2.1. Soft Landing Problem Formulation
The planetary surface fixed frame of reference is defined as
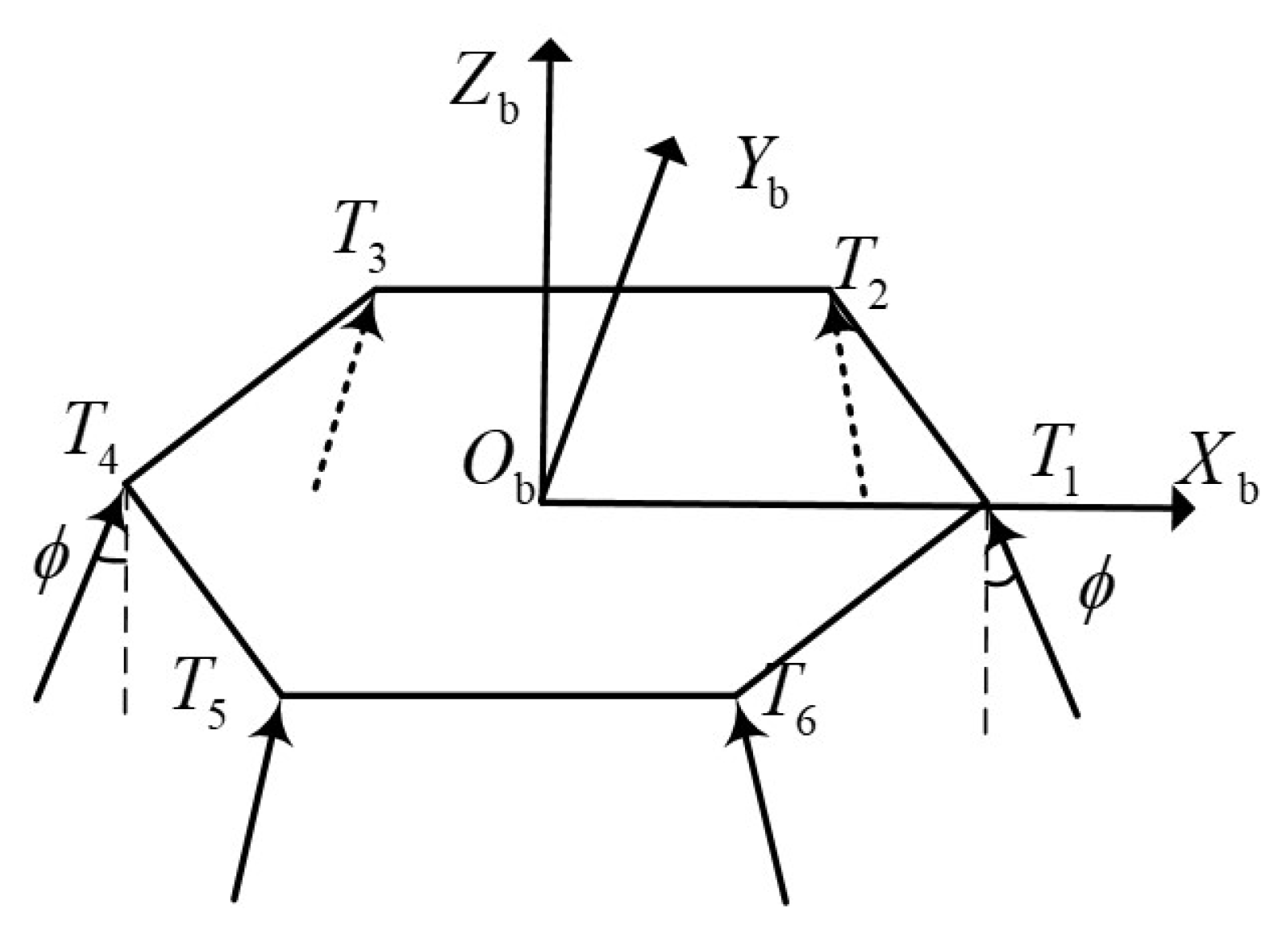
Figure 1. The forces acting on the lander in power descent include gravity, aerodynamic force, and engine thrust [
22].
As the powered descent begins at an altitude that is quite low compared to the planet’s radius, and the distance between the lander and target landing sites varies slightly during this phase, it is appropriate to assume that the planet’s gravity is a constant .
When it comes to the power descent phase, the lander has already released the parachute and the speed is on the order of 100 meters per second [
22]. Compared with planetary gravity, the acceleration caused by aerodynamic force was very small. Therefore, the external force on the lander was dominated by gravity, and the aerodynamic force caused by the wind field was added into the model as an environmental disturbance.
The lander is equipped with six thrusters deployed in body frame
as
Figure 2.
The thrust of each engine is
, and meets constraint
Let
be the vector composed of the thrusts of six thrusters, and the thrust vector in body frame can be obtained according to the geometric relation
Moreover, the same for the torque vector in body frame
The translation dynamics are expressed as
where
is the translational vector of the lander,
is the velocity vector, and
and
are the velocity and angular velocity in the body frame, respectively.
is the quaternion.
and
m are the inertia matrix and mass of the lander, respectively.
is the direction cosine matrix from the body frame to the surface fixed frame of reference.
Attitude dynamics are express as
During soft landing, the mass of the lander will gradually decrease with the fuel consumption, i.e.,
where
is the specific impulse of the engine, and the inertia matrix will also gradually decrease as the mass decreases. The shape of the lander is a cuboid of sides of length
with uniform mass distribution
The soft landing problem is described as a fuel optimization problem as
2.2. RL Basis
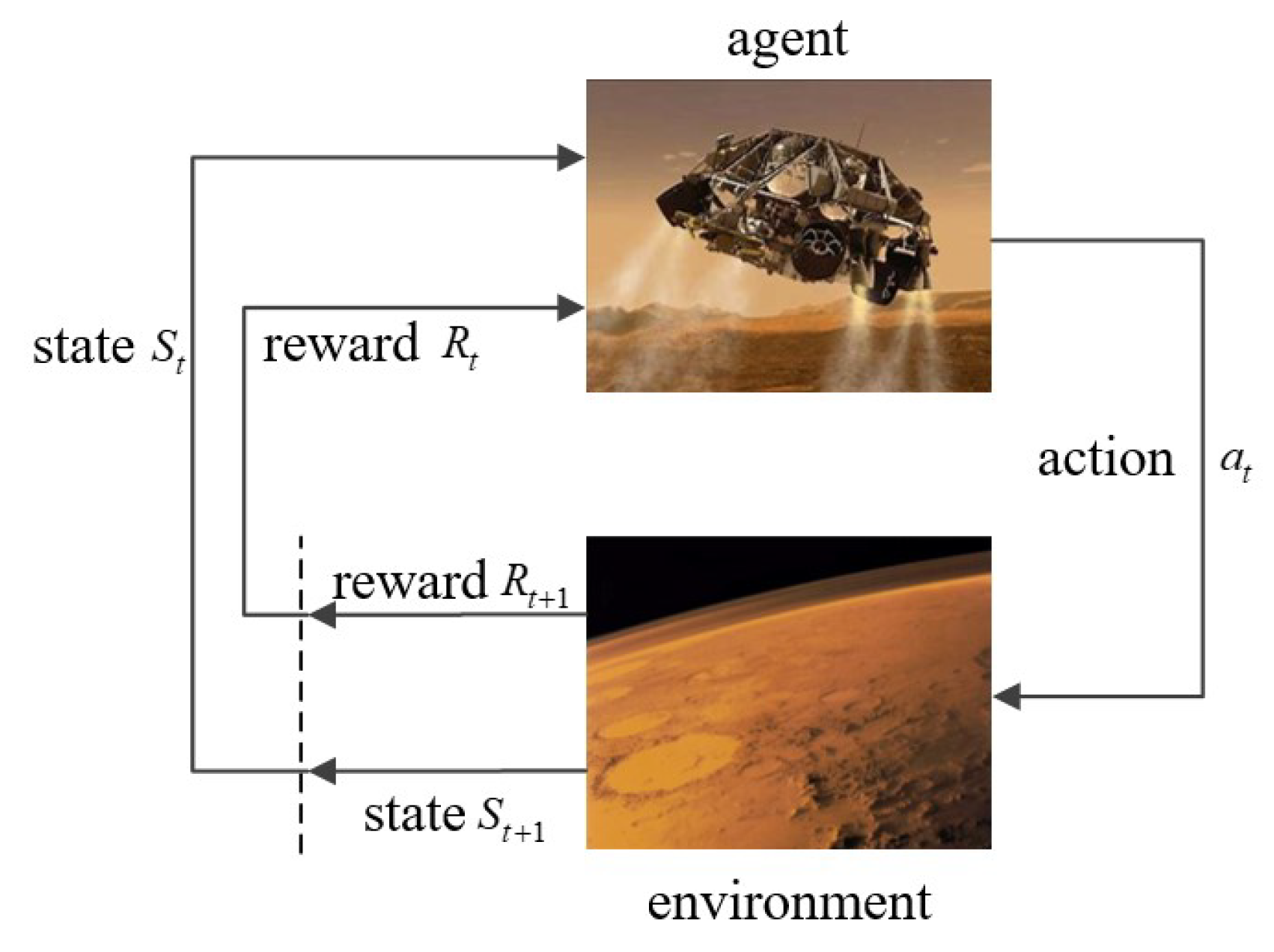
RL is a data-driven algorithm, which is different from supervised learning. RL obtains training data(experience) through interaction with the environment, as shown in
Figure 3.
At time step
t, the agent gets an observation
from the environment, then takes an action
according to the policy
, the environment transfers to the next state
based on the model
and returns a reward
. Define the accumulated return of an episode as
where
is the discount factor. When
, the agent only cares about the most recent rewards. While
, the agent has a longer horizon and cares more about the future reward. Moreover, the target is to update policy to maximize
.
DDPG, TD3, and SAC are three of the most successful and popular RL algorithms, so we chose them as the framework in this paper.
- (1)
DDPG
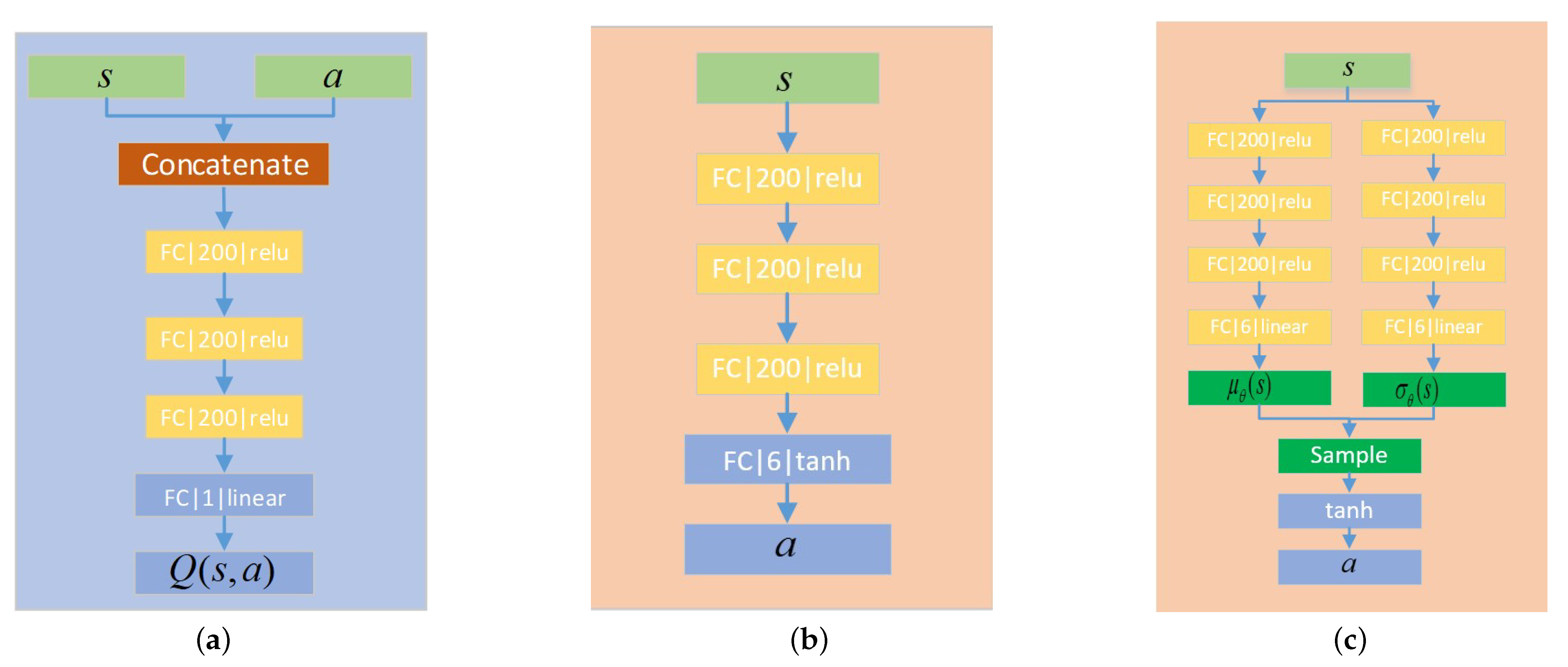
DDPG is a deterministic policy RL framework that outputs a deterministic action, and it is the result of the deep Q network (DQN) extended to continuous control space. DDPG has been extensively researched and applied to the field of continuous control. It learns both a value function and a policy. First, it approximates the value function via the Bellman equation with offline experience through gradient descent. Then, the policy is updated by maximizing the approximated value function.
DDPG is one of the standard algorithms that training a deep neural network to approximate Q function. It makes use of the past experience through the trick of replay buffer. When it is time to update, it randomly samples from the buffer. In order to stabilize the training process, the size of the replay buffer should be properly chosen. If it is too small, it can only store recent experiences, which makes the policy brittle. However, if it is too large, the possibility of sampling a good experience will decrease, and it takes more episodes for the training process to converge.
As shown in Algorithm 1, the whole learning process consists of two parts: Q-learning and policy learning.
According to Bellman equation, optimal
Q function under optimal policy satisfies
where
P is the environment model. Given the experience
, value function
under the policy
can be represented as
| Algorithm 1: DDPG based soft landing. |
![Sensors 21 08161 i001]() |
Setup a mean-squared Bellman error function as
where
is the value function target. In the condition of continuous action space, it is difficult to compute action
which maximizes
. Therefore, DDPG uses target network to solve this problem
where
is obtained via target policy
. With the training process going on, policy and value function will gradually converge to optimal policy and optimal value function respectively.
- (2)
TD3
TD3 is modified from DDPG. DDPG can perform well sometimes but it highly depends on the choice of hyperparameters. TD3 takes three critical tricks to make the training process more stable.
Clipped Double-Q Learning. TD3 learns two value function networks at the same time. When calculating the target, and are input to the two target value function networks at the same time after obtaining. When the value function network is updated, the smaller one is selected to compute the loss function of the error of the Bellman equation.
Target Policy Smoothing. The value function learning method of TD3 and DDPG is the same. When the value function network is updated, noise is added to the action output of the target policy network to avoid overexploitation of the value function
where
∼
is a mean-zero Gaussian noise, and
is the parameters of the target strategy network. Adding noise to the output action of the strategy network serves as regularization, which avoids the overexploitation of value function and stabilizes the training process.
Delayed Policy Updates. As the output of the target strategy network is used to compute the target of the value function, the agent can be brittle because of frequent strategy updates, so TD3 adopts the Delayed Policy Updates trick. When updating the strategy network, the update frequency of the strategy network is lower than that of the value function network. This helps to suppress the training fluctuation and makes the learning process more stable.
- (3)
SAC
SAC is an RL framework that maximizes cross-entropy. It applies the learning techniques of DDPG to the learning of random strategies and optimizes random strategies in an offline learning mode.
The agent starts from the initial state
∼
, samples from policy distribution
∼
, and gets an action
acting on the environment. Then, the environment returns a reward
and transfers to a new state
∼
according to the environmental model. Repeating the interacting process and the trajectory of the state,
can be obtained. The probability distribution of the trajectory
regarding the strategy
is expressed as
The maximum cross-entropy RL optimizes the cumulative return and cross-entropy of the strategy. For Markov decision processes (MDPs) with infinite loss rewards, the optimization objective can be expressed as
Moreover, the optimal policy is represented as
where
is the cross-entropy of strategy distribution, which can be added into the optimization target to encourage agents to explore the environment in training, and to improve the robustness of training results.
is the temperature coefficient, which is used to adjust the importance of cross-entropy, and thus plays a role in regulating the randomness of the optimal strategy. A large
encourages the agent to explore the environment. Therefore, the larger the
is, the more stochastic the strategy will be. While the smaller alpha is, it is more likely that the policy falls into a local optimal point. When
, maximizing cross-entropy RL degenerates into conventional RL that maximizes cumulative reward.
Based on the optimization objective above, the state value function is defined as
Moreover, the value function
Then, according to the Bellman equation,
SAC makes use of “Clipped Double Q-learning” and the Q-learning is similar to TD3 except for the compute of the target value function
According to Equation (
24), then
The updating of the policy network makes use of the re-parameterization trick
where the action distribution is Gaussian;
and
are the mean value and variance of the Gaussian distribution, respectively; and
is the standard Gaussian distribution. After sampling from the distribution, the action output is restricted to the constrained range through the Tanh activation function.
Besides, SAC makes use of the Clipped
Q trick when updating its strategy
The strategy optimization objective is finally represented as
Because of the inherent stochasticity, SAC can effectively avoid the overexploitation of value function.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}