
DeepLabV3+/Efficientnet Hybrid Network-Based Scene Area Judgment for the Mars Unmanned Vehicle System


Abstract
:1. Introduction
2. Description
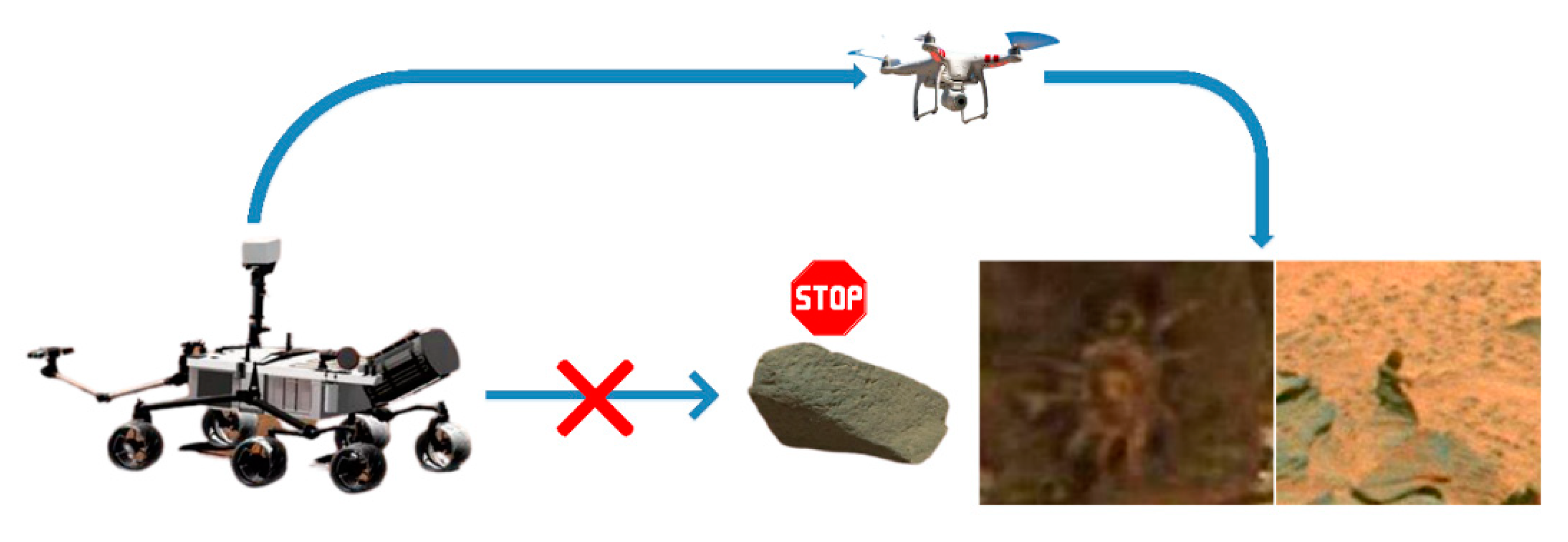
- Mars unmanned vehicle system. Due to the restriction of the harsh environment of Mars, the Mars unmanned ground vehicle is unable to reach the designated position. Therefore, the Mars unmanned vehicle system is conceived. The Mars unmanned vehicle system is composed of two parts: the Mars unmanned ground vehicle and the Mars unmanned aerial vehicle. The Mars unmanned vehicle system is equipped with artificial intelligence algorithms. The schematic of the Mars unmanned vehicle system is shown in Figure 1. When the Mars unmanned ground vehicle encounters obstacles, it cannot pass through them, thus failing to move forward. At this time, the Mars unmanned vehicle system launches the Mars unmanned aerial vehicle to bypass obstacles and discover interesting objects.
- 2.
- Feature extraction. The image taken by the camera is entered into the DeepLabV3+ network to extract image features. The feature is used as the input of the Efficientnet network to judge the scene area.
- 3.
- Scene area judgment. The output of the Efficientnet network is divided into three categories: safe area, report area, and dangerous area. Correspondingly, the Mars unmanned vehicle system performs pass, report, and send, respectively.
3. DeepLabV3+/Efficientnet Hybrid Network
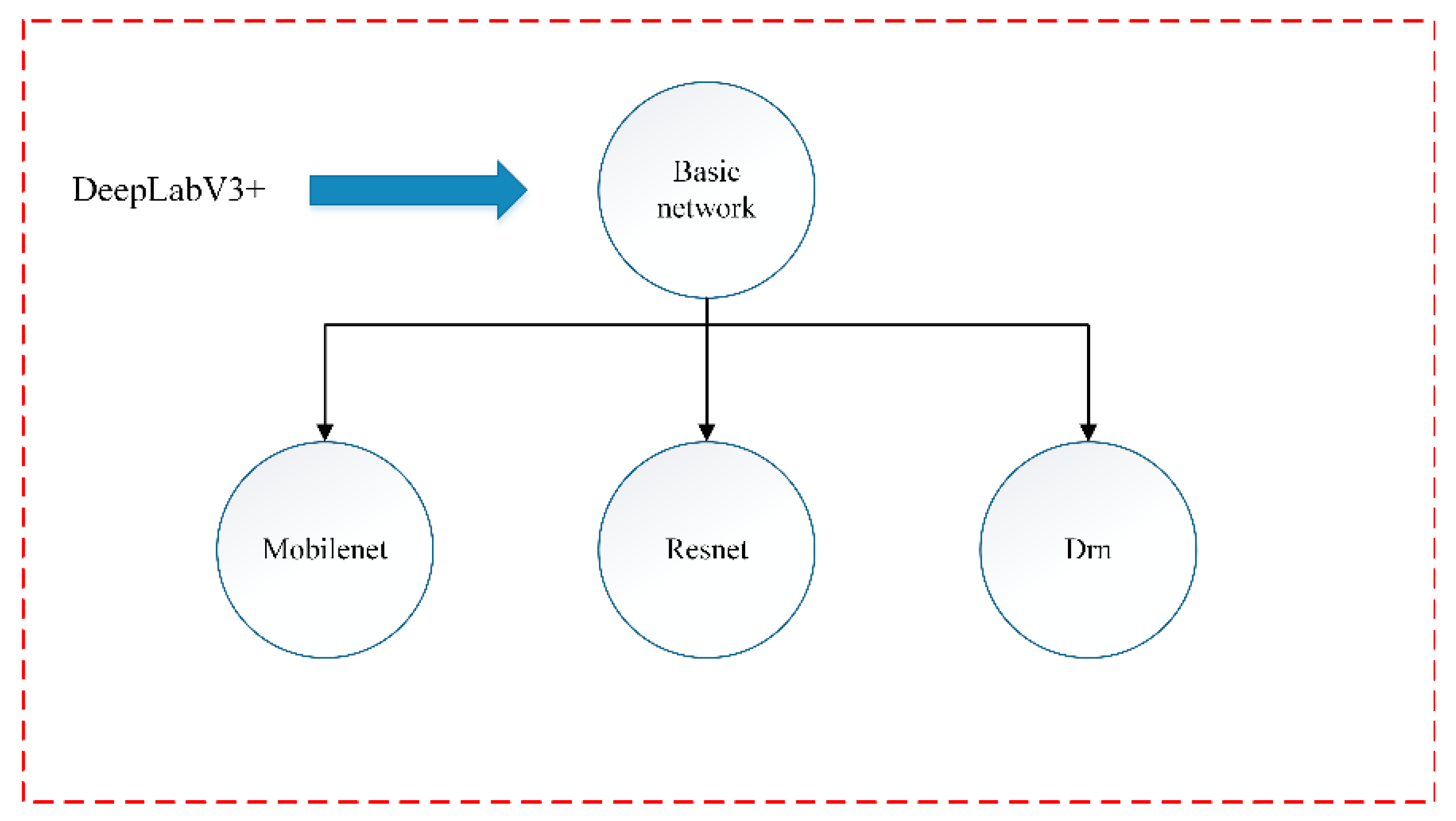
3.1. DeepLabV3+
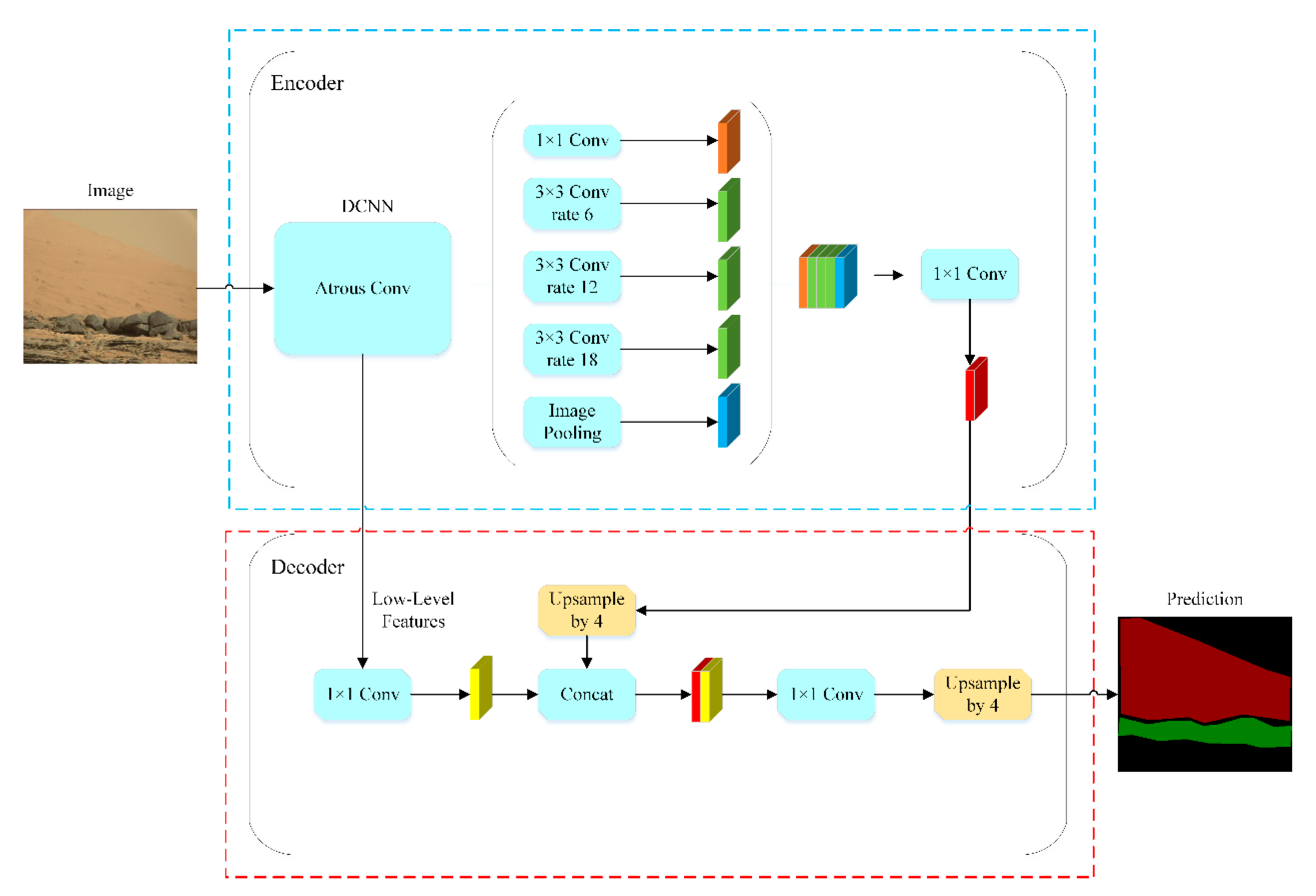
3.1.1. Structure Network Model of DeepLabV3+
3.1.2. Implementation Process of DeepLabV3+
- High-level semantic features are separately convolved and pooled in the hole convolution pyramid module. The module obtains five feature images and connects the five features obtained. The module uses a 1 × 1 convolutional layer to perform convolution operations for a single high-level semantic feature.
- Low-level semantic features are obtained by the hole convolutional layer. Furthermore, in the decoder, the semantic feature information is operated by the deep convolutional network layer. Low-level and high-level semantic features have the same resolution.
- Low-level and high-level semantic features are combined and refined through a 3 × 3 convolutional layer. The refined result adopts bilinear up-sampling four times to obtain the image of the feature extraction.
3.2. Efficientnet
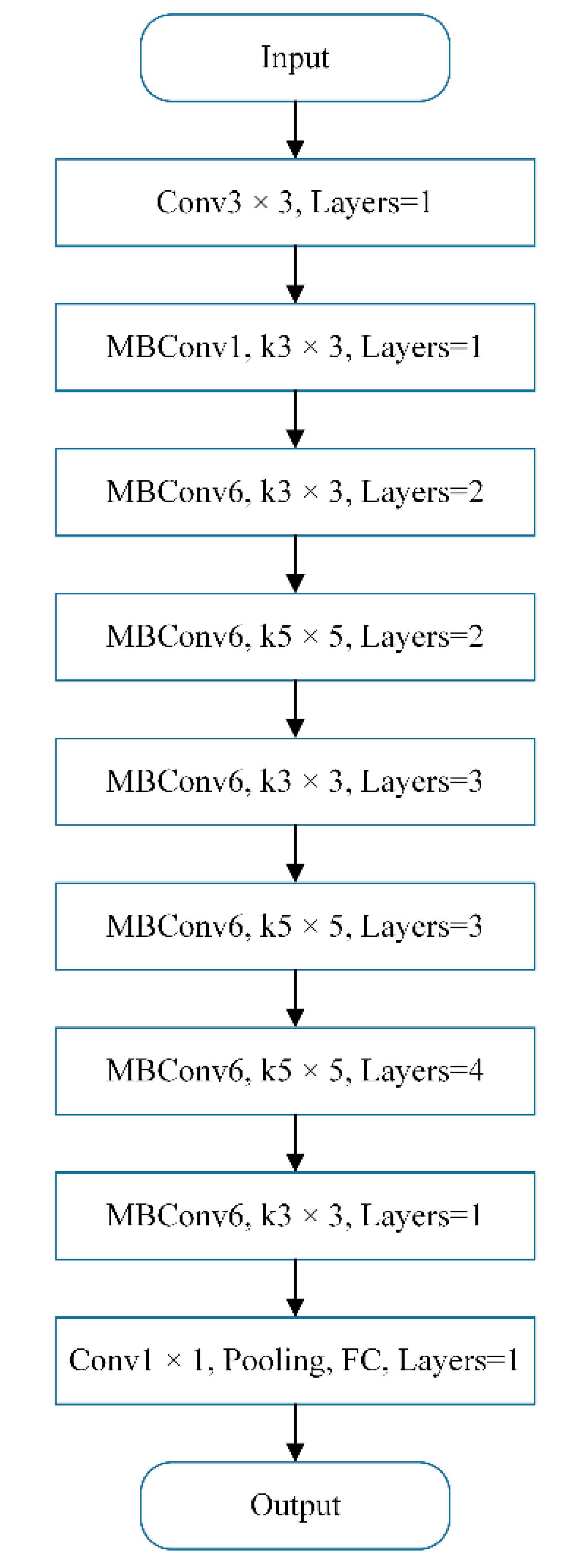
3.2.1. Structure Network Model of Efficientnet
3.2.2. Implementation Process of Efficientnet
- The image is extracted by a 3 × 3 convolutional layer and is entered by multiple block structures to further extract feature information.
- In order to enhance the ability to express features in high-dimensional space, and avoid the gradient disappearance during model training, ReLU (Rectified Linear Unit) function is used as the activation function of the network. ReLU activation function can accelerate the network convergence and reduce the value of the loss.
- Efficientnet uses the convolution-pooling-full connection operation to replace the classifier and the Softmax regression function to normalize the full connection layer. Efficientnet realizes the recognition of feature images and classification.
3.3. DeepLabV3+/Efficientnet Hybrid Network for Scene Area Judgment
4. Experiments
4.1. Dataset
4.2. Experiment Procedures
4.3. Results
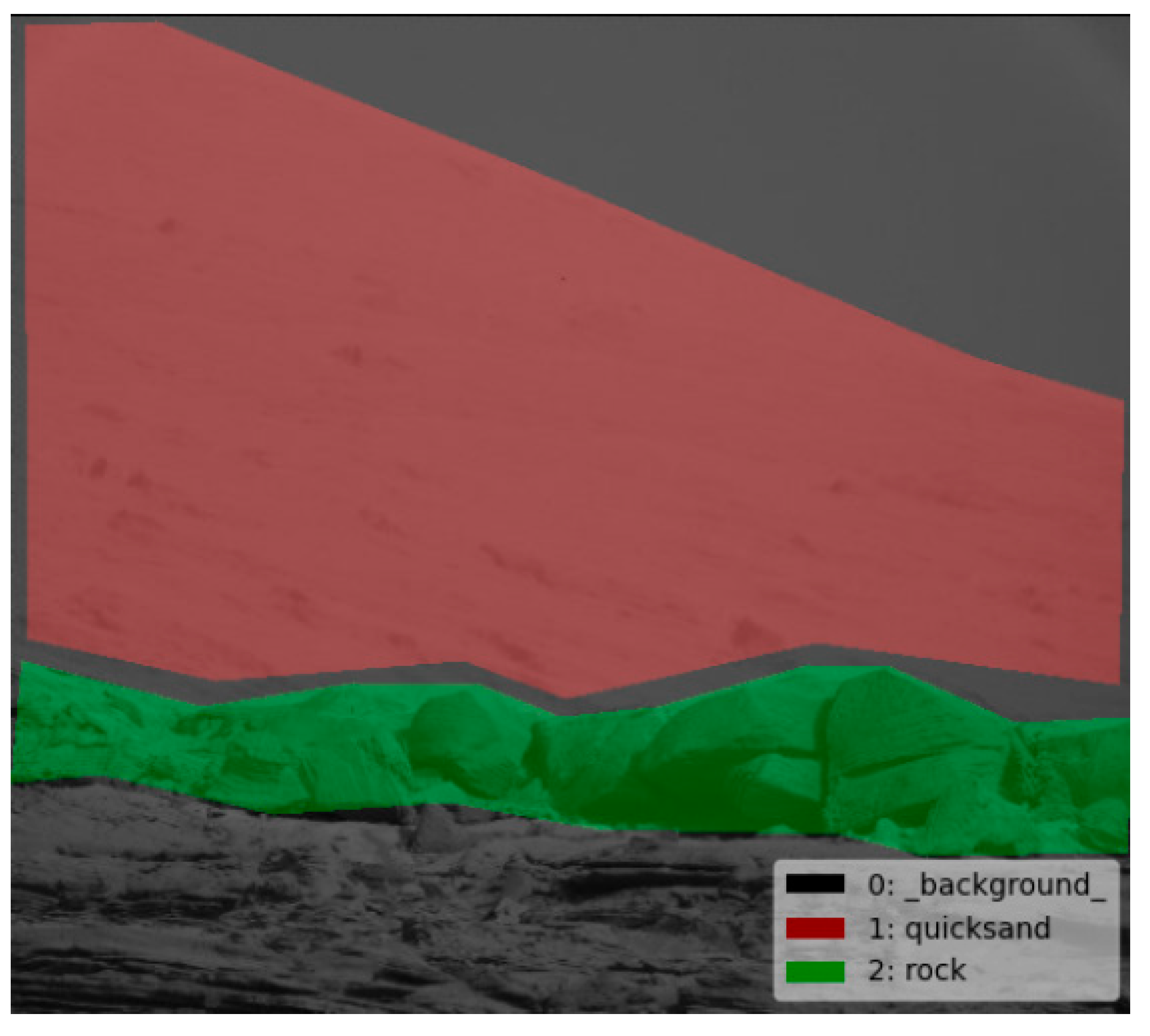
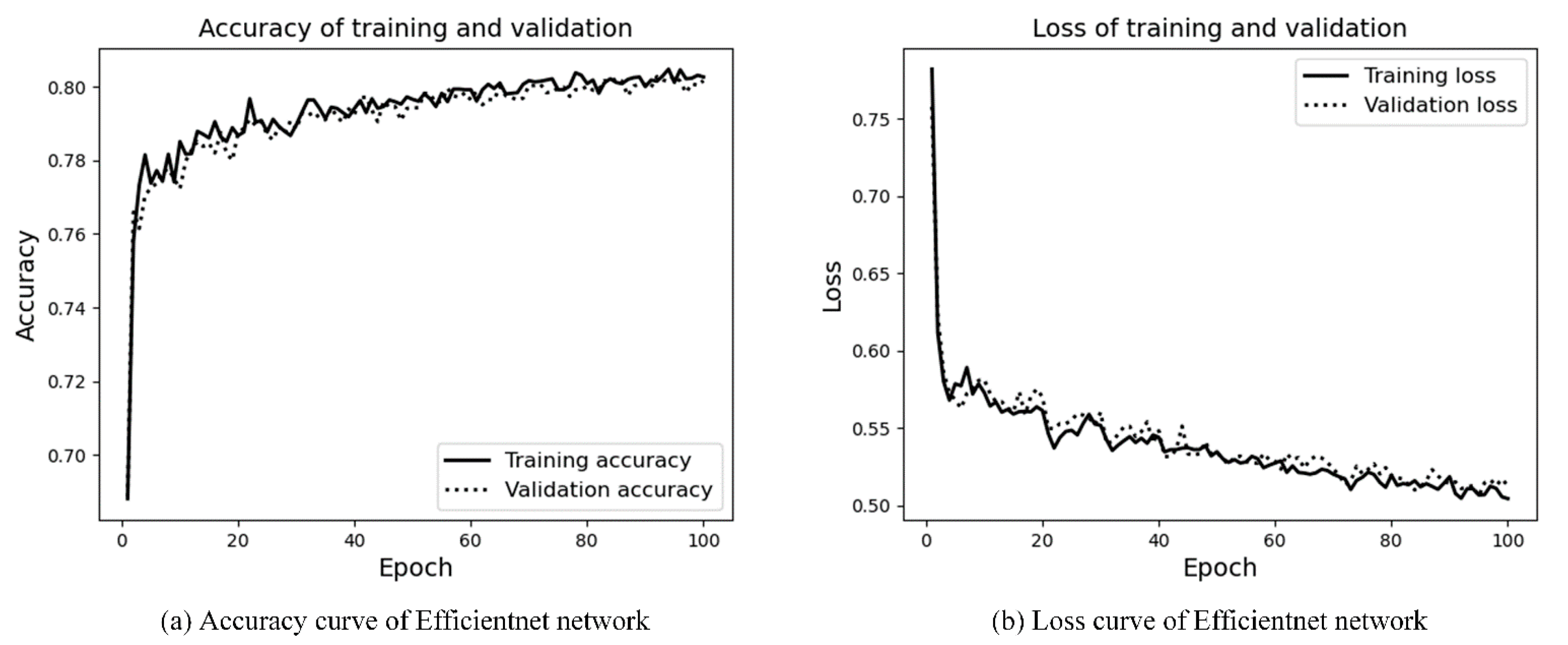
4.3.1. Feature Extraction
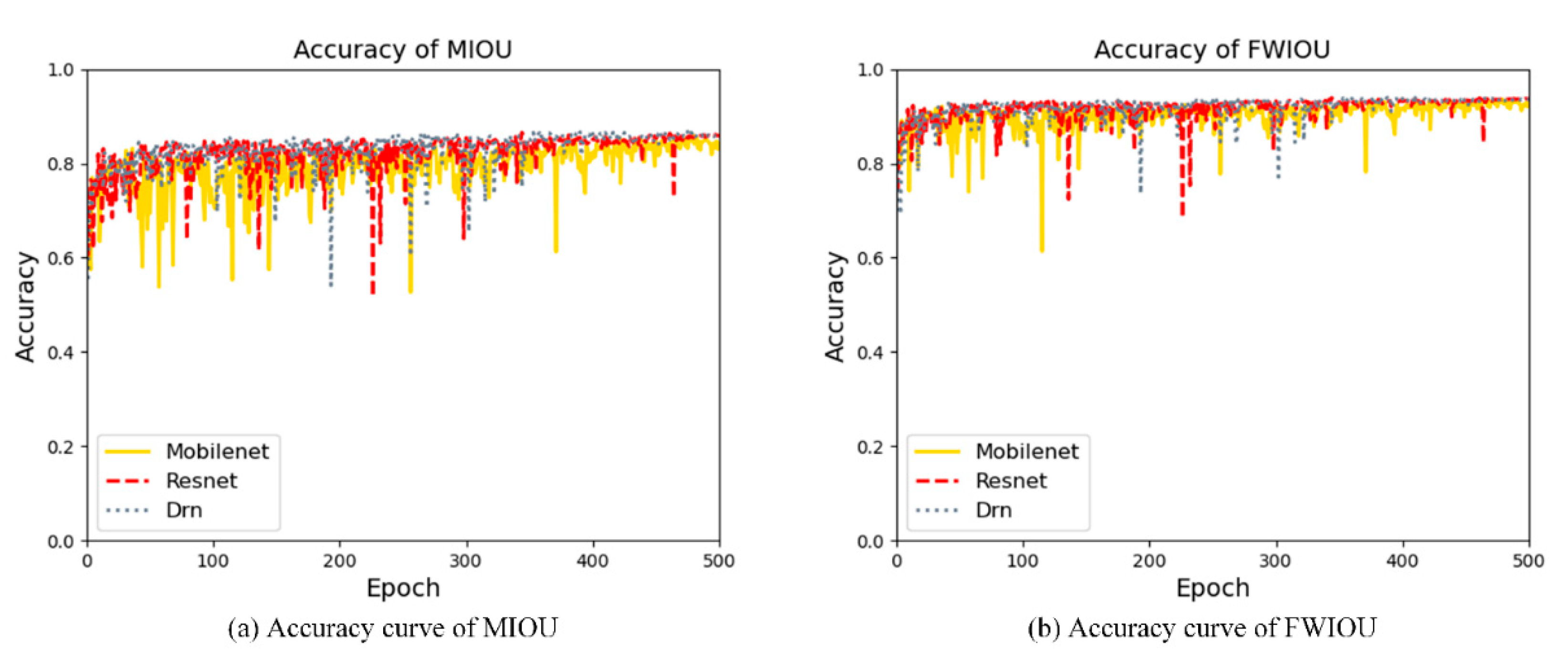
4.3.2. MIOU and FWIOU
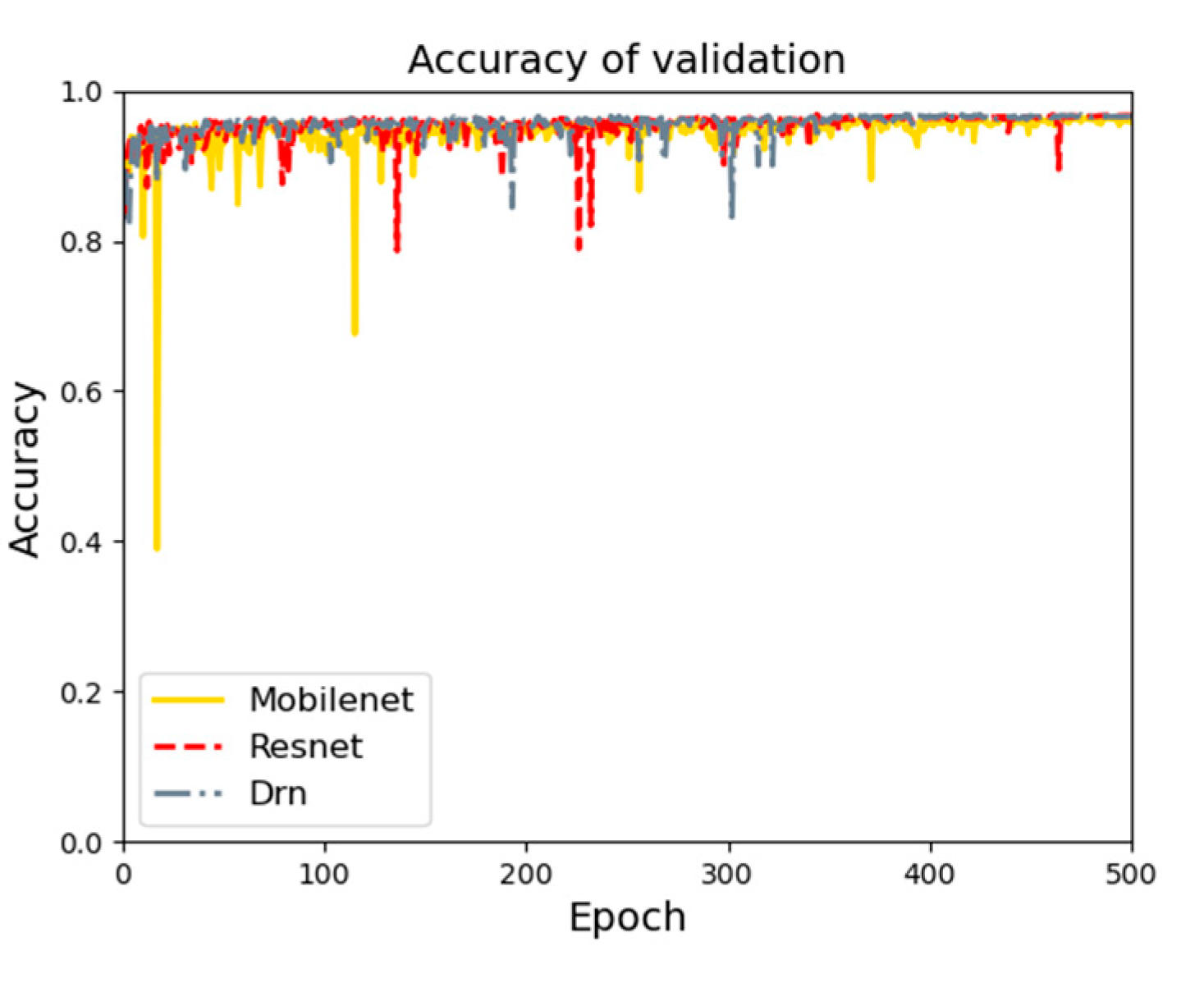
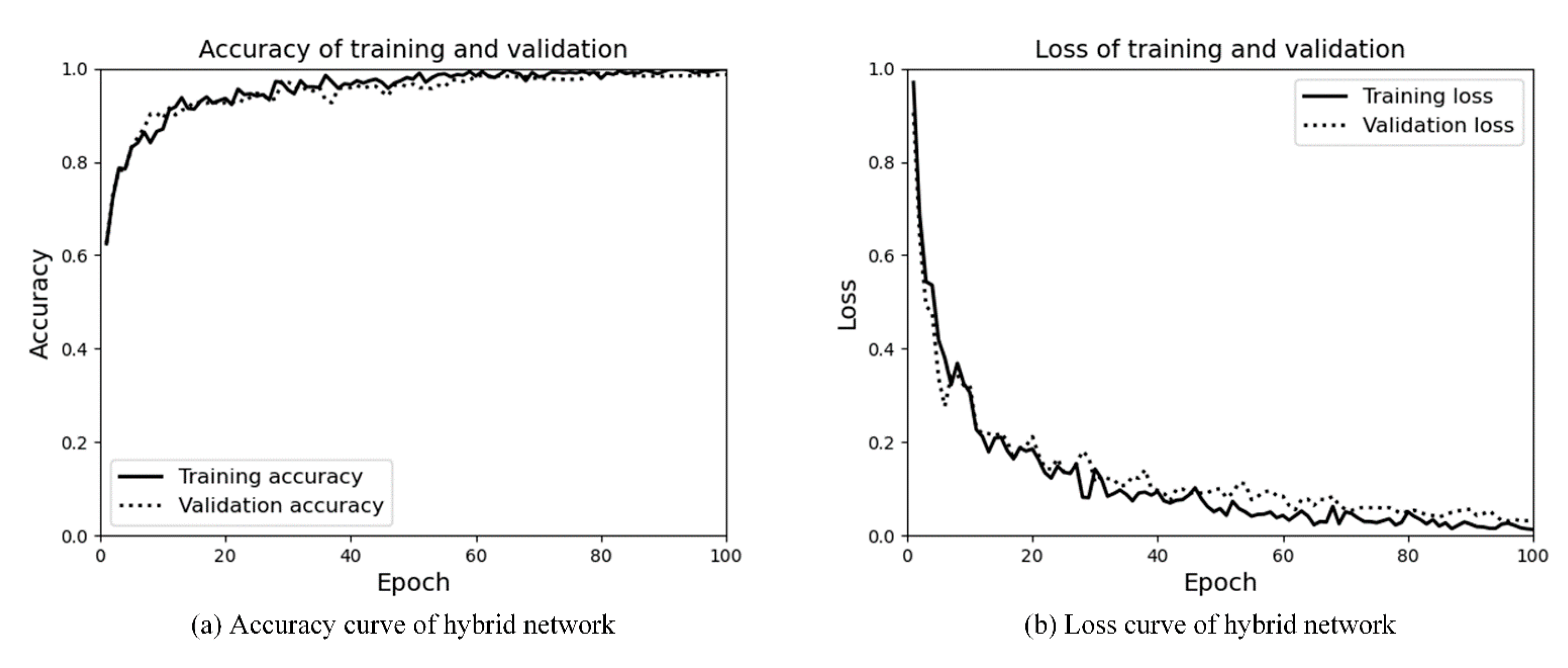
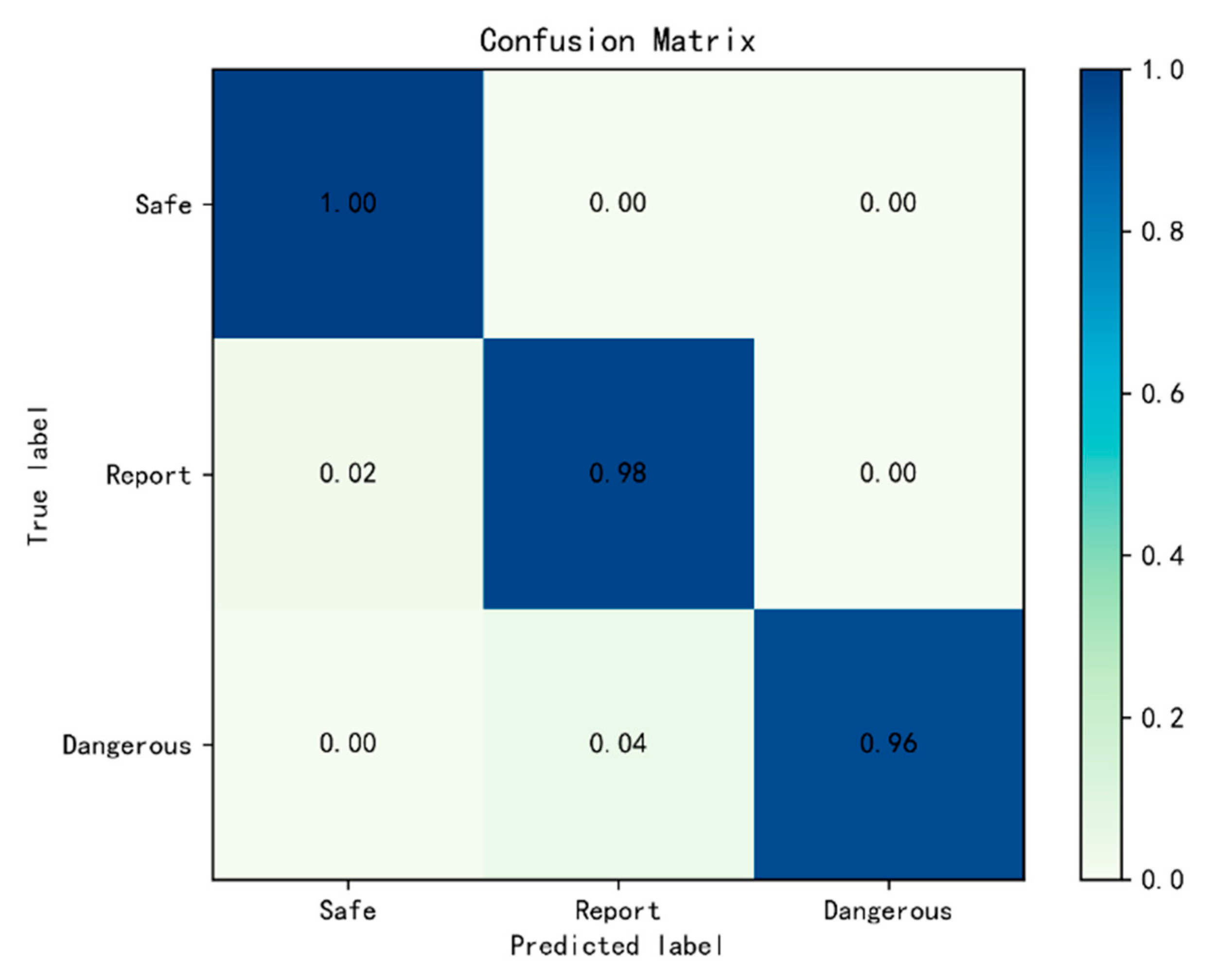
4.3.3. Hybrid Network for Scene Area Judgment
4.3.4. Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Fang, J.C.; Liu, G.; Wu, J. Solar flare TDOA navigation method using direct and reflected light for mars exploration. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 2469–2484. [Google Scholar] [CrossRef]
- Tseng, K.K.; Lin, J.; Chen, C.M.; Hassan, M.M. A fast instance segmentation with one-stage multi-task deep neural network for autonomous driving. Comput. Electr. Eng. 2021, 93, 107194. [Google Scholar] [CrossRef]
- Biesiadecki, J.J.; Leger, P.C.; Maimone, M.W. Tradeoffs between directed and autonomous driving on the Mars exploration rovers. Int. J. Robot. Res. 2007, 26, 91–104. [Google Scholar] [CrossRef]
- Simon, M.; Latorella, K.; Martin, J.; Cerro, J.; Lepsch, R.; Jefferies, S.; Goodliff, K.; Smitherman, D.; McCleskey, C.; Stromgre, C. NASA’s advanced exploration systems Mars transit habitat refinement point of departure design. In Proceedings of the 2017 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2017; pp. 1–34. [Google Scholar]
- Yang, B.; Ali, F.; Yin, P.; Yang, T.; Yu, Y.; Li, S.; Liu, X. Approaches for exploration of improving multi-slice mapping via forwarding intersection based on images of UAV oblique photogrammetry. Comput. Electr. Eng. 2021, 92, 107135. [Google Scholar] [CrossRef]
- Dorling, K.; Heinrichs, J.; Messier, G.G.; Magierowski, S. Vehicle routing problems for drone delivery. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 70–85. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Rui, T.; Zhang, S.; Fei, J.; Wang, X. A road segmentation method based on the deep auto-encoder with supervised learning. Comput. Electr. Eng. 2018, 68, 381–388. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, L.; Du, B. Kernel slow feature analysis for scene change detection. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2367–2384. [Google Scholar] [CrossRef]
- Simonyan, K.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1150–1210. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chen, H.; Wang, Y.; Xu, C.; Shi, B.; Xu, C.; Tian, Q.; Xu, C. AdderNet: Do we really need multiplications in deep learning? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1468–1477. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning; PMLR: Long Beach, CA, USA, 2019; pp. 6105–6114. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Li, J.; Li, K.; Yan, B. Scale-aware deep network with hole convolution for blind motion deblurring. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 658–663. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road extraction by using atrous spatial pyramid pooling integrated encoder-decoder network and structural similarity loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-loop matters: Dual regression networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5407–5416. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Michele, A.; Colin, V.; Santika, D.D. Mobilenet convolutional neural networks and support vector machines for palmprint recognition. Procedia Comput. Sci. 2019, 157, 110–117. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Wang, X.; Lu, A.; Liu, J.; Kang, Z.W.; Pan, C. Intelligent interaction model for battleship control based on the fusion of target intention and operator emotion. Comput. Electr. Eng. 2021, 92, 107196. [Google Scholar] [CrossRef]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart augmentation learning an optimal data augmentation strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Information | Rock | Quicksand | Background |
|---|---|---|---|
| Type | 2 | 1 | 0 |
| Dataset | Training Set | Validation Set | Total |
|---|---|---|---|
| Number | 480 | 130 | 610 |
| Data Augmentation | Training Set | Validation Set | Total |
|---|---|---|---|
| Number | 4800 | 1300 | 6100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, S.; Liu, J.; Kang, Z. DeepLabV3+/Efficientnet Hybrid Network-Based Scene Area Judgment for the Mars Unmanned Vehicle System. Sensors 2021, 21, 8136. https://doi.org/10.3390/s21238136
Hu S, Liu J, Kang Z. DeepLabV3+/Efficientnet Hybrid Network-Based Scene Area Judgment for the Mars Unmanned Vehicle System. Sensors. 2021; 21(23):8136. https://doi.org/10.3390/s21238136
Chicago/Turabian StyleHu, Shuang, Jin Liu, and Zhiwei Kang. 2021. "DeepLabV3+/Efficientnet Hybrid Network-Based Scene Area Judgment for the Mars Unmanned Vehicle System" Sensors 21, no. 23: 8136. https://doi.org/10.3390/s21238136
APA StyleHu, S., Liu, J., & Kang, Z. (2021). DeepLabV3+/Efficientnet Hybrid Network-Based Scene Area Judgment for the Mars Unmanned Vehicle System. Sensors, 21(23), 8136. https://doi.org/10.3390/s21238136