The YOLO algorithm creatively combines the two stages of the candidate region and target recognition into one, which accelerates the detection speed and has been widely used in the industry. There are three main algorithms in this series: YOLOv1 [
23], YOLOv2 [
24], and YOLOv3 [
25]. YOLOv3 is widely used in detection tasks. YOLO series algorithm is a one-stage algorithm, while Faster R-CNN is a two-stage algorithm. In principle, the one-stage algorithm is faster, but its accuracy is not as good as the two-stage algorithm. In other words, YOLOv3 is to reduce the precision value in exchange for improving the detection speed. Therefore, to ensure the real-time performance of the YOLOv3 algorithm, this paper will adopt two methods to improve the accuracy of the YOLOv3 algorithm and make it meet the requirements of jellyfish detection accuracy and speed. Specific improvements are as follows: (1) Optimize the Darknet53 feature extraction network of YOLOv3. The optimization method is to introduce a large-step cross-layer residual connection and add a top-down pyramid structure. (2) When training the improved network, two training methods, label smoothing, and the cosine annealing learning rate are introduced to improve the overall detection effect of the algorithm.
4.1. Improvement of Feature Extraction Network
- (1)
Large-step cross-layer residual connection method
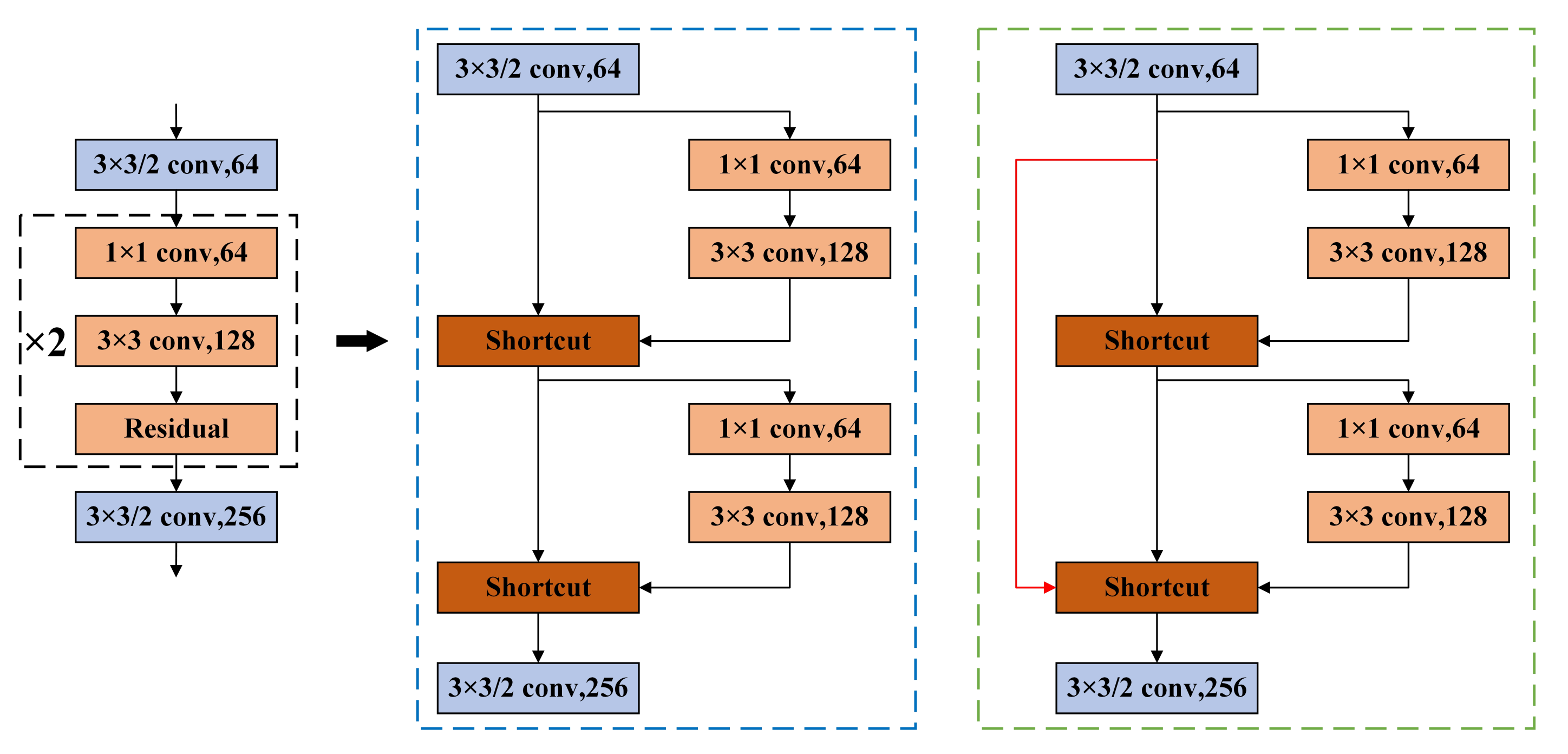
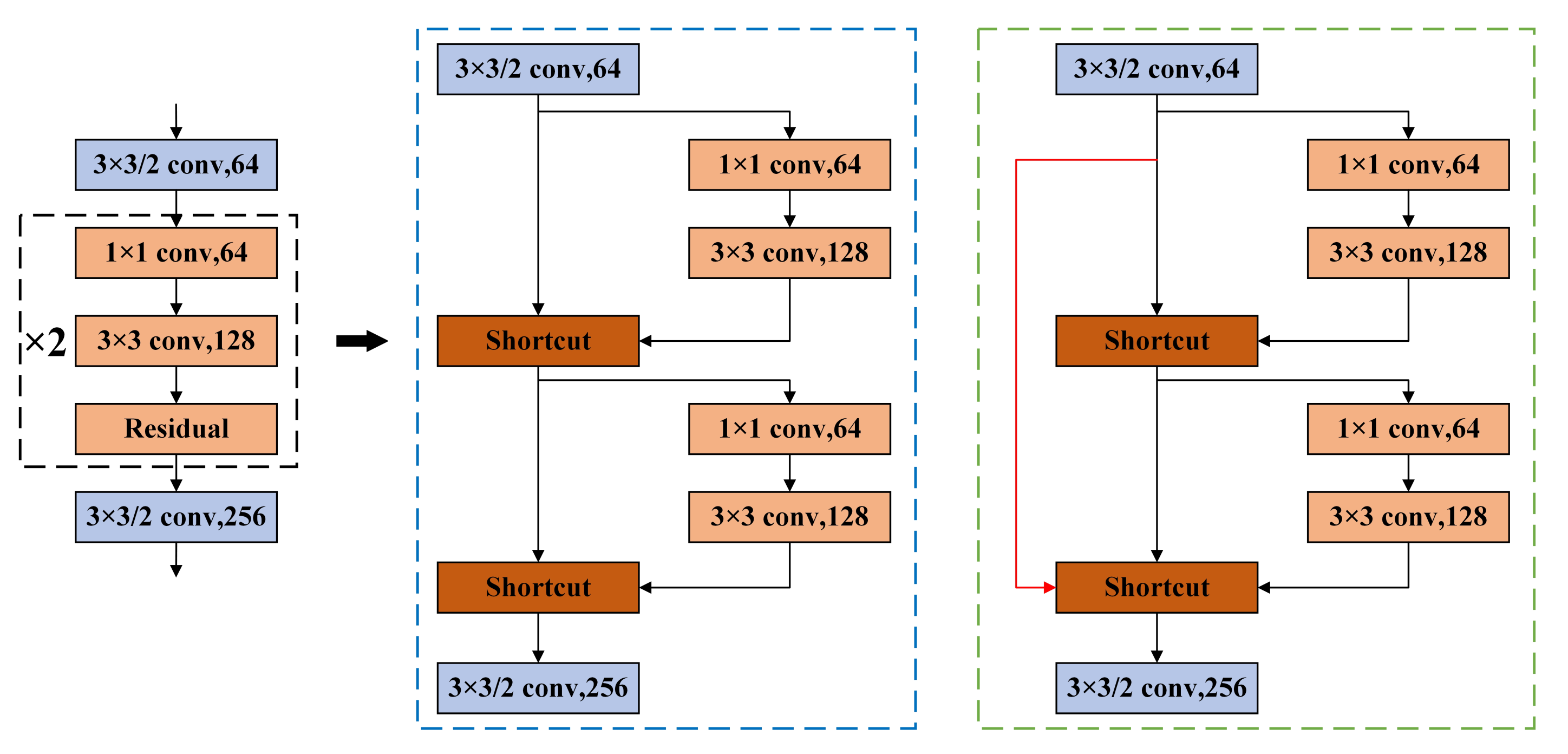
The feature extraction network of YOLOv3, Darknet53, is composed of a series of residual structures. The operation of each residual structure is as follows: perform a 3 × 3 convolution on the input layer1 with a step size of 2, and then save the convolution result layer1, perform 1 × 1, 3 × 3 convolutions again, and add the convolution result into layer2 as the final result. The residual structure of the Darknet53 network is composed of repeated stacking according to the specified times (1, 2, 4, 6, 8).
According to the residual network theory, it is easy to optimize the network when using the residual structure, and the residual structure can effectively reduce the gradient explosion. Based on this, this paper introduces an improved large-step cross-layer residual connection structure. The specific structure is as follows: the residual blocks in the original YOLOv3 are grouped: one group processes the feature map accordingly to the original Darknet53 structure, and the other group starts from the first layer of the current stack structure, and the feature maps are directly connected to the last layer of the current stack structure after only a small amount of processing (convolution, normalization, activation function) [
26].
Take the residual block stacked twice as an example, the network structure before and after improvement is shown in
Figure 3. The black dotted line shows the schematic diagram of the residual block stacked twice, the blue dotted line shows the original residual structure, and the green dotted line shows the improved residual structure. A long-step cross-layer residual connection is equivalent to adding a completely independent gradient propagation path in the process of back propagation, enhancing gradient information and the learning ability of convolution neural networks.
- (2)
Feature pyramid structure improvement method
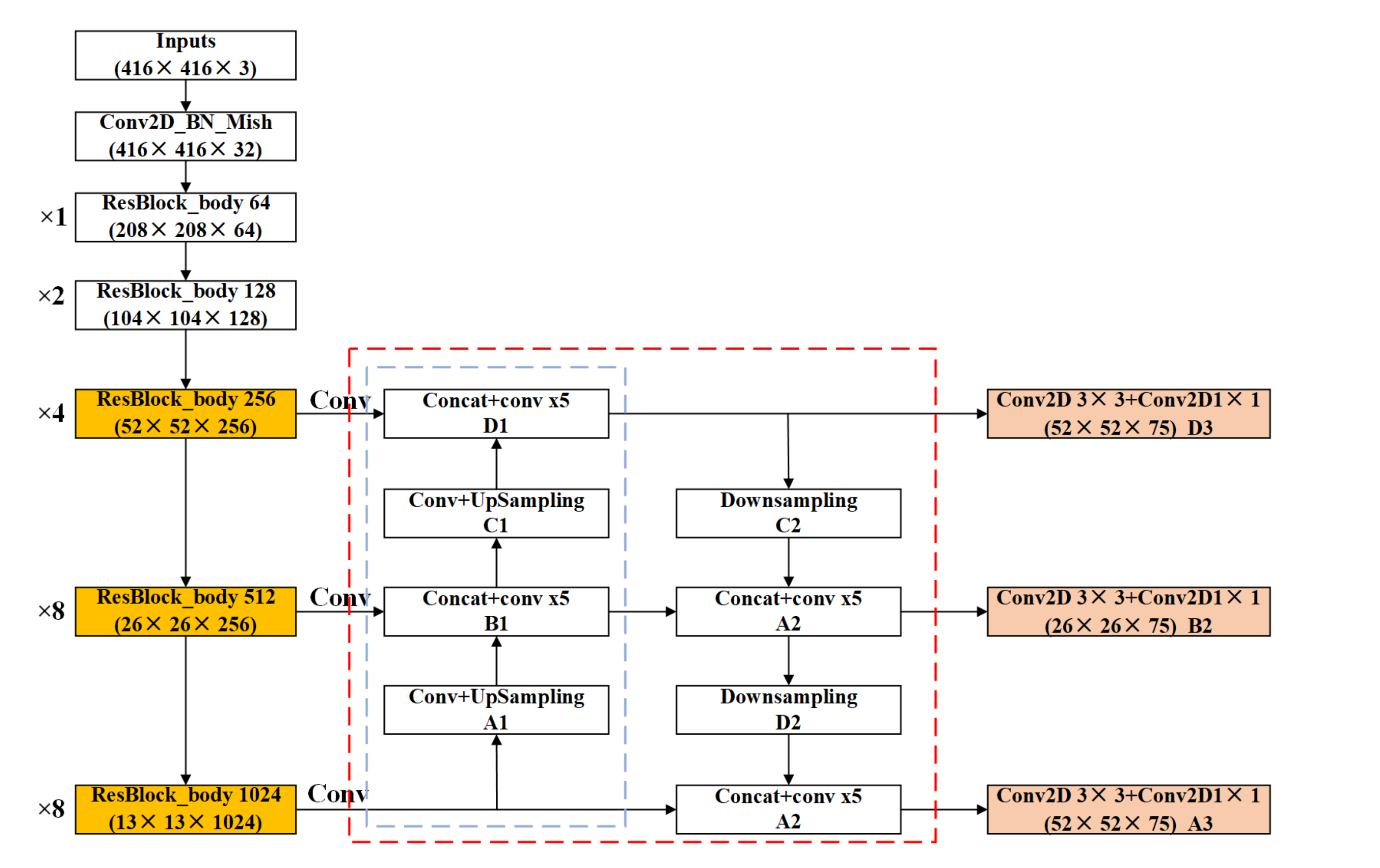
The feature pyramid structure (FPN) used in YOLOv3 mainly up samples the small-scale feature map (13 × 13) twice to obtain the size of the upper feature map (26 × 26), and then splices two feature maps (26 × 26) with the same size. In the same way, if the feature map obtained from the previous splicing is down-sampled twice to match the feature map with the same size in the original output, and then the two feature maps are spliced, the information contained in the newly obtained feature map will not be reduced, and a feature map that has richer semantic information and location information can be obtained theoretically [
27]. In this paper, the top-down sampling part is introduced into the FPN of YOLOv3 to enrich the features of the feature map. Specific operations are as follows:
Firstly, the feature map D1 (52 × 52) obtained by the network structure of Darknet53 in
Figure 3 is downsampled to obtain the feature map C2 (26 × 26).
Secondly, the feature map C2 and the feature map B1 are spliced again, and a new feature map B2 (26 × 26) is obtained again, which has a better effect on the detection of medium targets.
Thirdly, the feature map B2 (26 × 26) is downsampled and spliced with the original network output (13 × 13) feature map to generate a new feature map A2 (13 × 13), which is suitable for detecting large targets.
The network structures with the improved FPN are shown in
Figure 4. It can be seen that a very important feature of the FPN is to extract features repeatedly. In
Figure 4, the blue dotted line is the traditional FPN, which completes feature extraction from the bottom to top. In contrast, the red dotted line is the improved pyramid structure, which includes both top-down feature extraction and down-sampling feature extraction from the bottom to top.
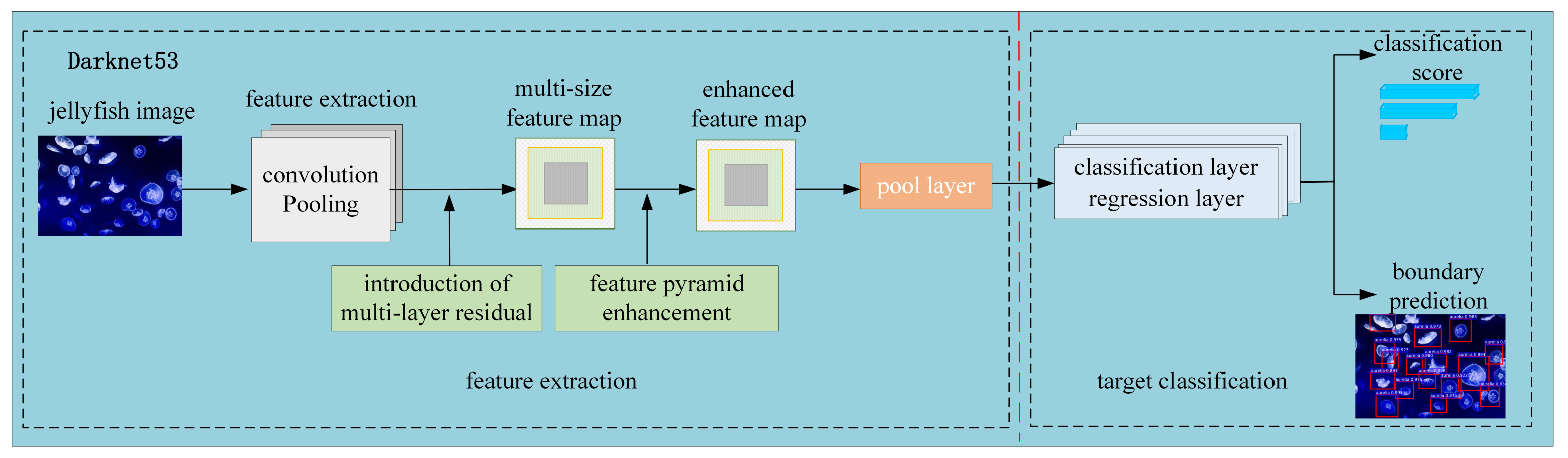
To sum up, the schematic diagram of the improved YOLOv3 algorithm is shown in
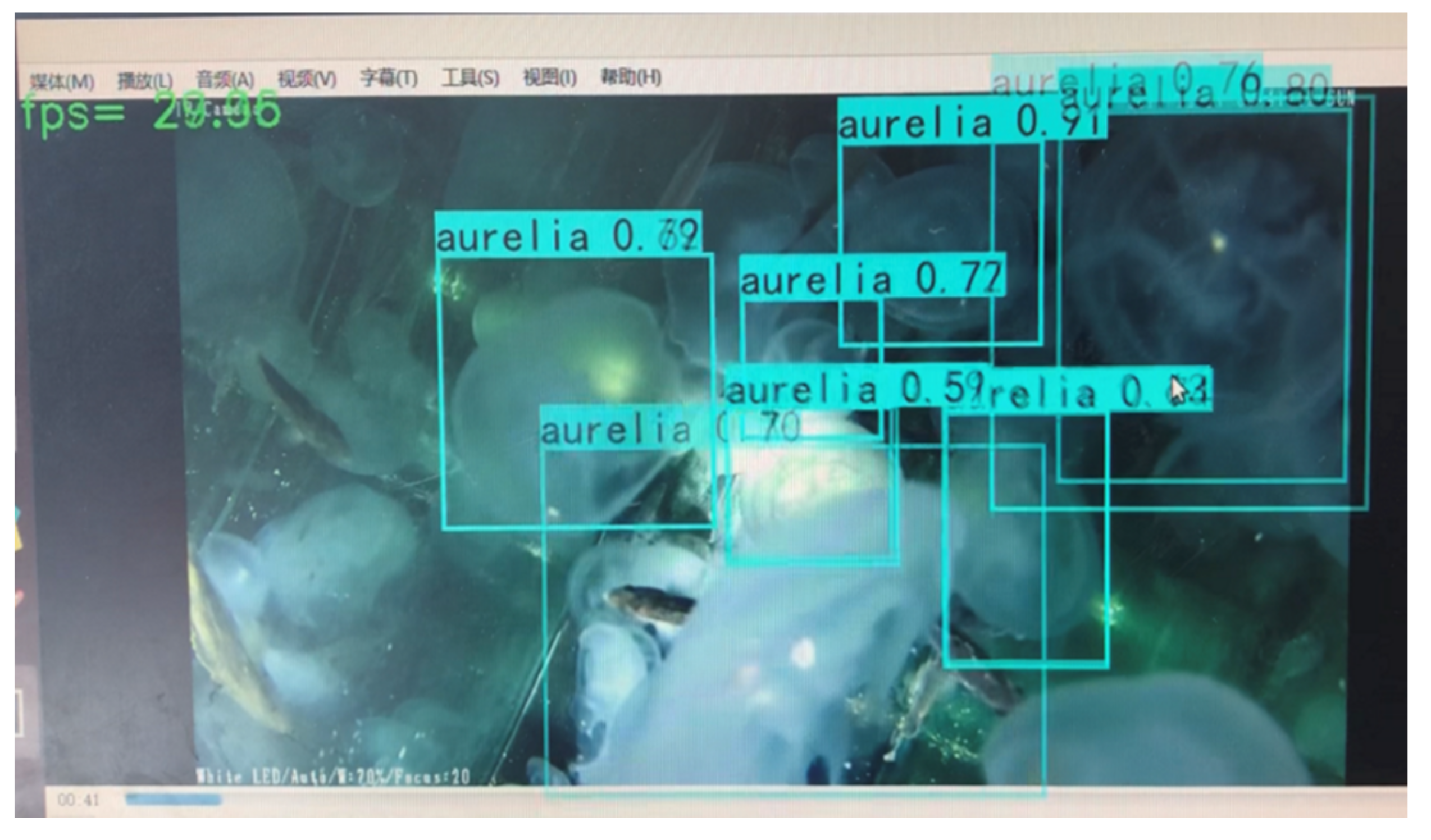
Figure 5. The features of the input jellyfish image are extracted by convolution, pooling, excitation function, etc. In this process, a multi-layer residual connection structure is introduced to output feature maps of three scales. After the improved FPN of the output feature map, the feature information is enhanced, and new feature maps with more information in three scales are generated. Then, the new feature map is sent to the subsequent pooling layer, classification layer, and regression layer. The jellyfish category (such as
A. aurita,
R. esculentum, etc.) in the boundary box is judged through the classification layer and the regression layer. The type’s confidence level is calculated. The position of the prior box is adjusted until it is adjusted to the target size, and the prediction of the target boundary box is completed.
4.2. Improvement of Training Method
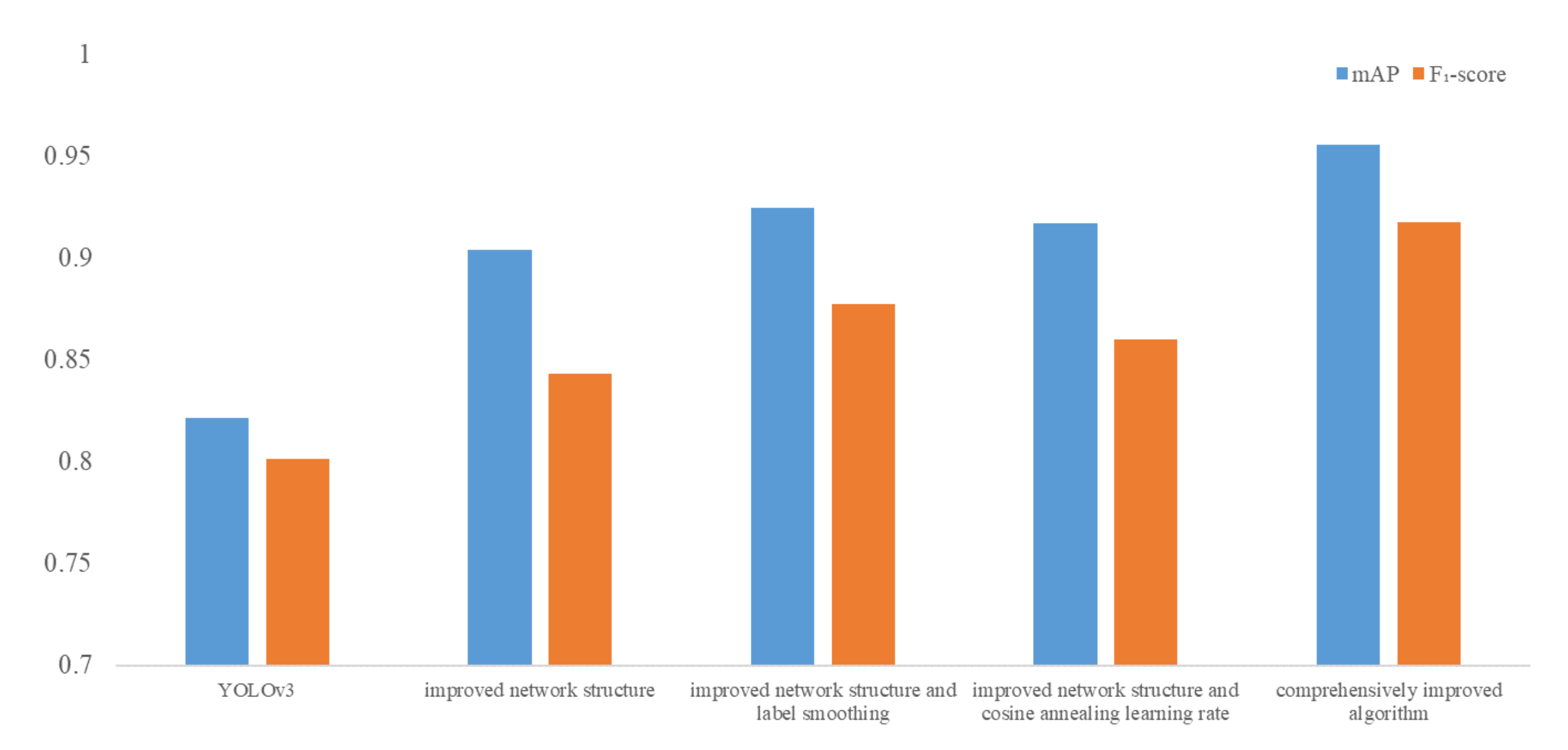
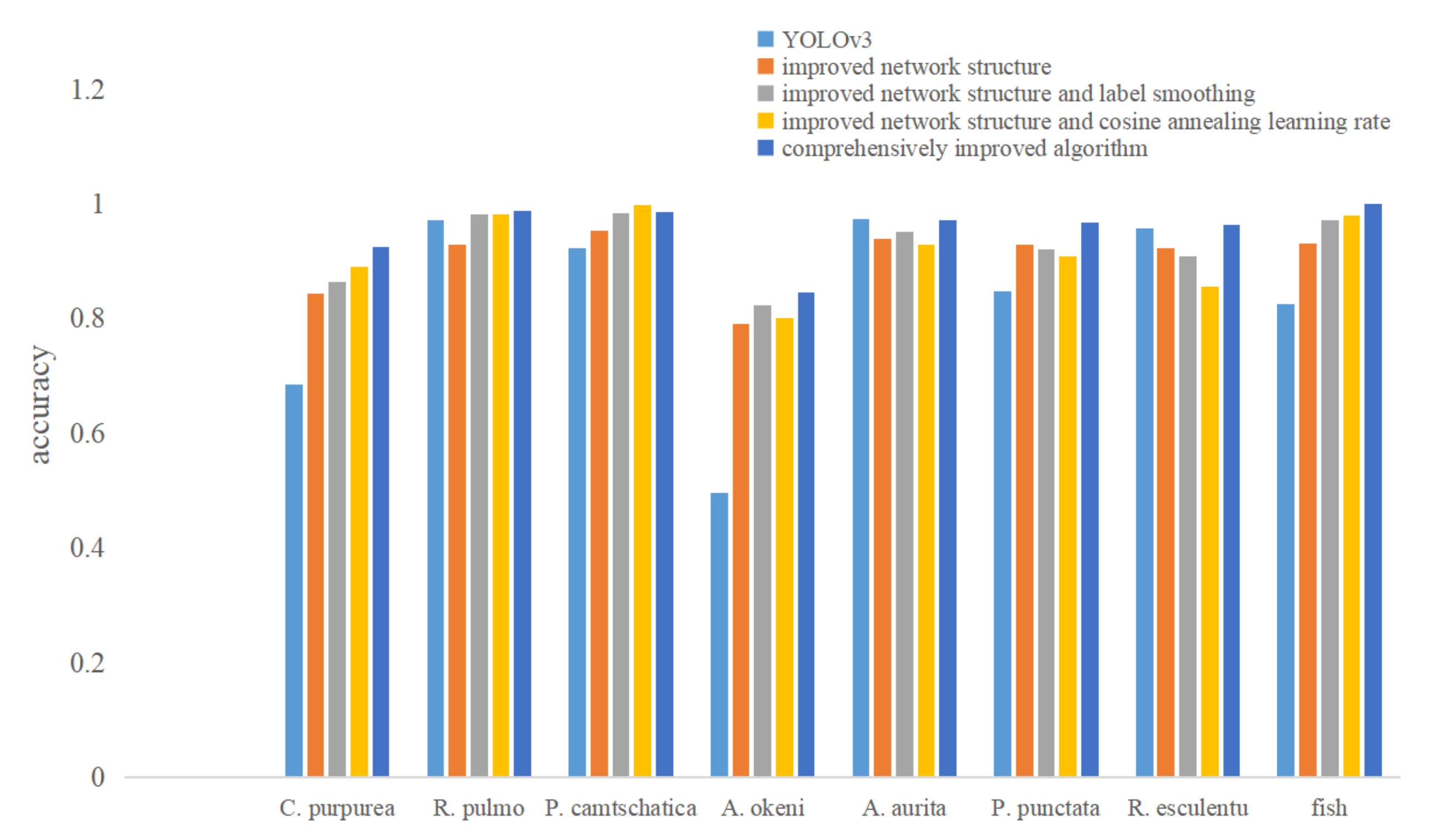
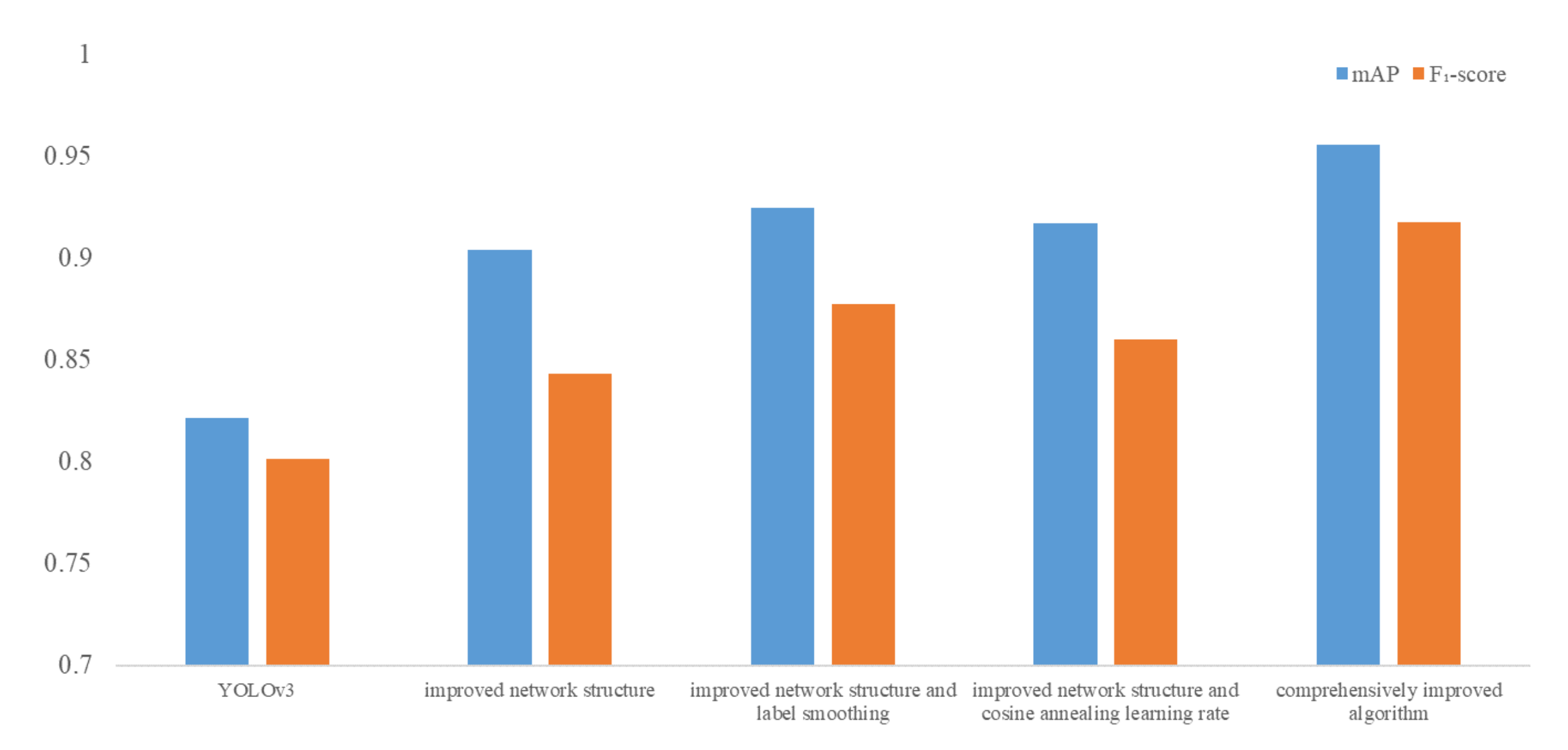
To further improve the detection accuracy, a comprehensive algorithm is proposed in this paper. That is, the improved network is used for the feature extraction network of the algorithm, and the label smoothing method and cosine annealing learning rate method are introduced when training the network.
- (1)
Label smoothing method
When designing a classification task algorithm, it is generally considered that the probability of the target category in the label vector in training data is 1, and the probability of the non-target category should be 0. That is, the corresponding relationship between input and output is shown in Equation (
1).
Because there are many kinds of jellyfishes, and most of the individual shapes are umbrella caps and elongated tentacles, there are some similarities between individuals. The jellyfish data set is artificially labeled, which will inevitably lead to labeling errors. In the training process of the CNN, if there are wrong labels, the training results will be negatively affected. If the model can be "informed" that there may be errors in the labels, the trained model will be immune to a few standard wrong samples. This idea is called label smoothing [
28]. Label smoothing refers to setting an error rate defined for the algorithm before network training, substituting (
) into training with the probability of
and substituting (
) into training with the probability of (
) in each iterative training. At this time, it is equivalent to smoothing the labels. Suppose the smoothing coefficient is set to 0.01, and the original labels in the second classification task are 0 and 1. In that case, the labels can be changed to 0.01 and 0.99 after smoothing, which means that the classification accuracy is punished a little so that the model should not be classified too accurately. The probability of over-fitting can be reduced. Therefore, the improved algorithm in this chapter also introduces the label smoothing method to improve the accuracy. Considering that the probability of wrong labeling will not exceed 1%, the smoothing coefficient in this paper is set to 0.01.
- (2)
Cosine annealing learning rate
When using CNN to detect the target, because the optimization function of the target may be multimodal, if the gradient descent method is used to optimize the target function, the parameters may fall into the local minimum and swing around the local minimum, thus failing to reach the global optimum. When the objective function is approaching the global minimum, the learning rate should be reduced appropriately to avoid the loss value swinging around the global maximum but never reaching the maximum. The idea of a simulated annealing algorithm is introduced into learning rate attenuation to obtain the cosine annealing learning rate [
29], which can effectively solve the above problems.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}