1. Introduction
An expression system is a molecular biology technique that uses model organisms such as bacteria, yeast, animal cells or plant cells to express exogenous gene proteins. In short, the expression process is the synthesis of proteins under the guidance of genes. The
Pichia pastoris expression system is a technically mature eukaryotic expression system, and one of the most successful foreign protein expression systems [
1]. The expression system of
Pichia pastoris has been developed for more than 30 years, and so far, nearly 1000 heterologous proteins have been successfully expressed by this system, which has a promising development [
2]. In addition, the low cost but high yield of the
Pichia pastoris expression system makes it economically valuable.
Pichia pastoris is also a facultative anaerobe, which is very easy to carry out genetic manipulation and cultivation on [
3]. The
Pichia pastoris expression system has obvious advantages in the processing, external separation, post-translational modification, and glycosylation modification of expression products [
4]. Nowadays, many regions are being plagued by the Coronavirus (COVID-19). In order to fight COVID-19, the recombinant expression of proteinase K in
Pichia pastoris has attracted widespread attention [
5,
6]. Protease K has drawn attention for its following capabilities: cracking the COVID-19 virus to release nucleic acid, eliminating ribonuclease (RNase) to prevent ribonucleic acid (RNA) degradation, and inactivating the COVID-19 virus to denature the virus protein [
7]. Therefore, protease K becomes an important component of nucleic acid detection kit for sample pretreatment, and plays a significant role in COVID-19 detection [
8]. However, the fermentation process of recombinant expression of protease K by
Pichia pastoris is nonlinear, coupled, uncertain, and time-varying [
9]. There are few online detection instruments for the key biomass variables of the
Pichia pastoris fermentation process (such as cell concentration, protease K concentration, etc.) [
10] As for the offline assay and analysis methods, the long interval of data acquisition drags down the real-time performance, and adds to the risk of flora pollution. Moreover, the assay results are often inaccurate, due to the large errors of human operation [
11]. With the development of the times, biosensors that can detect biomass on-line in real time emerge as the times require. Biosensors have the advantages of high sensitivity and a fast analysis speed; however, a highly automated, miniaturized and integrated biosensor is often very expensive [
12].
The above problems give rise to the soft sensor technology. The basic idea of this technology is to model the relationship between target and auxiliary variables, and thus estimate the target variables indirectly, without causing any pollution to flora. The Soft sensor technology is powerful and cost-effective, and it can work in harmony with other software and hardware, which means that it is highly compatible [
13]. However, in most cases, it is difficult for a single global soft sensor model to adequately and quickly characterize the process of a complex object. Furthermore, a single global soft sensor model is usually complex in structure and requires a lot of time to solve it. Wang and Han [
14] proposed a single soft sensor model based on a recurrent wavelet neural network and Gaussian process regression methods for online prediction of whether Chlortetracycline fermentation broth is contaminated by non-target bacteria. Although the experimental results show that the proposed soft sensor model can be used to predict the occurrence of pollution during the Chlortetracycline fermentation process, and the effectiveness of the modeling method is verified based on field data, the Chlortetracycline fermentation process is a very complex and non-linear process, and most microbial fermentation processes including Chlortetracycline can be divided into four stages: adjustment, logarithmic growth, stabilization and decay phases. During these four phases, the process characteristics of Chlortetracycline are completely different, especially during the exponential growth phase, when the fermentation process is most intense. Therefore, it is impractical to try to describe the complete fermentation process by a single soft sensor model. Although the soft sensor model proposed in this paper showed good prediction results for the Chlortetracycline fermentation process, the model has limitations and cannot be extended to soft sensor modelling of other microbial fermentation processes, i.e., it is not generalizable.
Therefore, in order to address the drawbacks of a single soft sensor model, multi-model soft sensor modeling strategies have attracted a great deal of scholarly attention [
15,
16,
17]. Scholars have found that using the divide and conquer modeling strategy, building a multi-local soft sensor model can greatly simplify the model structure, save calculation time, and fully mine the information of each sample, hence multi-local soft sensor modeling methods are becoming an inevitable trend in the development of soft sensor technology in the future [
18]. As a result, it is highly practical to build a multi-local soft sensor model that supports the real-time online measurement of key biomass variables in
Pichia pastoris fermentation, as well as the efficient (protease K yield) and high-quality generation of products (protease K quality).
Following the above ideas, Zhang and Cai [
19] presented a multi-model soft sensor modeling method based on the improved locally weighted partial least squares (LWPLS), and adopted the soft sensor model to predict the key biomass variables in the fermentation process of alkaline protease. Their approach copes well with the multi-stage and large lag features of microbial fermentation, and realizes good prediction accuracy. However, it is difficult to identify the structural and local parameters of the extremely complex model, and it is time-consuming to complete the heavy calculations. Hence, their approach is not applicable to a wide range of fermentation processes.
In order to avoid the problems mentioned above, this paper will apply a multi-model modeling method called piecewise affine (PWA), which is also called piecewise linear (PWL). Based on the idea of multi-model “decomposition-synthesis”, the PWA/PWL multi-model divides the sample space of the system into a finite number of sub-intervals, and each sub-interval is described by a PWA/PWL local model, which transforms the problem of solving a complex nonlinear system into the problem of solving several linear systems [
20]. The advantages of the PWA multi-model are that the model structure is very simple; after all, the structure of linear systems is far less complex than that of nonlinear systems, and PWA multi-model is less time consuming than other multi-models because the time to solve a linear system is much less than that to solve a nonlinear system [
21,
22]. These advantages have made PWA systems a hot research topic in the field of modeling, and they are widely used in many engineering practices. Sun and Wu [
23] applied a PWA model to speed regulation in longitudinal dynamics of intelligent vehicles. Muhammad and Michael [
24] applied a PWA modeling method to optimal planning of thermal energy systems for microgrids. Sindareh-Esfahani [
25] identified a discrete-time PWA model of a wind turbine during Maximum Power Point Tracking region. Mattsson and Zachariah [
26] applied the PWA modeling method to the identification of discrete-time nonlinear dynamic models of cascade tanks. All these cases proved the effectiveness and feasibility of the PWA modeling method. Therefore, in this paper, a PWA modeling method was applied to soft sensor modeling of key variables in the fermentation process of
Pichia pastoris.
In order to improve the prediction accuracy of the PWA multi-model, two model parameters must be optimized, i.e., the number of local models and the parameters of each local model. Too many local models will lead to complex models with a large computational effort and huge dimensionality of local model parameters while too few local models will lead to too simple models with poor prediction performance. In recent years, the research on intelligent optimization algorithms and its applications in model parameter optimization has been very active and has achieved encouraging results [
27,
28,
29]. Inspired by the foraging behavior of birds, a PSO algorithm as an intelligent swarm optimization algorithm has been successfully applied to the optimization of model parameters [
30,
31,
32]. The PSO algorithm has no crossover and variational operations, relies on particle velocity to complete the search, and only the optimal particle passes the information to other particles in the iterative evolution, which makes the search speed very fast. The PSO algorithm requires fewer parameters to be adjusted and has a simple structure, which is an effective method to solve practical engineering problems. Many numerical examples show that PSO is better than Differential Evolution (DE), Genetic Algorithm (GA) and Ant Colony Algorithm (ACO) in terms of search efficiency and convergence speed of the global optimal solution [
33,
34,
35]. This is why this algorithm is used in this paper to optimize the number of local models and the parameters of each local model. However, the PSO algorithm also has some drawbacks, such as the lack of dynamic adjustment of the speed, which is easy to fall into local optimum and requires the selection of appropriate parameters for different problems to achieve the optimal results. Therefore, it is essential to improve the PSO algorithm before the PSO algorithm is used to optimize the number of local models and the parameters of each local model. The reason why the PSO algorithm easily falls into local optimum is that the particle velocity cannot be dynamically adjusted, so the particle velocity must be constrained. The most effective way to constrain the particle velocity is to introduce a compression factor into the particle velocity update formula [
36]. However, the traditional compression factor has a fixed form and poor self-adaptability, which makes it difficult to achieve the desired constraint effect [
37]. Therefore, this paper will study an improved compression factor (ICF) that can make the compression factor change dynamically as the number of PSO iterations increases [
38]. Hence, this study eventually uses this ICF-PSO algorithm to optimize the number of local models and the parameters of each local model. The selection of specific parameters and performance analysis of the ICF-PSO algorithm will be analyzed in detail in the following. The complete PWA modeling process requires not only the optimization of the parameters of the PWA multi-model, but also the determination of the order of the PWA multi-model and the determination of dividing surfaces where each sub-model plays a role, all of which will be explained in detail in the following. To verify the feasibility of the ICF-PSO-PWA multi-model, this study obtained real and accurate original sample data through real fermentation experiments. Supported by these sample data, this study demonstrated the feasibility of applying the PWA multi-model to the
Pichia pastoris fermentation process through MATLAB simulations, and compared the ICF-PSO-PWA multi-model with the weighted least squares support vector regression model optimized by standard PSO algorithm (PSO-WLSSVR). The simulation results showed that the ICF-PSO-PWA multi-model can effectively predict the key biological variables of the
Pichia pastoris fermentation process online, and it outperformed the PSO-WLSSVR model.
In summary, the purpose of this study can be summarized into two aspects. The primary study focus is to construct and solve a PWA soft sensor multi-model based on the fermentation process of Pichia pastoris, and to demonstrate the effectiveness of the PWA soft sensor multi-model through simulations. The secondary study focus is to propose a novel ICF-PSO optimization algorithm to optimize the PWA soft sensor multi-model, which not only serves the primary study focus but also is an innovative point of this paper.
The rest of the paper is structured as follows:
Section 2 consists of materials and methods, which explains PWA model basics, determination of the PWA multi-model order, proposed ICF-PSO algorithm, determination of dividing surfaces and experimental work.
Section 3 includes results and discussion. The paper is concluded in
Section 4.
2. Materials and Methods
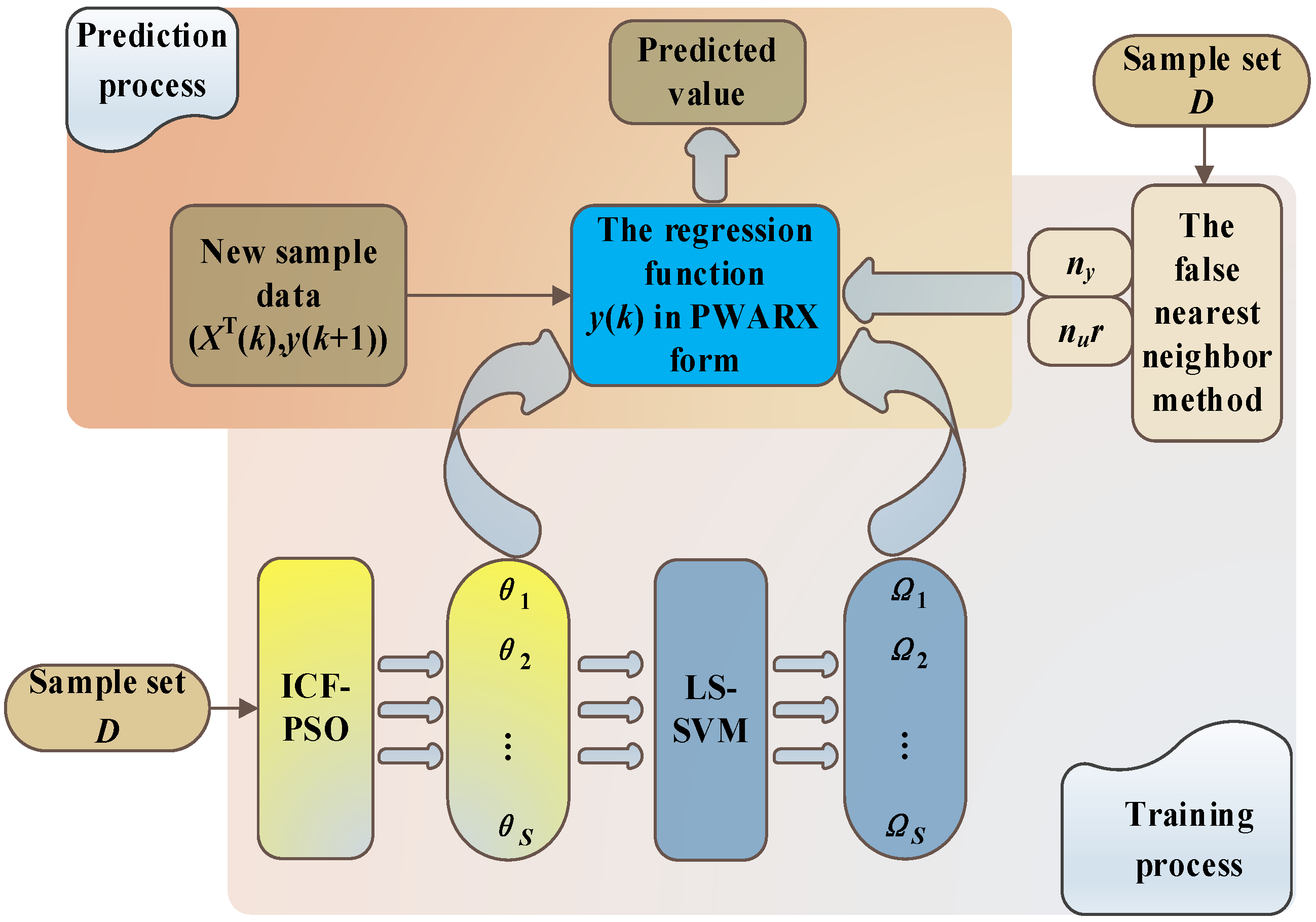
2.1. Structure Diagram of Overall Modeling Algorithm
In order to clarify the components of the prediction algorithm used in this study and their respective functions, this paper first constructs a diagram of the overall modeling algorithm structure here. The functions of each component are then explained in detail in the following sections of this paper. The overall modeling algorithm structure is shown in
Figure 1.
2.2. Description of PWA Modeling Algorithm
The existing sample data evidently testifies the nonlinearity of
Pichia pastoris fermentation. To facilitate the PWA modeling, the
Pichia pastoris fermentation (Multi-input Multi-output Nonlinear System) was decomposed into several multiple input single output (MISO) discrete time systems, each of which can be described as a piecewise auto-regressive exogenous (PWARX) model [
39]:
where,
is the system output;
is the error term.
The PWA mapping
can be defined as:
where,
X(
k)∈
Rn is the input vector, which consists of the output and input of the system in the past moment:
where,
k is a time series;
is the system output;
is the system input;
p is the system delay;
ny and
nu are the orders of the model (
n =
ny +
nu);
S is the number of models;
is the parameter vector of each linear local model of the PWA system.
The bounded input space
ΩN can be decomposed into
S closed polyhedral regions
. Assuming that these closed polyhedral regions have no overlapping parts except the common boundary:
where,
Ωi is a closed polyhedron:
, with
which determines the boundary of a closed polyhedron
Ωi, i.e., the dividing surface dividing
Ω i from other polyhedrons (
qi is the number of linear inequalities defining the
i-th polyhedron region), and
being an inequality:
Suppose the PWA model is unknown, and the modeling space consists of
N datasets on the fermentation process:
where,
ZN∈
R(n + 1)N. Then, the identification problem of the PWA aims to reconstruct the PWA mapping to characterize all the features of the original system, that is, to solve the following optimization problem:
where,
is the output predicted based on the input vector
X(
k) at time
k;
is the local PWA model of the current work space:
Then, Equation (2) can be represented as:
Therefore, the solution problem of MISO nonlinear system in each fermentation process can be transformed into a mixed integer quadratic programming (MIQP) problem [
40]:
where,
,
,
and
. It is not hard to see from the objective function
J1 that MIQP only identifies
θi. However, in order to identify
θi, several prerequisites are needed, namely, solving for the order
n of the input vector
X(
k) and determining the number of local models
S. The problem of identifying
n and
S is a problem of identifying two hyperparameters, and in this study the optimal
n and
S will be solved by different algorithms respectively. When
S and
n are known, the objective function
J1 becomes an easier-to-solve MIQP problem containing only one decision variable
θi. It is only necessary to find the optimal
θi by the corresponding optimization algorithm for
J1. After all the above parameters are determined, the range
Ωi in which the local model works can be easily determined by just the corresponding classification algorithm.
Without sufficient prior information, however, it is usually difficult to determine the number of models or the parameters of each local model. Therefore, this paper modifies the goal of optimization modeling from maximizing model accuracy by single optimization to maximizing the approximation degree of the model while minimizing the number of local models. That is, the single-objective Problem (6) was transformed into a multi-objective optimization problem:
where,
is an integer representing the number of local models;
is given by Equation (8), reflecting the approximation of the model. The value of
is negatively correlated with the approximation degree of the model. Thus, the goal of maximizing the approximation degree of the model is equivalent to minimizing the objective function
.
2.3. Determining Model Order
In the absence of sufficient prior information, it is a complex issue to determine the appropriate order of the PWA model. The topological delay embedding theorem [
41] suggests that a nonlinear system cannot be completely modeled if the final model has a too-small order; if the model order is too large, the modeling can be complete in theory, but the actual modeling will require heavy computations, and face lots of system noises and a large rounding error [
42].
The false nearest neighbor (FNN) method is suitable for determining the embedding dimension in the state space reconstruction of nonlinear time series. The core idea of this method is to iteratively determine the false and real neighboring points of a certain trajectory
xn, while increasing the embedding dimension in each iteration. The iterative process terminates when the number of false neighbors is zero, and outputs the minimum required embedding dimension. From the geometric perspective, the FNN is a very simple and easy approach to determine the embedding dimension [
43]. Hence, this paper adopts this method to calculate the order of the PWA multi-model.
Step 1. Determining the false nearest neighbor
Considering the input/output data on fermentation, construct the following
n-dimensional regression vector:
Rewrite the regression vector
X(n)(
k) as:
where,
.
Define the distance from
xi to
xj in
Rn by
norm:
Let
xp be the nearest point of
xη(p):
Then, N0 ≤ η(p) ≤ N, and η(p) is related to n, that is, η(p) is related to ny and nu.
As the embedding dimension changes from n to n + 1, the distance from xi to xj becomes:. If , namely, two non-adjacent points become two adjacent points when projected on the low trajectory, such adjacent points are the false neighbors.
Specifically,
xη(p) is considered as the false nearest neighbor of
xp if it satisfies:
where,
RT is a threshold value,
.
With the increase of dimension n, the ratio of false neighbors δ decreases, where δ is the ratio of false neighbors to total neighbors. When δ is less than a certain threshold δ0 or δ no longer changes with the change of n, then the geometric structure of the state space has been completely opened, and the dimension n at this time is the embedding dimension.
Step 2. Calculating the minimum embedding dimension
Firstly, define the variable
α(
p,
n):
Then, define the mean value of
α(
p,
n) with respect to
n as:
To capture the change of embedding dimension from
n to
n + 1, redefine:
The minimum embedding dimension of reconstructed state space can be judged according to the change of
E0(
n). If it is found that when the embedding dimension increases to a certain extent,
E0(
n) will no longer change or change to a very small extent, then
n + 1 is the required minimum embedding dimension. At this time, the corresponding
ny and
nu are the orders of the corresponding model [
44]. After using the false nearest neighbor method, the optimal order of the input vector (
nu) and output vector (
ny) of the PWA model are 1 and 2 respectively.
2.4. Collaborative Optimization of the Number and Parameters of the Models
In order to improve the prediction performance of PWA multi-models, the number of sub-models and the parameters of each sub-model must be optimized. The PSO is widely adopted for fuzzy system control, neural network training, and function optimization, because it is simple to define and easy to implement, with fast computing speed [
45]. Therefore, this paper applies the PSO to determine the number of models and to optimize the parameters of local models in the PWA multi-model, and introduces the ICF to improve the ability of the standard PSO to avoid the local optimum early and perform accurate local search thereafter.
2.4.1. PSO Algorithm
In the standard PSO algorithm, each particle in the swarm is of zero volume in the D-dimensional search space, and is represented by its current position. Each particle flies at a certain velocity in the search space, and keeps adjusting the velocity based on its experience and that of every other particle.
The current velocity and position of the
i-th particle can be defined as:
Then, the individual best-known position of the
i-th particle and the global best-known position of the swarm can be respectively expressed as:
For the generation
t + 1, the velocity and position of the
i-th particle in the
j-th dimension (1 ≤
j ≤
D) can be updated by:
where,
w is inertia weight;
c1 and
c2 are acceleration coefficients, both of which are constants;
r1,i and
r2,i are two random functions that change in the range of [0, 1].
In the position update Equation (21) of the standard PSO, if , which means that the current position of particle i is the best position it has experienced and also the best position the whole particle population has experienced so far, then the change of only depends on . This implies that when the swarm approaches a local optimal solution, its velocity will approach zero. This means that all particles tend to stop moving near the local optimal solution. Thus, the standard PSO would converge prematurely, and get stuck in the local optimal position. However, there are many local optimal solutions for non-convex problems, and the standard PSO will converge to a local optimum very easily. For these reasons, PSO must be improved.
2.4.2. ICF-PSO Algorithm
To overcome premature convergence, this paper improves the PSO into the ICF-PSO. The position update formula was not changed, while the velocity update formula was refined by introducing the ICF
μ:
where,
is the compression factor, which both restrains the velocity of particles and enhances the local search ability of the algorithm. Note that
δ and
σ are constants in
μ, both of which are key to the control of the constraint effect of the compression factor;
N is the total number of iterations;
G is the current number of iterations. The rationale for the improved compression factor is as follows. In this paper, the characteristic curve of
μ is made to be a monotonically decreasing curve in the first quadrant as the number of current iterations G increases by determining the appropriate values of
δ,
σ and
N. This curve must contain the following characteristics, that is, the value of
μ must vary between 1 and 0; the value of
μ must decrease rapidly at the beginning of the iteration, and then the rate of decrease of the value of
μ tends to smooth out as the iteration proceeds to the middle and later stages. The compression factor satisfying the above conditions is substituted into the velocity update formula of the standard PSO algorithm, which makes the particle velocity decrease continuously during the iteration process under the constraint of the compression factor. The particle velocity satisfies the following characteristics during the decreasing process, the particle can maintain a fast velocity at the beginning of the iteration, which can make the particle jump out of the local optimum effectively with the fastest speed, but the rate of particle velocity decreasing is fast during this time. As the iteration proceeds to the middle and later stages, the particle velocity becomes small and the particle velocity decreases very little and smoothly at this time. This kind of particle is able to search the global optimum precisely and smoothly, just like the carpet search of radar. The above is the rationale for the improved compression factor
μ. This paper will describe in detail how to determine reasonable values of
δ,
σ and
N, in the following subsections.
2.4.3. Determination of Parameter Values in ICF
This paper tries to maximize the efficiency and optimization effect of the compression factor by determining the value range of δ and σ. Firstly, the total number of iterations N was assumed to be 300. Secondly, both δ and σ must be positive numbers, according to mathematical knowledge (otherwise, μ will be meaningless). Finally, the value of the compression factor should decrease with the increase of G, judging by its functional features. Therefore, the value range of δ and σ could only be one of the two cases: (1) and ; (2) and . The variation curves of μ in these two cases are discussed in detail below:
- (1)
and
Figure 2a shows the curve of
μ with the increase of
σ at
δ = 0.5, and
Figure 2b shows the curve of
μ with the increase of
δ at
σ = π. It can be seen that when the value of
δ was constant, the constraint performance of ICF
μ was better at a larger
σ value; when the value of
σ was fixed, the smaller the value of
δ was, the better the constraint performance was. The values of
σ and
δ should be considered comprehensively to optimize the constraint performance of the ICF
μ. Experimental results show that, in case (1), the constraint performance of
μ is the best at
δ = 0.1 and
σ = 2π (
Figure 2c).
- (2)
and
Figure 2d shows the curve of
μ with the increase of
σ at
δ = 2π, and
Figure 2e shows the curve of
μ with the increase of
δ at
σ = 0.5. It can be seen that when the value of
δ was unchanged, the constraint performance of ICF
μ was better at a smaller
σ value; when the value of
σ was fixed, the larger the value of
δ was, the better the constraint performance was. The values of
σ and
δ should be considered comprehensively to optimize the constraint performance of the ICF
μ. Experimental results show that, in case (2), the constraint performance of
μ is the best at
δ = 24 and
σ = 0.01 (
Figure 2f).
To sum up, the compression factor μ has an optimal state in either case, depending on the values of δ and σ. Here, the δ and σ values in compression factor μ are set to 24 and 0.01, respectively.
In fact, the concept of compression factor
φ was put forward by Clerc et al. in as early as 1999 [
46]:
where,
ρ > 4 and
φ is the compression factor;
c1 and
c2 are acceleration constants. The problem is that the compression factor is too rigid [
47]. The value of
φ only depends on the size of
c1 and
c2, failing to consider the iterative effect. With the elapse of time, such a compression factor is no longer suitable for optimizing complex nonlinear systems. Compared with the original compression factor
φ, the improved compression factor
μ proposed by the authors can change iteratively, and adapt its constraint effect to the specific optimization task, in the light of the combined effect of factors like
δ,
σ,
N and
G.
The details of the performance analysis of the ICF-PSO algorithm are shown in the
Appendix A.
2.4.4. ICF-PSO Algorithm Applied to Optimize the Number and Parameters of PWA Local Models
The multi-objective optimization Problem (9) cannot be easily solved by the traditional phased strategy, because of the strong coupling between the two objective functions. Drawing on the idea of non-inferior optimal solution, this paper chooses to optimize objective function J1 by the step-by-step iterative method, in view of the fact that J1 depends heavily on J2 but J2 is independent of J1: First, select the non-optimal solution S that satisfies J2 and determine an optimal search threshold Yts for J1. Then, S is substituted into J1, and J1 is optimized to obtain the optimal solution of the corresponding local model parameter; if the optimized J1 cannot meet the preset threshold Yts, optimize S and re-optimize J1. Repeat these steps until the threshold Yts is satisfied.
To optimize objective function
J2, it is critical to reasonably divide the input space
ΩN into
S subspaces that satisfy conditional Equation (25), so as to determine the number of local models:
where,
Mi is the number of input vectors contained in the
i-th subspace;
is the
i-th input subspace.
After the input space dividing
Ωi is obtained, the corresponding sample dataset can be determined by:
where,
;
Zi is the sample dataset corresponding to
Ωi, which uniquely determines the modeling space of
f (
X(
k)).
When the system model is unknown, y(k)∈R can be replaced by the actually observed output. The difficulty of J2 is that the division of input space cannot be separated from the parameter identification of the local model. The strong coupling between the two objective functions makes it necessary to determine the number of models and estimate the model parameters simultaneously. Therefore, this paper employs the ICF-PSO algorithm, which excels in parallel search and data clustering to optimize the number of models and parameters.
During the optimization, the modeling parameters reflecting each local model are combined with the corresponding cluster center into a particle:
where,
is the cluster center of the
i-th cluster.
By the ICF-PSO algorithm, the study optimized the number of local models and the parameters of each local model at the same time [
48]. The detailed steps are as follows:
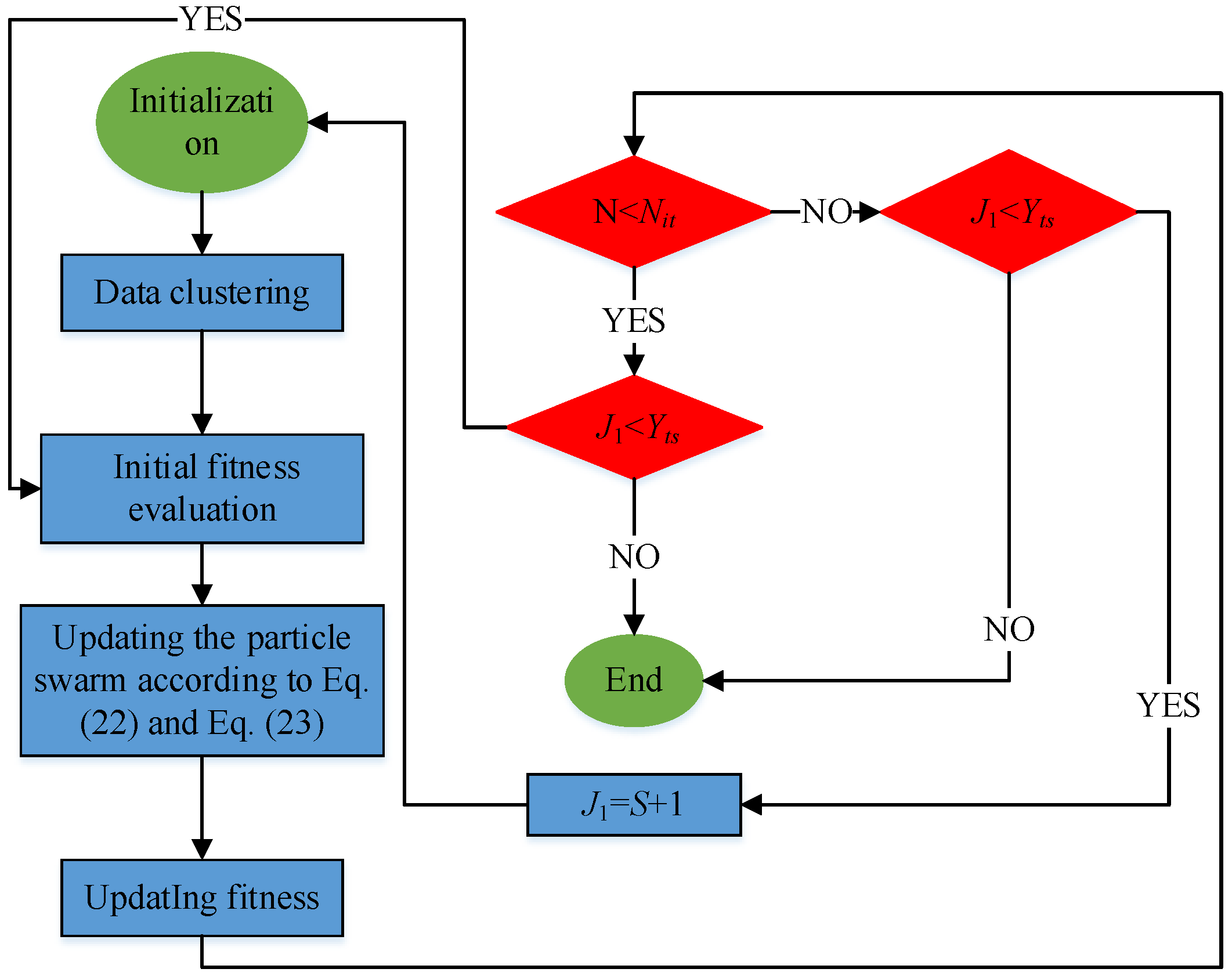
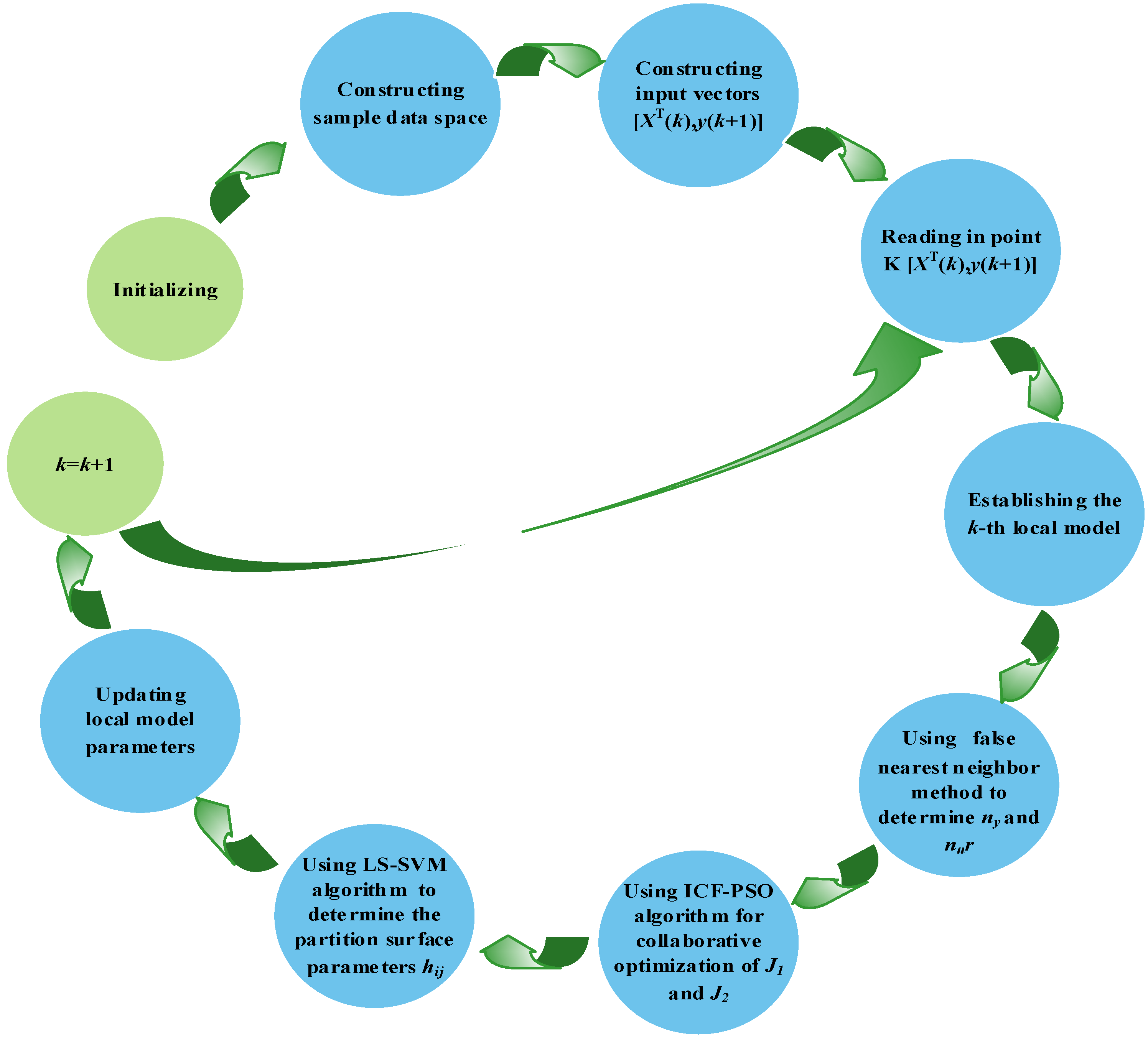
- (1)
Step 1. Initialization
Set the number of non-optimal models S = 1, swarm size NS, inertia weight w, acceleration coefficients c1 and c2, the threshold Yts of objective function J1, maximum allowable number of iterations Nit, initial position Pi and initial velocity of each particle Vi, etc.
- (2)
Step 2. Data clustering
Because the PWA system is locally linear, the data close to each other are very likely to fall into the same class. Thus, each local subspace
Zi can be divided by the distance between the data and the given cluster center. The specific method is to calculate the norm distance from each modeling space vector
z(
k) to a given cluster center
; if the modeling space vector is the closest to a given cluster center, it will be assigned to that cluster:
where,
.
- (3)
Step 3. Initial fitness evaluation
Evaluate the initial fitness of each particle according to the objective function J1.
- (4)
Step 4. Evolution of particle swarm
Update the position and velocity of particles according to Equations (22) and (23), respectively.
- (5)
Step 5. Fitness update
Cluster the data by Step 2, and update the fitness of each particle by objective function J1.
- (6)
Step 6. Termination conditions
- (1)
If the maximum number of iterations is not reached and the threshold of the objective function is not met, return to Step 3.
- (2)
If the maximum number of iterations is not reached, but the threshold of the objective function is met, terminate the algorithm.
- (3)
If the maximum number of iterations is reached and the threshold of the objective function is met, terminate the algorithm.
- (4)
If the maximum number of iterations is reached, but the threshold of the objective function is not met, go to Step 7.
- (7)
Step 7. Make J1 = S + 1, return to Step 1, and restart the search
The above steps can be organized into the following flow chart in
Figure 3.
2.5. Determination of Dividing Surfaces
So far, the sample space has been divided into S local spaces Ωi (i = 1, 2, ···, S). According to the definition of the PWA system in Equation (2), the convex polyhedrons with different scopes have no overlapping parts except the common boundary. Therefore, the problem of finding the optimal dividing surface is directly transformed into the linear division of cluster data. The least square support vector machine (LS-SVM) algorithm was selected to solve the optimal dividing surface between local PWA models. The selection was made because the LS-SVM is a classical classifier to handle small samples, and high-dimensional nonlinear data. The training speed of the model is accelerated, owing to the combination between the standard SVM and the least squares method.
2.5.1. Least Square Support Vector Machine
The core idea of LS-SVM is that in a given sample data set
, in which
xk∈
Rn and
yk∈{−1, 1}. To find the optimal classification hyperplane
, that is, to solve the following optimization problems [
49], namely
where,
is a function that maps input data to a high-dimensional feature space; weight vector
; error variables and offset values satisfy
and
;
is the weight coefficient, which can make LS-SVM find the optimal hyperplane and ensure the minimum deviation [
50].
Introducing Lagrange function into Equation (29), then
where,
is Lagrange multiplier;
xk is the support vector.
By deriving
w,
b,
ek,
αk in the above formula respectively, the following linear equation system about
α and
b can be obtained:
where,
y = [
y1,
,
yN];
α = [
α1,
,
αN]; 1
v = [1,
,1];
Ω is called a kernel matrix, and its expression is
where,
i,j = 1,
,
N. A set of
α and
b can be obtained by solving Equation (31). Finally, the classification hyperplane obtained by LS-SVM is shown below:
where, the kernel function must satisfy Mercer condition. The kernel function of this paper uses RBF kernel function. The expression of the RBF kernel function is shown below.
where,
σ is the width parameter of the function, which controls the radial range of action of the function.
2.5.2. LS-SVM Applied to Determine the Parameters of Dividing Surfaces
To begin with, a sample space is defined:
where,
.
The LS-SVM determines the dividing surface in two steps: First, find out the adjacent subspaces; Then, determine the parameters of dividing surfaces between adjacent subspaces. The specific steps are as follows:
Step 1. Determine the modeling subspaces adjacent to each other by the nearest neighbor rule of cluster center, namely:
Step 2. Determine the parameters of the dividing surface between two adjacent subspaces.
According to Equation (4), the dividing surface of two adjacent subspaces can be described as:
. Suppose
y(
i) = 1 for the sample belonging to
Ωi subspace, and
y(
j) = −1 for the samples belonging to
Ωj subspace. Then, kernel matrix
Ω in Equation (31) can be transformed by LS-SVM into:
Without changing other parameters in Equation (31),
N groups of
α and
b can be obtained by solving the new linear equation set. Finally, the dividing surface can be obtained by LS-SVM as:
where,
N =
Mi +
Mj is the total number of vectors in subspace
Ωi and subspace
Ωj.
Accordingly, the parameters of dividing surfaces can be obtained by:
Therefore, the parameters of dividing surfaces can be expressed as .
2.6. Modeling Steps of the PWA Soft Sensor Model
Let D be the sample dataset of the fermentation process. The sample dataset is a kind of MISO Problem (1). Then, the model identification problem is transformed into an MIQP optimization Problem (8). The optimal solution of the MIQP problem can be obtained by the following steps:
- (1)
Step 1. Determining model order
The FNN is introduced to determine the embedding dimension in the state space reconstruction of nonlinear time series in the fermentation process. The false nearest neighbor can be identified by Equation (15). When the dimension n increases continuously, the ratio δ of the false nearest neighbor will approach a threshold. The dimension at this very moment is taken as the embedding dimension. The change of embedding dimension is evaluated by E0(n) in Equation (18). When the embedding dimension n = ny + nu increases to a certain extent, E0(n) tends to be stable. At this moment, the ny and nu are the order of the corresponding model.
- (2)
Step 2. Collaborative optimization of the number and parameters of models
Because of their strong coupling, J1 and J2 must be determined synchronously. Therefore, the powerful parallel search ability of ICF-PSO algorithm is utilized to optimize the multi-objective optimization Problem (9). By the ICF-PSO, Equations (22) and (23) are updated, such that the particles can avoid the local optimum.
- (3)
Step 3. Determining dividing surfaces
The adjacent modeling subspaces {Zi, Zj} are determined by the nearest neighbor rule of cluster center, and the dividing surfaces of adjacent subspaces are determined by . By solving the new linear equation set, N groups of α and b are obtained. Then, the parameters and of dividing surfaces can be solved by Equation (38), namely, .
The modeling process of the PWA algorithm is illustrated in
Figure 4.
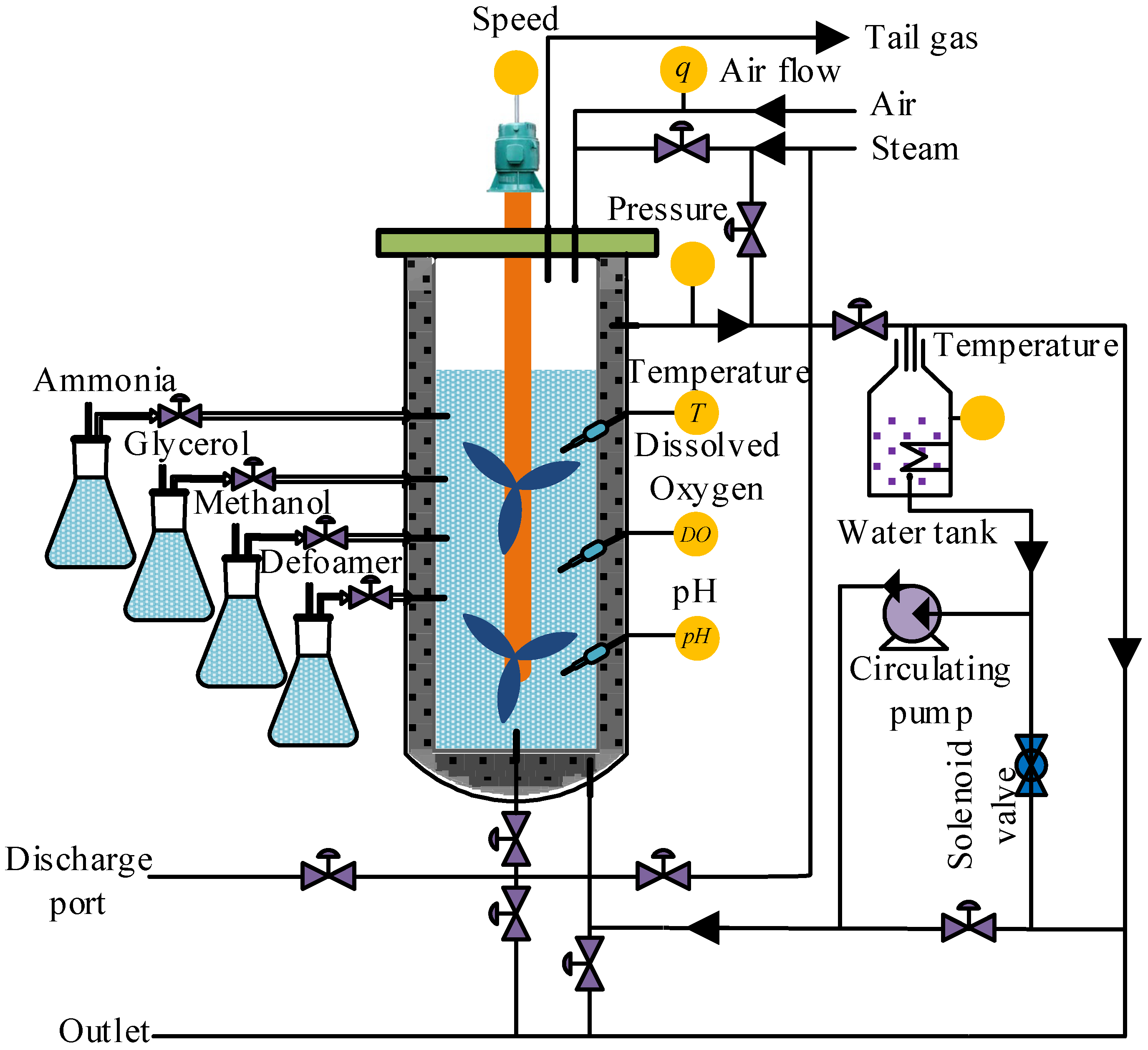
2.7. Introduction of Experimental Work
The online control of Pichia pastoris fermentation is a difficult problem, due to the complexity of the fermentation process, and the cost of online detection instruments for key biomass variables being very high. To provide information for the online control and to optimize the fermentation process, it is significant to establish real-time soft sensor models for cell concentration X and protease K concentration P.
The sample data used in this paper all came from the microbial fermentation lab of Zhenjiang Yangzhong Weikete Bioengineering Equipment Co., Ltd. (Zhenjiang, China), and the fermentation experiment equipment adopted RTY-C−100 L model. Taking
Pichia pastoris fermentation as the object, the
Pichia pastoris KM71, Mut
S constructed by the Key Laboratory of Animal Husbandry and Veterinary Institute of Shanghai Academy of Agricultural Sciences, was selected as the strain, and the expression vector and foreign genes were pPICZαA and IFNαcDNA [
51]. The experiment was carried out according to the schematic diagram of the
Pichia pastoris fermentation process (
Figure 5). After deeply analyzing the fermentation process, the temperature of fermentation broth
T, dissolved oxygen concentration
DO, pH of fermentation broth, air flow
q, stirring speed
v, and the pressure of fermentation tank
p were selected as auxiliary variables. In order to clarify the auxiliary and key biomass variables of the ICF-PSO-PWA model at a glance, a model expression with a generalized form for the input and output variables is given in Equation (39).
where,
is a generalized form of the complex nonlinear relationship between the auxiliary variables in the ICF-PSO-PWA model;
is any one of
X and
P. That is, the auxiliary variables (
T,
Do, pH,
q,
v,
p) are the input variables of the model we use, and the key biomass variables (
X,
P) are the output variables we need.
The initial values of the input variables in the fermentation process were set as follows: the pressure of the fermentation tank was controlled at 0.04 Mpa, the stirring speed of the motor was about 250 rpm, the fermentation temperature was controlled at about 28 ± 0.5 °C, and the air flow was controlled at the range of 1000–1200 L/h. The oxygen content was maintained between 35% and 45%, and the pH was 7.3.
Under normal fermentation conditions, the environmental variables of the fermentation processes were monitored by sensors every 5 min and uploaded to the host computer. The cell concentrations and protease K concentrations were measured offline every 1 h. The cell concentration was measured by the American Lehman Lamotte 1200 photoelectric colorimeter, and the concentration of proteinase k was measured by the UV−260 model automatic spectrophotometer of Shimadzu Corporation, Japan. The adjustment, logarithmic growth and stabilization phases in the fermentation processes were selected as the data collection time period, which was approximately the first 80 h of the fermentation process. Finally, 10 batches of sample data were extracted to apply our algorithm. Subsequently, 6 out of these 10 batches were used for training, the 7th and 8th batch for online correction of the initial PWA model, and the 9th and 10th batch for verifying the effectiveness and prediction accuracy of the PWA model. As the output variables are measured offline once every 1 h and the input variables once every 5 min, there is no one-to-one correspondence between the two, so the interpolation methods are used to convert the output variables offline every 1 h to the input variables every 5 min, forming a one-to-one correspondence. The data are then pre-processed by a coordinate transformation, which normalizes all sample data to between −1 and 1, making the calculation easier and faster. Through coordinate transformation and interpolation operation on 10 batches of sample data, a total of 960 sets of sample data were obtained at last, including 576 sets of sample data in training set, 204 sets of sample data in verification set and 180 sets of sample data in test set.
3. Results and Discussion
After determining that the order of input vector (
nu) is 1 and the order of output vector (
ny) is 2,
XT(
k) = [
uT(
k),
yT(
k),
yT(
k + 1)] is selected to form the input vector and the local model is chosen to be of the form
y(
k) = [
yT(
k − 1),
uT(
k − 1), 1]
θ. The dividing surface equation is
hi,j[
yT(
k − 1),
uT(
k − 1), 1]
T = 0, which separates the
i-th local model from the region where the
j-th local model is located. After using the ICF-PSO algorithm to optimize the PWA model, the number of local models is
S = 3, which exactly corresponds to the three phases of the sample data in this paper: adjustment, logarithmic growth and stable phase. The local model parameters
θi (
i = 1, 2, 3) and the parameters of dividing surfaces
hi,j are shown in the
Table 1.
To verify its performance, the ICF-PSO-PWA model was compared with the PSO-WLSSVR model based on global modeling, which used Gaussian radial basis kernel (RBF) function , with σ = 0.2, and penalty coefficient C = 10. The WLS-SVR model introduces the least squares algorithm and weights on the basis of the SVR model, which greatly enhances the prediction accuracy and generalization ability of the SVR model. It is a very good comparator. All simulation results were obtained based on MATLAB R2019b software.
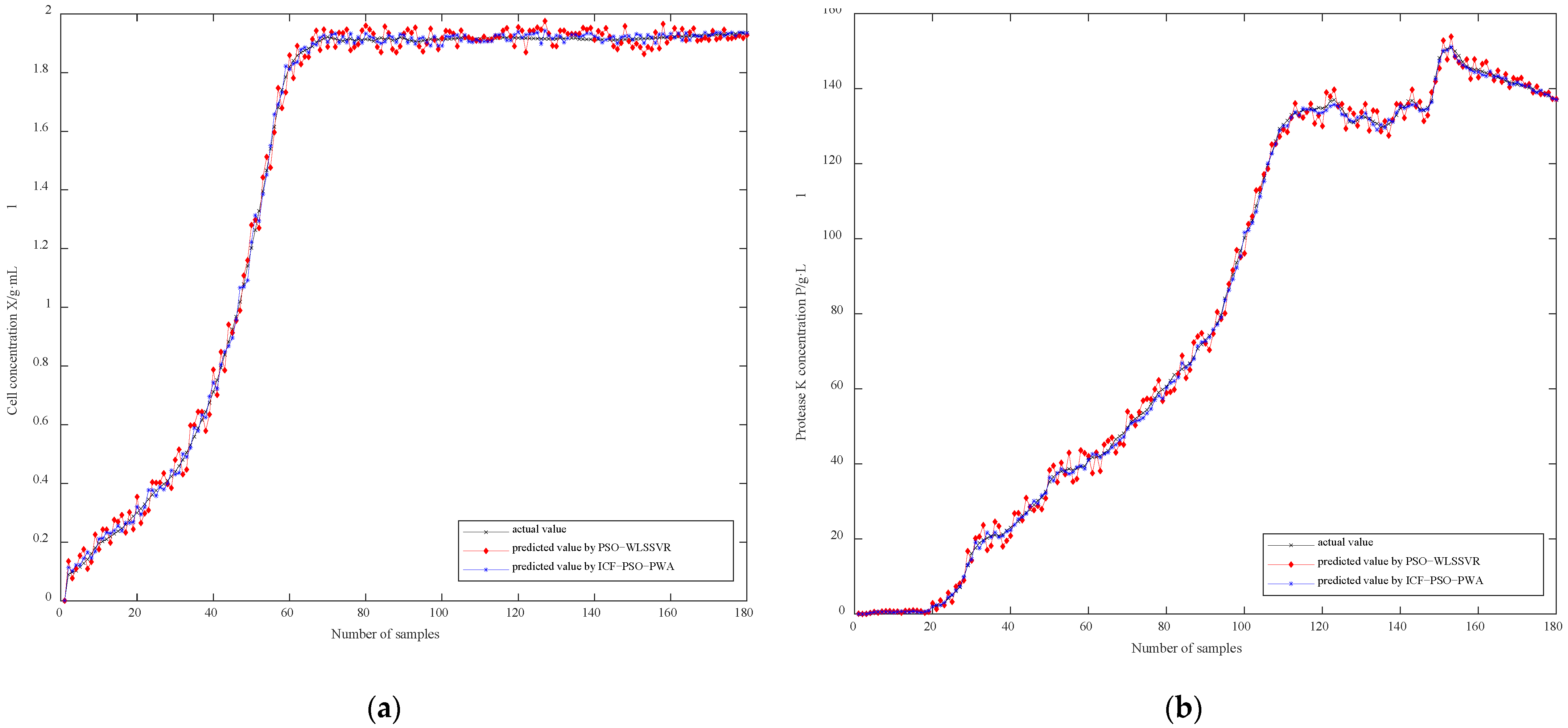
Figure 6a,b present the prediction results of soft sensor models based on ICF-PSO-PWA and PSO-WLSSVR, respectively. Obviously, the fitting effect of ICF-PSO-PWA soft sensor model is better than that of the PSO-WLSSVR model, regardless of the bacterial concentration or the concentration of protease K. In particular, the fitting effect of the PSO-WLSSVR model is clearly inferior to the ICF-PSO-PWA model in terms of the cell concentration in the later stage.
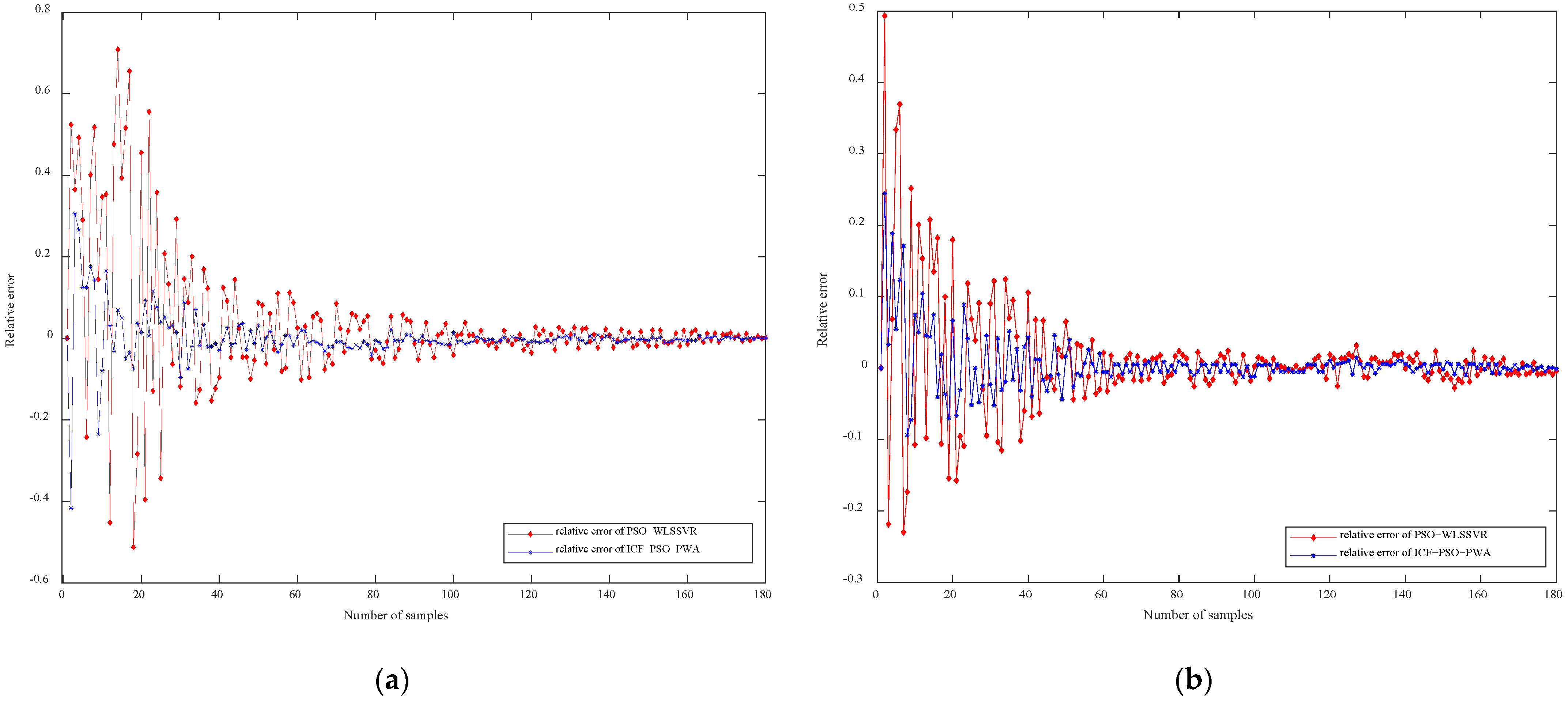
Figure 7a,b compare the relative error of cell concentration and protease K concentration based on ICF-PSO-PWA and PSO-WLSSVR, respectively. For both ICF-PSO-PWA and PSO-WLSSVR soft sensor models, the prediction errors gradually decrease with time and are eventually stabilized. However, the ICF-PSO-PWA soft sensor model has a much smaller error range, a relatively high accuracy in the whole sample interval, and an obviously smaller final error than the PSO-WLSSVR model.
Table 2 shows the mean absolute percentage error (MAPE) of cell concentration and proteinase K concentration based on ICF-PSO-PWA and PSO-WLSSVR. It can be seen from
Table 2 that compared with the PSO-WLSSVR soft sensor model, the ICF-PSO-PWA soft sensor model has an improved accuracy by 2.4642% when predicting the cell concentration, and an improved accuracy by 6.5127% when predicting the proteinase K concentration. The mean prediction accuracy of ICF-PSO-PWA soft sensor model has been improved by 4.4884%.
Furthermore, the root mean square errors (RMSEs) of the ICF-PSO-PWA and PSO-WLSSVR soft sensor models were tested on different scale datasets. The test results in
Table 3 show that, with the growing number of test samples, the RMSE of the PSO-WLSSVR soft sensor model increases, while that of the ICF-PSO-PWA model does not change significantly. This is because the latter model divides the working interval of the system into several subintervals, and models each subinterval separately; besides, multiple local models are used in place of the global single model, making full use of the information of each sample. As time goes by, the ICF-PSO-PWA model can adapt to the changing working conditions, and achieve excellent generalization performance and self-adaptability.




{kind=link}
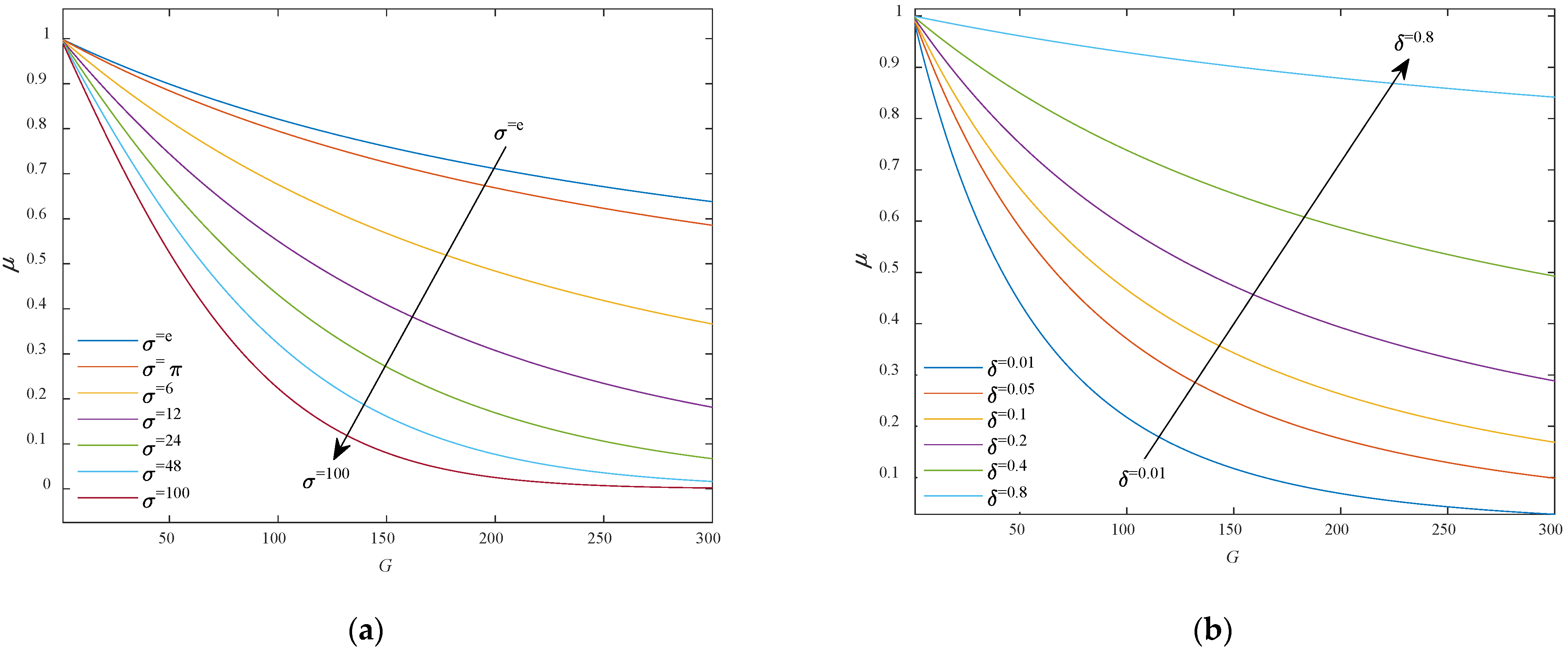{kind=link}
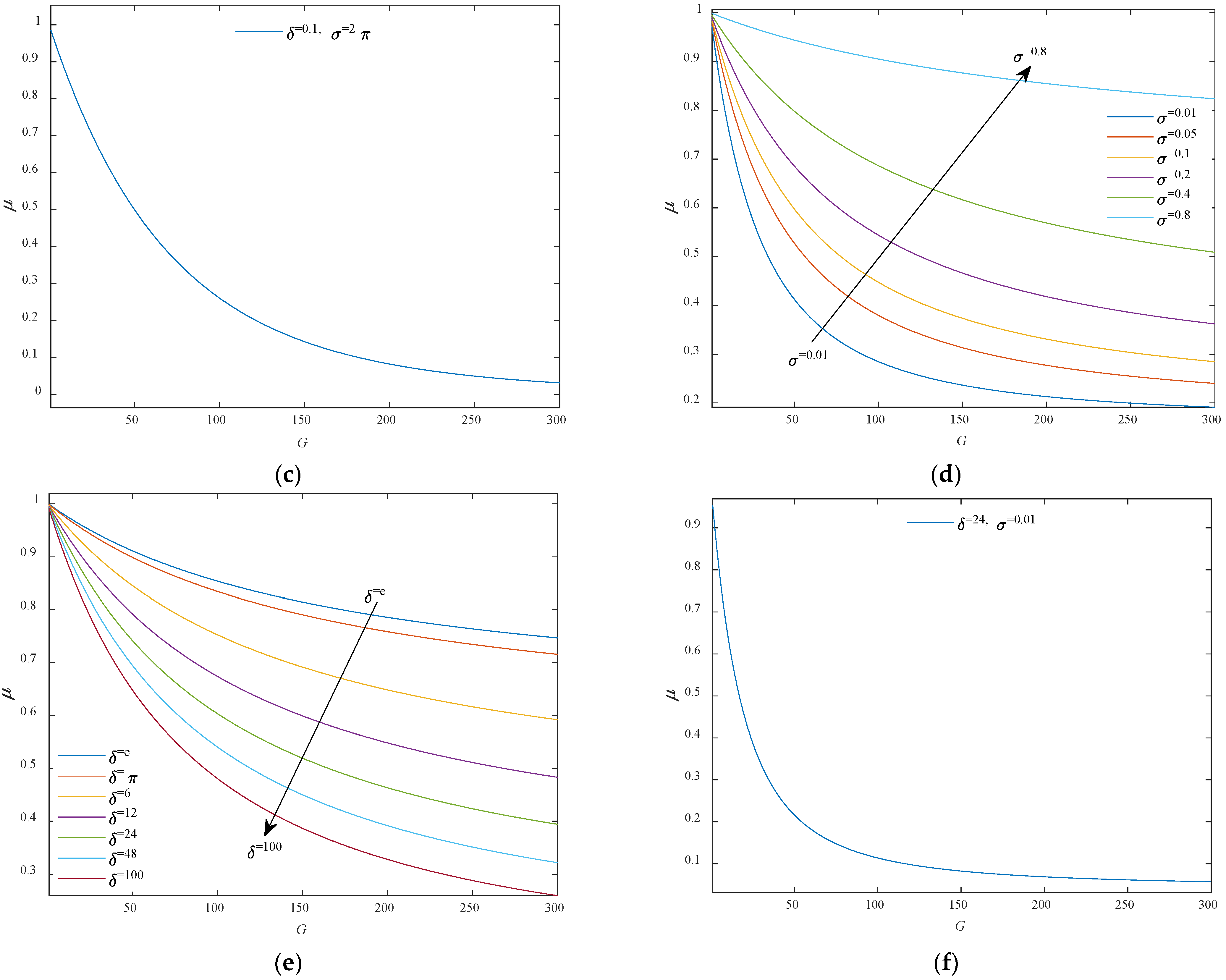{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










