
Detection and Segmentation of Mature Green Tomatoes Based on Mask R-CNN with Automatic Image Acquisition Approach


Abstract
:1. Introduction
2. Data Acquisition
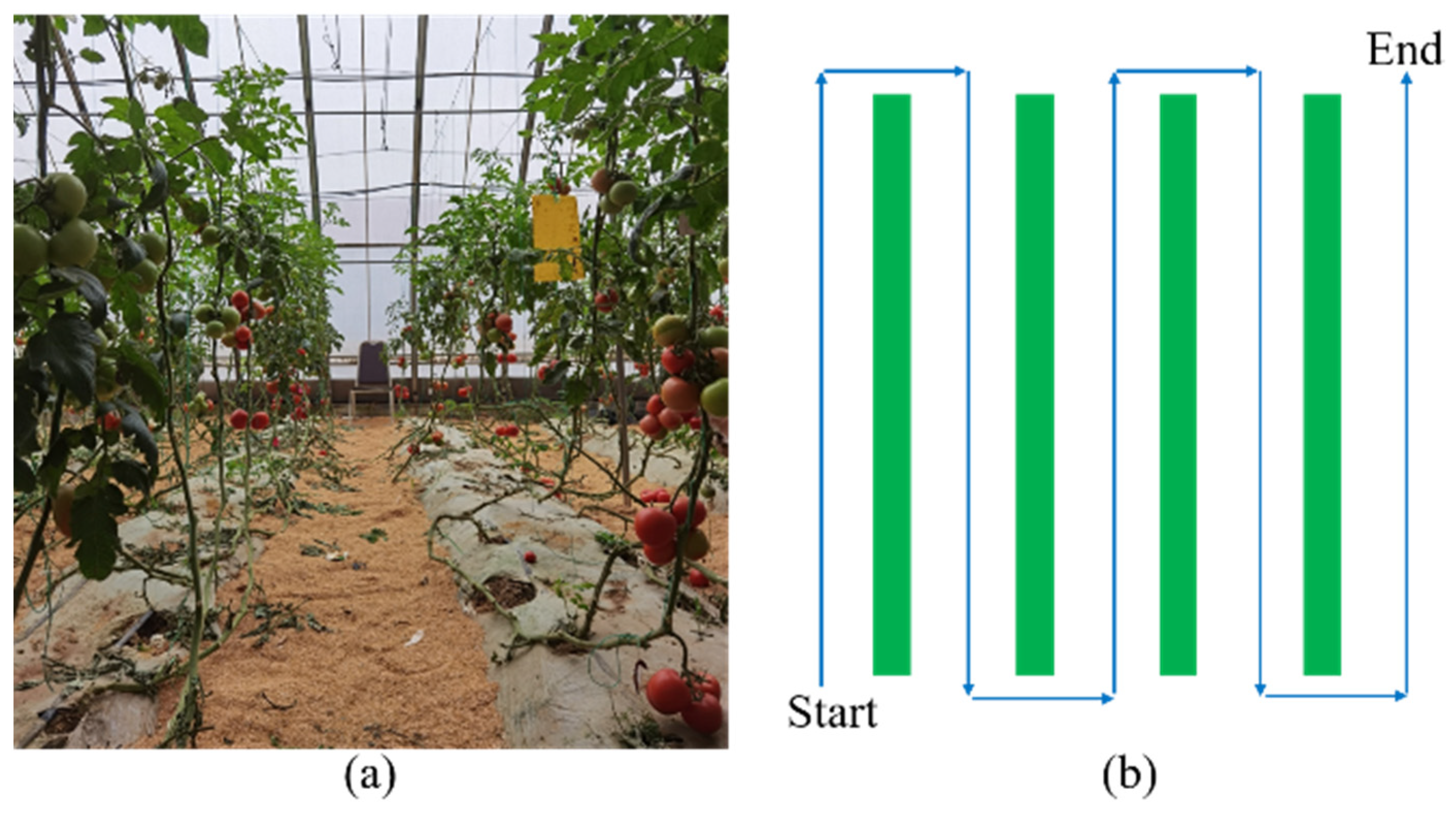
2.1. Design of the Greenhouse Mobile Robot
2.2. Mature Green Tomato Image Acquisition
3. Model Training and Loss Function
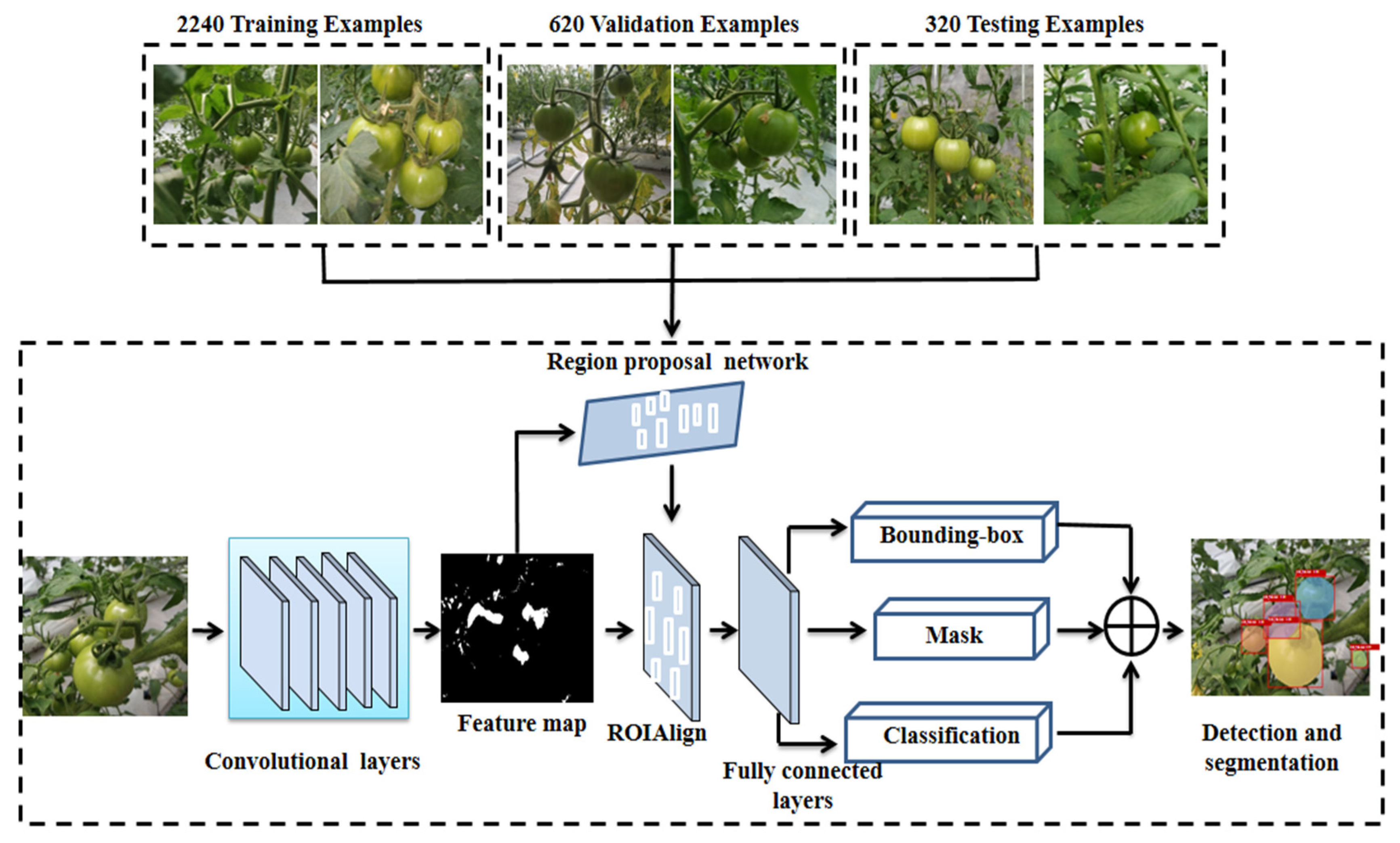
3.1. Image Labeling and Dataset Construction
3.2. Mature Green Tomato Detection and Segmentation Based on Mask R-CNN
3.2.1. Feature Extraction of Mature Green Tomato
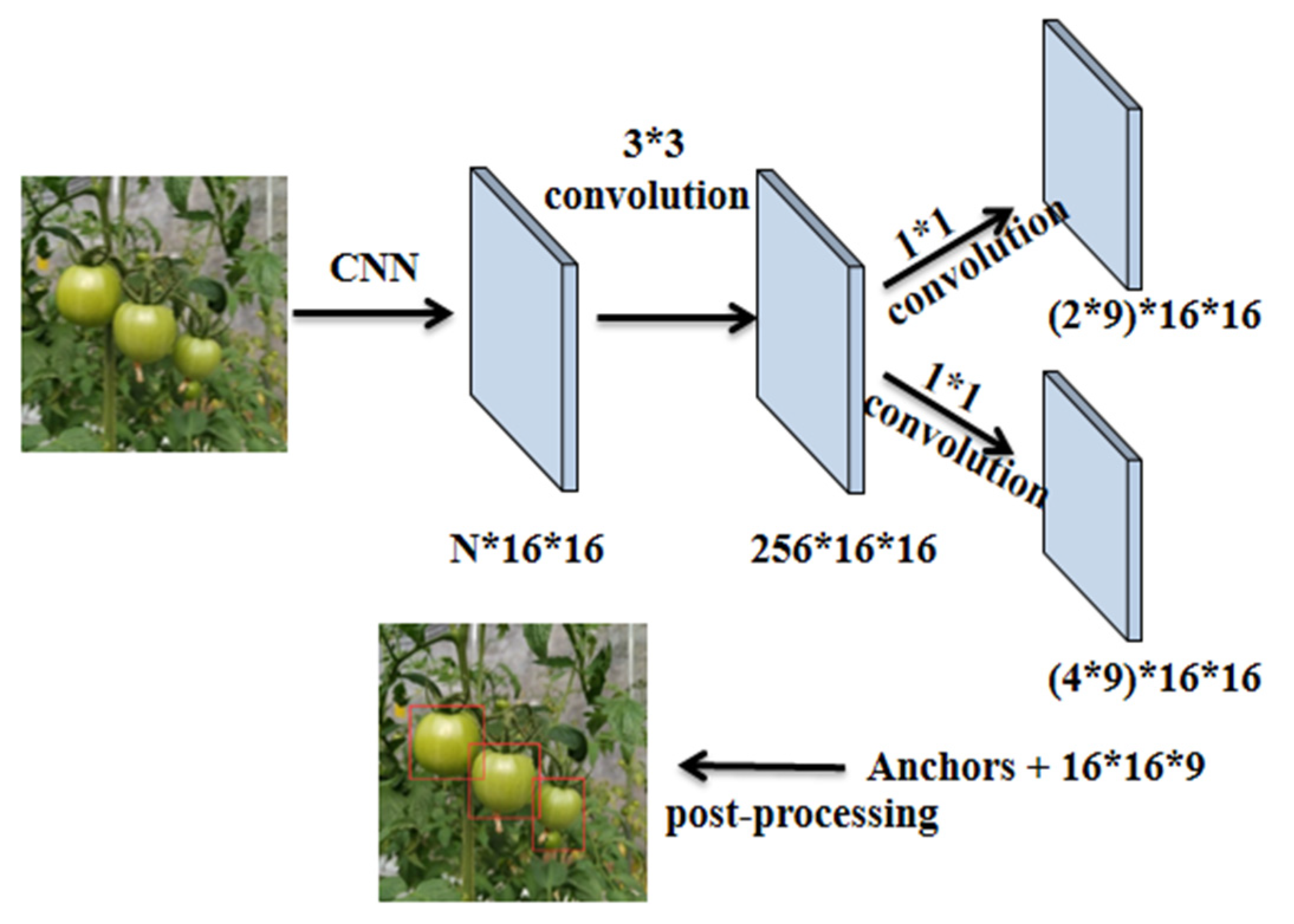
3.2.2. Region Proposal Network
3.2.3. ROIAlign Layer
3.2.4. Full Convolution Network Layer Segmentation
3.3. The Loss Function
3.4. Experiment Setup
4. Results
4.1. Model Performance Evaluation Indexes
4.2. Selection of Backbone Network
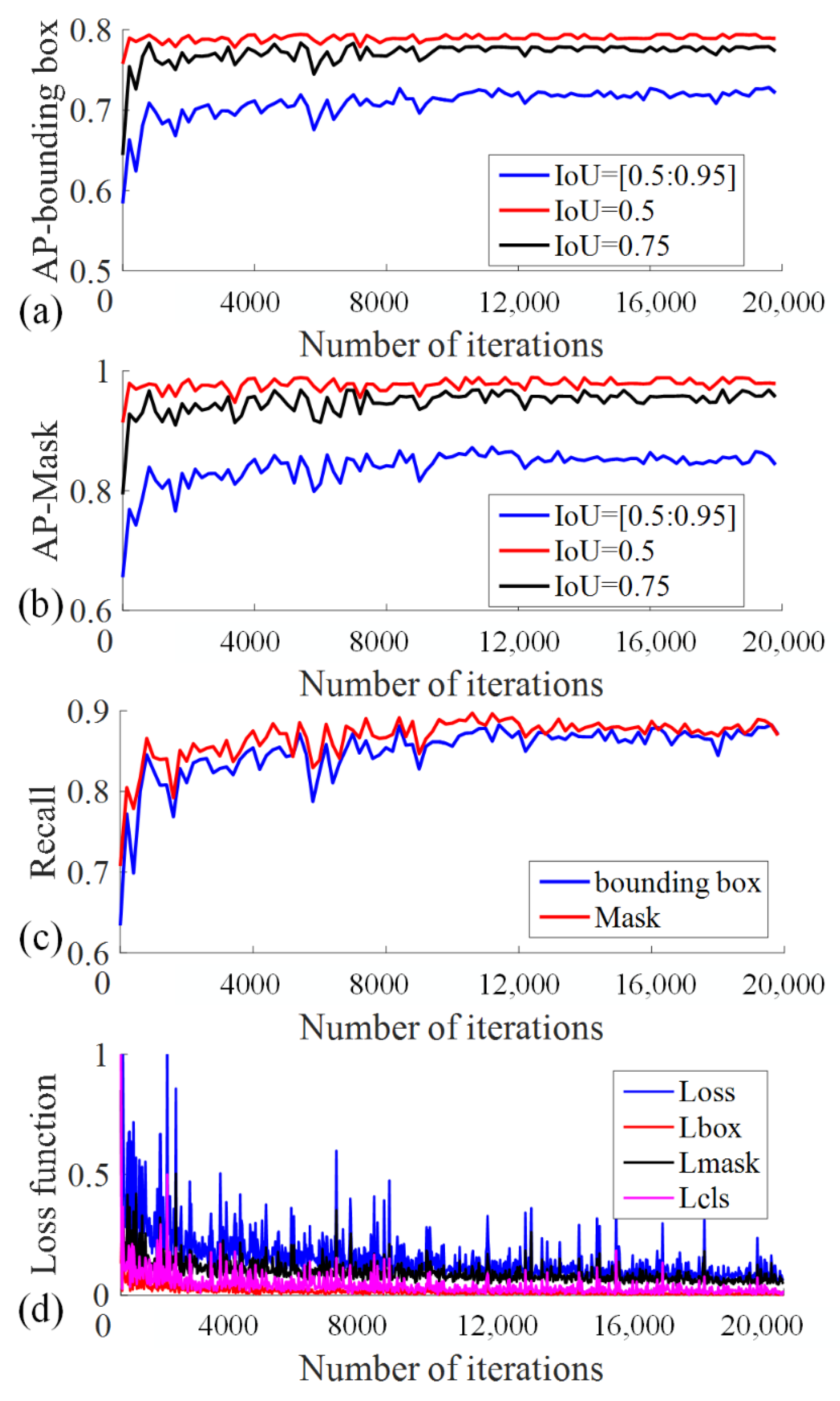
4.3. Model Performance on the Test Set
4.4. Model Performance in the Greenhouse Field Environment
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quinet, M.; Angosto, T.; Yuste-Lisbona, F.J.; Blanchard-Gros, R.; Bigot, S.; Martinez, J.P.; Lutts, S. Tomato Fruit Development and Metabolism. Front. Plant Sci. 2019, 10, 1554. [Google Scholar] [CrossRef] [Green Version]
- FAOSTAT. Available online: http://www.fao.org/faostat/en/#home (accessed on 12 September 2021).
- Oltman, A.E.; Jervis, S.M.; Drake, M.A. Consumer attitudes and preferences for fresh market tomatoes. J. Food Sci. 2014, 79, S2091–S2097. [Google Scholar] [CrossRef]
- Tiwari, G.; Slaughter, D.C.; Cantwell, M. Nondestructive maturity determination in green tomatoes using a handheld visible and near infrared instrument. Postharvest Biol. Technol. 2013, 86, 221–229. [Google Scholar] [CrossRef]
- Fatchurrahman, D.; Amodio, M.L.; de Chiara, M.L.V.; Chaudhry, M.M.A.; Colelli, G. Early discrimination of mature-and immature-green tomatoes (Solanum lycopersicum L.) using fluorescence imaging method. Postharvest Biol. Technol. 2020, 169, 111287. [Google Scholar] [CrossRef]
- Dhakal, R.; Baek, K.-H. Short period irradiation of single blue wavelength light extends the storage period of mature green tomatoes. Postharvest Biol. Technol. 2014, 90, 73–77. [Google Scholar] [CrossRef]
- Bapat, V.A.; Trivedi, P.K.; Ghosh, A.; Sane, V.A.; Ganapathi, T.R.; Nath, P. Ripening of fleshy fruit: Molecular insight and the role of ethylene. Biotechnol. Adv. 2010, 28, 94–107. [Google Scholar] [CrossRef]
- Arad, B.; Balendonck, J.; Barth, R.; Ben-Shahar, O.; Edan, Y.; Hellstrom, T.; Hemming, J.; Kurtser, P.; Ringdahl, O.; Tielen, T.; et al. Development of a sweet pepper harvesting robot. J. Field Robot. 2020, 37, 1027–1039. [Google Scholar] [CrossRef]
- Xiong, Y.; Ge, Y.Y.; Grimstad, L.; From, P.J. An autonomous strawberry-harvesting robot: Design, development, integration, and field evaluation. J. Field Robot. 2020, 37, 202–224. [Google Scholar] [CrossRef] [Green Version]
- Jia, W.K.; Zhang, Y.; Lian, J.; Zheng, Y.J.; Zhao, D.; Li, C.J. Apple harvesting robot under information technology: A review. Int. J. Adv. Robot. Syst. 2020, 17, 3. [Google Scholar] [CrossRef]
- Zhao, Y.S.; Gong, L.; Huang, Y.X.; Liu, C.L. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar] [CrossRef]
- Wan, P.; Toudeshki, A.; Tan, H.; Ehsani, R. A methodology for fresh tomato maturity detection using computer vision. Comput. Electron. Agric. 2018, 146, 43–50. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. Robust Tomato Recognition for Robotic Harvesting Using Feature Images Fusion. Sensors 2016, 16, 173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On plant detection of intact tomato fruits using image analysis and machine learning methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef] [Green Version]
- Dhakshina Kumar, S.; Esakkirajan, S.; Bama, S.; Keerthiveena, B. A microcontroller based machine vision approach for tomato grading and sorting using SVM classifier. Microprocess. Microsyst. 2020, 76, 103090. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Stein, M.; Bargoti, S.; Underwood, J. Image Based Mango Fruit Detection, Localisation and Yield Estimation Using Multiple View Geometry. Sensors 2016, 16, 1915. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Vilaplana, V.; Rosell-Polo, J.R.; Morros, J.-R. Ruiz-Hidalgo, J.; Gregorio, E. Multi-modal deep learning for Fuji apple detection using RGB-D cameras and their radiometric capabilities. Comput. Electron. Agric. 2019, 162, 689–698. [Google Scholar] [CrossRef]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of Key Organs in Tomato Based on Deep Migration Learning in a Complex Background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.-F.; Jia, R.-S.; Liu, Y.-B.; Zhao, C.-Y.; Sun, H.-M. Fast Method of Detecting Tomatoes in a Complex Scene for Picking Robots. IEEE Access 2020, 8, 55289–55299. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fruit detection, segmentation and 3D visualisation of environments in apple orchards. Comput. Electron. Agric. 2020, 171, 105302. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Kang, H.; Zhou, H.; Wang, X.; Chen, C. Real-Time Fruit Recognition and Grasping Estimation for Robotic Apple Harvesting. Sensors 2020, 20, 5670. [Google Scholar] [CrossRef]
- Huang, Y.-P.; Wang, T.-H.; Basanta, H. Using Fuzzy Mask R-CNN Model to Automatically Identify Tomato Ripeness. IEEE Access 2020, 8, 207672–207682. [Google Scholar] [CrossRef]
- Afonso, M.; Fonteijn, H.; Fiorentin, F.S.; Lensink, D.; Wehrens, R. Tomato Fruit Detection and Counting in Greenhouses Using Deep Learning. Front. Plant Sci. 2020, 11, 1759. [Google Scholar] [CrossRef]
- Tenorio, G.L.; Caarls, W. Automatic visual estimation of tomato cluster maturity in plant rows. Mach. Vis. Appl. 2021, 32, 78. [Google Scholar] [CrossRef]
- Benavides, M.; Cantón-Garbín, M.; Sánchez-Molina, J.A.; Rodríguez, F. Automatic tomato and peduncle location system based on computer vision for use in robotized harvesting. Appl. Sci. 2020, 10, 5887. [Google Scholar] [CrossRef]
- Pete, W. How Many Images Do You Need to Train A Neural Network. Available online: https://petewarden.com (accessed on 14 December 2017).
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Weinstein, B.G.; Marconi, S.; Bohlman, S.A.; Zare, A.; White, E.P. Individual Tree-Crown Detection in RGB Imagery Using Semi-Supervised Deep Learning Neural Networks. Remote Sens. 2019, 11, 1309. [Google Scholar] [CrossRef] [Green Version]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked autoencoders driven by semi-supervised learning for building extraction from near infrared remote sensing imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Kiran, B.R.; Thomas, D.M.; Parakkal, R. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone Network | FPS | F1-Scorebbox | F1-ScoreMask | Index |
|---|---|---|---|---|
| ResNet50 | 5.77 | 0.9336 | 0.9241 | 0.8531 |
| ResNet50-FPN | 26.10 | 0.9290 | 0.9284 | 0.9430 |
| ResNet101-FPN | 19.53 | 0.9265 | 0.9300 | 0.9135 |
| ResNeXt101-vd-FPN | 9.34 | 0.9302 | 0.9323 | 0.8710 |
| SENet154-vd-FPN | 3.49 | 0.9318 | 0.9345 | 0.8465 |
| Samples | Number of Mature Green Tomatoes by Manual | Number of Mature Green Tomatoes Identified by Mask R-CNN | Recognition Accuracy/% | ||||
|---|---|---|---|---|---|---|---|
| Unshaded/Lightly Shaded | Shaded More Than 50% | Total | Unshaded/Lightly Shaded | Shaded More Than 50% | Total | ||
| 1 | 6 | 1 | 7 | 6 | 1 | 7 | 100 |
| 2 | 3 | 0 | 3 | 3 | 0 | 3 | 100 |
| 3 | 7 | 2 | 9 | 7 | 1 | 8 | 88.9 |
| 4 | 7 | 1 | 8 | 7 | 1 | 8 | 100 |
| 5 | 9 | 3 | 12 | 9 | 2 | 11 | 91.7 |
| 6 | 4 | 0 | 4 | 4 | 0 | 4 | 100 |
| 7 | 5 | 1 | 6 | 5 | 0 | 5 | 83.3 |
| 8 | 3 | 0 | 3 | 3 | 0 | 3 | 100 |
| 9 | 8 | 2 | 10 | 8 | 1 | 9 | 90 |
| 10 | 6 | 2 | 8 | 6 | 2 | 8 | 100 |
| 11 | 10 | 3 | 13 | 9 | 3 | 12 | 92.3 |
| 12 | 9 | 2 | 11 | 9 | 1 | 10 | 90.9 |
| 13 | 7 | 1 | 8 | 6 | 1 | 7 | 87.5 |
| 14 | 6 | 0 | 6 | 6 | 0 | 6 | 100 |
| 15 | 11 | 3 | 14 | 10 | 2 | 12 | 92.9 |
| Total | 101 | 21 | 122 | 98 | 15 | 113 | 92.6 |
| Author | Method | Sensor | NO. Images | Reported Metrics |
|---|---|---|---|---|
| Huang et al., 2020 [31] | Mask R-CNN with ResNet-101-FPN | RGB camera | 900 images with data augmentation | Detection accuracy of cherry tomato is 98% |
| Afonso et al., 2020 [32] | Mask R-CNN with ResNext-101 | 4 RealSense cameras mounted on a pipe rail trolley | 123 images without data augmentation | F1-Score of red tomato is 0.93, and green tomato is 0.94 |
| Tenorio et al., 2021 [33] | MobileNetV1 CNN for detection & color space segmentation | RGB camera mounted on a pipe rail trolley | 254 images with data augmentation | Detection accuracy of cherry tomato cluster is 95.98% |
| Benavides et al., 2020 [34] | Sobel operator for detection, color-based segmentation and size-based segmentation | RGB camera located perpendicular to the soil surface | 175 images | Detection accuracy of beef tomato 90%, and cluster tomato is 79.7% |
| Proposed | Mask R-CNN with ResNet-50-FPN | RGB camera mounted on a mobile greenhouse robot | 3180 images without data augmentation | F1-Score of mask for green tomato is 0.9284 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zu, L.; Zhao, Y.; Liu, J.; Su, F.; Zhang, Y.; Liu, P. Detection and Segmentation of Mature Green Tomatoes Based on Mask R-CNN with Automatic Image Acquisition Approach. Sensors 2021, 21, 7842. https://doi.org/10.3390/s21237842
Zu L, Zhao Y, Liu J, Su F, Zhang Y, Liu P. Detection and Segmentation of Mature Green Tomatoes Based on Mask R-CNN with Automatic Image Acquisition Approach. Sensors. 2021; 21(23):7842. https://doi.org/10.3390/s21237842
Chicago/Turabian StyleZu, Linlu, Yanping Zhao, Jiuqin Liu, Fei Su, Yan Zhang, and Pingzeng Liu. 2021. "Detection and Segmentation of Mature Green Tomatoes Based on Mask R-CNN with Automatic Image Acquisition Approach" Sensors 21, no. 23: 7842. https://doi.org/10.3390/s21237842
APA StyleZu, L., Zhao, Y., Liu, J., Su, F., Zhang, Y., & Liu, P. (2021). Detection and Segmentation of Mature Green Tomatoes Based on Mask R-CNN with Automatic Image Acquisition Approach. Sensors, 21(23), 7842. https://doi.org/10.3390/s21237842