
Detection of Unilateral Arm Paresis after Stroke by Wearable Accelerometers and Machine Learning

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Aims
1.2. Related Work
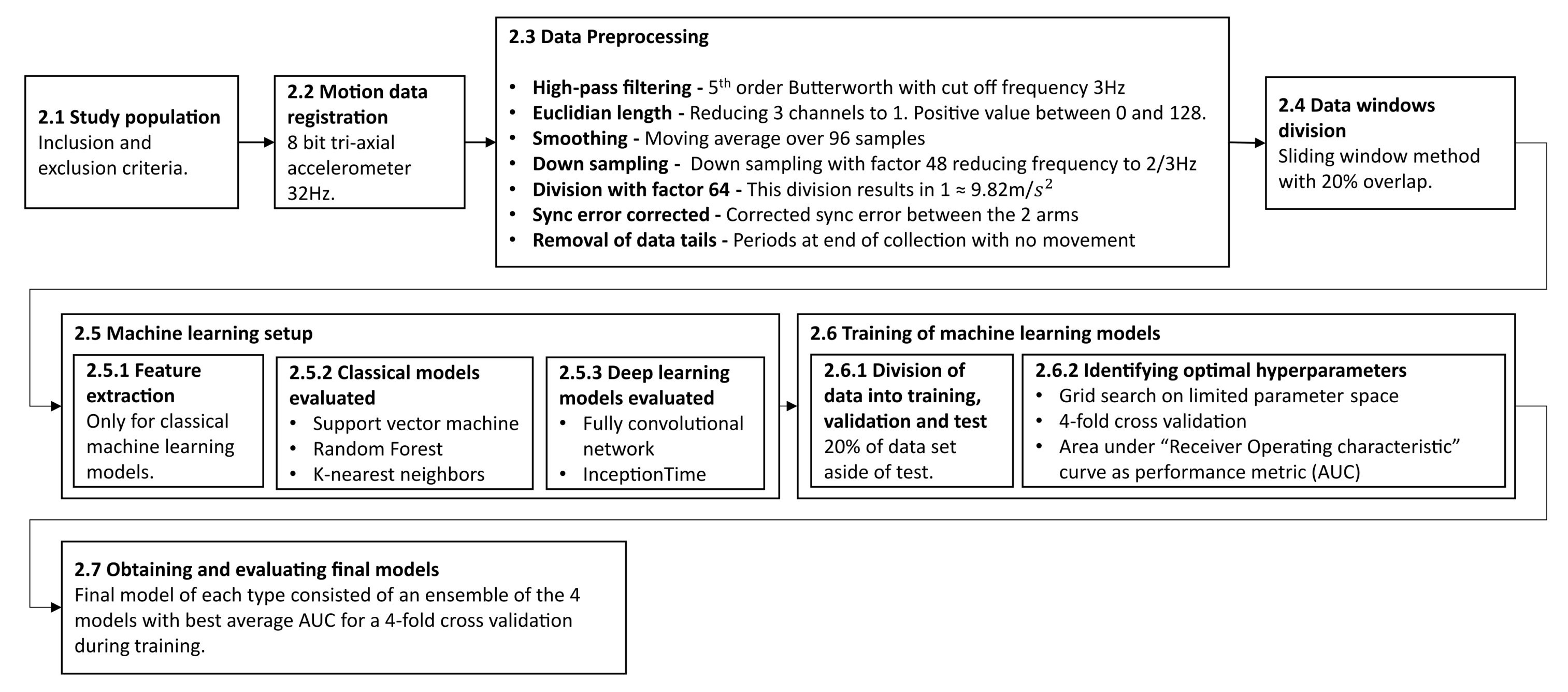
2. Materials and Methods
2.1. Study Population
- Recent stroke with unilateral arm motor deficit; AND
- No previous condition affecting the arm motor function of the unaffected arm.
- Age younger than 18; OR
- Inability to give informed consent; OR
- Unwillingness to participate.
- No previous condition affecting the arm motor function of either arm.
- Age younger than 18; OR
- Inability to give informed consent; OR
- Unwillingness to participate.
2.2. Motion Data Registration
2.3. Data Preprocessing
2.4. Dividing Data into Overlapping Windows Using a Sliding Window Approach
2.5. Machine Learning Training Setup
2.5.1. Features Used for Classical Machine Learning
- Mean of arm 1 and arm 2.
- Median of arm 1 and arm 2.
- Standard deviation of arm 1 and arm 2.
- Max value for arm 1 and arm 2.
- Difference in mean between arm 1 and arm 2.
- Difference in median between arm 1 and arm 2.
- Difference in standard deviation between arm 1 and arm 2.
- Difference in max value between arm 1 and arm 2
- Number of occurrences arm 1 is at least 0.01 larger than arm 2 divided by window length.
- Number of occurrences arm 2 is at least 0.01 larger than arm 1 divided by window length.
2.5.2. Classical Models Evaluated
2.5.3. Deep Learning Models Evaluated
2.6. Training of Machine Learning Models
2.6.1. Division of Data into Training, Validation, and Testing
2.6.2. Identifying Optimal Hyperparameters
2.6.3. Evaluating Model Performance
2.6.4. Obtaining and Evaluating the Final Models
3. Results
3.1. Study Population
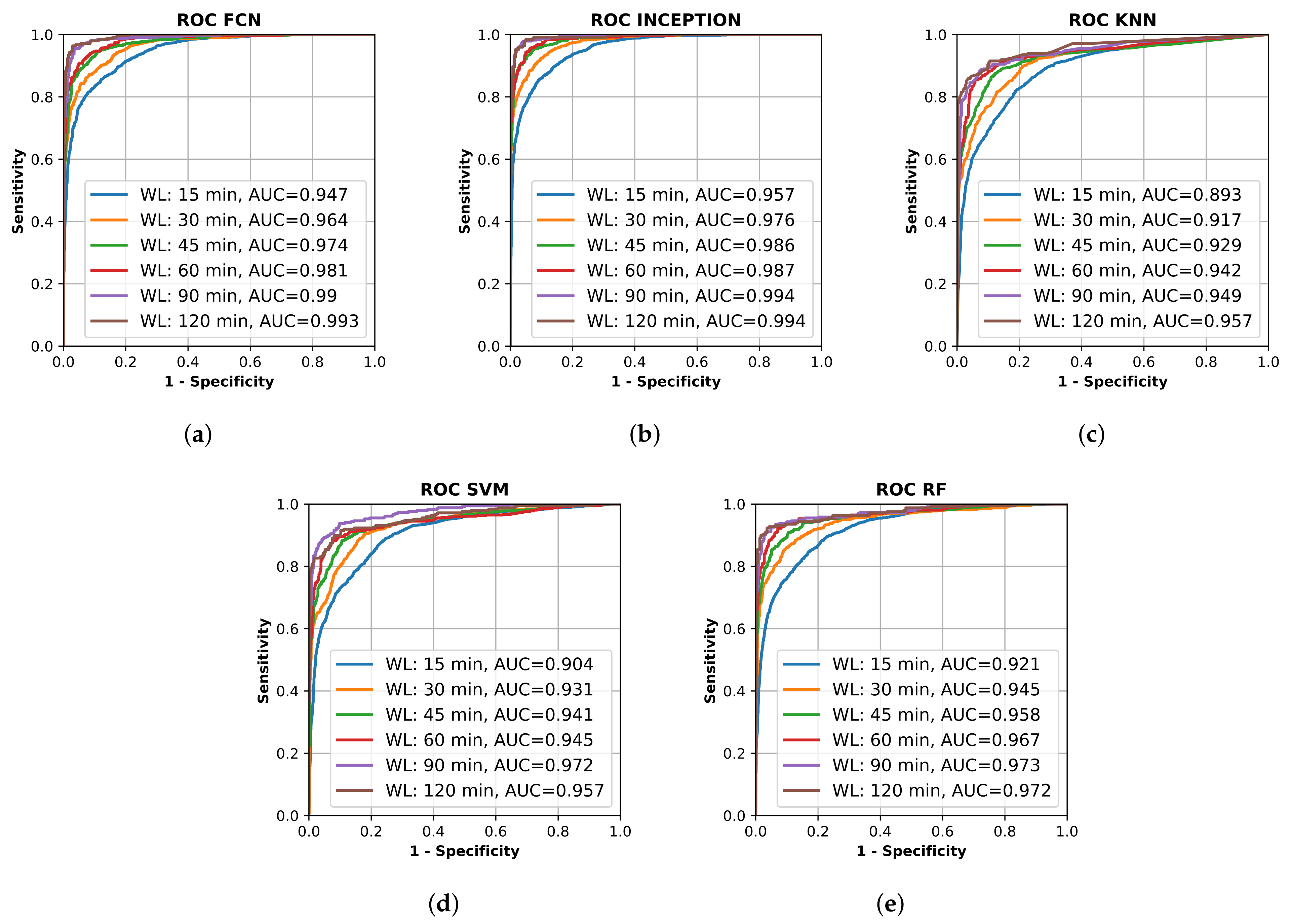
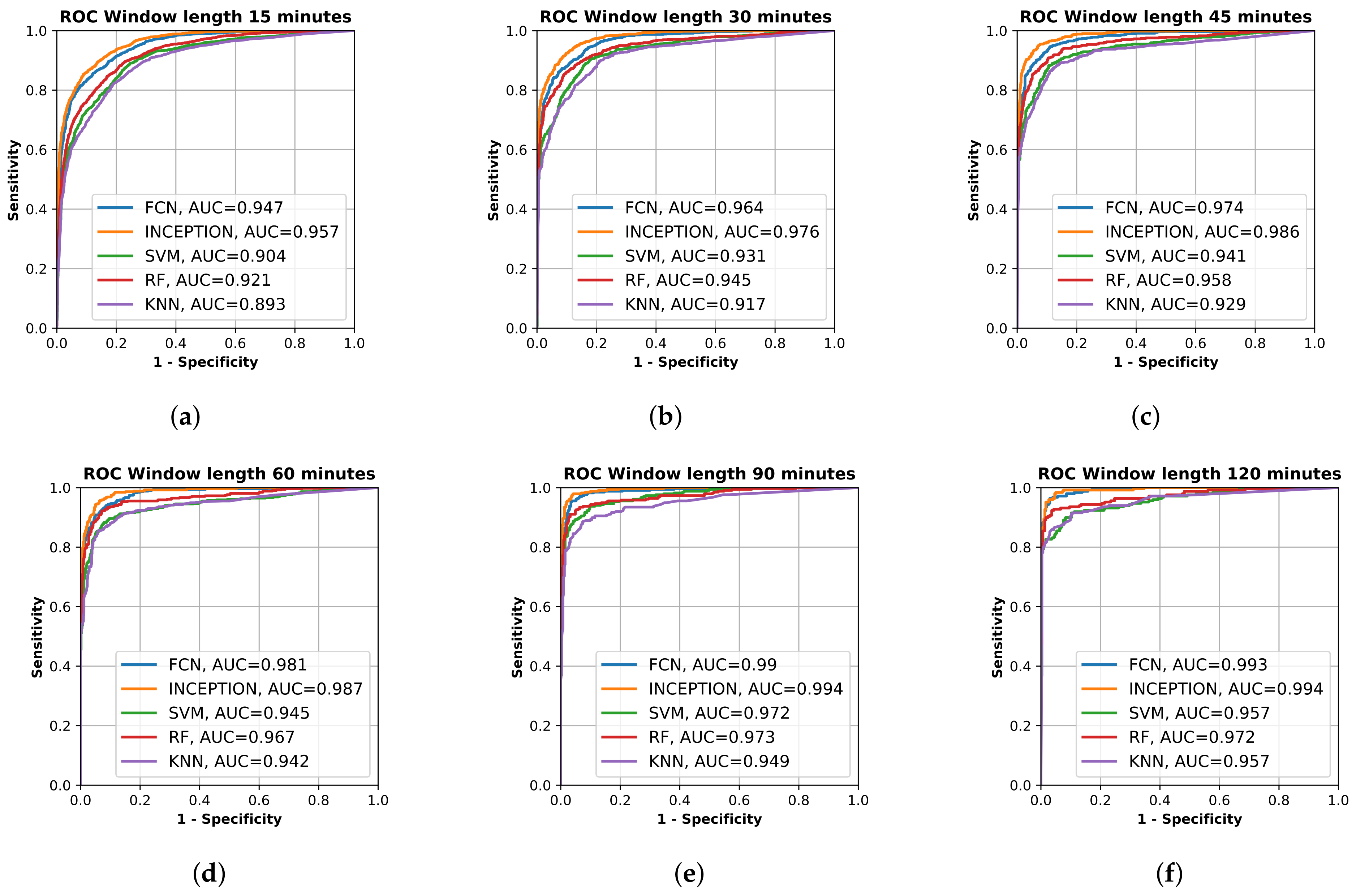
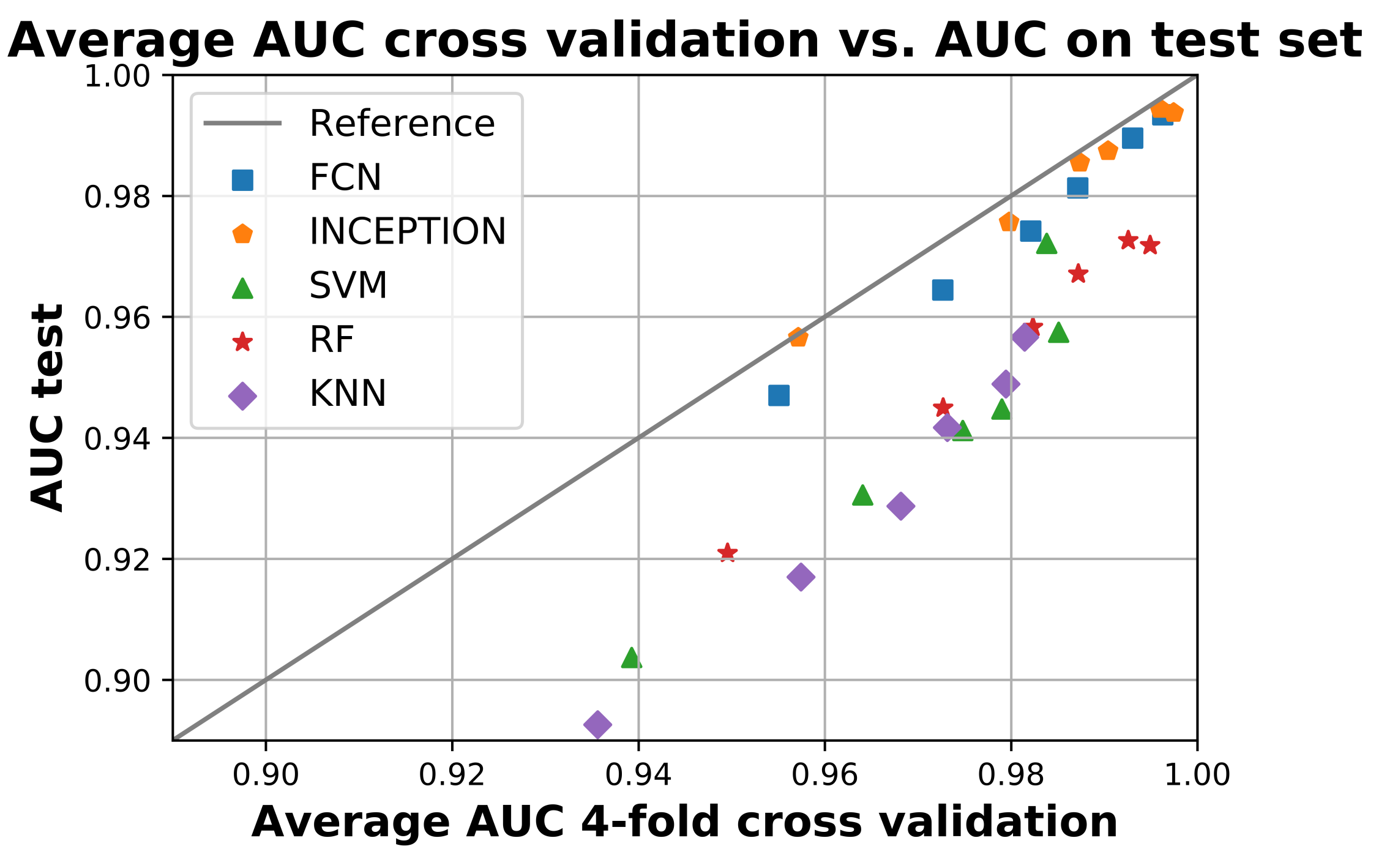
3.2. AUC Performance on Test Set
4. Discussion
4.1. Limitations
4.2. Analysis of Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ganesan, B.; Gowda, T.; Al-Jumaily, A.; Fong, K.; Meena, S.; Tong, R. Ambient assisted living technologies for older adults with cognitive and physical impairments: A review. Eur. Rev. Med Pharmacol. Sci. 2019, 23, 10470–10481. [Google Scholar] [CrossRef] [PubMed]
- Nakaoku, Y.; Ogata, S.; Murata, S.; Nishimori, M.; Ihara, M.; Iihara, K.; Takegami, M.; Nishimura, K. AI-Assisted In-House Power Monitoring for the Detection of Cognitive Impairment in Older Adults. Sensors 2021, 21, 6249. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Taylor, A.G.; Mielke, C.; Mongan, J. Automated detection of moderate and large pneumothorax on frontal chest X-rays using deep convolutional neural networks: A retrospective study. PLOS Med. 2018, 15. [Google Scholar] [CrossRef]
- Inui, T.; Kohno, H.; Kawasaki, Y.; Matsuura, K.; Ueda, H.; Tamura, Y.; Watanabe, M.; Inage, Y.; Yakita, Y.; Wakabayashi, Y.; et al. Use of a Smart Watch for Early Detection of Paroxysmal Atrial Fibrillation: Validation Study. JMIR Cardio 2020, 4, e14857. [Google Scholar] [CrossRef]
- Yang, T.Y.; Huang, L.; Malwade, S.; Hsu, C.Y.; Chen, Y.C. Diagnostic Accuracy of Ambulatory Devices in Detecting Atrial Fibrillation: Systematic Review and Meta-analysis. JMIR Mhealth Uhealth 2021, 9, e26167. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Zhang, H.; Liu, T.; Liang, Z.; Xia, Y.; Yan, L.; Xing, Y.; Shi, H.; Li, S.; et al. Mobile Photoplethysmographic Technology to Detect Atrial Fibrillation. J. Am. Coll. Cardiol. 2019, 74, 2365–2375. [Google Scholar] [CrossRef]
- Schrumpf, F.; Frenzel, P.; Aust, C.; Osterhoff, G.; Fuchs, M. Assessment of Non-Invasive Blood Pressure Prediction from PPG and rPPG Signals Using Deep Learning. Sensors 2021, 21, 6022. [Google Scholar] [CrossRef]
- Mouridsen, K.; Thurner, P.; Zaharchuk, G. Artificial Intelligence Applications in Stroke. Stroke 2020, 51, 2573–2579. [Google Scholar] [CrossRef]
- Soun, J.; Chow, D.; Nagamine, M.; Takhtawala, R.; Filippi, C.; Yu, W.; Chang, P. Artificial Intelligence and Acute Stroke Imaging. AJNR Am. J. Neuroradiol. 2020, 42, 2–11. [Google Scholar] [CrossRef]
- Bat-Erdene, B.O.; Saver, J.L. Automatic Acute Stroke Symptom Detection and Emergency Medical Systems Alerting by Mobile Health Technologies: A Review. J. Stroke Cerebrovasc. Dis. 2021, 30, 105826. [Google Scholar] [CrossRef]
- Herman, B.; Leyten, A.C.; van Luijk, J.H.; Frenken, C.W.; de Coul, A.A.O.; Schulte, B.P. Epidemiology of stroke in Tilburg, the Netherlands. The population-based stroke incidence register: 2. Incidence, initial clinical picture and medical care, and three-week case fatality. Stroke 1982, 13, 629–634. [Google Scholar] [CrossRef] [Green Version]
- Wade, D.T.; Wood, V.A.; Hewer, R.L. Recovery after stroke–the first 3 months. J. Neurol. Neurosurg. Psychiatry 1985, 48, 7–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bogousslavsky, J.; Melle, G.V.; Regli, F. The Lausanne Stroke Registry: Analysis of 1000 consecutive patients with first stroke. Stroke 1988, 19, 1083–1092. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kidwell, C.S.; Saver, J.L.; Schubert, G.B.; Eckstein, M.; Starkman, S. Design and retrospective analysis of the Los Angeles prehospital stroke screen (LAPSS). Prehospital Emerg. Care 1998, 2, 267–273. [Google Scholar] [CrossRef] [PubMed]
- Emberson, J.; Lees, K.R.; Lyden, P.; Blackwell, L.; Albers, G.; Bluhmki, E.; Brott, T.; Cohen, G.; Davis, S.; Donnan, G.; et al. Effect of treatment delay, age, and stroke severity on the effects of intravenous thrombolysis with alteplase for acute ischaemic stroke: A meta-analysis of individual patient data from randomised trials. Lancet 2014, 384, 1929–1935. [Google Scholar] [CrossRef] [Green Version]
- Goyal, M.; Menon, B.K.; van Zwam, W.H.; Dippel, D.W.J.; Mitchell, P.J.; Demchuk, A.M.; Dávalos, A.; Majoie, C.B.L.M.; van der Lugt, A.; de Miquel, M.A.; et al. Endovascular thrombectomy after large-vessel ischaemic stroke: A meta-analysis of individual patient data from five randomised trials. Lancet 2016, 387, 1723–1731. [Google Scholar] [CrossRef]
- Saver, J.L.; Goyal, M.; van der Lugt, A.; Menon, B.K.; Majoie, C.B.L.M.; Dippel, D.W.; Campbell, B.C.; Nogueira, R.G.; Demchuk, A.M.; Tomasello, A.; et al. Time to Treatment With Endovascular Thrombectomy and Outcomes From Ischemic Stroke: A Meta-analysis. JAMA 2016, 316, 1279. [Google Scholar] [CrossRef]
- Riksstroke—The Swedish Stroke Register. Quality of Swedish Stroke Care. 2019. Available online: riksstroke.org (accessed on 15 September 2021).
- Nogueira, R.G.; Jadhav, A.P.; Haussen, D.C.; Bonafe, A.; Budzik, R.F.; Bhuva, P.; Yavagal, D.R.; Ribo, M.; Cognard, C.; Hanel, R.A.; et al. Thrombectomy 6 to 24 Hours after Stroke with a Mismatch between Deficit and Infarct. N. Engl. J. Med. 2018, 378, 11–21. [Google Scholar] [CrossRef]
- Albers, G.W.; Marks, M.P.; Kemp, S.; Christensen, S.; Tsai, J.P.; Ortega-Gutierrez, S.; McTaggart, R.A.; Torbey, M.T.; Kim-Tenser, M.; Leslie-Mazwi, T.; et al. Thrombectomy for Stroke at 6 to 16 Hours with Selection by Perfusion Imaging. N. Engl. J. Med. 2018, 378, 708–718. [Google Scholar] [CrossRef] [PubMed]
- Uswatte, G.; Foo, W.L.; Olmstead, H.; Lopez, K.; Holand, A.; Simms, L.B. Ambulatory Monitoring of Arm Movement Using Accelerometry: An Objective Measure of Upper-Extremity Rehabilitation in Persons With Chronic Stroke. Arch. Phys. Med. Rehabil. 2005, 86, 1498–1501. [Google Scholar] [CrossRef]
- de Niet, M.; Bussmann, J.B.; Ribbers, G.M.; Stam, H.J. The Stroke Upper-Limb Activity Monitor: Its Sensitivity to Measure Hemiplegic Upper-Limb Activity During Daily Life. Arch. Phys. Med. Rehabil. 2007, 88, 1121–1126. [Google Scholar] [CrossRef]
- Shim, S.; Kim, H.; Jung, J. Comparison of Upper Extremity Motor Recovery of Stroke Patients with Actual Physical Activity in Their Daily Lives Measured with Accelerometers. J. Phys. Ther. Sci. 2014, 26, 1009–1011. [Google Scholar] [CrossRef] [Green Version]
- Johansson, D.; Malmgren, K.; Murphy, M.A. Wearable sensors for clinical applications in epilepsy, Parkinson’s disease, and stroke: A mixed-methods systematic review. J. Neurol. 2018, 265, 1740–1752. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Noorkõiv, M.; Rodgers, H.; Price, C.I. Accelerometer measurement of upper extremity movement after stroke: A systematic review of clinical studies. J. Neuroeng. Rehabil. 2014, 11, 144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Villar, J.R.; González, S.; Sedano, J.; Chira, C.; Trejo-Gabriel-Galan, J.M. Improving Human Activity Recognition and its Application in Early Stroke Diagnosis. Int. J. Neural Syst. 2015, 25, 1450036. [Google Scholar] [CrossRef]
- Bailey, R.R.; Klaesner, J.W.; Lang, C.E. An Accelerometry-Based Methodology for Assessment of Real-World Bilateral Upper Extremity Activity. PLoS ONE 2014, 9, e103135. [Google Scholar] [CrossRef] [PubMed]
- van der Pas, S.C.; Verbunt, J.A.; Breukelaar, D.E.; van Woerden, R.; Seelen, H.A. Assessment of Arm Activity Using Triaxial Accelerometry in Patients With a Stroke. Arch. Phys. Med. Rehabil. 2011, 92, 1437–1442. [Google Scholar] [CrossRef]
- Jeon, S.; Park, T.; Lee, Y.S.; Son, S.H.; Lee, H.; Eun, Y. RISK-Sleep: Real-Time Stroke Early Detection System During Sleep Using Wristbands. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 4333–4339. [Google Scholar] [CrossRef]
- Persson, E.; Lyckegård Finn, E. Investigating the Use of Machine Learning to Detect Unilateral Arm Weakness. Master’s Thesis, Lund University, Lund, Sweden, 2020; pp. 1404–6342. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: Hoboken, NJ, USA, 2021; Chapter 19; pp. 670–740. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer Science+Business Media LLC: New York, NY, USA, 2006; Chapter 7; pp. 325–359. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science+Business Media LLC: New York, NY, USA, 2017; Chapter 15.2; pp. 587–605. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar] [CrossRef] [Green Version]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive. 2015. Available online: www.cs.ucr.edu/eamonn/timeseriesdata/ (accessed on 14 September 2021).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. Inceptiontime: Finding alexnet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Fawcett, T. ROC graphs: Notes and practical considerations for researchers. Mach. Learn. 2004, 31, 1–38. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Pierot, L.; Jayaraman, M.V.; Szikora, I.; Hirsch, J.A.; Baxter, B.; Miyachi, S.; Mahadevan, J.; Chong, W.; Mitchell, P.J.; Coulthard, A.; et al. Standards of Practice in Acute Ischemic Stroke Intervention: International Recommendations. Am. J. Neuroradiol. 2018, 39, E112–E117. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Varible | Stroke Cases N = 84 | Controls N = 101 |
|---|---|---|
| Median age (range) | 76.5 (35–98) | 64 (22–92) |
| Female sex n (%) | 30 (35.7) | 53 (52.5) |
| Mean monitoring time, h (range) | 24.8 (3.8–53.2) | 25.5 (1.6–54.7) |
| Right side paresis n (%) | 38 (45.2) | - |
| Grade of arm paresis (NIHSS item 5) n (%) | ||
| No movement (4p) | 19 (22.6) | - |
| No effort against gravity (3p) | 36 (42.9) | - |
| Some effort against gravity (2p) | 21 (25.0) | - |
| Drift (1p) | 8 (9.5) | - |
| Pre-stroke mRS n (%) | ||
| 0 | 73 (86.9) | 101 (100) |
| 1 | 6 (7.1) | 0 |
| 2 | 4 (4.7) | 0 |
| Unknown | 1 (1.2) | 0 |
| Stroke subtype n (%) | ||
| Large artery occlusion | 34 (40.5) | - |
| Small artery occlusion | 37 (44.0) | - |
| Intracerebral hemorrhage | 12 (14.3) | - |
| Unknown | 1 (1.2) | - |
| Acute treatment n (%) | ||
| Intravenous thrombolysis (IVT) | 9 (10.7) | - |
| Thrombectomy +IVT | 12 (14.3) | - |
| No reperfusion treatment | 62 (73.8) | - |
| Unknown | 1 (1.2) | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wasselius, J.; Lyckegård Finn, E.; Persson, E.; Ericson, P.; Brogårdh, C.; Lindgren, A.G.; Ullberg, T.; Åström, K. Detection of Unilateral Arm Paresis after Stroke by Wearable Accelerometers and Machine Learning. Sensors 2021, 21, 7784. https://doi.org/10.3390/s21237784
Wasselius J, Lyckegård Finn E, Persson E, Ericson P, Brogårdh C, Lindgren AG, Ullberg T, Åström K. Detection of Unilateral Arm Paresis after Stroke by Wearable Accelerometers and Machine Learning. Sensors. 2021; 21(23):7784. https://doi.org/10.3390/s21237784
Chicago/Turabian StyleWasselius, Johan, Eric Lyckegård Finn, Emma Persson, Petter Ericson, Christina Brogårdh, Arne G. Lindgren, Teresa Ullberg, and Kalle Åström. 2021. "Detection of Unilateral Arm Paresis after Stroke by Wearable Accelerometers and Machine Learning" Sensors 21, no. 23: 7784. https://doi.org/10.3390/s21237784
APA StyleWasselius, J., Lyckegård Finn, E., Persson, E., Ericson, P., Brogårdh, C., Lindgren, A. G., Ullberg, T., & Åström, K. (2021). Detection of Unilateral Arm Paresis after Stroke by Wearable Accelerometers and Machine Learning. Sensors, 21(23), 7784. https://doi.org/10.3390/s21237784