
Video Desnowing and Deraining via Saliency and Dual Adaptive Spatiotemporal Filtering




Abstract
:1. Introduction
- Due to the interference of rain streaks and snowflakes, the existing snow or rain removal algorithms cannot effectively detect moving objects. We introduce a saliency map into moving object detection, which improves the ability of moving object detection in snow and rain videos because almost all moving objects in snow and rain videos have salience information, while snowflakes and rain streaks do not.
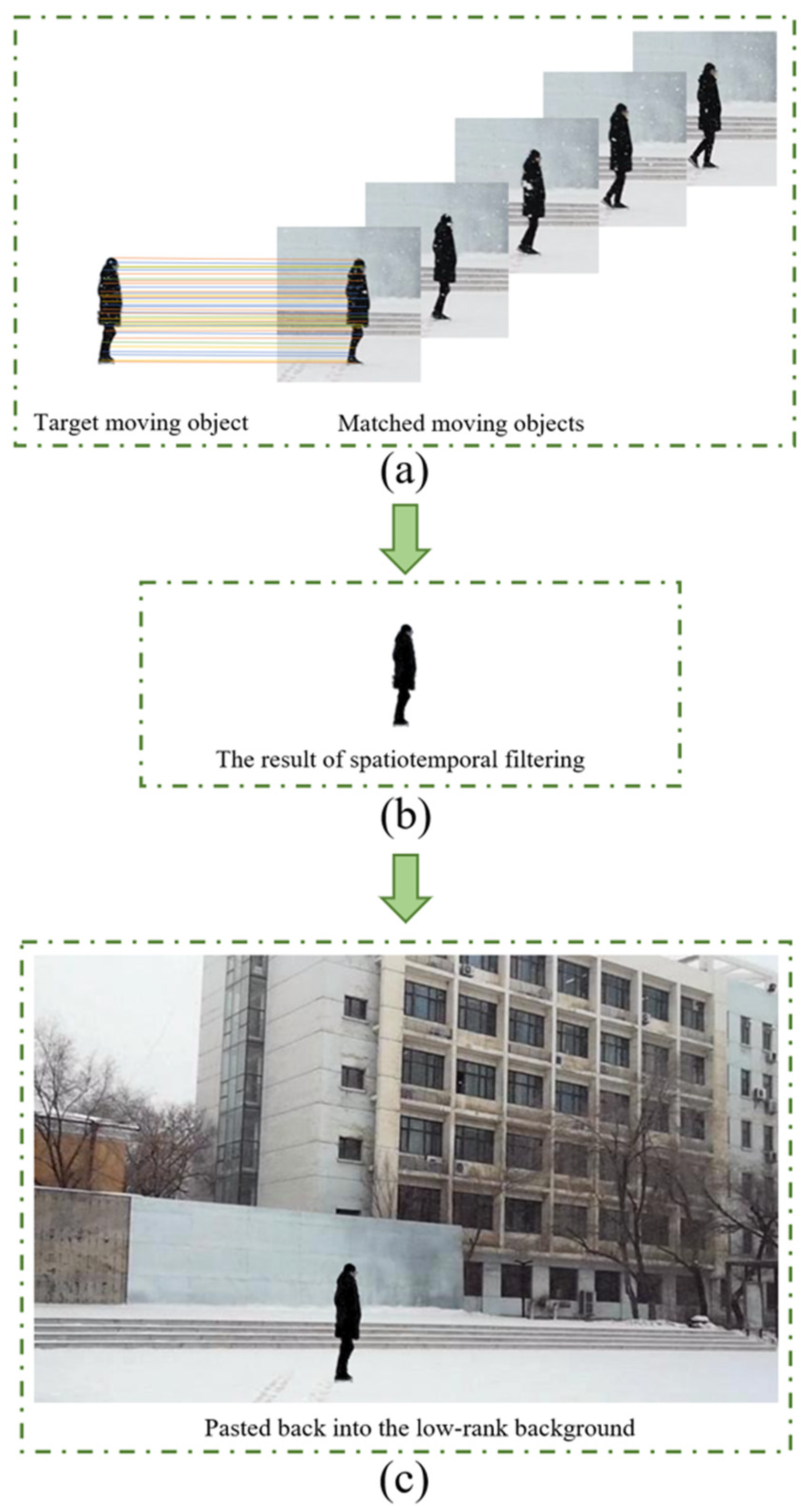
- Because snow and rain in videos cannot cover the same pixels all the time, feature point matching is utilized by us to address the time continuity of moving objects in snow or rain videos and mine the redundant information of moving objects in continuous frames. A dual adaptive minimum filtering method in the spatiotemporal domain is proposed by us to remove snow and rain in front of moving objects.
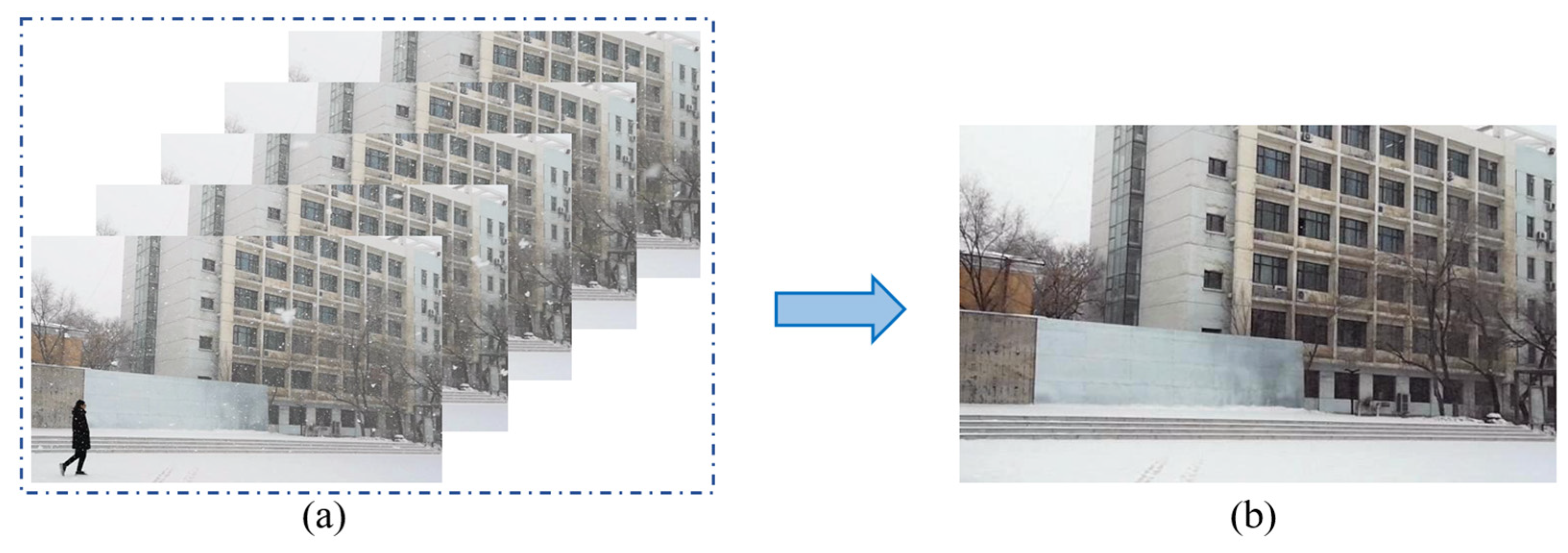
- In contrast to matrix decomposition, our tensor decomposition makes full use of the spatial location information and the correlation between the three channels of the color video. In our decomposition, the background is relatively static, and we uniformly regard sparse and dense snowflakes, rain streaks and moving objects as sparse components.
2. Related Work
2.1. Video Snow and Rain Removal Methods
2.2. Single Image Snow and Rain Removal Methods
- The previous desnowing and deraining algorithm cannot distinguish between sparse snowflakes/rain streaks and moving objects in heavy snow/rainstorms. We utilize saliency map to guide moving object detection, which can effectively avoid the influence of snowflakes/rain streaks.
- The existing desnowing and deraining algorithms cannot effectively remove the snowflakes and rain streaks in front of the moving object. Additionally, some methods deform the moving object. To solve these problems, we combine feature point matching and dual adaptive spatiotemporal filtering, proposed by us, to remove snowflakes and rain streaks in front of moving objects.
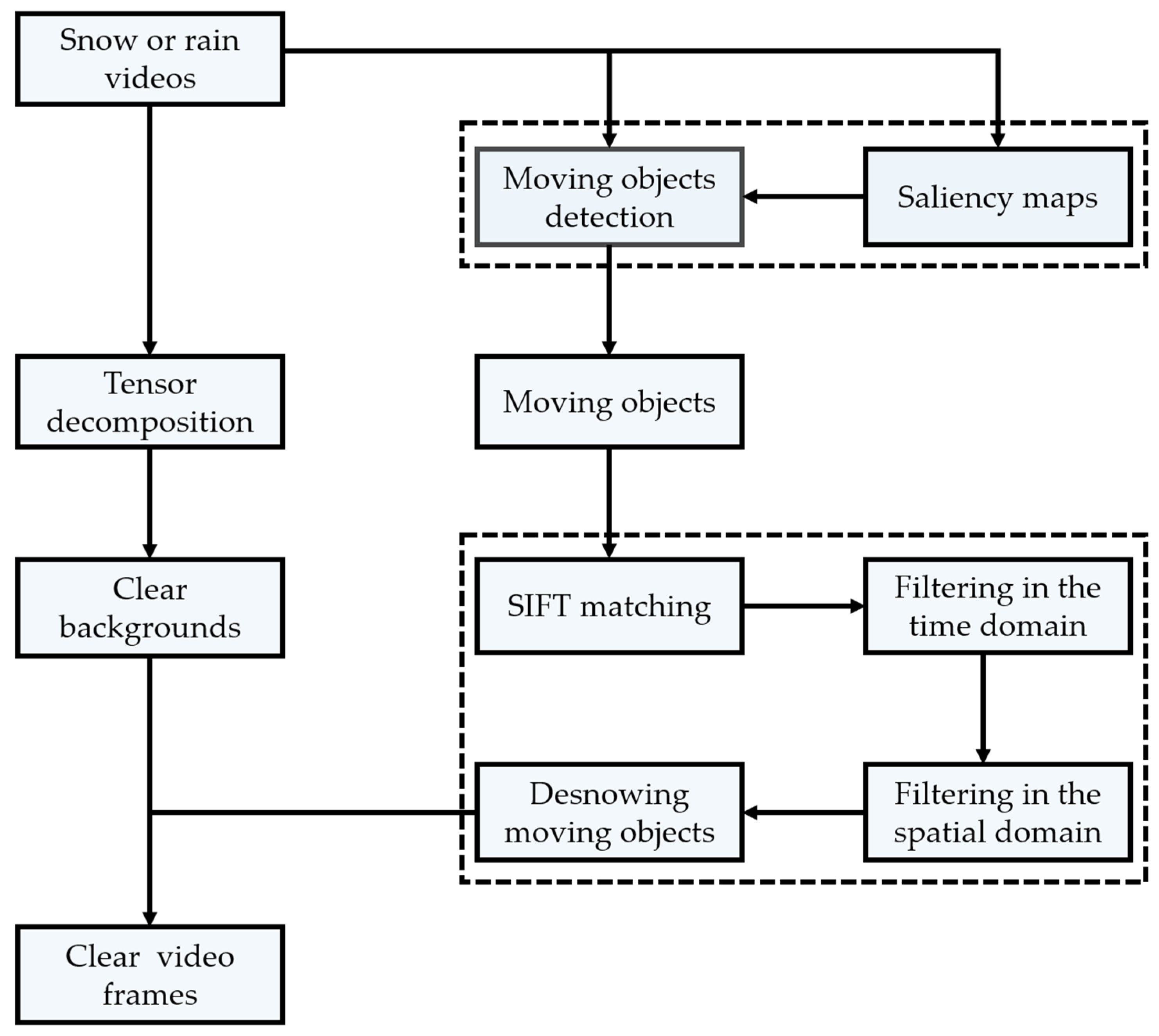
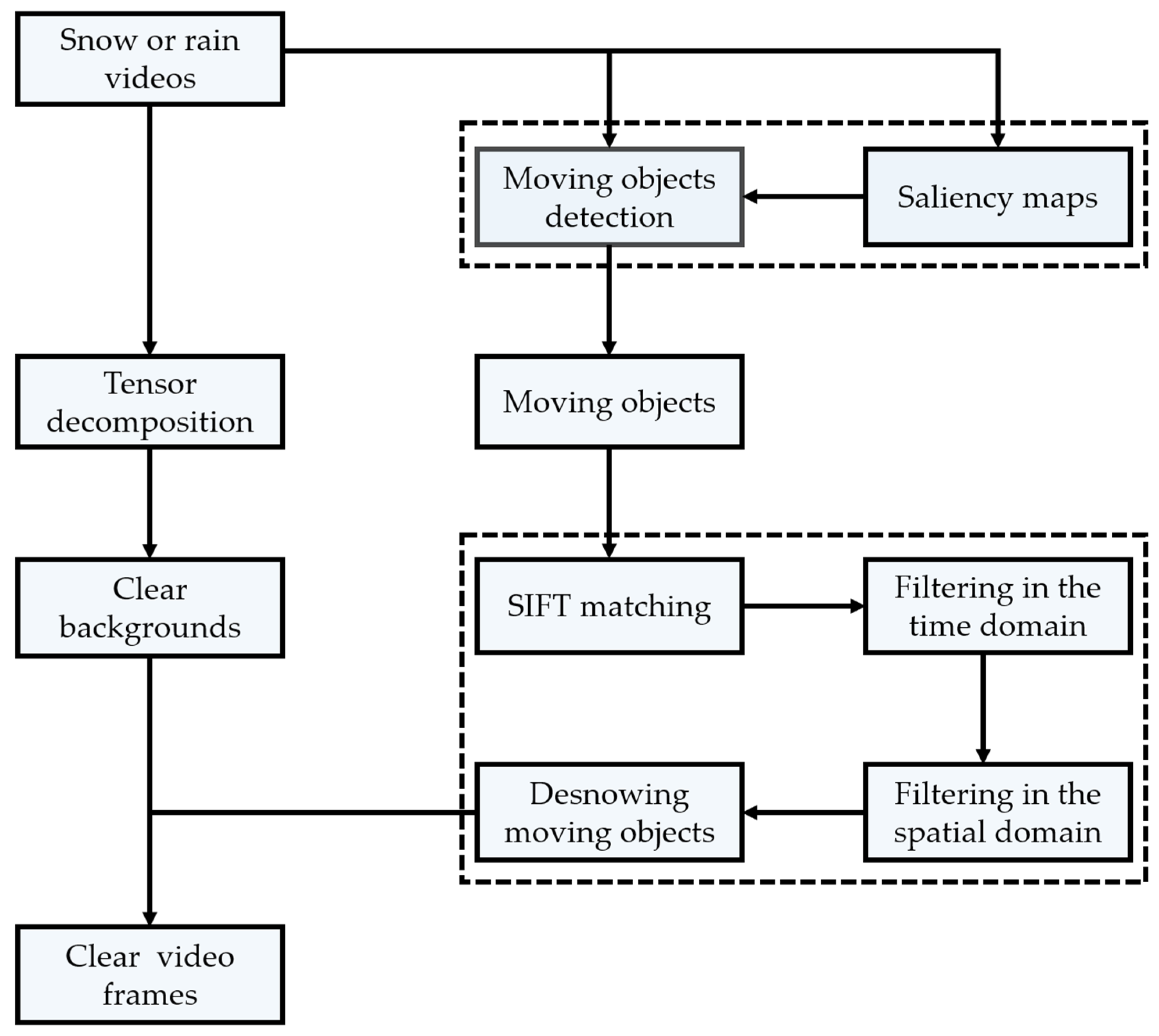
3. Proposed Method
3.1. Snow Video Background Modeling
3.2. Moving Object Modeling
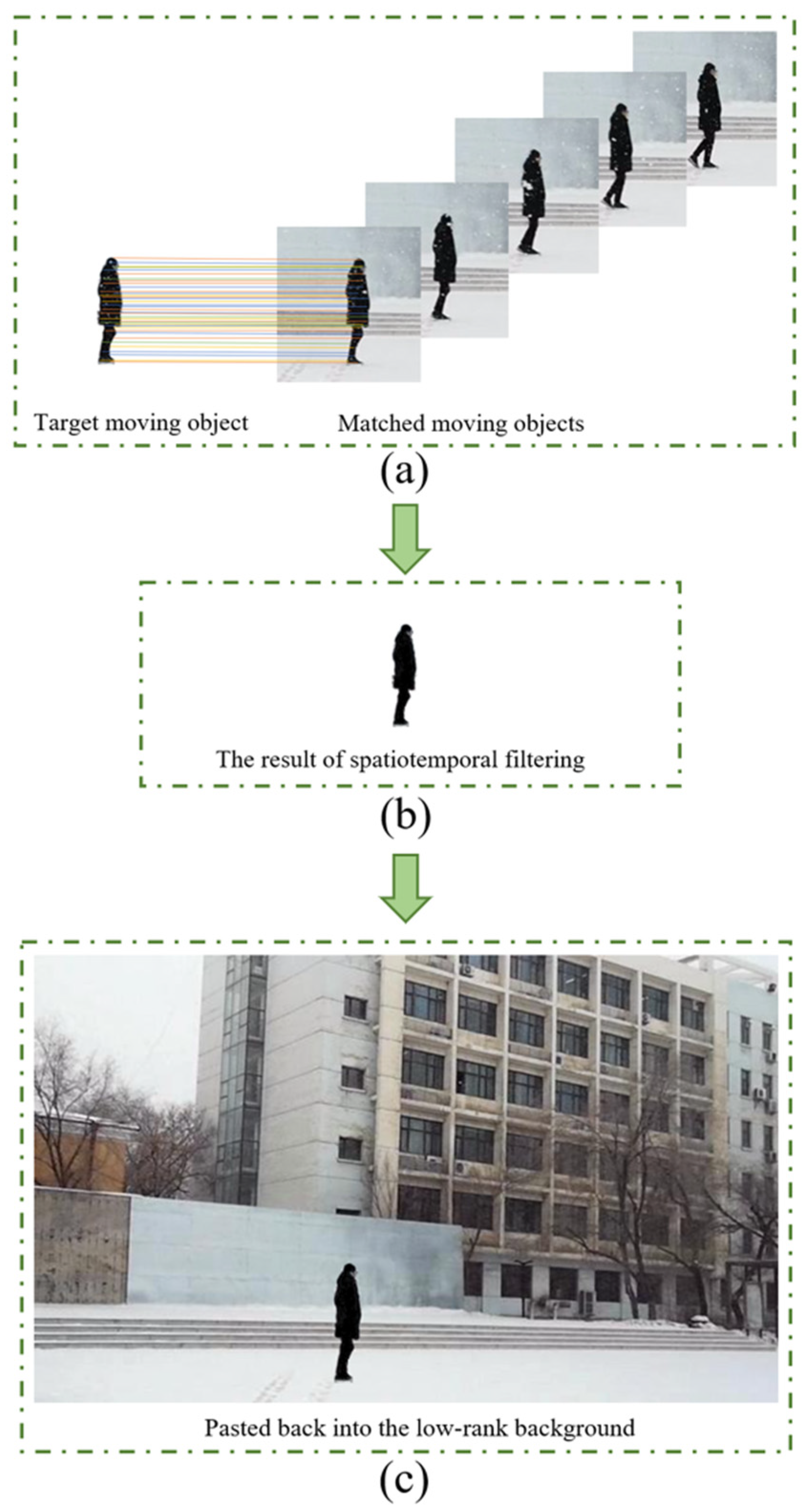
3.3. Feature Point Matching and Dual Adaptive Spatiotemporal Filtering
4. Experiment
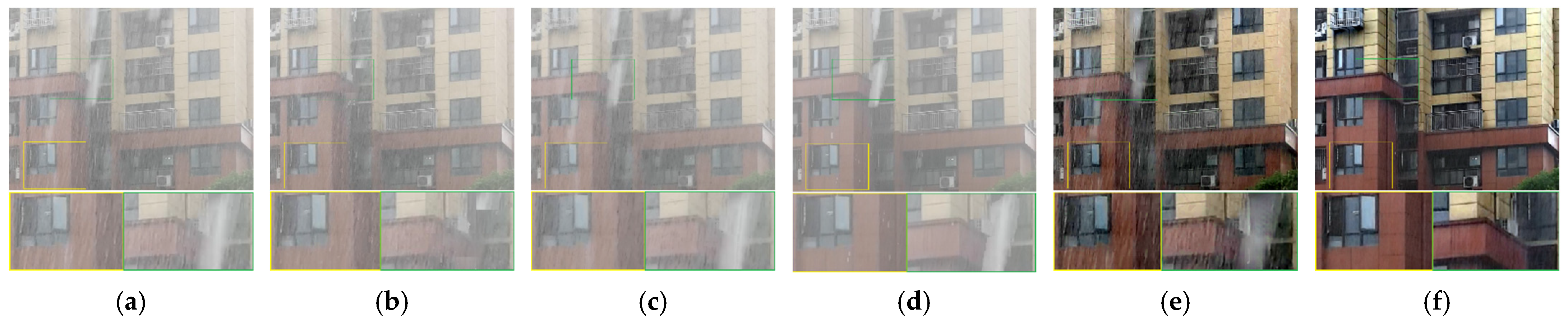
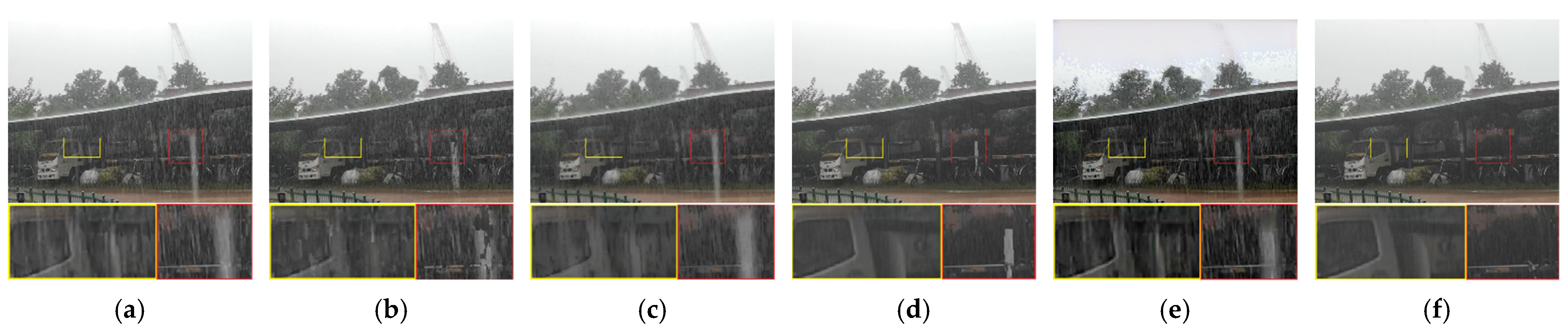
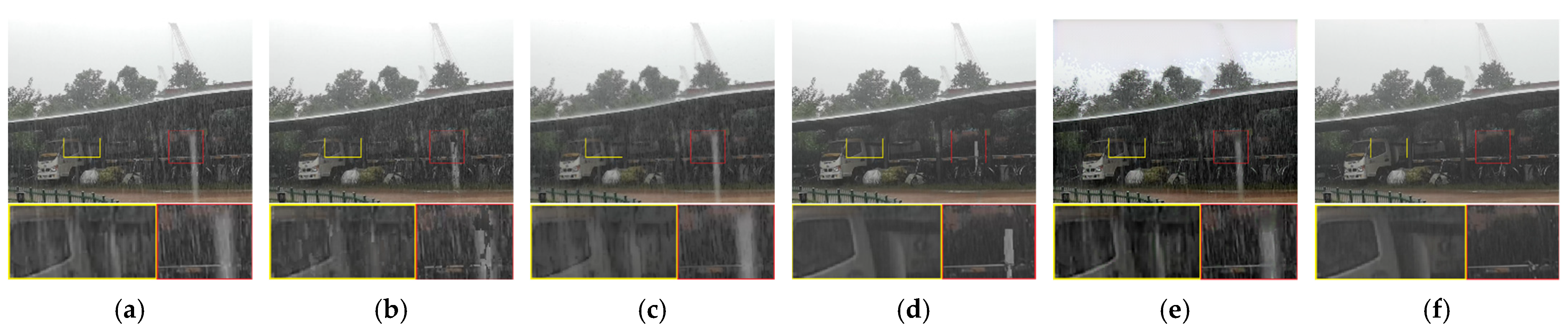
4.1. Comparation on Synthetic Snow and Rain Videos
4.2. Comparation on Real Snow and Rain Videos
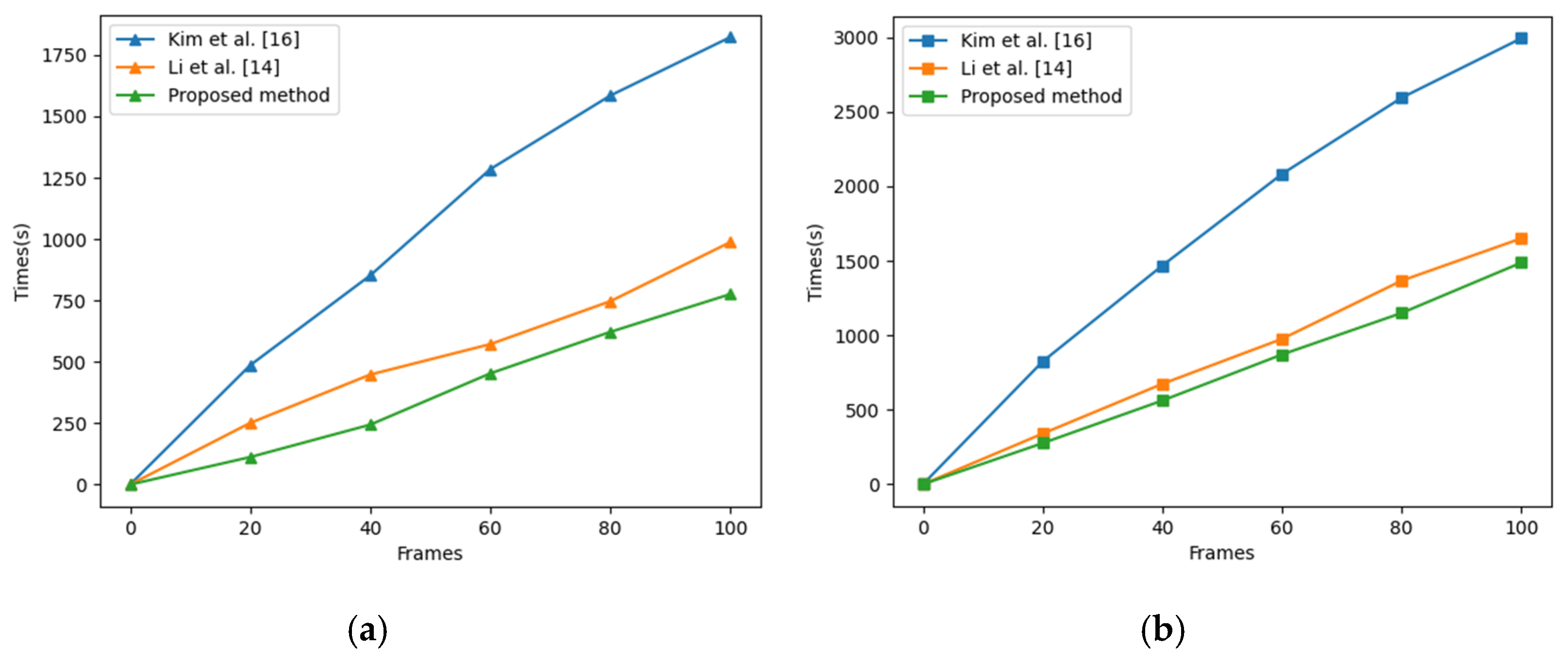
4.3. Time Complexity Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Garg, K.; Nayar, S.K. Detection and removal of rain from videos. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; p. I. [Google Scholar] [CrossRef]
- Zhang, X.; Li, H.; Qi, Y.; Leow, W.K.; Ng, T.K. Rain removal in video by combining temporal and chromatic properties. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 461–464. [Google Scholar]
- Brewer, N.; Liu, N. Using the shape characteristics of rain to identify and remove rain from video. In Proceedings of the Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR), Orlando, FL, USA, 4–6 December 2008; pp. 451–458. [Google Scholar]
- Park, W.-J.; Lee, K.-H. Rain removal using Kalman filter in video. In Proceedings of the 2008 International Conference on Smart Manufacturing Application, Goyangi, Korea, 9–11 April 2008; pp. 494–497. [Google Scholar]
- Pei, S.-C.; Tsai, Y.-T.; Lee, C.-Y. Removing rain and snow in a single image using saturation and visibility features. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Ding, X.; Chen, L.; Zheng, X.; Huang, Y.; Zeng, D. Single image rain and snow removal via guided L0 smoothing filter. Multimedia Tools Appl. 2016, 75, 2697–2712. [Google Scholar] [CrossRef]
- Xu, J.; Zhao, W.; Liu, P.; Tang, X. Removing rain and snow in a single image using guided filter. In Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering (CSAE), Zhangjiajie, China, 25–27 May 2012; pp. 304–307. [Google Scholar]
- Wang, Y.; Liu, S.; Chen, C.; Zeng, B. A hierarchical approach for rain or snow removing in a single color image. IEEE Trans. Image Process. 2017, 26, 3936–3950. [Google Scholar] [CrossRef]
- Shen, Y.; Ma, L.; Liu, H.; Bao, Y.; Chen, Z. Detecting and extracting natural snow from videos. Inf. Process. Lett. 2010, 110, 1124–1130. [Google Scholar] [CrossRef]
- Huiying, D.; Xuejing, Z. Detection and removal of rain and snow from videos based on frame difference method. In Proceedings of the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 5139–5143. [Google Scholar]
- Yang, T.; Nsabimana, V.; Wang, B.; Sun, Y.; Cheng, X.; Dong, H.; Qin, Y.; Zhang, B.; Ingrabire, F. Snow fluff detection and removal from video images. In Proceedings of the IECON 2017—43rd Annual Conference of the IEEE Industrial Electronics Society, Beijing, China, 29 October–1 November 2017; pp. 3840–3844. [Google Scholar]
- Wei, W.; Yi, L.; Xie, Q.; Zhao, Q.; Meng, D.; Xu, Z. Should we encode rain streaks in video as deterministic or stochastic? In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2516–2525. [Google Scholar]
- Ren, W.; Tian, J.; Han, Z.; Chan, A.; Tang, Y. Video desnowing and deraining based on matrix decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4210–4219. [Google Scholar]
- Li, M.; Cao, X.; Zhao, Q.; Zhang, L.; Meng, D. Online rain/snow removal from surveillance videos. IEEE Trans. Image Process. 2021, 30, 2029–2044. [Google Scholar] [CrossRef]
- Tian, J.; Han, Z.; Ren, W.; Chen, X.; Tang, Y. Snowflake removal for videos via global and local low-rank decomposition. IEEE Trans. Multimed. 2018, 20, 2659–2669. [Google Scholar] [CrossRef]
- Kim, J.-H.; Sim, J.-Y.; Kim, C.-S. Video deraining and desnowing using temporal correlation and low-rank matrix completion. IEEE Trans. Image Process. 2015, 24, 2658–2670. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Loquercio, A.; Scaramuzza, D.; Soatto, S. Unsupervised moving object detection via contextual information separation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 879–888. [Google Scholar]
- Javed, S.; Mahmood, A.; Al-Maadeed, S.; Bouwmans, T.; Jung, S.K. Moving object detection in complex scene using spatiotemporal structured-sparse RPCA. IEEE Trans. Image Process. 2018, 28, 1007–1022. [Google Scholar] [CrossRef]
- Pang, Y.; Ye, L.; Li, X.; Pan, J. Incremental learning with saliency map for moving object detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 640–651. [Google Scholar] [CrossRef]
- Hu, W.; Yang, Y.; Zhang, W.; Xie, Y. Moving object detection using tensor-based low-rank and saliently fused-sparse decomposition. IEEE Trans Image Process. 2016, 26, 724–737. [Google Scholar] [CrossRef]
- Xu, M.; Liu, B.; Fu, P.; Li, J.; Hu, Y.H.; Feng, S. Video salient object detection via robust seeds extraction and multi-graphs manifold propagation. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2191–2206. [Google Scholar] [CrossRef]
- Barnum, P.; Kanade, T.; Narasimhan, S. Spatio-temporal frequency analysis for removing rain and snow from videos. In Proceedings of the First International Workshop on Photometric Analysis for Computer Vision—PACV 2007, Rio de Janeiro, Brazil, 14–21 October 2007; p. 8. Available online: https://hal.inria.fr/PACV2007/inria-00264716v1 (accessed on 14 November 2021).
- Bossu, J.; Hautiere, N.; Tarel, J.-P. Rain or snow detection in image sequences through use of a histogram of orientation of streaks. Int. J. Comput. Vis. 2011, 93, 348–367. [Google Scholar] [CrossRef]
- Islam, M.R.; Paul, M. Video Rain-Streaks Removal by Combining Data-Driven and Feature-Based Models. Sensors 2021, 21, 6856. [Google Scholar] [CrossRef]
- Jiang, T.-X.; Huang, T.-Z.; Zhao, X.-L.; Deng, L.-J.; Wang, Y. A novel tensor-based video rain streaks removal approach via utilizing discriminatively intrinsic priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4057–4066. [Google Scholar]
- Jiang, T.-X.; Huang, T.-Z.; Zhao, X.-L.; Deng, L.-J.; Wang, Y. Fastderain: A novel video rain streak removal method using directional gradient priors. IEEE Trans. Image Process. 2018, 28, 2089–2102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, M.; Xie, Q.; Zhao, Q.; Wei, W.; Gu, S.; Tao, J.; Meng, D. Video rain streak removal by multiscale convolutional sparse coding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6644–6653. [Google Scholar]
- Yi, L.; Zhao, Q.; Wei, W.; Xu, Z. Robust online rain removal for surveillance videos with dynamic rains. Knowl.-Based Syst. 2021, 222, 107006. [Google Scholar] [CrossRef]
- Zheng, X.; Liao, Y.; Guo, W.; Fu, X.; Ding, X. Single-image-based rain and snow removal using multi-guided filter. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; pp. 258–265. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2482–2491. [Google Scholar]
- Ren, Y.; Nie, M.; Li, S.; Li, C. Single Image De-Raining via Improved Generative Adversarial Nets. Sensors 2020, 20, 1591. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, W.-T.; Fang, H.-Y.; Ding, J.-J.; Tsai, C.-C.; Kuo, S.-Y. JSTASR: Joint size and transparency-aware snow removal algorithm based on modified partial convolution and veiling effect removal. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 754–770. [Google Scholar]
- Jaw, D.-W.; Huang, S.-C.; Kuo, S.-Y. DesnowGAN: An efficient single image snow removal framework using cross-resolution lateral connection and GANs. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1342–1350. [Google Scholar] [CrossRef]
- Liu, Y.-F.; Jaw, D.-W.; Huang, S.-C.; Hwang, J.-N. DesnowNet: Context-aware deep network for snow removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Yun, M.; Tian, J.; Tang, Y.; Wang, G.; Wu, C. Stacked dense networks for single-image snow removal. Neurocomputing 2019, 367, 152–163. [Google Scholar] [CrossRef]
- Liu, Y.; Long, Z.; Huang, H.; Zhu, C. Low CP rank and tucker rank tensor completion for estimating missing components in image data. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 944–954. [Google Scholar] [CrossRef]
- Chen, Y.; Xiao, X.; Peng, C.; Lu, G.; Zhou, Y. Low-rank tensor graph learning for multi-view subspace clustering. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Wang, W.; Aggarwal, V.; Aeron, S. Tensor train neighborhood preserving embedding. IEEE Trans. Signal Process. 2018, 66, 2724–2732. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Huang, T.-Z.; He, W.; Yokoya, N.; Zhao, X.-L. Hyperspectral image compressive sensing reconstruction using subspace-based nonlocal tensor ring decomposition. IEEE Trans. Image Process. 2020, 29, 6813–6828. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 925–938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis: Exact recovery of corrupted low-rank tensors via convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5249–5257. [Google Scholar]
- Xu, H.; Zheng, J.; Yao, X.; Feng, Y.; Chen, S. Fast Tensor Nuclear Norm for Structured Low-Rank Visual Inpainting. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Cai, Y.; Dai, L.; Wang, H.; Chen, L.; Li, Y. A novel saliency detection algorithm based on adversarial learning model. IEEE Trans. Image Process. 2020, 29, 4489–4504. [Google Scholar] [CrossRef] [PubMed]
- Ji, W.; Li, X.; Wei, L.; Wu, F.; Zhuang, Y. Context-aware graph label propagation network for saliency detection. IEEE Trans. Image Process. 2020, 29, 8177–8186. [Google Scholar] [CrossRef]
- Zha, Z.-J.; Wang, C.; Liu, D.; Xie, H.; Zhang, Y. Robust deep co-saliency detection with group semantic and pyramid attention. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2398–2408. [Google Scholar] [CrossRef] [PubMed]
- Goyette, N.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection net: A new change detection benchmark dataset. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–8. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Howe, G.; Xu, M. End-to-End Robust Joint Unsupervised Image Alignment and Clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 3854–3866. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Pedestrians | |||
|---|---|---|---|---|
| PSNR | SSIM | FSIMc | VIF | |
| Kim et al. [16] | 32.952 | 0.986 | 0.986 | 0.842 |
| Wang et al. [8] | 28.940 | 0.933 | 0.917 | 0.462 |
| Li et al. [14] | 35.395 | 0.987 | 0.988 | 0.832 |
| Chen et al. [32] | 25.963 | 0.898 | 0.916 | 0.506 |
| proposed method | 36.287 | 0.988 | 0.989 | 0.858 |
| Algorithm | twoPositionPTZCam | |||
|---|---|---|---|---|
| PSNR | SSIM | FSIMc | VIF | |
| Kim et al. [16] | 35.725 | 0.984 | 0.988 | 0.803 |
| Wang et al. [8] | 31.255 | 0.930 | 0.952 | 0.521 |
| Li et al. [14] | 37.848 | 0.982 | 0.984 | 0.795 |
| Chen et al. [32] | 23.698 | 0.837 | 0.895 | 0.501 |
| proposed method | 38.694 | 0.986 | 0.988 | 0.816 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wu, R.; Jia, Z.; Yang, J.; Kasabov, N. Video Desnowing and Deraining via Saliency and Dual Adaptive Spatiotemporal Filtering. Sensors 2021, 21, 7610. https://doi.org/10.3390/s21227610
Li Y, Wu R, Jia Z, Yang J, Kasabov N. Video Desnowing and Deraining via Saliency and Dual Adaptive Spatiotemporal Filtering. Sensors. 2021; 21(22):7610. https://doi.org/10.3390/s21227610
Chicago/Turabian StyleLi, Yongji, Rui Wu, Zhenhong Jia, Jie Yang, and Nikola Kasabov. 2021. "Video Desnowing and Deraining via Saliency and Dual Adaptive Spatiotemporal Filtering" Sensors 21, no. 22: 7610. https://doi.org/10.3390/s21227610
APA StyleLi, Y., Wu, R., Jia, Z., Yang, J., & Kasabov, N. (2021). Video Desnowing and Deraining via Saliency and Dual Adaptive Spatiotemporal Filtering. Sensors, 21(22), 7610. https://doi.org/10.3390/s21227610