
Wearable IMU-Based Human Activity Recognition Algorithm for Clinical Balance Assessment Using 1D-CNN and GRU Ensemble Model


Abstract
:1. Introduction
2. Materials and Methods
2.1. Experiment
2.1.1. Motion and Experimental Protocol
2.1.2. Participants
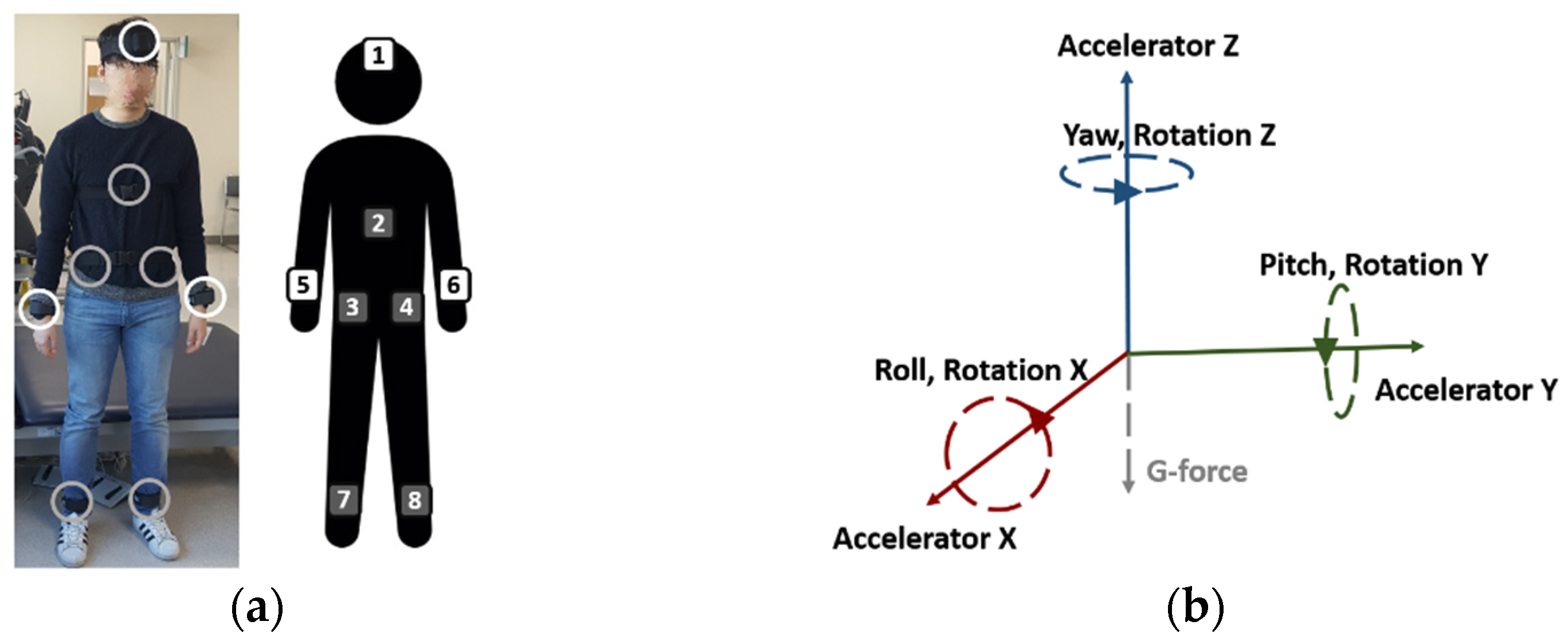
2.1.3. Equipment and Data
2.1.4. Output Data Description
2.2. Methodology of the Proposed Method
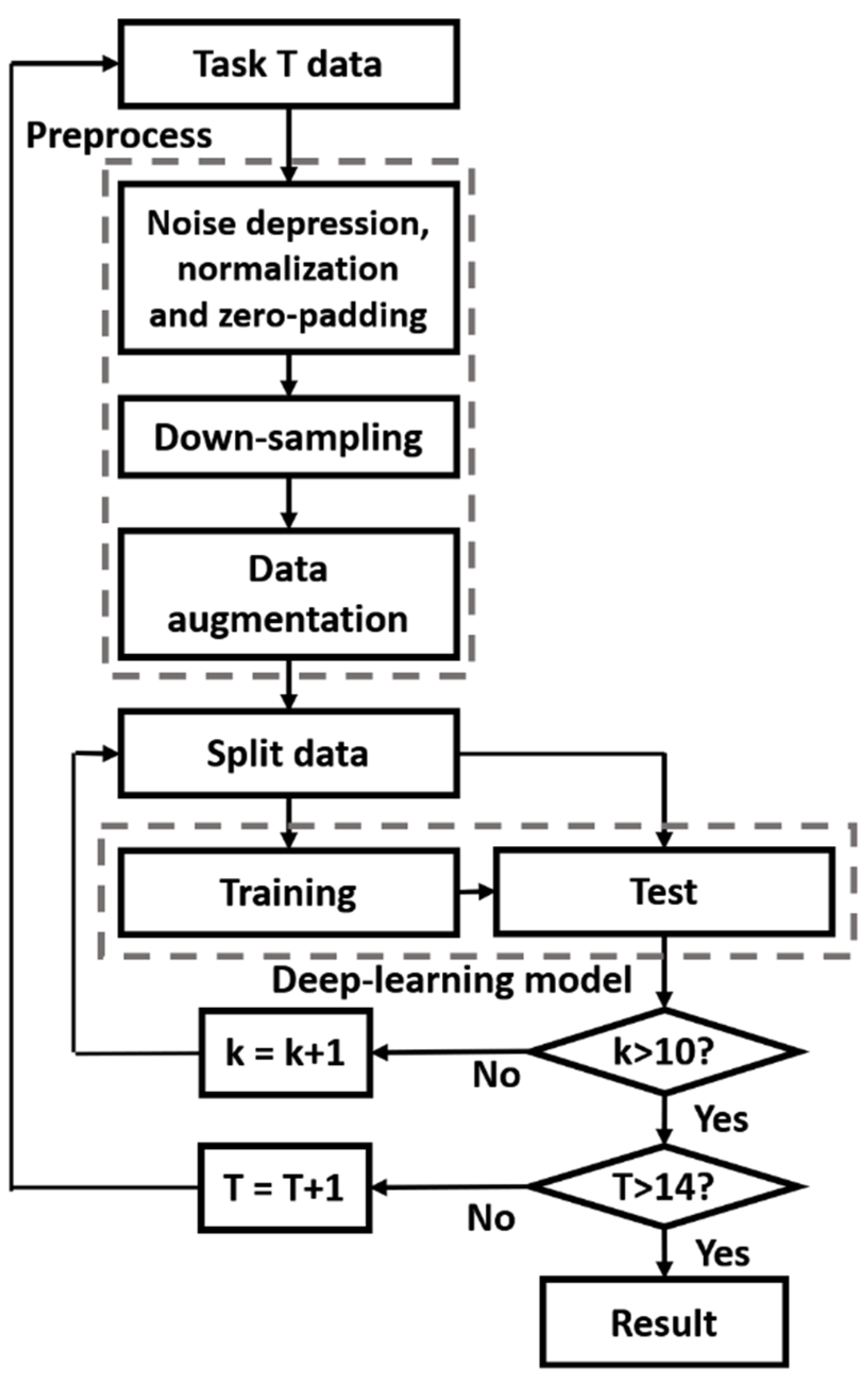
2.2.1. Preprocess
Noise Depression, Normalization, and Zero-Padding
Data Down-Sampling
- From the first person in Task 1, an n-point fixed Fourier transform was applied to each of the 72 sensor data outputs from the eight IMUs, and amplitudes from first to the n/2th were extracted.
- For each person, the amplitude values of all sensors were summed for each frequency component. The accumulated amplitude value for each N Hz frequency was calculated, where N = {1, 2, 3…50}. The accumulated amplitude for each frequency was divided by the sum of the amplitudes up to 50 Hz, which is the sum of all frequency components, and multiplied by 100 to obtain the percentage (%). Thereafter, the average percentage of the accumulated data for each frequency for all the subjects were calculated.
- Processes 1–2 were repeated until Task 14, and the average of all tasks in terms of the percentage of accumulated data/information were calculated for each frequency.
- The trend of the accumulated information was observed for each frequency, and a frequency having a small increase was selected. To restore up to the corresponding frequency component, the sampling rate was set to twice the frequency component based on the Nyquist sampling theory [30].
Data Augmentation Using the Over-Sampling Technique
- The class set of the scores was . The number of k samples with the closest Euclidean distance to a random sample, , is . can be obtained using the k-nearest neighbor algorithm.
- The number of new samples between and is , and the rule for generating is given by Equation (1):
- Steps 1 and 2 are repeated, so that the amount of class data in each class ) becomes N.
2.2.2. Classification Model
1D-CNN Head and GRU Head
1D-CNN, GRU Stacking Ensemble Model
Training and Evaluation
3. Results and Discussion
3.1. Improving Model Efficiency through a Data Down-Sampling Process
3.2. Classification Model
3.3. Improvement in Model Performance through Data Augmentation
3.4. Comparison with Previous Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Herdman, S.J.; Blatt, P.; Schubert, M.C.; Tusa, R.J. Falls in patients with vestibular deficits. Otol. Neurotol. 2000, 21, 847–851. [Google Scholar]
- Wolfson, L.I.; Whipple, R.; Amerman, P.; Kaplan, J.; Kleinberg, A. Gait and balance in the elderly: Two functional capacities that link sensory and motor ability to falls. Clin. Geriatr. Med. 1985, 1, 649–659. [Google Scholar] [CrossRef]
- Badura, P.; Pietka, E. Automatic berg balance scale assessment system based on accelerometric signals. Biomed. Signal Process. Control 2016, 24, 114–119. [Google Scholar] [CrossRef]
- Mohammadian Rad, N.; Van Laarhoven, T.; Furlanello, C.; Marchiori, E. Novelty detection using deep normative modeling for imu-based abnormal movement monitoring in parkinson’s disease and autism spectrum disorders. Sensors 2018, 18, 3533. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Romijnders, R.; Warmerdam, E.; Hansen, C.; Welzel, J.; Schmidt, G.; Maetzler, W. Validation of IMU-based gait event detection during curved walking and turning in older adults and Parkinson’s Disease patients. J. Neuroeng. Rehabil. 2021, 18, 1–10. [Google Scholar] [CrossRef]
- Yu, B.; Liu, Y.; Chan, K. A Survey of Sensor Modalities for Human Activity Recognition. In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Budapest, Hungary, 2–4 November 2020; INSTICC: Rua dos Lusíadas, Portugal, 2020; pp. 282–294. [Google Scholar]
- Vu, C.C.; Kim, J.K. Human motion recognition using SWCNT textile sensor and fuzzy inference system based smart wearable. Sens. Actuators A 2018, 283, 263–272. [Google Scholar] [CrossRef]
- Rodrigues, S.M.; Fiedler, P.; Küchler, N.; Domingues, P.R.; Lopes, C.; Borges, J.; Haueisen, J.; Vaz, F. Dry electrodes for surface electromyography based on architectured titanium thin films. Materials 2020, 13, 2135. [Google Scholar] [CrossRef]
- Raeis, H.; Kazemi, M.; Shirmohammadi, S. Human Activity Recognition with Device-Free Sensors for Well-Being Assessment in Smart Homes. IEEE Instrum. Meas. Mag. 2021, 24, 46–57. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Ponciano, V.; Pires, I.M.; Ribeiro, F.R.; Marques, G.; Villasana, M.V.; Garcia, N.M.; Zdravevski, E.; Spinsante, S. Identification of Diseases Based on the Use of Inertial Sensors: A Systematic Review. Electronics 2020, 9, 778. [Google Scholar] [CrossRef]
- Digo, E.; Agostini, V.; Pastorelli, S.; Gastaldi, L.; Panero, E. Gait Phases Detection in Elderly using Trunk-MIMU System. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2021), Vienna, Austria, 11–13 February 2021; pp. 58–65. [Google Scholar]
- Choudhury, N.A.; Moulik, S.; Roy, D.S. Physique-based Human Activity Recognition using Ensemble Learning and Smartphone Sensors. IEEE Sens. J. 2021, 21, 16852–16860. [Google Scholar] [CrossRef]
- Nan, Y.; Lovell, N.H.; Redmond, S.J.; Wang, K.; Delbaere, K.; van Schooten, K.S. Deep Learning for Activity Recognition in Older People Using a Pocket-Worn Smartphone. Sensors 2020, 20, 7195. [Google Scholar] [CrossRef]
- Wu, B.; Ma, C.; Poslad, S.; Selviah, D.R. An Adaptive Human Activity-Aided Hand-Held Smartphone-Based Pedestrian Dead Reckoning Positioning System. Remote Sens. 2021, 13, 2137. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Lu, J.; Zheng, X.; Sheng, M.; Jin, J.; Yu, S. Efficient Human Activity Recognition Using a Single Wearable Sensor. IEEE Internet Things J. 2020, 7, 11137–11146. [Google Scholar] [CrossRef]
- Vanrell, S.R.; Milone, D.H.; Rufiner, H.L. Assessment of homomorphic analysis for human activity recognition from acceleration signals. IEEE J. Biomed. Health Inform. 2017, 22, 1001–1010. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Pickle, N.T.; Shearin, S.M.; Fey, N.P. Dynamic neural network approach to targeted balance assessment of individuals with and without neurological disease during non-steady-state locomotion. J. Neuroeng. Rehabil. 2019, 16, 1–9. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor data acquisition and multimodal sensor fusion for human activity recognition using deep learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef] [Green Version]
- Ramanujam, E.; Perumal, T.; Padmavathi, S. Human activity recognition with smartphone and wearable sensors using deep learning techniques: A review. IEEE Sens. J. 2021, 21, 13029–13040. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. LSTM networks using smartphone data for sensor-based human activity recognition in smart homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Deep Convolutional Neural Network with RNNs for Complex Activity Recognition Using Wrist-Worn Wearable Sensor Data. Electronics 2021, 10, 1685. [Google Scholar] [CrossRef]
- Blum, L.; Korner-Bitensky, N. Usefulness of the Berg Balance Scale in stroke rehabilitation: A systematic review. Phys. Ther. 2008, 88, 559–566. [Google Scholar] [CrossRef]
- Muir, S.W.; Berg, K.; Chesworth, B.; Speechley, M. Use of the Berg Balance Scale for predicting multiple falls in community-dwelling elderly people: A prospective study. Phys. Ther. 2008, 88, 449–459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, Y.W.; Cho, W.H.; Joa, K.L.; Jung, H.Y.; Lee, S. A New Auto-Scoring Algorithm for Bance Assessment with Wearable IMU Device Based on Nonlinear Model. J. Mech. Med. Biol. 2020, 20, 2040011. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Khan, A.; Hammerla, N.; Mellor, S.; Plötz, T. Optimising sampling rates for accelerometer-based human activity recognition. Pattern Recognit. Lett. 2016, 73, 33–40. [Google Scholar] [CrossRef]
- Landau, H.J. Sampling, data transmission, and the Nyquist rate. Proc. IEEE 1967, 55, 1701–1706. [Google Scholar] [CrossRef]
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Reyes, M.C. A Comparative Performance Analysis of Data Resampling Methods on Imbalance Medical Data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, W.; Gao, Z.; Bian, J.; Chen, H.; Chang, Y.; Liu, T.Y. Self-paced ensemble for highly imbalanced massive data classification. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: New York, NY, USA; pp. 841–852. [Google Scholar]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Sun, J.; Lang, J.; Fujita, H.; Li, H. Imbalanced enterprise credit evaluation with DTE-SBD: Decision tree ensemble based on SMOTE and bagging with differentiated sampling rates. Inf. Sci. 2018, 425, 76–91. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, D.; Nie, T.; Kou, Y. A hybrid sampling algorithm combining M-SMOTE and ENN based on random forest for medical imbalanced data. J. Biomed. Inform. 2020, 107, 103465. [Google Scholar] [CrossRef]
- Abdoh, S.F.; Rizka, M.A.; Maghraby, F.A. Cervical cancer diagnosis using random forest classifier with SMOTE and feature reduction techniques. IEEE Access 2018, 6, 59475–59485. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Khorshidi, H.A.; Aickelin, U. Synthetic Over-sampling with the Minority and Majority classes for imbalance problems. arXiv 2020, arXiv:2011.04170. in preprint. [Google Scholar]
- Canizo, M.; Triguero, I.; Conde, A.; Onieva, E. Multi-head CNN–RNN for multi-time series anomaly detection: An industrial case study. Neurocomputing 2019, 363, 246–260. [Google Scholar] [CrossRef]
- Jiang, Z.; Lai, Y.; Zhang, J.; Zhao, H.; Mao, Z. Multi-factor operating condition recognition using 1D convolutional long short-term network. Sensors 2019, 19, 5488. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Wang, B.; Wan, T.; Tang, W. Multivariate abnormal detection for industrial control systems using 1D CNN and GRU. IEEE Access 2020, 8, 88348–88359. [Google Scholar] [CrossRef]
- Pasupa, K.; Sunhem, W. A comparison between shallow and deep architecture classifiers on small dataset. In Proceedings of the 2016 8th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 5–6 October 2016; IEEE: New York, NY, USA; pp. 1–6. [Google Scholar]
- Brigato, L.; Iocchi, L. A close look at deep learning with small data. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: New York, NY, USA; pp. 2490–2497. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. in preprint. [Google Scholar]
- Chen, H.; Ji, M. Experimental Comparison of Classification Methods under Class Imbalance. EAI Trans. Scalable Inf. Syst. 2021, sis18, e13. [Google Scholar] [CrossRef]
- Ordoñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qian, Y.; Bi, M.; Tan, T.; Yu, K. Very deep convolutional neural networks for noise robust speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2263–2276. [Google Scholar] [CrossRef]
- Tsironi, E.; Barros, P.; Weber, C.; Wermter, S. An analysis of convolutional long short-term memory recurrent neural networks for gesture recognition. Neurocomputing 2017, 268, 76–86. [Google Scholar] [CrossRef]
- Ahmad, W.; Kazmi, B.M.; Ali, H. Human activity recognition using multi-head CNN followed by LSTM. In Proceedings of the 2019 15th international conference on emerging technologies (ICET), Peshawar, Pakistan, 2–3 December 2019; IEEE: New York, NY, USA; pp. 1–6. [Google Scholar]
- Perenda, E.; Rajendran, S.; Pollin, S. Automatic modulation classification using parallel fusion of convolutional neural networks. In Proceedings of the 2019 3rd International Balkan Conference on Communications and Networking (IBCCN) (BalkanCom’19), Skopje, North Macedonia, 10–12 June 2019; IEEE: New York, NY, USA. [Google Scholar]
- Lee, K.; Kim, J.K.; Kim, J.; Hur, K.; Kim, H. CNN and GRU combination scheme for bearing anomaly detection in rotating machinery health monitoring. In Proceedings of the 2018 1st IEEE International Conference on Knowledge Innovation and Invention (ICKII), Jeju Island, Korea, 23–27 July 2018; IEEE: New York, NY, USA; pp. 102–105. [Google Scholar]
- Hamad, R.A.; Yang, L.; Woo, W.L.; Wei, B. Joint learning of temporal models to handle imbalanced data for human activity recognition. Appl. Sci. 2020, 10, 5293. [Google Scholar] [CrossRef]
- Hamad, R.A.; Hidalgo, A.S.; Bouguelia, M.R.; Estevez, M.E.; Quero, J.M. Efficient activity recognition in smart homes using delayed fuzzy temporal windows on binary sensors. IEEE J. Biomed. Health Inform. 2019, 24, 387–395. [Google Scholar] [CrossRef]
- Xu, M.; Yin, Z.; Wu, M.; Wu, Z.; Zhao, Y.; Gao, Z. Spectrum sensing based on parallel cnn-lstm network. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Virtual, Antwerp, Begium, 25 May–31 July 2020; IEEE: New York, NY, USA; pp. 1–5. [Google Scholar]
- Wang, K.J.; Makond, B.; Chen, K.H.; Wang, K.M. A hybrid classifier combining SMOTE with PSO to estimate 5-year survivability of breast cancer patients. Appl. Soft Comput. 2014, 20, 15–24. [Google Scholar] [CrossRef]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Task Description |
|---|---|
| 1 | Sitting to standing |
| 2 | Standing unsupported |
| 3 | Sitting unsupported |
| 4 | Standing to sitting |
| 5 | Transfers |
| 6 | Standing with eyes closed |
| 7 | Standing with feet together |
| 8 | Reaching forward with outstretched arms |
| 9 | Retrieving object from floor |
| 10 | Turning to look behind |
| 11 | Turning 360° |
| 12 | Placing alternate foot on stool |
| 13 | Standing with one foot in front |
| 14 | Standing on one foot |
| Model | C | G | DC | TC | C-G | C+G | DC+G |
|---|---|---|---|---|---|---|---|
| Mean accuracy (%) | 94.9 | 95.6 | 95.6 | 95.3 | 95.3 | 95.9 | 96.1 |
| Standard deviation of accuracy (%) | 4.4 | 4.1 | 4.0 | 4.4 | 4.7 | 4.1 | 3.8 |
| Max accuracy (%) | 99.8 | 99.8 | 100 | 99.8 | 100 | 100 | 100 |
| Min accuracy (%) | 87.1 | 87.4 | 87.6 | 86.4 | 85.7 | 87.2 | 88.8 |
| Mean epoch | 64.9 | 80.6 | 69.9 | 63.8 | 80.1 | 71.7 | 78.8 |
| Mean training time (s) | 5.172 | 21.351 | 8.383 | 10.270 | 13.304 | 21.729 | 26.551 |
| Epoch time (s) | 0.081 | 0.265 | 0.120 | 0.161 | 0.166 | 0.303 | 0.337 |
| Evaluation time (s) | 0.099 | 0.073 | 0.142 | 0.153 | 0.115 | 0.095 | 0.129 |
| Study | Badura’s Study | Kim’s Study | This Study |
|---|---|---|---|
| Classification model | Multi-layer perceptron (MLP) | Support vector Machine (SVM) | Double head 1D-CNN and single head GRU stacking ensemble |
| Feature extraction | Manual (Frequency and time domain feature, Feature selection: Fisher’s linear discriminant) | Manual (Frequency domain and energy feature, Feature selection: KPCA) | Automatic in deep learning |
| Sampling rate of data (Hz) | 100 | 100 | 20 (Introduce data down-sampling) |
| Data imbalance problem | Yes | Yes | No (Introduce data augmentation) |
| Amount of experimental data | 63 | 53 | 78 |
| Evaluation method | Random split Training: Test = 7:3 | Random split Training: Test = 7:3 | Mean accuracy of 10-fold cross validation |
| Task | Badura’s MLP Accuracy (%) | Kim’s SVM Accuracy (%) | DC+G Accuracy (%) |
|---|---|---|---|
| 1 | 87.5 | 100 | 98.5 |
| 2 | 92.2 | 100 | 98.5 |
| 3 | 100 | 100 | 99.6 |
| 4 | 89.1 | 87.5 | 99.0 |
| 5 | 70.3 | 76.5 | 96.7 |
| 6 | 89.1 | 100 | 97.9 |
| 7 | 76.6 | 100 | 99.0 |
| 8 | 76.6 | 92.9 | 98.9 |
| 9 | 89.1 | 100 | 97.8 |
| 10 | 70.3 | 78.6 | 98.2 |
| 11 | 78.1 | 100 | 97.8 |
| 12 | 79.7 | 80.0 | 98.2 |
| 13 | 62.5 | 90.0 | 98.1 |
| 14 | 67.2 | 100 | 99.1 |
| Average | 80.6 | 93.2 | 98.4 |
| Standard deviation | 10.9 | 9.1 | 0.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.-W.; Joa, K.-L.; Jeong, H.-Y.; Lee, S. Wearable IMU-Based Human Activity Recognition Algorithm for Clinical Balance Assessment Using 1D-CNN and GRU Ensemble Model. Sensors 2021, 21, 7628. https://doi.org/10.3390/s21227628
Kim Y-W, Joa K-L, Jeong H-Y, Lee S. Wearable IMU-Based Human Activity Recognition Algorithm for Clinical Balance Assessment Using 1D-CNN and GRU Ensemble Model. Sensors. 2021; 21(22):7628. https://doi.org/10.3390/s21227628
Chicago/Turabian StyleKim, Yeon-Wook, Kyung-Lim Joa, Han-Young Jeong, and Sangmin Lee. 2021. "Wearable IMU-Based Human Activity Recognition Algorithm for Clinical Balance Assessment Using 1D-CNN and GRU Ensemble Model" Sensors 21, no. 22: 7628. https://doi.org/10.3390/s21227628
APA StyleKim, Y.-W., Joa, K.-L., Jeong, H.-Y., & Lee, S. (2021). Wearable IMU-Based Human Activity Recognition Algorithm for Clinical Balance Assessment Using 1D-CNN and GRU Ensemble Model. Sensors, 21(22), 7628. https://doi.org/10.3390/s21227628