57 | 44.65 | 49.27 | 69.29 | 52.33 | 63.48 | 48.39 | 83.11 | 58.65 | 59.06 | 58.23 |
| Cascade RCNN + | VoVNetV2-57 | 48.12 | 51.24 | 70.08 | 54.29 | 65.26 | 50.04 | 84.96 | 60.57 | 61.06 | 60.08 |
| CrdNet | VoVNetV2-57 | 52.58 | 52.47 | 71.53 | 61.39 | 69.25 | 57.42 | 84.51 | 64.16 | 64.91 | 63.42 |
| Faster RCNN | HRNetV2-W32 | 49.36 | 56.43 | 76.54 | 65.89 | 67.78 | 61.96 | 88.41 | 66.62 | 66.93 | 66.31 |
| Cascade RCNN | HRNetV2-W32 | 52.43 | 59.42 | 79.74 | 67.34 | 69.24 | 64.20 | 93.31 | 67.95 | 68.47 | 67.44 |
| CrdNet − | HRNetV2-W32 | 53.58 | 60.74 | 80.63 | 69.74 | 71.24 | 66.95 | 92.46 | 70.76 | 71.04 | 70.49 |
| Faster RCNN + | HRNetV2-W32 | 50.63 | 57.58 | 77.93 | 66.23 | 68.72 | 62.30 | 88.93 | 67.47 | 68.14 | 66.81 |
| Cascade RCNN + | HRNetV2-W32 | 53.67 | 61.52 | 80.35 | 68.76 | 70.94 | 66.83 | 93.68 | 70.82 | 71.68 | 69.96 |
| CrdNet | HRNetV2-W32 | 55.64 | 61.97 | 80.86 | 71.38 | 72.99 | 69.61 | 93.42 | 72.27 | 73.18 | 71.35 |
| Faster RCNN | LrNet | 62.53 | 71.39 | 82.59 | 77.37 | 87.06 | 73.12 | 94.59 | 78.39 | 78.63 | 78.15 |
| Cascade RCNN | LrNet | 63.94 | 72.42 | 84.52 | 78.52 | 88.42 | 75.94 | 95.24 | 79.86 | 80.47 | 79.24 |
| CrdNet − | LrNet | 79.36 | 79.89 | 86.77 | 84.35 | 91.68 | 85.16 | 95.81 | 86.18 | 86.98 | 85.39 |
| Faster RCNN + | LrNet | 70.28 | 73.26 | 84.56 | 79.24 | 89.45 | 75.94 | 94.85 | 81.08 | 82.02 | 80.15 |
| Cascade RCNN + | LrNet | 71.25 | 74.84 | 85.27 | 80.76 | 90.63 | 76.91 | 94.99 | 82.09 | 82.80 | 81.39 |
| CrdNet | LrNet | 88.34 | 89.25 | 90.94 | 89.92 | 91.83 | 90.54 | 95.62 | 90.92 | 91.07 | 90.77 |
| Multiple Branches | LFAM | MSAM | Cascade | mAP (%) | mAP_B (%) | mAP_D (%) |
|---|---|---|---|---|---|---|
| √ | 71.89 | 72.35 | 71.43 | |||
| √ | √ | 78.26 | 78.65 | 77.87 | ||
| √ | √ | √ | 83.85 | 84.04 | 83.66 | |
| √ | √ | √ | √ | 90.92 | 91.07 | 90.77 |
| Backbone | mAP (%) | mAP_B (%) | mAP_D (%) |
|---|---|---|---|
| HRNetV2-W32 [28] | 72.27 | 73.18 | 71.35 |
| +LFAM | 83.60 | 83.86 | 83.34 |
| +MSAM | 90.92 | 91.07 | 90.77 |
| Method | No. of Branches | mAP (%) | mAP_B (%) | mAP_D (%) |
|---|---|---|---|---|
| CrdNet (baseline) | – | 80.23 | 80.36 | 80.10 |
| CrdNet | 3 branches (Equation (9) [19]) | 82.21 | 82.93 | 81.49 |
| CrdNet | 3 branches (Equation (10)) | 90.92 | 91.07 | 90.77 |
| Stage | mAP (%) | mAP_B (%) | mAP_D (%) |
|---|---|---|---|
| 1 | 83.85 | 84.04 | 83.66 |
| 2 | 86.26 | 87.15 | 85.37 |
| 3 | 90.92 | 91.07 | 90.77 |
| 4 | 90.38 | 90.67 | 90.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Chen, B.; Qin, J. A CNN-Based Length-Aware Cascade Road Damage Detection Approach. Sensors 2021, 21, 689. https://doi.org/10.3390/s21030689
Xu H, Chen B, Qin J. A CNN-Based Length-Aware Cascade Road Damage Detection Approach. Sensors. 2021; 21(3):689. https://doi.org/10.3390/s21030689
Chicago/Turabian StyleXu, Huiqing, Bin Chen, and Jian Qin. 2021. "A CNN-Based Length-Aware Cascade Road Damage Detection Approach" Sensors 21, no. 3: 689. https://doi.org/10.3390/s21030689
APA StyleXu, H., Chen, B., & Qin, J. (2021). A CNN-Based Length-Aware Cascade Road Damage Detection Approach. Sensors, 21(3), 689. https://doi.org/10.3390/s21030689